梯度下降是一种优化算法,它沿着目标函数的负梯度方向移动,以找到函数的最小值。
它是一种简单有效的技术,只需几行代码即可实现。它还为许多可以带来更好性能的扩展和修改提供了基础。该算法也为广泛使用的扩展,即随机梯度下降(用于训练深度学习神经网络)提供了基础。
在本教程中,您将学习如何从零开始实现梯度下降优化。
完成本教程后,您将了解:
- 梯度下降是优化可微分目标函数的通用过程。
- 如何在Python中从零开始实现梯度下降算法。
- 如何将梯度下降算法应用于目标函数。
通过我的新书《机器学习优化》启动您的项目,其中包括逐步教程和所有示例的Python源代码文件。
让我们开始吧。
如何从零开始实现梯度下降优化
图片由Bernd Thaller提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 梯度下降
- 梯度下降算法
- 梯度下降示例
梯度下降优化
梯度下降是一种优化算法。
它在技术上被称为一阶优化算法,因为它明确使用了目标函数的一阶导数。
一阶方法依赖梯度信息来帮助指导寻找最小值……
——第69页,《优化算法》,2019年。
一阶导数,或简称为“导数”,是目标函数在特定点(例如,对于特定输入)的变化率或斜率。
如果目标函数接受多个输入变量,则称为多元函数,输入变量可以被视为向量。反过来,多元目标函数的导数也可以被视为向量,通常被称为“梯度”。
- 梯度:多元目标函数的一阶导数。
导数或梯度指向输入处目标函数最陡峭上升的方向。
梯度指向切线超平面最陡峭上升的方向……
——第21页,《优化算法》,2019年。
具体来说,梯度的符号告诉您目标函数在该点是增加还是减少。
- 正梯度:函数在该点增加。
- 负梯度:函数在该点减少。
梯度下降指一种最小化优化算法,它沿着目标函数的负梯度方向“下坡”移动,以找到函数的最小值。
类似地,我们可以将梯度上升称为优化算法的最大化版本,它沿着梯度方向“上坡”移动,以找到目标函数的最大值。
- 梯度下降:最小化优化,沿着负梯度方向找到目标函数的最小值。
- 梯度上升:最大化优化,沿着梯度方向找到目标函数的最大值。
梯度下降算法的核心思想是沿着目标函数的梯度方向移动。
根据定义,该优化算法仅适用于导数函数存在且可以为所有输入值计算的目标函数。这不适用于所有目标函数,仅适用于所谓的可微分函数。
梯度下降算法的主要优点是它易于实现,并且对各种优化问题都有效。
梯度方法易于实现,并且通常表现良好。
——第115页,《优化导论》,2001年。
梯度下降指一类使用一阶导数导航到目标函数最优点(最小值或最大值)的算法。
主方法有许多扩展,通常以添加到算法中的特征命名,例如带动量的梯度下降、带自适应梯度的梯度下降等等。
梯度下降也是用于训练深度学习神经网络的优化算法(称为随机梯度下降,或SGD)的基础。在这种变体中,目标函数是一个误差函数,函数梯度是通过问题域样本的预测误差近似的。
现在我们对梯度下降优化有了高层次的理解,接下来让我们看看如何实现该算法。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
梯度下降算法
在本节中,我们将更深入地研究梯度下降算法。
梯度下降算法需要一个正在优化的目标函数和目标函数的导数函数。
目标函数f()返回给定输入集的分数,导数函数f'()返回给定输入集的目标函数的导数。
- 目标函数:计算给定输入参数集的分数。
导数函数:计算给定输入集的目标函数的导数(梯度)。
梯度下降算法需要问题中的一个起点(x),例如输入空间中随机选择的一个点。
然后计算导数,并在输入空间中迈出一步,预计会导致目标函数下坡移动(假设我们正在最小化目标函数)。
下坡移动首先计算在输入空间中移动的距离,该距离计算为步长(称为alpha或学习率)乘以梯度。然后从当前点减去该值,确保我们逆着梯度方向移动,即沿着目标函数向下移动。
- x_new = x – alpha * f'(x)
