机器学习预测模型的性能取决于您的数据,而您的数据性能取决于您准备数据以进行建模的方式。
数据准备最常见的方法是研究数据集并审查机器学习算法的期望,然后仔细选择最合适的数据准备技术来转换原始数据,以最好地满足算法的期望。这既慢又昂贵,并且需要大量的专业知识。
数据准备的另一种方法是,对原始数据进行一组常见且常用的数据准备技术的网格搜索。这是数据准备的一种替代理念,它将**数据转换视为建模管道的另一个超参数**,需要进行搜索和调整。
这种方法比传统的手动数据准备方法所需的专业知识更少,尽管它的计算成本很高。好处是它可以帮助发现非直观的数据准备解决方案,这些解决方案可以为给定的预测建模问题实现良好或最佳性能。
在本教程中,您将学习如何使用网格搜索方法对表格数据进行数据准备。
完成本教程后,您将了解:
- 网格搜索为表格数据的数据准备提供了一种替代方法,其中将转换作为建模管道的超参数进行尝试。
- 如何使用网格搜索方法进行数据准备,以提高标准分类数据集模型的性能,使其优于基线。
- 如何对数据准备方法的序列进行网格搜索,以进一步提高模型性能。
通过我的新书《机器学习数据准备》**启动您的项目**,包括*分步教程*和所有示例的*Python 源代码文件*。
让我们开始吧。

如何对数据准备技术进行网格搜索
照片由Wall Boat提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 数据准备的网格搜索技术
- 数据集和性能基线
- 葡萄酒分类数据集
- 基线模型性能
- 数据准备的网格搜索方法
数据准备的网格搜索技术
数据准备可能具有挑战性。
最常规定和遵循的方法是分析数据集,审查算法的要求,并转换原始数据以最好地满足算法的期望。
这可能有效,但也很慢,并且可能需要数据分析和机器学习算法方面的深厚专业知识。
另一种方法是将输入变量的准备视为建模管道的超参数,并将其与算法选择和算法配置一起进行调整。
这可能是一种“不应该起作用”或“不应该适用于该算法”的数据转换,但却能带来良好或出色的性能。或者,它可能是一个被认为“绝对需要”的输入变量缺乏数据转换,但却能带来良好或出色的性能。
这可以通过设计**数据准备技术和/或管道中数据准备技术序列的网格搜索**来实现。这可能涉及在单个选定的机器学习算法或一组机器学习算法上评估每个。
这种方法的优点是它总是能提供给出良好相对结果的建模管道建议。最重要的是,它可以在不需要深厚专业知识的情况下,为从业者发掘不明显和反直觉的解决方案。
我们可以通过一个实际示例来探索这种数据准备方法。
在我们深入研究一个实际示例之前,我们首先选择一个标准数据集并建立性能基线。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数据集和性能基线
在本节中,我们将首先选择一个标准机器学习数据集并在此数据集上建立性能基线。这将为在下一节中探索数据准备的网格搜索方法提供上下文。
葡萄酒分类数据集
我们将使用葡萄酒分类数据集。
该数据集有 13 个输入变量,描述了葡萄酒样本的化学成分,需要将葡萄酒分类为三种类型之一。
你可以在此处了解更多关于此数据集的信息:
无需下载数据集,因为我们将在实际示例中自动下载。
打开数据集并查看原始数据。以下列出了数据的前几行。
我们可以看到这是一个多类分类预测建模问题,具有数值输入变量,每个变量都有不同的比例。
|
1 2 3 4 5 6 |
14.23,1.71,2.43,15.6,127,2.8,3.06,.28,2.29,5.64,1.04,3.92,1065,1 13.2,1.78,2.14,11.2,100,2.65,2.76,.26,1.28,4.38,1.05,3.4,1050,1 13.16,2.36,2.67,18.6,101,2.8,3.24,.3,2.81,5.68,1.03,3.17,1185,1 14.37,1.95,2.5,16.8,113,3.85,3.49,.24,2.18,7.8,.86,3.45,1480,1 13.24,2.59,2.87,21,118,2.8,2.69,.39,1.82,4.32,1.04,2.93,735,1 ... |
以下示例加载数据集并将其分为输入和输出列,然后汇总数据数组。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 加载和汇总葡萄酒数据集的示例 from pandas import read_csv # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv' # 将数据集加载为数据帧 df = read_csv(url, header=None) # 检索 numpy 数组 data = df.values # 将列拆分为输入和输出变量 X, y = data[:, :-1], data[:, -1] # 汇总加载数据的形状 print(X.shape, y.shape) |
