拟合深度学习神经网络模型后,您必须在测试数据集上评估其性能。
这一点至关重要,因为报告的性能使您能够在这类候选模型之间进行选择,并与利益相关者沟通该模型在解决问题方面的能力。
Keras 深度学习 API 模型在可用于报告模型性能的指标方面非常有限。
我经常被问到类似这样的问题:
如何为我的模型计算精确率和召回率?
以及
如何为我的模型计算 F1 分数或混淆矩阵?
在本教程中,您将通过一个逐步的示例,了解如何计算指标来评估您的深度学习神经网络模型。
完成本教程后,您将了解:
- 如何使用 scikit-learn 指标 API 来评估深度学习模型。
- 如何使用 scikit-learn API 为最终模型制作类预测和概率预测。
- 如何使用 scikit-learn API 为模型计算精确率、召回率、F1 分数、ROC AUC 等指标。
开始您的项目,阅读我的新书《Python 深度学习》,其中包含分步教程以及所有示例的Python 源代码文件。
让我们开始吧。
- 2019年3月:首次发布
- 2020年1月更新:更新了Keras 2.3和TensorFlow 2.0的API。

如何为深度学习模型计算精确率、召回率、F1分数等指标
照片作者:John,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 二分类问题
- 多层感知器模型
- 如何计算模型指标
二分类问题
我们将以一个标准的二元分类问题作为本教程的基础,称为“两个圆”问题。
之所以称为两个圆问题,是因为该问题由绘制后显示两个同心圆的点组成,每个圆代表一个类别。因此,这是二元分类问题的一个示例。该问题有两个输入,可以解释为图上的 x 和 y 坐标。每个点属于内圆或外圆。
scikit-learn 库中的 make_circles() 函数允许您从两个圆问题生成样本。“n_samples”参数允许您指定要生成的样本数量,并平均分配给两个类别。“noise”参数允许您指定添加到每个点输入或坐标的随机统计噪声量,从而使分类任务更具挑战性。“random_state”参数指定了伪随机数生成器的种子,确保每次运行代码时都生成相同的样本。
下面的示例生成 1,000 个样本,具有 0.1 的统计噪声和种子 1。
|
1 2 |
# 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) |
生成后,我们可以创建数据集的图,以了解分类任务的难度。
下面的示例生成样本并绘制它们,根据类别对每个点进行着色,其中属于类别 0(外圆)的点显示为蓝色,属于类别 1(内圆)的点显示为橙色。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 两个圆问题的样本生成示例 from sklearn.datasets import make_circles from matplotlib import pyplot from numpy import where # 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 散点图,点按类别值着色 for i in range(2): samples_ix = where(y == i) pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1]) pyplot.show() |
运行示例将生成数据集并在图上绘制点,清楚地显示属于类别 0 和类别 1 的点的两个同心圆。
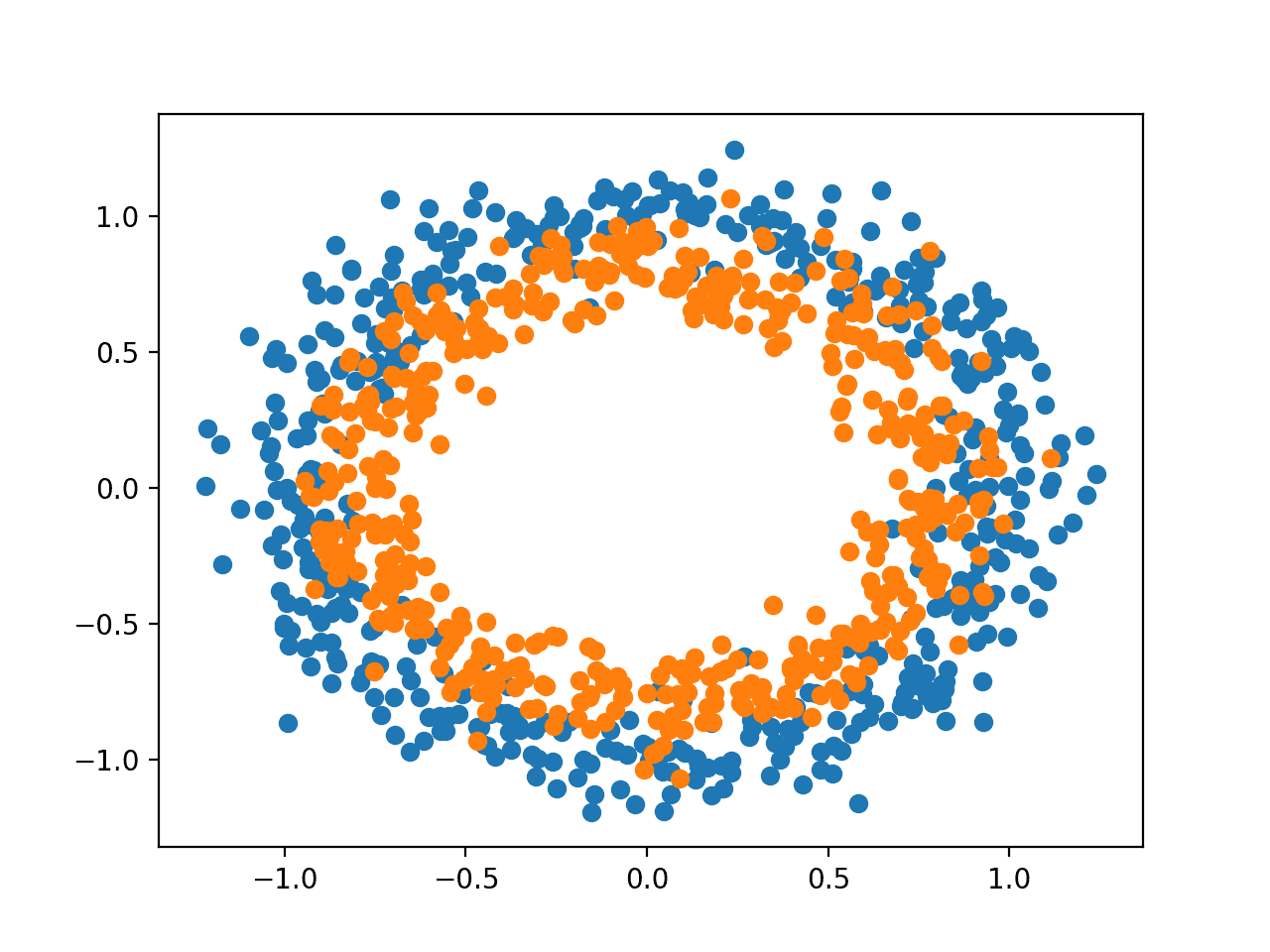
两个圆问题的样本散点图
多层感知器模型
我们将开发一个多层感知器(MLP)模型来解决这个二元分类问题。
该模型并未针对问题进行优化,但它很有效(比随机好)。
生成数据集的样本后,我们将它们分成两部分:一部分用于训练模型,另一部分用于评估训练好的模型。
|
1 2 3 4 |
# 分割成训练集和测试集 n_test = 500 trainX, testX = X[:n_test, :], X[n_test:, :] trainy, testy = y[:n_test], y[n_test:] |
接下来,我们可以定义我们的 MLP 模型。该模型很简单,需要来自数据集的 2 个输入变量,一个包含 100 个节点的隐藏层,以及 ReLU 激活函数,然后是一个包含单个节点和 sigmoid 激活函数的输出层。
该模型将预测一个介于 0 和 1 之间的值,该值将被解释为输入样本属于类别 0 还是类别 1。
|
1 2 3 4 |
