在传统上,训练深度神经网络是很有挑战性的,因为梯度消失意味着靠近输入层的权重在响应训练数据集计算出的误差时不会被更新。
深度学习领域的一项创新和重要的里程碑是贪婪逐层预训练,它使得非常深的神经网络能够成功训练,并在此之后取得了最先进的性能。
在本教程中,您将了解贪婪逐层预训练作为一种开发深度多层神经网络模型的技术。
完成本教程后,您将了解:
- 贪婪逐层预训练提供了一种开发深度多层神经网络的方法,而只需训练浅层网络。
- 预训练可以用于迭代加深一个监督模型或一个可以重新用作监督模型的无监督模型。
- 对于标记数据量少而未标记数据量大的问题,预训练可能很有用。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 更新于2019年9月:修复了将键转换为列表的图(感谢 Markus)
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。
- **2020年1月更新**:已针对 scikit-learn v0.22 API 的变更进行更新。

如何使用贪婪逐层预训练开发深度神经网络
照片作者:Marco Verch,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 贪婪逐层预训练
- 多类别分类问题
- 监督贪婪逐层预训练
- 无监督贪婪逐层预训练
贪婪逐层预训练
传统上,训练具有许多层的深度神经网络是具有挑战性的。
随着隐藏层数量的增加,传播到早期层的误差信息的数量急剧减少。这意味着靠近输出层的隐藏层中的权重会正常更新,而靠近输入层的隐藏层中的权重则更新很少或根本不更新。通常,这个问题阻碍了非常深的神经网络的训练,并被称为梯度消失问题。
神经网络复兴中的一个重要里程碑,最初允许开发更深的神经网络模型,是贪婪逐层预训练技术,通常简称为“预训练”。
2006年的深度学习复兴始于发现这种贪婪学习过程可以用于为所有层的联合学习过程找到一个好的初始化,并且该方法可以用于成功训练即使是全连接架构。
— 第528页,《深度学习》,2016年。
预训练包括将新隐藏层逐个添加到模型并重新拟合,允许新添加的模型从现有隐藏层学习输入,通常在保持现有隐藏层权重固定的情况下。这使得该技术被称为“逐层”,因为模型是逐层训练的。
该技术被称为“贪婪”,因为它是一种解决训练深度网络的更难问题的分段或逐层方法。作为一种优化过程,将训练过程划分为一系列逐层训练过程,被视为一种贪婪的捷径,很可能导致局部最优解的聚合,是获得足够好的全局解的捷径。
贪婪算法将问题分解为许多组件,然后单独解决每个组件的最优版本。不幸的是,组合单独最优的组件并不能保证产生最优的完整解决方案。
— 第323页,《深度学习》,2016年。
预训练基于这样的假设,即训练浅层网络比训练深层网络更容易,并设计了一种逐层训练过程,我们总是只拟合浅层模型。
…基于训练浅层网络比训练深层网络更容易的前提,这在几种情况下似乎得到了验证。
— 第529页,《深度学习》,2016年。
预训练的关键优点是
- 简化的训练过程。
- 促进更深层次网络的开发。
- 可用作权重初始化方案。
- 可能较低的泛化误差。
总的来说,预训练在优化和泛化方面都有帮助。
— 第325页,《深度学习》,2016年。
预训练主要有两种方法;它们是
- 监督贪婪逐层预训练。
- 无监督贪婪逐层预训练。
广义上,监督预训练包括将隐藏层逐个添加到在监督学习任务上训练过的模型中。无监督预训练包括使用贪婪逐层过程构建一个无监督自编码器模型,然后添加一个监督输出层。
通常使用“预训练”一词,不仅指预训练阶段本身,还指结合预训练阶段和监督学习阶段的整个两阶段协议。监督学习阶段可能涉及在预训练阶段学到的特征之上训练一个简单的分类器,或者可能涉及预训练阶段学到的整个网络的监督微调。
— 第529页,《深度学习》,2016年。
当您有大量未标记示例可用于在将使用少得多的示例微调模型权重之前初始化模型时,无监督预训练可能是合适的。
…我们可以预期,当标记示例的数量非常少时,无监督预训练将最有帮助。因为无监督预训练增加的信息来源是未标记数据,所以当我们预期无监督预训练在未标记示例数量非常多时表现最佳。
— 第532页,《深度学习》,2016年。
虽然先前层的权重是固定的,但在添加最后一层后,通常会对网络中的所有权重进行微调。因此,这使得预训练可以被视为一种权重初始化方法。
…它利用了深度神经网络的初始参数选择对模型有显著的正则化作用(并且在较小的程度上,可以改善优化)。
— 第530-531页,《深度学习》,2016年。
贪婪逐层预训练是深度学习历史上的一个重要里程碑,它使得早期开发比以往任何时候都更多的隐藏层成为可能。这种方法在某些问题上可能很有用;例如,文本数据最好使用无监督预训练,以便通过word2vec为单词及其相互关系提供更丰富的分布式表示。
如今,除了自然语言处理领域之外,无监督预训练在很大程度上已被放弃 […] 预训练的优势在于,可以一次在大量的未标记数据集上进行预训练(例如,使用包含数十亿词的语料库),学习一个好的表示(通常是单词,但也可以是句子),然后将其用于对训练集示例少得多的监督任务。
— 第535页,《深度学习》,2016年。
尽管如此,使用现代方法,如更好的激活函数、权重初始化、梯度下降变体和正则化方法,可能能够获得更好的性能。
如今,我们知道贪婪逐层预训练并非训练全连接深度架构所必需,但无监督预训练方法是第一个成功的方法。
— 第528页,《深度学习》,2016年。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
多类别分类问题
我们将使用一个小型多类分类问题作为基础,来演示贪婪逐层预训练对模型性能的影响。
scikit-learn 类提供了 make_blobs() 函数,可用于创建具有指定样本数、输入变量、类别以及类别内样本方差的多类分类问题。
该问题将配置为具有两个输入变量(表示点的x和y坐标),以及每个组内样本的标准差为2.0。我们将使用相同的随机状态(伪随机数生成器的种子)来确保我们始终获得相同的数据点。
|
1 2 |
# 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) |
结果是我们可以建模的数据集的输入和输出元素。
为了了解问题的复杂性,我们可以在二维散点图上绘制每个点,并根据类别值对每个点进行着色。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# blob 数据集的散点图 from sklearn.datasets import make_blobs from matplotlib import pyplot from numpy import where # 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 每个类别值的散点图 for class_value in range(3): # 选择具有类标签的点的索引 row_ix = where(y == class_value) # 绘制不同颜色点的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示图 pyplot.show() |
运行示例会生成整个数据集的散点图。我们可以看到,2.0的标准差意味着类别不是线性可分的(可由一条线分隔),这导致了许多模糊点。
