图像数据增强是一种通过创建数据集中图像的修改版本来人工扩展训练数据集大小的技术。
在更多数据上训练深度学习神经网络模型可以产生更熟练的模型,而增强技术可以创建图像的变体,从而提高拟合模型将其学习到的内容推广到新图像的能力。
Keras 深度学习神经网络库通过 ImageDataGenerator 类提供了使用图像数据增强来拟合模型的能力。
在本教程中,您将学习如何在训练深度学习神经网络时使用图像数据增强。
完成本教程后,您将了解:
- 图像数据增强用于扩展训练数据集,以提高模型的性能和泛化能力。
- Keras 深度学习库通过 ImageDataGenerator 类支持图像数据增强。
- 如何使用平移、翻转、亮度调节和缩放图像数据增强。
通过我的新书《计算机视觉深度学习》启动您的项目,其中包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2019 年 5 月更新:修复了绘图时像素值的数据类型。
- 2019 年 6 月更新:修复了 API 示例中的一个小错字(感谢 Georgios)。
教程概述
本教程分为八个部分;它们是:
- 图像数据增强
- 示例图像
- 使用 ImageDataGenerator 进行图像增强
- 水平和垂直平移增强
- 水平和垂直翻转增强
- 随机旋转增强
- 随机亮度增强
- 随机缩放增强
图像数据增强
深度学习神经网络的性能通常会随着可用数据量的增加而提高。
数据增强是一种通过现有训练数据人工创建新训练数据的技术。这是通过对训练数据中的示例应用特定领域的技术来创建新的和不同的训练示例。
图像数据增强可能是最著名的数据增强类型,它涉及创建训练数据集中图像的转换版本,这些版本与原始图像属于同一类别。
转换包括图像处理领域的一系列操作,例如平移、翻转、缩放等等。
目的是用新的、合理的示例来扩展训练数据集。这意味着训练集图像的变体很可能被模型看到。例如,对猫的图片进行水平翻转可能是有意义的,因为照片可能是从左边或右边拍摄的。对猫的照片进行垂直翻转是没有意义的,而且鉴于模型极不可能看到倒置的猫的照片,这可能不合适。
因此,很明显,用于训练数据集的特定数据增强技术的选择必须根据训练数据集的上下文和问题领域的知识仔细选择。此外,单独或协同实验数据增强方法以查看它们是否能对模型性能产生可测量的改进可能很有用,也许可以使用小型原型数据集、模型和训练运行。
现代深度学习算法,例如卷积神经网络 (CNN),可以学习与图像中位置无关的特征。然而,增强可以进一步辅助这种变换不变的学习方法,并且可以帮助模型学习对诸如从左到右到从上到下的顺序、照片中的光照水平等变换也具有不变性的特征。
图像数据增强通常仅应用于训练数据集,而不应用于验证或测试数据集。这与图像大小调整和像素缩放等数据准备不同;它们必须在与模型交互的所有数据集上一致执行。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
示例图像
我们需要一个示例图像来演示标准数据增强技术。
在本教程中,我们将使用 AndYaDontStop 拍摄的一张名为“带羽毛的朋友”的鸟类照片,该照片在宽松许可下发布。
下载图像并将其保存到当前工作目录中,文件名为“bird.jpg”。

AndYaDontStop 拍摄的《带羽毛的朋友》。
保留部分权利。
使用 ImageDataGenerator 进行图像增强
Keras 深度学习库提供了在训练模型时自动使用数据增强的功能。
这是通过使用 ImageDataGenerator 类实现的。
首先,可以实例化该类,并通过类构造函数的参数指定数据增强类型的配置。
支持一系列技术以及像素缩放方法。我们将重点介绍图像数据的五种主要数据增强技术;具体如下:
- 通过 width_shift_range 和 height_shift_range 参数进行图像平移。
- 通过 horizontal_flip 和 vertical_flip 参数进行图像翻转。
- 通过 rotation_range 参数进行图像旋转。
- 通过 brightness_range 参数进行图像亮度调节。
- 通过 zoom_range 参数进行图像缩放。
例如,可以构建一个 ImageDataGenerator 类的实例。
|
1 2 3 |
... # 创建数据生成器 datagen = ImageDataGenerator() |
构建完成后,可以为图像数据集创建迭代器。
迭代器将在每次迭代中返回一批增强图像。
可以通过 flow() 函数从内存中加载的图像数据集创建迭代器;例如:
|
1 2 3 4 5 |
... # 加载图像数据集 X, y = ... # 创建迭代器 it = datagen.flow(X, y) |
或者,可以为位于磁盘上指定目录中的图像数据集创建迭代器,其中该目录中的图像根据其类别组织到子目录中。
|
1 2 3 |
... # 创建迭代器 it = datagen.flow_from_directory(X, y, ...) |
创建迭代器后,可以通过调用 fit_generator() 函数来训练神经网络模型。
steps_per_epoch 参数必须指定构成一个 epoch 的样本批次数量。例如,如果您的原始数据集有 10,000 张图像,并且您的批次大小为 32,那么在增强数据上拟合模型时,steps_per_epoch 的合理值可能是 ceil(10,000/32),即 313 个批次。
|
1 2 3 4 |
# 定义模型 model = ... # 在增强数据集上拟合模型 model.fit_generator(it, steps_per_epoch=313, ...) |
数据集中的图像不直接使用。相反,只向模型提供增强图像。由于增强是随机执行的,这使得在训练期间可以生成和使用修改后的图像和原始图像的近似复制品(例如几乎没有增强)。
数据生成器还可以用于指定验证数据集和测试数据集。通常,使用单独的 ImageDataGenerator 实例,该实例可能具有与用于训练数据集的 ImageDataGenerator 实例相同的像素缩放配置(本教程不涉及),但不会使用数据增强。这是因为数据增强仅用作人工扩展训练数据集的技术,以提高模型在未增强数据集上的性能。
现在我们熟悉了如何使用 ImageDataGenerator,让我们来看看图像数据的一些特定数据增强技术。
我们将通过回顾图像增强后的示例来单独演示每种技术。这是一种很好的做法,建议在配置数据增强时使用。在训练时同时使用一系列增强技术也很常见。我们仅出于演示目的将技术隔离到每个部分一个。
