逐步开发深度卷积神经网络以对狗和猫的照片进行分类
狗与猫数据集是一个标准的计算机视觉数据集,涉及将照片分类为包含狗或猫。
尽管问题听起来很简单,但直到最近几年才使用深度学习卷积神经网络有效地解决。虽然数据集已有效解决,但它可以用作学习和实践如何从头开始开发、评估和使用卷积深度学习神经网络进行图像分类的基础。
这包括如何开发一个强大的测试框架来估计模型的性能,如何探索模型的改进,以及如何保存模型并在以后加载它以对新数据进行预测。
在本教程中,您将学习如何开发卷积神经网络来对狗和猫的照片进行分类。
完成本教程后,您将了解:
- 如何加载和准备狗和猫的照片以进行建模。
- 如何从头开始开发卷积神经网络用于照片分类并提高模型性能。
- 如何使用迁移学习开发照片分类模型。
通过我的新书《计算机视觉深度学习》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。
- 2021 年 12 月更新:修复“预处理照片尺寸(可选)”部分代码中的拼写错误

如何开发卷积神经网络以对狗和猫的照片进行分类
图片来自 Cohen Van der Velde,保留部分权利。
教程概述
本教程分为六个部分;它们是:
- 狗与猫预测问题
- 狗与猫数据集准备
- 开发基线 CNN 模型
- 开发模型改进
- 探索迁移学习
- 如何完成模型并进行预测
狗与猫预测问题
狗与猫数据集是指用于 2013 年 Kaggle 机器学习竞赛的数据集。
该数据集由狗和猫的照片组成,这些照片是来自一个更大的 300 万张手动标注照片数据集的子集。该数据集由 Petfinder.com 和 Microsoft 合作开发。
该数据集最初用作 CAPTCHA(或完全自动化的公共图灵测试,用于区分计算机和人类),即被认为人类认为微不足道但机器无法解决的任务,用于网站以区分人类用户和机器人。具体来说,该任务被称为“Asirra”或动物物种图像识别以限制访问,这是一种 CAPTCHA。该任务在 2007 年题为“Asirra:一种利用兴趣对齐手动图像分类的 CAPTCHA”的论文中进行了描述。
我们提出了 Asirra,这是一种 CAPTCHA,要求用户从一组 12 张猫和狗的照片中识别出猫。Asirra 对用户来说很容易;用户研究表明,人类在 30 秒内解决它的时间为 99.6%。除非机器视觉取得重大进展,否则我们预计计算机解决它的机会不会超过 1/54,000。
— Asirra:一种利用兴趣对齐手动图像分类的 CAPTCHA,2007。
在发布竞赛时,最先进的结果是通过 SVM 实现的,并在 2007 年一篇题为“针对 Asirra CAPTCHA 的机器学习攻击”(PDF)的论文中进行了描述,该论文实现了 80% 的分类准确率。正是这篇论文证明,在任务提出后不久,该任务不再适合作为 CAPTCHA。
……我们描述了一个分类器,它在区分 Asirra 中使用的猫和狗的图像时准确率为 82.7%。该分类器是支持向量机分类器的组合,这些分类器在从图像中提取的颜色和纹理特征上进行训练。[…]我们的结果建议在没有保护措施的情况下部署 Asirra 时要谨慎。
— 针对 Asirra CAPTCHA 的机器学习攻击,2007。
Kaggle 竞赛提供了 25,000 张带标签的照片:12,500 张狗和相同数量的猫。然后需要在包含 12,500 张未标记照片的测试数据集上进行预测。竞赛由 Pierre Sermanet(目前是 Google Brain 的研究科学家)赢得,他在测试数据集的 70% 子样本上实现了约 98.914% 的分类准确率。他的方法后来作为 2013 年题为“OverFeat:使用卷积网络的集成识别、定位和检测”的论文的一部分进行了描述。
数据集易于理解且足够小,可以放入内存中。因此,它已成为初学者开始使用卷积神经网络时一个很好的“hello world”或“入门”计算机视觉数据集。
因此,在此任务上,使用手动设计的卷积神经网络通常可以达到约 80% 的准确率,而使用迁移学习则可以达到 90% 以上的准确率。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
狗与猫数据集准备
该数据集可从 Kaggle 网站免费下载,但我认为您必须拥有 Kaggle 帐户。
如果您没有 Kaggle 帐户,请先注册。
通过访问狗与猫数据页面并单击“下载所有”按钮来下载数据集。
这将把 850 兆字节的文件“dogs-vs-cats.zip”下载到您的工作站。
解压文件后,您将看到 train.zip、train1.zip 和一个 .csv 文件。解压 train.zip 文件,因为我们将只关注此数据集。
您现在将有一个名为“train/”的文件夹,其中包含 25,000 张狗和猫的 .jpg 文件。照片通过其文件名进行标记,文件名为“dog”或“cat”。文件命名约定如下:
|
1 2 3 4 5 |
cat.0.jpg ... cat.124999.jpg dog.0.jpg dog.124999.jpg |
绘制狗和猫的照片
查看目录中的几张随机照片,您会发现照片是彩色的,并且具有不同的形状和大小。
例如,让我们加载并绘制单个图中狗的前九张照片。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 从狗与猫数据集中绘制狗的照片 from matplotlib import pyplot from matplotlib.image import imread # 定义数据集位置 folder = 'train/' # 绘制前几张图片 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 定义文件名 filename = folder + 'dog.' + str(i) + '.jpg' # 加载图像像素 image = imread(filename) # 绘制原始像素数据 pyplot.imshow(image) # 显示图 pyplot.show() |
运行示例会创建一个图形,显示数据集中狗的前九张照片。
我们可以看到有些照片是横向格式,有些是纵向格式,有些是方形。
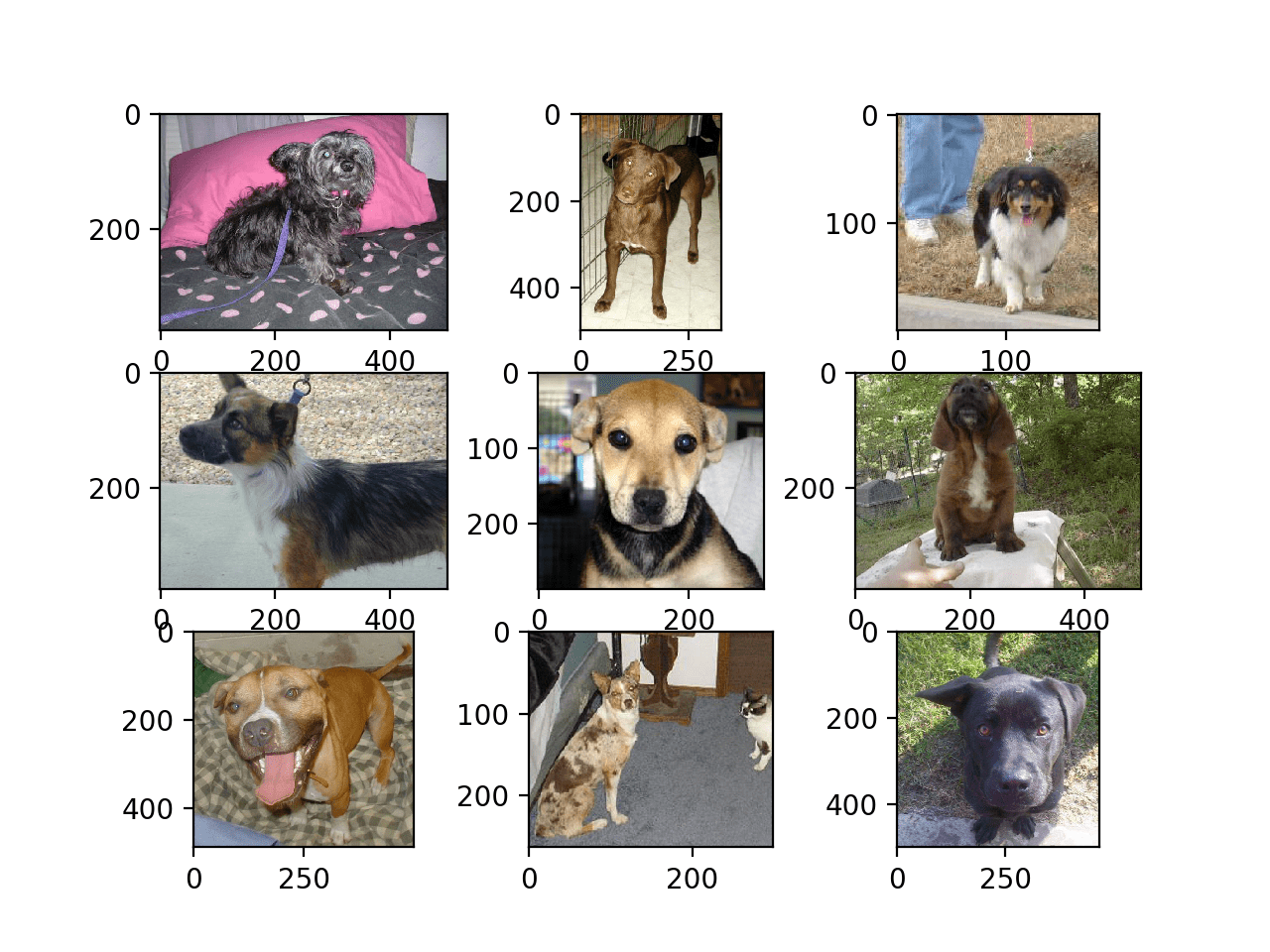
狗与猫数据集中狗的前九张照片
我们可以更新示例并将其更改为绘制猫的照片;完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 从狗与猫数据集中绘制猫的照片 from matplotlib import pyplot from matplotlib.image import imread # 定义数据集位置 folder = 'train/' # 绘制前几张图片 for i in range(9): # 定义子图 pyplot.subplot(330 + 1 + i) # 定义文件名 filename = folder + 'cat.' + str(i) + '.jpg' # 加载图像像素 image = imread(filename) # 绘制原始像素数据 pyplot.imshow(image) # 显示图 pyplot.show() |
同样,我们可以看到照片的大小都不同。
我们还可以看到一张照片中的猫几乎看不见(左下角),另一张照片中有两只猫(右下角)。这表明在此问题上拟合的任何分类器都必须具有鲁棒性。

狗与猫数据集中猫的前九张照片
选择标准化照片尺寸
照片在建模之前必须进行重塑,以便所有图像具有相同的形状。这通常是一个小的方形图像。
实现此目的有许多方法,尽管最常见的是简单的调整大小操作,它将拉伸和变形每个图像的宽高比并将其强制转换为新形状。
我们可以加载所有照片并查看照片宽度和高度的分布,然后设计一个新的照片尺寸,以最好地反映我们在实践中最可能看到的情况。
较小的输入意味着模型训练速度更快,通常此考虑因素在图像尺寸的选择中占主导地位。在这种情况下,我们将遵循这种方法,并选择 200×200 像素的固定尺寸。
预处理照片尺寸(可选)
如果我们想将所有图像加载到内存中,我们可以估计大约需要 12 GB 的 RAM。
即 25,000 张图像,每张图像有 200x200x3 像素,或 3,000,000,000 个 32 位像素值。
我们可以加载所有图像,重塑它们,并将它们存储为单个 NumPy 数组。这可以适应许多现代机器的 RAM,但不是所有机器,特别是如果您只有 8 GB 可用。
我们可以编写自定义代码将图像加载到内存中,并在加载过程中调整它们的大小,然后保存它们以供建模。
下面的示例使用 Keras 图像处理 API 加载训练数据集中所有 25,000 张照片,并将其重塑为 200×200 的方形照片。还根据文件名确定每张照片的标签。然后保存照片和标签的元组。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 加载狗与猫数据集,重塑并保存到新文件 from os import listdir from numpy import asarray from numpy import save from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array # 定义数据集位置 folder = 'train/' photos, labels = list(), list() # 枚举目录中的文件 for file in listdir(folder): # 确定类别 output = 0.0 if file.startswith('dog'): output = 1.0 # 加载图像 photo = load_img(folder + file, target_size=(200, 200)) # 转换为numpy数组 photo = img_to_array(photo) # 存储 photos.append(photo) labels.append(output) # 转换为 numpy 数组 photos = asarray(photos) labels = asarray(labels) print(photos.shape, labels.shape) # 保存重塑后的照片 save('dogs_vs_cats_photos.npy', photos) save('dogs_vs_cats_labels.npy', labels) |
运行示例可能需要大约一分钟才能将所有图像加载到内存中,并打印加载数据的形状以确认其已正确加载。
注意:运行此示例假设您有超过 12 GB 的 RAM。如果您没有足够的 RAM,可以跳过此示例;它仅作为演示提供。
|
1 |
(25000, 200, 200, 3) (25000,) |
运行结束后,将创建两个文件,名为“dogs_vs_cats_photos.npy”和“dogs_vs_cats_labels.npy”,其中包含所有调整大小的图像及其相关的类别标签。这些文件总共只有大约 12 GB,加载速度比单个图像快得多。
准备好的数据可以直接加载;例如
|
1 2 3 4 5 |
# 加载并确认形状 from numpy import load photos = load('dogs_vs_cats_photos.npy') labels = load('dogs_vs_cats_labels.npy') print(photos.shape, labels.shape) |
将照片预处理为标准目录
或者,我们可以使用 Keras ImageDataGenerator 类和 flow_from_directory() API 逐步加载图像。这将执行得更慢,但可以在更多机器上运行。
此 API 倾向于将数据划分为单独的 train/ 和 test/ 目录,并且在每个目录下都有一个用于每个类别的子目录,例如 train/dog/ 和 train/cat/ 子目录,以及 test 目录中的相同结构。然后图像被组织在子目录下。
我们可以编写一个脚本来创建具有这种首选结构的数据集的副本。我们将随机选择 25% 的图像(即 6,250 张)用于测试数据集。
首先,我们需要创建如下目录结构
|
1 2 3 4 5 6 7 |
dataset_dogs_vs_cats ├── test │ ├── cats │ └── dogs └── train ├── cats └── dogs |
我们可以使用 makedirs() 函数在 Python 中创建目录,并使用循环为 train/ 和 test/ 目录创建 dog/ 和 cat/ 子目录。
|
1 2 3 4 5 6 7 8 9 |
# 创建目录 dataset_home = 'dataset_dogs_vs_cats/' subdirs = ['train/', 'test/'] for subdir in subdirs: # 创建标签子目录 labeldirs = ['dogs/', 'cats/'] for labldir in labeldirs: newdir = dataset_home + subdir + labldir makedirs(newdir, exist_ok=True) |
接下来,我们可以枚举数据集中的所有图像文件,并根据其文件名将其复制到 dogs/ 或 cats/ 子目录中。
此外,我们可以随机决定将 25% 的图像保留到测试数据集中。这通过固定伪随机数生成器的种子来实现一致性,以便每次运行代码时都能获得相同的数据分割。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 设定随机数生成器种子 seed(1) # 定义用于验证的图片比例 val_ratio = 0.25 # 将训练数据集图像复制到子目录 src_directory = 'train/' for file in listdir(src_directory): src = src_directory + '/' + file dst_dir = 'train/' if random() < val_ratio: dst_dir = 'test/' if file.startswith('cat'): dst = dataset_home + dst_dir + 'cats/' + file copyfile(src, dst) elif file.startswith('dog'): dst = dataset_home + dst_dir + 'dogs/' + file copyfile(src, dst) |
完整的代码示例列在下面,并假设您已将下载的 train.zip 中的图像解压缩到当前工作目录的 train/ 中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 将数据集组织成有用的结构 from os import makedirs from os import listdir from shutil import copyfile from random import seed from random import random # 创建目录 dataset_home = 'dataset_dogs_vs_cats/' subdirs = ['train/', 'test/'] for subdir in subdirs: # 创建标签子目录 labeldirs = ['dogs/', 'cats/'] for labldir in labeldirs: newdir = dataset_home + subdir + labldir makedirs(newdir, exist_ok=True) # 设定随机数生成器种子 seed(1) # 定义用于验证的图片比例 val_ratio = 0.25 # 将训练数据集图像复制到子目录 src_directory = 'train/' for file in listdir(src_directory): src = src_directory + '/' + file dst_dir = 'train/' if random() < val_ratio: dst_dir = 'test/' if file.startswith('cat'): dst = dataset_home + dst_dir + 'cats/' + file copyfile(src, dst) elif file.startswith('dog'): dst = dataset_home + dst_dir + 'dogs/' + file copyfile(src, dst) |
运行示例后,您现在将拥有一个新的 dataset_dogs_vs_cats/ 目录,其中包含 train/ 和 val/ 子文件夹,以及进一步的 dogs/ 和 cats/ 子目录,正如所设计的那样。
开发基线 CNN 模型
在本节中,我们可以为狗与猫数据集开发一个基线卷积神经网络模型。
基线模型将建立一个最低模型性能,我们所有其他模型都可以与之进行比较,以及一个我们可以用作研究和改进基础的模型架构。
一个好的起点是 VGG 模型的通用架构原则。它们是一个好的起点,因为它们在 ILSVRC 2014 竞赛中取得了顶尖性能,并且因为该架构的模块化结构易于理解和实现。有关 VGG 模型的更多详细信息,请参阅 2015 年的论文《用于大规模图像识别的非常深的卷积网络》。
该架构涉及堆叠带有小型 3×3 滤波器的卷积层,然后是最大池化层。这些层共同形成一个块,并且这些块可以重复,其中每个块中的滤波器数量随着网络深度增加,例如模型前四个块的滤波器数量分别为 32、64、128、256。卷积层上使用填充以确保输出特征图的高度和宽度形状与输入匹配。
我们可以在狗与猫问题上探索这种架构,并比较具有 1、2 和 3 个块的该架构模型。
每个层将使用 ReLU 激活函数和 He 权重初始化,这些通常是最佳实践。例如,一个 3 块 VGG 风格的架构,其中每个块都有一个卷积层和池化层,可以在 Keras 中定义如下:
|
1 2 3 4 5 6 7 8 9 |
# 块 1 model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) # 块 2 model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) # 块 3 model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) |
我们可以创建一个名为 define_model() 的函数,它将定义一个模型并返回它,以便在数据集上进行拟合。然后可以自定义此函数来定义不同的基线模型,例如具有 1、2 或 3 个 VGG 样式块的模型版本。
该模型将使用随机梯度下降进行拟合,我们将从保守的学习率 0.001 和动量 0.9 开始。
该问题是一个二元分类任务,需要预测 0 或 1 的一个值。将使用一个带有 1 个节点和 sigmoid 激活的输出层,并且将使用二元交叉熵损失函数优化模型。
下面是 define_model() 函数的一个示例,用于为狗与猫问题定义一个带有 VGG 样式块的卷积神经网络模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model |
它可以根据需要调用来准备模型,例如
|
1 2 |
# 定义模型 model = define_model() |
接下来,我们需要准备数据。
这首先涉及到定义 ImageDataGenerator 的一个实例,它将像素值缩放到 0-1 的范围。
|
1 2 |
# 创建数据生成器 datagen = ImageDataGenerator(rescale=1.0/255.0) |
接下来,需要为训练和测试数据集准备迭代器。
我们可以使用数据生成器上的 flow_from_directory() 函数,并为 train/ 和 test/ 目录中的每一个创建一个迭代器。我们必须通过“class_mode”参数指定该问题是一个二元分类问题,并通过“target_size”参数以 200x200 像素大小加载图像。我们将批处理大小固定为 64。
|
1 2 3 4 5 |
# 准备迭代器 train_it = datagen.flow_from_directory('dataset_dogs_vs_cats/train/', class_mode='binary', batch_size=64, target_size=(200, 200)) test_it = datagen.flow_from_directory('dataset_dogs_vs_cats/test/', class_mode='binary', batch_size=64, target_size=(200, 200)) |
然后我们可以使用训练迭代器 (train_it) 来拟合模型,并使用测试迭代器 (test_it) 作为训练期间的验证数据集。
必须指定训练和测试迭代器的步数。这是一次 epoch 将包含的批次数量。这可以通过每个迭代器的长度来指定,并且将是训练和测试目录中图像总数除以批次大小 (64)。
模型将拟合 20 个 epoch,这是一个较小的数字,用于检查模型是否可以学习该问题。
|
1 2 3 |
# 拟合模型 history = model.fit_generator(train_it, steps_per_epoch=len(train_it), validation_data=test_it, validation_steps=len(test_it), epochs=20, verbose=0) |
一旦拟合,最终模型可以直接在测试数据集上进行评估,并报告分类准确性。
|
1 2 3 |
# 评估模型 _, acc = model.evaluate_generator(test_it, steps=len(test_it), verbose=0) print('> %.3f' % (acc * 100.0)) |
最后,我们可以根据在 fit_generator() 调用返回的“history”目录中存储的训练期间收集的历史记录创建图表。
历史记录包含每个 epoch 结束时测试和训练数据集上的模型准确性和损失。这些度量值在训练 epoch 上的折线图提供了学习曲线,我们可以用它们来了解模型是否过拟合、欠拟合或拟合良好。
下面的 summarize_diagnostics() 函数接收历史记录目录,并创建一个包含损失折线图和准确性折线图的单个图。然后,该图将保存到文件中,文件名基于脚本的名称。如果我们希望在不同的文件中评估模型的许多变体并自动为每个变体创建折线图,这会很有帮助。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='train') pyplot.plot(history.history['val_loss'], color='orange', label='test') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'] color='blue', label='train') pyplot.plot(history.history['val_accuracy'] color='orange', label='test') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() |
我们可以将所有这些结合到一个简单的测试工具中,用于测试模型配置。
下面列出了在狗和猫数据集上评估单块基线模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
