使用 Stable Diffusion Web UI 启动可以一键完成。之后,您可以从浏览器控制图像生成流程。该流程包含许多活动部分,并且在某种程度上都非常重要。要有效地命令 Stable Diffusion 生成图像,您应该能够识别浏览器中的小部件并了解它们的功能。在这篇文章中,您将了解 Stable Diffusion Web UI 中的许多组件以及它们如何影响您创建的图像。
通过我的书 《掌握 Stable Diffusion 数字艺术》开启您的项目。它提供了带有工作代码的自学教程。
让我们开始吧。

如何使用Stable Diffusion Web UI创建图像
照片由 Kelly Sikkema 拍摄。部分权利保留。
概述
本帖共分为四个部分:
- 启动 Web UI
- txt2img 选项卡
- img2img 选项卡
- 其他功能
启动 Web UI
在准备好 Python 环境、下载 web UI 代码并将模型检查点存储在适当的目录后,您可以使用以下命令启动 web UI:
|
1 |
./webui.sh |
通过编辑 webui-user.sh 中的变量可以自定义 web UI。一个例子是允许 web UI 服务器在一台计算机上运行,而您从另一台计算机启动浏览器。为此,您需要将以下行添加到 webui-user.sh 以允许通过网络访问服务器:
|
1 |
export COMMANDLINE_ARGS="--listen" |
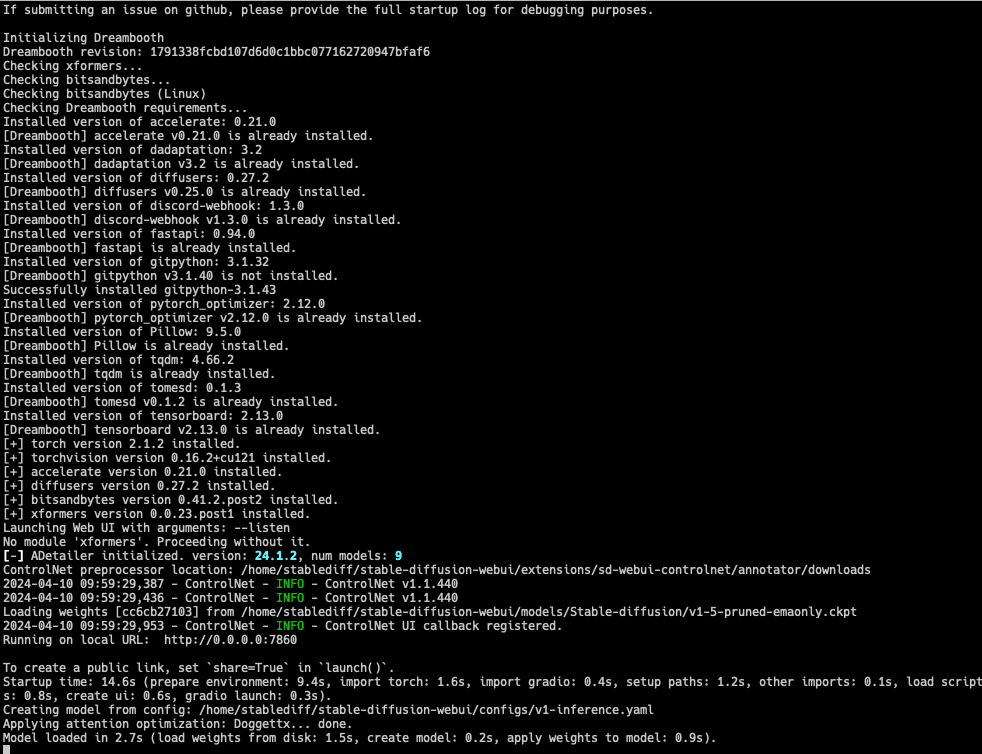
运行 ./webui.sh 将启动 Stable Diffusion 服务器。
