Wasserstein 生成对抗网络(简称 WGAN)是生成对抗网络的一个扩展,它提高了模型训练的稳定性,并提供了一个与生成图像质量相关的损失函数。
WGAN 的发展有其深厚的数学依据,尽管在实践中只需要对已建立的标准深度卷积生成对抗网络(DCGAN)进行少量修改。
在本教程中,您将学习如何从头开始实现 Wasserstein 生成对抗网络。
完成本教程后,您将了解:
- 标准深度卷积 GAN 与新型 Wasserstein GAN 之间的区别。
- 如何从头开始实现 Wasserstein GAN 的具体细节。
- 如何开发 WGAN 来生成图像并理解模型的动态行为。
用我的新书《Python 生成对抗网络》启动您的项目,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2021 年 1 月更新:已更新,以便层冻结与批处理归一化一起使用。

如何从头开始编写 Wasserstein 生成对抗网络 (WGAN)
照片由 Feliciano Guimarães 提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- Wasserstein 生成对抗网络
- Wasserstein GAN 实现细节
- 如何训练 Wasserstein GAN 模型
Wasserstein 生成对抗网络
Wasserstein GAN(简称 WGAN)由 Martin Arjovsky 等人在其 2017 年的论文《Wasserstein GAN》中提出。
它是 GAN 的一个扩展,寻求一种替代的生成器模型训练方法,以更好地逼近训练数据集中观察到的数据分布。
WGAN 不使用判别器来分类或预测生成图像是真实的还是虚假的概率,而是更改或替换判别器模型,用一个评分器来评估给定图像的真实性或虚假性。
这种改变的动机是理论上的论证,即训练生成器应该寻求最小化训练数据集中观察到的数据分布与生成样本中观察到的分布之间的距离。
WGAN 的好处在于,训练过程更稳定,对模型架构和超参数配置的选择不那么敏感。也许最重要的是,判别器的损失似乎与生成器创建的图像质量相关。
Wasserstein GAN 实现细节
尽管 WGAN 的理论基础很深奥,但实现 WGAN 只需要对标准深度卷积 GAN(DCGAN)做一些小的改动。
下图总结了论文中 WGAN 的主要训练循环。请注意模型中使用的推荐超参数。

Wasserstein 生成对抗网络的算法。
摘自:《Wasserstein GAN》。
WGAN 的实现差异如下:
- 在评分器模型的输出层使用线性激活函数(而不是 sigmoid)。
- 使用 -1 作为真实图像的标签,使用 1 作为虚假图像的标签(而不是 1 和 0)。
- 使用 Wasserstein 损失来训练评分器和生成器模型。
- 在每个 mini-batch 更新后,将评分器模型的权重限制在一个有限的范围内(例如 [-0.01, 0.01])。
- 在每次迭代中,评分器模型的更新次数应多于生成器模型(例如 5 次)。
- 使用 RMSProp 版本的梯度下降,设置小的学习率,不带动量(例如 0.00005)。
以标准 DCGAN 模型为起点,我们逐一来看这些实现细节。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
1. 评分器输出层的线性激活
DCGAN 在判别器的输出层使用 sigmoid 激活函数来预测给定图像为真实的概率。
在 WGAN 中,评分器模型需要在输出层使用线性激活来预测给定图像的“真实性”分数。
这可以通过在评分器模型的输出层将 'activation' 参数设置为 'linear' 来实现。
|
1 2 3 |
# 定义评分器模型的输出层 ... model.add(Dense(1, activation='linear')) |
线性激活是层的默认激活,所以实际上我们可以不指定激活来实现相同的结果。
|
1 2 3 |
# 定义评分器模型的输出层 ... model.add(Dense(1)) |
2. 真实和虚假图像的类别标签
DCGAN 使用 0 类代表虚假图像,1 类代表真实图像,这些类别标签用于训练 GAN。
在 DCGAN 中,这些是判别器期望达到的精确标签。WGAN 的评分器没有精确的标签。相反,它鼓励评分器输出不同的真实和虚假图像的分数。
这通过巧妙地利用正负类别标签的 Wasserstein 函数来实现。
WGAN 可以实现使用 -1 类别标签代表真实图像,+1 类别标签代表虚假或生成图像。
这可以通过 ones() NumPy 函数来实现。
例如
|
1 2 3 4 5 6 |
... # 生成类别标签,-1 代表“真实” y = -ones((n_samples, 1)) ... # 创建类别标签,1.0 代表“虚假” y = ones((n_samples, 1)) |
3. Wasserstein 损失函数
DCGAN 将判别器训练为一个二元分类模型,以预测给定图像为真实的概率。
为了训练这个模型,判别器使用二元交叉熵损失函数进行优化。相同的损失函数用于更新生成器模型。
WGAN 模型的主要贡献是使用了一个新的损失函数,它鼓励判别器预测给定输入看起来有多真实或虚假的分数。这将判别器的角色从分类器转变为评分器,用于评估图像的真实性或虚假性,并使分数之间的差异尽可能大。
我们可以将 Wasserstein 损失实现为 Keras 中的一个自定义函数,该函数计算真实或虚假图像的平均分数。
该分数对真实样本最大化,对虚假样本最小化。鉴于随机梯度下降是一个最小化算法,我们可以将类别标签乘以平均分数(例如,真实样本为 -1,虚假样本为 1,这不会产生影响),这确保了真实和虚假样本的损失对网络是最小化的。
下面列出了 Keras 的这个损失函数的高效实现。
|
1 2 3 4 5 |
from keras import backend # Wasserstein 损失的实现 def wasserstein_loss(y_true, y_pred): return backend.mean(y_true * y_pred) |
通过在编译模型时指定函数名称,可以将此损失函数用于训练 Keras 模型。
例如
|
1 2 3 |
... # 编译模型 model.compile(loss=wasserstein_loss, ...) |
4. 评分器权重裁剪
DCGAN 不使用任何梯度裁剪,尽管 WGAN 对评分器模型需要梯度裁剪。
我们可以将权重裁剪实现为 Keras 约束。
这是一个必须扩展Constraint类并定义__call__()函数实现以应用操作以及get_config()函数以返回任何配置的类。
我们还可以定义一个__init__()函数来设置配置,在本例中是权重超立方体的对称大小,例如 0.01。
下面定义了ClipConstraint类。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 将模型权重裁剪到给定的超立方体 class ClipConstraint(Constraint): # 初始化时设置裁剪值 def __init__(self, clip_value): self.clip_value = clip_value # 将模型权重裁剪到超立方体 def __call__(self, weights): return backend.clip(weights, -self.clip_value, self.clip_value) # 获取配置 def get_config(self): return {'clip_value': self.clip_value} |
要使用该约束,可以构造该类,然后通过设置kernel_constraint参数在层中使用它;例如
|
1 2 3 4 5 6 |
... # 定义约束 const = ClipConstraint(0.01) ... # 在层中使用约束 model.add(Conv2D(..., kernel_constraint=const)) |
该约束仅在更新评分器模型时需要。
5. 更新评分器比生成器更频繁
在 DCGAN 中,生成器和判别器模型必须以相等的次数进行更新。
具体来说,判别器在每次迭代中用一半的真实样本和一半的虚假样本进行更新,而生成器用一批生成的样本进行更新。
例如
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
... # 主要 GAN 训练循环 for i in range(n_steps): # 更新判别器 # 获取随机选择的“真实”样本 X_real, y_real = generate_real_samples(dataset, half_batch) # 更新评分器模型权重 c_loss1 = c_model.train_on_batch(X_real, y_real) # 生成“假”示例 X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 更新评分器模型权重 c_loss2 = c_model.train_on_batch(X_fake, y_fake) # 更新生成器 # 准备潜在空间中的点作为生成器的输入 X_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过评分器的误差更新生成器 g_loss = gan_model.train_on_batch(X_gan, y_gan) |
在 WGAN 模型中,评分器模型必须比生成器模型更新的次数更多。
具体来说,定义了一个新的超参数来控制评分器相对于生成器每次更新的更新次数,称为 n_critic,并将其设置为 5。
这可以实现在主 GAN 更新循环内的新循环中,例如
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
... # 主要 GAN 训练循环 for i in range(n_steps): # 更新评分器 for _ in range(n_critic): # 获取随机选择的“真实”样本 X_real, y_real = generate_real_samples(dataset, half_batch) # 更新评分器模型权重 c_loss1 = c_model.train_on_batch(X_real, y_real) # 生成“假”示例 X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 更新评分器模型权重 c_loss2 = c_model.train_on_batch(X_fake, y_fake) # 更新生成器 # 准备潜在空间中的点作为生成器的输入 X_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过评分器的误差更新生成器 g_loss = gan_model.train_on_batch(X_gan, y_gan) |
6. 使用 RMSProp 随机梯度下降
DCGAN 使用 Adam 版本的随机梯度下降,具有小的学习率和适度的动量。
WGAN 建议改用 RMSProp,学习率为 0.00005。
这可以在编译模型时在 Keras 中实现。例如
|
1 2 3 4 |
... # 编译模型 opt = RMSprop(lr=0.00005) model.compile(loss=wasserstein_loss, optimizer=opt) |
如何训练 Wasserstein GAN 模型
现在我们了解了 WGAN 的具体实现细节,我们可以实现该模型进行图像生成。
在本节中,我们将开发一个 WGAN 来从 MNIST 数据集中生成单个手写数字(“7”)。这是一个很好的 WGAN 测试问题,因为它是一个小型数据集,需要一个适中的模型,易于训练。
第一步是定义模型。
评分器模型以一个 28x28 的灰度图像作为输入,并输出图像的真实性或虚假性分数。它被实现为一个适中的卷积神经网络,使用了 DCGAN 设计的最佳实践,例如使用斜率为 0.2 的 LeakyReLU 激活函数、批量归一化,以及使用 2x2 步幅进行下采样。
评分器模型利用新的 ClipConstraint 权重约束在 mini-batch 更新后裁剪模型权重,并使用自定义的wasserstein_loss()函数、学习率为 0.00005 的 RMSProp 随机梯度下降进行优化。