# 狗与猫数据集的基线模型 import sys from matplotlib import pyplot from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD from keras.preprocessing.image import ImageDataGenerator # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='train') pyplot.plot(history.history['val_loss'], color='orange', label='test') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'] color='blue', label='train') pyplot.plot(history.history['val_accuracy'] color='orange', label='test') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 定义模型 model = define_model() # 创建数据生成器 datagen = ImageDataGenerator(rescale=1.0/255.0) # 准备迭代器 train_it = datagen.flow_from_directory('dataset_dogs_vs_cats/train/', class_mode='binary', batch_size=64, target_size=(200, 200)) test_it = datagen.flow_from_directory('dataset_dogs_vs_cats/test/', class_mode='binary', batch_size=64, target_size=(200, 200)) # 拟合模型 history = model.fit_generator(train_it, steps_per_epoch=len(train_it), validation_data=test_it, validation_steps=len(test_it), epochs=20, verbose=0) # 评估模型 _, acc = model.evaluate_generator(test_it, steps=len(test_it), verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
现在我们有了测试工具,让我们看看三个简单基线模型的评估。
单块 VGG 模型
单块 VGG 模型有一个卷积层,带有 32 个滤波器,后面跟着一个最大池化层。
该模型的 define_model() 函数在上一节中已经定义,但为了完整性,在此再次提供。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model |
运行此示例首先打印训练和测试数据集的大小,确认数据集已正确加载。
然后对模型进行拟合和评估,这在现代 GPU 硬件上大约需要 20 分钟。
|
1 2 3 |
找到属于 2 个类别的 18697 张图片。 找到属于 2 个类别的 6303 张图片。 > 72.331 |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型在测试数据集上实现了大约 72% 的准确率。
还创建了一个图,显示模型在训练(蓝色)和测试(橙色)数据集上的损失折线图和准确率折线图。
查看此图,我们可以看到模型在大约 12 个 epoch 时过度拟合了训练数据集。
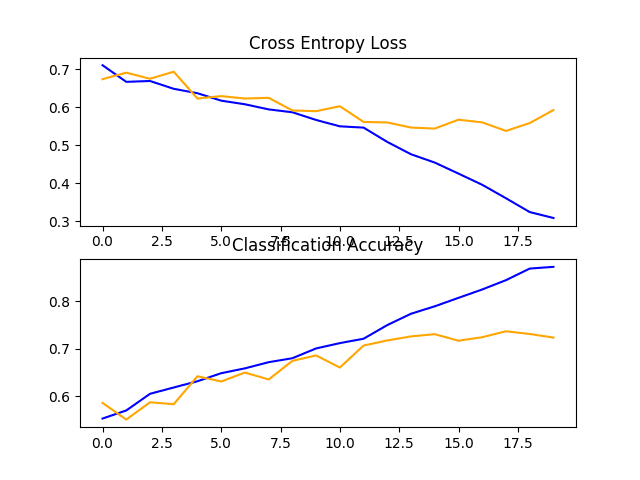
带有单个 VGG 块的基线模型在狗和猫数据集上的损失和准确率学习曲线图
两块 VGG 模型
两块 VGG 模型扩展了单块模型,并添加了第二个带有 64 个滤波器的块。
为了完整性,下面提供了此模型的 define_model() 函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model |
再次运行此示例会打印训练和测试数据集的大小,确认数据集已正确加载。
模型经过拟合和评估,并报告了测试数据集上的性能。
|
1 2 3 |
找到属于 2 个类别的 18697 张图片。 找到属于 2 个类别的 6303 张图片。 > 76.646 |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型性能略有改善,从一块模型的约 72% 准确率提高到两块模型的约 76% 准确率。
回顾学习曲线图,我们可以再次看到模型似乎已经过度拟合了训练数据集,在这种情况下,可能更早,在大约八个训练 epoch 时。
这很可能是模型容量增加的结果,我们可能会预期这种早期过度拟合的趋势会随着下一个模型继续下去。
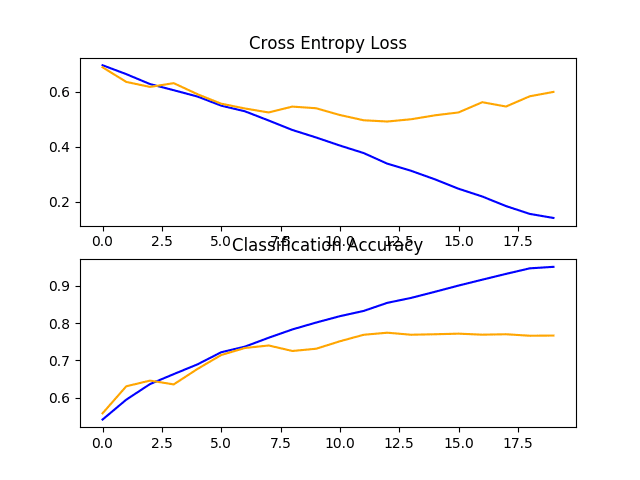
带有两个 VGG 块的基线模型在狗和猫数据集上的损失和准确率学习曲线图
三块 VGG 模型
三块 VGG 模型扩展了两块模型,并添加了第三个带有 128 个滤波器的块。
该模型的 define_model() 函数在上一节中已经定义,但为了完整性,在此再次提供。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model |
运行此示例将打印训练和测试数据集的大小,确认数据集已正确加载。
模型经过拟合和评估,并报告了测试数据集上的性能。
|
1 2 3 |
找到属于 2 个类别的 18697 张图片。 找到属于 2 个类别的 6303 张图片。 > 80.184 |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能进一步提升,从两块模型的约 76% 准确率提高到三块模型的约 80% 准确率。这个结果很好,因为它接近于论文中报告的使用 SVM 获得的约 82% 准确率的先前最先进水平。
回顾学习曲线图,我们可以看到类似的过拟合趋势,在这种情况下,可能推迟到第五或第六个 epoch。
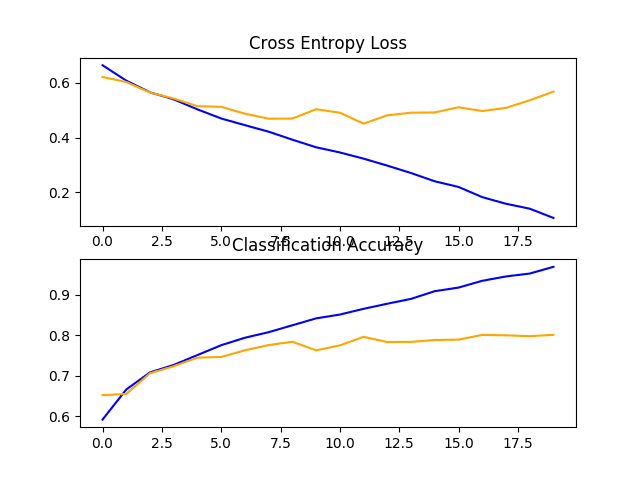
带有三个 VGG 块的基线模型在狗和猫数据集上的损失和准确率学习曲线图
讨论
我们探索了三种不同且基于 VGG 架构的模型。
结果总结如下,尽管考虑到算法的随机性,我们必须假设这些结果存在一些差异
- VGG 1: 72.331%
- VGG 2: 76.646%
- VGG 3: 80.184%
我们看到,随着容量的增加,性能有所提高,但也出现了类似的过拟合情况,而且发生得越来越早。
结果表明,该模型可能会受益于正则化技术。这可能包括 dropout、权重衰减和数据增强等技术。后者还可以通过扩展训练数据集,鼓励模型学习对位置进一步不变的特征,从而提高性能。
开发模型改进
在上一节中,我们开发了一个使用 VGG 风格块的基线模型,并发现了随着模型容量增加而性能提高的趋势。
在本节中,我们将从具有三个 VGG 块的基线模型(即 VGG 3)开始,并探索一些对模型的简单改进。
通过回顾模型在训练期间的学习曲线,模型显示出强烈的过拟合迹象。我们可以探索两种方法来尝试解决这种过拟合:dropout 正则化和数据增强。
这两种方法都预期会减缓训练期间的改进速度,并有望对抗训练数据集的过拟合。因此,我们将训练 epoch 的数量从 20 增加到 50,为模型提供更多改进空间。
Dropout 正则化
Dropout 正则化是一种计算成本低廉的深度神经网络正则化方法。
Dropout 通过概率性地移除或“丢弃”层的输入来工作,这些输入可以是数据样本中的输入变量,也可以是前一层的激活。它的作用是模拟大量具有非常不同网络结构的网络,反过来,使网络中的节点对输入通常更具鲁棒性。
有关 dropout 的更多信息,请参阅文章
通常,在每个 VGG 块之后可以应用少量 dropout,而更多的 dropout 应用于模型输出层附近的完全连接层。
下面是 define_model() 函数,用于更新的基线模型,其中添加了 Dropout。在这种情况下,每个 VGG 块之后应用 20% 的 dropout,在模型分类器部分的全连接层之后应用 50% 的较大 dropout 率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model |
为了完整性,下面列出了带有 dropout 的狗与猫数据集基线模型的完整代码列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
# 带有 dropout 的狗与猫数据集基线模型 import sys from matplotlib import pyplot from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten 从 keras.layers 导入 Dropout from keras.optimizers import SGD from keras.preprocessing.image import ImageDataGenerator # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='train') pyplot.plot(history.history['val_loss'], color='orange', label='test') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'] color='blue', label='train') pyplot.plot(history.history['val_accuracy'] color='orange', label='test') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 定义模型 model = define_model() # 创建数据生成器 datagen = ImageDataGenerator(rescale=1.0/255.0) # 准备迭代器 train_it = datagen.flow_from_directory('dataset_dogs_vs_cats/train/', class_mode='binary', batch_size=64, target_size=(200, 200)) test_it = datagen.flow_from_directory('dataset_dogs_vs_cats/test/', class_mode='binary', batch_size=64, target_size=(200, 200)) # 拟合模型 history = model.fit_generator(train_it, steps_per_epoch=len(train_it), validation_data=test_it, validation_steps=len(test_it), epochs=50, verbose=0) # 评估模型 _, acc = model.evaluate_generator(test_it, steps=len(test_it), verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
运行此示例首先拟合模型,然后报告模型在保留测试数据集上的性能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型性能略有提升,从基线模型的约 80% 准确率提高到添加 dropout 后的约 81% 准确率。
|
1 2 3 |
找到属于 2 个类别的 18697 张图片。 找到属于 2 个类别的 6303 张图片。 > 81.279 |
回顾学习曲线,我们可以看到 dropout 对模型在训练集和测试集上的改进速度产生了影响。
过拟合已被减少或延迟,尽管性能可能在运行结束时开始停滞。
结果表明,进一步的训练 epoch 可能会导致模型进一步改进。探索在 VGG 块之后稍微提高 dropout 率以及增加训练 epoch 数量也可能很有趣。
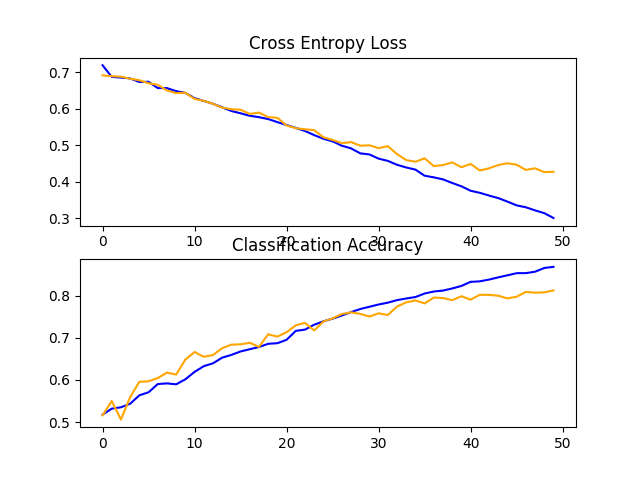
带有 dropout 的基线模型在狗和猫数据集上的损失和准确率学习曲线图
图像数据增强
图像数据增强是一种通过创建数据集中图像的修改版本来人工扩展训练数据集大小的技术。
在更多数据上训练深度学习神经网络模型可以产生更熟练的模型,并且增强技术可以创建图像的变体,从而提高拟合模型将其所学知识推广到新图像的能力。
数据增强还可以充当正则化技术,向训练数据添加噪声,并鼓励模型学习相同的特征,使其对输入中的位置不变。
对狗和猫的输入照片进行微小更改可能对这个问题很有用,例如小范围平移和水平翻转。这些增强可以作为用于训练数据集的 ImageDataGenerator 的参数指定。增强不应用于测试数据集,因为我们希望评估模型在未修改照片上的性能。
这需要我们为训练和测试数据集拥有单独的 ImageDataGenerator 实例,然后从各自的数据生成器创建训练和测试集的迭代器。例如
|
1 2 3 4 5 6 7 8 9 |
# 创建数据生成器 train_datagen = ImageDataGenerator(rescale=1.0/255.0, width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1.0/255.0) # 准备迭代器 train_it = train_datagen.flow_from_directory('dataset_dogs_vs_cats/train/', class_mode='binary', batch_size=64, target_size=(200, 200)) test_it = test_datagen.flow_from_directory('dataset_dogs_vs_cats/test/', class_mode='binary', batch_size=64, target_size=(200, 200)) |
在这种情况下,训练数据集中的照片将通过小范围(10%)随机水平和垂直平移以及随机水平翻转进行增强,从而创建照片的镜像。训练和测试步骤中的照片都将以相同的方式缩放其像素值。
为了完整性,下面列出了带有训练数据增强的狗和猫数据集基线模型的完整代码列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
# 带有数据增强的狗与猫数据集基线模型 import sys from matplotlib import pyplot from keras.utils import to_categorical from keras.models import Sequential 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD from keras.preprocessing.image import ImageDataGenerator # 定义cnn模型 def define_model(): model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same')) model.add(MaxPooling2D((2, 2))) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_initializer='he_uniform')) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='train') pyplot.plot(history.history['val_loss'], color='orange', label='test') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'] color='blue', label='train') pyplot.plot(history.history['val_accuracy'] color='orange', label='test') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 定义模型 model = define_model() # 创建数据生成器 train_datagen = ImageDataGenerator(rescale=1.0/255.0, width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1.0/255.0) # 准备迭代器 train_it = train_datagen.flow_from_directory('dataset_dogs_vs_cats/train/', class_mode='binary', batch_size=64, target_size=(200, 200)) test_it = test_datagen.flow_from_directory('dataset_dogs_vs_cats/test/', class_mode='binary', batch_size=64, target_size=(200, 200)) # 拟合模型 history = model.fit_generator(train_it, steps_per_epoch=len(train_it), validation_data=test_it, validation_steps=len(test_it), epochs=50, verbose=0) # 评估模型 _, acc = model.evaluate_generator(test_it, steps=len(test_it), verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
运行此示例首先拟合模型,然后报告模型在保留测试数据集上的性能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能提升了约 5%,从基线模型的约 80% 提高到带有简单数据增强的基线模型的约 85%。
|
1 |
> 85.816 |
回顾学习曲线,我们可以看到模型似乎能够进一步学习,即使在运行结束时,训练和测试数据集上的损失仍在持续下降。用 100 或更多 epoch 重复实验很可能会带来性能更好的模型。
探索其他增强方法可能很有趣,这些增强方法可能进一步鼓励学习对输入中位置不变的特征,例如轻微旋转和缩放。
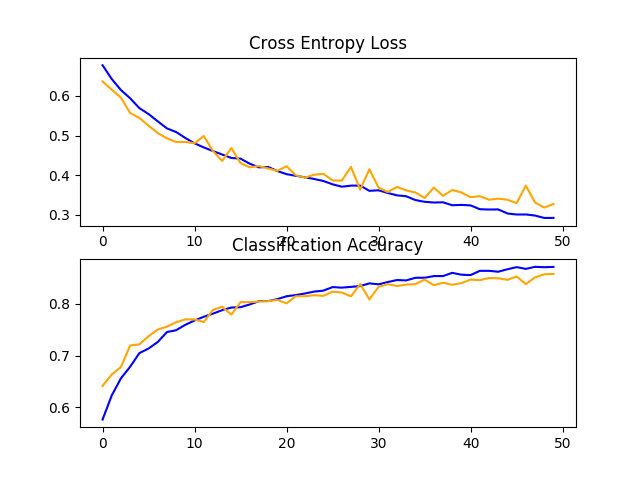
带有数据增强的基线模型在狗和猫数据集上的损失和准确率学习曲线图
讨论
我们探索了对基线模型的三种不同改进。
结果总结如下,尽管考虑到算法的随机性,我们必须假设这些结果存在一些差异
- 基线 VGG3 + Dropout:81.279%
- 基线 VGG3 + 数据增强:85.816%
正如预期的那样,正则化技术的添加减缓了学习算法的进展并减少了过拟合,从而在保留数据集上获得了改进的性能。很可能结合这两种方法并进一步增加训练 epoch 的数量将带来进一步的改进。
这只是在此数据集上可以探索的改进类型中的一个开始。除了对所描述的正则化方法进行调整之外,还可以探索其他正则化方法,例如权重衰减和早期停止。
可能值得探索学习算法的更改,例如学习率的更改、使用学习率调度或自适应学习率(例如Adam)。
探索替代模型架构也可能值得。所选的基线模型预计将提供比此问题所需的更多容量,而较小的模型训练速度更快,反过来可能会带来更好的性能。
探索迁移学习
迁移学习涉及使用在相关任务上训练过的模型的全部或部分。
Keras 提供了各种预训练模型,可以通过 Keras Applications API 完全或部分加载和使用。
一种有用的迁移学习模型是 VGG 模型之一,例如 VGG-16,它有 16 层,在开发时在 ImageNet 照片分类挑战赛中取得了最佳结果。
该模型由两个主要部分组成:由 VGG 块组成的特征提取器部分,以及由全连接层和输出层组成的分类器部分。
我们可以使用模型的特征提取部分,并添加一个针对狗和猫数据集量身定制的新分类器部分。具体来说,我们可以在训练期间固定所有卷积层的权重,只训练新的全连接层,这些层将学习解释从模型中提取的特征并进行二元分类。
这可以通过加载 VGG-16 模型来实现,从模型的输出端移除全连接层,然后添加新的全连接层来解释模型输出并进行预测。通过将“include_top”参数设置为“False”,可以自动移除模型的分类器部分,这还需要为模型指定输入形状,在本例中为 (224, 224, 3)。这意味着加载的模型在最后一个最大池化层处结束,之后我们可以手动添加一个 Flatten 层和新的分类器层。
下面的 define_model() 函数实现了这一点,并返回一个准备好进行训练的新模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 定义cnn模型 def define_model(): # 加载模型 model = VGG16(include_top=False, input_shape=(224, 224, 3)) # 将加载的层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加新的分类器层 flat1 = Flatten()(model.layers[-1].output) class1 = Dense(128, activation='relu', kernel_initializer='he_uniform')(flat1) output = Dense(1, activation='sigmoid')(class1) # 定义新模型 model = Model(inputs=model.inputs, outputs=output) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model |
创建完成后,我们可以像以前一样在训练数据集上训练模型。
在这种情况下,不需要太多的训练,因为只有新的全连接层和输出层具有可训练的权重。因此,我们将训练周期数固定为 10。
VGG16 模型是在特定的 ImageNet 挑战数据集上训练的。因此,它被配置为期望输入图像的形状为 224x224 像素。当从狗和猫数据集加载照片时,我们将使用此作为目标大小。
模型还期望图像居中。也就是说,要从输入中减去在 ImageNet 训练数据集上计算的每个通道(红、绿、蓝)的平均像素值。Keras 提供了一个函数,通过 preprocess_input() 函数对单个照片执行此准备。尽管如此,我们也可以通过将“featurewise_center”参数设置为“True”并手动指定用于居中的平均像素值作为 ImageNet 训练数据集的平均值:[123.68, 116.779, 103.939] 来实现相同的效果。
下面列出了用于狗与猫数据集迁移学习的 VGG 模型的完整代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
