了解如何从零开始为 CIFAR-10 对象分类数据集开发一个深度卷积神经网络模型。
CIFAR-10 小图片分类问题是计算机视觉和深度学习中的标准数据集。
尽管该数据集已经有效解决,但它仍可作为学习和实践如何从零开始开发、评估和使用卷积深度学习神经网络进行图像分类的基础。
这包括如何开发一个强大的测试框架来估计模型的性能,如何探索模型的改进,以及如何保存模型并在以后加载它以对新数据进行预测。
在本教程中,您将了解如何从零开始开发用于对象图片分类的卷积神经网络模型。
完成本教程后,您将了解:
- 如何开发一个测试工具,以对模型进行稳健评估,并为分类任务建立性能基线。
- 如何探索基线模型的扩展以改进学习和模型容量。
- 如何开发一个最终模型,评估最终模型的性能,并使用它对新图像进行预测。
通过我的新书《计算机视觉深度学习》启动您的项目,包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。

如何从零开始为 CIFAR-10 照片分类开发卷积神经网络
图片由 Rose Dlhopolsky 提供,保留部分权利。
教程概述
本教程分为六个部分;它们是:
- CIFAR-10 照片分类数据集
- 模型评估测试工具
- 如何开发基线模型
- 如何开发改进模型
- 如何进行进一步改进
- 如何完成模型并进行预测
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
CIFAR-10 照片分类数据集
CIFAR 是加拿大高级研究院(Canadian Institute For Advanced Research)的缩写,CIFAR-10 数据集与 CIFAR-100 数据集由 CIFAR 研究所的研究人员共同开发。
该数据集包含 60,000 张 32x32 像素的彩色照片,分为 10 个类别,如青蛙、鸟、猫、船等。类别标签及其标准关联整数值如下所示。
- 0: 飞机
- 1: 汽车
- 2: 鸟
- 3: 猫
- 4: 鹿
- 5: 狗
- 6: 青蛙
- 7: 马
- 8: 船
- 9: 卡车
这些图像非常小,远小于典型的照片,该数据集旨在用于计算机视觉研究。
CIFAR-10 是一个广为人知的数据集,广泛用于基准测试机器学习领域的计算机视觉算法。这个问题已经“解决”了。达到 80% 的分类准确率相对简单。该问题的最佳性能由深度学习卷积神经网络实现,在测试数据集上的分类准确率超过 90%。
以下示例使用 Keras API 加载 CIFAR-10 数据集,并绘制训练数据集中的前九张图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 加载 cifar10 数据集的示例 from matplotlib import pyplot from keras.datasets import cifar10 # 加载数据集 (trainX, trainy), (testX, testy) = cifar10.load_data() # 总结已加载的数据集 print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape)) print('Test: X=%s, y=%s' % (testX.shape, testy.shape)) # 绘制前几张图片 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 绘制原始像素数据 pyplot.imshow(trainX[i]) # 显示图 pyplot.show() |
运行该示例会加载 CIFAR-10 训练集和测试集,并打印它们的形状。
我们可以看到训练数据集中有 50,000 个样本,测试数据集中有 10,000 个样本,并且图像确实是 32x32 像素的正方形和彩色图像,具有三个通道。
|
1 2 |
训练集:X=(50000, 32, 32, 3), y=(50000, 1) 测试集:X=(10000, 32, 32, 3), y=(10000, 1) |
数据集中的前九张图像也已绘制出来。很明显,与现代照片相比,这些图像确实非常小;考虑到极低的像素分辨率,很难准确看出某些图像中表示的内容。
这种低分辨率很可能是顶级算法在该数据集上性能有限的原因。

CIFAR-10 数据集图像子集图示
模型评估测试工具
CIFAR-10 数据集可以作为开发和实践使用卷积神经网络解决图像分类问题的方法学的有用起点。
我们可以从头开始开发一个新模型,而不是回顾关于数据集上表现良好的模型的文献。
该数据集已经有一个明确定义的训练集和测试集,我们将使用它们。另一种方法是使用 k=5 或 k=10 的 k 折交叉验证。如果资源充足,这是可取的。在本例中,为了确保本教程中的示例在合理的时间内执行,我们不使用 k 折交叉验证。
测试工具的设计是模块化的,我们可以为每个部分开发一个单独的函数。这使得测试工具的特定方面可以在不影响其他部分的情况下进行修改或互换。
我们可以用五个关键元素来开发这个测试工具。它们是数据集的加载、数据集的准备、模型的定义、模型的评估和结果的呈现。
加载数据集
我们对数据集有一些了解。
例如,我们知道所有图像都是预分割的(例如,每张图像包含一个单独的对象),所有图像都具有相同的 32x32 像素正方形大小,并且图像是彩色的。因此,我们可以加载图像并几乎立即用于建模。
|
1 2 |
# 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() |
我们还知道有 10 个类别,并且这些类别表示为唯一的整数。
因此,我们可以对每个样本的类别元素使用独热编码,将整数转换为 10 个元素的二进制向量,其中类别值的索引为 1。我们可以使用 to_categorical() 实用函数来实现这一点。
|
1 2 3 |
# 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) |
load_dataset() 函数实现了这些行为,可用于加载数据集。
|
1 2 3 4 5 6 7 8 |
# 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY |
准备像素数据
我们知道数据集中每张图像的像素值是无符号整数,范围在无颜色和全颜色之间,即 0 到 255。
我们不知道如何最好地缩放像素值进行建模,但我们知道需要进行某种缩放。
一个好的起点是标准化像素值,例如,将它们重新缩放到 [0,1] 范围。这涉及首先将数据类型从无符号整数转换为浮点数,然后将像素值除以最大值。
|
1 2 3 4 5 6 |
# 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到 0-1 范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 |
下面的 prep_pixels() 函数实现了这些行为,并提供了需要缩放的训练集和测试集的像素值。
|
1 2 3 4 5 6 7 8 9 10 |
# 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm |
此函数必须在任何建模之前调用,以准备像素值。
定义模型
接下来,我们需要一种方法来构建神经网络模型。
下面的 define_model() 函数将定义并返回此模型,并且可以在我们以后希望评估的给定模型配置中填充或替换。
|
1 2 3 4 5 |
# 定义cnn模型 def define_model(): model = Sequential() # ... return model |
评估模型
定义模型后,我们需要对其进行拟合和评估。
拟合模型将要求指定训练 epoch 数量和批次大小。我们现在将使用通用的 100 个训练 epoch 和适中的 64 批次大小。
最好使用单独的验证数据集,例如,通过将训练数据集拆分为训练集和验证集。在本例中,我们不拆分数据,而是将测试数据集用作验证数据集,以保持示例的简单性。
测试数据集可以像验证数据集一样使用,并在每个训练 epoch 结束时进行评估。这将导致每个 epoch 在训练集和测试集上生成模型评估分数轨迹,这些轨迹可以稍后绘制。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0) |
模型拟合后,我们可以直接在测试数据集上评估它。
|
1 2 |
# 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) |
5. 呈现结果
模型评估完成后,我们可以呈现结果。
有两个关键方面需要呈现:模型在训练过程中的学习行为诊断和模型性能的估计。
首先,诊断涉及创建折线图,显示模型在训练期间在训练集和测试集上的性能。这些图对于了解模型是否过拟合、欠拟合或是否适合数据集非常有价值。
我们将创建一个包含两个子图的单一图形,一个用于损失,一个用于准确率。蓝色线条将表示模型在训练数据集上的性能,橙色线条将表示在保留测试数据集上的性能。下面的 summarize_diagnostics() 函数根据收集到的训练历史创建并显示此图。该图保存到文件中,具体来说,是一个与脚本同名且扩展名为“png”的文件。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='训练') pyplot.plot(history.history['val_loss'], color='orange', label='测试') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'], color='blue', label='训练') pyplot.plot(history.history['val_accuracy'] color='orange', label='测试') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() |
接下来,我们可以报告测试数据集上的最终模型性能。
这可以通过直接打印分类准确率来实现。
|
1 |
print('> %.3f' % (acc * 100.0)) |
完整示例
我们需要一个函数来驱动测试工具。
这涉及调用所有定义的函数。下面的 run_test_harness() 函数实现了这一点,可以调用它来启动对给定模型的评估。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 拟合模型 history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) |
我们现在已经拥有测试工具所需的一切。
下面列出了 CIFAR-10 数据集测试工具的完整代码示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
# 用于评估 cifar10 数据集上模型的测试工具 import sys from matplotlib import pyplot from keras.datasets import cifar10 from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() # ... return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='训练') pyplot.plot(history.history['val_loss'], color='orange', label='测试') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'], color='blue', label='训练') pyplot.plot(history.history['val_accuracy'] color='orange', label='测试') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 拟合模型 history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
此测试工具可以评估我们希望在 CIFAR-10 数据集上评估的任何 CNN 模型,并且可以在 CPU 或 GPU 上运行。
注意:目前未定义模型,因此此完整示例无法运行。
接下来,让我们看看如何定义和评估基线模型。
如何开发基线模型
我们现在可以研究 CIFAR-10 数据集的基线模型。
基线模型将建立一个最低模型性能,我们所有其他模型都可以与之进行比较,以及一个我们可以用作研究和改进基础的模型架构。
一个好的起点是 VGG 模型的通用架构原则。这些是一个很好的起点,因为它们在 ILSVRC 2014 竞赛中取得了顶尖性能,并且该架构的模块化结构易于理解和实现。有关 VGG 模型的更多详细信息,请参阅 2015 年论文“用于大规模图像识别的超深卷积网络”。
该架构涉及堆叠带有小型 3x3 滤波器的卷积层,然后是最大池化层。这些层共同构成一个块,并且这些块可以重复,其中每个块中的滤波器数量随着网络深度而增加,例如模型前四个块的 32、64、128、256。卷积层上使用填充以确保输出特征图的高度和宽度与输入匹配。
我们可以在 CIFAR-10 问题上探索这种架构,并比较具有 1、2 和 3 个块的该架构模型。
每个层都将使用 ReLU 激活函数和 He 权重初始化,这通常是最佳实践。例如,一个 3 块 VGG 风格的架构可以在 Keras 中定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 3 块 VGG 风格架构示例 model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) ... |
