在数据科学项目中,您收集的数据通常不是您想要的形状。通常,您需要创建派生特征、将数据子集聚合成摘要形式,或者根据某些复杂逻辑选择部分数据。这不是一个假设情况。无论项目大小,您在第一步获得的数据很可能远非理想。
作为一名数据科学家,您必须熟练地将数据格式化为正确的形状,以便后续步骤更容易。在下文中,您将学习如何在 Pandas 中对数据集进行切片和切块,以及将它们重新组装成截然不同的形式,以使有用数据更加突出,从而使分析更容易。
让我们开始吧。

协调数据:分段、拼接、透视和合并的交响曲
图片由 Samuel Sianipar 提供。保留部分权利。
概述
这篇文章分为两部分:
- 分割和连接:用 Pandas 编排
- 透视和合并:与 Pandas 共舞
分割和连接:用 Pandas 编排
您可能会提出一个有趣的问题:房产建造年份如何影响其价格?为了调查这一点,您可以将数据集按“销售价格”分为四个四分位数——低、中、高和高级——并分析这些细分市场中的建造年份。这种系统地划分数据集不仅为集中分析铺平了道路,而且还揭示了在集体审查中可能被隐藏的趋势。
细分策略:“销售价格”的四分位数
让我们首先创建一个新列,将属性的“销售价格”整齐地分类到您定义的价格类别中
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 导入 Pandas 库 import pandas as pd # 加载数据集 Ames = pd.read_csv('Ames.csv') # 定义四分位数 quantiles = Ames['SalePrice'].quantile([0.25, 0.5, 0.75]) # 对每一行进行分类的函数 def categorize_by_price(row): if row['SalePrice'] <= quantiles.iloc[0]: return 'Low' elif row['SalePrice'] <= quantiles.iloc[1]: return 'Medium' elif row['SalePrice'] <= quantiles.iloc[2]: return 'High' else: return 'Premium' # 应用函数创建新列 Ames['Price_Category'] = Ames.apply(categorize_by_price, axis=1) print(Ames[['SalePrice','Price_Category']]) |
通过执行上述代码,您已使用名为“Price_Category”的新列丰富了数据集。这是您获得的输出示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
销售价格 价格类别 0 126000 低 1 139500 中 2 124900 低 3 114000 低 4 227000 高级 ... ... ... 2574 121000 低 2575 139600 中 2576 145000 中 2577 217500 高级 2578 215000 高级 [2579 行 x 2 列] |
使用经验累积分布函数(ECDF)可视化趋势
现在,您可以将原始数据集分成四个数据框,并继续可视化每个价格类别中建造年份的累积分布。这个可视化将帮助您一目了然地了解与定价相关的房产建造的历史趋势。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 导入 Matplotlib 和 Seaborn import matplotlib.pyplot as plt import seaborn as sns # 将原始数据集按价格类别分成 4 个数据框 low_priced_homes = Ames.query('Price_Category == "Low"') medium_priced_homes = Ames.query('Price_Category == "Medium"') high_priced_homes = Ames.query('Price_Category == "High"') premium_priced_homes = Ames.query('Price_Category == "Premium"') # 设置样式以美观 sns.set_style("whitegrid") # 创建图形 