如何结合 Scikit-learn、CatBoost 和 SHAP 来实现可解释的树模型
图片作者 | ChatGPT
引言
机器学习工作流程通常需要在模型表现卓越和理解解释其预测之间取得微妙的平衡。当面对像 CatBoost 这样高性能的算法时,这种挑战会变得尤为突出,它能够取得优异的结果,但对于需要理解“为何”模型做出特定决策的利益相关者来说,它可能感觉像是一个黑箱。
解决方案在于结合三个库,它们可以完美地相互补充。 Scikit-learn 提供了构成大多数 ML 工作流程骨干的预处理生态系统和评估框架。 CatBoost 提供了最先进的梯度提升性能,并具有本地的类别特征处理能力。 SHAP (SHapley Additive exPlanations) 将这些高性能的预测转化为透明、可量化的解释。
在本教程中,您将了解如何在统一的工作流程中集成这三个库,从而实现准确性和可解释性。您将使用 Ames Housing 数据集 来预测房价——这是一个完美的用例,展示了性能和可解释性都很重要的实际应用。房地产专业人士不仅需要知道模型预测了什么,还需要确切地知道哪些特征驱动了这些预测以及驱动了多少。
在本教程结束时,您将了解如何创建从 scikit-learn 的预处理到 CatBoost 的建模再到 SHAP 的详细解释的无缝数据管道。您将学会比较特征重要性方法、解释复杂的特征交互,并量化类别特征(如邻里效应)的影响。最重要的是,您将拥有一个实用的框架,让任何基于树的模型都既准确又可解释。
先决条件
在开始本教程之前,您应该已
- 在系统上安装了 Python 3.7 或更高版本
- 基本熟悉 Python 语法和编程概念
- 成功安装了以下库
- Pandas (1.3.0 或更高版本)
- NumPy (1.20.0 或更高版本)
- scikit-learn (1.0.0 或更高版本)
- CatBoost (1.0.0 或更高版本)
- SHAP (0.40.0 或更高版本)
- Matplotlib (3.3.0 或更高版本),用于可视化
如果您需要安装这些包,可以使用 pip 进行安装
|
1 |
pip install pandas numpy scikit-learn catboost shap matplotlib |
本教程假定您对机器学习概念(如回归、训练/测试拆分和模型评估)有一定的基本了解。熟悉基于树的模型会很有帮助,但并非必需,因为我们会随着教程的进展解释关键概念。
构建在我们的 CatBoost 基础之上
在探索解释之前,我们需要一个值得解释的高性能模型。在我们 上一次关于 CatBoost 的探索 中,我们为 Ames Housing 数据集构建了一个优化的回归模型,其 R² 分数达到了令人印象深刻的 0.9310。该模型展示了 CatBoost 在处理缺失值和类别数据方面的本地能力,无需进行广泛的预处理。
现在,我们将重新创建那个优化的模型,作为我们集成工作的基础。目标是建立一个稳固的基准,然后通过我们三个库的集成来使其可解释。让我们从建立我们的基准模型开始,采用与我们之前 CatBoost 探索中获得优异结果相同的方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 构建在我们的 CatBoost 基础之上 import pandas as pd import numpy as np from catboost import CatBoostRegressor from sklearn.model_selection import cross_val_score # 加载数据集 (与 CatBoost 帖子相同) data = pd.read_csv('Ames.csv') X = data.drop(['SalePrice'], axis=1) y = data['SalePrice'] # 处理类别特征 (来自您的 CatBoost 帖子) cat_features = [col for col in X.columns if X[col].dtype == 'object'] X['Electrical'] = X['Electrical'].fillna(X['Electrical'].mode()[0]) X[cat_features] = X[cat_features].fillna('Missing') cat_features = X.select_dtypes(include=['object']).columns.tolist() # 训练我们的优化 CatBoost 模型 model = CatBoostRegressor(cat_features=cat_features, random_state=42, verbose=0) cv_scores = cross_val_score(model, X, y, cv=5, scoring='r2') print(f"CatBoost Cross-validated R² score: {cv_scores.mean():.4f}") |
这将输出
|
1 |
CatBoost Cross-validated R² score: 0.9310 |
我们成功地重新创建了我们高性能的 CatBoost 模型,其 R² 分数与我们之前的工作相同,为 0.9310。这让我们相信我们正在使用一个真正捕捉房价数据模式的模型。
这个基准模型展示了 CatBoost 功能的几个关键方面,使其成为我们集成工作流程的理想选择。该模型处理了数据集中所有 84 个特征,包括数值变量(如居住面积)和类别变量(如邻里),而无需手动编码或插补。CatBoost 的本地类别处理能力会自动学习对类别特征进行拆分的最佳方式,而其内置的正则化尽管维度很高,也能防止过拟合。
一致的交叉验证性能告诉我们,该模型在新数据上泛化良好——这正是我们在开始解释个体预测时所希望的。当模型表现不佳或不一致时,特征解释的意义就会减弱,因为底层模式并不可靠。
集成点 1:Scikit-learn → CatBoost 工作流程
现在我们将演示工作流程中的第一个集成点:scikit-learn 的预处理和评估工具如何与 CatBoost 无缝协作。虽然 CatBoost 可以自动处理许多预处理任务,但将其与 scikit-learn 结合可以让我们访问更广泛的数据科学工具生态系统,并建立可扩展到更复杂管道的模式。Scikit-learn 和 CatBoost 之间的无缝切换展示了这些库如何相互补充。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 集成点 1:Scikit-learn 预处理与 CatBoost from sklearn.model_selection import train_test_split from sklearn.metrics import r2_score, mean_squared_error # 使用 scikit-learn 拆分数据 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=None ) print(f"Training set: {X_train.shape[0]} samples") print(f"Test set: {X_test.shape[0]} samples") # 在训练数据上训练最终的 CatBoost 模型 final_model = CatBoostRegressor(cat_features=cat_features, random_state=42, verbose=0) final_model.fit(X_train, y_train) # 在测试集上评估 y_pred = final_model.predict(X_test) test_r2 = r2_score(y_test, y_pred) test_mse = mean_squared_error(y_test, y_pred) print(f"Test R² score: {test_r2:.4f}") print(f"Test MSE: ${test_mse:,.2f}") print(f"Test RMSE: ${np.sqrt(test_mse):,.2f}") |
这将导致
|
1 2 3 4 5 |
Training set: 2063 samples Test set: 516 samples Test R² score: 0.9335 Test MSE: $405,507,883.68 Test RMSE: $20,137.23 |
