梯度提升机是一种强大的集成机器学习算法,它使用决策树。
提升(Boosting)是一种通用的集成技术,它涉及按顺序将模型添加到集成中,其中后续模型纠正先前模型的性能。AdaBoost 是第一个实现提升承诺的算法。
梯度提升是 AdaBoost 的泛化,它改进了该方法的性能,并引入了来自自助聚合(bootstrap aggregation)的思想,以进一步改进模型,例如在拟合集成成员时随机采样样本和特征。
梯度提升在各种表格数据集上表现良好,即使不是最好的,并且像 XGBoost 和 LightBoost 这样的算法版本通常在赢得机器学习竞赛中发挥重要作用。
在本教程中,您将学习如何开发用于分类和回归的梯度提升集成算法。
完成本教程后,您将了解:
- 梯度提升集成是一种由决策树顺序添加到模型中而创建的集成算法。
- 如何使用 scikit-learn 对分类和回归问题应用梯度提升集成算法。
- 如何探究梯度提升模型超参数对模型性能的影响。
通过我的新书《使用 Python 的集成学习算法》启动您的项目,其中包括逐步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2020年8月更新:添加了常见问题部分。添加了网格搜索示例。

如何在 Python 中开发梯度提升机集成
图片由 Susanne Nilsson 提供,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 梯度提升算法
- 梯度提升 Scikit-Learn API
- 用于分类的梯度提升
- 用于回归的梯度提升
- 梯度提升超参数
- 探索树的数量
- 探索样本数量
- 探索特征数量
- 探索学习率
- 探索树深度
- 网格搜索超参数
- 常见问题
梯度提升机算法
梯度提升指的是一类集成机器学习算法,可用于分类或回归预测建模问题。
梯度提升也称为梯度树提升、随机梯度提升(一种扩展),以及梯度提升机,简称 GBM。
集成模型由决策树模型构建。树被一个接一个地添加到集成中,并进行拟合以纠正先前模型所做的预测错误。这是一种被称为“提升”的集成机器学习模型。
模型使用任何任意可微损失函数和梯度下降优化算法进行拟合。这赋予了该技术“梯度提升”的名称,因为在模型拟合时,损失梯度被最小化,很像神经网络。
一种生成分类器加权组合以优化[成本]的方法是函数空间中的梯度下降。
— Boosting Algorithms as Gradient Descent in Function Space, 1999。
朴素梯度提升是一种贪婪算法,可以快速过拟合训练数据集。
它可以通过惩罚算法各个部分的正则化方法来受益,并通过减少过拟合来总体上提高算法的性能。
基本梯度提升有三种增强类型可以提高性能
- 树的约束:例如树的深度和集成中使用的树的数量。
- 加权更新:例如用于限制每棵树对集成贡献程度的学习率。
- 随机抽样:例如在特征和样本的随机子集上拟合树。
随机抽样的使用通常会导致算法名称更改为“随机梯度提升”。
…在每次迭代中,从完整的训练数据集中随机(不放回)抽取训练数据的子样本。然后,使用随机选择的子样本而不是完整样本来拟合基本学习器。
— Stochastic Gradient Boosting, 1999。
梯度提升是一种有效的机器学习算法,通常是赢得表格和类似结构化数据集机器学习竞赛(如 Kaggle)的主要算法之一。
有关梯度提升算法的更多信息,请参阅教程。
现在我们已经熟悉了梯度提升算法,接下来看看如何在 Python 中拟合 GBM 模型。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
梯度提升 Scikit-Learn API
梯度提升集成可以从头开始实现,尽管对于初学者来说可能具有挑战性。
scikit-learn Python 机器学习库提供了梯度提升集成算法的实现。
该算法在现代版本的库中可用。
首先,通过运行以下脚本确认您正在使用该库的现代版本
|
1 2 3 |
# 检查 scikit-learn 版本 import sklearn print(sklearn.__version__) |
运行脚本将打印您的 scikit-learn 版本。
您的版本应该相同或更高。如果不是,您必须升级您的 scikit-learn 库版本。
|
1 |
0.22.1 |
梯度提升通过 GradientBoostingRegressor 和 GradientBoostingClassifier 类提供。
这两个模型的运行方式相同,并接受相同的参数,这些参数影响决策树的创建和添加到集成中的方式。
模型构建中使用了随机性。这意味着每次在相同数据上运行算法时,它都会生成一个略有不同的模型。