目标函数在给定点越陡峭,梯度的幅值越大,反过来,在搜索空间中迈出的步长也越大。
所迈出的步长大小使用步长超参数进行缩放。
- 步长(alpha):超参数,控制算法每次迭代在搜索空间中逆着梯度方向移动的距离。
如果步长太小,在搜索空间中的移动会很小,搜索将花费很长时间。如果步长太大,搜索可能会在搜索空间中跳跃并跳过最优解。
我们可以选择迈出非常小的步长并在每一步重新评估梯度,或者我们可以每次迈出大步长。第一种方法导致达到最小值的过程繁琐,而第二种方法可能导致通往最小值的路径更曲折。
——第114页,《优化导论》,2001年。
对于特定的目标函数,找到一个好的步长可能需要一些反复试验。
选择步长的难度使得很难找到目标函数的精确最优值。许多扩展涉及随时间调整学习率,以在不同维度上采取更小的步长或不同大小的步长,等等,以使算法能够精确定位函数的最优值。
计算一个点的导数并在输入空间中计算一个新点的过程会重复,直到满足某个停止条件。这可能是一个固定数量的步数或目标函数评估次数,在一定数量的迭代中目标函数评估没有改进,或者识别出搜索空间中的平坦(静止)区域,其梯度为零。
- 停止条件:决定何时结束搜索过程。
让我们看看如何在Python中实现梯度下降算法。
首先,我们可以将初始点定义为由边界定义的输入空间中随机选择的点。
边界可以与目标函数一起定义为一个数组,其中包含每个维度的最小值和最大值。 rand() NumPy函数可用于生成0-1范围内的随机数向量。
|
1 2 3 |
... # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) |
然后我们可以使用名为 derivative() 的函数计算该点的导数。
|
1 2 3 |
... # 计算梯度 gradient = derivative(solution) |
并在搜索空间中迈出一步,到达当前点下坡的新点。
新位置是使用计算出的梯度和 step_size 超参数计算的。
|
1 2 3 |
... # 迈出一步 solution = solution - step_size * gradient |
然后我们可以评估这个点并报告性能。
|
1 2 3 |
... # 评估候选点 solution_eval = objective(solution) |
此过程可以重复固定次数的迭代,由 n_iter 超参数控制。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 运行梯度下降 for i in range(n_iter): # 计算梯度 gradient = derivative(solution) # 迈出一步 solution = solution - step_size * gradient # 评估候选点 solution_eval = objective(solution) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) |
我们可以将所有这些内容组合成一个名为 gradient_descent() 的函数。
该函数接受目标函数和梯度函数的名称,以及目标函数的输入边界、迭代次数和步长,然后返回搜索结束时的解决方案及其评估。
下面列出了作为函数实现的完整梯度下降优化算法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 梯度下降算法 def gradient_descent(objective, derivative, bounds, n_iter, step_size): # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 运行梯度下降 for i in range(n_iter): # 计算梯度 gradient = derivative(solution) # 迈出一步 solution = solution - step_size * gradient # 评估候选点 solution_eval = objective(solution) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solution, solution_eval] |
