集成成员选择是指优化集成组成的算法。
这可能涉及从可用模型中构建集成,或从已完全定义的集成中修剪成员。
其目标通常是在对集成性能影响很小或没有影响的情况下,降低集成的模型或计算复杂度,有时还可以找到一个由集成成员组成的组合,该组合的性能优于直接使用所有贡献模型。
在本教程中,您将学习如何从头开始开发集成选择算法。
完成本教程后,您将了解:
- 集成选择涉及选择集成成员的子集,该子集比使用所有成员具有更低的复杂度,有时性能更好。
- 如何为分类开发和评估贪婪集成修剪算法。
- 如何从头开始开发和评估一个贪婪构建集成的算法。
启动您的项目,阅读我的新书 Ensemble Learning Algorithms With Python,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

Python 中集成的增长与剪枝
照片由 FaBio C 提供,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 集成成员选择
- 基线模型和投票
- 集成修剪示例
- 集成构建示例
集成成员选择
尽管集成可能有很多集成成员,但很难确定集成使用的是最佳成员组合。例如,与简单地使用所有成员相比,通过添加一个不同类型的模型或删除一个或多个模型,有可能获得更好的结果。
这可以通过加权平均集成和使用优化算法来找到每个成员的适当权重来解决,允许一些成员具有零权重,从而有效地从集成中删除它们。加权平均集成的问题在于所有模型都保留在集成中,可能需要比开发和维护所需的集成更复杂的集成。
另一种方法是优化集成本身的组成。自动选择或优化集成成员的通用方法称为集成选择。
两种常见方法包括集成构建和集成修剪。
- 集成构建:向集成中添加成员,直到不再观察到进一步的改进。
- 集成修剪:从集成中删除成员,直到不再观察到进一步的改进。
集成构建是一种模型从零开始,通过添加新成员直到不再观察到进一步改进的技术。这可以以贪婪的方式执行,即一次添加一个成员,仅当它们能提高模型性能时。
集成修剪是一种模型从所有可能的成员开始,并从集成中删除成员直到不再观察到进一步改进的技术。这可以以贪婪的方式执行,即一次删除一个成员,并且仅当它们的删除能提高整个集成的性能时。
给定一组训练好的个体学习器,集成修剪不是组合所有学习器,而是尝试选择个体学习器的子集来构成集成。
— 第 119 页,Ensemble Methods: Foundations and Algorithms,2012。
集成修剪和构建的一个优点是它可能导致更小的集成(更低的复杂度)和/或具有更好预测性能的集成。有时,如果能以模型复杂度大幅降低和维护负担大幅减轻来实现性能的小幅下降,也是可取的。或者,在某些项目中,预测能力比所有其他方面都更重要,而集成选择提供了一种尝试充分利用贡献模型的方法。
减少集成规模的两个主要原因:a) 降低计算开销:较小的集成需要较低的计算开销;b) 提高准确性:集成中的某些成员可能会降低整体的预测性能。
— 第 119 页,Pattern Classification Using Ensemble Methods,2010。
在预期少量集成成员性能更好的情况下,集成构建可能因计算效率原因而更受青睐,而在预期大量集成成员性能更好的情况下,集成修剪则更有效。
简单的贪婪集成构建和修剪与逐步特征选择技术有很多共同之处,例如回归中使用的技术(例如所谓的逐步回归)。
可以使用更复杂的技术,例如根据模型在数据集上的独立性能来选择要添加到集成或从集成中删除的成员,甚至可以使用全局搜索过程来尝试找到一组集成成员的组合,从而获得最佳的整体性能。
… 可以通过启发式搜索在可能的不同集成子集空间中进行搜索,同时评估候选子集的集体优点。
— 第 123 页,Pattern Classification Using Ensemble Methods,2010。
既然我们已经熟悉了集成选择方法,那么让我们探讨一下如何在 scikit-learn 中实现集成修剪和集成构建。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
基线模型和投票
在深入开发构建和修剪集成之前,让我们先建立一个数据集和基线。
我们将使用一个合成二分类问题作为本次调查的基础,该问题由 make_classification() 函数定义,包含 5,000 个示例和 20 个数值输入特征。
下面的示例定义了数据集并总结了其大小。
|
1 2 3 4 5 6 |
# 测试分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=5000, n_features=20, n_informative=10, n_redundant=10, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行该示例以可重现的方式创建数据集,并报告行数和输入特征,这与我们的预期一致。
|
1 |
(5000, 20) (5000,) |
接下来,我们可以选择一些候选模型来为我们的集成提供基础。
我们将使用五个标准的机器学习模型,包括逻辑回归、朴素贝叶斯、决策树、支持向量机和 K 近邻算法。
首先,我们可以定义一个函数,该函数将使用默认超参数创建每个模型。每个模型将定义为元组,包含名称和模型对象,然后添加到列表中。这种结构对于枚举模型名称以进行独立评估以及稍后在集成中使用都很有用。
下面的 `get_models()` 函数实现了这一点,并返回要考虑的模型列表。
|
1 2 3 4 5 6 7 8 9 |