当使用具有随机学习算法的机器学习算法时,通过对多次运行或交叉验证重复的性能进行平均来评估它们是一种很好的做法。在拟合最终模型时,可能需要增加树的数量,直到模型在重复评估中的方差减小,或者拟合多个最终模型并平均它们的预测。
让我们看看如何为分类和回归开发梯度提升集成。
用于分类的梯度提升
在本节中,我们将介绍如何将梯度提升用于分类问题。
首先,我们可以使用 make_classification() 函数 创建一个包含 1,000 个示例和 20 个输入特征的合成二元分类问题。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试分类数据集 来自 sklearn.datasets 导入 make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以在此数据集上评估梯度提升算法。
我们将使用重复分层 k 折交叉验证来评估模型,其中重复 3 次,折叠 10 次。我们将报告模型在所有重复和折叠中的平均准确度和标准差。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估用于分类的梯度提升算法 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import GradientBoostingClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 model = GradientBoostingClassifier() # 定义评估方法 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 在数据集上评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('平均准确率: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例报告了模型的平均准确度和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到默认超参数的梯度提升集成在此测试数据集上实现了约 89.9% 的分类准确率。
|
1 |
平均准确率:0.899 (0.030) |
我们还可以将梯度提升模型用作最终模型并进行分类预测。
首先,梯度提升集成在所有可用数据上进行拟合,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的二元分类数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 使用梯度提升进行分类预测 from sklearn.datasets import make_classification from sklearn.ensemble import GradientBoostingClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 model = GradientBoostingClassifier() # 在整个数据集上拟合模型 model.fit(X, y) # 进行单次预测 row = [0.2929949, -4.21223056, -1.288332, -2.17849815, -0.64527665, 2.58097719, 0.28422388, -7.1827928, -1.91211104, 2.73729512, 0.81395695, 3.96973717, -2.66939799, 3.34692332, 4.19791821, 0.99990998, -0.30201875, -4.43170633, -2.82646737, 0.44916808] yhat = model.predict([row]) # 总结预测 print('预测类别: %d' % yhat[0]) |
运行示例将梯度提升集成模型拟合到整个数据集,然后用于对新的数据行进行预测,就像我们在应用程序中使用模型时一样。
|
1 |
预测类别:1 |
现在我们已经熟悉了使用梯度提升进行分类,接下来看看回归的 API。
用于回归的梯度提升
在本节中,我们将介绍如何将梯度提升用于回归问题。
首先,我们可以使用 make_regression() 函数 创建一个包含 1,000 个示例和 20 个输入特征的合成回归问题。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试回归数据集 from sklearn.datasets import make_regression # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以在此数据集上评估梯度提升算法。
