编码器-解码器模型提供了一种使用循环神经网络的模式,用于解决具有挑战性的序列到序列预测问题,例如机器翻译。
注意力机制是编码器-解码器模型的扩展,它能提高该方法在处理长序列时的性能。全局注意力是注意力机制的简化版本,可能更容易在 Keras 等声明式深度学习库中实现,并且可能比经典的注意力机制取得更好的结果。
在这篇文章中,您将了解编码器-解码器循环神经网络模型的全局注意力机制。
阅读本文后,你将了解:
- 用于机器翻译等序列到序列预测问题的编码器-解码器模型。
- 提高编码器-解码器模型在长序列上性能的注意力机制。
- 简化注意力机制,并可能取得更好结果的全局注意力机制。
开始您的项目,阅读我的新书《Python 长短期记忆网络》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。

循环神经网络编码器-解码器的全局注意力机制简明介绍
照片作者:Kathleen Tyler Conklin,部分权利保留。
概述
本教程分为4个部分,它们是:
- 编码器-解码器模型
- 注意力机制
- 全局注意力
- 全局注意力详解
编码器-解码器模型
编码器-解码器模型是一种组织循环神经网络的方法,用于解决输入和输出时间步长不同的序列到序列预测问题。
该模型是为机器翻译问题开发的,例如将法语句子翻译成英语。
该模型包括两个子模型,如下所示:
- 编码器:一个 RNN 模型,将整个源序列读取到一个固定长度的编码中。
- 解码器:一个 RNN 模型,它使用编码后的输入序列并对其进行解码以输出目标序列。
下图显示了编码器和解码器模型之间的关系。

编码器-解码器网络示例
摘自《Sequence to Sequence Learning with Neural Networks》,2014 年。
长短期记忆循环神经网络通常用于编码器和解码器。用于描述源序列的编码器输出用于启动解码过程,该过程以迄今为止已生成的目标词为条件。具体来说,编码器在输入最后一个时间步的隐藏状态用于初始化解码器的状态。
LSTM 通过首先获得由 LSTM 的最后一个隐藏状态给出的输入序列 (x1, …, xT) 的固定维度表示 v,然后计算 y1, …, yT’ 的概率,使用标准 LSTM-LM 公式,其中初始隐藏状态设置为 x1, …, xT 的表示 v。
— Sequence to Sequence Learning with Neural Networks, 2014。
下图显示了源序列显式编码为上下文向量 c,该向量与迄今为止生成的词一起用于输出目标序列中的下一个词。
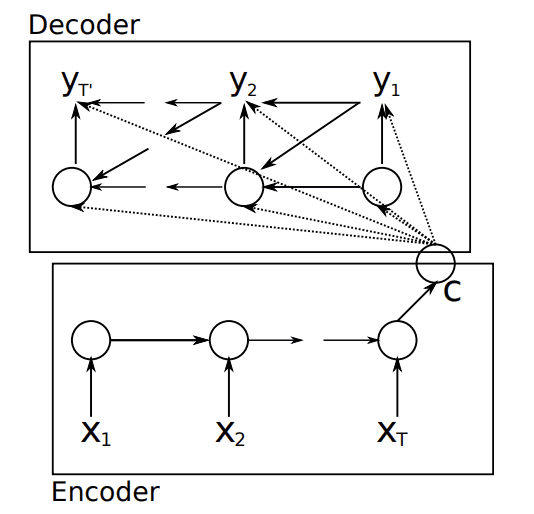
源序列编码为上下文向量,然后进行解码
摘自《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》,2014 年。
然而,[…], yt 和 h(t) 也取决于 yt−1 和输入序列的摘要 c。
— Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014。
注意力机制
事实证明,编码器-解码器模型是一种端到端模型,在机器翻译等具有挑战性的序列到序列预测问题上表现良好。
该模型在非常长的序列上似乎受到限制。人们认为原因是源序列的编码长度固定。
这种编码器-解码器方法的一个潜在问题是,神经网络需要能够将源句子的所有必要信息压缩到固定长度的向量中。这可能会使神经网络难以处理长句子,尤其是那些比训练语料库中的句子更长的句子。
— Neural Machine Translation by Jointly Learning to Align and Translate, 2015。
在他们 2015 年题为“Neural Machine Translation by Jointly Learning to Align and Translate” 的论文中,Bahdanau 等人描述了一种注意力机制来解决这个问题。