现在我们熟悉了梯度下降算法,接下来让我们看一个实际的例子。
梯度下降示例
在本节中,我们将通过一个将梯度下降应用于简单测试优化函数的示例。
首先,让我们定义一个优化函数。
我们将使用一个简单的一维函数,该函数将输入平方并将有效输入范围定义为-1.0到1.0。
下面的 objective() 函数实现了这个函数。
|
1 2 3 |
# 目标函数 def objective(x): return x**2.0 |
然后我们可以对范围内的所有输入进行采样,并计算每个输入的目标函数值。
|
1 2 3 4 5 6 7 |
... # 定义输入范围 r_min, r_max = -1.0, 1.0 # 以 0.1 为增量均匀采样输入范围 inputs = arange(r_min, r_max+0.1, 0.1) # 计算目标值 results = objective(inputs) |
最后,我们可以绘制输入(x轴)与目标函数值(y轴)的线图,以直观了解我们将要搜索的目标函数的形状。
|
1 2 3 4 5 |
... # 绘制输入与结果的线图 pyplot.plot(inputs, results) # 显示绘图 pyplot.show() |
下面的例子将这些内容结合在一起,并提供了一个绘制一维测试函数的例子。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 简单函数的图 from numpy import arange from matplotlib import pyplot # 目标函数 def objective(x): return x**2.0 # 定义输入范围 r_min, r_max = -1.0, 1.0 # 以 0.1 为增量均匀采样输入范围 inputs = arange(r_min, r_max+0.1, 0.1) # 计算目标值 results = objective(inputs) # 绘制输入与结果的线图 pyplot.plot(inputs, results) # 显示绘图 pyplot.show() |
运行该示例会创建函数输入(x轴)和函数计算输出(y轴)的线图。
我们可以看到熟悉的U形,称为抛物线。
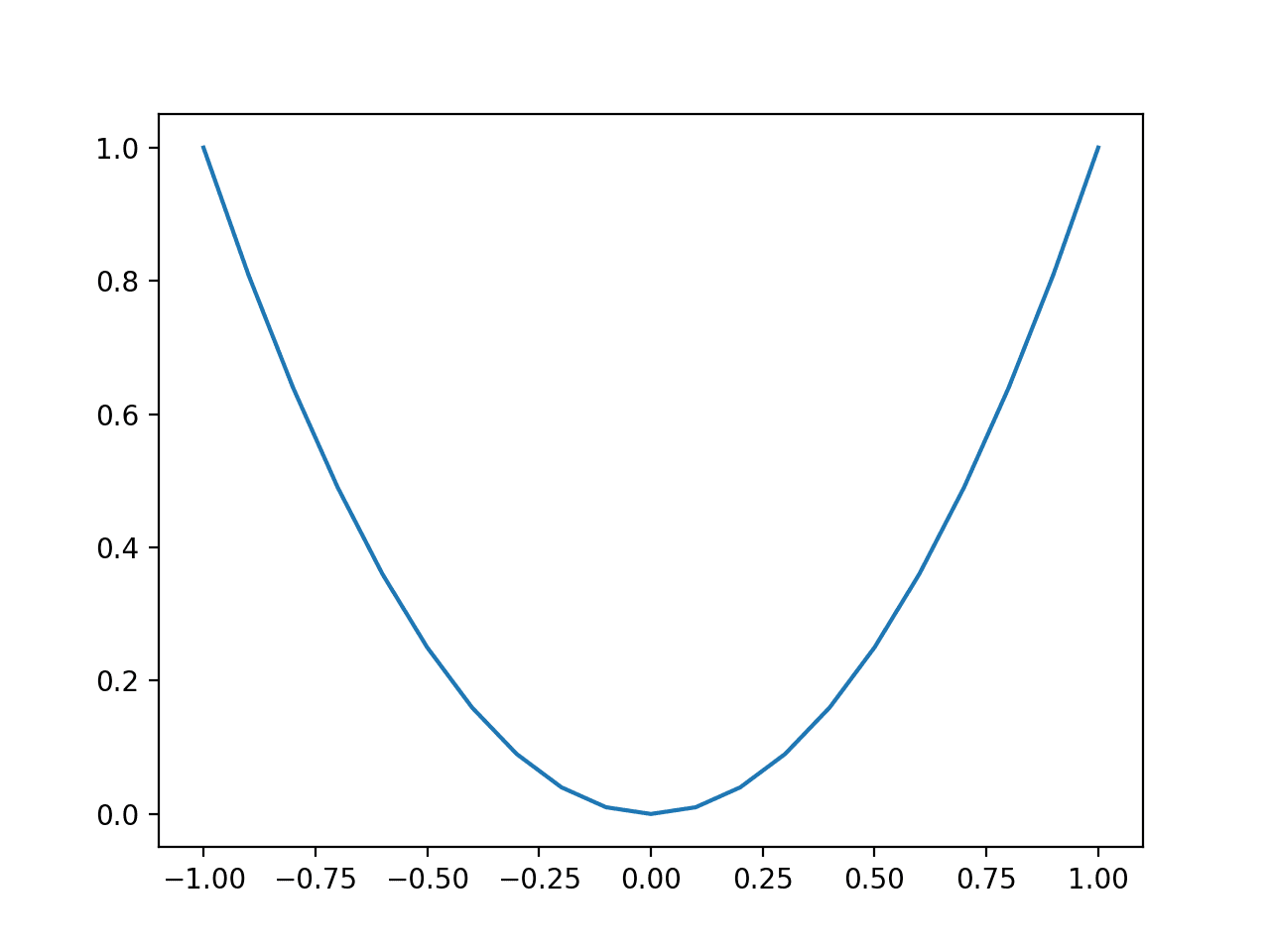
简单一维函数的线图
接下来,我们可以将梯度下降算法应用于此问题。
首先,我们需要一个函数来计算此函数的导数。
x^2的导数是x * 2,下面的 derivative() 函数实现了这一点。
|
1 2 3 |
# 目标函数的导数 def derivative(x): return x * 2.0 |
然后我们可以定义目标函数的边界、步长和算法的迭代次数。
我们将使用0.1的步长和30次迭代,这两者都是经过一些实验后发现的。
|
1 2 3 4 5 6 7 8 9 |
... # 定义输入范围 bounds = asarray([[-1.0, 1.0]]) # 定义总迭代次数 n_iter = 30 # 定义最大步长 step_size = 0.1 # 执行梯度下降搜索 best, score = gradient_descent(objective, derivative, bounds, n_iter, step_size) |