# 获取要评估的模型列表 定义 获取_模型(): models = list() models.append(('lr', LogisticRegression())) models.append(('knn', KNeighborsClassifier())) models.append(('tree', DecisionTreeClassifier())) models.append(('nb', GaussianNB())) models.append(('svm', SVC(probability=True))) 返回 models |
然后,我们可以定义一个函数,该函数接受单个模型和数据集,并在数据集上评估模型的性能。我们将使用重复分层 k 折交叉验证(10 折,3 次重复)来评估模型,这是机器学习中的一个良好实践。
下面的 `evaluate_model()` 函数实现了这一点,并返回所有折叠和重复的总分数列表。
|
1 2 3 4 5 6 7 |
# 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义模型评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores |
然后,我们可以创建模型列表并进行枚举,依次报告每个模型在合成数据集上的性能。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# 在合成数据集上评估标准模型 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=5000, n_features=20, n_informative=10, n_redundant=10, random_state=1) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = list() models.append(('lr', LogisticRegression())) models.append(('knn', KNeighborsClassifier())) models.append(('tree', DecisionTreeClassifier())) models.append(('nb', GaussianNB())) models.append(('svm', SVC(probability=True))) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义模型评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models: # 评估模型 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 总结结果 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例,在合成二分类数据集上评估每个独立的机器学习算法。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。可以尝试运行示例几次,并比较平均结果。
在这种情况下,我们可以看到 KNN 和 SVM 模型在此数据集上表现最好,平均分类准确率约为 95.3%。
这些结果提供了我们要求的集成在该数据集上表现更好的基线。
|
1 2 3 4 5 |
>lr 0.856 (0.014) >knn 0.953 (0.008) >tree 0.867 (0.014) >nb 0.847 (0.021) >svm 0.953 (0.010) |
生成一个图表,显示每个算法分类准确率的箱线图。
我们可以看到 KNN 和 SVM 算法的表现比其他算法好得多,尽管所有算法在不同方面都有其优势。这可能使它们成为集成中的良好候选者。
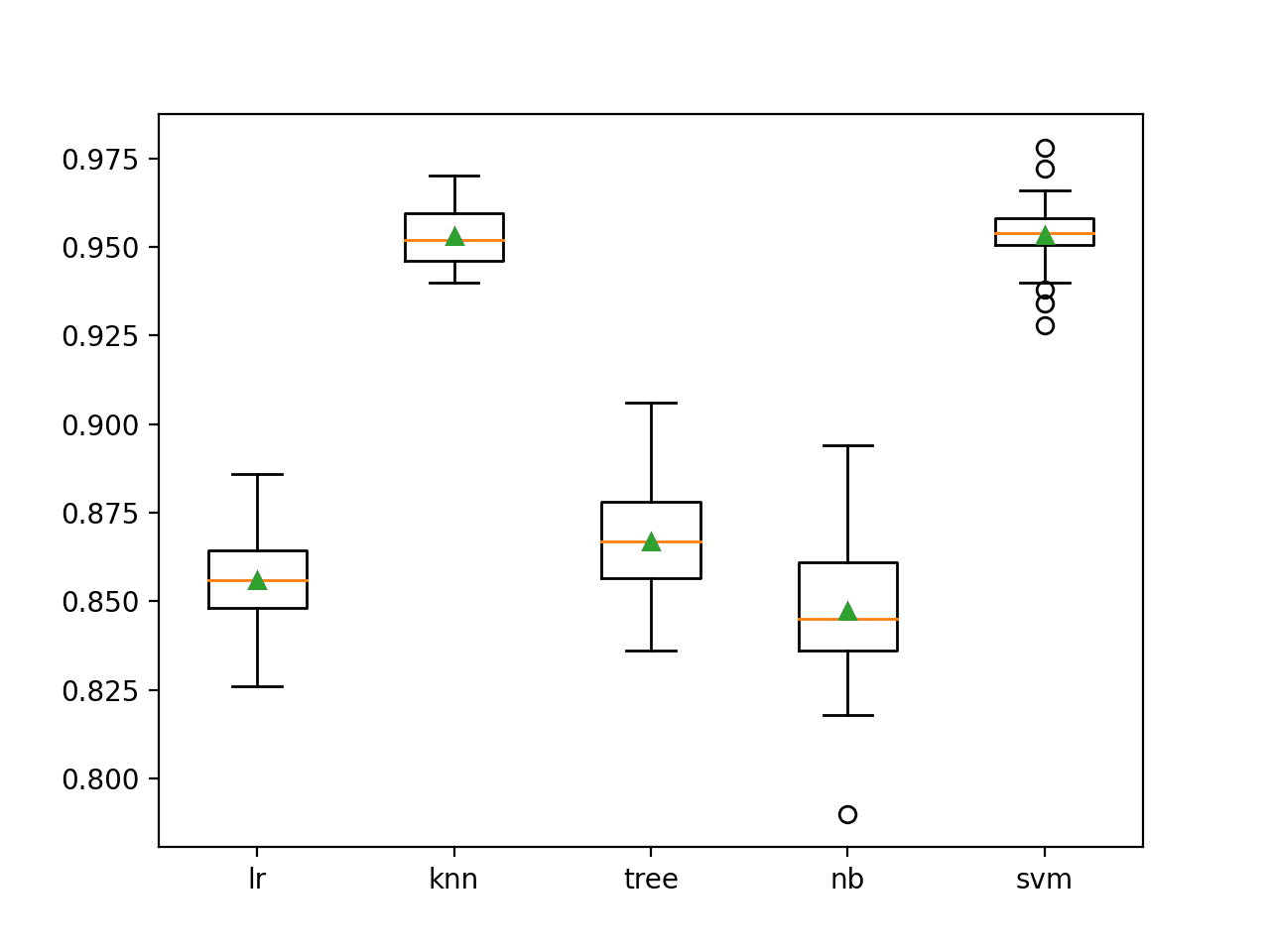
独立机器学习模型分类准确率的箱线图
接下来,我们需要建立一个使用所有模型的基线集成。这将为构建和修剪方法提供一个比较点,这些方法旨在通过更小的模型子集获得更好的性能。
在这种情况下,我们将使用投票集成进行软投票。这意味着每个模型将预测概率,然后由集成模型将这些概率相加,为每个输入样本选择最终的输出预测。
这可以通过 `VotingClassifier` 类实现,其中成员通过“estimators”参数设置,该参数期望一个模型列表,其中每个模型是一个元组,包含名称和配置好的模型对象,这与我们在上一节中的定义相同。
然后,我们可以通过“voting”参数设置要执行的投票类型,在本例中设置为“soft”。
|
1 2 3 |
... # 创建集成 ensemble = VotingClassifier(estimators=models, voting='soft') |
将这些内容结合起来,下面的示例在合成二分类数据集上评估了所有五个模型的软投票集成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 集成成员软投票的投票集成示例 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import VotingClassifier # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=5000, n_features=20, n_informative=10, n_redundant=10, random_state=1) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = list() models.append(('lr', LogisticRegression())) models.append(('knn', KNeighborsClassifier())) models.append(('tree', DecisionTreeClassifier())) models.append(('nb', GaussianNB())) models.append(('svm', SVC(probability=True))) 