梯度提升是决策树算法的一种集成。
考虑到它在实践中对各种数据集表现出色,它可能是结构化(表格)分类和回归预测建模问题最流行的技术之一。
梯度提升的一个主要问题是模型训练速度慢。当在包含数万个示例(行)的大型数据集上使用模型时,这尤其是一个问题。
通过将连续输入变量离散化(分箱)为几百个唯一值,可以显著加速添加到集成中的树的训练。实现此技术并围绕此转换下的输入变量调整训练算法的梯度提升集成称为**基于直方图的梯度提升集成**。
在本教程中,您将学习如何开发基于直方图的梯度提升树集成。
完成本教程后,您将了解:
- 基于直方图的梯度提升是一种用于训练梯度提升集成中使用的更快决策树的技术。
- 如何在 scikit-learn 库中使用基于直方图的梯度提升的实验实现。
- 如何将基于直方图的梯度提升集成与 XGBoost 和 LightGBM 第三方库结合使用。
通过我的新书《Python 集成学习算法》**启动您的项目**,其中包括所有示例的*分步教程*和*Python 源代码*文件。
让我们开始吧。

如何开发基于直方图的梯度提升集成
图片由 YoTuT 提供,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 直方图梯度提升
- 使用 Scikit-Learn 进行直方图梯度提升
- 使用 XGBoost 进行直方图梯度提升
- 使用 LightGBM 进行直方图梯度提升
直方图梯度提升
梯度提升是一种集成机器学习算法。
提升是指一类集成学习算法,它们按顺序向集成添加树模型。添加到集成中的每个树模型都试图纠正集成中已有的树模型所做的预测错误。
梯度提升是 AdaBoost 等提升算法到统计框架的推广,该框架将训练过程视为加性模型,并允许使用任意损失函数,极大地提高了该技术的能力。因此,梯度提升集成是大多数结构化(例如表格数据)预测建模任务的首选技术。
尽管梯度提升在实践中表现出色,但模型的训练速度可能很慢。这是因为树必须按顺序创建和添加,这与其他集成模型(如随机森林)不同,在随机森林中,集成成员可以并行训练,利用多个 CPU 核。因此,人们付出了大量努力来改进梯度提升训练算法的效率。
两个著名的库封装了许多用于训练梯度提升算法的现代效率技术,包括极端梯度提升 (XGBoost) 和轻量梯度提升机 (LightGBM)。
可以加速训练算法的一个方面是每棵决策树的构建,其速度受训练数据集中示例(行)数量和特征(列)数量的限制。大型数据集,例如数万个或更多示例,可能导致树的构建非常缓慢,因为在树的构建过程中必须考虑每个特征的每个值的分割点。
如果我们可以减少 #data 或 #feature,我们将能够大大加快 GBDT 的训练速度。
— LightGBM:一种高效的梯度提升决策树,2017。
通过减少连续输入特征的值数量,可以显著加快决策树的构建。这可以通过将值离散化或分箱到固定数量的桶中来实现。这可以将每个特征的唯一值数量从数万个减少到几百个。
这使得决策树能够对序数桶(整数)而不是训练数据集中的特定值进行操作。这种对输入数据的粗略近似通常对模型技能影响不大,如果不是改进模型技能的话,并且显著加速了决策树的构建。
此外,可以使用高效的数据结构来表示输入数据的分箱;例如,可以使用直方图,并且可以进一步调整树构建算法,以便在每棵树的构建中高效使用直方图。
这些技术最初是在 1990 年代后期开发的,旨在高效地在大数据集上开发单个决策树,但可用于决策树集成,例如梯度提升。
因此,在现代机器学习库中,通常将支持“*直方图*”的梯度提升算法称为**基于直方图的梯度提升**。
基于直方图的算法不是在排序的特征值上寻找分割点,而是将连续特征值分箱到离散的桶中,并使用这些桶在训练期间构建特征直方图。由于基于直方图的算法在内存消耗和训练速度方面都更高效,我们将在此基础上开展工作。
— LightGBM:一种高效的梯度提升决策树,2017。
现在我们熟悉了在梯度提升中为决策树构建添加直方图的想法,让我们回顾一下我们可以在预测建模项目中使用的一些常见实现。
支持该技术的主要有三个库;它们是 Scikit-Learn、XGBoost 和 LightGBM。
让我们依次仔细看看每一个。
**注意**:我们不竞速算法;相反,我们只是演示如何配置每个实现以使用直方图方法,并将其余不相关的超参数保持为其默认值。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
使用 Scikit-Learn 进行直方图梯度提升
scikit-learn 机器学习库提供了支持直方图技术的梯度提升的实验性实现。
具体来说,这由 HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 类提供。
为了使用这些类,您必须在项目中添加一行额外的代码,表明您乐于使用这些实验性技术,并且它们的行为可能会随着库的后续版本而改变。
|
1 2 3 |
... # 明确要求此实验性功能 from sklearn.experimental import enable_hist_gradient_boosting |
