深度学习神经网络是使用随机梯度下降优化算法进行训练的。
作为优化算法的一部分,必须反复估算模型当前状态的误差。这需要选择一个误差函数,通常称为损失函数,用于估算模型的损失,以便更新权重以减少下一次评估时的损失。
神经网络模型从示例中学习输入到输出的映射,损失函数的选择必须与特定预测建模问题(例如分类或回归)的框架相匹配。此外,输出层的配置也必须与所选的损失函数相适应。
在本教程中,您将学习如何为给定的预测建模问题选择深度学习神经网络的损失函数。
完成本教程后,您将了解:
- 如何为回归问题配置模型以使用均方误差和变体。
- 如何为二元分类配置模型以使用交叉熵和Hinge损失函数。
- 如何为多类别分类配置模型以使用交叉熵和KL散度损失函数。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019年10月更新:已更新至Keras 2.3和TensorFlow 2.0。
- 2020年1月更新:已更新以适应scikit-learn v0.22 API的变化

训练深度学习神经网络时如何选择损失函数
照片由 GlacierNPS提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 回归损失函数
- 均方误差损失
- 均方对数误差损失
- 平均绝对误差损失
- 二元分类损失函数
- 二元交叉熵
- Hinge损失
- 平方Hinge损失
- 多类别分类损失函数
- 多类别交叉熵损失
- 稀疏多类别交叉熵损失
- Kullback Leibler散度损失
我们将重点介绍如何选择和实现不同的损失函数。
有关损失函数的更多理论,请参阅此文章
回归损失函数
回归预测建模问题涉及预测一个实数值。
在本节中,我们将研究适用于回归预测建模问题的损失函数。
作为本次研究的背景,我们将使用scikit-learn库中make_regression()函数提供的标准回归问题生成器。该函数将从一个简单的回归问题中生成具有给定数量的输入变量、统计噪声和其他属性的示例。
我们将使用此函数定义一个具有20个输入特征的问题;其中10个特征有意义,10个不相关。总共将随机生成1,000个示例。伪随机数生成器将被固定,以确保每次运行代码时都能获得相同的1,000个示例。
|
1 2 |
# 生成回归数据集 X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=1) |
当实值输入和输出变量缩放到一个合理的范围时,神经网络通常表现更好。对于这个问题,每个输入变量和目标变量都服从高斯分布;因此,在这种情况下,标准化数据是可取的。
我们可以使用scikit-learn库中的StandardScaler转换器类来实现这一点。在实际问题中,我们会在训练数据集上准备缩放器并将其应用于训练集和测试集,但为了简化,我们将在将所有数据拆分为训练集和测试集之前对其进行缩放。
|
1 2 3 |
# 标准化数据集 X = StandardScaler().fit_transform(X) y = StandardScaler().fit_transform(y.reshape(len(y),1))[:,0] |
缩放后,数据将被平均分为训练集和测试集。
|
1 2 3 4 |
# 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
将定义一个小型多层感知器(MLP)模型来解决此问题,并为探索不同的损失函数提供基础。
该模型将如问题所定义,期望20个特征作为输入。该模型将有一个具有25个节点的隐藏层,并使用修正线性激活函数(ReLU)。输出层将有1个节点,因为要预测一个实数值,并将使用线性激活函数。
|
1 2 3 4 |
# 定义模型 model = Sequential() model.add(Dense(25, input_dim=20, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='linear')) |
该模型将使用学习率为0.01和动量为0.9的随机梯度下降进行拟合,这两个都是合理的默认值。
训练将进行100个epochs,并在每个epoch结束时评估测试集,以便我们可以在运行结束时绘制学习曲线。
|
1 2 3 4 |
opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='...', optimizer=opt) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) |
现在我们已经有了问题和模型的基础,我们可以看看评估三种适用于回归预测建模问题的常见损失函数。
尽管在这些示例中使用了MLP,但相同的损失函数也可以在训练CNN和RNN模型进行回归时使用。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
均方误差损失
均方误差(MSE)损失是回归问题的默认损失函数。
从数学上讲,如果目标变量的分布是高斯分布,它是最大似然推断框架下首选的损失函数。它是第一个要评估的损失函数,只有在有充分理由时才进行更改。
均方误差的计算方法是预测值和实际值之间平方差的平均值。结果始终为正,无论预测值和实际值的符号如何,完美值为0.0。平方意味着较大的错误会导致比小错误更多的误差,这意味着模型会因犯较大的错误而受到惩罚。
在Keras中,可以通过在编译模型时将损失函数指定为“mse”或“mean_squared_error”来使用均方误差损失函数。
|
1 |
model.compile(loss='mean_squared_error') |
建议输出层有一个用于目标变量的节点,并使用线性激活函数。
|
1 |
model.add(Dense(1, activation='linear')) |
下面列出了在所描述的回归问题上演示MLP的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 带有MSE损失函数的回归MLP from sklearn.datasets import make_regression from sklearn.preprocessing import StandardScaler from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from matplotlib import pyplot # 生成回归数据集 X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=1) # 标准化数据集 X = StandardScaler().fit_transform(X) y = StandardScaler().fit_transform(y.reshape(len(y),1))[:,0] # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(25, input_dim=20, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='linear')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='mean_squared_error', optimizer=opt) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 train_mse = model.evaluate(trainX, trainy, verbose=0) test_mse = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_mse, test_mse)) # 绘制训练过程中的损失 pyplot.title('Loss / Mean Squared Error') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的均方误差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型学习了问题,实现了零误差,至少到小数点后三位。
