批量归一化是一种旨在自动标准化深度学习神经网络中层输入的技巧。
一旦实现,批量归一化就会显著加速神经网络的训练过程,在某些情况下,通过温和的正则化效果也能提高模型的性能。
在本教程中,您将学习如何使用批量归一化来加速 Keras Python 中深度学习神经网络的训练。
完成本教程后,您将了解:
- 如何使用 Keras API 创建和配置 BatchNormalization 层。
- 如何将 BatchNormalization 层添加到深度学习神经网络模型中。
- 如何更新 MLP 模型以使用批量归一化来加速二元分类问题的训练。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。

如何通过批标准化加速深度神经网络的学习
照片来源:Angela and Andrew,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- Keras 中的批量归一化
- 模型中的批量归一化
- 批量归一化案例研究
Keras 中的批量归一化
Keras 通过 BatchNormalization 层提供对批量归一化的支持。
例如
|
1 |
bn = BatchNormalization() |
该层将转换输入,使其标准化,这意味着它们的均值为零,标准差为一。
在训练期间,该层将跟踪每个输入变量的统计数据,并使用它们来标准化数据。
此外,标准化输出可以使用学习到的 *Beta* 和 *Gamma* 参数进行缩放,这两个参数定义了转换输出的新均值和标准差。可以通过“center”和“scale”属性来配置该层,以控制是否使用这些附加参数。默认情况下,它们是启用的。
用于执行标准化的统计数据,例如每个变量的均值和标准差,会针对每个 mini batch 进行更新,并维护一个运行平均值。
“momentum”参数允许您控制在计算更新时要包含前一个 mini batch 的统计数据的多少。默认情况下,该值较高,为 0.99。可以将其设置为 0.0,仅使用当前 mini-batch 的统计数据,正如原始论文中所述。
|
1 |
bn = BatchNormalization(momentum=0.0) |
在训练结束时,该层当时的均值和标准差统计数据将用于标准化输入,当模型用于进行预测时。
跨所有 mini batch 估计均值和标准差的默认配置可能是合理的。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
模型中的批量归一化
批量归一化可以在模型的大多数点使用,并且可以与大多数类型的深度学习神经网络结合使用。
输入层和隐藏层输入
可以将 BatchNormalization 层添加到模型中,以标准化原始输入变量或隐藏层的输出。
不建议将批量归一化作为模型正确数据准备的替代方案。
尽管如此,在标准化原始输入变量时,该层必须指定 *input_shape* 参数;例如
|
1 2 3 4 |
... model = Sequential model.add(BatchNormalization(input_shape=(2,))) ... |