这定义了模型的特征检测器部分。这必须与模型的分类器部分结合使用,该分类器部分解释特征并预测给定照片属于哪个类别。
这可以针对我们研究的每个模型进行固定。首先,必须将模型特征提取部分输出的特征图展平。然后,我们可以用一个或多个全连接层来解释它们,然后输出预测。输出层必须有 10 个节点(对应 10 个类别),并使用 softmax 激活函数。
|
1 2 3 4 5 |
# 模型输出部分示例 model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) ... |
模型将使用随机梯度下降进行优化。
我们将使用适中的学习率 0.001 和较大的动量 0.9,这两者都是良好的通用起点。模型将优化多类别分类所需的分类交叉熵损失函数,并监控分类准确率。
|
1 2 3 |
# 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) |
我们现在有足够的元素来定义我们的 VGG 风格基线模型。我们可以定义具有 1、2 和 3 个 VGG 模块的三种不同模型架构,这需要我们定义 3 个单独版本的 define_model() 函数,如下所示。
为了测试每个模型,必须使用上一节中定义的测试工具以及下面定义的新版本的 define_model() 函数来创建新脚本(例如 model_baseline1.py、model_baseline2.py 等)。
让我们依次查看每个 define_model() 函数及其生成的测试工具的评估。
基线:1 个 VGG 块
下面列出了一个 VGG 块的 define_model() 函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
在测试工具中运行模型,首先打印测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型达到了略低于 70% 的分类准确率。
|
1 |
> 67.070 |
创建并保存了一个显示模型在训练和测试数据集上训练期间的学习曲线的图,包括损失和准确率。
在这种情况下,我们可以看到模型迅速过拟合测试数据集。如果我们查看损失图(顶部图),可以清楚地看到,模型在训练数据集(蓝色)上的性能持续提高,而测试数据集(橙色)上的性能先提高,然后在大约 15 个 epoch 后开始变差。
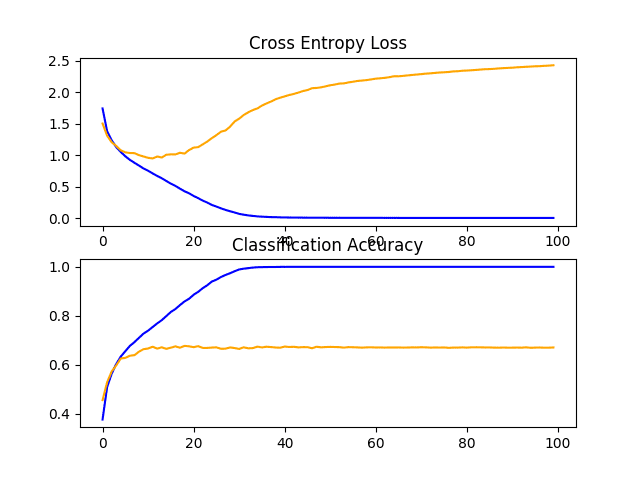
CIFAR-10 数据集上 VGG 1 基线学习曲线的折线图
基线:2 个 VGG 块
下面列出了两个 VGG 块的 define_model() 函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
在测试工具中运行模型,首先打印测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到具有两个块的模型比具有一个块的模型表现更好:这是一个好兆头。
|
1 |
> 71.080 |
创建并保存了显示学习曲线的图。在这种情况下,我们继续看到强烈的过拟合。
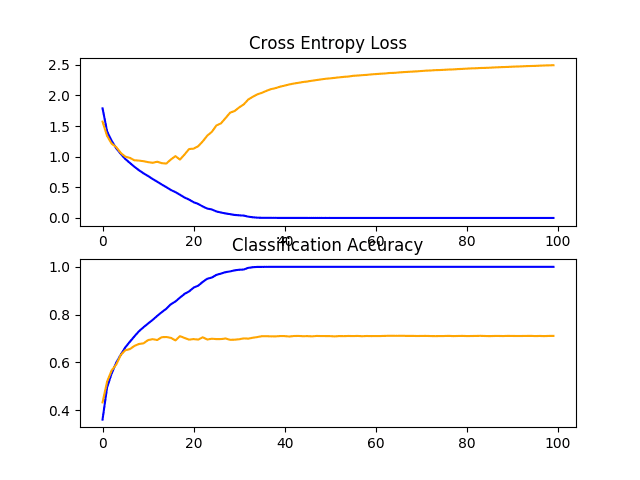
CIFAR-10 数据集上 VGG 2 基线学习曲线的折线图
基线:3 个 VGG 块
下面列出了三个 VGG 块的 define_model() 函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
在测试工具中运行模型,首先打印测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,随着模型深度的增加,性能再次适度提高。
|
1 |
> 73.500 |
回顾显示学习曲线的图形,我们再次看到在前 20 个训练周期内出现显著的过拟合。
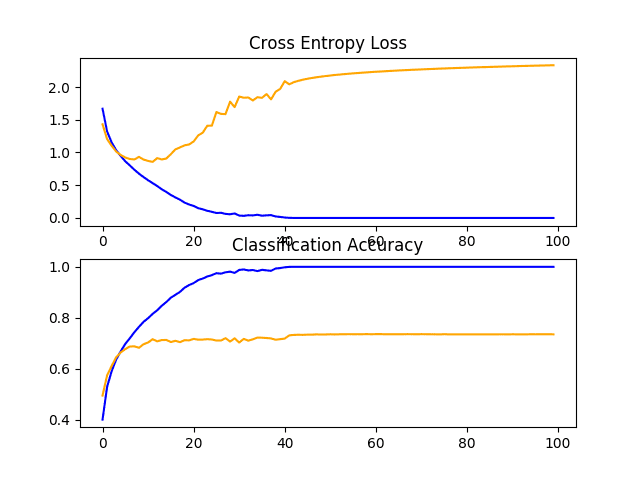
CIFAR-10 数据集上 VGG 3 基线学习曲线的折线图
讨论
我们探索了三种不同且基于 VGG 架构的模型。
结果总结如下,尽管考虑到算法的随机性,我们必须假设这些结果存在一些差异
- VGG 1: 67.070%
- VGG 2: 71.080%
- VGG 3: 73.500%
在所有情况下,模型都能够学习训练数据集,显示出训练数据集上的改进至少持续到 40 个 epoch,甚至可能更多。这是一个好兆头,因为它表明问题是可学习的,并且所有三个模型都有足够的能力来学习问题。
模型在测试数据集上的结果显示,随着模型深度的增加,分类准确率有所提高。如果评估四层和五层模型,这种趋势可能会继续,这可能是一个有趣的扩展。然而,所有三个模型都在大约 15 到 20 个 epoch 左右显示出相同的显著过拟合模式。
这些结果表明,具有三个 VGG 块的模型是我们的研究的一个良好起点或基线模型。
结果还表明,该模型需要正则化以解决测试数据集的快速过拟合问题。更一般地,结果表明研究减缓模型收敛(学习速率)的技术可能是有用的。这可能包括数据增强以及学习率调度、批次大小更改以及可能更多技术。
在下一节中,我们将研究一些用于改进模型性能的想法。
如何开发改进模型
现在我们已经建立了基线模型,即具有三个块的 VGG 架构,我们可以研究模型和训练算法的修改,以期提高性能。
我们将首先关注两个主要领域,以解决观察到的严重过拟合问题,即正则化和数据增强。
正则化技术
我们可以尝试许多正则化技术,尽管观察到的过拟合性质表明,早期停止可能不合适,而减缓收敛速率的技术可能有用。
我们将研究 dropout 和权重正则化或权重衰减的效果。
Dropout 正则化
Dropout 是一种简单技术,它会随机地从网络中删除节点。它具有正则化效果,因为剩余的节点必须适应以弥补被删除节点的不足。
有关 dropout 的更多信息,请参阅帖子
Dropout 可以通过添加新的 Dropout 层来添加到模型中,其中要删除的节点数量被指定为参数。有许多模式用于向模型添加 Dropout,包括在模型中的何处添加层以及使用多少 dropout。
在这种情况下,我们将在每个最大池化层之后和全连接层之后添加 Dropout 层,并使用固定的 20% dropout 率(例如,保留 80% 的节点)。
下面列出了带 dropout 的更新 VGG 3 基线模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.2)) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
完整的代码清单如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
# cifar10 数据集上带有 dropout 的基线模型 import sys from matplotlib import pyplot from keras.datasets import cifar10 from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten 从 keras.layers 导入 Dropout from keras.optimizers import SGD # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.2)) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='训练') pyplot.plot(history.history['val_loss'], color='orange', label='测试') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'], color='blue', label='训练') pyplot.plot(history.history['val_accuracy'] color='orange', label='测试') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 拟合模型 history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
在测试工具中运行模型会打印测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到分类准确率从没有 dropout 的约 73% 跃升到有 dropout 的约 83%,提升了约 10%。
|
1 |
> 83.450 |
回顾模型的学习曲线,我们可以看到过拟合问题已经得到解决。模型在大约 40 或 50 个 epoch 内收敛良好,此时测试数据集上没有进一步的改进。
这是一个很棒的结果。我们可以对该模型进行详细说明,并添加一个耐心值约为 10 个 epoch 的早期停止,以便在训练过程中在观察到没有进一步改进时保存一个在测试集上表现良好的模型。
我们还可以尝试探索一种学习率调度,当测试集上的改进停滞时降低学习率。
Dropout 表现良好,我们不知道所选择的 20% 速率是最佳的。我们可以探索其他 Dropout 速率,以及 Dropout 层在模型架构中的不同位置。
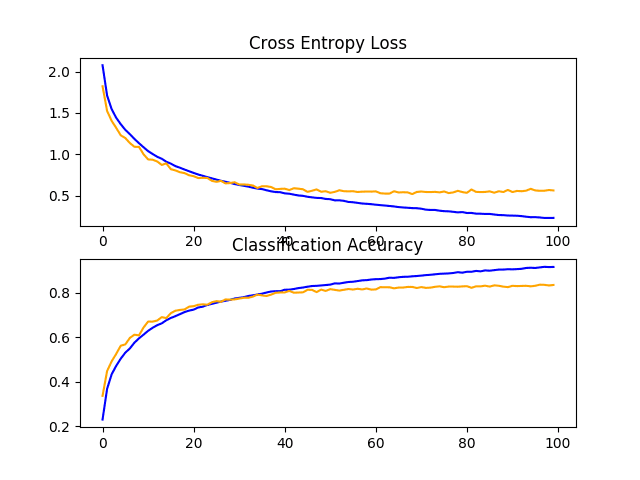
CIFAR-10 数据集上带有 Dropout 的基线模型学习曲线的折线图
权重衰减
权重正则化或权重衰减涉及更新损失函数,以根据模型权重的大小惩罚模型。
这具有正则化效果,因为较大的权重会导致模型更复杂且更不稳定,而较小的权重通常更稳定且更通用。
要了解有关权重正则化的更多信息,请参阅帖子
我们可以通过定义“kernel_regularizer”参数并指定正则化类型来将权重正则化添加到卷积层和全连接层。在这种情况下,我们将使用 L2 权重正则化,这是神经网络中最常见的类型,默认权重为 0.001 是合理的。
下面列出了带有权重衰减的更新基线模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001), input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform', kernel_regularizer=l2(0.001))) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
完整的代码清单如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
# cifar10 数据集上带有权重衰减的基线模型 import sys from matplotlib import pyplot from keras.datasets import cifar10 from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD 从 keras.regularizers 导入 l2 # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001), input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', kernel_regularizer=l2(0.001))) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform', kernel_regularizer=l2(0.001))) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='训练') pyplot.plot(history.history['val_loss'], color='orange', label='测试') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'], color='blue', label='训练') pyplot.plot(history.history['val_accuracy'] color='orange', label='测试') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 拟合模型 history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
在测试工具中运行模型,会打印测试数据集的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们看到模型在测试集上的性能没有提高;事实上,性能略有下降,从约 73% 降至约 72% 的分类准确率。
|
1 |
> 72.550 |
回顾学习曲线,我们确实看到过拟合有所减少,但效果不如 dropout。
我们也许可以通过增加权重(例如 0.01 甚至 0.1)来提高权重衰减的效果。
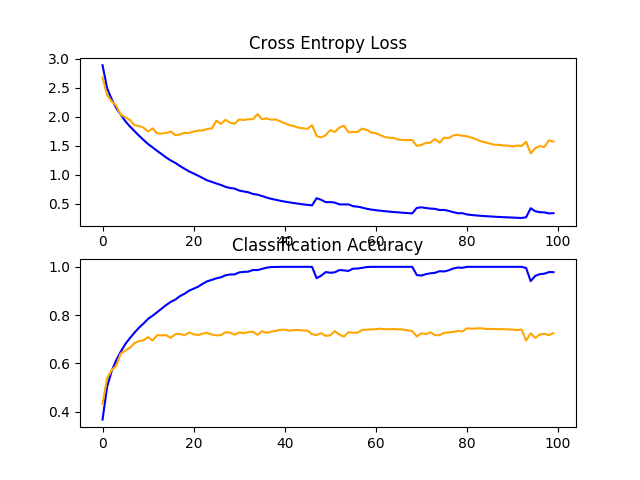
CIFAR-10 数据集上带有权重衰减的基线模型学习曲线的折线图
数据增强 (Data Augmentation)
数据增强涉及对训练数据集中的示例进行复制并进行小的随机修改。
这具有正则化效果,因为它既扩展了训练数据集,又允许模型以更通用的方式学习相同的通用特征。
可以应用许多类型的数据增强。鉴于数据集由小尺寸对象照片组成,我们不希望使用过度扭曲图像的增强,以使图像中有用的特征能够保留和使用。
可能有用的随机增强类型包括水平翻转、图像的微小位移,以及可能的小范围缩放或裁剪图像。