|
1 |
训练:0.000,测试:0.001 |
还创建了一个线图,显示了训练周期中训练集(蓝色)和测试集(橙色)的均方误差损失。
我们可以看到模型收敛得相当快,并且训练和测试性能保持一致。模型的性能和收敛行为表明均方误差非常适合神经网络学习这个问题。
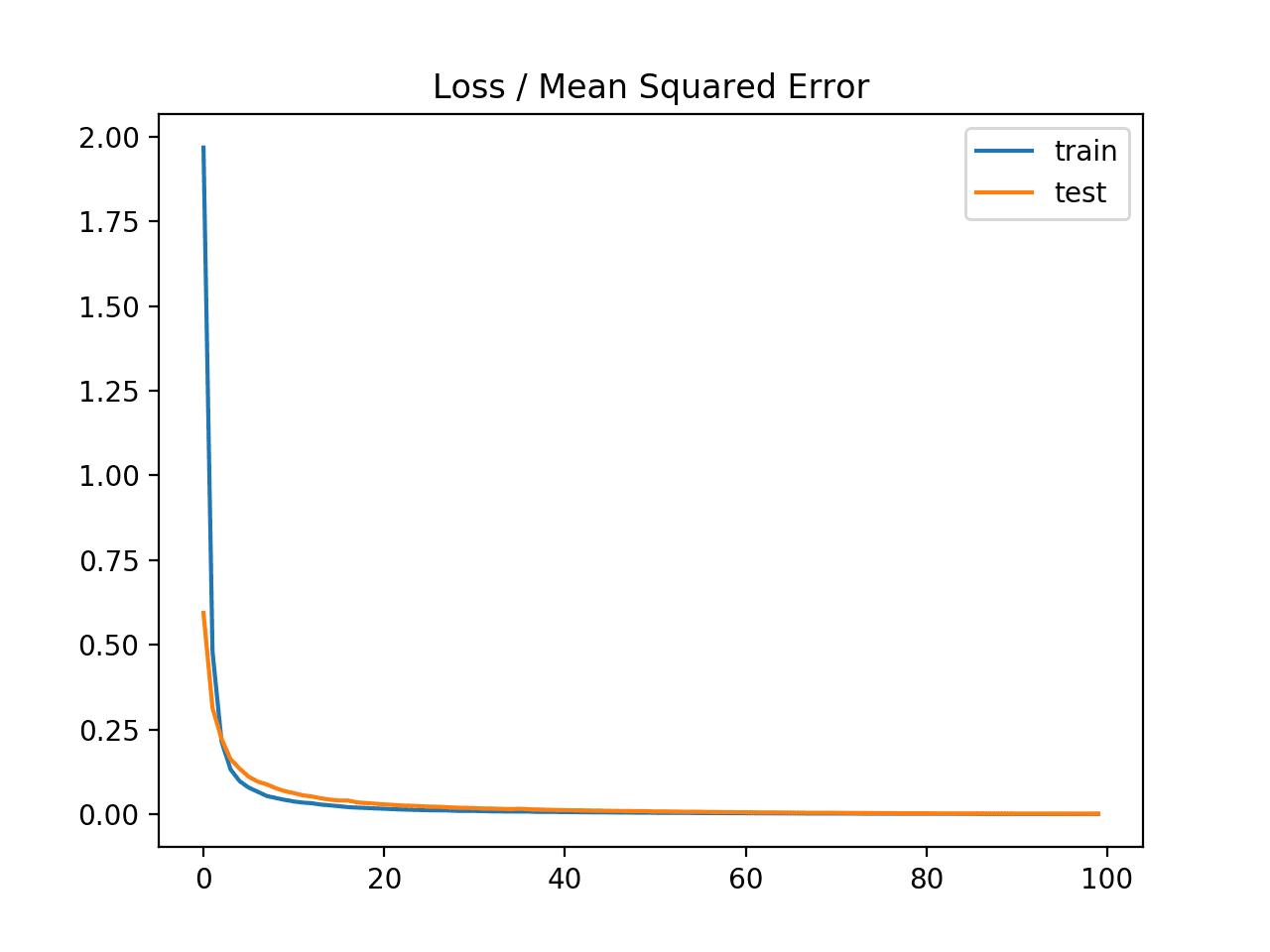
优化均方误差损失函数时训练周期中均方误差损失的线图
均方对数误差损失
在某些回归问题中,目标变量的分布可能主要是高斯分布,但可能存在异常值,例如远离平均值的大值或小值。
在这种情况下,平均绝对误差(MAE)损失是一个合适的损失函数,因为它对异常值更鲁棒。它的计算方法是实际值和预测值之间绝对差的平均值。
它具有减轻大预测值中大差异的惩罚效果。
作为一种损失度量,当模型直接预测未缩放的量时,它可能更合适。尽管如此,我们可以使用我们的简单回归问题来演示此损失函数。
模型可以更新为使用“mean_squared_logarithmic_error”损失函数,并保持输出层的相同配置。我们还将跟踪均方误差作为模型拟合时的度量,以便我们可以将其用作性能度量并绘制学习曲线。
|
1 |
model.compile(loss='mean_squared_logarithmic_error', optimizer=opt, metrics=['mse']) |
下面列出了使用MSLE损失函数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 带有MSLE损失函数的回归MLP from sklearn.datasets import make_regression from sklearn.preprocessing import StandardScaler from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from matplotlib import pyplot # 生成回归数据集 X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=1) # 标准化数据集 X = StandardScaler().fit_transform(X) y = StandardScaler().fit_transform(y.reshape(len(y),1))[:,0] # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(25, input_dim=20, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='linear')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='mean_squared_logarithmic_error', optimizer=opt, metrics=['mse']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 _, train_mse = model.evaluate(trainX, trainy, verbose=0) _, test_mse = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_mse, test_mse)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的MSE pyplot.子图(212) pyplot.title('Mean Squared Error') pyplot.plot(history.history['mean_squared_error'], label='train') pyplot.plot(history.history['val_mean_squared_error'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的均方误差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型在训练和测试数据集上的MSE略有恶化。它可能不适合这个问题,因为目标变量的分布是标准高斯分布。
|
1 |
训练:0.165,测试:0.184 |
还创建了一个线图,显示了训练周期中训练集(蓝色)和测试集(橙色)的均方对数误差损失(顶部),以及一个类似的均方误差图(底部)。
我们可以看到MSLE在100个epoch算法中收敛良好;MSE似乎表现出过拟合问题的迹象,从第20个epoch开始快速下降并开始上升。
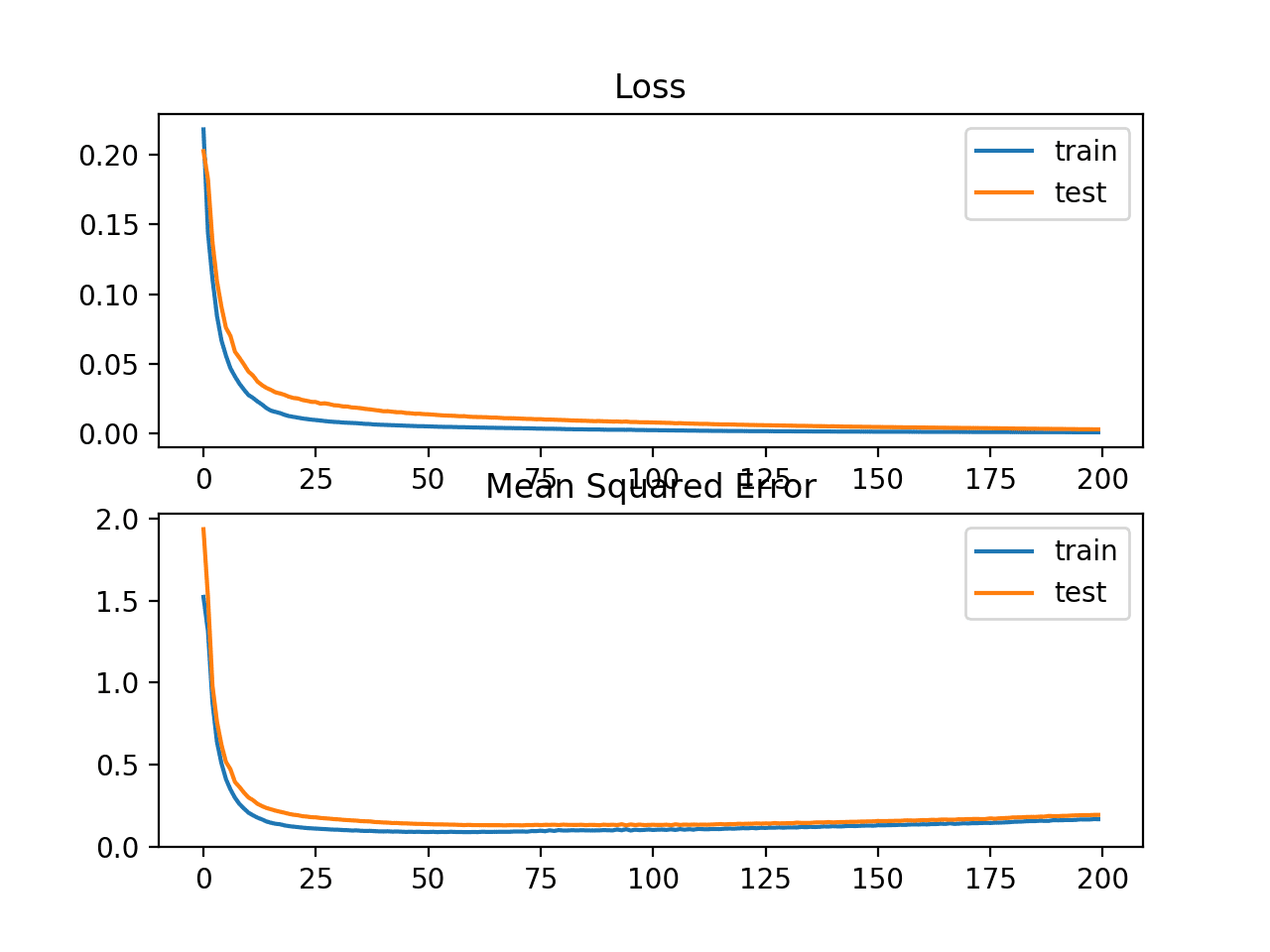
训练周期中均方对数误差损失和均方误差的线图
平均绝对误差损失
在一些回归问题中,目标变量的分布可能大部分是高斯分布,但可能存在异常值,例如远离平均值的大值或小值。
在这种情况下,平均绝对误差(MAE)损失是一个合适的损失函数,因为它对异常值更鲁棒。它的计算方法是实际值和预测值之间绝对差的平均值。
模型可以更新为使用“mean_absolute_error”损失函数,并保持输出层的相同配置。
|
1 |
model.compile(loss='mean_absolute_error', optimizer=opt, metrics=['mse']) |
下面列出了在回归测试问题上使用平均绝对误差作为损失函数的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 带有MAE损失函数的回归MLP from sklearn.datasets import make_regression from sklearn.preprocessing import StandardScaler from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from matplotlib import pyplot # 生成回归数据集 X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=1) # 标准化数据集 X = StandardScaler().fit_transform(X) y = StandardScaler().fit_transform(y.reshape(len(y),1))[:,0] # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(25, input_dim=20, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='linear')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='mean_absolute_error', optimizer=opt, metrics=['mse']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 _, train_mse = model.evaluate(trainX, trainy, verbose=0) _, test_mse = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_mse, test_mse)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的MSE pyplot.