下面的define_critic()函数实现了这一点,定义并编译了评分器模型并返回。图像的输入形状被参数化为一个默认函数参数,以便清晰明了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 定义独立的评分器模型 def define_critic(in_shape=(28,28,1)): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = ClipConstraint(0.01) # 定义模型 model = Sequential() # 下采样到 14x14 model.add(Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init, kernel_constraint=const, input_shape=in_shape)) model.add(BatchNormalization()) model.add(LeakyReLU(alpha=0.2)) # 下采样到 7x7 model.add(Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init, kernel_constraint=const)) model.add(BatchNormalization()) model.add(LeakyReLU(alpha=0.2)) # 评分,线性激活 model.add(Flatten()) model.add(Dense(1)) # 编译模型 opt = RMSprop(lr=0.00005) model.compile(loss=wasserstein_loss, optimizer=opt) return model |
生成器模型以潜在空间中的一个点作为输入,并输出一个 28x28 的灰度图像。
这通过使用全连接层来解释潜在空间中的点,并提供足够的激活来实现,这些激活可以重塑为输出图像(例如 7x7)的许多副本(在本例中为 128 个)。然后,使用转置卷积层对其进行两次上采样,每次都使激活的大小翻倍,面积增加四倍。
该模型使用了最佳实践,例如 LeakyReLU 激活、核大小是步幅大小的因子,以及输出层中的双曲正切 (tanh) 激活函数。
下面的define_generator()函数定义了生成器模型,但故意不编译它,因为它不直接训练,然后返回模型。潜在空间的大小被参数化为一个函数参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 定义独立的生成器模型 def define_generator(latent_dim): # 权重初始化 init = RandomNormal(stddev=0.02) # 定义模型 model = Sequential() # 7x7 图像的基础 n_nodes = 128 * 7 * 7 model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # 上采样到 14x14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)) model.add(BatchNormalization()) model.add(LeakyReLU(alpha=0.2)) # 上采样到 28x28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)) model.add(BatchNormalization()) model.add(LeakyReLU(alpha=0.2)) # 输出 28x28x1 model.add(Conv2D(1, (7,7), activation='tanh', padding='same', kernel_initializer=init)) return model |
接下来,可以定义一个 GAN 模型,它将生成器模型和评分器模型组合成一个更大的模型。
这个更大的模型将用于训练生成器中的模型权重,使用评分器模型计算的输出和误差。评分器模型是单独训练的,因此,在这个组合的 GAN 模型中,模型权重被标记为不可训练,以确保只有生成器模型的权重被更新。这个对评分器权重可训练性的更改仅在训练组合的 GAN 模型时生效,而不是在单独训练评分器时生效。
这个更大的 GAN 模型以潜在空间中的一个点作为输入,使用生成器模型生成一个图像,该图像作为输入馈送到评分器模型,然后输出真实或虚假的评分。该模型使用 RMSProp 和自定义的wasserstein_loss()函数进行拟合。
下面的define_gan()函数实现了这一点,它将已经定义的生成器和评分器模型作为输入。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 定义组合的生成器和评分器模型,用于更新生成器 def define_gan(generator, critic): # 使评分器中的权重不可训练 for layer in critic.layers: if not isinstance(layer, BatchNormalization): layer.trainable = False # 连接它们 model = Sequential() # 添加生成器 model.add(generator) # 添加评分器 model.add(critic) # 编译模型 opt = RMSprop(lr=0.00005) model.compile(loss=wasserstein_loss, optimizer=opt) return model |
现在我们已经定义了GAN模型,我们需要训练它。但是,在训练模型之前,我们需要输入数据。
第一步是加载和 缩放 MNIST 数据集。通过调用load_data() Keras 函数加载整个数据集,然后选择属于类别 7 的图像子集(约 5,000 张),例如手写的数字七。然后必须将像素值缩放到 [-1,1] 范围,以匹配生成器模型的输出。
下面的load_real_samples()函数实现了这一点,返回加载和缩放后的 MNIST 训练数据集子集,准备好进行建模。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 加载图像 def load_real_samples(): # 加载数据集 (trainX, trainy), (_, _) = load_data() # 选择给定类别的所有样本 selected_ix = trainy == 7 X = trainX[selected_ix] # 扩展到3D,例如添加通道 X = expand_dims(X, axis=-1) # 从整数转换为浮点数 X = X.astype('float32') # 从 [0,255] 缩放到 [-1,1] X = (X - 127.5) / 127.5 return X |
我们将要求在每次更新GAN模型时,从数据集中获取一个批次(或半个批次)的真实图像。实现这一目标的一个简单方法是每次从数据集中选择一个随机样本。
下面的 `generate_real_samples()` 函数实现了这一点,它将准备好的数据集作为参数,选择并返回图像的随机样本及其对应的标签给判别器,特别是目标值 -1 表示它们是真实图像。
|
1 2 3 4 5 6 7 8 9 |
# 选择真实样本 def generate_real_samples(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 选择图像 X = dataset[ix] # 生成类别标签,-1 表示“真实” y = -ones((n_samples, 1)) return X, y |
接下来,我们需要为生成器模型提供输入。这些是来自潜在空间的随机点,具体来说是高斯分布的随机变量。
下面的 `generate_latent_points()` 函数实现了这一点,它将潜在空间的尺寸作为参数,以及所需的点数,并将它们作为生成器模型的输入批次返回。
|
1 2 3 4 5 6 7 |
# 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 x_input = x_input.reshape(n_samples, latent_dim) return x_input |
接下来,我们需要使用潜在空间中的点作为生成器的输入,以生成新的图像。
下面的 `generate_fake_samples()` 函数实现了这一点,它将生成器模型和潜在空间的尺寸作为参数,然后生成潜在空间的点并使用它们作为生成器模型的输入。
该函数返回生成的图像及其对应的标签给判别器模型,特别是目标值 1 表示它们是假的或生成的。
|
1 2 3 4 5 6 7 8 9 |
# 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(generator, latent_dim, n_samples): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n_samples) # 预测输出 X = generator.predict(x_input) # 创建类别标签,1.0 表示“假” y = ones((n_samples, 1)) return X, y |
我们需要记录模型的性能。也许评估GAN性能最可靠的方法是使用生成器生成图像,然后对其进行审查和主观评估。
下面的 `summarize_performance()` 函数在训练过程中接收生成器模型,并使用它在一个10x10的网格中生成100张图像,然后将这些图像绘制出来并保存到文件中。模型此时也会保存到文件中,以防我们以后想用它生成更多图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 生成样本并保存为图,并保存模型 def summarize_performance(step, g_model, latent_dim, n_samples=100): # 准备伪示例 X, _ = generate_fake_samples(g_model, latent_dim, n_samples) # 将范围从[-1,1]缩放到[0,1] X = (X + 1) / 2.0 # 绘制图像 for i in range(10 * 10): # 定义子图 pyplot.subplot(10, 10, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(X[i, :, :, 0], cmap='gray_r') # 保存图到文件 filename1 = 'generated_plot_%04d.png' % (step+1) pyplot.savefig(filename1) pyplot.close() # 保存生成器模型 filename2 = 'model_%04d.h5' % (step+1) g_model.save(filename2) print('>Saved: %s and %s' % (filename1, filename2)) |
除了图像质量之外,跟踪模型随时间的损失和准确性也是一个好主意。
可以为每个模型更新跟踪判别器对真实和假样本的损失,以及生成器每个更新的损失。然后,可以使用这些来创建训练结束时的损失折线图。下面的 `plot_history()` 函数实现了这一点,并将结果保存到文件中。
|
1 2 3 4 5 6 7 8 9 |
# 创建GAN损失的折线图并保存到文件 def plot_history(d1_hist, d2_hist, g_hist): # 绘制历史记录 pyplot.plot(d1_hist, label='crit_real') pyplot.plot(d2_hist, label='crit_fake') pyplot.plot(g_hist, label='gen') pyplot.legend() pyplot.savefig('plot_line_plot_loss.png') pyplot.close() |
我们现在可以拟合GAN模型了。
