作者:Luis Bermudez
本篇博文将介绍一个用于试验图神经网络(GNN)的超参数、训练算法和其他参数的过程。在本篇博文中,我们将分享实验链的前两个阶段。我们用于进行推理的图数据集来自 Open Graph Benchmark (OGB)。如果您觉得有用,我们提供了一个关于GNN的简要概述以及关于OGB的简短概述。
实验目标和模型类型
我们调优了两种流行的GNN变体,以
- 提高在OGB排行榜预测任务上的性能。
- 最小化未来参考的训练成本(时间和轮数)。
- 分析在HPO迭代过程中,小批量与全图训练的行为。
- 演示一个迭代式超参数实验的通用流程。
我们使用两种流行的GNN框架实现了OGB排行榜条目的我们自己的实现:GraphSAGE 和关系图卷积网络 (RGCN)。然后,我们设计并执行了一种迭代式超参数调优实验方法,旨在找到一个耗时最短的优质模型。我们通过运行一个无约束的性能调优循环来定义质量,并使用结果来设定一个优化训练效率的约束调优循环的阈值。
对于GraphSAGE和RGCN,我们都实现了一个小批量方法和一个全图方法。采样是训练GNN的一个重要方面,而小批量过程与训练其他类型的神经网络不同。特别是,图的小批量化可能导致网络每批需要处理的数据量呈指数级增长——这被称为“邻域爆炸”。在下面的实验设计部分,我们将描述我们如何考虑到图小批量化的这一方面来进行调优。
有关GNN采样策略重要性的更多信息,请查阅以下资源:
现在,我们寻求根据上述实验目标找到我们模型的最佳版本。
迭代实验:优化至优质模型的时间
我们的HPO(超参数优化)实验过程包括三个阶段,对于每种模型类型,以及小批量和全图采样。这三个阶段包括:
- 性能:最佳性能是什么?
- 效率:我们能多快找到一个优质模型?
- 信任:我们如何选择最高质量的模型?
第一阶段利用了一个单指标SigOpt实验,该实验优化了小批量和全图实现下的验证损失。此阶段通过调优GraphSAGE和RCGN来找到最佳性能。
第二阶段定义了两个指标来衡量我们完成模型训练的速度:(a)GNN训练的挂钟时间,(b)GNN训练的总轮数。我们还利用第一阶段的知识来指导约束优化实验的设计。我们在满足验证损失大于质量目标的前提下最小化这些指标。