plt.figure(figsize=(10, 6)) # 在同一张图上绘制每个 ECDF sns.ecdfplot(data=low_priced_homes, x='YearBuilt', color='skyblue', label='Low') sns.ecdfplot(data=medium_priced_homes, x='YearBuilt', color='orange', label='Medium') sns.ecdfplot(data=high_priced_homes, x='YearBuilt', color='green', label='High') sns.ecdfplot(data=premium_priced_homes, x='YearBuilt', color='red', label='Premium') # 添加标签和标题以清晰显示 plt.title('按价格类别划分的建造年份ECDF', fontsize=16) plt.xlabel('建造年份', fontsize=14) plt.ylabel('ECDF', fontsize=14) plt.legend(title='价格类别', title_fontsize=14, fontsize=14) # 显示图表 plt.show() |
下面是 ECDF 图,它提供了您分类数据的视觉总结。ECDF,或经验累积分布函数,是一种用于描述数据集中数据点分布的统计工具。它表示低于或等于某个值的数据点的比例或百分比。本质上,它为您提供了一种可视化不同值之间数据点分布的方法,从而提供对数据形状、分布和集中趋势的见解。ECDF 图特别有用,因为它们可以轻松地比较不同数据集。请注意每个价格类别的曲线如何为您呈现多年来住房趋势的叙述。
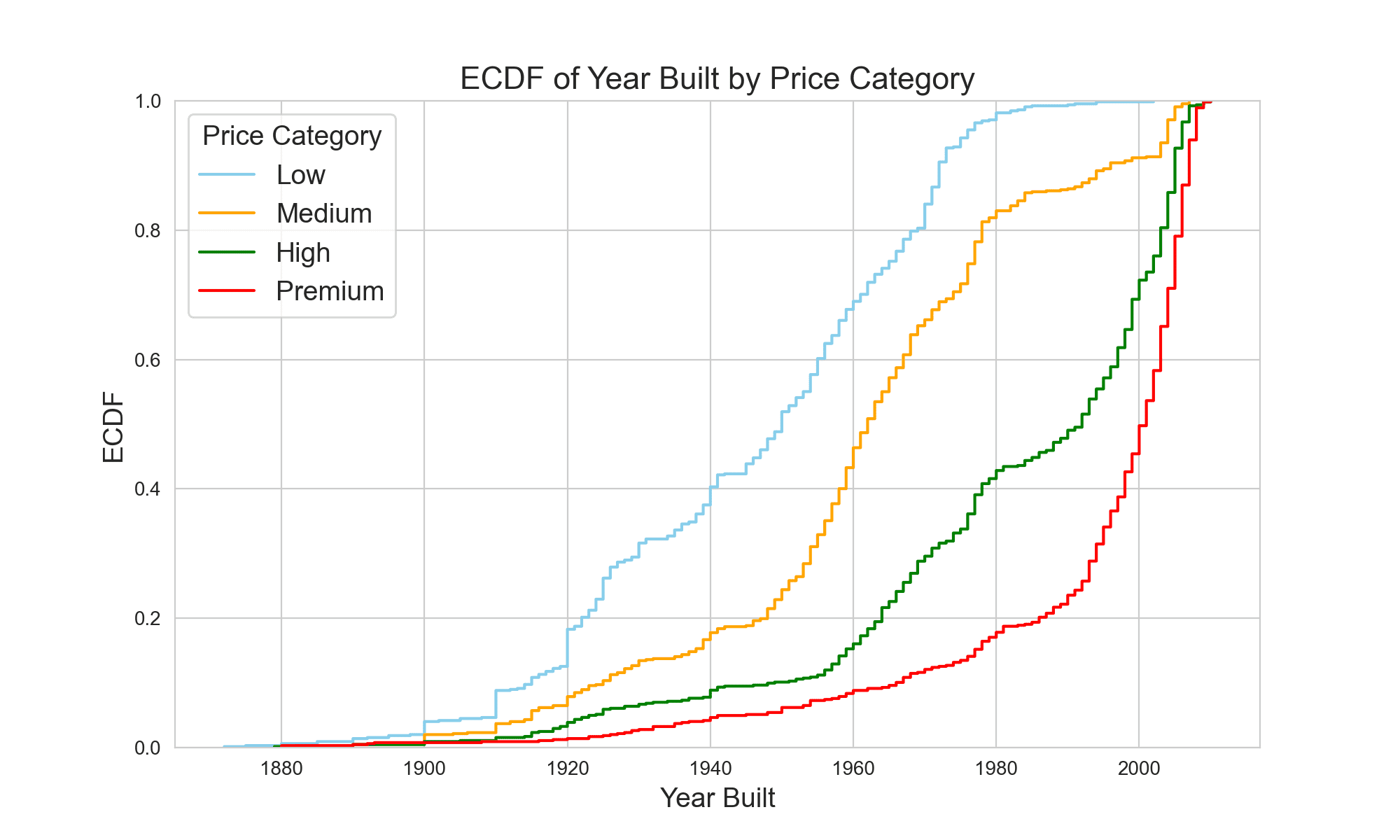 从图中可以看出,低价和中价房屋在早期建造的频率更高,而高价和高级房屋则倾向于较新的建造。鉴于您了解到房产年龄在不同价格段之间存在显著差异,您找到了使用
从图中可以看出,低价和中价房屋在早期建造的频率更高,而高价和高级房屋则倾向于较新的建造。鉴于您了解到房产年龄在不同价格段之间存在显著差异,您找到了使用 Pandas.concat() 的有力理由。
使用 Pandas.concat() 堆叠数据集
作为数据科学家,您经常需要堆叠数据集或其片段,以获取更深入的见解。Pandas.concat() 函数是您完成此类任务的瑞士军刀,它使您能够精确而灵活地组合 DataFrames。这个强大的函数让人想起 SQL 的 UNION 操作,因为它将来自不同数据集的行组合起来。然而,Pandas.concat() 凭借其更大的灵活性而脱颖而出——它允许 DataFrames 的垂直和水平连接。当您处理具有不匹配列的数据集或需要通过公共列对齐它们时,此功能变得不可或缺,大大扩展了您的分析范围。以下是您如何组合分段 DataFrames 以比较“经济适用房”和“豪华房”这两个更广泛的市场类别的方法
|
1 2 3 4 5 |
# 将低价和中价类别堆叠到“经济适用房”DataFrame 中 affordable_homes = pd.concat([low_priced_homes, medium_priced_homes]) # 将高价和高级类别堆叠到“豪华房”DataFrame 中 luxury_homes = pd.concat([high_priced_homes, premium_priced_homes]) |
通过这种方式,您可以并置和分析区分经济适用房和昂贵房产的特征。
通过我的书《数据科学初学者指南》启动您的项目。它提供了带有工作代码的自学教程。
透视和合并:与 Pandas 共舞
在将数据集分割为“经济适用房”和“豪华房”并探索其建造年份的分布之后,您现在将注意力转向另一个影响房产价值的维度:设施,重点是壁炉的数量。在您深入研究合并数据集——Pandas.merge() 作为与 SQL 的 JOIN 媲美的强大工具——之前,您必须首先通过更精细的视角检查您的数据。
数据透视表是总结和分析分段内特定数据点的绝佳工具。它们使您能够聚合数据并揭示可以为后续合并操作提供信息的模式。通过创建数据透视表,您可以编译一个清晰且有组织的总览,包括平均居住面积和房屋数量,按壁炉数量分类。这种初步分析不仅将丰富您对两个市场细分的理解,还将为复杂的合并技术奠定坚实的基础。