该模型训练10个训练周期,这是任意设定的,因为模型可能在最初几个周期后就开始生成可信的数字7。批次大小为64个样本,每个训练周期涉及6,265/64,约97个真实和假样本的批次以及模型更新。因此,模型将训练10个周期,每个周期97个批次,共970次迭代。
首先,判别器模型通过一个真实样本的半批次更新,然后是一个假样本的半批次更新,两者共同构成一个权重更新批次。根据WGAN算法的要求,这一过程重复 `n_critic`(5)次。
然后,生成器通过复合GAN模型进行更新。重要的是,为生成的样本设置的目标标签为-1(真实)。这会更新生成器,使其在下一批次中生成更好的真实样本。
下面的 `train()` 函数实现了这一点,它将定义的模型、数据集和潜在空间的尺寸作为参数,并使用默认参数设置周期数和批次大小。生成器模型在训练结束时保存。
每个迭代都会报告判别器和生成器模型的性能。每个周期都会生成并保存样本图像,并在运行结束时创建模型性能的折线图并保存。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 训练生成器和判别器 def train(g_model, c_model, gan_model, dataset, latent_dim, n_epochs=10, n_batch=64, n_critic=5): # 计算每个训练 epoch 的批次数量 bat_per_epo = int(dataset.shape[0] / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 计算半批样本的大小 half_batch = int(n_batch / 2) # 用于跟踪损失的列表 c1_hist, c2_hist, g_hist = list(), list(), list() # 手动枚举 epoch for i in range(n_steps): # 更新判别器的次数比生成器多 c1_tmp, c2_tmp = list(), list() for _ in range(n_critic): # 获取随机选择的“真实”样本 X_real, y_real = generate_real_samples(dataset, half_batch) # 更新评分器模型权重 c_loss1 = c_model.train_on_batch(X_real, y_real) c1_tmp.append(c_loss1) # 生成“假”示例 X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 更新评分器模型权重 c_loss2 = c_model.train_on_batch(X_fake, y_fake) c2_tmp.append(c_loss2) # 存储判别器损失 c1_hist.append(mean(c1_tmp)) c2_hist.append(mean(c2_tmp)) # 准备潜在空间中的点作为生成器的输入 X_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = -ones((n_batch, 1)) # 通过评分器的误差更新生成器 g_loss = gan_model.train_on_batch(X_gan, y_gan) g_hist.append(g_loss) # 总结此批次的损失 print('>%d, c1=%.3f, c2=%.3f g=%.3f' % (i+1, c1_hist[-1], c2_hist[-1], g_loss)) # 每“个周期”评估模型性能 if (i+1) % bat_per_epo == 0: summarize_performance(i, g_model, latent_dim) # 损失折线图 plot_history(c1_hist, c2_hist, g_hist) |
现在所有函数都已定义,我们可以创建模型,加载数据集,并开始训练过程。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 潜在空间的大小 latent_dim = 50 # 创建判别器 critic = define_critic() # 创建生成器 generator = define_generator(latent_dim) # 创建GAN gan_model = define_gan(generator, critic) # 加载图像数据 dataset = load_real_samples() print(dataset.shape) # 训练模型 train(generator, critic, gan_model, dataset, latent_dim) |
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 |
# 生成手写数字的WGAN示例 from numpy import expand_dims from numpy import mean from numpy import ones from numpy.random import randn from numpy.random import randint from keras.datasets.mnist import load_data from keras import backend from keras.optimizers import RMSprop from keras.models import Sequential from keras.layers import Dense from keras.layers import Reshape from keras.layers import Flatten 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU 从 keras.层 导入 BatchNormalization from keras.initializers import RandomNormal from keras.constraints import Constraint from matplotlib import pyplot # 将模型权重裁剪到给定的超立方体 class ClipConstraint(Constraint): # 初始化时设置裁剪值 def __init__(self, clip_value): self.clip_value = clip_value # 将模型权重裁剪到超立方体 def __call__(self, weights): return backend.clip(weights, -self.clip_value, self.clip_value) # 获取配置 def get_config(self): return {'clip_value': self.clip_value} # 计算Wasserstein损失 def wasserstein_loss(y_true, y_pred): return backend.mean(y_true * y_pred) # 定义独立的评分器模型 def define_critic(in_shape=(28,28,1)): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = ClipConstraint(0.01) # 定义模型 model = Sequential() # 下采样到 14x14 model.add(Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init, kernel_constraint=const, input_shape=in_shape)) model.add(BatchNormalization()) model.add(LeakyReLU(alpha=0.2)) # 下采样到 7x7 model.add(Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init, kernel_constraint=const)) model.add(BatchNormalization()) model.add(LeakyReLU(alpha=0.2)) # 评分,线性激活 model.add(Flatten()) model.add(Dense(1)) # 编译模型 opt = RMSprop(lr=0.00005) model.compile(loss=wasserstein_loss, optimizer=opt) return model # 定义独立的生成器模型 def define_generator(latent_dim): # 权重初始化 init = RandomNormal(stddev=0.02) # 定义模型 model = Sequential() # 7x7 图像的基础 n_nodes = 128 * 7 * 7 model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # 上采样到 14x14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)) model.add(BatchNormalization()) model.add(LeakyReLU(alpha=0.2)) # 上采样到 28x28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)) model.add(BatchNormalization()) model.add(LeakyReLU(alpha=0.2)) # 输出 28x28x1 model.add(Conv2D(1, (7,7), activation='tanh', padding='same', kernel_initializer=init)) return model # 定义组合的生成器和评分器模型,用于更新生成器 def define_gan(generator, critic): # 使评分器中的权重不可训练 for layer in critic.layers: if not isinstance(layer, BatchNormalization): layer.trainable = False # 连接它们 model = Sequential() # 添加生成器 model.add(generator) # 添加评分器 model.add(critic) # 编译模型 opt = RMSprop(lr=0.00005) model.compile(loss=wasserstein_loss, optimizer=opt) return model # 加载图像 def load_real_samples(): # 加载数据集 (trainX, trainy), (_, _) = load_data() # 选择给定类别的所有样本 selected_ix = trainy == 7 X = trainX[selected_ix] # 扩展到3D,例如添加通道 X = expand_dims(X, axis=-1) # 从整数转换为浮点数 X = X.astype('float32') # 从 [0,255] 缩放到 [-1,1] X = (X - 127.5) / 127.5 return X # 选择真实样本 def generate_real_samples(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 选择图像 X = dataset[ix] # 生成类别标签,-1 表示“真实” y = -ones((n_samples, 1)) 返回 X, y # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 x_input = x_input.reshape(n_samples, latent_dim) return x_input # 