深度学习技术能力的一个流行演示是图像数据中的目标识别。
机器学习和深度学习中对象识别的“你好世界”是用于手写数字识别的 MNIST 数据集。
在这篇文章中,您将学习如何使用 Keras 深度学习库在 Python 中开发一个深度学习模型,以在 MNIST 手写数字识别任务上实现接近最先进的性能。
完成本教程后,您将了解:
- 如何在 Keras 中加载 MNIST 数据集
- 如何开发和评估用于 MNIST 问题的基线神经网络模型
- 如何为 MNIST 实现和评估一个简单的卷积神经网络
- 如何为 MNIST 实现一个接近最先进的深度学习模型
通过我的新书《使用 Python 进行深度学习》启动您的项目,包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2016 年 6 月:首次发布
- 2016 年 10 月更新:更新至 Keras 1.1.0、TensorFlow 0.10.0 和 scikit-learn v0.18
- 2017 年 3 月更新:更新至 Keras 2.0.2、TensorFlow 1.0.1 和 Theano 0.9.0
- 2019 年 9 月更新:更新至 Keras 2.2.5 API
- 2022 年 7 月更新:更新至 TensorFlow 2.x API
请注意,本教程的扩展版本,请参阅

使用 Python 和 Keras 中的卷积神经网络识别手写数字
照片由 Jamie 拍摄,保留部分权利。
MNIST 手写数字识别问题描述
MNIST 问题是 Yann LeCun、Corinna Cortes 和 Christopher Burges 开发的一个数据集,用于评估机器学习模型在手写数字分类问题上的表现。
该数据集是从国家标准与技术研究院 (NIST) 提供的多个扫描文档数据集中构建的。数据集的名称由此而来,即 Modified NIST 或 MNIST 数据集。
数字图像取自各种扫描文档,经过大小归一化和居中处理。这使其成为评估模型的绝佳数据集,让开发人员能够专注于机器学习,而无需最少的数据清理或准备。
每个图像都是一个 28×28 像素的正方形(总共 784 像素)。使用标准的数据集拆分来评估和比较模型,其中 60,000 张图像用于训练模型,另外 10,000 张图像用于测试模型。
这是一个数字识别任务。因此,有十个数字(0 到 9)或十个类别需要预测。结果使用预测误差报告,这无非是反向的分类准确率。
出色的结果可以实现低于 1% 的预测误差。使用大型卷积神经网络可以实现大约 0.2% 的最先进预测误差。在 Rodrigo Benenson 的网页上列出了 MNIST 和其他数据集的最先进结果以及相关论文的链接。
Python 深度学习需要帮助吗?
参加我的免费为期两周的电子邮件课程,发现 MLP、CNN 和 LSTM(附代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
在 Keras 中加载 MNIST 数据集
Keras 深度学习库提供了一种方便的方法来加载 MNIST 数据集。
首次调用此函数时,数据集将自动下载并存储在您的主目录中 ~/.keras/datasets/mnist.npz,文件大小为 11MB。
这对于开发和测试深度学习模型非常方便。
为了演示加载 MNIST 数据集是多么容易,首先,编写一个小脚本来下载并可视化训练数据集中的前四张图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 绘制临时 mnist 实例 from tensorflow.keras.datasets import mnist import matplotlib.pyplot as plt # 加载(如果需要则下载)MNIST 数据集 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 绘制 4 张灰度图像 plt.subplot(221) plt.imshow(X_train[0], cmap=plt.get_cmap('gray')) plt.subplot(222) plt.imshow(X_train[1], cmap=plt.get_cmap('gray')) plt.subplot(223) plt.imshow(X_train[2], cmap=plt.get_cmap('gray')) plt.subplot(224) plt.imshow(X_train[3], cmap=plt.get_cmap('gray')) # 显示绘图 plt.show() |
您可以看到,下载和加载 MNIST 数据集就像调用 mnist.load_data() 函数一样简单。运行上面的示例,您应该会看到下面的图像。
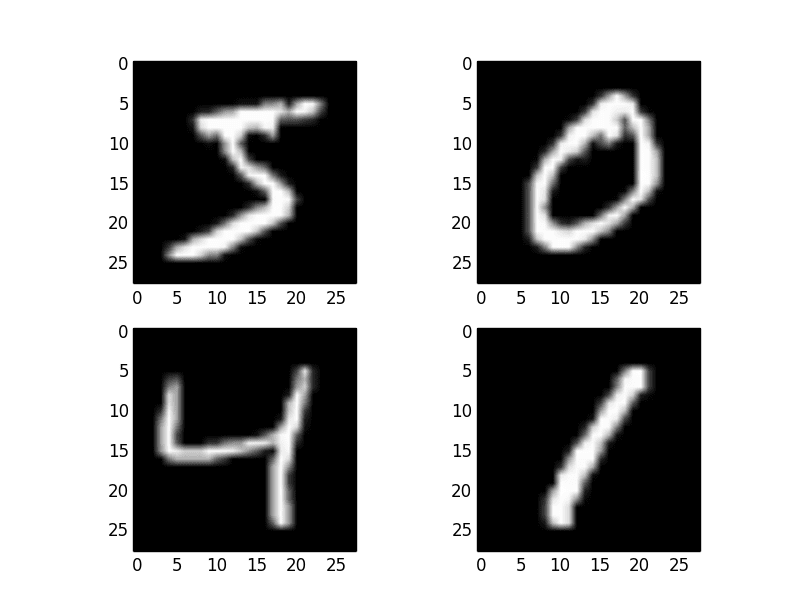
MNIST 数据集中的示例
带多层感知器的基线模型
您真的需要像卷积神经网络这样的复杂模型才能在 MNIST 上获得最佳结果吗?
使用只有单个隐藏层的非常简单的神经网络模型可以获得非常好的结果。在本节中,您将创建一个简单的多层感知器模型,该模型实现了 1.74% 的错误率。您将以此作为基线来比较更复杂的卷积神经网络模型。
让我们首先导入您需要的类和函数。
|
1 2 3 4 5 6 |
from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout from tensorflow.keras.utils import to_categorical ... |
现在,您可以使用 Keras 辅助函数加载 MNIST 数据集。
|
1 2 3 |
... # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() |
训练数据集被构造为一个三维数组,包含实例、图像宽度和图像高度。对于多层感知器模型,您必须将图像缩小为像素向量。在这种情况下,28×28 大小的图像将是 784 个像素输入值。
您可以使用 NumPy 数组上的 reshape() 函数轻松完成此转换。您还可以通过强制像素值的精度为 32 位来减少内存需求,这也是 Keras 默认使用的精度。
|
1 2 3 4 5 |
... # 将 28*28 图像展平为每张图像的 784 向量 num_pixels = X_train.shape[1] * X_train.shape[2] X_train = X_train.reshape((X_train.shape[0], num_pixels)).astype('float32') X_test = X_test.reshape((X_test.shape[0], num_pixels)).astype('float32') |
像素值是介于 0 和 255 之间的灰度值。在使用神经网络模型时,对输入值进行一些缩放几乎总是一个好主意。由于比例是众所周知且表现良好的,因此您可以通过将每个值除以最大值 255 来非常快速地将像素值归一化到 0 到 1 的范围。
|
1 2 3 4 |
... # 将输入从 0-255 归一化到 0-1 X_train = X_train / 255 X_test = X_test / 255 |
最后,输出变量是一个从 0 到 9 的整数。这是一个多类分类问题。因此,对类别值使用 One-Hot 编码,将类别整数向量转换为二进制矩阵是一个好习惯。
您可以使用 Keras 中内置的 tf.keras.utils.to_categorical() 辅助函数轻松完成此操作。
|
1 2 3 4 5 |
... # one hot 编码输出 y_train = to_categorical(y_train) y_test = to_categorical(y_test) num_classes = y_test.shape[1] |
现在您已经准备好创建您的简单神经网络模型。您将在一个函数中定义您的模型。如果您想稍后扩展示例并尝试获得更好的分数,这会很方便。
|
1 2 3 4 5 6 7 8 9 10 |
... # 定义基线模型 def baseline_model(): # 创建模型 model = Sequential() model.add(Dense(num_pixels, input_shape=(num_pixels,), kernel_initializer='normal', activation='relu')) model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model |
该模型是一个简单的神经网络,有一个隐藏层,其中神经元的数量与输入(784 个)相同。隐藏层中的神经元使用整流器激活函数。
输出层使用 softmax 激活函数,将输出转换为类似概率的值,并允许从十个类别中选择一个作为模型的输出预测。对数损失用作损失函数(在 Keras 中称为 categorical_crossentropy),并且高效的 ADAM 梯度下降算法用于学习权重。
现在您可以拟合和评估模型了。模型经过十个 epoch 的拟合,每 200 张图像更新一次。测试数据用作验证数据集,让您可以查看模型训练时的技能。使用 verbose 值为 2 以将每个训练 epoch 的输出减少到一行。
最后,使用测试数据集评估模型,并打印分类错误率。
|
1 2 3 4 5 6 7 8 |
... # 构建模型 model = baseline_model() # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("Baseline Error: %.2f%%" % (100-scores[1]*100)) |
将所有这些整合在一起后,完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# MNIST 数据集的基线 MLP from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.utils import to_categorical # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 将 28*28 图像展平为每张图像的 784 向量 num_pixels = X_train.shape[1] * X_train.shape[2] X_train = X_train.reshape((X_train.shape[0], num_pixels)).astype('float32') X_test = X_test.reshape((X_test.shape[0], num_pixels)).astype('float32') # 将输入从 0-255 归一化到 0-1 X_train = X_train / 255 X_test = X_test / 255 # one hot 编码输出 y_train = to_categorical(y_train) y_test = to_categorical(y_test) num_classes = y_test.shape[1] # 定义基线模型 def baseline_model(): # 创建模型 model = Sequential() model.add(Dense(num_pixels, input_shape=(num_pixels,), kernel_initializer='normal', activation='relu')) model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model # 构建模型 model = baseline_model() # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("Baseline Error: %.2f%%" % (100-scores[1]*100)) |
在 CPU 上运行示例可能需要几分钟。
注意:由于算法或评估过程的随机性或数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
您应该会看到下面的输出。这个用很少代码行定义的非常简单的网络实现了 2.3% 的可观错误率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
第 1/10 纪元 300/300 - 1s - 损失:0.2792 - 准确率:0.9215 - val_loss:0.1387 - val_accuracy:0.9590 - 1s/纪元 - 4ms/步 第 2/10 纪元 300/300 - 1s - 损失:0.1113 - 准确率:0.9676 - val_loss:0.0923 - val_accuracy:0.9709 - 929ms/纪元 - 3ms/步 第 3/10 纪元 300/300 - 1s - 损失:0.0704 - 准确率:0.9799 - val_loss:0.0728 - val_accuracy:0.9787 - 912ms/纪元 - 3ms/步 第 4/10 纪元 300/300 - 1s - 损失:0.0502 - 准确率:0.9859 - val_loss:0.0664 - val_accuracy:0.9808 - 904ms/纪元 - 3ms/步 第 5/10 纪元 300/300 - 1s - 损失:0.0356 - 准确率:0.9897 - val_loss:0.0636 - val_accuracy:0.9803 - 905ms/纪元 - 3ms/步 第 6/10 纪元 300/300 - 1s - 损失:0.0261 - 准确率:0.9932 - val_loss:0.0591 - val_accuracy:0.9813 - 907ms/纪元 - 3ms/步 第 7/10 纪元 300/300 - 1s - 损失:0.0195 - 准确率:0.9953 - val_loss:0.0564 - val_accuracy:0.9828 - 910ms/纪元 - 3ms/步 第 8/10 纪元 300/300 - 1s - 损失:0.0145 - 准确率:0.9969 - val_loss:0.0580 - val_accuracy:0.9810 - 954ms/纪元 - 3ms/步 第 9/10 纪元 300/300 - 1s - 损失:0.0116 - 准确率:0.9973 - val_loss:0.0594 - val_accuracy:0.9817 - 947ms/纪元 - 3ms/步 第 10/10 纪元 300/300 - 1s - 损失:0.0079 - 准确率:0.9985 - val_loss:0.0735 - val_accuracy:0.9770 - 914ms/纪元 - 3ms/步 基线误差:2.30% |
用于 MNIST 的简单卷积神经网络
既然您已经了解了如何加载 MNIST 数据集并训练一个简单的多层感知器模型,那么现在是时候开发一个更复杂的卷积神经网络(CNN)模型了。
Keras 确实提供了许多创建卷积神经网络的功能。
在本节中,您将为 MNIST 创建一个简单的 CNN,演示如何使用现代 CNN 实现的所有方面,包括卷积层、池化层和 Dropout 层。
第一步是导入所需的类和函数。
|
1 2 3 4 5 6 7 8 9 |
from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.utils import to_categorical ... |
接下来,您需要加载 MNIST 数据集并将其重塑,使其适合训练 CNN。在 Keras 中,用于二维卷积的层期望像素值具有 [像素][宽度][高度][通道] 的维度。
请注意,在此示例中,为了保持一致性,您强制使用所谓的通道优先排序。
在 RGB 的情况下,最后一个维度像素将为 3,分别表示红色、绿色和蓝色分量,就像每个彩色图像有三个图像输入一样。在 MNIST 的情况下,像素值为灰度,因此像素维度设置为 1。
|
1 2 3 4 5 6 |
... # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') |
和以前一样,将像素值归一化到 0 到 1 的范围并对输出变量进行 One-Hot 编码是一个好主意。
|
1 2 3 4 5 6 7 8 |
... # 将输入从 0-255 归一化到 0-1 X_train = X_train / 255 X_test = X_test / 255 # one hot 编码输出 y_train = to_categorical(y_train) y_test = to_categorical(y_test) num_classes = y_test.shape[1] |
接下来,定义你的神经网络模型。
卷积神经网络比标准的多层感知器更复杂,因此您将从使用一个简单结构开始,该结构使用所有元素以获得最先进的结果。下面总结了网络架构。
- 第一个隐藏层是一个称为 Convolution2D 的卷积层。该层有 32 个特征图,大小为 5×5,并使用整流器激活函数。这是输入层,它期望具有上述结构:[像素][宽度][高度] 的图像。
- 接下来,定义一个池化层,它采用最大值,称为 MaxPooling2D。它配置为 2×2 的池大小。
- 下一层是一个使用 Dropout 的正则化层。它被配置为随机排除层中 20% 的神经元,以减少过拟合。
- 接下来是一个将二维矩阵数据转换为向量的层,称为 Flatten。它允许输出由标准的全连接层处理。
- 接下来是一个包含 128 个神经元和整流器激活函数的全连接层。
- 最后,输出层有十个神经元,对应十个类别,并使用 softmax 激活函数为每个类别输出类似概率的预测。
和以前一样,模型使用对数损失和 ADAM 梯度下降算法进行训练。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... def baseline_model(): # 创建模型 model = Sequential() model.add(Conv2D(32, (5, 5), input_shape=(28, 28, 1), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(num_classes, activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model |
您以与多层感知器相同的方式评估模型。CNN 经过十个 epoch 的拟合,批量大小为 200。
|
1 2 3 4 5 6 7 8 |
... # 构建模型 model = baseline_model() # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("CNN Error: %.2f%%" % (100-scores[1]*100)) |
将所有这些整合在一起后,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# MNIST 数据集的简单 CNN from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.utils import to_categorical # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)).astype('float32') X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)).astype('float32') # 将输入从 0-255 归一化到 0-1 X_train = X_train / 255 X_test = X_test / 255 # one hot 编码输出 y_train = to_categorical(y_train) y_test = to_categorical(y_test) num_classes = y_test.shape[1] # 定义一个简单的 CNN 模型 def baseline_model(): # 创建模型 model = Sequential() model.add(Conv2D(32, (5, 5), input_shape=(28, 28, 1), activation='relu')) model.add(MaxPooling2D()) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(num_classes, activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model # 构建模型 model = baseline_model() # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("CNN Error: %.2f%%" % (100-scores[1]*100)) |