使用数据透视表创建有见地的摘要
让我们首先为“经济适用房”和“豪华房”类别构建数据透视表。这些表将汇总平均总居住面积(GrLivArea),并提供每个壁炉类别的房屋数量。这种分析至关重要,因为它说明了房屋吸引力和价值的一个关键方面——壁炉的存在和数量——以及这些特征在住房市场不同细分中的差异。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 创建包含平均居住面积和房屋数量的数据透视表 pivot_affordable = affordable_homes.pivot_table(index='Fireplaces', aggfunc={'GrLivArea': 'mean', 'Fireplaces': 'count'}) pivot_luxury = luxury_homes.pivot_table(index='Fireplaces', aggfunc={'GrLivArea': 'mean', 'Fireplaces': 'count'}) # 分别重命名列和索引标签 pivot_affordable.rename(columns={'GrLivArea': 'AvLivArea', 'Fireplaces': 'HmCount'}, inplace=True) pivot_affordable.index.name = 'Fire' pivot_luxury.rename(columns={'GrLivArea': 'AvLivArea', 'Fireplaces': 'HmCount'}, inplace=True) pivot_luxury.index.name = 'Fire' # 查看数据透视表 print(pivot_affordable) print(pivot_luxury) |
通过这些数据透视表,您现在可以轻松可视化和比较壁炉等特征与居住面积的相关性,以及它们在每个细分市场中的出现频率。第一个数据透视表是从“经济适用房”DataFrame 创建的,它表明此分组中的大多数房产都没有壁炉。
|
1 2 3 4 5 |
房屋数量 平均居住面积 壁炉 0 931 1159.050483 1 323 1296.808050 2 38 1379.947368 |
第二个数据透视表是从“豪华房”DataFrame 派生出来的,它说明此子集中的房产拥有 0 到 4 个壁炉,其中 1 个壁炉最常见。
|
1 2 3 4 5 6 7 |
房屋数量 平均居住面积 壁炉 0 310 1560.987097 1 808 1805.243812 2 157 1998.248408 3 11 2088.090909 4 1 2646.000000 |
随着数据透视表的创建,您已将数据提炼成一种形式,为下一个分析步骤做好了准备——使用 Pandas.merge() 融合这些见解,以了解这些特征在更广阔市场中的相互作用。
上面的数据透视表是最简单的一种。更高级的版本允许您不仅指定索引,还可以在参数中指定列。思路相似:您选择两个列,一个指定为 index 参数,另一个指定为 columns 参数,这两个列的值将被聚合并形成一个矩阵。矩阵中的值是 aggfunc 参数指定的结果。
您可以考虑以下示例,它产生与上面类似的结果
|
1 2 3 4 |
pivot = Ames.pivot_table(index="Fireplaces", columns="Price_Category", aggfunc={'GrLivArea':'mean', 'Fireplaces':'count'}) print(pivot) |
输出如下:
|
1 2 3 4 5 6 7 8 |
壁炉 居住面积 价格类别 高 低 中 高级 高 低 中 高级 壁炉 0 228.0 520.0 411.0 82.0 1511.912281 1081.496154 1257.172749 1697.439024 1 357.0 116.0 207.0 451.0 1580.644258 1184.112069 1359.961353 1983.031042 2 52.0 9.0 29.0 105.0 1627.384615 1184.888889 1440.482759 2181.914286 3 5.0 NaN NaN 6.0 1834.600000 NaN NaN 2299.333333 4 NaN NaN NaN 1.0 NaN NaN NaN 2646.000000 |