集成顺利进行,测试 R² 分数为 0.9335,证实了我们模型强大的性能。这为 SHAP 解释提供了一个可靠的基础——我们希望解释一个做出可信预测的模型。
集成点 2:CatBoost → SHAP 解释
现在我们到达第二个集成点:使用 SHAP 将我们高性能的 CatBoost 模型转化为可解释系统。虽然传统的特征重要性告诉我们哪些变量平均来说最重要,但 SHAP 更进一步,量化了每个特征对每个个体预测的确切贡献。
这次集成不仅揭示了哪些特征很重要,还揭示了它们在不同上下文和值范围内的表现。对于我们的房价预测,这意味着我们可以回答诸如“为什么模型为这个特定房屋预测了这个价格?”以及“不同的邻里如何影响定价,具体影响多少?”之类的问题。让我们初始化 SHAP,并比较它与 CatBoost 的本地方法相比如何衡量特征重要性。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# 集成点 2:CatBoost → SHAP 解释 import shap import matplotlib.pyplot as plt # 初始化 SHAP TreeExplainer 用于 CatBoost explainer = shap.TreeExplainer(final_model) # 计算测试集的 SHAP 值 print("Calculating SHAP values...") shap_values = explainer.shap_values(X_test) print(f"SHAP values calculated for {shap_values.shape[0]} predictions") print(f"Each prediction explained by {shap_values.shape[1]} features") # 比较 CatBoost vs SHAP 特征重要性 catboost_importance = final_model.get_feature_importance() shap_importance = np.mean(np.abs(shap_values), axis=0) # SHAP 全局特征重要性图 (主视觉) plt.figure(figsize=(12, 8)) shap.summary_plot( shap_values, X_test, feature_names=X.columns.tolist(), plot_type="bar", max_display=10, # Top 10 for better legibility show=False ) plt.title('Global Feature Importance (SHAP)', fontweight='bold', fontsize=16, pad=20) plt.tight_layout() plt.show() # 支持 CatBoost 排名表 catboost_ranking = pd.DataFrame({ 'Feature': X.columns, 'CatBoost_Importance': catboost_importance }).sort_values('CatBoost_Importance', ascending=False) print("CatBoost Feature Importance Rankings (Top 10):") print("=" * 45) print("Rank Feature Importance") print("-" * 45) for i in range(10): feat = catboost_ranking.iloc[i]['Feature'] importance = catboost_ranking.iloc[i]['CatBoost_Importance'] print(f"{i+1:2d}. {feat:<20s} {importance:6.1f}") |
This should output the below results and visual

在这里,SHAP 的 TreeExplainer 为所有 516 个测试预测计算了 84 个特征的确切解释。SHAP 和 CatBoost 重要性排名之间的比较揭示了这些方法如何衡量特征重要性的有趣见解。