我们将研究简单增强对基线图像的影响,特别是水平翻转和图像高度和宽度 10% 的位移。
这可以使用 Keras 中的 ImageDataGenerator 类实现;例如
|
1 2 3 4 |
# 创建数据生成器 datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) # 准备迭代器 it_train = datagen.flow(trainX, trainY, batch_size=64) |
这可以在训练期间使用,通过将迭代器传递给 model.fit_generator() 函数并定义单个 epoch 中的批次数量。
|
1 2 3 |
# 拟合模型 steps = int(trainX.shape[0] / 64) history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=100, validation_data=(testX, testY), verbose=0) |
模型无需更改。
下面列出了支持数据增强的 run_test_harness() 函数的更新版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 创建数据生成器 datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) # 准备迭代器 it_train = datagen.flow(trainX, trainY, batch_size=64) # 拟合模型 steps = int(trainX.shape[0] / 64) history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=100, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) |
完整的代码清单如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
# cifar10 数据集上带有数据增强的基线模型 import sys from matplotlib import pyplot from keras.datasets import cifar10 from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD from keras.preprocessing.image import ImageDataGenerator # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='训练') pyplot.plot(history.history['val_loss'], color='orange', label='测试') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'], color='blue', label='训练') pyplot.plot(history.history['val_accuracy'] color='orange', label='测试') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 创建数据生成器 datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) # 准备迭代器 it_train = datagen.flow(trainX, trainY, batch_size=64) # 拟合模型 steps = int(trainX.shape[0] / 64) history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=100, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
在测试工具中运行模型会打印测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们看到模型性能又有了大幅提升,就像我们使用 dropout 时看到的那样。在本例中,基线模型从约 73% 提高到约 84%,提升了约 11%。
|
1 |
> 84.470 |
回顾学习曲线,我们看到模型性能有了类似的提升,就像我们使用 dropout 时一样,尽管损失图表明测试集上的模型性能可能比使用 dropout 时更早停滞。
结果表明,结合使用 dropout 和数据增强的配置可能有效。
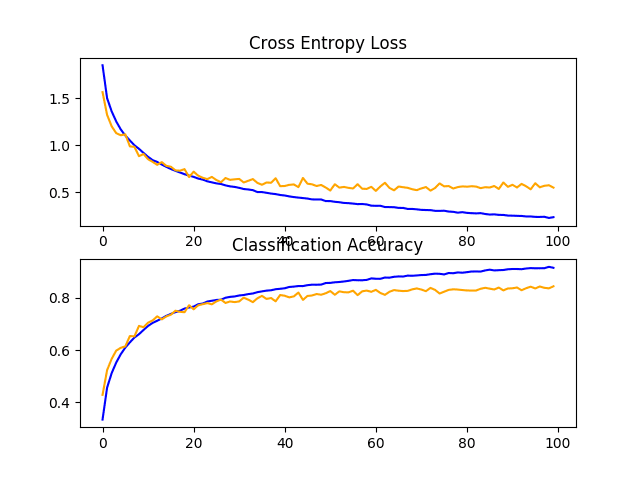
CIFAR-10 数据集上带有数据增强的基线模型学习曲线的折线图
讨论
在本节中,我们探讨了三种旨在减缓模型收敛速度的方法。
结果总结如下:
- 基线 + Dropout: 83.450%
- 基线 + 权重衰减: 72.550%
- 基线 + 数据增强: 84.470%
结果表明,Dropout 和数据增强都产生了预期的效果,而权重衰减,至少对于所选配置而言,则没有。
现在模型学习得很好,我们可以寻求改进已有的工作,以及组合有效的方法。
如何进行进一步改进
在上一节中,我们发现,当在基线模型中添加 dropout 和数据增强时,模型能够很好地学习问题。
我们现在将研究这些技术的改进,看看是否能进一步提高模型的性能。具体来说,我们将探讨 dropout 正则化的一种变体以及 dropout 与数据增强的结合。
学习速度已经放慢,因此我们将研究增加训练 epoch 的数量,以便在需要时为模型提供足够的空间,以揭示学习曲线中的学习动态。
Dropout 正则化的变体
Dropout 效果非常好,所以研究 dropout 在模型中应用方式的变体可能很有价值。
一个可能有趣的变体是将 dropout 数量从 20% 增加到 25% 或 30%。另一个可能有趣的变体是使用逐层增加 dropout 的模式,例如第一个块 20%,第二个块 30%,依此类推,直到模型分类器部分中全连接层达到 50%。
这种随着模型深度增加而增加 dropout 的模式很常见。它很有效,因为它迫使模型深处的层比靠近输入的层进行更多的正则化。
下面定义了更新后使用随模型深度增加 dropout 百分比模式的基线模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.3)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
为完整性起见,下面提供了包含此更改的完整代码清单。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
# cifar10 数据集上带有递增 dropout 的基线模型 import sys from matplotlib import pyplot from keras.datasets import cifar10 from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten 从 keras.layers 导入 Dropout from keras.optimizers import SGD # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.3)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='训练') pyplot.plot(history.history['val_loss'], color='orange', label='测试') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'], color='blue', label='训练') pyplot.plot(history.history['val_accuracy'] color='orange', label='测试') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 拟合模型 history = model.fit(trainX, trainY, epochs=200, batch_size=64, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
在测试工具中运行模型会打印测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能从固定 dropout 的约 83% 适度提升到递增 dropout 的约 84%。
|
1 |
> 84.690 |
回顾学习曲线,我们可以看到模型收敛良好,测试数据集上的性能可能在大约 110 到 125 个 epoch 时停滞。与固定 dropout 的学习曲线相比,我们可以看到学习速率再次进一步减慢,从而可以在不过拟合的情况下进一步优化模型。
这是对该模型进行研究的富有成效的领域,也许更多的 dropout 层和/或更激进的 dropout 可能会带来进一步的改进。
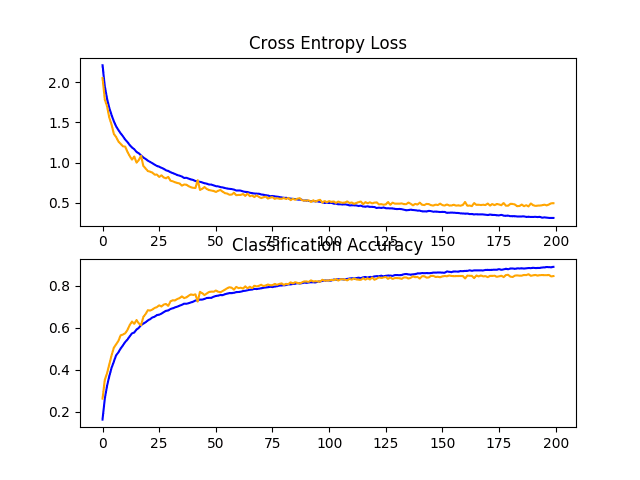
CIFAR-10 数据集上带有递增 Dropout 的基线模型学习曲线的折线图
Dropout 和数据增强
在上一节中,我们发现 dropout 和数据增强都显著提高了模型性能。
在本节中,我们可以尝试将这两种模型更改结合起来,看看是否能进一步提高性能。具体来说,是否同时使用这两种正则化技术比单独使用其中任何一种技术能带来更好的性能。
下面提供了带有固定 dropout 和数据增强的模型的完整代码清单,以供参考。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
# cifar10 数据集上带有 dropout 和数据增强的基线模型 import sys from matplotlib import pyplot from keras.datasets import cifar10 from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD from keras.preprocessing.image import ImageDataGenerator from keras.layers import Dropout # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.2)) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='训练') pyplot.plot(history.history['val_loss'], color='orange', label='测试') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'], color='blue', label='训练') pyplot.plot(history.history['val_accuracy'] color='orange', label='测试') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 创建数据生成器 datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) # 准备迭代器 it_train = datagen.flow(trainX, trainY, batch_size=64) # 拟合模型 steps = int(trainX.shape[0] / 64) history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=200, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
在测试工具中运行模型会打印测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到,正如我们所希望的,同时使用这两种正则化技术使得模型在测试集上的性能得到了进一步提升。在本例中,结合固定 dropout(约 83%)和数据增强(约 84%)使得分类准确率提高到约 85%。
|
1 |
> 85.880 |
回顾学习曲线,我们可以看到模型的收敛行为也优于单独使用固定 dropout 或数据增强。学习速度减慢但没有过拟合,从而实现了持续改进。
该图还表明,学习可能尚未停滞,如果允许继续,可能会继续改进,但可能非常微弱。
如果使用递增 dropout 模式而不是整个模型深度中的固定 dropout 率,结果可能会进一步改进。
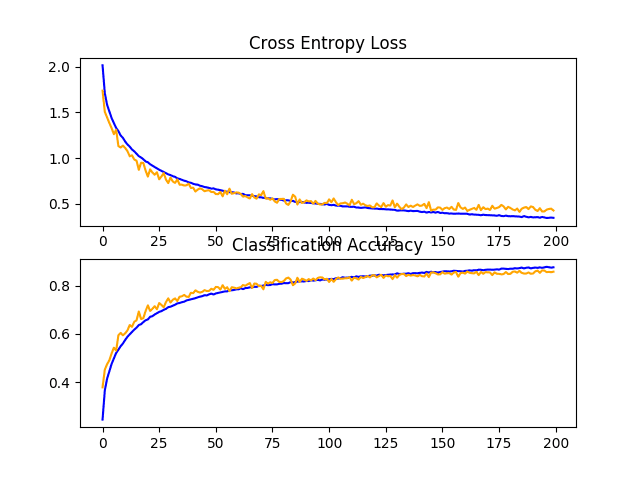
CIFAR-10 数据集上带有 Dropout 和数据增强的基线模型学习曲线的折线图
Dropout、数据增强和批归一化
我们可以从几个方面扩展前面的示例。
首先,我们可以将训练周期数从 200 增加到 400,以给模型更多的改进机会。
接下来,我们可以添加批量归一化,以稳定学习并可能加速学习过程。为了抵消这种加速,我们可以通过将 dropout 从固定模式更改为递增模式来增加正则化。
更新后的模型定义如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(BatchNormalization()) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.3)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