# 用于狗和猫数据集迁移学习的 vgg16 模型 import sys from matplotlib import pyplot from keras.utils import to_categorical from keras.applications.vgg16 import VGG16 from keras.models import Model from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD from keras.preprocessing.image import ImageDataGenerator # 定义cnn模型 def define_model(): # 加载模型 model = VGG16(include_top=False, input_shape=(224, 224, 3)) # 将加载的层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加新的分类器层 flat1 = Flatten()(model.layers[-1].output) class1 = Dense(128, activation='relu', kernel_initializer='he_uniform')(flat1) output = Dense(1, activation='sigmoid')(class1) # 定义新模型 model = Model(inputs=model.inputs, outputs=output) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model # 绘制诊断学习曲线 def summarize_diagnostics(history): # 绘制损失 pyplot.subplot(211) pyplot.title('交叉熵损失') pyplot.plot(history.history['loss'], color='blue', label='train') pyplot.plot(history.history['val_loss'], color='orange', label='test') # 绘制准确率 pyplot.subplot(212) pyplot.title('分类准确率') pyplot.plot(history.history['accuracy'] color='blue', label='train') pyplot.plot(history.history['val_accuracy'] color='orange', label='test') # 保存图到文件 filename = sys.argv[0].split('/')[-1] pyplot.savefig(filename + '_plot.png') pyplot.close() # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 定义模型 model = define_model() # 创建数据生成器 datagen = ImageDataGenerator(featurewise_center=True) # 为居中指定 imagenet 平均值 datagen.mean = [123.68, 116.779, 103.939] # 准备迭代器 train_it = datagen.flow_from_directory('dataset_dogs_vs_cats/train/', class_mode='binary', batch_size=64, target_size=(224, 224)) test_it = datagen.flow_from_directory('dataset_dogs_vs_cats/test/', class_mode='binary', batch_size=64, target_size=(224, 224)) # 拟合模型 history = model.fit_generator(train_it, steps_per_epoch=len(train_it), validation_data=test_it, validation_steps=len(test_it), epochs=10, verbose=1) # 评估模型 _, acc = model.evaluate_generator(test_it, steps=len(test_it), verbose=0) print('> %.3f' % (acc * 100.0)) # 学习曲线 summarize_diagnostics(history) # 入口点,运行测试工具 run_test_harness() |
运行此示例首先拟合模型,然后报告模型在保留测试数据集上的性能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到该模型取得了令人印象深刻的结果,在保留测试数据集上的分类准确率约为 97%。
|
1 2 3 |
找到属于 2 个类别的 18697 张图片。 找到属于 2 个类别的 6303 张图片。 > 97.636 |
回顾学习曲线,我们可以看到模型快速拟合数据集。它没有表现出强烈的过拟合,尽管结果表明分类器中额外的容量和/或使用正则化可能有所帮助。
这种方法还有许多改进之处,包括在模型的分类器部分添加 dropout 正则化,甚至可以微调模型特征检测器部分中部分或所有层的权重。
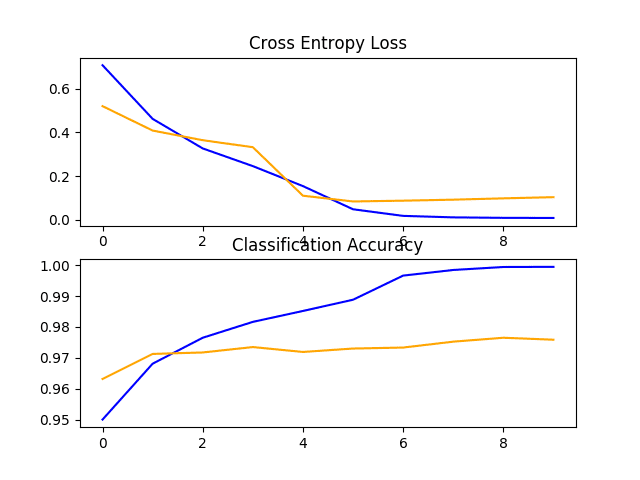
狗和猫数据集上 VGG16 迁移学习模型的损失和准确率学习曲线的线图
如何完成模型并进行预测
只要我们有想法、时间和资源来测试它们,模型改进过程就可以继续下去。
在某个时刻,必须选择并采用最终的模型配置。在这种情况下,我们将保持简单,并将 VGG-16 迁移学习方法作为最终模型。
首先,我们将通过在整个训练数据集上拟合模型并将模型保存到文件中以备将来使用来最终确定我们的模型。然后我们将加载保存的模型并用它对单个图像进行预测。
准备最终数据集
最终模型通常在所有可用数据(例如所有训练和测试数据集的组合)上进行拟合。
在本教程中,我们将演示最终模型仅在训练数据集上进行拟合,因为我们只有训练数据集的标签。
第一步是准备训练数据集,以便 ImageDataGenerator 类可以通过 flow_from_directory() 函数加载它。具体来说,我们需要创建一个新目录,其中所有训练图像都组织到 dogs/ 和 cats/ 子目录中,而无需区分 train/ 或 test/ 目录。
这可以通过更新我们在教程开头开发的脚本来实现。在这种情况下,我们将为整个训练数据集创建一个新的 finalize_dogs_vs_cats/ 文件夹,其中包含 dogs/ 和 cats/ 子文件夹。
结构将如下所示
|
1 2 3 |
finalize_dogs_vs_cats ├── cats └── dogs |
下面列出了更新后的脚本以供完整性参考。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 将数据集组织成有用的结构 from os import makedirs from os import listdir from shutil import copyfile # 创建目录 dataset_home = 'finalize_dogs_vs_cats/' # 创建标签子目录 labeldirs = ['dogs/', 'cats/'] for labldir in labeldirs: newdir = dataset_home + labldir makedirs(newdir, exist_ok=True) # 将训练数据集图像复制到子目录 src_directory = 'dogs-vs-cats/train/' for file in listdir(src_directory): src = src_directory + '/' + file if file.startswith('cat'): dst = dataset_home + 'cats/' + file copyfile(src, dst) elif file.startswith('dog'): dst = dataset_home + 'dogs/' + file copyfile(src, dst) |
保存最终模型
我们现在准备在整个训练数据集上拟合最终模型。
必须更新 flow_from_directory() 以从新的 finalize_dogs_vs_cats/ 目录加载所有图像。
|
1 2 3 |
# 准备迭代器 train_it = datagen.flow_from_directory('finalize_dogs_vs_cats/', class_mode='binary', batch_size=64, target_size=(224, 224)) |
此外,对 fit_generator() 的调用不再需要指定验证数据集。
|
1 2 |
# 拟合模型 model.fit_generator(train_it, steps_per_epoch=len(train_it), epochs=10, verbose=0) |
拟合后,我们可以通过在模型上调用 *save()* 函数并传入所选文件名,将最终模型保存到 H5 文件中。
|
1 2 |
# 保存模型 model.save('final_model.h5') |
请注意,保存和加载 Keras 模型需要您的工作站上安装 h5py 库。
下面列出了在训练数据集上拟合最终模型并将其保存到文件的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# 将最终模型保存到文件 from keras.applications.vgg16 import VGG16 from keras.models import Model from keras.layers import Dense from keras.layers import Flatten from keras.optimizers import SGD from keras.preprocessing.image import ImageDataGenerator # 定义cnn模型 def define_model(): # 加载模型 model = VGG16(include_top=False, input_shape=(224, 224, 3)) # 将加载的层标记为不可训练 for layer in model.layers: layer.trainable = False # 添加新的分类器层 flat1 = Flatten()(model.layers[-1].output) class1 = Dense(128, activation='relu', kernel_initializer='he_uniform')(flat1) output = Dense(1, activation='sigmoid')(class1) # 定义新模型 model = Model(inputs=model.inputs, outputs=output) # 编译模型 opt = SGD(lr=0.001, momentum=0.9) model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy']) return model # 运行测试工具以评估 cifar10 数据集上的模型 def run_test_harness(): # 定义模型 model = define_model() # 创建数据生成器 datagen = ImageDataGenerator(featurewise_center=True) # 为居中指定 imagenet 平均值 datagen.mean = [123.68, 116.779, 103.939] # 准备迭代器 train_it = datagen.flow_from_directory('finalize_dogs_vs_cats/', class_mode='binary', batch_size=64, target_size=(224, 224)) # 拟合模型 model.fit_generator(train_it, steps_per_epoch=len(train_it), epochs=10, verbose=0) # 保存模型 model.save('final_model.h5') # 入口点,运行测试工具 run_test_harness() |
运行此示例后,您的当前工作目录中将有一个名为“final_model.h5”的 81 兆字节大文件。
进行预测
我们可以使用保存的模型对新图像进行预测。
该模型假设新图像是彩色的,并且已进行分割,以便一张图像至少包含一只狗或一只猫。
下面是狗和猫比赛测试数据集中提取的图像。它没有标签,但我们可以清楚地看出这是一张狗的照片。您可以将其保存到当前工作目录中,文件名为“sample_image.jpg”。

狗 (sample_image.jpg)
我们将假装这是一张全新的、未见过的图像,按照所需方式准备好,并查看我们如何使用保存的模型来预测图像所代表的整数。对于此示例,我们期望“狗”的类别为“1”。
注意:图像的子目录(每个类别一个)由 flow_from_directory() 函数按字母顺序加载,并为每个类别分配一个整数。子目录“cat”在“dog”之前,因此类别标签被分配整数:cat=0, dog=1。这可以通过在训练模型时调用 flow_from_directory() 中的“classes”参数来更改。
首先,我们可以加载图像并强制其大小为 224x224 像素。然后可以调整加载的图像大小,使其在数据集中只有一个样本。像素值也必须居中,以匹配模型训练期间数据准备的方式。load_image() 函数实现了这一点,并将返回准备好进行分类的加载图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 加载并准备图像 def load_image(filename): # 加载图像 img = load_img(filename, target_size=(224, 224)) # 转换为数组 img = img_to_array(img) # 重塑为具有 3 个通道的单个样本 img = img.reshape(1, 224, 224, 3) # 居中像素数据 img = img.astype('float32') img = img - [123.68, 116.779, 103.939] return img |
接下来,我们可以像上一节中那样加载模型,并调用 predict() 函数来预测图像中的内容,将其表示为“0”到“1”之间的数字,分别代表“猫”和“狗”。
|
1 2 |
# 预测类别 result = model.predict(img) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 为新图像进行预测。 from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.models import load_model # 加载并准备图像 def load_image(filename): # 加载图像 img = load_img(filename, target_size=(224, 224)) # 转换为数组 img = img_to_array(img) # 重塑为具有 3 个通道的单个样本 img = img.reshape(1, 224, 224, 3) # 居中像素数据 img = img.astype('float32') img = img - [123.68, 116.779, 103.939] return img # 加载图像并预测类别 def run_example(): # 加载图像 img = load_image('sample_image.jpg') # 加载模型 model = load_model('final_model.h5') # 预测类别 result = model.predict(img) print(result[0]) # 入口点,运行示例 run_example() |
运行示例首先加载并准备图像,加载模型,然后正确预测加载的图像代表“狗”或类别“1”。
|
1 |
1 |
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 调整正则化。探索对基线模型中使用的正则化技术的微小更改,例如不同的 dropout 率和不同的图像增强。
- 调整学习率。探索对用于训练基线模型的学习算法的更改,例如备用学习率、学习率调度或自适应学习率算法,例如 Adam。
- 备用预训练模型。探索用于问题迁移学习的备用预训练模型,例如 Inception 或 ResNet。
如果您探索了这些扩展中的任何一个,我很想知道。
请在下面的评论中发布您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- Asirra:利用兴趣对齐手动图像分类的 CAPTCHA, 2007.
- 针对 Asirra CAPTCHA 的机器学习攻击, 2007.
- OverFeat:使用卷积网络的集成识别、定位和检测, 2013.
API
文章
总结
在本教程中,您学习了如何开发卷积神经网络来对狗和猫的照片进行分类。
具体来说,你学到了:
- 如何加载和准备狗和猫的照片以进行建模。
- 如何从头开始开发卷积神经网络用于照片分类并提高模型性能。
- 如何使用迁移学习开发照片分类模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






谢谢!本教程太棒了。我已经看过你的例子,但我很好奇你的模型生成花了多长时间。代码已经在笔记本电脑上运行了将近 4 小时。不确定这算不算长时间。谢谢
我想我是在 AWS 上使用 p3 实例 (GPU) 运行的。我不记得花了多长时间,抱歉。也许几个小时?
Paul,我在 Mac 上尝试了该模型——运行没有任何问题,成功编译了所有测试用例的代码
训练
500 只猫,500 只狗 –
测试
250 只猫 + 狗
对于大型数据集,我内存不足——我将在云端运行它
谢谢!本教程很棒。我用我自己收集的鱼类数据集仔细阅读了你的代码。它变成了一个多类别问题,但模型不适合那个多类别问题。你上面提到的最终模型我的准确率是 66.667。任何提高准确率的建议都将不胜感激。谢谢
干得好!
是的,我这里有一些建议
https://machinelearning.org.cn/start-here/#better
你需要添加一个 'softmax' 层而不是 sigmoid 层,对吧。
model.add(Dense(num_classes, activation='softmax'))。
我希望它会对你有用。
你好。谢谢你的这个教程。
我对使用 R 而不是 Python 的类似内容很感兴趣。你碰巧知道主要用于数据准备的类似代码吗?
抱歉,我没有 Keras 在 R 中的示例。
你好,谢谢你的分享,我从 2019 年 3 月开始学习你的课程,真的很有帮助!现在我计划用我的数据集来对儿童手写文本进行分类,期待你的建议,提前感谢!
中文文本看起来像“你”,“我”,“他”,“她”等等,总共大约 2000 个,但它们不是电脑打印的,而是孩子手写的,我有文本的图片。
目前我有两个想法来完成以下工作,它们是
父母说出单词,孩子做听力作业,(人工智能检查孩子是否写出正确的文本。
1. 第一个是训练一个超级模型来区分所有文本,
2. 为每个文本训练一个模型,并使用此模型检查孩子的作业(这可行,因为我知道孩子将要写什么文本)
你觉得哪个更好,或者你有什么其他好的建议,非常感谢!
-Charles
听起来很有趣!
也许可以尝试对每个原型进行原型设计,并加倍努力处理最有趣/有趣/最有可能奏效的情况?
Jason,你好,当我尝试训练一个模型时,它看起来很好,但是当我尝试加载模型时,它会抛出以下错误
ValueError('Cannot create group in read only mode.')
你知道这里有什么问题吗?
非常感谢!
我已经解决了故障,请忽略上面的问题,我现在正在做选项 2:配对比较,比如狗和猫,你有没有多重比较的示例代码?比如狗、猫、猴子、鸟等等。
谢谢!
不客气。
是的,就在这里。
https://machinelearning.org.cn/how-to-develop-a-cnn-from-scratch-for-cifar-10-photo-classification/
我以前从未见过这个错误,抱歉。
或许仔细检查一下所有库是否都是最新的?
也许可以尝试在 stackoverflow 上搜索/发布?
明白了,我将尝试学习 10 张照片分类,我已修复模型加载问题,
分享我的错误,也许有人会遇到同样的问题,希望这有帮助。
Charles:下面的代码在示例代码中运行良好,但无法加载我的文本图像训练模型,这让我感到很奇怪
=============================================
from keras.models import load_model
loaded_model = load_model('text_model')
Charles:我用另一种方式加载,对我来说似乎工作正常
=============================================
from keras.models import model_from_json
loaded_model = model_from_json('text_model')
顺便问一下,我有一个关于数据集旋转的问题,因为我没有那么多图像,所以我尝试旋转图像以增加数据集,分类准确率很快从 97% 下降到 53%。
我所做的是创建 3 个文件夹,将我的数据集复制到每个文件夹中,然后
文件夹 1. 旋转图像 90 度
文件夹 2. 旋转图像 180 度
文件夹 3. 旋转图像 270 度
将所有图像复制到 folderX 并基于所有图像训练模型。
更多关于模型加载的信息在这里
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
也许可以尝试图像增强
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
感谢教程!
您是否有图像分割的示例,用于在应用分类模型之前进行特征选择?
实际上,我在基于区域的图像分割方面遇到了问题。
这是我的代码!
# 从狗与猫数据集中绘制猫的照片
from matplotlib import pyplot
from matplotlib.image import imread
from PIL import Image
from skimage.color import rgb2gray
import numpy as np
import cv2
import matplotlib.pyplot as plt
from scipy import ndimage
import os, sys
# 定义数据集位置
folder = 'test/'
folder1 = ' ('
folder2 = ')'
folder3 = '2/'
# 绘制前几张图片
path = '1/'
dirs = os.listdir( path )
def resize()
for item in dirs
if os.path.isfile(path+item)
im = Image.open(path+item)
f, e = os.path.splitext(path+item)
g, d = os.path.splitext(folder3+item)
gray = rgb2gray(im)
gray_r = gray.reshape(gray.shape[0]*gray.shape[1])
for i in range(gray_r.shape[0])
if gray_r[i] > gray_r.mean()
gray_r[i] = 3
elif gray_r[i] > 0.5
gray_r[i] = 2
elif gray_r[i] > 0.25
gray_r[i] = 1
else
gray_r[i] = 0
gray = gray_r.reshape(gray.shape[0],gray.shape[1])
imResize = gray.resize((200,200), Image.ANTIALIAS)
imResize.save(g + '.jpg', 'JPEG', quality=100)
resize()
我收到错误“if rgb.ndim == 2
AttributeError: 'JpegImageFile' object has no attribute 'ndim'”
你能帮帮我吗!
不完全是,但也许这个模型会有帮助
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
你好 Jason,
一如既往的精彩教程。
你能解释一下你为什么使用 SGD 作为 GD 优化器吗?
你是否也尝试了 RSMProp 和 Adam,并凭经验发现 SGD 具有更高的准确性,还是有其他原因?
谢谢
最好从 Adam 或类似算法开始,但如果您有时间,SGD 和微调学习率和动量通常可以获得出色甚至更好的结果。
我能否编译并运行测试工具,以评估一个仅包含全卷积神经网络块(不含全连接层/密集层)用于边缘检测的模型?非常感谢。
可能。
你好,我需要你的帮助。我在这行代码上感到困惑。
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=50, verbose=0)
我知道这里,train_it 是训练图像,我们将用于训练目的。但是你把数据的标签列表传到哪里去了呢?我知道对于分类相关的问题,必须传递标签类。
你能帮我一下吗?
