梯度下降是一种优化算法,它沿着目标函数的负梯度方向移动,以找到函数的最小值。
梯度下降的一个限制是,对于所有输入变量都使用一个固定步长(学习率)。梯度下降的扩展,如自适应估计(Adam)算法,为每个输入变量使用一个单独的步长,但可能会导致步长快速减小到非常小的值。
AdaMax 是梯度下降的 Adam 版本的扩展,它将该方法推广到无穷范数(最大值),并且可能在某些问题上产生更有效的优化。
在本教程中,您将学习如何从头开始开发 AdaMax 梯度下降优化。
完成本教程后,您将了解:
- 梯度下降是一种优化算法,它利用目标函数的梯度来导航搜索空间。
- AdaMax 是梯度下降的 Adam 版本的扩展,旨在加速优化过程。
- 如何从头开始实现 AdaMax 优化算法,并将其应用于目标函数并评估结果。
立即开始您的项目,阅读我的新书 《机器学习优化》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
从零开始用AdaMax实现梯度下降优化
照片由 Don Graham 拍摄,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 梯度下降
- AdaMax 优化算法
- 带有 AdaMax 的梯度下降
- 二维测试问题
- 带有 AdaMax 的梯度下降优化
- AdaMax 优化的可视化
梯度下降
梯度下降是一种优化算法。
它在技术上被称为一阶优化算法,因为它明确使用了目标函数的一阶导数。
一阶方法依赖梯度信息来帮助指导寻找最小值……
——第69页,《优化算法》,2019年。
一阶导数,或简称为“导数”,是目标函数在特定点(例如,对于特定输入)的变化率或斜率。
如果目标函数有多个输入变量,则称其为多元函数,输入变量可以被视为一个向量。反过来,多元目标函数的导数也可以被视为一个向量,通常称为梯度。
- 梯度:多元目标函数的一阶导数。
导数或梯度指向特定输入处目标函数最陡峭上升的方向。
梯度下降指一种最小化优化算法,它沿着目标函数的负梯度方向“下坡”移动,以找到函数的最小值。
梯度下降算法需要一个被优化的目标函数以及目标函数的导数函数。目标函数 f() 返回给定输入集的得分,而导数函数 f'() 返回给定输入集的该目标函数的导数。
梯度下降算法需要问题中的一个起始点(x),例如输入空间中随机选择的一个点。
然后计算导数,并在输入空间中迈出一步,预计会导致目标函数下坡移动(假设我们正在最小化目标函数)。
通过首先计算在输入空间中移动的距离(计算为步长(称为 alpha 或学习率)乘以梯度)来实现下坡移动。然后将其从当前点减去,确保我们沿着梯度的反方向移动,即沿着目标函数的下降方向。
- x(t) = x(t-1) – step_size * f'(x(t))
给定点处目标函数越陡峭,梯度的幅值越大,反之,在搜索空间中迈出的步长也越大。所迈步长的大小由步长超参数进行缩放。
- 步长:控制算法每次迭代中逆着梯度在搜索空间中移动距离的超参数。
如果步长太小,在搜索空间中的移动会很小,搜索将花费很长时间。如果步长太大,搜索可能会在搜索空间中跳跃并跳过最优解。
现在我们熟悉了梯度下降优化算法,让我们来看看 AdaMax 算法。
AdaMax 优化算法
AdaMax 算法是自适应估计(Adam)优化算法的扩展。更广泛地说,它是梯度下降优化算法的扩展。
该算法由 Diederik Kingma 和 Jimmy Lei Ba 在 2014 年的论文“Adam: A Method for Stochastic Optimization”中进行了描述。
Adam 可以理解为根据过去梯度的缩放 L2 范数(平方)的倒数来更新权重。AdaMax 将此扩展到过去梯度的所谓无穷范数(最大值)。
在 Adam 中,对单个权重的更新规则是根据其个体当前和过去梯度的(缩放)L^2 范数的倒数来缩放它们的梯度。
— Adam: A Method for Stochastic Optimization, 2014。
