如何从头开始开发卷积神经网络以进行MNIST手写数字分类。
MNIST手写数字分类问题是计算机视觉和深度学习中使用的标准数据集。
尽管该数据集已经得到了有效的解决,但它可以用作学习和练习如何从头开始开发、评估和使用卷积深度学习神经网络进行图像分类的基础。这包括如何开发一个健壮的测试工具来估计模型性能,如何探索模型改进,以及如何保存模型并在稍后加载它以对新数据进行预测。
在本教程中,您将学习如何从头开始开发一个卷积神经网络来对手写数字进行分类。
完成本教程后,您将了解:
- 如何开发一个测试工具,以对模型进行稳健评估,并为分类任务建立性能基线。
- 如何探索基线模型的扩展以改进学习和模型容量。
- 如何开发一个最终模型,评估最终模型的性能,并使用它对新图像进行预测。
通过我的新书 《计算机视觉深度学习》 开启您的项目,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于2019年12月:为TensorFlow 2.0和Keras 2.3更新了示例。
- 更新于2020年1月:修复了模型在交叉验证循环外部定义的错误。
- 更新于2021年11月:更新为使用TensorFlow 2.6

如何从头开始开发卷积神经网络以进行MNIST手写数字分类
照片由 Richard Allaway 拍摄,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- MNIST手写数字分类数据集
- 模型评估方法
- 如何开发基线模型
- 如何开发改进模型
- 如何完成模型并进行预测
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
开发环境
本教程假设您使用的是独立的Keras,运行在TensorFlow之上,使用Python 3。如果您需要有关设置开发环境的帮助,请参阅本教程
MNIST手写数字分类数据集
MNIST 数据集是修改后的美国国家标准与技术研究所数据集的缩写。
这是一个包含60,000个28x28像素的灰度手写数字(0到9)的微小正方形图像的数据集。
任务是将给定的手写数字图像分类到 10 个类别中的一个,这些类别代表从 0 到 9(包括 0 和 9)的整数值。
这是一个被广泛使用且深入理解的数据集,在很大程度上已经被“解决”了。表现最好的模型是深度学习卷积神经网络,在保留的测试数据集上可以达到99%以上的分类准确率,错误率在0.4%到0.2%之间。
下面的示例使用Keras API加载MNIST数据集,并绘制训练数据集中前九张图像的图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 加载 mnist 数据集示例 from tensorflow.keras.datasets import mnist from matplotlib import pyplot as plt # 加载数据集 (trainX, trainy), (testX, testy) = mnist.load_data() # 总结已加载的数据集 print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape)) print('Test: X=%s, y=%s' % (testX.shape, testy.shape)) # 绘制前几张图片 for i in range(9): # 定义子图 plt.subplot(330 + 1 + i) # 绘制原始像素数据 plt.imshow(trainX[i], cmap=plt.get_cmap('gray')) # 显示图 plt.show() |
运行该示例会加载MNIST的训练和测试数据集,并打印它们的形状。
我们可以看到训练数据集中有 60,000 个样本,测试数据集中有 10,000 个样本,并且图像确实是 28x28 像素的正方形。
|
1 2 |
训练集:X=(60000, 28, 28), y=(60000,) 测试集:X=(10000, 28, 28), y=(10000,) |
还会创建数据集中前九张图像的图,展示了要分类图像的自然手写特征。

MNIST数据集图像子集的图
模型评估方法
尽管MNIST数据集已经得到了有效的解决,但它可以作为开发和实践使用卷积神经网络解决图像分类任务的方法论的一个有用的起点。
我们可以从头开始开发一个新模型,而不是回顾关于数据集上表现良好的模型的文献。
该数据集已经有一个定义好的训练集和测试集供我们使用。
为了估计模型在给定训练运行中的性能,我们可以将训练集进一步划分为训练集和验证集。然后可以绘制每个运行中模型在训练集和验证集上的性能,以提供学习曲线和对模型学习情况的洞察。
Keras API通过在训练模型时向`model.fit()`函数指定“validation_data”参数来支持这一点,该参数将返回一个对象,该对象描述了模型在每个训练时期在选定的损失和指标上的性能。
|
1 2 |
# 在训练期间记录模型在验证集上的性能 history = model.fit(..., validation_data=(valX, valY)) |
为了普遍估计模型在问题上的性能,我们可以使用k折交叉验证,可能是五折交叉验证。这将考虑模型在训练集和测试集差异方面的方差,以及学习算法的随机性。模型性能可以取为k折的平均性能,并给出标准差,如果需要,可以用来估计置信区间。
我们可以使用scikit-learn API中的KFold类来实现给定神经网络模型的k折交叉验证评估。有许多方法可以实现这一点,尽管我们可以选择一种灵活的方法,即仅使用`KFold`类来指定每个拆分的行索引。
|
1 2 3 4 5 6 7 8 |
# 神经网络的k折交叉验证示例 数据 = ... # 准备交叉验证 kfold = KFold(5, shuffle=True, random_state=1) # 枚举划分 for train_ix, test_ix in kfold.split(data): model = ... ... |
我们将保留实际的测试数据集,并将其作为最终模型的评估。
如何开发基线模型
第一步是开发一个基线模型。
这是至关重要的,因为它既涉及开发测试工具的基础设施,以便我们设计的任何模型都能在数据集上进行评估,又通过模型在问题上的性能建立了基线,所有改进都可以与之进行比较。
测试工具的设计是模块化的,我们可以为每个部分开发一个单独的函数。这允许我们根据需要单独修改或替换测试工具的某个方面,而不影响其他部分。
我们可以用五个关键元素来开发这个测试工具。它们是数据集的加载、数据集的准备、模型的定义、模型的评估和结果的呈现。
加载数据集
我们对数据集有一些了解。
例如,我们知道图像都是预先对齐的(例如,每张图像只包含一个手绘数字),图像的大小都是相同的28x28像素正方形,并且图像是灰度的。
因此,我们可以加载图像并将数据数组重塑为具有单个颜色通道。
|
1 2 3 4 5 |
# 加载数据集 (trainX, trainY), (testX, testY) = mnist.load_data() # 将数据集重塑为单通道 trainX = trainX.reshape((trainX.shape[0], 28, 28, 1)) testX = testX.reshape((testX.shape[0], 28, 28, 1)) |
我们还知道有 10 个类别,并且这些类别表示为唯一的整数。
因此,我们可以对每个样本的类别元素使用one-hot编码,将整数转换为一个10个元素的二进制向量,其中类值索引为1,其他所有类为0。我们可以使用`to_categorical()`实用函数来实现这一点。
|
1 2 3 |
# 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) |
load_dataset() 函数实现了这些行为,可用于加载数据集。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = mnist.load_data() # 将数据集重塑为单通道 trainX = trainX.reshape((trainX.shape[0], 28, 28, 1)) testX = testX.reshape((testX.shape[0], 28, 28, 1)) # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY |
准备像素数据
我们知道数据集中每张图像的像素值是在0到255之间的无符号整数,代表黑色到白色。
我们不知道如何最好地缩放像素值进行建模,但我们知道需要进行某种缩放。
一个好的起点是归一化灰度图像的像素值,例如将它们缩放到[0,1]的范围。这包括首先将数据类型从无符号整数转换为浮点数,然后将像素值除以最大值。
|
1 2 3 4 5 6 |
# 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到 0-1 范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 |
下面的`prep_pixels()`函数实现了这些行为,它接收需要缩放的训练集和测试集的像素值。
|
1 2 3 4 5 6 7 8 9 10 |
# 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm |
此函数必须在任何建模之前调用,以准备像素值。
定义模型
接下来,我们需要为该问题定义一个基线卷积神经网络模型。
该模型有两个主要方面:由卷积层和池化层组成的特征提取前端,以及将进行预测的分类器后端。
对于卷积前端,我们可以从一个带有较小滤波器尺寸(3,3)和适中滤波器数量(32)的卷积层开始,然后是一个最大池化层。然后可以将滤波器图展平,为分类器提供特征。
鉴于该问题是一个多类别分类任务,我们知道需要一个具有10个节点的输出层来预测图像属于这10个类别中每个类别的概率分布。这也将需要使用softmax激活函数。在特征提取器和输出层之间,我们可以添加一个全连接层来解释特征,这里使用100个节点。