它拟合了模型。
我们正在使用数据生成器,您可以在此处了解更多信息
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
我理解得对吗?当我们使用 `flow_from_directory` 方法时,训练图像所在的文件夹名称会自动用作标签?是真的吗?
是的,目录中的文件夹代表类别。
在你提到的链接中,你提到了
# 创建迭代器
it = datagen.flow_from_directory(X, y, …)
这意味着你传递了 X 和标签列表。但在那个分类问题中,你只传递了训练图像的路径。
请帮帮我。我这一点真的很困惑。。。
flow_from_directory() 函数接受一个路径,请参阅此处的一个示例
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
这段代码是开源的吗?我们可以在我们的项目中使用这段代码吗?有人能在这方面指导我吗?
我的代码受版权保护,但你可以在自己的项目中使用它,更多详情请见此处
https://machinelearning.org.cn/faq/single-faq/can-i-use-your-code-in-my-own-project
我不明白为什么你在模型中使用了两个密集层。此外,密集层的目的是什么,以及你如何选择密集层中的神经元数量?选择的标准是什么?
我做了一些尝试和错误。
更多信息在这里
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
据我所知,我们在密集层中提到总输出类别的数量,在你的例子中是 2 个(猫和狗),那么为什么你在密集层中提到 1 呢?
其次,你最后添加的带有 128 个节点的密集层目的是什么?
请帮我理解这个概念?
第一个密集层解释特征。第二个进行分类预测。
是的,我明白第二个密集层进行分类预测。但在你的例子中,有两个类别(猫和狗),那么你为什么在密集层上使用 1 个节点呢?
model.add(Dense(1, activation=’sigmoid’))
所以应该是 2 个,不是吗?
Sigmoid 激活函数用于二元分类问题。
0 代表第一个类别,1 代表第二个类别。
这被称为伯努利响应。
如果同一张图片中有一只猫和一只狗,这段代码会起作用吗?有什么办法可以让我统计图片中宠物的数量吗?
不。这个问题假设图片中只有一“个”东西,它要么是狗,要么是猫。
我们在构建问题时必须做出假设,例如限制问题以使其更容易解决。
你好,
非常感谢这个教程。它解释得很清楚,并且对我有用。
我想扩展这个程序,让它使用摄像头进行实时识别。有什么办法可以帮助我吗?或者你有没有关于这方面的不同教程?
你可以将该模型应用于视频的每一帧,或者一部分帧。
嗨,Jason,
在迁移学习部分,我没有看到你如何将 VGG16 的权重初始化为“imagenet”。那么你只是在使用 VGG16 结构还是使用了已初始化权重的结构?我可能漏掉了什么。
谢谢,
它们在 Keras 中默认初始化为 ImageNet。
感谢您的本教程。您的教程非常棒,我觉得它非常有用。我不明白为什么我们只传递训练数据来保存最终模型?我们不需要同时传递验证数据吗?您为什么要使用 fit_generator 而不是 fit?当我运行已保存的模型时,在训练过程中我没有收到任何反馈或输出,而在运行迁移学习时,我会在每个步骤都收到输出,并且可以看到损失正在下降。我如何更改保存模型部分以在训练模型时获取反馈?
我们使用 `fit_generator()` 是因为我们使用了渐进式加载。
你可以将 `verbose` 设置为 1 或 2,以在训练期间获取反馈。
谢谢你。
我正在尝试将类别激活图添加到您的最终模型代码中。根据我的理解,我只需要执行以下操作:
替换
# 添加新的分类器层
flat1 = Flatten()(model.layers[-1].output)
class1 = Dense(128, activation=’relu’, kernel_initializer=’he_uniform’)(flat1)
output = Dense(1, activation=’sigmoid’)(class1)
用
# 添加新的分类器层
class1 = GlobalAveragePooling2D()(model.layers[-1].output)
output = Dense(1, activation=’sigmoid’)(class1)
然后训练模型,最后生成热图。我不确定我的热图是否正确。您有没有我可以一步一步遵循的教程来生成类别激活图?
谢谢
很好的问题。
我没有示例,但感谢您的建议!
很棒的教程!
一个问题,在3%的模型.predict(img)无法识别狗或猫的情况下,它会返回什么?
谢谢。
它会出错。将狗识别成猫,或者将猫识别成狗。
事实上,如果你看那些棘手的案例,它会出错,因为它们很难处理或者数据很糟糕。
你好,我又来了,我尝试修改您的代码以使用 `model.fit()` 而不是 `model.fit_generator()`,但我得到了非常糟糕的结果,实际上,我的损失在第一个 epoch 就接近于零了。
我尽我所能尝试了所有方法来改善结果,但我失败了。如果您能查看我的代码并告诉我这段代码有什么问题,我将不胜感激。
这是我训练模型时的输出:
++++++++++++++++++++++++++++++++++++++
第 1/10 纪元
32/18750 […………………………] – ETA: 46:03 – loss: 3.0541 – acc: 0.2812
64/18750 […………………………] – ETA: 23:30 – loss: 1.5280 – acc: 0.6406
96/18750 […………………………] – ETA: 15:58 – loss: 1.0187 – acc: 0.7604
128/18750 […………………………] – ETA: 12:11 – loss: 0.7641 – acc: 0.8203
160/18750 […………………………] – ETA: 9:55 – loss: 0.6113 – acc: 0.8562
192/18750 […………………………] – ETA: 8:24 – loss: 0.5094 – acc: 0.8802
224/18750 […………………………] – ETA: 7:20 – loss: 0.4366 – acc: 0.8973
256/18750 […………………………] – ETA: 6:31 – loss: 0.3820 – acc: 0.9102
288/18750 […………………………] – ETA: 5:53 – loss: 0.3396 – acc: 0.9201
320/18750 […………………………] – ETA: 5:23 – loss: 0.3056 – acc: 0.9281
352/18750 […………………………] – ETA: 4:58 – loss: 0.2778 – acc: 0.9347
384/18750 […………………………] – ETA: 4:38 – loss: 0.2547 – acc: 0.9401
416/18750 […………………………] – ETA: 4:21 – loss: 0.2351 – acc: 0.9447
448/18750 […………………………] – ETA: 4:06 – loss: 0.2183 – acc: 0.9487
480/18750 […………………………] – ETA: 3:53 – loss: 0.2038 – acc: 0.9521
512/18750 […………………………] – ETA: 3:42 – loss: 0.1910 – acc: 0.9551
544/18750 […………………………] – ETA: 3:32 – loss: 0.1798 – acc: 0.9577
576/18750 […………………………] – ETA: 3:23 – loss: 0.1698 – acc: 0.9601
608/18750 […………………………] – ETA: 3:15 – loss: 0.1609 – acc: 0.9622
640/18750 [>………………………..] – ETA: 3:07 – loss: 0.1528 – acc: 0.9641
672/18750 [>………………………..] – ETA: 3:01 – loss: 0.1455 – acc: 0.9658
704/18750 [>………………………..] – ETA: 2:55 – loss: 0.1389 – acc: 0.9673
736/18750 [>………………………..] – ETA: 2:50 – loss: 0.1329 – acc: 0.9688
768/18750 [>………………………..] – ETA: 2:47 – loss: 0.1273 – acc: 0.9701
800/18750 [>………………………..] – ETA: 2:47 – loss: 0.1223 – acc: 0.9712
18750/18750 [==============================] – 84s 4ms/step – loss: 0.0052 – acc: 0.9988 – val_loss: 1.2813e-07 – val_acc: 1.0000
这是我的代码
+++++++++++++
import keras
from keras.layers import Dropout
来自 keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping
import numpy as np
import os
import cv2
import random
import matplotlib.pyplot as plt
from os import listdir
from numpy import save, load
import time
data_dir = os.path.join(“data”,”finalize_dogs_vs_cats”)
image_size = 224
EPOCHS = 10
num_classes = 2
save_model = ‘Models\simple_nn.model’
save_label = ‘Models\simple_nn_lb.pickle’
save_plot = ‘Models\simple_nn_plot.png’
data_path = ‘data/dogs-vs-cats’
photoes_name = os.path.join(data_path, ‘simple_dogs_vs_cats_photos.npy’)
labels_name = os.path.join(data_path, ‘simple_dogs_vs_cats_labels.npy’)
def prepare_data(in_data_dir, in_image_size)
imagePaths = []
# 定义数据集位置
folder = os.path.join(data_path, ‘train/’)
# 枚举目录中的文件
for file in listdir(folder)
imagePath = os.path.join(folder, file) # create path to dogs and cats
imagePaths.append(imagePath)
random.seed(42)
random.shuffle(imagePaths)
data, labels = list(), list()
for imagePath in imagePaths
image = cv2.imread(imagePath)
image = cv2.resize(image, (in_image_size, in_image_size))
data.append(image)
label = imagePath.split(os.path.sep)[-2]
# 确定类别
output = 0.0
if label.lower().startswith(‘cat’)
output = 1.0
labels.append(output)
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype=”float”) / 255.0
labels = np.array(labels)
print(data.shape, labels.shape)
# 保存重塑后的照片
save(photoes_name, data)
save(labels_name, labels)
return data, labels
def define_model()
model = Sequential()
model.add(Conv2D(32, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’, input_shape=(image_size, image_size, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation=’relu’, kernel_initializer=’he_uniform’, padding=’same’))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation=’relu’, kernel_initializer=’he_uniform’))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation=”softmax”))
# 编译模型
opt = SGD(lr=0.0001, momentum=0.9)
model.compile(optimizer=opt, loss=’categorical_crossentropy’, metrics=[‘accuracy’])
model .summary()
return model
def main()
do_data_preparation = False
if(do_data_preparation)
data, labels = prepare_data(data_dir, image_size)
data = load(photoes_name)
labels = load(labels_name)
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.25, random_state=42)
trainY = keras.utils.to_categorical(trainY, num_classes)
testY = keras.utils.to_categorical(testY, num_classes)
model = define_model()
NAME = f’Cat-vs-dog-cnn-64×2-{int(time.time())}’
filepath = “Model-{epoch:02d}-{val_acc:.3f}” # unique file name that will include the epoch and the validation acc for that epoch
checkpoint = ModelCheckpoint(“Models/{}.model”.format(filepath, monitor=’val_acc’, verbose=1, save_best_only=True,
mode=’max’)) # saves only the best ones
tensorBoard = TensorBoard(log_dir=’Models\logs\{}’.format(NAME))
early_stop = EarlyStopping(monitor=’val_loss’, patience=1, verbose=1, mode=’auto’)
callback_list = [checkpoint, early_stop, tensorBoard]
# train the neural network
H = model.fit(trainX, trainY, validation_data=(testX, testY),
epochs=EPOCHS, batch_size=32, verbose=1, callbacks=callback_list)
# evaluate the network
print(“[INFO] evaluating network…”)
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=num_classes))
# plot the training loss and accuracy
N = np.arange(0, EPOCHS)
plt.style.use(“ggplot”)
plt.figure()
plt.plot(N, H.history[“loss”], label=”train_loss”)
plt.plot(N, H.history[“val_loss”], label=”val_loss”)
plt.plot(N, H.history[“acc”], label=”train_acc”)
plt.plot(N, H.history[“val_acc”], label=”val_acc”)
plt.title(“Training Loss and Accuracy (Simple NN)”)
plt.xlabel(“Epoch #”)
plt.ylabel(“Loss/Accuracy”)
plt.legend()
plt.savefig(save_plot)
# save the model and label binarizer to disk
print(“[INFO] serializing network and label binarizer…”)
model.save(save_model)
main()
我很乐意回答具体问题,但我没有能力审查和调试你的代码,抱歉。
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
我在这里有点新手,但你能解释一下低损失和高精度怎么会是糟糕的结果吗?你是如何仅仅基于此来推断的?验证准确率看起来也不错!那么这怎么会是糟糕的结果呢?我不知道我这里是不是错过了什么
我们如何判断 `model.predict(img)` 输出为 1,以及 1 代表狗的依据是什么?
很好的问题。
我们通过将类别映射到整数来准备数据。碰巧我们将猫映射为 0,狗映射为 1,但我们可以按我们希望的任何方式进行映射。
嗨,Jason,
你太棒了!!你在几个小时内回复了我。这太棒了。
顺便说一句,我错过了下面几行。这就是我不得不问那个问题的原因。
注意:图像的子目录,每个类别一个,由 `flow_from_directory()` 函数按字母顺序加载,并为每个类别分配一个整数。子目录“cat”在“dog”之前,因此类别标签被分配整数:cat=0,dog=1。这可以通过在训练模型时调用 `flow_from_directory()` 中的“classes”参数来更改。
感谢您与世界分享您的知识。
谢谢。
没问题,很高兴这个教程有帮助!
你好,
我也有一个二元分类问题。我想对合成深度图像和真实深度图像进行分类。我开发了一个像您的模型一样的二元分类器,但经过 50 个 epoch 后,准确率仍然保持在 0.5,损失达到 0.7。我每个类别有 500 张图像 -> 总共 1000 张图像。图像是灰度的。
您有什么办法可以改善这个问题吗?
这里有一个图像对示例:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/735
此致
是的,你可以在这里学习如何诊断模型问题并提高性能
https://machinelearning.org.cn/start-here/#better
我只想感谢你的时间和努力。
每当我尝试给模型一张不包含猫或狗的图片时,它都会预测为狗或猫。
如何显示假设准确率的百分比?
以及如何打印一条消息,表明模型不确定或“未找到猫或狗”
if result[0] == 0
print(‘我认为这是一只狗’)
elif result[0] == 1
print(‘我认为这是一只猫’)
else
print(‘未找到猫或狗’)
是的,模型只在狗/猫上训练过,因此它在推理时只期望看到这些。
你可以用一张图片调用 `predict()` 来获取预测的概率。
没有“未知”类别,如果你愿意,可以这样训练它。
非常感谢 Jason 撰写所有这些关于机器学习的文章和教程,我非常感谢您在博客上回答每一个问题的努力。
我认为你是一个超级英雄。
<3
感谢您的支持,我深表感谢!
我有一个类似的情况,希望预测结果是“狗”、“猫”或“两者都不是”。请问如何最好地训练一个“未知”类别?我是否只需要使用不包含猫或狗的随机照片作为未知类别?
你的训练数据集中需要包含不符合任何一个类别(并且与你未来预期看到的类似)的照片,并训练模型将这些照片分配给“两者都不是”类别。
我无法理解那个。。。
steps_per_epoch=len(train_it)
我是说你为什么在代码中提到 `steps_per_epoch = len(train_it)`?
这表明一个 epoch 中的“步数”是训练数据集中样本(图像)的数量。
有关样本和 epoch 的更多信息,请参阅此处。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-a-batch-and-an-epoch
嗨,我需要你的帮助。
我正在尝试在有限的数据上运行一个 CNN 模型块进行测试。但每次运行代码时,我都会得到不同的准确率输出,尽管参数相同。
我如何才能在每次运行代码时都获得相同的结果?
我尝试通过使用 `numpy.random.seeds` 来固定种子。。。但这不起作用。
你能帮我解决这个问题吗?
这是一个非常常见的问题,我在这里回答了
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
嗨,Jason,
实际上,我正在有限的数据上训练我的模型,并且 epoch 数量有限。我也固定了种子(正如我在问题中提到的)。但每次运行模型时,在相同的配置下我仍然面临不同的输出。。。
请问您能告诉我可能还有什么问题吗?
是的,固定种子可能是一场徒劳的战斗,我不推荐这样做。
https://machinelearning.org.cn/reproducible-results-neural-networks-keras/
C:\Users\Yali\Desktop\dogvscat\data\train\
回溯(最近一次调用)
文件“data_processing.py”,第 25 行,在
photo = load_img(image_path + file, target_size=(200, 200))
文件“C:\Users\Yali\Anaconda3\envs\DC\lib\site-packages\keras_preprocessing\image\utils.py”,第 110 行,在 load_img
img = pil_image.open(path)
文件“C:\Users\Yali\Anaconda3\envs\DC\lib\site-packages\PIL\Image.py”,第 2770 行,在 open
fp = builtins.open(filename, “rb”)
PermissionError: [Errno 13] Permission denied: ‘C:\\Users\\Yali\\Desktop\\Melanoma\\data\\train\\cat’
您好,我遇到了这个问题,能帮我一下吗?
看起来是你的 Python 安装问题?
也许尝试重新安装
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
嗨,我也遇到了这个问题,并且用
解决了
pip pytest-shutil install
抱歉,我的问题没有自行解决。
我仍然收到错误
copyfile(src, dst)
文件“C:\Python\Python37\lib\shutil.py”,第 120 行,在 copyfile 中
with open(src, ‘rb’) as fsrc
PermissionError: [Errno 13] 权限被拒绝:’train // cats’
问题可能出在使用反斜杠,而应该使用正斜杠?
我有一个错误,不知道如何修复。我在模型创建过程中遇到了这个错误。我在下面分享了。
TypeError: fit_generator() 收到一个意外的关键字参数 ‘step_per_epoch’
很抱歉听到这个消息,我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好 Jason,很棒的文章。
我有一个问题,我见过的大多数图像分类问题都试图对给定的所有类别进行分类。
我想说的是,假设我们要分类 10 种鸟类和 10 种动物,总共 20 个类别,那么我们如何才能创建一个 CNN,它首先判断图像是鸟还是动物,然后在此基础上根据它属于 10 个类别中的哪一个进行分类。
这样做对于 CNN 来说会不会比分类全部 20 个类别更容易呢?
有这样的 CNN 实现吗?
好问题,那可能是一个两步分类问题,例如,首先分类动物类型,然后是具体的物种。
直接预测物种通常更有效。原因是第一步的错误会使第二步无关紧要。
尽管如此,你可以为你的数据集尝试这两种方法并比较结果。
您能分享一下最终训练好的模型吗?我很好奇它与其他几个解决方案相比如何
抱歉,我不分享最终模型,因为它们太大。
谢谢。这是我读过的最好的图像分类文章之一。但我对 steps_per_epoch 有点困惑。您将其定义为 len(train_it),但我看到在其他一些博客中将其定义为 len(train_it)/batch_size。
我得到了一个不同的数据集,总共有 8000 张猫和狗的图像,准确率为 70%(您的准确率为 85%。哇)。我正在使用带有 dropout 和数据增强的 3 层 VGG 模型。
我可以将这个 VGG 3 模型扩展到多类别(大约 10 个类别)吗?
谢谢。
train_it 已经分批处理了。
是的,VGG 在内部是一个多类别模型。
嗨,我需要你的帮助。
我使用 ImageDataGenerator 和 flow_from_directory 进行训练和验证。
通过使用模型检查点,我得到了我的训练模型名称为 model.hdf5。
现在我想对单张图片进行预测。我该怎么做?在训练数据中,我的 input_shape 是 (90,90,3)
你能帮我解决如何对单张图片进行预测的问题吗?
请查看“如何最终确定模型并进行预测”一节
我确切地展示了这一点!
我还有另一个问题。
你为什么在对单张图片进行预测时这样做?
img = img – [123.68, 116.779, 103.939]
这些值是什么?你刚刚减去了什么?
当我使用你的代码对单张图片进行预测时,我得到了这些结果。
[0. 1. 0. 0.]
这是什么意思?这些结果显示了什么?
请详细回答
正如我在帖子中提到的——以与训练数据相同的方式准备图像
这是一篇很好的文章,但是先生,我的数据集存在以下形式的问题
我想像上面提到的那样维护数据集,所以我将数据图像生成器用于此类问题。你能在这方面指导我吗?