# 定义模型 model = Sequential() model.add(Dense(100, input_shape=(2,), activation='relu')) model.add(Dense(1, activation='sigmoid')) |
模型将使用二元交叉熵损失函数进行拟合,我们将使用高效的随机梯度下降的 Adam 版本。模型还将监控分类准确率指标。
|
1 2 |
# 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
我们将以 300 个训练周期拟合模型,默认批量大小为 32 个样本,并在每个训练周期结束时在测试数据集上评估模型的性能。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=300, verbose=0) |
训练结束后,我们将在训练集和测试集上再次评估最终模型,并报告分类准确率。
|
1 2 3 |
# 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) |
最后,将使用折线图对模型在训练期间在训练集和测试集上的性能进行图形化显示,分别显示损失和分类准确率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的准确率 pyplot.子图(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
将所有这些要素结合起来,下面列出了在两个圆问题上训练和评估 MLP 的完整代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 两个圆问题的多层感知器模型 from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot # 生成数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 分割成训练集和测试集 n_test = 500 trainX, testX = X[:n_test, :], X[n_test:, :] trainy, testy = y[:n_test], y[n_test:] # 定义模型 model = Sequential() model.add(Dense(100, input_shape=(2,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=300, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的准确率 pyplot.子图(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例可以在 CPU 上非常快速地拟合模型(不需要 GPU)。
注意:鉴于算法或评估程序的随机性质,或数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
该模型经过评估,报告了在训练集和测试集上的分类准确率分别约为 83% 和 85%。
|
1 |
训练:0.838,测试:0.850 |
创建了一个图,显示了两个折线图:一个用于模型在训练和测试集上的损失的学习曲线,另一个用于模型在训练和测试集上的分类准确率。
这些图表明该模型与问题拟合良好。
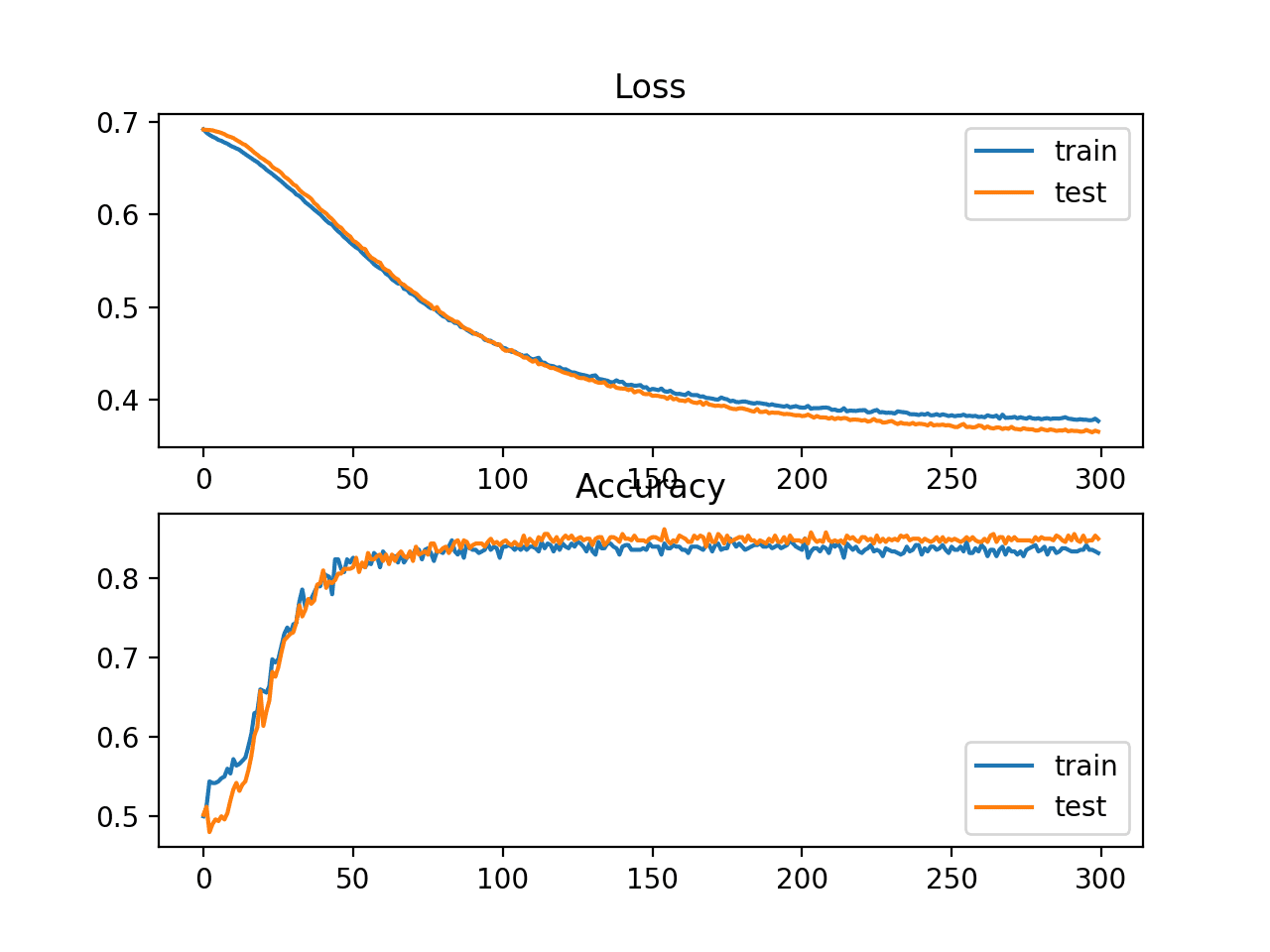
显示 MLP 在训练期间在两个圆问题上的损失和准确率学习曲线的折线图
如何计算模型指标
也许您需要使用 Keras 指标 API 不支持的附加指标来评估您的深度学习神经网络模型。
Keras 指标 API 非常有限,您可能希望计算精确率、召回率、F1 分数等指标。
计算新指标的一种方法是在 Keras API 中自行实现它们,并让 Keras 在模型训练和模型评估期间为您计算它们。
有关此方法的帮助,请参阅教程
这在技术上可能具有挑战性。
一个更简单的替代方法是使用您的最终模型为测试数据集做出预测,然后使用 scikit-learn 指标 API 计算您想要的任何指标。
在二元分类问题上,神经网络模型除了分类准确率外,通常需要的三个指标是:
- 精确率
- 回顾
- F1 分数
在本节中,我们将使用 scikit-learn 指标 API 计算这三个指标以及分类准确率,我们还将计算三个不太常见但可能很有用的附加指标。它们是:
- Cohen's Kappa
- ROC AUC
- 混淆矩阵.
