在预测建模问题中,当训练数据集相对于未标记样本的数量较小时,这类问题具有挑战性。
神经网络在这些类型的问题上可以表现良好,但它们在训练或留出验证数据集上测得的模型性能可能存在高方差。这使得选择哪个模型作为最终模型存在风险,因为在训练过程结束时,没有明确的信号表明哪个模型优于另一个。
水平投票集成是一种解决此问题的简单方法,其中将训练结束时连续训练周期保存的模型集合用作集成模型,与随机选择单个最终模型相比,它平均能产生更稳定和更好的性能。
在本教程中,您将学习如何使用水平投票集成来降低最终深度学习神经网络模型的方差。
完成本教程后,您将了解:
- 选择一个在训练数据集上具有高方差的最终神经网络模型是具有挑战性的。
- 水平投票集成提供了一种通过单次训练运行来减少方差并提高具有高方差模型的平均模型性能的方法。
- 如何使用Python中的Keras开发一个水平投票集成模型,以提高多层感知器模型在多类分类中的最终性能。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019年2月更新:删除了对完整代码示例中未使用的验证数据集的引用。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。
- 2020年1月更新:已针对 scikit-learn v0.22 API 的更改进行更新。

如何通过水平投票集成来减少最终深度学习模型的方差
图片来源:Fatima Flores,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 水平投票集成
- 多类别分类问题
- 多层感知器模型
- 保存水平模型
- 进行水平集成预测
水平投票集成
集成学习结合了多个模型的预测。
在使用深度学习方法进行集成学习时面临的一个挑战是,鉴于使用非常大的数据集和大型模型,一次训练运行可能需要几天、几周甚至几个月。训练多个模型可能不可行。
模型集合的另一个来源是单个模型在训练过程中不同时间点的状态。
水平投票是Jingjing Xie等人于2013年在他们的论文《具有深度表示的分类的水平和垂直集成》中提出的一种集成方法。
该方法涉及使用训练结束前连续的几个周期内的多个模型进行集成预测。
这种方法是专门为那些训练数据集相对于模型所需的预测数量较小的预测建模问题而开发的。这导致模型在训练过程中性能方差较大。在这种情况下,考虑到性能方差,使用训练过程结束时的最终模型或任何给定模型都是有风险的。
…分类的错误率将首先下降,然后随着训练周期的增加趋于稳定。但是,当标记训练集的大小过小时,错误率会波动[…]因此很难选择一个“神奇”的周期来获得可靠的输出。
— 《具有深度表示的分类的水平和垂直集成》,2013年。
相反,作者建议使用训练过程中连续几个周期(例如最后200个周期)中的所有模型进行集成。这样得到的集成预测与集成中任何单个模型的预测一样好,甚至更好。
为了减少不稳定性,我们提出了一种名为水平投票的方法。首先,选择在相对稳定周期范围内训练的网络。每个标签的概率预测由标准分类器通过所选周期的顶层表示生成,然后进行平均。
— 《具有深度表示的分类的水平和垂直集成》,2013年。
因此,水平投票集成方法为以下两种情况提供了理想的方法:一种是给定模型需要大量计算资源进行训练,另一种是由于使用相对较小的训练数据集导致训练方差较大,从而使最终模型选择具有挑战性。
现在我们已经熟悉了水平投票,我们可以实现这个过程。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
多类别分类问题
我们将使用一个小的多类分类问题作为演示水平投票集成的基础。
scikit-learn 提供了 make_blobs() 函数,可用于创建具有规定样本数量、输入变量、类别和类别内样本方差的多类分类问题。
该问题有两个输入变量(表示点的 x 和 y 坐标),并且每个组内点的标准差为 2.0。我们将使用相同的随机状态(伪随机数生成器的种子),以确保我们始终获得相同的数据点。
|
1 2 |
# 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) |
结果是我们可以建模的数据集的输入和输出元素。
为了了解问题的复杂性,我们可以将每个点绘制在二维散点图上,并按类别值对每个点进行着色。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# blob 数据集的散点图 from sklearn.datasets import make_blobs from matplotlib import pyplot from pandas import DataFrame # 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 散点图,点按类别值着色 df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y)) colors = {0:'red', 1:'blue',2:'green'} fig, ax = pyplot.subplots() grouped = df.groupby('label') for key, group in grouped: group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key]) pyplot.show() |