也许可以将样式目录折叠到类目录中。
您可以编写脚本为您复制文件,或者您可以手动操作。另外,您可以编写自定义数据生成器来加载具有此结构的数据。我的博客上有您可以作为起点使用的示例。
另请参阅此
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
样式是一个子目录……其中包含图像
嗨,Jason,
我使用以下 2D CNN 进行二进制分类,数据集为 {14189 个样本(行,400 个特征(列),1 个标签(列)}。数据形状为 (20,20,1) 作为第一个零填充层的输入。现在我想在我的代码中最后一个 2D CNN 块之后添加 LSTM 层。请告诉我 LSTM 层代码。我的 2D CNN 代码和数据形状如下
trn_file = 'PSSM_4_Seg_400_DCT_1_14189_CNN.csv'
nb_classes = 2
nb_kernels = 3
nb_pools = 2
# 加载训练数据集
dataset = numpy.loadtxt(trn_file, delimiter = “,”) # , ndmin = 2)
print(dataset.shape)
# 分割为输入 (X) 和输出 (Y) 变量
X = dataset[:,1:401].reshape(len(dataset),20,20,1)
Y = dataset[:, 0]
model = Sequential()
model.add(ZeroPadding2D((1, 1), input_shape = ( 20, 20,1)))
model.add(Conv2D(4, nb_kernels, nb_kernels, activation = 'relu'))
model.add(MaxPooling2D(strides = (nb_pools, nb_pools), dim_ordering = 'th'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(8, nb_kernels, nb_kernels, activation = 'relu'))
model.add(MaxPooling2D(strides = (nb_pools, nb_pools), dim_ordering = 'th'))
model.add(ZeroPadding2D((1, 1)))
model.add(Conv2D(16, nb_kernels, nb_kernels, activation = 'relu'))
model.add(MaxPooling2D(strides = (nb_pools, nb_pools), dim_ordering = 'th'))
## 在卷积基础之上添加模型
model.add(Flatten())
model.add(Dense(32, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes)) #全连接层
model.add(Activation(‘sigmoid’))
LSTM 不适合图像分类。
是的,LSTM 不适合图像分类。我只是想展示 LSTM 对图像的性能。请告诉我最后一个 CNN 层之后的 LSTM 代码。
这不仅仅是“不合适”,我认为这是不可行的。
嗨,Jason,
当我们不使用 ImageDataGenerator 预处理数据时,就像您提供的调整图像大小的可选示例那样,它需要 12 GB RAM 才能运行,为什么像素值没有像 ImageDataGenerator 那样重新缩放到 1.0/255.0?
您的文章太棒了!!!
谢谢。
抱歉,我不理解这个问题,因为 ImageDataGenerator 在所有示例中都使用了。
如果你是指,为什么我们有时归一化,有时标准化像素——那么前者是一种好习惯,后者是使用预训练模型的必要条件。
该示例在此文章的“预处理照片大小(可选)”部分提供,您在其中写道
“如果我们想将所有图像加载到内存中,我们可以估计它大约需要 12 GB RAM。”
在该示例中,图像从未重新缩放。
图像在调用 load_img() 时被调整大小,例如调整为 200 像素的宽度和高度。
哦,天哪!我指的是重新缩放像素,而不是调整大小,抱歉。
这在您提供的 ImageDataGenerator 示例中通过以下方式完成
datagen = ImageDataGenerator(rescale=1.0/255.0)
我的问题是
在“预处理照片大小(可选)”示例中,像素值的重新缩放是在哪个阶段完成的?
很抱歉提了一个误导性问题
没有。像素缩放是在我们拟合模型时完成的。
嗨,
我想问一下,在训练模型时,我们需要定义各种层,如卷积层、激活层、池化层、全连接层等。训练数据必须通过这些层的各个阶段。
那么为什么我们在测试时不需要定义这些各种层呢?我的意思是,我们应该也像在训练阶段那样,使用各种层来塑造我们的数据。简而言之,我们也应该将各种层应用于测试数据,然后使用训练好的模型进行预测。。。
等待您的回复。。。
在测试期间,模型已经定义和训练完毕。我们只需加载它并像“程序”一样使用它。
你好,
我使用带标签的卫星照片(二进制预测——是否有特定物体)而不是猫狗实现了这个算法(代码示例)。
我的训练和测试准确率都很好,分别为 95% 和 82% 左右。
然而,当我在一个大型保留集(14K 图像)上运行模型时,我基本上得到了大量的假阳性预测,准确率要低得多
并且几乎没有真阳性。
我会说我只有大约 1400 张图像的训练集和 1120 张图像的测试集,所以我承认我的数据量很小。
然而,我不确定为什么我在保留集上看到如此差的性能?我的假设是模型过拟合了?
干得好!
也许保留集与训练集有显著差异?
也许模型过度拟合了训练集?
这有助于诊断问题
https://machinelearning.org.cn/start-here/#better
你好,我运行代码时遇到以下错误。
AttributeError: 模块‘tensorflow’没有属性‘get_default_graph’
谢谢,
Karthik
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我有一个在 CNN 中训练好的模型,现在我想测试一张随机图像,我该怎么做……?
加载图像并使用模型进行预测。
请参阅“进行预测”部分,了解一个确切的示例。
非常好的文章。写得很好,对于像我这样的机器学习初学者来说,相当容易理解。在用 25k 张图片训练模型后,当我给它喂食随机的猫狗图片时,它非常可靠地预测了猫/狗。为了好玩,我给它喂了一张船的图片,它告诉我既不是猫也不是狗。成功了!然而,当我给它喂食一张老鼠的图片时,预测结果认为是猫,当我给它喂食一张袋鼠的图片时,它说它是狗。有没有办法让它更准确?也许使用更大的数据集?
谢谢。
太酷了!
是的,你可以输入其他事物的图像,并鼓励它预测第三个标签“我不知道”或“不是猫也不是狗”。
感谢您的回复,Jason。更大的数据集能否减少袋鼠/老鼠的假阳性?还是我应该寻找其他方法?
有可能,但最好测试许多候选解决方案,看看哪个能产生最大的效果。
它怎么会给你一艘船?
预测结果不总是返回 0 或 1 吗?
我还有另一个问题是关于目标大小参数的。我的图像最初是 640x640 的卫星图像。
然而,如果我想使用像 MobileNet 这样的预训练模型,我能使用的最大尺寸似乎是 224。
我可以接受,只要它不会降低性能或准确性。我不清楚将 target_size 从 640 减小到 224 会产生什么影响?
我相信大多数模型,例如 VGG,会随着图像大小而扩展。
如果这是您关心的问题,我建议您运行测试以计算图像缩放的影响。
你好 Jason,我有一个关于 ImageDataGenerator.flow_from_directory 的问题,我正在使用 VGG-16 进行迁移学习,如何为 datagen.flow_from_directory 和 model.fit_generator 添加 VGG16 preprocess_input?代码如下
datagen = ImageDataGenerator()
train_gen = datagen.flow_from_directory()
model.fit_generator(train_gen)
在哪里添加 preprocess_input?
您可以使用这里的示例
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
嗨,很棒的博客!
能不能区分猫嘴里有没有猎物?
我有猫叼着猎物的照片和猫没有叼猎物的照片。
或者比较只会证明它是一只猫吗?
是的,但您必须在该类别上训练模型,例如“猫”与狗与“嘴里有东西的猫”
谢谢你的回答 🙂
一个标签是否足够?
我的猫有猎物
和一个标签
我的猫没有猎物?
是的,如果这是项目的目标。
嗨……您是否有使用 CNN 比较宠物而不仅仅是识别宠物的示例?例如,我有一张我的狗的照片,我想知道我的狗是否在我的数据集中其他照片中。
我不知道我是否表达清楚了。但这就像要知道某只特定的宠物是否在其他照片中。
你能帮我吗?
听起来像图片搜索。抱歉,我没有。
嗨,我还有另一个问题
运行脚本时
“用于猫狗数据集迁移学习的 VGG16 模型”
我的电脑总是崩溃。不幸的是,我只有 8GB RAM 的工作内存。
我可以更改设置以使其运行吗?
也许可以尝试使用渐进式加载
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
也许可以尝试在 ec2 实例上运行它
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
嗨,也许我错了。
我只使用了我的图片,每个标签最多 150 张,用于实现。
所有其他脚本都工作了,除了这个脚本。
“用于猫狗数据集迁移学习的 VGG16 模型”
这里是用于创建 VGG16 模型的图像转换。(如果我理解正确的话)
脚本也启动了,但短时间后进程冻结,最终 Windows 弹出消息说出现问题,计算机必须重新启动。这可能确实只与内存有关。
也许模型本身对您的机器来说太大了?
也许可以尝试在 AWS EC2 上运行?
您是否有示例说明如何将本地图像上传到 AWS,然后使用 python 脚本进行训练?
在你的博客里
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
这一切都与 AWS 的建立有关。但接下来呢?
我想在 AWS 中运行您的示例中的所有脚本,然后将创建的模型保存到本地,以便我可以在我的程序中使用。
是的,我在这里展示了如何将文件复制到 AWS 实例
https://machinelearning.org.cn/command-line-recipes-deep-learning-amazon-web-services/
我有一个关于改进预训练 VGG16 模型的声明的问题
“这种方法可以进行许多改进,包括在模型的分类器部分添加 dropout 正则化,甚至可以微调模型特征检测器部分中部分或所有层的权重。”
我将如何向 VGG16 模型中已有的层添加 dropout 正则化?
我将如何微调部分或所有层的权重?
您可以重新定义抽象模型以拥有 dropout 层,同时使用相同的权重层。这需要一些工作,抱歉,我没有示例。
微调意味着以较小的学习率在您的数据集上进行训练。
你好,
我试过了……但是
我有点绝望了。
我无法从您的示例中选择 AWS,因为我只能选择免费产品。
然后我按照以下说明设置了一个 AWS。
https://aws.amazon.com/de/getting-started/tutorials/launch-a-virtual-machine/
我以为我可以在这里安装一个带有 Keras 和 Tensorflwo 的环境。
通过 Git-Bash 访问工作正常。
tensorflow_p36
它不起作用 🙁
‘source activate tensorflow_p36’
您有什么想法吗?
我发现您的教程对猫狗分类非常有帮助。但是,您是否有任何教程指导我们如何将模型预测提交到 Kaggle?我是编程新手,从未参加过任何 Kaggle 比赛,所以如果我能按照您的任何教程进行操作,将非常有帮助。
谢谢。
不,抱歉,我没有关于该主题的教程。
你好,我正在尝试使用普通模型(非迁移学习,非 VGG 16)运行 `load_image` 和 `run_example` 函数,但所有预测结果都为零。我是否需要对 `load_image` 和 `run_example` 函数进行一些小的调整(例如,重新缩放?)以便普通模型能够正常工作?
可能需要,而且模型可能需要仔细选择学习率。
我认为不是学习率的问题,因为训练和验证结果接近 90%。发生的情况是,当我尝试使用通过 `run_example` 保存的模型对一组保留图像进行预测时,我得到了 100% 的零预测。我相信我需要调整 `load_image` 和 `run_example` 函数中的代码,以使其适用于您不使用迁移学习的第一个 CNN 模型?
也许可以确认您正在以与训练数据相同的方式准备测试数据,例如像素缩放。
你好,
我现在已经可以在 Jupyter Notebook 上运行代码了。
不幸的是,我收到一条错误消息
KeyError traceback(最近一次调用在最后)
in ()
68
69 # 入口点,运行测试工具
---> 70 run_test_harness ()
在 run_test_harness () 中
65 print ('>% .3f'% (acc * 100.0))
66 # 学习曲线
---> 67 summarize_diagnostics (history)
68
69 # 入口点,运行测试工具
在 summarize_diagnostics (history) 中
38 pyplot.subplot (212)
39 pyplot.title ('分类准确度')
---> 40 pyplot.plot (history.history ['accuracy'], color = 'blue', label = 'train')
41 pyplot.plot (history.history ['val_accuracy'], color = 'orange', label = 'test')
42 # 将图保存到文件
KeyError: 'accuracy'
有 3 个函数似乎无法工作。
我使用的是带有“conda_tensorflow_p36”的 Jupyter Notebook
我建议不要在 Notebook 中运行,而是在命令行中运行。
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
嗨 Jason,这确实是一个非常有用的教程。
我一直在阅读不同的资料,有一些问题想问。
1. 对于分类问题,标签应该进行分类编码还是独热编码,例如使用 `to_categorical` 命令?
对于二分类,只有 2 个类别,0 和 1。
但是当类别数 > 2 时,如何标记?
2. 在输出层,您使用 `Dense(1)` 并带有 Sigmoid 激活。
我在另一个网站上看到过在二分类中使用 `Dense(2)` 并带有 Softmax 激活的情况。
是什么指导了这种选择?两种选项是等效的吗?
提前感谢您的回复 🙂
是的,类别标签使用独热编码,请看这里
https://machinelearning.org.cn/why-one-hot-encode-data-in-machine-learning/
是的,对于多分类,输出将更改为 n 个节点的 n 个类别和 Softmax 激活。
我有很多例子,也许可以从这里开始
https://machinelearning.org.cn/multi-class-classification-tutorial-keras-deep-learning-library/
嗨 Jason,感谢您的快速回复。
另一个问题:如果不同类别的图像数量不平衡,例如 2 个类别中图像比例为 9:1,应该使用什么指标?
通常大多数深度学习教程都显示损失和准确度。但在数据不平衡的情况下,准确度不应该是一个好的指标。
不客气。
很好的问题。
如果两个类别相等,则使用 G-mean;如果不是,则使用 F-measure。如果您正在预测概率,则使用 ROC AUC 或 PR AUC。
这有帮助吗?
抱歉,我不是很清楚。您指的是 F1 分数吗?
对于数据不平衡的多分类,应该使用什么指标?
F1-score 就是 F-measure。
您可以使用相同的度量。
嗨 Jason,我的理解是 Keras 中的默认指标是准确度。
我们如何获得测试数据集上的 F1 分数?
另一个问题,对于多分类问题,迭代器中的 `class_mode` 的值会是什么?
不,默认是您选择优化的损失。
这里有使用其他指标的示例
https://machinelearning.org.cn/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
`class_mode` 将设置为 'categorical'。您可以在这里查看 API
https://keras.org.cn/preprocessing/image/
嗨,Jason,
我遇到了类别之间数据不平衡的问题,并且在训练集和测试集上都获得了较低的准确度。
我正在尝试数据增强和模型改进(更改层数和节点数)。
我还想“查看测试数据中某些示例的预测结果”,以及它们的实际类别标签是什么。因为我使用生成器函数(`model.fit_generator` 和 `model.evaluate_generator`)来拟合和评估模型性能,有没有办法/代码可以实现这个功能?
我已经查看了您的教程
https://machinelearning.org.cn/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
https://machinelearning.org.cn/custom-metrics-deep-learning-keras-python/
尽管我可以轻松计算数值数据的指标,但我不知道如何对自定义图像执行此操作。
提前感谢。
这些指标作用于预测结果,而不是图像。
嗨,Jason,
谢谢您的回复。
我正在使用本教程开发一个用于 3 个类别的样本分类器——所有图像都是灰度图。
我已将模型定义中的第一行修改为
`model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 1)))`
但是,当我运行 `model.fit_generator` 时,我收到以下错误
`ValueError: Error when checking input: expected conv2d_1_input to have shape (200, 200, 1) but got array with shape (200, 200, 3)`
但我已使用命令对所有图像进行了检查
`image_name.mode` (Pillow 库)
所有图像都返回 'L',这表示灰度。
有什么建议吗?
错误表明您的图像有 3 个通道。也许将它们更改为灰度。
这个可能会有帮助
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
你好,
添加 `color_mode` 选项解决了这个问题。
`train_it = train_datagen.flow_from_directory('./runData/train/', color_mode='grayscale', class_mode='categorical', batch_size=64, target_size=(200, 200))`
`test_it = test_datagen.flow_from_directory('./runData/test/', color_mode='grayscale', class_mode='categorical', batch_size=64, target_size=(200, 200))`
==========================================================
另一个问题:'32/32' 是什么意思?我在模型拟合过程中得到了它。
Epoch 1/50
`32/32 [==============================] – 199s 6s/step – loss: 10.2217 – acc: 0.3450 – val_loss: 11.4814 – val_acc: 0.2877`
很高兴听到这个!
你好 Jason,
我有一个关于深度学习模型的基本问题——我的项目
实时摄像头对准我们的猫门,模型应该识别猫嘴里是否有猎物。
我创建了一个图像大小为 64x64 的 h5 模型,当我用图像测试模型时,我得到了很高的命中率。
如果我用视频文件(我用于训练的图像也是从视频文件创建的)测试模型,命中率也非常好。
如果我用实时摄像头测试模型,识别效果不好或根本不起作用。
正如我所说,视频文件以及因此产生的照片都来自实时摄像头。条件基本上是相同的。这就是为什么我不理解实时摄像头上的低命中率。你是否需要在这里特别注意?你有什么想法吗?
恭喜您取得进展。
您可能需要充当侦探,探索数据管道,并寻找两种情况下数据可能存在的任何差异。甚至可以手动审查数据。
嗨,Jason,
感谢这个很棒的教程!我现在有了更好的理解,但不幸的是我运行您的代码仍然遇到错误。我总是得到
`File "C:/Users/Rafael/Desktop/Python/Test Cats vs Dogs/temp.py", line 99, in summarize_diagnostics`
pyplot.plot(history.history[‘accuracy’], color=’blue’, label=’train’)
KeyError: 'accuracy'
知道我为什么会收到 `accuracy` 的 KeyError 吗?
非常感谢!非常感谢您的工作!
谢谢
拉斐尔
您需要更新到 Keras 2.3。
很有意思!
但是,如何对猫和狗进行分类并过滤掉其他所有东西,例如汽车?
很好的问题!
也许可以在训练期间添加一个“其他”类别。
嗨 Jason,这个教程很棒,非常容易理解,如果您想深入了解,也有很好的指导!作为一个完全的初学者,我花了大约 4 个小时才消化它。
快速提问:有没有办法获取预测的概率?我尝试只用一张图片(有猫、狗或其他随机物体的图片)调用 `predict()`,但它总是返回 0 或 1。
谢谢!
是的,这是样本的二项式分布概率
https://machinelearning.org.cn/discrete-probability-distributions-for-machine-learning/
您可以将其解释为
P(class==1) = yhat
P(class==0) = 1 – yhat
我相信默认情况下,猫是类别 0,狗是类别 1。
感谢教程!
如果我使用上面的代码对 6 张人脸进行分类,我需要进行哪些更改?
也许可以看看这个教程:
https://machinelearning.org.cn/how-to-perform-face-detection-with-classical-and-deep-learning-methods-in-python-with-keras/
谢谢您,先生!但我想知道的是,我如何将 VGG16 用于人脸分类?
我认为这不是一个合适的模型。
是否可以修改上面的代码用于 6 张人脸的分类?
不,它不适用于人脸检测或人脸识别。
谢谢您,先生,您的教程是互联网上所有可用资源中最好的,特别是对于初学者。感谢您的快速回复。
谢谢!
嗨,Jason,
感谢您提供这个使用迁移学习进行图像分类的教程!
在我的 Mac 上运行,训练整个模型(VGG16 冻结模型 + 顶部全连接层可训练)使用 `flow_from_directory` 迭代器按批次加载图像,大约需要 5 个小时。
我获得了 97.98% 的准确度,但我也在我的顶部全连接模型可训练层上实现了 Dropout、BatchNormalization 和 l2 权重衰减作为正则化器。与您提出的模型相比没有改进。
我还将目录中的图像转换为 numpy 文件,但不是大的 npy 格式,我应用了 numpy npz 压缩文件(包括图像和标签),最终体积为 3.7 GB(小于您的 12 G)。但是压缩文件需要 10 分钟的时间,读取(加载)并转换为标准数组又需要 10 分钟,此外还需要 RAM 来处理它。
为了节省 CPU 时间,我不想使用 'flow_from_directory' 作为迭代器按批次加载图像,而是想利用现有的 numpy 文件直接获取完整的 X 输入和 Y 标签数组,将这些 X 输入转换为可训练的顶部全连接模型的新输入,避免每次都通过 VGG16 '冻结' 模型(用作特征提取器)传递它们。
我得到了更少的 CPU 时间(1.5 小时 vs 之前的 5 小时),但由于某种编码原因,我得到了糟糕的验证图像准确度(50%,根本没有学习),即使我得到了相同的图像训练学习结果(大约 99.8%)。所以我的代码肯定有问题……
因此,我想知道您是否有任何教程推荐,解释获取图像输入通过迁移学习(例如 VGG16 或其他)冻结模型转换,以及新的可训练顶部全连接模型顶部训练方法,以便检查适当的代码行。
谢谢
JG
一如既往的精彩工作,JG!