运行示例后,会打印每个 epoch 的训练和验证测试的准确率,最后打印分类错误率。
注意:由于算法或评估过程的随机性或数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在 GPU 上(例如,在 AWS 上)运行一个 epoch 可能需要大约 45 秒。您可以看到该网络的错误率为 1.19%,这比我们上面简单的多层感知器模型要好。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
第 1/10 纪元 300/300 [==============================] - 4s 12ms/步 - 损失:0.2372 - 准确率:0.9344 - val_loss:0.0715 - val_accuracy:0.9787 第 2/10 纪元 300/300 [==============================] - 4s 13ms/步 - 损失:0.0697 - 准确率:0.9786 - val_loss:0.0461 - val_accuracy:0.9858 第 3/10 纪元 300/300 [==============================] - 4s 13ms/步 - 损失:0.0483 - 准确率:0.9854 - val_loss:0.0392 - val_accuracy:0.9867 第 4/10 纪元 300/300 [==============================] - 4s 13ms/步 - 损失:0.0366 - 准确率:0.9887 - val_loss:0.0357 - val_accuracy:0.9889 第 5/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0300 - 准确率:0.9909 - val_loss:0.0360 - val_accuracy:0.9873 第 6/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0241 - 准确率:0.9927 - val_loss:0.0325 - val_accuracy:0.9890 第 7/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0210 - 准确率:0.9932 - val_loss:0.0314 - val_accuracy:0.9898 第 8/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0167 - 准确率:0.9945 - val_loss:0.0306 - val_accuracy:0.9898 第 9/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0142 - 准确率:0.9956 - val_loss:0.0326 - val_accuracy:0.9892 第 10/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0114 - 准确率:0.9966 - val_loss:0.0322 - val_accuracy:0.9881 CNN 错误率:1.19% |
用于 MNIST 的大型卷积神经网络
既然您已经了解了如何创建一个简单的 CNN,那么让我们看看一个能够接近最先进结果的模型。
您将导入类和函数,然后像前面的 CNN 示例一样加载和准备数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 用于 MNIST 数据集的更大的 CNN from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.utils import to_categorical # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)).astype('float32') X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)).astype('float32') # 将输入从 0-255 归一化到 0-1 X_train = X_train / 255 X_test = X_test / 255 # one hot 编码输出 y_train = to_categorical(y_train) y_test = to_categorical(y_test) num_classes = y_test.shape[1] ... |
这次您将定义一个包含额外卷积层、最大池化层和全连接层的大型 CNN 架构。网络拓扑可以总结如下:
- 30 个特征图的卷积层,大小为 5×5
- 在 2*2 补丁上进行最大池化的池化层
- 15 个特征图的卷积层,大小为 3×3
- 在 2*2 补丁上进行最大池化的池化层
- 概率为 20% 的 Dropout 层
- 展平层
- 具有 128 个神经元和整流器激活的全连接层
- 具有 50 个神经元和整流器激活的全连接层
- 输出层
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
... # 定义更大的模型 def larger_model(): # 创建模型 model = Sequential() model.add(Conv2D(30, (5, 5), input_shape=(28, 28, 1), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(15, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(50, activation='relu')) model.add(Dense(num_classes, activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model |
与前两个实验一样,模型经过十个 epoch 的拟合,批量大小为 200。
|
1 2 3 4 5 6 7 8 |
... # 构建模型 model = larger_model() # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("Large CNN Error: %.2f%%" % (100-scores[1]*100)) |
将所有这些整合在一起后,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# 用于 MNIST 数据集的更大的 CNN from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.utils import to_categorical # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)).astype('float32') X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)).astype('float32') # 将输入从 0-255 归一化到 0-1 X_train = X_train / 255 X_test = X_test / 255 # one hot 编码输出 y_train = to_categorical(y_train) y_test = to_categorical(y_test) num_classes = y_test.shape[1] # 定义更大的模型 def larger_model(): # 创建模型 model = Sequential() model.add(Conv2D(30, (5, 5), input_shape=(28, 28, 1), activation='relu')) model.add(MaxPooling2D()) model.add(Conv2D(15, (3, 3), activation='relu')) model.add(MaxPooling2D()) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(50, activation='relu')) model.add(Dense(num_classes, activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model # 构建模型 model = larger_model() # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("Large CNN Error: %.2f%%" % (100-scores[1]*100)) |
运行示例会打印每个 epoch 的训练和验证数据集的准确率,以及最终的分类错误率。
注意:由于算法或评估过程的随机性或数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
该模型每个 epoch 运行大约 100 秒。这个稍大的模型实现了 0.83% 的可观分类错误率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
第 1/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.4104 - 准确率:0.8727 - val_loss:0.0870 - val_accuracy:0.9732 第 2/10 纪元 300/300 [==============================] - 5s 15ms/步 - 损失:0.1062 - 准确率:0.9669 - val_loss:0.0601 - val_accuracy:0.9804 第 3/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0771 - 准确率:0.9765 - val_loss:0.0555 - val_accuracy:0.9803 第 4/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0624 - 准确率:0.9812 - val_loss:0.0393 - val_accuracy:0.9878 第 5/10 纪元 300/300 [==============================] - 4s 15ms/步 - 损失:0.0521 - 准确率:0.9838 - val_loss:0.0333 - val_accuracy:0.9892 第 6/10 纪元 300/300 [==============================] - 4s 15ms/步 - 损失:0.0453 - 准确率:0.9861 - val_loss:0.0280 - val_accuracy:0.9907 第 7/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0415 - 准确率:0.9866 - val_loss:0.0322 - val_accuracy:0.9905 第 8/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0376 - 准确率:0.9879 - val_loss:0.0288 - val_accuracy:0.9906 第 9/10 纪元 300/300 [==============================] - 4s 14ms/步 - 损失:0.0327 - 准确率:0.9895 - val_loss:0.0245 - val_accuracy:0.9925 第 10/10 纪元 300/300 [==============================] - 4s 15ms/步 - 损失:0.0294 - 准确率:0.9904 - val_loss:0.0279 - val_accuracy:0.9910 大型 CNN 错误率:0.90% |
这不是一个优化的网络拓扑。也不是对近期论文中网络拓扑的复现。您有很大的机会来调整和改进此模型。
您能达到的最佳错误率是多少?
在评论中发布您的配置和最佳分数。
MNIST 资源
MNIST 数据集经过深入研究。以下是您可能想查阅的一些额外资源。
- 官方 MNIST 数据集网页
- Rodrigo Benenson 的网页,列出了最先进的结果
- 使用此数据集的 Kaggle 竞赛(查看脚本和论坛部分以获取示例代码)
- 在浏览器中可以测试的只读 MNIST 训练模型(非常酷)
总结
在这篇文章中,您发现了 MNIST 手写数字识别问题以及使用 Keras 库在 Python 中开发的能够取得出色结果的深度学习模型。
通过本教程,您学会了
- 如何在 Keras 中加载 MNIST 数据集并生成数据集图表
- 如何重塑 MNIST 数据集并开发一个简单但性能良好的多层感知器模型来解决该问题
- 如何使用 Keras 创建用于 MNIST 的卷积神经网络模型
- 如何开发和评估能够达到接近世界级结果的更大规模的 MNIST CNN 模型。
您对手写识别深度学习或这篇文章有任何疑问吗?请在评论中提出您的问题,我将尽力回答。


")



感谢您的教程。它很棒。尽管(听起来可能很傻)我如何实际操作呢?我的意思是,如果我想看它预测图像的答案,我该怎么做?
再次感谢。
以其当前形式,它不是一个健壮的系统。
您必须提供具有相同尺寸的数字图像。
很棒的工作!!
但你能用一个样本图像来展示它的实际应用吗?
先生,请帮帮我!!
pip install tensorflow
错误:找不到满足 tensorflow 要求的版本(来自版本:无)
错误:找不到匹配 tensorflow 的分发版本
python 版本是 3.8.2
Win 10
我已经为此努力了一个月,但没有得到完美的解决方案,我觉得您可以帮助我解决这个问题
我推荐这个教程
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
如何预测新图像的答案:https://blog.luisfred.com.br/reconhecimento-de-escrita-manual-com-redes-neurais-convolucionais/
使用 model.predict()
请告诉我这里使用了什么前端和后端
Keras 前端,TensorFlow 后端。
此 URL 现已下线。它已更改为 https://medium.com/luisfredgs/reconhecimento-de-escrita-manual-com-redes-neurais-convolucionais-6fca996af39e
你好,我也在做这个项目,我选择它作为我的软件工程毕业设计,所以我希望得到你的帮助,以更好地理解它。
miansahilawais@gmail.com
您有识别数字的可用程序吗?
仅此教程中的示例,Adrian。
你拿到工作程序了吗?
当我使用 MLP 运行基线模型时,我得到的结果比您展示的差得多(错误率为 53.64%)。您知道为什么我使用相同的代码会看到如此截然不同的结果吗?谢谢。
你好 Matthew,这些数字如此不同令人惊讶。
Theano 后端?还是 TensorFlow?什么平台?什么版本的 Python?
尝试运行示例 3 次并报告所有 3 个分数。
我也有同样的问题。我使用 Theano 后端。平台:Pycharm。版本 3.5
很抱歉听到这个消息,Adrian。
您在命令行上运行它能成功吗?
我也遇到了同样的问题,错误率非常高:51.08%、43.26%和52.01%。但我后来发现我忘记将像素值从 0-255 归一化到 0-1。修正后,我现在得到了 1.93% 的基线错误。
你能解释一下这种归一化的效果吗?
是的,我在这里有一篇关于这个主题的巨长文章。
https://machinelearning.org.cn/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/
谢谢!
要获得如此高的错误率,代码肯定是复制不正确或类似的原因。除此之外,请注意,每次运行此代码时,最终输出都会略有不同,因为神经网络中存在 Dropout 层。它每次运行时都会随机选择 20% 的神经元,从而略微影响最终结果。
是的。但是即使我删除了 dropout 层,结果精度也各不相同。有什么想法吗?精度不应该改变,对吧?
每次运行代码,您都会得到不同的准确率。请参阅此帖子
https://machinelearning.org.cn/randomness-in-machine-learning/
哇!我现在明白了。谢谢你
您能否提供一个简单的 CNN 示例,例如在 UCI 存储库数据集中。CNN 是否可以应用于数值特征。
抱歉,我没有这样的例子。
你好 Jason,我尝试运行脚本,但是基线模型花费了太多时间……它已经运行了 20 多个小时,仍然在第 4 个纪元,您能提出一些加快过程的方法吗?我正在使用 4 GB 内存的计算机,并在 Anaconda Theano 后端 Keras 上运行
很抱歉听到这个消息,Dinesh。
也许可以尝试在 AWS 上进行训练。
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
嗨,Jason,
您使用什么机器配置来运行模型?您是否使用了 GPU 来提高性能?您花了多长时间?
另外,AWS 是一个付费平台,有没有免费的平台可以运行 ML 算法?
谢谢
我使用的是一台 8 核、8GB 内存的机器。它在合理的时间内完成了内存操作。
AWS 的价格非常合理,我认为每小时不到 1 美元。非常适合像这样的单次模型。
对我来说,10 个 epoch 大约 6 分钟就运行完了,也是 4GB 内存。检查你的代码?
干得好!
嗨!很棒的文章!我试了一下,但第一个 CNN 似乎无法编译。我得到了
ValueError:过滤器不得大于输入:过滤器:(5, 5) 输入:(1, 28)
就在 model = baseline_model() 之后
我已更新示例,请再试一次!
你好 Jason,我试了一下,但是出现了下面的错误。我使用的是 tensorflow r0.11。我不确定这是否是原因。
使用 TensorFlow 后端。
回溯(最近一次调用)
文件“/Users/Jack/.pyenv/versions/3.5.1/lib/python3.5/site-packages/tensorflow/python/framework/common_shapes.py”,第 594 行,在 call_cpp_shape_fn 中
状态)
文件“/Users/Jack/.pyenv/versions/3.5.1/lib/python3.5/contextlib.py”,第 66 行,在 __exit__ 中
下一个(self.gen)
文件“/Users/Jack/.pyenv/versions/3.5.1/lib/python3.5/site-packages/tensorflow/python/framework/errors.py”,第 463 行,在 raise_exception_on_not_ok_status 中
pywrap_tensorflow.TF_GetCode(状态))
tensorflow.python.framework.errors.InvalidArgumentError: 负维度大小由 5 减去 1 引起
哎呀,Jack,这看起来不太好。
看起来 API 已经改变了。我将深入研究并修复示例。
好的,我已更新示例。
首先,我建议使用 TensorFlow 0.10.0,而不是 0.11,因为最新版本存在问题。
其次,您必须添加以下两行才能使 CNN 正常工作
修复方案取自此处:https://github.com/fchollet/keras/issues/2681
希望这能帮到你,Jack。
你好,Jason。
感谢这篇很棒的教程。
您的评论尚未解决问题,我们仍然遇到相同的错误,您能否修改您的模型以与TensorFlow后端一起工作?