这不是 scikit-learn 支持的分类模型的指标的完整列表;但是,计算这些指标将向您展示如何使用 scikit-learn API 计算您可能需要的任何指标。
有关支持指标的完整列表,请参阅
本节中的示例将计算 MLP 模型的指标,但计算指标的代码也适用于其他模型,例如 RNN 和 CNN。
我们可以使用与前面章节相同的代码来准备数据集,以及定义和拟合模型。为了使示例更简单,我们将这些步骤的代码放入一个简单的函数中。
首先,我们可以定义一个名为 get_data() 的函数,该函数将生成数据集并将其拆分为训练集和测试集。
|
1 2 3 4 5 6 7 8 9 |
# 生成并准备数据集 def get_data(): # 生成数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 分割为训练集和测试集 n_test = 500 trainX, testX = X[:n_test, :], X[n_test:, :] trainy, testy = y[:n_test], y[n_test:] return trainX, trainy, testX, testy |
接下来,我们将定义一个名为 get_model() 的函数,该函数将定义 MLP 模型并将其拟合在训练数据集上。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 定义并拟合模型 def get_model(trainX, trainy): # 定义模型 model = Sequential() model.add(Dense(100, input_shape=(2,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=300, verbose=0) return model |
然后,我们可以调用 get_data() 函数来准备数据集,并调用 get_model() 函数来拟合并返回模型。
|
1 2 3 4 |
# 生成数据 trainX, trainy, testX, testy = get_data() # 拟合模型 model = get_model(trainX, trainy) |
现在我们有了一个在训练数据集上拟合的模型,我们可以使用 scikit-learn 指标 API 中的指标来评估它。
首先,我们必须使用模型进行预测。大多数指标函数需要将真实类别值(例如 testy)与预测类别值(yhat_classes)进行比较。我们可以使用模型上的 predict_classes() 函数直接预测类别值。
某些指标,如 ROC AUC,需要预测类别概率(yhat_probs)。可以通过调用模型的 predict() 函数来检索这些。
有关使用 Keras 模型进行预测的更多帮助,请参阅文章
我们可以使用模型进行类预测和概率预测。
|
1 2 3 4 |
# 预测测试集的概率 yhat_probs = model.predict(testX, verbose=0) # 预测测试集的离散类别 yhat_classes = model.predict_classes(testX, verbose=0) |
预测以二维数组形式返回,每行代表测试数据集中的一个样本,每列代表一个预测。
scikit-learn 指标 API 需要将实际值和预测值作为一维数组进行比较,因此,我们必须将二维预测数组减少为一维数组。
|
1 2 3 |
# 减少到一维数组 yhat_probs = yhat_probs[:, 0] yhat_classes = yhat_classes[:, 0] |
现在我们可以为您的深度学习神经网络模型计算指标了。我们可以从计算分类准确率、精确率、召回率和 F1 分数开始。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 准确率:(tp + tn) / (p + n) accuracy = accuracy_score(testy, yhat_classes) print('Accuracy: %f' % accuracy) # 精确率 tp / (tp + fp) precision = precision_score(testy, yhat_classes) print('Precision: %f' % precision) # 召回率 tp / (tp + fn) recall = recall_score(testy, yhat_classes) print('Recall: %f' % recall) # F1 分数: 2 tp / (2 tp + fp + fn) f1 = f1_score(testy, yhat_classes) print('F1 score: %f' % f1) |
请注意,计算指标就像选择我们感兴趣的指标并调用函数,传入真实类别值(testy)和预测类别值(yhat_classes)一样简单。
我们还可以计算一些附加指标,例如 Cohen's kappa、ROC AUC 和混淆矩阵。
请注意,ROC AUC 需要预测类别概率(yhat_probs)作为参数,而不是预测类别(yhat_classes)。
|
1 2 3 4 5 6 7 8 9 |
# kappa kappa = cohen_kappa_score(testy, yhat_classes) print('Cohens kappa: %f' % kappa) # ROC AUC auc = roc_auc_score(testy, yhat_probs) print('ROC AUC: %f' % auc) # 混淆矩阵 matrix = confusion_matrix(testy, yhat_classes) print(matrix) |
现在我们知道了如何使用 scikit-learn API 为深度学习神经网络计算指标,我们可以将所有这些元素整合到一个完整的示例中,如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
# 使用 sklearn 计算神经网络模型指标的演示 from sklearn.datasets import make_circles from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score from sklearn.metrics import cohen_kappa_score from sklearn.metrics import roc_auc_score from sklearn.metrics import confusion_matrix from keras.models import Sequential from keras.layers import Dense # 生成并准备数据集 def get_data(): # 生成数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 分割为训练集和测试集 n_test = 500 trainX, testX = X[:n_test, :], X[n_test:, :] trainy, testy = y[:n_test], y[n_test:] return trainX, trainy, testX, testy # 定义并拟合模型 def get_model(trainX, trainy): # 定义模型 model = Sequential() model.add(Dense(100, input_shape=(2,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=300, verbose=0) return model # 生成数据 trainX, trainy, testX, testy = get_data() # 拟合模型 model = get_model(trainX, trainy) # 预测测试集的概率 yhat_probs = model.predict(testX, verbose=0) # 预测测试集的离散类别 yhat_classes = model.predict_classes(testX, verbose=0) # 减少到一维数组 yhat_probs = yhat_probs[:, 0] yhat_classes = yhat_classes[:, 0] # 准确率:(tp + tn) / (p + n) accuracy = accuracy_score(testy, yhat_classes) print('Accuracy: %f' % accuracy) # 精确率 tp / (tp + fp) precision = precision_score(testy, yhat_classes) print('Precision: %f' % precision) # 召回率 tp / (tp + fn) recall = recall_score(testy, yhat_classes) print('Recall: %f' % recall) # F1 分数: 2 tp / (2 tp + fp + fn) f1 = f1_score(testy, yhat_classes) print('F1 score: %f' % f1) # kappa kappa = cohen_kappa_score(testy, yhat_classes) print('Cohens kappa: %f' % kappa) # ROC AUC auc = roc_auc_score(testy, yhat_probs) print('ROC AUC: %f' % auc) # 混淆矩阵 matrix = confusion_matrix(testy, yhat_classes) print(matrix) |
注意:鉴于算法或评估程序的随机性质,或数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
运行示例会准备数据集、拟合模型,然后计算并报告在测试数据集上评估的模型指标。
|
1 2 3 4 5 6 7 8 |
准确率: 0.842000 精确率: 0.836576 召回率: 0.853175 F1 分数: 0.844794 Cohen's kappa: 0.683929 ROC AUC: 0.923739 [[206 42] [ 37 215]] |
如果您需要有关如何解释给定指标的帮助,可以从 scikit-learn API 文档中的“分类指标指南”开始: 分类指标指南
另外,请查看您指标的维基百科页面;例如: 精确率和召回率,维基百科。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
API
文章
总结
在本教程中,您通过一个逐步示例学习了如何计算指标来评估您的深度学习神经网络模型。
具体来说,你学到了:
- 如何使用 scikit-learn 指标 API 来评估深度学习模型。
- 如何使用 scikit-learn API 为最终模型制作类预测和概率预测。
- 如何使用 scikit-learn API 计算模型准确率、精确率、召回率、F1 分数、ROC、AUC 等。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






非常有用的 scikit-learn 库模块(API),可以避免自己构建和开发函数。谢谢!.