非常酷。我宁愿选择更大的文件而不是更慢的速度。我没有耐心 🙂 内存和磁盘都很便宜。
不确定,也许是这个
https://machinelearning.org.cn/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
嗨,Jason,
感谢这个教程。我正在学习这些内容并测试这个教程,但我的帖子中的某些代码出现了问题(请看这个 http://prntscr.com/qxocpy)。请问您在 AWS 中使用什么内核?
看这里
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
嗨,Jason,
很棒的教程。
我正在尝试为此生成一个训练好的模型,以便我可以将其加载到我的 Jetson Nano 上并运行推理,用于一篇关于 GPU 基准测试的博客文章和播客。我理解您为什么不共享模型。它们可能很大,人们需要亲身经历这个过程,否则他们将无法学习。
所以,我阅读了这个教程,它看起来非常简单明了,直到我意识到这无法在我的 OSX/16gb 内存系统或 Colab 上运行。因此,我正在研究在 AWS 上进行训练(我有一个免费层账户),但我注意到它将需要 “p3.2xlarge” 实例,每小时 3.00 美元。
所以问题是
在 EC2 上完成最高准确度和最低误差的训练需要多少小时?
我将预留 20% 的正常运行时间,以确保一切正常运行,以防万一。
谢谢
抱歉,我不记得了,但时间不长。
Jason,
您知道 Colab 有一个每月 9.95 美元的升级版,名为“Colab Pro”吗?它将处理器内存加倍到 32GB,并拥有四个 CPU 和一个 GPU。
我正在认真考虑使用它来训练您在本教程中提到的模型。
你觉得呢?
抱歉,Google Colab Pro 的内存是 24GB。
我目前没有使用 Colab 的计划。我认为 Notebook 不是一个好主意。
Jason,
我通过 Notebook 学习。我也曾使用 IDE 编写独立运行的脚本。但是 Notebook 是一种分享代码和帮助他人学习的好方法。它允许人们在实时环境中尝试事物,并查看单个单元的运行情况。
抱歉,您认为 Notebook 不是一个好主意。许多人不是这样认为的。
它们可能客观上好,也可能不好。
我教初学者,六年的初学者教学经验告诉我,它们对刚接触这个平台的工程师来说是多么痛苦。
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
嗨 Jason,我还不理解在最后一个密集层中指定 1 的概念。许多文章说它代表我们拥有的类别数量。那么,上面不应该是 2 吗?
在什么情况下我们应该写 2,那又意味着什么?
在二分类的情况下,我们可以使用 1 并用它来预测类别 1 的概率,因为我们可以将类别值 1 的概率计算为 1 - yhat。
这称为二项式概率分布。
谢谢!所以,本质上,如果有超过两个类别,我们就需要指定三个?
如果类别多于 2 个,则必须将输出层中的节点数设置为与类别数匹配,使用 Softmax 激活和分类交叉熵损失。这是一个示例
https://machinelearning.org.cn/how-to-develop-a-cnn-from-scratch-for-cifar-10-photo-classification/
谢谢!
谢谢你,Jason,提供这个内容丰富的教程。
出于教育和趣味,我使用了 Jason 的代码片段,并将 SGD 替换为 Adam 优化器。通过使用 0.001 的学习率,我得到了以下结果。
对于单块 VGG 模型,SGD 优化器在 20 个 epoch 后达到了 72.331% 的准确度。Adam 优化器在相同数量的 epoch 后达到了 69.253% 的准确度。
对于两块 VGG 模型,SGD 优化器在 20 个 epoch 后达到了 76.646% 的准确度。Adam 优化器在相同数量的 epoch 后达到了 71.759% 的准确度。
对于三块 VGG 模型,SGD 优化器在 20 个 epoch 后达到了 80.184% 的准确度。Adam 优化器在相同数量的 epoch 后达到了 73.870% 的准确度。
对于带有 Dropout (0.2, 0.2, 0.2, 0.5) 的 VGG-3 模型,SGD 优化器在 50 个 epoch 后达到了 81.279% 的准确度。Adam 优化器在相同数量的 epoch 后达到了 84.769% 的准确度。此外,另一个带有 Dropout (0.2, 0.3, 0.4, 0.5) 的 VGG-3 模型使用 Adam 达到了 85.118% 的准确度。
对于 VGG-3 和图像数据增强模型,SGD 优化器在 50 个 epoch 后达到了 85.816% 的准确度。Adam 优化器在相同数量的 epoch 后达到了 91.449% 的准确度。
对于具有 Dropout(0.2、0.3、0.4、0.5)和图像数据增强模型的 VGG-3,Adam 优化器在 50 个 epoch 后达到了 90.227% 的准确率。
Colab 脚本可在 https://github.com/daines-analytics/deep-learning-projects/tree/master/py-keras-classification-cats-vs-dogs-take9 获取,以防其他人想查看或尝试不同的方法。
非常酷,谢谢分享!
嗨,Jason,
感谢您的教程,它们启发我探索了许多问题,以获取更深入和广泛的机器学习概念。
以下是我在对您的代码进行了一些修改以回答其他问题后,想分享的一些结果
1) 训练整个模型(冻结的 VGG16 - 无头部 - 加上我自己的顶部头部 - 带有多个正则化层,如 dropout、批量归一化和 l1_l2 权重衰减)。
我使用了一个 15 GB 的直接 npz 文件!(总结了所有图像数据集中的狗和猫(224,224,3),因为如果我使用压缩格式(只有 3.78 GB),读取它需要 10 分钟!)。
在所有这些情况下,CPU 代码执行大约需要 5 小时。
1.1) 使用无数据增强和 0-1 之间的数据归一化,我获得了 88.8% 的准确率。
1.2) 使用无数据预处理(既不推荐的 VGG16 preprocess_input,也不在 0 到 1 之间归一化,也无数据增强),我获得了 96.4% 的准确率。
我对此感到惊讶,因为这些是原始图像数据!甚至没有发生溢出。
1.3) 使用您的数据增强(featurewise_center)和简单的数据预处理(其余图像是 featurewise_center 的平均值),我获得了 96.8% 的准确率。
1.4) 我获得了 98.1%(最高)的准确率,但使用了我自己的数据增强加上 VGG16 的 preprocess_input。
2) 当我单独训练我的顶部模型时,为了避免每次都通过 VGG16 传递图像,所以我一次性获得了 VGG16 的图像输出(25000, 7,7,512),对应于我的图像(25000, 224,224,3),为了节省时间,总共大约需要 40 分钟(每次训练 2 分钟,第一次获取 VGG16 输出端的新图像文件(已转换)需要 38 分钟)。
因此,与整个模型 5 小时的 CPU 运行时间相比,时间大大减少。因此,强烈建议单独训练顶部模型!
2.1) 当使用我自己的数据增强加上 VGG16 的预处理输入时,我的顶部模型单独获得了 97.9% 的准确率。
2.2) 当不使用数据增强加上 VGG16 的预处理输入时,我的顶部模型单独获得了 97.7% 的准确率。
3) 我还将 VGG16 迁移模型(5 个卷积块内的 19 个冻结层模型)替换为 XCEPTION(14 个块内的 132 个冻结层模型,根据 Keras 是更好的图像识别模型)。
3.1) 我获得了 98.6% 的最高准确率!用于我自己的数据增强和 XCEPTION 的预处理输入……而且代码在通过 XCEPTION 模型(25000, 7,7, 2048)进行图像转换后,运行了 8 分钟!
h5 模型权重是 102 MB
4) 结论
4.1) 当我尝试单独使用顶部模型(我的顶部)(不使用任何迁移学习,例如 VGG16 模型),并且我使用(不是 flow_from_directory 方法,而是直接使用图像的 npz 文件(15 GB)加上所有要拟合的权重(h5 文件是 154 MB))时,…
python 崩溃了!……由于 RAM 不足(我有 16 GB)。
4.2) 当我解决了这个问题(通过以批处理作为迭代器进行训练以绕过 RAM 内存问题)并且我没有使用任何迁移学习(例如 VGG16)时,主要结论是……
顶部模型本身(密集模型)不学习!我的意思是准确率在 49.9% 到 50.1% 之间。
因此,如果我们要让模型学习,之前的卷积层或特征提取的使用是至关重要的!
4.3) 使用不同的归一化预处理输入甚至数据增强,没有太大差异……
4.4) 训练顶部模型,在一次性完成特征提取后,只需要几分钟的训练,就能获得最高准确率!
4.5) 我还尝试在加载之前 10 个 epoch 训练的 h5 模型权重后(例如再进行 10 个 epoch)重新训练顶部模型,但并没有提高准确率……所以看起来 10 个 epoch 的训练足以达到“学习成熟度”!
此致,
JG
精彩的探索,感谢分享!
您被要求训练一个模型来区分狗和猫。您有 7000 个猫特征数据点,而狗特征数据点只有 50 个。您获得了 97% 的准确率。
这个准确率值可靠吗?
您可以使用哪些指标来测试性能?
您可以采取哪些措施来提高性能?
您能回答这些问题吗?
不行。
有关指标,请参阅此内容
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
嗨,Jason,
一个与此线程相关的问题——我想运行一个二元图像分类问题。
一个类别有 200 张只有一种动物物种的图像,而另一个类别也有
200 张图像,但包含所有其他动物的混合图像——而且,这些“其他”动物的数量在类别内并不相等。例如——如果这个类别有狗和猫的图像,那么它们的数量不相等——150 和 50。
我们能相信我们得到的总体分类准确率吗?
也许可以使用对照实验来测试和发现答案。
谢谢 Jason – 祝好。
不客气!
感谢您非常有用的教程。
我有一个问题
如何打印名称(dog)而不是数字(1)?
也许可以使用 if 语句。
🙂
train_it = datagen.flow_from_directory(………)
label_map = (train_it.class_indices)
.
.
.
# 加载并准备图像
def load_image(filename)
# 加载图像
img = load_img(filename, color_mode = “grayscale”, target_size=(28, 28))
# 转换为数组
img = img_to_array(img)
# 重塑为单通道的单个样本
img = img.reshape(1, 28, 28, 1)
# 准备像素数据
img = img.astype(‘float32’)
img = img / 255.0
return img
# 预测类别
img = load_image(‘/content/znak9_4779.png’)
pred = model.predict_classes(img)
for name, znak in label_map.items()
if znak == pred[0]
print(name)
嗨 Marcus!您能提供打印猫或狗而不是“0”或“1”的代码吗?
嗨,Jason,
很棒的教程!我一直在不同的数据集(良性与恶性皮肤癌)上使用此教程。一切都进展顺利,直到我遇到 dropout。准确率从 79.697% 下降到 45.455%。更具体地说,从图表来看,这大约发生在第 15 个 epoch。我将进一步调整 dropout 值,但您能提供更多关于我正在调整什么的信息吗?或者把我引向您可能觉得有用的其他资源?这样我就可以了解什么可能适用于这些数据。
再次感谢您的教程,我很高兴找到您的网站。看来我将在这里花费更多时间!
祝好,
Chidi
也许 dropout 不适合您的数据集。
您可以在此处了解有关 dropout 的更多信息
https://machinelearning.org.cn/dropout-for-regularizing-deep-neural-networks/
你好
感谢您的出色工作。我需要帮助,用胶囊网络代替 CNN 来完成这项工作。我找到了如下的胶囊网络代码:
import numpy as np
from keras import layers, models, optimizers
from keras import backend as K
from keras.utils import to_categorical
import matplotlib.pyplot as plt
from utils import combine_images
from PIL import Image
from capsulelayers import CapsuleLayer, PrimaryCap, Length, Mask
K.set_image_data_format(‘channels_last’)
def CapsNet(input_shape, n_class, routings)
"""
A Capsule Network on MNIST.
:param input_shape: data shape, 3d, [width, height, channels]
:param n_class: number of classes
:param routings: number of routing iterations
:return: Two Keras Models, the first one used for training, and the second one for evaluation.
eval_modelcan also be used for training."""
x = layers.Input(shape=input_shape)
# Layer 1: Just a conventional Conv2D layer
conv1 = layers.Conv2D(filters=256, kernel_size=9, strides=1, padding=’valid’, activation=’relu’, name=’conv1′)(x)
# Layer 2: Conv2D layer with
squashactivation, then reshape to [None, num_capsule, dim_capsule]primarycaps = PrimaryCap(conv1, dim_capsule=8, n_channels=32, kernel_size=9, strides=2, padding=’valid’)
# Layer 3: Capsule layer. Routing algorithm works here.
digitcaps = CapsuleLayer(num_capsule=n_class, dim_capsule=16, routings=routings,
name=’digitcaps’)(primarycaps)
# Layer 4: This is an auxiliary layer to replace each capsule with its length. Just to match the true label’s shape.
# If using tensorflow, this will not be necessary. 🙂
out_caps = Length(name=’capsnet’)(digitcaps)
# Decoder network.
y = layers.Input(shape=(n_class,))
masked_by_y = Mask()([digitcaps, y]) # The true label is used to mask the output of capsule layer. For training
masked = Mask()(digitcaps) # Mask using the capsule with maximal length. For prediction
# Shared Decoder model in training and prediction
decoder = models.Sequential(name=’decoder’)
decoder.add(layers.Dense(512, activation=’relu’, input_dim=16*n_class))
decoder.add(layers.Dense(1024, activation=’relu’))
decoder.add(layers.Dense(np.prod(input_shape), activation=’sigmoid’))
decoder.add(layers.Reshape(target_shape=input_shape, name=’out_recon’))
# Models for training and evaluation (prediction)
train_model = models.Model([x, y], [out_caps, decoder(masked_by_y)])
eval_model = models.Model(x, [out_caps, decoder(masked)])
# manipulate model
noise = layers.Input(shape=(n_class, 16))
noised_digitcaps = layers.Add()([digitcaps, noise])
masked_noised_y = Mask()([noised_digitcaps, y])
manipulate_model = models.Model([x, y, noise], decoder(masked_noised_y))
return train_model, eval_model, manipulate_model
def margin_loss(y_true, y_pred)
"""
Margin loss for Eq.(4). When y_true[i, :] contains not just one
1, this loss should work too. Not test it.:param y_true: [None, n_classes]
:param y_pred: [None, num_capsule]
:return: a scalar loss value.
"""
L = y_true * K.square(K.maximum(0., 0.9 – y_pred)) + \
0.5 * (1 – y_true) * K.square(K.maximum(0., y_pred – 0.1))
return K.mean(K.sum(L, 1))
def train(model, data, args)
"""
Training a CapsuleNet
:param model: the CapsuleNet model
:param data: a tuple containing training and testing data, like
((x_train, y_train), (x_test, y_test)):param args: arguments
:return: The trained model
"""
# unpacking the data
(x_train, y_train), (x_test, y_test) = data
# callbacks
log = callbacks.CSVLogger(args.save_dir + ‘/log.csv’)
tb = callbacks.TensorBoard(log_dir=args.save_dir + ‘/tensorboard-logs’,
batch_size=args.batch_size, histogram_freq=int(args.debug))
checkpoint = callbacks.ModelCheckpoint(args.save_dir + ‘/weights-{epoch:02d}.h5′, monitor=’val_capsnet_acc’,
save_best_only=True, save_weights_only=True, verbose=1)
lr_decay = callbacks.LearningRateScheduler(schedule=lambda epoch: args.lr * (args.lr_decay ** epoch))
# 编译模型
model.compile(optimizer=optimizers.Adam(lr=args.lr),
loss=[margin_loss, ‘mse’],
loss_weights=[1., args.lam_recon],
metrics={‘capsnet’: ‘accuracy’})
"""
# Training without data augmentation
model.fit([x_train, y_train], [y_train, x_train], batch_size=args.batch_size, epochs=args.epochs,
validation_data=[[x_test, y_test], [y_test, x_test]], callbacks=[log, tb, checkpoint, lr_decay])
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
感谢又一个很棒的教程。我想告诉您,您的一个顶部图的轴标签与底部图的标题重叠,您可以使用
pyplot.tight_layout这样修复:# plot loss
plt.subplot(211)
plt.tight_layout(h_pad=2)
plt.title('Cross Entropy Loss')
plt.plot(history.history['loss'], color='blue', label='train')
plt.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
plt.subplot(212)
plt.title('Classification Accuracy')
plt.plot(history.history['accuracy'], color='blue', label='train')
plt.plot(history.history['val_accuracy'], color='orange', label='test')
谢谢。
非常有用的指南,不过我有一些建议。
1) 使用优化器 Nadam
2) 使用 3 层,每层 dropout 0.1,末尾 dropout 0.3
3) 使用数据增强
4) 将数据集加载到 Numpy 数组中,而不是使用 flow_from_directory,如上述评论中建议的
希望这些信息有所帮助。
谢谢。
好建议,谢谢!
嗨 Jason,这是一个很棒的教程!我是这个领域的新手,一切都正常运行。我很好奇是否有办法找出输入图像的哪些特征对分类结果贡献最大。例如,是猫的眼睛还是狗的鼻子?有没有办法在原始图像中突出显示这些相关特征?也许猫的照片被正确识别部分是因为它们主要是在室内拍摄的,而狗则是在室外拍摄的?我读到某个地方,一种稀有鱼类与其他鱼类的区别是根据幸运渔民手中拿着他们的稀有渔获物来区分的:)。
谢谢!
也许吧。有一些技术可以突出模型在进行预测时“看”得最好或关注的图像部分。
我没有关于这方面的教程,也许最接近的是
https://machinelearning.org.cn/how-to-visualize-filters-and-feature-maps-in-convolutional-neural-networks/
谢谢,Jason!我会尝试的!
您能分享一下这个分类的混淆矩阵吗?
是的,请看这个
https://machinelearning.org.cn/confusion-matrix-machine-learning/
嗯……我得到的结果一团糟。当准确率达到 95% 时,混淆矩阵显示所有预测都是猫。如果能得到任何建议,我将不胜感激。
也许可以尝试从头开始重新训练模型?
嗨,Jason,
显然,VGG16 模型除了 (224 *224) 之外,还可以接受 (200*200) 的输入大小。根据您的经验或知识,当我们使用 200*200 时,会有什么不好的后果吗?
谢谢
目前没有。模型非常通用,您可以剪掉输入并将其重新定义为许多不同的尺寸,模型将继续良好地工作。
谢谢!
嗨,Jason,
如何将 VGG19 模型用于分类问题?我应该更改哪些参数。
也许您可以使用上述教程中的代码作为起点?
我们可以将相同的方法用于场景分类吗?
也许试试看?
一如既往的出色工作,非常感谢您。最后,您在一个图像上测试了保存的模型,如何在一个测试集(包含多个图像)上测试保存的模型?
谢谢。
您可以通过对每个图像调用预测,或者将多个图像加载到数组中并对数组调用预测来测试模型。
如果您需要帮助调用 keras 模型上的预测,请参阅此内容
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
非常感谢,我打算尝试一下。
祝你好运。
这个教程的代码有 git 仓库吗?
没有,您可以直接复制它,方法如下
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
哪里可以找到这个教程的 tensorflow 1.x / keras 版本
该教程需要 keras 2.3 和 tensorflow 2,抱歉,我没有 tensorflow 1 的教程。
也许您可以将示例调整为该版本的 tensorflow – 我确信几乎不需要任何更改。
如何知道狗被标记为 1,猫被标记为 0??
提前感谢!
标签首先被排序 => [“cats”, “dogs”],然后编码 => [0, 1]
嗨,Jason!
我使用您的代码开发了一个二分类器。我一步步地遵循了您的方法,即首先使用 1 块 VGG,然后是 2 块 VGG,最后我尝试了 3VGG。模型的准确率没有显著提高。在所有情况下都保持在 55% 以下。然而,当我使用迁移学习时,它在第 4 个 epoch 达到了 100% 的准确率,损失呈负指数级下降。这说得通吗?
干得好!
是的,预训练模型的效果显著更好。
我应该把 epoch 设为 4(或 5)吗,因为在第 3 个 epoch 之后,训练和验证准确率都达到了 100%。在第 5 个 epoch 之后,准确率下降了 0.02。我还需要运行 10 个 epoch 吗?
