梯度下降是一种优化算法,它沿着目标函数的负梯度方向移动,以找到函数的最小值。
梯度下降的一个局限性是,如果梯度变得平缓或曲率较大,搜索的进度会减慢。动量可以添加到梯度下降中,它为更新引入了一些惯性。通过结合预测新位置的梯度而不是当前位置的梯度,这种方法可以进一步改进,这被称为Nesterov加速梯度(NAG)或Nesterov动量。
梯度下降的另一个局限性是,所有输入变量都使用相同的步长(学习率)。梯度下降的扩展,如自适应矩估计(Adam)算法,为每个输入变量使用单独的步长,但这可能导致步长迅速减小到非常小的值。
Nesterov加速自适应矩估计,或简称Nadam,是Adam算法的扩展,它结合了Nesterov动量,可以提高优化算法的性能。
在本教程中,您将学习如何从零开始开发使用Nadam的梯度下降优化算法。
完成本教程后,您将了解:
- 梯度下降是一种优化算法,它利用目标函数的梯度来导航搜索空间。
- Nadam是梯度下降的Adam版本的扩展,它结合了Nesterov动量。
- 如何从零开始实现Nadam优化算法,并将其应用于目标函数并评估结果。
通过我的新书《机器学习优化》启动您的项目,书中包含逐步教程和所有示例的Python源代码文件。
让我们开始吧。
从零开始使用 Nadam 进行梯度下降优化
图片由BLM Nevada提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 梯度下降
- Nadam优化算法
- 使用Nadam的梯度下降
- 二维测试问题
- 使用Nadam的梯度下降优化
- Nadam优化可视化
梯度下降
梯度下降是一种优化算法。
它在技术上被称为一阶优化算法,因为它明确使用了目标函数的一阶导数。
一阶方法依赖梯度信息来帮助指导寻找最小值……
——第69页,《优化算法》,2019年。
一阶导数,或简称为“导数”,是目标函数在特定点(例如,对于特定输入)的变化率或斜率。
如果目标函数有多个输入变量,则称之为多元函数,输入变量可以看作一个向量。相应地,多元目标函数的导数也可以看作一个向量,通常称为梯度。
- 梯度:多元目标函数的一阶导数。
导数或梯度指向特定输入处目标函数最陡峭上升的方向。
梯度下降指一种最小化优化算法,它沿着目标函数的负梯度方向“下坡”移动,以找到函数的最小值。
梯度下降算法需要一个被优化的目标函数和目标函数的导数函数。目标函数 *f()* 返回给定输入集的分数,导数函数 *f'()* 返回给定输入集的目标函数的导数。
梯度下降算法需要问题中的一个起点(x),例如输入空间中随机选择的一个点。
然后计算导数,并在输入空间中迈出一步,预计会导致目标函数下坡移动(假设我们正在最小化目标函数)。
下坡移动首先计算在输入空间中移动的距离,该距离等于步长(称为 alpha 或学习率)乘以梯度。然后将其从当前点减去,确保我们逆着梯度移动,即沿着目标函数向下移动。
- x(t) = x(t-1) – step_size * f'(x(t))
给定点处目标函数越陡峭,梯度的幅值越大,反之,在搜索空间中迈出的步长也越大。所迈步长的大小由步长超参数进行缩放。
- 步长:控制算法每次迭代中逆着梯度在搜索空间中移动距离的超参数。
如果步长太小,在搜索空间中的移动会很小,搜索将花费很长时间。如果步长太大,搜索可能会在搜索空间中跳跃并跳过最优解。
现在我们已经熟悉了梯度下降优化算法,接下来我们看看Nadam算法。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Nadam优化算法