如果您能在此代码片段(示例)中添加绘制(可视化) ROC 曲线、混淆矩阵的代码,以(确定最佳阈值概率以决定在哪里放置“标记”以决定何时为正或负或 0/1),我将不胜感激。
另外,我明白这些指标仅适用于二元分类(F1、精确率、召回率、AOC 曲线)?但我知道 Cohen's kappa 和混淆矩阵也适用于多类别!。谢谢。
很好的建议,谢谢。
我使用了以下代码来获取 F1 分数的模型结果
nn = MLPClassifier(activation=’relu’,alpha=0.01,hidden_layer_sizes=(20,10))
print (“F1-Score by Neural Network, threshold =”,threshold ,”:” ,predict(nn,train, y_train, test, y_test))
现在我想获取以上代码中准确率、精确率和召回率的所有其他指标结果,但我不知道如何在上面的代码中使用它们。
你到底遇到了什么问题?
非常感谢您的支持..
from sklearn.neural_network import MLPClassifier
threshold = 200
train, y_train, test, y_test = prep(data,threshold)
nn = MLPClassifier(activation=’relu’,alpha=0.01,hidden_layer_sizes=(20,10))
print (“F1-Score by Neural Network, threshold =”,threshold ,”:” ,predict(nn,train, y_train, test, y_test))
我使用了上面您网站上的代码来获取模型的 F1 分数,现在我正在为同一模型查找准确率、精确率和召回率。
也许可以看看这个
https://scikit-learn.cn/stable/modules/model_evaluation.html
您好,非常感谢您的网站,它非常有帮助!
我遇到了一个与此帖子相关的问题,也许您可以帮助我🙂
我试图理解为什么使用“model.evaluate”与“model.predict”然后计算指标会得到不同的指标...
我正在进行语义分割。
我有一个包含 24 张图片的评估集。
我有一个自定义的 DICE INDEX 指标,定义如下:
”
def dice_coef(y_true, y_pred)
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum (y_true_f * y_pred_f)
result =(2 * intersection)+1 / (K.sum(y_true_f) + K.sum(y_pred_f))+1
return result
”
当我使用 model.evaluate 时,我得到一个 dice 分数为 0.9093835949897766。
当我使用 model.predict 然后计算指标时,我得到一个 dice 分数为 0.9092264051238695。
为了更精确:我将 model.predict 和 model.evaluate 中的 batchsize 设置为 24,以确保问题不是由 batch size 引起的。我不知道当 batch size 大于(例如 32)评估集中的样本数量时会发生什么...
最后,在使用 model.prediction 计算指标后,我运行
”
dice_result = 0
for y_i in range(len(y))
dice_result += tf.Session().run(tf.cast(dice_coef(y[y_i], preds[y_i]),
tf.float32))
tf.Session().close
dice_result /= (len(y))
”
我是否认为 tf.float32 转换是差异的原因?
(也许“model.evaluate”所有都用 tensorflow 张量计算,最后返回一个浮点数,而我每循环一次就将张量转换为 float32?)
您认为有什么解释吗?
感谢您的帮助。
祝好!
Thibault
我怀疑 evaluate 分数是在批次之间平均的。
也许可以使用 predict,然后计算所有预测的分数。
谢谢你的回复。
我的评估集只有 24 张图片,所以如果“model.evaluate”按批次计算,并且批次大小为 24,它将一次性对整个评估集计算指标。因此,它应该与“model.predict”然后对评估集进行指标计算得到相同的结果?
这就是为什么我不理解这里的差异。
祝您有美好的一天。
Thibault
我建议调用 predict,然后使用结果调用您选择的 sklearn 指标。
好的🙂
如果我最终决定不使用我的自定义 dice 分数,而是信任 Sklearn,是否有可能在训练期间将此库与 Keras 一起使用?
事实上,在训练结束时,我会得到一个显示每个 epoch 的损失和 dice 的图表。
我希望这些图表与最终结果一致?
再次感谢您的帮助!
祝您有美好的一天
Thibault
我预计图表将是对训练性能的一个公平总结。
为了展示一个算法,我建议使用最终模型进行预测,并重新绘制结果。
好的,我今天处理了这个问题。
我解决了这个问题。万一其他人有类似问题。
事实是,当我调整输入网络的地真掩码大小时,我没有在调整大小后进行阈值处理,所以我在边缘得到了 0 和 1 以外的值,我的自定义 dice 分数得到了错误的结果。
现在我在调整大小后立即添加了阈值处理,并获得了所有我使用的函数相同的 Gethog!
另外,请注意类型转换(float32 vs float64 vs int)!
无论如何,我非常感谢您的可用性。
祝您有美好的一天
干得好!
如何计算多类分类问题的精确率、召回率、F1 分数和 AUC
您可以使用相同的方法,得分是在类别之间平均的。
您的课程信息量极大,教授。我正试图使用这种方法来计算多类分类问题的 F1 分数,但我一直收到错误消息
“ValueError: 分类指标无法处理多标签指示和二元目标的混合” 如果您能指导我哪里做错了,我将不胜感激?这是相关的代码
# 生成并准备数据集
def get_data()
n_test = 280
Xtrain, Xtest = X[:n_test, :], X[n_test:, :]
ytrain, ytest = y[:n_test], y[n_test:]
return X_train, y_train, X_test, y_test
# 定义并拟合模型
def get_model(Xtrain, ytrain)
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=max_sequence_length))
model.add(SpatialDropout1D(0.2))
model.add(LSTM(150, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(5, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’, optimizer= “adam”, metrics=[‘accuracy’])
model.fit(X_train, y_train, epochs=2, batch_size=15,callbacks=[EarlyStopping(monitor=’loss’)])
return model
# 生成数据
X_train, y_train, X_test, y_test = get_data()
# 拟合模型
model = get_model(X_train, y_train)
# 预测测试集的概率
yhat_probs = model.predict(X_test, verbose=0)
# 预测测试集的离散类别
yhat_classes = model.predict_classes(X_test, verbose=0)
# 减少到一维数组
yhat_probs = yhat_probs.flatten()
yhat_classes = yhat_classes.flatten()
# 准确率:(tp + tn) / (p + n)
accuracy = accuracy_score(y_test, yhat_classes)
print(‘Accuracy: %f’ % accuracy)
# 精确率 tp / (tp + fp)
precision = precision_score(y_test, yhat_classes)
print(‘Precision: %f’ % precision)
# 召回率 tp / (tp + fn)
recall = recall_score(y_test, yhat_classes)
print(‘Recall: %f’ % recall)
# F1 分数: 2 tp / (2 tp + fp + fn)
f1 = f1_score(y_test, yhat_classes)
print(‘F1 score: %f’ % f1)
# kappa
kappa = cohen_kappa_score(testy, yhat_classes)
print(‘Cohens kappa: %f’ % kappa)
# ROC AUC
auc = roc_auc_score(testy, yhat_probs)
print(‘ROC AUC: %f’ % auc)
# 混淆矩阵
matrix = confusion_matrix(y_test, yhat_classes)
print(matrix)
也许检查一下您的数据是否符合您打算使用的度量标准的期望?