运行示例,我们可以看到数据集已正确加载,并且有 179 行数据,其中包含 13 个输入变量和一个目标变量。
|
1 |
(178, 13) (178,) |
接下来,让我们评估此数据集上的模型并建立性能基线。
基线模型性能
我们可以通过评估原始输入数据上的模型来建立葡萄酒分类任务的性能基线。
在这种情况下,我们将评估逻辑回归模型。
首先,我们可以定义一个函数来加载数据集并执行一些最小的数据准备,以确保输入是数值的,并且目标是标签编码的。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 准备数据 def load_dataset(): # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv' df = read_csv(url, header=None) data = df.values X, y = data[:, :-1], data[:, -1] # 最少准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) return X, y |
我们将使用重复分层 k 折交叉验证的黄金标准来评估模型,其中包含 10 折和 3 次重复。
|
1 2 3 4 5 6 7 |
# 评估模型 def evaluate_model(X, y, model): # 定义交叉验证过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores |
然后我们可以调用该函数来加载数据集,定义我们的模型,然后评估它,报告平均值和标准差精度。
|
1 2 3 4 5 6 7 8 9 |
... # 获取数据集 X, y = load_dataset() # 定义模型 model = LogisticRegression(solver='liblinear') # 评估模型 scores = evaluate_model(X, y, model) # 报告表现 print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
综合起来,在原始葡萄酒分类数据集上评估逻辑回归模型的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 葡萄酒数据集上的基线模型性能 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.model_selection import cross_val_score 从 sklearn.线性模型 导入 LogisticRegression # 准备数据 def load_dataset(): # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv' df = read_csv(url, header=None) data = df.values X, y = data[:, :-1], data[:, -1] # 最少准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义交叉验证过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 获取数据集 X, y = load_dataset() # 定义模型 model = LogisticRegression(solver='liblinear') # 评估模型 scores = evaluate_model(X, y, model) # 报告表现 print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行示例评估模型性能并报告分类准确性的平均值和标准差。
**注意**:考虑到算法或评估过程的随机性或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到在原始输入数据上拟合的逻辑回归模型实现了大约 95.3% 的平均分类准确度,提供了性能基线。
|
1 |
准确度:0.953 (0.048) |
接下来,让我们探讨是否可以使用基于网格搜索的数据准备方法来提高性能。
数据准备的网格搜索方法
在本节中,我们将探讨是否可以使用网格搜索方法进行数据准备来提高性能。
第一步是定义一系列要评估的建模管道,其中每个管道定义一个(或多个)数据准备技术,并以一个将转换后的数据作为输入的模型结束。