这是理想的,因为它意味着问题是非平凡的,并且可以允许神经网络模型找到许多不同的“足够好”的候选解决方案。
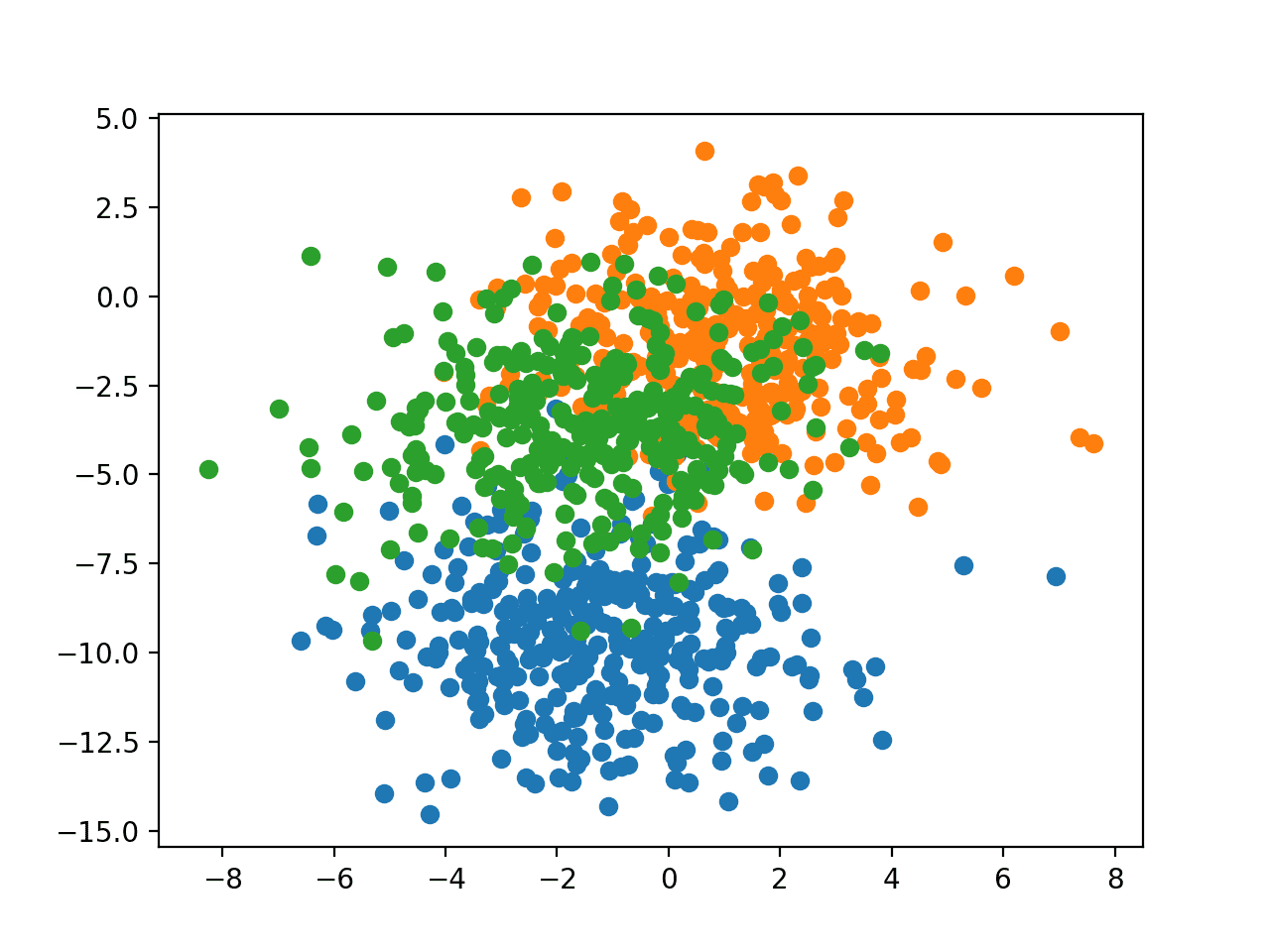
具有三个类别且点按类别值着色的 Blob 数据集散点图
监督贪婪逐层预训练
在本节中,我们将使用贪婪逐层监督学习来构建一个用于 blobs 监督学习多类分类问题的深度多层感知器(MLP)模型。
对于这个简单的预测建模问题,不需要预训练。相反,这是一个关于如何执行监督贪婪逐层预训练的演示,它可以作为更大型、更具挑战性的监督学习问题的模板。
作为第一步,我们可以开发一个函数来创建该问题的1000个样本,并将其平均分成训练集和测试集。下面的prepare_data()函数实现了这一点,并以输入和输出组件的形式返回训练集和测试集。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 准备数据 def prepare_data(): # 生成 2d 分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 对输出变量进行独热编码 y = to_categorical(y) # 分割为训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, testX, trainy, testy |
我们可以调用此函数来准备数据。
|
1 2 |
# 准备数据 trainX, testX, trainy, testy = prepare_data() |
接下来,我们可以训练和拟合一个基础模型。
这将是一个 MLP,它接收数据集中的两个输入变量的两个输入,并具有一个具有10个节点的隐藏层,并使用整流线性激活函数。输出层有三个节点,用于预测每个类的概率,并使用 softmax 激活函数。
|
1 2 3 4 |
# 定义模型 model = Sequential() model.add(Dense(10, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(3, activation='softmax')) |
该模型使用随机梯度下降进行拟合,具有合理的默认学习率0.01和较高的动量值0.9。模型使用交叉熵损失进行优化。
|
1 2 3 |
# 编译模型 opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) |
然后,模型将在训练数据集上拟合100个 epoch,默认批大小为32个示例。
|
1 2 |
# 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) |
下面的get_base_model()函数将这些元素整合在一起,接收训练数据集作为参数,并返回一个已拟合的基础模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 定义并拟合基础模型 def get_base_model(trainX, trainy): # 定义模型 model = Sequential() model.add(Dense(10, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(3, activation='softmax')) # 编译模型 opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) return model |
我们可以调用此函数来准备基础模型,之后我们可以逐个添加层。
|
1 2 |
# 获取基础模型 model = get_base_model(trainX, trainy) |
我们需要能够轻松地评估模型在训练集和测试集上的性能。
下面的evaluate_model()函数接收训练集和测试集以及一个模型作为参数,并返回这两个数据集上的准确率。
|
1 2 3 4 5 |
# 评估已拟合的模型 def evaluate_model(model, trainX, testX, trainy, testy): _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) return train_acc, test_acc |
我们可以调用此函数来计算和报告基础模型的准确率,并将分数存储在一个字典中,键是模型中的层数(目前是两层,一层隐藏层和一层输出层),以便之后绘制层数与准确率的关系图。
|
1 2 3 4 |
# 评估基础模型 scores = dict() train_acc, test_acc = evaluate_model(model, trainX, testX, trainy, testy) print('> layers=%d, train=%.3f, test=%.3f' % (len(model.layers), train_acc, test_acc)) |
我们现在可以概述贪婪逐层预训练的过程。
需要一个函数,该函数可以添加一个新隐藏层并重新训练模型,但只更新新添加层和输出层中的权重。
这首先需要存储当前的输出层,包括其配置和当前的权重集合。
|
1 2 |
# 记住当前的输出层 output_layer = model.layers[-1] |
然后从模型层堆栈中移除输出层。
|
1 2 |
# 移除输出层 model.pop() |
然后可以将模型中所有剩余层标记为不可训练,这意味着当再次调用fit()函数时,它们的权重将不会被更新。
|
1 2 3 |
# 将所有剩余层标记为不可训练 for layer in model.layers: layer.trainable = False |
然后我们可以添加一个新的隐藏层,在本例中,其配置与基础模型中添加的第一个隐藏层相同。
|
1 2 |
# 添加一个新的隐藏层 model.add(Dense(10, activation='relu', kernel_initializer='he_uniform')) |
最后,可以重新添加输出层,然后模型可以在训练数据集上重新拟合。
|
1 2 3 4 |
# 重新添加输出层 model.add(output_layer) # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) |
我们可以将所有这些元素整合到一个名为add_layer()的函数中,该函数将模型和训练数据集作为参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 添加一个新层并仅重新训练新层 def add_layer(model, trainX, trainy): # 记住当前的输出层 output_layer = model.layers[-1] # 移除输出层 model.pop() # 将所有剩余层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加一个新的隐藏层 model.add(Dense(10, activation='relu', kernel_initializer='he_uniform')) # 重新添加输出层 model.add(output_layer) # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) |