Nesterov加速自适应矩估计(Nesterov-accelerated Adaptive Moment Estimation),或简称 Nadam 算法,是自适应矩估计(Adam)优化算法的扩展,它增加了Nesterov加速梯度(NAG)或Nesterov动量,这是一种改进的动量类型。
更广泛地说,Nadam算法是梯度下降优化算法的扩展。
该算法由Timothy Dozat在2016年题为“将Nesterov动量纳入Adam”的论文中描述。尽管该论文的一个版本于2015年作为一份题为斯坦福大学项目报告发表。
动量向梯度下降算法添加了梯度的指数衰减移动平均(一阶矩)。这有助于平滑嘈杂的目标函数并改进收敛。
Adam是梯度下降的扩展,它增加了梯度的一阶和二阶矩,并自动为每个被优化的参数调整学习率。NAG是动量的扩展,其中更新是使用参数的预测更新的梯度而不是实际当前变量值执行的。在某些情况下,这会减慢搜索速度,当找到最优解时,而不是过度搜索。
Nadam是Adam的扩展,它使用NAG动量而不是经典动量。
我们展示了如何修改 Adam 的动量分量以利用 NAG 的见解,然后我们提出了初步证据,表明这种替换可以提高收敛速度和所学模型的质量。
— 将 Nesterov 动量纳入 Adam, 2016。
让我们逐步了解算法的每个元素。
Nadam使用衰减步长(_alpha_)和一阶矩(_mu_)超参数,这可以提高性能。为简化起见,我们暂时忽略这方面,并假设常数值。
首先,我们必须为每个被优化的参数在搜索过程中维护梯度的一阶和二阶矩,分别表示为 _m_ 和 _n_。它们在搜索开始时被初始化为 0.0。
- m = 0
- n = 0
算法以迭代方式执行,时间 t 从 t=1 开始,每次迭代都涉及计算一组新的参数值 x,例如从 x(t-1) 到 x(t)。
如果我们将重点放在更新一个参数上,可能会更容易理解该算法,这可以通过向量运算推广到更新所有参数。
首先,计算当前时间步的梯度(偏导数)。
- g(t) = f'(x(t-1))
接下来,使用梯度和超参数“_mu_”更新一阶矩。
- m(t) = mu * m(t-1) + (1 – mu) * g(t)
然后使用“_nu_”超参数更新二阶矩。
- n(t) = nu * n(t-1) + (1 – nu) * g(t)^2
接下来,使用 Nesterov 动量对一阶矩进行偏置校正。
- mhat = (mu * m(t) / (1 – mu)) + ((1 – mu) * g(t) / (1 – mu))
然后对二阶矩进行偏差校正。
注:偏差校正是 Adam 的一个方面,它抵消了一阶和二阶矩在搜索开始时初始化为零的事实。
- nhat = nu * n(t) / (1 – nu)
最后,我们可以计算此迭代的参数值。
- x(t) = x(t-1) – alpha / (sqrt(nhat) + eps) * mhat
其中 alpha 是步长(学习率)超参数,_sqrt()_ 是平方根函数,_eps_(_epsilon_)是一个很小的值,例如 1e-8,用于避免除以零错误。
回顾一下,该算法有三个超参数;它们是
- alpha:初始步长(学习率),典型值为0.002。
- mu:一阶矩的衰减因子(Adam中的_beta1_),典型值为0.975。
- nu:二阶矩的衰减因子(Adam中的_beta2_),典型值为0.999。
就是这样。