一般来说,AdaMax 会为优化问题中的每个参数自动调整一个单独的步长(学习率)。
让我们逐步了解算法的每个元素。
首先,我们必须在搜索过程中为每个优化参数维护一个动量向量和一个指数加权无穷范数,分别称为*m*和*u*。
它们在搜索开始时初始化为 0.0。
- m = 0
- u = 0
该算法随时间 t(从 t=1 开始)进行迭代执行,每次迭代都涉及计算一组新的参数值 x,例如从*x(t-1)*变为*x(t)*。
如果我们将重点放在更新一个参数上,可能会更容易理解该算法,这可以通过向量运算推广到更新所有参数。
首先,计算当前时间步的梯度(偏导数)。
- g(t) = f'(x(t-1))
接下来,使用梯度和超参数*beta1*更新动量向量。
- m(t) = beta1 * m(t-1) + (1 – beta1) * g(t)
使用*beta2*超参数更新指数加权无穷范数。
- u(t) = max(beta2 * u(t-1), abs(g(t)))
其中*max()*选择参数的最大值,*abs()*计算绝对值。
然后我们可以更新参数值。这可以分解为三个部分;第一部分计算步长参数,第二部分计算梯度,第三部分使用步长和梯度计算新参数值。
让我们从使用称为*alpha*的初始步长超参数以及一个随时间衰减的*beta1*版本(此时间步长为*beta1(t)*)计算参数步长开始
- step_size(t) = alpha / (1 – beta1(t))
用于更新参数的梯度计算如下:
- delta(t) = m(t) / u(t)
最后,我们可以计算此迭代的参数值。
- x(t) = x(t-1) – step_size(t) * delta(t)
或者完整的更新方程可以表述为:
- x(t) = x(t-1) – (alpha / (1 – beta1(t))) * m(t) / u(t)
回顾一下,该算法有三个超参数;它们是
- alpha:初始步长(学习率),典型值为0.002。
- **beta1**:一阶动量的衰减因子,典型值为 0.9。
- **beta2**:无穷范数的衰减因子,典型值为 0.999。
论文中建议的 beta1(t) 的衰减计划是通过将初始 beta1 值提高到 t 次幂来计算的,尽管也可以使用其他衰减计划,例如保持值不变或更积极地衰减。
- beta1(t) = beta1^t
就是这样。
有关 Adam 算法背景下 AdaMax 算法的完整推导,我建议阅读论文。
- Adam:一种随机优化方法, 2014.
接下来,我们看看如何在Python中从头开始实现该算法。
带有 AdaMax 的梯度下降
在本节中,我们将探讨如何实现带有 AdaMax 动量的梯度下降优化算法。
二维测试问题
首先,让我们定义一个优化函数。
我们将使用一个简单的二维函数,它将每个维度的输入平方,并将有效输入范围定义为-1.0到1.0。
下面的 objective() 函数实现了这一点。
|
1 2 3 |
# 目标函数 def objective(x, y): return x**2.0 + y**2.0 |
我们可以创建一个数据集的三维图来感受响应曲面的曲率。
下面列出了绘制目标函数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 绘制测试函数的三维图 from numpy import arange from numpy import meshgrid from matplotlib import pyplot # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 定义输入范围 r_min, r_max = -1.0, 1.0 # 以 0.1 为增量均匀采样输入范围 xaxis = arange(r_min, r_max, 0.1) yaxis = arange(r_min, r_max, 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 使用 jet 配色方案创建曲面图 figure = pyplot.figure() axis = figure.gca(projection='3d') axis.plot_surface(x, y, results, cmap='jet') # 显示绘图 pyplot.show() |