两种方法在顶级表现者上达成一致:GrLivArea 和 OverallQual 在两个排名中都占主导地位,证实了它们是房价最重要的影响因素。然而,在中层排名中出现了显著差异。Neighborhood 在 SHAP 重要性中排名第三,但在 CatBoost 重要性中排名第四,而 TotalBsmtSF 则显示出相反的模式。这些差异凸显了一个关键区别:CatBoost 重要性反映了特征在树拆分中使用的频率,而 SHAP 重要性衡量了对最终预测的实际影响幅度。
SHAP 条形图提供了特征影响幅度的清晰可视化,显示 GrLivArea 的平均影响几乎是其他任何特征的两倍。这种量化方法意味着我们可以肯定地说,居住面积的变化对预测的影响大约是总体质量变化的两倍,是邻里效应的三倍。
此比较验证了我们模型的特征学习能力,并为下一阶段的分析奠定了基础。我们已经确定了哪些特征在全局上最重要,但 SHAP 的真正优势在于理解这些特征在不同上下文中的行为以及它们之间的相互作用。
通过依赖性图理解特征交互
虽然全局重要性排名告诉我们哪些特征平均而言最重要,但它们并没有揭示特征在不同值范围内的行为,也没有揭示它们如何相互作用。SHAP 依赖性图通过显示特征值与其对个体预测的影响之间的关系来解决这些限制。
这些图将我们从“OverallQual很重要”推进到“OverallQual显示出逐步增长,其影响取决于其他房屋特征”。对于我们的房价模型,这种细节级别有助于解释驱动价格的因素,以及这些驱动因素在不同情况下的作用方式。让我们探讨一下我们最重要的特征在独立以及与其他变量交互时的表现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 高级 SHAP 分析:理解特征交互 fig, axes = plt.subplots(2, 2, figsize=(15, 12)) fig.suptitle('SHAP Dependence Plots: Standalone vs Interactive Effects', fontsize=16, fontweight='bold') # 顶部行:GrLivArea (我们的第一特征) # 图 1:GrLivArea 单独效果 shap.dependence_plot( "GrLivArea", shap_values, X_test, interaction_index=None, ax=axes[0,0], show=False ) axes[0,0].set_title('Living Area: Standalone Effect', fontweight='bold') # 图 2:GrLivArea 与 TotalBsmtSF 交互效果 shap.dependence_plot( "GrLivArea", shap_values, X_test, interaction_index="TotalBsmtSF", ax=axes[0,1], show=False ) axes[0,1].set_title('Living Area (colored by Basement Size)', fontweight='bold') # 底部行:OverallQual (我们的第二特征) # 图 3:OverallQual 单独效果 shap.dependence_plot( "OverallQual", shap_values, X_test, interaction_index=None, ax=axes[1,0], show=False ) axes[1,0].set_title('Overall Quality: Standalone Effect', fontweight='bold') # 图 4:OverallQual 与 YearBuilt 交互效果 shap.dependence_plot( "OverallQual", shap_values, X_test, interaction_index="YearBuilt", ax=axes[1,1], show=False ) axes[1,1].set_title('Overall Quality (colored by Year Built)', fontweight='bold') plt.tight_layout() plt.show() |