水平和垂直平移增强
图像平移意味着将图像的所有像素沿一个方向移动,例如水平或垂直,同时保持图像尺寸不变。
这意味着一些像素将被裁剪掉,图像中将有一个区域必须指定新的像素值。
ImageDataGenerator 构造函数中的 width_shift_range 和 height_shift_range 参数分别控制水平和垂直平移量。
这些参数可以指定一个浮点值,该值表示图像宽度或高度的百分比(介于 0 和 1 之间)来平移。或者,可以指定像素数来平移图像。
具体来说,对于每张图像,将从无平移和百分比或像素值之间的一个范围中采样一个值,并执行平移,例如 [0, value]。或者,您可以指定一个元组或数组,其中包含将从中采样平移的最小和最大范围;例如:[-100, 100] 或 [-0.5, 0.5]。
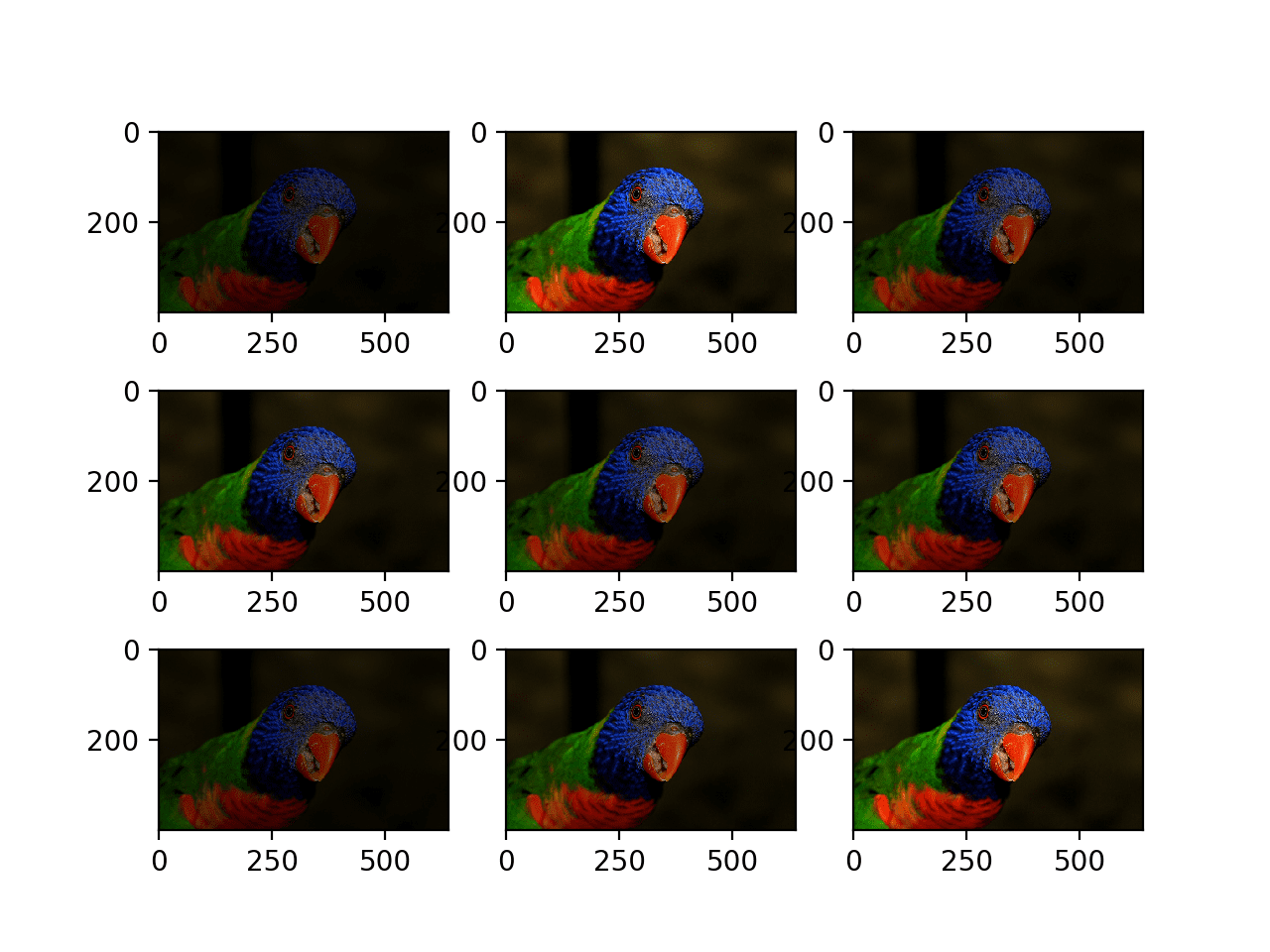
以下示例演示了使用 width_shift_range 参数在 [-200,200] 像素之间进行水平平移,并生成生成图像的图来演示效果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 水平平移图像增强示例 from numpy import expand_dims from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.preprocessing.image import ImageDataGenerator from matplotlib import pyplot # 加载图像 img = load_img('bird.jpg') # 转换为numpy数组 data = img_to_array(img) # 将维度扩展到单个样本 samples = expand_dims(data, 0) # 创建图像数据增强生成器 datagen = ImageDataGenerator(width_shift_range=[-200,200]) # 准备迭代器 it = datagen.flow(samples, batch_size=1) # 生成样本并绘图 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 生成一批图像 batch = it.next() # 转换为无符号整数以供查看 image = batch[0].astype('uint8') # 绘制原始像素数据 pyplot.imshow(image) # 显示图 pyplot.show() |
运行示例将创建配置为图像增强的 ImageDataGenerator 实例,然后创建迭代器。然后循环调用迭代器九次,并绘制每个增强图像。
我们可以在结果图中看到,执行了一系列不同的随机选择的正向和负向水平平移,并且图像边缘的像素被复制以填充由平移创建的图像的空白部分。
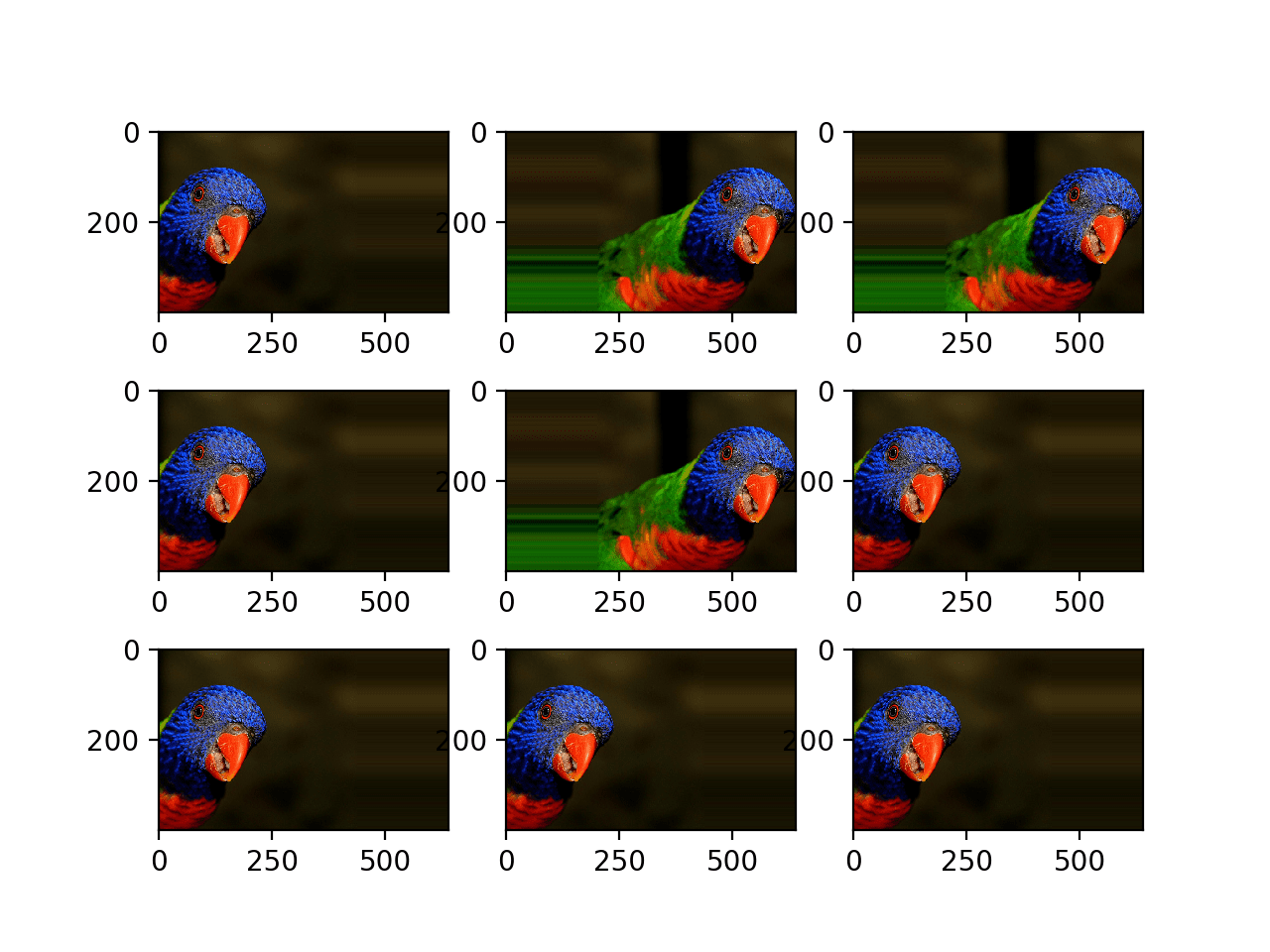
随机水平平移生成的增强图像图
下面是更新后的相同示例,它通过 height_shift_range 参数执行图像的垂直平移,在本例中,将图像高度的 0.5 指定为图像平移的百分比。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 垂直平移图像增强示例 from numpy import expand_dims from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.preprocessing.image import ImageDataGenerator from matplotlib import pyplot # 加载图像 img = load_img('bird.jpg') # 转换为numpy数组 data = img_to_array(img) # 将维度扩展到单个样本 samples = expand_dims(data, 0) # 创建图像数据增强生成器 datagen = ImageDataGenerator(height_shift_range=0.5) # 准备迭代器 it = datagen.flow(samples, batch_size=1) # 生成样本并绘图 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 生成一批图像 batch = it.next() # 转换为无符号整数以供查看 image = batch[0].astype('uint8') # 绘制原始像素数据 pyplot.imshow(image) # 显示图 pyplot.show() |
运行示例将创建用随机正向和负向垂直平移增强的图像图。
我们可以看到,水平和垂直的正向和负向平移对于所选照片可能都有意义,但在某些情况下,图像边缘复制的像素可能对模型没有意义。
请注意,可以通过“fill_mode”参数指定其他填充模式。
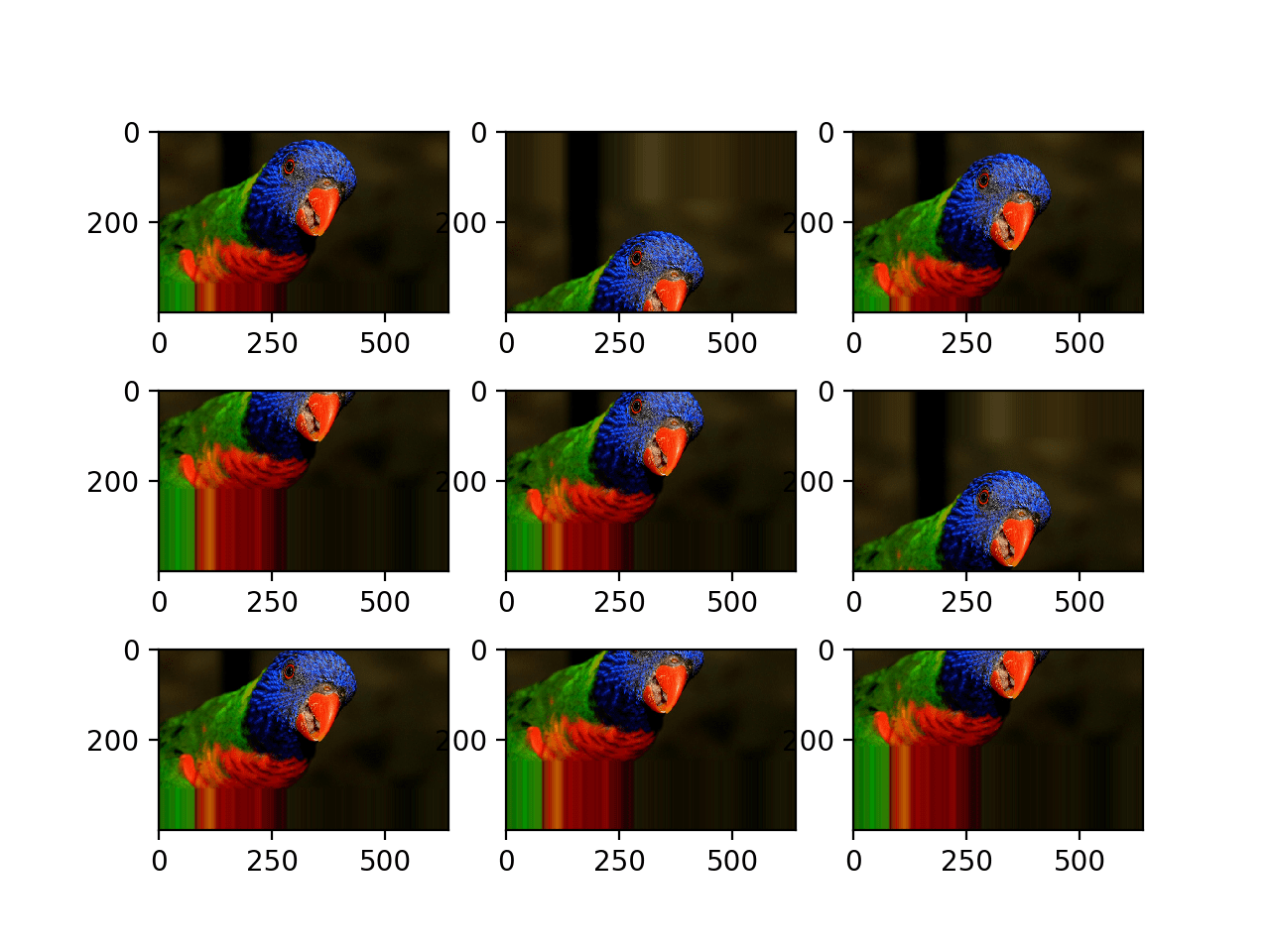
随机垂直平移的增强图像图
水平和垂直翻转增强
图像翻转意味着分别反转像素的行或列,对应于垂直或水平翻转。
翻转增强由 ImageDataGenerator 类构造函数中的布尔型 horizontal_flip 或 vertical_flip 参数指定。对于本教程中使用的鸟类照片等照片,水平翻转可能是有意义的,但垂直翻转则不然。
对于其他类型的图像,例如航空照片、宇宙学照片和显微照片,垂直翻转可能是有意义的。
以下示例演示了通过 horizontal_flip 参数对所选照片进行水平翻转增强。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 水平翻转图像增强示例 from numpy import expand_dims from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.preprocessing.image import ImageDataGenerator from matplotlib import pyplot # 加载图像 img = load_img('bird.jpg') # 转换为numpy数组 data = img_to_array(img) # 将维度扩展到单个样本 samples = expand_dims(data, 0) # 创建图像数据增强生成器 datagen = ImageDataGenerator(horizontal_flip=True) # 准备迭代器 it = datagen.flow(samples, batch_size=1) # 生成样本并绘图 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 生成一批图像 batch = it.next() # 转换为无符号整数以供查看 image = batch[0].astype('uint8') # 绘制原始像素数据 pyplot.imshow(image) # 显示图 pyplot.show() |