运行示例将创建目标函数的三维曲面图。
我们可以看到熟悉的碗形,全局最小值在 f(0, 0) = 0。
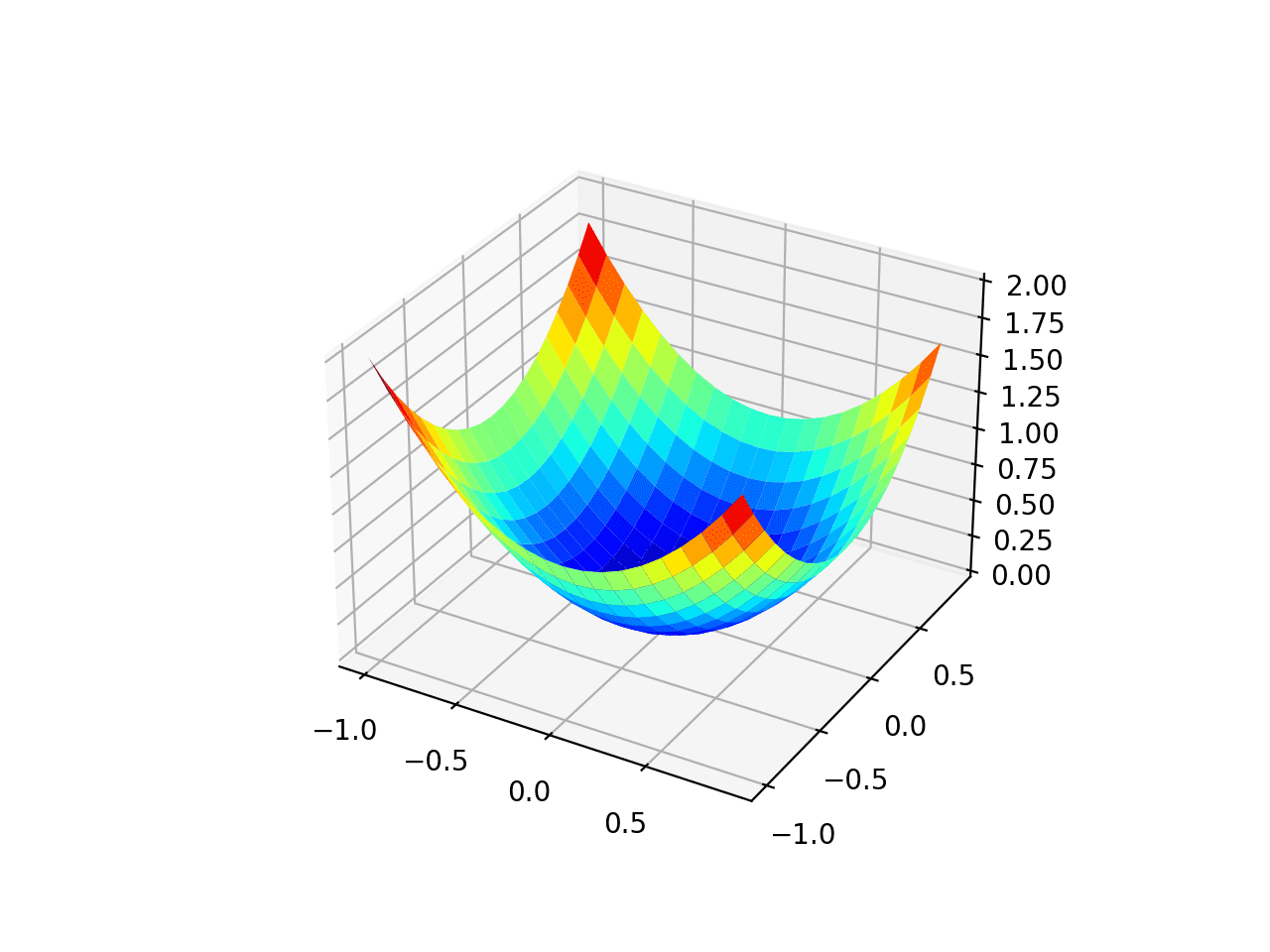
测试目标函数的三维图
我们还可以创建函数的二维图。这将在以后我们想要绘制搜索进度时提供帮助。
以下示例创建了目标函数的等高线图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 绘制测试函数的等高线图 from numpy import asarray from numpy import arange from numpy import meshgrid from matplotlib import pyplot # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 以 0.1 为增量均匀采样输入范围 xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 使用50个级别和jet颜色方案创建填充等高线图 pyplot.contourf(x, y, results, levels=50, cmap='jet') # 显示绘图 pyplot.show() |
运行示例将创建目标函数的二维等高线图。
我们可以看到碗状被压缩成用颜色梯度显示的等高线。我们将使用这个图来绘制搜索过程中探索的特定点。
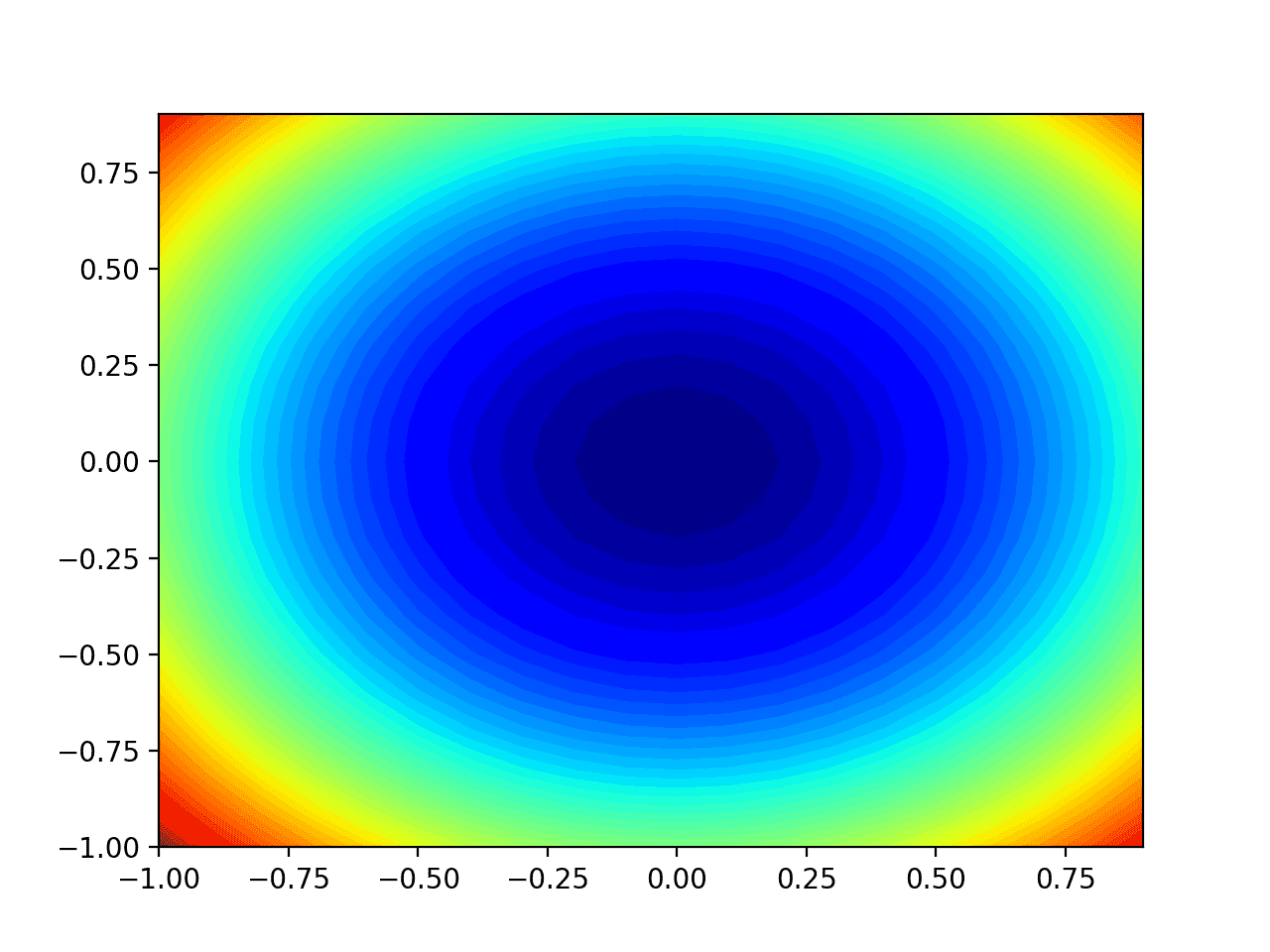
测试目标函数的二维等高线图
既然我们有了测试目标函数,让我们看看如何实现 AdaMax 优化算法。
带有 AdaMax 的梯度下降优化
我们可以将带有 AdaMax 的梯度下降应用于测试问题。
首先,我们需要一个函数来计算此函数的导数。
x^2 在每个维度上的导数是 x * 2。
- f(x) = x^2
- f'(x) = x * 2
derivative() 函数如下实现。
|
1 2 3 |
# 目标函数的导数 def derivative(x, y): return asarray([x * 2.0, y * 2.0]) |
接下来,我们可以实现 AdaMax 梯度下降优化。
首先,我们可以在问题的边界内选择一个随机点作为搜索的起点。
这假设我们有一个数组,它定义了搜索的边界,每行一个维度,第一列定义最小值,第二列定义最大值。
|
1 2 3 |
... # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) |
接下来,我们需要初始化动量向量和指数加权无穷范数。
|
1 2 3 4 |
... # 初始化动量向量和加权无穷范数 m = [0.0 for _ in range(bounds.shape[0])] u = [0.0 for _ in range(bounds.shape[0])] |
然后我们运行由“_n_iter_”超参数定义的固定迭代次数。
|
1 2 3 4 |
... # 运行梯度下降迭代 for t in range(n_iter): ... |
第一步是计算当前参数集的导数。
|
1 2 3 |
... # 计算梯度 g(t) g = derivative(x[0], x[1]) |
接下来,我们需要执行 AdaMax 更新计算。我们将使用命令式编程风格一次处理一个变量,以提高可读性。
实际上,我建议使用NumPy向量操作以提高效率。
|
1 2 3 4 |
... # 逐个变量构建解 for i in range(x.shape[0]): ... |
首先,我们需要计算动量向量。