与上一节一样,我们将使用重复的 k 折交叉验证评估模型,其中包含三次重复和 10 折。我们将报告模型在所有重复和折叠中的平均绝对误差 (MAE)。scikit-learn 库将 MAE 设为负值,以便最大化而不是最小化。这意味着较大的负 MAE 更好,完美模型的 MAE 为 0。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估用于回归的梯度提升集成 from numpy import mean from numpy import std from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedKFold from sklearn.ensemble import GradientBoostingRegressor # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # 定义模型 model = GradientBoostingRegressor() # 定义评估过程 cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1) # 报告表现 print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例报告了模型的平均准确度和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到默认超参数的梯度提升集成实现了大约 62 的 MAE。
|
1 |
MAE: -62.475 (3.254) |
我们还可以将梯度提升模型用作最终模型并进行回归预测。
首先,梯度提升集成在所有可用数据上进行拟合,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的回归数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 用于回归预测的梯度提升集成 from sklearn.datasets import make_regression from sklearn.ensemble import GradientBoostingRegressor # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # 定义模型 model = GradientBoostingRegressor() # 在整个数据集上拟合模型 model.fit(X, y) # 进行单次预测 row = [0.20543991, -0.97049844, -0.81403429, -0.23842689, -0.60704084, -0.48541492, 0.53113006, 2.01834338, -0.90745243, -1.85859731, -1.02334791, -0.6877744, 0.60984819, -0.70630121, -1.29161497, 1.32385441, 1.42150747, 1.26567231, 2.56569098, -0.11154792] yhat = model.predict([row]) # 总结预测 print('预测值: %d' % yhat[0]) |
运行示例将梯度提升集成模型拟合到整个数据集,然后用于对新的数据行进行预测,就像我们在应用程序中使用模型时一样。
|
1 |
预测值:37 |
现在我们已经熟悉了使用 scikit-learn API 评估和使用梯度提升集成,接下来我们看看如何配置模型。
梯度提升超参数
在本节中,我们将更仔细地研究一些您应该考虑为梯度提升集成调整的超参数以及它们对模型性能的影响。
可能对模型性能影响最大的四个关键超参数是集成中模型的数量、学习率、通过用于训练每个模型的数据样本大小或树分割中使用的特征来控制模型方差,以及最后是决策树的深度。
在本节中,我们将更仔细地研究这些超参数各自的影响,尽管它们都相互作用,应该一起或成对调整,例如学习率与集成大小,以及样本大小/特征数量与树深度。
有关梯度提升算法超参数调整的更多信息,请参阅教程。
探索树的数量
梯度提升集成算法的一个重要超参数是集成中使用的决策树的数量。
回想一下,决策树是按顺序添加到模型中的,以努力纠正和改进先前树所做的预测。因此,更多的树通常更好。树的数量还必须与学习率保持平衡,例如,更多的树可能需要更小的学习率,更少的树可能需要更大的学习率。
树的数量可以通过“n_estimators”参数设置,默认为 100。