当用于标准化隐藏层的输出时,该层可以像任何其他层一样添加到模型中。
|
1 2 3 4 5 |
... model = Sequential ... model.add(BatchNormalization()) ... |
在激活函数之前或之后使用
BatchNormalization 归一化层可用于在上一层的激活函数之前或之后标准化输入。
引入该方法的原始论文建议在上一层的激活函数之前添加批量归一化,例如
|
1 2 3 4 5 6 |
... model = Sequential model.add(Dense(32)) model.add(BatchNormalization()) model.add(Activation('relu')) ... |
一些报告的实验表明,在上一层的激活函数之后添加批量归一化层会带来更好的性能;例如
|
1 2 3 4 5 |
... model = Sequential model.add(Dense(32, activation='relu')) model.add(BatchNormalization()) ... |
如果时间和资源允许,在您的模型上测试这两种方法并采用性能最佳的方法可能是值得的。
让我们看看如何将批量归一化与一些常见的网络类型结合使用。
MLP 批量归一化
下面的示例在 Dense 隐藏层之间的激活函数之后添加了批量归一化。
|
1 2 3 4 5 6 7 8 |
# mlp 的批量归一化示例 from keras.layers import Dense from keras.layers import BatchNormalization ... model.add(Dense(32, activation='relu')) model.add(BatchNormalization()) model.add(Dense(1)) ... |
CNN 批量归一化
下面的示例在卷积层和最大池化层之间的激活函数之后添加了批量归一化。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# cnn 的批量归一化示例 from keras.layers import Dense 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import BatchNormalization ... model.add(Conv2D(32, (3,3), activation='relu')) model.add(Conv2D(32, (3,3), activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D()) model.add(Dense(1)) ... |
RNN 批量归一化
下面的示例在 LSTM 和 Dense 隐藏层之间的激活函数之后添加了批量归一化。
|
1 2 3 4 5 6 7 8 9 |
# lstm 的批量归一化示例 from keras.layers import Dense 从 keras.layers 导入 LSTM from keras.layers import BatchNormalization ... model.add(LSTM(32)) model.add(BatchNormalization()) model.add(Dense(1)) ... |
批量归一化案例研究