子图(212) pyplot.title('Mean Squared Error') pyplot.plot(history.history['mean_squared_error'], label='train') pyplot.plot(history.history['val_mean_squared_error'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的均方误差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型学习了问题,实现了接近零的误差,至少到小数点后三位。
|
1 |
训练:0.002,测试:0.002 |
还创建了一个线图,显示了训练周期中训练集(蓝色)和测试集(橙色)的平均绝对误差损失(顶部),以及一个类似的均方误差图(底部)。
在这种情况下,我们可以看到MAE确实收敛,但显示出颠簸的路线,尽管MSE的动态似乎没有受到太大影响。我们知道目标变量是标准高斯分布,没有大的异常值,因此MAE在这种情况下不合适。
如果我们最初没有缩放目标变量,那么在这种情况下它可能更适合这个问题。
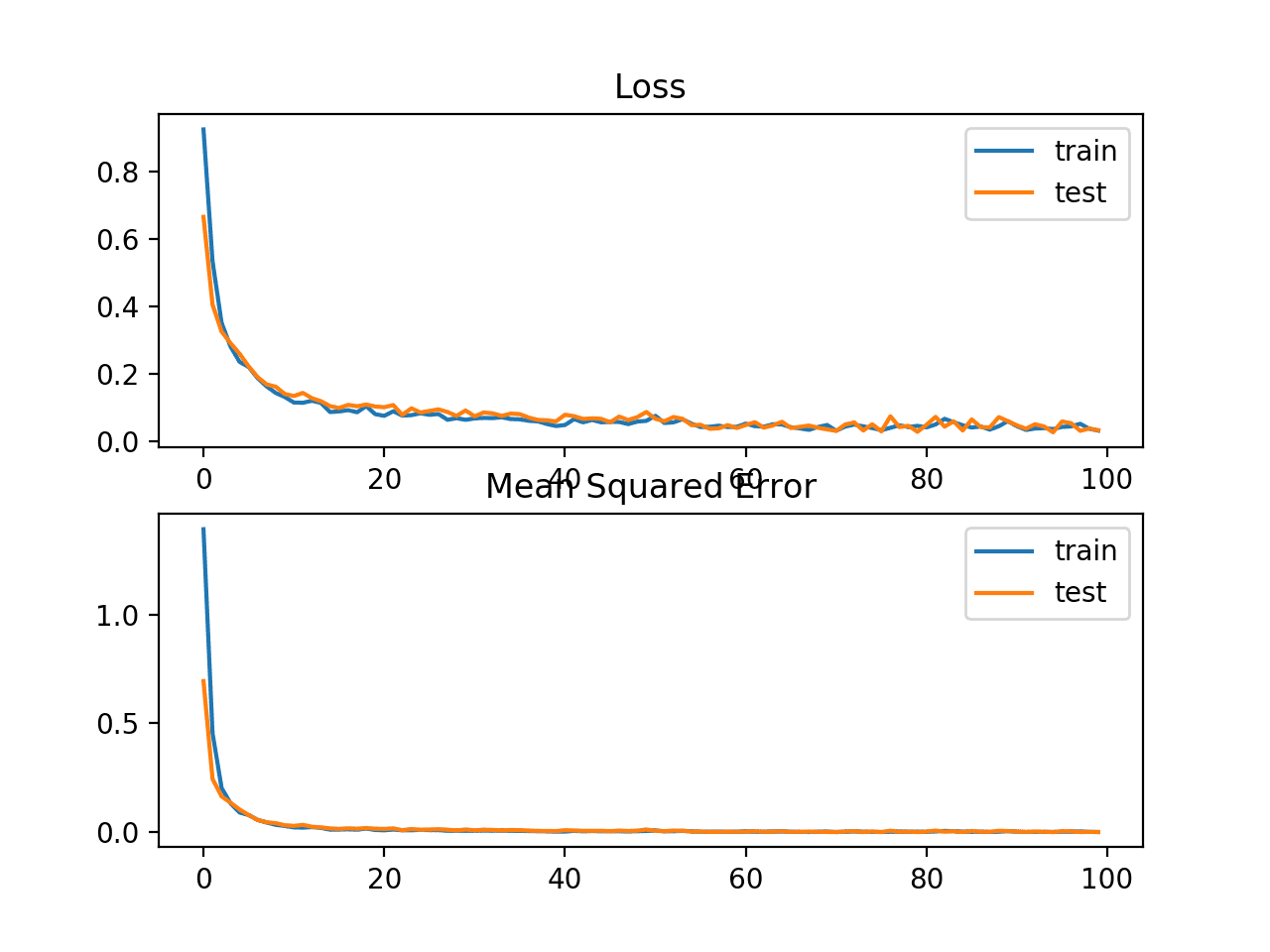
训练周期中平均绝对误差损失和均方误差的线图
二元分类损失函数
二元分类是指将示例分配给两个标签之一的预测建模问题。
这个问题通常被框定为预测第一个或第二个类别的值为0或1,并且通常通过预测示例属于类别值1的概率来实现。
在本节中,我们将研究适用于二元分类预测建模问题的损失函数。
我们将以scikit-learn中的圆形测试问题生成示例作为本次研究的基础。圆形问题涉及从二维平面上的两个同心圆中抽样,其中外圆上的点属于类别0,内圆上的点属于类别1。样本中添加了统计噪声,以增加模糊性并使问题更具挑战性。
我们将生成1,000个示例并添加10%的统计噪声。伪随机数生成器将用相同的值进行播种,以确保我们始终获得相同的1,000个示例。
|
1 2 |
# 生成圆 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) |
我们可以创建数据集的散点图,以了解我们正在建模的问题。完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 带类别颜色点的圆形数据集散点图 from sklearn.datasets import make_circles from numpy import where from matplotlib import pyplot # 生成圆 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 选择每个类别标签的点的索引 for i in range(2): samples_ix = where(y == i) pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1], label=str(i)) pyplot.legend() pyplot.show() |
运行示例将创建示例的散点图,其中输入变量定义了点的位置,类别值定义了颜色,类别0为蓝色,类别1为橙色。
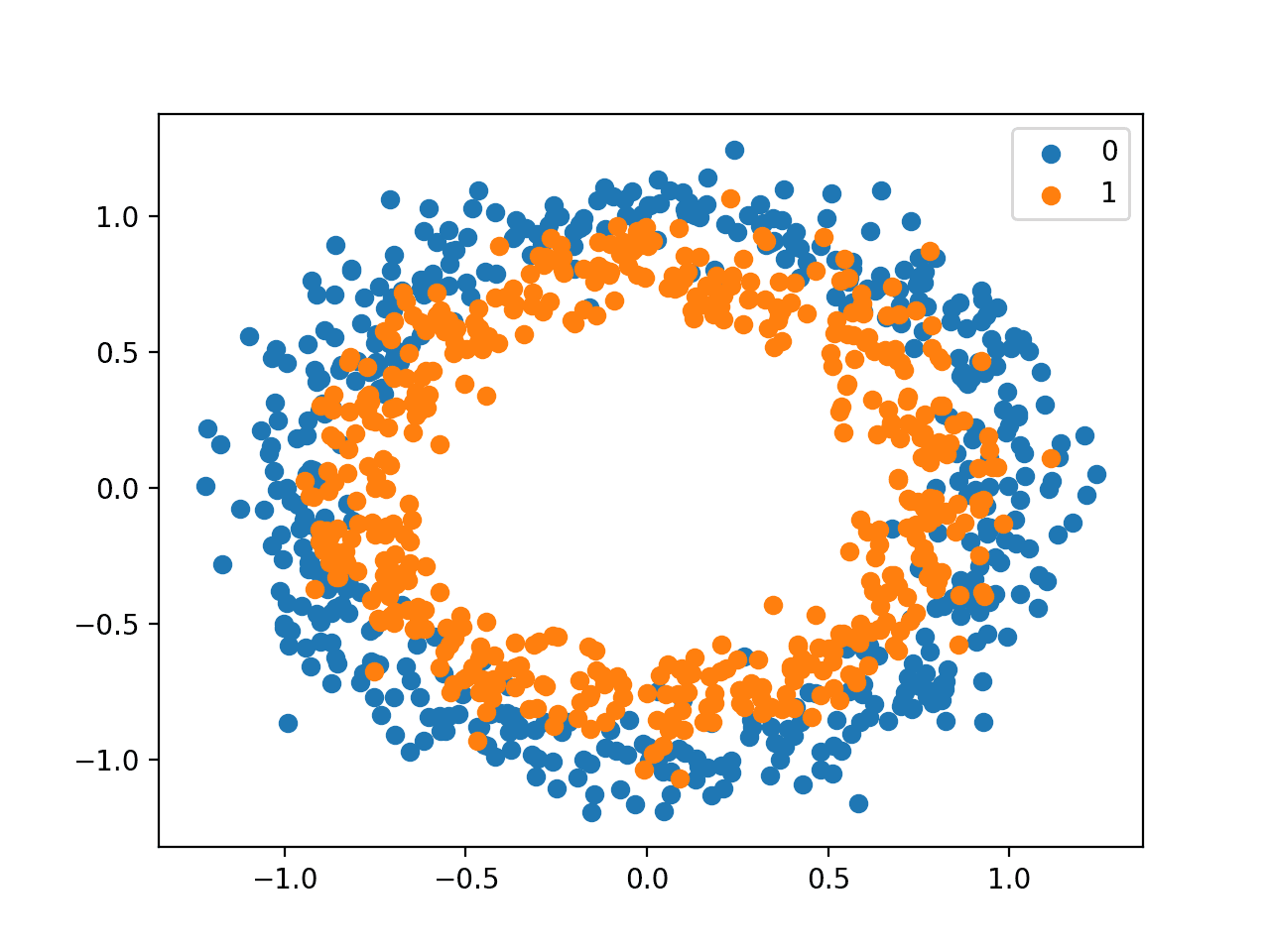
圆形二元分类问题数据集的散点图
这些点已经合理地围绕0缩放,几乎在[-1,1]范围内。在这种情况下我们不会重新缩放它们。
数据集平均分为训练集和测试集。
|
1 2 3 4 |
# 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
可以定义一个简单的MLP模型来解决这个问题,该模型期望两个输入变量对应数据集中的两个特征,一个具有50个节点的隐藏层,一个修正线性激活函数,以及一个需要根据损失函数的选择进行配置的输出层。
|
1 2 3 4 |
# 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='...')) |
该模型将使用学习率为0.01和动量为0.9的合理默认随机梯度下降进行拟合。
|
1 2 |
opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='...', optimizer=opt, metrics=['accuracy']) |
我们将训练模型200个训练周期,并在每个训练周期结束时根据损失和准确性评估模型的性能,以便我们可以绘制学习曲线。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0) |
现在我们已经有了问题和模型的基础,我们可以看看评估三种适用于二元分类预测建模问题的常见损失函数。
尽管在这些示例中使用了MLP,但相同的损失函数也可以在训练CNN和RNN模型进行二元分类时使用。
二元交叉熵损失
交叉熵是用于二元分类问题的默认损失函数。
它旨在用于目标值为{0, 1}集合的二元分类。
从数学上讲,它是最大似然推断框架下首选的损失函数。它是第一个要评估的损失函数,只有在有充分理由时才进行更改。
交叉熵将计算一个分数,该分数概括了预测类别1的实际概率分布与预测概率分布之间的平均差异。分数最小化,完美的交叉熵值为0。
在Keras中,通过在编译模型时将“binary_crossentropy”指定为损失函数来指定交叉熵。
|
1 |
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) |
该函数要求输出层配置为单个节点和“sigmoid”激活函数,以便预测类别1的概率。
|
1 |
model.add(Dense(1, activation='sigmoid')) |
下面列出了带交叉熵损失的MLP解决两圆形二元分类问题的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 带有交叉熵损失的圆形问题MLP from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的准确率 pyplot.子图(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型很好地学习了问题,在训练数据集上实现了约83%的准确率,在测试数据集上实现了约85%的准确率。这些分数相当接近,表明模型可能没有过拟合或欠拟合。
|
1 |
训练:0.836,测试:0.852 |
还创建了一个图表,显示了两个线图,顶部显示了训练集(蓝色)和测试集(橙色)的交叉熵损失随epoch的变化,底部显示了分类准确率随epoch的变化。
该图显示训练过程收敛良好。损失图平滑,因为误差在概率分布之间是连续的,而准确率线图显示颠簸,因为训练集和测试集中的示例最终只能被预测为正确或不正确,提供了较少颗粒度的性能反馈。
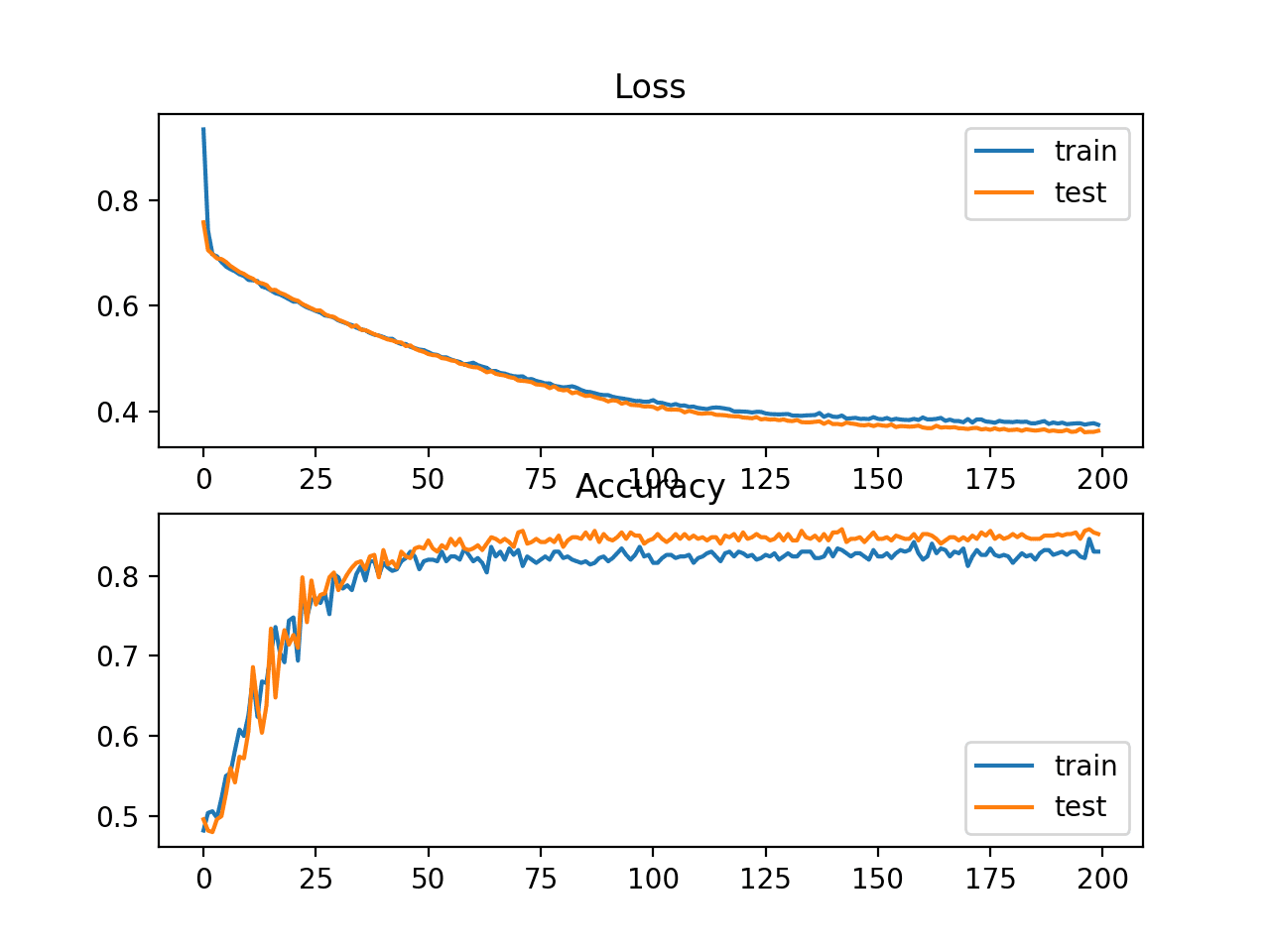
两圆形二元分类问题中交叉熵损失和分类准确率随训练周期变化的线图