接下来,我们看看如何在Python中从头开始实现该算法。
使用Nadam的梯度下降
在本节中,我们将探讨如何使用Nadam动量实现梯度下降优化算法。
二维测试问题
首先,让我们定义一个优化函数。
我们将使用一个简单的二维函数,它将每个维度的输入平方,并将有效输入范围定义为-1.0到1.0。
下面的 _objective()_ 函数实现了这个函数
|
1 2 3 |
# 目标函数 def objective(x, y): return x**2.0 + y**2.0 |
我们可以创建一个数据集的三维图来感受响应曲面的曲率。
下面列出了绘制目标函数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 绘制测试函数的三维图 from numpy import arange from numpy import meshgrid from matplotlib import pyplot # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 定义输入范围 r_min, r_max = -1.0, 1.0 # 以 0.1 为增量均匀采样输入范围 xaxis = arange(r_min, r_max, 0.1) yaxis = arange(r_min, r_max, 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 使用 jet 配色方案创建曲面图 figure = pyplot.figure() axis = figure.gca(projection='3d') axis.plot_surface(x, y, results, cmap='jet') # 显示绘图 pyplot.show() |
运行示例将创建目标函数的三维曲面图。
我们可以看到熟悉的碗形,全局最小值在 f(0, 0) = 0。
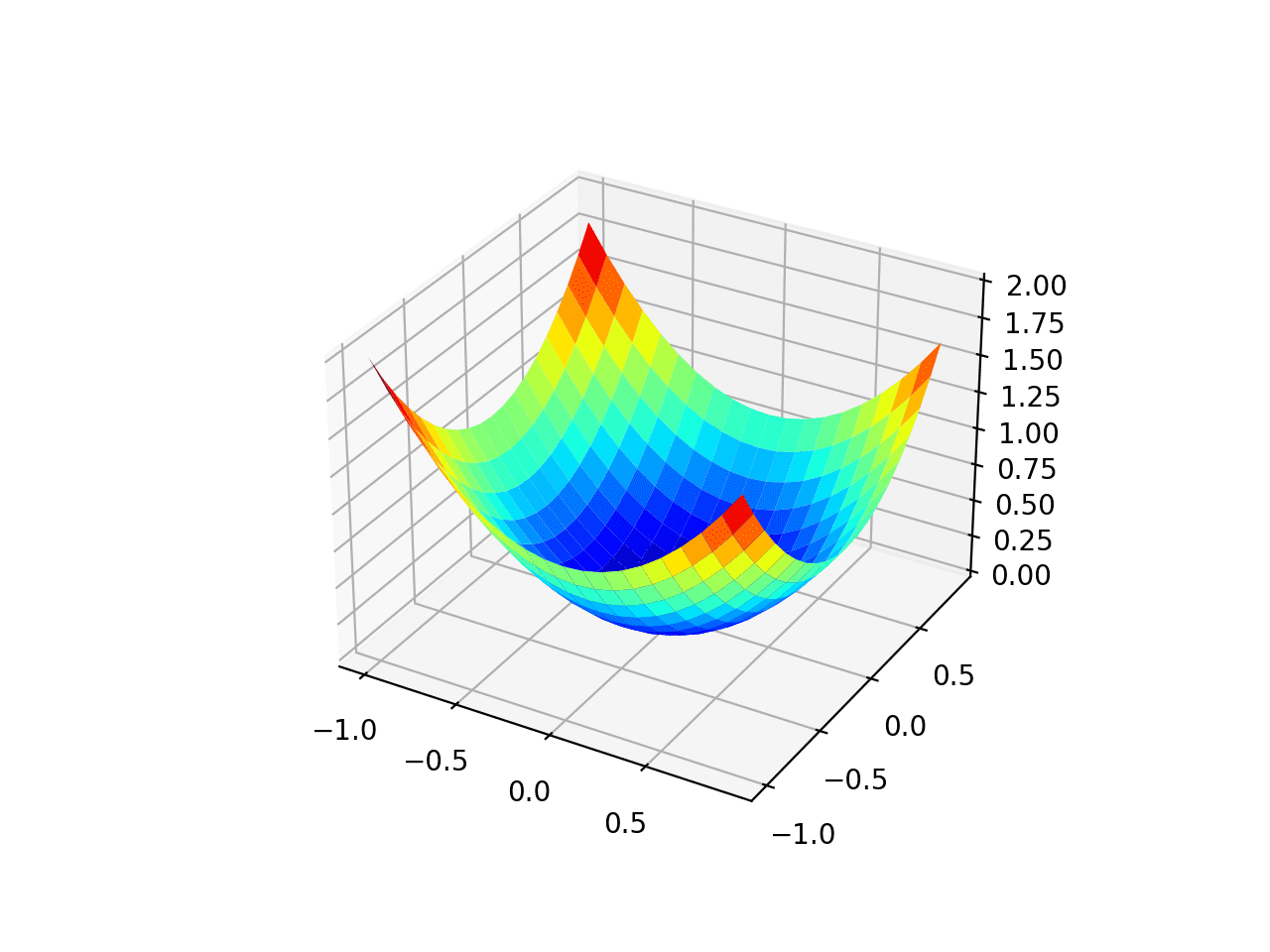
测试目标函数的三维图
我们还可以创建函数的二维图。这将在以后我们想要绘制搜索进度时提供帮助。
以下示例创建了目标函数的等高线图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 绘制测试函数的等高线图 from numpy import asarray from numpy import arange from numpy import meshgrid from matplotlib import pyplot # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 以 0.1 为增量均匀采样输入范围 xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 使用50个级别和jet颜色方案创建填充等高线图 pyplot.contourf(x, y, results, levels=50, cmap='jet') # 显示绘图 pyplot.show() |
运行示例将创建目标函数的二维等高线图。
我们可以看到碗状被压缩成用颜色梯度显示的等高线。我们将使用这个图来绘制搜索过程中探索的特定点。
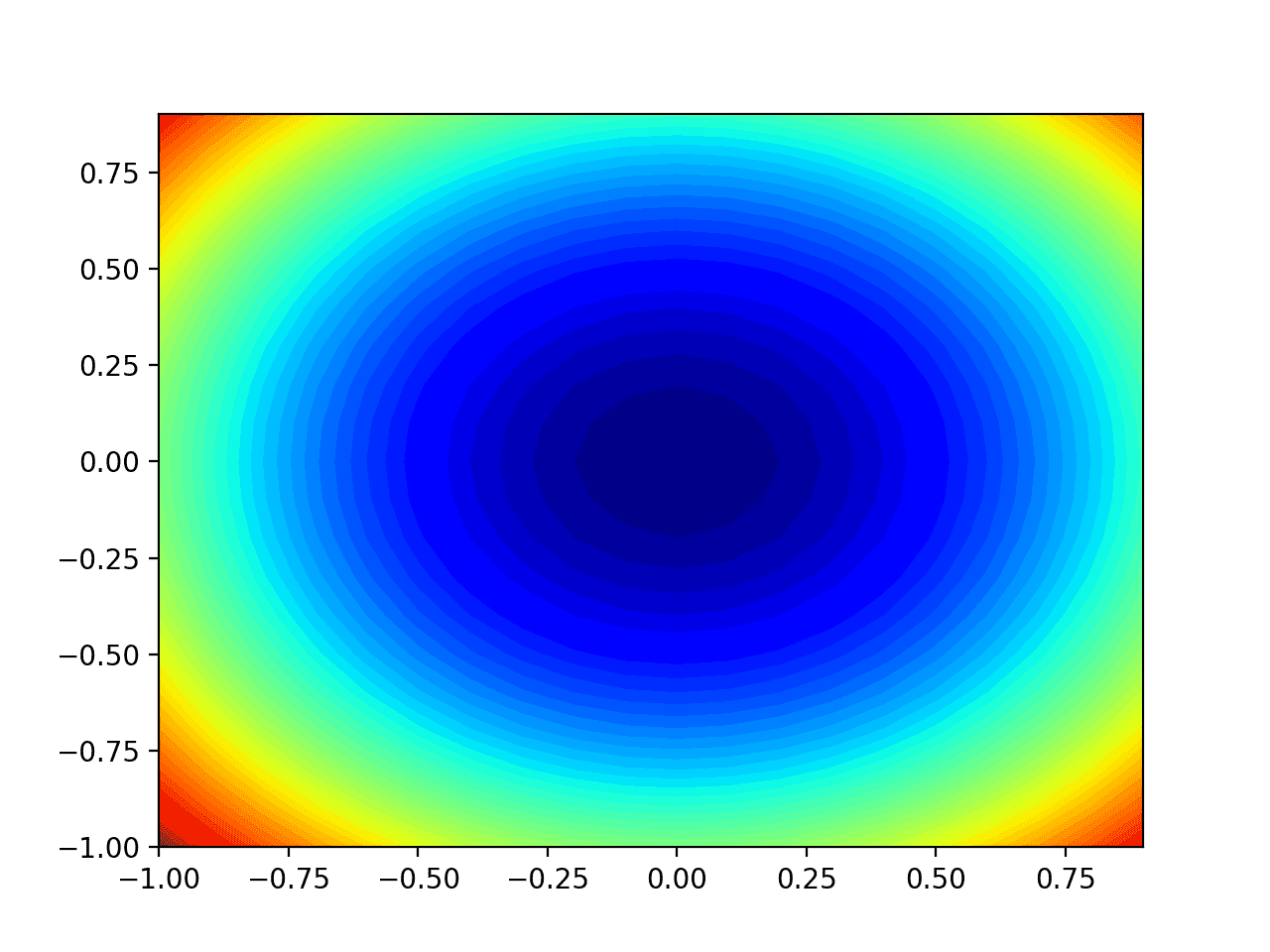
测试目标函数的二维等高线图
现在我们有了一个测试目标函数,接下来我们来看看如何实现 Nadam 优化算法。