Keras更改了其输入格式。它现在是[宽度, 高度, 像素],而不是[像素, 宽度, 高度]。
在Conv2D和reshape调用中将input_shape = (28, 28, 1)更改为(28, 28, 1)。
在Input层Conv2D中使用参数:data_format='channels_first'
model.add(Conv2D(32, kernel_size=(3, 3) , activation=’relu’,data_format=’channels_first’, input_shape=(1,28,28)))
或者您需要更改默认的Keras配置
在~/.keras/keras.json中
从“image_data_format”: “channels_last” => “image_data_format”: “channels_first”
谢谢
谢谢,它解决了我的问题。
很高兴听到。
嗨,感谢您提供的精彩教程!
我尝试用测试集进行预测,并得到了独热编码的预测。我只是想知道是否有内置函数可以将其转换回原始标签(0,1,2,3…)。
好问题,Abhai。
如果您使用scikit-learn执行独热编码,它提供了逆变换来将编码后的预测转换回原始值。
https://scikit-learn.cn/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
那将是我首选的起点。
你好,
非常感谢您一如既往的简明扼要和全面的说明和讨论。
很高兴你觉得这篇文章有用,Berisha。
你好,
完成学习后,如何使用此网络识别自己的图片。
好问题gs,我目前没有示例。
您需要以与MNIST数据集相同的方式编码您自己的图片——主要是缩放到相同大小。然后将它们作为像素值矩阵加载,您就可以进行预测了。
Jason你能详细说明一下吗???拜托
感谢您的建议,我希望将来能涵盖它。
你好,
感谢您提供了一个很棒的示例,但是如何保存网络的 currentState,
我的意思是网络学习了60000个示例,然后它测试并尝试猜测10000个
但是如果我想每天都使用它,例如,我怎样才能每天使用它而无需每天训练它?
好问题,请参阅此文章,了解如何保存您的网络
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
Jason,您的书是否解释了“为什么”您在此教程中选择了各种层,并阐明了如何以及为何为不同的数据集选择某些设计?
不,只讲了方法,John。
“为什么”很难,在大多数情况下,最好的结果是通过试错法实现的。没有“神经网络理论”可以帮助您配置它们。
你好
当我尝试对自己的图像进行预测时,网络出错了
这让我很沮丧。
我使用命令 model.predict_classes(img)
请问有没有办法获得我手写数字的正确答案
也许你需要更多不同的训练示例,Nassim?
也许一些图像增强可以使您的模型更健壮?
Jason,你真是个了不起的教程,事实上你是最棒的,非常容易上手,我喜欢你所有的教程,谢谢你!事实上,
我一度使用GPU实现了0.74的错误率,运行时间大约30秒。
干得好,安东尼!
感谢这篇很棒的教程。只有一个地方我不明白。在Convolution2D层中,有一个border_mode=”valid”参数。这是做什么的?它的目的是什么?Keras文档似乎也没有对此进行解释。
杰森,出色的教程。我非常喜欢阅读和实现它。我刚刚发现,如果你安装了cuDNN,它会使事情变得更快(至少对于我尝试过的玩具示例)。我建议任何阅读本文的人安装cuDNN并配置theano来使用它。你只需将其放入
[dnn]
enabled = True
在theanorc文件中。
好棒,谢谢你的提示,Sanjaya。
如果您本地没有硬件,请参阅此帖子了解如何在AWS上使用GPU运行。
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
嗨,Jason,
我正在尝试将CONVOLUTION1D应用于IRIS数据。
代码如下
—————————————————————————————–
max_features = 150
maxlen = 4
batch_size = 16
embedding_dims = 3
nb_epoch = 3
nb_classes =3
dropoutVal = 0.5
nb_filter = 5
hidden_dims = 500
filter_length = 4
import pandas as pd
data_load = pd.read_csv(“iris.csv”)
data = data_load.ix[:,0:4]
target = data_load.ix[:,4]
X_train = np.array(data[:100].values.astype(‘float32’))
Y_train = np.array(target[:100])
Y_train = np_utils.to_categorical(Y_train,nb_classes)
X_test = np.array(data[100:].values.astype(‘float32′))
Y_test = np.array(target[100:])
Y_test = np_utils.to_categorical(Y_test,nb_classes)
std = StandardScaler()
X_train = X_train_scaled = std.fit_transform(X_train)
X_test = X_test_scaled = std.transform(X_test)
X_train1 = sequence.pad_sequences(X_train_scaled,maxlen=maxlen)
X_test1 = sequence.pad_sequences(X_test_scaled,maxlen=maxlen)
model = Sequential()
model.add(Embedding(max_features,embedding_dims,input_length=maxlen))
model.add(Convolution1D(nb_filter=nb_filter,filter_length=filter_length, border_mode=’valid’,activation=’relu’))
model.add(GlobalMaxPooling1D())
model.add(Dense(hidden_dims,activation=’softmax’))
model.add(Dense(nb_classes))
model.add(Activation(‘sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
model.fit(X_train1, Y_train, nb_epoch=5, batch_size=10)
scores = model.evaluate(X_test1, Y_test, verbose=0)
predictions = model.predict(X_test1)
—————————————————————————————-
我想检查我是否朝这个方向走对了。
我的准确率没有超过66%,这相当令人惊讶。
我的嵌入层做得对吗?因为当我查看嵌入层权重时,我发现我设置的层参数与我检索到的权重之间存在差异。
请指教。
此致
Ganesh
我建议对鸢尾花数据集使用MLP而不是CNN。
请看这篇文章
https://machinelearning.org.cn/multi-class-classification-tutorial-keras-deep-learning-library/
嗨 Jason
非常感谢您的精彩教程。
顺便问一下,您能解释一下为什么MLP比CNN更适合鸢尾花数据集吗?非常感谢。
祝好,
Lua
因为数据是表格形式(例如花卉测量),而不是图像形式(例如照片)。
如果数据是照片,那么CNN将是首选方法。
非常感谢这篇帖子。(
不客气,Ger。
你能告诉我如何给系统一张图片,然后它告诉我图片上的数字是多少吗?对不起,我是新手,谢谢!
嗨 Remon,
图像必须缩放到与网络预期尺寸相同的尺寸。
此外,在此示例中,网络期望图像具有特定的比例,并且是黑色背景上的白色数字。新的示例必须以相同的方式准备。
我们将如何准备?
例如,谷歌关于Python“图像”的教程
http://effbot.org/imagingbook/introduction.htm
你好 jason,
您的代码片段
————————-
在“加载数据”步骤中
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 重塑为 [样本][像素][宽度][高度]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype(‘float32’)
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype(‘float32’)
您正在使用mnist数据。它是什么样的数据结构?
如何将图像(列表)和标签(列表)预处理成这种结构并将其馈送给Keras模型?
这行代码到底
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype(‘float32’)
是做什么的?
谢谢
joseph
嗨 Joe,
MNIST数据在Keras中可用。
它以NumPy像素数据数组的形式存储。
与CNN一起使用时,数据会重塑为以下格式:[样本,像素,宽度,高度]
希望这能有所帮助。
嗨 Jason,是什么让您选择128个神经元用于全连接层?(计算进入全连接层的激活数量,它远大于128)谢谢!
试错法,Amy。
谢谢!
嗨 @Jason Brownlee,首先,您的教程太棒了..!!
在以下几行中有一个小问题
小型卷积神经网络
# 构建模型
model = baseline_model()
大型卷积神经网络
# 构建模型
model = larger_model()
使用最新版本的Tensorflow会抛出AttributeError
=> AttributeError: module ‘tensorflow.python’ has no attribute ‘control_flow_ops’ <=
解决方案
添加以下行
import tensorflow as tf
tf.python.control_flow_ops = tf
参考
https://github.com/fchollet/keras/issues/3857
你能更新一下代码吗..!!
再次感谢你的精彩教程。
继续努力..!!
谢谢你的留言,Shaik,我会调查的。
您的帖子非常适合Keras的入门。我非常喜欢它,先生。
谢谢Mouze。
您好,先生,感谢您精彩的写作和详尽的解释。我已经尝试过了,它有效。但是,我如何使用自己的手写数据集而不是MNIST数据来训练网络。
如果您能对此有所启发,将非常有帮助。
提前感谢。
嗨 Faruk,
一般来说,您需要首先使数据在维度上保持一致。
从那里,您可以将数据分成训练/测试集或类似的东西,并开始探索不同的配置。
这有帮助吗?也许我误解了问题?
嗨
感谢您的详细解释。我成功地训练了您在此处介绍的所有网络。但是,当我想使用训练好的模型进行一些预测时,使用这段代码
im=misc.imread(‘test8.png’)
im=im[:,:,1]
im=im.flatten()
print(model.predict(im))
它给我一个错误
ValueError: 检查时出错:预期的dense_input_1形状为(None, 784),但得到的数组形状为(784, 1)
“im”的形状是(,784),我如何输入一个大小为(None,784)的数组?
嗨 Arash,
考虑如下重塑
嗨,Jason,
感谢您精彩的教程!
我有一个关于“model.add(Dropout(0.2))”的问题。正如您在帖子中指出的“下一层是使用Dropout的正则化层,称为Dropout。它被配置为随机排除层中20%的神经元以减少过拟合。”Dropout在Keras中被视为一个独立的层,而不是对现有层(如卷积层和全连接层)的正则化操作。这是如何实现的?
由于这个Dropout位于MaxPooling和下一个全连接层之间,Dropout应用于了权重的哪个部分?
非常感谢!
好问题,它会影响插入它所在层之间的权重。
嗨 Jason 先生,我们有没有机会将 AdaBoost 应用于手写数字识别,我想知道实际的准确率是多少
我没有,我建议使用 sklearn 的 adaboost 实现。
您好,先生,感谢您详细的解释。我已经尝试过了,它运行良好。但是,我如何使用自己的手写数据集而不是MNIST数据集来训练网络。
如果您能对此有所启发,将不胜感激。
提前感谢。
您需要从文件中加载数据,调整它以使其具有相同的维度,然后拟合您的模型。
抱歉,我目前没有处理自定义数据的示例。
我用theano后端尝试了简单的CNN。
”’ImportError: (‘编译节点时发生以下错误’, DotModulo(A, s, m, A2, s2, m2), ‘\n’, ‘/home/pramod/.theano/compiledir_Linux-4.8–generic-x86_64-with-debian-stretch-sid-x86_64-2.7.13-64/tmpXpzrkl/d16654b784f584f17fdc481825fd2cca.so: undefined symbol: _ZdlPvm’, ‘[DotModulo(A, s, m, A2, s2, m2)]’)”’
我在运行基线模型时遇到了这个错误。
您能告诉我如何纠正这个错误吗?我尝试了多种安装theano的方法,包括pip和conda。
我猜我的theano安装有问题。
不知所措,请帮忙。
谢谢你
我没有见过这个错误,抱歉。
我的许多学生在使用Anaconda Python的Keras和Theano时都取得了巨大的成功。
上面是原封不动的代码,只做了一个更改
X_train = X_train[:-20000 or None]
y_train = y_train[:-20000 or None]
以减少在Mac OSX El Capitan(GeForce 650M,512MB)上运行时的内存使用。
错误率稍高,为
1.51%
我使用Keras和tensorflow-GPU后端。
谢谢你的留言,Chris!
嗨,Jason,
对于像我这样的初学者来说,这确实是对Keras和数字识别的绝佳介绍。
您正在使用MNIST数据集,它以腌制对象的形式存在(我猜)。但我的问题是,如何将一组现有图像转换为这种腌制对象?
其次,您正在计算与您的测试数据集相比的错误率。但是假设我有一张写有数字的图像,您如何在不改变太多上述程序的情况下返回它的类别标签。
谢谢你,Vikalp。
我建议将您的图像数据加载为numpy数组并直接使用它们。
您可以使用网络进行预测 (y = model.predict(x)),并使用 numpy argmax() 函数将独热编码的输出转换为类别索引。
嗨,Jason,
感谢您的快速回复。
我正在研究您建议的方法。以下是该代码
color_image = cv2.imread(“two.jpg”)
gray_image = cv2.cvtColor(color_image, cv2.COLOR_BGR2GRAY)
a = model.predict(numpy.array(gray_image))
print(a)
但得到以下错误
ValueError: 检查时出错:预期的 dense_1_input 形状为 (None, 784) 但得到的数组形状为 (1024, 791)
我不确定我是否做得对。请指导我。谢谢。
加载的图像必须与用于拟合模型的图像具有完全相同的尺寸。
您可能需要调整其大小。
你成功了吗?能给我代码吗
你好,
我尝试按照您在另一篇文章中描述的方式保存和加载模型,但我总是遇到以下错误
ValueError: 检查模型目标时出错:期望 dense_3 的形状为 (None, 1),但得到的数组形状为 (10000, 10)
错误发生在
score = model.evaluate(…)
加载后的行
#
# 保存模型和权重
print("正在保存模型...")
model_json = model.to_json()
with open('mnist_model.json', 'w') as json_file
json_file.write(model_json)
model.save_weights("mnist_weights.h5")
print("模型已保存到磁盘")
# 加载模型和权重
print("正在加载模型...")
with open('mnist_model.json') as json_file
model_json = json_file.read()
model = model_from_json(model_json)
model.load_weights('mnist_weights.h5')
print("模型已从磁盘加载")
print("正在编译模型...")
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
scores = model.evaluate(X_test, y_test, verbose=0)print("基线错误:%.2f%%" % (100-scores[1]*100))
如何获得预测输出的精确度、召回率和F值?