我们将定义一个函数来创建这些管道作为元组列表,其中每个元组定义管道的简称和管道本身。我们将评估一系列不同的数据缩放方法(例如 MinMaxScaler 和 StandardScaler)、分布转换(QuantileTransformer 和 KBinsDiscretizer)以及降维转换(PCA 和 SVD)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 获取要评估的建模管道 def get_pipelines(model): pipelines = list() # 归一化 p = Pipeline([('s',MinMaxScaler()), ('m',model)]) pipelines.append(('norm', p)) # 标准化 p = Pipeline([('s',StandardScaler()), ('m',model)]) pipelines.append(('std', p)) # 分位数 p = Pipeline([('s',QuantileTransformer(n_quantiles=100, output_distribution='normal')), ('m',model)]) pipelines.append(('quan', p)) # 离散化 p = Pipeline([('s',KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform')), ('m',model)]) pipelines.append(('kbins', p)) # pca p = Pipeline([('s',PCA(n_components=7)), ('m',model)]) pipelines.append(('pca', p)) # svd p = Pipeline([('s',TruncatedSVD(n_components=7)), ('m',model)]) pipelines.append(('svd', p)) return pipelines |
然后我们可以调用此函数以获取转换列表,然后枚举每个转换,评估它并报告沿途的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... # 获取建模管道 pipelines = get_pipelines(model) # 评估每个管道 results, names = list(), list() for name, pipeline in pipelines: # 评估 scores = evaluate_model(X, y, pipeline) # 总结 print('>%s: %.3f (%.3f)' % (name, mean(scores), std(scores))) # 存储 results.append(scores) names.append(name) |
运行结束时,我们可以为每组分数创建一个箱线图,并直观地比较结果分布。
|
1 2 3 4 |
... # 绘制结果 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
综上所述,在葡萄酒分类数据集上对数据准备技术进行网格搜索的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
# 比较葡萄酒分类数据集的数据准备方法 from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import LabelEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import QuantileTransformer from sklearn.preprocessing import KBinsDiscretizer 从 sklearn.分解 导入 PCA from sklearn.decomposition import TruncatedSVD from matplotlib import pyplot # 准备数据 def load_dataset(): # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv' df = read_csv(url, header=None) data = df.values X, y = data[:, :-1], data[:, -1] # 最少准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义交叉验证过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 