集成学习是一种机器学习方法,它结合了多个模型的预测结果,以期获得更好的预测性能。
集成学习有许多不同的类型,但所有方法都具备两个关键特性:它们要求贡献模型有所不同,以便它们产生不同的误差;它们结合预测结果,试图利用每个不同模型的优势。
然而,集成学习如何做到这一点尚不清楚,尤其是在分类和回归类型的预测建模问题中。理解集成学习在结合预测时究竟做了什么,对于在预测建模项目中选择和配置合适的模型至关重要。
在这篇文章中,你将探索集成学习方法工作原理背后的直觉。
阅读本文后,你将了解:
- 集成学习方法通过结合由贡献成员学习到的映射函数来工作。
- 分类集成学习最好通过成员的决策边界组合来理解。
- 回归集成学习最好通过成员的超平面组合来理解。
通过我的新书《使用Python的集成学习算法》启动你的项目,书中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。

建立对集成学习工作原理的直觉
图片由Marco Verch拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 集成学习是如何工作的
- 分类集成学习的直觉
- 回归集成学习的直觉
集成学习是如何工作的
集成学习指的是结合两个或更多模型的预测结果。
使用集成方法的目的是提高预测能力,使其优于任何单个贡献成员。
这个目标是直接的,但集成方法究竟如何实现这一点尚不清楚。
培养对集成技术工作原理的直觉至关重要,因为它将帮助你为预测任务选择和配置特定的集成方法,并解释其结果,从而提出进一步提高性能的替代方案。
考虑一个简单的集成,它在训练数据集的略微不同样本上训练两个模型并平均它们的预测。
每个成员模型都可以独立用于进行预测,但我们希望通过平均它们的预测来提高性能。只有当每个模型做出不同的预测时,这种情况才可能发生。
不同的预测意味着在某些情况下,模型1会犯少量错误,模型2会犯更多错误,而在其他情况下则相反。平均它们的预测旨在减少这两个模型所做预测中的这些错误。
反过来,要使模型做出不同的预测,它们必须对预测问题做出不同的假设。更具体地说,它们必须学习从输入到输出的不同映射函数。在简单情况下,我们可以通过在训练数据集的不同样本上训练每个模型来实现这一点,但还有许多其他方法可以实现这种差异;训练不同类型的模型就是其中之一。
这些要素是一般意义上集成方法的工作方式,即:
- 成员为同一个问题学习不同的映射函数。这是为了确保模型产生不同的预测误差。
- 成员做出的预测以某种方式进行组合。这是为了确保预测误差的差异得到利用。
我们不仅仅是平滑预测误差,尽管我们也可以这样做;相反,我们平滑了由贡献成员学习到的映射函数。
改进的映射函数可以做出更好的预测。
这是一个更深层次的观点,理解它很重要。让我们更仔细地看看它对分类和回归任务意味着什么。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
分类集成学习的直觉
分类预测建模指的是需要从输入示例中预测类别标签的问题。
模型可以预测明确的类别标签(例如,一个分类变量),或者所有可能的分类结果的概率。
在简单情况下,集成成员预测的明确类别标签可以通过投票来组合,例如,统计众数或得票最多的标签决定集成结果。集成成员预测的类别概率可以求和并归一化。
实际上,在分类任务中,集成学习正在进行类似这样的过程,但其影响体现在从输入示例到类别标签或概率的映射函数上。让我们暂时只关注标签。
思考分类映射函数最常见的方法是使用图表,其中输入数据代表由输入变量范围定义的n维空间中的一个点,称为特征空间。例如,如果我们有两个输入特征x和y,都在0到1的范围内,那么输入空间将是一个二维平面,数据集中的每个示例都将是该平面上的一个点。然后,根据类别标签,每个点可以被赋予颜色或形状。
学习如何分类点的模型实际上是在特征空间中绘制线条来分隔示例。我们可以通过在网格中采样特征空间中的点来获取模型如何根据每个类别标签划分特征空间的图。
模型在特征空间中对示例进行分离的过程称为决策边界,而模型如何在特征空间中对点进行分类的网格或图称为决策边界图。
现在考虑一个集成,其中每个模型都有不同的输入到输出的映射。实际上,每个模型都有不同的决策边界,或者对如何根据类别标签在特征空间中进行划分有不同的想法。每个模型将以不同的方式绘制线条并产生不同的错误。
当我们结合这些多个不同模型的预测时,实际上我们正在平均决策边界。我们正在定义一个新的决策边界,它试图从贡献成员学习到的所有关于特征空间的不同视图中学习。
下图摘自《集成机器学习》第1页,对此进行了有用的描述。
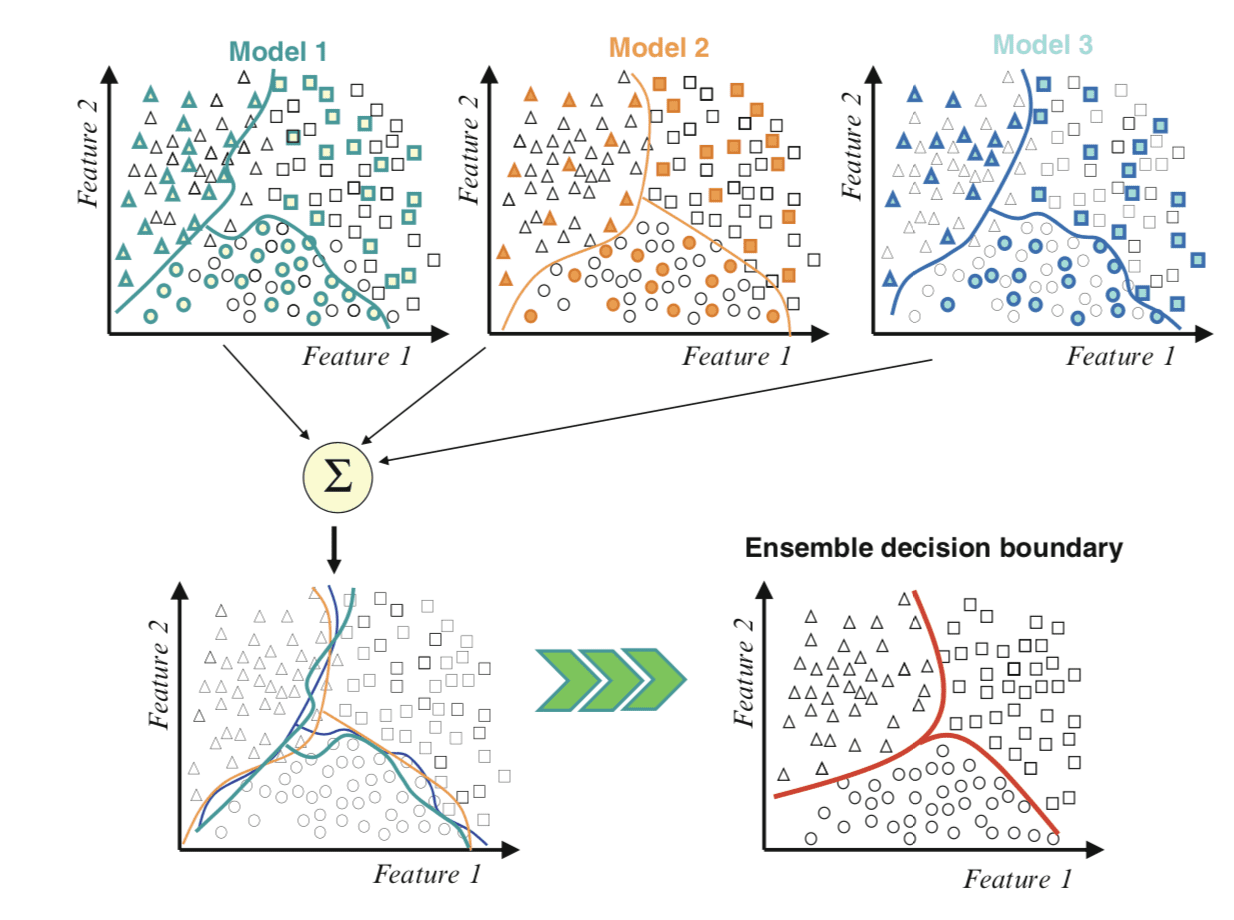
使用集成方法组合决策边界的示例
摘自《集成机器学习》,2012年。
我们可以看到顶部的贡献成员,每个成员在特征空间中都有不同的决策边界。然后,左下方将所有决策边界绘制在同一张图上,显示它们如何不同并产生不同的错误。