下面的示例探讨了树的数量在 10 到 5,000 之间对性能的影响。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# 探索梯度提升树的数量对性能的影响 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import GradientBoostingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() # 定义要考虑的树的数量 n_trees = [10, 50, 100, 500, 1000, 5000] for n in n_trees: models[str(n)] = GradientBoostingClassifier(n_estimators=n) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集结果 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): # 评估模型 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 沿途总结性能 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个配置的决策树数量的平均准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到该数据集的性能一直提高到大约 500 棵树,之后性能似乎趋于平稳。与 AdaBoost 不同,在这种情况下,梯度提升似乎不会随着树的数量增加而过拟合。
|
1 2 3 4 5 6 |
>10 0.830 (0.037) >50 0.880 (0.033) >100 0.899 (0.030) >500 0.919 (0.025) >1000 0.919 (0.025) >5000 0.918 (0.026) |
为每个配置的树数量创建了准确率分数的箱线图。
我们可以看到模型性能和集成规模增加的总体趋势。
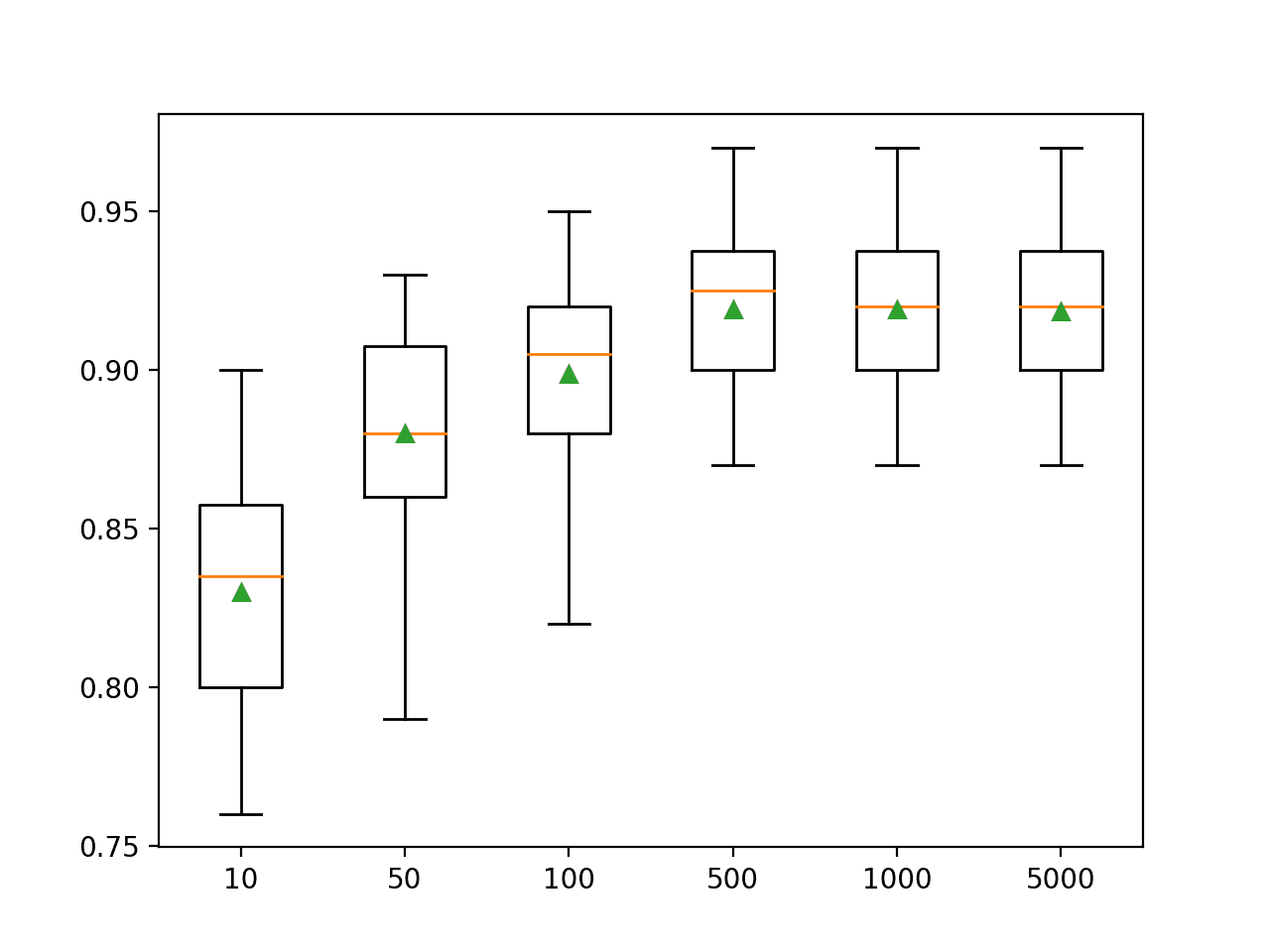
梯度提升集成规模与分类准确率的箱线图
探索样本数量
用于拟合每棵树的样本数量可以变化。这意味着每棵树都在训练数据集的随机选定子集上拟合。
使用较少的样本会为每棵树引入更多的方差,尽管它可以提高模型的整体性能。
用于拟合每棵树的样本数量由“subsample”参数指定,可以设置为训练数据集大小的一部分。默认情况下,它设置为 1.0 以使用整个训练数据集。
下面的示例演示了样本大小对模型性能的影响。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
# 探索梯度提升集成样本数量对性能的影响 from numpy import mean from numpy import std from numpy import arange from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import GradientBoostingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() # 探索从 10% 到 100% 以 10% 为增量的样本比率 for i in arange(0.1, 1.1, 0.1): key = '%.1f' % i models[key] = GradientBoostingClassifier(subsample=i) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集结果 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): # 评估模型 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 沿途总结性能 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个配置的样本大小的平均准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到平均性能对于训练数据集大小约一半的样本(例如 0.4 或更高)可能是最佳的。
|
1 2 3 4 5 6 7 8 9 10 |
>0.1 0.872 (0.033) >0.2 0.897 (0.032) >0.3 0.904 (0.029) >0.4 0.907 (0.032) >0.5 0.906 (0.027) >0.6 0.908 (0.030) >0.7 0.902 (0.032) >0.8 0.901 (0.031) >0.9 0.904 (0.031) >1.0 0.899 (0.030) |