默认情况下,命令 ./webui.sh 将在端口 7860 上启动服务器,您可以通过浏览器访问它。如果您从桌面运行,可以使用 URL http://127.0.0.1:7860;但如果从另一台计算机运行,则需要使用该计算机的 IP 地址而不是 127.0.0.1。您的浏览器应显示类似以下的 UI:
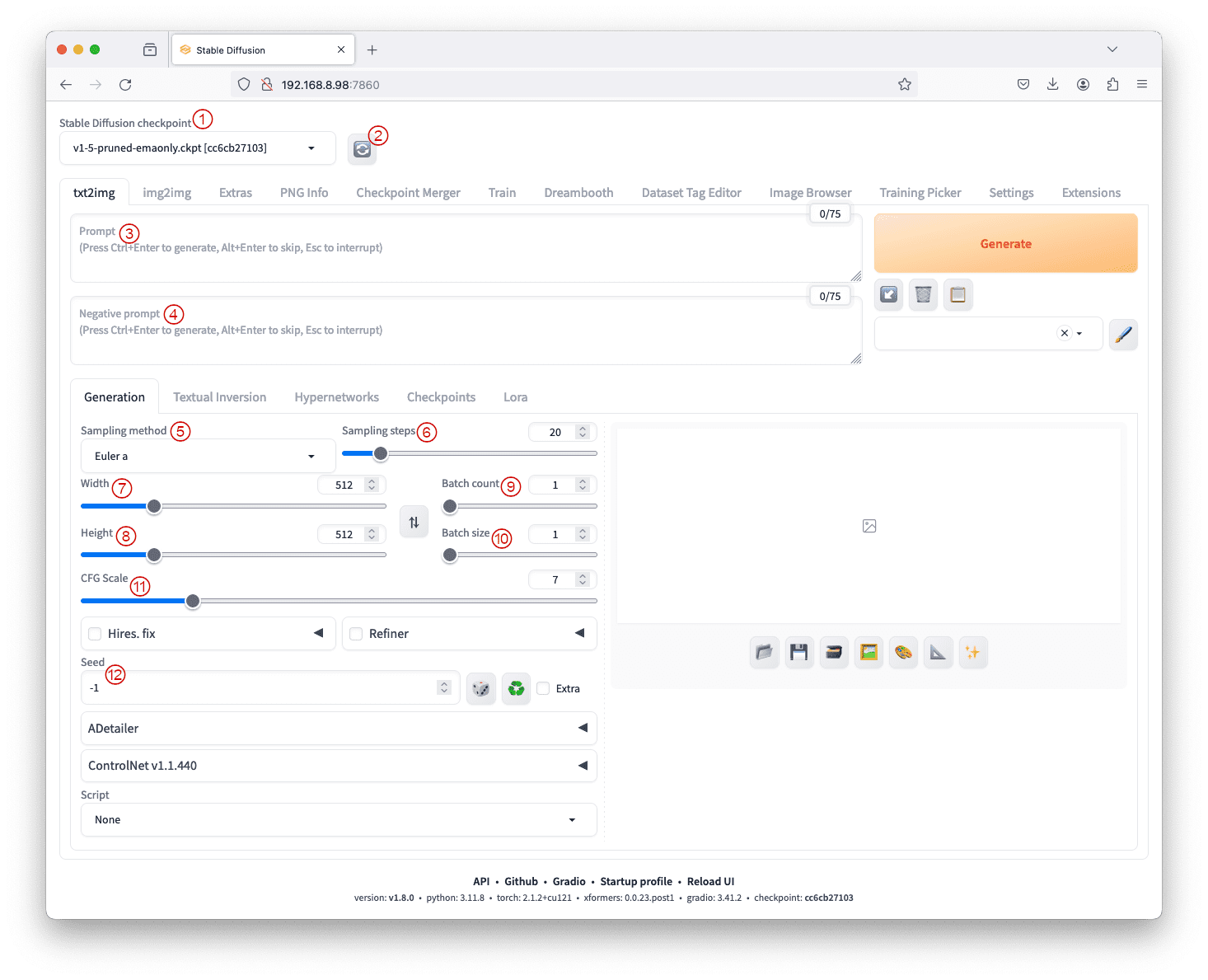
Stable Diffusion Web UI
在左上角,您可以看到一个下拉框用于选择检查点。检查点提供不同的绘画风格,例如更逼真的照片或更像卡通。您可以将多个检查点存储在模型目录中,但只有一个用于流程。在下拉框下方,有多个“选项卡”,您可以以不同的方式生成图像。每个选项卡都有不同的控件集。其中大部分用于为生成流程提供参数。
让我们了解一下有哪些旋钮和参数可用于生成所需的图像。这些参数共同作用,帮助将算法引导到正确的方向。
txt2img 选项卡
UI 的启动页面显示 txt2img 选项卡 — Stable Diffusion 将文本提示转换为图像的基础功能。顾名思义,这允许我们通过文本向算法描述我们想要或不想要的图像,算法将其转换为嵌入向量以生成图像。参考上图,您拥有如下解释的控件:
- 检查点,标记为 ①。此下拉菜单允许我们选择模型。确保模型文件放置在正确的文件夹中,如模型安装指南(上一章介绍)中所述。可以在 https://civitai.com/ 上找到大量的检查点和 safetensors。