您可以收集预测,然后使用sklearn的工具。
https://scikit-learn.cn/stable/modules/classes.html#module-sklearn.metrics
嗨,Jason,
很棒的网站和教程。我理解您尚未能够描述如何预处理我们自己的图像,以便在我们的MNIST训练模型中读取,正如这里的许多其他人所问的那样。如果您没有时间解释如何做到这一点,我完全理解。
您能否指导我如何继续我的搜索以做到这一点?我尝试创建一个新的28x28像素图像,黑色背景,白色前景用于图像绘制,将其转换为灰度(用于1,28,28输入维度)。然后我将其除以255。这些自定义图像的预测准确率非常低(该模型在MNIST测试图像上的准确率为99%)。
查看各个特征,我发现如上所述预处理的自定义图像的十进制位置与MNIST图像的十进制位置似乎大不相同,十进制和0的位置与MNIST数据相比大相径庭。完全不同的模式。这让我相信除了上面直观的步骤之外,一定还有更复杂的预处理。我查阅了MNIST页面上关于预处理如何进行的说明,但不知道如何在python中实现这些说明。似乎也有一些预处理脚本,但我无法使它们工作。
关于我如何继续寻找预处理自定义图像的方法,还有其他建议吗?谷歌上的所有说明都过于复杂,或者实现似乎失败了。
一般来说,您需要在一个代表您以后需要进行预测的图像类型的数据上训练模型。
图像需要具有相同的尺寸(宽度x高度)和相同的颜色。
如果您预计字符在图像中的位置会有很大变化,您可以使用图像增强来创建具有随机变换的输入数据副本。
https://machinelearning.org.cn/image-augmentation-deep-learning-keras/
希望这些能作为一个开始有所帮助。
嘿,你能告诉我如何让mnist数据集可读吗,我已经以csv格式下载了它,现在我想让我的图像可读
嗨,Jason,
谢谢您的精彩课程!
我的问题是,为什么像素应该标准化到0…1?
我有这样的输入
70.67, 3170.27, 56.31, 1.28, 0.39, 0
204.70, 26419.57, 162.54, 0.42, -0.97, 1
173.70, 20141.12, 141.92, 0.61, -1.14, 3
219.80, 42211.29, 205.45, 0.55, -1.41, 0
243.00, 43254.00, 207.98, 0.23, -1.73, 0
241.22, 21973.94, 148.24, 0.07, -0.60, 3
245.42, 46176.45, 214.89, 0.29, -1.80, 0
164.78, 25253.94, 158.91, 1.08, -0.13, 0
115.29, 9792.57, 98.96, 0.56, -1.25, 1
最后一行是我分离并转换为独热编码的结果。
我尝试了许多模型和许多不同的参数,但都没有学习到任何东西。即使尝试对几个列进行过采样并查看模型是否可以重现训练输出也失败了!
但是您的所有示例都运行正常,并产生与您描述的相同的结果。所以我的设置:最新的Python 3.6,在Windows 10上运行Anaconda,应该都没问题。
所以我担心我的输入有问题:(。我应该标准化它们吗?我该怎么做?稍后我还会遇到混合输入:数字和字符串。我该如何处理这个问题?
如果能得到您的帮助,将不胜感激!
谢谢!
(请原谅我学校学到的很差的英语)
与神经网络一起工作时,输入数据必须进行缩放,否则,大的输入会使网络产生偏差。
谢谢 Jason 的回复!
与此同时,我在这里找到了我需要的一切
https://scikit-learn.cn/stable/modules/preprocessing.html#preprocessing
我的模型现在可以工作了。预测效果不如我所愿(只有~30%),但足以继续…
谢谢!
很高兴听到这个消息。
嗨,Jason,
感谢!这真的很有帮助。我只是想知道;我意识到你使用了所有60,000个训练数据。如果你只使用1万或3万个训练数据,但仍能达到低错误率,代码会是什么样子?
谢谢!
您可以根据需要选择任意数量的训练数据来拟合模型。
您可以使用数组索引来选择所需的数据量。
https://docs.scipy.org.cn/doc/numpy/reference/arrays.indexing.html
你好,
谢谢你的代码。
我有一个问题。
我如何向此代码添加新的激活函数?
我找到了可以添加激活函数的地方,但我不知道应该在哪里添加新激活函数的导数。
如果您能帮助我,我将不胜感激。
谢谢。
Ehsan。
嗨 Ehsan,
您可以指定层之间的激活函数(例如 model.add(...))或在层上指定(例如 Dense(activation='...'))。
你好,
我无法运行上面的例子。
得到以下错误。
runfile(‘C:/Users/Paul/Desktop/CNN.py’, wdir=’C:/Users/Paul/Desktop’)
回溯(最近一次调用)
File “”, line 1, in
runfile(‘C:/Users/Paul/Desktop/CNN.py’, wdir=’C:/Users/Paul/Desktop’)
文件“C:\Users\Paul\Anaconda2\lib\site-packages\spyderlib\widgets\externalshell\sitecustomize.py”,第714行,在runfile中
execfile(filename, namespace)
文件“C:\Users\Paul\Anaconda2\lib\site-packages\spyderlib\widgets\externalshell\sitecustomize.py”,第74行,在execfile中
exec(compile(scripttext, filename, 'exec'), glob, loc)
文件“C:/Users/Paul/Desktop/CNN.py”,第54行,在
model = larger_model()
文件“C:/Users/Paul/Desktop/CNN.py”,第40行,在larger_model中
model.add(Conv2D(30, (5, 5), input_shape=(1, 28, 28), activation=’relu’))
TypeError: __init__() takes at least 4 arguments (4 given)
你能帮我一下吗?
很抱歉听到这个消息,Paul,您的错误原因对我来说并不明显。
也许请确认您已安装所有库的最新版本,并且代码没有复制粘贴错误。
干得好,Jason,谢谢你…它对我有用。我使用的是Anaconda和GPU
干得好 Jose!
你好团队,我有以下疑问,请帮我
# 创建模型
model = Sequential()
model.add(Conv2D(30, (5, 5), input_shape=(1, 28, 28), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
在上面的代码中,input shape=(1,28,28)用于二值图像,对于彩色图像我们保留(3,28,28)...但对于非图像数据我们保留什么?
我有一个包含10248个观测值和18个变量的数据集,其中包括目标变量。
input_shape应该保留什么?
请帮帮我。
CNN用于图像数据。
对于非图像数据,您可能需要考虑使用MLP。对于序列数据,请考虑使用RNN。
先生,我的神经网络输入是一个numpy数组,例如 [[1,1,1,2], [1,2,1,2], ……..],在这行代码中
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype(‘float32’)
编译器抛出错误
ValueError: 新数组的总大小必须保持不变
期待问题的解决方案
如果您的数据不是图像数据,请考虑从MLP而不是CNN开始。
嗨,Jason。很棒的教程!这是我的第一个CNN,我简直不敢相信它真的有效,太兴奋了!
我只是想知道为什么在CNN中不需要使用“kernel_initializer=”来初始化权重?在基线MLP中,您初始化了每一层,而在CNN中,这些行不存在,无论是卷积层、最大池化层还是最终的全连接层。
我错过了什么吗?提前感谢。
有一个默认的kernel_initializer
https://keras.org.cn/layers/convolutional/
干得好。谢谢先生。完成训练和测试后,我想预测一个字符,我有一个包含新手写字符的新字符图像。我该怎么做呢,先生。请帮助我
我如何评估我的模型并估计它们在未见数据上的性能?
在未见数据上。
请看这篇文章
https://machinelearning.org.cn/evaluate-skill-deep-learning-models/
嗨,Jason
我的问题是
test_data用于在您已经定义模型(通过使用train_data)后检查模型。
为什么您在模型训练中使用测试数据?
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# 模型的最终评估
scores = model.evaluate(X_test, y_test, verbose=0)
它仅用于报告模型在训练期间(验证数据集)未见过的数据上的性能。
嗨 Jason,我仍然不清楚(Keras如何划分数据集)?
验证数据就是测试数据本身吗..?
这就是我在模型拟合方程中看到的!
所以数据集只被Keras划分为训练集和测试集..
然后用测试数据而不是验证数据进行拟合?
我无法理解,但就是这样!
我说的对吗?
非常感谢你
saeed
您可以在这里了解更多关于验证数据集的信息
https://machinelearning.org.cn/difference-test-validation-datasets/
晚上好,我非常喜欢您关于手写字符识别的解释,它对我理解Keras中CNN的架构和操作非常有帮助。但是,我有一个疑问,您有没有好的教程可以处理CNN的人脸识别问题……我已经尝试过OpenCV、dlib等其他方法……但是,我想用CNN来实现。
谢谢你……
很好的建议,谢谢。
如何预测新的测试示例?
在整个可用数据集上拟合模型,然后将图像传递给
嗨,Jason。在Keras中用mnist和CNN玩耍的开始,您的帖子非常有帮助!
谢谢!
我有一个问题:在我的测试中,我得到了糟糕的概率分布。在大多数情况下,预测类得到1,其他类得到0。我尝试找出如何获得更具信息量的分布,特别是为了能够找到可能的预测错误。最初我以为结果与sigmoid激活函数有关,但在模型中我们只有ReLu和Sofmax线性函数。关于如何获得更具描述性的概率分布,有什么建议吗?
我刚才看到我们正在使用Sofplus而不是Softmax函数。我将尝试线性函数和relu函数,看看输出有什么不同 =)
告诉我进展如何。
嗯,首先我必须纠正我函数名称上的错误。我从最后一个例子中的相同模型开始,即使用Softmax:一个非线性函数。当用predict_proba()激活时,在概率ndarray中得到二元0或1。
用线性函数进行一次测试,学习收敛缓慢,我决定暂时放弃这个测试……
用Softplus(我曾认为它类似于线性函数)得到非归一化的概率数组,但更有趣的是,在模型未能预测的情况下,概率数组中的所有值都为零!这在试图捕获模型无法预测的情况时非常有用。
最后一次使用Sigmoid进行测试,我得到了与Softplus相同的行为,在失败的情况下,predict_proba()返回的所有值都为0,但在正确预测的情况下,预测类的值为1。这在归一化概率下更有意义,但没有一种情况具有非二元概率分布。
总结一下:效果最好的函数仍然是Softmax;当用predict_proba()激活时,没有一个函数得到非二元分布;Softplus和Sigmoid在失败情况下predict_proba()返回的所有值都为0时表现出有趣的特性。
总而言之,我仍在努力寻找一种方法来获得更具描述性的概率分布。
模型不是试图输出概率,它正在近似一个函数。
无论如何,您都必须对输出进行处理才能得到类似概率的值。
更新…
我发现我的错误了。在预测中,我只是忘记将像素值从0-255的uint8归一化到0-1的浮点数。我想也许这种输入会饱和,并将所有情况下的输出设置为1或0。
很高兴你弄明白了。
感谢您的另一篇精彩文章。您能否为我们指出可能有助于检测网络学习到的哪些图像块/区域与预测最相关的技术?这类似于特征重要性。
例如,是否有可能分析最后一个隐藏层以找出给定图像的哪些部分对做出十个预测之一贡献最大?
这是一个我希望将来能涵盖的领域。
嗨,Jason,我尝试在我的Windows 8.1机器上运行这个代码教程,安装了theano 0.9和keras 2.0.5,使用了Geforce 940M GPU,但我的模型基线错误率最差,几乎达到90%。请帮忙
考虑多运行几次示例。
先生,我试过了,但它没有帮助我。请建议。
Jason,我正在尝试使用 Kaggle 竞赛中的相同数据集来重现这些结果,但我在 CNN 部分遇到了一个奇怪的问题。
当我使用常规神经网络模型时,它在几个 epoch 内达到了接近 99% 的训练集准确率。然而,当我使用本文中的 CNN 代码时,第一个 epoch 的准确率约为 53-54%,并且在训练集上仅缓慢地爬升到最高约 94% 的准确率。
我使用的是 42000 张图像而不是 60000 张图像的训练集,但我无法想象这会对模型的性能产生如此大的影响。有什么其他可能出错的地方吗?
(顺便说一下,我两种神经网络都使用 tensorflow 后端)
仔细检查您是否已对输入数据进行了归一化。
这似乎已经解决了问题。现在我在第一个 epoch 就有了 90% 的准确率。在接下来的操作中,我想我可能在之前已经对像素值进行了归一化之后,又不小心再次将它们除以了 255。
很高兴听到您解决了问题,Stefan。
谢谢你的帮助。您知道有什么文章解释不同类型的网络拓扑以及如何决定使用哪种网络吗?这都是试错法吗,还是有某些类型的网络适合不同的问题?
很好的问题。
通常,无论如何,都以 MLP 作为基线。它们可以做很多事情,并为更复杂的模型提供一个很好的起点。
将 CNN 用于具有空间输入(如图像)的问题,但也值得在文本、音频和其他模拟数据上尝试。
将 RNN 用于具有时间分量(例如随时间变化的观测值)作为输入和/或输出的问题。
这有帮助吗?
非常感谢,这很有帮助。我还想知道是否有任何标准方法可以确定特征图的大小和数量、池化层补丁以及全连接层中的神经元数量。我见过一些关于全连接层中神经元数量的经验法则,但我不确定如何在不反复运行网络的情况下决定选择哪个值。
顺便抱歉一直打扰您,我很感谢您的帮助。
据我所知没有。在这个阶段,它更多的是艺术而非科学。测试。
在为您的 2D 神经网络创建模型时,您为什么选择 32 作为滤波器输出维度?我正在自学这个过程,并对如何优化这些变量很感兴趣。
这是任意的,32 在 CNN 演示中常用。
我建议针对您的问题调整模型的超参数以获得最佳性能。
你好 Jason!你知道我为什么会收到这个错误吗?https://stackoverflow.com/questions/45479009/how-to-train-a-keras-ltsm-with-a-multidimensional-input
抱歉,我无法为您调试代码,我没有这个能力。我相信您能理解。
你好 Jason,你用 DropConnect 试过这个吗,你能告诉我如何在 MNIST 中实现 Dropconnect 吗?