所有层都将使用ReLU激活函数和He权重初始化方案,这两者都是最佳实践。
我们将使用一个保守的随机梯度下降优化器配置,学习率为0.01,动量为0.9。将优化分类交叉熵损失函数,这适用于多类别分类,我们将监控分类准确率指标,这在10个类别中示例数量相等的情况下是合适的。
下面的`define_model()`函数将定义并返回此模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(100, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(learning_rate=0.01, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
评估模型
定义模型后,我们需要对其进行评估。
模型将使用五折交叉验证进行评估。选择k=5是为了提供重复评估的基线,并且不会因为运行时间过长而导致k值过大。每个测试集将占训练数据集的20%,或约12,000个示例,接近该问题实际测试集的大小。
在进行划分之前,训练数据集会被打乱,并且每次都会进行样本打乱,以便我们评估的任何模型在每个折叠中都具有相同的训练集和测试集,从而为模型之间的比较提供公平的基准。
我们将为基线模型训练10个训练周期,默认批大小为32个示例。每个折叠的测试集将用于在训练运行的每个周期中评估模型,以便我们以后可以创建学习曲线,并在运行结束时用于估计模型性能。因此,我们将跟踪每个运行产生的历史记录以及该折叠的分类准确率。
下面的`evaluate_model()`函数实现了这些行为,它将训练数据集作为参数,并返回可以稍后总结的准确率分数和训练历史列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 使用k折交叉验证评估模型 def evaluate_model(dataX, dataY, n_folds=5): scores, histories = list(), list() # 准备交叉验证 kfold = KFold(n_folds, shuffle=True, random_state=1) # 枚举划分 for train_ix, test_ix in kfold.split(dataX): # 定义模型 model = define_model() # 选择训练和测试的行 trainX, trainY, testX, testY = dataX[train_ix], dataY[train_ix], dataX[test_ix], dataY[test_ix] # 拟合模型 history = model.fit(trainX, trainY, epochs=10, batch_size=32, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 存储分数 scores.append(acc) histories.append(history) return scores, histories |
5. 呈现结果
模型评估完成后,我们可以呈现结果。
需要呈现两个关键方面:模型在训练过程中的学习行为诊断和模型性能的估计。这些可以使用单独的函数来实现。
首先,诊断包括创建折线图,显示模型在k折交叉验证的每个折叠中在训练集和测试集上的性能。这些图对于了解模型是否过拟合、欠拟合或与数据集匹配良好非常有用。
我们将创建一个包含两个子图的图形,一个用于损失,一个用于准确率。蓝色线条表示模型在训练集上的性能,橙色线条表示在保留测试集上的性能。下面的`summarize_diagnostics()`函数根据收集的训练历史创建并显示此图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 绘制诊断学习曲线 def summarize_diagnostics(histories): for i in range(len(histories)): # 绘制损失 plt.subplot(2, 1, 1) plt.title('Cross Entropy Loss') plt.plot(histories[i].history['loss'], color='blue', label='train') plt.plot(histories[i].history['val_loss'], color='orange', label='test') # 绘制准确率 plt.subplot(2, 1, 2) plt.title('Classification Accuracy') plt.plot(histories[i].history['accuracy'], color='blue', label='train') plt.plot(histories[i].history['val_accuracy'], color='orange', label='test') plt.show() |
接下来,可以通过计算均值和标准差来汇总每次交叉验证过程中收集到的分类准确率分数。这提供了对在该数据集上训练的模型平均预期性能的估计,并对均值的平均方差进行了估计。我们还将通过创建和显示箱须图来汇总分数的分布。
下面的 summarize_performance() 函数实现了给定模型评估期间收集的分数列表的此功能。
|
1 2 3 4 5 6 7 |
# 总结模型性能 def summarize_performance(scores): # 打印摘要 print('Accuracy: mean=%.3f std=%.3f, n=%d' % (mean(scores)*100, std(scores)*100, len(scores))) # box and whisker plots of results plt.boxplot(scores) plt.show() |
完整示例
我们需要一个函数来驱动测试工具。
这包括调用所有已定义的函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 评估模型 scores, histories = evaluate_model(trainX, trainY) # 学习曲线 summarize_diagnostics(histories) # summarize estimated performance summarize_performance(scores) |
现在我们拥有了所需的一切;基准卷积神经网络模型在 MNIST 数据集上的完整代码示例列示如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
# baseline cnn model for mnist from numpy import mean from numpy import std from matplotlib import pyplot as plt from sklearn.model_selection import KFold from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.optimizers import SGD # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = mnist.load_data() # 将数据集重塑为单通道 trainX = trainX.reshape((trainX.shape[0], 28, 28, 1)) testX = testX.reshape((testX.shape[0], 28, 28, 1)) # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(100, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(learning_rate=0.01, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 使用k折交叉验证评估模型 def evaluate_model(dataX, dataY, n_folds=5): scores, histories = list(), list() # 准备交叉验证 kfold = KFold(n_folds, shuffle=True, random_state=1) # 枚举划分 for train_ix, test_ix in kfold.split(dataX): # 定义模型 model = define_model() # 选择训练和测试的行 trainX, trainY, testX, testY = dataX[train_ix], dataY[train_ix], dataX[test_ix], dataY[test_ix] # 拟合模型 history = model.fit(trainX, trainY, epochs=10, batch_size=32, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 存储分数 scores.append(acc) histories.append(history) return scores, histories # 绘制诊断学习曲线 def summarize_diagnostics(histories): for i in range(len(histories)): # 绘制损失 plt.subplot(2, 1, 1) plt.title('Cross Entropy Loss') plt.plot(histories[i].history['loss'], color='blue', label='train') plt.plot(histories[i].history['val_loss'], color='orange', label='test') # 