- 刷新按钮,标记为 ②。位于检查点下拉框旁边,此按钮用于更新可用模型的列表。如果您将新模型添加到检查点文件夹但不想重新启动 web UI 服务器,可以使用它来刷新列表。
- 提示文本框,标记为 ③。这是期望图像描述所在的位置。提供详细具体的提示(将在下一篇文章中详细介绍)以及关键词,可以增强生成过程。
- 负面提示文本框,标记为 ④。对于使用 v2 模型,此选项是可选但重要的,负面提示有助于指定图像中不应包含的内容。总的来说,我们不想要的内容不太具体,并且可以为许多用例保存。
- 采样方法和步数,分别标记为 ⑤ 和 ⑥。第一个扩散算法需要一百多步才能创建图像,但我们找到了加快速度的方法。这些参数决定了去噪过程算法和采样步数。采样方法的选择会影响速度和质量之间的平衡。
为了平衡速度、质量和良好的收敛性,DPM++ 2M Karras 配合 20-30 步或 UniPC 配合 20-30 步是一些不错的选择。另一方面,DPM++ SDE Karras 配合 10-15 步或 DDIM 配合 10-15 步提供最佳的图像质量,但收敛速度较慢。 - 宽度和高度,分别标记为 ⑦ 和 ⑧。它们指定输出图像的大小,确保与所选模型兼容。通常建议根据是否使用 v1 或 v2 模型进行调整。通常保持默认的 512×512 像素,只有在想要不同的宽高比时才更改。
- 批次数量和大小,分别标记为 ⑨ 和 ⑩。这些设置控制图像生成流程的运行次数以及每次运行生成的图像数量。批次大小是指单次生成生成的图像数量。批次数量是指生成的次数。
建议使用一个批次大小和较高的批次数量,以最少的峰值资源消耗生成多个高分辨率图像。虽然速度较慢,但图像质量比仅运行 512×512 图像的批次要高得多。