第三阶段选择超参数空间中距离合理的优质模型。根据OGB的指导方针,我们使用10个不同的随机种子运行相同的训练。我们还使用GNNExplainer来分析模型间的模式。(我们将在未来的博文中更详细地介绍第三阶段)
如何运行代码
代码位于此仓库。要运行代码,您需要执行以下步骤:
- 免费注册或登录以获取您的API令牌。
- 克隆仓库。
- 创建虚拟环境并运行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 将API令牌设置为环境变量 > export SIGOPT_API_TOKEN=<> # 安装所需的库 > pip install –r requirements.txt # 进入 experiments/ 目录并运行: > python create_experiment.py \ --model \ --dataset \ --training-method --optimization-target # 进入 experiments/ 目录并运行: > python run_experiment.py \ --experiment-id \ --model \ --dataset \ --training-method \ --optimization-target |

第一阶段结果:设计实验以最大化准确率
在实验的第一阶段,超参数调优实验是在Xeon集群上进行的,使用Jenkins调度模型训练在集群节点上运行。Docker容器被用作执行环境。总共有四个实验流,对应下表中每一行,所有这些都旨在最小化验证损失。
| GNN类型 | 数据集 (Dataset) | 采样 | 优化目标 | 最佳验证损失 | 最佳验证准确率 |
| GraphSAGE | ogbn-products | 小批量 | 验证损失 | 0.269 | 0.929 |
| GraphSAGE | ogbn-products | 全图 | 验证损失 | 0.306 | 0.92 |
| RGCN | ogbn-mag | 小批量 | 验证损失 | 1.781 | 0.506 |
| RGCN | ogbn-mag | 全图 | 验证损失 | 1.928 | 0.472 |
表1 – 第一阶段实验结果
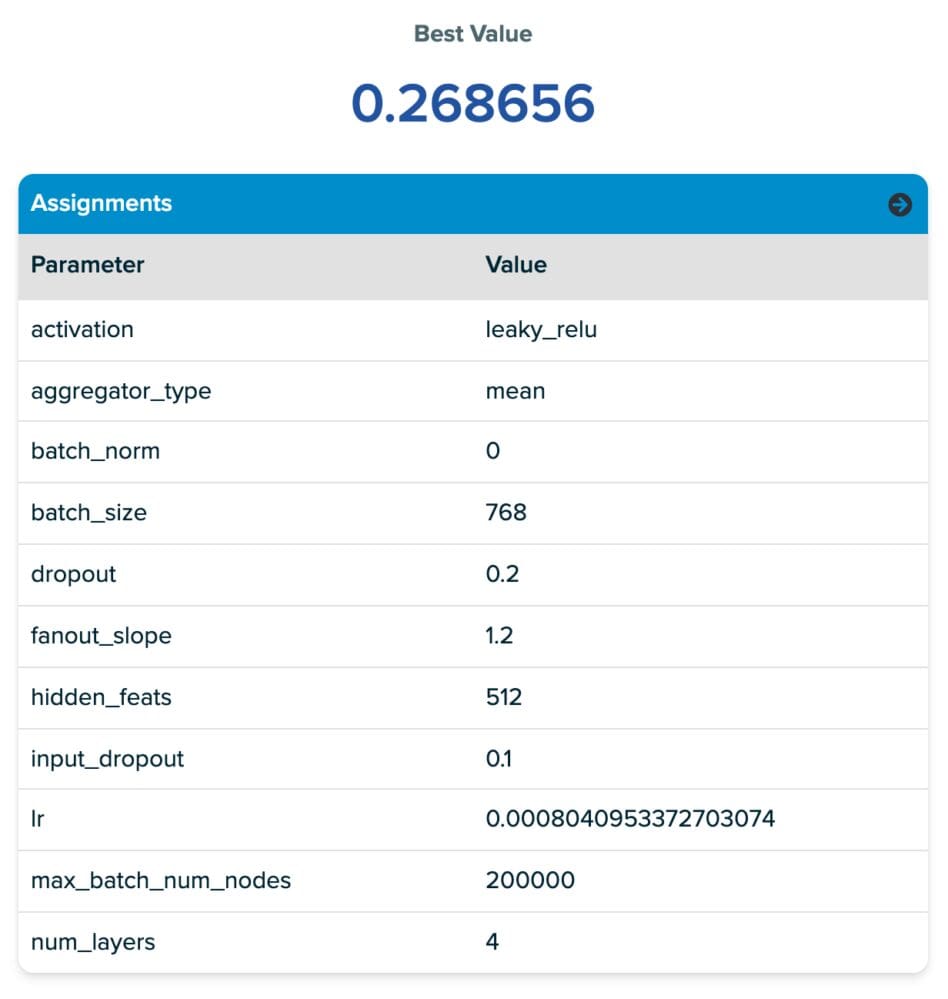