Hinge损失
二元分类问题除了交叉熵之外,还有一种替代方案是Hinge损失函数,主要用于支持向量机(SVM)模型。
它旨在用于目标值为集合{-1, 1}的二元分类。
Hinge损失函数鼓励示例具有正确的符号,当实际和预测类别值之间的符号存在差异时,会分配更多的误差。
使用Hinge损失的性能报告好坏参半,有时在二元分类问题上比交叉熵表现更好。
首先,目标变量必须修改为{-1, 1}集合中的值。
|
1 2 |
# 将y从{0,1}更改为{-1,1} y[where(y == 0)] = -1 |
Hinge损失函数可以在编译函数中指定为“hinge”。
|
1 |
model.compile(loss='hinge', optimizer=opt, metrics=['accuracy']) |
最后,网络的输出层必须配置为具有一个带有双曲正切激活函数的单个节点,该激活函数能够输出范围在[-1, 1]内的单个值。
|
1 |
model.add(Dense(1, activation='tanh')) |
下面列出了带Hinge损失函数的MLP解决两圆形二元分类问题的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 带有Hinge损失的圆形问题MLP from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from matplotlib import pyplot from numpy import where # 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 将y从{0,1}更改为{-1,1} y[where(y == 0)] = -1 # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='tanh')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='hinge', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的准确率 pyplot.子图(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能略低于使用交叉熵,所选模型配置在训练集和测试集上的准确率低于80%。
|
1 |
训练:0.792,测试:0.740 |
还创建了一个图表,显示了两个线图,顶部显示了训练集(蓝色)和测试集(橙色)的Hinge损失随epoch的变化,底部显示了分类准确率随epoch的变化。
Hinge损失的图表显示模型已经收敛,并且在两个数据集上都具有合理的损失。分类准确率图表也显示出收敛的迹象,尽管其技能水平可能低于此问题所需的水平。
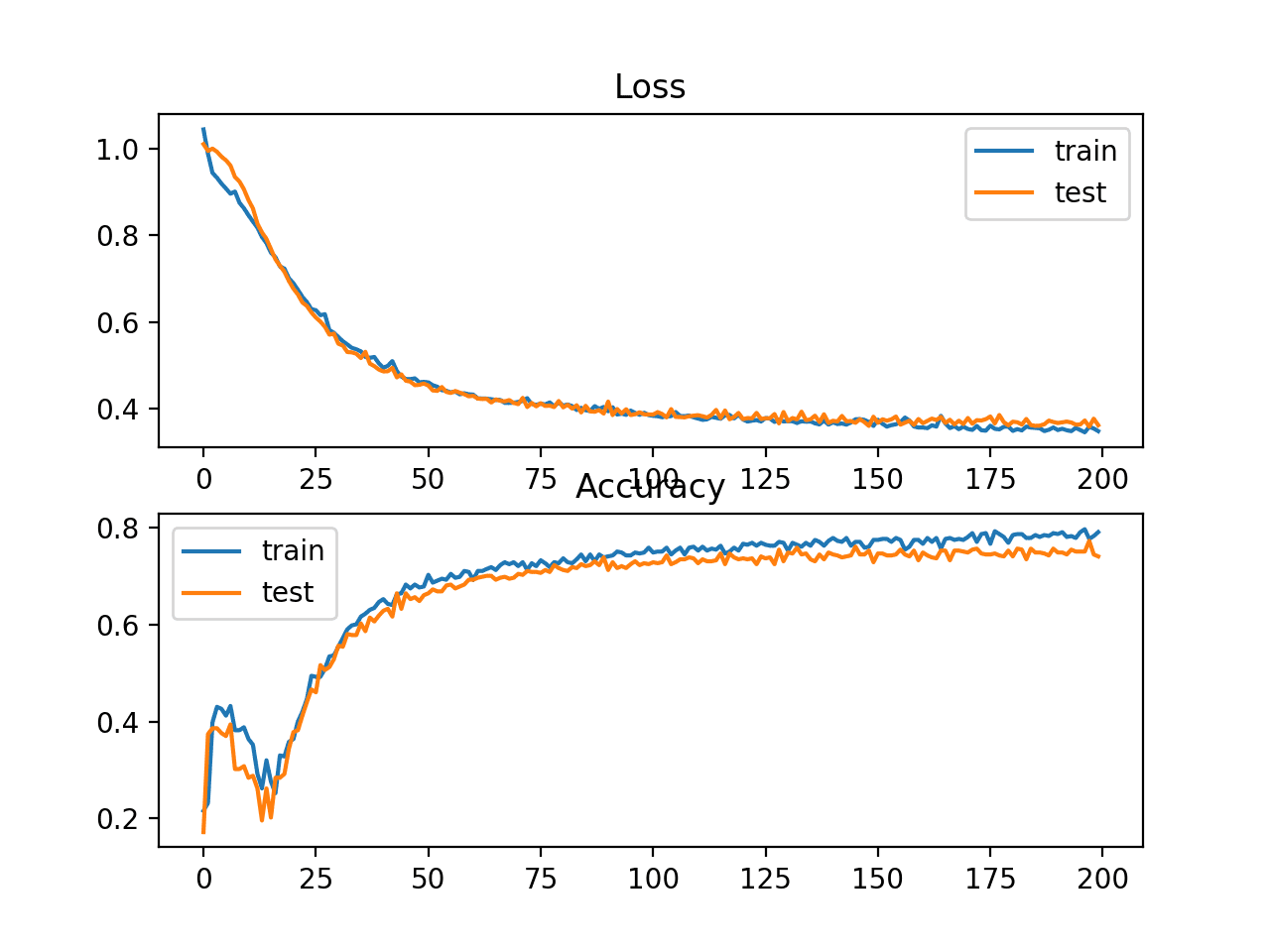
两圆形二元分类问题中Hinge损失和分类准确率随训练周期变化的线图
平方Hinge损失
Hinge损失函数有许多扩展,通常是SVM模型研究的主题。
一个流行的扩展被称为平方Hinge损失,它只是简单地计算Hinge损失的平方。它具有平滑误差函数表面并使其在数值上更容易处理的效果。
如果使用Hinge损失确实在给定二元分类问题上产生了更好的性能,那么平方Hinge损失可能也是合适的。
与使用Hinge损失函数一样,目标变量必须修改为{-1, 1}集合中的值。
|
1 2 |
# 将y从{0,1}更改为{-1,1} y[where(y == 0)] = -1 |
在定义模型时,可以在`compile()`函数中将平方Hinge损失指定为“squared_hinge”。
|
1 |
model.compile(loss='squared_hinge', optimizer=opt, metrics=['accuracy']) |
最后,输出层必须使用一个带有双曲正切激活函数的单个节点,该激活函数能够输出范围在[-1, 1]内的连续值。
|
1 |
model.add(Dense(1, activation='tanh')) |
下面列出了带平方Hinge损失函数的MLP解决两圆形二元分类问题的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 带有平方Hinge损失的圆形问题MLP from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from matplotlib import pyplot from numpy import where # 生成二维分类数据集 X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # 将y从{0,1}更改为{-1,1} y[where(y == 0)] = -1 # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='tanh')) opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='squared_hinge', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=200, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的准确率 pyplot.子图(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到对于这个问题和所选的模型配置,Hinge平方损失可能不合适,导致训练集和测试集上的分类准确率低于70%。
|
1 |
训练:0.682,测试:0.646 |
还创建了一个图表,显示了两个线图,顶部显示了训练集(蓝色)和测试集(橙色)的平方Hinge损失随epoch的变化,底部显示了分类准确率随epoch的变化。
损失图显示,模型确实收敛了,但误差曲面的形状不如其他损失函数平滑,其中权重的微小变化会导致损失的巨大变化。
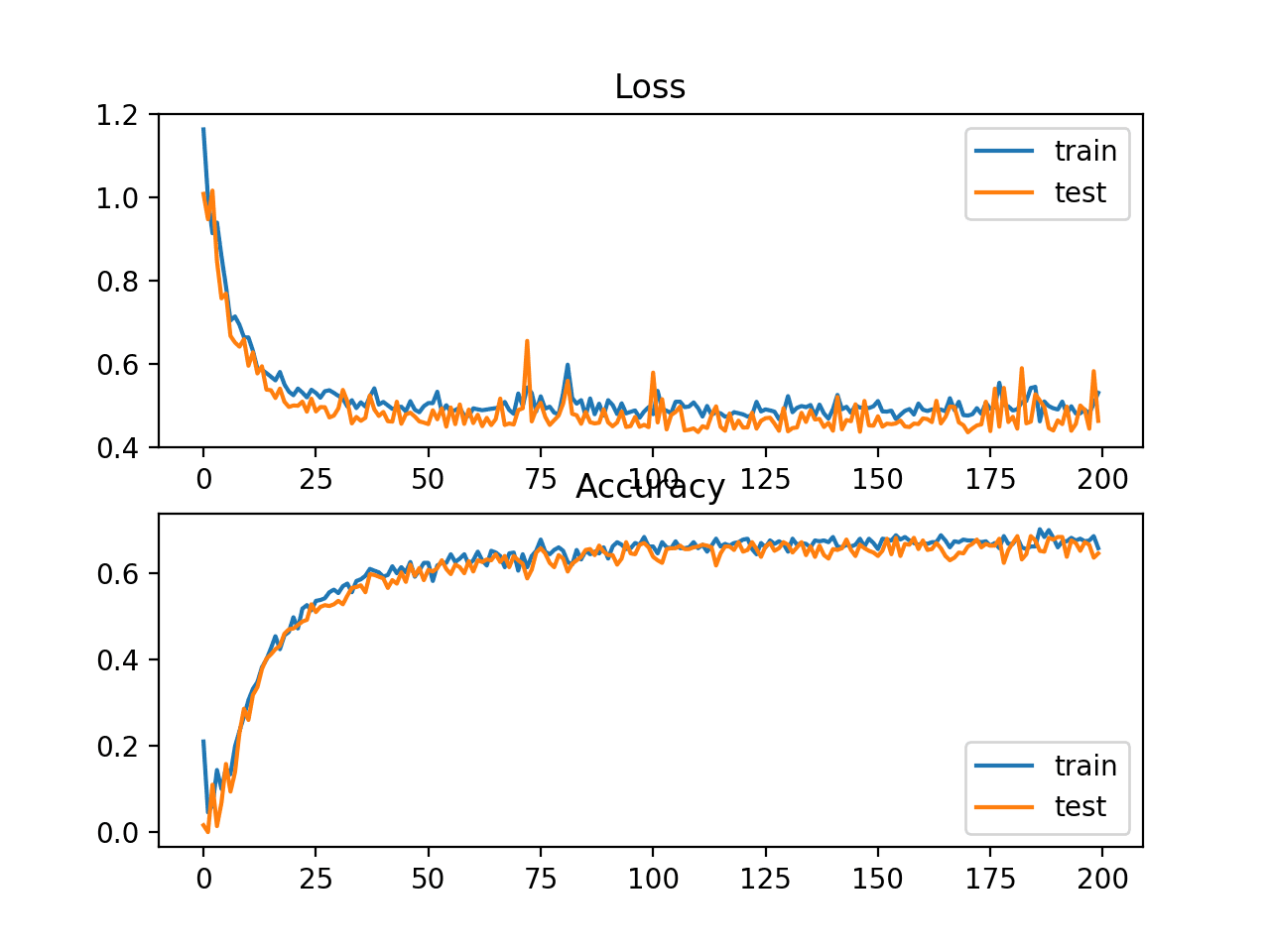
两圆形二元分类问题中平方Hinge损失和分类准确率随训练周期变化的线图
多类别分类损失函数
多类别分类是指示例被分配到两个以上类别中的一个或多个类别中的预测建模问题。
这个问题通常被框定为预测一个整数值,其中每个类别被分配一个从0到(num_classes - 1)的唯一整数值。这个问题通常通过预测示例属于每个已知类别的概率来实现。
在本节中,我们将研究适用于多类别分类预测建模问题的损失函数。
我们将使用斑点问题作为研究基础。scikit-learn提供的make_blobs()函数提供了一种根据指定数量的类别和输入特征生成示例的方法。我们将使用此函数生成1,000个三类别分类问题,其中包含2个输入变量的示例。伪随机数生成器将一致地播种,以便每次运行代码时都会生成相同的1,000个示例。
|
1 2 |
# 生成数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) |
这两个输入变量可以视为二维平面上点的*x*和*y*坐标。
下面的示例创建了一个散点图,显示了整个数据集,并按类别成员对点进行着色。
|
1 2 3 4 5 6 7 8 9 10 11 |