为每个配置的树数量创建了准确率分数的箱线图。
我们可以看到模型性能提高的总体趋势,可能在 0.4 左右达到峰值,并保持相对稳定。
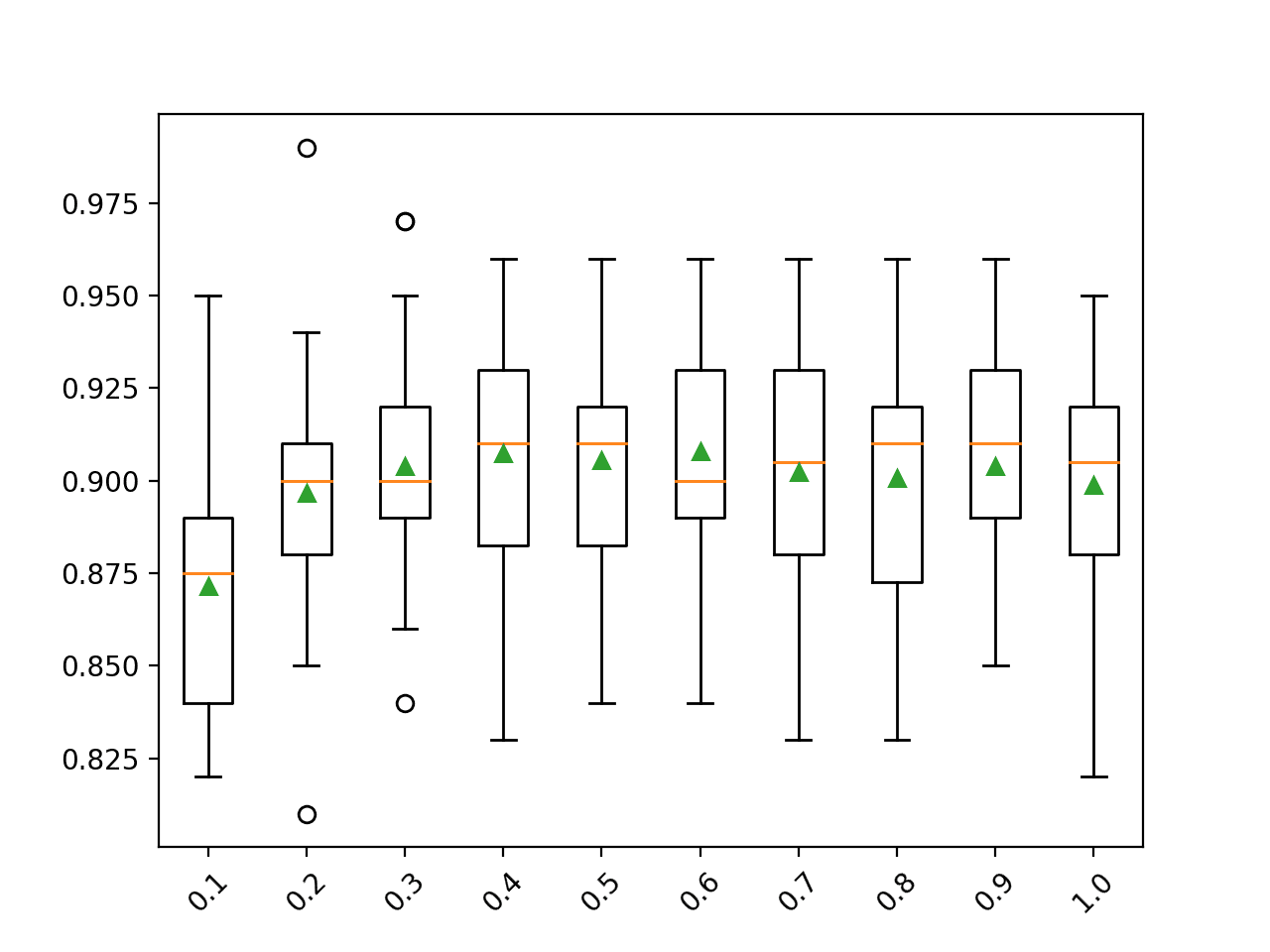
梯度提升集成样本大小与分类准确率的箱线图
探索特征数量
用于拟合每棵决策树的特征数量可以变化。
与更改样本数量一样,更改特征数量会向模型引入额外的方差,这可能会提高性能,尽管它可能需要增加树的数量。
每棵树使用的特征数量作为随机样本,由“max_features”参数指定,默认为训练数据集中的所有特征。
下面的示例探讨了特征数量对测试数据集模型性能的影响,范围在 1 到 20 之间。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# 探索梯度提升特征数量对性能的影响 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import GradientBoostingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() # 探索从 1 到 20 的特征数量 for i in range(1,21): models[str(i)] = GradientBoostingClassifier(max_features=i) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集结果 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): # 评估模型 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 沿途总结性能 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个配置的特征数量的平均准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到平均性能增加到特征数量的一半左右,之后基本保持不变。令人惊讶的是,删除一半的输入变量影响如此之小。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>1 0.864 (0.036) >2 0.885 (0.032) >3 0.891 (0.031) >4 0.893 (0.036) >5 0.898 (0.030) >6 0.898 (0.032) >7 0.892 (0.032) >8 0.901 (0.032) >9 0.900 (0.029) >10 0.895 (0.034) >11 0.899 (0.032) >12 0.899 (0.030) >13 0.898 (0.029) >14 0.900 (0.033) >15 0.901 (0.032) >16 0.897 (0.028) >17 0.902 (0.034) >18 0.899 (0.032) >19 0.899 (0.032) >20 0.899 (0.030) |
为每个配置的树数量创建了准确率分数的箱线图。
我们可以看到模型性能提高的总体趋势,可能在八九个特征左右达到峰值,并保持相对稳定。
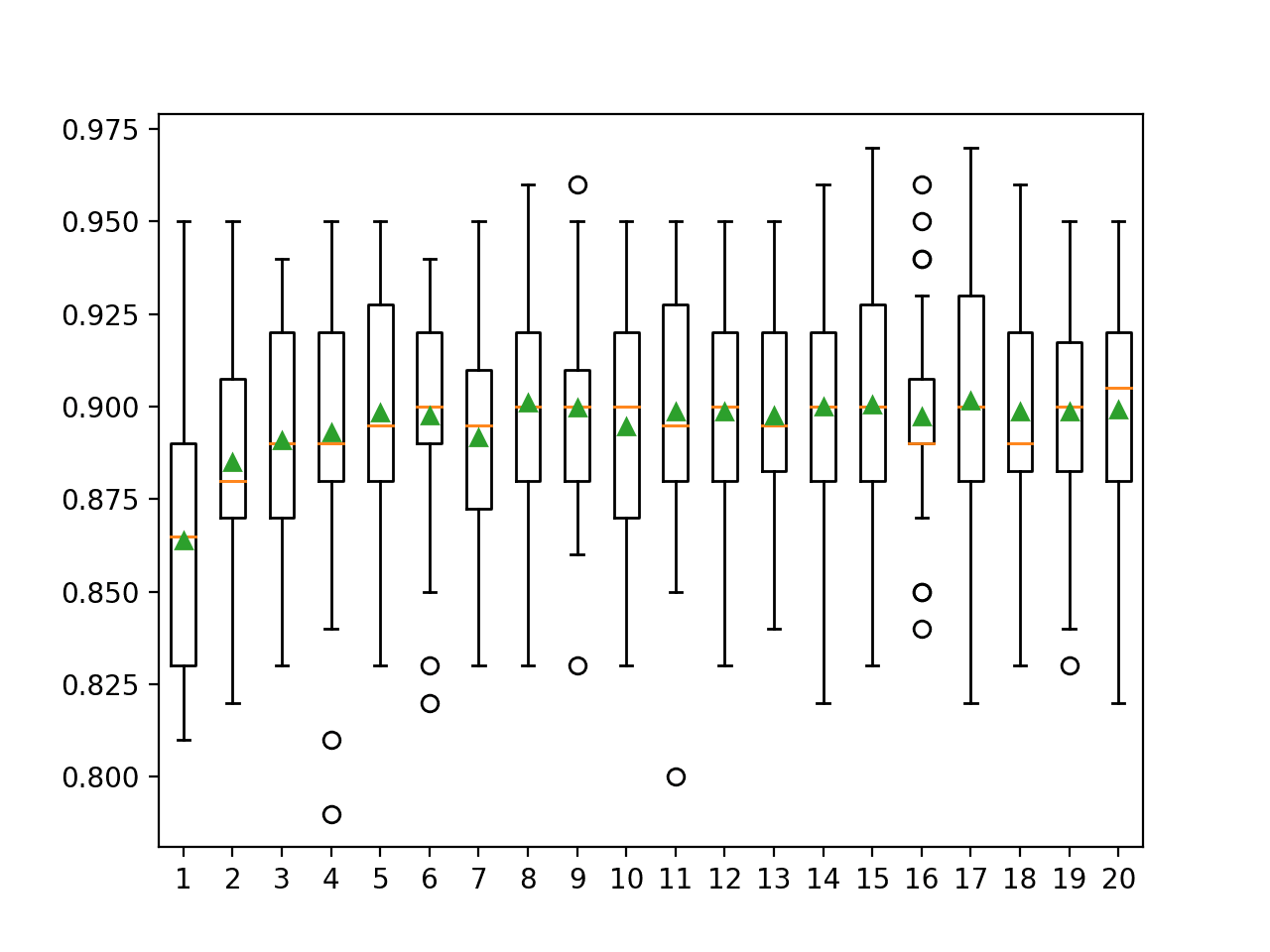
梯度提升集成特征数量与分类准确率的箱线图
探索学习率
学习率控制每个模型对集成预测的贡献量。
较小的学习率可能需要在集成中使用更多的决策树,而较大的学习率可能需要较少的树。通常以对数刻度探索学习率值,例如在 0.0001 和 1.0 之间。
学习率可以通过“learning_rate”参数控制,默认为 0.1。
下面的示例探讨了学习率,并比较了 0.0001 和 1.0 之间值的影响。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# 探索梯度提升集成学习率对性能的影响 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import GradientBoostingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() # 定义要探索的学习率 for i in [0.0001, 0.001, 0.01, 0.1, 1.0]: key = '%.4f' % i