梯度是优化和机器学习中常用的术语。
例如,深度学习神经网络使用随机梯度下降进行拟合,许多用于拟合机器学习算法的标准优化算法都使用梯度信息。
要理解什么是梯度,您需要理解什么是来自微积分领域的导数。这包括如何计算导数及其值。对导数的理解直接适用于理解如何在优化和机器学习中计算和解释梯度。
在本教程中,您将了解导数和梯度在机器学习中的基本概念。
完成本教程后,您将了解:
- 函数导数是指函数对于给定输入的改变。
- 梯度只是多元函数的一个导数向量。
- 如何计算和解释简单函数的导数。
开始您的项目,阅读我的新书《机器学习优化》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
机器学习中的梯度是什么?
照片由Roanish拍摄,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 什么是导数?
- 什么是梯度?
- 计算导数的示例
- 如何解释导数
- 如何计算函数的导数
什么是导数?
在微积分中,导数是实值函数在给定点的变化率。
例如,函数f()对于变量x的导数f'(x)是函数f()在点x的变化率。
它可能变化很大,例如非常弯曲,或者变化很小,例如轻微弯曲,或者根本不变化,例如平坦或静止。
如果一个函数可导,那么我们可以计算函数变量的所有输入点的导数。并非所有函数都是可导的。
一旦我们计算出导数,我们就可以在许多方面使用它。
例如,给定输入值x和该点的导数f'(x),我们可以使用导数估计函数f(x)在附近点delta_x(x的变化量)的值,如下所示:
- f(x + delta_x) = f(x) + f'(x) * delta_x
在这里,我们可以看到f'(x)是一条直线,我们通过沿着直线移动delta_x来估计函数在附近点的值。
我们可以在优化问题中使用导数,因为它们告诉我们如何改变输入以使目标函数增加或减少输出,从而使我们更接近函数的最小值或最大值。
导数在优化中有用,因为它们提供了有关如何更改给定点以改进目标函数的信息。
— 第32页,优化算法,2019。
寻找可用于近似附近值的直线是微分的初步发展的主要原因。这条直线被称为切线或函数在给定点的斜率。
寻找曲线的切线问题[...]涉及寻找相同类型的极限[...]这种特殊类型的极限称为导数,我们将看到它可以解释为科学或工程中的任何变化率。
— 第104页,微积分,第8版,2015。
下面提供了一个函数在某点的切线示例,摘自《优化算法》第19页。
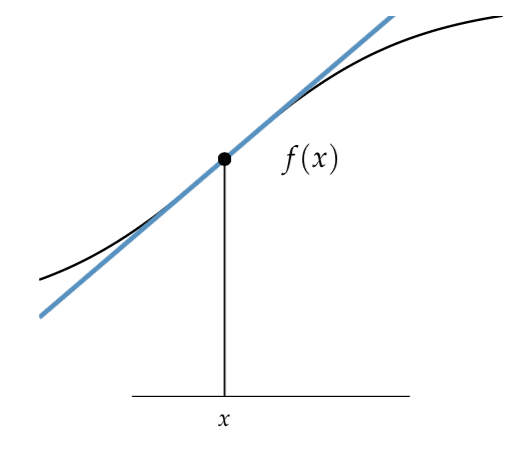
函数在给定点的切线
摘自《优化算法》。
严格来说,前面描述的导数称为一阶导数。
二阶导数(或二阶导数)是导数函数的导数。也就是说,变化率的变化率,或者函数的变化量改变了多少。
- 一阶导数:目标函数的变化率。
- 二阶导数:一阶导数函数的变化率。
二阶导数的自然用途是近似附近点的一阶导数,正如我们可以使用一阶导数来估计目标函数在附近点的值一样。
既然我们知道了什么是导数,那么让我们来看看梯度。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
什么是梯度?