scikit-learn 文档声称,这些基于直方图的梯度提升实现比库提供的默认梯度提升实现快几个数量级。
当样本数量大于数万个样本时,这些基于直方图的估计器可能比 GradientBoostingClassifier 和 GradientBoostingRegressor 快几个数量级。
— 基于直方图的梯度提升,Scikit-Learn 用户指南。
这些类可以像任何其他 scikit-learn 模型一样使用。
默认情况下,集成对每个连续输入特征使用 255 个 bin,这可以通过“max_bins”参数设置。将其设置为较小的值,例如 50 或 100,可能会进一步提高效率,尽管这可能会牺牲一些模型技能。
树的数量可以通过“max_iter”参数设置,默认为 100。
|
1 2 3 |
... # 定义模型 model = HistGradientBoostingClassifier(max_bins=255, max_iter=100) |
下面的示例展示了如何在包含 10,000 个示例和 100 个特征的合成分类数据集上评估直方图梯度提升算法。
模型使用重复分层 k 折交叉验证进行评估,并报告所有折叠和重复的平均准确率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 评估用于分类的 sklearn 直方图梯度提升算法 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.experimental import enable_hist_gradient_boosting from sklearn.ensemble import HistGradientBoostingClassifier # 定义数据集 X, y = make_classification(n_samples=10000, n_features=100, n_informative=50, n_redundant=50, random_state=1) # 定义模型 model = HistGradientBoostingClassifier(max_bins=255, max_iter=100) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集分数 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行该示例将评估模型在合成数据集上的性能,并报告平均值和标准差分类准确率。
**注意**:考虑到算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到 scikit-learn 直方图梯度提升算法在合成数据集上实现了约 94.3% 的平均准确率。
|
1 |
准确率:0.943 (0.007) |
我们还可以探索 bin 数量对模型性能的影响。
下面的示例评估了模型在每个连续输入特征上使用不同数量的 bin(从 50 到大约 250,增量为 50)时的性能。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# 比较 sklearn 直方图梯度提升的 bin 数量 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.experimental import enable_hist_gradient_boosting from sklearn.ensemble import HistGradientBoostingClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=10000, n_features=100, n_informative=50, n_redundant=50, random_state=1) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() for i in [10, 50, 100, 150, 200, 255]: models[str(i)] = HistGradientBoostingClassifier(max_bins=i, max_iter=100) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集分数 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): # 评估模型并收集分数 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 沿途报告性能 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例将评估每个配置,报告沿途的平均分类准确率和标准差,最后绘制分数分布图。