综合来看,下面列出了将梯度下降优化应用于一维测试函数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 一维函数梯度下降示例 from numpy import asarray from numpy.random import rand # 目标函数 def objective(x): return x**2.0 # 目标函数的导数 def derivative(x): return x * 2.0 # 梯度下降算法 def gradient_descent(objective, derivative, bounds, n_iter, step_size): # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 运行梯度下降 for i in range(n_iter): # 计算梯度 gradient = derivative(solution) # 迈出一步 solution = solution - step_size * gradient # 评估候选点 solution_eval = objective(solution) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solution, solution_eval] # 定义输入范围 bounds = asarray([[-1.0, 1.0]]) # 定义总迭代次数 n_iter = 30 # 定义步长 step_size = 0.1 # 执行梯度下降搜索 best, score = gradient_descent(objective, derivative, bounds, n_iter, step_size) print('Done!') print('f(%s) = %f' % (best, score)) |
运行示例会从搜索空间中的一个随机点开始,然后应用梯度下降算法,并在此过程中报告性能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到算法在大约20-30次迭代后找到了一个很好的解,函数评估值约为0.0。请注意,此函数的最优值在f(0.0) = 0.0处。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
>0 f([-0.36308639]) = 0.13183 >1 f([-0.29046911]) = 0.08437 >2 f([-0.23237529]) = 0.05400 >3 f([-0.18590023]) = 0.03456 >4 f([-0.14872018]) = 0.02212 >5 f([-0.11897615]) = 0.01416 >6 f([-0.09518092]) = 0.00906 >7 f([-0.07614473]) = 0.00580 >8 f([-0.06091579]) = 0.00371 >9 f([-0.04873263]) = 0.00237 >10 f([-0.0389861]) = 0.00152 >11 f([-0.03118888]) = 0.00097 >12 f([-0.02495111]) = 0.00062 >13 f([-0.01996089]) = 0.00040 >14 f([-0.01596871]) = 0.00025 >15 f([-0.01277497]) = 0.00016 >16 f([-0.01021997]) = 0.00010 >17 f([-0.00817598]) = 0.00007 >18 f([-0.00654078]) = 0.00004 >19 f([-0.00523263]) = 0.00003 >20 f([-0.0041861]) = 0.00002 >21 f([-0.00334888]) = 0.00001 >22 f([-0.0026791]) = 0.00001 >23 f([-0.00214328]) = 0.00000 >24 f([-0.00171463]) = 0.00000 >25 f([-0.0013717]) = 0.00000 >26 f([-0.00109736]) = 0.00000 >27 f([-0.00087789]) = 0.00000 >28 f([-0.00070231]) = 0.00000 >29 f([-0.00056185]) = 0.00000 完成! f([-0.00056185]) = 0.000000 |
现在,让我们感受一下良好步长的重要性。
将步长设置为一个较大的值,例如1.0,然后重新运行搜索。
|
1 2 3 |
... # 定义步长 step_size = 1.0 |
运行示例,使用较大的步长并检查结果。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
我们可以看到搜索没有找到最优解,而是在域中跳跃,在这种情况下,在0.64820935和-0.64820935之间。
|
1 2 3 4 5 6 7 8 |
... >25 f([0.64820935]) = 0.42018 >26 f([-0.64820935]) = 0.42018 >27 f([0.64820935]) = 0.42018 >28 f([-0.64820935]) = 0.42018 >29 f([0.64820935]) = 0.42018 完成! f([0.64820935]) = 0.420175 |
现在,尝试一个更小的步长,例如1e-8。
|
1 2 3 |
... # 定义步长 step_size = 1e-5 |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
重新运行搜索,我们可以看到算法从起点沿着目标函数的斜坡非常缓慢地移动。
|
1 2 3 4 5 6 7 8 |
... >25 f([-0.87315153]) = 0.76239 >26 f([-0.87313407]) = 0.76236 >27 f([-0.8731166]) = 0.76233 >28 f([-0.87309914]) = 0.76230 >29 f([-0.87308168]) = 0.76227 完成! f([-0.87308168]) = 0.762272 |
这两个快速示例强调了选择过大或过小步长的问题,以及针对给定目标函数测试许多不同步长值的重要性。
最后,我们可以将学习率改回0.1,并在目标函数的图上可视化搜索的进展。
首先,我们可以更新 gradient_descent() 函数,将优化过程中找到的所有解决方案及其分数存储为列表,并在搜索结束时返回它们,而不是返回找到的最佳解决方案。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 梯度下降算法 def gradient_descent(objective, derivative, bounds, n_iter, step_size): # 跟踪所有解决方案 solutions, scores = list(), list() # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 运行梯度下降 for i in range(n_iter): # 计算梯度 gradient = derivative(solution) # 迈出一步 solution = solution - step_size * gradient # 评估候选点 solution_eval = objective(solution) # 存储解决方案 solutions.append(solution) scores.append(solution_eval) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solutions, scores] |