运行示例会创建九张增强图像的图。
我们可以看到,水平翻转是随机应用于某些图像而不是其他图像的。
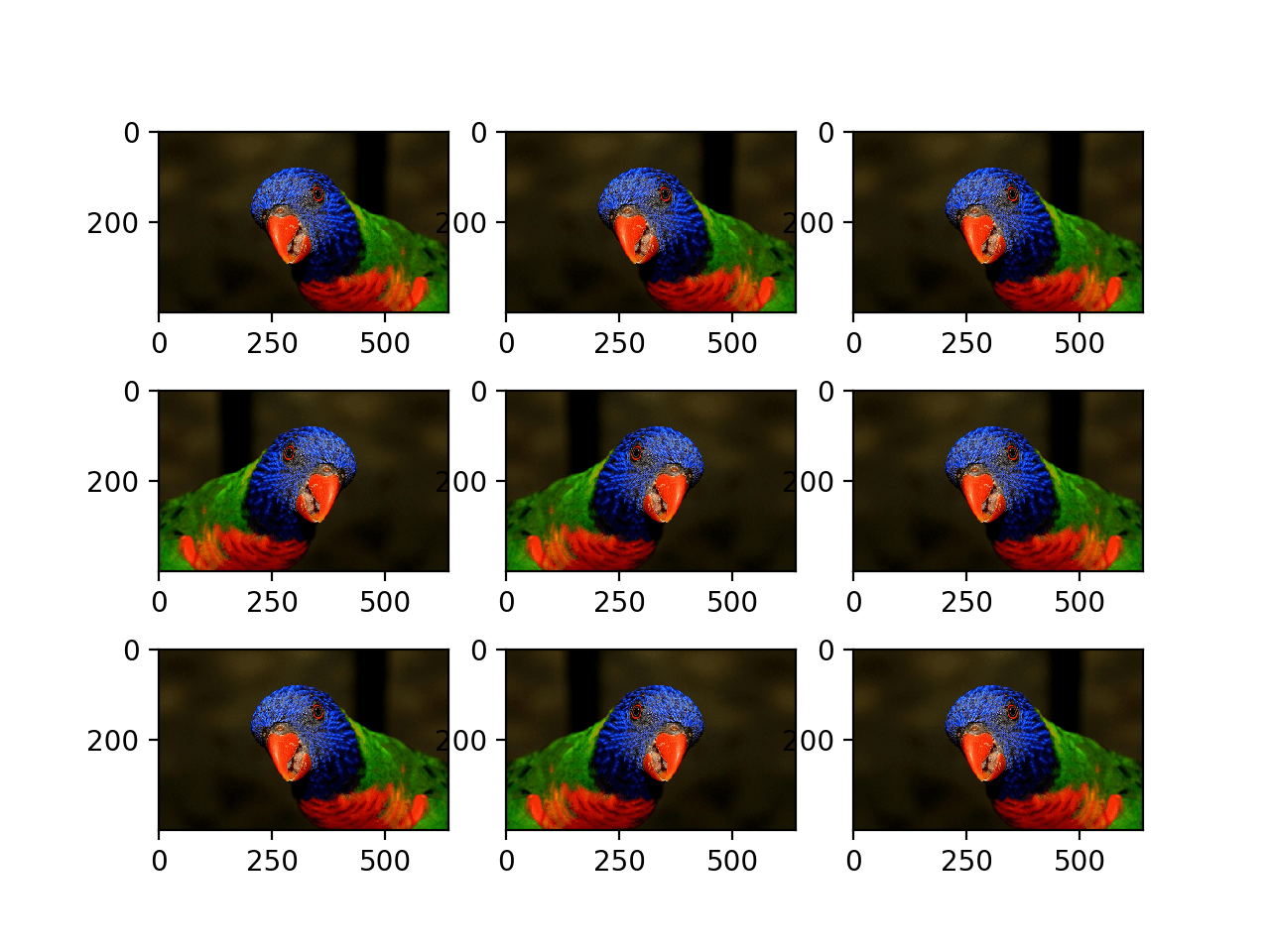
随机水平翻转的增强图像图
随机旋转增强
旋转增强会将图像随机顺时针旋转给定度数,范围为 0 到 360。
旋转可能会将像素旋转出图像帧,并使帧的某些区域没有像素数据,这些区域必须填充。
以下示例演示了通过 rotation_range 参数进行随机旋转,图像旋转范围为 0 到 90 度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 随机旋转图像增强示例 from numpy import expand_dims from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.preprocessing.image import ImageDataGenerator from matplotlib import pyplot # 加载图像 img = load_img('bird.jpg') # 转换为numpy数组 data = img_to_array(img) # 将维度扩展到单个样本 samples = expand_dims(data, 0) # 创建图像数据增强生成器 datagen = ImageDataGenerator(rotation_range=90) # 准备迭代器 it = datagen.flow(samples, batch_size=1) # 生成样本并绘图 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 生成一批图像 batch = it.next() # 转换为无符号整数以供查看 image = batch[0].astype('uint8') # 绘制原始像素数据 pyplot.imshow(image) # 显示图 pyplot.show() |
运行示例会生成旋转图像的示例,在某些情况下显示像素旋转出帧和最近邻填充。
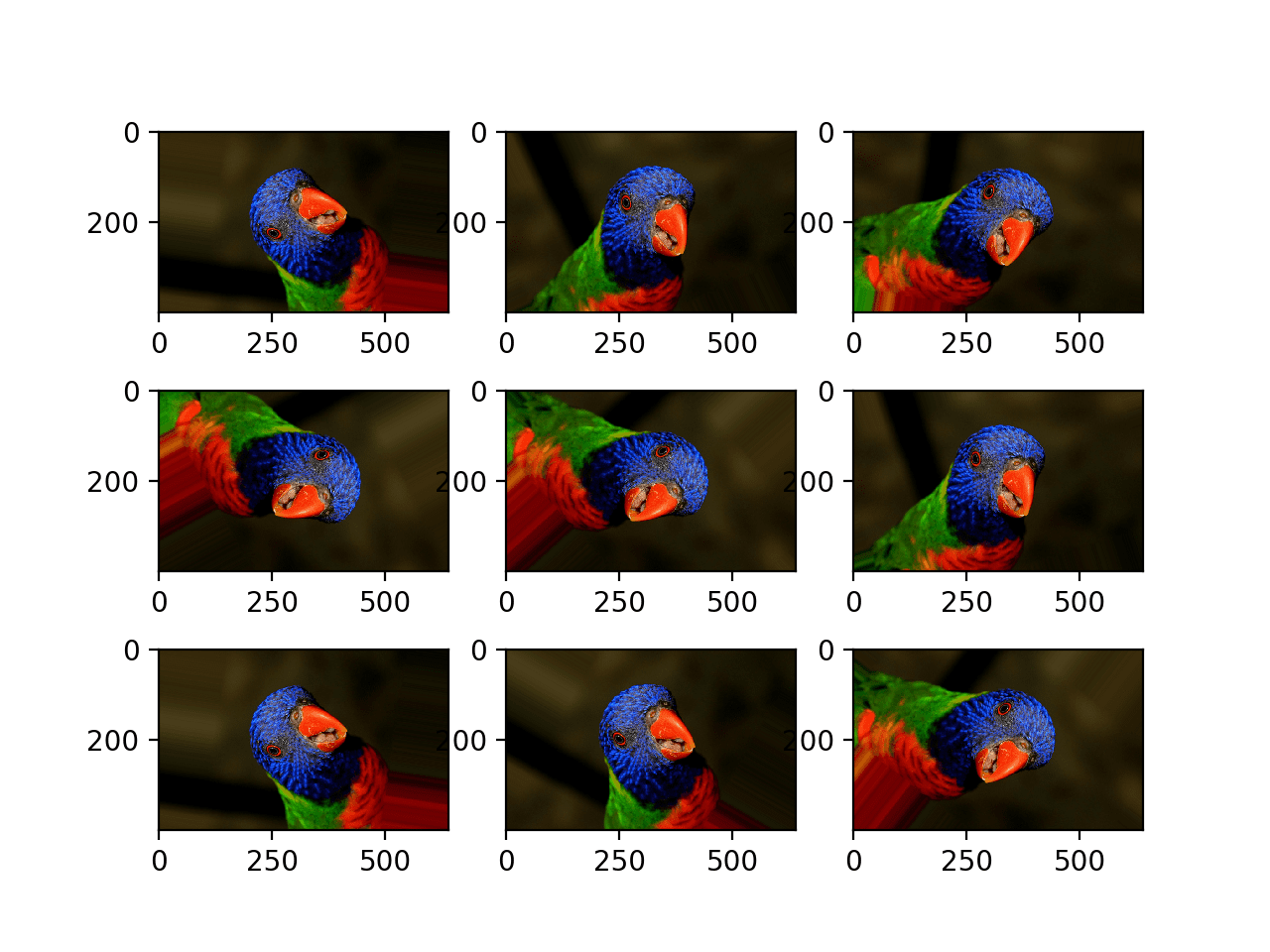
随机旋转增强生成的图像图
随机亮度增强
图像的亮度可以通过随机调暗图像、增亮图像或两者兼年来增强。
目的是让模型能够泛化训练于不同照明水平的图像。
这可以通过向 ImageDataGenerator() 构造函数指定 brightness_range 参数来实现,该参数将最小和最大范围指定为一个浮点数,表示用于选择增亮量的百分比。
小于 1.0 的值会使图像变暗,例如 [0.5, 1.0],而大于 1.0 的值会使图像变亮,例如 [1.0, 1.5],其中 1.0 对亮度没有影响。
以下示例演示了亮度图像增强,允许生成器随机将图像变暗,范围介于 1.0(无变化)和 0.2 或 20% 之间。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 增亮图像增强示例 from numpy import expand_dims from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.preprocessing.image import ImageDataGenerator from matplotlib import pyplot # 加载图像 img = load_img('bird.jpg') # 转换为numpy数组 data = img_to_array(img) # 将维度扩展到单个样本 samples = expand_dims(data, 0) # 创建图像数据增强生成器 datagen = ImageDataGenerator(brightness_range=[0.2,1.0]) # 准备迭代器 it = datagen.flow(samples, batch_size=1) # 生成样本并绘图 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 生成一批图像 batch = it.next() # 转换为无符号整数以供查看 image = batch[0].astype('uint8') # 绘制原始像素数据 pyplot.imshow(image) # 显示图 pyplot.show() |
运行示例显示了应用了不同程度的变暗的增强图像。
随机亮度增强生成的图像图
随机缩放增强
缩放增强会随机放大图像,并分别在图像周围添加新像素值或插值像素值。
图像缩放可以通过 ImageDataGenerator 构造函数中的 zoom_range 参数进行配置。您可以将缩放百分比指定为单个浮点数或指定为数组或元组。
如果指定一个浮点数,则缩放范围将为 [1-值, 1+值]。例如,如果您指定 0.3,则范围将为 [0.7, 1.3],即介于 70%(放大)和 130%(缩小)之间。
缩放量是从每个维度(宽度、高度)的缩放区域中均匀随机采样的。
缩放可能感觉不直观。请注意,小于 1.0 的缩放值将放大图像,例如 [0.5,0.5] 使图像中的对象放大 50% 或更近,而大于 1.0 的值将缩小图像 50%,例如 [1.5, 1.5] 使图像中的对象更小或更远。缩放 [1.0,1.0] 没有效果。