运行示例将生成整个数据集的散点图。我们可以看到,标准差为 2.0 意味着这些类别不是线性可分的(不能用一条线分隔),导致许多模糊的点。
这是可取的,因为它意味着问题并非微不足道,并且可以让神经网络模型找到许多不同的“足够好”的候选解决方案,从而产生高方差。

具有三个类别且点按类别值着色的 Blob 数据集散点图
多层感知器模型
在定义模型之前,我们需要设计一个适用于水平投票集成的问题。
在我们的问题中,训练数据集相对较小。具体来说,训练数据集与留出数据集的样本比例为 10:1。这模仿了一种情况,即我们可能有大量的未标记样本,以及少量带标记样本用于训练模型。
我们将从斑点问题中创建 1100 个数据点。模型将在前 100 个点上进行训练,其余 1000 个将保留在测试数据集中,模型无法使用。
|
1 2 3 4 5 6 7 |
# 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) |
这是一个多类分类问题,我们将使用输出层上的 softmax 激活函数对其进行建模。
这意味着模型将预测一个包含三个元素的向量,其中每个元素表示样本属于三个类别之一的概率。因此,我们必须对类别值进行独热编码,最好在将行拆分为训练集、测试集和验证集之前进行,以便只需调用一个函数。
|
1 |
y = to_categorical(y) |
接下来,我们可以定义和组合模型。
该模型将期望具有两个输入变量的样本。模型然后有一个包含25个节点和整流线性激活函数的单层隐藏层,然后是一个包含三个节点以预测三个类别中每个类别的概率的输出层和一个softmax激活函数。
由于问题是多类问题,我们将使用分类交叉熵损失函数来优化模型,并使用高效的 Adam 随机梯度下降变体。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(25,input_dim=2,activation='relu')) model.add(Dense(3,activation='softmax')) model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy']) |
模型将进行1000个训练周期,我们将在每个周期在训练集上评估模型,并将测试集用作验证集。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=1000, verbose=0) |
运行结束时,我们将评估模型在训练集和测试集上的性能。
|
1 2 3 4 |
# 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
最后,我们将绘制模型在训练集和验证集上每个训练周期的准确率学习曲线。
|
1 2 3 4 5 |
# 模型准确率的学习曲线 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 为 blob 数据集开发一个 mlp from sklearn.datasets import make_blobs from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot # 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 独热编码输出变量 y = to_categorical(y) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) # 定义模型 model = Sequential() model.add(Dense(25,input_dim=2,activation='relu')) model.add(Dense(3,activation='softmax')) model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=1000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 模型准确率的学习曲线 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印每个数据集的形状以进行确认,然后打印最终模型在训练集和测试集上的性能。
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。建议运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型在训练数据集上实现了约 85% 的准确率,我们知道这是乐观的,而在测试数据集上实现了约 80% 的准确率,我们预计这会更现实。
|
1 2 |
(100, 2) (1000, 2) 训练:0.850,测试:0.804 |
还创建了一条线图,显示了模型在训练集和测试集上每个训练周期的准确率学习曲线。
我们可以看到,整个运行过程中的训练准确率更加乐观,正如我们从最终分数中也注意到的那样。我们也可以看到,模型在训练数据集上的准确率方差很高,这与测试集相比是预期的。
模型的方差突出表明,选择运行结束时的模型或大约第800个周期以后的任何模型都是具有挑战性的,因为训练数据集的准确率方差很高。我们还在测试数据集上看到了方差的弱化版本。

绘制每个训练周期中模型在训练集和测试集上的准确率学习曲线
既然我们已经确定该模型是水平投票集成的良好候选,我们就可以开始实施该技术了。
保存水平模型
实现水平投票集成可能有很多方法。