抱歉,我没有在 Keras 中使用过 Drop Connect。
初始化/默认特征图从何而来?它们长什么样/检查什么?
Matt,你具体指什么?
你好,我是机器学习新手
print(model.predict_classes(x_test[1:5]))
print(y_test[1:5])
这里我想要预测 x_test 中的前五个元素,输出是
[2 1 0 4](前五个元素)
[[ 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]]
我的问题是,在上面的预测中我得到了一个 2D 数组,如果我想用数字打印出来
[2]
[1]
[0]
[4]
这听起来像是一个 Python 数组问题。
您可以将预测作为每个预测的第一个元素来访问
你好,
我看到每个人都渴望检查自己的手写图像,请按照以下步骤操作
1)打开画图工具并写下任意数字(0-9),然后将其保存为 28×28 像素的图像。
2)使用此代码进行预测
import cv2
test = cv2.imread(‘Test Image’)
test = cv2.cvtColor( test, cv2.COLOR_RGB2GRAY )
test = test.reshape(1, 1, 28, 28)
test = cv2.bitwise_not(test)
pred = model.predict_classes(test)
print(pred)
谢谢!享受神经网络吧。
感谢分享。
你好,
我试了你的代码,但是它抛出了以下错误
ValueError: 检查时出错:预期 dense_1_input 具有 2 个维度,但获得了形状为 (1, 1, 28, 28) 的数组
有什么想法吗?
你好,
我得到了同样的错误。你解决了吗?
萨利姆
你能告诉我“测试图像”应该保存在哪个位置吗?
在您的代码文件所在的同一目录中。
第三个输出打印是不是有错字?
代码是这样写的
print(“Baseline Error: %.2f%%” % (100-scores[1]*100))
而输出屏幕显示
CNN 错误:x.xx%
是的,我已经纠正了这个错字。
您好,非常感谢您提供这个程序。我已经运行了程序并训练了模型,它正在工作,那么我如何将其用于从我自己的图像输入中检测数字?
您的新图像需要与 MNIST 示例以相同的方式格式化和调整大小。
抱歉,我没有示例。
我如何从这个程序中获取训练模型?这样我就可以将模型用于我的程序,以便从图像输入中检测数字。
您可以训练模型并保存它,然后稍后在您的应用程序中加载它。这篇帖子向您展示了如何操作。
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
嗨,Jason,
感谢分享代码,我学到了很多。我还将它用于一篇学校论文(我进行了一项“实验”,其中我改变了训练集的大小并观察了准确率)。这可以吗(如果我引用它的话,当然)?
谢谢!!!
干得好!
当然可以,请引用本网站或此页面即可。
嗨,Jason,
我正在学习神经网络课程,我很欣赏您为像我这样的新手所做的工作。在那门课程中,他们提出将这个分类问题作为线性回归问题来对两个类别进行分类。这个使用 mnist 数据集的问题也是线性回归分类 10 个类别吗?
谢谢!
抱歉,我没有用于分类的线性回归示例。
你的例子不是通过线性回归来计算给定图像属于特定类别的概率吗?
上面的例子演示了一个神经网络,而不是线性回归。
嗨,Jason,
感谢如此精彩的教程!!!我非常感谢您投入时间精力编写代码和文本,并回答每个人的问题!
当我尝试按照“用于 MNIST 的简单卷积神经网络”下的代码运行时,我收到以下错误。您能帮忙吗?我正在 Jupyter Notebook 上使用 Tensorflow 1.2.1 版本。
预先感谢,
苏格拉底
________________________________________________________
AttributeError Traceback (最近一次调用)
in ()
44
45 # 构建模型
—> 46 model = baseline_model()
47
48 # 拟合模型
在 baseline_model() 中
32 # 创建模型
33 model = Sequential()
—> 34 model.add(Conv2D(32, (5, 5), input_shape=(1, 28, 28), activation=’relu’))
35 model.add(MaxPooling2D(pool_size=(2, 2)))
36 model.add(Dropout(0.2))
~\Anaconda3\envs\tensorflow-sessions\lib\site-packages\keras\models.py 中的 add(self, layer)
462 # 并创建连接当前层的节点
463 # 到我们刚刚创建的输入层。
–> 464 layer(x)
465
466 if len(layer.inbound_nodes[-1].output_tensors) != 1
~\Anaconda3\envs\tensorflow-sessions\lib\site-packages\keras\engine\topology.py 中的 __call__(self, inputs, **kwargs)
601
602 # 实际调用层,收集输出、掩码和形状。
–> 603 output = self.call(inputs, **kwargs)
604 output_mask = self.compute_mask(inputs, previous_mask)
605
~\Anaconda3\envs\tensorflow-sessions\lib\site-packages\keras\layers\convolutional.py 中的 call(self, inputs)
162 padding=self.padding,
163 data_format=self.data_format,
–> 164 dilation_rate=self.dilation_rate)
165 if self.rank == 3
166 outputs = K.conv3d(
~\Anaconda3\envs\tensorflow-sessions\lib\site-packages\keras\backend\tensorflow_backend.py 中的 conv2d(x, kernel, strides, padding, data_format, dilation_rate)
3178 raise ValueError(‘未知数据格式 ‘ + str(data_format))
3179
-> 3180 x, tf_data_format = _preprocess_conv2d_input(x, data_format)
3181
3182 padding = _preprocess_padding(padding)
~\Anaconda3\envs\tensorflow-sessions\lib\site-packages\keras\backend\tensorflow_backend.py 中的 _preprocess_conv2d_input(x, data_format)
3060 tf_data_format = ‘NHWC’
3061 if data_format == ‘channels_first’
-> 3062 if not _has_nchw_support()
3063 x = tf.transpose(x, (0, 2, 3, 1)) # NCHW -> NHWC
3064 else
~\Anaconda3\envs\tensorflow-sessions\lib\site-packages\keras\backend\tensorflow_backend.py 中的 _has_nchw_support()
268 “””
269 explicitly_on_cpu = _is_current_explicit_device(‘CPU’)
–> 270 gpus_available = len(_get_available_gpus()) > 0
271 return (not explicitly_on_cpu and gpus_available)
272
~\Anaconda3\envs\tensorflow-sessions\lib\site-packages\keras\backend\tensorflow_backend.py 中的 _get_available_gpus()
254 global _LOCAL_DEVICES
255 if _LOCAL_DEVICES is None
–> 256 _LOCAL_DEVICES = get_session().list_devices()
257 return [x.name for x in _LOCAL_DEVICES if x.device_type == ‘GPU’]
258
AttributeError: ‘Session’ 对象没有属性 ‘list_devices’
________________________________________________________
看起来是您的 TensorFlow 版本或 Keras 版本有问题。请确保您安装了最新版本。
另外,或许可以先尝试在 CPU 上运行,然后再尝试在 GPU 上运行。
感谢您的即时回复,Jason!
以下是 Keras 和 Tensorflow 的版本
Keras:2.1.1
Tensorflow:1.2.1
我也不是在 GPU 上运行它。事实上,我的机器没有 GPU。它是一台带有 Intel(R) Core(TM) i5-5200U CPU @ 2.20GHz 的 T450s 联想笔记本电脑。
我建议更新到最新版本的 Keras 2.1.2 和 TensorFlow 1.4.1。
谢谢 Jason!
彻底卸载了 Anaconda 并重新安装。然后在上面安装了 TensorFlow 和 Keras。它运行良好!!!
干得好!
嗨 Jason,我发现你的帖子信息量很大,但是我遇到了一个错误,提示“无法导入名称‘backend’”。我该如何解决呢?
也许仔细检查一下你的 Keras 版本是否是最新的?
最后,输出变量是介于 0 到 9 之间的整数。应该是 0 到 0.9。
不,这里我评论的是我们归一化之前的输出范围。
非常感谢。
请问,我有一个问题。如何使用 keras 创建我自己的自定义池化层,而不是使用传统的最大池化层?
再次感谢。
我没做过那个。也许你可以使用现有的 Keras 代码作为模板?
嗨,Jason,
我喜欢你的代码,它对我帮助很大!
我有一个问题:在您的简单 CNN 示例中,为什么您选择 Conv2D(32,(5,5),..)(我的意思是您为什么选择 32 和 5 这些数字)。还有,为什么您在第五层选择了 128 个神经元?
在您更大的 CNN 示例中,为什么您选择 Conv2D(30,..)。我搞不清楚您选择这些数字而不是其他数字(例如 31、32、33、34)的原因。
谢谢!
我做了一些尝试和错误。
我达到了
CNN 错误率:0.67%
我使用了高级 PReLU 激活而不是 relu,但不确定这是否真的有帮助,因为我不知道如何最好地初始化 alpha,所以就保持默认了。
我还会尝试使用优化器。可能会尝试比 ADAM 更高级的优化器。
干得好!
在构建基线模型时,我遇到了“值错误:检查目标时出错:预期 dense_8 具有形状 (None, 784),但得到了形状 (60000, 10) 的数组”错误。我还进行了一次热编码,但仍然遇到相同的错误。
解决方案是什么?
这真是一篇好文章,对许多从事 CNN 工作的学生很有用。
我是 Jagadeesh,目前在 AMRITA UNIVERSITY(印度)读本科 (B.Tech)。我们正在尝试使用 CNN 对产品评论进行情感分析。我的项目设计如下
步骤 1:从亚马逊收集带标签的数据集
步骤 2:使用 word2vec 工具,将文本转换为向量
步骤 3:将这些向量作为输入馈送给 CNN。
现在我们卡在将文本转换为向量这一步,word2vec 为一个单词提供了许多向量,我不知道如何从为该单词生成的 180 个向量中获取单个向量。
请好心帮助我。
我必须在 2 月 20 日之前完成这个项目。
谢谢你,先生。
我有一些关于 word2vec 的帖子可能会有所帮助,或许可以从这里开始
https://machinelearning.org.cn/develop-word-embeddings-python-gensim/
你好
我运行了简单的 CNN,但什么都没发生。我怎么才能知道代码正在运行呢?
我在 jupyter notebook 中编写了代码。
尝试从命令行运行。
尝试在 fit() 函数调用上启用详细输出。
再次问好
它奏效了,CNN 错误率为 0.93%。
我真的非常感谢您提供的有用代码。
干得好!
你好
我有一个用于波斯语手写数字的数据集,它包含 10 个文件夹,分别对应 10 个数字 (0, 1, 2, ..., 9),每个文件夹中包含 6000 个样本,每个样本都是 61*61 大小的二值图像(黑白)。
现在我如何在您的“用于 MNIST 的大型卷积神经网络”代码中加载此数据集?
数据是存储在 MNIST 图像中还是矩阵中?
再次非常感谢您的帮助。
他的教程可能会给您一些想法
https://blog.keras.org.cn/building-powerful-image-classification-models-using-very-little-data.html
你好,Jason。🙂
我已经把它降到了 0.16% 🙂 会继续调整。
感谢您的教程,它非常有用且易于理解!🙂
祝好!
干得好!
嗨,Jason,
我是神经网络新手。所以这个问题听起来可能很傻,但它确实困扰着我。
在“用于 MNIST 的简单卷积神经网络”部分,我看到您在第一个卷积层使用了 32 个 5×5 滤波器。对吗?为什么只使用 32 个滤波器?有什么数学原因吗?即使在 Tensorflow 指南网站 https://tensorflowcn.cn/tutorials/layers 上,我也发现他们使用了 32 个滤波器。如果我使用 100 个滤波器或者 10 个或 64 个呢?
我理解了本节之前的部分。也感谢您提供如此棒、易于理解的教程。
谢谢。
没有特定原因,这是试错法,32 是惯例,因为它通常能很好地适应 GPU 内存。尝试一下,看看什么适用于您的数据。
这只适用于数字吗?我如何自定义它以识别手写单词?
谢谢!
也许先将单词分割成字母?
谢谢您的快速回复.. 即使如此,我仍然对标签部分感到困惑。我们是否将单词本身标记为标签,还是只使用映射到它的整数值?
您分割的每个字母都需要映射到标签结果。
你好!
非常感谢这篇精彩的教程。
我跟着你做,但是当我尝试拟合模型时,我得到一个 InternalError: GPU sync failed。
有什么办法解决这个问题吗?
我正在使用 Keras + tensorflow 和 GPU
这听起来像是您的环境有问题。也许可以尝试在 stackoverflow 上搜索/发帖?
我最后只是卸载了 Tensorflow 并重新安装了 CPU 版本。虽然慢了一点,但没有错误了 🙂
很高兴听到这个消息,Casey!
你好。谢谢你的出色帖子。
你能告诉我 set_image_dim_ordering 的作用吗?
这行代码强制 Keras 框架在每个平台上以相同的方式工作,无论后端如何。这有助于我解释如何准备输入数据。
你好,
我是机器学习新手。首先,感谢您提供如此棒的教程。
我运行了示例代码,一切正常。有没有办法可以使用您的示例代码来使用我自己的训练和测试图像集?
谢谢
是的。您需要准备数据,确保所有图像的大小一致。
然后加载数据,并像我们处理 MNIST 示例一样使用它。
嗨,Jason,
我擅自将您的代码用于 Google Colab 的 Notebook 示例,并在其中提到了您。
如果这不符合您的意愿,请告诉我。
https://colab.research.google.com/notebook#fileId=15t4LIQdLVe4y_X1t6Mup0IZ4uO0h8mSJ
感谢这些精彩的教程!
卡洛斯
我很乐意让您玩弄代码,但我宁愿它不要被重新发布到其他地方并公开。
对于卷积模型,我认为您需要进行一些修正
1. MaxPooling2D
data_format 的默认值为“channels_last”,而您的数据已重新格式化,通道在数据维度之前……它应该是
MaxPooling2D(pool_size=(2,2), data_format=’channels_first’)
2. 拟合/评估
您有以下代码
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# 模型的最终评估
scores = model.evaluate(X_test, y_test, verbose=0)
您已经从测试中提取了验证数据。虽然测试数据未经训练,但您通常会将验证数据和测试数据解耦,例如
split = 1./6. # 在拟合期间使用训练集中的 10,000 个元素作为验证
model.fit(X_train, y_train, validation_split=split, epochs=10, batch_size=200, verbose=2)
^^^^^^^^^^^^^^^^^^^^
像以前一样评分。
感谢您的示例代码,它很有帮助。
uDude
嗨!