您可以通过比较(例如)零壁炉的低价和中价房屋数量分别为 520 和 411 来看到结果是相同的,即 931 = 520+411,正如您之前获得的。您看到第二级列标有低、中、高和高级,因为您将“Price_Category”指定为 pivot_table() 中的 columns 参数。aggfunc 参数的字典给出了顶级列。
迈向更深层次的洞察:利用 Pandas.merge() 进行比较分析
在阐明了壁炉、房屋数量和居住面积在分段数据集中的关系之后,您已准备好将分析更进一步。通过 Pandas.merge(),您可以叠加这些见解,类似于 SQL 的 JOIN 操作根据相关列组合来自两个或更多表的记录。这种技术将允许您在共同属性上合并分段数据,从而实现超越分类的比较分析。
我们的第一个操作使用外连接来组合经济适用房和豪华房数据集,确保两个类别的数据都不会丢失。这种方法特别有启发性,因为它揭示了房屋的全部范围,无论它们是否共享相同数量的壁炉。
|
1 2 |
pivot_outer_join = pd.merge(pivot_affordable, pivot_luxury, on='Fire', how='outer', suffixes=('_aff', '_lux')).fillna(0) print(pivot_outer_join) |
|
1 2 3 4 5 6 7 |
HmCount_aff AvLivArea_aff HmCount_lux AvLivArea_lux 壁炉 0 931.0 1159.050483 310 1560.987097 1 323.0 1296.808050 808 1805.243812 2 38.0 1379.947368 157 1998.248408 3 0.0 0.000000 11 2088.090909 4 0.0 0.000000 1 2646.000000 |
在这种情况下,外连接的功能类似于右连接,捕获了两个市场细分中存在的所有不同壁炉类别。有趣的是,在经济适用房价格范围内没有拥有 3 或 4 个壁炉的房产。您需要为 suffixes 参数指定两个字符串,因为“HmCount”和“AvLivArea”列在 pivot_affordable 和 pivot_luxury 这两个 DataFrame 中都存在。您会看到,对于 3 和 4 个壁炉,“HmCount_aff”为零,因为您需要它们作为外连接的占位符来匹配 pivot_luxury 中的行。
接下来,您可以使用内连接,重点关注经济适用房和豪华房共享相同壁炉数量的交集。这种方法突出了两个细分市场之间的核心相似之处。
|
1 2 |
pivot_inner_join = pd.merge(pivot_affordable, pivot_luxury, on='Fire', how='inner', suffixes=('_aff', '_lux')) print(pivot_inner_join) |
|
1 2 3 4 5 |
HmCount_aff AvLivArea_aff HmCount_lux AvLivArea_lux 壁炉 0 931 1159.050483 310 1560.987097 1 323 1296.808050 808 1805.243812 2 38 1379.947368 157 1998.248408 |
有趣的是,在这种情况下,内连接的功能类似于左连接,展示了两个数据集中存在的类别。您没有看到对应于 3 个和 4 个壁炉的行,因为它是内连接的结果,并且在 DataFrame pivot_affordable 中没有这样的行。
最后,交叉连接允许您检查经济适用房和豪华房属性的每种可能组合,提供对不同特征在整个数据集中的相互作用的全面视图。结果有时被称为两个 DataFrame 行的笛卡尔积。
|
1 2 3 4 5 6 |