由于图像生成是一个随机过程,通过分批生成多个图像可以让您从多个结果中选择最佳结果。 - 无分类器自由引导尺度,标记为 ⑪。无分类器自由引导 (CFG) 尺度参数允许我们控制模型在多大程度上遵循提示,范围从几乎忽略它(值为 1)到严格遵循它(值为 30)。说极端情况,非常低的 CFG 分数意味着提示几乎被忽略,生成的图像是随机的。这可能不符合使用 txt2img 的目的。另一方面,较高的 CFG 值会迫使系统遵循提示,但可能会扭曲图像本身。这类似于提示的过拟合。
- 随机种子,标记为 ⑫。种子值影响潜在空间中的初始随机张量,控制图像的内容。固定种子有助于在调整提示时保持可重复性。
您可以通过在提示框中描述您想要生成的内容(除非您替换了默认的嵌入模型,否则为英语),来尝试一下。设置好这些并点击右上角的“生成”按钮后,您可以看到 Stable Diffusion 模型逐渐为您创建图像。下面是提示“一个外星人在丛林中探险”的示例,所有其他参数均为默认值。

如上所述,生成的图像尺寸由宽度和高度参数指定。如果您需要比这更大的图像,可以勾选“Hires. fix”(高分辨率修复)框,然后单击三角形展开框以获取更多选项。
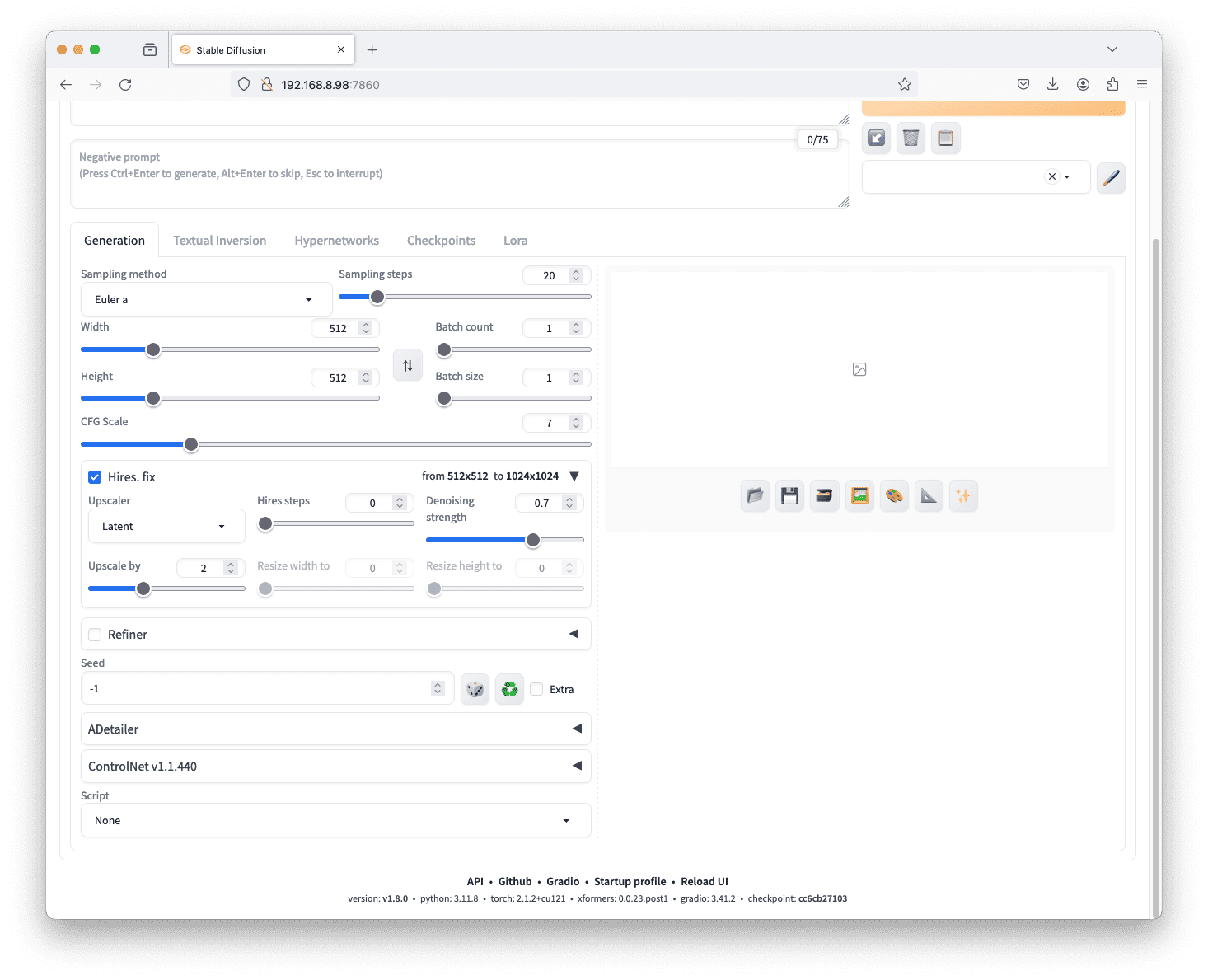
“Hires. fix”下的参数
这会将一个超分辨率深度学习模型应用于 Stable Diffusion 的输出。它解决了 Stable Diffusion 的原生分辨率限制,为在较小尺寸下生成的图像提供了放大功能。我们可以从各种放大和调整参数中进行选择,例如“放大倍数”(图像宽度和高度的倍数)以获得所需结果。