# blob 数据集的散点图 from sklearn.datasets import make_blobs from numpy import where from matplotlib import pyplot # 生成数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 选择每个类别标签的点的索引 for i in range(3): samples_ix = where(y == i) pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1]) pyplot.show() |
运行示例将创建一个散点图,显示数据集中的1,000个示例,其中属于0、1和2类别的示例分别用蓝色、橙色和绿色着色。
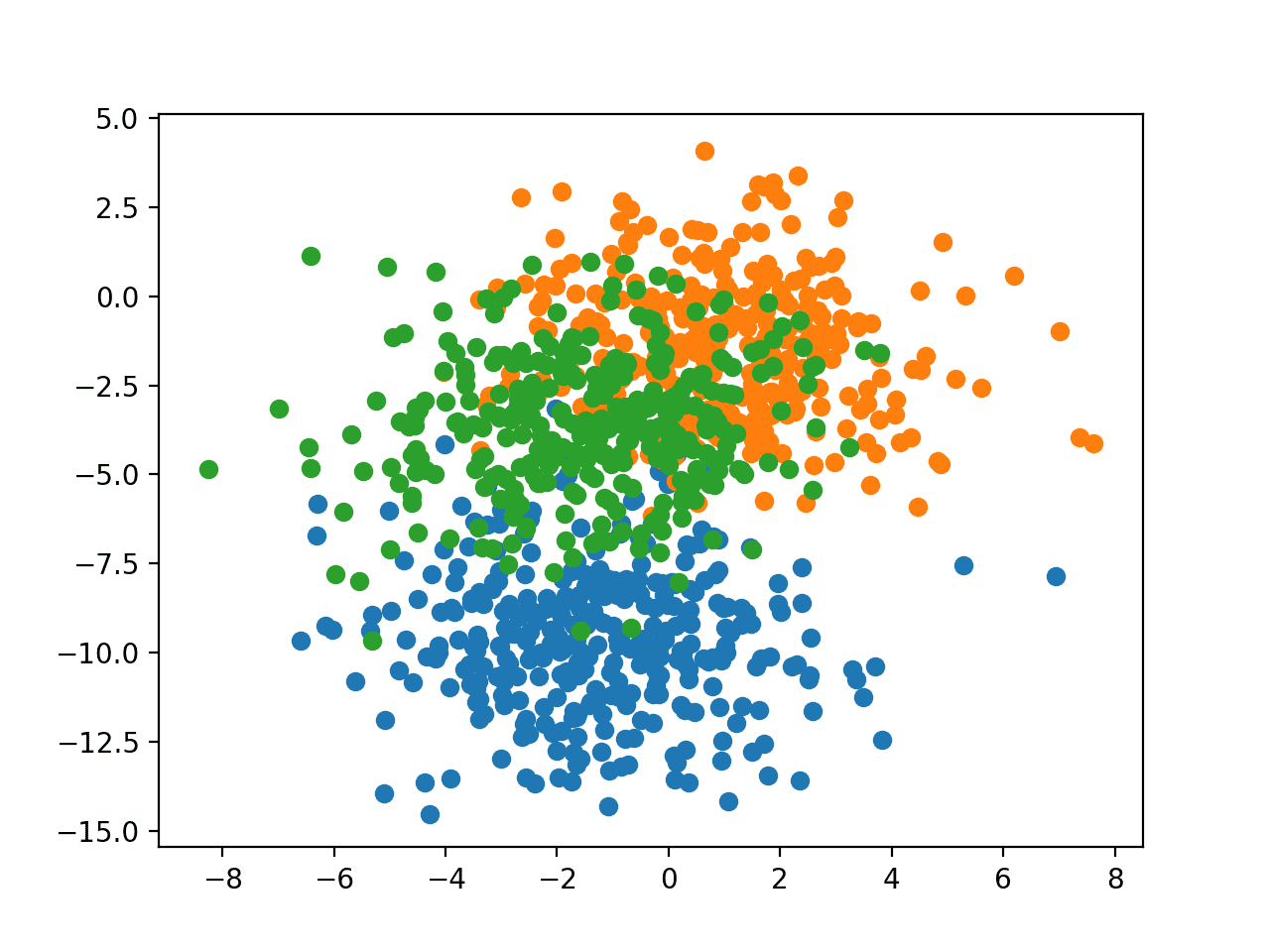
从斑点多类别分类问题生成的示例的散点图
输入特征是高斯分布,可以通过标准化受益;然而,为了简洁起见,在此示例中我们将保持值未缩放。
数据集将平均分为训练集和测试集。
|
1 2 3 4 |
# 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
将使用一个小型MLP模型作为探索损失函数的基础。
该模型期望两个输入变量,隐藏层中有50个节点和修正线性激活函数,以及一个必须根据损失函数的选择进行定制的输出层。
|
1 2 3 4 |
# 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(..., activation='...')) |
该模型使用随机梯度下降进行拟合,学习率为0.01,动量为0.9,这些都是合理的默认值。
|
1 2 3 |
# 编译模型 opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='...', optimizer=opt, metrics=['accuracy']) |
该模型将在训练数据集上拟合100个epoch,测试数据集将用作验证数据集,这使我们能够在每个训练epoch结束时评估训练集和测试集上的损失和分类准确率,并绘制学习曲线。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) |
现在我们已经有了问题和模型的基础,我们可以看看评估三种适用于多类别分类预测建模问题的常见损失函数。
尽管在这些示例中使用了MLP,但相同的损失函数也可以在训练CNN和RNN模型进行多类别分类时使用。
多类别交叉熵损失
交叉熵是用于多类别分类问题的默认损失函数。
在这种情况下,它旨在用于多类别分类,其中目标值在集合{0, 1, 3, …, n}中,每个类别被分配一个唯一的整数值。
从数学上讲,它是最大似然推断框架下首选的损失函数。它是第一个要评估的损失函数,只有在有充分理由时才进行更改。
交叉熵将计算一个分数,该分数总结了问题中所有类别的实际概率分布与预测概率分布之间的平均差异。分数被最小化,完美的交叉熵值为0。
在Keras中,通过在编译模型时将“categorical_crossentropy”指定为损失函数来指定交叉熵。
|
1 |
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) |
该函数要求输出层配置有*n*个节点(每个类别一个),在此示例中为三个节点,并使用“softmax”激活函数来预测每个类别的概率。
|
1 |
model.add(Dense(3, activation='softmax')) |
反过来,这意味着目标变量必须进行独热编码。
这是为了确保每个示例的实际类别值的预期概率为1.0,而所有其他类别值的预期概率为0.0。这可以使用to_categorical() Keras函数实现。
|
1 2 |
# 独热编码输出变量 y = to_categorical(y) |
下面列出了带交叉熵损失的MLP解决多类别斑点分类问题的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 带有交叉熵损失的斑点多类别分类问题MLP from sklearn.datasets import make_blobs from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.utils import to_categorical from matplotlib import pyplot # 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 独热编码输出变量 y = to_categorical(y) # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(3, activation='softmax')) # 编译模型 opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的准确率 pyplot.子图(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型表现良好,在训练数据集上实现了约84%的分类准确率,在测试数据集上实现了约82%的分类准确率。
|
1 |
训练:0.840,测试:0.822 |
还创建了一个图表,显示了两个线图,顶部显示了训练集(蓝色)和测试集(橙色)的交叉熵损失随epoch的变化,底部显示了分类准确率随epoch的变化。
在这种情况下,图表显示模型似乎已经收敛。交叉熵和准确率的线图都显示出良好的收敛行为,尽管有些颠簸。鉴于没有过拟合或欠拟合的迹象,模型可能配置良好。在这种情况下,可以调整学习率或批量大小以平滑收敛。
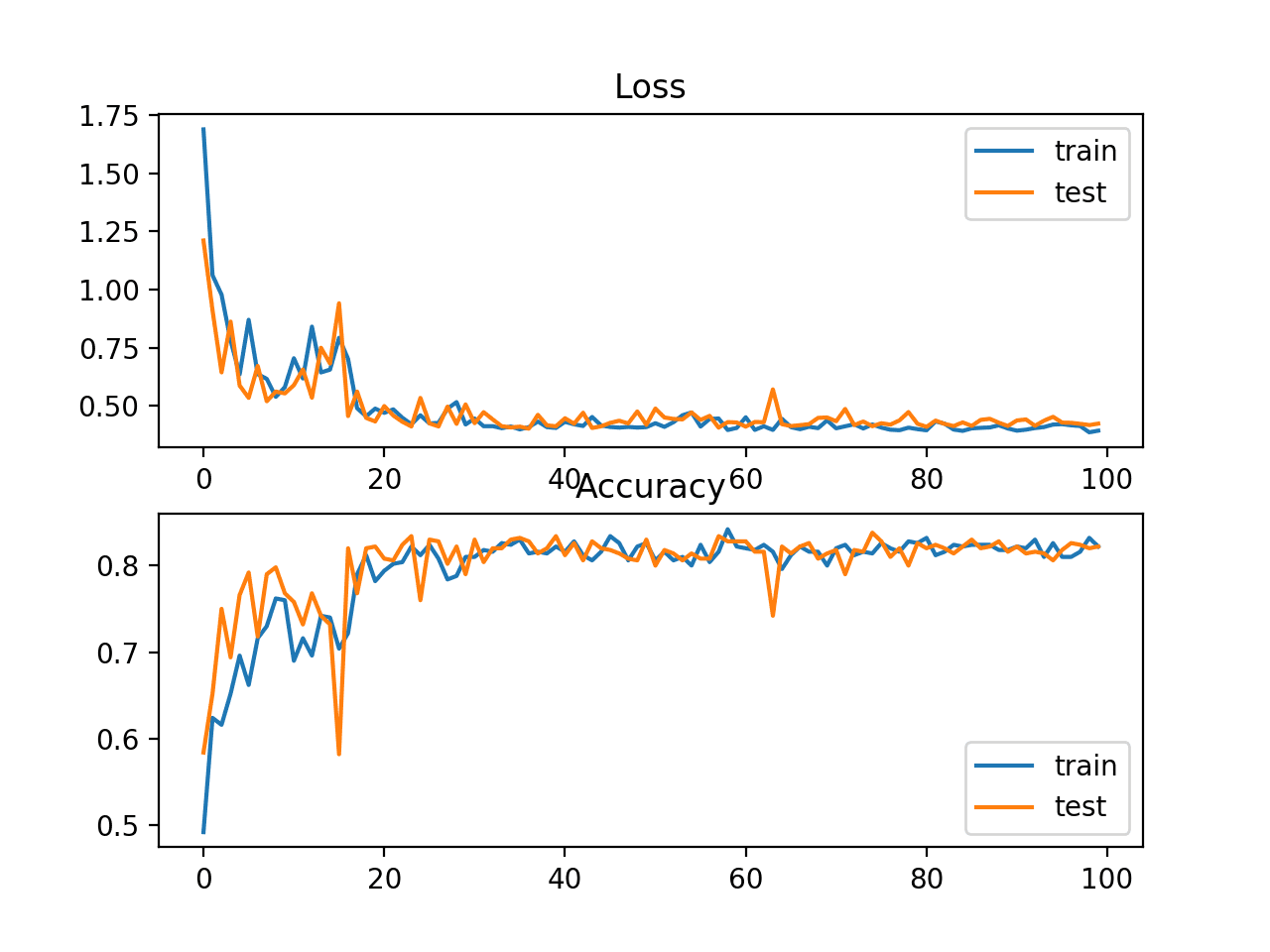
斑点多类别分类问题中交叉熵损失和分类准确率随训练周期变化的线图
稀疏多类别交叉熵损失
在使用交叉熵处理具有大量标签的分类问题时,独热编码过程可能会带来一些麻烦。
例如,预测词汇表中的单词可能包含成千上万个类别,每个标签一个。这意味着每个训练示例的目标元素可能需要一个包含成千上万个零值的独热编码向量,这需要大量的内存。
稀疏交叉熵通过执行相同的交叉熵误差计算来解决这个问题,而无需在训练前对目标变量进行独热编码。
在Keras中,多类别分类可以使用“sparse_categorical_crossentropy”调用`compile()`函数来使用稀疏交叉熵。
|
1 |
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=['accuracy']) |
该函数要求输出层配置有*n*个节点(每个类别一个),在此示例中为三个节点,并使用“softmax”激活函数来预测每个类别的概率。
|
1 |
model.add(Dense(3, activation='softmax')) |
不需要对目标变量进行独热编码,这是此损失函数的一个优点。
下面列出了在斑点多类别分类问题上使用稀疏交叉熵训练MLP的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 带有稀疏交叉熵损失的斑点多类别分类问题MLP from sklearn.datasets import make_blobs from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from matplotlib import pyplot # 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(3, activation='softmax')) # 编译模型 opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的准确率 pyplot.子图(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型在该问题上取得了良好的性能。实际上,如果您多次重复实验,稀疏和非稀疏交叉熵的平均性能应该是可比的。