以下示例演示了放大图像,例如使照片中的对象变大。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 缩放图像增强示例 from numpy import expand_dims from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.preprocessing.image import ImageDataGenerator from matplotlib import pyplot # 加载图像 img = load_img('bird.jpg') # 转换为numpy数组 data = img_to_array(img) # 将维度扩展到单个样本 samples = expand_dims(data, 0) # 创建图像数据增强生成器 datagen = ImageDataGenerator(zoom_range=[0.5,1.0]) # 准备迭代器 it = datagen.flow(samples, batch_size=1) # 生成样本并绘图 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 生成一批图像 batch = it.next() # 转换为无符号整数以供查看 image = batch[0].astype('uint8') # 绘制原始像素数据 pyplot.imshow(image) # 显示图 pyplot.show() |
运行示例会生成放大图像的示例,显示了随机放大,在宽度和高度维度上都不同,这也随机改变了图像中对象的纵横比。
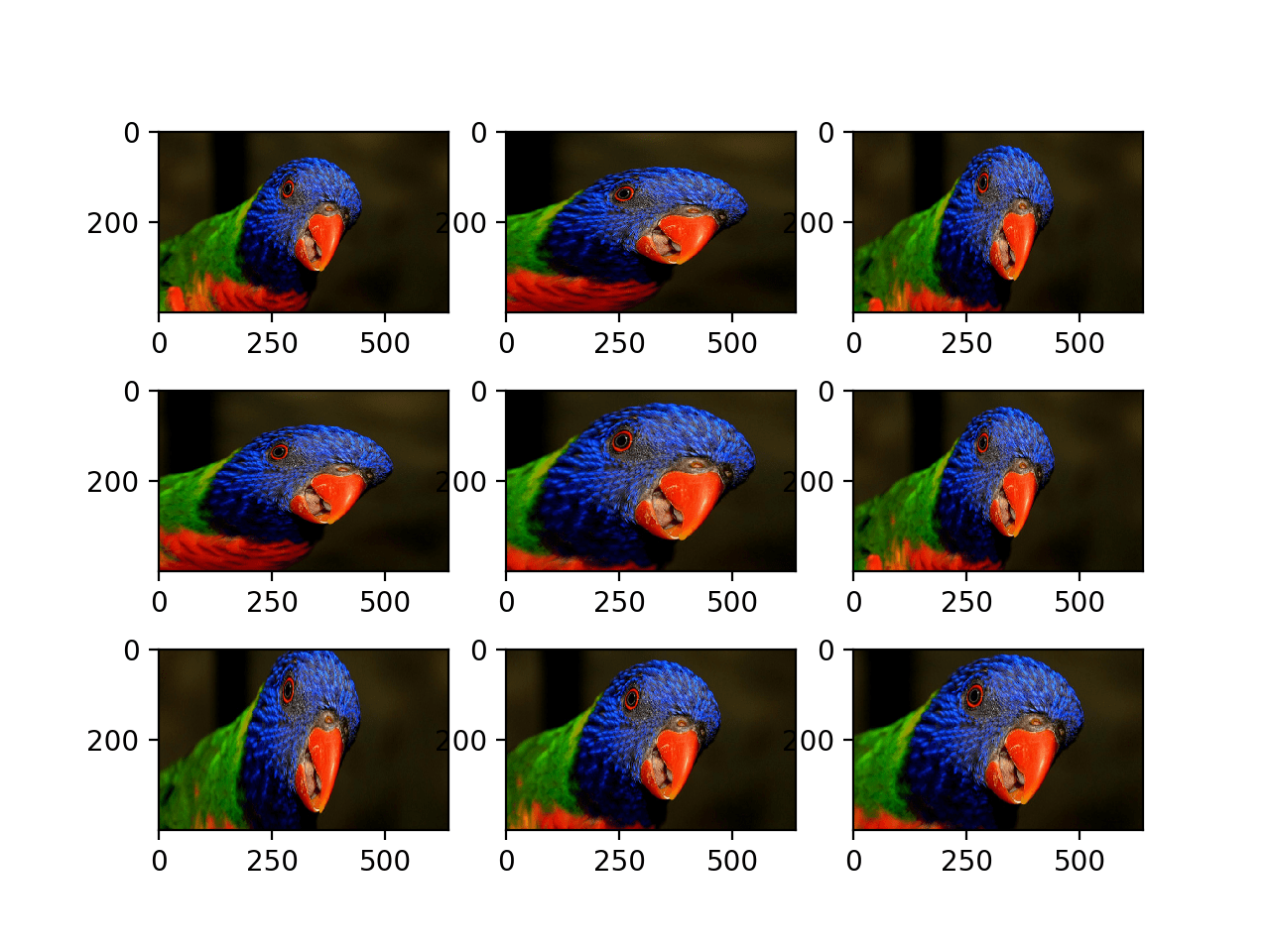
随机缩放增强生成的图像图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
API
文章
总结
在本教程中,您学习了如何在训练深度学习神经网络时使用图像数据增强。
具体来说,你学到了:
- 图像数据增强用于扩展训练数据集,以提高模型的性能和泛化能力。
- Keras 深度学习库通过 ImageDataGenerator 类支持图像数据增强。
- 如何使用平移、翻转、亮度调节和缩放图像数据增强。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






谢谢您,Jason 先生,
精彩、简洁、精炼的教程。
收到了您的最新书籍(计算机视觉深度学习)。恳请您写一篇关于 CNN + LSTM 的博客。
谢谢你的支持!
我有一些关于 CNN LSTM 的文章,也许可以从这里开始
https://machinelearning.org.cn/cnn-long-short-term-memory-networks/
还有这里
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
非常感谢您提供的精彩教程。但我有一个问题,那就是
我们是否可以在一个对象调用中总结所有技术?我的意思是您在一个数据生成器对象中使用了所有数据增强,因为我看到有些人这样做,但我没有完全理解。
祝好。
很好的问题!
是的,您可以在一个增强配置中使用任何技术。
你好,Jason,解释得非常棒。我真的很喜欢你的博客。我有一个问题……增强技术会减少向 CNN 模型提供训练图像数量的必要性吗?我的意思是,如果我想生成一个用于识别我脸的 CNN 模型,我需要多少训练图像样本?
增强有助于减少训练图像的数量吗?
谢谢!
是的,我希望您可以使用更少的真实示例来训练一个更好或更好的模型。
有没有一种技术或解决方案可以在数据是数字而不是图像时增加我的数据量,谢谢?
是的,这叫做过采样。例如
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
尊敬的先生,
我们是否需要将所有通过图像增强技术生成的图像保存在训练数据集数据中?
不行。
我们如何保存结果??
调用 flow() 时指定保存位置,此处有更多详细信息
https://keras.org.cn/api/preprocessing/image/
嗨 Jason
感谢您精彩的教程和书籍。
我正在使用 Raspberry PI 识别晚上经常出现在我农场的动物。ImageNet 数据集没有单色图像。请告诉我可以在哪里获取此类数据集或廉价但优质的夜视摄像头来构建我自己的数据集。将尝试数据增强方法
ImageNet 模型在提取特征方面仍然非常出色。
也许可以从迁移学习开始,并在您领域特定的图像上调整一些输出层。
Jason,
第一个示例(水平平移图像增强)中的第 22 行出现以下错误:
回溯(最近一次调用)
文件“horizontal_shift_img_gen.py”,第 40 行,在
batch = it.next()
文件“C:\Anaconda3\envs\python\lib\site-packages\keras\preprocessing\image.py”,第 809 行,在 next 中
x = self.image_data_generator.random_transform(x.astype(K.floatx()))
文件“C:\Anaconda3\envs\python\lib\site-packages\keras\preprocessing\image.py”,第 556 行,在 random_transform 中
ty = np.random.uniform(-self.width_shift_range, self.width_shift_range) * x.shape[img_col_axis]
TypeError: bad operand type for unary -: ‘list’
很抱歉听到这个消息,您能确认您的 Keras 版本是最新的吗?
例如 2.2.4 或更高版本?
感谢这篇文章!!
我有一个问题,如果我们向 ImageDataGenerator 传递多个方法,例如
ImageDataGenerator(rotation_range=60,vertical_flip=True)。
顺序重要吗?
不。我认为顺序是固定的并且在内部定义的。
你好,
感谢您的本教程!我目前正在开发用于图像分割的 CNN,但我没有很多数据,这就是为什么我想进行数据增强。但是我有点困惑,增强应该在哪些数据上进行。只在训练集上吗?还是在训练集和验证集上?
在您的帖子中,您说应该只在训练集上进行,但您能解释一下为什么吗?
验证集上的数据增强会负面影响准确性吗?
感谢您的帮助,
亚历山德拉
仅在训练数据集上,因为您正在提供更多数据来训练模型,而不是评估模型。
用于测试集的数据增强可能会导致对模型技能的评估存在偏差。
亲爱的Jason
一如既往的优秀文章。
只是一个问题,我们可以使用这些技术来增加时间序列的训练集吗?
如果可以,如何做?