可以调用该函数,我们可以获取搜索过程中找到的解决方案及其分数的列表。
|
1 2 3 |
... # 执行梯度下降搜索 solutions, scores = gradient_descent(objective, derivative, bounds, n_iter, step_size) |
我们可以像以前一样创建目标函数的线图。
|
1 2 3 4 5 6 7 |
... # 以 0.1 为增量均匀采样输入范围 inputs = arange(bounds[0,0], bounds[0,1]+0.1, 0.1) # 计算目标值 results = objective(inputs) # 绘制输入与结果的线图 pyplot.plot(inputs, results) |
最后,我们可以将找到的每个解决方案绘制为红点,并用线连接这些点,以便我们能够看到搜索如何向下移动。
|
1 2 3 |
... # 绘制找到的解决方案 pyplot.plot(solutions, scores, '.-', color='red') |
综合来看,下面列出了在一维测试函数上绘制梯度下降搜索结果的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# 绘制一维函数上梯度下降搜索的示例 from numpy import asarray from numpy import arange from numpy.random import rand from matplotlib import pyplot # 目标函数 def objective(x): return x**2.0 # 目标函数的导数 def derivative(x): return x * 2.0 # 梯度下降算法 def gradient_descent(objective, derivative, bounds, n_iter, step_size): # 跟踪所有解决方案 solutions, scores = list(), list() # 生成初始点 solution = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 运行梯度下降 for i in range(n_iter): # 计算梯度 gradient = derivative(solution) # 迈出一步 solution = solution - step_size * gradient # 评估候选点 solution_eval = objective(solution) # 存储解决方案 solutions.append(solution) scores.append(solution_eval) # 报告进度 print('>%d f(%s) = %.5f' % (i, solution, solution_eval)) return [solutions, scores] # 定义输入范围 bounds = asarray([[-1.0, 1.0]]) # 定义总迭代次数 n_iter = 30 # 定义步长 step_size = 0.1 # 执行梯度下降搜索 solutions, scores = gradient_descent(objective, derivative, bounds, n_iter, step_size) # 以 0.1 为增量均匀采样输入范围 inputs = arange(bounds[0,0], bounds[0,1]+0.1, 0.1) # 计算目标值 results = objective(inputs) # 绘制输入与结果的线图 pyplot.plot(inputs, results) # 绘制找到的解决方案 pyplot.plot(solutions, scores, '.-', color='red') # 显示绘图 pyplot.show() |