返回 模型 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 创建集成 ensemble = VotingClassifier(estimators=models, voting='soft') # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估集成 scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 总结结果 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行该示例,使用重复分层 k 折交叉验证来评估所有模型的软投票集成,并报告所有折叠和重复的平均准确率。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。可以尝试运行示例几次,并比较平均结果。
在这种情况下,我们可以看到投票集成实现的平均准确率约为 92.8%。这低于单独使用的 SVM 和 KNN 模型,它们的准确率约为 95.3%。
这个结果突出表明,在本例中,所有模型的简单投票集成会导致模型具有更高的复杂性和更差的性能。也许我们可以找到一个子集,其性能优于任何单个模型,并且比简单地使用所有模型具有更低的复杂性。
|
1 |
平均准确率:0.928 (0.012) |
接下来,我们将探讨从集成中修剪成员。
集成修剪示例
在本节中,我们将探讨如何从头开始开发一个贪婪的集成修剪算法。
在这种情况下,我们将使用贪婪算法,这种算法易于实现。这涉及到从集成中删除一个成员并评估性能,然后对集成中的每个成员重复此过程。如果删除某个成员能带来性能的最佳改进,则该成员将被永久从集成中删除,然后重复该过程。直到不再能实现进一步的改进。
它之所以被称为“贪婪”算法,是因为它在每一步都寻求最佳的改进。有可能最佳成员组合不在贪婪改进的路径上,在这种情况下,贪婪算法将找不到它,而可以使用全局优化算法代替。
首先,我们可以定义一个函数来评估候选模型列表。该函数将接收模型列表和数据集,并从模型列表中构建一个投票集成,并使用重复分层 k 折交叉验证评估其性能,返回平均分类准确率。
此函数可用于评估从集成中移除每个候选对象的效果。下面的 `evaluate_ensemble()` 函数实现了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 评估模型列表 def evaluate_ensemble(models, X, y): # 检查是否没有模型 if len(models) == 0: return 0.0 # 创建集成 ensemble = VotingClassifier(estimators=models, voting='soft') # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估集成 scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 返回平均分数 return mean(scores) |
接下来,我们可以定义一个执行单轮修剪的函数。
首先,使用当前集成中的所有模型建立性能基线。然后对模型列表进行枚举,逐个删除,并评估删除模型对集成的影响。如果删除模型能提高性能,则记录新的分数和被删除的具体模型。
重要的是,试删除操作是对模型列表的副本进行操作,而不是对模型列表本身。这是为了确保我们只在知道能从当前步骤中可能删除的所有成员中获得最佳改进时,才从列表中删除集成成员。
下面的 `prune_round()` 函数在给定当前集成模型列表和数据集的情况下实现这一点,并返回分数改进(如果有)以及实现该分数的最佳移除模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 对集成进行单轮修剪 def prune_round(models_in, X, y): # 建立基线 baseline = evaluate_ensemble(models_in, X, y) best_score, removed = baseline, None # 枚举删除每个候选对象,看看是否能提高性能 for m in models_in: # 复制所选模型的列表 dup = models_in.copy() # 删除此模型 dup.remove(m) # 评估新集成 result = evaluate_ensemble(dup, X, y) # 检查是否有新的最佳结果 if result > best_score: # 存储新的最佳结果 best_score, removed = result, m return best_score, removed |
接下来,我们需要驱动修剪过程。
这包括通过反复调用 `prune_round()` 函数来运行一轮修剪,直到不再取得性能上的改进。
如果该函数返回 `None` 作为要移除的模型,我们就知道不可能进行单次贪婪改进,并且可以返回最终的模型列表。否则,将所选模型从集成中移除,然后继续该过程。