是的,也许可以使用早期停止。
https://machinelearning.org.cn/how-to-stop-training-deep-neural-networks-at-the-right-time-using-early-stopping/
Jason!我想知道您是否发表过关于图像标注或语义分割的文章?
不完全是,这可能是最接近的。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
Jason!如果我要从各种图像中识别手套和汽车等特定对象,我将如何训练数据集,以及我需要多少文件作为数据集(例如 JASON、.csv 和图像)。您能推荐任何文章吗?
听起来像是目标检测。
https://machinelearning.org.cn/how-to-perform-object-detection-with-yolov3-in-keras/
嘿,杰森!
顺便说一句,博客很棒!
学到了很多我的 Udemy 老师都没能教给我的东西。
我有一个疑问。我正在使用 Google Colab 训练我的数据集(比您的少一点,10000 张图像)。
问题1)那么我应该使用相同的 imagenet 平均值吗?如果不是,我如何找到我的数据集的平均值?
由于如果每个 epoch 都必须加载图像,Google Colab 训练速度很慢,我预加载了图像。现在我使用 datagen.flow 而不是 datagen.flow from directory。
Q2s) 我的疑问是,在您的最终模型中,图像是按比例缩放以适应 (0,1) 像素之间,还是您只使用了均值归一化?如果我想在均值归一化之前缩放它们,我的均值会改变吗?
另外,您在 Patreon 上吗?我真的很想为您的出色工作捐款。
谢谢!
也许可以尝试一下看看!
谢谢,是的,您可以在这里捐款
https://machinelearning.org.cn/support/
Jason!这是我访问过的最好的机器学习博客,从中受益匪浅。您写过关于 OpenPose 或姿态估计/检测的文章吗?
谢谢!
不,还没有。
您好,Brownlee 先生,我按照您的说明操作,我的猫狗分类模型完美运行,但是当我使用此代码创建我的面部表情识别模型时,我的代码
result = model.predict(image)
print(result[0])
return [nan]
我已将我的图片分成 8 个独立的文件夹(这样 flow_from_directory() 就会知道有 8 个标签)
根据您的经验,请您告诉我这可能是什么原因。我刚接触机器学习,这个学期才开始了解它
谢谢!
这很令人惊讶。您可能需要仔细调试您的模型/数据,以了解它为什么会预测 NaN。
天啊!谢谢您的回复。先生,我的数据集是否混合了黑白图片和彩色图片,这会不会有什么变化?
还有,请问再问一个问题。那么,我仍然可以使用您在 run_test_harness() 中定义的 define_model() VGG16 版本和 datagen.mean = [123.68, 116.779, 103.939] 的相同设置,对吗?
是的,在数据集中混合黑白图像和彩色图像可能具有挑战性。
也许只尝试彩色或只尝试黑白,并比较结果。
嗨,Jason,
我对机器学习和人工智能很感兴趣。我想学习一切。我是一名 Python 中级用户,但我想从简单的线性回归到深度神经网络,全面了解所有内容。我懂一些理论(只是 3Blue1Brown 的视频哈哈)。但我希望能够训练任何我想到的模型。我应该采取什么步骤?我的第一步应该是什么?请帮助我。
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/how-do-i-self-study-machine-learning
你好 Jason,
请问我在将猫狗文件写入使用 'makedir()' 创建的相应子目录时遇到了问题。错误消息是
PermissionError: [Errno 13] 权限被拒绝:C:\Users\Wolf\Documents\LETI-LTM\Code \CNN\dataset_dogs_vs_cats。
我通常通过在运行代码之前关闭所有工作目录或文件来解决这个问题。我正在以管理员身份在 anaconda 上运行我的 Jupyter notebook,但问题仍然无法解决!
我有一台 8 GB 内存的机器。这个问题会是内存不足引起的吗?我正在考虑转向云端,但不知道这是否能解决问题。
欢迎任何人的建议。
非常感谢。
看起来是权限问题。
确保您从命令行运行示例
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
你好 Jason,
感谢您的回复!
我总是使用运行按钮运行我的 Jupyter notebook,并且像我在之前的帖子中解释的那样简单地解决了权限问题。但我不知道这个示例出了什么问题。尽管按照您的建议使用了命令提示符,它仍然不起作用。错误消息相同。
我不明白出了什么问题?请进一步解释一下?
我怀疑内存太小,我想知道如果我开一个云账户,这类问题是否也会发生在云账户中?
很抱歉听到这个消息,我最好的通用建议在这里
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嘿,杰森!
这个可以用来分类两种以上的动物吗?
是的,你可以修改它,或者可以从这个教程开始
https://machinelearning.org.cn/how-to-develop-a-cnn-from-scratch-for-cifar-10-photo-classification/
感谢您这项出色的工作,当我运行代码时,它显示:
找到属于 3 个类别的 10100 张图片。
找到属于 3 个类别的 2000 张图片。
我的代码完全相同,我的数据文件夹结构如下。
数据
————test
—cat
—dog
————train
—cat
—dog
为什么有 3 个类别而不是 2 个,因为这个损失变成了 'nan',模型完全失败了。
很抱歉,我不知道。也许这些建议中的一些会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
已修复:类别错误。
我发现错误的原因是 ImageDatagenerator 在 notebook 中会自动创建检查点文件夹,这些文件夹隐藏在您的数据文件夹中。这就是它检测到 3 个类别而不是 2 个的原因,所以我必须列出所有内容,然后删除检查点文件夹。
干得好!
Jason – 感谢您的教程。我正在尝试在 tensorboard 中创建一个混淆矩阵。我有一个相同类型的数据集,但很难使其工作。我按照 Tensor 教程 https://tensorflowcn.cn/tensorboard/image_summaries 操作。但它有预标记的 .gz 文件,所以不确定如何使其工作。有什么建议或参考资料吗?基本上问题是——如果我尝试为猫狗问题创建 tensorboard 混淆矩阵,我该怎么做?任何参考资料/建议都将很有用。
抱歉,我没有关于 TensorBoard 的教程,我无法就此主题提供好的建议。
Tensorboard 不是问题。我正在努力为猫/狗等示例提供预测值,其中数据位于包含 jpeg 图像的文件夹中,并且类别是“文件夹名称”。您网站上的 cifar 示例非常清晰,但无法获得数字形式的真实/预测值。那么如何通过猫/狗示例获得 (train_images, train_labels), (test_images, test_labels)?例如,根据 https://tensorflowcn.cn/tensorboard/image_summaries 的混淆矩阵如下:
def log_confusion_matrix(epoch, logs)
# 使用模型预测验证数据集中的值。
test_pred_raw = model.predict(test_images)
test_pred = np.argmax(test_pred_raw, axis=1)
# 计算混淆矩阵。
cm = sklearn.metrics.confusion_matrix(test_labels, test_pred)
# 将混淆矩阵记录为图像摘要。
figure = plot_confusion_matrix(cm, class_names=class_names)
cm_image = plot_to_image(figure)
# 将混淆矩阵记录为图像摘要。
with file_writer_cm.as_default()
tf.summary.image(“Confusion Matrix”, cm_image, step=epoch)
# 定义每 epoch 回调。
cm_callback = keras.callbacks.LambdaCallback(on_epoch_end=log_confusion_matrix)
我不明白如何使用当前的猫/狗示例使 “test_pred_raw = model.predict(test_images)” 起作用。Cifar 结构在“视觉上”也与猫/狗不同。
我不确定我是否理解您遇到的问题。
– 通常,加载图像和已知标签。
– 预测标签
– 使用 sklearn 函数将预测标签与预期标签进行比较。
如果您在那部分遇到问题,请尝试使用上述代码手动加载一些图像和标签。
好主意。我没想到这一点。谢谢……让我试试看。
谢谢。
当我执行程序时,我没有图表,为什么?我完全按照您的做法做了,我得到了结果,但是 (traincats/traindogs 和 testcats/testdogs) 字段是空的
感谢您的回答
确保您从命令行而不是笔记本运行示例
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
我在 Jupyter 中使用 .pynb 扩展名执行,您认为这会造成问题吗?我需要安装 .py 扩展名吗?
我不建议使用 notebook
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
我刚刚用命令提示符试过了,它还是不行
很抱歉听到这个消息,这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
谢谢,现在可以用了
很高兴听到这个消息!
你好,
首先,非常感谢您的这个教程,我真的很感激,但我有一个问题。
我想知道您是否能帮我解决它。
一切都完美运行,我从 Anaconda 的命令提示符运行了脚本,但我有一个问题:图表是空的。
我不知道为什么会这样,但如果您能告诉我,那将会有很大帮助。
现在可以用了,谢谢
太棒了,做得好!
很抱歉听到这个消息,我不知道为什么会这样。也许可以尝试再次运行并确保所有库都已更新?
感谢您的这个示例。我刚开始将计算机视觉作为爱好,所以一切都是新的。我已经运行代码一段时间了,现在是 Epoch 5/10,已经运行了好几个小时。这正常吗?它一直在计数 72/293……等等……我得到 loss: 8.3727e-04,accuracy: 1.0000 这正常吗?我需要让它一直运行吗?我期望看到 final_model.h5 文件,但它还没有出现。
我是一名化学家,所以这一切对我来说都比较新。我一周前才第一次安装 Linux。
是的,在带有 GPU 的 AWS EC2 实例上运行代码可能会更快。
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
或者尝试更少的 epoch,只是为了查看端到端的过程。
它完成了并直接回到了命令行。我在任何地方都没有看到 final_model.h5 文件。我漏掉了什么吗?
感谢您之前的回复。我会去了解一下 AWS。
它将位于您执行的 Python 脚本所在的同一目录中。
你好,非常感谢这个教程,我想知道我是否可以输入两个字段,一个用于训练,一个用于测试,我不想将训练数据分开(训练和测试),我已准备好两个字段要放置。
请问能帮帮我吗?
您说的“两个字段”是什么意思?请您详细说明一下吗?
一个名为 train 的字段,另一个名为 test(这个不是从 train 中提取的)。
更改后的代码是这样的
—–
from shutil import copyfile
from random import seed
from random import random
# 创建目录
dataset_home = 'C:/Users/T/dataset_dogs_vs_cats/'
subdirs = ['train/']
dataset_home2 = 'C:/Users/T/dataset_dogs_vs_cats/'
subdirs2 = ['test/']
for subdir in subdirs
# 创建标签子目录
labeldirs = ['dogs/', 'cats/']
for labldir in labeldirs
newdir = dataset_home + subdir + labldir
makedirs(newdir, exist_ok=True)
for subdir2 in subdirs2
# 创建标签子目录
labeldirs2 = ['dogs/', 'cats/']
for labldir2 in labeldirs2
newdir2 = dataset_home2 + subdir2 + labldir2
makedirs(newdir2, exist_ok=True)
# 将训练数据集图像复制到子目录
src_directory = 'C:/Users/T/train/'
for file in listdir(src_directory)
src = src_directory + ‘/’ + file
dst_dir = ‘train/’
if file.startswith('cat')
dst = dataset_home + dst_dir + 'cats/' + file
copyfile(src, dst)
elif file.startswith('dog')
dst = dataset_home + dst_dir + 'dogs/' + file
copyfile(src, dst)
# copy testing dataset images into subdirectories
src_directory = 'C:/Users/Nour/test/cat/'
src_directory2 = 'C:/Users/Nour/test/dog/'
for file in listdir(src_directory)
src = src_directory + ‘/’ + file
dst_dir = 'test/'
#if file.startswith('cat')
dst = dataset_home + dst_dir + 'cat/' + file
copyfile(src, dst)
----
我不知道现在如何上传测试字段
您能帮帮我吗?
问题在于测试图片没有像训练图片那样命名为 cat. 和 dog.,所以我不知道如何将它们上传到我的程序中
非常感谢您的时间
很抱歉您遇到问题,但我没有能力调试您的代码,也许这会有所帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
另外,也许可以从教程中可用的代码开始,并根据您的用例进行调整以节省时间。
嗨,Jason,
非常感谢您提供的精彩教程,我运行了它,它按预期工作,我甚至设法修改此代码进行多类别分类,并且我以超过 98% 的准确率完成了它,并且在未知数据上的预测也表现出色。现在我有一个疑问,即我如何才能使此代码在图像中同时存在猫和狗时提取这两种动物,这就是我如何从该模型在相机馈送上进行预测的方式。我是否必须使用 OpenCV 开发一些动物检测,然后将每次检测都输入到此模型中?请帮助我。
谢谢
不客气。
两种动物是不同的问题,您可能需要使用目标检测。
https://machinelearning.org.cn/how-to-perform-object-detection-in-photographs-with-mask-r-cnn-in-keras/
首先感谢这篇文章。
但我想知道为什么这张图看起来是那样的?以及我如何修复它?它看起来像是重叠了。如果可以,您能修复代码吗?
我找到了它 (
def summarize_diagnostics(history)
# 绘制损失
# 绘制损失
pyplot.subplot(211)
pyplot.tight_layout(h_pad=2)
pyplot.title(‘交叉熵损失’)
pyplot.plot(history.history[‘loss’], color=’blue’, label=’train’)
pyplot.plot(history.history[‘val_loss’], color=’orange’, label=’test’)
# 绘制准确率
pyplot.subplot(212)
pyplot.title(‘分类准确率’)
pyplot.plot(history.history[‘accuracy’], color=’blue’, label=’train’)
pyplot.plot(history.history[‘val_accuracy’], color=’orange’, label=’test’)
# pyplot.show()
filename = sys.argv[0].split(‘/’)[-1]
pyplot.savefig(filename + ‘_plot.png’)
pyplot.close()
抱歉,我不明白您的问题,请您详细说明或重新陈述一下?
嗨,Jason,
您的图表标题重叠了。这就是为什么我按照之前的建议将这段代码 (pyplot.tight_layout(h_pad=2)) 添加到您的代码中。
尽管在代码中看起来没问题,但当我查看 .png 文档时,仍然存在问题。您能解决这个问题吗?
我明白了。
也许您可以查阅/查看 matplotlib API,以更改图中标题的大小/位置。
模型使用了多少个隐藏层?请回复
另外,请指定它们的尺寸(输出神经元为一个,输入为长度乘以宽度乘以通道数)
模型摘要显示了所有这些信息。
您可以调用 model.summary() 并计算层数。
嗨,Jason!
感谢您提供这个精彩的教程!
请问我有两个问题
第一个是为什么我应该从头开始创建和训练模型,而我可以使用迁移学习?换句话说,我应该在什么时候使用迁移学习技术?
第二个是您从哪里获得用于对数据集进行中心化的均值 “[123.68, 116.779, 103.939]”,并且是否需要进行中心化?
提前感谢
不客气。
从迁移学习开始,如果时间和资源允许,可以探索从头开始的模型,看看能否做得更好。
好问题。我认为是一篇论文。
你好 Jason,运行代码后
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=20, verbose=0)
ValueError: 要求检索元素 0,但序列长度为 0
我遇到了上述错误,如果您能纠正我将非常有帮助。
我是机器学习新手,这可能不是一个很好的/令人愉快的提问。但请不要忽视……
非常感谢!
很抱歉您遇到了错误,也许这会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
请问您测试集和验证集使用的是相同的数据集吗?如果是,训练集、验证集和测试集的数据分布是怎样的?
没有,我们将数据分成训练集和测试集。也许可以重新阅读教程。
但是验证数据集在哪里呢?也许您正在将测试数据用于验证,然后使用 evaluate_generator() 对测试数据进行预测。
请看我的另一个回复。你是对的,验证集和测试集彼此不同,并且必须是训练过的网络从未见过的数据。
当我尝试读取训练和测试图像时,出现以下错误
—————————————————————————
PermissionError Traceback (最近一次调用)
in
15 output = 1.0
16 # 加载图像
—> 17 photo = load_img(folder + file, target_size=(200, 200))
18 # 转换为 numpy 数组
19 photo = img_to_array(photo)
~\anaconda3\lib\site-packages\keras_preprocessing\image\utils.py in load_img(path, grayscale, color_mode, target_size, interpolation)
111 raise ImportError(‘无法导入 PIL.Image。’
112 ‘使用
load_img需要 PIL。’)–> 113 with open(path, ‘rb’) as f
114 img = pil_image.open(io.BytesIO(f.read()))
115 if color_mode == ‘grayscale’
PermissionError: [Errno 13] 权限被拒绝:‘C:\\Users\\Owner\\Documents\\Deep learning with keras and tensor flow\\Pet_classfication_project\\train\\cats’
看起来你的工作站有权限问题。
也许可以和你的管理员谈谈。
您好,非常感谢您这篇精彩的教程。我有一个问题
我将使用 Kaggle 中的所有图像。
——训练数据通过文件名标记,带有“dog”或“cat”字样。
——数据未标记,它们以数字命名(1,2,…..)。
所以我需要用“dog”或“cat”标记所有测试数据吗?
是的,当我们加载数据时,cat 将映射到类别 0,dog 将映射到类别 1。
我没有正确解释情况。我想使用 Kaggle 上找到的所有数据(训练和测试),但您只使用了训练集(您将其分为训练集和测试集)。
然后使用所有数据
我将使用 train-it (25000) 张标记为 (cat / dog) 的图片
validate-it (我必须使用 train-it 中的相同图片,但“拆分 = 0.1 或 0.3”),因为您使用了 fit_generator,我不知道如何做。
test-it (15000) 张未标记的图片。
我的问题是:我需要标记 test-it 吗?
谢谢你的回复
我相信官方测试集没有标签。
如果你想利用所有数据,也许你可以首先在所有未标记图像上训练一个自编码器,然后只在训练集上训练一个监督学习模型。
我不明白,我该怎么做?
抱歉,我没有关于图像数据自编码器的教程。
如果我按照您的教程操作并添加一个测试文件(未标记),这是否错误?
像这样
# 准备迭代器
train_it = datagen.flow_from_directory(‘dataset_dogs_vs_cats/train/’,
class_mode=’binary’, batch_size=64, target_size=(200, 200))
test_it = datagen.flow_from_directory(‘dataset_dogs_vs_cats/test/’,
class_mode=’binary’, batch_size=64, target_size=(200, 200))
test = datagen.flow_from_directory(‘dataset_dogs_vs_cats/test1/’,
class_mode=’binary’, batch_size=64, target_size=(200, 200))
# 拟合模型
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=20, verbose=0)
# 评估模型
_, acc = model.evaluate_generator(test, steps=len(test), verbose=0)
print(‘> %.3f’ % (acc * 100.0))
你只能在拥有目标标签的数据集上进行评估。在这种情况下,图像被组织成狗和猫的目录。
如果你有“test1”数据集的“标签”,那么你的方法我相信会奏效。
好的,非常感谢。
我找到了绘图问题的解决方案:您的更新中第二个绘图没有标题。
import matplotlib.pyplot as plt
# 绘制诊断学习曲线
def summarize_diagnostics(history)
# 绘制损失
plt.subplot(211)
plt.title(‘交叉熵损失’)
plt.plot(history.history[‘loss’], color=’blue’, label=’train’)
plt.plot(history.history[‘val_loss’], color=’orange’, label=’test’)
# 绘制准确率
plt.subplot(212)
plt.title(‘分类准确率’)
plt.plot(history.history[‘accuracy’], color=’blue’, label=’train’)
plt.plot(history.history[‘val_accuracy’], color=’orange’, label=’test’)
plt.tight_layout()
# 保存绘图到文件
filename = sys.argv[0].split(‘/’)[-1]
plt.savefig(filename + ‘_plot.png’)
plt.close()
很高兴听到您解决了问题。
嗨,Jason博士,
我能问一个关于标签或训练数据的问题吗?
训练数据中所有标签都是序列的,比如 CAT.1 CAT.2 等。
如果其中一个文件丢失,会导致训练崩溃吗?
不确定我是否理解,抱歉。也许可以试试看。
你好,我是 Zhi。
在教程中,我遇到了一些问题。我正在使用代码,但似乎无法获得 vgg 模型(准确率)的图表。供您参考,我正在使用 google collab。
也许尝试在您自己的工作站上从命令行运行。
有几个问题,请教
1-) 为什么预测中使用的图像没有归一化(除以 255)?
2-) 使用“binary_accuracy”指标而不是“accuracy”不是更合适吗?