|
1 |
训练:0.832,测试:0.818 |
还创建了一个图表,显示了两个线图,顶部显示了训练集(蓝色)和测试集(橙色)的稀疏交叉熵损失随epoch的变化,底部显示了分类准确率随epoch的变化。
在这种情况下,图表显示模型在训练过程中在损失和分类准确率方面都表现出良好的收敛性。
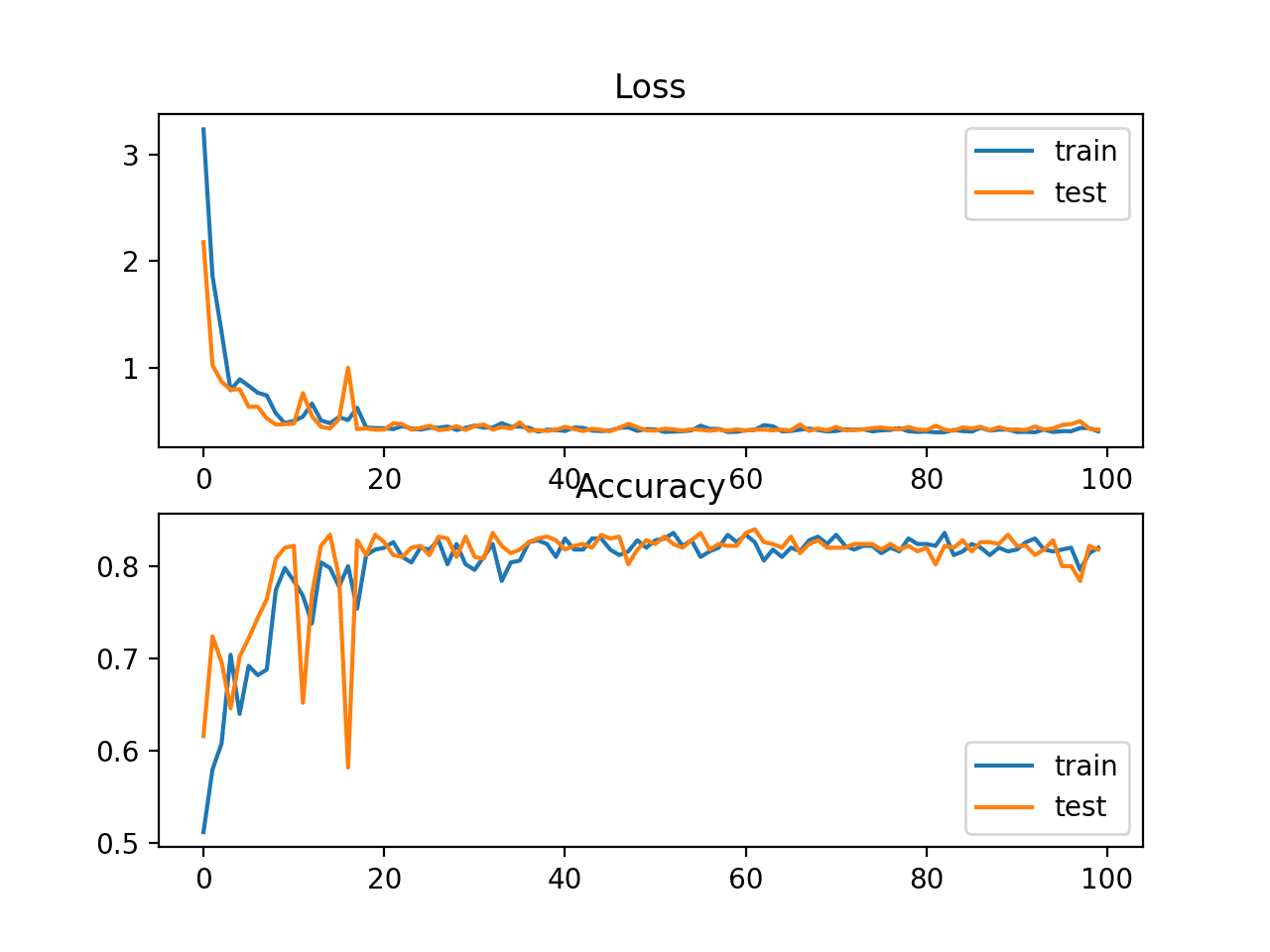
斑点多类别分类问题中稀疏交叉熵损失和分类准确率随训练周期变化的线图
Kullback Leibler散度损失
Kullback Leibler散度,简称KL散度,是衡量一个概率分布与基线分布差异的指标。
KL散度损失为0表示分布相同。实际上,KL散度的行为与交叉熵非常相似。它计算如果使用预测概率分布来近似所需的目标概率分布,会损失多少信息(以位为单位)。
因此,KL散度损失函数更常用于学习近似比简单多类别分类更复杂函数的模型,例如在自编码器中,用于在必须重建原始输入的模型下学习密集的特征表示。在这种情况下,KL散度损失是首选。尽管如此,它也可以用于多类别分类,在这种情况下,它在功能上等同于多类别交叉熵。
在Keras中,通过在`compile()`函数中指定“kullback_leibler_divergence”来使用KL散度损失。
|
1 |
model.compile(loss='kullback_leibler_divergence', optimizer=opt, metrics=['accuracy']) |
与交叉熵一样,输出层配置有*n*个节点(每个类别一个),在此示例中为三个节点,并使用“softmax”激活函数来预测每个类别的概率。
此外,与分类交叉熵一样,我们必须对目标变量进行独热编码,使其类别值的预期概率为1.0,而所有其他类别值的预期概率为0.0。
|
1 2 |
# 独热编码输出变量 y = to_categorical(y) |
下面列出了带KL散度损失的MLP解决斑点多类别分类问题的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 带有KL散度损失的斑点多类别分类问题MLP from sklearn.datasets import make_blobs from keras.layers import Dense from keras.models import Sequential from keras.optimizers import SGD from keras.utils import to_categorical from matplotlib import pyplot # 生成二维分类数据集 X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2) # 独热编码输出变量 y = to_categorical(y) # 分割成训练集和测试集 n_train = 500 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(3, activation='softmax')) # 编译模型 opt = SGD(lr=0.01, momentum=0.9) model.compile(loss='kullback_leibler_divergence', optimizer=opt, metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制训练过程中的损失 pyplot.子图(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # 绘制训练期间的准确率 pyplot.子图(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例首先打印模型在训练数据集和测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们看到与交叉熵损失得到的结果相似的性能,在这种情况下,训练集和测试集的准确率约为82%。
|
1 |
训练:0.822,测试:0.822 |
还创建了一个图表,显示了两个线图,顶部显示了训练集(蓝色)和测试集(橙色)的KL散度损失随epoch的变化,底部显示了分类准确率随epoch的变化。
在这种情况下,图表显示了损失和分类准确率都具有良好的收敛行为。鉴于度量之间的相似性,评估交叉熵很可能会产生几乎相同的行为。
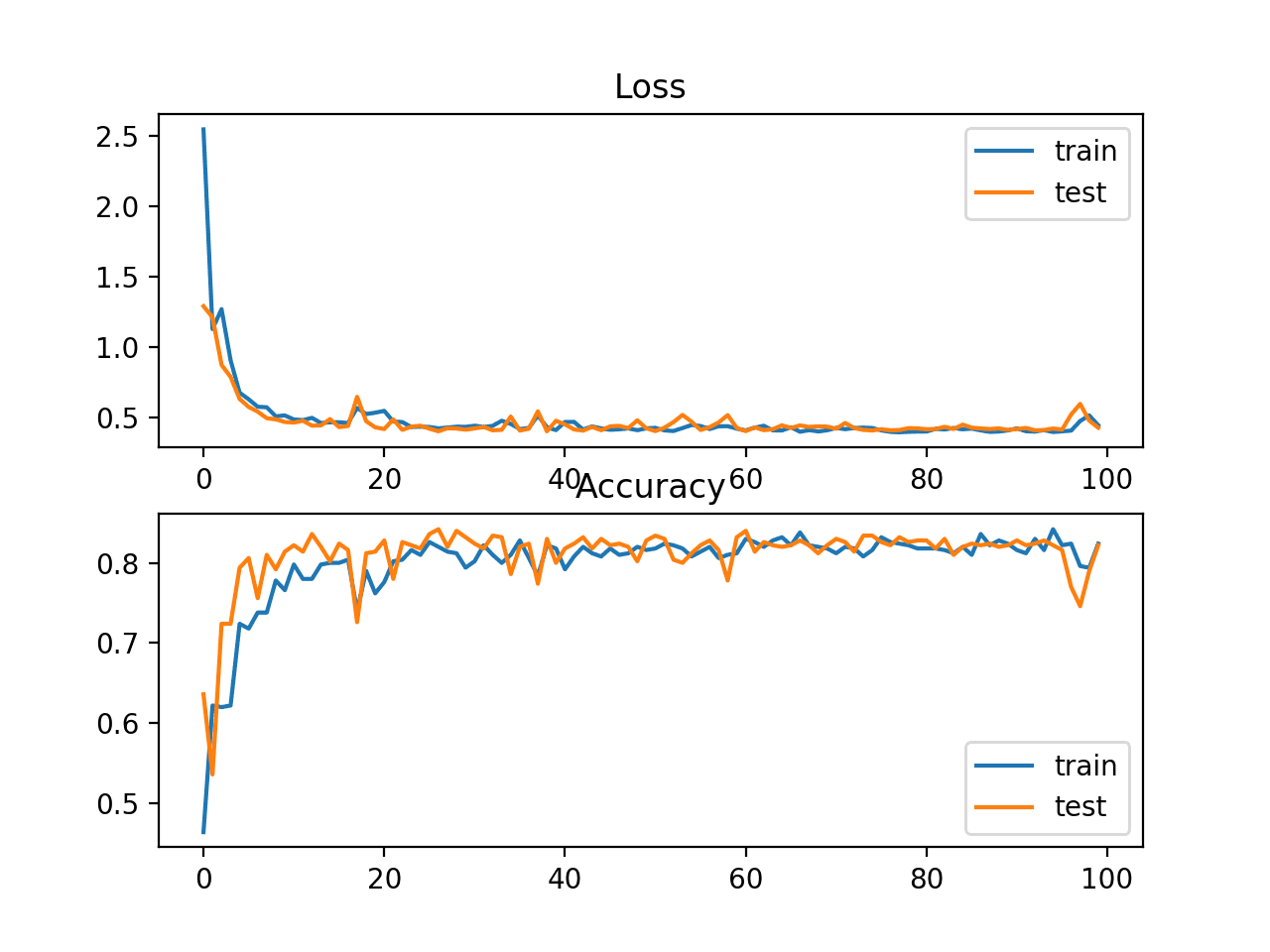
斑点多类别分类问题中KL散度损失和分类准确率随训练周期变化的线图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
论文
- 关于深度神经网络分类中的损失函数, 2017.
API
- Keras 损失函数 API
- Keras 激活函数 API
- sklearn.preprocessing.StandardScaler API
- sklearn.datasets.make_regression API
- sklearn.datasets.make_circles API
- sklearn.datasets.make_blobs API
文章
总结
在本教程中,您学习了如何为给定的预测建模问题选择深度学习神经网络的损失函数。
具体来说,你学到了:
- 如何为回归问题配置模型以使用均方误差和变体。
- 如何为二元分类配置模型以使用交叉熵和Hinge损失函数。
- 如何为多类别分类配置模型以使用交叉熵和KL散度损失函数。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







这是一篇非常好的关于损失函数的教程,我很久以前就发现了你的博客,但今天才读到这篇文章。肯定会阅读更多文章!
安东尼乌斯·卡斯伯根
谢谢,很高兴能帮到你,安东尼乌斯!
我是Jason,你一如既往可靠的博客的忠实追随者。
我需要你为我的回归问题提供建议,其中输入特征具有不同的概率分布。我们需要对它们进行不同的缩放吗?最后,建议也缩放目标变量吗?
谢谢
丹尼斯
也许吧。这确实取决于数据。
通常缩放目标变量也是个好主意。
我注意到您将 StandardScaler 应用于特征数据和响应变量数据。在您的网站上,有许多示例您没有缩放响应变量数据。为什么在这个示例中您这样做了。
这是回归的好习惯。为了简洁起见,我经常省略它,因为教程的重点是其他内容。
你好,Jason Brownlee,
我非常感谢您的博客让我学到了很多AI。你能帮我吗?
对于二元交叉熵任务,我可以让Dense的输出层有2个节点而不是1个,如下所示吗?
model.add(Dense(2, activation=’sigmoid’))
为什么在输出层中使用2个节点并使用sigmoid激活?
我想要获得值1和值0各自的概率。
是的。具体问题是什么?
@sanjie 我认为你只需要一个,因为另一个的概率将是1减去你得到的那个。例如:你得到是1的概率是0.63,那么是0的概率是1-0.63 = 0.27。否则,你可以用2个神经元和softmax结束网络。后一种策略适用于任意数量。
你好,
我一直在阅读这篇文章和另一篇关于“如何使用DL指标”的文章,这让我产生了一个疑问。显然我们可以创建自定义指标,但在keras中我们不能创建自定义损失函数。还是我错了?