也许最简单的方法是手动驱动训练过程,一次一个周期,然后在达到周期数上限后保存模型。
例如,在我们的测试问题中,我们将训练模型 1000 个周期,并可能从第 950 个周期开始保存模型(例如,包括第 950 个周期到第 999 个周期)。
|
1 2 3 4 5 6 7 8 |
# 拟合模型 n_epochs, n_save_after = 1000, 950 for i in range(n_epochs): # fit model for a single epoch model.fit(trainX, trainy, epochs=1, verbose=0) # check if we should save the model if i >= n_save_after: model.save('models/model_' + str(i) + '.h5') |
可以使用模型上的 `save()` 函数并指定包含周期数的文件名来将模型保存到文件。
为避免源文件混乱,我们将所有模型保存到当前工作目录下的新“`models/`”文件夹中。
|
1 2 |
# 创建模型目录 makedirs('models') |
请注意,在 Keras 中保存和加载神经网络模型需要您安装 h5py 库。
您可以使用 pip 安装此库,如下所示:
|
1 |
pip install h5py |
将所有这些联系起来,以下是模型在训练数据集上拟合并保存最后50个周期的所有模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 训练过程中保存水平投票集成成员 from sklearn.datasets import make_blobs from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot from os import makedirs # 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 独热编码输出变量 y = to_categorical(y) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) # 定义模型 model = Sequential() model.add(Dense(25,input_dim=2,activation='relu')) model.add(Dense(3,activation='softmax')) model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy']) # 创建模型目录 makedirs('models') # 拟合模型 n_epochs, n_save_after = 1000, 950 for i in range(n_epochs): # fit model for a single epoch model.fit(trainX, trainy, epochs=1, verbose=0) # check if we should save the model if i >= n_save_after: model.save('models/model_' + str(i) + '.h5') |
运行示例将创建“`models/`”文件夹并将 50 个模型保存到该目录中。
请注意,要重新运行此示例,您必须删除“`models/`”目录,以便脚本可以重新创建它。
进行水平集成预测
现在我们已经创建了模型,我们可以在水平投票集成中使用它们。
首先,我们需要将模型加载到内存中。这很合理,因为模型很小。如果您正在尝试使用非常大的模型开发水平投票集成,那么一次加载一个模型,进行预测,然后加载下一个模型并重复该过程可能会更容易。
下面的 `load_all_models()` 函数将从“`models/`”目录加载模型。它以起始和结束周期作为参数,以便您可以尝试不同组的在连续周期内保存的模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 从文件加载模型 def load_all_models(n_start, n_end): all_models = list() for epoch in range(n_start, n_end): # 为此集成模型定义文件名 filename = 'models/model_' + str(epoch) + '.h5' # 从文件加载模型 model = load_model(filename) # 添加到成员列表 all_models.append(model) print('>loaded %s' % filename) return all_models |
我们可以调用该函数来加载所有模型。
然后,我们可以反转模型列表,以便将运行结束时的模型放在列表的开头。这对于稍后测试不同大小的投票集成将有所帮助,包括从运行结束向前追溯训练周期顺序包含模型,以防最佳模型确实在运行结束时出现。
|
1 2 3 4 5 |
# 按顺序加载模型 members = load_all_models(950, 1000) print('Loaded %d models' % len(members)) # 反转已加载的模型,以便我们先构建最后一个模型的集成 members = list(reversed(members)) |
接下来,我们可以在测试数据集上评估每个保存的模型,以及来自训练的最后 n 个连续模型的投票集成。