使用Nadam的梯度下降优化
我们可以将使用 Nadam 的梯度下降应用于测试问题。
首先,我们需要一个函数来计算此函数的导数。
x^2 的导数在每个维度上都是 x * 2。
- f(x) = x^2
- f'(x) = x * 2
下面的 derivative() 函数实现了这一点。
|
1 2 3 |
# 目标函数的导数 def derivative(x, y): return asarray([x * 2.0, y * 2.0]) |
接下来,我们可以使用 Nadam 实现梯度下降优化。
首先,我们可以在问题的边界内选择一个随机点作为搜索的起点。
这假设我们有一个数组,它定义了搜索的边界,每行一个维度,第一列定义最小值,第二列定义最大值。
|
1 2 3 4 |
... # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) |
接下来,我们需要初始化矩向量。
|
1 2 3 4 |
... # 初始化衰减移动平均 m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] |
然后我们运行由“_n_iter_”超参数定义的固定迭代次数。
|
1 2 3 4 |
... # 运行梯度下降迭代 for t in range(n_iter): ... |
第一步是计算当前参数集的导数。
|
1 2 3 |
... # 计算梯度 g(t) g = derivative(x[0], x[1]) |
接下来,我们需要执行Nadam更新计算。为了可读性,我们将使用命令式编程风格一次计算一个变量。
实际上,我建议使用NumPy向量操作以提高效率。
|
1 2 3 4 |
... # 逐个变量构建解 for i in range(x.shape[0]): ... |
首先,我们需要计算矩向量。
|
1 2 3 |
... # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] |
然后是二阶矩向量。
|
1 2 3 |
... # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 |
然后是偏差校正的Nesterov动量。
|
1 2 3 |
... # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) |
偏置校正二阶矩。
|
1 2 3 |
... # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) |
最后更新参数。
|
1 2 3 |
... # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat |
然后对每个要优化的参数重复此操作。
在迭代结束时,我们可以评估新的参数值并报告搜索的性能。
|
1 2 3 4 5 |
... # 评估候选点 score = objective(x[0], x[1]) # 报告进展 print('>%d f(%s) = %.5f' % (t, x, score)) |