首先感谢您的示例,我尝试运行代码,但 python 在运行时出现错误
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype(‘float32’)
X_test = X_test.reshape(X_test.shape[0], num_pixels).astype(‘float32’)
IndexError Traceback (最近一次调用)
in ()
—-> 1 num_pixels = X_train.shape[1] * X_train.shape[2]
2 X_train = X_train.reshape(X_train.shape[0], num_pixels).astype(‘float32’)
3 X_test = X_test.reshape(X_test.shape[0], num_pixels).astype(‘float32’)
4 X_train = X_train / 255
5 X_test = X_test / 255
IndexError: 元组索引超出范围
您能确认一下您的环境是最新的并且您已按原样复制了所有代码吗?
感谢您,Jason,提供这个教程。我是神经网络新手,您的教程对我帮助很大。我得到了 0.70 的错误率,并且能够用我自己的图像进行预测,效果非常好。
干得好!
Jason,很棒的文章!我有一个简单的问题,如果你能回答我的话,我想用新的图像输入重新训练我的模型(这意味着将这个图像数组及其标签添加到我的数据集中)。
也许这篇帖子会给你一些想法
https://blog.keras.org.cn/building-powerful-image-classification-models-using-very-little-data.html
非常感谢您的回复!!!
嗨,Jason,
我是新手,非常感谢!!!这对初学者来说是一个很棒的示例,可以让他们亲自动手编写代码。
在加载图像并尝试预测输出时,我遇到了一些错误。我使用的是带有多层感知器的基线模型示例代码。
下面是我的示例代码,用于加载图像。
img_pred = cv2.imread(“C:/ProgramData/Anaconda3/mycode/PythonApplication2/PythonApplication2/1.png”, 0)
#print(img_pred)
如果 img_pred.shape != [28,28]
img2 = cv2.resize(img_pred, (28, 28))
img_pred = img2.reshape(28,28,-1);
否则
imp_pred = img_pred.reshape(28,28,-1);
img_pred = img_pred.reshape(1, 1, 28, 28)
pred = model.predict_classes(img_pred)
pred_proba = model.predict_proba(img_pred)
print(pred_proba)
我得到的错误是
ValueError: 检查时出错:预期 dense_1_input 具有 2 个维度,但获得了形状为 (1, 1, 28, 28) 的数组
任何帮助解决此问题都将不胜感激。
谢谢,
萨利姆
听到这些错误我很抱歉。
也许重塑为 [1,28,28]?
您可以在此处了解更多关于重塑数组的信息
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
我试过了,没用。
这是我的完整代码,看看这是否有助于解决问题。
import numpy
from keras.datasets import mnist
来自 keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.utils import np_utils
import cv2
# 设置随机种子以保证结果可复现
seed = 7
numpy.random.seed(seed)
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 将 28*28 图像展平为每张图像的 784 向量
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype(‘float32’)
X_test = X_test.reshape(X_test.shape[0], num_pixels).astype(‘float32′)
# 将输入从 0-255 归一化到 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot 编码输出
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
# 定义基线模型
def baseline_model()
# 创建模型
model = Sequential()
model.add(Dense(num_pixels, input_dim=num_pixels, kernel_initializer=’normal’, activation=’relu’))
model.add(Dense(num_classes, kernel_initializer=’normal’, activation=’softmax’))
# 编译模型
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
return model
# 构建模型
model = baseline_model()
# 拟合模型
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# 模型的最终评估
scores = model.evaluate(X_test, y_test, verbose=0)
print(“Baseline Error: %.2f%%” % (100-scores[1]*100))
img_pred = cv2.imread(“C:/ProgramData/Anaconda3/mycode/PythonApplication2/PythonApplication2/1.png”, 0)
#print(img_pred)
如果 img_pred.shape != [28,28]
img2 = cv2.resize(img_pred, (28, 28))
img_pred = img2.reshape(28,28,-1);
否则
imp_pred = img_pred.reshape(28,28,-1);
img_pred = img_pred.reshape(1, 28, 28)
pred = model.predict_classes(img_pred)
print(pred_proba)
pred_proba = model.predict_proba(img_pred)
print(pred_proba)
嗨,Jason,
如果我完成了模型的训练和测试,并且性能足够好,我如何识别真实图像?因为我想要识别一张图像中的字母,而我的图像与模型的矩阵大小不同。
这篇文章可能会有帮助
https://blog.keras.org.cn/building-powerful-image-classification-models-using-very-little-data.html
你好 Jason,
我可以用你的代码处理另一个数据集吗?
如果可以,
那么我需要做出什么类型的改变呢?
谢谢你
是的。更改确实取决于数据。
我尽量提供足够的上下文,以便您可以自己进行这些更改。
嗨,Jason 先生
如果我想使用 14*28 图像作为 CNN 输入,我应该在您的主简单 CNN 代码中更改哪些参数?
我只是更改了与输入大小相关的数字,我的意思是将所有 28,28 更改为 14,28,但我遇到了错误“ValueError: Error when checking target: expected dense_5 to have 2 dimensions, but got array with shape (60001, 10, 2)”。
谢谢你的帮助
您将在“input_shape”参数中指定图像大小。
感谢您撰写如此精彩的文章。只是想知道是否有类似于 MNIST 的字母数据集。由于 Tesseract OCR 在我的应用程序中工作不正常,我希望有一个类似的模型来识别手写或印刷字母。
请告诉我,
再次感谢
我相信有,但我不太了解,抱歉。
当我尝试运行 CNN 代码时,我收到了这个错误
--
ValueError 回溯 (最近一次调用)
in ()
1 #构建模型
—-> 2 model = larger_model()
3 #拟合模型
4 model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=10, batch_size=200, verbose=2)
5
在 larger_model() 中
9 model.add(Dropout(0.2))
10 model.add(Flatten())
—> 11 model.add(Dense(128, activation=’relu’))
12 model.add(Dense(50, activation=’relu’))
13 model.add(Dense(num_classes, activation=’softmax’))
~\Anaconda3\lib\site-packages\keras\models.py 中的 add(self, layer)
490 output_shapes=[self.outputs[0]._keras_shape])
491 else
–> 492 output_tensor = layer(self.outputs[0])
493 if isinstance(output_tensor, list)
494 raise TypeError(‘Sequential 模型中的所有层 ‘
~\Anaconda3\lib\site-packages\keras\engine\topology.py 中的 __call__(self, inputs, **kwargs)
590 ‘
layer.build(batch_input_shape)‘)591 if len(input_shapes) == 1
–> 592 self.build(input_shapes[0])
593 else
594 self.build(input_shapes)
~\Anaconda3\lib\site-packages\keras\layers\core.py 中的 build(self, input_shape)
840 name=’kernel’,
841 regularizer=self.kernel_regularizer,
–> 842 constraint=self.kernel_constraint)
843 if self.use_bias
844 self.bias = self.add_weight(shape=(self.units,),
~\Anaconda3\lib\site-packages\keras\legacy\interfaces.py 中的 wrapper(*args, **kwargs)
89 warnings.warn(‘更新您的
' + object_name +调用到 Keras 2 API:’ + signature, stacklevel=2)90 '
—> 91 return func(*args, **kwargs)
92 wrapper._original_function = func
93 return wrapper
~\Anaconda3\lib\site-packages\keras\engine\topology.py 中的 add_weight(self, name, shape, dtype, initializer, regularizer, trainable, constraint)
411 if dtype is None
412 dtype = K.floatx()
–> 413 weight = K.variable(initializer(shape),
414 dtype=dtype,
415 name=name,
~\Anaconda3\lib\site-packages\keras\initializers.py 中的 __call__(self, shape, dtype)
215 limit = np.sqrt(3. * scale)
216 return K.random_uniform(shape, -limit, limit,
–> 217 dtype=dtype, seed=self.seed)
218
219 def get_config(self)
~\Anaconda3\lib\site-packages\keras\backend\theano_backend.py 中的 random_uniform(shape, minval, maxval, dtype, seed)
2304 seed = np.random.randint(1, 10e6)
2305 rng = RandomStreams(seed=seed)
-> 2306 return rng.uniform(shape, low=minval, high=maxval, dtype=dtype)
2307
2308
~\Anaconda3\lib\site-packages\theano\sandbox\rng_mrg.py 中的 uniform(self, size, low, high, ndim, dtype, nstreams, **kwargs)
860 raise ValueError(
861 “指定大小包含维度值 862 size)
863
864 else
ValueError: (‘指定大小包含维度值 <= 0', (-150, 128))
听到这个消息我很难过,这里有一些想法
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好
请问您能帮我找到导致您的简单 CNN 识别错误的错误分类样本吗?
我想确切地知道哪些类别在学习和分类过程中导致了最大的错误。
非常感谢
混淆矩阵将帮助您了解模型所犯错误的类型
https://machinelearning.org.cn/confusion-matrix-machine-learning/
你好,Jason Brownlee 博士
我希望提高识别准确率?
我使用你的简单 CNN 处理我的数据,得到了 2.64% 的错误率。
现在,通过添加层是否有可能提高我的准确率?
你还有什么建议可以实现这个目标?
是否需要对图像进行预处理?
感谢你对混淆矩阵的指导,我已经成功运行并得到了表格。
现在我想看看那些被错误分类的图像,我该怎么做?
这里有一些想法可以尝试
https://machinelearning.org.cn/improve-deep-learning-performance/
嗨,Jason!
我想尝试一些我自己捕获的图像。我的图像有 3 位数字。
有没有办法知道 CNN 预测的结果?我想知道结果是否可以与原始图像数字进行比较?
您的图像必须与训练数据以相同的方式准备。
网络的输出是类别,也是图像上表示的整数。
我想训练脑部图像,并且需要对其进行分割……
先生,请给我一些博客指导。
抱歉,我没有处理大脑图像或分割图像的示例。
我尝试过一个带有单层隐藏层的简单神经网络。我反复运行脚本时得到了不同的准确率。原因是什么?
这是网络的一个特性,您可以在这里了解更多信息
https://machinelearning.org.cn/randomness-in-machine-learning/
InvalidArgumentError 回溯(最近一次调用在最后)
~\Anaconda3\lib\site-packages\tensorflow\python\framework\common_shapes.py 中的 _call_cpp_shape_fn_impl(op, input_tensors_needed, input_tensors_as_shapes_needed, require_shape_fn)
685 graph_def_version, node_def_str, input_shapes, input_tensors,
–> 686 input_tensors_as_shapes, status)
687 except errors.InvalidArgumentError as err
~\Anaconda3\lib\site-packages\tensorflow\python\framework\errors_impl.py 中的 __exit__(self, type_arg, value_arg, traceback_arg)
472 compat.as_text(c_api.TF_Message(self.status.status)),
–> 473 c_api.TF_GetCode(self.status.status))
474 # 从内存中删除底层状态对象,否则它会一直存在
InvalidArgumentError: ‘conv2d_1/convolution’(op: ‘Conv2D’)因从 1 中减去 5 导致负维度大小,输入形状:[?,1,28,28], [5,5,28,32]。
处理上述异常时,发生了另一个异常
ValueError 回溯 (最近一次调用)
in ()
1 # 构建模型
—-> 2 model = baseline_model()
3 # 拟合模型
4 model.fit(X_train, Y_train, validation_data=(X_eval, Y_eval), epochs=10, batch_size=200, verbose=2)
5 # 模型的最终评估
在 baseline_model() 中
2
3 model = Sequential()
—-> 4 model.add(Conv2D(32, (5, 5), input_shape=(1, 28, 28), activation=’relu’))
5 model.add(MaxPooling2D(pool_size=(2, 2)))
6 model.add(Dropout(0.2))
~\Anaconda3\lib\site-packages\keras\models.py 中的 add(self, layer)
465 # 并创建连接当前层的节点
466 # 到我们刚刚创建的输入层。
–> 467 layer(x)
468
469 if len(layer._inbound_nodes[-1].output_tensors) != 1
~\Anaconda3\lib\site-packages\keras\engine\topology.py 中的 __call__(self, inputs, **kwargs)
617
618 # 实际调用层,收集输出、掩码和形状。
–> 619 output = self.call(inputs, **kwargs)
620 output_mask = self.compute_mask(inputs, previous_mask)
621
~\Anaconda3\lib\site-packages\keras\layers\convolutional.py 中的 call(self, inputs)
166 padding=self.padding,
167 data_format=self.data_format,
–>> 168 dilation_rate=self.dilation_rate)
169 if self.rank == 3
170 outputs = K.conv3d(
~\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py 中的 conv2d(x, kernel, strides, padding, data_format, dilation_rate)
3333 strides=strides,
3334 padding=padding,
-> 3335 data_format=tf_data_format)
3336
3337 if data_format == ‘channels_first’ and tf_data_format == ‘NHWC’
~\Anaconda3\lib\site-packages\tensorflow\python\ops\nn_ops.py 中的 convolution(input, filter, padding, strides, dilation_rate, name, data_format)
752 dilation_rate=dilation_rate,
753 name=name, data_format=data_format)
–>> 754 return op(input, filter)
755
756
~\Anaconda3\lib\site-packages\tensorflow\python\ops\nn_ops.py 中的 __call__(self, inp, filter)
836
837 def __call__(self, inp, filter): # pylint: disable=redefined-builtin
–>> 838 return self.conv_op(inp, filter)
839
840
~\Anaconda3\lib\site-packages\tensorflow\python\ops\nn_ops.py 中的 __call__(self, inp, filter)
500
501 def __call__(self, inp, filter): # pylint: disable=redefined-builtin
–>> 502 return self.call(inp, filter)
503
504
~\Anaconda3\lib\site-packages\tensorflow\python\ops\nn_ops.py 中的 __call__(self, inp, filter)
188 padding=self.padding,
189 data_format=self.data_format,
–>> 190 name=self.name)
191
192
~\Anaconda3\lib\site-packages\tensorflow\python\ops\gen_nn_ops.py 中的 conv2d(input, filter, strides, padding, use_cudnn_on_gpu, data_format, dilations, name)
723 “Conv2D”, input=input, filter=filter, strides=strides,
724 padding=padding, use_cudnn_on_gpu=use_cudnn_on_gpu,
–>> 725 data_format=data_format, dilations=dilations, name=name)
726 _result = _op.outputs[:]
727 _inputs_flat = _op.inputs
~\Anaconda3\lib\site-packages\tensorflow\python\framework\op_def_library.py 中的 _apply_op_helper(self, op_type_name, name, **keywords)
785 op = g.create_op(op_type_name, inputs, output_types, name=scope,
786 input_types=input_types, attrs=attr_protos,
–>> 787 op_def=op_def)
788 return output_structure, op_def.is_stateful, op
789
~\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py 中的 create_op(self, op_type, inputs, dtypes, input_types, name, attrs, op_def, compute_shapes, compute_device)
3160 op_def=op_def)
3161 self._create_op_helper(ret, compute_shapes=compute_shapes,
->> 3162 compute_device=compute_device)
3163 return ret
3164
~\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py 中的 _create_op_helper(self, op, compute_shapes, compute_device)
3206 # compute_shapes 参数。
3207 if op._c_op or compute_shapes: # pylint: disable=protected-access
->> 3208 set_shapes_for_outputs(op)
3209 # TODO(b/XXXX): 在移除 _USE_C_API 标志后,将其移动到 Operation.__init__。
3210 self._add_op(op)
~\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py 中的 set_shapes_for_outputs(op)
2425 return _set_shapes_for_outputs_c_api(op)
2426 else
->> 2427 return _set_shapes_for_outputs(op)
2428
2429
~\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py 中的 _set_shapes_for_outputs(op)
2398 shape_func = _call_cpp_shape_fn_and_require_op
2399
->> 2400 shapes = shape_func(op)
2401 if shapes is None
2402 raise RuntimeError(
~\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py 中的 call_with_requiring(op)
2328
2329 def call_with_requiring(op)
->> 2330 return call_cpp_shape_fn(op, require_shape_fn=True)
2331
2332 _call_cpp_shape_fn_and_require_op = call_with_requiring
~\Anaconda3\lib\site-packages\tensorflow\python\framework\common_shapes.py 中的 call_cpp_shape_fn(op, require_shape_fn)
625 res = _call_cpp_shape_fn_impl(op, input_tensors_needed,
626 input_tensors_as_shapes_needed,
–>> 627 require_shape_fn)
628 if not isinstance(res, dict)
629 # 处理 _call_cpp_shape_fn_impl 调用 unknown_shape(op) 的情况。
~\Anaconda3\lib\site-packages\tensorflow\python\framework\common_shapes.py 中的 _call_cpp_shape_fn_impl(op, input_tensors_needed, input_tensors_as_shapes_needed, require_shape_fn)
689 missing_shape_fn = True
690 else
–>> 691 raise ValueError(err.message)
692
693 if missing_shape_fn
ValueError: ‘conv2d_1/convolution’(op: ‘Conv2D’)因从 1 中减去 5 导致负维度大小,输入形状:[?,1,28,28], [5,5,28,32]。
也许确认您已安装最新版本的 Keras、TensorFlow,并且已从教程中复制了所有代码?