通常建议从批次中选择最佳图像,然后从 img2img 选项卡调整大小以放大分辨率,而不是直接要求 Stable Diffusion 模型生成巨幅输出。
img2img 选项卡
在 txt2img 选项卡旁边,img2img 选项卡是用户利用图像到图像功能的地方。常见用途包括图像修复、草图绘制以及将一个图像转换为另一个图像。
虽然仍然可以看到提示和负面提示文本框,但 img2img 选项卡允许用户执行图像到图像的转换。典型过程包括:
- 将基础图像拖放到“生成”部分下的 img2img 子选项卡中。
- 调整宽度或高度以保持新图像的宽高比。
- 设置采样方法、采样步数和批次大小。
- 为新图像编写提示。
- 按“生成”按钮创建图像,并调整去噪强度。
- img2img 选项卡中的其他参数包括调整大小模式和去噪强度,它们控制图像在转换过程中变化的程度。
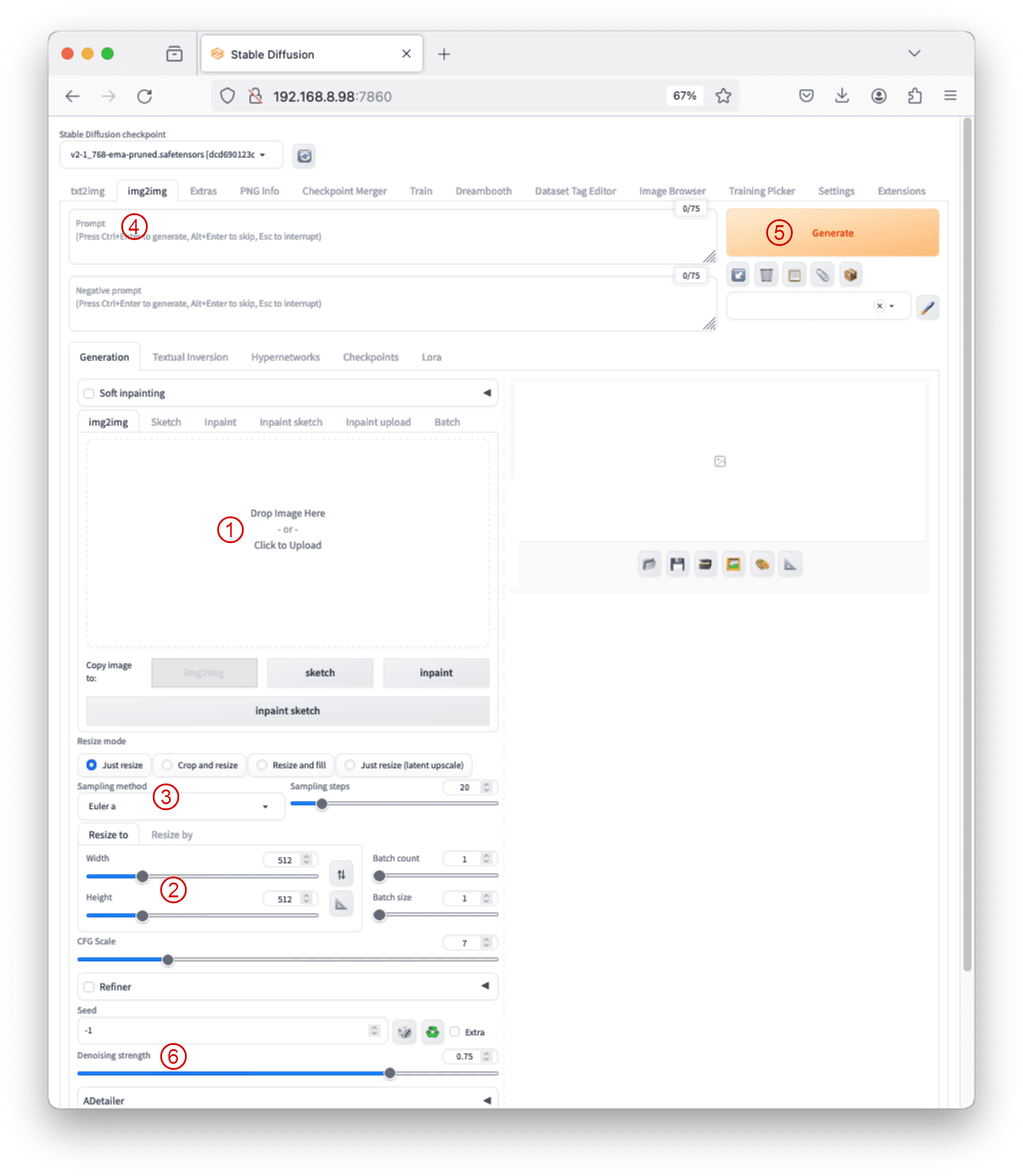
img2img 的典型工作流程
最重要的设置之一是去噪强度。它表示模型对输入图像的艺术自由度。此参数的值较低意味着必须保留图像的风格,而值较高意味着在风格、颜色等方面限制最少。
让我们通过下面使用相同提示“戴太阳镜的女人”的两个示例来更好地理解这一点。
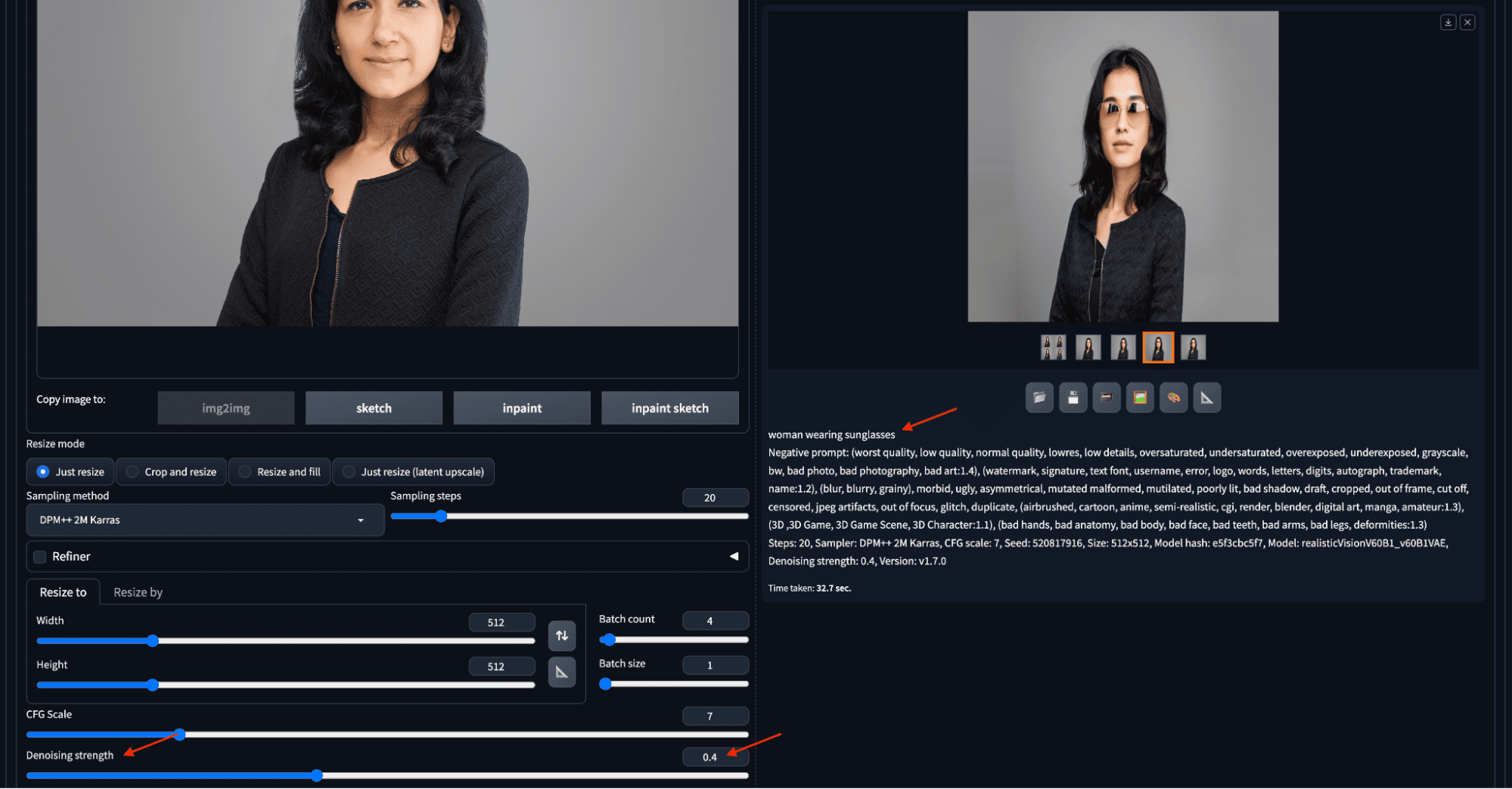
使用 img2img 将头像制作成戴太阳镜。
在第一个示例中,将图像上传到 img2img 子选项卡,将去噪强度设置为 0.4,输入提示,然后单击“生成”。生成的图像将显示在右侧。生成的图像几乎保留了除脸部以外的所有内容,包括输入图像的颜色和风格。它准确地反映了提示中的指令:戴太阳镜。