models[key] = GradientBoostingClassifier(learning_rate=i) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集结果 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): # 评估模型 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 沿途总结性能 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个配置的学习率的平均准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到更大的学习率在此数据集上获得了更好的性能。我们期望对于较小的学习率,向集成中添加更多树会进一步提高性能。
这突出了树的数量(训练速度)和学习率之间的权衡,例如,我们可以通过使用较少的树和较大的学习率来更快地拟合模型。
|
1 2 3 4 5 |
>0.0001 0.761 (0.043) >0.0010 0.781 (0.034) >0.0100 0.836 (0.034) >0.1000 0.899 (0.030) >1.0000 0.908 (0.025) |
为每个配置的树数量创建了准确率分数的箱线图。
我们可以看到模型性能随着学习率的增加而增加的总体趋势。
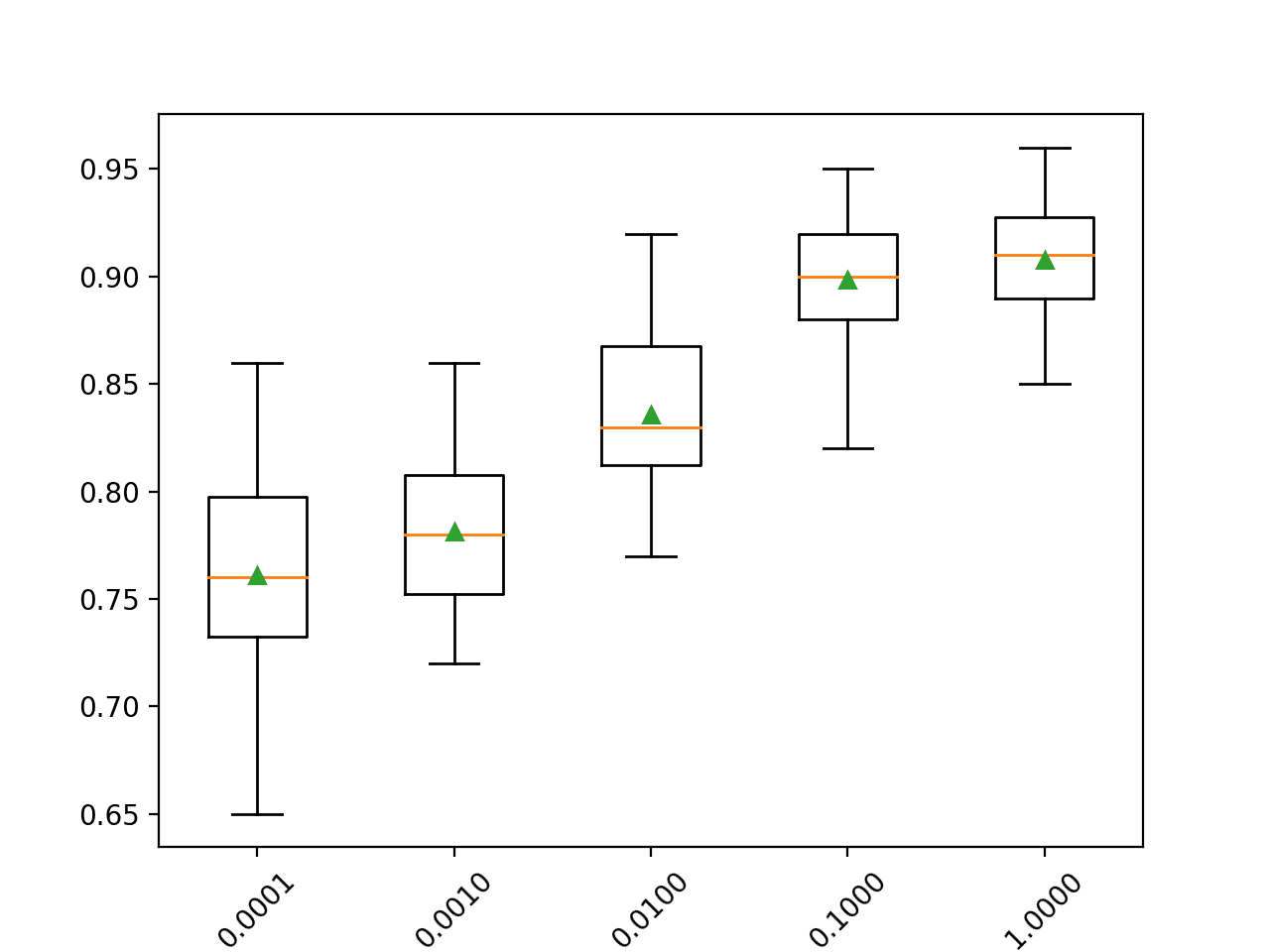
梯度提升集成学习率与分类准确率的箱线图
探索树深度
与改变用于拟合每个决策树的样本和特征数量类似,改变每棵树的深度是梯度提升的另一个重要超参数。
树的深度控制了每棵树对训练数据集的专业化程度:它可能有多通用或过拟合。首选的树既不太浅也不太通用(如 AdaBoost),也不太深也不太专业(如自助聚合)。
梯度提升在具有适中深度的树上表现良好,在技能和通用性之间找到了平衡。
树的深度通过“max_depth”参数控制,默认为 3。
下面的示例探讨了 1 到 10 之间的树深度以及对模型性能的影响。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# 探索梯度提升树深度对性能的影响 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import GradientBoostingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() # 定义要探索的树最大深度,范围在 1 到 10 之间 for i in range(1,11): models[str(i)] = GradientBoostingClassifier(max_depth=i) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集结果 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): # 评估模型 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 沿途总结性能 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个配置的树深度的平均准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到性能随着树的深度而提高,可能在深度为 3 到 6 左右达到峰值,之后更深、更专业的树会导致性能下降。
|
1 2 3 4 5 6 7 8 9 10 |
>1 0.834 (0.031) >2 0.877 (0.029) >3 0.899 (0.030) >4 0.905 (0.032) >5 0.916 (0.030) >6 0.912 (0.031) >7 0.908 (0.033) >8 0.888 (0.031) >9 0.853 (0.036) >10 0.835 (0.034) |
为每个配置的树深度的准确率分布创建了一个箱线图。
我们可以看到模型性能随着树的深度增加到一定程度的总体趋势,在此之后,过度专业的树会导致性能迅速下降。

梯度提升集成树深度与分类准确率的箱线图
网格搜索超参数
梯度提升的配置可能具有挑战性,因为该算法有许多影响模型在训练数据上行为的关键超参数,并且这些超参数相互作用。
因此,通常的做法是使用搜索过程来发现适用于给定预测建模问题的模型超参数配置。流行的搜索过程包括随机搜索和网格搜索。
在本节中,我们将介绍网格搜索梯度提升算法关键超参数的常见范围,您可以将其用作自己项目的起点。这可以使用 GridSearchCV 类并指定一个将模型超参数名称映射到要搜索的值的字典来实现。