下面的 `prune_ensemble()` 函数实现了这一点,并返回最终集成中使用的模型以及通过我们的评估程序获得的分数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 从头开始修剪集成 def prune_ensemble(models, X, y): best_score = 0.0 # 修剪集成直到不再有改进 while True: # 从集成中移除一个模型 score, removed = prune_round(models, X, y) # 检查是否没有改进 if removed is None: print('>no further improvement') break # 跟踪最佳分数 best_score = score # 从列表中删除模型 models.remove(removed) # 沿途报告结果 print('>%.3f (removed: %s)' % (score, removed[0])) return best_score, models |
我们可以将所有这些内容整合到合成二元分类数据集上的集成剪枝的示例中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
# 分类集成剪枝示例 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import VotingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=5000, n_features=20, n_informative=10, n_redundant=10, random_state=1) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = list() models.append(('lr', LogisticRegression())) models.append(('knn', KNeighborsClassifier())) models.append(('tree', DecisionTreeClassifier())) models.append(('nb', GaussianNB())) models.append(('svm', SVC(probability=True))) 返回 模型 # 评估模型列表 def evaluate_ensemble(models, X, y): # 检查是否没有模型 if len(models) == 0: return 0.0 # 创建集成 ensemble = VotingClassifier(estimators=models, voting='soft') # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估集成 scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 返回平均分数 return mean(scores) # 对集成进行单轮修剪 def prune_round(models_in, X, y): # 建立基线 baseline = evaluate_ensemble(models_in, X, y) best_score, removed = baseline, None # 枚举删除每个候选对象,看看是否能提高性能 for m in models_in: # 复制所选模型的列表 dup = models_in.copy() # 删除此模型 dup.remove(m) # 评估新集成 result = evaluate_ensemble(dup, X, y) # 检查是否有新的最佳结果 if result > best_score: # 存储新的最佳结果 best_score, removed = result, m return best_score, removed # 从头开始修剪集成 def prune_ensemble(models, X, y): best_score = 0.0 # 修剪集成直到不再有改进 while True: # 从集成中移除一个模型 score, removed = prune_round(models, X, y) # 检查是否没有改进 if removed is None: print('>no further improvement') break # 跟踪最佳分数 best_score = score # 从列表中删除模型 models.remove(removed) # 沿途报告结果 print('>%.3f (removed: %s)' % (score, removed[0])) return best_score, models # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 剪枝集成 score, model_list = prune_ensemble(models, X, y) names = ','.join([n for n,_ in model_list]) print('Models: %s' % names) print('Final Mean Accuracy: %.3f' % score) |
运行示例将执行集成剪枝过程,报告每轮移除的模型以及模型被移除后的准确率。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。可以尝试运行示例几次,并比较平均结果。
在这种情况下,我们可以看到进行了三轮剪枝,移除了朴素贝叶斯、决策树和逻辑回归算法,只剩下支持向量机(SVM)和 K 最近邻(KNN)算法,它们的平均分类准确率约为 95.7%。这比单独使用 SVM 和 KNN 达到的 95.3% 要好,也明显优于将所有模型组合在一起。
然后,可以通过“estimators”参数将最终的模型列表用于一个新的最终投票集成模型,对整个数据集进行拟合,并用于在新数据上进行预测。
