注意力机制是为了提高机器翻译中 Encoder-Decoder RNN 的性能而开发的。
在本教程中,您将了解 Encoder-Decoder 模型中的注意力机制。
完成本教程后,您将了解:
- 关于 Encoder-Decoder 模型和机器翻译的注意力机制。
- 如何一步一步实现注意力机制。
- 注意力机制的应用和扩展。
通过我的新书《NLP 深度学习》启动您的项目,书中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 更新于 2017 年 12 月:修复了第四步中的一个小错别字,感谢 Cynthia Freeman。
教程概述
本教程分为4个部分,它们是:
- 编码器-解码器模型
- 注意力模型
- 注意力机制的实际应用示例
- 注意力的扩展
编码器-解码器模型
循环神经网络的 Encoder-Decoder 模型在两篇论文中被提出。
两者都开发了这项技术来解决机器翻译中输入序列和输出序列长度不同的序列到序列的性质。
Ilya Sutskever 等人在论文《Sequence to Sequence Learning with Neural Networks》中使用了 LSTM 来实现。
Kyunghyun Cho 等人在论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中也提出了该模型。这项工作以及一些相同的作者(Bahdanau、Cho 和 Bengio)后来开发了他们特定的模型来开发注意力模型。因此,我们将快速回顾一下该论文中描述的 Encoder-Decoder 模型。
从高层次来看,该模型由两个子模型组成:一个编码器和一个解码器。
- 编码器:编码器负责遍历输入时间步,并将整个序列编码成一个固定长度的向量,称为上下文向量。
- 解码器:解码器负责遍历输出时间步,同时读取上下文向量。
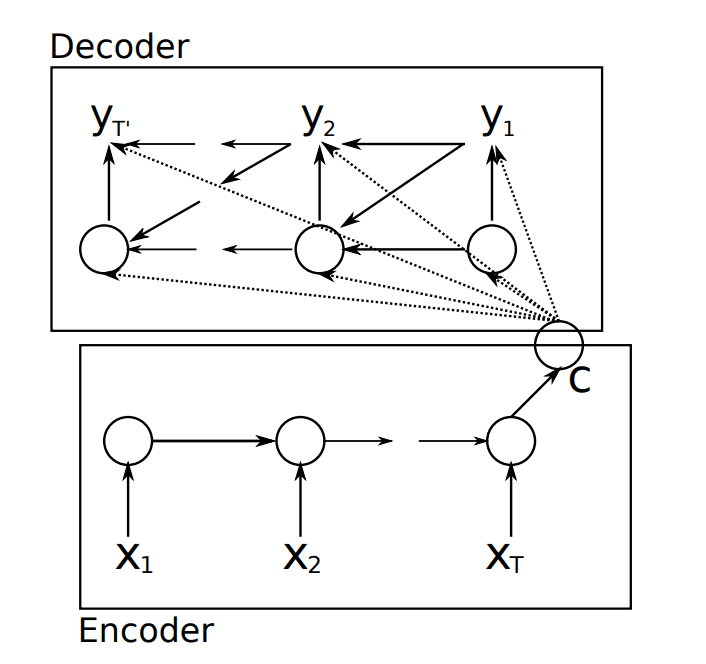
Encoder-Decoder 循环神经网络模型。
摘自“Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation”
我们提出了一个新颖的神经网络架构,该架构学会将可变长度序列编码为固定长度向量表示,并将给定的固定长度向量表示解码回可变长度序列。
— Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation, 2014。
该模型的关键在于,整个模型(包括编码器和解码器)是端到端训练的,而不是单独训练各个部分。
该模型是通用描述的,因此可以使用不同的特定 RNN 模型作为编码器和解码器。
作者没有使用流行的长短期记忆(LSTM)RNN,而是开发并使用了他们自己的简单类型的 RNN,后来称为门控循环单元(GRU)。
此外,与 Sutskever 等人的模型不同,解码器在前一个时间步的输出被作为输入来解码下一个输出时间步。您可以在上图看到,输出 y2 使用了上下文向量 (C),以及从解码 y1 传递过来的隐藏状态和输出 y1。
…… y(t) 和 h(i) 都依赖于 y(t−1) 和输入序列的摘要 c。
— Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation, 2014
注意力模型
注意力机制由 Dzmitry Bahdanau 等人在其论文《Neural Machine Translation by Jointly Learning to Align and Translate》中提出,该论文可以看作是他们之前关于 Encoder-Decoder 模型工作的自然延伸。