我看到了预处理中的错误。感谢您的快速回复!
很高兴听到这个消息。
嗨 @Eric Rac .
我遇到了同样的错误。您是如何纠正多类分类的?
您好,我尝试了相同的方法,但最后收到了错误消息“分类指标无法处理多标签指示和多类目标的混合”
您好!您又发布了一个很棒的帖子!谢谢!
我想计算每个类别的精确率、召回率、F1 分数,而不仅仅是平均值。这可能吗?
提前感谢你
是的,我相信 sklearn 的分类报告将提供这些信息。
我也认为您可以配置 sklearn 的每个指标函数来报告每个类别的分数。
非常感谢您的快速回复!我会尝试计算它们的。
没问题。告诉我您的情况。
我使用了
from sklearn.metrics import precision_recall_fscore_support
precision_recall_fscore_support(y_test, y_pred, average=None)
print(classification_report(y_test, y_pred, labels=[0, 1]))
这对我来说效果很好。
再次感谢!
干得好!
“history.history[‘val_acc’]”计算的准确率与“accuracy = accuracy_score(testy, yhat_classes)”计算的准确率不同,这是如何计算的?
它应该是一样的,例如,在每个 epoch 结束时计算分数。
谢谢你
嗨 Jason,我需要一个 RNN 代码,通过它可以找到特定数据集的分类和混淆矩阵。
有很多例子可供您开始,也许可以从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
我使用以下公式计算了准确率、精确率、召回率和 F1 分数。
accuracy = metrics.accuracy_score(true_classes, predicted_classes)
precision=metrics.precision_score(true_classes, predicted_classes)
recall=metrics.recall_score(true_classes, predicted_classes)
f1=metrics.f1_score(true_classes, predicted_classes)
即使增加了节点数量并进行了所有类型的调整,指标仍然保持在 49% 到 52% 的非常低的值。
例如
精确率 召回率 f1分数 支持数
nu 0.49 0.34 0.40 2814
u 0.50 0.65 0.56 2814
avg / total 0.49 0.49 0.48 5628
混淆矩阵显示 FP 和 FN 的值非常高
confusion= [[ 953 1861]
[ 984 1830]]
我该怎么做才能提高性能?
对于准确率、精确率、召回率和 F1 的低值,准确率和损失图也很奇怪。
验证数据集的准确率始终高于训练数据集;同样,验证损失也低于训练数据集;而预期的则是相反的。
如何克服这个问题?
测试集上的结果优于训练集可能表明测试集不能代表问题,例如,它太小了。
谢谢
不客气。
我在这里提供了一些建议
https://machinelearning.org.cn/start-here/#better
嗨,解释得很棒,但我想在每个 epoch 计算 f1 分数和 auc,我该如何实现?
这取决于您使用的库——如果是 Keras,只需将其添加到 compile() 函数的“metrics”中即可。请参阅 https://keras.org.cn/api/metrics/ 了解长列表。
ValueError: 检查输入时出错:expected dense_74_input to have shape (2,) but got array with shape (10,)
我收到了这个错误,我不知道接下来该做什么。
听到这个消息我很难过,我这里有一些建议可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我正在进行二元文本分类,我的 X_val 形状为 (85, 1, 62, 300),我的 Y_val 形状为 (85, 2)。执行此行时出现错误
yhat_classes = saved_model.predict_classes(X_val, verbose=0)
AttributeError: ‘Model’ object has no attribute ‘predict_classes’
我的代码片段如下
cv_scores, models_history = list(), list()
start_time = time.time()
for train, test in myCViterator
# 分割我们的数据
X_train, X_val, y_train, y_val = df_claim.loc[train].word.tolist(), df_claim.loc[test].word.tolist(), df_label.loc[train].fact.tolist(), df_label.loc[test].fact.tolist()
X_train = np.array(X_train)
X_val = np.array(X_val)
y_train = np.array(y_train)
y_val = np.array(y_val)
# 评估我们的模型
model_history, val_acc, saved_model = evaluate_model(X_train, X_val, y_train, y_val)
# 绘制训练过程中的损失
pyplot.subplot(211)
pyplot.title(‘Loss’)
pyplot.plot(model_history.history[‘loss’], label=’train’)
pyplot.plot(model_history.history[‘val_loss’], label=’test’)
pyplot.legend()
pyplot.show()
# 绘制训练期间的准确率
pyplot.subplot(212)
pyplot.title(‘Accuracy’)
pyplot.plot(model_history.history[‘acc’], label=’train’)
pyplot.plot(model_history.history[‘val_acc’], label=’test’)
pyplot.legend()
pyplot.show()
print(“\n 此模型的指标:”)
print(‘> Accuracy: %.3f’ % val_acc)
cv_scores.append(val_acc)
models_history.append(model_history)
print(y_val.shape)
# Scikit-learn 指标
# 预测测试集的概率
yhat_probs = saved_model.predict(X_val, verbose=0)
# 预测测试集的离散类别
#yhat_classes = np.argmax(yhat_probs, axis=1)
yhat_classes = saved_model.predict_classes(X_val, verbose=0)
# 减少到一维数组
yhat_probs = yhat_probs[:, 0]
#yhat_classes = yhat_classes[:, 0]
# 准确率:(tp + tn) / (p + n)
accuracy = accuracy_score(y_val, yhat_classes)
print(‘> Accuracy: %f’ % accuracy)
# 精确率 tp / (tp + fp)
precision = precision_score(y_val, yhat_classes)
print(‘> Precision: %f’ % precision)
# 召回率 tp / (tp + fn)
recall = recall_score(y_val, yhat_classes)
print(‘> Recall: %f’ % recall)
# F1 分数: 2 tp / (2 tp + fp + fn)
f1 = f1_score(y_val, yhat_classes)
print(‘> F1 score: %f’ % f1)
# kappa
kappa = cohen_kappa_score(y_val, yhat_classes)
print(‘> Cohens kappa: %f’ % kappa)
# ROC AUC
auc = roc_auc_score(y_val, yhat_probs)
print(‘> ROC AUC: %f’ % auc)
# 混淆矩阵
matrix = confusion_matrix(y_val, yhat_classes)
print(matrix)
print(“\n\n”)
print(“— %s seconds —” % (time.time() – start_time))
print(‘估计 5 折交叉验证的准确率:%.3f (%.3f)’ % (np.mean(cv_scores), np.std(cv_scores)))
如果您的模型被 scikit-learn 包装,那么 predict_classes() 将不可用,它是 Keras 模型上的函数。相反,您可以使用 predict()。
我尝试使用 predict() 方法,然后获取向量的 argmax(使用 yhat_classes = np.argmax(yhat_probs, axis=1)),但随后在尝试获取准确率时出现另一个错误。
accuracy = accuracy_score(y_val, yhat_classes)
ValueError: 分类指标无法处理多标签指示和二元目标的混合
我找到了解决方案,显然我还需要将 'y_val' 减少到 1d 数组 lol。
非常感谢您的帮助和这篇很棒的文章!
很高兴听到这个!
您好,您能向我解释一下您是如何解决这个问题的吗?
也许我遇到了同样的问题,但我无法解决。
真的非常感谢!