|
1 2 3 4 5 6 |
>0.939 (移除:nb) >0.948 (移除:tree) >0.957 (移除:lr) >无进一步改进 模型:knn,svm 最终平均准确率:0.957 |
现在我们熟悉了开发和评估集成剪枝方法,接下来我们将看反向的集成成员增长。
集成构建示例
在本节中,我们将从头开始探索如何开发一个贪婪集成增长算法。
贪婪集成增长的结构与成员的贪婪剪枝非常相似,只是方向相反。我们从一个没有模型的集成开始,然后添加一个性能最好的模型。之后,模型会逐个添加,只有当它们能提升模型在添加模型之前的性能时才会添加。
大部分代码与剪枝情况相同,因此我们可以专注于不同之处。
首先,我们必须定义一个函数来执行一轮集成增长。这涉及枚举所有可以添加的候选模型,并逐一评估将每个模型添加到集成中的效果。然后,该函数将返回导致最大改进的单个模型及其得分。
下面的 `grow_round()` 函数实现了这种行为。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 执行一轮集成增长 def grow_round(models_in, models_candidate, X, y): # 建立基线 baseline = evaluate_ensemble(models_in, X, y) best_score, addition = baseline, None # 枚举添加每个候选模型,看看是否可以提高性能 for m in models_candidate: # 复制所选模型的列表 dup = models_in.copy() # 添加候选模型 dup.append(m) # 评估新集成 result = evaluate_ensemble(dup, X, y) # 检查是否有新的最佳结果 if result > best_score: # 存储新的最佳结果 best_score, addition = result, m return best_score, addition |
接下来,我们需要一个函数来驱动增长过程。
这包括一个循环,该循环运行增长轮,直到没有进一步的添加可以带来性能的改进。对于可以进行的每次添加,都会更新集成中的模型主列表,并报告当前集成中的模型列表以及性能。
`grow_ensemble()` 函数实现了这一点,并返回贪婪确定地产生最佳性能的模型列表以及预期的平均准确率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 从头开始增长集成 def grow_ensemble(models, X, y): best_score, best_list = 0.0, list() # 增长集成直到没有进一步的改进 while True: # 将一个模型添加到集成中 score, addition = grow_round(best_list, models, X, y) # 检查是否没有改进 if addition is None: print('>no further improvement') break # 跟踪最佳分数 best_score = score # 从候选模型列表中移除新模型 models.remove(addition) # 将新模型添加到集成中的模型列表中 best_list.append(addition) # 沿途报告结果 names = ','.join([n for n,_ in best_list]) print('>%.3f (%s)' % (score, names)) return best_score, best_list |
将以上内容结合起来,下面列出了在合成二元分类数据集上进行贪婪集成增长的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
# 分类集成增长示例 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import VotingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=5000, n_features=20, n_informative=10, n_redundant=10, random_state=1) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = list() models.append(('lr', LogisticRegression())) models.append(('knn', KNeighborsClassifier())) models.append(('tree', DecisionTreeClassifier())) models.append(('nb', GaussianNB())) models.append(('svm', SVC(probability=True))) 返回 模型 # 评估模型列表 def evaluate_ensemble(models, X, y): # 检查是否没有模型 if len(models) == 0: return 0.0 # 创建集成 ensemble = VotingClassifier(estimators=models, voting='soft') # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估集成 scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 返回平均分数 return mean(scores) # 执行一轮集成增长 def