绘制准确率 plt.subplot(2, 1, 2) plt.title('Classification Accuracy') plt.plot(histories[i].history['accuracy'], color='blue', label='train') plt.plot(histories[i].history['val_accuracy'], color='orange', label='test') plt.show() # 总结模型性能 def summarize_performance(scores): # 打印摘要 print('Accuracy: mean=%.3f std=%.3f, n=%d' % (mean(scores)*100, std(scores)*100, len(scores))) # box and whisker plots of results plt.boxplot(scores) plt.show() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 评估模型 scores, histories = evaluate_model(trainX, trainY) # 学习曲线 summarize_diagnostics(histories) # summarize estimated performance summarize_performance(scores) # 入口点,运行测试工具 run_test_harness() |
运行示例会打印交叉验证过程中每次折叠的分类准确率。这有助于了解模型评估的进展情况。
注意:您的结果可能会有所不同,具体取决于算法或评估过程的随机性,或者数值精度的差异。考虑多次运行示例并比较平均结果。
我们可以看到模型在两种情况下达到了完美的技能,在一种情况下达到了低于 98% 的准确率。这些都是不错的结果。
|
1 2 3 4 5 |
> 98.550 > 98.600 > 98.642 > 98.850 > 98.742 |
接下来,将显示一个诊断图,从而深入了解模型在每次折叠中的学习行为。
在这种情况下,我们可以看到模型通常能获得良好的拟合,训练和测试学习曲线收敛。没有明显的过拟合或欠拟合迹象。
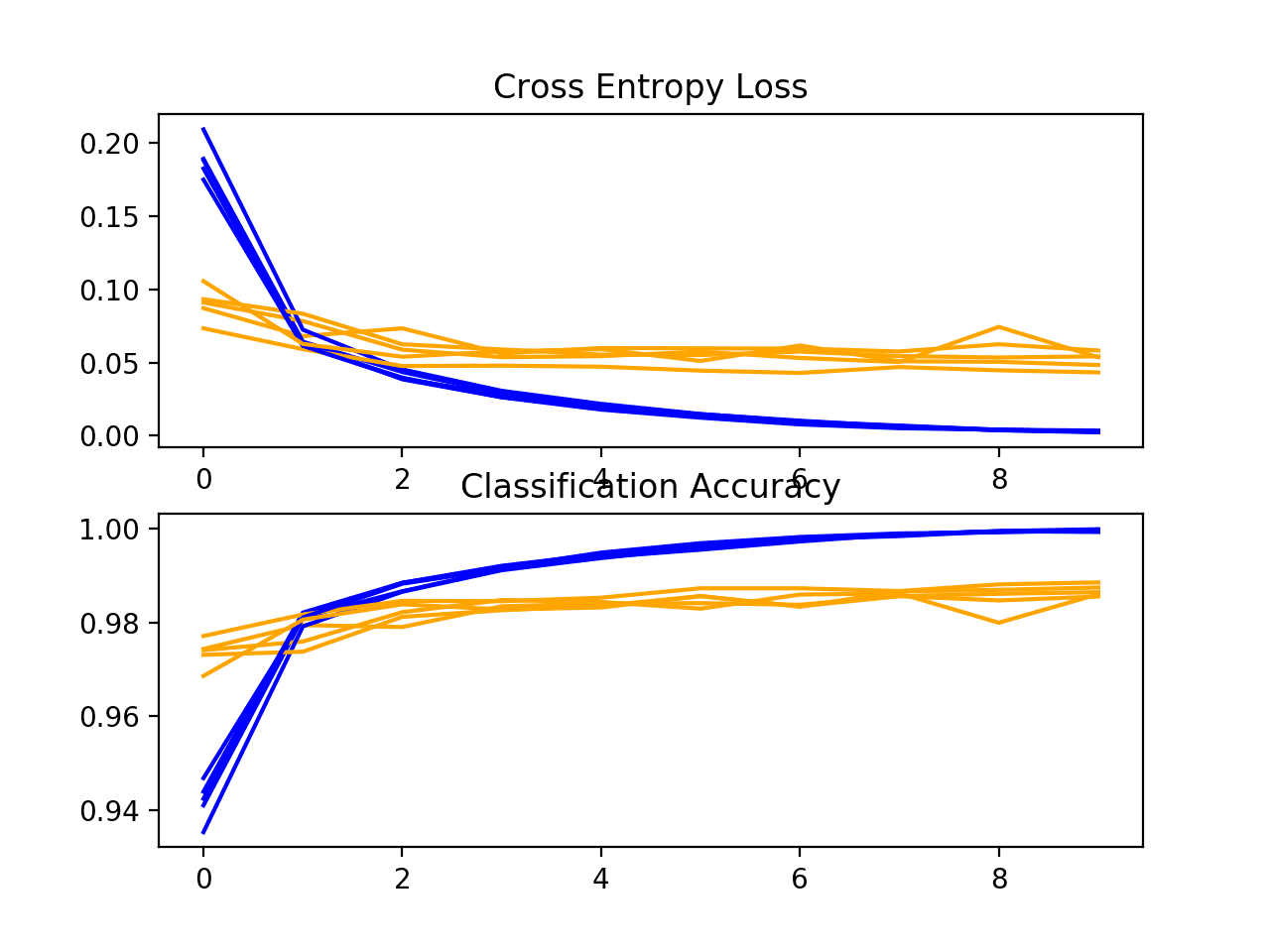
k 交叉验证期间基准模型损失和准确率学习曲线
接下来,将计算模型性能的摘要。
我们看到在这种情况下,模型的估计技能约为 98.6%,这是合理的。
|
1 |
Accuracy: mean=98.677 std=0.107, n=5 |
最后,将创建箱须图来汇总准确率分数的分布。
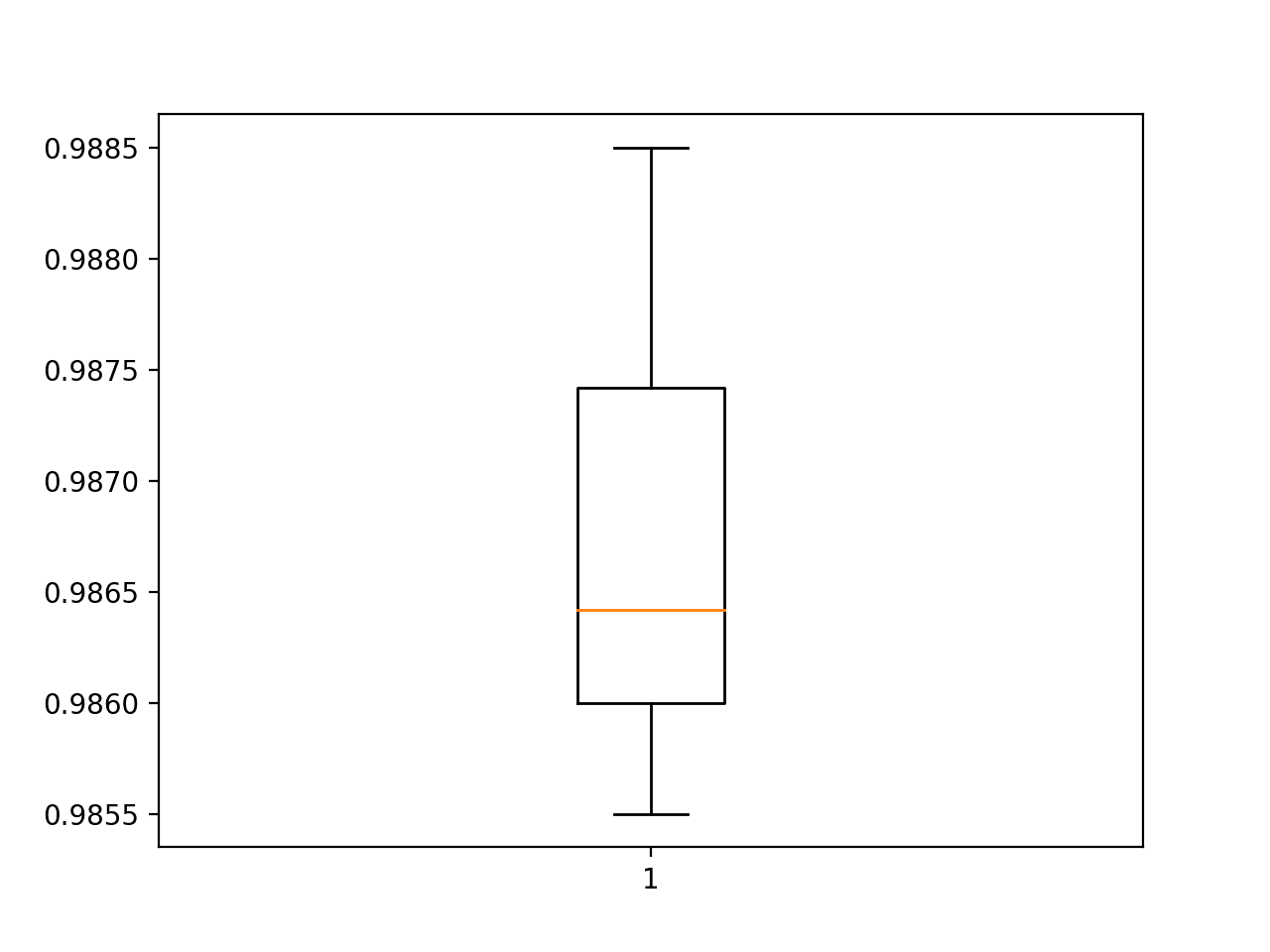
使用 k 交叉验证评估的基准模型准确率分数的箱须图
现在我们有了一个健壮的测试框架和一个性能良好的基准模型。
如何开发改进模型
我们可以通过多种方式探索基准模型的改进。
我们将研究模型配置中通常会带来改进的领域,即所谓的“低垂的果实”。第一个是学习算法的更改,第二个是模型深度的增加。
学习的改进
学习算法的许多方面都可以进行探索以求改进。
也许最重要的杠杆点是学习率,例如评估更小或更大的学习率值的影响,以及在训练期间改变学习率的计划。
另一种可以快速加速模型学习并带来巨大性能改进的方法是批量归一化。我们将评估批量归一化对我们的基准模型的影响。
批量归一化可以在卷积层和全连接层之后使用。它具有改变层输出分布的效果,特别是通过标准化输出来实现。这有助于稳定和加速学习过程。
我们可以更新模型定义,在卷积层和密集层的激活函数后使用批量归一化。下面列出了带有批量归一化的 define_model() 函数的更新版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(100, activation='relu', kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(learning_rate=0.01, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
完整的代码列表(包括此更改)如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
# cnn model with batch normalization for mnist from numpy import mean from numpy import std from matplotlib import pyplot as plt from sklearn.model_selection import KFold from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.optimizers import SGD from tensorflow.keras.layers import BatchNormalization # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = mnist.load_data() # 将数据集重塑为单通道 trainX = trainX.reshape((trainX.shape[0], 28, 28, 1)) testX = testX.reshape((testX.shape[0], 28, 28, 1)) # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)) model.add(BatchNormalization()) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(100, activation='relu', kernel_initializer='he_uniform')) model.add(BatchNormalization()) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(learning_rate=0.01, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 使用k折交叉验证评估模型 def evaluate_model(dataX, dataY, n_folds=5): scores, histories = list(), list() # 准备交叉验证 kfold = KFold(n_folds, shuffle=True, random_state=1) # 枚举划分 for train_ix, test_ix in kfold.split(dataX): # 定义模型 model = define_model() # 选择训练和测试的行 trainX, trainY, testX, testY = dataX[train_ix], dataY[train_ix], dataX[test_ix], dataY[test_ix] # 拟合模型 history = model.fit(trainX, trainY, epochs=10, batch_size=32, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 存储分数 scores.append(acc) histories.append(history) return scores, histories # 绘制诊断学习曲线 def summarize_diagnostics(histories): for i in range(len(histories)): # 绘制损失 plt.subplot(2, 1, 1) plt.title('Cross Entropy Loss') plt.plot(histories[i].history['loss'], color='blue', label='train') plt.plot(histories[i].history['val_loss'], color='orange', label='test') # 绘制准确率 plt.subplot(2, 1, 2) plt.title('Classification Accuracy') plt.plot(histories[i].history['accuracy'], color='blue', label='train') plt.plot(histories[i].history['val_accuracy'], color='orange', label='test') plt.show() # 总结模型性能 def summarize_performance(scores): # 打印摘要 print('Accuracy: mean=%.3f std=%.3f, n=%d' % (mean(scores)*100, std(scores)*100, len(scores))) # box and whisker plots of results plt.boxplot(scores) plt.show() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 评估模型 scores, histories = evaluate_model(trainX, trainY) # 学习曲线 summarize_diagnostics(histories) # summarize estimated performance summarize_performance(scores) # 入口点,运行测试工具 run_test_harness() |
再次运行示例会报告交叉验证过程中每次折叠的模型性能。
注意:您的结果可能会有所不同,具体取决于算法或评估过程的随机性,或者数值精度的差异。考虑多次运行示例并比较平均结果。
我们可以看到,与基准模型相比,模型性能可能略有下降。