我们想知道每个模型在测试数据集上的实际表现如何,更重要的是,模型在测试数据集上的性能分布,以便我们了解从运行结束时选择的平均模型在实践中表现如何(好或坏)。
我们不知道水平投票集成中应该包含多少成员。因此,我们可以测试不同数量的连续成员,从最终模型开始向后追溯。
首先,我们需要一个函数来使用集成成员列表进行预测。每个成员预测三个输出类别中每个类别的概率。这些概率被加起来,我们使用 argmax 选择支持最多的类别。下面的 `ensemble_predictions()` 函数实现了这种基于投票的预测方案。
|
1 2 3 4 5 6 7 8 9 10 |
# 为多类分类进行集成预测 def ensemble_predictions(members, testX): # 进行预测 yhats = [model.predict(testX) for model in members] yhats = array(yhats) # 跨集成成员求和 summed = numpy.sum(yhats, axis=0) # 跨类求 argmax result = argmax(summed, axis=1) return result |
接下来,我们需要一个函数来评估给定大小的集成成员子集。
需要选择子集,进行预测,并通过将预测与预期值进行比较来估计集成的性能。下面的 `evaluate_n_members()` 函数实现了这种集成大小评估。
|
1 2 3 4 5 6 7 8 |
# 评估集成中的特定数量成员 def evaluate_n_members(members, n_members, testX, testy): # 选择成员子集 subset = members[:n_members] # 进行预测 yhat = ensemble_predictions(subset, testX) # 计算准确率 return accuracy_score(testy, yhat) |
现在我们可以枚举从1到50不同大小的水平投票集成。每个成员单独评估,然后评估该大小的集成并记录分数。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 在保留集上评估不同数量的集成 single_scores, ensemble_scores = list(), list() for i in range(1, len(members)+1): # 评估具有 i 个模型的集成 ensemble_score = evaluate_n_members(members, i, testX, testy) # 单独评估第 i 个模型 testy_enc = to_categorical(testy) _, single_score = members[i-1].evaluate(testX, testy_enc, verbose=0) # 总结这一步 print('> %d: single=%.3f, ensemble=%.3f' % (i, single_score, ensemble_score)) ensemble_scores.append(ensemble_score) single_scores.append(single_score) |
评估结束后,我们将报告单个模型在测试数据集上的分数分布。平均分是如果我们选择任何一个保存的模型作为最终模型,我们所期望的平均分。
|
1 2 |
# 总结单个最终模型的平均准确度 print('Accuracy %.3f (%.3f)' % (mean(single_scores), std(single_scores))) |
最后,我们可以绘制分数。每个独立模型的得分用蓝色圆点表示,并为每个连续模型的集成创建折线图(橙色)。
|
1 2 3 4 5 |
# 绘制分数与集成成员数量的关系 x_axis = [i for i in range(1, len(members)+1)] pyplot.plot(x_axis, single_scores, marker='o', linestyle='None') pyplot.plot(x_axis, ensemble_scores, marker='o') pyplot.show() |
我们期望一个规模适中的集成模型将优于随机选择的模型,并且在选择集成模型规模时存在收益递减的点。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
# 使用水平投票集成加载模型并进行预测 from sklearn.datasets import make_blobs from sklearn.metrics import accuracy_score from keras.utils import to_categorical from keras.models import load_model from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot from numpy import mean from numpy import std import numpy from numpy import array from numpy import argmax # 从文件加载模型 def load_all_models(n_start, n_end): all_models = list() for epoch in range(n_start, n_end): # 