在这种情况下,我们将对梯度提升的四个关键超参数进行网格搜索:集成中使用的树的数量、学习率、用于训练每棵树的子样本大小以及每棵树的最大深度。我们将为每个超参数使用一系列流行的、性能良好的值。
每个配置组合都将使用重复的 k 折交叉验证进行评估,并且将使用平均分数(在本例中为分类准确率)比较配置。
下面列出了在我们的合成分类数据集上对梯度提升算法的关键超参数进行网格搜索的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 在分类数据集上对梯度提升的关键超参数进行网格搜索的示例 from sklearn.datasets import make_classification from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.model_selection import GridSearchCV from sklearn.ensemble import GradientBoostingClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 使用默认超参数定义模型 model = GradientBoostingClassifier() # 定义要搜索的值网格 grid = dict() grid['n_estimators'] = [10, 50, 100, 500] grid['learning_rate'] = [0.0001, 0.001, 0.01, 0.1, 1.0] grid['subsample'] = [0.5, 0.7, 1.0] grid['max_depth'] = [3, 7, 9] # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义网格搜索过程 grid_search = GridSearchCV(estimator=model, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy') # 执行网格搜索 grid_result = grid_search.fit(X, y) # 总结最佳分数和配置 print("最佳: %f 使用 %s" % (grid_result.best_score_, grid_result.best_params_)) # 总结所有评估的分数 means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) |
运行示例可能需要一些时间,具体取决于您的硬件。运行结束时,首先报告获得最佳分数的配置,然后是考虑的所有其他配置的分数。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到学习率为 0.1、最大深度为 7 层、500 棵树和 70% 的子样本的配置表现最好,分类准确率约为 94.6%。
模型可能在更多的树(例如 1,000 或 5,000 棵)下表现更好,尽管在这种情况下没有测试这些配置,以确保网格搜索在合理的时间内完成。
|
1 2 3 4 5 6 7 |
最佳: 0.946667 使用 {'learning_rate': 0.1, 'max_depth': 7, 'n_estimators': 500, 'subsample': 0.7} 0.529667 (0.089012) 带有: {'learning_rate': 0.0001, 'max_depth': 3, 'n_estimators': 10, 'subsample': 0.5} 0.525667 (0.077875) 带有: {'learning_rate': 0.0001, 'max_depth': 3, 'n_estimators': 10, 'subsample': 0.7} 0.524000 (0.072874) 带有: {'learning_rate': 0.0001, 'max_depth': 3, 'n_estimators': 10, 'subsample': 1.0} 0.772667 (0.037500) 带有: {'learning_rate': 0.0001, 'max_depth': 3, 'n_estimators': 50, 'subsample': 0.5} 0.767000 (0.037696) 带有: {'learning_rate': 0.0001, 'max_depth': 3, 'n_estimators': 50, 'subsample': 0.7} ... |
常见问题
在本节中,我们将仔细研究您在使用梯度提升集成过程时可能遇到的一些常见难点。
问:集成中应该使用什么算法?