|
1 2 3 4 5 |
> 98.475 > 98.608 > 98.683 > 98.783 > 98.667 |
将创建学习曲线图,在此图中显示学习速度(每个 epoch 的改进)似乎与基准模型没有区别。
这些图表明,批量归一化(至少在此实现中)没有提供任何好处。
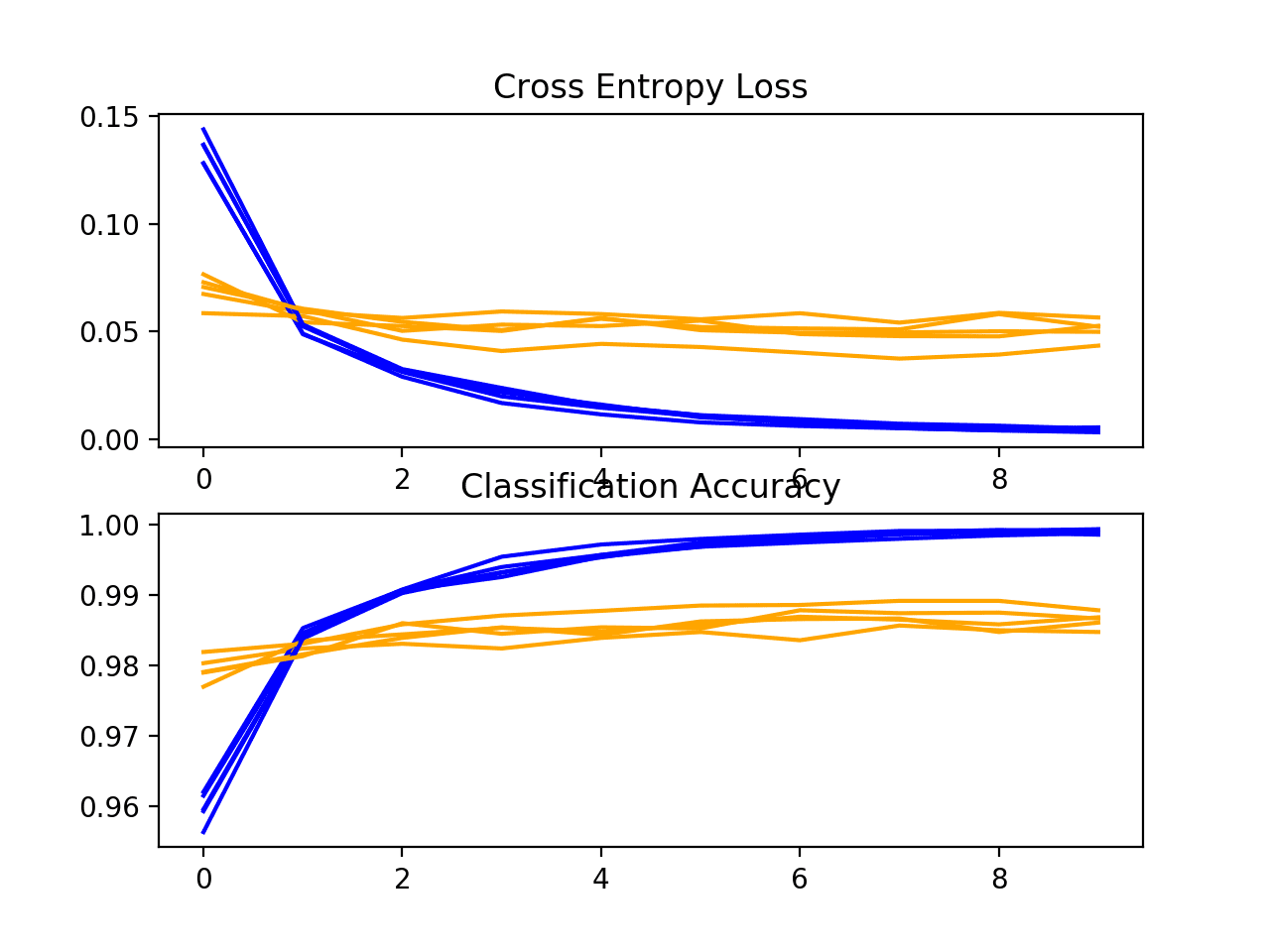
k 交叉验证期间 BatchNormalization 模型损失和准确率学习曲线
接下来,将展示模型的估计性能,显示模型平均准确率略有下降:与基准模型的 98.677 相比为 98.643。
|
1 |
Accuracy: mean=98.643 std=0.101, n=5 |
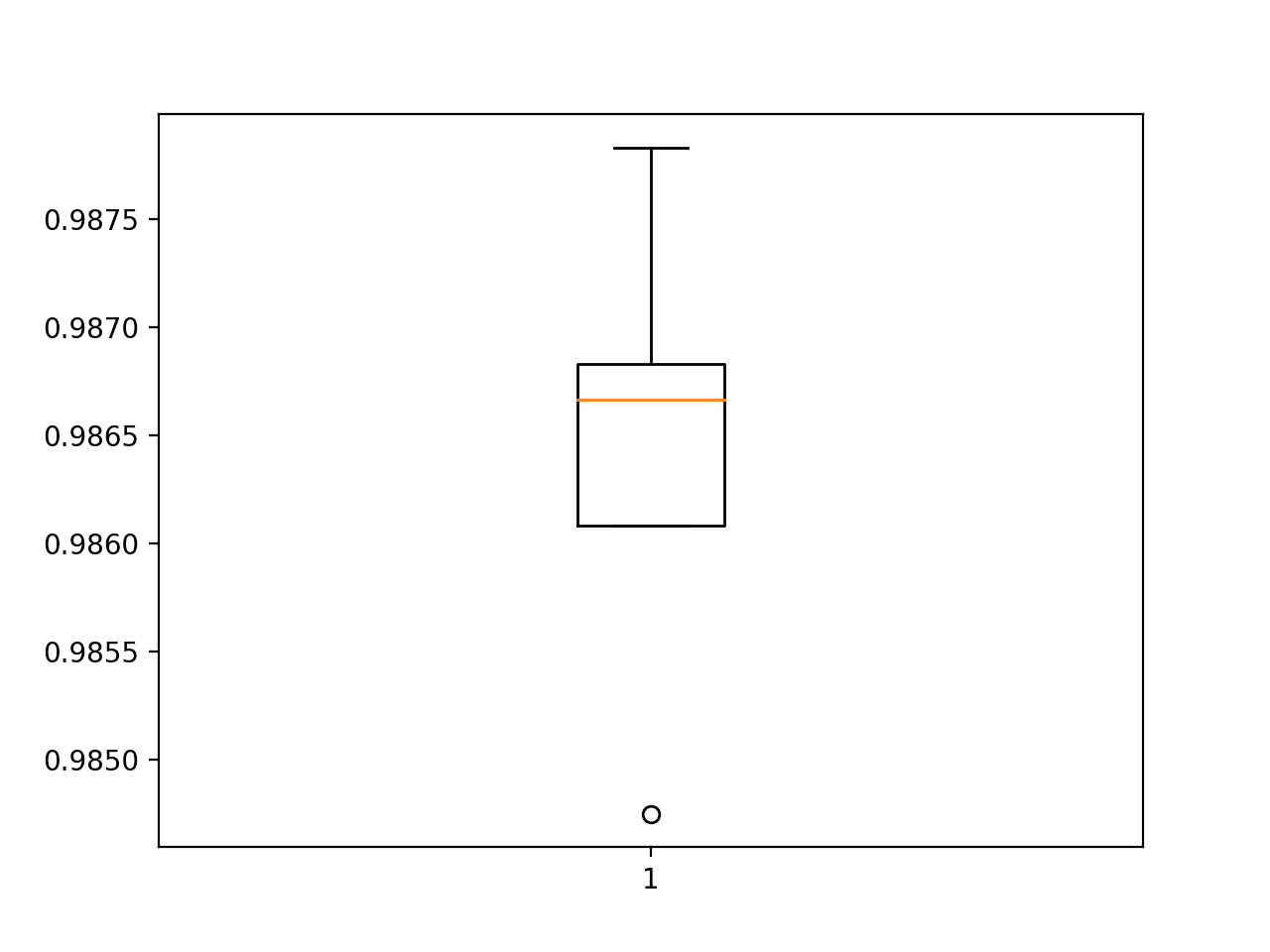
使用 k 交叉验证评估的 BatchNormalization 模型准确率分数的箱须图
增加模型深度
有许多方法可以更改模型配置以探索基准模型的改进。
两种常见的方法是更改模型特征提取部分的容量,或更改模型分类器部分的容量或功能。也许影响最大的点是特征提取器的更改。
我们可以通过在 VGG 类模式下增加特征提取器部分的深度,即在保持滤波器尺寸相同的情况下,添加更多的卷积层和池化层,同时增加滤波器数量。在这种情况下,我们将添加一个双卷积层,每个层有 64 个滤波器,然后是另一个最大池化层。
下面列出了带有此更改的 define_model() 函数的更新版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(100, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(learning_rate=0.01, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model |
为了完整起见,下面提供了包括此更改在内的整个代码列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
# deeper cnn model for mnist from numpy import mean from numpy import std from matplotlib import pyplot as plt from sklearn.model_selection import KFold from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.optimizers import SGD # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = mnist.load_data() # 将数据集重塑为单通道 trainX = trainX.reshape((trainX.shape[0], 28, 28, 1)) testX = testX.reshape((testX.shape[0], 28, 28, 1)) # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(100, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(learning_rate=0.01, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 使用k折交叉验证评估模型 def evaluate_model(dataX, dataY, n_folds=5): scores, histories = list(), list() # 准备交叉验证 kfold = KFold(n_folds, shuffle=True, random_state=1) # 枚举划分 for train_ix, test_ix in kfold.split(dataX): # 定义模型 model = define_model() # 选择训练和测试的行 trainX, trainY, testX, testY = dataX[train_ix], dataY[train_ix], dataX[test_ix], dataY[test_ix] # 拟合模型 history = model.fit(trainX, trainY, epochs=10, batch_size=32, validation_data=(testX, testY), verbose=0) # 评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 存储分数 scores.append(acc) histories.append(history) return scores, histories # 绘制诊断学习曲线 def summarize_diagnostics(histories): for i in range(len(histories)): # 绘制损失 plt.subplot(2, 1, 1) plt.title('Cross Entropy Loss') plt.plot(histories[i].history['loss'], color='blue', label='train') plt.plot(histories[i].history['val_loss'], color='orange', label='test') # 绘制准确率 plt.subplot(2, 1, 2) plt.title('Classification Accuracy') plt.plot(histories[i].history['accuracy'], color='blue', label='train') plt.plot(histories[i].history['val_accuracy'], color='orange', label='test') plt.show() # 总结模型性能 def summarize_performance(scores): # 打印摘要 print('Accuracy: mean=%.3f std=%.3f, n=%d' % (mean(scores)*100, std(scores)*100, len(scores))) # box and whisker plots of results plt.boxplot(scores) plt.show() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 评估模型 scores, histories = evaluate_model(trainX, trainY) # 学习曲线 summarize_diagnostics(histories) # summarize estimated performance summarize_performance(scores) # 入口点,运行测试工具 run_test_harness() |
运行示例会打印交叉验证过程中每次折叠的模型性能。
注意:您的结果可能会有所不同,具体取决于算法或评估过程的随机性,或者数值精度的差异。考虑多次运行示例并比较平均结果。
每次折叠的分数可能表明比基准模型有所改进。
|
1 2 3 4 5 |
> 99.058 > 99.042 > 98.883 > 99.192 > 99.133 |
将创建学习曲线图,在此图中,模型仍然很好地拟合了问题,没有明显的过拟合迹象。图表甚至可能表明进一步的训练 epoch 可能有用。
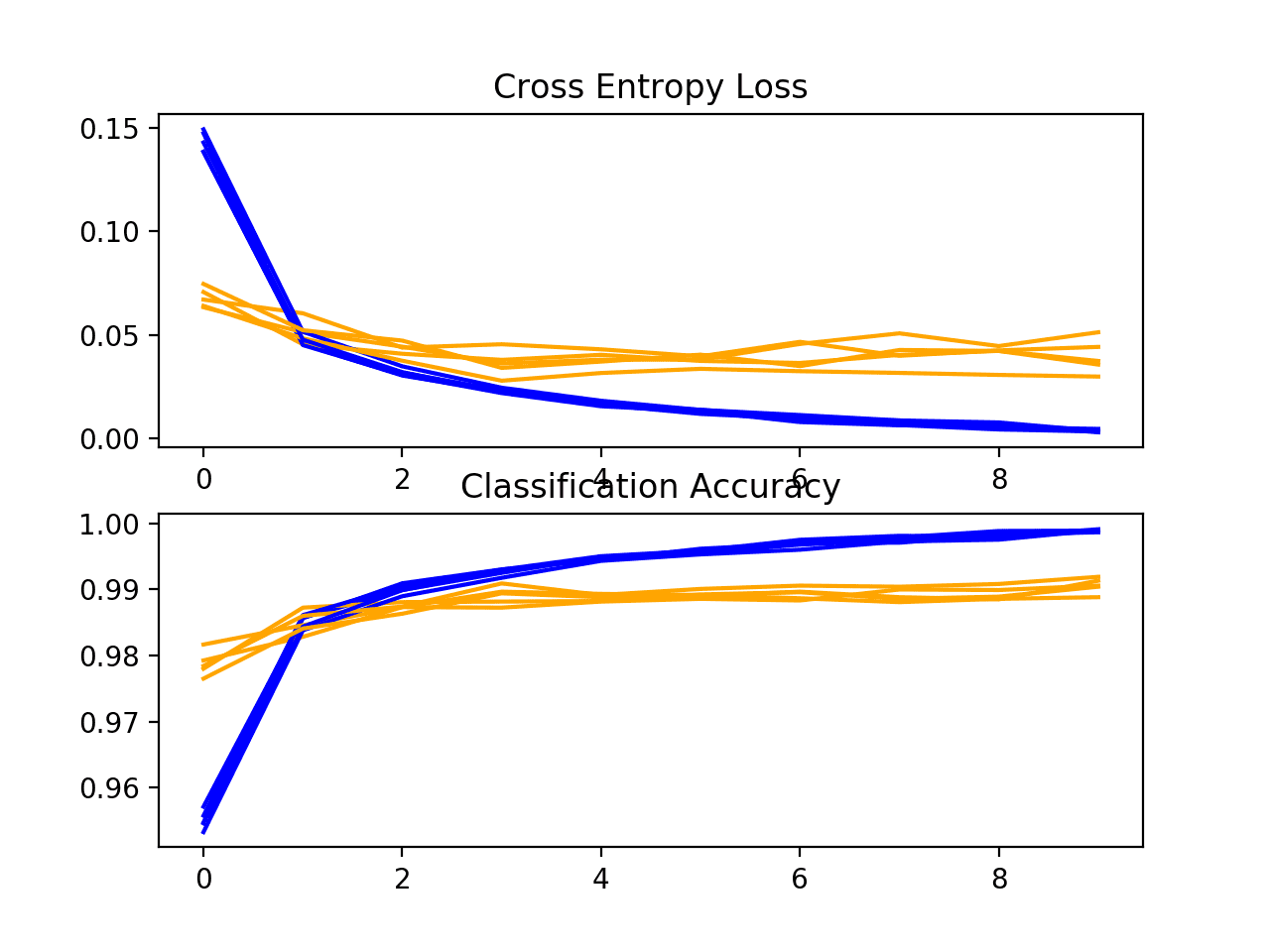
k 交叉验证期间更深层模型损失和准确率学习曲线
接下来,将展示模型的估计性能,与基准模型相比,性能略有提高,从 98.677 提高到 99.062,标准差也略有下降。
|
1 |
Accuracy: mean=99.062 std=0.104, n=5 |
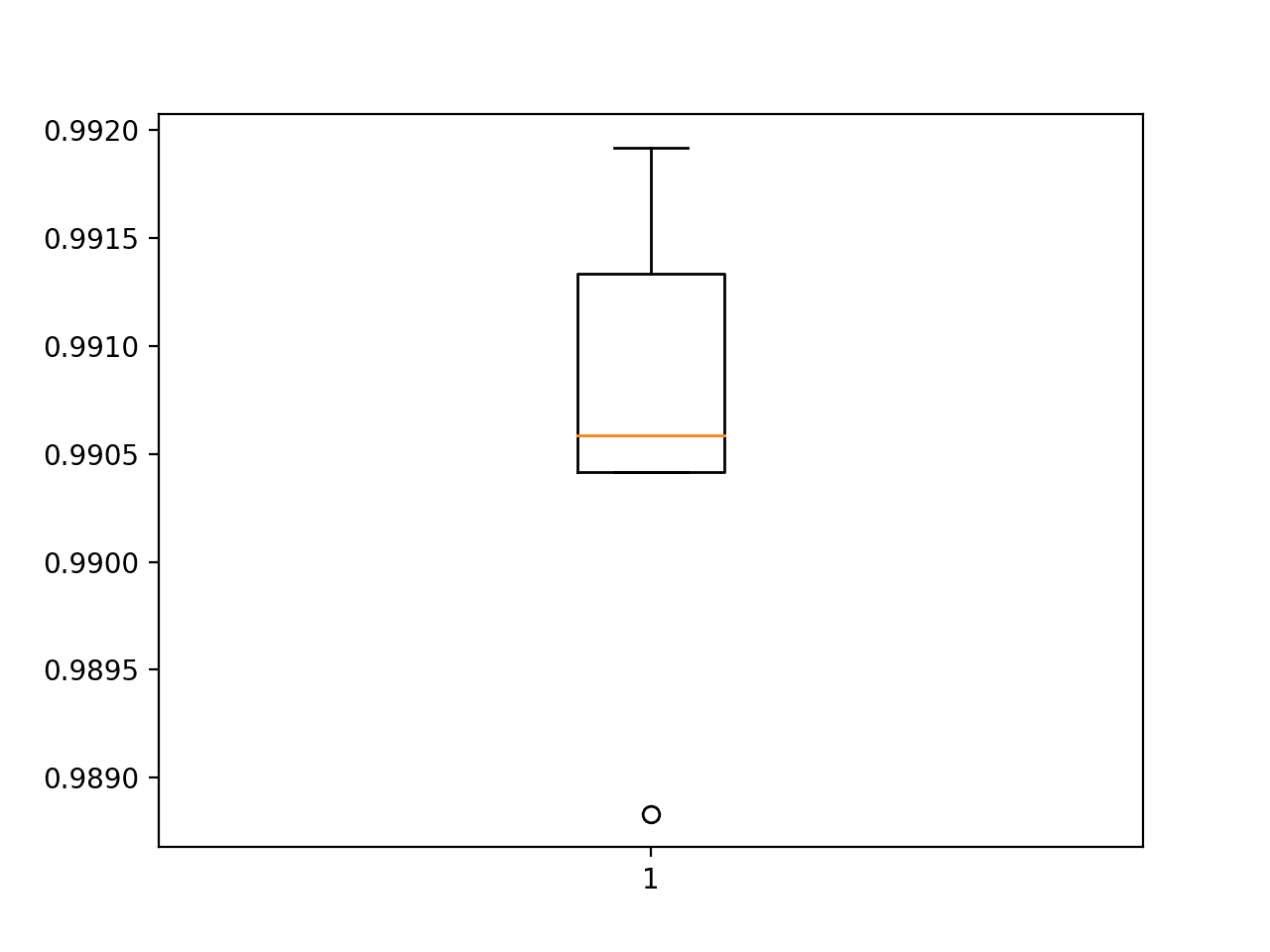
使用 k 交叉验证评估的更深层模型准确率分数的箱须图
如何完成模型并进行预测
只要我们有想法、时间和资源来测试它们,模型改进过程就可以继续下去。
最终必须选择并采用一个模型配置。在这种情况下,我们将选择更深层的模型作为我们的最终模型。
首先,我们将对整个训练数据集进行模型拟合,并将模型保存到文件以供将来使用。然后,我们将加载模型并评估其在保留测试数据集上的性能,以了解所选模型在实践中的实际表现。最后,我们将使用保存的模型对单个图像进行预测。
保存最终模型
最终模型通常拟合所有可用数据,例如所有训练和测试数据集的组合。
在此教程中,我们特意保留了一个测试数据集,以便我们可以估计最终模型的性能,这在实践中可能是一个好主意。因此,我们将仅在训练数据集上拟合模型。
|
1 2 |
# 拟合模型 model.fit(trainX, trainY, epochs=10, batch_size=32, verbose=0) |
拟合后,我们可以通过在模型上调用 *save()* 函数并传入所选文件名,将最终模型保存到 H5 文件中。
|
1 2 |
# 保存模型 model.save('final_model.h5') |
注意,保存和加载 Keras 模型要求在您的工作站上安装 h5py 库。
将在下面列出将最终深度模型拟合到训练数据集并将其保存到文件的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