您好!我训练后,model.fit() 和 model.evaluate() 方法得到的准确率不同。是什么问题?我该如何获得两者之间的正确准确率?
在 fit 期间,分数是根据样本批次平均估算的。
使用 evaluate() 来真实评估模型的性能。
谢谢 Jason
嗨 Jason
在没有 dropout 的情况下,我的验证准确率和测试准确率都比训练准确率好。可能是什么问题?
也许测试集或验证集太小,导致结果在统计上存在噪声?
我将测试大小设置为 40%(0.4)。
我还设置了测试集大小为0.4
非常感谢这个有用的教程。
我想知道如何在多标签CNN中计算精确率、召回率和F1分数。
我的意思是为输出中的每个标签获取这些指标。
非常感谢您的帮助。
我相信上面的教程已经展示了如何计算这些指标。
计算完之后,您可以根据您的标签打印结果。
嗨,Jason,
每当我对机器学习有疑问时,你的文章总能给我clarification。非常感谢。
我的问题是:能否绘制分类器的Kappa误差度量图?
谢谢。
是的,您可能需要自己实现它以便在Keras中使用,请参阅此处的RMSE示例,您可以对其进行改编。
https://machinelearning.org.cn/custom-metrics-deep-learning-keras-python/
我想知道如何在我的回复中上传图片,然而,我的损失和准确率的学习曲线图与您的图示完全不同,训练线和测试线并没有像您的图那样叠在一起,它们的方向完全相反。
考虑到我已经在两个不同的数据集上测试了您的代码,一个数据集是平衡的(f1-score为70%),另一个数据集是不平衡的(f1-score为33%),问题可能出在哪里?
您可以将图片上传到社交媒体、github或像imgur这样的图片托管服务。
我不确定是否理解了您的问题,抱歉。也许您可以详细说明一下?
感谢您精彩的帖子。我有一个问题。如果我们使用one-hot编码来处理标签,通过使用Keras的np_utils.to_categorical进行预处理,我们应该如何使用model.predict()?
抱歉,我不明白,它们没有关联。具体问题是什么?
抱歉,我没有说清楚我的问题。
在帖子中的示例中,如果标签是one-hot编码的,那么在使用model.predict()时,会取argmax值来预测。
代码如下,在此代码中,yhat_classes不能取argmax,所以我认为model.predict_classes()不能用于one-hot编码标签。
这里的结果并不比您帖子中的结果好。
我的问题是,在使用model.predict()时,是否应该使用one-hot编码?
from sklearn.datasets import make_circles
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import cohen_kappa_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import confusion_matrix
来自 keras.models import Sequential
from keras.layers import Dense
import keras
import numpy as np
# 生成并准备数据集
def get_data()
# 生成数据集
X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)
# 分割成训练集和测试集
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
return trainX, trainy, testX, testy
# 定义并拟合模型
def get_model(trainX, trainy)
# 定义模型
model = Sequential()
model.add(Dense(100, input_dim=2, activation=’relu’))
model.add(Dense(num_classes, activation=’sigmoid’))
# 编译模型
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
# 拟合模型
model.fit(trainX, trainy, epochs=300, verbose=0)
return model
# 生成数据
trainX, trainy, testX, testy = get_data()
# One hot encode labels
num_classes = 2
trainy = keras.utils.to_categorical(trainy, num_classes)
testy = keras.utils.to_categorical(testy, num_classes)
# 拟合模型
model = get_model(trainX, trainy)
# 预测测试集的概率
yhat_probs = model.predict(testX, verbose=0)
# 预测测试集的离散类别
yhat_classes = model.predict_classes(testX, verbose=0).reshape(-1,1)
yhat_probs_inverse = np.argmax(yhat_probs,axis=1).reshape(-1,1)
testy_inverse = np.argmax(testy, axis=1).reshape(-1,1)
# 减少到一维数组
yhat_probs = yhat_probs_inverse[:, 0]
yhat_classes = yhat_classes[:, 0]
# 准确率:(tp + tn) / (p + n)
accuracy = accuracy_score(testy_inverse, yhat_classes)
print(‘Accuracy: %f’ % accuracy)
# 精确率 tp / (tp + fp)
precision = precision_score(testy_inverse, yhat_classes)
print(‘Precision: %f’ % precision)
# 召回率 tp / (tp + fn)
recall = recall_score(testy_inverse, yhat_classes)
print(‘Recall: %f’ % recall)
# F1 分数: 2 tp / (2 tp + fp + fn)
f1 = f1_score(testy_inverse, yhat_classes)
print(‘F1 score: %f’ % f1)
# kappa
kappa = cohen_kappa_score(testy_inverse, yhat_classes)
print(‘Cohens kappa: %f’ % kappa)
# ROC AUC
auc = roc_auc_score(testy_inverse, yhat_probs_inverse)
print(‘ROC AUC: %f’ % auc)
# 混淆矩阵
matrix = confusion_matrix(testy_inverse, yhat_classes)
print(matrix)
—————————————————————————–
>>Accuracy: 0.852000
Precision: 0.858871
Recall: 0.845238
F1 score: 0.852000
Cohens kappa: 0.704019
ROC AUC: 0.852055
[[213 35]
[39 213]]
如果您对目标进行one-hot编码,predict()调用将输出类别成员的概率,predict_classes()调用将直接返回类别。
要了解predict()和predict_classes()之间的区别,请参阅此文。
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
非常感谢。很有用的回复。
不客气。
我使用了Cohen Kappa来查找两个标注者之间的内部标注者一致性。
rater1 = [0,1,1]
rater2 = [1,1,1]
labels=[0,1]
print(“cohen_kappa_score”,cohen_kappa_score(rater1, rater2, labels=labels))
为什么我得到的结果是0?
我不知道具体原因,也许预测没有技能?
嗯,我不是在做分类问题,我是在衡量标注者之间的一致性,这被称为内部标注者一致性,正如这里提到的 https://en.wikipedia.org/wiki/Cohen%27s_kappa。Cohen Kappa是其中的一种方法。我期望得到一个很高的值,因为标注者的意见几乎相同,但我对得到负值感到惊讶。
我对那个任务不熟悉。
我正在使用SVHN数据库,在使用上面的代码后,我得到的precision\Recall\F1值都相同。
这看起来不正确。
也许可以尝试调试您的代码来找出故障原因。
谢谢,这非常有帮助和清晰。我唯一遇到的困难,并且还没有找到解决方案的是,如何将其应用于多标签分类问题?
我的Keras模型(非Sequential)的输出是来自一个具有sigmoid激活的Dense层,用于8个可能的类别。样本可以属于多个类别。如果我执行model.predict(),我会得到每个类别的概率。
pred[0]
array([0.9876269 , 0.08615541, 0.81185186, 0.6329404 , 0.6115263 ,
0.11617774, 0.7847705 , 0.9649658 ], dtype=float32)
我的y看起来是这样的,对于8个类别中的每个类别都有一个二元分类。
[1 0 1 1 1 0 1 1]
predict_classes只适用于Sequential,那么在这种情况下,我该如何才能获得一个包含每个类别的precision、recall和f-1的分类报告?