第二个示例具有更高的去噪强度值 0.7,因此允许算法生成更多随机图像。我们还将批次数量设置为 4,以便创建更多输出。右侧四个候选图像的颜色、姿势和风格各不相同,如下所示:
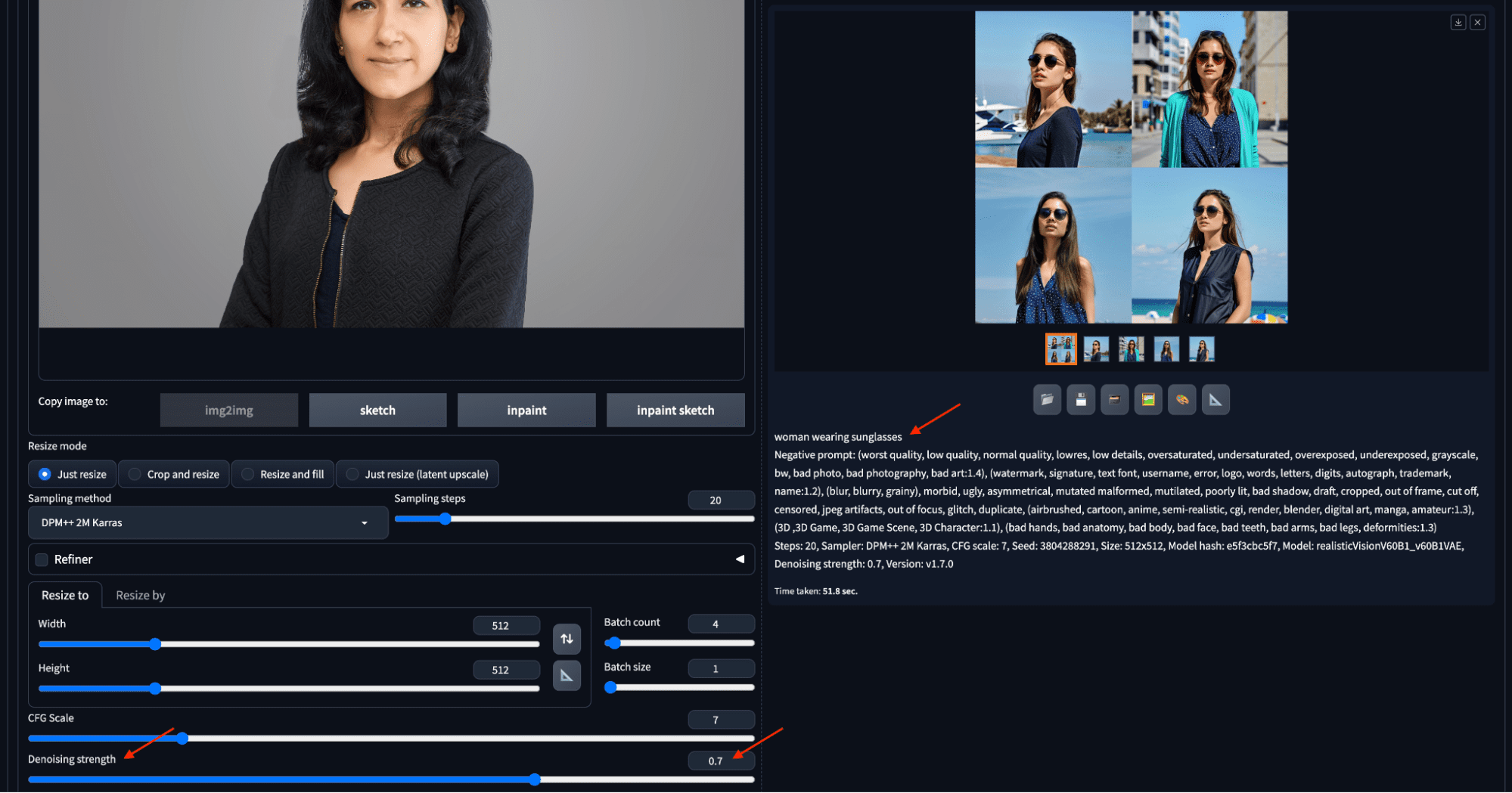
增加去噪强度将生成与输入更偏离的图像。
草图和图像修复
除了上传图像,用户还可以使用颜色草图工具绘制初始图片,从而实现创意修改或全新的构图。草图功能允许用户输入背景图像,用颜色绘制草图,并根据草图和 accompanying 提示生成图像。
img2img 选项卡中一个广泛使用的功能是图像修复,它解决了生成图像中的小缺陷。除了上传图像,您还可以将从 txt2img 选项卡生成的图像发送到 img2img 选项卡进行图像修复。之后,您可以绘制图像以创建蒙版。去噪强度、蒙版内容和批次大小的调整也会影响图像修复过程。示例如下:
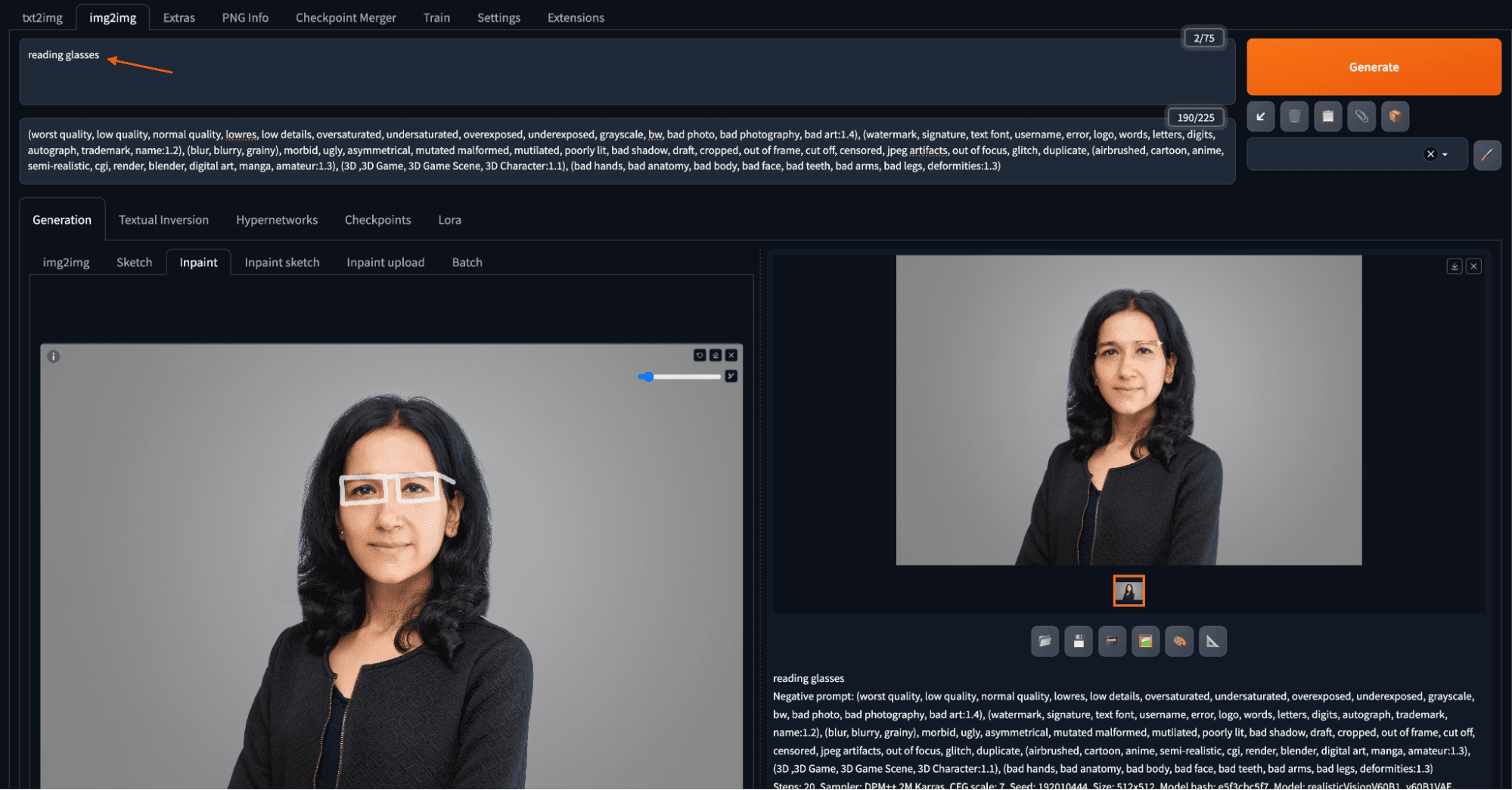
通过图像修复为肖像添加一副眼镜。
您可以在输入图像上绘制一个蒙版,指定阅读眼镜应该出现的位置。绘制时,您可以使用键盘快捷键进行缩放和平移,从而在处理小区域时提高精度。键盘快捷键包括 Alt+滚轮(macOS 为 Option+滚轮)用于缩放,Ctrl+滚轮用于调整画笔大小,“R”用于重置缩放,“S”用于进入/退出全屏,以及按住“F”同时移动光标进行平移。完成蒙版创建后,在提示文本框中输入“阅读眼镜”并单击“生成”。