# 将最终模型保存到文件 from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.optimizers import SGD # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = mnist.load_data() # 将数据集重塑为单通道 trainX = trainX.reshape((trainX.shape[0], 28, 28, 1)) testX = testX.reshape((testX.shape[0], 28, 28, 1)) # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform')) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(100, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(10, activation='softmax')) # 编译模型 opt = SGD(learning_rate=0.01, momentum=0.9) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy']) return model # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 定义模型 model = define_model() # 拟合模型 model.fit(trainX, trainY, epochs=10, batch_size=32, verbose=0) # 保存模型 model.save('final_model.h5') # 入口点,运行测试工具 run_test_harness() |
运行此示例后,您的当前工作目录中将有一个名为“final_model.h5”的 1.2MB 文件。
评估最终模型
我们现在可以加载最终模型并在保留测试数据集上对其进行评估。
如果我们有兴趣向项目利益相关者展示所选模型的性能,我们可能会这样做。
模型可以通过 *load_model()* 函数加载。
下面列出了加载保存的模型并在测试数据集上对其进行评估的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 在测试数据集上评估深度模型 from tensorflow.keras.datasets import mnist from tensorflow.keras.models import load_model from tensorflow.keras.utils import to_categorical # 加载训练和测试数据集 def load_dataset(): # 加载数据集 (trainX, trainY), (testX, testY) = mnist.load_data() # 将数据集重塑为单通道 trainX = trainX.reshape((trainX.shape[0], 28, 28, 1)) testX = testX.reshape((testX.shape[0], 28, 28, 1)) # 独热编码目标值 trainY = to_categorical(trainY) testY = to_categorical(testY) return trainX, trainY, testX, testY # 缩放像素 def prep_pixels(train, test): # 将整数转换为浮点数 train_norm = train.astype('float32') test_norm = test.astype('float32') # 归一化到0-1范围 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # 返回归一化图像 return train_norm, test_norm # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 加载数据集 trainX, trainY, testX, testY = load_dataset() # 准备像素数据 trainX, testX = prep_pixels(trainX, testX) # 加载模型 model = load_model('final_model.h5') # 在测试数据集上评估模型 _, acc = model.evaluate(testX, testY, verbose=0) print('> %.3f' % (acc * 100.0)) # 入口点,运行测试工具 run_test_harness() |
运行示例将加载保存的模型并在保留测试数据集上评估模型。
注意:您的结果可能会有所不同,具体取决于算法或评估过程的随机性,或者数值精度的差异。考虑多次运行示例并比较平均结果。
将计算并打印模型在测试数据集上的分类准确率。在此情况下,我们可以看到模型达到了 99.090% 的准确率,略低于 1%,这已经相当不错了,并且与估计的 99.753%(标准差约零点五个百分点,例如 99% 的分数)相当接近。
|
1 |
> 99.090 |
进行预测
我们可以使用保存的模型对新图像进行预测。
该模型假设新图像是灰度的,已经对齐,因此一张图像包含一个居中的手写数字,并且图像的大小是正方形的,尺寸为 28×28 像素。
下面是从 MNIST 测试数据集中提取的一张图像。您可以将其保存在当前工作目录中,文件名为“sample_image.png”。

Sample Handwritten Digit
我们将这张图像视为一个全新的、未见过的图像,并按照要求进行了准备,看看如何使用保存的模型来预测图像代表的整数(例如,我们期望是“7”)。
首先,我们可以加载图像,强制其为灰度格式,并强制其尺寸为 28×28 像素。然后可以调整加载的图像大小,使其具有单个通道并代表数据集中的单个样本。load_image() 函数实现了这一点,并将返回已加载的、准备好进行分类的图像。
重要的是,像素值的准备方式与拟合最终模型时训练数据集的像素值准备方式相同,在本例中为归一化。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 加载并准备图像 def load_image(filename): # 加载图像 img = load_img(filename, grayscale=True, target_size=(28, 28)) # 转换为数组 img = img_to_array(img) # reshape into a single sample with 1 channel img = img.reshape(1, 28, 28, 1) # 准备像素数据 img = img.astype('float32') img = img / 255.0 return img |
接下来,我们可以像上一节一样加载模型,然后调用 predict() 函数来获取预测分数,然后使用 argmax() 来获得图像代表的数字。
|
1 2 3 |
# 预测类别 predict_value = model.predict(img) digit = argmax(predict_value) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 为新图像进行预测。 from numpy import argmax from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.models import load_model # 加载并准备图像 def load_image(filename): # 加载图像 img = load_img(filename, grayscale=True, target_size=(28, 28)) # 转换为数组 img = img_to_array(img) # reshape into a single sample with 1 channel img = img.reshape(1, 28, 28, 1) # 准备像素数据 img = img.astype('float32') img = img / 255.0 return img # 加载图像并预测类别 def run_example(): # 加载图像 img = load_image('sample_image.png') # 加载模型 model = load_model('final_model.h5') # 预测类别 predict_value = model.predict(img) digit = argmax(predict_value) print(digit) # 入口点,运行示例 run_example() |
运行示例将首先加载和准备图像,加载模型,然后正确预测加载的图像代表数字“7”。
|
1 |
7 |
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 调整像素缩放。探索与基准模型相比,其他像素缩放方法(包括居中和标准化)如何影响模型性能。
- 调整学习率。探索与基准模型相比,不同的学习率如何影响模型性能,例如 0.001 和 0.0001。
- 调整模型深度。探索如何将更多层添加到模型中以与基准模型相比来影响模型性能,例如另一组卷积层和池化层,或者模型分类器中的另一个密集层。
如果您探索了这些扩展中的任何一个,我很想知道。
请在下面的评论中发布您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
文章
总结
在本教程中,您将学习如何从头开始为 MNIST 手写数字分类开发卷积神经网络。
具体来说,你学到了:
- 如何开发一个测试工具,以对模型进行稳健评估,并为分类任务建立性能基线。
- 如何探索基线模型的扩展以改进学习和模型容量。
- 如何开发一个最终模型,评估最终模型的性能,并使用它对新图像进行预测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






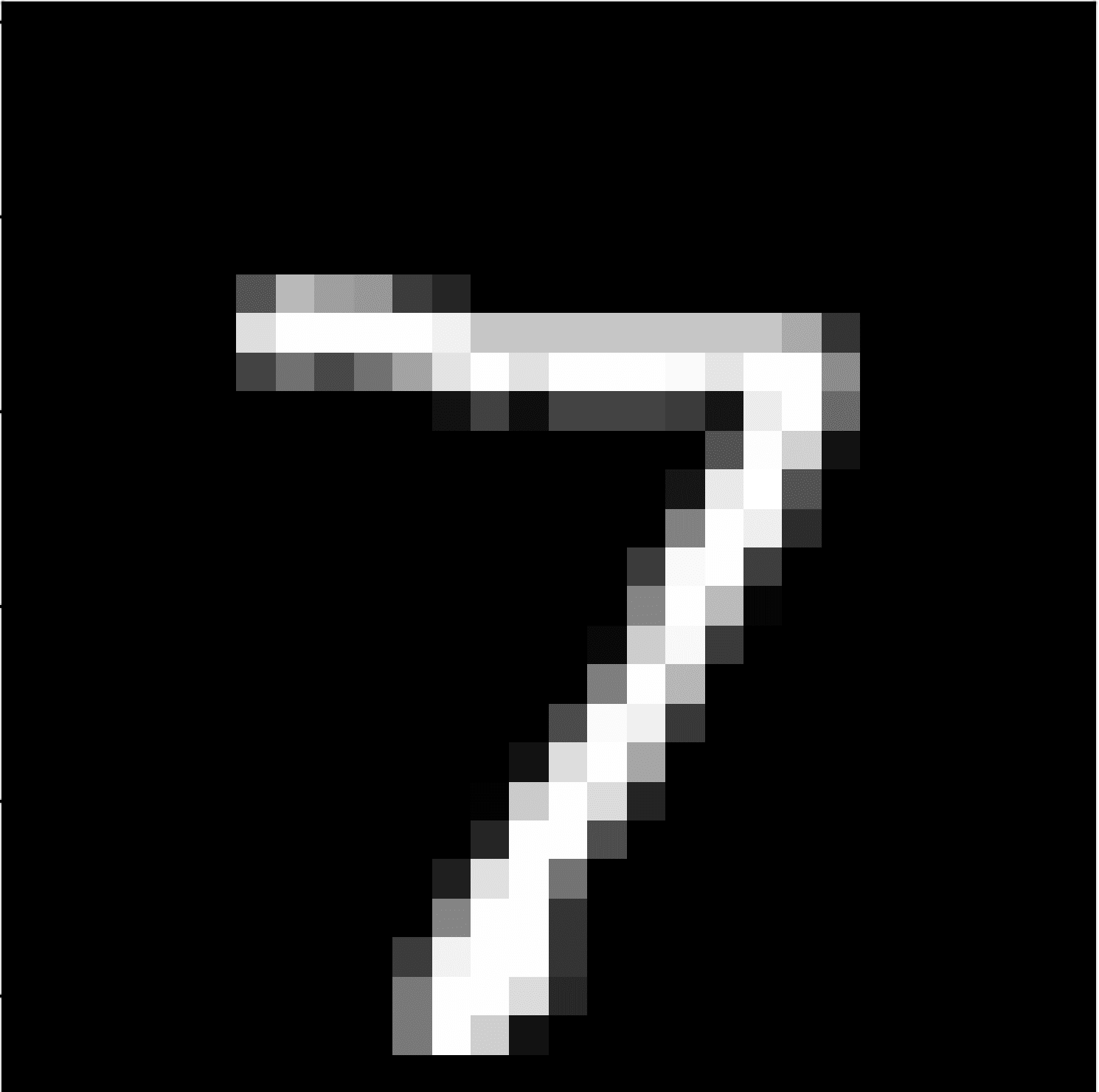{kind=link}
Jason 先生,非常感谢您精彩的教程!您能为我们从头开始构建一个使用真实图像进行边缘检测的模型吗?