然后可以根据我们希望添加到模型中的层数来重复调用此函数。
在这种情况下,我们将一次添加10层,并在添加每个附加层后评估模型的性能,以了解它如何影响性能。
训练和测试准确率分数与模型中的层数一起存储在字典中。
|
1 2 3 4 5 6 7 8 9 10 |
# 添加层并评估更新后的模型 n_layers = 10 for i in range(n_layers): # 添加层 add_layer(model, trainX, trainy) # 评估模型 train_acc, test_acc = evaluate_model(model, trainX, testX, trainy, testy) print('> layers=%d, train=%.3f, test=%.3f' % (len(model.layers), train_acc, test_acc)) # 存储分数用于绘图 scores[len(model.layers)] = (train_acc, test_acc) |
在运行结束时,会创建一个折线图,显示模型中的层数(x轴)与训练集和测试集上的模型准确率。我们期望添加层可以提高模型在训练数据集甚至测试数据集上的性能。
我们期望添加层可以提高模型在训练数据集上的性能,甚至可能在测试数据集上。
|
1 2 3 4 5 |
# 绘制添加的层数与准确率的关系图 pyplot.plot(list(scores.keys()), [scores[k][0] for k in scores.keys()], label='train', marker='.') pyplot.plot(list(scores.keys()), [scores[k][1] for k in scores.keys()], label='test', marker='.') pyplot.legend() pyplot.show() |
将所有这些元素结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
# 斑点分类问题的监督贪婪层式预训练 from sklearn.datasets import make_blobs from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.utils import to_categorical from matplotlib import pyplot # 准备数据 def prepare_data(): # 生成 2d 分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 对输出变量进行独热编码 y = to_categorical(y) # 分割为训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, testX, trainy, testy # 定义并拟合基础模型 def get_base_model(trainX, trainy): # 定义模型 model = Sequential() model.add(Dense(10, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(3, activation='softmax')) # 编译模型 opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) return model # 评估已拟合的模型 def evaluate_model(model, trainX, testX, trainy, testy): _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) return train_acc, test_acc # 添加一个新层并仅重新训练新层 def add_layer(model, trainX, trainy): # 记住当前的输出层 output_layer = model.layers[-1] # 移除输出层 model.pop() # 将所有剩余层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加一个新的隐藏层 model.add(Dense(10, activation='relu', kernel_initializer='he_uniform')) # 重新添加输出层 model.add(output_layer) # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) # 准备数据 trainX, testX, trainy, testy = prepare_data() # 获取基础模型 model = get_base_model(trainX, trainy) # 评估基础模型 scores = dict() train_acc, test_acc = evaluate_model(model, trainX, testX, trainy, testy) print('> layers=%d, train=%.3f, test=%.3f' % (len(model.layers), train_acc, test_acc)) scores[len(model.layers)] = (train_acc, test_acc) # 添加层并评估更新后的模型 n_layers = 10 for i in range(n_layers): # 添加层 add_layer(model, trainX, trainy) # 评估模型 train_acc, test_acc = evaluate_model(model, trainX, testX, trainy, testy) print('> layers=%d, train=%.3f, test=%.3f' % (len(model.layers), train_acc, test_acc)) # 存储分数用于绘图 scores[len(model.layers)] = (train_acc, test_acc) # 绘制添加的层数与准确率的关系图 pyplot.plot(list(scores.keys()), [scores[k][0] for k in scores.keys()], label='train', marker='.') pyplot.plot(list(scores.keys()), [scores[k][1] for k in scores.keys()], label='test', marker='.') pyplot.legend() pyplot.show() |
运行此示例将报告基础模型(两层)在训练和测试集上的分类准确率,然后报告在添加每个附加层(从三层到十二层)后的分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能有所不同。考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到基线模型在此问题上表现相当不错。随着层数的增加,我们可以大致看到模型在训练数据集上的准确率有所提高,这可能是因为它开始过度拟合数据。我们看到测试数据集上的分类准确率有所下降,这可能是由于过度拟合。