**注意**:考虑到算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到增加 bin 的数量可能会降低模型在该数据集上的平均准确率。
我们可能会期望 bin 数量的增加也可能需要增加树的数量(max_iter),以确保模型能够有效探索和利用额外的分割点。
重要的是,拟合一个每棵树使用 10 或 50 个 bin 的集成比每个输入变量使用 255 个 bin 的集成要快得多。
|
1 2 3 4 5 6 |
>10 0.945 (0.009) >50 0.944 (0.007) >100 0.944 (0.008) >150 0.944 (0.008) >200 0.944 (0.007) >255 0.943 (0.007) |
通过箱线图和胡须图比较了每个配置的准确率分数分布。
在这种情况下,我们可以看到增加直方图中的 bin 数量似乎会减少分布的范围,尽管它可能会降低模型的平均性能。
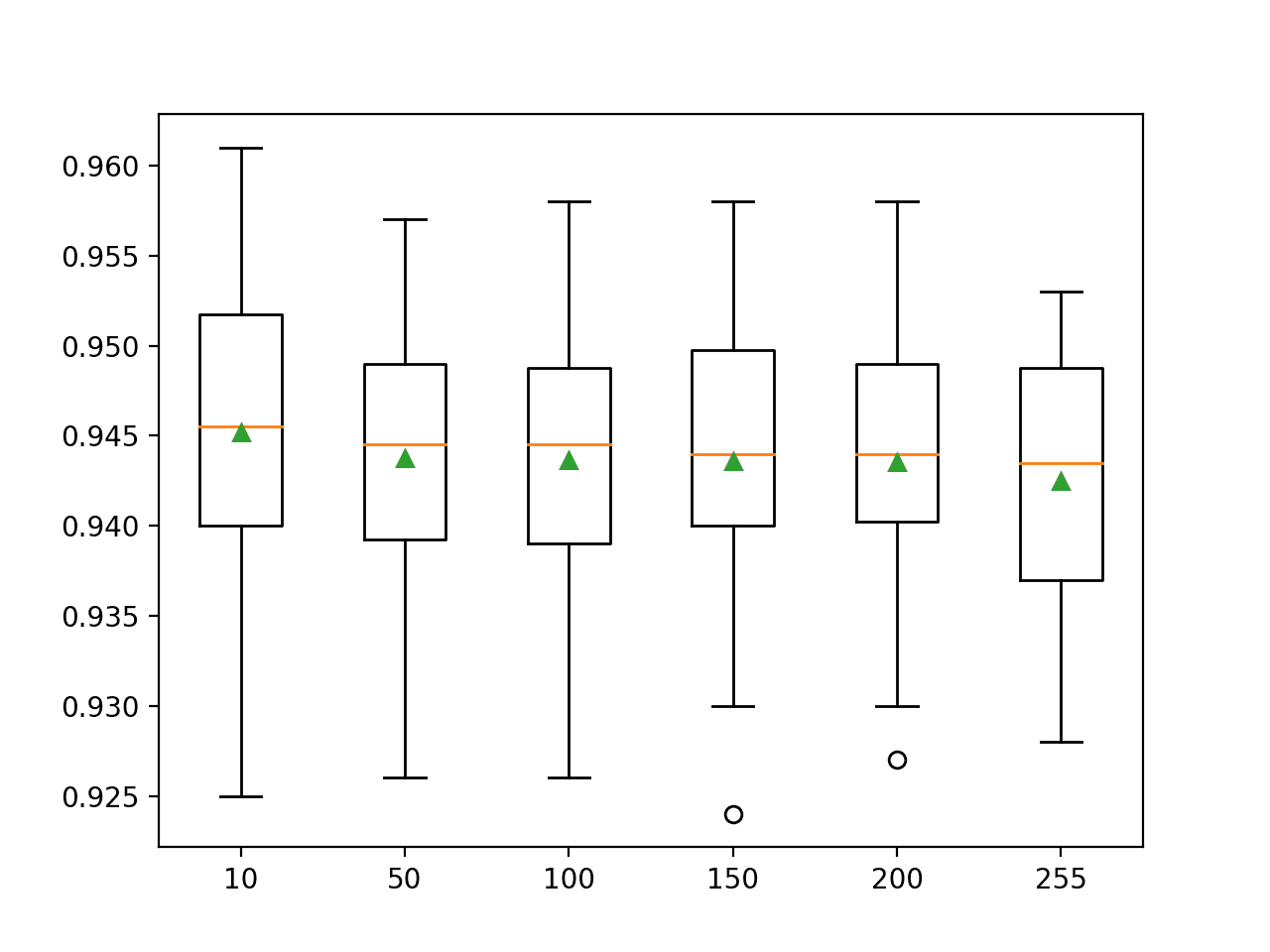
Scikit-Learn 直方图梯度提升集成中 Bin 数量的箱线图和胡须图
使用 XGBoost 进行直方图梯度提升
极限梯度提升,简称 XGBoost,是一个提供高度优化梯度提升实现的库。
该库中实现的技术之一是使用连续输入变量的直方图。
XGBoost 库可以使用您喜欢的 Python 包管理器(例如 Pip)安装;例如
|
1 |
sudo pip install xgboost |
我们可以通过 XGBClassifier 和 XGBRegressor 类开发用于 scikit-learn 库的 XGBoost 模型。
训练算法可以通过将“tree_method”参数设置为“approx”来配置为使用直方图方法,并且 bin 的数量可以通过“max_bin”参数设置。
|
1 2 3 |
... # 定义模型 model = XGBClassifier(tree_method='approx', max_bin=255, n_estimators=100) |
下面的示例演示了如何评估配置为使用直方图或近似技术构建树的 XGBoost 模型,该模型对每个连续输入特征使用 255 个 bin,模型中包含 100 棵树。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估用于分类的 xgboost 直方图梯度提升算法 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from xgboost import XGBClassifier # 定义数据集 X, y = make_classification(n_samples=10000, n_features=100, n_informative=50, n_redundant=50, random_state=1) # 定义模型 model = XGBClassifier(tree_method='approx', max_bin=255, n_estimators=100) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集分数 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行该示例将评估模型在合成数据集上的性能,并报告平均值和标准差分类准确率。
**注意**:考虑到算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到 XGBoost 直方图梯度提升算法在合成数据集上实现了约 95.7% 的平均准确率。
|
1 |
准确率:0.957 (0.007) |
使用 LightGBM 进行直方图梯度提升
轻量梯度提升机,简称 LightGBM,是另一个像 XGBoost 一样提供高度优化梯度提升实现的第三方库。
它可能在 XGBoost 之前就实现了直方图技术,但 XGBoost 后来也实现了相同的技术,这突显了梯度提升库之间的“梯度提升效率”竞争。
LightGBM 库可以使用您喜欢的 Python 包管理器(例如 Pip)安装;例如
|
1 |
sudo pip install lightgbm |
我们可以通过 LGBMClassifier 和 LGBMRegressor 类开发用于 scikit-learn 库的 LightGBM 模型。
训练算法默认使用直方图。每个连续输入变量的最大 bin 数可以通过“max_bin”参数设置。
|
1 2 3 |
... # 定义模型 model = LGBMClassifier(max_bin=255, n_estimators=100) |