很好的建议,谢谢。
我有两个问题
首先,假设我的图像尺寸为 7611 x 7811,如何在 CNN 模型中处理如此大的图像尺寸?
第二个问题是关于我们的图像尺寸不同(不相同)的情况。
我建议在建模之前先缩小图像尺寸,例如小于 1000 像素,如果可能的话甚至小于 500 像素。
然后我建议将图像归一化到相同的大小。
为了缩小图像尺寸,哪种方法更好?使用机器学习还是普通的图像压缩方法?
使用图像压缩算法。
当我们缩小图像尺寸时,这意味着会丢失图像中的许多精细细节。
确实如此。
您是如何制作这个项目的?请帮助我们……我们不明白如何制作这个项目…… Taranpreetkaur
你到底遇到了什么问题?
原始错误是:No module named _multiarray_umath, keras .imageprocessing
导入 numpy c 扩展失败。
有什么想法吗?
听到这个消息我很难过。
也许可以尝试检查您的 Keras 和 TensorFlow 版本是否是最新的?
抱歉,不用担心,我设法解决了。我想我重新安装了一些东西。
不过我还有另一个问题。如果数据预测的值错误,我该如何为学习添加数据?我认为我需要关于如何添加数据以及如何以 MNIST 数据格式添加数据的建议。谢谢
很高兴听到这个消息。
也许您在获得新数据时可以重新拟合模型?
Jason,您知道吗,对于“17”,它返回了“7”。这实际上很好,但是如果您能给我一些建议,如何将此变成“出色”呢?我可以根据空格将像素数据分成两部分,或者识别“17”的最佳方法是什么?谢谢
我认为该模型一次支持一个字符,尝试将多个字符拆分为单个字符输入。
太棒了!我非常享受。
谢谢!
Jason,
非常感谢本教程。我对 CNN 的结构有一个问题。在本教程(以及其他关于 MNIST 数字数据集的描述)中,常见的结构似乎是 CNN 滤波器的数量为 32。每个滤波器是 5×5,步幅为 1。但是(如果这在某处得到了解释,我深表歉意),我似乎找不到为什么选择 32 个滤波器。即为什么不是 16 或 64(或 14 或 28)。能否解释一下原因?
此致
Victor
这是任意的。
尝试不同的滤波器数量并比较结果。
Jason,
感谢您对这个的详细解释。我想运行您的代码并进行跟进,看看它是如何工作的。当我尝试运行基准 CNN 模型用于 MNIST 的完整示例时,我收到以下错误
KeyError 回溯(最近的调用在最后)
in
107
108 # entry point, run the test harness
–> 109 run_test_harness()
in run_test_harness()
102 scores, histories = evaluate_model(model, trainX, trainY)
103 # learning curves
–> 104 summarize_diagnostics(histories)
105 # summarize estimated performance
106 summarize_performance(scores)
在 summarize_diagnostics(histories) 中
79 pyplot.subplot(212)
80 pyplot.title(‘分类准确率’)
—> 81 pyplot.plot(histories[i].history[‘acc’], color=’blue’, label=’训练’)
82 pyplot.plot(histories[i].history[‘val_acc’], color=’orange’, label=’测试’)
83 pyplot.show()
KeyError: ‘acc’
有什么想法是什么意思吗?
是的,API已更改。
我已经更新了示例。
感谢告知!
请问如何训练一个简单的卷积网络来识别数字(MNIST)?谢谢。这是我想看到的。
请参阅上面的教程获取示例。
我想创建一个与MNIST完全相同的图像,例如使用画图工具,并使用predict_classes API对其进行测试。
是否可以在不使用python API的情况下实现?
我看不出为什么不。
嗨,Jason,
感谢这个优秀的教程!我对K折交叉验证有两个问题。在您的“入门介绍”文章中,您说在切换保留集时会丢弃模型。所以我的问题是
1) 在这里,您似乎没有在K折交叉验证的迭代之间丢弃模型。为什么?
2) 模型准确率在每次迭代后都会提高。那么简单平均又有什么公平性呢?极端地说:如果只训练1个epoch呢?那么您将在第一个折叠上获得94%的准确率,然后在第二个折叠上获得98.5%。等等,产生一个差得多的平均值和一个巨大的标准差。在此问题的基础上,我还想问为什么在这种情况下标准差能公平地代表模型。
再次感谢精彩的材料!
Alex
不客气。
这看起来像一个错误。我将更新教程。
感谢指出!
感谢Jason解决了我的上一个问题。我还有另一个问题。您在某个地方说没有明显的过拟合迹象。但看起来验证准确率的橙色线与训练准确率的蓝色线相比,仍然相对较低。这是否不是过拟合的迹象?或者我误解了图表?
问得好,Alexander。
它们足够接近,我不会将其归类为过拟合,而是认为这是一个良好的拟合。
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
你好 Jason,
当我执行最终代码时,出现以下错误:“AttributeError: module ‘tensorflow’ has no attribute ‘get_default_graph’”。我已经安装了Tensorflow 2.0,降级到前一个版本是否可以解决此问题?
感谢您的时间和这篇精彩的文章!
确认您已安装Keras 2.3和Tensorflow 2.0。
你好 Jason,
我安装了Tensorflow 2.0和Keras 2.2.4。我尝试将Keras更新到2.3,但在Windows 10上找不到方法。我也尝试切换到VB中的Linux,但我在那里遇到权限问题。您有什么建议吗?我将非常感激。
您可以尝试
或者,如果您使用的是anaconda
你好 Jason,
感谢教程和所有答案!
我有自己的图像集,每个类别都在一个单独的文件夹中。我该如何上传数据集而不是写
# 加载数据集
(trainX, trainY), (testX, testY) = mnist.load_data()
如果您能给出一些建议,那就太好了!
这里有一个例子
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
谢谢!
不客气。
嗨,Jason,
感谢您的文章!!!
您是否有计划实现“信息瓶颈理论”?即在体系结构中找到主要的信息以及各个层之间的互信息?
这对您来说似乎更容易还是更难??
抱歉,我没听说过,您有链接吗?
def load_image(filename)
# 加载图像
img = load_img(filename, grayscale=True, target_size=(28, 28))
# 转换为数组
img = img_to_array(img)
# 重塑为单通道的单个样本
img = img.reshape(1, 28, 28, 1)
# 准备像素数据
img = img.astype(‘float32’)
img = img / 255.0
return img
以上代码中的“filename”是什么意思?
它是函数的一个参数——您想加载的文件的名称。
您是指保存模型的文件名吗?
不,正如函数名称所示,该函数加载图像。
谢谢!
不客气。
将数据重塑为单个颜色通道的目的是什么?这对于模型定义中的2D卷积步骤是必需的吗?我问这个问题是因为我查看过的其他数字分类示例直接将训练/测试数据展平,但那些没有2D卷积层。
CNN层期望数据具有包括通道维度的3D形状。
https://machinelearning.org.cn/convolutional-layers-for-deep-learning-neural-networks/
如果有人想创建一个新的MNIST,他们应该如何设置数据?在这些示例中,我们可以使用来自分配器的精选数据集,但这并没有解释如何设置数据来运行模型。
例如,如果我想创建我自己的MNIST来确定图片是扑克牌,我该如何设置图片并告诉机器那是什么图片?
好问题,请看这个
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
嗨,Jason Brownlee,
我想制作一个手写字母模型,请推荐哪种数据集比较好?
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/where-can-i-get-a-dataset-on-___
Jason,非常感谢您分享您的知识。我刚开始学习Python,Tensorflow和机器学习。我理解了所有的数学和过程,但在编码方面遇到了困难。您的示例一次性成功了。太棒了。
您是否有更简单的CNN示例,只有4个隐藏层,如下所示?
1. 784个节点的输入层
2. 第一个卷积层:5x5x32
3. 第一个最大池化层
4. 第二个卷积层 5x5x64
5. 第二个最大池化层
6. 10个节点的输出层
谢谢。
您可以直接参考上面的示例进行改编。
嗨 Jason。我能问一下你为什么重塑数据吗?MNIST的图像已经是灰度(1通道)了。我不太明白为什么需要执行这个步骤。另外,trainx.shape[0]/testX.shape[0]在这里做什么?
# 将数据集重塑为单通道
trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))
testX = testX.reshape((testX.shape[0], 28, 28, 1))
CNN的输入必须明确定义通道,而灰度图像默认情况下不是这样。
我能问一下为什么热编码是10个二进制向量吗?为什么选择10?
因为有10个类别。
嗨 Jason!非常感谢您,这是一个很棒的教程!
只有一个问题,我有点困惑。
我们是否训练了两次模型?一次是进行K折交叉验证,然后在保存模型之前,使用model.fit?
====
model = define_model()
model.fit(trainX, trainY, epochs=10, batch_size=32, verbose=0)
model.save(‘final_model.h5’)
====
交叉验证将训练k个模型,并用于估计在新数据上进行预测时的性能。这些模型将被丢弃。
一旦我们选择了最终的模型配置,我们就用所有数据来拟合模型,并用它来开始进行预测。
很好,我想的就是这个!再次感谢您提供如此出色的教程。
不客气。
在K折交叉验证中,每次K迭代都会定义一个新模型。那么这意味着每次都训练了一个新模型吗?但是,在每次迭代中训练新模型有什么用呢?
您所说的模型配置是指最优的define_model()吗?一旦确定了最优模型,我们就在整个训练集上进行训练?我无法理解K折中的K次迭代如何反映我们对最佳模型配置的理解。
是的,每次迭代都会训练一个新模型,进行评估,然后丢弃。
其目的是估计模型配置在对预测问题中的未标记数据进行预测时的性能。
一旦我们有了这个估计,我们就可以选择使用该配置(与其他配置相比)。最终模型可以拟合所有数据,我们可以开始对我们不知道标签的新数据进行实际预测。
非常感谢。我还有另一个问题。我尝试在未见过测试数据上运行最终模型。但是每次运行结果当然都不同。因此,我决定运行10次并平均测试结果,就像蒙特卡洛模拟一样。但是同样,在这种情况下,model = define_model()应该放在哪里?它是应该放在for循环内部进行平均,还是在运行这10次迭代之前就定义好,考虑到这个平均结果是在测试数据上的?因为在kfold中您会丢弃它。
不客气。
是的,您可以通过拟合多个最终模型并平均其预测来减少预测中的方差。
https://machinelearning.org.cn/how-to-reduce-model-variance/
这里有一个代码示例。
https://machinelearning.org.cn/model-averaging-ensemble-for-deep-learning-neural-networks/
如果我将所有这些都写在一个名为-mnist_classification的类中,那么
AttributeError: ‘mnist_classification’ object has no attribute ‘astype’
这个.astype错误出现了,请问先生能帮我找出原因吗?