我们可以将所有这些内容组合成一个名为 nadam() 的函数,该函数接受目标函数和导数函数的名称以及算法超参数,并在搜索结束时返回找到的最佳解决方案及其评估结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# nadam梯度下降算法 def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # 初始化衰减移动平均 m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # 评估候选点 score = objective(x[0], x[1]) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] |
然后我们可以定义函数的边界和超参数,并调用函数执行优化。
在这种情况下,我们将运行算法50次迭代,初始alpha为0.02,mu为0.8,nu为0.999,这些值是经过一些尝试和错误后找到的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 50 # 步长 alpha = 0.02 # 平均梯度因子 mu = 0.8 # 平均梯度平方因子 nu = 0.999 # 使用nadam执行梯度下降搜索 best, score = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) |
在运行结束时,我们将报告找到的最佳解决方案。
|
1 2 3 4 |
... # 总结结果 print('Done!') print('f(%s) = %f' % (best, score)) |
将所有这些联系起来,下面列出了将Nadam梯度下降应用于我们的测试问题的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
# 使用Nadam对二维测试函数进行梯度下降优化 from math import sqrt from numpy import asarray from numpy.random import rand from numpy.random import seed # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 目标函数的导数 def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # nadam梯度下降算法 def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # 初始化衰减移动平均 m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # 评估候选点 score = objective(x[0], x[1]) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 50 # 步长 alpha = 0.02 # 平均梯度因子 mu = 0.8 # 平均梯度平方因子 nu = 0.999 # 使用nadam执行梯度下降搜索 best, score = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) print('Done!') print('f(%s) = %f' % (best, score)) |
运行示例将使用Nadam优化算法应用于我们的测试问题,并报告算法每次迭代的搜索性能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。建议运行几次示例并比较平均结果。