表中第一行的参数值在SigOpt平台截图(表格正下方)中提供。从参数截图中,您会注意到我们的调优空间包含许多常见的神经网络超参数。您还会注意到一些新的参数,称为fanout slope(扇出斜率)和max_batch_num_nodes(最大批次节点数)。这两个参数都与深度图库MultiLayerNeighborSampler的一个参数有关,该参数决定了在消息传递过程中考虑多少邻居节点。我们在设计空间中引入这两个新参数,以鼓励SigOpt从一个相当大的调优空间中选择“好的”扇出值,而不直接调优扇出数量,因为我们发现当通过多层采样进行消息传递时,这通常会导致过长的训练时间(邻域爆炸)。这种方法的目标是在限制邻域爆炸问题的同时探索小批量采样空间。我们引入的这两个参数是:
- 扇出斜率 (Fanout Slope):控制每跳/GNN层的扇出速率。增加它就像乘以扇出,即图中每个额外跳中采样的节点数量。
- 最大批次节点数 (Max Batch Num Nodes):设置每个批次的节点最大数量的阈值,如果与扇出斜率产生的总样本数。
下面我们看到RGCN第一阶段的实验配置。我们的GraphSAGE实验在小批量和全图实现之间也存在类似的偏差。

RGCN小批量调优实验 – 参数空间
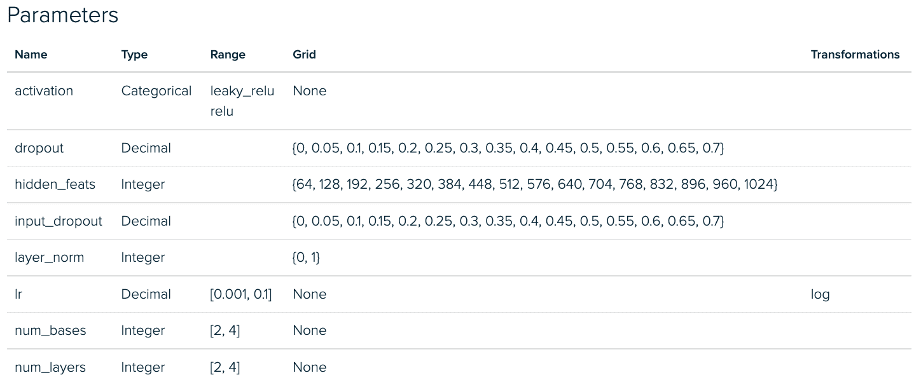
RGCN全图调优实验 – 参数空间
通过小批量方法调优GraphSAGE,我们发现我们引入的参数中,fanout_slope在预测准确率方面很重要,而max_batch_num_nodes相对不重要。特别是,我们发现max_batch_num_nodes的值越低,表现越好。
小批量RGCN的结果也显示出类似的情况,尽管max_batch_num_nodes参数的影响略大。所有四个超参数调优流的运行都在性能没有在十个周期后改进时进行了提前停止。
该过程产生了以下分布:
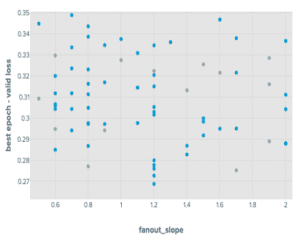
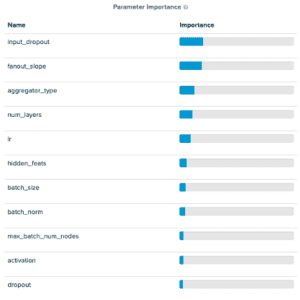
GraphSAGE在OGBN products上调优实验结果
接下来,我们使用这些实验结果来指导后续一轮专注于尽快达到质量目标的实验设计。对于质量目标,我们将验证损失的约束设置为(最佳验证损失* 1.05),将验证准确率的约束设置为(最佳准确率* 0.95)。