|
1 2 3 4 5 6 7 8 9 10 11 |
> layers=2, train=0.816, test=0.830 > layers=3, train=0.834, test=0.830 > layers=4, train=0.836, test=0.824 > layers=5, train=0.830, test=0.824 > layers=6, train=0.848, test=0.820 > layers=7, train=0.830, test=0.826 > layers=8, train=0.850, test=0.824 > layers=9, train=0.840, test=0.838 > layers=10, train=0.842, test=0.830 > layers=11, train=0.850, test=0.830 > layers=12, train=0.850, test=0.826 |
还会创建一个折线图,显示随着向模型添加的每个附加层,训练集(蓝色)和测试集(橙色)的准确率。
在这种情况下,该图表明训练数据集存在轻微的过度拟合,但在添加七个层后,测试数据集的性能可能更好。
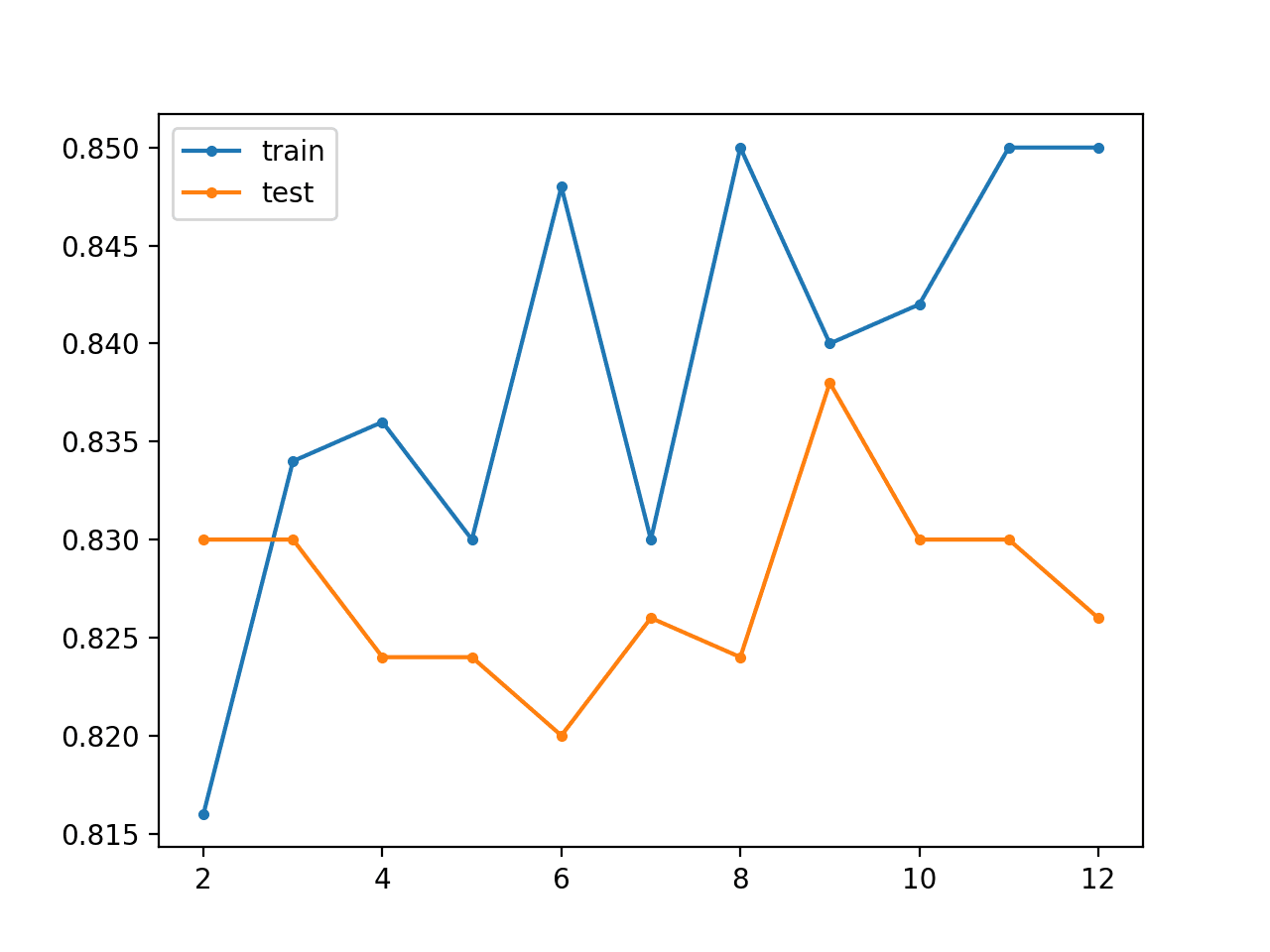
无监督贪婪层式预训练折线图,显示模型层数与斑点分类问题的训练集和测试集分类准确率
此示例的一个有趣扩展是允许模型中的所有权重以较小的学习率进行微调,训练较多的轮次,以查看这是否可以进一步减少泛化误差。
无监督贪婪逐层预训练
在本节中,我们将探讨使用无监督模型进行贪婪层式预训练。
具体来说,我们将开发一个自动编码器模型,该模型将被训练来重构输入数据。为了使用此无监督模型进行分类,我们将移除输出层,添加并拟合一个用于分类的新输出层。
这比先前的监督贪婪层式预训练稍微复杂一些,但我们可以重用先前部分中的许多相同思想和代码。
第一步是定义、拟合和评估自动编码器模型。我们将使用与前一部分相同的两层基线模型,不同之处在于修改它以预测输入作为输出,并使用均方误差来评估模型重构给定输入样本的好坏程度。
下面的 `base_autoencoder()` 函数实现了这一点,它接受训练集和测试集作为参数,然后定义、拟合和评估基线无监督自动编码器模型,打印训练集和测试集上的重构误差,并返回模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 定义、拟合和评估基线自动编码器 def base_autoencoder(trainX, testX): # 定义模型 model = Sequential() model.add(Dense(10, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(2, activation='linear')) # 编译模型 model.compile(loss='mse', optimizer=SGD(lr=0.01, momentum=0.9)) # 拟合模型 model.fit(trainX, trainX, epochs=100, verbose=0) # 评估重构损失 train_mse = model.evaluate(trainX, trainX, verbose=0) test_mse = model.evaluate(testX, testX, verbose=0) print('> reconstruction error train=%.3f, test=%.3f' % (train_mse, test_mse)) return model |
我们可以调用此函数来准备我们的基线自动编码器,然后我们可以向其中添加层并进行贪婪训练。
|
1 2 |
# 获取基线自动编码器 model = base_autoencoder(trainX, testX) |
在斑点多类分类问题上评估自动编码器模型需要几个步骤。
隐藏层将用作分类器的基础,新输出层必须先进行训练,然后才能用于进行预测,之后才能将原始输出层加回,以便我们可以继续向自动编码器添加层。
第一步是引用然后移除自动编码器模型的输出层。
|
1 2 3 4 |
# 记住当前的输出层 output_layer = model.layers[-1] # 移除输出层 model.pop() |
自动编码器中所有剩余的隐藏层都必须标记为不可训练,这样在训练新输出层时权重才不会被更改。
|
1 2 3 |
# 将所有剩余层标记为不可训练 for layer in model.layers: layer.trainable = False |
我们现在可以添加一个新输出层,该层预测示例属于每个三个类别的概率。模型还必须使用适合多类分类的新损失函数重新编译。
|
1 2 3 4 |
# 添加新的输出层 model.add(Dense(3, activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.01, momentum=0.9), metrics=['accuracy']) |
然后可以在训练数据集上重新拟合模型,特别是对输出层进行训练,以使用自动编码器学习到的特征作为输入来做出类别预测。
然后可以在训练集和测试集上评估拟合模型的分类准确率。
|
1 2 3 4 5 |
# 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) |
最后,我们可以将自动编码器重新组合起来,但要移除分类输出层,加回原始自动编码器输出层,并使用适合重构的损失函数重新编译模型。
|
1 2 3 4 |
# 将模型重新组合起来 model.pop() model.add(output_layer) model.compile(loss='mse', optimizer=SGD(lr=0.01, momentum=0.9)) |
我们可以将此整合到一个 `evaluate_autoencoder_as_classifier()` 函数中,该函数接受模型以及训练集和测试集,然后返回训练集和测试集的分类准确率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 将自动编码器评估为分类器 def evaluate_autoencoder_as_classifier(model, trainX, trainy, testX, testy): # 记住当前的输出层 output_layer = model.layers[-1] # 移除输出层 model.pop() # 将所有剩余层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加新的输出层 model.add(Dense(3, activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.01, momentum=0.9), metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) # 将模型重新组合起来 model.pop() model.add(output_layer) model.compile(loss='mse', optimizer=SGD(lr=0.01, momentum=0.9)) return train_acc, test_acc |