在这种情况下,我们可以看到在约44次搜索迭代后找到了一个接近最优的解,输入值接近0.0和0.0,评估结果为0.0。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... >40 f([ 5.07445337e-05 -3.32910019e-03]) = 0.00001 >41 f([-1.84325171e-05 -3.00939427e-03]) = 0.00001 >42 f([-6.78814472e-05 -2.69839367e-03]) = 0.00001 >43 f([-9.88339249e-05 -2.40042096e-03]) = 0.00001 >44 f([-0.00011368 -0.00211861]) = 0.00000 >45 f([-0.00011547 -0.00185511]) = 0.00000 >46 f([-0.0001075 -0.00161122]) = 0.00000 >47 f([-9.29922627e-05 -1.38760991e-03]) = 0.00000 >48 f([-7.48258406e-05 -1.18436586e-03]) = 0.00000 >49 f([-5.54299505e-05 -1.00116899e-03]) = 0.00000 完成! f([-5.54299505e-05 -1.00116899e-03]) = 0.000001 |
Nadam优化可视化
我们可以在域的等高线图上绘制Nadam搜索的进展。
这可以提供对算法迭代过程中搜索进展的直观感受。
我们必须更新 nadam() 函数,以维护搜索过程中找到的所有解决方案的列表,然后在搜索结束时返回此列表。
包含这些更改的更新版本函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# nadam梯度下降算法 def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): solutions = list() # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # 初始化衰减移动平均 m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # 评估候选点 score = objective(x[0], x[1]) # 存储解决方案 solutions.append(x.copy()) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return solutions |
然后我们可以像以前一样执行搜索,这次检索解决方案列表而不是最终的最佳解决方案。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 50 # 步长 alpha = 0.02 # 平均梯度因子 mu = 0.8 # 平均梯度平方因子 nu = 0.999 # 使用nadam执行梯度下降搜索 solutions = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) |
然后我们可以像以前一样创建目标函数的等高线图。
|