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(generator, latent_dim, n_samples): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n_samples) # 预测输出 X = generator.predict(x_input) # 创建类别标签,1.0 表示“假” y = ones((n_samples, 1)) 返回 X, y # 生成样本并保存为图,并保存模型 def summarize_performance(step, g_model, latent_dim, n_samples=100): # 准备伪示例 X, _ = generate_fake_samples(g_model, latent_dim, n_samples) # 将范围从[-1,1]缩放到[0,1] X = (X + 1) / 2.0 # 绘制图像 for i in range(10 * 10): # 定义子图 pyplot.subplot(10, 10, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(X[i, :, :, 0], cmap='gray_r') # 保存图到文件 filename1 = 'generated_plot_%04d.png' % (step+1) pyplot.savefig(filename1) pyplot.close() # 保存生成器模型 filename2 = 'model_%04d.h5' % (step+1) g_model.save(filename2) print('>Saved: %s and %s' % (filename1, filename2)) # 创建GAN损失的折线图并保存到文件 def plot_history(d1_hist, d2_hist, g_hist): # 绘制历史记录 pyplot.plot(d1_hist, label='crit_real') pyplot.plot(d2_hist, label='crit_fake') pyplot.plot(g_hist, label='gen') pyplot.legend() pyplot.savefig('plot_line_plot_loss.png') pyplot.close() # 训练生成器和判别器 def train(g_model, c_model, gan_model, dataset, latent_dim, n_epochs=10, n_batch=64, n_critic=5): # 计算每个训练 epoch 的批次数量 bat_per_epo = int(dataset.shape[0] / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 计算半批样本的大小 half_batch = int(n_batch / 2) # 用于跟踪损失的列表 c1_hist, c2_hist, g_hist = list(), list(), list() # 手动枚举 epoch for i in range(n_steps): # 更新判别器的次数比生成器多 c1_tmp, c2_tmp = list(), list() for _ in range(n_critic): # 获取随机选择的“真实”样本 X_real, y_real = generate_real_samples(dataset, half_batch) # 更新评分器模型权重 c_loss1 = c_model.train_on_batch(X_real, y_real) c1_tmp.append(c_loss1) # 生成“假”示例 X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 更新评分器模型权重 c_loss2 = c_model.train_on_batch(X_fake, y_fake) c2_tmp.append(c_loss2) # 存储判别器损失 c1_hist.append(mean(c1_tmp)) c2_hist.append(mean(c2_tmp)) # 准备潜在空间中的点作为生成器的输入 X_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = -ones((n_batch, 1)) # 通过评分器的误差更新生成器 g_loss = gan_model.train_on_batch(X_gan, y_gan) g_hist.append(g_loss) # 总结此批次的损失 print('>%d, c1=%.3f, c2=%.3f g=%.3f' % (i+1, c1_hist[-1], c2_hist[-1], g_loss)) # 每“个周期”评估模型性能 if (i+1) % bat_per_epo == 0: summarize_performance(i, g_model, latent_dim) # 损失折线图 plot_history(c1_hist, c2_hist, g_hist) # 潜在空间的大小 latent_dim = 50 # 创建判别器 critic = define_critic() # 创建生成器 generator = define_generator(latent_dim) # 创建GAN gan_model = define_gan(generator, critic) # 加载图像数据 dataset = load_real_samples() print(dataset.shape) # 训练模型 train(generator, critic, gan_model, dataset, latent_dim) |
运行示例很快,在没有GPU的现代硬件上大约需要10分钟。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
首先,在训练循环的每次迭代中,判别器和生成器模型的损失都会报告到控制台。具体来说,c1是判别器在真实样本上的损失,c2是判别器在生成样本上的损失,g是生成器通过判别器训练的损失。
c1分数在损失函数中被反转了;这意味着如果它们显示为负数,则实际上是正数,如果显示为正数,则实际上是负数。c2分数的符号保持不变。
回想一下,Wasserstein损失在训练期间寻求真实和假样本的分数差异更大。我们可以在运行结束时看到这一点,例如在最后一个周期,真实样本的 `c1` 损失为5.338(实际上是-5.338),假样本的 `c2` 损失为-14.260,这种大约10个单位的分离至少在前几次迭代中是一致的。
我们还可以看到,在这种情况下,模型将生成器的损失分数设定在20左右。同样,回想一下,我们通过判别器模型更新生成器,并将生成的样本视为真实样本,目标值为-1,因此该分数可以解释为大约-20的值,接近假样本的损失。
|
1 2 3 4 5 6 7 8 9 10 11 |
... >961, c1=5.110, c2=-15.388 g=19.579 >962, c1=6.116, c2=-15.222 g=20.054 >963, c1=4.982, c2=-15.192 g=21.048 >964, c1=4.238, c2=-14.689 g=23.911 >965, c1=5.585, c2=-14.126 g=19.578 >966, c1=4.807, c2=-14.755 g=20.034 >967, c1=6.307, c2=-16.538 g=19.572 >968, c1=4.298, c2=-14.178 g=17.956 >969, c1=4.283, c2=-13.398 g=17.326 >970, c1=5.338, c2=-14.260 g=19.927 |
在运行结束时创建并保存损失折线图。
该图显示了在真实样本上的判别器损失(蓝色)、在假样本上的判别器损失(橙色)以及在判别器用假样本更新生成器时的损失(绿色)。
在审查WGAN的学习曲线时,一个重要的因素是趋势。
WGAN的好处在于,损失与生成的图像质量相关。较低的损失意味着更好的图像质量,并且训练过程稳定。
在这种情况下,较低的损失具体指的是判别器报告的生成图像的较低Wasserstein损失(橙色线)。该损失的符号不因目标标签而反转(例如,目标标签为+1.0),因此,一个表现良好的WGAN应该显示该线随着生成模型图像质量的提高而呈下降趋势。
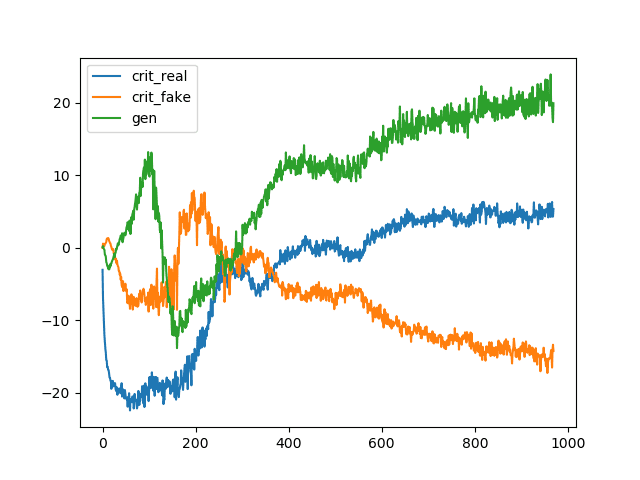
瓦塞尔斯坦生成对抗网络(WGAN)的损失和准确性折线图
在这种情况下,更多的训练似乎能带来更好的生成图像质量,大约在第200-300个周期出现一个主要的障碍,之后模型的质量保持得相当好。
在这个障碍之前和周围,图像质量很差;例如
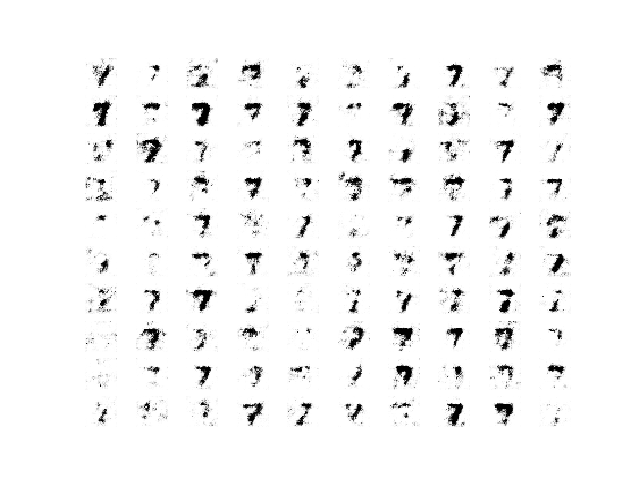
来自瓦塞尔斯坦GAN在第97个周期生成的100张手写数字7的样本。
在此周期之后,WGAN继续生成可信的手写数字。
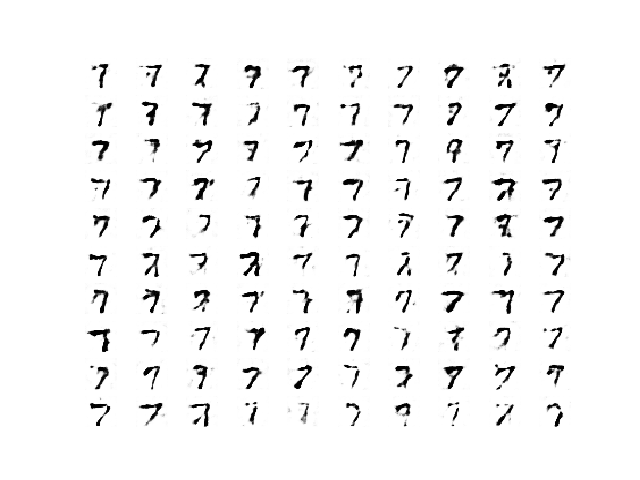
来自瓦塞尔斯坦GAN在第970个周期生成的100张手写数字7的样本。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- Wasserstein GAN, 2017.
- 改进瓦塞尔斯坦GAN的训练, 2017.
API
- Keras 数据集 API.
- Keras 序列模型 API
- Keras卷积层API
- 我如何“冻结”Keras层?
- MatplotLib API
- NumPy 随机抽样 (numpy.random) API
- NumPy 数组操作例程
文章
- 瓦塞尔斯坦GAN,GitHub.
- 瓦塞尔斯坦生成对抗网络(WGANS)项目,GitHub.
- Keras-GAN:生成对抗网络的 Keras 实现,GitHub.
- 改进的WGAN,keras-contrib项目,GitHub。
总结
在本教程中,您将学习如何从头开始实现瓦塞尔斯坦生成对抗网络。
具体来说,你学到了:
- 标准深度卷积 GAN 与新型 Wasserstein GAN 之间的区别。
- 如何从头开始实现 Wasserstein GAN 的具体细节。
- 如何开发 WGAN 来生成图像并理解模型的动态行为。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...


 in Keras")



感谢您的精彩教程
我对两件事感到好奇
1. 权重裁剪具体是做什么的?(我读了Keras的clip_by_value()函数的源代码,但还是不明白它到底做了什么)
2. 根据您之前的文章,我知道判别器的输出只是一个实数,用于优化生成器,只要 critic(fake) > critic(real)。判别器是瓦塞尔斯坦距离。因此,瓦塞尔斯坦损失能否在普通CNN中替代CNN的损失函数,如MSE、PSNR?比如,我正在使用瓦塞尔斯坦损失训练一个去模糊CNN,如果我最小化这个损失值,那么我的CNN就会收敛吗?我理解得对吗?
感谢阅读我的问题
好问题。
权重裁剪确保权重值(模型参数)保持在预定义的范围内。
您可以使用MSE,但它不同。事实上,这被称为最小二乘GAN,它不收敛,但效果非常好。
感谢您的回复!
在我第一个问题中,我仍然不理解“保持在预定义的范围内”。在我第二个问题中,存在一些误解。
问题1:假设我的权重是这样的 W = [0.3 -2.5, 4.5, 0.05, -0.02],那么 clip(W, (-0.1, 0.1)) 的结果是什么?
问题2:我知道最小二乘GAN,我的问题是:“如何将瓦塞尔斯坦损失度量作为损失函数应用到正常的CNN架构中(不是GAN架构)?”。我已经在网上搜索答案,但没有研究采用这种瓦塞尔斯坦距离作为其正常CNN的损失函数。我没弄明白他们不使用的原因。
很抱歉我的英语不好
希望您能明白我的意思。
谢谢你
好问题。
裁剪定义如下:
– 如果权重小于-0.01,则设置为-0.01。
– 如果权重大于0.01,则设置为0.01。
我不确定它是否是适合普通图像分类任务的损失函数。也就是说,您不能。
非常感谢您,先生
不客气。
好文!