注意力机制提供了一种更丰富的源序列编码,用于构建可以被解码器使用的上下文向量。
注意力机制允许模型学习在预测目标序列中的每个词时,应该关注源序列中的哪些编码词以及关注的程度。

带注意力的编码器-解码器模型示例
摘自《Neural Machine Translation by Jointly Learning to Align and Translate》,2015 年。
来自编码器的每个输入时间步的隐藏状态被收集起来,而不是源序列最后一个时间步的隐藏状态。
为目标序列中的每个输出词专门构建一个上下文向量。首先,使用神经网络对编码器的每个隐藏状态进行评分,然后使用 softmax 函数进行归一化,以得到编码器隐藏状态上的概率。最后,使用这些概率计算编码器隐藏状态的加权和,以提供要用于解码器的上下文向量。
有关 Bahdanau 注意力机制如何工作的更完整解释以及一个示例,请参阅文章
全局注意力
在他们题为“Effective Approaches to Attention-based Neural Machine Translation” 的论文中,斯坦福 NLP 研究员 Minh-Thang Luong 等人提出了一种用于机器翻译的编码器-解码器模型的注意力机制,称为“全局注意力”。
它被提议作为 Bahdanau 等人在其论文“Neural Machine Translation by Jointly Learning to Align and Translate” 中提出的注意力机制的简化版本。在 Bahdanau 注意力中,注意力计算需要前一个时间步的解码器输出。
另一方面,全局注意力仅利用当前时间步的编码器和解码器输出。这使其在 Keras 等矢量化库中实现具有吸引力。
… 我们的计算路径更简单;我们从 ht -> at -> ct -> ~ht 进行预测 […] 另一方面,在任何时间 t,Bahdanau 等人(2015)都从前一个隐藏状态 ht−1 -> at -> ct -> ht 构建,然后通过深度输出和 maxout 层进行预测。
— Effective Approaches to Attention-based Neural Machine Translation, 2015。
Luong 等人论文中评估的模型与 Bahdanau 等人提出的模型不同(例如,输入序列反转而不是双向输入,LSTM 而不是 GRU 元素以及 dropout 的使用),但是,全局注意力模型在标准的机器翻译任务上取得了更好的结果。
… 全局注意力方法带来了 +2.8 BLEU 的显著提升,使我们的模型比 Bahdanau 等人的基本注意力系统稍好。
— Effective Approaches to Attention-based Neural Machine Translation, 2015。
接下来,让我们仔细看看全局注意力是如何计算的。
全局注意力详解
全局注意力是循环神经网络注意力编码器-解码器模型的扩展。
虽然它最初是为机器翻译开发的,但它也适用于其他语言生成任务,例如字幕生成和文本摘要,甚至一般序列预测任务。
我们可以将全局注意力的计算分为以下计算步骤,用于预测给定输入序列的单个时间步的编码器-解码器网络。请参阅论文以获取相关方程。
- 问题。输入序列作为输入提供给编码器 (X)。
- 编码。编码器 RNN 对输入序列进行编码并输出相同长度的序列 (hs)。
- 解码。解码器解释编码并输出目标解码 (ht)。
- 对齐。使用目标解码对每个编码时间步进行评分,然后使用 softmax 函数对分数进行归一化。提出了四种不同的评分函数。
- 点积:目标解码和源编码之间的点积。
- 通用:目标解码与加权源编码之间的点积。
- 拼接:对拼接的源编码和目标解码进行神经网络处理。
- 位置:目标解码的加权 softmax。
- 上下文向量。通过计算加权和将对齐权重应用于源编码,得到上下文向量。
- 最终解码。将上下文向量和目标解码拼接、加权,并通过 tanh 函数传递。