1 2 3 4 5 6 7 8 9 10 |
... # 以 0.1 为增量均匀采样输入范围 xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 使用50个级别和jet颜色方案创建填充等高线图 pyplot.contourf(x, y, results, levels=50, cmap='jet') |
最后,我们可以将搜索过程中找到的每个解决方案绘制成一个由线连接的白点。
|
1 2 3 4 |
... # 将样本绘制为黑色圆圈 solutions = asarray(solutions) pyplot.plot(solutions[:, 0], solutions[:, 1], '.-', color='w') |
将所有这些结合起来,下面列出了在测试问题上执行Nadam优化并将结果绘制在等高线图上的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
# 在测试函数的等高线图上绘制nadam搜索示例 from math import sqrt from numpy import asarray from numpy import arange from numpy import product from numpy.random import rand from numpy.random import seed from numpy import meshgrid from matplotlib import pyplot from mpl_toolkits.mplot3d import Axes3D # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 目标函数的导数 def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # nadam梯度下降算法 def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): solutions = list() # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # 初始化衰减移动平均 m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # 评估候选点 score = objective(x[0], x[1]) # 存储解决方案 solutions.append(x.copy()) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return solutions # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 50 # 步长 alpha = 0.02 # 平均梯度因子 mu = 0.8 # 平均梯度平方因子 nu = 0.999 # 使用nadam执行梯度下降搜索 solutions = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) # 以 0.1 为增量均匀采样输入范围 xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 使用50个级别和jet颜色方案创建填充等高线图 pyplot.contourf(x, y, results, levels=50, cmap='jet') # 将样本绘制为黑色圆圈 solutions = asarray(solutions) pyplot.plot(solutions[:, 0], solutions[:, 1], '.-', color='w') # 显示绘图 pyplot.show() |
运行示例像以前一样执行搜索,但在此情况下,创建了目标函数的等高线图。