我将GAN训练在所有9个数字上,结果很疯狂。有很多数字看起来像是两个数字的混合体……我的模型喜欢生成0和8的混合体。有一些想法可以限制这种效果,例如:使用更大的潜在空间、将类别作为输入馈送到网络、使用更大的卷积模型、可能添加一个连接到判别器输出的全连接层,我的模型可以使用它作为类别预测器(??),当然还有更长时间的训练。
干得好,James!
所以我实现了你的模型,就像你提供的那样,但我的损失函数看起来完全不同。在400个周期后,Crit_real和crit_fake都下降到-150,而gen在400个周期后上升到150。
到目前为止,生成的图像看起来还不错,但之后它们就全黑了。
你能解释一下为什么会这样吗?
你改变了损失函数,结果很糟糕。抱歉,我不知道为什么,只知道你改变了损失函数。
也许可以先试试列出的代码?
我正在我的框架中实现相同的模型,并且遇到了类似的问题:比如生成黑色的图像。我将问题缩小到我们任意初始化卷积/Conv2dTranspose 滤波器权重的方式。不同的框架执行方式不同,因此相同的超参数在不同框架上运行的人那里可能不起作用。
你好,Hidden Machine……权重初始化是训练神经网络的关键方面,尤其是在 WGAN 等生成对抗网络 (GAN) 中。不同的框架可能有不同的默认初始化方法,从而导致训练性能的差异。以下是为你的自定义框架中的 WGAN 实现正确初始化权重的分步指南。
### WGAN 的权重初始化
为了在不同框架之间获得一致的结果,你可以使用 Xavier(Glorot)初始化或 He 初始化等特定的权重初始化方法。以下是在 WGAN 中从头开始实现 Xavier 初始化。
#### 分步实现
1. **定义 Xavier 初始化函数:**
```python
import numpy as np
def xavier_init(size):
in_dim = size[0]
xavier_stddev = 1. / np.sqrt(in_dim / 2.)
return np.random.normal(0, xavier_stddev, size=size)
2. **将 Xavier 初始化应用于模型权重:**
在定义模型层(例如卷积层)时,你可以应用 Xavier 初始化函数来初始化权重。
pythonimport torch
import torch.nn as nn
def weights_init_xavier(m)
classname = m.__class__.__name__
if classname.find('Conv') != -1 or classname.find('Linear') != -1
fan_in, fan_out = nn.init._calculate_fan_in_and_fan_out(m.weight.data)
std = np.sqrt(2.0 / (fan_in + fan_out))
nn.init.normal_(m.weight.data, 0.0, std)
if m.bias is not None
m.bias.data.fill_(0)
class Generator(nn.Module)
def __init__(self, z_dim)
super(Generator, self).__init__()
self.main = nn.Sequential(
# 在此处定义你的层
)
def forward(self, x)
return self.main(x)
class Discriminator(nn.Module)
def __init__(self)
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# 在此处定义你的层
)
def forward(self, x)
return self.main(x)
z_dim = 100
G = Generator(z_dim)
D = Discriminator()
# 应用 Xavier 初始化
G.apply(weights_init_xavier)
D.apply(weights_init_xavier)
3. **实现 WGAN 训练循环:**
确保你遵循 WGAN 训练过程,包括使用 Wasserstein 损失和梯度惩罚。
pythonimport torch.optim as optim
def gradient_penalty(D, real_data, fake_data)
alpha = torch.rand(real_data.size(0), 1, 1, 1).to(real_data.device)
interpolates = alpha * real_data + ((1 - alpha) * fake_data)
interpolates = interpolates.requires_grad_(True)
d_interpolates = D(interpolates)
fake = torch.ones(d_interpolates.size()).to(real_data.device)
gradients = torch.autograd.grad(outputs=d_interpolates, inputs=interpolates,
grad_outputs=fake, create_graph=True, retain_graph=True, only_inputs=True)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
lr = 0.0002
betas = (0.5, 0.999)
n_critic = 5
lambda_gp = 10
optimizer_D = optim.Adam(D.parameters(), lr=lr, betas=betas)
optimizer_G = optim.Adam(G.parameters(), lr=lr, betas=betas)
for epoch in range(num_epochs)
for i, (real_images, _) in enumerate(dataloader)
real_images = real_images.to(device)
# 训练判别器
for _ in range(n_critic)
noise = torch.randn(batch_size, z_dim, 1, 1).to(device)
fake_images = G(noise)
real_validity = D(real_images)
fake_validity = D(fake_images)
gp = gradient_penalty(D, real_images.data, fake_images.data)
d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gp
optimizer_D.zero_grad()
d_loss.backward()
optimizer_D.step()
# 训练生成器
noise = torch.randn(batch_size, z_dim, 1, 1).to(device)
fake_images = G(noise)
fake_validity = D(fake_images)
g_loss = -torch.mean(fake_validity)
optimizer_G.zero_grad()
g_loss.backward()
optimizer_G.step()
### 总结
通过使用 Xavier 初始化等方法正确初始化模型权重,可以缓解与任意初始化相关的问题。这种方法有助于确保你的 WGAN 生成有意义的图像,而不是黑色的图像。此外,遵循使用 Wasserstein 损失和梯度惩罚的正确 WGAN 训练过程对于稳定的训练至关重要。
我使用了你的模型,一次在本地的 MS Surface Pro 3 上(当然速度很慢),一次在 Google 的 Colab 上,结果在系数和最终的损失/准确性图上差异很大。我没有在建议的损失函数上做任何更改。
这是可以预期的结果吗?
是的,有时模型可能相当不稳定,它们可能很棘手。
我在 Colab 中将机器从 CPU 改为 GNU,结果与脚本相似。
太棒了!
我正在尝试将 Wasserstein 损失用于 pix2pix,但尚未获得任何好结果。一件奇怪的事情是,在最后一百步,无论我设置 1000 步还是 5000 步,最后一百步 g_loss 突然开始飙升,例如:
>935, c1=-8.903, c2=-5.745 g=9.406
>936, c1=-12.613, c2=-9.001 g=-5.578
>937, c1=-9.143, c2=-8.499 g=-8.585
>938, c1=-12.172, c2=-5.203 g=1.296
>939, c1=-11.419, c2=-7.457 g=2.835
>940, c1=-11.785, c2=-7.998 g=-6.124
>941, c1=-12.427, c2=-8.275 g=-2.679
>942, c1=-12.758, c2=-8.763 g=4.127
>943, c1=-9.551, c2=-6.013 g=6.745
>944, c1=-9.443, c2=-8.791 g=-3.048
>945, c1=-10.753, c2=-7.275 g=-2.918
>946, c1=-12.762, c2=-8.732 g=10.906
>947, c1=-10.392, c2=-5.713 g=-7.287
>948, c1=-12.502, c2=-8.810 g=0.580
>949, c1=-12.936, c2=-9.329 g=-2.742
>950, c1=-7.656, c2=-7.766 g=-1.436
>951, c1=-10.732, c2=-4.744 g=-7.908
>952, c1=-12.870, c2=-9.123 g=5.914
>953, c1=-9.666, c2=-7.812 g=6.430
>954, c1=-12.867, c2=-7.669 g=11.883
>955, c1=-10.069, c2=-9.066 g=-4.029
>956, c1=-13.045, c2=-9.065 g=11.350
>957, c1=-11.683, c2=-0.542 g=11.850
>958, c1=-10.341, c2=-7.843 g=-0.476
>959, c1=-13.147, c2=-9.353 g=-3.374
>960, c1=-6.914, c2=-6.306 g=-3.759
即使我把步数减少到 500 步,最后几步仍然是这样。
另一个问题是我的 g_loss 从大约 80 开始,然后下降,而不是从 0 开始。
我根本得不到好的结果。你有什么建议吗?
好问题。
嗯,我没有什么现成的建议,除了确保实现正确,并尝试做一些小的改动,看看是否能找出问题的根源。进行调试!
告诉我进展如何。
你好,
感谢这篇帖子。它非常有帮助。我计划做一个关于根据文本数据生成假句子/文本/评论的项目。我在网上做了一些研究,发现 softmax 编码器/解码器是为 GAN 生成假文本的最佳方式。另一种方法是通过强化学习。你能给我一些关于如何使用文本数据而不是图像数据的想法吗?
我建议为文本使用语言模型而不是 GAN。
https://machinelearning.org.cn/start-here/#nlp
感谢所有 NLP 的链接。我们可以将单词分解为向量,然后将它们输入判别器,然后生成一些随机文本来判断评论/句子是否确实来自数据,或者只是由生成器生成的吗?