我理解自定义损失函数需要其梯度才能执行反向传播,但你知道我们是否可以在 Keras 中做到这一点吗?
谢谢
你可以创建自定义损失函数,但确实需要知道你在做什么。
布朗利博士,您好,
我有一个要求非常高的数据集,并且正在对此数据集进行二元分类。我没有使用 keras 导入,而是使用了新 TensorFlow 2.0 alpha 中的 “tf.keras”。当我复制您的绘图代码来显示“loss”和“val_loss”时,我得到了一个非常有趣的图表。我想展示这些图表。我如何在回复组中包含图表?
查尔斯
也许您可以将图表发布到您的网站、博客、图像托管网站或github,并链接到它们?
我把我的笔记本放在GitHub上。请看
https://github.com/CBrauer/CypressPoint.github.io/blob/master/rocket.ipynb
任何评论都将不胜感激。
查尔斯
从损失图来看,你似乎过拟合了。
请看这篇文章
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
平均绝对误差损失如何对异常值具有鲁棒性?
误差异常值,而不是数据中的异常值。
在我看来,MAE 会将类型1和类型2错误视为相同的错误。
所以我可能不会称之为“对模型错误具有鲁棒性”——但也许这里的用例是,当类型1和类型2对业务的成本相同,并且一个不比另一个影响更大时。
感谢分享。
我如何定义一个新的损失函数,其中误差是根据所有预测值的平均值计算的,即损失 = y_pred - mean(y_pred)?
你可以定义一个损失函数来做任何你希望做的事情。
要计算张量的平均值,请使用Keras后端
from keras import backend as K
…
K.mean(…)
嗨,Jason,
感谢您的精彩博客。
我想知道我们是否必须只使用二元交叉熵进行自编码器训练?如果使用二元交叉熵,我们是否应该将输入转换为(0,1)之间?
如果您正在处理二元序列,那么二元交叉熵可能更合适。
嗨,Jason,
很棒的教程!
通过查看损失图,我可以看到与我自己的经验有一些相似之处。但这总是让我有些困扰:损失是否应该像你展示的MSE那样趋于平稳?我之所以问这个问题,是因为我在自己的问题中看到了这种行为,我担心这可能是一个糟糕的局部最小值。
这篇文章将有助于解释损失图
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
首先,非常感谢您的努力。当我寻找深度学习解决方案时,您的博客总是正确的选择。非常感谢。
我的问题是关于二元分类损失函数。
我有一个二元输出,我将输出值编码为-1或1,就像您在Hinge损失函数中提到的那样。
此外,输入变量是分类(多类)或二元的。我将二元变量编码为0或1,并使用Label Binarizer编码分类变量。我正在使用Conv1D网络。
我是否应该更改输入变量的编码,使其与输出格式相似?我的意思是,最终,输入变量是否应该为-1或1,而不是0或1,以便执行Hinge损失函数?
提前感谢
谢谢!
Hinge损失只关心模型的输出,例如,输出必须在[-1,1]范围内,并且您应该使用tanh激活函数。
您可以将输入设置为您想要的任何形式,尽管通常建议进行归一化或标准化。
Jason,我觉得你写错了。在这网页上搜索“logistic”。它会出现在2个地方。我想你本意是说“logarithmic”……对吗?
谢谢。
已更新以保持一致性。
嗨,Jason,
我只是想确认我的理解,因为我对神经网络和 Keras 还很陌生。由于 MLP 至少需要 3 层(输入层、隐藏层和输出层),那么 input_dim=20 是你的输入层吗?
谢谢!
MLP 可以只有 1 层,没有规定。
input_dim 总是定义给定输入样本中的输入数量。
“完美的交叉熵值为0。”
完美的交叉熵值难道不应该等于真实分布的熵,而不是零吗?也许这就是你的图中损失似乎收敛到约0.4的原因?
不,交叉熵计算的是两个分布之间的差异。
更准确地说,是编码一个分布中的事件与另一个分布中的事件所需的平均总位数。
在实践中,我们永远不会达到零,除非我们过度拟合,或者问题微不足道。
val_loss 从哪里来?我收到错误 “‘KeyError: ‘val_loss’”
它来自历史记录,但它假设您在训练模型时使用了验证数据集。
嗨,Jason,
我有一个回归问题,其中有 7 个输入变量,并希望使用它们来估计两个输出变量。这两个变量的范围是 0 到 1,但它们是不同的,并且取决于 7 个变量的组合。我必须训练两个不同的模型,还是可以用一个模型来完成?
谢谢
听起来你可以将其建模为一个多输出回归问题,并尝试将MSE损失作为第一步?
谢谢 Jason,不过,我还没有真正找到如何进行多输出回归。这仅仅是你的网络最后一层是一个 Dense 层的问题,如下所示吗?
model.add(Dense(2))
model.compile(loss=’mean_squared_error’, optimizer=’Adam’)
再次感谢。
没错!
嗨,Jason,
我已经为我的多输出回归问题收集了数据。我在这里看到一个可能的问题,因为我试图预测的输出直方图看起来像一个多峰(骆驼背)曲线,大约有4个峰值,并且bin计数的值范围非常大(最小值35到最大值5000)。我现在已经确定了9个输入变量和2个输出变量。(两个输出变量都具有前面描述的分布)。
在回归问题中,是否存在数据增强这样的事情?我是否应该增强数据,因为我对数据所做的一切都不会反映现实,因为我正在尝试建模一个物理动态系统?
有,但也许可以从一个简单的监督学习模型开始,先让它工作起来。
我正在做我的第一个神经网络问题,一个回归分析,1个输入,但8个输出。我正在对 x 输入的幂级数进行拟合,并试图学习幂级数展开的前 8 个系数。我想使用 MSE 损失函数,但我如何告诉模型我正在寻找的功能形式?我真的希望能够打印出输出层中学习到的系数。
好问题。
神经网络的诀窍在于你不需要告诉它函数。你要么不知道函数,要么在你的情况下,你假装不知道它,然后你让网络单独从输入和输出中学习函数。
这有帮助吗?
我想我在 Keras 文档中找到了。我必须自定义一个损失函数,这就是我输入幂级数功能的地方。这很酷——一些输出系数,我可以优化这些系数以获得随机的最佳拟合。我可以用分析方法来做,但手动操作有点麻烦。当有大量数据时,听起来很容易!
很高兴听到这个消息。告诉我你的进展。
嗨,Jason,
我需要实现一个如下所示的自定义损失函数
average_over_all_samples_in_batch( sum_over_k( x_true-x(k) ) )
其中k是隐藏层的索引。因此,x(k)指的是隐藏层k的一个输出。当然,这是我实际损失函数的简化版本,足以捕捉我问题的本质。为了提供一些背景,我的神经网络有点像一个递归检测网络。
我使用tensorflow函数式API实现我的模型,其中包含一些自定义层,所有这些都封装在一个模型中,然后我使用model.compile、model.fit等方法训练它。
您能建议我如何实现自定义损失函数吗?或者有没有我可以参考的资源?我一直找不到任何明确的资源。
暂时不方便,我想你得做一些实验才能知道是否可行。
嗨 Jason
我实现了一个用于网络数据集异常检测的自编码器算法,但我的损失值仍然很高,准确率只有68%,这不太好。您是否有自编码器代码可以帮助我更好地理解这个领域,因为我仍然是机器学习和深度学习领域的新手。此外,我在编写模型结果可视化代码方面也遇到问题。感谢您的指导。我真的很喜欢您的教程。
抱歉,我没有很多自编码器示例。
这些教程可能会帮助您提高性能
https://machinelearning.org.cn/start-here/#better
嗨,Jason。我是深度学习的新手,您的博客真的很有帮助。
我想知道为什么我们在这里使用 [:,0]
y = StandardScaler().fit_transform(y.reshape(len(y),1))[:,0]
获取第一列。
更多关于数组索引和切片的信息
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
我如何在我的研究工作中引用你的文章
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/how-do-i-reference-or-cite-a-book-or-blog-post
它简洁明了,易于理解,并且清晰地说明了如何应用损失的概念。
谢谢!
嗨,Jason,
感谢您的精彩教程。
多标签分类(其中一个或多个类别可以分配给一个输入)应该使用什么?
另外,我认为,如果您能添加每个损失函数的数学公式(或带有numpy的python代码),那就太好了。
二元交叉熵损失。
感谢您的建议。
你好,
我有一个关于将MSE损失函数用于图像到图像类型的回归问题的问题,但是我的训练数据分辨率是标签数据的4倍。在尝试训练模型时,由于目标和输出的形状不同,代码在使用MSE时崩溃了。该怎么办?
谢谢,
Yochanan
也许尝试不同的模型?不同的数据准备?不同的损失函数?等等。
没事了,谢谢
不客气。
嗨 Jason,您有关于在 Keras 中实现自定义损失函数的教程吗?
谢谢
我有一个自定义指标的例子,可以作为损失函数使用
https://machinelearning.org.cn/custom-metrics-deep-learning-keras-python/
你好 Jason,
感谢您的文章。我有一个问题。损失函数中是否可能返回一个浮点值而不是一个张量?例如,假设我有三个NN和一个全局变量score(NN3的y_pred的平均值)。我希望NN1返回score值,NN2返回(score*-1),NN3的损失为(NN1 Loss – NN2 Loss)。我已按这种方式编写代码,但我几乎肯定它不起作用。
def NN1Loss()
def loss(y_true, y_pred)
global N1_loss, score
score = tf.cast(score, “float32”)
return score + K.mean(y_true-y_pred)*0
return loss
本教程将向您展示如何创建可适应为损失函数的自定义指标
https://machinelearning.org.cn/custom-metrics-deep-learning-keras-python/
嗨,Jason,
关于第一个损失图(在优化均方误差损失函数时,均方误差损失在训练周期上的线图),似乎大约第30个周期到第100个周期是不必要的(因为损失已经无限小)。
你仍然选择让数据集通过神经网络100次,这是有原因的吗?
谢谢你
是的,为了使所有例子保持一致。
我们在这个教程中演示损失函数,而不是试图获得最好的模型或训练方案。
明白了,谢谢。
然而,我遇到过一个情况,我的模型(线性回归)的预测只在约100个 epoch 内表现良好,而损失图却非常快地达到了接近零(比如在第10个 epoch 时)。
您知道可能导致这种现象的任何原因吗?
(当我减少 epoch 数量时,因为它们看似不必要,模型的预测效果明显变差)。
谢谢!
也许可以探索你的模型的学习曲线
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
嗨,Jason,
感谢这个很棒的教程!稀疏多类交叉熵损失可以用于二类分类问题吗?谢谢!
也许可以,但为什么不直接使用二元交叉熵并建模二项式分布呢?
题外话。
问题是如何为人工神经网络提供大量它们实际可以使用的外部内存。也许If-Except-If树可以提供一个答案。
https://discourse.numenta.org/t/numenta-research-meeting-july-27/7760/3
如果神经网络能够容忍几次跨越神经/符号边界,那么我认为它们应该能够学习如何使用If-Except-If树作为一种联想记忆形式。
https://github.com/S6Regen/If-Except-If-Tree
感谢分享。
嗨,Jason,
感谢您的文章。我注意到当我在 PyTorch 中使用 L2/MSE 损失训练 LSTM 时,它收敛得相当快。另一方面,当使用 L1/MAE 损失时,网络在大致相同的 epoch 数内收敛,但在再一个 epoch 之后,它只输出极小的值——几乎像一条直线。MSE 没有这样的问题,即使在比 MAE 训练两倍的 epoch 之后也没有。
您认为在 RNN 方面,MAE 比 MSE 更容易过拟合吗?还是“直线/小范围输出”是由于其他原因?
此致
这是个难题。我认为这真的取决于具体的数据集和模型,例如,这些元素和损失函数都会相互作用。
嗨,Jason,
我使用铰链损失进行分类没有问题。但是,当我使用L1交叉熵损失函数(y.log(yhat)-(1-y)log(1-yhat))时,我得到了一个奇怪的结果,出现以下错误:RuntimeWarning: invalid value encountered in log。
我知道这是因为负数造成的,我不知道如何避免负数?