为了完整性,下面提供了包含递增 dropout、数据增强、批量归一化和 400 个训练 epoch 的模型的完整代码清单。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 |
# cifar10 数据集上带有 dropout 和数据增强的基线模型 import sys from matplotlib import pyplot from keras.datasets import cifar10 from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD from keras.preprocessing.image import ImageDataGenerator 从 keras.layers 导入 Dropout from keras.layers import BatchNormalization # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(BatchNormalization()) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.3)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='训练') pyplot.plot(history.history['val_loss'], color='orange', label='测试') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'], color='blue', label='训练') pyplot.plot(history.history['val_accuracy'] color='orange', label='测试') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 创建数据生成器 datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) # 准备迭代器 it_train = datagen.flow(trainX, trainY, batch_size=64) # 拟合模型 steps = int(trainX.shape[0] / 64) history = model.fit_generator(it_train, steps_per_epoch=steps, epochs=400, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
在测试工具中运行模型会打印测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型性能进一步提升至约 88% 的准确率,优于单独使用 dropout 和数据增强(约 84%),也优于单独使用递增 dropout(约 85%)。
|
1 |
> 88.620 |
回顾学习曲线,我们可以看到模型训练在近 400 个 epoch 的整个过程中持续改进。我们可能会看到测试数据集在大约 300 个 epoch 时略有下降,但改进趋势仍在继续。
该模型可能受益于更多的训练周期。
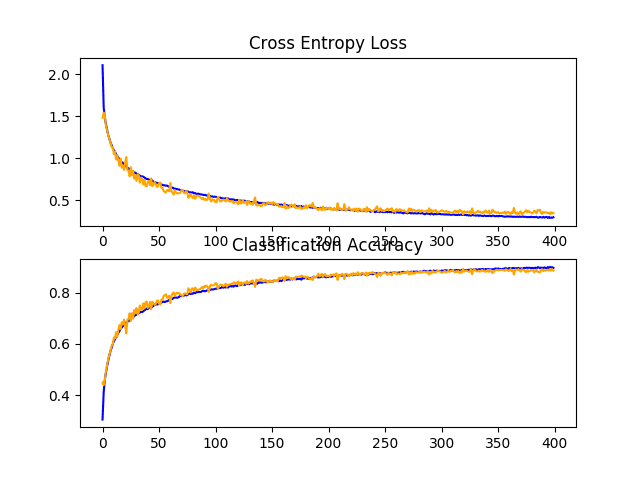
CIFAR-10 数据集上具有递增 Dropout、数据增强和批量归一化的基线模型的学习曲线折线图
讨论
在本节中,我们探讨了两种方法,旨在扩展我们已知会带来改进的模型更改
结果总结如下:
- 基线 + 递增 Dropout: 84.690%
- 基线 + Dropout + 数据增强: 85.880%
- 基线 + 递增 Dropout + 数据增强 + 批量归一化: 88.620%
模型现在学习良好,并且我们能够很好地控制学习速率而不会出现过拟合。
我们可能会通过额外的正则化实现进一步的改进。这可以通过在后期层中进行更激进的 dropout 来实现。进一步增加权重衰减可能会改善模型。
到目前为止,我们还没有调整学习算法的超参数,例如学习率,这可能是最重要的超参数。我们可能会期望通过学习率的自适应变化获得进一步的改进,例如使用自适应学习率技术,例如 Adam。这些类型的变化可能有助于在模型收敛后对其进行优化。
如何完成模型并进行预测
只要我们有想法、时间和资源来测试它们,模型改进过程就可以继续下去。
在某个时候,必须选择并采用最终的模型配置。在这种情况下,我们将保持简单,使用基线模型(带有 3 个块的 VGG)作为最终模型。
首先,我们将通过在整个训练数据集上拟合模型并将其保存到文件中以备后用,来最终确定我们的模型。然后,我们将加载模型并评估其在保留测试数据集上的性能,以了解所选模型在实践中的实际表现。最后,我们将使用保存的模型对单个图像进行预测。
保存最终模型
最终模型通常拟合所有可用数据,例如所有训练和测试数据集的组合。
在本教程中,为了使示例保持简单,我们将演示仅在训练数据集上拟合的最终模型。
第一步是在整个训练数据集上拟合最终模型。
|
1 2 |
# 拟合模型 model.fit(trainX, trainY, epochs=100, batch_size=64, verbose=0) |
拟合后,我们可以通过在模型上调用 *save()* 函数并传入所选文件名,将最终模型保存到 H5 文件中。
|
1 2 |
# 保存模型 model.save('final_model.h5') |
注意:保存和加载 Keras 模型需要您的工作站上安装 h5py 库。
下面列出了在训练数据集上拟合最终模型并将其保存到文件的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# 将最终模型保存到文件 from keras.datasets import cifar10 from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3))) model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 拟合模型 model.fit(trainX, trainY, epochs=100, batch_size=64, verbose=0) # 保存模型 model.save('final_model.h5') # 入口点,运行测试工具 run_test_harness() |
运行此示例后,您将在当前工作目录中获得一个名为“*final_model.h5*”的 4.3 兆字节文件。
评估最终模型
我们现在可以加载最终模型并在保留测试数据集上对其进行评估。
如果我们有兴趣向项目利益相关者展示所选模型的性能,我们可能会这样做。
测试数据集用于评估和选择候选模型。因此,它不能作为好的最终测试保留数据集。尽管如此,在这种情况下,我们仍将它用作保留数据集。
模型可以通过 *load_model()* 函数加载。
下面列出了加载保存的模型并在测试数据集上对其进行评估的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# 在测试数据集上评估深度模型 from keras.datasets import cifar10 from keras.models import load_model 从 keras.utils 导入 to_categorical # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = cifar10.load_data() # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 加载模型 model = load_model('final_model.h5') # 在测试数据集上评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 入口点,运行测试工具 run_test_harness() |
运行示例将加载保存的模型并在保留测试数据集上评估模型。
计算并打印模型在测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到该模型达到了约 73% 的准确率,非常接近我们在测试工具中评估模型时所看到的结果。
|
1 |
73.750 |
进行预测
我们可以使用保存的模型对新图像进行预测。
该模型假设新图像是彩色的,它们已被分割,以便一个图像包含一个居中的对象,并且图像尺寸为 32×32 像素的正方形。
以下是从 CIFAR-10 测试数据集中提取的图像。您可以将其以文件名“*sample_image.png*”保存到当前工作目录中。

鹿
我们将假装这是一张全新的、从未见过的图像,以所需的方式准备,并看看我们如何使用保存的模型来预测该图像所代表的整数。
对于此示例,我们期望“*鹿*”的类别为“*4*”。
首先,我们可以加载图像并强制将其大小设置为 32×32 像素。然后可以将加载的图像调整大小,使其具有单个通道并表示数据集中的单个样本。*load_image()* 函数实现了这一点,并将返回准备好进行分类的加载图像。
重要的是,像素值的准备方式与拟合最终模型时训练数据集的像素值准备方式相同,在本例中为归一化。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 加载并准备图像 def load_image(filename): # 加载图像 img = load_img(filename, target_size=(32, 32)) # 转换为数组 img = img_to_array(img) # 重塑为具有 3 个通道的单个样本 img = img.reshape(1, 32, 32, 3) # 准备像素数据 img = img.astype('float32') img = img / 255.0 return img |
接下来,我们可以像上一节中那样加载模型,并调用 *predict_classes()* 函数来预测图像中的对象。
|
1 2 |
# 预测类别 result = model.predict_classes(img) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 为新图像进行预测。 from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.models import load_model # 加载并准备图像 def load_image(filename): # 加载图像 img = load_img(filename, target_size=(32, 32)) # 转换为数组 img = img_to_array(img) # 重塑为具有 3 个通道的单个样本 img = img.reshape(1, 32, 32, 3) # 准备像素数据 img = img.astype('float32') img = img / 255.0 return img # 加载图像并预测类别 def run_example(): # 加载图像 img = load_image('sample_image.png') # 加载模型 model = load_model('final_model.h5') # 预测类别 result = model.predict_classes(img) print(result[0]) # 入口点,运行示例 run_example() |
运行示例首先加载并准备图像,然后加载模型,并正确预测加载的图像代表“*鹿*”或类别“*4*”。
|
1 |
4 |
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 像素缩放。探索替代的像素缩放技术,例如居中和标准化,并比较性能。
- 学习率。探索替代学习率、自适应学习率和学习率调度,并比较性能。
- 迁移学习。探索使用迁移学习,例如在此数据集上使用预训练的 VGG-16 模型。
如果您探索了这些扩展中的任何一个,我很想知道。
请在下面的评论中发布您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
API
文章
- 分类数据集结果,这张图片的类别是什么?
- CIFAR-10,维基百科.
- CIFAR-10 数据集和 CIFAR-100 数据集.
- CIFAR-10 – 图像中的物体识别,Kaggle.
- 简单 CNN 90%以上,Pasquale Giovenale,Kaggle.
总结
在本教程中,您学习了如何从头开始开发用于对象照片分类的卷积神经网络模型。
具体来说,你学到了:
- 如何开发一个测试工具,以对模型进行稳健评估,并为分类任务建立性能基线。
- 如何探索基线模型的扩展以改进学习和模型容量。
- 如何开发一个最终模型,评估最终模型的性能,并使用它对新图像进行预测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






{kind=link}
抛出错误 train 未定义。有什么解决这个问题的建议吗?
我在这里有一些建议可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
抱歉,但如果你使用所有这些 Keras 库,你可能不应该使用“从头开始”这个词。那是虚假广告。
这里的“从头开始”意味着不使用预训练模型或迁移学习,而是从随机(头开始)训练模型权重以获得可用的模型。
感谢您的帖子。如果您将优化器切换到 Adam 和 CyclicLR,您的训练时间和性能将如何变化,这会很有趣。谢谢!