在本节中,我们将演示如何使用批量归一化来加速 MLP 在一个简单的二元分类问题上的训练。
此示例为将批量归一化应用于您自己的分类和回归神经网络提供了模板。
二分类问题
我们将使用一个标准的二分类问题,该问题定义了两个二维同心圆的观测值,每个类别一个圆。
每个观测值有两个输入变量,尺度相同,类别输出值为 0 或 1。此数据集被称为“circles”(圆圈)数据集,因为绘制时每个类别的观测值形状是圆圈状的。
我们可以使用 make_circles() 函数 从此问题生成观测值。我们将为数据添加噪声并设置随机数生成器的种子,以便每次运行代码时都会生成相同的样本。
|
1 2 |
# 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) |
我们可以绘制数据集,其中两个变量被用作图上的 *x* 和 *y* 坐标,类别值被用作观测值的颜色。
生成数据集并绘制它的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 带类别颜色点的圆形数据集散点图 from sklearn.datasets import make_circles from numpy import where from matplotlib import pyplot # 生成圆 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 选择每个类别标签的点的索引 for i in range(2): samples_ix = where(y == i) pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1], label=str(i)) pyplot.legend() pyplot.show() |
运行示例会创建一个散点图,显示每个类别的观测值的同心圆形状。
我们可以看到数据点分散中的噪声,这使得圆圈不那么明显。
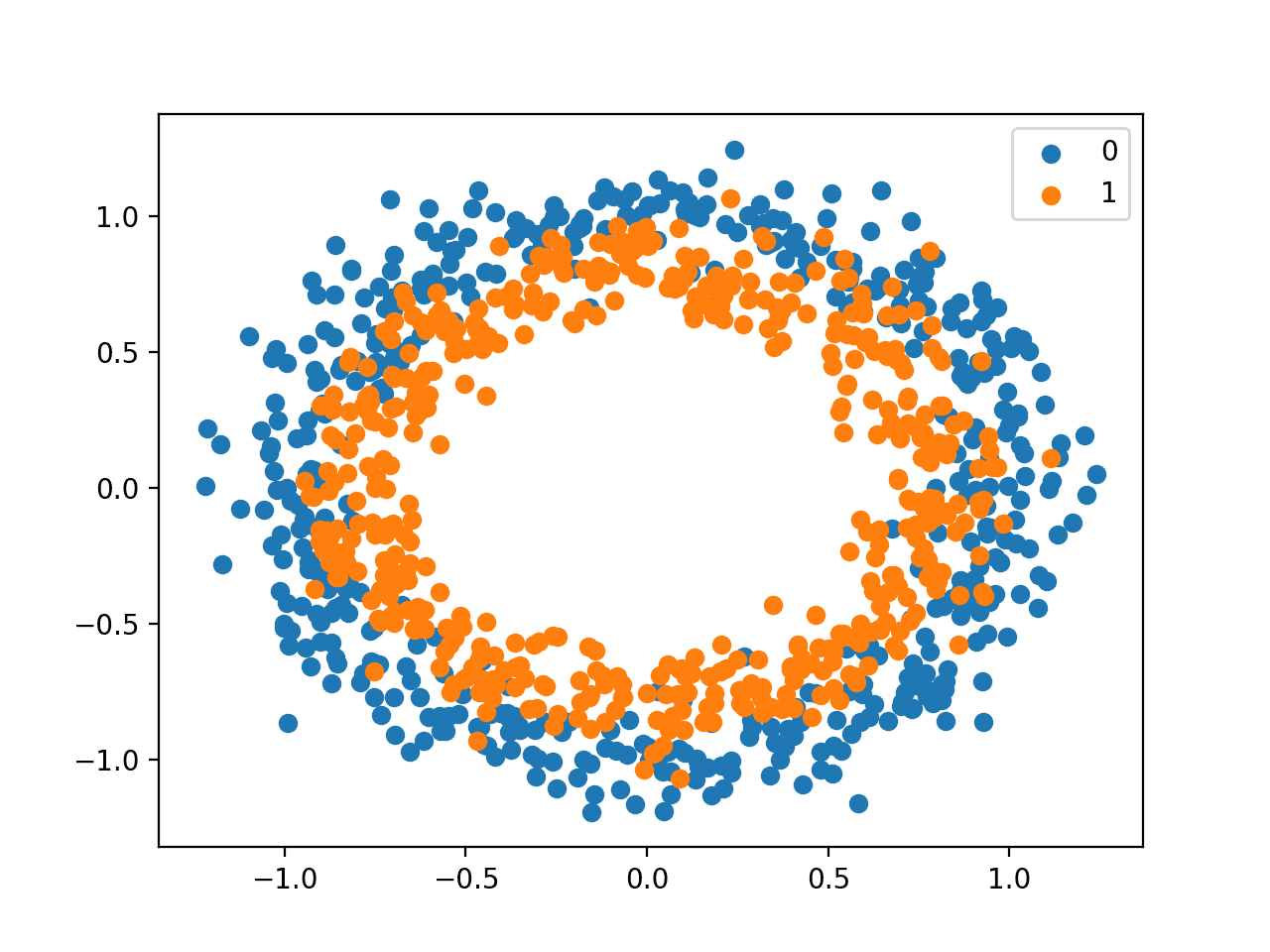
显示类别值的圆圈数据集散点图
这是一个很好的测试问题,因为这些类别不能用一条线分开,例如,它们不是线性可分的,需要一种非线性方法(如神经网络)来解决。
多层感知器模型
我们可以开发一个多层感知机模型(MLP)作为此问题的基线。
首先,我们将把生成的 1,000 个样本分成训练集和测试集,每个集有 500 个示例。这将为模型提供足够大的样本进行学习,并对其性能进行同样大小(公平)的评估。
|
1 2 3 4 |
# 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
我们将定义一个简单的 MLP 模型。网络必须在可见层中有两个输入,对应于数据集中有两个变量。
该模型将有一个具有 50 个节点的单个隐藏层(任意选择),并使用修正线性激活函数(ReLU)和 He 随机权重初始化方法。输出层将是一个具有 sigmoid 激活函数的单个节点,能够预测问题中外部圆圈的 0 和内部圆圈的 1。