最后,我们可以将这些边界组合起来,在右下方创建一个新的广义决策边界,它能更好地捕捉特征空间的真实但未知的划分,从而带来更好的预测性能。
回归集成学习的直觉
回归预测建模指的是需要从输入示例中预测数值的问题。
在简单情况下,集成成员做出的数值预测可以使用均值等统计量进行组合,尽管也可以使用更复杂的组合方式。
与分类类似,集成学习的效果是每个贡献成员的映射函数被平均或组合。
思考回归映射函数最常见的方法是使用线图,其中输出变量是添加到输入特征空间的另一个维度。然后,特征空间和目标变量维度之间的关系可以概括为超平面,例如多维空间中的一条线。
这很费解,所以让我们考虑最简单的情况,我们有一个数值输入和一个数值输出。想象一个平面或图表,其中 x 轴表示输入特征,y 轴表示目标变量。我们可以将数据集中的每个示例作为该图表上的一个点进行绘制。
学习从输入到输出映射的模型实际上学习了一个连接特征空间中的点到目标变量的超平面。我们可以在输入特征空间中采样一个网格点,以推导出目标变量的值,并绘制一条线来连接它们以表示这个超平面。
在我们的二维情况下,这是一条穿过图中点的直线。任何直线没有穿过图中的点都表示一个预测误差,从直线到点的距离就是误差的大小。
现在考虑一个集成,其中每个模型都有不同的输入到输出的映射。实际上,每个模型都有不同的超平面将特征空间连接到目标。每个模型将绘制不同的线条并产生不同大小的误差。
当我们结合这些多个不同模型的预测时,我们实际上是在平均这些超平面。我们正在定义一个新的超平面,它试图从所有不同的特征中学习如何将输入映射到输出。
下图给出了一个一维输入特征空间和目标空间以及不同学习到的超平面映射的例子。
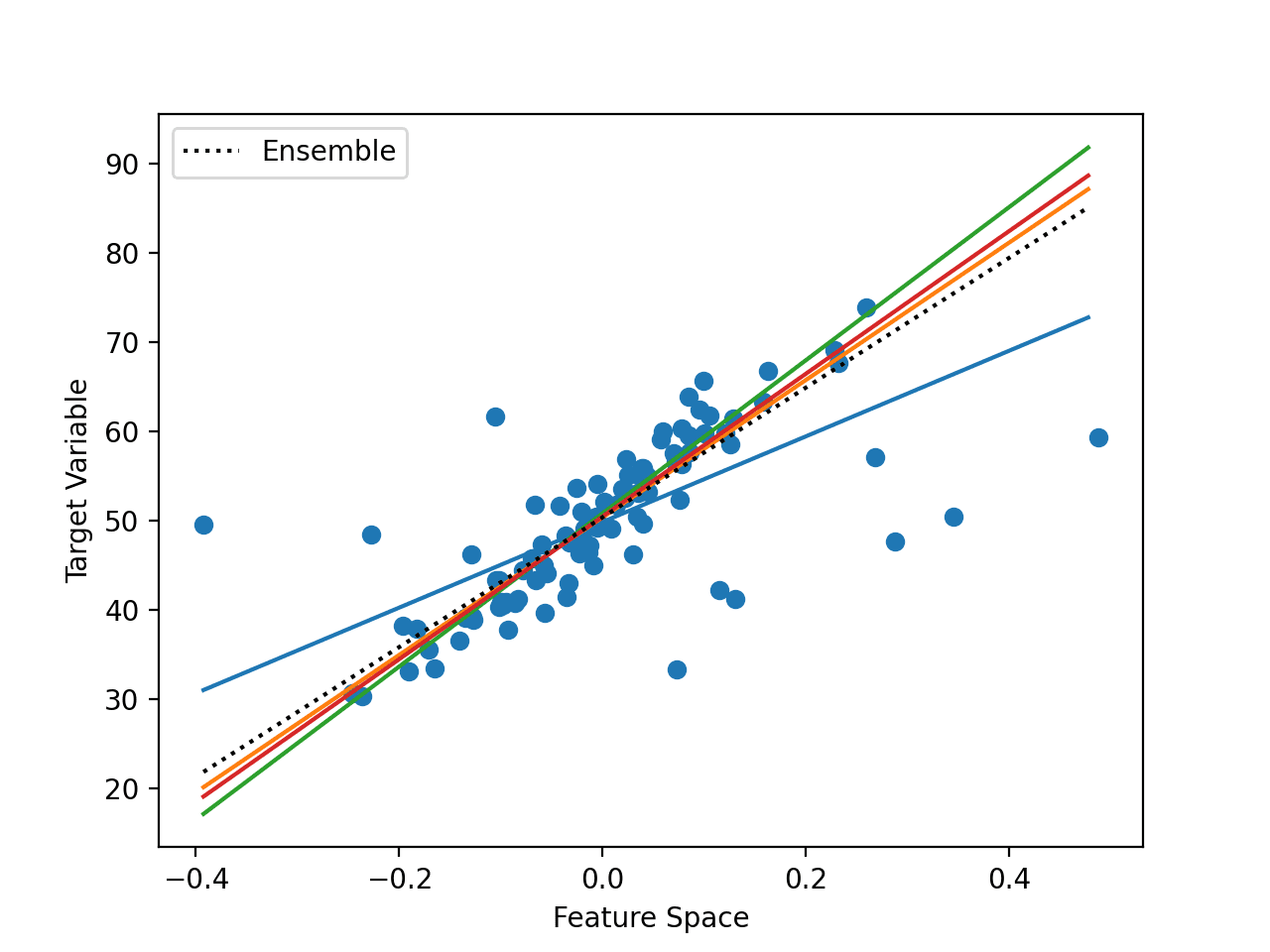
使用集成方法组合超平面的示例
我们可以看到代表训练数据集中点的圆点。我们还可以看到穿过数据的许多不同的直线。模型不必学习直线,但在此示例中,它们确实学习了直线。
最后,我们可以看到一条虚线黑线,显示了所有模型的集成平均值,从而降低了预测误差。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用集成方法进行模式分类, 2010.
- 集成方法, 2012.
- 集成机器学习, 2012.
- 数据挖掘中的集成方法, 2010.
文章
总结