祝好
也许吧。很抱歉我没有示例,我建议研究一下该领域常见的做法。
Jason 教程非常棒。
然而,我很难理解图像通常应该如何开始。我正在做我的本科项目,我正在训练一个模型来识别 3 种类型的枪支,即 AK-47、FN SCAR 和手枪。它们是纯粹的图像,即没有人拿着枪,图像上没有太多背景。我的模型训练得很好,准确率达到 96%,验证准确率达到 94%(Keras 和 TensorFlow)。正如我的导师所期望的那样,它是从头开始的。然而,我的模型无法正确分类人们拿着特定类型枪支的图像。例如,在 2300 张图像中,它错误分类了大约 2000 张。现在我尝试使用 Kaggle 猫狗图像训练一个猫狗模型,它也无法正确分类猫在树上或狗在海滩上周围有人等情况。那么训练和验证图像究竟应该是什么样子,因为我认为 Kaggle 图像是图像应该是什么样子的完美示例??
这个可能会有帮助
https://machinelearning.org.cn/much-training-data-required-machine-learning/
将增强图像保存在训练数据集中然后用于训练是否可以?
是的。
我正在尝试使用 .flow(save_to_dir=””) 保存我的增强图像,但它不工作,我在文件夹中没有看到任何图像。有没有不同的方法来指定桌面上的文件夹作为接收文件夹?
很抱歉您遇到问题,也许这些技巧会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
尝试指定所有这些参数,看看图像是否已保存
save_to_dir=”/content/gdrive/MyDrive/StanfordCarsDataset/ResnetAugmented”,
save_prefix='ResnetAugmented',
save_format='jpg',
嗨,Jason,
我的图像增亮方面有一个问题,即当我尝试将图像保存到我的目录时,它显示没有任何变化,而使用“pyplot.imshow()”显示时按预期工作。
期待您的有利回复,谢谢。
也许再次检查您是否正在保存正确的图像?
你好,我似乎也遇到了同样的问题,你解决了吗?
一如既往的精彩文章。我有一个关于这句话的问题
“或者,可以为位于磁盘上指定目录中的图像数据集创建迭代器,其中该目录中的图像根据其类别组织到子目录中。”
为了简单起见,假设有 52 个子目录,每个目录中都有一张扑克牌的图像。我想为每张牌创建增强的训练图像。
1. 这种子目录结构是最好的方法吗?
2. 如果是,如何自动化处理每个子目录中的图像?
好问题,我在这篇文章中展示了如何操作
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
完美。我现在明白了如何从目录加载图像。我想我可能卡在了图像增强部分。根据我上面的例子,我只有 52 个类别中的每个类别的一张图像。在这种情况下,它是每张扑克牌的原始艺术作品。寻找这些牌的额外图像很难,因为它们很稀有。因此,我的想法是为训练集甚至验证集生成我自己的图像。对于测试集,我设想使用我的手机摄像头或网络摄像头。有几件事我不明白。或者也许只是一件事。
1. 看来这些图像是即时生成的。有没有办法存储它们,或者它们是否应该存储以备将来使用?
2. 训练完成后如何保存模型?
是的,您可以存储生成的图像。请参阅 flow() 函数上的 save_to_dir 参数。
您可以通过调用 model.save() 来保存训练好的模型,此处有更多信息
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
谢谢!您认为使用相机或网络摄像头进行测试有意义吗?或者我也应该为此使用生成的图像?
也许可以原型化这两种方法,看看哪种最适合您的项目或有意义。
使用数据来指导决策。
关于论文中通常引用的随机裁剪 (4+1) 呢?这应该是数据准备阶段的一部分吗?水平/垂直平移可以替代随机裁剪吗?
是的,随机裁剪是一个很好的方法。
平移可以模拟它,有点像。
嗨,Jason,
我们如何将此方法用于灰度图像?(形状:124,95)当我尝试时,我收到一个错误
raise TypeError(“Invalid dimensions for image data”)
TypeError: 图像数据维度无效
您必须将每个灰度图像的二维矩阵更改为具有 1 个通道的三维矩阵。
您可以使用 expand_dims() numpy 函数。
你好 Jason,我可以将这些图像保存为数组或数据帧用于深度学习吗?
是的,有一个配置选项可以将增强图像保存到文件中。
Jason,您能解释一下如何使用配置来保存图像吗?
祝好,
Yunus
没问题,请参阅此处列出的 flow() 函数的参数
https://keras.org.cn/preprocessing/image/
啊。我需要的一部分!谢谢!
这对于这个新手来说有点令人费解。我得到一个正确显示增强的图,但是当我向 datagen.flow() 添加参数以保存到目录时,我只得到图像的副本。在某些情况下,会应用旋转,但从未应用任何其他转换,例如 brightness_range 或 shear_range。有什么想法吗?
这很令人惊讶,保存的图像应该与 flow() 返回的图像相同——它们是相同的像素数据。
如果不是这种情况,也许您审查案例的方式存在错误,或者 Keras 中存在错误?
这里的一个资源可能会有所帮助
https://machinelearning.org.cn/get-help-with-keras/
Jason,您能解释一下如何生成更多具有细微变化的图像吗?细微之处,我认为可以通过对宽度、高度等参数进行微小调整来实现。但是,我不确定如何将计数(示例中为 9)增加到更高的数字。再次感谢。
祝好
萨曼娜
您可以绘制任意数量的子图,也许可以查看此处的 API
https://matplotlib.net.cn/3.1.0/api/_as_gen/matplotlib.pyplot.subplot.html
又做了一些测试,结果表明所有定位参数都输出了正确的图像(shear_range、zoom_range、rotation_range……等)。我以为问题可能只是通道转换,因为 brightness_range 生成了正确的图,但保存时是相同的图像,但我刚刚尝试了 channel_shift_range,它似乎工作正常。有什么想法吗?
很抱歉,我不知道,也许可以尝试发布到 Keras 用户组?
我有一个困惑。增强数据后,为什么我们不同时在单个训练 epoch 中使用它们,而是随机选择它们。
请帮忙。
如果我们随机选择样本并扰动它们,其想法是所有图像都将在训练过程中被覆盖。
这有帮助吗?
是的,这很有道理,但既然我们现在有更多的训练图像,难道我们不能将它们全部包含在一起并增加每个 epoch 的训练数据量吗?
这基本上就是正在发生的事情。
非常感谢您的快速回复。我仍然很抱歉打扰您,但我仍然会问您这个问题。
例如,假设我最初有 3000 张图像作为训练数据。我发现由于数据不足,模型性能不佳。现在,如果我找到一个包含 6000 张图像的新数据集,那么我将把它放入训练中,并让所有图像都运行通过每个 epoch。我不会在这里进行任何随机选择。
现在,在数据增强的情况下,我们所做的是我们从增强集中随机选择图像,每个 epoch 以保持数据计数为 3000。
所以,我的问题是为什么不将所有增强图像都包含在训练集中并增加训练数据的大小呢?
为什么要每个 epoch 都随机选择呢?
我希望您能理解我的意思。
此外,如果我在这里有什么误解,请纠正我。
我们使用数据增强是因为我们没有足够的数据。
数据增强通过复制图像并以某种方式更改它来工作。
因此,我们不再需要训练数据集中的原始图像,因为我们将有许多不同的原始图像的修改副本。原始图像的内容已经多次贡献到训练数据集中。
这有帮助吗?
您可以通过设置 steps_per_epoch > num_of_samples/batch_size 来实现这一点。但这是否会改善结果,我不太确定!
好建议!
Jason!首先感谢您的教程。不过有几件事需要注意。
1. 我认为 'it = dataset.flow(X, y)' 应该是 'it = datagen.flow(X, y)'。
2. 我们是不是必须先用 'datagen.fit(X_train)' 拟合数据?如果我不这样做,它会抛出一个错误,说图像生成器尚未拟合任何训练数据……
再次感谢,请继续保持。
感谢您的错字。
仅当需要计算统计数据时(例如用于缩放像素的均值/标准差),才需要拟合数据生成器。
尊敬的先生
感谢您的代码和宝贵的图像增强信息。但我将图像保存为九张图像在一张图像中。如何将这九张图像一张一张地分开。
ImageDataGenerator 可以为您做到这一点,请参阅 save_to_directory 参数
https://keras.org.cn/preprocessing/image/
你好,Jason!
我不明白为什么当您说
“steps_per_epoch 参数必须指定构成一个 epoch 的样本批次数量。例如,如果您的原始数据集有 10,000 张图像,并且您的批次大小为 32,那么在增强数据上拟合模型时,steps_per_epoch 的合理值可能是 ceil(10,000/32),即 313 个批次”
您将 steps_per_epoch 设置为 313。这是否意味着在每个 epoch 中,我们训练的数据量与未应用数据增强时相同 (10,000)?
我发现将 step_per_epoch 固定为 64 更合理,因为那意味着我们现在的数据集中有 19200 张图像(考虑到 batch_size 为 32)
非常感谢您的工作!
是的,没错。不确定这为什么是个问题?
如果需要更多训练,请增加 epoch 数量。
我的意思是,在您的示例中,如果我们最终在每个 epoch 中使用相同数量的图像,为什么有必要进行数据增强?
我曾期望数据增强将有助于在每个 epoch 中使用更多数据。
我明白了。好点子。
因为图像每次都不同,这意味着我们可以增加 epoch 数量并拥有“更多数据”。
您好,非常感谢您的帖子——它非常棒,有助于更好地理解增强的工作原理!!!
不过有一个问题——我不确定,我们是不是应该使用 floor 而不是 ceil?
我以为通过指定 steps_per_epoch,我们想跳过最后一个奇数批次。如果是这样,那么我们应该取 312,而不是 313。我的数学计算是
10,000/32 = 312.5,所以我们有 312 个完整的批次,我们应该将其纳入拟合并丢弃剩余的。
ceil(312.5) -> 313
floor(312.5) -> 312
再次感谢您!
是的,你也可以那样做!
在最后一段中,我指的是 600 steps_per_epoch 而不是 64
我希望训练一个 FCNN,即一个给定图像预测掩码的网络。有没有一种方法可以轻松生成训练数据,以便对输入图像和目标掩码应用相同的增强?
为什么不使用 CNN 来实现这一点?
亲爱的 Jason,
非常棒的教程。
您对目标检测的增强有什么看法?
有没有实现?
谢谢。
这将是一个好主意。很抱歉,我没有关于这个主题的教程。
很棒的教程!您知道如何使用 Keras 添加随机噪声吗?
一种可能的方法
keras.layers.GaussianNoise(stddev)
是的,请看这篇文章
https://machinelearning.org.cn/how-to-improve-deep-learning-model-robustness-by-adding-noise/
关于在泛化开始受到影响之前,您的数据应该/可以增强多少,有什么通用规则吗?如果您对数据集中的每个“真实”图像应用随机效果以获得 5-6 张新照片,您是否会降低真实世界测试用例的性能?