好建议!
早上好,先生。
感谢您给我发邮件。
你做得非常出色。
您能帮我从头开始使用 CNN 训练 BRATS 数据库上的分割模型吗?
请给我发相关的邮件。
非常感谢,先生。
我在本书中提供了一些用于图像分割的 Mask R-CNN 示例,可能有所帮助
https://machinelearning.org.cn/deep-learning-for-computer-vision/
请回答我这些问题。
什么是 epoch?
如何将 3D 图像转换为 2D。
如何应用权重和偏差?
谢谢
这解释了 epoch 是什么
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-a-batch-and-an-epoch
抱歉,我不知道“3D 图像”。
权重和偏差位于层内,并通过训练模型进行更新。
也许关于神经网络应该教的第一件事是加权和作为线性联想记忆。以一般的方式,因为有一些限制。
如果权重多于要学习的模式,则会进行误差校正,并且神经元可以定义为分支过程。
https://discourse.numenta.org/t/towards-demystifying-over-parameterization-in-deep-learning/5985
这在早期的文献中就已经知道了。它是否被遗忘了一点?
谢谢,Sean。
# 将整数转换为浮点数
train_norm = train.astype(‘float32’)
test_norm = test.astype(‘float32’)
# 归一化到 0-1 范围
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
运行此代码时出现错误。
NameError: name ‘train’ is not defined。
请您帮我解决这个问题吗?
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
这是有史以来最棒的教程!您能帮我加载我自己收集的数据集吗?我使用以下代码为我的数据集构建了数据结构。
for file in listdir(folder)
# 确定类别
output = 0.0
if file.startswith(‘G’)
output = 1.0
elif file.startswith(‘M’)
output = 2.0
elif file.startswith(‘C’)
output = 4.0
elif file.startswith(‘S’)
output = 5.0
elif file.startswith(‘G1’)
output = 6.0
elif file.startswith(‘R’)
output = 7.0
# 加载图片
photo = load_img(folder + file, target_size=(200, 200))
# 转换为numpy数组
photo = img_to_array(photo)
# 存储
photos.append(photo)
labels.append(output)
labeldirs = [‘G/’, ‘M/’, ‘C/’, ‘S/’, ‘G1/’, ‘R/’]
for labldir in labeldirs
newdir = dataset_home + subdir + labldir
makedirs(newdir, exist_ok=True)
src_directory = ‘test/’
for file in listdir(src_directory)
src = src_directory + ‘/’ + file
dst_dir = ‘train/’
if random() < val_ratio
dst_dir = 'test/'
if file.startswith('G')
dst = dataset_home + dst_dir + 'G/' + file
copyfile(src, dst)
elif file.startswith('M')
dst = dataset_home + dst_dir + 'M/' + file
copyfile(src, dst)
elif file.startswith('G1')
dst = dataset_home + dst_dir + 'G1/' + file
copyfile(src, dst)
elif file.startswith('R')
dst = dataset_home + dst_dir + 'R/' + file
copyfile(src, dst)
elif file.startswith('C')
dst = dataset_home + dst_dir + 'C/' + file
copyfile(src, dst)
elif file.startswith('S')
dst = dataset_home + dst_dir + 'S/' + file
copyfile(src, dst)
我如何加载和使用这种数据集结构来配合本教程,因为本教程只使用 Keras API 加载数据集,如下所示:
def load_dataset()
# 加载数据集
(trainX, trainY), (testX, testY) = cifar10.load_data()
# 独热编码目标值
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
请帮忙?
谢谢!
也许这个教程会帮助您加载您的数据集
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
谢谢,我已经按照建议加载了它
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
但是如何继续本教程的结构呢。
我使用了图像数据生成器,现在我准备了迭代器 train_it 和 test_it,您能指导我如何进一步用于以下函数吗?
def load_dataset()
# 加载数据集
(trainX, trainY), (testX, testY) = cifar10.load_data()
# 独热编码目标值
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
语句 (trainX, trainY), (testX, testY) = train_it 可以吗?
谢谢!
抱歉,我没明白。您具体遇到了什么问题?
谢谢!
我已成功加载数据集,如所示
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
我使用了图像数据生成器并为 train_it 和 test_it 创建了迭代器。
您能详细说明我如何在本教程的以下代码中使用 train_it 和 test_it 吗?
def load_dataset()
# 加载数据集
(trainX, trainY), (testX, testY) = cifar10.load_data()
# 独热编码目标值
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
当我将 (trainX, trainY), (testX, testY) = cifar10.load_data() 替换为 (trainX, trainY), (testX, testY) = (train_it , test_it ) 时。我收到以下错误
加载-准备内存错误。
任何帮助将不胜感激。
使用 ImageDataGenerator 的想法是它不会将所有数据加载到内存中,而是每次加载一批图像。
也许可以在此教程中查看其用法示例
https://machinelearning.org.cn/how-to-develop-a-convolutional-neural-network-to-classify-photos-of-dogs-and-cats/
先生,我在加载数据集时收到此错误
~\.conda\envs\tensorflow\lib\urllib\request.py in open(self, fullurl, data, timeout)
525
–> 526 response = self._open(req, data)
527
~\.conda\envs\tensorflow\lib\urllib\request.py in _open(self, req, data)
543 result = self._call_chain(self.handle_open, protocol, protocol +
–> 544 ‘_open’, req)
545 if result
~\.conda\envs\tensorflow\lib\urllib\request.py in _call_chain(self, chain, kind, meth_name, *args)
503 func = getattr(handler, meth_name)
–> 504 result = func(*args)
505 if result is not None
~\.conda\envs\tensorflow\lib\urllib\request.py in https_open(self, req)
1360 return self.do_open(http.client.HTTPSConnection, req,
-> 1361 context=self._context, check_hostname=self._check_hostname)
1362
~\.conda\envs\tensorflow\lib\urllib\request.py in do_open(self, http_class, req, **http_conn_args)
1319 except OSError as err: # timeout error
-> 1320 raise URLError(err)
1321 r = h.getresponse()
URLError
处理上述异常时,发生了另一个异常
异常回溯(最近一次调用)
in
7 print(‘> %.3f’ % (acc * 100.0))
8 summarizse_diagnostics(history)
—-> 9 run_test_harness()
10
in run_test_harness()
1 def run_test_harness()
—-> 2 trainX, trainY, testX, testY = load_dataset()
3 trainX, testX = prep_pixels(trainX, testX)
4 model = define_model()
5 history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
in load_dataset()
1 def load_dataset()
—-> 2 (trainX, trainY), (testX, testY) = cifar10.load_data()
3 trainY = to_categorical(trainY)
4 testY = to_categorical(testY)
5 return trainX, trainY, testX, testY
~\.conda\envs\tensorflow\lib\site-packages\keras\datasets\cifar10.py in load_data()
20 dirname = ‘cifar-10-batches-py’
21 origin = ‘https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz’
—> 22 path = get_file(dirname, origin=origin, untar=True)
23
24 num_train_samples = 50000
~\.conda\envs\tensorflow\lib\site-packages\keras\utils\data_utils.py in get_file(fname, origin, untar, md5_hash, file_hash, cache_subdir, hash_algorithm, extract, archive_format, cache_dir)
224 raise Exception(error_msg.format(origin, e.code, e.msg))
225 except URLError as e
–> 226 raise Exception(error_msg.format(origin, e.errno, e.reason))
227 except (Exception, KeyboardInterrupt)
228 if os.path.exists(fpath)
Exception: URL fetch failure on https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz: None — [WinError 10060] 连接尝试失败,因为连接方在一段时间后没有正确响应,或者建立的连接失败,因为连接的主机没有响应。
你能告诉我替代方法吗?
谢谢
听到这个消息我很难过,看起来你可能遇到了互联网连接问题。
也许再试运行一次代码?
也许尝试另一个互联网连接?
也许在另一天/时间尝试?
也许在另一台电脑上尝试?
希望这能作为第一步有所帮助。
您的代码(如下)在 Jupyter Notebook 中没有留下任何输出,好像什么都没有运行。在 Spyder 中运行相同的代码会抛出大量错误。您能帮我解决这个问题吗,因为我想学习 thor 基于网络的示例页面上提供的关于修改训练模型的以下示例。
提前感谢。
# 用于评估 cifar10 数据集上模型的测试工具
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
来自 keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
from keras.utils import np_utils
import tensorflow as ts
# 加载训练和测试数据集
def load_dataset()
# 加载数据集
(trainX, trainY), (testX, testY) = cifar10.load_data()
# 独热编码目标值
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# 缩放像素
def prep_pixels(train, test)
# 将整数转换为浮点数
train_norm = train.astype(‘float32’)
test_norm = test.astype(‘float32′)
# 归一化到 0-1 范围
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# 返回归一化图像
return train_norm, test_norm
# 定义cnn模型
def define_model()
model = Sequential()
model.add(Conv2D(32, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’, input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(Conv2D(64, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(Conv2D(128, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(MaxPooling2D((2, 2)))
# 输出部分
# 模型输出部分示例
model.add(Flatten())
model.add(Dense(128, activation=’relu’, kernel_initializer=’he_uniform’))
model.add(Dense(10, activation=’softmax’))
# 编译模型
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss=’categorical_crossentropy’, metrics=[‘accuracy’])
return model
# 绘制诊断学习曲线
def summarize_diagnostics(history)
# 绘制损失
pyplot.subplot(211)
pyplot.title(‘交叉熵损失’)
pyplot.plot(history.history[‘loss’], color=’blue’, label=’train’)
pyplot.plot(history.history[‘val_loss’], color=’orange’, label=’test’)
# 绘制准确率
pyplot.subplot(212)
pyplot.title(‘分类准确率’)
pyplot.plot(history.history[‘acc’], color=’blue’, label=’train’)
pyplot.plot(history.history[‘val_acc’], color=’orange’, label=’test’)
# 保存绘图到文件
filename = sys.argv[0].split(‘/’)[-1]
pyplot.savefig(filename + ‘_plot.png’)
pyplot.close()
# 运行测试工具以评估 cifar10 数据集上的模型
def run_test_harness()
# 加载数据集
trainX, trainY, testX, testY = load_dataset()
# 准备像素数据
trainX, testX = prep_pixels(trainX, testX)
# 定义模型
model = define_model()
# 拟合模型
history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
# 评估模型
_, acc = model.evaluate(testX, testY, verbose=0)
print(‘> %.3f’ % (acc * 100.0))
# 学习曲线
summarize_diagnostics(history)
# 入口点,运行测试工具
run_test_harness()
我建议不要将所有示例都用于 notebook 或 IDE
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
相反,我建议从命令行运行
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
我在这里描述
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
希望这能有所帮助。
感谢您的回复和您的网页。我也发现问题出在我身上。当我将参数(例如 epochs=1,verbose=1)放入 model.fit.generator(…,…)时,我发现模型需要超过 70 小时才能运行 epochs = 400。verbose=1 的输出太惊人了!