grow_round(models_in, models_candidate, X, y): # 建立基线 baseline = evaluate_ensemble(models_in, X, y) best_score, addition = baseline, None # 枚举添加每个候选模型,看看是否可以提高性能 for m in models_candidate: # 复制所选模型的列表 dup = models_in.copy() # 添加候选模型 dup.append(m) # 评估新集成 result = evaluate_ensemble(dup, X, y) # 检查是否有新的最佳结果 if result > best_score: # 存储新的最佳结果 best_score, addition = result, m return best_score, addition # 从头开始增长集成 def grow_ensemble(models, X, y): best_score, best_list = 0.0, list() # 增长集成直到没有进一步的改进 while True: # 将一个模型添加到集成中 score, addition = grow_round(best_list, models, X, y) # 检查是否没有改进 if addition is None: print('>no further improvement') break # 跟踪最佳分数 best_score = score # 从候选模型列表中移除新模型 models.remove(addition) # 将新模型添加到集成中的模型列表中 best_list.append(addition) # 沿途报告结果 names = ','.join([n for n,_ in best_list]) print('>%.3f (%s)' % (score, names)) return best_score, best_list # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 增长集成 score, model_list = grow_ensemble(models, X, y) names = ','.join([n for n,_ in model_list]) print('Models: %s' % names) print('Final Mean Accuracy: %.3f' % score) |
运行示例会逐步将一个模型添加到集成中,并报告集成模型的平均分类准确率。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。可以尝试运行示例几次,并比较平均结果。
在这种情况下,我们可以看到集成增长找到了与贪婪集成剪枝相同的解决方案,其中 SVM 和 KNN 的集成达到了约 95.6% 的平均分类准确率,这比任何单独的模型或所有模型的组合都有所提高。
|
1 2 3 4 5 |
>0.953 (svm) >0.956 (svm,knn) >无进一步改进 模型:svm,knn 最终平均准确率:0.956 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
- 集成方法:基础和算法, 2012.
- 使用集成方法进行模式分类, 2010.
API
总结
在本教程中,您学习了如何从头开始开发集成选择算法。
具体来说,你学到了:
- 集成选择涉及选择集成成员的子集,该子集比使用所有成员具有更低的复杂度,有时性能更好。
- 如何为分类开发和评估贪婪集成修剪算法。
- 如何从头开始开发和评估一个贪婪构建集成的算法。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……






非常感谢 Jason 先生提供的这些精彩信息。期待更多像这样的精彩教程和文章。
谢谢!
有趣且有用的文章!是否有任何方法可以学习集成中的最佳权重,而不是简单的投票机制?(例如,使用另一个模型来学习集成模型的权重,从而获得更好的性能?)如果有,这篇博文是否已经发布了涵盖此研究工作或讨论的文章?期待您的未来教程和分享。
谢谢。
是的,堆叠可以拟合模型来组合预测,以最小化损失/误差。
https://machinelearning.org.cn/stacking-ensemble-machine-learning-with-python/
太棒了!感谢您的回复和信息。让我来研究一下您分享的文章……
不客气。
非常感谢您的分享!但我有一个问题。在您的文章中,软投票被用作集成学习的示例。但是,当我使用软加权时,基础分类器的权重是不可用的。我该如何为软加权投票设置权重?我期待您的回复!再次感谢!
你好 Sazang……你可能会觉得以下内容很有趣
https://vitalflux.com/hard-vs-soft-voting-classifier-python-example/
非常感谢您的分享!在您的文章中,使用了软投票。但是,一个问题是,我该如何为软加权投票模型设置权重?
你好 Sazang……你可能会觉得以下内容很有帮助
https://machinelearning.org.cn/voting-ensembles-with-python/
期待您的回复!
谢谢你的分享!我想知道如何设置软加权投票的权重,因为我需要使用软加权投票进行预测,并且我已经尝试设置但失败了。您能否给出一些好的建议?期待您的回复!再次感谢!
你好 Za Sha……你可能会觉得以下内容很有帮助
https://machinelearning.org.cn/voting-ensembles-with-python/
我可以留下一条回复吗?
当然可以,Za sha!