很抱歉听到这个消息,这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
感谢这篇教程。它非常有帮助。
不客气,我很高兴听到这个消息。
嗨,我正在尝试为此问题构建一个CNN。我的输出层有10个神经元。当我尝试在y_train和y_test进行One-Hot编码后拟合我的模型时,我得到一个错误,即标签和logits不匹配。但是,在没有one-hot编码的情况下,模型可以完美拟合。您能解释一下吗?
也许您可以将上面的教程作为起点,并为您的项目进行改编?
这是关于MNIST最好的文章,但我有一个问题:“是否必须使用高性能GPU才能运行这些代码?”
谢谢!
不,您可以在CPU上运行,可能只是需要多花几分钟。
嗨 Jason
感谢这篇精彩的教程。它一定会帮助许多新兴研究人员。
我有一个问题。
您能帮我一下吗,如果我需要处理完整的自拍手写单词图像(20个不同的类别,总共约20000张图像),而不是单个字符?该如何做?
也许可以先分割单词中的字母,然后再进行分类。
谢谢回复,但我希望采用无分割的方法。
也许可以使用CNN读取图像,然后使用LSTM解释图像特征并一次输出一个字母。
也许可以使用CNN读取图像,然后使用LSTM解释图像特征并一次输出一个字母。
您能否分享更多关于如何做到这一点的细节?
嗨 Prasad…您可能需要考虑为您的目的使用CNN-LSTM模型。
https://machinelearning.org.cn/cnn-long-short-term-memory-networks/
嗨 Jason
感谢这篇精彩的教程。
不客气。
感谢Jason Brownlee提供的优秀教程。我是您的大粉丝,我经常关注您所有的机器学习和深度学习模型。我从这个网站学到了很多知识,但在完成机器学习教程后,我总会想到一个问题:如何将这些模型应用于移动应用程序(Android、iOS等),以便从中获得更多乐趣和知识?您是否推荐任何链接可以提供此类项目,例如天气预测应用?再次感谢。
谢谢。
抱歉,我不知道如何在移动设备上使用模型。
我知道这迟到了一年,但请看这个基于 tensorflow 和 keras 的移动应用:https://medium.com/@timanglade/how-hbos-silicon-valley-built-not-hotdog-with-mobile-tensorflow-keras-react-native-ef03260747f3
感谢 Jason Brownlee 的教程。
我可以只使用相同的模型,但传入我自己的(人类)数据集,并进行一些小的修改来检测是否摔倒吗?
谢谢。
当然可以。
你好,除了使用智能手机进行人体活动识别之外,你是否还有基于无线和移动网络做的任何项目?
我不这么认为。也许可以试试博客搜索。
感谢详细的解释!
你能否不做预训练模型进行颜色化教程?
提前感谢
好建议,谢谢!
期待同样的 🙂
嘿 Jason,这是一个非常好的教程,我没明白 predict_classes 中为什么得到 7?模型最后一层是 softmax 激活函数,它将是 10 个浮点数的概率分布。我无法理解的是我们如何得到 7?
我的意思是这 10 个概率如何变成 1 个预测数字?
它怎么知道是 7 呢?我们不是对 Y 值进行了热编码吗?
通过 argmax。
https://machinelearning.org.cn/argmax-in-machine-learning/
谢谢。
predict_classes() 函数会为你执行预测概率的 argmax。
如果你不熟悉 argmax,请看这个。
https://machinelearning.org.cn/argmax-in-machine-learning/
谢谢 Jason,一切都清楚了,非常感谢!
很高兴听到这个消息。
嘿,这段代码不兼容 Tensorflow 2 吗?我遇到了以下错误。
E tensorflow/stream_executor/cuda/cuda_driver.cc:314] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
是的,您可以在这里了解更多
https://machinelearning.org.cn/faq/single-faq/do-you-support-tensorflow-2
这个错误看起来是你的开发环境出了问题。
你好!
感谢这篇精彩的文章,对我的项目帮助很大!
不过我有一个问题,我正在尝试从手机中获取一张图片,然后使用该图片来预测数字,但它对这张图片不起作用。我应该对这张图片做什么?
我使用在线工具将其调整为 28×28,甚至尝试了图像的灰度版本进行预测。
任何建议或线索都将受到赞赏!
提前感谢!
你必须像训练集中的图像一样准备图像。例如,白色前景,黑色背景,灰度,相同的图像尺寸。
嗨,Jason,
一如既往的出色教程!
我实现了你的教程的两个变体。
我从 sklearn 库的 digits 数据集中加载图像(它只使用 1,797 个图像,分辨率低得多 8 x 8 位 vs MNIST 70,000 和 28,28 像素分辨率。相反,它使用更少的数据特征,因此在此数据集上速度更快。
此外,我将此多类问题应用于 Sklearn 的其他库分类器模型,如 SVC()、logisticRegression()、ExtraTreesClassifier()、XGBClassifier()、RandomForestClassifier() 等。
我的主要结果是:
– 对于简单的 CNN 基线模型(没有其他深度层,没有其他 BatchNormalization()),我获得了 98.4% 的准确率和 1.1 的 sigma;而从 SVC 获得了 98.8%……但只使用了 8×8 像素分辨率,这是一个很好的新发现!。
但是当我将要预测的最终图像减小到 8 x 8 像素,以便应用我的训练模型时,我在那里获得了如此高的分数,但我将数字 7 错误地预测为数字 9。
我猜当我加载 7 的图像并将其裁剪到 8x8 像素的较小尺寸时,在裁剪图像的过程中我丢失了重要的图像特征……而 MNIST 的 28x28 像素仍然保留了图像的关键数字特征,你怎么看?
谢谢你,Jason。
谢谢。
非常好的实验!
是的,较大的图像可能在数据集的挑战性案例中提供了更多的上下文。
嗨,Jason,
你总是有非常有趣的博文。
我能够基于 Char74K 数据集训练一个 CNN。我很满意,因为模型文件只有 42MB,预测数字的时间很快。
我之前使用了一个 kNN 模型(在同一个数据集上),文件大小为 680MB!
谢谢,
Hannes
谢谢。
干得好!
嗨,Jason,
很棒的文章!!
我只有一个疑问,在 evaluate 方法中,为什么我们要为每个 fold 创建一个新模型?
谢谢,
k 折交叉验证就是这样工作的,我们有一个新的训练集,并为每个折叠拟合一个新模型,然后对所有模型的性能进行平均,以估计模型在新数据上的性能。
你可以在这里了解更多
https://machinelearning.org.cn/k-fold-cross-validation/
感谢这篇精彩的教程!
我有一些 MLP 的经验,但没有 CNN 的经验。如果我的数据中的每个样本的形状都是 16x1(行),值为 0.01 到 0.99 之间,并且模型需要为 15 个类别执行分类,那么尝试使用 CNN 有什么原因吗?如果我将样本从 16x1 重塑为 4x4,那么应该使用什么过滤器大小和适量的过滤器?还是最好不要重塑,尝试使用 Conv1D 层的模型?谢谢。
如果输入在图像或序列中存在空间关系,CNN 可以是有效的。
如果你有表格数据(例如,不是图像也不是序列),那么 CNN 没有意义。
嗨,Jason,
非常感谢你精彩的教程。我正在使用 pycharm 运行你的代码,并且我有一个带有正确 CUDA 的 GPU,但你的代码只能在我的 CPU 上运行。
是我遗漏了什么吗?
谢谢。🙂
抱歉 Jason,原来是我的 CuDNN 安装出了问题,我进行了修复并解决了问题。🙂
再次感谢这个很棒的教程。🙂
没问题!
很高兴听到你解决了问题。
代码与硬件无关——两者都可以运行。
如果它在你的 CPU 上运行,那么你需要更改你的 tensorflow 库的配置。我没有这方面的教程,抱歉。
嗨,Jason,
非常感谢这个教程,帮助很大!我开发了自己的 CNN,根据平均准确率来看,效果相当不错。然而,验证集的交叉熵损失低于训练集的损失。这是欠拟合的迹象吗?如果是,如果我想将模型应用于未见过的数据,我应该修改模型吗?
不客气。
干得好!
如果性能不佳,学习曲线可以帮助诊断问题,这可以帮助你解释学习曲线。
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
嗨,Jason,
非常感谢这个教程,帮助很大!我开发了自己的 CNN,根据平均准确率来看,效果相当不错。然而,验证集的交叉熵损失低于训练集的损失。这是欠拟合的迹象吗?如果是,如果我想将模型应用于未见过的数据,我应该修改模型吗?
不客气。
也许首先关注模型的样本外性能,然后进行优化。
嗨,Jason,
以前我很感谢你提供的教程,我在这里学到了很多。如果我想显示预测结果的概率值怎么办?(例如 50.67% 这样的)
谢谢!
你可以调用 model.predict() 然后将结果乘以 100 来得到百分比。
感谢你的教程!
我创建了一张具有与 sample_image.png 相同特征的图像(1490×1480,黑色背景,白色前景),在 Paint 中打开它,输入了一个“6”(当然不带引号),将字体大小增加到 1000(这样它就会占据大部分画布),然后保存它。但是,代码似乎无法识别它。它似乎认为它是“1”、“8”或其他数字。
有什么建议为什么会这样吗?
也许图像本身或其准备过程(例如像素缩放)与训练数据集存在一些重要的差异?
Jason 你好——精彩的文章!!只是好奇你为什么必须做 evaluate 来获取准确率,而 fit 调用已经返回了它?我刚才检查了 histories,它们与 evaluate 调用返回的完全相同。evaluate 调用还有其他原因吗?
谢谢!
不,在调用 fit 时不会计算保留数据集上的准确率。我们必须手动在新数据上进行预测或使用 evaluate 函数。
感谢回复!!我看到 fit 和 evaluate 调用对验证都使用了相同的数据 (testX, testY)。因此,fit 调用返回的对象已经包含 evaluate 调用要返回的数据。我说得对吗?
# 拟合模型
history = model.fit(trainX, trainY, epochs=10, batch_size=32, validation_data=(testX, testY), verbose=0)
# 评估模型
_, acc = model.evaluate(testX, testY, verbose=0)
通常,将测试数据用作验证数据不是一个好主意,我这样做是为了让示例保持简单。
Hi Jason,感谢这个很棒的教程!
我不明白为什么我们不使用 k-fold 中创建的模型。我本以为我们会将这 k 个模型的结果合并成一个模型并保存。如果我们不这样做,那有什么用呢?
k 折交叉验证期间创建的模型会被丢弃。它们只用于估计模型/管道在未见示例上的性能。
一旦我们选择了一个配置,我们就可以在所有数据上拟合最终模型,并使用它来对新示例进行预测。
https://machinelearning.org.cn/train-final-machine-learning-model/
非常感谢 Jason!!!这个教程非常有帮助,它解决了我的项目的一半问题!!!再次感谢!..
不客气。
感谢你出色的教程。是否可以将其用于网络摄像头进行识别任务?
也许可以尝试一下。
你好!非常感谢 Jason 提供的这个精彩资源。我目前正在使用学校租用的电脑——你认为我可以在 CoLabs 中实现这段代码吗?
不客气。
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/do-code-examples-run-on-google-colab
嗨,Jason,
非常感谢
如果可能,请就 HMM 的实现提供建议。
感谢您的建议,也许将来会考虑。
我正在开发一个手写字符识别模型,但准确率非常低,我认为这不仅仅是因为我的数据集很小,我还有一些东西没有理解,你能帮助我改进吗?