这可以解决问题
from keras import backend as K
K.set_image_dim_ordering(‘th’)
🙂
是的,这强制代码使用通道优先顺序。
你好,Brownlee 先生
首先,我再次感谢您提供的上述代码。
我已将其应用于我的数据库(28*28 图像),效果良好。
现在我有一个问题,
如果我想用从数字图像中提取的 HOG 特征来馈送 CNN,我该怎么做?
我的意思是,我想使用每个图像的 HOG 特征,而不是将 28*28 图像作为 CNN 的输入。
感谢您的帮助
也许可以构建一个多头模型,输入包含一个 CNN 输入和一个向量输入。
这篇文章可能会给你一些想法:
https://machinelearning.org.cn/keras-functional-api-deep-learning/
我不清楚你为什么把那部分注释掉,像这样:
# 重塑为 [样本][像素][宽度][高度]
这使得问题的形状从 (60000, 28, 28) 变成了 (60000, 1, 28, 28)。
但是因为像素维度永远是 1,这实际上对你有什么用?我知道文章说“重塑它以使其适合用于训练 CNN。” 但许多其他使用 MNIST 的例子并没有这样做。
那么,重塑为什么会使其更适合而不是更不适合呢?
CNN 期望有一个或多个通道。对于黑白图像,这是一个通道;对于 RGB 图像,这是三个通道。
我们必须满足模型的期望。
嗨,Jason,
非常感谢如此精彩的教程!!
我有几个问题:
1. 对于包含手写文本行的图像,CNN 更好还是 RNN 更好(我不知道文本是否属于序列预测)?
2. 如何训练模型以识别包含一系列手写文本的图像?我应该用所有可能的类别和标签进行训练吗?
3. 我需要将文本分割成单个字符再进行评估吗?如果需要,请提供分割的参考资料。
谢谢
通常,CNN 最适合图像数据。LSTM 可以帮助对图像序列进行建模。
也许可以从清晰地定义你的问题开始。
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
我相信有很多方法可以对你的问题进行建模,也许可以探索几种方法,看看哪种最适合你的特定数据集。还要考虑你的问题类型在文献中流行的哪些方法。
你好
我的数据库包含向量,每个向量有 144 个元素。(1, 144)。
我想对这些向量进行分类。(CNN 的输入是向量)
你能给我展示一下如何编写代码吗?
我真的很需要它。
非常感谢
当然,你具体遇到了什么问题?
我的问题是:
1. 如何将我的数据库保存在我的系统中,以便可能对 CNN 输入有用?(所有向量都应该保存在一个矩阵中吗?例如,我有 10 个类别,每个类别有 6000 个样本,每个样本由一个 144 个元素的向量表示,如何保存这些向量以及以什么格式保存?)(我用 matlab2017 从图像中提取特征向量,然后我想将它们用作 Keras (jupyter notebook) 中 CNN 的输入,用于识别过程)
2. 在一个简单的 CNN 中,输入是图像,现在我应该如何修改 CNN 代码以读取我的向量而不是图像作为输入?
我的意思是,在您上面代码的“输入加载”和“独热编码输出”部分,需要更改哪些函数或代码?
非常感谢您的帮助
Keras 期望数字向量作为输入。您可以按照您希望的任何方式保存数据,然后加载它并将其转换为 NumPy 数字数组。
CNN 的输入是向量,它们可以是图像,也可以不是。搜索博客,我展示了如何将 CNN 用于许多其他情况,例如文本和时间序列。
你好 Jason,你能为你的简单 CNN MNIST 画一个架构图吗?
谢谢你
当然,您可以使用 plot_model() 函数来绘制您的架构。您可以在这里了解更多:
https://machinelearning.org.cn/visualize-deep-learning-neural-network-model-keras/
亲爱的 Jason,
首先,我要感谢您精彩的数据科学教程。它确实是一个真正的学习指南。
其次,我在代码实现上遇到了一个问题。您能帮忙看看并给出解决方案吗?
错误报告
在多层感知器基线模型示例中,我在下面这行代码处遇到了以下错误:
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=128, verbose=2)
错误
ValueError: Error when checking target: expected dense_12 to have 2 dimensions, but got array with shape (60000, 10, 2, 2, 2, 2, 2, 2)
您能否告诉我接下来该如何处理?
看起来你的数据形状和模型期望的不同。
您是深度学习界的杰森·伯恩!文章精彩,易读易懂,最令人惊叹的是您几乎回复了所有问题,回复率似乎接近 99%,甚至包括重复的问题。
很抱歉多次发帖,但我无法决定确切发在哪里。
JB,我目前专注于一个用例,我需要阅读此链接上的图纸:https://imgur.com/a/Mg8YrgE
并且需要通过深度学习和图像处理完成以下任务:
1) 读取所有非常清晰的文本,特别是像 8-N-120XXX-A01-NO 这样的行代码。我尝试了带有 LSTM 的 Tesseract 4.0,它可以识别所有文本,但它是最好的 OCR 吗?或者您建议使用其他方法?
2) 计算图像中文本的位置。这可以用 Tesseract 实现吗?
3) 通过一个已经训练好的 CNN 模型检测所有符号,无论是大是小,并通过边界框获取它们的位置。
请随意回复您能回答的任何问题,并请指导我获取有用的资源以实现我的目标。非常感谢,请继续发布深度学习的新趋势和有用信息。
谢谢。
你具体遇到了什么问题?例如,你卡在哪里了?
感谢您的回复,Jason。我卡在了:
1) Tesseract 几乎能给我图像中的所有文本,但我也需要文本位置。
2) 检测图像中的符号及其位置,有什么好的方法吗?纯图像处理还是 CNN?
谢谢
我预计需要大量的原型开发。我也预计需要结合计算机视觉方法和 CNN。
你好 Jason,你说的“大量原型设计”是什么意思?你是说迭代试错法吗?你能具体说明哪些计算机视觉方法会有用吗?
想象一下,在一份签名文件上,你必须检测手写签名及其在文件上的位置。你会如何处理?
非常感谢您的回复。
我的意思是尝试不同的方法,看看哪种有效。
我无法指导你最好的方法。应用机器学习是关于发现什么最有效,没有人知道,你无法被告知。
我可以概述我可能如何解决这个问题,但我没有免费/任何咨询的能力,抱歉。
Jason,很棒的帖子!谢谢你。
正如您在帖子中提到的:“您有很多机会来调整和改进此模型。”
如果您能建议哪些参数最值得推荐(如果不是全部)进行调整,以及可能的调整方法,那将非常棒。应该使用网格搜索、随机搜索还是贝叶斯优化来调整呢?如果您能对此有所阐述,那就太好了。
正则化方法将是一个很好的起点。
更多想法在这里
https://machinelearning.org.cn/improve-deep-learning-performance/
为什么我会收到以下错误??
使用 TensorFlow 后端。
在 60000 个样本上训练,在 10000 个样本上验证
纪元 1/1
2018-11-20 01:11:49.591336: I tensorflow/core/platform/cpu_feature_guard.cc:141] 您的 CPU 支持此 TensorFlow 二进制文件未编译使用的指令:AVX2 FMA
– 6s – 损失:0.2783 – 准确率:0.9211 – 验证损失:0.1408 – 验证准确率:0.9575
基线错误:4.25%
回溯(最近一次调用)
文件“cnn2clean.py”,第 91 行,在
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=1, batch_size=200)
文件“/root/anaconda3/lib/python3.6/site-packages/keras/engine/training.py”,第 952 行,在 fit
batch_size=batch_size)
文件“/root/anaconda3/lib/python3.6/site-packages/keras/engine/training.py”,第 789 行,在 _standardize_user_data
exception_prefix=’target’)
文件“/root/anaconda3/lib/python3.6/site-packages/keras/engine/training_utils.py”,第 128 行,在 standardize_input_data
‘形状为 ’ + str(data_shape))
ValueError: 检查目标时出错:预期 dense_5 具有 2 个维度,但得到的数组形状为 (60000, 10, 2)
nkp-Inspiron-15-3567 pca #
看起来您的数据与您的脚本不匹配。您可以更改数据或更改模型。
你好,布朗利先生
我关于简单 CNN 有 2 个问题:
1. 如果我想知道训练阶段和评估阶段各需要多长时间?我该如何实现?您能教我如何修改上面的代码以获取我提到的时间吗?
2. 如果我想在每个卷积层之后查看输出图像,我该如何实现?我的意思是,我想知道一个样本图像在经过卷积层过滤器处理后会发生什么。我如何将卷积层的输出显示为图像?
如果您能为这些目的提供 Keras 代码,我将不胜感激。
不,模型收敛具有挑战性。我们无法保证结果或所需时间。
您可以绘制中间表示,抱歉,我没有示例。
萨拉姆(祝你平安)杰森。
我是沙赫巴兹
你是我的机器学习老师,但我想问一下,这是一个完整的 OCR 吗,还是还需要进一步的工作?我可以在我的毕业设计中使用它吗?请教我如何为大学毕业设计开发我的 OCR 系统。
我将非常感谢您的好意……
抱歉,这是我唯一关于这个主题的例子。
我的笔记本电脑有问题。请解决它。
回溯(最近一次调用)
文件 "C:/python/python37/testpy6.py", 第 17 行, 在
(x_train, y_train), (x_test, y_test) = mnist.load_data()
文件 "C:\python\python37\lib\site-packages\keras\datasets\mnist.py", 第 23 行, 在 load_data
file_hash=’8a61469f7ea1b51cbae51d4f78837e45′)
文件 "C:\python\python37\lib\site-packages\keras\utils\data_utils.py", 第 222 行, 在 get_file
urlretrieve(origin, fpath, dl_progress)
文件 "C:\python\python37\lib\urllib\request.py", 第 277 行, 在 urlretrieve
block = fp.read(bs)
文件 "C:\python\python37\lib\http\client.py", 第 449 行, 在 read
n = self.readinto(b)
文件 "C:\python\python37\lib\http\client.py", 第 493 行, 在 readinto
n = self.fp.readinto(b)
文件 "C:\python\python37\lib\socket.py", 第 586 行, 在 readinto
return self._sock.recv_into(b)
文件 "C:\python\python37\lib\ssl.py", 第 1009 行, 在 recv_into
return self.read(nbytes, buffer)
文件 "C:\python\python37\lib\ssl.py", 第 871 行, 在 read
return self._sslobj.read(len, buffer)
文件 "C:\python\python37\lib\ssl.py", 第 631 行, 在 read
v = self._sslobj.read(len, buffer)
ConnectionResetError: [WinError 10054] 现有连接被远程主机强制关闭
>>>
抱歉,我没有遇到过这个问题,也许可以尝试在 Stack Overflow 上提问?
请告诉我解决方案……如何将此模型应用于图像或视频(API)?
抱歉,我没有关于处理视频数据的教程。
# 用于根据训练好的模型预测本地存储图像的代码
# 我的本地图像已经是 28 x 28
import numpy as np
from PIL import Image
from keras.preprocessing import image
img = image.load_img('文件路径包含完整文件名')# , target_size=(32,32))
img = image.img_to_array(img)
img = img.reshape((1,) + img.shape)
#img = img/255
img = img.reshape(-1,784)
img_class=model.predict_classes(img)
prediction = img_class[0]
classname = img_class[0]
print(“Class: “,classname)
干得好!