理论上,任何支持实例加权的高方差算法都可以用作集成的基础。
最常用于速度和模型性能的算法是具有有限树深度(例如 4 到 8 层)的决策树。
问:应该使用多少个集成成员?
集成中树的数量应根据数据集的具体情况和其他超参数(如学习率)进行调整。
问:集成树太多会不会过拟合?
是的,梯度提升模型会过拟合。
使用搜索过程(例如网格搜索)仔细选择模型超参数非常重要。
学习率,也称为收缩率,可以设置为较小的值,以减慢学习速度,同时增加集成中使用的模型数量,从而减少过拟合的影响。
问:梯度提升的缺点是什么?
梯度提升的配置可能具有挑战性,通常需要网格搜索或类似的搜索过程。
训练梯度提升模型可能非常缓慢,因为树必须按顺序添加,这与装袋和堆叠模型不同,后者的集成成员可以并行训练。
问:什么问题适合提升?
梯度提升在各种回归和分类预测建模问题上表现良好。
考虑到它平均表现出色,它可能是结构化数据(表格数据)最流行的算法之一。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
论文
- 边缘弧线, 1998.
- 随机梯度提升, 1999.
- 将算法提升为函数空间中的梯度下降, 1999.
API
文章
总结
在本教程中,您学习了如何开发用于分类和回归的梯度提升集成。
具体来说,你学到了:
- 梯度提升集成是一种由决策树顺序添加到模型中而创建的集成算法。
- 如何使用 scikit-learn 对分类和回归问题应用梯度提升集成算法。
- 如何探究梯度提升模型超参数对模型性能的影响。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……

 Ensemble in Python")
 Ensemble")



尊敬的Jason博士,
我对 GradientBoostingClassifier 有一个问题。
在您的示例中,y 的值为 0 或 1。
我的问题是 GradientBoostingClassifier 是否可以用于 y 包含 0、1、2 或 3 值的情况。
换句话说——GradientBoostingClassifier 是否可以用于预测 0、1、2 或 3 整数值?
谢谢你,
悉尼的Anthony
是的,这是多分类问题,梯度提升支持它。
尊敬的Jason博士,
我还有一个问题。
我们知道 make_classification 函数会生成高斯特征和整数因变量 y。
我们还知道 make_classification 不仅可以生成 0/1,还可以生成 0,1,2,3,4 离散值。
第一个问题:
我在 stackexchange 论坛上提了一个问题,询问是否存在一个类似于 make_classification 的函数,但它不是生成高斯特征,而是生成整数特征?
到目前为止,stackexchange 论坛一个多星期没有回复。
第二个问题
假设我们可以制作我们自己的 make_classification_with_integer_features 版本,我们可以使用以下函数吗?
谢谢你,
悉尼的Anthony
抱歉,我不知道有这样的内置函数,我无法为您准备这样一个函数。
尊敬的Jason博士,
谢谢你的回复。我不是要求任何人制作一个函数,如果该函数不可用/不是现成的。我可以自己编写。
假设我编写了一个生成函数,该函数生成属于整数集合的分类 Y 和属于整数集合的特征 X,并调用该函数
cross_val_score 函数是否可以计算属于整数集合的特征 X 的分数?
谢谢你,
悉尼的Anthony
如果目标是分类,则分层交叉验证方案与输入的數據類型无关。
尊敬的Jason博士,
非常感谢。
我正在开发一个函数,该函数接受属于整数集的 X 和属于整数集的 y。这是一个原型,当它工作时,我会把它放在这里。
谢谢你,
悉尼的Anthony
太棒了!
尊敬的Jason博士,
这是我对 make_classification_Y_with_integer_features_X 的实现
现在我将生成一个包含 1000 个样本和 20 个特征的集合。
似乎有效,需要在模型生成方面进行改进,尤其是在特征 X 和分类 Y 的分布方面。例如,泊松分布。
问题 – 0.52 分数的解释
谢谢你
悉尼的Anthony
干得好!
更多关于标准差的信息在这里
https://en.wikipedia.org/wiki/Standard_deviation
谢谢,帮助很大。
不客气!
感谢您创建这个平台,我总是用它来实践我学习的任何机器学习算法。我有一个关于 gradientboosting 中的 subsample 参数的问题,因为当我们添加另一棵树时,我们试图修正残差误差,subsample 如何减少方差?
不客气。
嗯...凭直觉,子样本会增加方差,而不是减少方差。
如果我有多个具有不同数据集的客户(例如客户 1 - 36 个月的数据和客户 2 - 12 个月的数据),如果我在同一时间为客户设置训练数据模型,最快的方法是查看模型对所有客户是否有效。我有超过 600,000 名客户,历史数据长度不一……
也许可以从您的较大数据集中抽取具有代表性的客户样本来评估您的模型。
有没有从头开始用 numpy 实现算法的?我没找到。
抱歉我不知道。我想我还没有。
嗨,Jason,
感谢这篇精彩的教程
我们是否可以将梯度提升算法用于决策树以外的任何模型?
您推荐任何这方面的教程吗?
谢谢
是的,或者可能取决于你正在进行的提升的复杂性,尽管其他方法效果不佳。