梯度是具有多个输入变量的函数的导数。
它是一个术语,用于从线性代数的角度来指代函数的导数。特别是当线性代数与微积分相遇时,称为向量微积分。
梯度是导数对多元函数的推广。它捕捉了函数的局部斜率,使我们能够预测在任何方向上从一点开始的小步的影响。
— 第21页,优化算法,2019。
多个输入变量共同定义一个值向量,例如输入空间中的一个点,该点可以提供给目标函数。
具有输入变量向量的目标函数的导数也类似地是一个向量。这个每个输入变量的导数向量就是梯度。
- 梯度(向量微积分):一个接受输入变量向量的函数的导数向量。
您可能还记得高中代数或预备微积分中的概念,梯度通常也指二维图上的直线斜率。
它计算为函数在y轴上的变化(上升)除以函数在x轴上的变化(运行),简化为规则:“上升除以运行”。
- 梯度(代数):直线的斜率,计算为上升除以运行。
我们可以看到,这对于一个变量的函数是一个简单而粗略的近似。微积分中的导数函数更加精确,因为它使用极限来找到函数在某一点的精确斜率。这种来自代数的梯度思想是相关的,但对于优化和机器学习中使用的梯度思想并不直接有用。
接受多个输入变量(例如,输入变量向量)的函数可以称为多元函数。
函数相对于某个变量的偏导数是指假设所有其他输入变量保持不变时的导数。
— 第21页,优化算法,2019。
梯度(导数向量)中的每个分量都是目标函数的偏导数。
偏导数假设函数的所有其他变量都保持不变。
- 偏导数:多元函数的其中一个变量的导数。
在代数中使用方阵很有用,二阶导数的方阵称为Hessian矩阵。
多元函数的Hessian是一个矩阵,其中包含所有相对于输入的二阶导数。
— 第21页,优化算法,2019。
我们可以互换使用梯度和导数,尽管在优化和机器学习领域,我们通常使用“梯度”,因为我们通常关注多元函数。
导数的直观理解直接转化为梯度,只是维度更多。
现在我们对导数和梯度的概念有了初步了解,让我们来看一个计算导数的示例。
计算导数的示例
让我们通过一个示例来具体说明导数。
首先,让我们定义一个简单的二维函数,该函数对输入进行平方,并将有效输入范围定义为-1.0到1.0。
- f(x) = x^2