为此集成模型定义文件名 filename = 'models/model_' + str(epoch) + '.h5' # 从文件加载模型 model = load_model(filename) # 添加到成员列表 all_models.append(model) print('>loaded %s' % filename) return all_models # 为多类分类进行集成预测 def ensemble_predictions(members, testX): # 进行预测 yhats = [model.predict(testX) for model in members] yhats = array(yhats) # 跨集成成员求和 summed = numpy.sum(yhats, axis=0) # 跨类求 argmax result = argmax(summed, axis=1) return result # 评估集成中的特定数量成员 def evaluate_n_members(members, n_members, testX, testy): # 选择成员子集 subset = members[:n_members] # 进行预测 yhat = ensemble_predictions(subset, testX) # 计算准确率 return accuracy_score(testy, yhat) # 生成二维分类数据集 X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2) # 分割成训练集和测试集 n_train = 100 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] print(trainX.shape, testX.shape) # 按顺序加载模型 members = load_all_models(950, 1000) print('Loaded %d models' % len(members)) # 反转已加载的模型,以便我们先构建最后一个模型的集成 members = list(reversed(members)) # 在保留集上评估不同数量的集成 single_scores, ensemble_scores = list(), list() for i in range(1, len(members)+1): # 评估具有 i 个模型的集成 ensemble_score = evaluate_n_members(members, i, testX, testy) # 单独评估第 i 个模型 testy_enc = to_categorical(testy) _, single_score = members[i-1].evaluate(testX, testy_enc, verbose=0) # 总结这一步 print('> %d: single=%.3f, ensemble=%.3f' % (i, single_score, ensemble_score)) ensemble_scores.append(ensemble_score) single_scores.append(single_score) # 总结单个最终模型的平均准确度 print('Accuracy %.3f (%.3f)' % (mean(single_scores), std(single_scores))) # 绘制分数与集成成员数量的关系 x_axis = [i for i in range(1, len(members)+1)] pyplot.plot(x_axis, single_scores, marker='o', linestyle='None') pyplot.plot(x_axis, ensemble_scores, marker='o') pyplot.show() |
首先,将 50 个保存的模型加载到内存中。
|
1 2 3 4 5 6 7 8 9 10 11 |
... >加载了 models/model_990.h5 >加载了 models/model_991.h5 >加载了 models/model_992.h5 >加载了 models/model_993.h5 >加载了 models/model_994.h5 >加载了 models/model_995.h5 >加载了 models/model_996.h5 >加载了 models/model_997.h5 >加载了 models/model_998.h5 >加载了 models/model_999.h5 |
接下来,在保留测试数据集上评估每个单一模型的性能,并创建该大小(1、2、3 等)的集成模型,并在保留测试数据集上进行评估。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