我看不出为什么不。
嗨,Jason,
我正在尝试从包含一些 .jpg 图像的目录中加载数据集。我正在尝试遵循你的加载数据集教程,但似乎有些问题。当我运行代码时,程序一直运行。你能指导一下如何加载自定义数据集图像,如猫、汽车,而不是内置的 mnist 数据集吗?这是我的代码和输出。
trainX = datagen.flow_from_directory(‘/celeb/train’, class_mode=’binary’, batch_size=64)
X = np.array(trainX, dtype=’float32′)
X = expand_dims(X, axis=-1)
X = X.astype(‘float32’)
X = (X – 127.5) / 127.5
print(trainX.shape)
找到 5 类中的 93 张图像。
程序卡住了。没有打印 X 或 trainX 值的输出。
也许这会有帮助。
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
出于某种原因,当我尝试在 Tensorflow 2 中使用 Keras 运行此示例时,它无法收敛。
我已在 Colab 和 Kaggle 上都尝试过,并且仅在降级我的 TF 版本至 1.14 时才有效。
其他人遇到过这个问题吗?
GAN 不会收敛,它们会找到平衡。
也许可以从这里的一些更简单的教程开始,以了解 GAN 的基础知识。
https://machinelearning.org.cn/start-here/#gans
我已在 Google cloud 上使用 TF 2.7.0 和 Keras 2.7.0 进行尝试。GAN 无法生成任何图像。我不确定我能否更改为 TF 1.14。
在完整的示例中,在 train() 方法的第 209 行,为什么我们有 “y_gan = -ones((n_batch, 1))”?这不会给假样本标签 -1 吗?我认为真实样本的标签是 -1,而假样本的标签是 1。
哎呀,我应该保持一致的,抱歉。
这两种方法都一样。
在完整的示例中,第 58 行,为什么 Dense 层没有提供 kernel_constraint 参数?批评者(critic)的这一层不需要权重裁剪,如果需要,为什么?
顺便说一句,感谢你提供的这个很棒的教程!
那是输出层,我通常不对输出层添加约束。
为什么?习惯/经验吧。也许试试看。
有什么技巧可以改编此代码以使用梯度惩罚而不是权重裁剪吗?
IMO,你关于 GAN 的系列是你现在在互联网上最有帮助的内容,谢谢!
谢谢。
没有。据我回忆,在 Keras 中实现梯度惩罚是一个挑战。我相信一些聪明人已经解决了。
嗨 Jason
读了你的一本书……发了几次邮件……🙂
我认为这就是 Lennert S 的问题所在。因为我的情况类似。在 Tensor flow 1.15 上,它可以很好地稳定,并且 CPU 和 GPU 的结果都很好。复制粘贴你的代码。
在 Tensorflow 2.0+ 上,我得到 100 个黑色小方块,并且它不稳定。这之间肯定有区别。我之前在玩 GAN 时将问题缩小到 batchnorm,移除 BN 有所改善。但对于 WGAN 却不行,所以我不太确定。
想知道你是否理解这里发生了什么?你有没有用 TF 2.0 试过这个?
如果需要,我可以把我的(你的)图发给你吗?
Greg
真有趣。我没有遇到过这种情况。我会去调查一下(已添加到 Trello)。
更新:我在 Keras 2.3 和 Tensoflow 2.1 上没有发现任何问题。
尝试运行示例几次,并检查不同 epoch 的结果。
这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我遇到了同样的问题,Keras 2.3 和 Tensoflow 2.2 的结果不同。
为什么新版本在训练这些 GAN 时会出现问题,因为我在 LSGAN 和 WGAN 中都看到了失败。
尝试运行代码几次并比较结果。
我也是。WGAN 和 LSGAN 在 TensorFlow 上都有同样的问题。
所有示例都已在 Keras 2.4 和 TensorFlow 2.3 上重新测试,没有遇到任何问题。
也许可以确认一下你的库版本,然后尝试在带有 GPU 的 AWS EC2 实例上运行以加快速度。
在 Google Cloud VM 上运行
tensorflow: 2.7.0
keras: 2.7.0
其他库
scipy: 1.7.3
numpy: 1.19.5
matplotlib: 3.5.1
pandas: 1.3.5
statsmodels: 0.13.1
sklearn: 1.0.1
我看到了黑色的方块。我在 Google Cloud VM 上使用的是 Tesla T4 GPU。你能建议如何让 GAN 生成数字吗?
我尝试了 tensorflow 1.15 和 2.3 但都没有结果。但是,通过移除判别器/定义判别器中的批标准化层,网络似乎又能产生令人满意的结果。如果有人知道为什么批标准化如此有问题,那将非常有趣。
另外:非常感谢你分享你的见解并提供如此好的 Wasserstein GAN 的解释!
此致
干得好!
不仅仅是批标准化,GAN 本身就很难训练。
移除批标准化确实很有帮助。谢谢!
嗨,Jason,
我猜你的意思是你的损失图的 x 轴是“迭代次数”(步数),而不是 epoch?有 10 个 epoch,每个 epoch 有 97 步。否则,我得到了与你类似的结果“7”。我注意到在大约第 194 步时有一个相当急剧的“过渡”,此时所有生成的图像都变得非常暗,但在一个 epoch 后,这种黑暗会从背景中消退,从而留下一个漂亮的“7”图像。感谢本教程!
不客气!
我想我现在明白了:在第一步(内循环)中,你试图通过调整判别器的 w 参数及其后续裁剪来找到真实和生成数据集的这两个固定统计分布之间的最大差异。这是为了确保差异更接近真实的 Wasserstein 距离,即我们在 Lipshitz 空间中。在第二步(外循环)中,你试图通过调整生成器(通过 theta 参数)来最小化这个最佳定义的差异,使其分布更接近真实分布。
我不明白的是——为什么 c2 和 g 的损失符号不同?在这两种情况下,它都是由判别器估计的相同的生成器损失。在这两种情况下,它都基于假样本进行评估并按原样打印出来。
我们试图改进生成器(g),这与判别器(c)的能力/期望是相反的。
你好,我对损失函数感到困惑,论文中给出了两个生成器和判别器的损失,它们是不同的,那么你如何将这两个损失转换成课程中的同一个损失函数呢?谢谢你,Jason。
也许这个教程会有帮助
https://machinelearning.org.cn/how-to-implement-wasserstein-loss-for-generative-adversarial-networks/
嗨,Jason,
你是否有关于改进 WGAN 方法的实现?
目前还没有。
顺便说一下,先生,这就像你博客上的其他文章一样,是一个精彩的解释。它在我的项目中给了我很大的帮助。
但是,当我最初训练上述实现以用于我的数据集和 MNIST 时,损失一直在上升(在我的数据集中,它上升到 25000 之后我才终止了进程!)。然后我发现代码的第 58 行,Dense 层缺少一个激活函数!所以我只是添加了一个“sigmoid”激活函数,从那时起一切都很顺利!
谢谢。
那是错误的。激活函数是线性的,损失可以上升或下降——它不是 MSE!
也许重读一下教程。
哎呀!我的错!谢谢你的指导,先生!
不客气。
嗨,Jason,
你是否有 WGAN 用于 MNIST 数据集的实现。
是的,上面的教程正是这个!
嗨
感谢这篇帖子。它非常有帮助。如何添加检查点?有没有办法添加检查点?
谢谢
你可以在每次评估时手动保存模型。或者在手动更新期间随时手动保存。
感谢您的及时答复,您能为我写一段代码,或者更新一下检查点的代码吗? 提前感谢!
请看上面教程中的`summarize_performance()`函数——它会保存模型。您可以将其修改为在您想要的时候保存。
`summarize_performance()`函数会保存每个epoch的权重。但我有点困惑,当我的训练停止时,我该如何从最后保存的epoch权重开始重新训练?
谢谢
您可以加载模型并继续训练过程。
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
你好,感谢您的教程。
我想问一下,为什么我的结果值这么大。
>962, c1=-412.128, c2=390.963 g=-370.047
>963, c1=-411.156, c2=391.335 g=-367.996
>964, c1=-414.337, c2=387.317 g=-372.890
>965, c1=-412.908, c2=388.804 g=-371.697
>966, c1=-408.901, c2=387.349 g=-375.952
>967, c1=-412.134, c2=392.314 g=-372.287
>968, c1=-416.299, c2=388.089 g=-372.689
>969, c1=-411.435, c2=390.020 g=-373.012
>970, c1=-413.991, c2=391.278 g=-376.979
WGAN可以做到这一点。请监控生成的图像。
我正在尝试在CIFAR-10上训练WGAN,完全遵循相同的方法,可能只更改了架构。但我无法获得好的结果。看看结果。生成的图像质量也不好。
>1, c1=-1.686, c2=-4.668 g=13.810
>2, c1=-9.374, c2=-9.605 g=16.668
>14, c1=-36.906, c2=-38.834 g=-33.304
>17, c1=-38.848, c2=-40.553 g=-37.991
>18, c1=-39.186, c2=-41.070 g=-38.564
>26, c1=-43.379, c2=-45.001 g=-43.369
>27, c1=-43.877, c2=-45.480 g=-43.876
>1505, c1=-1617.052, c2=-1619.644 g=959.692
>1506, c1=-1618.585, c2=-1620.744 g=1155.889
干得不错。
关注生成的图像,而不是损失。
考虑更改模型架构。
Jason您好,我遇到了和其他人一样的问题。我采用了您DCGAN实现中用于cifar 10的架构。将最后一个激活函数改为Linear,并在Critic中使用了梯度裁剪。使用RMS Prop和Wasserstein损失,其余一切都与本教程相同。我目前拥有一台Dgx-2,因此我尝试了许多超参数,例如批大小、学习率、滤波器和层数,但损失一直在增加,定期保存的输出图像完全是黑色的,我实在不明白为什么WGAN声称稳定,但在我们这里却无法提供任何输出。
您可能需要为新数据集调整架构。例如,大型模型。
布朗利博士,您好,
感谢您分享这些精彩的教程,解释得非常好。我通过遵循您的教程学到了很多。
对于这个教程,我实现了它,并注意到‘trainable’可能会给一些用户带来问题。例如,在我的`main()`函数中,我使用您的代码创建了`critic_model`、`generator_model`和`GAN_model`。如果我打印这三者的摘要,我会注意到`critic_model`中的几乎所有参数都是非训练的。然而,同样的 Keras 代码,如果我只注释掉`GAN_model`,并打印另外两个模型的摘要,那么`critic_model`中的所有参数都将变为训练的。
因此,我的猜测是,当我们编译`GAN_model`时,`trainable`属性被改变了,即使我们事先已经编译了`critic_model`。如果我们在编译`critic_model`后更改‘trainable’,它仍然可能受到影响。
在训练阶段,我们可能只需要在适当的循环下明确指定`critic_model.trainable=True`和`critic_model.trainable=False`。
不客气。
不需要,一旦调用编译,模型中的所有层的训练都是固定的,并且这种状态会为单独的模型保留——例如,在不同模型中使用具有不同训练状态的层重用不会造成问题。
在这里了解更多
我该如何冻结层并进行微调?