啊,忘了!有时最简单的解决方案就在我们眼前,但我们却看不到……
predicted[predicted>=0.5] = 1
predicted[predicted<0.5] = 0
问题解决了!😀
不错。
是的,对于多标签分类,您为每个标签获得一个二元预测。
如果您想要一个多类别分类(互斥类别),请使用softmax激活函数,然后使用argmax来获得单个类别。
# 定义模型
model = Sequential()
model.add(embedding_layer)
model.add(Conv1D(filters=128, kernel_size=5, activation=’relu’))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(1, activation=’sigmoid’))
打印(model.summary())
# 编译网络
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
# 拟合网络
model.fit(Xtrain, ytrain, epochs=15, verbose=2)
# 评估
loss, acc = model.evaluate(Xtest, ytest, verbose=0)
# 预测测试集的概率
yhat_probs = model.predict(Xtest, verbose=0)
# 预测测试集的离散类别
yhat_classes = model.predict_classes(Xtest, verbose=0)
# 减少到一维数组
yhat_probs = yhat_probs[:, 0]
yhat_classes = yhat_classes[:, 0]
# 准确率:(tp + tn) / (p + n)
accuracy = accuracy_score(ytest, yhat_classes)
print(‘Accuracy: %f’ % accuracy)
# 精确率 tp / (tp + fp)
precision = precision_score(ytest, yhat_classes)
print(‘Precision: %f’ % precision)
# 召回率 tp / (tp + fn)
recall = recall_score(ytest, yhat_classes)
print(‘Recall: %f’ % recall)
# F1 分数: 2 tp / (2 tp + fp + fn)
f1 = f1_score(ytest, yhat_classes)
print(‘F1 score: %f’ % f1)
# 混淆矩阵
matrix = confusion_matrix(ytest, yhat_classes)
print(matrix)
但我的输出显示
Accuracy: 0.745556
Precision: 0.830660
Recall: 0.776667
TypeError: ‘numpy.float64’ object is not callable
如何解决这个问题??
很抱歉听到这个消息,这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
如何用我的数据(file.csv)替换make_circles?如何修改代码?
这会教你如何加载CSV。
https://machinelearning.org.cn/load-machine-learning-data-python/
非常感谢 Jason,我真的很喜欢这些代码,请问这些指标 Precision、F1 score 和 Recall 能否也应用于序列到序列的RNN预测?
也许可以,但并非真正适用。如果输出是文本,请考虑BLEU或ROGUE等指标。
好的,谢谢您的回复,那么对于RNN序列到序列的输出是数字的,您会选择什么指标?
如果您是每个样本预测一个值,那么MAE或RMSE是很好的起始指标。
你好。我正在使用SVM算法以及一个用于学习二元分类的库。我该如何制作一个f1_score图表呢?
谢谢。
什么是f1 score图表?您具体要绘制什么?
我的数据集包含推文,并且有两个类别:犯罪和非犯罪。我打算生成f1_score,因为数据集不平衡,所以f1_score是衡量模型效果更合适的指标。
谢谢。
好问题,这将帮助您为项目选择指标。
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
实际上,我知道该使用什么指标,我知道就是f1_score,但是,我无法用SVM实现它。
为什么不?
在神经网络中,我将每个epoch的f1_score绘制在图上,但在SVM中我不知道如何做。
抱歉,我没有处理图数据的示例。
在神经网络中,我将每个epoch的f1_score绘制在图上,但在SVM中我不知道如何做。
注意:抱歉重复发送消息,这是个错误。
如果有人创建了您喜欢的报告或图表,也许可以问问他们是如何制作的?
非常感谢。
不客气!
尊敬的先生,
如何在深度学习中实现100%的召回率?
请提供一些提高深度学习中召回率的技巧。
此外,我正在尝试文本分类,所有数据集都存在不平衡问题。
我们已经应用了smote方法来解决不平衡问题,smote方法没有报错。
对于不平衡文本分类应用smote方法是否是一个好方法?是否有其他方法可以提高不平衡文本分类的召回率?
这里有一些提高模型性能的建议。
https://machinelearning.org.cn/start-here/#better
尊敬的Jason先生,
Keras函数式API没有predict_classes函数。有什么建议吗?如何计算函数式API情况下的度量?
是的,使用predict()然后对结果应用argmax。
https://machinelearning.org.cn/argmax-in-machine-learning/
一些度量,比如ROC AUC,需要类别的预测概率(yhat_probs)。这些可以通过调用模型的predict()函数来获得。
我真的不明白为什么yhat_classes也用于ROC AUC。如果您能解释一下,那就太好了。另外,当您说“预测类别概率”时,我们是否应该使用“predict_proba”而不是“predict”?
非常感谢
在keras中,predict()函数在分类任务中返回概率。
非常感谢!精彩的教程。
谢谢。
尊敬的Jason先生,
感谢您的大力支持。我正在对四类图像进行分类,每个类别的图像数量相等(测试集共480张图像,每个类别120张)。我从测试数据集中计算度量,包括accuracy、Precision、Recall和F1-score。我使用了三种方法来计算这些度量:第一种是您解释过的scikit-learn API,第二种是打印分类报告,第三种是使用混淆矩阵。在这三种方法中,我得到了所有四个度量值都相同的(0.92)。所有四个度量值都获得相同的值是否可能,还是我做错了什么?根据您的经验,请澄清并提出前进的建议。
谢谢和问候
也许是吧。检查您的测试环境是否存在错误。
另外,我建议选择一个度量并进行优化。
感谢您的快速回复。我将附上我的测试代码,希望您的经验能提供解决方案。
#四类分类问题
class_labels = list(test_it.class_indices.keys())
y_true = test_it.classes
test_it.reset() #
Y_pred = model.predict(test_it, STEP_SIZE_TEST,verbose=1)
y_pred1 = np.argmax(Y_pred, axis=1, out=None)
target_names = [‘Apple’, ‘Orange, ‘Mango’,’Guava’]
cm = confusion_matrix(y_true, y_pred1)
print(‘Confusion Matrix’)
print(cm)
print(‘Classification Report’)
print(classification_report(test_it.classes, y_pred1, target_names=class_labels))
ax= plt.subplot()
sns.heatmap(cm, annot=True, ax = ax, cmap=’Blues’, fmt=’d’ );
ax.set_xlabel(‘Predicted labels’);ax.set_ylabel(‘True labels’);
ax.set_title(‘Confusion Matrix’);
ax.xaxis.set_ticklabels([‘Apple’, ‘Orange, ‘Mango’,’Guava’]);
ax.yaxis.set_ticklabels([‘Apple’, ‘Orange, ‘Mango’,’Guava’]);
accuracy = accuracy_score(y_true, y_pred1)
print(‘Accuracy: %f’ % accuracy)
precision = precision_score(y_true, y_pred1, average=’micro’)
print(‘Precision: %f’ % precision)
recall = recall_score(y_true, y_pred1, average=’micro’)
print(‘Recall: %f’ % recall)
f1 = f1_score(y_true, y_pred1,average=’micro’)
print(‘F1 score: %f’ % f1)
非常感谢并致以问候。
抱歉,我没有能力审查/调试您的代码。也许这个会有帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
感谢您的快速回复。
我的问题是:所有度量是否可能相同?例如,在scikit-learn的分类报告(识别手写数字的例子)中,所有值都显示为0.97。我附上链接供参考:
https://scikit-learn.cn/stable/auto_examples/classification/plot_digits_classification.html#sphx-glr-auto-examples-classification-plot-digits-classification-py
请求评论。
抱歉,我不明白你的问题。也许你可以重新措辞?