获取要评估的建模管道 def get_pipelines(model): pipelines = list() # 归一化 p = Pipeline([('s',MinMaxScaler()), ('m',model)]) pipelines.append(('norm', p)) # 标准化 p = Pipeline([('s',StandardScaler()), ('m',model)]) pipelines.append(('std', p)) # 分位数 p = Pipeline([('s',QuantileTransformer(n_quantiles=100, output_distribution='normal')), ('m',model)]) pipelines.append(('quan', p)) # 离散化 p = Pipeline([('s',KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform')), ('m',model)]) pipelines.append(('kbins', p)) # pca p = Pipeline([('s',PCA(n_components=7)), ('m',model)]) pipelines.append(('pca', p)) # svd p = Pipeline([('s',TruncatedSVD(n_components=7)), ('m',model)]) pipelines.append(('svd', p)) return pipelines # 获取数据集 X, y = load_dataset() # 定义模型 model = LogisticRegression(solver='liblinear') # 获取建模管道 pipelines = get_pipelines(model) # 评估每个管道 results, names = list(), list() for name, pipeline in pipelines: # 评估 scores = evaluate_model(X, y, pipeline) # 总结 print('>%s: %.3f (%.3f)' % (name, mean(scores), std(scores))) # 存储 results.append(scores) names.append(name) # 绘制结果 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例评估每个管道的性能并报告分类准确性的平均值和标准差。
**注意**:考虑到算法或评估过程的随机性或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到标准化输入变量和使用分位数变换都取得了最好的结果,分类准确度约为 98.7%,比没有数据准备的基线(分类准确度为 95.3%)有所提高。
您可以将自己的建模管道添加到 *get_pipelines()* 函数中并比较其结果。
你能取得更好的结果吗?
在下面的评论中告诉我。
|
1 2 3 4 5 6 |
>norm: 0.976 (0.031) >std: 0.987 (0.023) >quan: 0.987 (0.023) >kbins: 0.968 (0.045) >pca: 0.963 (0.039) >svd: 0.953 (0.048) |
生成了一个图表,显示了箱线图,总结了每种数据准备技术的分类准确度分数分布。我们可以看到标准化和分位数转换的分数分布紧凑且非常相似,并且有一个异常值。我们可以看到其他转换的分数分布范围更大,并且向下倾斜。
结果可能表明,数据集标准化可能是数据准备和相关转换(例如分位数转换)中的重要一步,甚至幂转换如果与标准化结合使用,通过使一个或多个输入变量更趋向高斯分布,可能会带来好处。
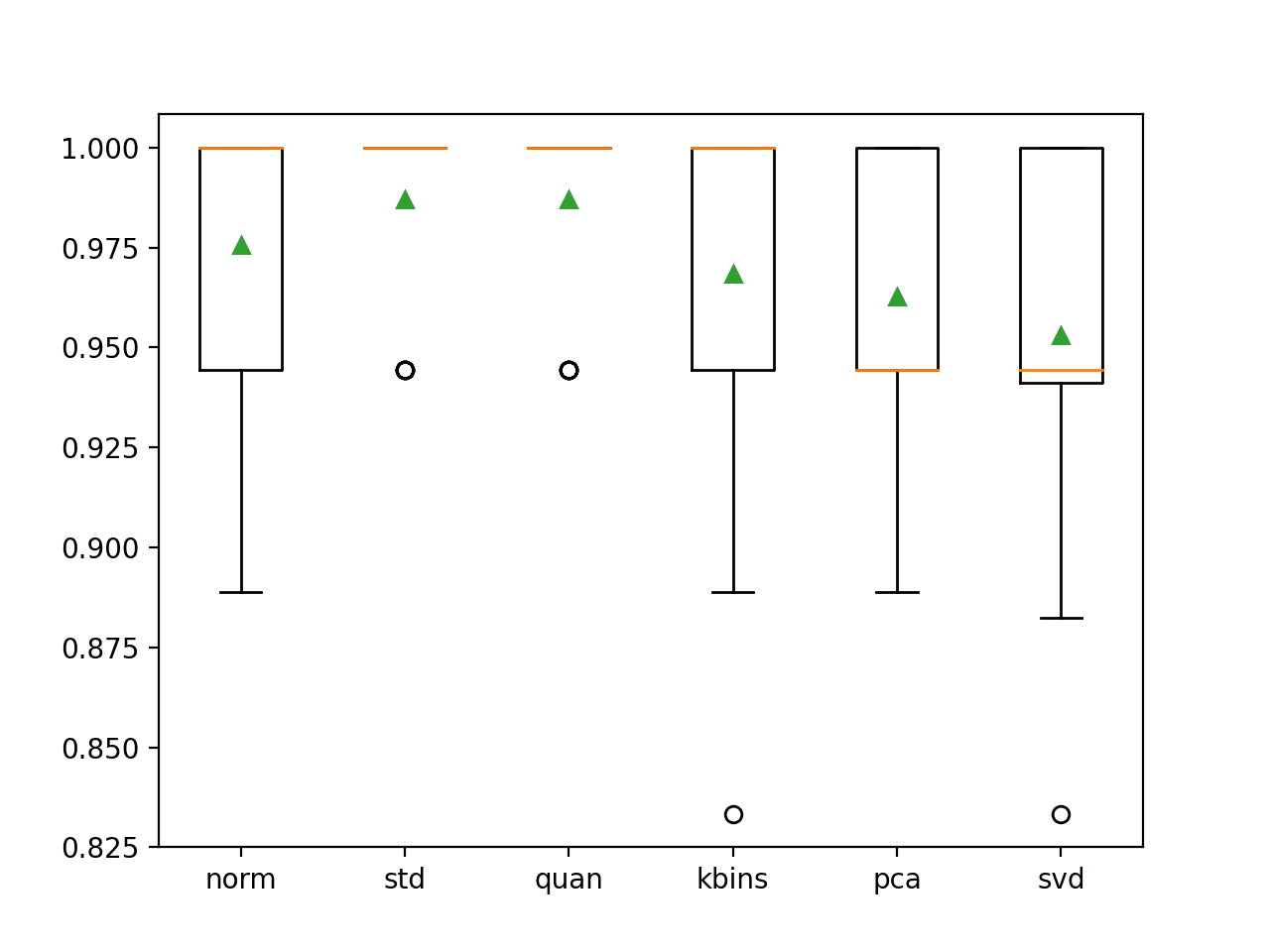
葡萄酒分类数据集上不同数据转换的分类准确度箱线图
我们还可以探索转换序列,看看它们是否能提高性能。
例如,我们可能希望在标准化转换后应用 RFE 特征选择,以查看是否可以使用更少的输入变量(即更低的复杂性)获得相同或更好的结果。
我们可能还想看看在数据缩放转换之前进行幂转换是否能在数据集上取得良好性能,因为我们认为分位数转换的成功可能预示着这一点。
下面提供了包含转换序列的更新后的 *get_pipelines()* 函数。
|
1 2 3 4 5 6 7 8 9 10 |