# 重置索引以显示交叉连接 pivot_affordable.reset_index(inplace=True) pivot_luxury.reset_index(inplace=True) pivot_cross_join = pd.merge(pivot_affordable, pivot_luxury, how='cross', suffixes=('_aff', '_lux')).round(2) print(pivot_cross_join) |
结果如下,它展示了交叉连接的结果,但在本数据集的上下文中没有提供任何特殊见解。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Fire_aff HmCount_aff AvLivArea_aff Fire_lux HmCount_lux AvLivArea_lux 0 0 931 1159.05 0 310 1560.99 1 0 931 1159.05 1 808 1805.24 2 0 931 1159.05 2 157 1998.25 3 0 931 1159.05 3 11 2088.09 4 0 931 1159.05 4 1 2646.00 5 1 323 1296.81 0 310 1560.99 6 1 323 1296.81 1 808 1805.24 7 1 323 1296.81 2 157 1998.25 8 1 323 1296.81 3 11 2088.09 9 1 323 1296.81 4 1 2646.00 10 2 38 1379.95 0 310 1560.99 11 2 38 1379.95 1 808 1805.24 12 2 38 1379.95 2 157 1998.25 13 2 38 1379.95 3 11 2088.09 14 2 38 1379.95 4 1 2646.00 |
从合并数据中提取见解
完成这些合并操作后,您可以深入研究它们揭示的见解。每种连接类型都揭示了住房市场的不同方面
- 外连接揭示了最广泛的房产范围,强调了所有价位上壁炉等设施的多样性。
- 内连接细化了您的视图,专注于经济适用房和豪华房在壁炉数量上的直接比较,提供了标准市场产品的更清晰图景。
- 交叉连接提供了特征的详尽组合,非常适合假设分析或了解潜在市场扩张。
进行这些合并后,您观察到经济适用房中
- 没有壁炉的房屋平均总居住面积约为 1159 平方英尺,构成了最大的细分市场。
- 随着壁炉数量增加到一,平均居住面积扩大到约 1296 平方英尺,突显了居住空间的显著增加。
- 有两个壁炉的房屋数量较少,但平均居住面积甚至更大,约为 1379 平方英尺,这突出了一种趋势,即额外设施与更宽敞的居住空间相关。
相比之下,您观察到豪华房中
- 豪华住宅的起步点是无壁炉房屋,平均面积为 1560 平方英尺,明显大于经济适用房。
- 随着壁炉数量的增加,平均居住面积的跳跃更为明显,带一个壁炉的房屋平均约为 1805 平方英尺。
- 带两个壁炉的房屋进一步放大了这一趋势,平均居住面积接近 1998 平方英尺。房屋中罕见地出现三个甚至四个壁炉标志着居住空间的显著增加,带四个壁炉的房屋面积最大,高达 2646 平方英尺。
这些观察结果提供了一个引人入胜的视角,说明壁炉等设施不仅增加了房屋的吸引力,而且似乎是更大居住空间的标志,尤其是在您从经济适用房市场转向豪华房市场时。
想开始学习数据科学新手指南吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
教程
资源
总结
在本次使用 Python 和 Pandas 深入探索数据协调技术的过程中,您深入了解了数据集的分割、连接、透视和合并的复杂性。从根据价格类别将数据集划分为有意义的片段,到可视化建筑年份的趋势,再到使用 Pandas.concat() 堆叠数据集并分析更广泛的市场类别,以及使用数据透视表总结和分析片段中的数据点,您涵盖了广泛的基本数据操作和分析技术。此外,通过利用 Pandas.merge() 比较分段数据集并从不同类型的合并操作(外连接、内连接、交叉连接)中获取见解,您解锁了数据集成和探索的力量。掌握了这些技术,数据科学家和分析师可以自信地驾驭复杂的数据环境,发现隐藏的模式,并提取有价值的见解,从而推动明智的决策。
具体来说,你学到了:
- 如何根据价格类别将数据集划分为有意义的片段并可视化建筑年份的趋势。
- 使用
Pandas.concat()堆叠数据集并分析更广泛的市场类别。 - 数据透视表在总结和分析片段内数据点中的作用。
- 如何利用
Pandas.merge()比较分段数据集并从不同类型的合并操作(外连接、内连接、交叉连接)中获取见解。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。







暂无评论。