|
1 2 3 |
... # m(t) = beta1 * m(t-1) + (1 - beta1) * g(t) m[i] = beta1 * m[i] + (1.0 - beta1) * g[i] |
接下来,我们需要计算指数加权无穷范数。
|
1 2 3 |
... # u(t) = max(beta2 * u(t-1), abs(g(t))) u[i] = max(beta2 * u[i], abs(g[i])) |
然后是更新中使用的步长。
|
1 2 3 |
... # step_size(t) = alpha / (1 - beta1(t)) step_size = alpha / (1.0 - beta1**(t+1)) |
以及变量的变化。
|
1 2 3 |
... # delta(t) = m(t) / u(t) delta = m[i] / u[i] |
最后,我们可以计算变量的新值。
|
1 2 3 |
... # x(t) = x(t-1) - step_size(t) * delta(t) x[i] = x[i] - step_size * delta |
然后对每个要优化的参数重复此操作。
在迭代结束时,我们可以评估新的参数值并报告搜索的性能。
|
1 2 3 4 5 |
... # 评估候选点 score = objective(x[0], x[1]) # 报告进展 print('>%d f(%s) = %.5f' % (t, x, score)) |
我们可以将所有这些内容整合到一个名为*adamax()*的函数中,该函数接受目标函数和导数函数的名称以及算法超参数,并返回在搜索结束时找到的最佳解决方案及其评估结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 带有 adamax 的梯度下降算法 def adamax(objective, derivative, bounds, n_iter, alpha, beta1, beta2): # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 初始化动量向量和加权无穷范数 m = [0.0 for _ in range(bounds.shape[0])] u = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降的迭代 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(x.shape[0]): # m(t) = beta1 * m(t-1) + (1 - beta1) * g(t) m[i] = beta1 * m[i] + (1.0 - beta1) * g[i] # u(t) = max(beta2 * u(t-1), abs(g(t))) u[i] = max(beta2 * u[i], abs(g[i])) # step_size(t) = alpha / (1 - beta1(t)) step_size = alpha / (1.0 - beta1**(t+1)) # delta(t) = m(t) / u(t) delta = m[i] / u[i] # x(t) = x(t-1) - step_size(t) * delta(t) x[i] = x[i] - step_size * delta # 评估候选点 score = objective(x[0], x[1]) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] |
然后我们可以定义函数的边界和超参数,并调用函数执行优化。