如果您认为在浏览器上绘制蒙版太困难,可以使用 Photoshop 等其他绘图工具创建蒙版图像。然后在“图像修复上传”选项卡中分别上传图像和蒙版。
您还可以设置批次大小以一次创建多张图像,所有图像都基于相同的提示和输入。这使您能够从大量变体中选择最佳输出。
上述示例保留了原始图像,但通过在图像的蒙版区域大致绘制眼镜的结构,使用图像修复功能添加了眼镜。图像修复的一些值得注意的设置包括蒙版模糊(蒙版外部像素可以改变的范围)、图像修复区域(蒙版是用于保留还是更改)以及表示周围区域以产生变化的去噪强度。
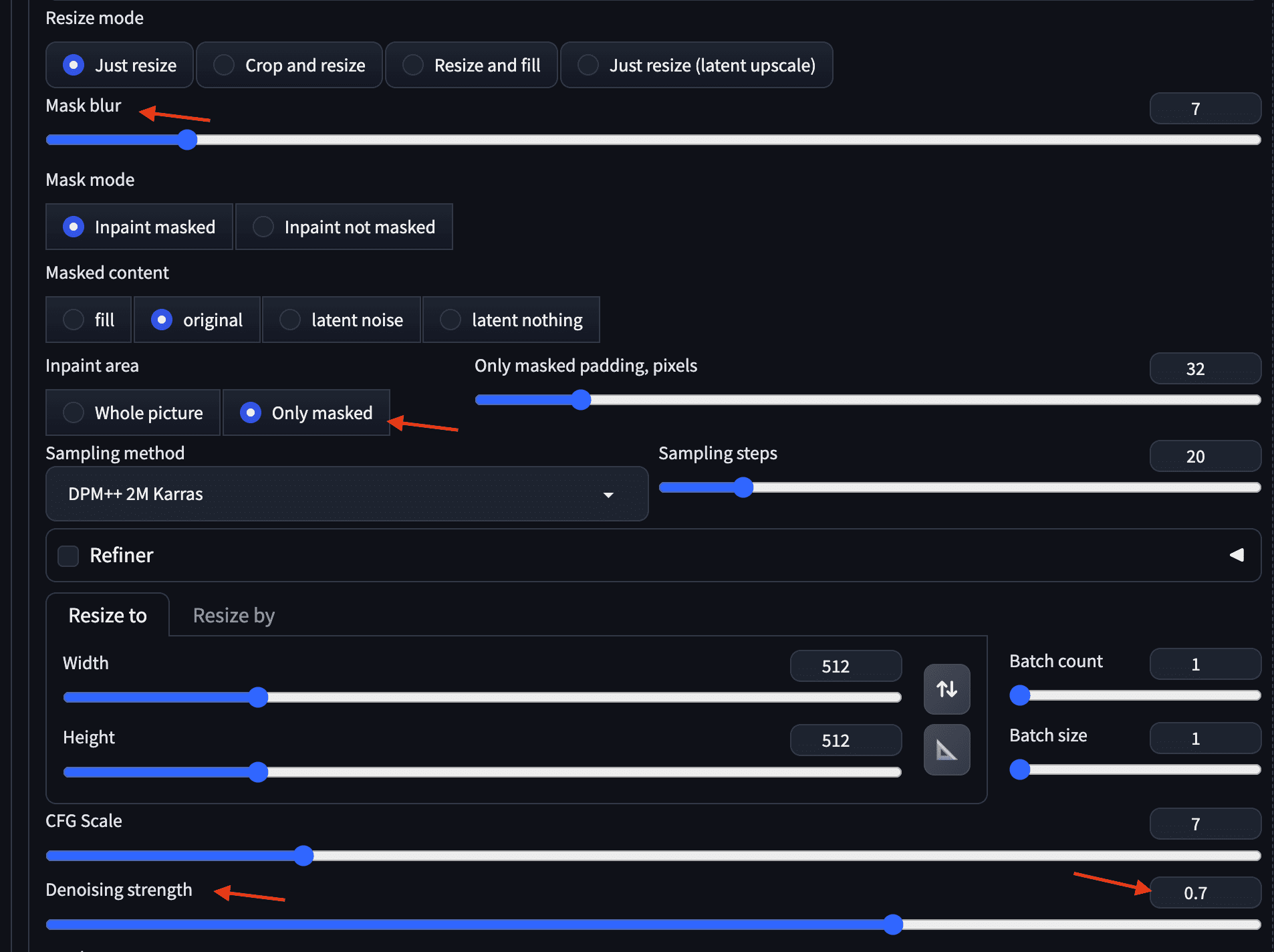
图像修复的一些有用参数
图像修复的一个更高级的版本是图像修复草图。在进行图像修复时,您创建一个蒙版,并且只有蒙版部分会根据提示重新生成。在图像修复草图中,您使用彩色铅笔在图像上绘制,您绘制的内容与提示一起控制输出。例如,相同的阅读眼镜提示会生成一副红色镜框的眼镜,因为草图是红色的。
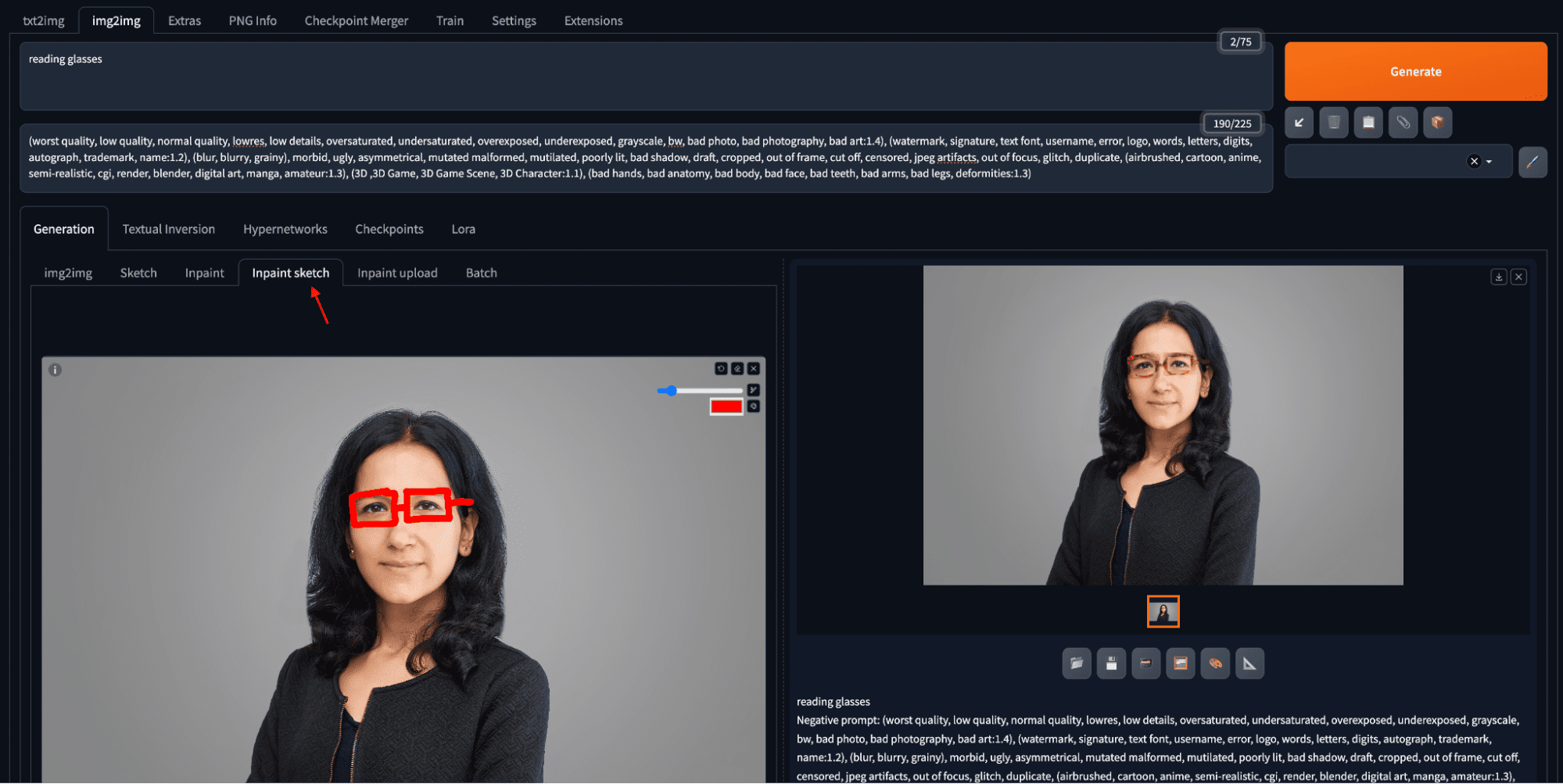
使用图像修复草图创建红色镜框的阅读眼镜。
其他功能
正如您已经注意到的,web UI 不仅仅是 txt2img 和 img2img。实际上,您可以通过安装扩展程序来为 web UI 添加更多功能。以下是一些顶级选项卡:
- Extras 选项卡:它允许您提供要调整大小的图像。技术上讲,您只调用了流程的超分辨率步骤。
- PNG Info:如果您生成了一张图像并将其保存为 PNG 文件到您的磁盘,则有关如何生成此图像的详细信息会存储在图像的 EXIF 数据中。此工具可以帮助从您上传的生成图像中检索提示和设置等参数值。