也许可以试试这些建议。
https://machinelearning.org.cn/improve-deep-learning-performance/
我可以使用这段代码来处理任何字符数据集吗?
也许可以尝试一下。
你能为提交给《高中科学杂志》(http://jhss.scholasticahq.com)的手稿提供同行评审吗?手稿标题为:“实现量子卷积神经网络以实现高效图像识别”。摘要:机器学习有许多现实世界的应用,从模拟宇宙到计算化学。由于概率是机器学习的基石,因此优化软硬件以获得最佳结果至关重要。经典计算机通常用于机器学习程序。然而,从高维数据学习通常需要过多的计算时间和电力,而且可能无法达到最高的准确率。量子计算环境可以用来创建比经典计算更准确的模型。为了测试这种量子优势,我们实现了一个量子卷积神经网络 (QCNN),它在量子领域中与经典卷积神经网络 (CNN) 的结构相似。由于缺乏具有大量量子比特的量子计算机,物理学家,即 John Preskill,引入了“嘈杂中等规模量子”(NISQ) 的概念,它构成了经典计算机和量子计算机之间的混合接口。在 QCNN 的背景下,数据处理和成本函数优化将在经典计算机上执行,而变分量子电路 (VQC) 生成的概率将在量子计算机上进行评估。QCNN 由经典到量子的数据编码器、用于纠缠量子比特状态的簇状态量子电路、用于高效特征提取的量子卷积和池化层的变分量子电路系列、量子到经典的数据解码器组成,这将导致输出。CNN 和 QCNN 都可以从 2D 图像等数据中提取特征,并且可以使用准确率和时间等指标来比较性能。
抱歉,我无法对你的手稿进行同行评审。
如果我们被要求设计一个项目来使用分类算法从 MNIST 中识别数字分类,我们应该使用上面的那个吗?
是的
精彩的教程!!
当我实现代码时,我遇到了这个错误:“AttributeError: ‘Sequential’ object has no attribute ‘predict_classes’”
有什么建议可以纠正这个错误吗?
我使用这个模型作为示例,当我输入一个手写数字时,它一直给出错误的预测。你能告诉我可能是什么问题吗?
当我使用黑色背景的印刷数字时,它能准确读取。
不过,我对 CNN 模型做了一些小改动,使其成为多池化模型。
如果你愿意,我可以分享代码。
由于我没见过你的笔迹,所以无法判断。但这个MNIST数据集是28x28像素的灰度图,白色背景黑色字。试着模仿这种设置,效果会好很多。如果你的图像更复杂(例如,你扫描的图像背景不是单一颜色,或者字母比数字更复杂,笔画更多),那么你需要一个更大的网络来识别它。
你在其他回答中提到,输入需要重新整形,因为卷积层需要带有通道维度的输入。你知道这是Keras特有的吗?
我正在尝试对56x56的灰度图像(0->255)进行分类,到目前为止,我已经将它们归一化到[-1,1]。但是,它们仍然是56x56矩阵形式的2D图像。我正在使用PyTorch。你知道我是否也需要重新整形来添加单个通道吗?
这取决于你构建模型的方式,可能是必要的,也可能不是。
为什么在“增加模型深度”部分有两个64过滤器的conv2D副本?
model.add(Conv2D(64, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’))
我尝试了使用一个或两个此类层来构建模型,结果相同。
另外,我将训练轮数增加到15,并且在准确率的均值和标准差上都看到了轻微的提高。
如果你发现增加更多层没有区别,那就继续使用较少层数的模型,因为它能节省时间和内存。
增加训练轮数可以帮助更好地训练,但你可能也会遇到过拟合。因此,你需要用验证集进行检查,以确认“改进”。
我尝试了最多25个训练轮,并使用verbose=1在model.fit调用中查看了损失。损失在大约20个训练轮时触底,之后开始波动。
这是从第10个到第25个训练轮的一次运行。模型在测试集上获得了99.260%的准确率。
Epoch 10/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0079 – accuracy: 0.9972
Epoch 11/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0061 – accuracy: 0.9980
Epoch 12/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0060 – accuracy: 0.9980
Epoch 13/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0058 – accuracy: 0.9978
Epoch 14/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0045 – accuracy: 0.9984
Epoch 15/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0042 – accuracy: 0.9987
Epoch 16/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0035 – accuracy: 0.9988
Epoch 17/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0031 – accuracy: 0.9991
Epoch 18/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0024 – accuracy: 0.9992
Epoch 19/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0026 – accuracy: 0.9993
Epoch 20/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0020 – accuracy: 0.9994
Epoch 21/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0020 – accuracy: 0.9994
Epoch 22/25
1875/1875 [==============================] – 7s 3ms/step – loss: 0.0027 – accuracy: 0.9991
Epoch 23/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0032 – accuracy: 0.9989
Epoch 24/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0022 – accuracy: 0.9993
Epoch 25/25
1875/1875 [==============================] – 6s 3ms/step – loss: 0.0020 – accuracy: 0.9993
> 99.260
结果不错!
这些作者:https://arxiv.org/pdf/2008.10400v2.pdf 通过结合一些相当简单的技术,获得了99.91%的准确率:增加模型深度、增加卷积核大小、数据增强、在所有conv2D层之间加入批归一化、禁用卷积输出的边缘填充以减小conv2D层之间的图大小而不是使用最大池化(我发现这很巧妙),以及通过多个模型进行投票。他们很好地分析了每种技术并将结果与其他常见的CNN进行了比较。
他们目前在这个排名中名列前茅:https://paperswithcode.com/sota/image-classification-on-mnist
感谢分享。
那么在训练期间,模型的训练数据准确率超过了99.9%,但最终测试数据的准确率是99.26%。这两个值都超过99%时,它们之间的差异足够近,可以认为模型没有过拟合吗?
我无法给出关于什么算是合理的指导。但准确率超过99%时,我认为这对于此目的已经足够好了。
你好Patrick…以下资源将为你提供关于如何避免深度神经网络过拟合的见解。
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
此致,
谢谢你
不客气,Andrew!
不客气,Andrew!
你好,
不知道你是否会看到,但如果你回复,我会感谢你。我希望自己尝试这段代码,因为我希望能更多地了解神经网络。
不幸的是,我给Python一张我在画图(电脑应用程序)中制作的图片,这张图片被调整到了28*28,而且图片是可见的,我已经检查过了。
图片中我画的是数字2,但它显示是4,我也尝试了更多次,但都不成功。
我想知道问题出在哪里。
另外,如果你能回复我的电子邮件,我将不胜感激,以便检查问题是出在图片还是代码上。
你好Gilad…你检查过你模型的总体准确率了吗?
是的,准确率是96%,这就是为什么我觉得奇怪。
我不确定问题是否在于图片,但我希望知道问题出在哪里。
我可以发送给你我使用的图片吗?也许问题就在那里。
总之,感谢您的帮助。
我的实际准确率是99.140,抱歉之前的错误。
James,非常感谢,终于成功了,是我的图片不好。
我画的数字是黑色的,背景是白色的,但这并不是计算机训练的方式。
感谢你的反馈Gilad!继续努力!
依我看,这是我读过的最好的教程。它帮助我第一次就理解了CNN。谢谢你,亲爱的James。
谢谢你的反馈和支持Anbu!
你好James,
教程很棒。我在从整数转换为浮点数时遇到了“name ‘train’ is not defined”的错误。你能帮我解决一下吗?谢谢。
你好Viswa…感谢你的反馈!你是复制粘贴的代码还是自己输入的?可能是复制粘贴代码时出现的问题。
哦!我明白了。非常感谢您的教程,我从您那里学到了很多。
您能否详细说明一下为什么使用具有特定100个节点的密集层来开发基线模型?
train_norm = train.astype(‘float32’)
你好Jason,这个方法来自哪个库?
因为在你的代码中没有定义train,我想看看这个方法是如何工作的。
train_norm = train.astype(‘float32’)
NameError: name ‘train’ is not defined
你好Carde…请参阅教程末尾附近的完整代码列表。
将dropout()添加到数字分类模型中是否可以?因为在使用dropout时我获得了最佳准确率。
你好Suhas…是的,这种方法是合理的,很高兴知道你能够提高模型的准确率!Dropout确实有助于避免过拟合。
最终代码和代码测试结果在哪里?
你好abdool…最终的代码列表已在本帖中提供。它不可见吗?
你好,对于改进的深度,有多少隐藏层?
你好Ashbrocolli…这些层可以在下面注释之后的部分找到
“更改后的完整代码列表如下。”
你好@James Carmichael,我想知道“to_categorical”是如何工作的。我看了文档,上面说如果类别的数量没有指定,那么它将被推断为max(y) + 1,如果y是一个向量。令我惊讶的是,我知道MNIST数据集的类别数量是10,但如果没有将这个数字指定为参数,该函数就会返回一个形状为(60000,10)的向量,但这是怎么发生的?我真的很想知道max(y)+1是如何在图像上工作的,并给出正确的num_classes,也就是10。
提前感谢您的回答。
抱歉,我明白了。因为“y”是一个从0到9的标签向量,所以max(y)+1会返回10(num_classes),这其实很明显。我感到困惑是因为我在打印“y”时遇到了问题,它没有显示预期的值。
谢谢!
感谢更新Rabiaa!做得好!
教程已过时。不建议初学者使用。在如今这个时代,事情可以做得更简单、更清晰。
谢谢你的反馈!
非常感谢您的这项有趣的工作。
在加载、重塑和归一化图像后,我绘制了这些图像,但仍然得到相同的结果,这是正常的吗?
嗨,Jason,
在我正在撰写的一篇论文中,我被要求根据CNN实现(任何合理的架构都可以)包含EMNIST数字分类的操作次数(大约)。我正在考虑参考您的MNIST网络,因为我认为它们在EMNIST数据上也能很好地工作。
您是否估计了您任何网络所需的操作次数?
另外,您是否实际尝试过使用EMNIST数字数据集?
谢谢,
罗伯特
你好Robert…请澄清“操作次数”的含义。这将使我们能够更好地指导您。
您发布教程已经很久了。但我遇到了一个问题。无论我使用什么图像,输出都是“1”,我不知道为什么。你能帮我吗?
你好Karim…看起来您的模型可能过拟合到某个特定类别,或者未能正常学习。以下是一些需要检查的方面:
1. **数据预处理**:确保您的图像已正确预处理。对于MNIST,图像应该是灰度的(1个通道)并且大小为28x28像素,像素值经过归一化(通常在0到1之间或进行标准化)。
2. **模型架构**:如果您的模型架构过于简单,它可能无法很好地泛化。确保您有足够的层(例如,卷积层和密集层)和单元来捕捉数字分类的复杂性。然而,没有正则化的过深网络也可能导致问题。
3. **损失函数和激活函数**:验证您在最后一层使用了
softmax激活函数,并为多类别分类使用了交叉熵损失。4. **模型训练**:如果您的模型训练的轮数太少或没有对训练数据进行适当的混洗,它可能无法有效学习。反之,在有限的子集上过度训练也可能导致它偏向特定输出。
5. **评估**:如果您在模型收敛或测试之前打印预测,模型可能仍然输出随机或有偏差的结果。请确保在进行预测时保存并加载已训练的模型版本。
检查这些应该有助于您缩小问题范围。如果问题仍然存在,请随时分享更多关于模型结构和训练循环的细节,以便获得更具体的指导!