注意力机制被提出是为了解决 Encoder-Decoder 模型将输入序列编码成一个固定长度向量,并从中解码每个输出时间步的局限性。据信,当解码长序列时,这个问题会更加突出。
这种编码器-解码器方法的一个潜在问题是,神经网络需要能够将源句子的所有必要信息压缩成一个固定长度的向量。这可能使神经网络难以处理长句子,尤其是那些比训练语料库中的句子更长的句子。
— Neural Machine Translation by Jointly Learning to Align and Translate, 2015。
注意力机制被提议作为一种同时进行对齐和翻译的方法。
对齐是机器翻译中识别输入序列的哪些部分与输出中的每个单词相关的过程,而翻译是使用相关信息选择适当输出的过程。
……我们引入了一种对编码器-解码器模型的扩展,该模型可以同时学习对齐和翻译。每次模型生成一个翻译单词时,它都会(软)搜索源句子中的一组位置,其中最相关的信息集中在那里。然后,模型根据与这些源位置相关的上下文向量以及所有先前生成的目标单词来预测目标单词。
— Neural Machine Translation by Jointly Learning to Align and Translate, 2015。
注意力模型不是将输入序列编码成一个单一的固定上下文向量,而是为每个输出时间步开发一个专门过滤的上下文向量。
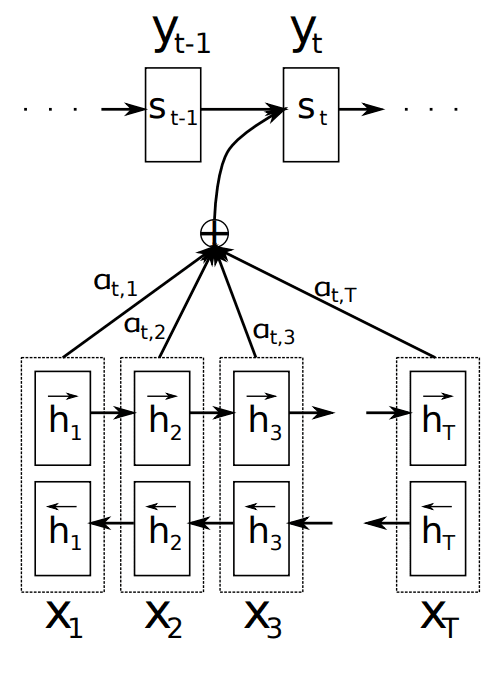
注意力机制示例
摘自“Neural Machine Translation by Jointly Learning to Align and Translate”,2015。
与 Encoder-Decoder 论文一样,该技术应用于机器翻译问题,并使用 GRU 单元而不是 LSTM 记忆单元。在这种情况下,使用双向输入,输入序列同时以正向和反向提供,然后将它们连接起来再传递给解码器。
为了避免重复计算注意力的公式,我们将通过一个实际示例来理解。
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
注意力机制的实际应用示例
在本节中,我们将通过一个小的实际示例来具体说明注意力机制。具体来说,我们将通过非向量化项来逐步介绍计算过程。
这将为您提供足够详细的理解,使您能够将注意力机制添加到您自己的 Encoder-Decoder 实现中。
这个实际示例分为以下 6 个部分
- 问题
- 编码
- 对齐
- 加权
- 上下文向量
- 解码
1. 问题
这个问题是一个简单的序列到序列预测问题。
有三个输入时间步
|
1 |
x1, x2, x3 |
模型需要预测 1 个时间步
|
1 |
y1 |
在本例中,我们将忽略 Encoder 和 Decoder 中使用的 RNN 类型,并忽略双向输入层的用法。这些元素对于理解 Decoder 中注意力的计算并不重要。
2. 编码
在 Encoder-Decoder 模型中,输入将被编码为单个固定长度的向量。这是 Encoder 模型在最后一个时间步的输出。
|
1 |
h1 = Encoder(x1, x2, x3) |
注意力模型需要访问 Encoder 在每个输入时间步的输出。论文称这些为每个时间步的“注释”。在本例中
|
1 |
h1, h2, h3 = Encoder(x1, x2, x3) |
3. 对齐
Decoder 一次输出一个值,该值可能被传递给更多层,最后输出当前输出时间步的预测 (y)。