# 获取要评估的建模管道 def get_pipelines(model): pipelines = list() # 标准化 p = Pipeline([('s',StandardScaler()), ('r', RFE(estimator=LogisticRegression(solver='liblinear'), n_features_to_select=10)), ('m',model)]) pipelines.append(('std', p)) # 缩放和幂转换 p = Pipeline([('s',MinMaxScaler((1,2))), ('p', PowerTransformer()), ('m',model)]) pipelines.append(('power', p)) return pipelines |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
# 比较葡萄酒分类数据集的数据准备方法序列 from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import LabelEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import QuantileTransformer from sklearn.preprocessing import PowerTransformer from sklearn.preprocessing import KBinsDiscretizer 从 sklearn.分解 导入 PCA from sklearn.decomposition import TruncatedSVD 从 sklearn.特征选择 导入 RFE from matplotlib import pyplot # 准备数据 def load_dataset(): # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv' df = read_csv(url, header=None) data = df.values X, y = data[:, :-1], data[:, -1] # 最少准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义交叉验证过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 获取要评估的建模管道 def get_pipelines(model): pipelines = list() # 标准化 p = Pipeline([('s',StandardScaler()), ('r', RFE(estimator=LogisticRegression(solver='liblinear'), n_features_to_select=10)), ('m',model)]) pipelines.append(('std', p)) # 缩放和幂转换 p = Pipeline([('s',MinMaxScaler((1,2))), ('p', PowerTransformer()), ('m',model)]) pipelines.append(('power', p)) return pipelines # 获取数据集 X, y = load_dataset() # 定义模型 model = LogisticRegression(solver='liblinear') # 获取建模管道 pipelines = get_pipelines(model) # 评估每个管道 results, names = list(), list() for name, pipeline in pipelines: # 评估 scores = evaluate_model(X, y, pipeline) # 总结 print('>%s: %.3f (%.3f)' % (name, mean(scores), std(scores))) # 存储 results.append(scores) names.append(name) # 绘制结果 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例评估每个管道的性能并报告分类准确性的平均值和标准差。
**注意**:考虑到算法或评估过程的随机性或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到带有特征选择的标准化使准确度从 98.7% 额外提高了 98.9%,尽管数据缩放和幂变换并未比分位数变换提供任何额外的好处。
|
1 2 |
>std: 0.989 (0.022) >power: 0.987 (0.023) |
创建了一个图表,显示了箱线图,总结了每种数据准备技术的分类准确度分数分布。
