3 个策略,用于设计实验并管理预测建模问题的复杂性
您的预测建模问题。
开始一个新的时间序列预测项目非常困难。
给定多年的数据,拟合深度学习模型可能需要数天或数周。您究竟该如何开始呢?
对于一些从业者来说,这可能导致在项目最开始时就陷入瘫痪,甚至拖延。而另一些人则可能陷入只尝试和使用过去有效的方法的陷阱,而不是真正探索问题。
在本文中,您将发现一些实用的策略,当您将多层神经网络和长短期记忆(LSTM)循环神经网络模型等深度学习方法应用于时间序列预测问题时,可以用来上手。
本文中的策略并非万无一失,但它们是我在处理大型时间序列数据集时发现的、经过严格考验的经验法则。
阅读本文后,你将了解:
- 一种平衡思想探索和利用对您的问题有效的策略。
- 一种快速学习并扩展思想以数据来确认它们是否在更广泛的问题上成立的策略。
- 一种应对您的问题构架的复杂性和所选深度学习模型的复杂性的策略。
通过我的新书《深度学习时间序列预测》来**启动您的项目**,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。
1. 探索与利用的策略
在寻找一个在您的问题上表现良好的模型时,平衡探索和利用非常重要。
我建议采用两种不同的方法,应同时使用
- 诊断。
- 网格搜索。
诊断
诊断包括使用一组超参数进行一次运行,并为每个训练周期绘制模型在训练集和测试集上的技能跟踪图。
这些图提供了对过拟合或欠拟合的洞察,以及特定超参数集的潜力。
它们是健全性检查或深入研究可探索参数范围的种子,可以防止您在超过合理要求的时间周期或过大的网络上浪费时间。
下面是一个诊断图的示例,展示了训练和验证的 RMSE 在训练周期中的变化。
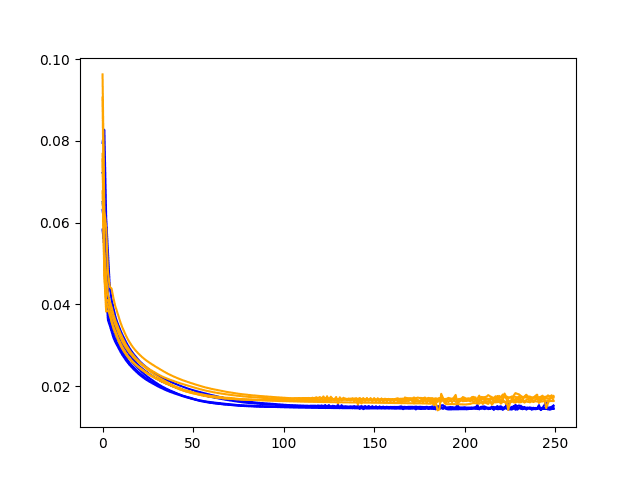
示例诊断折线图:训练周期中训练和测试损失的比较
网格搜索
基于诊断结果的学习,网格搜索提供了对特定模型超参数(如神经元数量、批大小等)的组合扫描。
它们允许您以一种分块的方式系统地调整特定的超参数值。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
交错使用这两种方法
我建议交错进行诊断运行和网格搜索运行。
您可以通过诊断来抽查您的假设,并通过网格搜索结果来获取有前景想法的最佳表现。
我强烈建议您测试您关于模型的每一个假设。这包括数据缩放、权重初始化,甚至激活函数、损失函数等选择等简单事项。
结合下面的数据处理策略,您将能够快速建立一个关于在您的预测问题上哪些有效、哪些无效的地图。
下面是一个模型的批次大小网格搜索结果示例,展示了每个实验重复 30 次的结果分布。
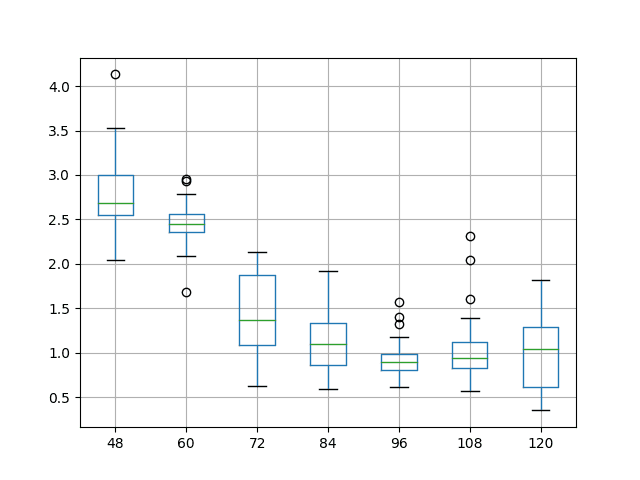
示例箱线图:不同模型参数值的模型技能比较
2. 数据大小处理策略
我建议首先使用较小的数据样本来测试想法,然后逐渐增加数据量,看看在小样本中学到的东西在大样本上是否成立。
例如,如果您有多年每小时的测量数据,您可以按如下方式拆分数据:
- 1 周样本。
- 1 个月样本。
- 1 年样本。
- 所有数据。
另一种方法是在整个数据集上拟合和探索模型,其中每个模型可能需要数天才能拟合,这反过来意味着您的学习速度会大大降低。
这种方法的好处是,您可以在几分钟内快速测试想法,并进行多次重复(例如,统计显著性),然后稍后只将那些有前景的想法扩展到越来越多的数据上。
通常,对于构建良好的监督学习问题,学习成果会随着数据的增加而扩展。尽管如此,风险在于不同数据规模的问题存在显著差异,并且发现的结果可能不成立。您可以通过更简单的、训练速度更快的模型来检查这一点,并尽早弄清楚这是否是一个问题。