对齐模型对每个编码的输入 (h) 与 Decoder 的当前输出 (s) 的匹配程度进行评分 (e)。
评分的计算需要 Decoder 在前一个输出时间步的输出,例如 s(t-1)。在为 Decoder 的第一个输出评分时,它将是 0。
评分使用函数 a() 进行。我们可以为第一个输出时间步的每个注释 (h) 进行评分,如下所示:
|
1 2 3 |
e11 = a(0, h1) e12 = a(0, h2) e13 = a(0, h3) |
我们对这些分数使用两个下标,例如 e11,其中第一个“1”表示输出时间步,第二个“1”表示输入时间步。
我们可以想象,如果我们有一个具有两个输出时间步的序列到序列问题,那么稍后我们可以为第二个时间步的注释评分(假设我们已经计算了 s1)
|
1 2 3 |
e21 = a(s1, h1) e22 = a(s1, h2) e23 = a(s1, h3) |
函数 a() 在论文中被称为对齐模型,并实现为前馈神经网络。
这是一个传统的一层网络,其中每个输入(s(t-1) 和 h1、h2、h3)都被加权,使用双曲正切 (tanh) 激活函数,输出也被加权。
4. 加权
接下来,使用 softmax 函数对对齐分数进行归一化。
分数的归一化允许它们被视为概率,指示每个编码的输入时间步(注释)与当前输出时间步相关的可能性。
这些归一化分数称为注释权重。
例如,给定计算出的对齐分数 (e),我们可以按如下方式计算 softmax 注释权重 (a):
|
1 2 3 |
a11 = exp(e11) / (exp(e11) + exp(e12) + exp(e13)) a12 = exp(e12) / (exp(e11) + exp(e12) + exp(e13)) a13 = exp(e13) / (exp(e11) + exp(e12) + exp(e13)) |
如果我们有两个输出时间步,第二个输出时间步的注释权重将按如下方式计算:
|
1 2 3 |
a21 = exp(e21) / (exp(e21) + exp(e22) + exp(e23)) a22 = exp(e22) / (exp(e21) + exp(e22) + exp(e23)) a23 = exp(e23) / (exp(e21) + exp(e22) + exp(e23)) |
5. 上下文向量
接下来,每个注释 (h) 都乘以注释权重 (a),以生成一个新的注意力上下文向量,从中可以解码当前的输出时间步。
为了简化,我们只有一个输出时间步,因此我们可以如下计算单个元素的上下文向量(使用括号方便阅读):
|
1 |
c1 = (a11 * h1) + (a12 * h2) + (a13 * h3) |
上下文向量是注释的加权和,并经过归一化的对齐分数。
如果我们有两个输出时间步,上下文向量将包含两个元素 [c1, c2],计算如下:
|
1 2 |
c1 = a11 * h1 + a12 * h2 + a13 * h3 c2 = a21 * h1 + a22 * h2 + a23 * h3 |
6. 解码
解码然后按照 Encoder-Decoder 模型进行,但在此情况下使用当前时间步的注意力上下文向量。
Decoder 的输出 (s) 在论文中被称为隐藏状态。
|
1 |
s1 = Decoder(c1) |
这可能会被馈送到额外的层,最终作为该时间步的预测 (y1) 输出模型。
注意力的扩展
本节将探讨 Bahdanau 等人的注意力机制的一些额外应用。
硬注意力和软注意力