据我所知没有。
或许可以对您的项目进行敏感性分析,以发现限制?
嗨,Jason,
感谢您的教程。
如果我们要将原始的未增强图像和增强图像都包含在训练中,模型需要哪行代码?
谢谢。
未增强的图像将被增强图像覆盖——例如,它是数据的超集。
增强不是取代原始图像吗?如果我们想同时包含这些原始图像和增强图像呢?
不,它们被用来代替原始的。
很好的文章,展示了一些 Keras 图像增强的细节!
问题:您能展示一下图像增强带来的学习曲线改进吗?
不幸的是,其中一些增强对鹦鹉的扭曲太大,以至于在某些情况下它看起来不像鹦鹉。
问题:这些特定的自动鹦鹉图像增强在实际评估性能中,是否实际上是适得其反,损害了模型的鹦鹉检测能力?
好问题,这真的取决于模型的选择。
是的,有些不会帮助模型性能。您必须审查增强并选择您认为会提高性能的增强,或者进行测试。
或者查看最佳实践
https://machinelearning.org.cn/best-practices-for-preparing-and-augmenting-image-data-for-convolutional-neural-networks/
到目前为止,我进行的一些(实际上是所有)测试都表明,Keras 图像增强严重损害了验证分数,而不是提高了它,与相同的代码相比。
您可能需要测试您的代码,就像我一样,看看它在验证集上的预测中是否真的如愿以偿。
我目前正在调查增加生成器选项的值是否会
steps_per_epoch=8 与 steps_per_epoch=80(例如)
当使用增强时,实际上会产生有益效果,正如其他人所理论的。
如果不行,那么我就没主意了,Keras 图像增强必须放弃,转而使用其他真正有效的方法,例如我自己手动在 Keras 之外进行所有图像预处理。
使用 80 步训练需要更长时间,例如在 GPU 上训练一个曾经需要 5 分钟的数据集需要 5 小时。
数据增强的选择是针对特定问题的,例如您的图像数据。
也许这里的最佳实践会给您一些想法,了解哪些可能适合您的数据集
https://machinelearning.org.cn/best-practices-for-preparing-and-augmenting-image-data-for-convolutional-neural-networks/
首先,感谢您审阅了文献并总结了在那些著名且成功的深度学习项目中使用过的图像增强技术。我想强调的是,这些研究似乎都没有使用 Keras 图像增强(如果我错了请指正)。它们是在 Keras 发布之前进行的。所以,关键点在于:您是否愿意接受一个君子之约,向我们展示一个可重现的数据集和代码示例,我们可以直接运行使用 Keras 图像增强和不使用 Keras 图像增强两种情况,并且使用增强后的性能在验证集上得到显著提升?需要明确的是:这并不是为了让任何人难堪,也不是为了证明某物不好。我们的目的是建设性地找到一种方法,使 Keras 图像增强能够如预期般工作,并且是可证明和可重现的。它必须在验证性能方面真正起作用,而不仅仅是可视化或查看图像增强效果,而且要在一个可重现的项目中实现。否则,我们需要采用不同的工具集,或者在预处理阶段手动进行。我还没有机会阅读您所有的出版物,所以您可能已经做到了这一点,我只有通过提问才能确定。感谢您的众多出版物。
感谢您的反馈,Geoffrey。我目前正全身心投入一个项目,但将来我可能会准备一些自定义示例。
我在图像分类项目中给出了一些数据增强的示例,也许可以从这里开始
https://machinelearning.org.cn/how-to-develop-a-convolutional-neural-network-to-classify-satellite-photos-of-the-amazon-rainforest/
或者这里
https://machinelearning.org.cn/how-to-develop-a-cnn-from-scratch-for-cifar-10-photo-classification/
至于 Keras 代码的一些最佳实践,我想只有裁剪(crop)是缺失的,我见过一些第三方函数可以插入 ImageDataGenerator 来实现它,也许您可以搜索一下,看看哪个看起来可靠?
感谢这篇精彩的指南!图像增强是在图像调整大小之前还是之后应用?再次感谢。
图像应先调整大小,然后进行增强。
有什么具体原因吗?
这不是强制性的,而是一种效率优化。对较少的像素执行变换效果更好。
先生,您能帮我如何在深度学习中自定义图像吗?
你到底遇到了什么问题?
嘿,Jason!一个问题:我的模型输入一张图像并输出5个数组(热力图)。有没有办法根据每个输入图像接收到的变换来相应地调整输出?谢谢,工作很棒!!
很好的问题!
如果您正在执行平移/缩放等操作,也许您可以将相同的变换应用于输入和输出。不过,我相信您必须手动完成此操作。
我不明白下面这句话的意思。
“steps_per_epoch 参数必须指定构成一个 epoch 的样本批次数量。例如,如果您的原始数据集有 10,000 张图像,并且您的批次大小为 32,那么在增强数据上拟合模型时,steps_per_epoch 的合理值可能是 ceil(10,000/32),即 313 个批次。”
更多关于批次和 epoch 的信息在这里
https://machinelearning.org.cn/difference-between-a-batch-and-an-epoch/
你好 Suraj,
我的理解是,“ImageDataGenerator”每次都会“返回”一个“新图像”,该图像经过旋转、缩放等参数给定的随机变换。
如果您从 10,000 张图像开始,批次大小为 32,steps_per_epoch 参数设置为 10,000/32,那么每个 epoch 您将“遍历”这 10,000 张图像。
在第一个 epoch 中,图像会有一个变换,在第二个 epoch 中,相同的图像会有另一个变换。
因此,在每个 epoch 中,您都在处理一组略微不同的图像。
如果您增加 epoch 的数量,您将处理 10,0000 个新的、略微“不同”的样本。
我说的对吗?
听起来是对的。
我还是不明白一件事!我们如何对这个进行超参数调优,或者默认配置是否可以?我有一个主要使用卷积层的神经网络模型,我正在使用这个图像生成器,但每次都会过拟合。有没有什么可能的原因?我正在尝试避免使用 dropout。
我有一些减少过拟合的建议在这里
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
我们可以用坐标训练我们的卫星图像分类数据集吗?如果可以,机器学习和深度学习分类分别需要多少坐标?
您具体指坐标是什么意思?
卫星图像分类示例是处理图像的,您可以在剪切它们之前根据它们的经纬度定义瓦片/图像,对吗?
嗨,Jason,
我正在做一个图像分割项目,所以我也需要将增强应用到掩码上。我的意思是,当旋转/翻转/平移/缩放图像时,相同的变换也应该应用到相应的掩码上,对吗?但是当我尝试
it = datagen.flow(X, y, batch_size=1) 时,我看到变换只应用于 X,而没有应用于 y 中的掩码。
您有什么解决方案建议吗?
顺便说一句,请注意,并非所有类型的增强都适用于掩码。例如,在亮度增强的情况下,改变掩码的亮度是没有意义的。
谢谢!
好问题。抱歉,我没有保持掩码与增强一致的示例。
也许有一些专门的库可以做到这一点?我没见过,抱歉。
我使用下面的代码将生成的增强图像保存到目录中,
———-
i = 0
for batch in train_generator
i += 1
if i > k: #k=1,2,3…
break
———–
根据 k 的不同值,会在目录中生成并保存不同数量的图像。但是,我找不到它的序列,我的意思是,给定 k 和批次大小,增强图像的数量是多少?它是确定性的还是随机的?
抱歉,我没跟上。或许您可以详细说明一下?
抱歉我的问题不清楚。
请告诉我如何设置目录中生成的增强图像的数量?您提到我们可以生成增强图像并将其保存到目录中,那么,我如何设置要保存到目录中的图像数量?
其次,假设我有 1000 个训练图像样本,通过数据增强,训练过程中会使用多少图像?我期望 1000 个原始图像和 X 个增强图像,X 的值是多少?如果我错了请告诉我。
它们可以作为模型训练过程的一部分自动保存。
如果您想预先生成增强图像,可以编写自己的循环并生成足够的批次示例,直到您满意为止。
对于训练,每个训练步骤都会生成增强图像。您将有足够的增强图像来满足您所需的训练量。您无需预先生成它们——它们是根据训练过程的需要生成的。这样更清楚了吗?
谢谢您的回复,
我明白您的意思,但我想知道在每个步骤中,有多少增强图像会参与训练过程?
正如您所说,“……根据训练过程的需要……”,但是模型是根据什么因素来决定在给定步骤中是否需要数据增强的呢?
所有图像都将进行增强。
每个批次中的每个图像都将进行增强。您可以将批次大小乘以 epoch 数量来确定使用的增强图像数量。
有兴趣使用增强来混合缩放和旋转操作。我需要多次放大,并随着放大过程截取快照,然后将它们全部旋转一个完整周期。这两种方向操作方法可以混合使用吗?如果可以,您能给我一些指导吗?
是的,您可以组合增强,只需使用您希望使用的每个增强的参数即可。
你好先生,
我有个问题
首先,我们可以将imagedatagenerator用于测试集吗?或者我们可以将增强数据用于测试集吗?如果不能,为什么?
其次,imagedatagenerator每次变换会生成多少次增强图像?
谢谢你
通常我们不增强测试集,只增强训练集。
这是因为我们试图创建更多的训练数据,以便更好地拟合模型。
增强功能会随机应用于生成的每张图像。
如果我同时有其他格式的数据(比如文本),我该如何进行图像增强?
您可以尝试文本增强方法,如果存在此类方法的话。
因为鸟的图像是RGB格式,有3个通道,你为什么要用“expand_dims”?
为了添加API所需的“样本”维度。
你好先生,
我目前正在开发一个用于多分类(3个类别)的CNN,但我没有太多数据(每个类别只有100张图像)。我已经将数据分成70%训练集和30%验证集(总共210张训练数据,90张验证数据)。我尝试使用ImageDataGenerator来增强训练数据。最终,我仍然得到很低的验证准确率(0.30)。有什么建议可以提高验证准确率吗?如果需要更多的验证数据,您会推荐多少验证数据?
是的,请参阅此处的建议
https://machinelearning.org.cn/start-here/#better
还有这里
https://machinelearning.org.cn/best-practices-for-preparing-and-augmenting-image-data-for-convolutional-neural-networks/
将图像增强为 3 乘 3 后,如何将其单独保存到磁盘?