模型将使用随机梯度下降进行训练,学习率为 0.01,动量为 0.9,并将使用二元交叉熵损失函数来指导优化。
|
1 2 3 4 5 6 |
# 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) |
定义完成后,模型就可以在训练数据集上进行拟合。
我们将使用留出的测试数据集作为验证数据集,并在每个训练 epoch 结束时评估其性能。模型将进行 100 个 epoch 的训练,这是经过一些试验和错误后确定的。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) |
在运行结束时,模型将在训练集和测试集上进行评估,并报告准确率。
|
1 2 3 4 |
# 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
最后,创建折线图显示模型在每个训练 epoch 结束时在训练集和测试集上的准确率,提供学习曲线。
这张学习曲线图很有用,因为它能让人了解模型学习问题的速度和效果。
|
1 2 3 4 5 |
# 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
将这些元素联系起来,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 两个圆圈问题的 mlp from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例将拟合模型并在训练集和测试集上对其进行评估。
注意:您的结果可能因算法或评估程序的随机性或数值精度的差异而有所不同。请尝试运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型在留出数据集上取得了约 84% 的准确率,并且在训练集和测试集上都取得了相当的性能,考虑到两个数据集的大小相同且组成相似。
|
1 |
训练:0.838,测试:0.846 |
创建了一个图表,显示了训练集(蓝色)和测试集(橙色)上分类准确率的折线图。
该图显示了模型在训练过程中在两个数据集上的性能相当。我们可以看到,性能在最初的 30 到 40 个 epoch 内跃升至 80% 以上的准确率,然后才缓慢改进。
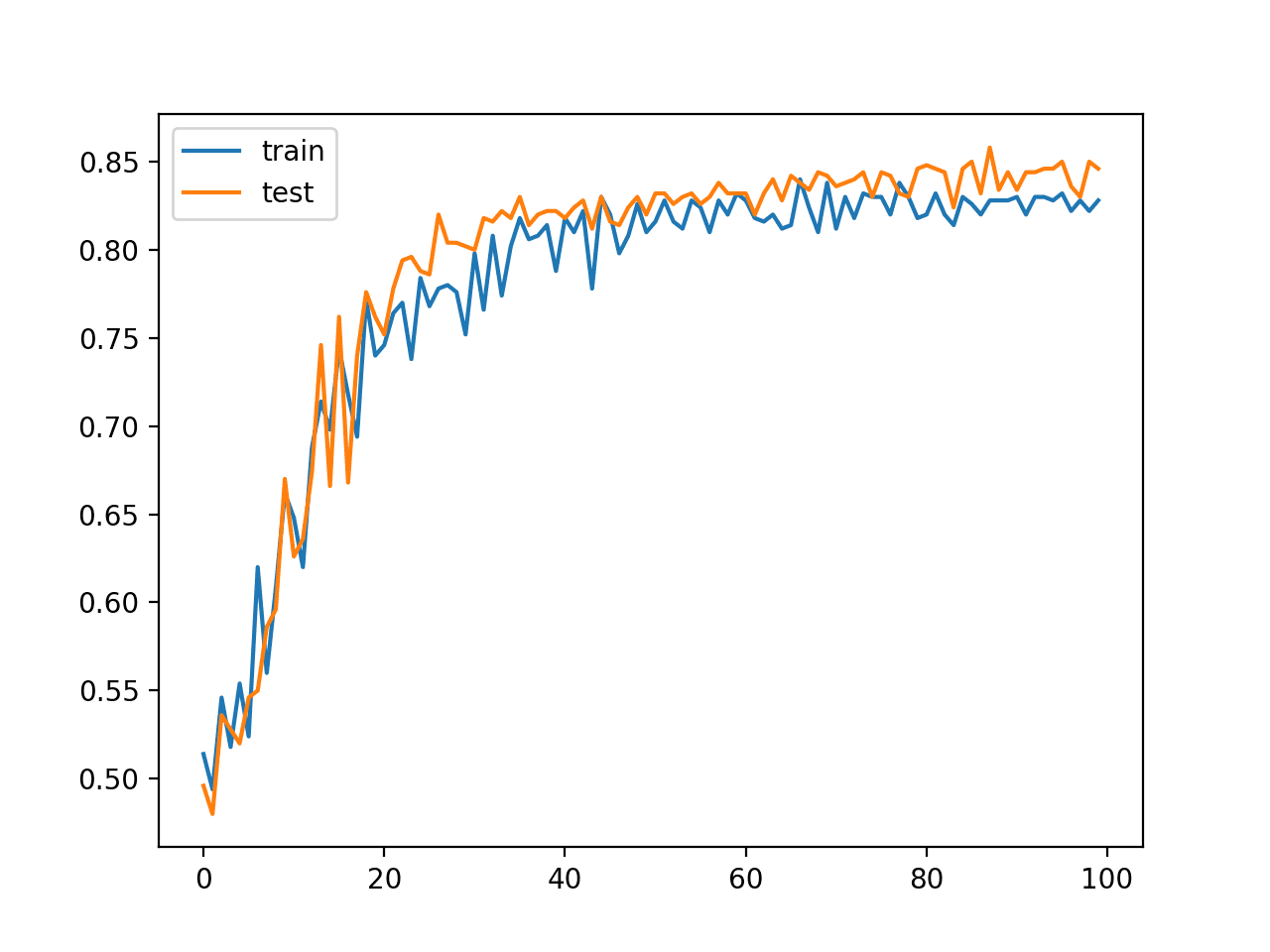
MLP 在训练 epoch 期间在训练和测试数据集上的分类准确率折线图
这个结果,特别是模型在训练过程中的动态,提供了一个基线,可以与添加了批量归一化的同一模型进行比较。
带批量归一化的 MLP
上一节介绍的模型可以更新以添加批量归一化。
预期是,添加批量归一化将加速训练过程,在更少的训练 epoch 中提供相似或更好的分类准确率。批量归一化还据称提供了一种温和的正则化形式,这意味着它可能通过在留出测试数据集上分类准确率的小幅提高来提供对泛化误差的小幅降低。
可以在模型中将新的 BatchNormalization 层添加到隐藏层之后、输出层之前。具体来说,是在先前隐藏层的激活函数之后。