在 2015 年的论文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》中,Kelvin Xu 等人将注意力机制应用于图像数据,使用卷积神经网络作为图像数据的特征提取器来解决照片字幕生成问题。
他们开发了两种注意力机制,一种称为“软注意力”,它类似于上述带有加权上下文向量的注意力机制,第二种称为“硬注意力”,它针对每个单词对上下文向量中的元素做出明确的决策。
他们还提出了双重注意力,即将注意力集中在图像的特定部分。
丢弃前一个隐藏状态
有一些应用对该机制进行了简化,使得最后一个输出时间步的隐藏状态 (s(t-1)) 被从注释评分(如上第 3 步)中移除。
有两个例子:
- 文档分类的层次注意力网络, 2016.
- 用于关系分类的基于注意力的双向长短期记忆网络, 2016
其效果是模型没有获得前一个解码输出的信息,而这本应有助于对齐。
这在论文中的方程中有体现,并且不清楚这是对模型有意进行的更改,还是仅仅是方程中的遗漏。在两篇论文中都没有看到对丢弃该项的讨论。
研究前一个隐藏状态
Minh-Thang Luong 等人在其 2015 年的论文《Effective Approaches to Attention-based Neural Machine Translation》中明确重构了前一个解码器隐藏状态在注释评分中的使用。另请参见论文的演示和相关 Matlab 代码。
他们开发了一个框架来对比评分注释的不同方法。他们的框架明确列出了注释评分中不包括前一个隐藏状态。
取而代之的是,他们将前一个注意力上下文向量作为输入传递给解码器。目的是让解码器了解过去的对齐决策。
……我们提出了一种输入馈送方法,其中注意力向量 ht 在下一个时间步与输入连接(……)。具有此类连接的效果是双重的:(a) 我们希望模型充分了解先前的对齐选择,(b) 我们创建了一个跨越水平和垂直方向的非常深的网络。
— Effective Approaches to Attention-based Neural Machine Translation, 2015。
下图是该论文中此方法的图片。请注意虚线明确显示了解码器的注意力隐藏状态输出 (ht) 如何在下一个时间步为解码器提供输入。
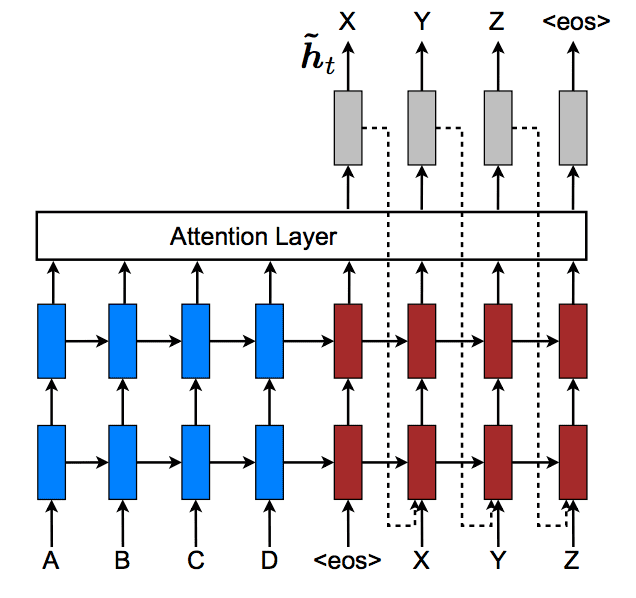
将隐藏状态作为输入馈送给解码器
摘自“Effective Approaches to Attention-based Neural Machine Translation”,2015。
他们还开发了“全局”与“局部”注意力,其中局部注意力是对该方法的一种修改,该方法学习一个固定大小的窗口来应用于每个输出时间步的注意力向量。这被视为 Xu 等人提出的“硬注意力”的一种更简单的方法。
全局注意力有一个缺点,那就是它必须为每个目标词关注源端的所有词,这很昂贵,而且可能使翻译长序列(例如段落或文档)变得不切实际。为了解决这个缺陷,我们提出了一种局部注意力机制,该机制选择在每个目标词上只关注源位置的一小部分。
— Effective Approaches to Attention-based Neural Machine Translation, 2015。
该论文对全局和局部注意力以及不同注释评分函数的分析表明,局部注意力在翻译任务上能提供更好的结果。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
Encoder-Decoder 论文
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation, 2014.