> 1: 单个=0.814, 集成=0.814 > 2: 单个=0.816, 集成=0.816 > 3: 单个=0.812, 集成=0.816 > 4: 单个=0.812, 集成=0.815 > 5: 单个=0.811, 集成=0.815 > 6: 单个=0.812, 集成=0.812 > 7: 单个=0.812, 集成=0.813 > 8: 单个=0.817, 集成=0.814 > 9: 单个=0.819, 集成=0.814 > 10: 单个=0.822, 集成=0.816 > 11: 单个=0.822, 集成=0.817 > 12: 单个=0.821, 集成=0.818 > 13: 单个=0.822, 集成=0.821 > 14: 单个=0.820, 集成=0.821 > 15: 单个=0.817, 集成=0.820 > 16: 单个=0.819, 集成=0.820 > 17: 单个=0.816, 集成=0.819 > 18: 单个=0.815, 集成=0.819 > 19: 单个=0.813, 集成=0.819 > 20: 单个=0.812, 集成=0.818 > 21: 单个=0.812, 集成=0.818 > 22: 单个=0.810, 集成=0.818 > 23: 单个=0.812, 集成=0.819 > 24: 单个=0.815, 集成=0.819 > 25: 单个=0.816, 集成=0.819 > 26: 单个=0.817, 集成=0.819 > 27: 单个=0.819, 集成=0.819 > 28: 单个=0.816, 集成=0.819 > 29: 单个=0.817, 集成=0.819 > 30: 单个=0.819, 集成=0.820 > 31: 单个=0.817, 集成=0.820 > 32: 单个=0.819, 集成=0.820 > 33: 单个=0.817, 集成=0.819 > 34: 单个=0.816, 集成=0.819 > 35: 单个=0.815, 集成=0.818 > 36: 单个=0.816, 集成=0.818 > 37: 单个=0.816, 集成=0.818 > 38: 单个=0.819, 集成=0.818 > 39: 单个=0.817, 集成=0.817 > 40: 单个=0.816, 集成=0.816 > 41: 单个=0.816, 集成=0.816 > 42: 单个=0.816, 集成=0.817 > 43: 单个=0.817, 集成=0.817 > 44: 单个=0.816, 集成=0.817 > 45: 单个=0.816, 集成=0.818 > 46: 单个=0.817, 集成=0.818 > 47: 单个=0.812, 集成=0.818 > 48: 单个=0.811, 集成=0.818 > 49: 单个=0.810, 集成=0.818 > 50: 单个=0.811, 集成=0.818 |
粗略地说,我们可以看到集成模型似乎优于大多数单一模型,始终保持约 81.8% 的准确率。
接下来,报告单一模型准确率的分布。我们可以看到,随机选择任何一个保存的模型,其准确率平均为 81.6%,标准差为 0.3%,非常紧凑。
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。建议运行示例几次并比较平均结果。
我们要求水平集成模型优于这个平均值才能有用。
|
1 |
准确度 0.816 (0.003) |
最后,创建一个图表,总结每个单一模型(蓝色圆点)和包含 1 到 50 个成员的集成模型的性能。
从蓝色圆点可以看出,模型在训练周期内没有结构,例如,如果在训练过程中最后几个模型更好,那么准确率从左到右会呈下降趋势。
我们可以看到,随着我们添加更多的集成成员,水平投票集成模型的性能(橙色线)越好。在这个问题上,我们可能会看到在 23 到 33 个训练周期之间性能趋于平稳;这可能是一个不错的选择。
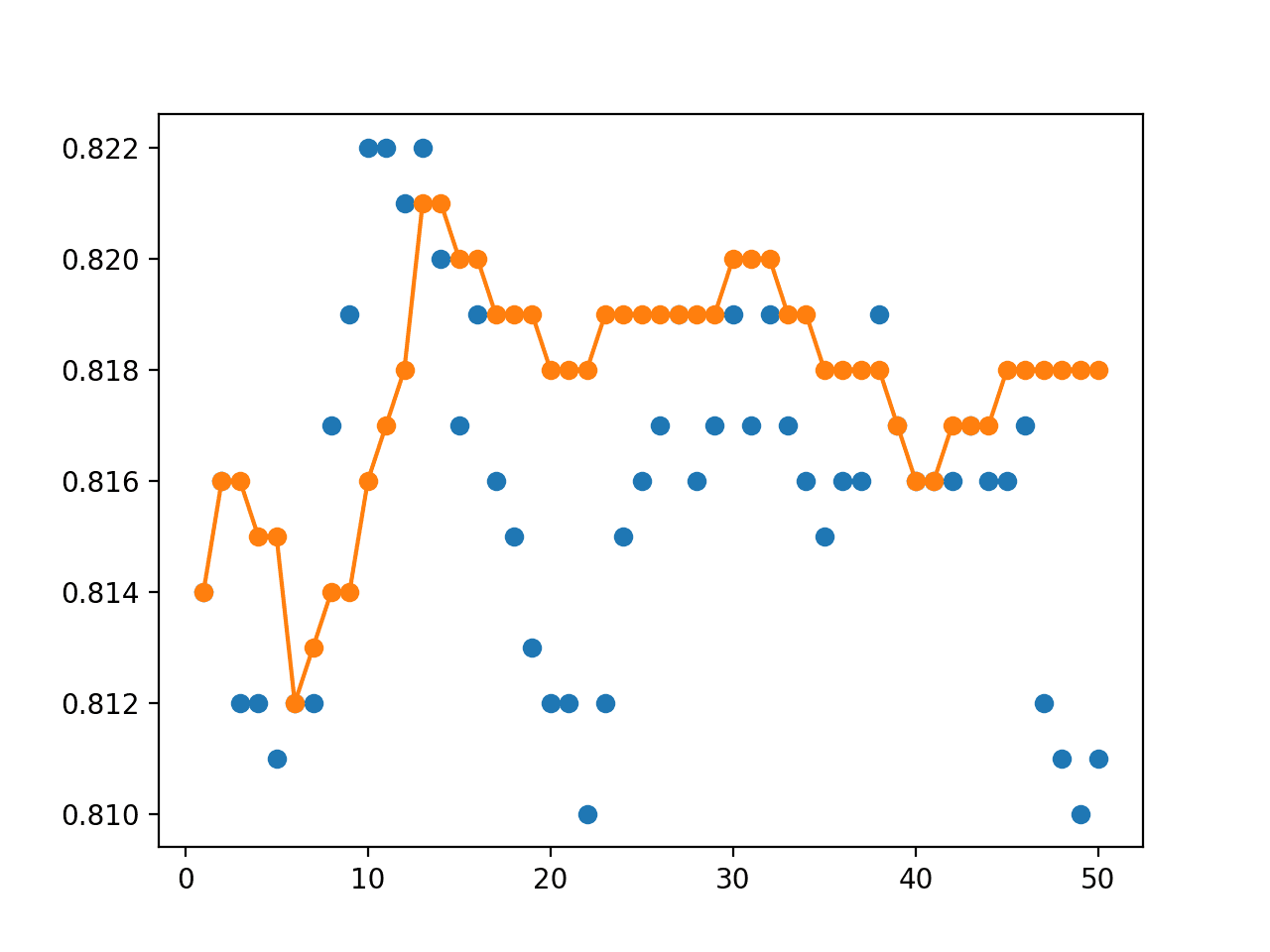
显示单个模型准确率(蓝色圆点)与具有水平投票集成的不同大小集成模型准确率的线图
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 数据集大小。使用更小或更大尺寸的数据集重复实验,并保持类似的训练与测试样本比例。
- 更大的集成模型。使用数百个最终模型重新运行示例,并报告大型集成模型大小对测试集准确率的影响。
- 模型的随机抽样。重新运行示例,并比较具有相同大小、通过连续训练周期保存的模型与随机选择的保存模型的集成性能。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 带有深度表示的水平和垂直分类集成, 2013.
API
- Keras 顺序模型入门
- Keras核心层API
- scipy.stats.mode API
- numpy.argmax API
- sklearn.datasets.make_blobs API
- 我如何保存 Keras 模型?
- Keras回调API
总结
在本教程中,您学习了如何使用水平投票集成来减少最终深度学习神经网络模型的方差。
具体来说,你学到了:
- 选择在训练数据集上具有高方差的最终神经网络模型具有挑战性。
- 水平投票集成提供了一种通过单次训练运行来减少方差并提高具有高方差模型的平均模型性能的方法。
- 如何使用Python中的Keras开发一个水平投票集成模型,以提高多层感知器模型在多类分类中的最终性能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







布朗利博士,您好,
我们如何将 K 折交叉验证与这种集成策略一起使用?比如说,我想使用 10 折交叉验证评估模型,那么将有 10 个子集。我们需要为每个子集保存 50 个模型吗?您能分享一些这方面的信息吗?
最诚挚的问候,谢谢!
Ankush
也许您可以在内存中评估所有模型。
也许交叉验证不适用于如此复杂的集成。
也许您可以简化实现并将复杂性抽象到 API 后面。
先生,我们如何将水平集成应用于我们的 CSV 数据
上面的代码示例对您不起作用吗?