教程很有帮助。
您可以配置 imagedatagenerator 直接保存增强图像。或许可以查阅 API。
感谢您的教程。我研究了您关于过采样(如 SMOTE)的另一个教程,我知道它不能用于图像数据。根据您的说法,我可以使用图像数据增强来解决不平衡数据问题。因为我将数据增强技术视为解决小型数据集的一种方法,所以我通常将数据增强应用于所有数据类别。那么,我可以使用特定类别的数据增强来解决不平衡数据问题吗?如果可以,我该怎么做?
万分感谢。您的教程和回答对我帮助很大。
是的,我相信您可以使用图像增强,就像 SMOTE 一样,来对给定类别进行过采样。
我没有示例,但也许您可以使用图像生成器生成许多图像,将它们保存到文件中,然后将子集与您的训练数据一起使用来拟合您的模型。或者尝试类似的方法。
先生,我们可以将数据增强与预训练的 CNN 一起使用吗?
当然可以。
首先,感谢分享这么好的文章。我有一个疑问。如果在以下语句中将 batch_size=2,输出会是什么?
it = datagen.flow(samples, batch_size=1)
我们如何才能看到 batch_size=1 和 batch_size=2 之间的区别?请帮助。
批次大小控制每次调用/生成器返回的图像数量。
感谢您的回答。假设我创建了一个 batch_size=2 的批次,这意味着现在每个批次将有两张图像,如果我想显示每个批次的两张图像怎么办?
例如
iter=datagen.flow(samples,batch_size=2)
让我们只创建一个包含两张图像的批次,如下所示;
for i in range(1)
plt.subplot(120+i+1)
batch=iter.next()
plt.imshow(batch[0].astype(‘uint8’))
当我检查 batch.shape 时,它说只有一张图像。请解释一下,因为我是初学者..
我不知道,您可能需要调试您的代码或发布到 stackoverflow。
我的猜测是您只有一张图像,因为您的迭代只有 1 次 - range(1)。增加 range 的值并增加 subplot 的大小。
嗨,Jason,
感谢您撰写如此精彩的文章。
我想要分类 9 种不同的物体,我的训练数据是不平衡的(某些类别的数据不足),所以我决定重新采样我的数据集。我只想对数据量较少的类别进行重新采样。
我所做的是创建了一个简单的代码来读取这些类别中的图像,然后对它们应用水平翻转和高斯滤波器,然后我将它们保存到我的目录中。
我只使用一个简单的脚本,像下面的代码一样生成和保存图像文件,这使我的数据量翻了三倍。我没有使用 Keras 提供的任何 ImageDataGenerator。您认为我走在正确的轨道上吗?我这样做生成图像可以吗?
directory = ”
for file in os.listdir(directory)
img = cv2.imread(directory + file)
Flip_Horizontal = cv2.flip(img, 1) # 1 表示水平翻转
#现在保存
cv2.imwrite(file + ‘_flip’ + ‘.jpg’, Flip_Horizontal)
不客气。
这听起来是个很棒的方法,做得好!
嗨,Jason,
非常感谢这篇有趣的文章。
我正在进行交通标志检测和识别,我的数据集非常非常不平衡(从 20000 个示例到只有 1 个)。
1. 我没有找到关于是否可以对每个类别应用不同类型增强的信息?
2. 是否有可能在增强后对所有训练示例进行洗牌?如果不能,那么我们会在一个批次中只得到通过少数原始图片转换生成的示例吗?
3. 在检测中,我有坐标标签——边界框。变换后坐标会重新计算吗?还是我应该手动操作?
谢谢!
好建议,希望我将来能做到。
洗牌是增强的一部分。
这是一个棘手的问题。我认为您可能需要数据感知的增强。例如,专门用于对象识别的增强程序,而不是更一般的图像分类。
嗨,Jason,
感谢您的教程。
我正在训练一个深度神经网络并使用数据增强。
有一些方形的医学图像。
您知道在旋转图像时,避免像素丢失的最佳方法是什么吗?
旋转的安全范围是多少?
顺便说一句,我尝试过用“最近邻”填充,但我想知道是否存在其他方法。
好问题。
也许可以尝试几种不同的方法,并评估其对模型性能的影响。
我有一些汽车图像,我的目标是扩展我的训练数据集,我想将新生成的图像和原始图像结合起来,并基于它们训练一个深度神经网络来执行分类任务。
在这篇博客文章中:https://www.pyimagesearch.com/2019/07/08/keras-imagedatagenerator-and-data-augmentation/
“Keras ImageDataGenerator 类不是一个‘加法’操作。它不会获取原始数据,对其进行随机转换,然后返回原始数据和转换后的数据。”
您会建议哪种方法来扩展数据集?
从增强开始,看看它能带你多远。
您所说的增强是指
方法1:数据集生成并扩展现有数据集,还是
方法2:即时图像增强或示例
基本上,当我们希望确保我们的网络在训练的每个 epoch 中都能看到数据的新变化时,我们可以使用即时图像增强。
我不认为这有助于平衡我们的数据集。我可能可以使用方法1来平衡我们的数据集:数据集生成并扩展现有数据集。
这样,我们的“假”图像将形成一个增强的训练集,与我们的真实世界数据一起使用。
请看一下这个网站的数据集部分,他们也为我的数据集做了类似的事情
https://www.aicitychallenge.org/2020-data-and-evaluation/
您认为方法1是一个好方法吗?我很少见到有人这样做。
如果增强足够激进,您也许可以使用它来平衡数据集。
抱歉,我没有能力阅读和评论您的链接。
图像增强后,我如何知道数据集的大小?
谢谢
它是无限大的。
焦点转移到只要模型继续改进就一直训练。
先生,你好
我们如何在训练前保存增强图像?
我正在处理图像分类问题,每个类别的图像数量不同。
我想生成一些增强图像,以便每个类别的图像数量相同,然后我将在原始图像和增强图像组成的更大数据集上训练我的 CNN 模型。
好问题。
您可以配置图像增强并将其设置为将图像保存到文件中,然后手动循环遍历生成器。之后再加载这些图像并用它们来训练模型。
请您解释一下如何在循环中手动枚举生成器。在这种情况下,我们如何使用新数据集和旧数据集进行训练?我们是分别训练,也就是说先用原始数据集训练,然后再用新的增强数据集训练?还是将所有两个数据集放在一个文件夹中进行训练?
提前感谢
我们不会在旧数据集和新数据集上进行训练,只在增强数据集上进行训练,因为它是原始数据集的超集。
是的,博客上有很多示例,使用博客搜索可以看到深度学习中如何使用增强的示例。
嗨 Jason
感谢您的知识分享。
您能否提供关于如何将所有这些增强方法与自定义数据生成器一起使用的指导。在我的项目中,我没有使用内置的 ImageDataGenerator 类。相反,我通过继承 keras.utils.sequence 类创建了自定义数据生成器。我不想通过在代码中编写所有这些方法然后将它们应用于批次来使代码冗长。您能建议一种更好的方法来直接从 keras 访问这些预存在的方法以供我使用吗?
谢谢,
不客气。
或许可以直接查看 Keras 源代码,了解这些方法的实现方式?
@Jason Brownie
除了图像之外,还有哪些数据集的数据增强技术?比如我有一个包含 134 个疾病实例的数据集。我如何增强数据集并合成增加实例?
你可以对表格数据使用 SMOTE
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
我对增强有点困惑。如果我将所有增强技术一起使用在 Keras 的 ImageDataGenerator 中,那么这些技术是全部应用于一张图像,还是单独应用于图像?
例如,如果我对一张图像使用 5 种技术,增强后会生成 5 张图像吗?
它们都应用于每张图像。
即使在评论区也有很多信息。感谢您不断回答所有评论中的问题。
在这种情况下我有点困惑
如果我正在对图像增强应用 5 种不同的技术,例如旋转、宽度平移、高度平移、剪切、水平翻转
那么每张图像都应用了这 5 种技术吗?
如果是,当我们一次对图像应用更多技术时,图像不会变形吗?
不客气。
正确。
是的,这有可能。增强是一门艺术。
在使用您的增强进行建模之前,请务必审查其效果,以确保其合理。
感谢您的教程!
不客气!
对于医学图像,例如 X 射线图像和 CT 扫描数据,翻转、旋转和剪切因子有什么标准吗?谢谢
也许有,您可以查阅相关文献。
你好,谢谢你。这很有帮助。
我想对我的数据集进行一些图像增强。只有 800 张图像,所以我需要更多。但是,我还想为这个新生成的数据集创建新的目标(标签),我该如何做到?
谢谢!
修改后的输入图像版本将与原始图像具有相同的目标。imagedatagenerator 会为您完成此操作。
谢谢你的及时回复,Jason。最后一个问题。
我有一些质量不佳的图像。你建议使用什么预处理方法来应对图像质量不佳的问题(去噪、色彩饱和度或图像增强)?
如果建议使用不止一种方法,应该先进行哪种?我的意思是,它们应该以什么顺序在图像上实现。
CNN 的权衡是什么?
非常感谢。
好问题,或许可以尝试一些方法,例如标准化、归一化、白化、缩放大小等,看看哪种方法效果最好。
你好 Jason,请您帮我解决这个问题。
我尝试对我的目标标签进行数据增强,但我收到此错误。“
ValueError: `x` (图像张量) 和 `y` (标签) 的长度应相同。发现:x.shape = (1, 192, 192, 3),y.shape = (560,)”
我的目标标签不是图像,只是一个 NumPy 数组,包含我的类别。那么,我如何将其转换为一个 4 维数组,使其与我的图像具有相同的长度,以便进行增强?
提前感谢
抱歉,原因不明显。也许您可以尝试将您的代码和错误发布到 stackoverflow。
精彩的教程!
一旦我增强了图像,有没有办法将图像分成9张单独的图像用于图像训练?我不是 Python 专家,真的不想复制粘贴图像数百次。
Branden,您具体是什么意思?
例如,您不需要这样做,因为您可以直接使用 imagedatagenerator 来训练您的模型。
啊,我正尝试将图像输入 Azure Computer Vision,这需要单个图像。
您可以手动运行增强过程,并将其配置为将图像保存到文件中。
感谢您的详细信息。我也喜欢这篇文章 [Keras 亮度范围:使用 ImageDataGenerator 进行数据增强][1]
[1]: https://www.datasciencelearner.com/python-zip_longest-function-implementation/
感谢分享。
这是一篇很棒的文章,帮助我在自己的项目中实现了数据增强。但是,有没有办法使用 Keras 或 TensorFlow2.0 将高斯模糊作为预处理技术?我必须在 ImageDataGenerator 中实现高斯模糊,还是专门为模糊技术创建一个 depthwiseconv2D 层?
谢谢!
抱歉,我一时不确定。
你能给我解释一下你为什么选择 330 + 1 + i 的子图吗?
我试过其他数字,但不太明白为什么 330 效果很好。
谢谢!