第二阶段结果:为效率设计实验
在实验的第二阶段,我们寻找能尽快训练并满足我们质量目标的模型。我们在AWS m6.8xlarge实例上的Xeon处理器上训练了这些模型。我们的优化任务是:
- 最小化总运行时间
- 前提是验证损失小于或等于观察到的最佳值的1.05倍
- 前提是验证准确率大于或等于观察到的最佳值的0.95倍
以这种方式构建我们的优化目标,得到了这些指标结果:
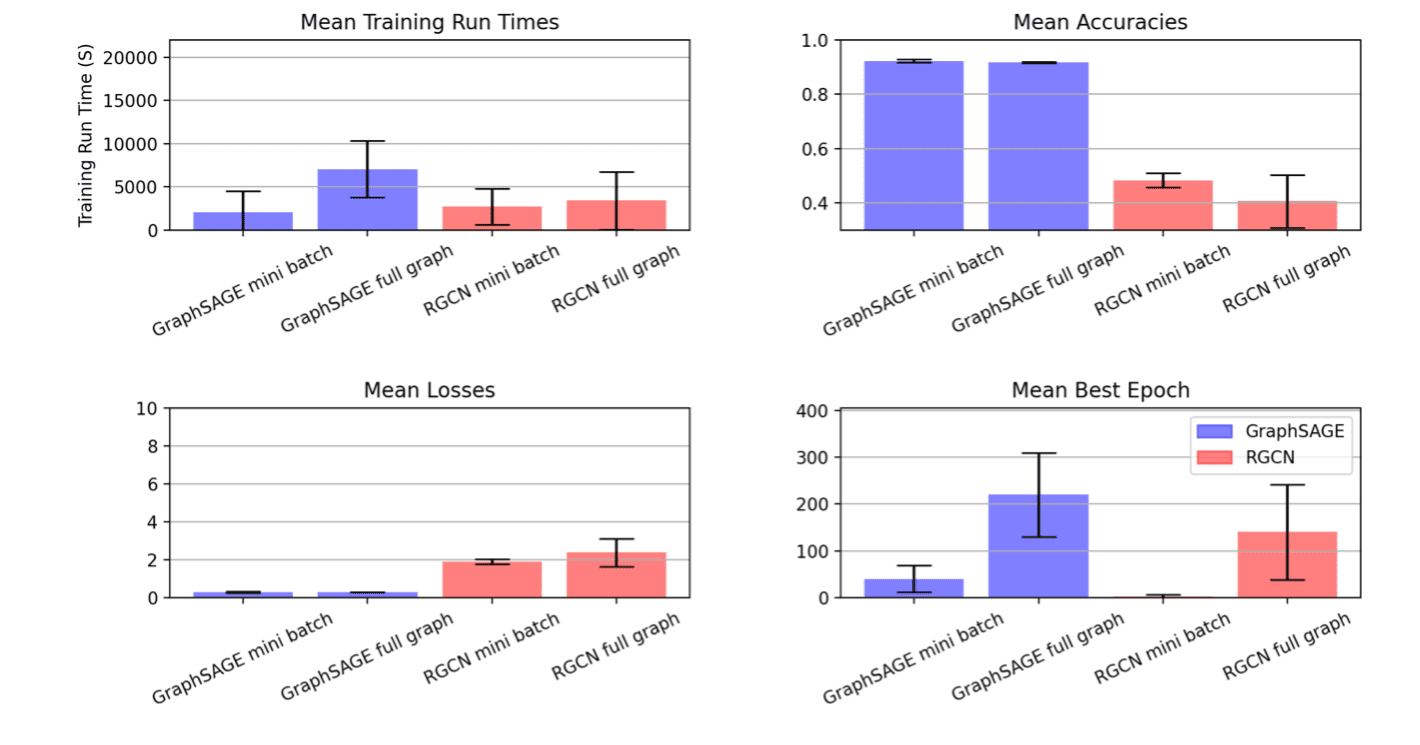
| GNN类型 | 数据集 | 采样 | 优化 目标 |
最佳时间 | 验证准确率 |
| GraphSAGE | ogbn-products | 小批量 | 训练时间,轮数 | 933.529 | 0.929 |
| GraphSAGE | ogbn-products | 全图 | 训练时间,轮数 | 3791.15 | 0.923 |
| RGCN | ogbn-mag | 小批量 | 训练时间,轮数 | 155.321 | 0.515 |
| RGCN | ogbn-mag | 全图 | 训练时间,轮数 | 534.192 | 0.472 |
请注意,本项目旨在展示迭代实验过程。目标不是在第一阶段和第二阶段之间保持除指标空间之外的所有因素不变,因此我们在第二轮实验中对调优空间进行了调整。在上面的图中,RGCN小批量运行的结果显示,在我们根据第一阶段实验的分析显著修剪了可搜索的超参数域后,运行方差大幅降低。
讨论
在结果中,很明显SigOpt优化器正在找到大量满足我们性能阈值的候选运行,同时显著减少了训练时间。这不仅对本实验周期有用,而且从这项额外工作中获得的见解很可能在将来处理GraphSAGE和RGCN在ogbn-products和ogbn-mag上的类似调优任务的工作流中得到重用。在后续的博文中,我们将研究该过程的第三阶段。我们将选择一些高质量、低运行时的模型配置,并探讨如何使用GNNExplainer等最先进的可解释性工具来进一步深入了解如何选择正确的模型。
要查看SigOpt是否能为您和您的团队带来类似的结果,请免费注册使用。
本篇博文最初发布于sigopt.com。






暂无评论。