在这种情况下,我们可以看到搜索过程中找到的每个解决方案都显示为一个白点,从最优值上方开始,并逐渐靠近图中中心的最优值。
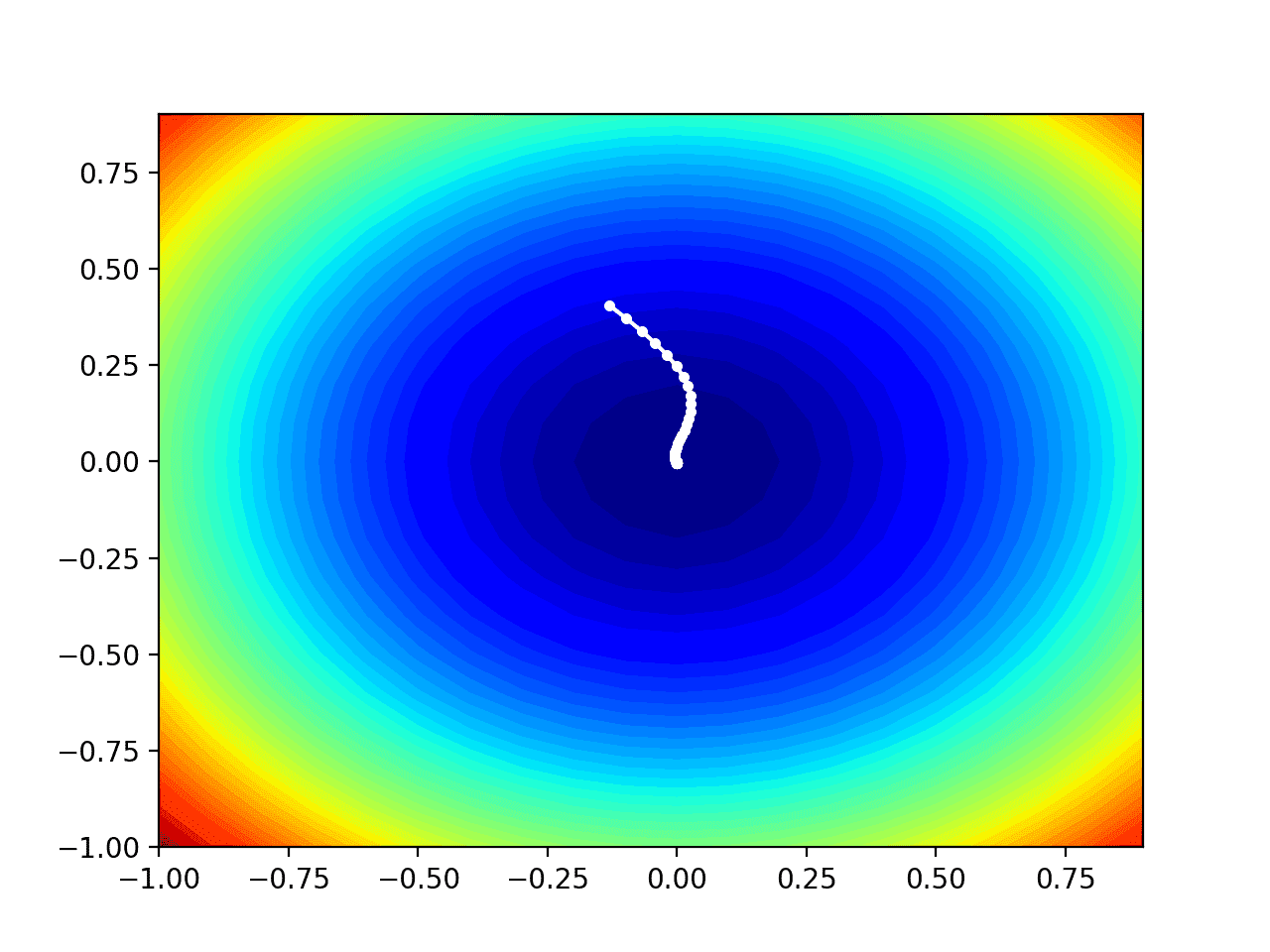
显示Nadam搜索结果的测试目标函数等高线图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 将Nesterov动量纳入Adam, 2016.
- 将Nesterov动量纳入Adam,斯坦福报告, 2015.
- 求解收敛速度为 O(1/k^2) 的凸规划问题的方法, 1983.
- Adam:一种随机优化方法, 2014.
- 梯度下降优化算法概述, 2016.
书籍
API
文章
总结
在本教程中,您学习了如何从零开始开发使用Nadam的梯度下降优化算法。
具体来说,你学到了:
- 梯度下降是一种优化算法,它利用目标函数的梯度来导航搜索空间。
- Nadam是梯度下降的Adam版本的扩展,它结合了Nesterov动量。
- 如何从零开始实现Nadam优化算法,并将其应用于目标函数并评估结果。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







谢谢Jason又一篇精彩的教程。讲解和演示都非常出色。
不客气!
你好,Jason,文章写得真棒!
但我对代码中的这部分感到困惑
mhat = (mu * m[i] / (1.0 – mu)) + ( (1 – mu) * g[i] / (1.0 – mu) )
我猜 (1 – mu) * g[i] / (1.0 – mu) 有一个错别字,因为它等于 g[i]。
谢谢!
很好的问题!
是的,它是正确的——但被简化了。
通常在最后的部分,“mu”被计算为一个衰减值,例如mu(t)。你可以在Nadam论文和Ruder的总结论文中看到这一点。
尊敬的Jason博士,
首先感谢您再次“从零开始”演示使用“NADAM”进行优化,以及之前“从零开始”涉及“Nesterov动量”的演示,网址为https://machinelearning.org.cn/gradient-descent-with-nesterov-momentum-from-scratch/
是的,在https://tensorflowcn.cn/api_docs/python/tf/keras/optimizers/Nadam有一个NADAM实现,“从零开始”系列算法是用于学习这些算法的“幕后”版本。
请问
NADAM是RMSProp的“Nesterov动量”的实现,它比“Nesterov动量”或“Adam”优化器有任何优势吗?或者您是使用所有算法来找出哪个能给出最优结果?
提前感谢你
悉尼的Anthony
在某些问题上它会有帮助。
您可以尝试不同的优化器,或者如果您对目标函数有所了解或熟悉某个特定的优化器,您可能希望选择一个而不是另一个。
尊敬的Jason博士,
谢谢你,
悉尼的Anthony
不客气。