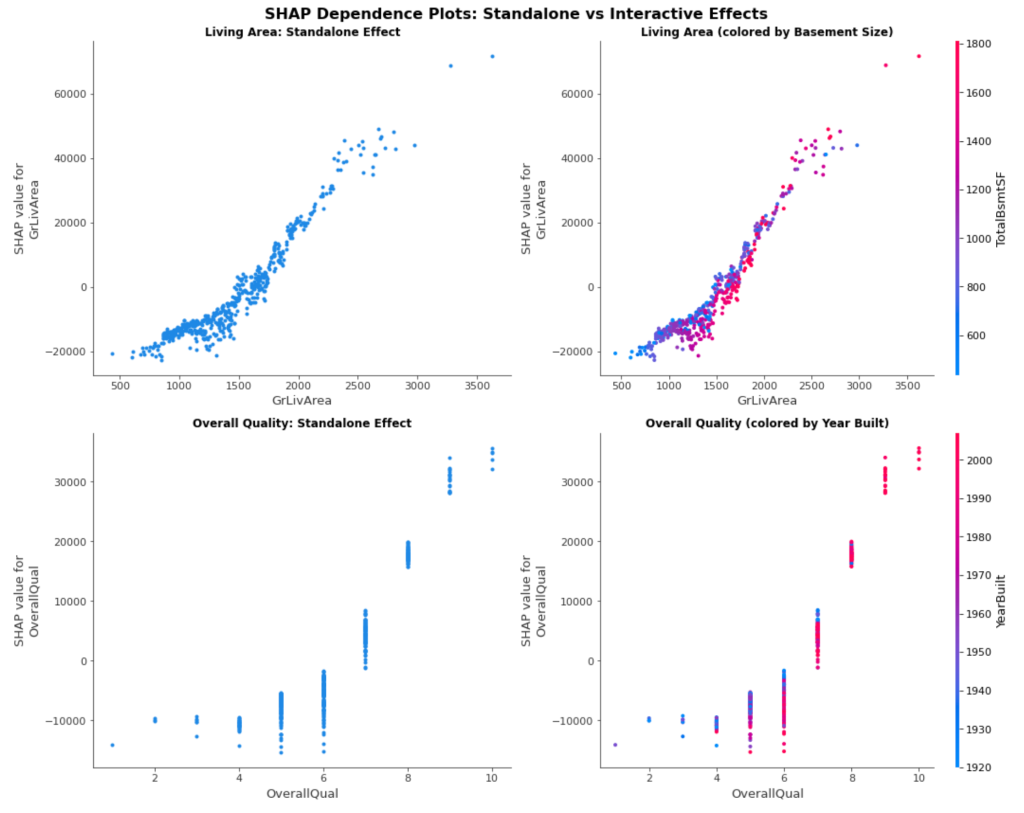
这些依赖性图揭示了 CatBoost 学习到的关于特征关系的复杂模式。独立图证实了我们的预期:居住面积与房屋价值呈强烈的正相关,而总体质量显示出与离散质量等级相对应的清晰的逐步增加。
交互图增加了传统特征重要性完全无法捕捉的复杂性。按地下室大小着色的居住面积图显示了房屋的总面积如何影响价值——对于大于 2300 平方英尺的房屋,拥有更大地下室的房屋(颜色更红)在相同的居住面积下通常会获得更高的 SHAP 值。这表明买家重视全面的空间,而不仅仅是地上平方英尺。
总体质量与建造年份的交互揭示了质量溢价中的时间效应。尽管质量在所有时期都始终驱动着价值,但颜色模式表明,质量等级在不同的建造时期可能具有不同的含义或市场价值。这反映了随着时间的推移,建筑标准和买家期望的变化。
这些图表展示了为什么 SHAP 依赖性分析超越了基本的特征重要性。我们不再仅仅知道“居住面积很重要”,而是理解居住面积的影响取决于房屋的总体大小状况。与其仅仅说“质量驱动价值”,不如看到质量效应在不同的建造时期有所不同。
量化类别特征效应
虽然我们之前的分析侧重于数值特征交互,但 SHAP 最有价值的功能之一是解释 CatBoost 如何处理类别特征。在我们的全局重要性分析中,Neighborhood 排名第三,但与数值特征不同,类别特征效应很难从传统重要性分数中解释。
SHAP 通过量化每个邻里对房价的确切美元影响来弥合这一差距。此分析将类别特征效应从抽象的重要性分数转化为具体的估值洞察,直接为房地产决策提供信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 类别特征聚焦:SHAP 如何解释 CatBoost 的类别处理 import pandas as pd # 聚焦于 Neighborhood - 我们的顶级类别特征 neighborhood_analysis = pd.DataFrame({ 'Neighborhood': X_test['Neighborhood'], 'SHAP_Impact': shap_values[:, X_test.columns.get_loc('Neighborhood')] }) # 按邻里分组并计算统计数据 neighborhood_stats = neighborhood_analysis.groupby('Neighborhood').agg({ 'SHAP_Impact': ['mean', 'count', 'std'] }).round(0) neighborhood_stats.columns = ['Avg_SHAP_Impact', 'House_Count', 'Std_Deviation'] neighborhood_stats = neighborhood_stats.sort_values('Avg_SHAP_Impact', ascending=False) print("Neighborhood Impact Analysis:") print("=" * 60) print("Neighborhood Avg Impact Count Std Dev") print("-" * 60) for idx, row in neighborhood_stats.head(10).iterrows(): print(f"{idx:<25s} {row['Avg_SHAP_Impact']:8.0f} {row['House_Count']:6.0f} {row['Std_Deviation']:8.0f}") print(f"\nKey Insights:") print(f"• Most premium neighborhood: {neighborhood_stats.index[0]} (+${neighborhood_stats.iloc[0]['Avg_SHAP_Impact']:,.0f})") print(f"• Most discounted neighborhood: {neighborhood_stats.index[-1]} (${neighborhood_stats.iloc[-1]['Avg_SHAP_Impact']:,.0f})") print(f"• CatBoost learned {len(neighborhood_stats)} distinct neighborhood patterns") # Quick visualization of top/bottom neighborhoods top_bottom = pd.concat([neighborhood_stats.head(5), neighborhood_stats.tail(5)]) plt.figure(figsize=(12, 6)) colors = ['green' if x > 0 else 'red' for x in top_bottom['Avg_SHAP_Impact']] plt.barh(range(len(top_bottom)), top_bottom['Avg_SHAP_Impact'], color=colors, alpha=0.7) plt.yticks(range(len(top_bottom)), top_bottom.index) plt.xlabel('Average SHAP Impact ($)') plt.title('Neighborhood Premium/Discount Effects (Top 5 & Bottom 5)', fontweight='bold') plt.axvline(x=0, color='black', linestyle='-', alpha=0.3) plt.gca().invert_yaxis() # This flips the y-axis so top values appear at top plt.tight_layout() plt.show() |
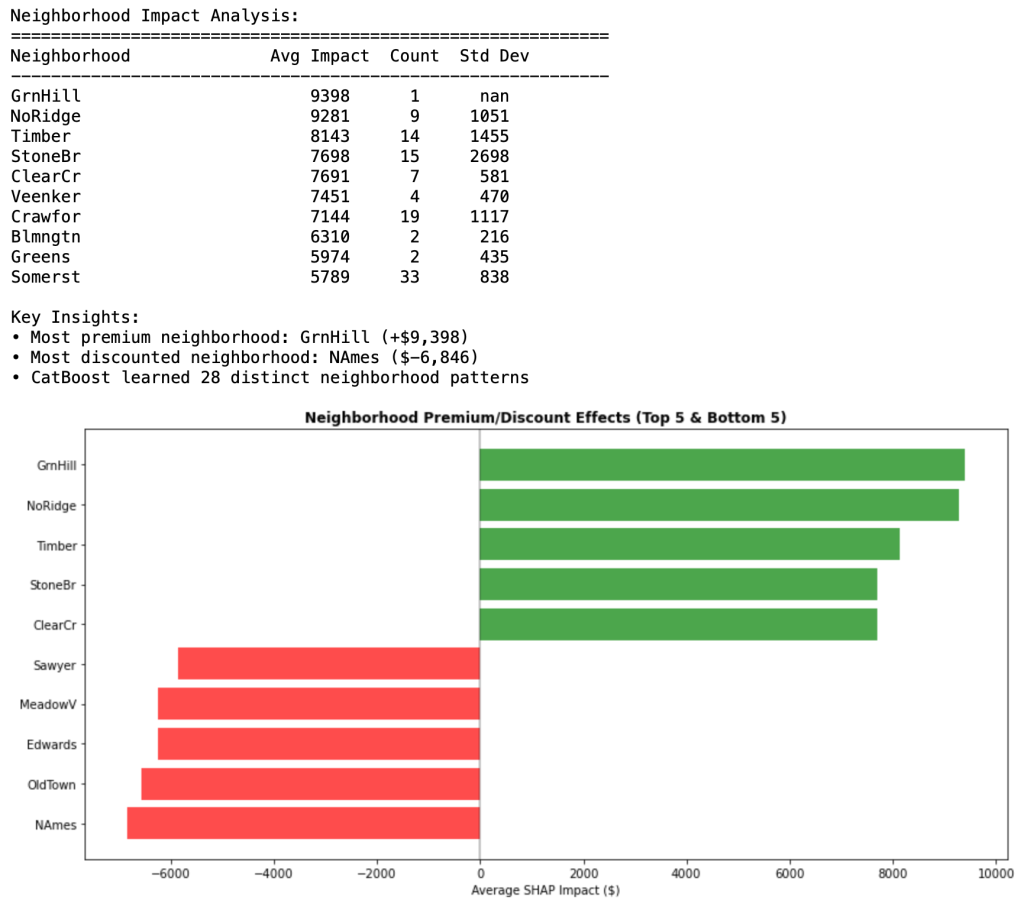
本次分析揭示了 CatBoost 自动学习到的复杂的类别模式。在没有任何手动编码或预处理的情况下,CatBoost 识别出了 28 种不同的社区定价模式,影响范围从 GrnHill 的 9,398 美元溢价到 NAmes 的 6,846 美元折扣——纯粹基于位置,其差价超过 16,000 美元。
结果展示了 CatBoost 原生的类别处理能力。该模型学习到,像 GrnHill、NoRidge 和 Timber 这样的优质社区的房屋可以带来可观的溢价,而像 NAmes、OldTown 和 Edwards 这样的地区则会持续降低房屋价值。标准差列揭示了社区内部的一致性——ClearCr 等一些地区表现出非常一致的影响(低标准差),而 StoneBr 等其他地区的影响则更加多变。
可视化使这些模式可以立即被解读。房地产专业人士现在可以量化诸如“该社区通常会为房屋价值增加 7,000 美元”或“从 NAmes 搬到 GrnHill 会使预期价值增加约 16,000 美元,其他条件不变”之类的陈述。这种精确度将类别特征理解从一般直觉转变为具体、可量化的见解。
这种类别分析展示了完整的集成工作流程:scikit-learn 提供了数据框架,CatBoost 在没有手动编码的情况下学习了复杂的类别模式,而 SHAP 使这些学习到的模式透明化且可量化。
结论
您已成功集成三个关键的机器学习库,创建了一个能够同时实现高性能和完全可解释性的工作流程。从在房屋价格预测中实现了 0.9335 R² 的 CatBoost 模型开始,您利用了 scikit-learn 的生态系统进行数据处理,并利用 SHAP 的解释性使每个预测都透明且可量化。
这种集成方法可以扩展到我们的住房示例之外。相同的 TreeExplainer 可以与其他梯度提升框架(如 XGBoost 和 LightGBM)无缝协作,而 scikit-learn 的预处理工具可以适应任何数据集。最重要的是,您现在拥有一个框架来回答应用机器学习中最重要的问题:“模型的性能如何?”以及“它为什么做出该预测?”
CatBoost 的原生类别处理能力、SHAP 的精确特征影响量化以及 scikit-learn 的强大预处理相结合,为可解释的机器学习提供了完整的解决方案。无论您是预测房价、客户行为还是业务成果,这种三库方法都能确保您的模型既准确又易于理解。






暂无评论。