最终解码通过 softmax 进行,以预测序列中下一个词在输出词汇表上的概率。
下图提供了计算全局注意力时数据流的高层概念。
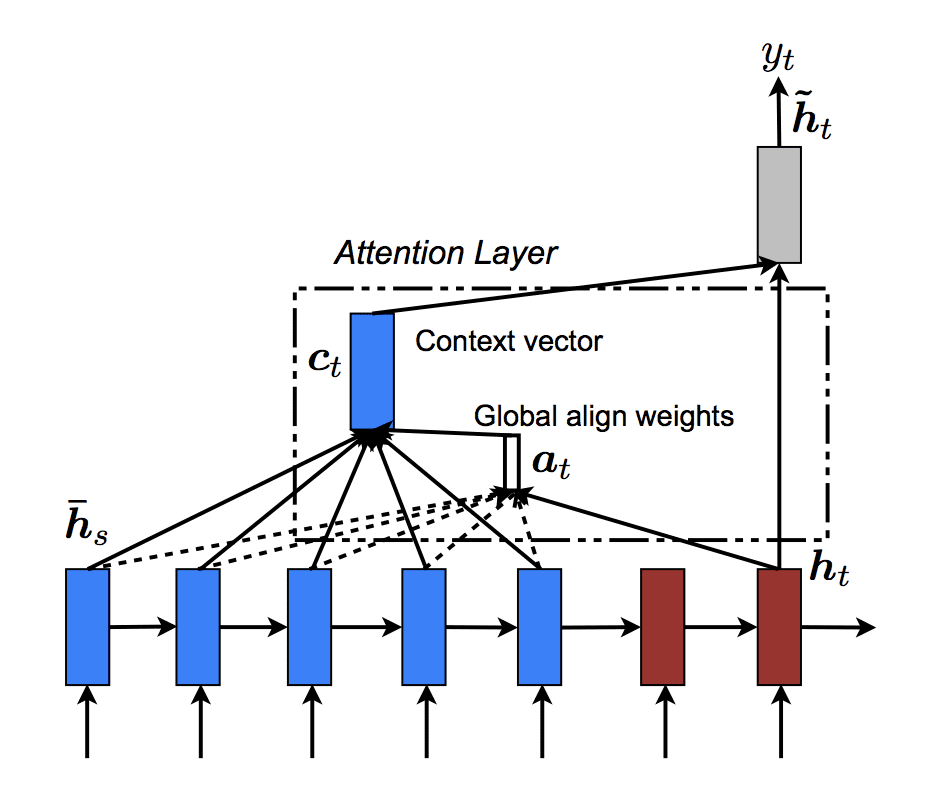
编码器-解码器循环神经网络中全局注意力的描绘。
摘自《Effective Approaches to Attention-based Neural Machine Translation》。
作者评估了所有评分函数,并普遍发现简单的点积评分函数表现良好。
有趣的是,点积在全局注意力中效果很好…
— Effective Approaches to Attention-based Neural Machine Translation, 2015。
由于其更简单的数据流,全局注意力可能是实现声明式深度学习库(如 TensorFlow、Theano 和 Keras 等包装器)的良好选择。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
编码器-解码器
- 使用神经网络进行序列到序列学习, 2014.
- 使用 RNN 编码器-解码器学习短语表示进行统计机器翻译, 2014.
- 编码器-解码器长短期记忆网络
注意力机制
全局注意力
- 基于注意力的神经机器翻译的有效方法, 2015.
总结
在这篇文章中,您了解了编码器-解码器循环神经网络模型的全局注意力机制。
具体来说,你学到了:
- 用于机器翻译等序列到序列预测问题的编码器-解码器模型。
- 提高编码器-解码器模型在长序列上性能的注意力机制。
- 简化注意力机制,并可能取得更好结果的全局注意力机制。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






嗨,jason
请在您的教程和代码中实现更多注意力机制(例如这里描述的)。
谢谢您。
谢谢。Keras 很快就会有注意力机制了。
我已经在 Keras 中自己实现了这个,但它一定有一些严重的 bug,因为结果非常糟糕。
你好 Jason,
非常感谢您的教程——它们非常有帮助。我一直在阅读有关注意力机制的几篇论文,但在阅读了您的帖子后,我才真正理解了整体概念。谢谢。
我一直在尝试自己用 Keras 实现全局注意力。鉴于使用点积对齐得分的变体不要求任何可学习的权重(如果我错了请纠正我),是否可以使用 lambda 函数/层来实现?这也应该是可能的,因为在任何时间步,Luong 的注意力机制只依赖于源隐藏状态 (h_s) 和目标隐藏状态 (h_t)。我的想法是,至少点积得分的实现不需要继承 Recurrent Layer 类——但我不完全确定。有什么想法?
澄清:关于依赖性,我的意思是,在任何时间步,对齐得分仅取决于 h_s 和**当前** h_t。与 Bahdanau 的情况不同,它还依赖于前一个 h_t。
是的,通过一些转换层和一个 lambda 函数可以很容易地实现全局注意力。我曾尝试过一个下午,但它变得有点混乱,结果也不佳。我个人在等待 Keras 内置的注意力机制。
在 Luong 注意力中,我真的不确定评分是如何完成的…
如果编码器的输出是 [ num_steps, batch_size, enc_hidden_size ],而当前解码目标是 [ 1, batch_size, enc_hidden_size ],我们如何进行秩为 3 的张量的矩阵乘法?
嗨 Jason,您能分享一下 Keras 中全局注意力的代码吗?
抱歉,目前我还没有一个完整的示例。我希望将来能抽出时间来写一个。
尊敬的先生,
我有一些评论,从中我提取了一些方面,现在我想生成一个抽象摘要,同时关注方面和内容,我该怎么做?
也许可以尝试一个抽象摘要算法?
嗨 Jason
非常感谢您宝贵的教程。
请指导我回答这个问题:注意力、自注意力与多头注意力有什么区别?它们各自解决了对方无法解决的什么问题?
谢谢您。
抱歉,我没有关于此比较的教程。