运行示例会像以前一样在目标函数上执行梯度下降搜索,但在这种情况下,搜索过程中找到的每个点都会被绘制出来。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到搜索从函数左侧大约一半的位置开始,然后逐步向下移动到盆地的底部。
我们可以看到,在目标函数曲率较大的部分,导数(梯度)也较大,因此步长也较大。类似地,当我们接近最优值时,梯度较小,因此步长也较小。
这突出表明步长用作目标函数梯度(曲率)幅值的比例因子。
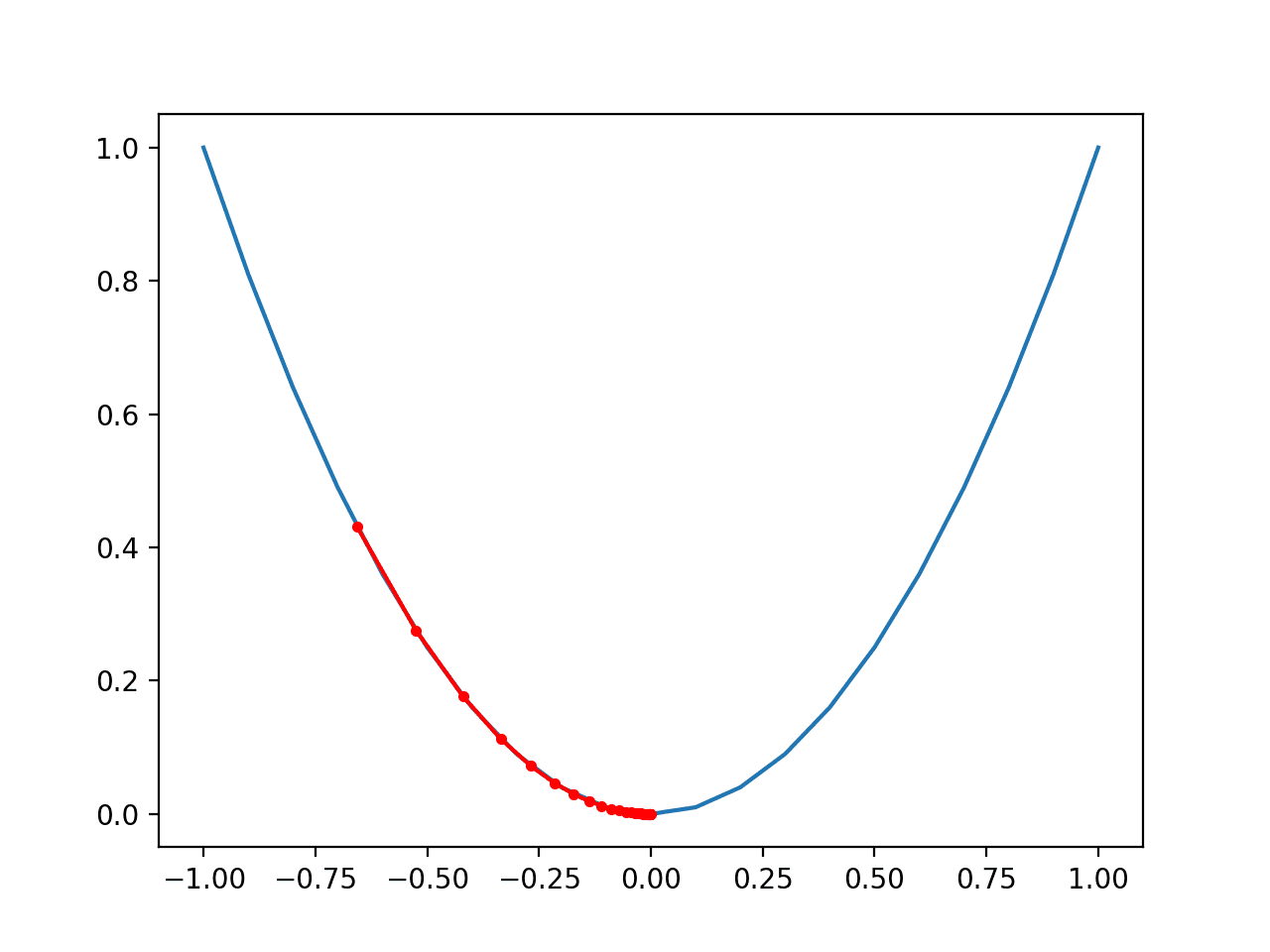
一维目标函数上梯度下降进展图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
API
文章
总结
在本教程中,您学习了如何从零开始实现梯度下降优化。
具体来说,你学到了:
- 梯度下降是优化可微分目标函数的通用过程。
- 如何在Python中从零开始实现梯度下降算法。
- 如何将梯度下降算法应用于目标函数。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







好东西。你的“从零开始”博客是我的最爱!
谢谢!
谢谢你,Jason。等你什么时候有时间,能不能写一篇关于使用预训练模型进行时间序列预测的博客。我看到了你关于CNN的帖子。我想知道你是否可以写一篇关于预训练LSTM、随机森林或MLP模型的帖子
感谢您的建议。
这是一个很好的概述。我想看到的是关于当你不知道目标函数的导数是什么时该怎么做的讨论。毕竟,找到抛物线的最小值是相当微不足道的。当您有一个大型多维空间需要搜索且计算时间至关重要时会发生什么?如何确定梯度?如何决定每个维度中的步长是多少?谢谢您的本教程。
谢谢。
如果您没有导数,可以使用直接搜索方法(Nelder-Mead)或随机方法,如遗传算法、模拟退火、差分进化等。
大空间意味着需要更多的搜索。如果评估速度慢,您可以使用替代函数/代理函数。
难道不能以某种方式使用梯度下降并数值估计梯度吗?例如,使用有限差分……
是的,可以。但问题在于,当您有一个2D函数时,当前点周围有无限多个点(在一个圆上)。如何有效地评估有限差分是一个问题。实际上,Nelder-Mead算法正是这样做的,请参阅https://machinelearning.org.cn/how-to-use-nelder-mead-optimization-in-python/
你好 Jason,
你做了 f(x) = x ^ 2,f'是 2x。当 x > 0 时,梯度为正,你减少 x,从而最小化损失。
然而,当 f(x) = x ^ 2 – 4 时,只是添加一个常数:梯度也变为 2x。
最小值将在 x = 2 处,为零。当 x = 1 时,梯度变为正,
x := x – alpha * (2x)
将减少 x 而不是增加它。我们如何解决这个问题?(不取二阶导数)
梯度可能是正的或负的,这确保我们以正确的方向移动系数以减少损失。
哦,是 f = (x-2) ^ 2
不是 x^2 -4,是我的错。
循序渐进,非常清楚
谢谢!
嗯,你在哪里找到一个名为“derivative”的函数?
您必须根据您的目标函数来定义它。例如,如果目标函数是 f(x)=x*x,那么导数函数就是 f(x)=x。
但如果你的目标函数不同,返回的是RMSE、ROC_AUC或其他一些指标。你如何推导出来呢?
你好 Henrik……以下内容可能对你有帮助
https://www.statology.org/rmse-python/