在多类别分类中,三个评估指标(accuracy、precision、recall)是否可能收敛到相同的值?
在此参考中,显示了一个分类报告,其中所有三个指标的值都相同:
https://scikit-learn.cn/stable/auto_examples/classification/plot_digits_classification.html#sphx-glr-auto-examples-classification-plot-digits-classification-py
也许可以。
你最棒了
谢谢!
多类别分类怎么办??
谢谢
您可以直接将指标用于二元分类或多类别分类。
• 一个池塘里有1400条鱼和300只虾。为了捕鱼,
我们撒网。捕获了700条鱼和200只虾。请计算
精确率、召回率和F1分数。
有人能给我答案吗?
也许这会有帮助。
https://machinelearning.org.cn/precision-recall-and-f-measure-for-imbalanced-classification/
如何打印使用一个数据集进行训练,使用另一个数据集进行测试的精确率、召回率?
使用第一个数据集拟合模型,对第二个数据集进行预测,并使用预测结果计算指标。
先生,那已经完成了。您能否提供这方面的参考代码?
也许从这里开始
https://machinelearning.org.cn/train-test-split-for-evaluating-machine-learning-algorithms/
嗨,Jason,
非常感谢您的教程,对我帮助很大。我想知道是否可以使用 Tensorflow/Keras 内置的 API(例如 tf.keras.metrics.Precision)来获取序列到序列模型的指标(精确率/召回率),该模型的每个时间步的输出标签是作为多类别情况进行独热编码的?如果答案是肯定的,您是否有任何参考或示例可以参考?如果不是,您是否有任何建议可以尝试获取它们?谢谢。
是的,但还没有例子。感谢您的建议,我们将考虑。
明白了。谢谢。
你好,
我得到了一台新的 PC,上面安装了 tensorflow 2.7.0,当我尝试我以前的二元分类代码(这是按照本教程创建的)时,我得到了以下错误
AttributeError: ‘Sequential’ object has no attribute ‘predict_classes’
有什么线索可以解决这个问题吗?
谢谢
是的,每当您看到
替换为
这是因为在 Keras API 的最新版本中删除了 predict_classes()。
y = np.argmax(v) 不会返回类别。
嗨 Emml……您在执行代码时遇到了什么结果?
这是我从文章中得到的内容。执行了训练/测试分割。然后,测试集在训练期间同时用作验证数据和测试数据,报告了在原始分割中称为测试集的数据上的 F1 分数。让测试集兼作验证集是否正确?实际上,我可以说明您报告的是验证集(恰好与测试集相同)上的 F1 分数。
我个人认为这是可以接受的。您希望进行验证或测试的原因是获得一个指标来告诉您模型的性能有多好。因此,您不希望您的训练集也用于评分,因为否则您就无法知道它是否过拟合。但即使如此,训练期间的测试是从测试集中抽样的,而训练后的验证使用的是整个测试集。因此,您看到的东西并不完全相同。
我真的很感谢你,Jason,你让我的项目得以完成,你对我们许多人产生了积极的影响。非常感谢。
Lawrence,反馈很棒!
您好,
我真的很想知道如何使用 sklearn 库中的 f1_score 作为 keras 编译器中的指标,以便将其用作 ModelCheckpoint 的 monitor 参数来保存具有最佳 f1_score 的模型并在之后用于预测?
我真的很想找出答案?或者您能否告诉我如何通过创建自定义指标来执行此类操作?
此致!
AttributeError: ‘Sequential’ object has no attribute ‘predict_classes’
嗨 Asif……请详细说明错误。您是复制粘贴的代码还是自己输入的?
你好。
如果我们想将分类模型应用于不平衡数据,我们应该
– 使用成本矩阵或对类别应用权重。
– 避免使用准确率来优化模型,而是使用 F1 分数,甚至更好的是 AUC ROC 或 AUC PR。
我的问题是……我们应该只使用这些建议中的一个还是同时使用两者?
我的意思是,如果我们使用 AUC_PR……我们还需要对输入应用权重吗?
反之亦然
如果我们使用权重……是否仍然建议使用 AUC_PR 而不是简单地使用准确率?
n_test = 500
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
return trainX, trainy, testX, testy
Cell In[62], line 4
return trainX, trainy, testX, testy
^
SyntaxError: ‘return’ outside function
我该如何解决这个问题??
谢谢
这个教程做得很好。
嗨 Andrea……
SyntaxError: 'return' outside function错误发生是因为return语句在函数之外使用。在 Python 中,return只能在函数内部使用,将结果返回给调用者。要解决这个问题,您需要将代码包装在函数定义中。以下是一个定义一个函数来将数据分割为训练集和测试集,然后返回它们的示例:
pythondef split_data(X, y, n_test=500):
trainX, testX = X[:n_test, :], X[n_test:, :]
trainy, testy = y[:n_test], y[n_test:]
return trainX, trainy, testX, testy
# Example usage
trainX, trainy, testX, testy = split_data(X, y)
这样,
return语句就在split_data函数内部了,您可以调用此函数来获取您想要的数据分割。嗨
我想为每个算法(如随机森林、逻辑回归和另外两个)创建条形图,并将参数设置为准确率、精确率、召回率、F1 分数。我已经计算了参数值,但需要一个代码来创建这 4 个算法的条形图。
这是一个简单的 Python 代码,使用 **Matplotlib** 创建一个分组条形图,比较**准确率**、**精确率**、**召回率**和**F1 分数**在**4 种不同的算法**(如随机森林、逻辑回归等)之间的差异。
您只需要在指示的地方**填入您的值**。
pythonimport matplotlib.pyplot as plt
import numpy as np
# 算法名称
algorithms = ['Random Forest', 'Logistic Regression', 'SVM', 'KNN'] # 自定义名称
# 每个算法的指标(请替换为您的实际计算值)
accuracy = [0.91, 0.88, 0.89, 0.86]
precision = [0.90, 0.85, 0.87, 0.84]
recall = [0.92, 0.86, 0.88, 0.85]
f1_score = [0.91, 0.85, 0.87, 0.84]
# 分组条形图位置
x = np.arange(len(algorithms))
width = 0.2
# 绘图
plt.figure(figsize=(10, 6))
plt.bar(x - 1.5*width, accuracy, width, label='Accuracy')
plt.bar(x - 0.5*width, precision, width, label='Precision')
plt.bar(x + 0.5*width, recall, width, label='Recall')
plt.bar(x + 1.5*width, f1_score, width, label='F1 Score')
# 标签和标题
plt.xlabel('Algorithms')
plt.ylabel('Scores')
plt.title('Performance Comparison of ML Algorithms')
plt.xticks(x, algorithms)
plt.ylim(0, 1.1)
plt.legend()
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
—
### ✅ 注意事项
– 您可以**替换为其他模型**,例如 XGBoost、朴素贝叶斯等。
– 确保所有指标列表(accuracy, precision 等)的长度与算法数量相同。