最后,当您将模型扩展到更多数据时,您还可以减少实验的重复次数,以加快结果的周转速度。
3. 模型复杂度策略
与数据大小一样,模型的复杂性是必须管理的另一个问题,并且可以进行扩展。
我们可以从监督学习问题的构架和模型本身两个方面来看待这个问题。
模型构架复杂度
例如,我们可以假设一个时间序列预测问题,其中包含外生变量(例如,多个输入序列或多元输入)。
我们可以扩展问题的复杂性,看看在一个复杂级别(例如,单变量输入)上有效的内容是否在更复杂的级别(多元输入)上成立。
例如,您可以按以下方式处理模型复杂性:
- 单变量输入,单步输出。
- 单变量输入,多步输出。
- 多元输入,单步输出。
- 多元输入,多步输出。
这也适用于多元预测。
在每一步,目标都是证明增加的复杂性可以提升模型的技能。
例如
- 神经网络模型能否优于持久性预测模型?
- 神经网络模型能否优于线性预测模型?
- 外生输入变量能否提升模型相对于单变量输入的技能?
- 直接的多步预测能否比递归的单步预测更具技能?
如果这些问题无法解决,或者很容易解决,这将有助于您快速确定问题的构架和所选模型的类型。
模型能力复杂性
在处理 LSTM 等更复杂的神经网络模型时,也可以使用相同的方法。
例如
- 将问题建模为输入到输出的映射(例如,无内部状态或 BPTT)。
- 将问题建模为具有输入序列内部状态的映射问题(无 BPTT)。
- 将问题建模为具有内部状态和 BPTT 的映射问题。
在每一步,增加的模型复杂性必须展示出不低于先前复杂性级别的技能。换句话说,增加的模型复杂性必须通过模型技能或能力的相应增加来证明其合理性。
例如
- LSTM 能否在具有窗口的 MLP 上取得优势?
- 具有内部状态且不使用 BPTT 的 LSTM 能否优于每样本重置状态的 LSTM?
- 具有输入序列 BPTT 的 LSTM 能否优于每时间步更新的 LSTM?
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
总结
在本教程中,您将了解到如何克服深度学习项目开始时可能出现的瘫痪状态。
具体来说,您将了解到如何系统地分解复杂性以及可以用来快速获得结果的策略。
- 一种平衡思想探索和利用对您的问题有效的策略。
- 一种快速学习并扩展思想以数据来确认它们是否在更广泛的问题上成立的策略。
- 一种策略,用于导航您的问题的构架复杂性和您所选深度学习模型的复杂性。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。
")
")

")


你好,
又一次精彩的写作!
在“模型能力复杂性”部分,您写了两遍相同的句子:“它们是健全性检查或深入研究可探索参数范围的种子,可以防止您在超过合理要求的时间周期或过大的网络上浪费时间。”
此致!
BPTT 总是被使用,但如果只给它一个元素的序列,它就没有“时间”来工作。
使用深度学习的时间序列应该有多长?
很好的问题。
在使用 RNN 时,研究人员建议的限制是每个序列 200-400 个时间步,但您可以拥有多个序列并手动管理内部状态的重置。
有些基本上是无限的!
但请为您的项目进行测试,并找出在序列长度和重置状态之前的长度方面收益递减的点。
我有一些关于 BPTT 的文章,我建议阅读,请使用博客搜索。
在“诊断”段落中,您写了一句话两次:“它们是健全性检查或深入研究可探索参数范围的种子,可以防止您在超过合理要求的时间周期或过大的网络上浪费时间。”
谢谢,已修正。