很高兴听到这个消息。
我还有一个最后的问题。如果你查看 https://en.wikipedia.org/wiki/CIFAR-10,你会看到 14 篇在 8 年内发表的参考文献,这些参考文献将 CIFAR-10 数据集上测试集可视化保证的不确定性从 21.1% 降低到 1%。我已经开始研究这些论文,发现大多数技术都令人望而生畏。有些提供了 Github 源代码链接,但大多数没有。作为比我更有经验的实践者,我想知道您对这些相当详细的阐述的方向和最终结果有何看法?我好奇神经网络的制定是否会有算法突破,如果会,考虑到竞争的速度,实现最佳结果的方法(以及商业回报考虑)是否意味着实现这种最佳结果的方法将成为专有的,并且不再是库可访问的开源材料?衷心感谢您的帖子。
好问题。
我看到的模式是,惊人的突破来自于复杂的定制方法,然后一些聪明的孩子找到了一种更简单、更通用的方法来做同样的事情,这成为了新常态——并被放入库/工具中。循环往复。
history = model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
—————————————————————————
NameError Traceback (最近一次调用)
in ()
1 # 拟合模型
—-> 2 model.fit(trainX, trainY, epochs=100, batch_size=64, validation_data=(testX, testY), verbose=0)
NameError: 名称“model”未定义
看起来您遗漏了一些代码行。
我有一些建议可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
这绝对是我读过的最好的文章之一。非常感谢您,Jason。
谢谢!
你的“教程”太棒了。你真的知道如何为像我这样的初学者简化它。
非常感谢
谢谢!
嗨,Jason,
关于图像多类分类的深入且非常广泛的课程..
400 个 epoch 让我的 mac pro i7 (6 核) 运行了 16 小时。
很高兴我将训练好的模型保存为“h5 文件格式”,我加载模型并重新运行了额外的 100 个 epoch,获得了 88.570 的准确率(接近您的 88.6%),但我不仅应用了您推荐的 3 种正则化器(dropout + 批量归一化 + 数据增强),还应用了权重衰减(l2)和 3 个 CNN VGG 块。
所以添加 kernel_regularizer 到前三个正则化器,甚至再训练 100 个 epoch 也不会获得更高的准确率…
我在最后一次训练历史图中看到,在总共 500 个 epoch 的最后 100 个 epoch 中,测试(但不是训练数据)性能出现了一些不稳定(准确率或损失出现超过 10% 的快速波动,但最终稳定在 88% 左右)。
对我来说,这意味着在此参数选择下(l2、可变 dropout、SGD、数据增强失真、批量归一化!)是一种渐近方法。
我预计更改为 Adam 优化器或 l1-l2 权重正则化器不会有太大改进,但如果我增加 VGG 块的数量,肯定会有所改进…
无论如何,我想尝试使用 VGG16(没有顶部层)和我自己训练的密集层分类器作为顶部来应用迁移学习改进方法…如果我得到一些结果,我会报告。
致敬
谢谢!
做得好,感谢您报告您的发现。
迁移学习将解决这个问题!
请问,我想知道如何应用迁移学习?
看这里
https://machinelearning.org.cn/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
或者更普遍地说
https://machinelearning.org.cn/how-to-improve-performance-with-transfer-learning-for-deep-learning-neural-networks/
还有一些理论
https://machinelearning.org.cn/transfer-learning-for-deep-learning/
嗨,Jason,
我对结果的解释有点困惑,但我在这里分享
1) 当我使用您的模型“VGG3”并增加了 dropout 率 + 数据增强 + 批量归一化,包括批量归一化、dropout 和 l1-l2 权重衰减时,我得到了与您相似的结果,准确率约为 88%,它需要超过 16 小时的 CPU 时间,但是
2) 当使用 VGG16(不带其顶层)作为迁移学习到我们的头部,并且使用您的数据增强配置文件和 VGG16 自己的 preprocess_input,并且我训练整个模型(VGG16 权重冻结模型 + 我们的头部)时,CPU 时间减少到 2.5 小时,但我得到了可笑的 63.6% 的准确率……我无法理解这一点……
3) 好吧,当我获得 VGG16 冻结模型(不带顶层)的输出(相同的数据增强和数据预处理)作为我们头部模型的新输入时,CPU 时间现在减少到 2 分钟(之前是 2.5 小时,因为我不再每次都通过冻结的 VGG16 模型传递输入,而只在第一次传递并保存它们),但准确率仍然在 64% 左右,所以我仍然不明白这怎么可能?如果 VGG16 训练模型比这里提出的 VGG3 好得多……
4) 我知道我很好地应用了 VGG16 模型,因为当我解冻 VGG16 的最后一个块(块号 5)(如 F. Chollet 在他的帖子中提议的那样)时,我开始获得更好的结果(仅 50 个 epoch 获得 81% 的准确率,而 400 个 epoch 获得 88% 似乎是合理的),但现在 CPU 时间攀升到 2.5 小时
5) 当我重新训练模型(当第 4 项中保存了之前的权重时)时,我仅在 50 个 epoch 内就获得了 82.3% 的准确率……
所以我认为,如果我解冻 VGG16(迁移学习)块 5(作为使用我们自己的 CIFAR 数据集重新训练模型的一种方式),我就会开始获得预期的结果路径……但单独使用 VGG16 冻结权重并将其输出注入到我们的头部模型中……并没有像预期那样在准确率和 CPU 时间方面解决问题……所以我对这种预期的迁移学习行为(无需解冻任何内部块)有点困惑……(!)
此致,
JG
有趣的发现!
也许图像大小与 Imagenet 图像大小不同,这会影响检测到的特征。
当我运行这段代码,尝试拟合时,我得到了模型未定义的错误,但如果我删除 cnn 模型中的函数,那么我得到了结果
也许你跳过了一些示例代码?
非常有用的教程!奇怪的是,当使用增强和 dropout 时,我无法复制您 83% 和 84% 的准确率,当两者都使用时,准确率正好稳定在 80%,尽管我已将架构和数据加载器几乎逐行复制到 Colab 中,并使用 Keras。
对于任何感兴趣的人,我使用递增 dropout、数据增强、Nadam 优化算法以及一个内部 Keras 函数获得了最佳结果,该函数允许您在验证损失平台时降低学习率。具体代码如下:
callbacks_list = [tf.keras.callbacks.ReduceLROnPlateau(monitor=”val_loss”, factor=0.5, patience=5)]
将以下内容插入到 history.fit 命令中
callbacks=callbacks_list
这种方法在 100 个 epoch 后始终达到 82%,且过拟合非常小。据推测,延长 epoch 数量是可行的,所以我希望在接下来的几天内通过调整它达到 88% 或更高。
抱歉回复冗长。
谢谢你制作这个,Jason!它对我非常有用!
谢谢!
也许尝试训练模型几次。
做得好。
我对图像分类使用了 4 个类别的预测,但它只给出了两个值,当我打印结果值时,它给出了 2 和 3,而不是 0 和 1,这是什么错误
import sys
import os
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
来自 keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense, Activation
from keras.layers import Conv2D, MaxPooling2D
from keras import callbacks
import time
start = time.time()
train_data_path = ‘/content/Alzheimer_s Dataset/train’
validation_data_path = ‘/content/Alzheimer_s Dataset/test’
img_width, img_height = 150, 150
batch_size = 32
samples_per_epoch = 1000
validation_steps = 300
nb_filters1 = 32
nb_filters2 = 64
conv1_size = 3
conv2_size = 2
pool_size = 2
classes_num = 4
lr = 0.0004
model = Sequential()
model.add(Conv2D(nb_filters1,kernel_size=(conv1_size, conv1_size),input_shape=(img_width, img_height,3)))
model.add(Activation(“relu”))
model.add(MaxPooling2D(pool_size=(pool_size, pool_size)))
model.add(Conv2D(nb_filters2,kernel_size=(conv2_size,conv2_size)))
model.add(Activation(“relu”))
model.add(MaxPooling2D(pool_size=(pool_size, pool_size)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation(“relu”))
model.add(Dropout(0.5))
model.add(Dense(classes_num, activation=’softmax’))
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=lr),
metrics=['accuracy'])
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_path,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode=’categorical’)
validation_generator = test_datagen.flow_from_directory(
validation_data_path,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode=’categorical’)
"""
Tensorboard 日志
"""
log_dir = ‘./tf-log/’
tb_cb = callbacks.TensorBoard(log_dir=log_dir, histogram_freq=0)
cbks = [tb_cb]
model.fit_generator(
train_generator,
samples_per_epoch=samples_per_epoch,
epochs=20,
validation_data=validation_generator,
callbacks=cbks,
validation_steps=validation_steps)
target_dir = ‘/content/gdrive/My Drive/’
if not os.path.exists(target_dir)
os.mkdir(target_dir)
model.save(‘/content/gdrive/My Drive/modelnew.h5’)
model.save_weights(‘/content/gdrive/My Drive/weights1.h5’)
#计算执行时间
end = time.time()
dur = end-start
if dur60 and dur<3600
dur=dur/60
print("执行时间:",dur,"分钟")
else
dur=dur/(60*60)
print("执行时间:",dur,"小时")
—–
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array
from keras.models import Sequential, load_model
import time
start = time.time()
# 定义路径
model_path = '/content/gdrive/My Drive/modelnew.h5'
model_weights_path = '/content/gdrive/My Drive/weights1.h5'
test_path = '/content/Alzheimer_s Dataset/test/'
# 加载预训练模型
model = load_model(model_path)
model.load_weights(model_weights_path)
# 定义图像参数
img_width, img_height = 150, 150
# 预测函数
def predict(file)
x = load_img(file, target_size=(img_width,img_height))
x = img_to_array(x)
x = np.expand_dims(x, axis=0)
array = model.predict(x)
result = array[0]
print(result)
answer = np.argmax(result)
print(answer)
if answer == 0
print("预测:轻度痴呆")
elif answer == 1
print("预测:重度痴呆")
elif answer == 2
print("预测:非痴呆")
return answer
# 遍历目录中的每个图像
for i, ret in enumerate(os.walk(test_path))
for i, filename in enumerate(ret[2])
if filename.startswith(".")
continue
print(ret[0] + '/' + filename)
result = predict(ret[0] + '/' + filename)
print(" ")
#计算执行时间
end = time.time()
dur = end-start
if dur60 and dur<3600
dur=dur/60
print("执行时间:",dur,"分钟")
else
dur=dur/(60*60)
print("执行时间:",dur,"小时")
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
这段代码需要运行多长时间?
执行速度取决于您的硬件。
在 AWS EC2 上快速运行
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
你好,我收到以下错误
ValueError: 形状 (None, 10) 和 (None, 3) 不兼容
谁能帮帮我
先谢谢了
这可能有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
不需要使用 numpy.astype(float),因为 python 在除法时可以隐式转换为浮点数。只是说说而已:)
这个网站太棒了!喜欢这些文章和教程,做得非常出色:)
谢谢。
如何打印模型的延迟,即执行所需的时间
对输入的一个批次进行推理?我应该在这里添加什么代码..