下面的示例以0.1的增量对该函数进行采样,计算每个输入的函数值,并绘制结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 简单函数的图 from numpy import arange from matplotlib import pyplot # 目标函数 def objective(x): return x**2.0 # 定义输入范围 r_min, r_max = -1.0, 1.0 # 以 0.1 为增量均匀采样输入范围 inputs = arange(r_min, r_max+0.1, 0.1) # 计算目标值 results = objective(inputs) # 绘制输入与结果的线图 pyplot.plot(inputs, results) # 显示绘图 pyplot.show() |
运行该示例会创建函数输入(x轴)和函数计算输出(y轴)的线图。
我们可以看到熟悉的U形曲线,称为抛物线。
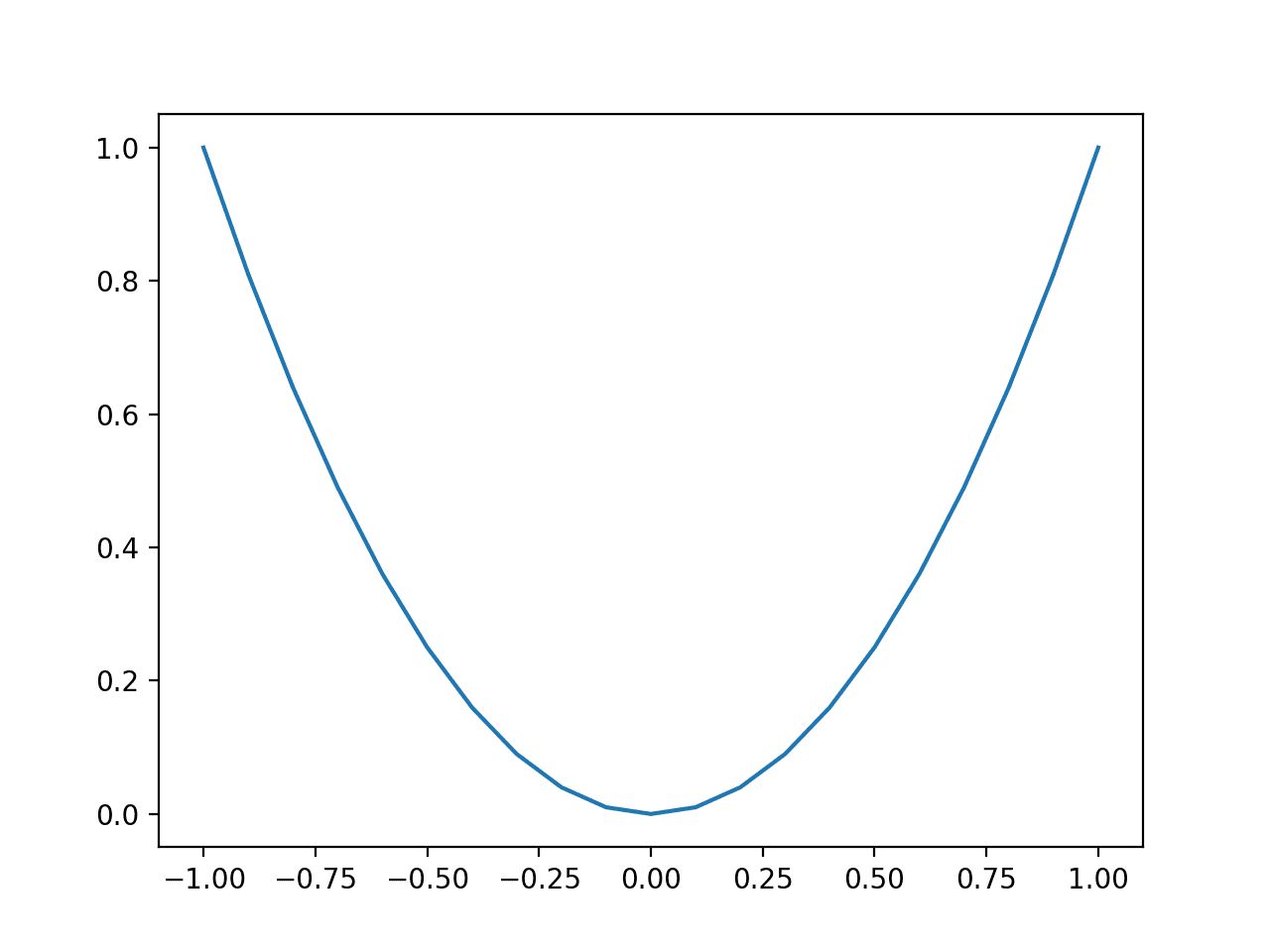
简单一维函数折线图
我们可以看到形状两侧有很大的变化或陡峭的曲线,我们期望那里有大的导数,而函数中间有一个平坦的区域,我们期望那里有小的导数。
让我们通过计算-0.5和0.5(陡峭)以及0.0(平坦)处的导数来验证这些预期。
函数导数计算如下:
- f'(x) = x * 2
下面的示例计算了我们目标函数特定输入点的导数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 计算目标函数的导数 # 目标函数的导数 def derivative(x): return x * 2.0 # 计算导数 d1 = derivative(-0.5) print('f\'(-0.5) = %.3f' % d1) d2 = derivative(0.5) print('f\'(0.5) = %.3f' % d2) d3 = derivative(0.0) print('f\'(0.0) = %.3f' % d3) |
运行示例会打印出特定输入值的导数值。
我们可以看到,函数陡峭点的导数是-1和1,函数平坦部分的导数是0.0。
|
1 2 3 |
f'(-0.5) = -1.000 f'(0.5) = 1.000 f'(0.0) = 0.000 |
既然我们知道如何计算函数的导数,那么让我们看看如何解释导数的值。
如何解释导数
导数的值可以解释为变化率(大小)和方向(符号)。
- 导数的大小:变化量。
- 导数的符号:变化的方向。
导数为0.0表示目标函数没有变化,这称为驻点。
一个函数可能有一个或多个驻点,而函数的局部或全局最小值(山谷底部)或最大值(山峰)是驻点的例子。
梯度指向切超平面最陡上升的方向...