在这篇文章中,你了解了集成学习方法工作原理背后的直觉。
具体来说,你学到了:
- 集成学习方法通过结合由贡献成员学习到的映射函数来工作。
- 分类集成学习最好通过成员的决策边界组合来理解。
- 回归集成学习最好通过成员的超平面组合来理解。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……






尊敬的Jason博士,
感谢您激起了我的兴趣,尤其是倒数第二张照片“使用集成方法组合决策边界的示例 摘自《集成机器学习》,2012年”
您是否已经做过或者能否在“鸢尾花数据集”上做一个使用集成方法组合决策边界的例子?我注意到我见过“花萼长度”与“花萼宽度”的四个不同鸢尾花种类的图。
这将是一个很好的例子,可以根据花萼宽度和花萼长度来预测花朵属于哪个物种。
谢谢你,
悉尼的Anthony
你可以使用任何你喜欢的集成方法来组合子模型的决策边界。
例如,绘制每个子模型的决策边界,然后使用投票集成方法,并绘制集成模型的边界进行比较。
尊敬的Jason博士,
您的网站上是否有任何Python代码,可以显示鸢尾花物种(setosa,virginica和versicolor)的“萼片长度”与“萼片宽度”之间的边界线,以及鸢尾花物种(setosa,virginica和versicolor)的“花瓣长度”与“花瓣宽度”之间的边界线——类似于https://i.stack.imgur.com/YijL7.png中的图表?
请您提供清晰的解释,特别是关于模型以及在一个物种边界内出现另一个物种数据的情况。
谢谢你,
没有,但是这个教程将向你展示如何为一个给定的数据集绘制这样的线条
https://machinelearning.org.cn/plot-a-decision-surface-for-machine-learning/
尊敬的Jason博士,
谢谢你。
此外,了解了该技术的名称,关键词是:绘图,决策面。
我找到了更多的网站。基本上,它与前面提到的网站“plot-a-decision-surface-for-machine-learning”中使用的技术相同。
关键是学习如何根据每个特征的最小值和最大值,而不是实际数据,来重构“数据”。从排列、网格化、扁平化的数据中,我们创建一个网格并对网格进行预测。
还有更多细节,但关键是学习如何重构数据。
谢谢你,
悉尼的Anthony
感谢您对集成学习如此清晰的解释
不客气。