您可以使用 timeit
https://docs.pythonlang.cn/3/library/timeit.html
另一个很棒且富有启发性的案例研究。
但是我找不到抑制 load_dataset 大量打印输出的方法。
这个通用问题在 stackoverflow 上也未得到解答。(verbose=0) 不起作用。
很抱歉打扰您这么琐碎的事情,但——有什么想法吗?
谢谢。
手头没有,抱歉尼克。
所有这些库(keras、tf、sklearn)都会“倾泻”到 stdout 或 stderr。如果我在行业中编写了这样的代码,那将会引起各种麻烦。
是否可以在上述模型中实现箱线图?如果可以,如何实现?
是的,重复评估,然后使用 pyplot.boxplot() 绘制结果
你好先生,
非常感谢这类帖子,它们帮助我建立了机器学习和深度学习之旅的基础。
您能帮我澄清一个疑问吗,我们的模型由于添加了 Conv2D 层而非常健壮,但我们没有在模型中添加任何 Dropout 层。那么通过这种方法,我们的模型是否会遭受过拟合?
请就此问题发表您的看法。
谢谢
不需要 Dropout,如果你喜欢,可以添加它或其他正则化技术。
您可以通过查看学习曲线来测试您的模型是否过拟合。
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
您能给我一个代码,用于将驱动器上的数据集(即:存储在 C 驱动器中的数据集)导入到 Jupyter Notebook,而不是从 Keras 或 Tensorflow 导入到 Jupyter Notebook 吗?
是的,这将帮助您从文件中加载图像数据
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
我们的防火墙阻止执行:“from keras.datasets import cifar10”
我可以在另一台计算机上执行该命令并(以某种方式)存储在二进制文件中,然后传输到“受防火墙保护”的计算机以允许类似“(trainX, trainY), (testX, testY) = ”的操作
我忘记了如何存储和检索本地“cifar10”文件的内容。
干得不错。
或许还可以重新配置个人防火墙,以允许有效的软件开发。
我刚刚从暂时的疯狂中恢复过来。这是我自己的问题的答案
只需将 cifar-10-batches-py.tar.gz 复制到 ~.keras/datasets
很棒。
模型给定后,run_test_harness() 函数通常需要多长时间才能运行一次?
这取决于您的硬件。
感谢这篇宝贵的文章。您知道有什么论文使用 VGG16(直到此页面上提到的 block3)实现 CIFAR-10 并获得相同准确率的吗?我实现了它并获得了 83.25% 的准确率!现在我想将它添加到我的论文中,我需要一个已发表的参考文献。
没有,抱歉。
我通过稍微修改,在 300 个 epoch 中达到了 90.09% 的准确率——第一个 CNN 块是 48(而不是 32)。第二个和第三个保持不变。为什么我们必须在每个块中复制过滤器?
即
model = Sequential()
model.add(Conv2D(48, kernel_size = 3, activation=’relu’, padding=’same’, input_shape=(32, 32, 3)))
model.add(BatchNormalization())
model.add(Conv2D(48, kernel_size = 3, activation=’relu’, padding=’same’))
model.add(BatchNormalization())
model.add(Conv2D(48, kernel_size = 5, activation=’relu’, padding=’same’, strides=2))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Conv2D(64, kernel_size = 3, activation=’relu’, padding=’same’))
model.add(BatchNormalization())
model.add(Conv2D(64, kernel_size = 3, activation=’relu’, padding=’same’))
model.add(BatchNormalization())
model.add(Conv2D(64, kernel_size = 5, activation=’relu’, padding=’same’, strides=2))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Conv2D(128, kernel_size = 3, activation=’relu’, padding=’same’))
model.add(BatchNormalization())
model.add(Conv2D(128, kernel_size = 3, activation=’relu’, padding=’same’))
model.add(BatchNormalization())
model.add(Conv2D(128, kernel_size = 5, activation=’relu’, padding=’same’, strides=2))
model.add(Dropout(0.4))
model.add(Conv2D(256, kernel_size = 4, activation=’relu’, padding=’same’))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
我用这个技巧将准确率提高到了 91.08%
checkpoint = ModelCheckpoint(filepath, monitor=’val_accuracy’, save_best_only=True, mode=’max’, verbose = 0)
for i in range(0, 10)
history = model.fit(datagen.flow(X_train, y_train, batch_size=64),
validation_data=(X_test, y_test),
steps_per_epoch=len(X_train)/64,
callbacks=[checkpoint],
epochs=10, verbose = 0)
model.load_weights(filepath) # magic
干得好!
干得好!
我们不必如此,这只是一个常见的惯例。
你好
我是 Python 和深度学习的新手,但为了我的大学期末考试,我需要运行并学习一些图像数据上的深度学习样本过程。我正在使用 Google Colab 并运行您的代码(如下),但它一直运行却没有结果。我想可能是数据集加载时间太长了。所以第一个问题是,我是否正确地运行了这段代码?(我没有下载数据集,而是像您的代码那样在线加载它)
这段代码(您的代码)正在生成 final_model.h5 文件,并且需要很长时间(也许我错了)
所以如果可以的话,请帮助我简单地运行完整的代码(只需复制粘贴)来生成模型,然后在我自己的图像上重新运行已保存的模型并获得输出
谢谢。我真的是个新手,所以请原谅我。
—————————————————————
import sys
from matplotlib import pyplot
from keras.datasets import cifar10
from keras.utils import to_categorical
来自 keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.optimizers import SGD
# 加载训练和测试数据集
def load_dataset()
# 加载数据集
(trainX, trainY), (testX, testY) = cifar10.load_data()
# 独热编码目标值
trainY = to_categorical(trainY)
testY = to_categorical(testY)
return trainX, trainY, testX, testY
# 缩放像素
def prep_pixels(train, test)
# 将整数转换为浮点数
train_norm = train.astype(‘float32’)
test_norm = test.astype(‘float32′)
# 归一化到 0-1 范围
train_norm = train_norm / 255.0
test_norm = test_norm / 255.0
# 返回归一化图像
return train_norm, test_norm
# 定义cnn模型
def define_model()
model = Sequential()
model.add(Conv2D(32, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’, input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(Conv2D(64, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(Conv2D(128, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation=’relu’, kernel_initializer=’he_uniform’))
model.add(Dropout(0.2))
model.add(Dense(10, activation=’softmax’))
# 编译模型
opt = SGD(lr=0.001, momentum=0.9)
model.compile(optimizer=opt, loss=’categorical_crossentropy’, metrics=[‘accuracy’])
return model
# 绘制诊断学习曲线
def summarize_diagnostics(history)
# 绘制损失
pyplot.subplot(211)
pyplot.title(‘交叉熵损失’)
pyplot.plot(history.history[‘loss’], color=’blue’, label=’train’)
pyplot.plot(history.history[‘val_loss’], color=’orange’, label=’test’)
# 绘制准确率
pyplot.subplot(212)
pyplot.title(‘分类准确率’)
pyplot.plot(history.history[‘accuracy’], color=’blue’, label=’train’)
pyplot.plot(history.history[‘val_accuracy’], color=’orange’, label=’test’)
# 保存绘图到文件
filename = sys.argv[0].split(‘/’)[-1]
pyplot.savefig(filename + ‘_plot.png’)
pyplot.close()
# 运行测试工具以评估 cifar10 数据集上的模型
def run_test_harness_save()
# 加载数据集
trainX, trainY, testX, testY = load_dataset()
# 准备像素数据
trainX, testX = prep_pixels(trainX, testX)
# 定义模型
model = define_model()
# 拟合模型
model.fit(trainX, trainY, epochs=1, batch_size=1, verbose=0)
# 保存模型
model.save(‘final_model.h5’)
# 运行测试工具以评估 cifar10 数据集上的模型
———————————————————————
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/do-code-examples-run-on-google-colab
嗨,又是我
我试了很多次,终于运行成功了
为了快速得到答案,我在 echo 1 中测试了它,结果成功了(当然给了错误的答案)
然后我将 echo 设置为 100,并再次运行。到现在已经运行了 7 个小时!
我正在使用 google colab,所以我不认为硬件有问题
这正常吗?!
第二个问题是,我如何获得“狗”、“猫”等答案,而不是数字?
运行了将近 8 小时后保存了模型 )
准确率超过 80%
但我仍然不知道这些数字
对于汽车,我得到 5,等等……
如何获得对象名称(猫或汽车...)而不是数字?
请参阅“如何完成模型并进行预测”部分,了解如何对新照片进行预测。
干得好!
那会花很长时间。也许在 AWS EC2 实例上运行会更快
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
感谢您如此精彩的讲解!
我有一个或许很蠢(而且绝对是新手)的问题
在平坦化之后,密集层中选择 128 个单元的原因是什么,除了经验证的良好预测性能之外?无论使用 1 个、2 个还是 3 个块,128 这个值都保持不变。
我明白第二个密集层输出 10 是因为有 10 个类别,但不明白前一个层中的 128。
谢谢!
这不是一个愚蠢的问题,而是一个关键且开放的问题。
我们无法知道一个模型在数据集上的最佳配置,相反,我们必须通过反复试验来发现哪些效果好/最好。
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
你好 jason,
我正在尝试使用这个数据集解决一个 11 类别图像分类问题:https://www.kaggle.com/mikewallace250/tiny-imagenet-challenge/tasks?taskId=2535。
我尝试了您的模型架构,并使用了数据增强、不同的 dropout、批量归一化。但准确率没有超过 65%。您能建议如何改进吗?