|
1 2 3 4 5 6 7 |
# 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Dense(1, activation='sigmoid')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) |
修改后的完整示例代码如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 激活函数后用于两个圆圈问题的 mlp 批量归一化 from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense 从 keras.层 导入 BatchNormalization from keras.optimizers import SGD from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Dense(1, activation='sigmoid')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练集和测试集上的分类准确率。
注意:您的结果可能因算法或评估程序的随机性或数值精度的差异而有所不同。请尝试运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型在训练集和测试集上的性能相当,准确率约为 84%,与上一节相比非常相似,甚至略好。
|
1 |
训练:0.846,测试:0.848 |
还创建了学习曲线图,显示了每个训练 epoch 在训练集和测试集上的分类准确率。
在这种情况下,我们可以看到模型学习的速度比上一节没有批量归一化的模型更快。具体来说,我们可以看到训练集和测试集上的分类准确率在最初的 20 个 epoch 内就跃升到 80% 以上,而没有批量归一化的模型则需要 30 到 40 个 epoch。
该图还显示了批量归一化在训练期间的效果。我们可以看到训练数据集上的性能低于测试数据集:训练数据集上的分数低于模型在训练结束时的性能。这可能是由于每个 mini batch 收集和更新的输入所致。
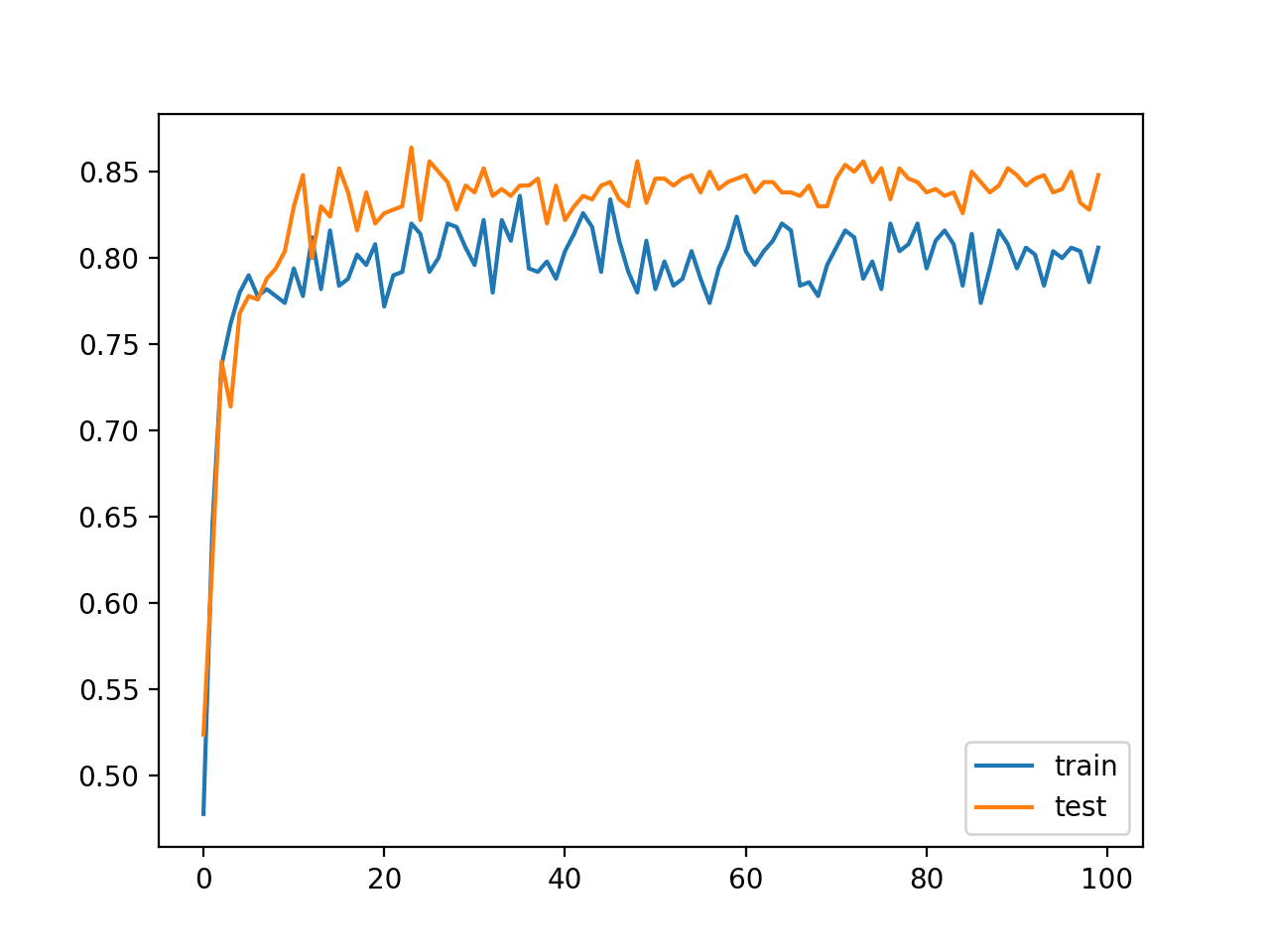
带批量归一化的 MLP 在激活函数后,在训练 epoch 期间在训练和测试数据集上的分类准确率折线图
我们还可以尝试模型的一个变体,即在隐藏层的激活函数之前应用批量归一化,而不是之后。
|
1 2 3 4 5 6 7 8 |
# 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Dense(1, activation='sigmoid')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) |
包含此模型更改的完整代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# 激活函数前用于两个圆圈问题的 mlp 批量归一化 from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense from keras.layers import Activation 从 keras.