下面的示例演示了如何评估配置为使用直方图或近似技术构建树的 LightGBM 模型,该模型对每个连续输入特征使用 255 个 bin,模型中包含 100 棵树。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估用于分类的 lightgbm 直方图梯度提升算法 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from lightgbm import LGBMClassifier # 定义数据集 X, y = make_classification(n_samples=10000, n_features=100, n_informative=50, n_redundant=50, random_state=1) # 定义模型 model = LGBMClassifier(max_bin=255, n_estimators=100) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集分数 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行该示例将评估模型在合成数据集上的性能,并报告平均值和标准差分类准确率。
**注意**:考虑到算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到 LightGBM 直方图梯度提升算法在合成数据集上实现了约 94.2% 的平均准确率。
|
1 |
准确率:0.942 (0.006) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
论文
- Sprint:用于数据挖掘的可伸缩并行分类器, 1996.
- CLOUDS:用于大型数据集的决策树分类器, 1998.
- 通信和内存高效的并行决策树构建, 2003.
- LightGBM:一种高效的梯度提升决策树, 2017.
- XGBoost:一个可扩展的树形增强系统, 2016.
API
- sklearn.ensemble.HistGradientBoostingClassifier API.
- sklearn.ensemble.HistGradientBoostingRegressor API.
- XGBoost,快速直方图优化增长器,速度提升 8 到 10 倍
- xgboost.XGBClassifier API.
- xgboost.XGBRegressor API.
- lightgbm.LGBMClassifier API.
- lightgbm.LGBMRegressor API.
总结
在本教程中,您学习了如何开发基于直方图的梯度提升树集成。
具体来说,你学到了:
- 基于直方图的梯度提升是一种用于训练梯度提升集成中使用的更快决策树的技术。
- 如何在 scikit-learn 库中使用基于直方图的梯度提升的实验实现。
- 如何将基于直方图的梯度提升集成与 XGBoost 和 LightGBM 第三方库结合使用。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……






太棒了,贾森!
您知道我们是否可以从基于直方图的梯度提升中获取特征重要性吗?
很好的问题!
目前看来不能。
亲爱的贾森,您迄今为止所做的一切工作给我留下了深刻的印象。我一口气购买了您的全部 17 或 19 本书,当然是打折的 ;-)。尽管这些材料应该让我一直忙到我 5 岁的儿子可以上大学^^,但我仍然有一个关于主题的问题。
我尝试在 scikit-learn 管道中使用 LGBM 上的 param max_bin
steps = [(‘LGBM’, classifiers[0])]
pipeline = Pipeline(steps)
params = {
‘LGBM__objective’:[‘binary’],
‘LGBM__num_leaves’: [8, 16, 24, 32],
‘LGBM__max_depth’: [3, 4, 5, 6, 7, 10, 15],
‘LGBM__learning_rate’: [0.05, 0.1],
‘LGBM__min_child_samples’: [2, 3, 4, 10],
‘LGBM__is_unbalance’: [‘true’],
‘LGBM__boosting_type’:[‘gdbt’],
‘LGBM__num_round’: [1000, 5000, 10000],
‘LGBM__max_bin’: [255],
‘LGBM__verbose’: [0],
‘LGBM__force_row_wise’: [‘true’]
}
random_lgb_bin = RandomizedSearchCV(estimator = pipeline, param_distributions=params, cv=5)
然而,我没有看到分数、auc 或精度召回率有任何显著变化,即使在查看性能时也没有。每个循环完成所需的时间或多或少相同。是我做错了什么还是它明确取决于数据?数据来自 UCI
https://www.kaggle.com/uciml/adult-census-income
祝好,
Patrick
谢谢,你做得很好!
它可能对该数据集没有影响,也许可以尝试不同的数据集?
我猜 max_bin 适用于所有输入特征。您可以为每个特征指定 max_bin 值吗?
我不确定你能。这可能需要自定义代码。