那是 subplot() 的旧格式,与行和列有关。
API 现在已经更改,并且简单得多,例如 subplot(rows, cols, current_index)
https://matplotlib.net.cn/3.3.2/api/_as_gen/matplotlib.pyplot.subplot.html
你好 Jason,感谢您的详细示例和解释,但您有 R 语言的示例吗?至少我们这些使用 R 的人应该能够受益于您的专业知识。
抱歉,我没有 R 语言中深度学习的示例。
我们如何对 3D 图像进行数据增强 [输入大小: 128,144,128],它会报错 “不支持的通道 128”
抱歉,我没有“3D 图像”的经验。
你好 Jason,
我想指定一个我希望图像旋转的特定角度——[15, 30, 45, 60, 75, 90],而不是让它在 -90 到 90 之间随机选择。我该怎么做?
另外,我能否实现水平或垂直翻转功能,使其翻转所有传递给它的图像,而不是随机选择是否翻转?
您可以在使用增强之前手动进行。
或许使用标准的图像预处理工具
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
感谢您的文章。我想问您是否了解任何关于当您有子类和它们的超类时使用 CNN 的资源。例如,猫与狗及其物种。
也许可以使用模型层次结构,一个用于顶层,一个用于每个子层。
谢谢你。你知道有没有实现这种模型的示例代码或书籍吗?
抱歉,我没有。
好建议,谢谢。也许我将来会准备一个关于这个的教程。
谢谢您,Brownlee 博士——内容很棒。看起来 Keras ImageDataGenerator (IDG) 是从指定范围内随机抽取并应用值,无论是亮度还是旋转等。情况确实如此吗?根据您的经验,它会产生更好的数据集吗?
不客气。
正确。
在某些问题上它可能很有帮助,也许您可以尝试一下并查看它对您的预测问题的影响。
谢谢。是的,我会尝试一下。我也看到那9张imshow图像与我 save_to_dir 的图像不尽相同。无论如何——随机生成是很不错的——你只需要设置边界就可以完成!很棒的东西——真的。
谢谢。
嗨,Jason,
我对我的数据集使用 ImageDataGenerator 进行数据增强,我想保存增强后的图像,我在 flow_from_directory 方法中选择了保存目录的名称,但当我检查文件夹时,里面什么都没有保存。
我只是想确认数据增强对我是否有效。
请问,您知道原因是什么以及为什么它不保存图像吗?
谢谢你
抱歉,我不知道为什么您的图片没有保存,或许您可以查看 API 以确认您配置正确。
你好 jason,
请问我有一个关于预处理的问题。我知道图像增强被认为是一种预处理技术,从你的代码中我可以看到你使用了 Keras 的 ImageDataGenerator 函数,它会随机旋转、翻转和移动数据集图像,但它会提取特征吗?提取了哪些特征以及为什么?
请原谅我的问题可能听起来很愚蠢,我是一个新手。
谢谢你
数据增强不会提取特征。它只是创建更多与训练集图像相似的图像,以便我们能更好地训练模型。
先生,如果我们将用于目标检测的数据集图像进行增强(翻转、旋转等),这是否意味着我们需要为数据增强过程创建的每张新图像创建新的 xml 文件(用于注释),还是 xml 文件会自动生成?
是的,如果图像发生了变化,那么注释也可能需要更改——如果图像中对象的位置移动了。
我正在研究用于目标检测的增强技术,但我想知道是将其作为模型输入之前应用增强还是在训练期间应用更有效。
它们是同一件事——效果相同。使用您最舒服的方法。
先生您好,这篇文章真的很有帮助。我现在正在研究一个 X 光图像分类器。我总共使用了 6 个不同的类别,由于 X 光数据较少,我使用了 6 种不同的“图像增强”技术。最初,我的训练文件夹中有 13,000 张图像。所以我的问题是,在执行完“图像增强”技术后,我能否知道每个类别有多少张图像或总共的图像数量?
如果您能回答我这个问题,将会有很大的帮助,谢谢 🙂
增强过程中会有无限数量的图像。也许我不理解您的问题?
嗨,Jason,
感谢这篇好文章。我有一个关于图像预处理的问题。
我有一个像素格式的图像数据,我正在通过 ImageGenerator 函数增强像素数据。
我应该在增强之前还是之后重新缩放和归一化数据?它会对性能产生任何影响吗?什么是最好的方法?
谢谢你!
不客气。
您可以将像素数据作为增强的一部分(之前)进行缩放。这有助于模型,并且不会影响增强过程。
嗨,Jason,
感谢您的回复。将图像像素数据除以 255.0 以使其范围在 [0,1] 内与最小-最大归一化相同,只是名称不同吗?我说的对吗?
谢谢!
同样的事情,同样的名称。我们正在归一化(缩放)像素值。
嗨,Jason,
如果我这样使用 train_datagen = ImageDataGenerator(),没有任何预处理和增强,那么我的模型收敛更快,并给出比 train_datagen = ImageDataGenerator(rescale=1./255) 更高的准确率。这正常吗?还是我做错了什么。但是如果不对图像进行重新缩放,当我尝试显示图像时,它会显示所有图像都在一个白色框中,看不到任何内容。我做错了什么?
谢谢!
当然,有时数据增强并没有帮助。
非常感谢您的出色教程和书籍。
先生,我有一个问题,我想在 preprocessing_function(datagenerator) 上进行自适应阈值(使用 opencv),但函数无效,我如何在 imagae.datagenerator 上应用自适应阈值、模糊图像等方法。
谢谢您,先生
您可能需要编写自定义代码。
非常感谢您的教程。
我有一个问题,如果我每张图像只有一个边界框,我如何根据图像所做的更改来修改这个边界框?
例如,对于旋转,我如何获得旋转矩阵来改变我的边界框?
谢谢先生。
不客气。
好问题,您可能需要使用了解您的边界框的数据增强实现/库。
嗨,Jason,
非常感谢您的教程。剪切(shear)是一种平移变换吗?正如我们将缩放(zoom)称为缩放(scaling)一样。我们能把剪切(shear)称为平移变换吗?如果剪切(shear)是一种平移变换,那么高度和宽度平移(height and width shifts)又是什么呢?
这将是很大的帮助!!
谢谢!
我想是的。
Browniee 先生,写得真好!!我有一个小问题,是关于深度学习工具包 (DLTK) 的……我们可以在 ImageDataGenerator 中使用 DLTK 的数据增强和数据归一化技术吗?
抱歉,我对“DLTK”不熟悉。
没关系。谢谢你的尝试!
你好,先生,我在 Colab Google 上运行了这个
# 增亮图像增强示例
来自 numpy 导入 expand_dims
来自 keras.preprocessing.image 导入 load_img
来自 keras.preprocessing.image 导入 img_to_array
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
# 加载图像
img = load_img(‘bird.jpg’)
# 转换为numpy数组
数据 = img_to_array(img)
# 将维度扩展到单个样本
样本 = expand_dims(数据, 0)
# 创建图像数据增强生成器
datagen = ImageDataGenerator(brightness_range=[0.2,1.0])
# 准备迭代器
it = datagen.flow(samples, batch_size=1)
# 生成样本并绘图
for i in range(9)
# 定义子图
pyplot.subplot(330 + 1 + i)
# 生成图像批次
batch = it.next()
# 转换为无符号整数以便查看
图像 = 批次[0].astype(‘uint8’)
# 绘制原始像素数据
pyplot.imshow(图像)
# 显示图
pyplot.show()
它说“IndentationError: expected an indented block”
我是 CNN 深度学习的新手,请问如何解决这个问题?
这将帮助您正确复制代码
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
谢谢,先生,解决了
干得好!
嗨,Jason,
今天我使用 Google Colabs 逐步完成了您的教程,没有遇到任何问题。教程很棒,解释得很清楚。感谢您的发布。你太棒了!!
谢谢!
你好,
这正是我一直在寻找的,但是如何将原始数据和增强数据结合起来训练最终的分类 CNN。这会导致训练 x = 2.训练 Y(例如:训练 x = 2000,训练 y = 1000),而 CNN 不能接受输入变量数量不一致的情况
如果你是指将图像并排放置,那么你是正确的。如果你的输入形状改变了,模型就不能使用了。如果你是指通过数据增强来生成更多的输入数据(即图像),你并没有改变输入变量,只是在数据集中获得了更多的样本。
你好,
我们知道输入数据样本必须组合起来进行分类。那么添加特征呢?我是指将原始数据和增强数据附加到特征轴(像素,(fo+fa))上,其中 fo 是原始特征,fa 是增强特征。这样做有意义吗?
不确定你为什么要那样做。数据增强是为了稍微扭曲图像,以便机器学习模型能够同样识别轻微修改后的图像。
这很有道理。我能想到一个例子,fo 是原始图像,fa 是 Sobel 边缘检测后的图像。但这样做就像对输入进行预处理。然后你完成一个这样的模型,在预测步骤中,你也需要对所有输入进行相同的预处理。
你好,
例如,当我们在图像分类中使用 CNN 并且我们有 10 个类别时,但是每个类别中的样本数量存在很大差异。
例如,某些类别包含 1000 个样本,而其他类别包含 200 个,正如我们所知,在这种情况下,算法会因为这种差异而产生偏差,所以问题是:数据增强是仅应用于这些小类别(样本数量少)以实现某种平衡,还是应用于所有类别并平等地增加类别样本?
谢谢你
是的。或者,200 个样本就足够了,那么你可以将 1000 个样本的类别欠采样到 200 个(即从 1000 个中选择 200 个),然后应用数据增强。
嗨 Jason
感谢这篇精彩的帖子,我有一个不平衡的数据集,包含图像如下:
类别 0 724
类别 1 1084
类别 2 492
类别 3 818
类别 4 352
训练好的 CNN 将所有内容都分类为类别 1,我应该采用什么方法?
嗨 Akshenndra…以下内容可能有助于您提高分类模型的准确性
https://machinelearning.org.cn/failure-of-accuracy-for-imbalanced-class-distributions/
你好,
我对我现有的数据库进行了数据增强,以获得平衡数据。因为原始数据库的数据不平衡(例如:类别 1:60 张图像,类别 2:2999 张…)。
然后我构建了一个分类器来评估平衡数据和不平衡数据的性能。当我使用不平衡数据时,我得到了很高的准确率(98%),但在混淆矩阵中,数据量低的类别的表现不佳。然而,使用平衡数据时,模型准确率较低(约 80%),但混淆矩阵给出了所有类别几乎相等的性能。
我不知道如何比较这些结果,以及应该将哪个视为我的数据库的最佳分类器??你觉得呢?
你好,我如何在 ImageDataGenerator 中添加多个 preprocessing_functions?