- Settings 选项卡:可以在此选项卡中调整许多设置,包括模型和输出的目录。最有用的设置之一是“面部修复”。此功能应用了一个额外的模型,旨在修复面部的缺陷。用户可以在 Settings 选项卡中选择一个面部修复模型,并将其应用于 txt2img 选项卡中的所有生成图像。调整 CodeFormer 权重参数可以微调修复效果。
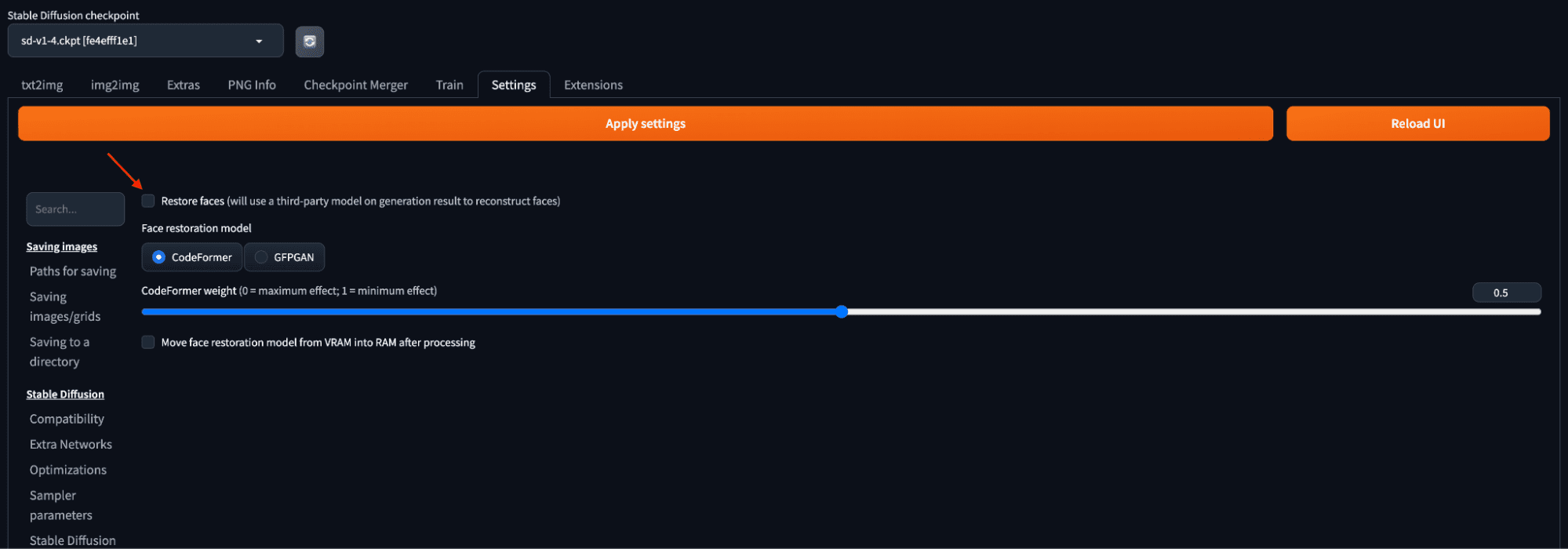
使用 CodeFormer 模型进行面部修复设置。
进一步阅读
学习 web UI 的最佳资源是 GitHub 上的工具 wiki 页面。
总结
在这篇文章中,您学习了如何从浏览器调用 Stable Diffusion Web UI。
虽然 Stable Diffusion 是一个非常强大的工具,但它在某些输出属性的精确控制方面仍然存在不足。它面临着某些情况下图像质量下降和颜色不准确的问题。在使用它时,您应该牢记其局限性。AI 生成图像的世界每天都在变得更好,并且比以往任何时候都更快。在下一篇文章中,让我们了解一些强大的提示技术,以扩展生成图像的极限。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
本书提供了自学教程,包含 Python 中的所有工作代码,引导您从新手成长为图像生成专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都是为了帮助您创建令人惊叹的数字艺术。






暂无评论。