此函数可用于评估基线自动编码器模型,然后将准确率分数与模型中的层数(在本例中为两层)一起存储在字典中。
|
1 2 3 4 5 |
# 评估基础模型 scores = dict() train_acc, test_acc = evaluate_autoencoder_as_classifier(model, trainX, trainy, testX, testy) print('> classifier accuracy layers=%d, train=%.3f, test=%.3f' % (len(model.layers), train_acc, test_acc)) scores[len(model.layers)] = (train_acc, test_acc) |
我们现在准备好定义为模型添加和预训练层的过程。
添加层的过程与上一节中的监督情况基本相同,只是我们优化的是重构损失而不是新层的分类准确率。
下面的 `add_layer_to_autoencoder()` 函数向自动编码器模型添加一个新的隐藏层,更新新层和隐藏层的权重,然后报告训练集和测试集输入数据上的重构误差。该函数确实会重新标记所有先前的层为不可训练,这有点多余,因为我们已经在 `evaluate_autoencoder_as_classifier()` 函数中完成了此操作,但如果决定在自己的项目中使用此函数,我将其保留了下来。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 添加一个新层并仅重新训练新层 def add_layer_to_autoencoder(model, trainX, testX): # 记住当前的输出层 output_layer = model.layers[-1] # 移除输出层 model.pop() # 将所有剩余层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加一个新的隐藏层 model.add(Dense(10, activation='relu', kernel_initializer='he_uniform')) # 重新添加输出层 model.add(output_layer) # 拟合模型 model.fit(trainX, trainX, epochs=100, verbose=0) # 评估重构损失 train_mse = model.evaluate(trainX, trainX, verbose=0) test_mse = model.evaluate(testX, testX, verbose=0) print('> reconstruction error train=%.3f, test=%.3f' % (train_mse, test_mse)) |
现在我们可以反复调用此函数,添加层,并通过使用自动编码器作为评估新分类器的基础来评估其效果。
|
1 2 3 4 5 6 7 8 9 10 |
# 添加层并评估更新后的模型 n_layers = 5 for _ in range(n_layers): # 添加层 add_layer_to_autoencoder(model, trainX, testX) # 评估模型 train_acc, test_acc = evaluate_autoencoder_as_classifier(model, trainX, trainy, testX, testy) print('> classifier accuracy layers=%d, train=%.3f, test=%.3f' % (len(model.layers), train_acc, test_acc)) # 存储分数用于绘图 scores[len(model.layers)] = (train_acc, test_acc) |
与之前一样,收集所有准确率分数,并使用它们来创建模型层数与训练集和测试集准确率的折线图。
|
1 2 3 4 5 6 |
# 绘制添加的层数与准确率的关系图 keys = list(scores.keys()) pyplot.plot(keys, [scores[k][0] for k in keys], label='train', marker='.') pyplot.plot(keys, [scores[k][1] for k in keys], label='test', marker='.') pyplot.legend() pyplot.show() |
将这一切结合起来,下面列出了用于斑点多类分类问题的无监督贪婪层式预训练的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
# 无监督贪婪层式预训练用于斑点分类问题 from sklearn.datasets import make_blobs from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.utils import to_categorical from matplotlib import pyplot # 准备数据 def prepare_data(): # 生成 2d 分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 对输出变量进行独热编码 y = to_categorical(y) # 分割为训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, testX, trainy, testy # 定义、拟合和评估基线自动编码器 def base_autoencoder(trainX, testX): # 定义模型 model = Sequential() model.add(Dense(10, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(2, activation='linear')) # 编译模型 model.compile(loss='mse', optimizer=SGD(lr=0.01, momentum=0.9)) # 拟合模型 model.fit(trainX, trainX, epochs=100, verbose=0) # 评估重构损失 train_mse = model.evaluate(trainX, trainX, verbose=0) test_mse = model.evaluate(testX, testX, verbose=0) print('> reconstruction error train=%.3f, test=%.3f' % (train_mse, test_mse)) return model # 将自动编码器评估为分类器 def evaluate_autoencoder_as_classifier(model, trainX, trainy, testX, testy): # 记住当前的输出层 