- 使用神经网络进行序列到序列学习, 2014.
注意力论文
- 通过联合学习对齐和翻译的神经机器翻译, 2015.
- 展示、关注和讲述:带视觉注意力的神经图像标题生成, 2015.
- 文档分类的层次注意力网络, 2016.
- 用于关系分类的基于注意力的双向长短期记忆网络, 2016
- 基于注意力的神经机器翻译的有效方法, 2015.
更多关于注意力机制
- 长短期记忆循环神经网络中的注意力机制
- 讲座 10:神经机器翻译和带注意力的模型,斯坦福大学,2017
- 讲座 8 – 使用注意力生成语言,牛津大学。
总结
在本教程中,您了解了 Encoder-Decoder 模型中的注意力机制。
具体来说,你学到了:
- 关于 Encoder-Decoder 模型和机器翻译的注意力机制。
- 如何一步一步实现注意力机制。
- 注意力机制的应用和扩展。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。






老师您好,感谢您的精彩教程。我不太理解上下文向量在模型中的实际用途。我们应该将状态向量 s_t 与 c_t 拼接([s_t;c_t])还是在计算完 c_t 后用 c_t 替换 s_t?
很好的问题。
它通常用作解码器的初始状态。
或者,它也可以用作解码器的输入,或者用作解码器下游的输入,正如您所描述的那样。
你好,
我一直在努力解决机器翻译中的注意力问题。
如果上下文向量作为初始状态传递给解码器,那么它会不会在所有时间步上传播?它如何在每个时间步获取新的上下文向量?
另外,初始状态需要隐藏状态和单元状态(上下文向量)。如果我初始化解码器状态,应该用什么代替隐藏状态?
如果我将上下文向量作为输入提供给解码器 LSTM,会出现形状问题。
请提供帮助。
你好,
我是这个领域的新手,我参加了 Andrew Ng 在 Coursera 上的序列模型课程。在他的注意力模型实现中,上下文向量实际上是作为输入进入解码器 LSTM 的,而不是作为初始状态。
示例代码如下(使用 Keras):
decoder_LSTM_cell = LSTM(128, return_state = True)
context = output_of_attention
s, _, c = decoder_LSTM_cell(context, initial_state = [s,c])
其中 s 和 c 是解码器 LSTM 在每个时间步的隐藏状态和单元状态。
非常感谢,Jason。
但是我的问题是,如果上下文向量 Ci 是时间步 i 的解码器的 initial_state,那么它的初始单元状态是什么?我的理解是,我们需要为 LSTM 单元提供隐藏状态和单元状态。谢谢!
很棒的教程。
在实际示例中,您说“有三个输入时间步”。为什么是三个?是因为您设置问题的方式而决定是三个吗?还是说,定义上,Encoder Decoder with Attention 总是会有三个时间步?也许是因为您决定设置问题,使其有三个 token(单词)输入?(我感觉我的问题表明了极大的无知。我应该先阅读更基础的教程吗?)