— 第21页,优化算法,2019。
导数的符号告诉您目标函数在该点是增加还是减少。
- 正导数:函数在该点增加。
- 负导数:函数在该点减少。
这可能会令人困惑,因为从上一节的图来看,函数f(x)的值在y轴上对于-0.5和0.5是增加的。
这里的诀窍是始终从左到右读取函数图,例如,沿着y轴从左到右跟随x值的变化。
事实上,当从左到右读取时,x=-0.5附近的值是减少的,因此导数为负;而x=0.5附近的值是增加的,因此导数为正。
我们可以想象,如果我们想仅通过梯度信息找到上一节中函数的最小值,如果梯度为负,我们将增加x输入值以向下移动,或者如果梯度为正,我们将减小x输入值以向下移动。
这是梯度下降(和梯度上升)一类优化算法的基础,这些算法可以访问函数的梯度信息。
现在我们知道了如何解释导数的值,让我们看看如何找到函数的导数。
如何计算函数的导数
找到输出目标函数f()变化率的导数函数f'()称为微分。
有许多方法(算法)可以计算函数的导数。
在某些情况下,我们可以使用微积分的工具来计算函数的导数,无论是手动还是使用自动求解器。
计算函数导数的一般技术包括:
可以使用SymPy Python库进行符号微分。
诸如Theano和TensorFlow之类的计算库可用于自动微分。
如果您的函数很容易用纯文本指定,您还可以使用在线服务。
一个例子是Wolfram Alpha网站,它可以为您计算函数的导数;例如:
并非所有函数都是可导的,有些可导的函数可能难以用某些方法找到其导数。
计算函数的导数超出了本教程的范围。请参考一本好的微积分教科书,例如“拓展阅读”部分中的书籍。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
文章
总结
在本教程中,您了解了导数和梯度在机器学习中的基本概念。
具体来说,你学到了:
- 函数导数是指函数对于给定输入的改变。
- 梯度只是多元函数的一个导数向量。
- 如何计算和解释简单函数的导数。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。





 Ensemble")

尊敬的Jason博士,
我们从微积分中知道,著名的公式d/dx(x**2) = 2x和d/dx(sin(x)) = cos x等等。
也就是说,我们知道如何计算已知函数的梯度。
问题:当公式不明确已知时,如何从数据中计算梯度?
谢谢你,
悉尼的Anthony
通过数据和机器学习模型,我们计算误差函数(RMSE或交叉熵)的梯度,该误差函数是预期输出和预测输出之间的差异。
f(x + delta_x) = f(x) + f'(x) * delta_x
我一直能跟上,直到我看到这部分
f(x + delta_x) = f(x) + f'(x) * delta_x
这是一个任意的数学定义吗?如果不是,这个定义的依据是什么?
您如何根据这个方程判断f'(x)是一条直线?
f'(x)是x的导数。
一种方法是假设因变量(例如,y)在连续的数据点集之间呈线性变化(设自变量为x)。从数据中,设y=y1在x=x1处,y=y2在x=x2处。那么在x=x1和x=x2之间,计算梯度的一个相当普遍的近似方法是(y2-y1)/(x2-x1)。然后,数据集可以被图形化地表示为所谓的分段线性曲线。
谢谢。