output_layer = model.layers[-1] # 移除输出层 model.pop() # 将所有剩余层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加新的输出层 model.add(Dense(3, activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.01, momentum=0.9), metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) # 将模型重新组合起来 model.pop() model.add(output_layer) model.compile(loss='mse', optimizer=SGD(lr=0.01, momentum=0.9)) return train_acc, test_acc # 添加一个新层并仅重新训练新层 def add_layer_to_autoencoder(model, trainX, testX): # 记住当前的输出层 output_layer = model.layers[-1] # 移除输出层 model.pop() # 将所有剩余层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加一个新的隐藏层 model.add(Dense(10, activation='relu', kernel_initializer='he_uniform')) # 重新添加输出层 model.add(output_layer) # 拟合模型 model.fit(trainX, trainX, epochs=100, verbose=0) # 评估重构损失 train_mse = model.evaluate(trainX, trainX, verbose=0) test_mse = model.evaluate(testX, testX, verbose=0) print('> reconstruction error train=%.3f, test=%.3f' % (train_mse, test_mse)) # 准备数据 trainX, testX, trainy, testy = prepare_data() # 获取基线自动编码器 model = base_autoencoder(trainX, testX) # 评估基础模型 scores = dict() train_acc, test_acc = evaluate_autoencoder_as_classifier(model, trainX, trainy, testX, testy) print('> classifier accuracy layers=%d, train=%.3f, test=%.3f' % (len(model.layers), train_acc, test_acc)) scores[len(model.layers)] = (train_acc, test_acc) # 添加层并评估更新后的模型 n_layers = 5 for _ in range(n_layers): # 添加层 add_layer_to_autoencoder(model, trainX, testX) # 评估模型 train_acc, test_acc = evaluate_autoencoder_as_classifier(model, trainX, trainy, testX, testy) print('> classifier accuracy layers=%d, train=%.3f, test=%.3f' % (len(model.layers), train_acc, test_acc)) # 存储分数用于绘图 scores[len(model.layers)] = (train_acc, test_acc) # 绘制添加的层数与准确率的关系图 keys = list(scores.keys()) pyplot.plot(keys, [scores[k][0] for k in keys], label='train', marker='.') pyplot.plot(keys, [scores[k][1] for k in keys], label='test', marker='.') pyplot.legend() pyplot.show() |
运行此示例将报告基础模型(两层)以及添加每个附加层(从三层到十二层)后,模型在训练集和测试集上的重构误差和分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能有所不同。考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到重构误差从低开始,实际上接近完美,然后随着训练缓慢增加。训练数据集上的准确率似乎随着编码器层数的增加而降低,尽管测试准确率似乎随着层数的增加而提高,至少直到模型有五层,之后性能似乎会崩溃。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> reconstruction error train=0.000, test=0.000 > classifier accuracy layers=2, train=0.830, test=0.832 > reconstruction error train=0.001, test=0.002 > classifier accuracy layers=3, train=0.826, test=0.842 > reconstruction error train=0.002, test=0.002 > classifier accuracy layers=4, train=0.820, test=0.838 > reconstruction error train=0.016, test=0.028 > classifier accuracy layers=5, train=0.828, test=0.834 > reconstruction error train=2.311, test=2.694 > classifier accuracy layers=6, train=0.764, test=0.762 > reconstruction error train=2.192, test=2.526 > classifier accuracy layers=7, train=0.764, test=0.760 |
还会创建一个折线图,显示随着向模型添加的每个附加层,训练集(蓝色)和测试集(橙色)的准确率。
在这种情况下,该图表明无监督贪婪层式预训练可能有一些微小的优势,但也许超过五层后模型会变得不稳定。
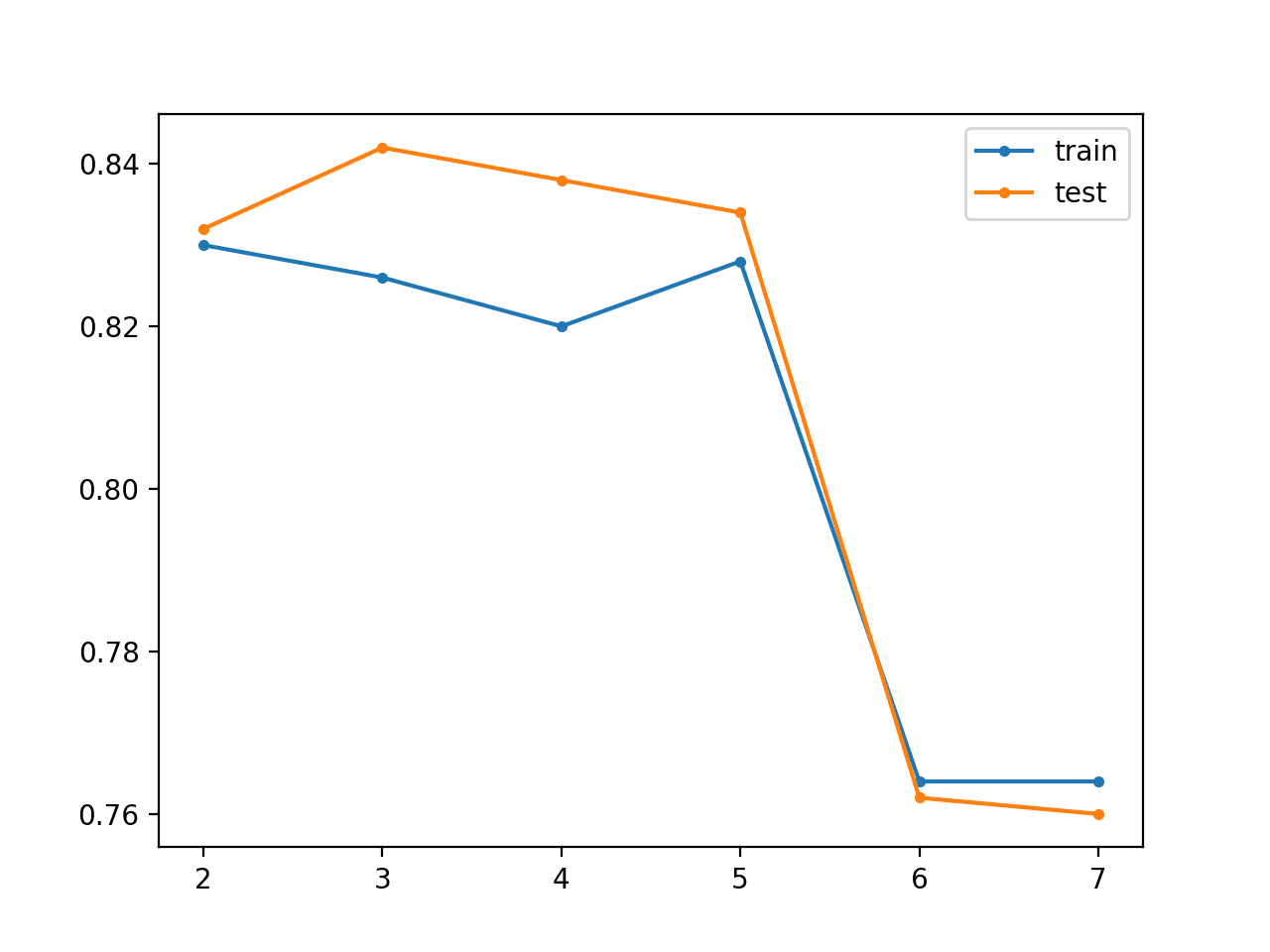
无监督贪婪层式预训练折线图,显示模型层数与斑点分类问题的训练集和测试集分类准确率
一个有趣的扩展是探索在拟合分类器输出层之前或之后对模型所有权重进行微调是否能提高性能。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 深度网络的贪婪层式训练, 2007.