这是任意的,只是作为一个例子。
为了准确起见,我认为您在第 4 步中是指 a13 和 a23,而不是两次 a12 和 a22。
谢谢 Cynthia,已修复!
嗨,Jason,
这是一篇很棒的文章!!
我有一个问题,在对齐部分,e 是用来告诉 h1、h2... 与当前“s”匹配程度的分数,然后继续计算权重并形成上下文向量。最后我们解码上下文向量以获得“s”。第一个“s”和第二个“s”之间有什么区别?所有的分数和权重都是从第一个“s”派生出来的,然后我们用这些值来得到“s”?这对我来说似乎很奇怪……我理解得对吗?谢谢!
你好,
据我所知,“s”恰好是解码器 LSTM 的隐藏状态输出,您没有考虑 LSTM 层和时间步的差异,这介于上下文向量和隐藏输出“s”之间。
特定时间步的上下文向量是在解码器 LSTM 上一个时间步的输出(“s”)和编码器 LSTM 的隐藏状态输出的帮助下生成的。
所以,在您的问题中,第一个“s”实际上是解码器 LSTM 上一个时间步的输出,它用于生成当前时间步的上下文向量,然后将其作为输入馈送给解码器 LSTM,这会生成您问题中的第二个“s”。然后,这个“s”将在下一个时间步等中使用。
Jason 您好,感谢您的文章!
我一直在网上寻找这个问题的答案,但一直找不到——大家都对此保持沉默。
因为对齐模型 a() 内部包含一个矩阵,这是否意味着我们的 LSTM 被限制在固定数量的时间步?换句话说,我的英译法翻译必须包含,例如,正好 10 个英文字符才能翻译成,例如,正好 12 个法文字符?
强加这个限制似乎很重要,因为 LSTM 必须学习输入状态的权重,因此时间步的数量必须永不改变——我说的对吗?
然后这将大大抵消 RNN 的大部分优势
是的。
不,您可以处理长序列,例如一次处理一个段落。
嗨,Jason,
我最近读了一篇论文,其中 LSTM 神经网络的注意力机制被用于时间序列预测
https://arxiv.org/abs/1704.02971
我正在考虑将其应用于北京污染数据集,看看它是否能比您在其中一个教程中提出的经典 LSTM 表现更好。
我想知道您的看法,以及您是否知道在时间序列预测中已经有实现,或者是否有任何有用的材料可供我使用/阅读。
非常感谢,
Marco
感谢您提供论文链接。我会阅读的。
我不知道是否有实现,也许您可以联系作者,看看他们是否愿意分享他们的代码?
字体太小了。但内容非常好!谢谢。
谢谢 Fred。
嘿 Jason,我想澄清一下关于上下文向量“c”的一个小疑问,即上下文向量的期望输出是什么……?它是一个数字还是一个向量数组?
一个向量。
能给我举个例子吗?🙂
对于“Instead of decoding the input sequence into a single fixed context vector…”这句,应该是“Instead of encoding the input sequence…”吧?
是的,是错别字。谢谢,已修复。
嗯,我可能有点笨,但我不明白这些——为什么这么复杂?
我之前在 OCR 上有个想法——我们不能就这样做吗?
将标签(一个词或句子)翻译成固定大小的向量——其中每个字符都获得一个特定的数字/索引(就像一个字典)
现在只需进行训练,然后告诉CNN将我的输入特征/激活映射到标签向量——它代表了我应该检测的单词。就是这样。
这有意义吗?现实吗?
我需要自定义损失函数吗?
感谢任何关于此事的评论。
在您的情况下,可能不需要注意力机制,这听起来像是一个直接的图像分类任务。
实际上你说得对!感谢您的回答,并帮助我重新思考🙂
不客气。
注意力模型如何用于从手写图像生成文本(字符序列)?