层 导入 BatchNormalization from keras.optimizers import SGD from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Dense(1, activation='sigmoid')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练集和测试集上的分类准确率。
注意:您的结果可能因算法或评估程序的随机性或数值精度的差异而有所不同。请尝试运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型在训练集和测试集上的性能相当,但略逊于没有批量归一化的模型。
|
1 |
训练:0.826,测试:0.830 |
学习曲线在训练集和测试集上的折线图也讲述了不同的故事。
该图显示模型学习的速度可能与没有批量归一化的模型相同,但模型在训练集上的性能要差得多,准确率在 70% 到 75% 之间波动,这同样可能是由于每个 mini batch 收集和使用的统计数据造成的。
至少对于此模型配置在此特定数据集上,批量归一化在修正线性激活函数之后似乎更有效。
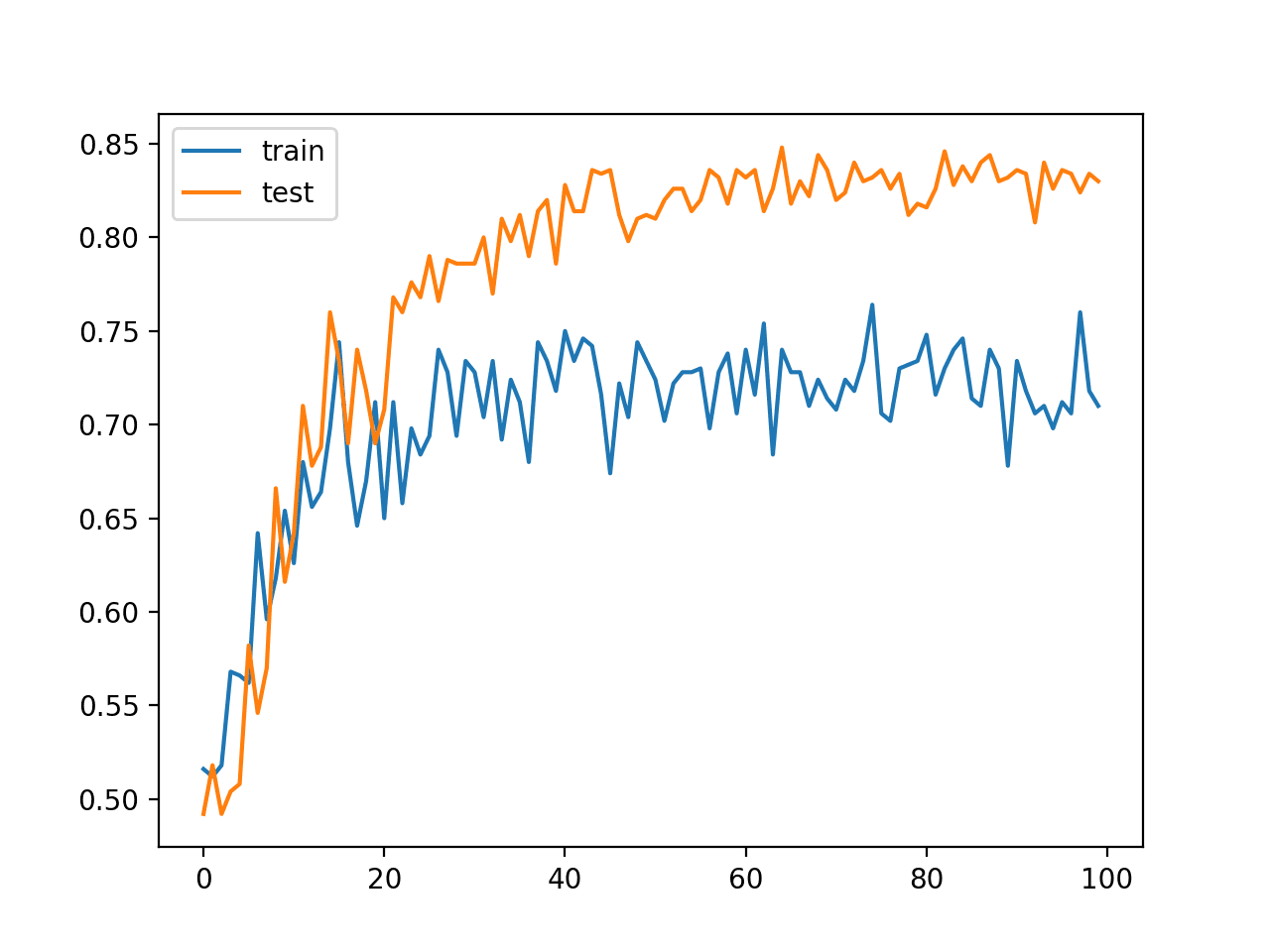
带批量归一化的 MLP 在激活函数前,在训练和测试数据集上的分类准确率折线图
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 不带 Beta 和 Gamma。更新示例以不使用批量归一化层中的 beta 和 gamma 参数并比较结果。
- 不带动量。更新示例以在训练期间不使用批量归一化层中的动量并比较结果。
- 输入层。更新示例以在模型输入后使用批量归一化并比较结果。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
API
- Keras正则化器API
- Keras核心层API
- Keras卷积层API
- Keras循环层API
- BatchNormalization Keras API
- sklearn.datasets.make_circles
文章
总结
在本教程中,您学习了如何使用批量归一化来加速 Keras Python 中深度学习神经网络的训练。
具体来说,你学到了:
- 如何使用 Keras API 创建和配置 BatchNormalization 层。
- 如何将 BatchNormalization 层添加到深度学习神经网络模型中。
- 如何更新 MLP 模型以使用批量归一化来加速二元分类问题的训练。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







嗨,Jason,
很棒的文章。呈现得很好。
是否有关于何时使用 BN 在激活函数之前或之后的数学证明?
谢谢!
我没有看到任何证明,发现都是经验性的——就像应用机器学习中的许多东西一样。
谢谢!