先生,请帮助我解决这个错误
ValueError: (‘无效的
distribution参数:预期为 {“normal”, “uniform”} 之一,但得到’,’truncated_normal’)我无法看到这里的代码提供了 truncated_normal。但如果您仍然看到它,很可能是您在代码中混合了不兼容的包版本。
先生,我正在将此代码与我的数据集一起使用
# 从文件加载模型
def load_all_models(n_start, n_end)
all_models = list()
for epoch in range(n_start, n_end)
# 为此集成定义文件名
filename = ‘models/model_’ + str(epoch) + ‘.h5’
# 从文件加载模型
model = load_model(filename)
# 添加到成员列表
all_models.append(model)
print(‘>已加载 %s’ % filename)
return all_models
# 为多类分类进行集成预测
def ensemble_predictions(members, testX)
# 进行预测
yhats = [model.predict(testX) for model in members]
yhats = array(yhats)
# 对集成成员求和
summed = numpy.sum(yhats, axis=0)
# 对类别求argmax
result = argmax(summed, axis=1)
return result
# 评估集成中的特定数量成员
def evaluate_n_members(members, n_members, testX, testy)
# 选择成员子集
subset = members[:n_members]
# 进行预测
yhat = ensemble_predictions(subset, testX)
# 计算准确率
return accuracy_score(testy, yhat)
# 生成二维分类数据集
# 加载数据集
dataframe = read_csv(“parkdata.csv”, delimiter=”,”)
# 分割为输入 (X) 和输出 (Y) 变量
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
print(X.shape, y.shape)
#X = dataset[:,0:10]
# 确保所有数据都是浮点值
X = X.astype(‘float32’)
# 将字符串编码为整数
y = LabelEncoder().fit_transform(y)
# 分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
# 确定输入特征的数量
n_features = X.shape[1]
# 按顺序加载模型
members = load_all_models(950, 1000)
print(‘已加载 %d 个模型’ % len(members))
# 反转已加载的模型,以便我们先构建最后一个模型的集成
members = list(reversed(members))
# 在保留集上评估不同数量的集成
single_scores, ensemble_scores = list(), list()
for i in range(1, len(members)+1)
# 评估具有 i 个成员的模型
ensemble_score = evaluate_n_members(members, i, X_test, y_test)
# 单独评估第 i 个模型
testy_enc = to_categorical(y_test)
_, single_score = members[i-1].evaluate(X_test, testy_enc, verbose=0)
# 总结此步骤
print(‘> %d: 单个=%.3f, 集成=%.3f’ % (i, single_score, ensemble_score))
ensemble_scores.append(ensemble_score)
single_scores.append(single_score)
# 总结单个最终模型的平均准确度
print(‘准确度 %.3f (%.3f)’ % (mean(single_scores), std(single_scores)))
# 绘制分数与集成成员数量的关系
x_axis = [i for i in range(1, len(members)+1)]
pyplot.plot(x_axis, single_scores, marker=’o’, linestyle=’None’)
pyplot.plot(x_axis, ensemble_scores, marker=’o’)
pyplot.show()
并收到以下错误
ValueError: (‘无效的
distribution参数:预期为 {“normal”, “uniform”} 之一,但得到’,’truncated_normal’)先生,如果我将激活函数更改为 uniform,它会给出以下错误
# 使用水平投票集成加载模型并进行预测
from sklearn.datasets import make_blobs
from sklearn.metrics import accuracy_score
from keras.utils import to_categorical
from keras.models import load_model
来自 keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
from numpy import mean
from numpy import std
import numpy
from numpy import array
from numpy import argmax
# 从文件加载模型
def load_all_models(n_start, n_end)
all_models = list()
for epoch in range(n_start, n_end)
# 为此集成定义文件名
filename = ‘models1/model_’ + str(epoch) + ‘.h5’
# 从文件加载模型
model = load_model(filename)
# 添加到成员列表
all_models.append(model)
print(‘>已加载 %s’ % filename)
return all_models
# 为多类分类进行集成预测
def ensemble_predictions(members, testX)
# 进行预测
yhats = [model.predict(testX) for model in members]
yhats = array(yhats)
# 对集成成员求和
summed = numpy.sum(yhats, axis=0)
# 对类别求argmax
result = argmax(summed, axis=1)
return result
# 评估集成中的特定数量成员
def evaluate_n_members(members, n_members, X_test, y_test)
# 选择成员子集
subset = members[:n_members]
# 进行预测
yhat = ensemble_predictions(subset, X_test)
# 计算准确率
return accuracy_score(y_test, yhat)
# 生成二维分类数据集
# 加载数据集
dataframe = read_csv(“parkdata.csv”, delimiter=”,”)
# 分割为输入 (X) 和输出 (Y) 变量
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
print(X.shape, y.shape)
#X = dataset[:,0:10]
# 确保所有数据都是浮点值
X = X.astype(‘float32’)
# 将字符串编码为整数
y = LabelEncoder().fit_transform(y)
# 分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
# 确定输入特征的数量
n_features = X.shape[1]
# 按顺序加载模型
members = load_all_models(950, 1000)
print(‘已加载 %d 个模型’ % len(members))
# 反转已加载的模型,以便我们先构建最后一个模型的集成
members = list(reversed(members))
# 在保留集上评估不同数量的集成
single_scores, ensemble_scores = list(), list()
for i in range(1, len(members)+1)
# 评估具有 i 个成员的模型
ensemble_score = evaluate_n_members(members, i, X_test, y_test)
# 单独评估第 i 个模型
testy_enc = to_categorical(y_test)
_, single_score = members[i-1].evaluate(X_test, testy_enc, verbose=0)
# 总结此步骤
print(‘> %d: 单个=%.3f, 集成=%.3f’ % (i, single_score, ensemble_score))
ensemble_scores.append(ensemble_score)
single_scores.append(single_score)
# 总结单个最终模型的平均准确度
print(‘准确度 %.3f (%.3f)’ % (mean(single_scores), std(single_scores)))
# 绘制分数与集成成员数量的关系
x_axis = [i for i in range(1, len(members)+1)]