我取yhat的绝对值,但损失图看起来很奇怪(负损失值在零以下)。
使用交叉熵损失时,目标必须为0或1(二元)。
我们可以使用地球移动距离作为自编码器中的损失函数吗?
也许可以,可以尝试一下并与简单的重建误差进行比较。
嗨,Jason,
LSTM优化器损失函数中是否有“最大绝对误差”?我想预测时间序列,需要最大绝对误差。如果没有,我如何手动实现?
需要最大绝对误差。如果没有,我如何手动实现?
提前感谢
什么是最大绝对误差?
嗨,杰森,
当我尝试测试“使用mae损失函数进行回归”的代码时,我得到了以下错误。
我使用 Googlecolab 测试了你的代码。
训练:0.002,测试:0.002
—————————————————————————
KeyError 回溯(最近的调用在最后)
in ()
—-> 1 导入 MLP_regre
/content/drive/My Drive/GooCo_app/MLP_regre.py in ()
36 pyplot.subplot(212)
37 pyplot.title(‘Mean Squared Error’)
—> 38 pyplot.plot(history.history[‘mean_squared_error’], label=’train’)
39 pyplot.plot(history.history[‘val_mean_squared_error’], label=’test’)
40 pyplot.legend()
KeyError: ‘mean_squared_error’
很抱歉听到这个消息,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我遇到了同样的问题,我在文档中阅读了相关内容。
我通过使用“mse”而不是“mean_squared_error”,以及使用“val_mse”而不是“val_mean_squared_error”解决了这个问题。
干得好。
均方绝对误差损失函数可以用于 MLP 分类器吗?如果不能,哪种损失函数最适合 MLP 分类器?
是的,如果你喜欢的话。
最好的损失函数是与您项目想要优化的指标紧密契合的函数。
嗨,Jason,
感谢您的精彩教程。我有一个关于多类分类的问题。
正如您所说,“问题通常被框定为预测一个整数值……”。然而,如果我们有一些类别需要根据这些类别中的内容和顺序(原始值)在 PyTorch 中包含自定义损失,您会如何建议?
例如,假设我们有类别“A1B1”、“A2B1”、“A2B2”、“A1B2”。因此,我需要实现一个自定义损失(至少作为交叉熵损失的可学习正则化)。为简单起见,这可以是类别元素之间的某种距离。
谢谢你
交叉熵正是如此。
嗨,Jason,
谢谢。如果我错了请原谅。我明白交叉熵计算的是两个分布(输入类和输出类之间)的差异。但是,我需要捕获类元素的影响,如果某个部分被错误分类,则“惩罚”网络以纠正“整个”类的分布。例如,如果输入数据是“A1B1”而预测是“A2B1”,我必须创建一些自定义类交叉熵损失,并考虑错误分类类第一部分的影响。这个问题有更多部分的类——我在这里将其简化为两部分,只是为了提供一个简单的示例。
如果能得到任何建议或对我的推理的纠正,我将不胜感激。
谢谢你
为什么不将它们视为互斥类别,并平等地惩罚所有错误分类呢?
您可以为您喜欢的“差点命中”开发自定义惩罚,并将其添加到交叉熵损失中。
嗨,Jason,
谢谢你。
“为什么不把它们当作互斥的类,并对所有错误分类都施以同样的惩罚?”
• 我不太明白“把它们当作”是什么意思。您能好心地给出更多说明吗?我会区别对待它们,因为如果网络错误分类了第一部分或其他部分,那么(重要性上)是有区别的。
“如果你愿意,你可以为‘差点命中’制定一个自定义惩罚,并将其添加到交叉熵损失中。”
• 您在您的网站或某些书籍中有这方面的例子吗?
谢谢你
我的意思是:将问题建模为这些类别是互斥的。
我可能在博客上有一些自定义损失函数的例子,也许你可以改编这里的例子。
https://machinelearning.org.cn/custom-metrics-deep-learning-keras-python/
是否提供用于评估上述混淆矩阵和其他参数的代码?另外,一个好的模型是否需要训练和测试准确率相同?
如果您需要混淆矩阵方面的帮助,可以从这里开始
https://machinelearning.org.cn/confusion-matrix-machine-learning/
太感谢了!!!我非常喜欢这个网站。对新手来说太有帮助了。
不客气。
非常感谢这个非常有价值的博客!
恕我直言,我有一个关于损失函数的问题:我建立了一个 Conv1D 模型,用于将项目分类为 6 个类别(从 0 到 5)。
因此,我使用交叉熵损失函数,该函数会惩罚高概率错误,也会惩罚与正确答案相关的低概率。这正是我所寻找的。
但交叉熵认为类别是独立的,而我希望减少两个相邻类别之间的错误损失,并增加距离较远的类别之间的错误损失:即,当模型预测 0(猫)而实际是 1(狗)时,减少损失;当模型预测 0(猫)而实际是类别 5(鱼)时,增加损失。
有没有办法在分类问题的损失计算中嵌入类别邻近性?提前感谢您的任何帮助!
不客气。
也许可以尝试均方误差损失?
嗨,Jason,
我很欣赏这篇关于机器学习中损失函数选项的简洁教程!
时不时地,在处理了许多 MLP、CNN、LSTM 网络之后,停下来总结所有用于我们机器学习算法的损失函数的影响和实现选项,这非常有用!
非常有启发性!
谢谢!
嗨,Jason,非常感谢您的博客,我经常使用它!!!
我有一个关于损失函数的问题,也许您可以帮忙。
我正在构建一个输出三个值(总和为 100%)(土壤科学中称为质地)的模型。在过去的文献中,他们根据 R 平方值与 1:1 直线和 RMSE 来衡量模型成功度,每个输出都独立计算(总共 3 个)。这两个值(R 平方和 RMSE)都受到测试集总范围(最大值-最小值)的很大影响,因此很难评估模型的成功度。
我的问题是,您是否知道一种考虑训练集和测试集值范围的损失函数?
谢谢!
不客气。
听起来像多类分类,你可以用交叉熵而不是RMSE或R^2进行评估。交叉熵损失函数也适用,例如,分类交叉熵。
训练集中的类别值必须具有相同的范围,例如,每个标签为0-1。
嗨,jason
感谢这个博客,我学到了很多。
关于损失函数的选择问题
它在使用EarlyStopping回调时是否有影响?
如果有,你能给我一个例子或一个列表吗?
例如:如果我使用 kullback_leibler_divergence,我是否应该应用像 EarlyStopping(monitor=’val_loss’, patience=15) 这样的回调
或者我应该使用另一个值来监控?
不客气。
损失函数定义了问题。Early stopping 仅仅有助于减少模型的过拟合/提高泛化能力——它不关心你使用什么损失函数。
你好,杰森,
谢谢你的这个很棒的教程。
我研究过模型是使用损失函数训练的。那么成本函数在模型开发中扮演什么角色呢?
我也研究过权重是使用损失函数更新的,我们需要定义成本函数
损失函数和成本函数是同一回事。
好博客,如果你有时间,自定义损失函数会是一个受欢迎的博客。
感谢您的建议!
嗨,Jason!
我写这封信给您,距离上次已经大约2年了。当时我从您的机器学习文章中学到了很多。现在我又在阅读您的深度学习文章了!非常感谢您提供了这么多精彩的解释。这对我意义重大!请继续多写一些博客。
谢谢你。
嗨,Jason,
如果目标分布是强双峰分布,您会推荐哪种损失函数?
感谢所有精彩的博文。它们对我的神经网络开发有很大帮助。
嗨,Brendan……下面的内容可能有助于澄清
https://towardsdatascience.com/anchors-and-multi-bin-loss-for-multi-modal-target-regression-647ea1974617
嗨,Jason,
感谢这个精彩的教程。
我正在尝试设计一个深度神经网络,该模型需要读取一堆 xls 文件,目标预测在 3 个类别(1、2 和 3)之间。
我尝试使用了上面提到的所有损失函数,但没有一个损失函数能够提高“准确性”。您会建议哪种损失函数?
嗨,Yas……您可能需要考虑优化技术和/或特征选择以提高准确性
https://machinelearning.org.cn/feature-selection-to-improve-accuracy-and-decrease-training-time/
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
嗨 James,
我的任务目标是“训练一个分类器”,但不使用特征选择。我现在有一个更大的数据集(1400个CSV文件),但准确率仍然只有32%左右。
我听说在使用数据集训练模型之前,使用一些过滤器可能会有帮助。您有这方面的教程吗?
或者还有其他建议给我吗?
谢谢!
好文章!我正在大量使用它进行复习。
快速提问:在MSLE中,我注意到你说在两个示例图中,一个显示过拟合的迹象,因为错误随着epoch的进展再次开始上升。
如果它是过拟合,为什么两条线都上升?训练线不应该继续下降,而测试线应该上升,以表明模型现在正在适应训练数据,牺牲了泛化能力吗?
嗨,Bernie……以下资源可能有助于澄清
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
你好,
我目前正在写我的学士论文,我正处于研究阶段,我需要帮助!
我学会了如何训练用于二元分类的网络,但根据我的理论,这是一个多类分类,有超过 100 个类别(蛇类型检测)。
我学到的输出函数的激活函数是 sigmoid,
现在我困惑于应该使用哪种损失/激活函数!如何将最后一层的输出与激活函数转换为超过 1000 个类别的概率!
我应该用于多类吗!
感谢任何帮助!
嗨,阿贝德……您可能会对以下内容感兴趣
https://machinelearning.org.cn/choose-an-activation-function-for-deep-learning/
嗨,Jason,我以为我留下了一个评论,但它不在这里显示,所以我再次留下。如果重复了,我深表歉意。我真的很高兴找到了这篇文章,因为我一直在寻找如何实现二元分类的铰链损失,但找不到明确的指导。我正在尝试探索语义分割模型(Unet/resnet/deeplab+SVM)中的集成技术,并将与单一模型的使用进行比较。我发现我可以使用铰链损失,它与 SVM 的工作方式相同,所以我想尝试一下。我实际上有两个问题,一个是
1. 您认为它也适用于语义分割任务吗?它的逻辑是相同的,所以理论上应该可以,但我对此并不自信,因为我是计算机视觉领域的新手。
2. 如果我可以将此应用于语义模型。我是否应该为模型的每一层都使用 tanh 激活函数?还是只用于最后一层?提前非常感谢!
嗨 dspeanut……您可能会对以下内容感兴趣
https://www.jeremyjordan.me/semantic-segmentation/
问题:当在金融情境中决定一个因子(因子数量),例如股票市场中的因子。我使用深度学习来获得 W,W 是梯度下降数,就像回归中的斜率。这个 W 会是我的因子吗?
在 f(xi, W, b) = Wxi + b 中,多维情况。如果 W 可以是因子的详细数值?(因子用于金融情境,例如股票的因子……)我不太确定。
嗨,Helena……以下资源可能对您有用
https://wandb.ai/site/articles/fundamentals-of-neural-networks
非常感谢您的教程!!
一篇从不同角度撰写的综合文章。我认为文章可能给出了答案,我也应该处理有偏差的数据。
嗨 Jason,我有一个 Unet 模型,我正在尝试训练它进行图像分割,但我的损失是负的,准确率很低。我可能认为我使用的损失函数是错误的,即二元交叉熵,您建议使用其他哪些损失函数?
嗨,莎拉……您可能会发现以下资源很有用
https://dev.to/_aadidev/3-common-loss-functions-for-image-segmentation-545o
嗨,Jason,
当我们使用早期融合训练多模态网络进行多类分类(如文档图像分类,10-15个类别),使用OCR文本(BERT)和文档图像(VGG16)时,哪种损失函数是理想的?
嗨 Mujeeb……您可能会对以下资源感兴趣
https://towardsdatascience.com/handwriting-to-text-conversion-using-time-distributed-cnn-and-lstm-with-ctc-loss-function-a784dccc8ec3