- 为什么无监督预训练有助于深度学习, 2010.
书籍
总结
在本教程中,您了解了贪婪层式预训练作为开发深度多层神经网络模型的一种技术。
具体来说,你学到了:
- 贪婪逐层预训练提供了一种开发深度多层神经网络的方法,而只需训练浅层网络。
- 预训练可以用于迭代加深一个监督模型或一个可以重新用作监督模型的无监督模型。
- 对于标记数据量少而未标记数据量大的问题,预训练可能很有用。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







太棒了!先点赞再阅读!
谢谢!
非常漂亮的内容,感谢分享,谢谢
谢谢,很高兴对您有帮助。
我感谢你的帖子。我喜欢阅读你漂亮的帖子。你涵盖了机器学习的所有主题和子主题。如果你以后继续更新更多关于机器学习的内容,我会很高兴。
谢谢。
太棒了,优雅的代码!我以为这被称为级联层。
谢谢。
我以前没听过这个说法,你还记得在哪里读到的吗?
嗨,Jason,
感谢您总是分享有趣的帖子
在第一个示例中,监督贪婪层式预训练,似乎在第 52 行之后缺少了两行:即
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
否则,我得到了一个回溯,消息是“模型需要在被使用之前进行编译。”
祝好
谢谢。
也许你复制代码时错过了 `compile()` 行?
嗯,我在第一个示例中看不到它
model.add(Dense(10, activation=’relu’, kernel_initializer=’he_uniform’))
# 重新添加输出层
model.add(output_layer)
# 拟合模型
model.fit(trainX, trainy, epochs=100, verbose=0)
但它在第二个示例中存在
我是否弄错了?
真的吗?
另外,也许可以确认你使用的是 Keras 2.2.4+
嗨,Jason博士,
在第二个示例中,在无监督训练自动编码器之后,为什么在微调阶段冻结编码器层而只训练输出层?
我认为在无监督预训练中编码器层所学到的东西被用作微调阶段的初始化,并且我们对整个模型进行微调。
我漏掉了什么吗?!!!!
好问题。
我选择微调解码器,但这有点随意。如果你愿意,可以选择微调整个模型。
嗨,Jason,
感谢您的教程和精彩内容。快速提问,如果我正确理解了深度学习(Bengio)书中的引述……有了 Keras 中如今可用的现代激活函数、dropout 等,贪婪层式预训练是否已经过时了?您会建议将其应用于大型数据集和重要神经网络架构,还是今天应该完全忽略它?
另外,我听过许多来源说“深度神经网络比宽神经网络学得更好,如果训练得当”。“深度神经网络比宽神经网络学得更好”这句话是指贪婪层式预训练吗?
对于较小的模型,更倾向于使用替代方法。
之所以描述该方法,是因为该方法在历史原因上仍然具有普遍的趣味性,并且在某些情况下很有用,例如迁移学习和逐步增长大型模型(如 GAN)的场景。
在极限情况下,深层和宽层并不重要。您选择的数据集和模型的具体细节提供了重要的背景信息,您应该进行实验。
或许可以测试一下它对您特定问题的帮助/实用性?
嗨,Jason,
感谢分享这篇教程,
我有一个单一的时间序列数据,我想将其输入到我的机器中,以便进行时间序列预测。
但我不知道如何整理我的数据并将其输入机器,以便它能捕捉模式并进行预测。
您有什么建议给我吗?
谢谢你
此致
是的,您可以从这里开始。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
好的,谢谢您,先生!
不客气。
嗨,Jason,
一如既往的精彩文章。
我目前有一个多输入模型,并且正在使用 Keras API。我可以在我的模型上实现贪婪的逐层预训练吗?
谢谢
或许可以尝试一下,并将其与使用 ReLU 等现代激活函数的静态 MLP 模型进行比较。
您好,Johnson 博士,
感谢您分享这段代码和教程。作为 Keras 的新用户,我有一个问题。我想用贪婪的逐层方法设计一个简单的监督式自编码器网络。各层的节点数分别为 28、20、15、10、15、20、28。当我尝试添加新层时,会收到一个错误。
这是我的代码,在每次迭代中,hiddennodes 是上面提到的数字之一:def add_layer(model, trainX, trainy,hiddennodes)
# 记住当前的输出层
output_layer = model.layers[-1]
# 移除输出层
model.pop()
# 将所有剩余层标记为不可训练
`for layer in model.layers`
layer.trainable = False
# 添加一个新的隐藏层
model.add(Dense(hiddennodes, activation=’relu’, kernel_initializer=’he_uniform’))
# 重新添加输出层
model.add(output_layer)
# 拟合模型
model.fit(trainX, trainy, epochs=100, verbose=0)
但是我收到了这个错误:“Input 0 is incompatible with layer dense_3: expected axis -1 of input shape to have value 20 but got shape (None, 15) ”
如果您能帮助我,我将不胜感激。
祝好,
Saeid
我很乐意帮忙,但我没有能力调试您的代码。\
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
谢谢你。
不客气。
嗨
为什么第二个例子被认为是无监督学习问题?我们训练模型来根据输入 X 预测标签 X,所以这仅仅是尝试让模型学习线性函数 y = X。所以对我来说,这看起来像一个回归问题。
我究竟遗漏了什么?