(手写识别和相应文本的生成)。
抱歉,我没有这方面的例子。
先生您好。解码器怎么知道何时结束?我的意思是,在翻译一个句子时,我们怎么知道目标句子应该有多少个词?
您可以决定停止调用它,或者它可以输出一个“序列结束”标记。
是的,但解码器怎么“知道”何时结束?这是训练的结果吗?这意味着解码器将EOS视为一个正常的单词,对吗?
它会学习序列的长度以及何时结束。
这适用于编码器-解码器类型的模型,例如作为示例的字幕生成器中的语言模型。
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/
“函数a()在论文中被称为对齐模型,并实现为一个前馈神经网络。”——关于函数a(.)的一个问题
它使用什么目标值?我的意思是,如果a(.)是“一个传统单层网络,其中每个输入(s(t-1)和h1、h2、h3)都被加权,使用双曲正切(tanh)激活函数,输出也被加权”,那么这个网络的目标值是什么?
提前感谢,我无法通过谷歌找到答案。
Jason又一篇优秀的教程。嘿Jason,这是互联网上关于编码器-解码器最清晰的解释。我只想提个请求。你能否做一个关于如何使用:tf.keras.layers.AdditiveAttention层的教程。因为Keras易于实现和理解,所以在其中使用Attention层也会很容易。所以,我请求Jason做一个关于这个的教程。
提前感谢!
抱歉,我的意思是关于注意力在编码器-解码器中最清晰的解释。
谢谢。
是的,我希望很快能写一些关于这个主题的新教程。
你好,Jason。本教程中您教授的注意力是Bahdanau注意力还是哪种注意力?
是的。
您能做一个关于如何实现这里描述的内容的教程吗?因为我刚开始接触机器学习。
是的。
你好 Jason,
a21 = exp(e21) / (exp(e21) + exp(e22) + exp(e23))
这里的exp是什么意思?
这是论文中描述的注意力层的一个方面的规范。
您能否做一个关于在Keras中对NLP任务实现这些内容的教程!
感谢您的建议。
你好Jason,我在机器翻译问题上测试了我的第一个Bahdanau注意力模型。但不幸的是,没有注意力机制的模型比有注意力机制的模型表现更好。这可能是什么原因?
也许注意力机制不适合您的模型。
也许您的模型需要进行微调。
也许需要另一种注意力机制。
…
您是否有带有注意力的编码器-解码器RNN的实际工作示例代码?如果有,您能否给我链接?
目前还没有。
Transformer网络与带有注意力层的编码器-解码器RNN有什么区别?
谢谢你。
抱歉,我没有关于Transformer的教程。我希望将来能写关于这个主题的文章。
您最好的文章之一!
谢谢!希望您喜欢。
你好。我感到困惑的是,当计算上下文向量时,他们说使用的是解码器的最后一个隐藏状态,但当我查看示例代码时,解码器直到时间步t-1的所有隐藏状态都用于注意力层。哪个是正确的?谢谢。
注意力应该包括所有时间步。
你好Jason,感谢精彩的教程。我希望您仍然在回答问题,尽管距离上次提问已有两年了……
在“编码”部分,您写道:
h1 = Encoder(x1, x2, x3) 但在下面两行您写道:
h1, h2, h3 = Encoder(x1, x2, x3)。
我的传统数学训练使我难以理解您的意思。Encoder函数要么返回一个结果(如h1),要么返回三个结果。是哪种情况?
或者,既然您说第一行返回的是*最后一个*时间步的结果,也许您指的是:
h3 = Encoder(x1, x2, x3)?
在这种情况下,一般表达式将是:h_i = Encoder(x_(i-2), x_(i-1), x_i)(下划线表示下标)。
如果您能弄清楚这一点,我将不胜感激!
你好Robert……这里有一份关于注意力数学的非常有启发性的资料。
https://www.youtube.com/watch?v=UPtG_38Oq8o
谢谢James。我同意,这个系列的全部三个视频都非常棒,并且回答了我大部分问题。