在这种情况下,我们将运行算法 60 次迭代,初始学习率为 0.02,beta 值为 0.8,beta2 值为 0.99,这些值是在一些试错后找到的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 60 # 步长 alpha = 0.02 # 平均梯度因子 beta1 = 0.8 # 平均梯度平方因子 beta2 = 0.99 # 使用 adamax 进行梯度下降搜索 best, score = adamax(objective, derivative, bounds, n_iter, alpha, beta1, beta2) |
在运行结束时,我们将报告找到的最佳解决方案。
|
1 2 3 4 |
... # 总结结果 print('Done!') print('f(%s) = %f' % (best, score)) |
将所有这些结合起来,下面列出了 AdaMax 梯度下降应用于我们的测试问题的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# 使用 adamax 对二维测试函数进行梯度下降优化 from numpy import asarray from numpy.random import rand from numpy.random import seed # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 目标函数的导数 def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # 带有 adamax 的梯度下降算法 def adamax(objective, derivative, bounds, n_iter, alpha, beta1, beta2): # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 初始化动量向量和加权无穷范数 m = [0.0 for _ in range(bounds.shape[0])] u = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降的迭代 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(x.shape[0]): # m(t) = beta1 * m(t-1) + (1 - beta1) * g(t) m[i] = beta1 * m[i] + (1.0 - beta1) * g[i] # u(t) = max(beta2 * u(t-1), abs(g(t))) u[i] = max(beta2 * u[i], abs(g[i])) # step_size(t) = alpha / (1 - beta1(t)) step_size = alpha / (1.0 - beta1**(t+1)) # delta(t) = m(t) / u(t) delta = m[i] / u[i] # x(t) = x(t-1) - step_size(t) * delta(t) x[i] = x[i] - step_size * delta # 评估候选点 score = objective(x[0], x[1]) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 60 # 步长 alpha = 0.02 # 平均梯度因子 beta1 = 0.8 # 平均梯度平方因子 beta2 = 0.99 # 使用 adamax 进行梯度下降搜索 best, score = adamax(objective, derivative, bounds, n_iter, alpha, beta1, beta2) # 总结结果 print('Done!') print('f(%s) = %f' % (best, score)) |
运行该示例可将 AdaMax 优化算法应用于我们的测试问题,并报告算法每次迭代的搜索性能。
注意:鉴于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑多次运行该示例并比较平均结果。