你好,Jason!
为什么 BN 应用于 LSTM 之后?因为 LSTM 的输出在 tanh 之后是 [-1, 1]?
谢谢!
为什么不?
我以为批量归一化是为了将值缩放到 [-1, 1] 附近,所以我想如果 lstm 的输出已经是 [-1, 1],就没有必要添加 BN 了?你能否详细说明一下应用 BN 在 tanh 或 sigmoid 之后的优点?
非常感谢!
我不记得有这方面的资料,也许可以参考原始论文?
谢谢回复 ^ ^
你好!我理解它的目的是保持激活分布的前两个经验矩的稳定,这样神经元/节点就不会在学习这种分布上花费精力。原始论文说:
一如既往的优秀教程!
有一个问题不太清楚,是否可以使用批量归一化来替代预处理?我的意思是,通常在将数据输入网络之前,您需要先对其进行标准化。有多种方法可以做到这一点,例如MinMax缩放器。我们可以用一个简单的批量归一化层作为我们网络中的输入层来替代这些方法吗?
不行。我建议您在建模之前继续正确地准备数据。
谢谢!
那么,我们是否需要进行标准化(应用一些缩放器minmax或标准缩放器),然后在顺序模型中应用批量归一化?
我建议将输入数据的缩放与批量归一化分开考虑。
谢谢Jason。您能否更具体地说明为什么不建议在输入中使用BatchNormalization而不是StandardScaler?我可能遗漏了一点,但我没看到区别。
是的,StandardScaler在数据准备作为单独的步骤时提供了更多的控制。Batch Norm是从每个样本批次中估计mu和sigma。
感谢您提供精彩的文章和书籍,它们确实帮助我开始了机器学习之旅。
我非常需要您帮助我解决一个问题,我写了这段代码来使用lstm将文档分类到20个主题,它运行良好,训练准确率是99%,但测试准确率是7%。经过研究,这个问题似乎是过拟合问题,所以我尝试了所有我能找到的解决方案,但都没有用(我尝试了dropout层、验证集分割、改变优化器、改变学习率、尝试了BN),所以这是我的代码,我希望您能帮我解决它。
docs=[]
test_d=[]
for filename in glob.glob(os.path.join(“train”, ‘*.txt’))
with open(filename,’r’) as f
content=f.read()
#text=map(str.rstrip, f.readlines())
#for line in content
#line = line.replace(“\n”, “”)
content = content.split(‘\n’)
content = ” “.join(content)
docs.append(content)
embeddings_index = dict()
f = open(‘glove.6B.100d.txt’)
for line in f
values = line.split()
word = values[0]
coefs = asarray(values[1:],)
embeddings_index[word] = coefs
f.close()
print(‘Loaded %s word vectors.’ % len(embeddings_index))
embedding_matrix = zeros((vocab_size, embedding_dim))
for word, i in t.word_index.items()
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None
embedding_matrix[i] = embedding_vector
labels=array([])
encoder = LabelEncoder()
encoder.fit(labels)
encoded_Y = encoder.transform(labels)
dummy_y = np_utils.to_categorical(encoded_Y)
model = Sequential()
e = Embedding(vocab_size, embedding_dim , weights=[embedding_matrix], input_length=max_length, trainable=False)
model.add(e)
model.add(BatchNormalization())
model.add(SpatialDropout1D(0.2))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2,return_sequences=True))
#model.add(LSTM(50, return_sequences=True))
model.add(Flatten())
#model.add(Dense(25, activation=’relu’))
model.add(BatchNormalization())
model.add(Dense(20, activation=’softmax’))
# 编译模型
opt = adam(lr=0.8)
model.compile(optimizer=’RMSprop’, loss=’categorical_crossentropy’, metrics=[‘acc’])
# 总结模型
打印(model.summary())
#class_weight = class_weight.compute_class_weight(‘balanced’,numpy.unique(dummy_y),dummy_y)
#class_weights = class_weight.compute_class_weight(‘balanced’,np.unique(np.ravel(dummy_y,order=’C’)),np.ravel(dummy_y,order=’C’))
# 拟合模型
model.fit(padded_docs, dummy_y, validation_split=0.30, epochs=10, verbose=2)
# 评估模型
loss, accuracy = model.evaluate(padded_docs, dummy_y, verbose=2)
print(‘Train Accuracy: %f’ % (accuracy*100))
labels=[]
for filename in glob.glob(os.path.join(“test”, ‘*.txt’))
with open(filename,’r’) as f
content=f.read()
content = content.split(‘\n’)
content = ” “.join(content)
test_d.append(content)
t = Tokenizer()
t.fit_on_texts(test_d)
encoded_docs = t.texts_to_sequences(test_d)
test_d=[]
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding=’post’)
encoder = LabelEncoder()
encoder.fit(test_labels)
encoded_Y = encoder.transform(test_labels)
# 将整数转换为虚拟变量(即独热编码)
dummy_y = np_utils.to_categorical(encoded_Y)
loss, accuracy = model.evaluate(padded_docs, dummy_y, verbose=2)
print(‘Test Accuracy: %f’ % (accuracy*100))
print(‘\007’)
提前感谢您的帮助,我将非常感激!