https://keras.org.cn/getting_started/faq/#how-can-i-freeze-layers-and-do-finetuning
这个概念是否也适用于tensorflow.js?当我第一次尝试运行训练时,我在 Critic 中遇到一个错误,如下所示:
Error: variableGrads() expects at least one of the input variables to be trainable, but none of the 16 variables is trainable。
嗨 Alejandro…这个问题在这里讨论过:
https://github.com/tensorflow/tfjs/issues/153
感谢 Jason 提供的这篇很棒的文章!
如果我使用 pix2pix,其中判别器的训练也有 `x_realB` 作为输入,就像:
d_loss1 = d_model.train_on_batch([X_realA, X_realB], y_real), 我是否需要更改`wasserstein_loss`函数的输入来处理额外的`x_realB`输入(`def wasserstein_loss(y_true, y_pred)`)?
另一个问题是,c1和c2损失在训练结束时是否必须具有不同的符号,就像您的结果一样?如果在训练期间两者都带有负号是否是错误的,并且可以通过更改超参数来修复?
不客气。
我没有将wloss与pix2pix一起使用,您可能需要进行实验。
我看到在您的训练结束时,c1和c2损失具有不同的符号,具有不同的符号是否重要,或者它们可以具有相同的符号(都是负数)并且仍然是有效的训练?
您的`gen_loss`(绿色图)之所以增加,是因为您使用标签-1来训练生成器吗?如果我们改用标签+1(您用于critic的假样本),`gen_loss`会降低吗?
谢谢!
不是必需的,我相信教程中已经讨论过这个问题。
也许可以。
我不太明白如何解释 critic 损失和 gen_loss。在我的例子中,所有的损失都在下降,我不确定这些值及其范围如何解释。关于 WGAN 中损失解释的任何阅读建议?
谢谢。
好问题——一般来说,损失不能直接解释。
你好,
我尝试实现了一个条件 WGAN,我只是将标签添加到生成器和 Critic 的输入中,并像往常一样进行嵌入和连接,但 GAN 没有任何学习。有什么想法 WGAN 是否可以像普通 DCGAN 一样进行条件化?
干得好!
不知道,需要进行实验。
你好,
感谢您的精彩文章!您的文章总是令人印象深刻。
我尝试实现了一个带有 Wasserstein 损失(WACGAN)的辅助分类 GAN,通过遵循您的教程(WGAN、ACGAN 和 CGAN)。但是,我在计算损失值时感到困惑。
# WGAN 损失(Critic 模型)
c_loss1 = c_model.train_on_batch(X_real, y_real)
# CGAN 损失(判别器)
d_loss1, _ = d_model.train_on_batch([X_real, labels_real], y_real)
# ACGAN 损失(判别器模型)
_, dr_1, dr_2 = d_model.train_on_batch(X_real, [y_real, labels_real])
这是我计算损失的代码
# WACGAN 损失(我的尝试)
_, dr_1, dr_2 = d_model.train_on_batch(X_real, [y_real, labels_real])
我对于哪个值代表 Critic 模型的损失感到困惑。因为在 ACGAN 中,我们可以有两个损失值(真实/虚假样本的损失和分类的损失)。
我想问
d_r1 是 critic 对样本的损失,d_r2 是 critic 对分类的损失,这是正确的吗?
因为当我尝试检查值时,d_r1 总是给出 -1.0 的值,而 d_r2 在每次迭代时都给出不同的值。
抱歉提出这样的问题。
您能否就此情况提供一些信息?
非常感谢!
抱歉,我没有将 ACGAN 适配为使用 WGAN 损失,我无法给出好的即时建议。
你好,我正在尝试使用这个示例,但是用时间序列数据而不是图像,所以我使用双向 LSTM 而不是卷积网络。我尝试使用您在这里使用的相同的 `kernel_constraint`,但我收到了一个错误。
ValueError: Unknown constraint: ClipConstraint
我使用了`ClipConstraint`。
这是我的 Critic
def define_critic()
# 权重初始化
init = RandomNormal(stddev=0.02)
# 权重约束
const = ClipConstraint(0.01)
# 定义模型
model = Sequential()
model.add(
Bidirectional(LSTM(128, activation=’tanh’, return_sequences=True, kernel_initializer=init, kernel_constraint=const), input_shape=(TIME_STEPS, NUM_OF_FEATURES)))
model.add(LeakyReLU(alpha=0.2))
model.add(Bidirectional(LSTM(128, activation=’tanh’, kernel_initializer=init, kernel_constraint=const)))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(1, activation=’linear’))
# 编译模型
opt = RMSprop(lr=0.00005)
model.compile(loss=wasserstein_loss, optimizer=opt)
model.summary()
return model
您有什么想法是什么地方出错了?
谢谢!
我很想帮忙,但我没有能力调试您的示例,抱歉。也许这些技巧会有帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
你好,抱歉,我无意让你调试我的代码。
我将重新表述一下问题。
这个教程中的`ClipConstraint`也应该适用于 LSTM 层吗?如果适用,我是否通过仅将`kernel_initializer=init, kernel_constraint=const`添加到我的模型的每个 LSTM 层来正确使用它?
非常感谢!
也许可以——您可能需要进行实验/调整。凭经验来说,我认为它不适合 LSTM。
亲爱的 Jason,
感谢您的文章,它们非常鼓舞人心!
我发现 WGAN 实现中的一个细节与原始论文略有不同,我认为这可能会给您的读者带来一些麻烦。
原则上,在训练 Wasserstein 损失时,它的定义是:
# Wasserstein 损失的实现
def wasserstein_loss(y_true, y_pred)
return backend.mean(y_true * y_pred)
然而,我不得不为我的应用程序定制模型,在我看来,使用您示例中的以下成本是没问题的:
disc_cost = tf.reduce_mean(crit_fake – crit_real)
然而,在 WGAN 的原始论文 arXiv:1701.07875v3 中很清楚,实际的 Critic 损失是:
disc_cost = tf.reduce_mean(crit_fake) – tf.reduce_mean(crit_real)
因此,对于至少像我这样的读者来说,应该清楚,在定制 Critic 损失时:
tf.reduce_mean(crit_fake – crit_real) 不等于 tf.reduce_mean(crit_fake) – tf.reduce_mean(crit_real)
感谢分享。
亲爱的 Jason,
非常感谢您的详尽解释。我对于您说的以下陈述感到困惑:
“WGAN 的好处在于损失与生成的图像质量相关。较低的损失意味着更好的图像质量,并且训练过程稳定。
在这种情况下,较低的损失特指 Critic(橙色线)报告的生成图像的较低 Wasserstein 损失。此损失的符号不会被目标标签(例如,目标标签为 +1.0)反转,因此,性能良好的 WGAN 应该显示这条线随着生成模型图像质量的提高而下降。”
假设生成器训练完美,Critic 无法区分真实和虚假样本。我估计大约 50% 的生成图像和 50% 的真实图像将被赋予非常正/负的分数。然后,我期望 `loss_critic` 在真实样本上和 `loss_critic` 在虚假样本上都趋于 0,因为我平均了批次中或多或少相等存在的正负分数(除了均值前面的符号)。
除了我之前的观点,我仍然不明白为什么一个训练良好的 WGAN 应该在生成图像上的 `critic_loss` 下降:这意味着 Critic 会继续为生成图像分配非常负面的值,从而将它们标记为极不现实。因此,生成器做得非常糟糕。
提前感谢您的关注。
不客气。
是的,损失永远不会静止,模型会保持对抗状态,永远地推动损失向前/分开。
非常感谢。很难理解损失函数,但是有了第二篇文章就清楚了。
现在——它只在 CPU 上运行(在 Win 10 下)——但在 6-8 个 epoch 左右,损失经历了疯狂的波动,然后 `crit_fake` 变得非常高(尽管图像质量还可以)。和您的不一样。
如果您有兴趣,我将 PNG 上传到了 flickr:https://flic.kr/p/2kAPvoT
我建议专注于图像质量,并在训练期间保存模型的多个不同版本——选择图像质量最好的那个。
此外,尝试运行几次以查看是否有区别——考虑到学习算法的随机性。
感谢您的教程。我有一个小问题。
在损失和准确性的折线图中,您提到 gen(绿线)约为 -20,接近虚假样本的损失。
这是否表明生成器性能不佳,即使 `crit_fake`(橙线)的趋势是下降的?