在这种情况下,我们可以看到,在搜索大约 35 次迭代后,找到了一个接近最优的解,输入值接近 0.0 和 0.0,评估结果为 0.0。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
... >33 f([-0.00122185 0.00427944]) = 0.00002 >34 f([-0.00045147 0.00289913]) = 0.00001 >35 f([0.00022176 0.00165754]) = 0.00000 >36 f([0.00073314 0.00058534]) = 0.00000 >37 f([ 0.00105092 -0.00030082]) = 0.00000 >38 f([ 0.00117382 -0.00099624]) = 0.00000 >39 f([ 0.00112512 -0.00150609]) = 0.00000 >40 f([ 0.00094497 -0.00184321]) = 0.00000 >41 f([ 0.00068206 -0.002026 ]) = 0.00000 >42 f([ 0.00038579 -0.00207647]) = 0.00000 >43 f([ 9.99977780e-05 -2.01849176e-03]) = 0.00000 >44 f([-0.00014145 -0.00187632]) = 0.00000 >45 f([-0.00031698 -0.00167338]) = 0.00000 >46 f([-0.00041753 -0.00143134]) = 0.00000 >47 f([-0.00044531 -0.00116942]) = 0.00000 >48 f([-0.00041125 -0.00090399]) = 0.00000 >49 f([-0.00033193 -0.00064834]) = 0.00000 完成! f([-0.00033193 -0.00064834]) = 0.000001 |
AdaMax 优化的可视化
我们可以将 AdaMax 搜索的进展绘制在定义域的等高线上。
这可以提供对算法迭代过程中搜索进展的直观感受。
我们必须更新 adamax() 函数,以维护搜索过程中找到的所有解决方案的列表,然后在搜索结束时返回此列表。
包含这些更改的更新版本函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 带有 adamax 的梯度下降算法 def adamax(objective, derivative, bounds, n_iter, alpha, beta1, beta2): solutions = list() # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 初始化动量向量和加权无穷范数 m = [0.0 for _ in range(bounds.shape[0])] u = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降的迭代 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(x.shape[0]): # m(t) = beta1 * m(t-1) + (1 - beta1) * g(t) m[i] = beta1 * m[i] + (1.0 - beta1) * g[i] # u(t) = max(beta2 * u(t-1), abs(g(t))) u[i] = max(beta2 * u[i], abs(g[i])) # step_size(t) = alpha / (1 - beta1(t)) step_size = alpha / (1.0 - beta1**(t+1)) # delta(t) = m(t) / u(t) delta = m[i] / u[i] # x(t) = x(t-1) - step_size(t) * delta(t) x[i] = x[i] - step_size * delta # 评估候选点 score = objective(x[0], x[1]) solutions.append(x.copy()) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return solutions |