pyplot.plot(x_axis, single_scores, marker=’o’, linestyle=’None’)
pyplot.plot(x_axis, ensemble_scores, marker=’o’)
pyplot.show()
文件 “C:\Users\LENOVO\.spyder-py3\untitled15.py”,第 80 行,在
members = load_all_models(950, 1000)
文件 “C:\Users\LENOVO\.spyder-py3\untitled15.py”,第 37 行,在 load_all_models
model = load_model(filename)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\engine\saving.py”,第 492 行,在 load_wrapper
return load_function(*args, **kwargs)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\engine\saving.py”,第 584 行,在 load_model
model = _deserialize_model(h5dict, custom_objects, compile)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\engine\saving.py”,第 274 行,在 _deserialize_model
model = model_from_config(model_config, custom_objects=custom_objects)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\engine\saving.py”,第 627 行,在 model_from_config
return deserialize(config, custom_objects=custom_objects)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\layers\__init__.py”,第 168 行,在 deserialize
printable_module_name='layer')
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\utils\generic_utils.py”,第 147 行,在 deserialize_keras_object
list(custom_objects.items())))
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\engine\sequential.py”,第 301 行,在 from_config
custom_objects=custom_objects)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\layers\__init__.py”,第 168 行,在 deserialize
printable_module_name='layer')
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\utils\generic_utils.py”,第 149 行,在 deserialize_keras_object
return cls.from_config(config[‘config’])
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\engine\base_layer.py”,第 1179 行,在 from_config
return cls(**config)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\legacy\interfaces.py”,第 91 行,在 wrapper
return func(*args, **kwargs)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\layers\core.py”,第 877 行,在 __init__
self.kernel_initializer = initializers.get(kernel_initializer)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\initializers.py”,第 515 行,在 get
return deserialize(identifier)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\initializers.py”,第 510 行,在 deserialize
printable_module_name=’initializer’)
文件 “C:\Users\LENOVO\anaconda3\envs\tensorflow\lib\site-packages\keras\utils\generic_utils.py”,第 140 行,在 deserialize_keras_object
‘: ‘ + class_name)
ValueError: 未知初始化器:GlorotUniform
我无法调试您的代码,但您愿意卸载您的库并重新安装吗?
您好!本教程非常棒,但是代码返回了许多错误。我建议上传或附上已经测试过且状况良好的 .ipynb 或 python 代码,这样我们就可以专注于理解概念而不是解决语法问题。我是您忠实的粉丝,先生,我关注着您。
—————————————————————————
ValueError 回溯 (最近一次调用)
in ()
1 # 拟合模型
—-> 2 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=1000, verbose=0)
1 帧
/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/func_graph.py 中的 autograph_handler(*args, **kwargs)
1145 except Exception as e: # pylint:disable=broad-except
1146 if hasattr(e, “ag_error_metadata”)
-> 1147 raise e.ag_error_metadata.to_exception(e)
1148 else
1149 raise
ValueError:在用户代码中
文件 “/usr/local/lib/python3.7/dist-packages/keras/engine/training.py”,第 1021 行,在 train_function *
返回step_function(self, iterator)
文件 “/usr/local/lib/python3.7/dist-packages/keras/engine/training.py”,第 1010 行,在 step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
文件 “/usr/local/lib/python3.7/dist-packages/keras/engine/training.py”,第 1000 行,在 run_step **
outputs = model.train_step(data)
文件 “/usr/local/lib/python3.7/dist-packages/keras/engine/training.py”,第 860 行,在 train_step
loss = self.compute_loss(x, y, y_pred, sample_weight)
文件 “/usr/local/lib/python3.7/dist-packages/keras/engine/training.py”,第 919 行,在 compute_loss
y, y_pred, sample_weight, regularization_losses=self.losses)
文件 “/usr/local/lib/python3.7/dist-packages/keras/engine/compile_utils.py”,第 201 行,在 __call__
loss_value = loss_obj(y_t, y_p, sample_weight=sw)
文件 “/usr/local/lib/python3.7/dist-packages/keras/losses.py”,第 141 行,在 __call__
losses = call_fn(y_true, y_pred)
文件 “/usr/local/lib/python3.7/dist-packages/keras/losses.py”,第 245 行,在 call **
return ag_fn(y_true, y_pred, **self._fn_kwargs)
文件 “/usr/local/lib/python3.7/dist-packages/keras/losses.py”,第 1790 行,在 categorical_crossentropy
y_true, y_pred, from_logits=from_logits, axis=axis)
文件 “/usr/local/lib/python3.7/dist-packages/keras/backend.py”,第 5083 行,在 categorical_crossentropy
target.shape.assert_is_compatible_with(output.shape)
ValueError: 形状 (None, 1) 和 (None, 3) 不兼容