也许 WGAN 中一个完美的生成器应该让 gen 的损失(绿色)接近 `crit_real`(蓝色)的损失,而不是 `crit_fake`(橙色)的损失?
希望得到您的答复。
我不确定 WGAN 的学习曲线是否可以解释。
为什么 WGAN 损失有时表示为 critic/discriminator 步骤的 `-critic(true_dist)+critic(fake_dist)`,而 generator/actor 步骤表示为 `-critic(fake_dist)`?
确实是为什么!
感谢您这篇深入的文章和示例代码。我有一个可能很简单的问题。我阅读了 2017 年介绍 GAN 中 Wasserstein 损失的论文,并在该论文中有一个定理,说明以下几点是等价的:
1. W_loss(P_real, P_t) –> 0(当 t –> infinity 时)
2. P_t 在分布上收敛到 P_real
其中 P_t 是我们模型生成的概率分布,由 t 参数化,P_real 是我们想要建模的分布。
根据这一点,随着损失趋近于 0,我们难道不应该看到最好的结果吗?而且随着 epoch 的进行,损失难道不应该趋向于 0 吗?为什么更负的虚假损失对应于更好的图像?我认为只有当真实损失同样增长时,总损失才趋向于 0。如果虚假损失骤降但真实损失几乎恒定,我们就不应该收敛。生成器的损失也一样(考虑到 -1 的符号,它只是增长或减少),难道我们不想要一个趋向于 0 的损失吗?
不客气。
不,我们在实践中看不到这一点。
对于那些询问梯度惩罚的人,您可以在 Keras 文档中找到:https://keras.org.cn/examples/generative/wgan_gp/
感谢分享。
Jason,我正在尝试生成表格数据,但是是序列数据。例如,客户会话点击数据,如:
SessionID | ItemClickedId | CategoryItemClickedId |HourClicked | DayClicked | MonthClicked
01 | 20 | 100 | 02 | 12 | 03
01 | 20 | 100 | 02 | 12 | 03
01 | 21 | 100 | 03 | 12 | 03
01 | 21 | 100 | 03 | 12 | 03
01 | 21 | 100 | 03 | 12 | 03
这个例子显示了客户在会话 01 中点击了两个项目,编号为 20 和 21,类别相同,时间在凌晨 2 点和 3 点。
你能帮帮我吗?我应该使用哪种 GAN 和技术?
谢谢
我建议为表格数据使用 SMOTE 等方法。
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
Jason,又一个很棒的东西。我正在尝试用 Wasserstein 损失修改我的 AC Gan,我有两个问题。首先,这个“`kernel_constraint=const`”我可以用于生成器,还是只用于判别器模型?我的第二个问题是,我是否应该只用于 ConV 层,因为我只想使用 Dense 层,这是否也可以避免过拟合?
谢谢。
两种情况都可以——也许可以尝试一下看看。
那么这是否意味着我可以使用它,它不仅用于判别器,还可以用于生成器损失?
尝试一下,看看会发生什么。
你好,感谢分享。我有一个问题。“1. Critic 输出层的线性激活
DCGAN 在判别器的输出层使用 sigmoid 激活函数……”
我正在阅读 DCGAN 的相关论文指南。它说:“在判别器的所有层中使用 LeakyReLU 激活。”
您能否澄清一下?谢谢。
也许可以尝试两者,然后找出最适合您特定数据集的方法。
嗨,布朗利,
感谢您有用的帖子和信息!从逻辑上讲,根据您的知识,是否有可能创建一个辅助分类 Wasserstein GAN?我正在尝试创建一个!但是,损失值在 epoch 一之后变为 NaN……
不确定,尝试一下看看。
感谢您的回答!
布朗利博士,您好,
我希望您在 COVID-19 大流行期间一切安好。感谢您精彩而有价值的文章。
我有一个关于普通 GAN 和 Wasserstein GAN 的一般性问题。根据您的在线文章,当一个常规 GAN 被训练时,最终它应该在生成器和判别器之间达到一个平衡(我认为这称为纳什均衡)。此外,在达到这个状态后,如果继续训练过程,判别器可能会为生成器产生错误的损失并打破这种平衡(因此,生成的图像质量会变差)。这在 Wasserstein GAN 中是否也是如此?为了更清楚地说明,我想知道如果一个 WGAN 完全达到了生成器和 Critic 之间的平衡,这种平衡状态是否像普通 GAN 一样容易被打破?
还有关于 WGAN 的一个问题,如何检查它是否已经达到了最终的平衡?这种类型的网络是否会随着训练过程的进行而无限期地变好?
最后,最后一个问题,FID 分数是否是检查 WGAN 生成的虚假图像质量的合适参数?
人们普遍认为 WGAN 在平衡点能够保持稳定。但我还没有找到任何论文来证明或反驳这一点(如果您知道有,我很乐意学习)。无论您是否处于平衡点,都可以尝试绘制损失函数与训练周期图,以查看是否已达到平台期。
Jason,你似乎没有编译你的生成器!是吗?
是的。如前所述,“故意不编译它,因为它不是直接训练的”。
基于 conda 安装,这些导入语句可以正常工作……
# 生成手写数字的WGAN示例
from numpy import expand_dims
from numpy import mean
from numpy import ones
from numpy.random import randn
from numpy.random import randint
import tensorflow as tf
from tensorflow import keras
from tensorflow.python.keras.layers import Input, Dense
from tensorflow.keras import layers
from tensorflow.python.keras import Sequential
from tensorflow.keras.layers import Reshape,Flatten,Conv2D, Conv2DTranspose,LeakyReLU,BatchNormalization
from tensorflow.python.keras.datasets.mnist import load_data
from tensorflow.python.keras import backend
from tensorflow.keras.optimizers import RMSprop
from tensorflow.python.keras.initializers import RandomNormal
from tensorflow.python.keras.constraints import Constraint
from matplotlib import pyplot
我已经购买并享用了您的一些课程。我想回馈一下,以帮助保持这些出色且有用的示例的运行。2021年9月20日
谢谢。希望您也喜欢这里的其他博文!
感谢您的教程。我不理解这段代码
# 使判别器中的权重不可训练
for layer in critic.layers
if not isinstance(layer, BatchNormalization)
layer.trainable = False
为什么我们不冻结判别器的 Batch Norm 层?我认为我们需要冻结判别器的所有层?
大家好。为什么它只生成数字 7?是模式崩溃的原因吗?用上面的代码有可能生成其他数字吗?
谢谢。
请查看完整代码的第 109 行。这是特意为举例而为的。
您能否提供一个 Python 示例,说明如何定量评估生成的数据?
*您能否提供一个 Python 示例,说明如何定量评估生成数据与原始数据之间的相似性?
对于每个机器学习专家来说,处理 MNIST 数据集都很容易,因为大多数博客都使用该数据集编写关于神经网络的内容。如果作者使用其他高分辨率数据集来真正让他们的文章值得尝试解决实际问题,那就更好了。此外,machinelearningmastery 的大多数代码都无法运行。请让您的博客更易于遵循和功能化。
感谢 Asifa 的反馈!
你好!
只有一个问题:当我们定义一个将生成器和判别器模型合并成一个更大的模型时,为什么我们要冻结所有层但 BatchNormalization 的权重?
谢谢!
你好 Laura……我不明白你的问题。你能再说一遍,以便我能更好地帮助你吗?
非常感谢您的教程!
我有一个关于下面几行代码的问题
# 使判别器中的权重不可训练
for layer in critic.layers
if not isinstance(layer, BatchNormalization)
layer.trainable = False
为什么我们不冻结判别器的 Batch Norm 层?我认为我们需要冻结判别器的所有层?
你好 Rave……你实现你的想法了吗?
我们可以用 WGAN 训练文本数据吗?如果可以,如何训练?如果有人知道,请分享代码
只使用文本数据集,不用图片
你好 Basma……请说明您想用模型实现什么,以便我们能更好地帮助您。
非常感谢您的教程!
我尝试将本教程的代码与您的 cGAN 教程结合起来,以得出条件 WGAN。虽然这似乎是一件很直接的事情,但我想知道您是否会预期会出现任何重大困难?
非常感谢!
你好 Henk……不客气!我没有预期会有任何重大困难。请继续您的想法,我们可以讨论结果。
为什么生成器损失的假数据标签是 1?不应该是 -1 吗?算法中看起来是这样的。如果判别器试图最大化来自假数据的判别器输出的负值,那么生成器就应该试图最小化它。Keras 实现的生成器损失是“ -tf.reduce_mean(fake_img)”。在您的代码中,生成器损失是“backend.mean(y_true * y_pred)”,其中“y_true”是 +1 而不是 -1。
感谢 Nate 的反馈!您的理解是正确的!