然后我们可以像以前一样执行搜索,这次检索解决方案列表而不是最终的最佳解决方案。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 60 # 步长 alpha = 0.02 # 平均梯度因子 beta1 = 0.8 # 平均梯度平方因子 beta2 = 0.99 # 使用 adamax 进行梯度下降搜索 solutions = adamax(objective, derivative, bounds, n_iter, alpha, beta1, beta2) |
然后我们可以像以前一样创建目标函数的等高线图。
|
1 2 3 4 5 6 7 8 9 10 |
... # 以 0.1 为增量均匀采样输入范围 xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 使用50个级别和jet颜色方案创建填充等高线图 pyplot.contourf(x, y, results, levels=50, cmap='jet') |
最后,我们可以将搜索过程中找到的每个解决方案绘制成一个由线连接的白点。
|
1 2 3 4 |
... # 将样本绘制为黑色圆圈 solutions = asarray(solutions) pyplot.plot(solutions[:, 0], solutions[:, 1], '.-', color='w') |
将所有这些结合起来,下面列出了在测试问题上执行 AdaMax 优化并将结果绘制在等高线图上的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
# 在测试函数的等高线图上绘制 adamax 搜索的示例 from numpy import asarray from numpy import arange from numpy.random import rand from numpy.random import seed from numpy import meshgrid from matplotlib import pyplot from mpl_toolkits.mplot3d import Axes3D # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 目标函数的导数 def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # 带有 adamax 的梯度下降算法 def adamax(objective, derivative, bounds, n_iter, alpha, beta1, beta2): solutions = list() # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) # 初始化动量向量和加权无穷范数 m = [0.0 for _ in range(bounds.shape[0])] u = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降的迭代 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(x.shape[0]): # m(t) = beta1 * m(t-1) + (1 - beta1) * g(t) m[i] = beta1 * m[i] + (1.0 - beta1) * g[i] # u(t) = max(beta2 * u(t-1), abs(g(t))) u[i] = max(beta2 * u[i], abs(g[i])) # step_size(t) = alpha / (1 - beta1(t)) step_size = alpha / (1.0 - beta1**(t+1)) # delta(t) = m(t) / u(t) delta = m[i] / u[i] # x(t) = x(t-1) - step_size(t) * delta(t) x[i] = x[i] - step_size * delta # 评估候选点 score = objective(x[0], x[1]) solutions.append(x.copy()) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return solutions # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 60 # 步长 alpha = 0.02 # 平均梯度因子 beta1 = 0.8 # 平均梯度平方因子 beta2 = 0.99 # 使用 adamax 进行梯度下降搜索 solutions = adamax(objective, derivative, bounds, n_iter, alpha, beta1, beta2) # 以 0.1 为增量均匀采样输入范围 xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 使用50个级别和jet颜色方案创建填充等高线图 pyplot.contourf(x, y, results, levels=50, cmap='jet') # 将样本绘制为黑色圆圈 solutions = asarray(solutions) pyplot.plot(solutions[:, 0], solutions[:, 1], '.-', color='w') # 显示绘图 pyplot.show() |
运行示例像以前一样执行搜索,但在此情况下,创建了目标函数的等高线图。
在这种情况下,我们可以看到搜索过程中找到的每个解决方案都显示为一个白点,从最优值上方开始,并逐渐靠近图中中心的最优值。
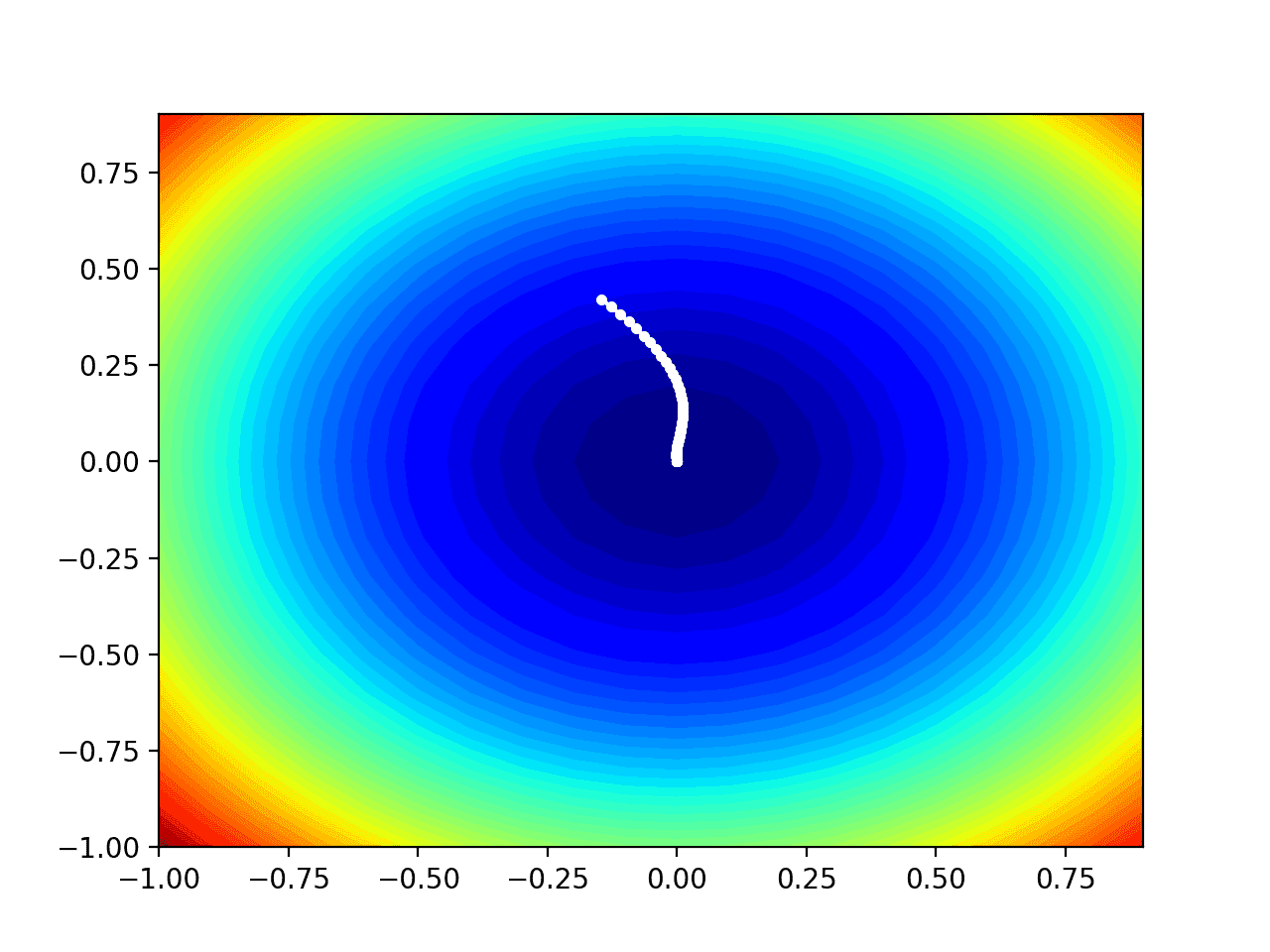
显示 AdaMax 搜索的测试目标函数等高线图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- Adam:一种随机优化方法, 2014.
- 梯度下降优化算法概述, 2016.
书籍
API
文章
- 梯度下降,维基百科.
- 随机梯度下降,维基百科.
- 梯度下降优化算法综述, 2016.
总结
在本教程中,您了解了如何从头开始开发 AdaMax 梯度下降优化。
具体来说,你学到了:
- 梯度下降是一种优化算法,它利用目标函数的梯度来导航搜索空间。
- AdaMax 是梯度下降的 Adam 版本的扩展,旨在加速优化过程。
- 如何从头开始实现 AdaMax 优化算法,并将其应用于目标函数并评估结果。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







Jason,我可以将您的帖子翻译成我的语言(并附上指向您帖子的来源链接)吗?提前谢谢。
请不要翻译这些帖子
https://machinelearning.org.cn/faq/single-faq/can-i-translate-your-posts-books-into-another-language
你好。我在坦桑尼亚攻读博士学位。我是 Sokoine 农业大学的一名讲师。机器学习在这里相当新。我达到那个阶段时,您能审查我的模型吗?感谢您宝贵的课程。
抱歉,我没有能力审查您的模型。