谢谢。
并且我在我的 jupyter notebook 上运行代码,结果如下
[py]
ValueError 回溯 (最近一次调用)
in
79 print(‘YYYYYYY’)
80
—> 81 pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
82 pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
83 pyplot.legend()
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/pyplot.py in plot(scalex, scaley, data, *args, **kwargs)
2787 return gca().plot(
2788 *args, scalex=scalex, scaley=scaley, **({“data”: data} if data
-> 2789 is not None else {}), **kwargs)
2790
2791
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_axes.py in plot(self, scalex, scaley, data, *args, **kwargs)
1664 “””
1665 kwargs = cbook.normalize_kwargs(kwargs, mlines.Line2D._alias_map)
-> 1666 lines = [*self._get_lines(*args, data=data, **kwargs)]
1667 for line in lines
1668 self.add_line(line)
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in __call__(self, *args, **kwargs)
223 this += args[0],
224 args = args[1:]
–> 225 yield from self._plot_args(this, kwargs)
226
227 def get_next_color(self)
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in _plot_args(self, tup, kwargs)
389 x, y = index_of(tup[-1])
390
–> 391 x, y = self._xy_from_xy(x, y)
392
393 if self.command == ‘plot’
~/miniconda3/envs/sandbox/lib/python3.7/site-packages/matplotlib/axes/_base.py in _xy_from_xy(self, x, y)
268 if x.shape[0] != y.shape[0]
269 raise ValueError(“x and y must have same first dimension, but ”
-> 270 “have shapes {} and {}”.format(x.shape, y.shape))
271 if x.ndim > 2 or y.ndim > 2
272 raise ValueError(“x and y can be no greater than 2-D, but have ”
ValueError: x and y must have same first dimension, but have shapes (1,) and (11,)
[/py]
为了解决这个问题,我更改了以下 2 行:
[py]
pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
[/py]
到
[py]
pyplot.plot(list(scores.keys()), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(list(scores.keys()), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
[/py]
不要使用 notebook。
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
感谢您的建议。我尝试在纯 python 解释器 3.7 中运行,行为完全相同。然而,下面的更改使其可以工作。
从
pyplot.plot(scores.keys(), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(scores.keys(), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
到
pyplot.plot(list(scores.keys()), [scores[k][0] for k in scores.keys()], label=’train’, marker=’.’)
pyplot.plot(list(scores.keys()), [scores[k][1] for k in scores.keys()], label=’test’, marker=’.’)
我正在使用的 matplotlib 版本是:
>>> matplotlib.__version__
‘3.1.0’
好的,感谢您的说明。
我们正在重构输入,而不是预测。
正如帖子中所述:
感谢您的反馈。
您能否详细说明重构输入数据与无监督学习之间的关系?
仅对输入数据进行建模的想法是一种无监督学习任务。例如,对输入进行密度建模。
使用自编码器的想法是将无监督学习问题框架化为监督学习问题。这非常巧妙!
您好!感谢并祝贺这篇出色的帖子。
只有一个问题
我能否修改“add layer”函数以添加具有不同节点数的层?
例如:10-6-3-6-10 而不是 10-10-10-10-10?
当然可以。
非常出色的帖子。
谢谢。
谢谢您!一如既往,非常好的帖子。
我已将其实现到堆叠的 LSTM 中,使用了 Keras 的函数式 API。
对于第一次贪婪训练,只使用一个 LSTM,它不应该返回序列到最后一个密集层。但是,当弹出最后一个层并添加 LSTM 层时,已经预训练过的现有 LSTM 层需要 return_sequence。
您对如何处理这个问题有什么想法吗?我尝试在第一次(现有)LSTM 层训练后将 return_sequence 设置为 true,但正如预料的那样,这不起作用。
听起来很有趣!
我认为您需要重新定义具有 return_sequences 设置为 true 的层。
如果模型不支持此操作,请将权重复制到新网络并重新定义该层。
谢谢你,
我想问一个关于数据集的问题。那么,在这种情况下我该如何划分我的数据集?
例如,如果我有一个包含 60,000 个样本的数据集
(?% 用于无监督预训练)
(?% 用于监督微调)
(?% 验证)
(?% 测试)
尝试不同的组合,看看哪种最适合您的数据集。
预训练是否对具有大量监督数据的 CNN 训练有用?(真或假)并附带一些解释。
请指导。
也许吧。这取决于数据和模型的选择。
您说:“一个有趣的的扩展是探索在拟合分类器输出层之前或之后,对所有权重进行微调是否能提高性能。”
在这个例子中,我该如何使用微调?谢谢!
使用较小的学习率来微调模型。
为了微调,在 evaluate_autoencoder_as_classifier 函数中修改代码是否正确?
`for layer in model.layers`
layer.trainable = True
或许可以尝试一些事情。
嗨,Jason,
例如:10-6-3-6-10 而不是 10-10-10-10-10 会导致错误。
致敬
一如既往的非常棒的帖子!感谢分享您的知识!!!
在倒数第二个引言中写道:“如今,无监督预训练在很大程度上已被抛弃。”
那么,您知道当今最广泛使用的初始化方法是什么吗?或者什么是“最先进”的初始化方法?
谢谢。
是的,我们使用具有 ReLU 的深度模型。
非常详尽的解释,我从第一天起就一直关注您的博客来研究深度学习。
非常感谢你,Jason。
我看到一些文献提到了微调阶段,其中确实先前的隐藏层与分类层一起被进一步训练。这意味着初始化层权重就像它们之前学到的那样,但不将训练设置为 False 吗?
谢谢。
是的,这意味着我们保留先前的训练权重,并使用较小的学习率来优化它们。
Jason,再次感谢您的精彩教程。我有一个关于无监督预训练部分的问题:我的理解是,我们有一些大量的无标签数据,比如 trainX,然后我们有一个相对少量的有标签数据,比如 trainX1,trainy1,当然还有一些测试数据,testX1 和 testy1。我们应该使用 trainX 构建自编码器(在 base_autoencoder 函数中,我们有 model.fit(trainX, trainX, epochs=100, verbose=0)),然后我们应该使用 trainX1 和 trainy1 而不是 trainX 和 trainy 来评估模型,对吗?
如果您愿意,可以尝试一下。
感谢您的帖子!然而,有一点我不明白的是自编码器在这个例子中的用法。据我所理解的自编码器作为分类预处理的用法,它们应该压缩输入,以便增加“压缩”层(连接编码器和解码器部分的那一层)中的信息含量。因此,如果您有 n 维输入,自编码器可以用来将其压缩到 m 维,其中 m < n。
然而,在示例中,维度是增加的。理想情况下,层应该能够简单地将信息传递(有点像恒等函数)到下一层。在我看来,添加这些额外的层只会给数据增加噪声。您的结果中分类精度的逐渐下降也证实了我的看法。
您能解释一下这种布局的原因吗?
这是对方法的演示——也许是针对一个过于简单的问题,理想情况下我们应该使用更大的输入。