我的训练代码
import os
import tensorflow as tf
from tensorflow import keras
from keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
#from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers import Dense
from keras.layers.convolutional import MaxPooling2D
from keras.layers import Flatten
from keras.layers import Dropout
from keras.layers import BatchNormalization
from keras.optimizers import SGD
os.environ[“CUDA_VISIBLE_DEVICES”] = ‘0’
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
‘TinyImageNet/train’,
target_size=(256, 256),
batch_size=32,
classes= [‘0′,’3′,’6′,’7′,’10’,’11’,’12’,’13’,’18’,’19’,’21’],
class_mode=’categorical’)
classes = train_generator.class_indices
inverted_classes = dict(map(reversed, classes.items()))
print(inverted_classes)
validation_generator = test_datagen.flow_from_directory(
‘TinyImageNet/val’,
target_size=(256, 256),
batch_size=32,
classes= [‘0′,’3′,’6′,’7′,’10’,’11’,’12’,’13’,’18’,’19’,’21’],
class_mode=’categorical’)
classifier = Sequential()
classifier.add(Convolution2D(filters = 32,padding=’same’,kernel_size = (3,3), activation = ‘relu’, input_shape = (256,256,3)))
classifier.add(Convolution2D(32,(3,3),activation = ‘relu’, padding=’same’))
classifier.add(MaxPooling2D(pool_size = (2,2), strides=2))
classifier.add(Dropout(0.2))
classifier.add(Convolution2D(64,(3,3),activation = ‘relu’))
classifier.add(Convolution2D(64,(3,3),activation = ‘relu’))
classifier.add(MaxPooling2D(pool_size = (2,2), strides=2))
classifier.add(Dropout(0.3))
classifier.add(Convolution2D(128,(3,3),activation = ‘relu’))
classifier.add(Convolution2D(128,(3,3),activation = ‘relu’))
classifier.add(MaxPooling2D(pool_size = (2,2), strides=2))
classifier.add(Dropout(0.4))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = ‘relu’))
classifier.add(Dropout(0.5))
classifier.add(Dense(units = 11 , activation = ‘softmax’))
opt = SGD(lr=0.2, momentum=0.9)
classifier.compile(optimizer = opt, loss = ‘categorical_crossentropy’, metrics = [‘categorical_accuracy’,’accuracy’])
classifier.summary()
classifier.fit_generator(train_generator,validation_data=validation_generator, epochs = 100, steps_per_epoch = 60)
print(“Training Completed….”)
classifier.save(“model_1.h5”)
print(“Model saved Successfully…”)
我的测试代码
import numpy as np
import tensorflow as tf
from keras.preprocessing.image import ImageDataGenerator
from keras.preprocessing import image
from keras.models import load_model
from sklearn.metrics import confusion_matrix, accuracy_score
import matplotlib.pyplot as plt
import cv2
test_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = test_datagen.flow_from_directory(
‘TinyImageNet/val’,
target_size=(256, 256),
batch_size=10,
classes= [‘0′,’3′,’6′,’7′,’10’,’11’,’12’,’13’,’18’,’19’,’21’],
class_mode=’categorical’,
shuffle=False)
model = load_model(‘model_5.h5′)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print(“model loaded”)
classes = validation_generator.class_indices
filenames = validation_generator.filenames
nb_samples = len(filenames)
print(nb_samples)
validation_generator.reset()
pred= model.predict_generator(validation_generator, nb_samples,verbose=1)
predicted_class_indices=np.argmax(pred,axis=1)
labels=validation_generator.class_indices
for i in labels
print(labels[i])
labels2=dict((v,k) for k,v in labels.items())
predictions=[labels2[k] for k in predicted_class_indices]
print(“prediction class are : “, predicted_class_indices)
print(“labels are : “, labels)
print(“predictions: “, predictions[:5])
loss, acc = model.evaluate_generator(validation_generator, verbose=1)
print(‘loss: ‘, loss, ‘accuracy: ‘, acc*100)
pred = np.array([np.argmax(x) for x in pred])
y_test = validation_generator.classes[validation_generator.index_array]
print(‘accuracy_score: ‘, (accuracy_score(y_test, pred)*100))
cm = confusion_matrix(y_test, pred)
cm = cm.astype(‘float’) / cm.sum(axis=1)[:, np.newaxis]
print(cm)
cm.diagonal()
acc_each_class = cm.diagonal()
print(‘accuracy of each class: \n’)
for i in range(len(classes))
print(acc_each_class[i])
img_rows = 256
img_cols = 256
#model = load_model(‘model_1.h5’)
file = ‘0_1000.jpg’
img = cv2.cvtColor(cv2.imread(file),cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (img_rows,img_cols))
test_image = image.img_to_array(img)
test_image = np.expand_dims(test_image, axis=0)
prediction = model.predict(test_image)
print(prediction)
我推荐使用这里的技术来诊断神经网络问题并提高模型性能。
https://machinelearning.org.cn/start-here/#better
使用 testX 和 testY 进行模型评估预测,所以您是使用“已见过”的数据而不是“未见过”的数据来预测模型?
因为您将测试集用作验证数据。
我的问题是,使用“已见过”的数据作为评估/预测,是否可以说我们的模型足够好(没有过拟合)?
不完全是,我们正在评估模型在训练期间未使用的数据上的表现。
理想情况下,我们应该使用验证数据集来调整模型。
https://machinelearning.org.cn/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset
我用 40 个 epoch 训练了我的模型,但是当我尝试用一些图像进行预测时,所有图像的结果都等于 4,我的模型出了什么问题,请帮助我
这里的教程将帮助您诊断模型问题并提供提高模型性能的技术。
https://machinelearning.org.cn/start-here/#better
做得太棒了,恭喜!
谢谢!
你好,Jason。
对目标变量进行独热编码的原因是什么?
谢谢,
维迪亚
这样模型可以学习输入到输出类别标签的多项式概率分布。
例如,这就是我们建模多类别问题的方式。
谢谢您的回复。
我尝试了不对目标变量进行独热编码。我能够预测测试图像的每个类别的概率。基于此,我预测了类别,如下所示
例如
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
print(predictions.shape)
print(predictions[0])
## 根据概率最大值,预测类别。
test_predicted_labels = []
for i in range(len(predictions))
pred_label = np.argmax(predictions[i])
test_predicted_labels.append(pred_label)
这是输出。
—————–
(10000, 10)
[0.08861145 0.08834625 0.08928947 0.1760501 0.08857722 0.10344525
0.08981362 0.08847508 0.09888937 0.08850213]
使用上面的 test_predicted_labels,我打印了分类报告。
我遗漏了什么吗?独热编码目标会带来什么好处?
谢谢!
这与好处无关,它是使用分类交叉熵损失建模多类别分类问题的要求。
也许我们是在各说各话?
明白了!谢谢 Jason。
嗨,Jason,
感谢您对基线模型改进提出的这些精彩建议。我想请教一下,使用测试数据作为模型训练的验证数据是否会导致数据泄露。
谢谢
是的,会的,我在这里有更详细的解释
https://machinelearning.org.cn/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset
感谢详细信息。我将准确率从 73% 提高到 85%
干得好!
Brownlee 先生,文章写得真棒。
只有一个问题。
除了对目标变量进行独热编码,您本可以使用 sparse_categorical_crossentropy 损失。您没有采用这种方法有什么特别原因吗?
谢谢!
不完全是。你可以使用任何你喜欢的编码方式。
很棒的介绍,有没有办法达到 ~99% 的准确率?
也许您知道不同的架构可以做到这一点
也许可以。
是的,请参阅以下一些提示
https://machinelearning.org.cn/start-here/#better
嗨,Jason,
非常好的教程,如果您不介意,我有一些改进建议
1. 使用纯代码而不是像 [1]、[2] 中那样的函数。这有助于初学者更清晰地理解内容,并使其更容易将代码移植到其他工具(例如 PyTorch)。
2. 添加笔记本版本,例如 google colab 来运行和测试代码,这有助于避免调试或回答调试问题(我已经创建了一个 colab 笔记本,如果您喜欢,我可以与您分享)。
3. 也许可以以相同的教程为基础,制作另一个教程,更详细地解释不同的训练曲线、它们的含义以及如何修改模型以获得更好的性能。
[1] https://tensorflowcn.cn/guide/keras/writing_a_training_loop_from_scratch
[2] https://medium.com/analytics-vidhya/write-your-own-custom-data-generator-for-tensorflow-keras-1252b64e41c3
感谢您的建议!
非常感谢先生……我通过关注您的 MACHINE LEARNING MASTERY 开启了我的机器学习之旅
如果可能的话,您能否制作一个关于使用深度学习预测药物-疾病关联的教程
抱歉,我们没有相关的领域知识。如果您能获取数据,您可以尝试将其他教程中的代码应用于此,看看是否能奏效。
我有一个问题
为什么权重衰减技术不适用于此模型?
谢谢你!
嗨,我用一个新颖的架构,只有 2M 个参数,没有在 CIFAR-10 上进行任何额外的数据增强,在 100 个 epoch 后,训练数据集上达到了 98.88% 的准确率,验证数据集上达到了 74.0% 的准确率。您认为值得进一步研究吗?
训练准确率似乎有点低,但我不太确定。因为您能达到的最佳效果取决于您的模型架构。
Jason 先生,您的工作非常出色!我可以在 MLP 网络中应用相同的技术(dropout、数据增强、批量归一化)吗?您对 CIFAR10 数据集的 MLP 架构有什么建议?
您好,非常棒的工作!我可以在 MLP 网络中应用相同的技术(dropout、数据增强、批量归一化)吗?您对 MLP 架构,特别是针对 Cifar10 数据集有什么建议?
嗨 Efe……以下内容可能对您有帮助。
https://pvss.github.io/MLP+of+CIFAR-10
此致,
你好。谢谢你的网站。我训练了我的网络并获得了 88% 的准确率。然后,当我运行预测时,我的网络输出只检测到鹿。你检查过其他图片并查看你网络的答案吗?
嗨 Xavier……以下内容可能会有所帮助
https://stats.stackexchange.com/questions/198463/how-to-increase-accuracy-of-all-cnn-c-on-cifar-10-test-set
这段代码会留下
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Input, Conv2D, Dense, Flatten, Dropout
from tensorflow.keras.layers import GlobalMaxPooling2D, MaxPooling2D
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.models import Model
这个错误
from tensorflow.keras.layers import Input, Conv2D, Dense, Flatten, Dropout
ModuleNotFoundError: No module named ‘tensorflow.keras’
但是当我尝试安装它时
pip install tensorflow.keras
它会给出另一个错误
ERROR: Could not find a version that satisfies the requirement tensorflow.keras (from versions: none)
ERROR: No matching distribution found for tensorflow.keras
嗨,Sampath……在您排查本地安装问题时,可以尝试使用 Google Colab 来继续进行您的模型开发。
https://machinelearning.org.cn/google-colab-for-machine-learning-projects/
你好!
您如何计算您报告的准确率?您报告的是不同训练的平均值还是不同训练中最好的一个?
嗨,约翰……有很多方法,例如以下方法:
要从多次执行中确定 CNN(卷积神经网络)分类器的准确性,您可以遵循以下步骤:
1. **交叉验证**:执行交叉验证,通常使用 K 折交叉验证,在数据集的不同子集上训练和测试您的模型。这有助于确保模型在各种未见过的数据样本上表现良好。
2. **重复运行**:多次训练和测试 CNN(重复运行),以平均由不同的权重初始化或数据分区引起的变异性。
3. **记录指标**:每次运行模型时,记录关键性能指标,如准确性、精确度、召回率和 F1 分数。这些指标将提供对性能的全面视图。
4. **平均结果**:计算所有运行中这些指标的平均值和标准差,以评估模型的整体性能和稳定性。
5. **置信区间**:为您的准确性估计建立置信区间,以了解模型的真实准确性可能落入的范围。
通过遵循这些步骤,您可以可靠地估计您的 CNN 分类器的准确性和鲁棒性,确保它在不同数据集和初始化条件下始终如一地表现。
感谢您的回答。
我想知道您是如何计算的,因为我正在尝试复现教程的准确率结果。例如,当您在第二个基线模型中声明获得了 71.080 的准确率时。这个 71.080 是如何计算出来的?
提前感谢您的回答