您好,很棒的教程!
我有几个问题:
1) 您认为这个教程还算新颖吗,还是最近几年有什么更好的新东西?
2) 在更大的模型中,每个 Conv2D 和全连接层之后的输出维度是多少?
谢谢你
我认为这个模型可以改进。
您可以通过查看 model.summary() 的输出来获取所有层的输出维度。
非常感谢您的解释
我想问你,如何对普通图像进行操作
也许从这里开始
https://machinelearning.org.cn/object-recognition-convolutional-neural-networks-keras-deep-learning-library/
感谢您的教程。
我是神经网络和框架的初学者。我想问一下,在这个例子中,权重是如何初始化的?以及这个模型是否通过我们在 model.fit 中决定的 epoch 数量进行训练,我是否可以修改它,使模型重复直到满足某个条件?
权重用小的随机值初始化。
是的,您根据指定的训练周期数进行拟合。
谢谢 Jason:) 这篇文章对于理解 CNN 非常有帮助。
我该如何显示结果?
这篇帖子只看到了分数……我希望看到图像。
谢谢。
你说的显示结果具体是什么意思?
如果你想实现一个真正的数字识别应用程序,你必须首先检查它是否是一个数字,然后你可以使用这个解决方案来查看它是什么数字(或者颠倒顺序)。这个一般问题更难。所以这里解决的问题是:“当你知道它是一个数字时,它是什么数字”。一个不检查输入的应用程序是不好的……
试试上面的链接 http://myselph.de/neuralNet.html,画一个 X 字符,你可能会得到预测 = 8。画一个 H,你会得到 4。
我在哪里可以找到更一般问题的解决方案?
你也可以尝试我的应用程序 gubboit.se/digitapp。我打算解决更一般的问题。
谢谢。
你好,杰森
感谢您的教程,它对初学者非常有帮助。
我想知道如何以数组形式保存每一层(隐藏层、输出层)的输出?
我尝试了 model.layers[i].output,但它只给我 Tensor(“dense_1/Relu:0”, shape=(?, 128), dtype=float32) 的结果
通常,您保存整个模型,而不是每一层。
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
谢谢你的快速回复,我会努力学习的。
非常非常感谢,
不客气。
嗨,Jason,
我得到了 0.80 的错误率。谢谢您的教程!!
您能指导我如何在自己的手写字符数据集上训练这个模型吗?
谢谢 🙂
是的,首先收集数据,然后加载它,接着对其进行缩放并输入到模型中。
您可以在这里看到每个步骤的示例。
https://machinelearning.org.cn/start-here/#dlfcv
嗨 Jason,感谢您的教程!我这个周末刚开始玩机器学习,它帮了我大忙!我制作了一个 tkinter 画布,可以自由绘制数字,然后将其输入模型进行预测。起初我感到很沮丧,因为结果与 CNN 模型训练后给出的 0.75% 错误率相去甚远。有些数字几乎从未被正确预测!
直到我阅读了上面提到的 JavaScript 实现网页链接,我才意识到预处理的重要性。在将图像居中并重新缩放后,错误率变得可以忽略不计,即使是绘制得很糟糕的数字也能正确识别!
干得好,听起来是个有趣的项目扩展!
嗨,Jason,
感谢您的教程,我想知道我是否可以在我正在构建的项目中使用这段代码?
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-i-use-your-code-in-my-own-project
嗨,Jason,
我是机器学习新手
我想运行这段代码,但我不知道它需要什么环境设置。
您能帮我吗?
是的,请按照此教程设置您的环境。
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
你好,
感谢这个好的例子…
但是它只识别单个数字。
如果我想检测
123 X 435
234 X 543
987 X 453
这种手写信息一行一行地,我该如何实现?提前感谢
一种方法可能是先将输入分割成数字,然后对每个数字进行分类。
你能提供相关的教程吗?
谢谢你的建议,希望能将来实现。
但是分段真的有效吗?像我提到的一样逐行获取数字?这可能吗,或者有没有其他使用深度学习(Keras)的完美方法?
是的,它有效。抱歉,我没有关于这个主题的教程供您参考。
先生,请解释一下我们如何在我们的应用程序图像上应用已经训练好的模型。
您可以对新图像调用 model.predict()。
这会有帮助
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
先生,为了这段代码,我需要 Streamlit 画布
我还有一个疑问,就是隐藏层是否已经包含在内了
“Streamlit 画布”是什么?
这里如何提供自己的数据集?
这也许能帮助您加载数据集。
https://machinelearning.org.cn/how-to-load-convert-and-save-images-with-the-keras-api/
当我运行 build_model 函数时遇到了一个错误。
但是消息没有显示任何错误的行?
# 使用对数损失和 ADAM 梯度下降构建模型函数
def baseline_model()
# 创建模型
model = Sequential()
model.add(Conv2D(32, (5, 5), # 滤波器和核
input_shape=(1, 28, 28),
activation='relu'))
model.add(MaxPooling2D())
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
—————————————————————————
InvalidArgumentError 回溯(最近一次调用在最后)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/ops.py in _create_c_op(graph, node_def, inputs, control_inputs, op_def)
1879 尝试
-> 1880 c_op = pywrap_tf_session.TF_FinishOperation(op_desc)
1881 except errors.InvalidArgumentError as e
InvalidArgumentError: 由于从 1 中减去 5 导致维度大小为负,原因在于 ‘{{node conv2d_4/Conv2D}} = Conv2D[T=DT_FLOAT, data_format=”NHWC”, dilations=[1, 1, 1, 1], explicit_paddings=[], padding=”VALID”, strides=[1, 1, 1, 1], use_cudnn_on_gpu=true](Placeholder, conv2d_4/Conv2D/ReadVariableOp)’,输入形状为:[?,1,28,28], [5,5,28,32]。
处理上述异常时,发生了另一个异常
ValueError 回溯 (最近一次调用)
18 帧
in ()
1 # 运行模型函数
—-> 2 model = baseline_model()
3
4 # 通过 fit 函数训练模型
5 model.fit(X_train, y_train,
在 baseline_model() 中
5 model.add(Conv2D(32, (5, 5), # 滤波器和核
6 input_shape=(1, 28, 28),
—-> 7 activation='relu'))
8 model.add(MaxPooling2D())
9 model.add(Dropout(0.2))
/usr/local/lib/python3.7/dist-packages/tensorflow/python/training/tracking/base.py in _method_wrapper(self, *args, **kwargs)
528 self._self_setattr_tracking = False # pylint: disable=protected-access
529 尝试
-> 530 结果 = 方法(self, *args, **kwargs)
531 最后
532 self._self_setattr_tracking = previous_value # pylint: disable=protected-access
/usr/local/lib/python3.7/dist-packages/keras/engine/sequential.py in add(self, layer)
200 # 并创建连接当前层
201 # 到我们刚刚创建的输入层的节点。
-> 202 layer(x)
203 set_inputs = True
204
/usr/local/lib/python3.7/dist-packages/keras/engine/base_layer.py in __call__(self, *args, **kwargs)
975 如果 _in_functional_construction_mode(self, inputs, args, kwargs, input_list)
976 返回 self._functional_construction_call(inputs, args, kwargs,
-> 977 input_list)
978
979 # 维护关于 `Layer.call` 堆栈的信息。
/usr/local/lib/python3.7/dist-packages/keras/engine/base_layer.py in _functional_construction_call(self, inputs, args, kwargs, input_list)
1113 # 检查层构建后设置的输入假设,例如输入形状。
1114 outputs = self._keras_tensor_symbolic_call(
-> 1115 inputs, input_masks, args, kwargs)
1116
1117 如果 outputs 为 None
/usr/local/lib/python3.7/dist-packages/keras/engine/base_layer.py in _keras_tensor_symbolic_call(self, inputs, input_masks, args, kwargs)
846 返回 tf.nest.map_structure(keras_tensor.KerasTensor, output_signature)
847 否则
-> 848 返回 self._infer_output_signature(inputs, args, kwargs, input_masks)
849
850 def _infer_output_signature(self, inputs, args, kwargs, input_masks)
/usr/local/lib/python3.7/dist-packages/keras/engine/base_layer.py in _infer_output_signature(self, inputs, args, kwargs, input_masks)
886 self._maybe_build(inputs)
887 inputs = self._maybe_cast_inputs(inputs)
-> 888 outputs = call_fn(inputs, *args, **kwargs)
889
890 self._handle_activity_regularization(inputs, outputs)
/usr/local/lib/python3.7/dist-packages/keras/layers/convolutional.py in call(self, inputs)
247 inputs = tf.pad(inputs, self._compute_causal_padding(inputs))
248
-> 249 outputs = self._convolution_op(inputs, self.kernel)
250
251 如果 self.use_bias
/usr/local/lib/python3.7/dist-packages/tensorflow/python/util/dispatch.py in wrapper(*args, **kwargs)
204 “””调用目标,如果出现 TypeError 则回退到调度器。”””
205 尝试
-> 206 返回目标(*args, **kwargs)
207 except (TypeError, ValueError)
208 # 注意:convert_to_eager_tensor 目前会引发 ValueError,而不是
/usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/nn_ops.py in convolution_v2(input, filters, strides, padding, data_format, dilations, name)
1136 data_format=data_format,
1137 dilations=dilations,
-> 1138 name=name)
1139
1140
/usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/nn_ops.py in convolution_internal(input, filters, strides, padding, data_format, dilations, name, call_from_convolution, num_spatial_dims)
1266 data_format=data_format,
1267 dilations=dilations,
-> 1268 name=name)
1269 否则
1270 如果 channel_index == 1
/usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/nn_ops.py in _conv2d_expanded_batch(input, filters, strides, padding, data_format, dilations, name)
2720 data_format=data_format,
2721 dilations=dilations,
-> 2722 name=name)
2723 返回 squeeze_batch_dims(
2724 input,
/usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/gen_nn_ops.py in conv2d(input, filter, strides, padding, use_cudnn_on_gpu, explicit_paddings, data_format, dilations, name)
971 padding=padding, use_cudnn_on_gpu=use_cudnn_on_gpu,
972 explicit_paddings=explicit_paddings,
-> 973 data_format=data_format, dilations=dilations, name=name)
974 _result = _outputs[:]
975 如果 _execute.must_record_gradient()
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/op_def_library.py in _apply_op_helper(op_type_name, name, **keywords)
748 op = g._create_op_internal(op_type_name, inputs, dtypes=None,
749 name=scope, input_types=input_types,
-> 750 attrs=attr_protos, op_def=op_def)
751
752 # `outputs` 作为单独的返回值返回,以便输出
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/func_graph.py in _create_op_internal(self, op_type, inputs, dtypes, input_types, name, attrs, op_def, compute_device)
599 return super(FuncGraph, self)._create_op_internal( # pylint: disable=protected-access
600 op_type, captured_inputs, dtypes, input_types, name, attrs, op_def,
-> 601 compute_device)
602
603 def capture(self, tensor, name=None, shape=None)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/ops.py in _create_op_internal(self, op_type, inputs, dtypes, input_types, name, attrs, op_def, compute_device)
3567 input_types=input_types,
3568 original_op=self._default_original_op,
-> 3569 op_def=op_def)
3570 self._create_op_helper(ret, compute_device=compute_device)
3571 return ret
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/ops.py in __init__(self, node_def, g, inputs, output_types, control_inputs, input_types, original_op, op_def)
2040 op_def = self._graph._get_op_def(node_def.op)
2041 self._c_op = _create_c_op(self._graph, node_def, inputs,
-> 2042 control_input_ops, op_def)
2043 name = compat.as_str(node_def.name)
2044
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/ops.py in _create_c_op(graph, node_def, inputs, control_inputs, op_def)
1881 except errors.InvalidArgumentError as e
1882 # 为向后兼容性转换为 ValueError。
-> 1883 raise ValueError(str(e))
1884
1885 return c_op
ValueError: Negative dimension size caused by subtracting 5 from 1 for ‘{{node conv2d_4/Conv2D}} = Conv2D[T=DT_FLOAT, data_format=”NHWC”, dilations=[1, 1, 1, 1], explicit_paddings=[], padding=”VALID”, strides=[1, 1, 1, 1], use_cudnn_on_gpu=true](Placeholder, conv2d_4/Conv2D/ReadVariableOp)’ with input shapes: [?,1,28,28], [5,5,28,32]。
代码看起来没问题,但似乎你的输入形状可能是原因。
输入形状怎么了?
这是我加载数据时的代码:
——————————————————————————————————————–
# 加载数字数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
——————————————————————————————————————–
然后我进行转换,我一直按照您的代码操作:
——————————————————————————————————————–
# 将数据重塑为 [samples][width][heights][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)).astype('float32')
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)).astype('float32')
——————————————————————————————————————–
然后我将数字数据归一化为 0-1:
——————————————————————————————————————–
# 将输入归一化从 0-255 到 0-1
X_train = X_train / 255
X_test = X_test / 255
——————————————————————————————————————–
然后我对每个输出进行独热编码:
——————————————————————————————————————–
# 对每个输出标签进行独热编码
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
——————————————————————————————————————–
这是我运行 build_model 函数时的代码:
——————————————————————————————————————–
# 运行模型函数
model = baseline_model()
# 通过 fit 函数训练模型
model.fit(X_train, y_train,
validation_data = (X_test, y_test),
epochs=10, batch_size= 200, verbose=2)
——————————————————————————————————————–
抱歉,如果我在模型构建阶段之前的代码中犯了错误,我可能没有意识到,所以如果我错了,你能纠正我吗?
我太忙了,无法为每个人调试代码。我的建议是,直接运行代码,看看是否出现任何错误。通常,模型中的错误会在您开始训练时立即导致一些错误。
嗨
基线卷积模型函数定义中似乎有一个错误
你在卷积层中定义的输入形状是 1,28,28,但你在下一节中使用了 28,28,1,并且你使用了通道在后的布局,但写成了 [像素][宽度][高度]
你说的没错。已更正。