我们可以看到,两个转换管道的结果分布都很紧凑,除了异常值之外几乎没有分散。
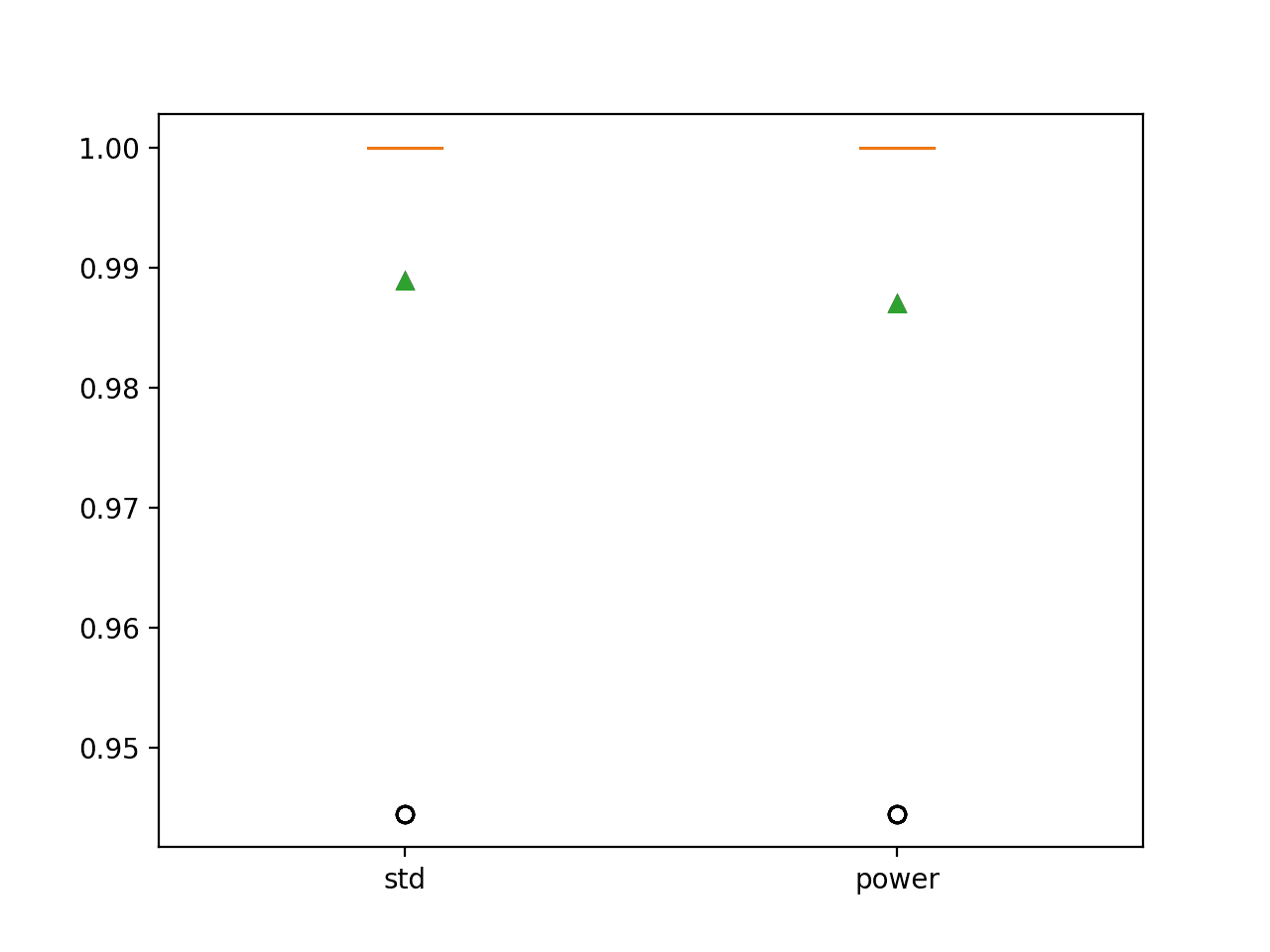
葡萄酒分类数据集上不同数据转换序列的分类准确度箱线图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
API
总结
在本教程中,您学习了如何使用网格搜索方法对表格数据进行数据准备。
具体来说,你学到了:
- 网格搜索为表格数据的数据准备提供了一种替代方法,其中将转换作为建模管道的超参数进行尝试。
- 如何使用网格搜索方法进行数据准备,以提高标准分类数据集模型的性能,使其优于基线。
- 如何对数据准备方法的序列进行网格搜索,以进一步提高模型性能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







一如既往的好帖子。我可以知道如何将网格搜索应用于 LSTM(神经网络)模型吗?因为选择超参数对于获得最佳结果非常重要。提前感谢 Jason。
是的,请参阅本教程
https://machinelearning.org.cn/how-to-grid-search-deep-learning-models-for-time-series-forecasting/
尊敬的Jason博士,
我从您的网站下载了文件“wine.csv”。
加载数据集时似乎存在格式错误。
如果我按照上面的代码下载
上面看起来不太对劲。所以我又在 read_csv 中添加了一个参数
结论
对于下载的文件 wine.csv,您需要让 read_csv 包含参数 delim_whitespace = True,否则,如果没有该参数,您将得到我的评论开头所示的混乱。
希望这有帮助。
悉尼的Anthony
这是 CSV 格式的数据集
https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv
所有数据集都位于此处
https://github.com/jbrownlee/Datasets
尊敬的Jason博士,
感谢您的本教程。
在“数据准备的网格搜索方法”小标题下有一个函数叫
我注意到传递“模型”参数并没有附加到管道中。也没有将“模型”作为管道的一部分添加。
所以我重写了模块,没有传递“模型”参数,例如
我使用 get_pipelines() 函数获得了相同的结果。
在 get_pipelines 中传递“model”变量的目的是什么?它没有附加到 get_pipelines(model) 函数中的特定管道。
在 get_pipelines() 函数中不包含“model”参数会产生相同的结果
谢谢你,
悉尼的安东尼。
尊敬的Jason博士,
问题已解决 - “模型”变量仍然用作 get_pipelines() 中各种管道的步骤,因为“模型”是一个全局变量。
我们得到相同结果的原因是,无论是 get_pipelines(model) 还是 get_pipelines(),“模型”仍然被添加到 get_pipelines(model) 或 get_pipelines() 中的步骤中。
在 get_pipelines() 中,如何在不需要“模型”参数的情况下传递模型?
答案是“模型”是全局的。
它是如何全局的?
答案是“模型”是一个全局变量,函数 get_pipelines() 在 get_pipelines() 中使用了全局声明的变量“模型”。
您可能会问,它如何在 get_pipelines() 中使用?
答案:以下是 get_pipelines() 中使用的几行典型代码
结论——这就是使用全局变量的危险。如果一个模块/函数需要传递给一个模块,参数需要与全局变量不同名称,以限制全局变量的作用域。
谢谢你,
悉尼的Anthony
不,“model”作为参数传递给 get_pipelines(),并在其中添加到每个管道的末尾。
该模型在该函数中添加到每个管道的末尾。
尊敬的Jason博士,
谢谢您的回复。我应该说得更清楚些。
是的,在“那个函数内”,‘model’ 被添加到每个管道的末尾。同时,没有必要将函数声明为 get_pipelines(model),因为 ‘model’ (i) 在函数外部声明,并且 (ii) 因为 ‘model’ 在函数外部声明,所以在您的 get_pipelines(model) 版本中,get_pipelines() 内部可以使用 ‘model’ 而无需传递参数 ‘model’。
因此,您示例中的“model”是全局的。
谢谢,感谢您的回复。
悉尼的Anthony
是的,但我不建议使用/依赖全局变量,因此它作为函数的参数提供,以便在函数内部使用。
尊敬的Jason博士,
谢谢,我很感激。它澄清了全局变量的危险。
悉尼的安东尼。