我有一些建议可能会有所帮助
https://machinelearning.org.cn/start-here/#better
“动量”参数允许您控制在计算更新时,从前一个小批量统计数据中包含多少比例的统计数据。
您能更清楚地解释一下这句话吗?
是的,该值将是先前值和当前值的加权平均值,例如,0.9是此值,0.1是上一个值,这使得该值具有一定的历史记录。
“动量”参数允许您控制在计算更新时,从前一个小批量统计数据中包含多少比例的统计数据。默认情况下,此值保持较高,为0.99。根据原始论文所述,可以将其设置为0.0,只使用当前小批量的统计数据。
论文引用?
任何关于神经网络的书都会描述这一点。也许从这里开始
https://amzn.to/36HsYfq
嗨,Jason,
您是否阅读过有关在CNN中应用Batch Normalization的最佳实践?原始的BN层似乎表明BN可以应用于CNN的任何层:https://arxiv.org/pdf/1502.03167.pdf。但是,BN在卷积层之后如何应用有一些注意事项,我还在努力理解:https://stackoverflow.com/questions/38553927/batch-normalization-in-convolutional-neural-network。一个keras示例会非常有帮助。
是的,在池化之前。
请参阅上面用于CNN的batch norm示例。
如果我们在池化后使用BN会怎样?我观察到,这并不会影响性能。另外,您能澄清一下我们是否可以在CNN中同时使用dropout和MN吗?如果可以,实现的顺序应该是怎样的?
好问题,我在这里回答
https://machinelearning.org.cn/batch-normalization-for-training-of-deep-neural-networks/
感谢您的慷慨支持。
不客气。
此外,请您分享
(1) CNN 기반 시계열 분류 구현 모델 상세 정보
(2 ) 시계열 분류를 위한 LSTM 또는 CNN?
(3) 순차 모델 또는 함수형 API 모델을 선호하는가?
(4) 입력 시계열 데이터를 어떻게 증강하고 제안된 모델에 구현하는가?
您可以在此处找到其中大部分示例
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨,Jason先生,
请解释图中所示的准确率曲线出现波动或锯齿状行为的可能原因。在几乎所有材料中,图形都显示为平滑的。但在实际操作中,我们会出现波动。也请提供克服此问题的建议。
谢谢并致以问候
您可以拟合多个最终模型并集成它们的预测,以平滑预测的准确性。
https://machinelearning.org.cn/how-to-reduce-model-variance/
在函数式API中连接复杂的(可能多输入的)流时,BN还有文章未描述的其他应用吗?
或连接Inception模块中各种卷积的输出。
总的来说,是否有专注于自定义NN架构的资源(书籍/网站)?
这可以帮助您学习如何编写复杂的架构。
https://machinelearning.org.cn/how-to-implement-major-architecture-innovations-for-convolutional-neural-networks/
也许这个函数式API的例子可以适应您的需求。
https://machinelearning.org.cn/keras-functional-api-deep-learning/
嗨 Jason
我只想检查一下Batch Normalisation的输出,给定一个输入。
例如,给定输入为numpy数组:[[[1.,2,3]],[[3,4,1]]],我期望BatchNormalisation将其转换为[[[-2,0,0],[0,0,-2]]]
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.layers import BatchNormalization
x=np.array([[[1.,2,3]],[[3,4,1]]])
y=BatchNormalization()(x)
然而,这个输出y与x相同。
您能帮忙提供代码来获取使用BatchNormalisation归一化的x吗?
请记住,批量归一化是在批次上对输入进行标准化,其中内部系数在训练期间学习并在推理期间应用。
我不希望以您描述的方式使用该层会有效。例如:直接进行推理。
是的,它不会。
我正在学习神经网络,并希望评估每个层的输出。
您可以使用函数式API定义一个模型,其中每个层都传递到下一层,并且还可以用作输出层。
这将帮助您开始使用函数式API。
https://machinelearning.org.cn/keras-functional-api-deep-learning/
你好 jason,
您的文章很棒。
每当我添加具有不同动量的批量归一化时,结果都会变差,模型也无法收敛!
我发现这个问题反复出现,但没有 accepted 解决方案。
(Python 3.9 - Spyder 实现)
你好 Ahmed…感谢反馈!以下背景信息可能有助于澄清
https://machinelearning.org.cn/batch-normalization-for-training-of-deep-neural-networks/
https://towardsdatascience.com/curse-of-batch-normalization-8e6dd20bc304