3-) 使用阈值进行预测不是更合适吗?(sigmoid!)
if (result > 0.5)
print (‘dog’)
else
print (‘cat’)
非常感谢!
新的图像像素已居中,或许可以重新检查代码。
准确率适用于 2 个类别或多个类别。它是相同的度量。
是的,您应该根据您的应用解释预测概率。
Jason 先生,您好!
感谢您的鼎力支持。
我有一个基本疑问。如何考虑“未分类类别/未知类别”。假设,在上述模型中,我输入了肺部CT扫描图像或汽车图像,它们既不匹配狗类别,也不匹配猫类别。在这种情况下,预期会产生什么结果,是否有办法解决这个问题?
好问题。
也许可以解释预测概率,并将低概率标记为“未知”。
也许在训练期间向数据集中添加一个“其他”类别并提供一些示例。
也许可以查阅文献,看看如何处理这种情况。
我如何使用多张图片测试模型并将结果保存到CSV文件?
您可以直接将多张图片作为输入传递给您的模型。
本教程向您展示如何将结果数组保存到文件
https://machinelearning.org.cn/how-to-save-a-numpy-array-to-file-for-machine-learning/
assalam-o-alaikum 先生,我在这里问一个问题,如何标记五个对象,每个对象至少有10张图像,并使用分类SVM在Python代码中对不同对象进行分类.. 请帮帮我..
也许可以从一个预训练模型开始,看看它是否足够好,无需更改即可用于您的图像。
如果不行,也许可以使用上述教程为您的数据集训练一个自定义模型。
嗨,Jason,感谢这篇很棒的教程!我有一个关于模型拟合的问题。在训练周期中,测试集上的验证准确率逐渐提高,在最后几个周期又下降了。如果我最后运行“model.evaluate_generator”,它返回的是最后一个周期的验证准确率,这个值肯定比第13个周期等验证准确率低。我如何确保“model.evaluate_generator”返回相应周期的最高验证准确率,而不仅仅是最后一个周期的验证准确率?
不客气。
好问题!你可以使用“提前停止”等技术,它会在模型在未见/验证数据上表现最佳时停止训练或将模型保存到文件。
提前停止的理论
https://machinelearning.org.cn/early-stopping-to-avoid-overtraining-neural-network-models/
提前停止的例子
https://machinelearning.org.cn/how-to-stop-training-deep-neural-networks-at-the-right-time-using-early-stopping/
感谢这些非常有用的链接!
不客气。
我注意到,如果您在 summarize_diagnostics 函数中添加 'pyplot.tight_layout()' 这行代码,它有助于提高子图的可读性 :)
谢谢!
我认真学习了您的教程,并编译了自己的仓库:https://github.com/MartinTschendel/ImageClassifier 现在我真的很好奇如何将这样的模型投入生产,以便人们例如可以使用移动应用程序,扫描图片并从应用程序中获得答案,判断它是猫还是狗:)
干得好!
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/how-do-i-deploy-my-python-file-as-an-application
嗨,Jason,
感谢您的文章。当我加载保存的模型并使用 model.predict 时,我得到以下结果:
WARNING:tensorflow:最近7次调用中,有6次 触发了 tf.function 重新追踪。追踪成本很高,过多的追踪可能是由于 (1) 在循环中重复创建 @tf.function,(2) 传递不同形状的张量,(3) 传递 Python 对象而不是张量。对于 (1),请在循环外部定义您的 @tf.function。对于 (2),@tf.function 具有 experimental_relax_shapes=True 选项,该选项会放宽参数形状,从而避免不必要的重新追踪。对于 (3),请参阅 https://tensorflowcn.cn/tutorials/customization/performance#python_or_tensor_args 和 https://tensorflowcn.cn/api_docs/python/tf/function 以获取更多详细信息。
您知道为什么会发生这种情况吗?它在我加载模型时发生。如果在训练后使用 model.predict,就不会发生。
您大概可以忽略此警告消息。
我们如何制作一个进度条来显示正在训练?
你可以在 fit() 调用中设置 verbose=1
谢谢你。
我想我在这里真正理解了迁移学习。我使用 Xception 实现了 99.40% 的准确率。唯一的问题是——我不得不删除 (featurewise_center=True),因为结果明显更差。您有任何文章解释这个参数吗?
干得好!
是的,这个可能会有帮助
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
嗨,Jason,我对代码有点困惑,我试图用2000张图片进行分类,然后我在这一行遇到了问题
_, accuracy = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
当我运行这一行时,它显示如下
—————————————————————————
IndexError Traceback (最近一次调用)
in
1 # 评估模型
—-> 2 _, accuracy = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
C:\Anaconda3\envs\tf-gpu\lib\site-packages\keras\legacy\interfaces.py in wrapper(*args, **kwargs)
89 warnings.warn(‘Update your
' + object_name + 'call to the ‘ +90 ‘Keras 2 API: ‘ + signature, stacklevel=2)
—> 91 return func(*args, **kwargs)
92 wrapper._original_function = func
93 return wrapper
C:\Anaconda3\envs\tf-gpu\lib\site-packages\keras\engine\training.py in evaluate_generator(self, generator, steps, callbacks, max_queue_size, workers, use_multiprocessing, verbose)
1789 workers=workers,
1790 use_multiprocessing=use_multiprocessing,
-> 1791 verbose=verbose)
1792
1793 @interfaces.legacy_generator_methods_support
C:\Anaconda3\envs\tf-gpu\lib\site-packages\keras\engine\training_generator.py in evaluate_generator(model, generator, steps, callbacks, max_queue_size, workers, use_multiprocessing, verbose)
418 enqueuer.stop()
419
–> 420 averages = [float(outs_per_batch[-1][0])] # index 0 = ‘loss’
421 for i in range(1, len(outs))
422 averages.append(np.float64(outs_per_batch[-1][i]))
IndexError: 列表索引超出范围
你能帮我吗?谢谢
要对新图像进行分类,只需调用 model.predict(),请参阅此处
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
嗨,Jason,
感谢这篇很棒的文章。我想请教一下您用于 ImageDataGenerator 类的 flow_from_dictionary 方法以及它与您在其他文章中使用的 flow 方法的区别。您能详细说明它们的优缺点吗?
我相信它用于已经加载到内存中的数据集,而不是您想从磁盘加载的数据集。
谢谢!
嗨,Jason,
我的验证交叉熵有问题。它一开始很低,然后一直保持在0.1左右。我该怎么解决?这是针对迁移学习模型的。我们使用的是您的确切代码,但我们无法生成与您的交叉熵图相同或相似的图。
也许检查一下您是否正在使用最新的 Python 库?
也许检查一下您是否完全复制了代码?
或许可以尝试多运行几次这个例子?
也许可以尝试调整学习超参数?
嗨,Jason,
我检查了我的代码并在不同的电脑上运行了示例,它们几乎相同。现在我正在尝试调整超参数。
但是,您能否看一眼我的交叉熵曲线,看看您是否一眼就能看出问题所在?
https://stackoverflow.com/questions/66552630/why-is-my-val-loss-starting-low-and-increasing-does-it-even-matters-with-transfe
也许您的验证数据集太小或不能代表预测问题?
提前停止会有帮助吗?
也许可以尝试一下并比较结果?
你好。我尝试修改你的特征提取器,使其“类似 Inception”,以在相同参数预算下工作。即 3 个块,每个块包含 6 个卷积
(3×1)(1×3)BatchNorm(3×1)(1×3)BatchNorm(3×1)(1×3)MaxPool2D+Drop。
该模型拥有108K参数,与您的VGG3模型大小(101.5K参数)相当。它在35个周期内达到了91.68%的准确率。
感谢分享!
干得好!
嘿,Jason,很棒的教程!关于使用GPU的一个问题……
我在我的笔记本电脑上使用带有Tensorflow GPU的Anaconda环境中成功运行了代码,我的显卡是NVIDIA Quadro RTX 5000。但是运行过程中,我的GPU根本没有被使用,只有我的CPU被100%使用。我们需要修改代码以将计算分配给GPU吗,还是我做错了其他事情……提前感谢!
代码不需要任何更改。
您可能需要更改Tensorflow库安装的配置。我建议查阅文档。
我将其扩展为识别浣熊和狐狸(~1.0)以及非浣熊和狐狸(~0.0)。感谢您的教程!
干得好!
你好。
感谢您的教程。
我刚刚制作了这个例子。我已经得到了final.h5。但是我无法进行预测。出现了错误。请帮帮我
这是您的代码
# 为新图像进行预测。
来自 keras.preprocessing.image 导入 load_img
来自 keras.preprocessing.image 导入 img_to_array
from keras.models import load_model
# 加载并准备图像
def load_image(filename)
# 加载图像
img = load_img(filename, target_size=(224, 224))
# 转换为数组
img = img_to_array(img)
# 重塑为具有3个通道的单个样本
img = img.reshape(1, 224, 224, 3)
# 中心像素数据
img = img.astype(‘float32’)
img = img – [123.68, 116.779, 103.939]
return img
# 加载图像并预测类别
def run_example()
# 加载图像
img = load_image(‘sample_image.jpg’)
# 加载模型
model = load_model(‘final_model.h5’)
# 预测类别
result = model.predict(img)
print(result[0])
# 入口点,运行示例
run_example()
这是错误信息
runfile(‘D:/Doctorant/муур нохой таних/dog_cat/train/dog_cat_final.py’, wdir=’D:/Doctorant/муур нохой таних/dog_cat/train’)
回溯(最近一次调用)
文件“D:\Doctorant\муур нохой таних\dog_cat\train\dog_cat_final.py”,第37行,在
run_example()
文件“D:\Doctorant\муур нохой таних\dog_cat\train\dog_cat_final.py”,第31行,在run_example
model = load_model(‘final_model.h5’)
文件“D:\Doctorant\anaconda\envs\tf-gpu\lib\site-packages\tensorflow\python\keras\saving\save.py”,第181行,在load_model
isinstance(filepath, h5py.File) or h5py.is_hdf5(filepath)))
文件“D:\Doctorant\anaconda\envs\tf-gpu\lib\site-packages\h5py\_hl\base.py”,第44行,在is_hdf5
return h5f.is_hdf5(filename_encode(fname))
文件“D:\Doctorant\anaconda\envs\tf-gpu\lib\site-packages\h5py\_hl\compat.py”,第114行,在filename_encode
return filename.encode(WINDOWS_ENCODING, “strict”)
UnicodeEncodeError: 'mbcs' 编解码器无法编码位置 0-1 的字符:无效字符
抱歉,我不熟悉这个错误,也许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
在运行制作最终数据集目录的脚本时,我遇到了一个错误
这是直接从这里复制的代码
# 将数据集组织成有用的结构from os import makedirs
from os import listdir
from shutil import copyfile
# 创建目录
dataset_home = 'finalize_dogs_vs_cats/'
# 创建标签子目录
labeldirs = ['dogs/', 'cats/']
for labldir in labeldirs:
newdir = dataset_home + labldir
makedirs(newdir, exist_ok=True)
# 将训练数据集图像复制到子目录中
src_directory = 'dataset_dogs_vs_cats/train/'
for file in listdir(src_directory):
src = src_directory + '/' + file
if file.startswith('cat'):
dst = dataset_home + 'cats/' + file
copyfile(src, dst)
elif file.startswith('dog'):
dst = dataset_home + 'dogs/' + file
copyfile(src, dst)
以及错误信息
IsADirectoryError 回溯(最近一次调用在最后)
in ()
16 如果文件以“cat”开头
17 dst = dataset_home + ‘cats/’ + file
—> 18 copyfile(src, dst)
19 否则如果文件以“dog”开头
20 dst = dataset_home + ‘dogs/’ + file
/usr/lib/python3.7/shutil.py 中的 copyfile(src, dst, follow_symlinks)
118 os.symlink(os.readlink(src), dst)
119 否则
–> 120 with open(src, ‘rb’) as fsrc
121 with open(dst, ‘wb’) as fdst
122 copyfileobj(fsrc, fdst)
IsADirectoryError: [Errno 21] 是一个目录:'dataset_dogs_vs_cats/train//cats'
由于train后面有2个'/',我从src目录中删除了一个
现在出现了同样的错误,只是最后一行没有2个'/',现在只有一个了
很抱歉听到这个消息,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
最终数据集和我们一开始创建的数据集是否相同,最终的数据集是包含所有图像还是复制了我们之前用val_ratio = 0.25创建的数据集?
抱歉,我不明白,您能重新措辞您的问题吗?
对于最终模型,我们运行了一个创建最终目录的脚本,那么该目录与我们在最终化模型之前用于开发模型的目录不同吗?它包含整个数据集还是数据集的一部分?
通常,最终模型在所有数据上进行拟合,并用于对新数据进行预测。
先生,
我想下载猫和狗的图片,但Kaggle对我来说无法使用(我在罗马尼亚,东欧)。我想问是否可以从其他网站下载图片?您的网站非常有帮助,但由于我无法下载,我无法继续进行工作。
提前感谢。
诚挚地,
Gheorghe Gardu
抱歉,我不能。
教授您好,请问如果我想进行黑白图像分析,如何获取像素均值,例如datagen.mean = [123.68, 116.779, 103.939]?非常感谢您的回复!
也许可以计算每张图像或数据集中所有图像的平均像素值。
嘿,Jason,又一篇很棒的文章。我喜欢你构建这个程序的方式。
我今天运行了这个程序,在两行上收到了2个警告,说`model.fit_generator`和`model.evaluate_generator`已被弃用。我用`model.fit`和`model.evaluate`替换了这两个方法调用,程序就可以工作了。
祝好,
Basil Latif
也许你可以忽略这些警告。
先生,
如何添加后验概率或贝叶斯方法来量化和利用CNN中的不确定性
我不确定您的问题,也许可以查阅scholar.google.com上的文献
你好,
非常感谢您这篇非常重要的文章。我们可以在tensorflow 2.6.0和keras 2.6.0中使用您的代码吗?
大部分应该可以工作,但我没有测试过。
嗨,
我在迁移学习代码中遇到了这个错误。(Tensor 2.6.0 & Keras 2.6.0)
flat1 = tf.keras.layers.Flatten()(model.layers[-1].output)
文件“C:\Program Files\Python39\lib\site-packages\keras\engine\base_layer.py”,第1037行,在__call__
outputs = call_fn(inputs, *args, **kwargs)
文件“C:\Program Files\Python39\lib\site-packages\keras\layers\core.py”,第656行,在call
flattened_shape = tf.constant([inputs.shape[0], -1])
文件“C:\Program Files\Python39\lib\site-packages\tensorflow\python\framework\constant_op.py”,第271行,在constant
return _constant_impl(value, dtype, shape, name, verify_shape=False,
文件“C:\Program Files\Python39\lib\site-packages\tensorflow\python\framework\constant_op.py”,第283行,在_constant_impl
return _constant_eager_impl(ctx, value, dtype, shape, verify_shape)
文件“C:\Program Files\Python39\lib\site-packages\tensorflow\python\framework\constant_op.py”,第308行,在_constant_eager_impl
t = convert_to_eager_tensor(value, ctx, dtype)
文件“C:\Program Files\Python39\lib\site-packages\tensorflow\python\framework\constant_op.py”,第106行,在convert_to_eager_tensor
return ops.EagerTensor(value, ctx.device_name, dtype)
ValueError: 尝试将值 (None) 转换为不受支持的类型 () 的张量。
请参阅以下答案:https://stackoverflow.com/questions/67860096/got-valueerror-attempt-to-convert-a-value-none-with-an-unsupported-type-cla
你好Jason,一如既往的精彩教程。我想寻求一些帮助,因为我在运行测试工具时遇到了这个错误
PIL.UnidentifiedImageError: 无法识别图像文件
我正在从cmd运行代码,并在StackOverFlow上搜索了一段时间,但我无法理解它,因为我没有使用io.BytesIO函数。
非常感谢!
此错误表示 Pillow 无法读取该特定图像格式。
PIL.UnidentifiedImageError: 无法识别图像文件
由于无法编辑原始消息,请编辑为完整的错误信息。
你知道如何使用nvidia tao吗?我不知道怎么用它!
谢谢,Jason博士,这篇高效的博客。
此外,我想知道是否可以使用 `flow_from_directory` 函数来训练多输入模型,而不是使用 Keras 函数式 API(正如您在博客中解释的:https://machinelearning.org.cn/keras-functional-api-deep-learning/)?我无法连接两个输入通道。
我有两个输入和一个输出。请分享任何示例/代码以供指导。
感谢您的宝贵指导和建议。
查看此处的文档:https://tensorflowcn.cn/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator#flow_from_directory
你可能做不到。这个函数不那么灵活。
你好!有没有办法可以打印“Cat”或“Dog”而不是0或1?谢谢!
打印(“Cat” 如果是0 否则 “Dog”)
这是您要找的吗?
是的!我试过了,但没用 🙁
你好!
如果值不是0或1会发生什么?这意味着什么?
例如
[4.2455602e-14]
这是预期的。例如,您应该将所有低于0.5的值视为0,否则视为1。
你好Maira……分类网络的实际输出代表是0或1的概率。因此,对于您的示例,该数字将代表是1的概率非常低,因此它将被视为0。以下资源讨论了用于将输出转换为相对概率的“softmax”激活函数。
https://machinelearning.org.cn/softmax-activation-function-with-python/
此致,
你好Jason,非常感谢您分享如此精彩的教程!
不过,我在“预处理照片尺寸(可选)”部分有点困惑。在代码第14和15行中,如果输入是猫的图像,输出类别将是1.0。
这难道不是与我们想要的(猫=0,狗=1)相反吗?还是我有什么误解?
你说得对。已更正。
你好,Jason!
感谢您提供如此出色的教程!但是,当我尝试对4个类别进行分类时,打印出的输出都是“1”。如果想对超过2个类别进行分类,需要进行哪些更改?
这取决于您如何设计它,您可以尝试OvR或OvO模型:https://machinelearning.org.cn/one-vs-rest-and-one-vs-one-for-multi-class-classification/
你好Phil……感谢你的好意和你的问题!请提供你当前的代码清单,以便我们进一步调查。
此致,
嗨,Jason,
感谢您的本教程!我是机器学习新手,希望您能帮我回答下面的一些问题。
我能否知道为什么在拟合模型时您将测试数据用作验证数据,而不是使用单独的验证数据集?测试数据在评估模型时再次使用……这难道不会因为模型在验证期间已经接触过相同的数据集而夸大测试准确性吗?
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=11, verbose=1
_, acc = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
print(‘> %.3f’ % (acc * 100.0))
换句话说,在我看来,您的示例中测试集和验证集是相同的?
你好Xuan……在这种情况下,你说的没错,它们是互换使用的。以下资源将帮助澄清训练集、测试集和验证集之间的区别。
https://machinelearning.org.cn/difference-test-validation-datasets/
此致,
你好,
非常感谢您回答我之前的问题 🙂
我还有另一个关于迁移学习示例的输出层的问题:为什么输出密集层只有一个节点?我以为既然我们在分类猫和狗,就应该有两个节点?
# 添加新的分类器层
flat1 = Flatten()(model.layers[-1].output)
class1 = Dense(128, activation=’relu’, kernel_initializer=’he_uniform’)(flat1)
output = Dense(1, activation=’sigmoid’)(class1)
嗨 Lee……如果您的目标是二元分类,您只需要一个输出。这个输出可以是1或0,其中1代表“狗”,0代表“猫”。
我喜欢说话
在预测图像时,除了加载和调整大小之外,我们还需要对图像做什么,因为您这里将其转换为浮点类型并进行了减法运算。
在预测之前,应该对图像进行哪些更改。
具体来说,我想创建一个深度学习模型来检测眼睛,所以它的数据将是实时的。
嗨 Ridham……以下资源将对您有所帮助
https://machinelearning.org.cn/data-preparation-for-machine-learning-7-day-mini-course/
我能否知道为什么在拟合模型时您将测试数据用作验证数据,而不是使用单独的验证数据集?测试数据在评估模型时再次使用……这难道不会因为模型在验证期间已经接触过相同的数据集而夸大测试准确性吗?
history = model.fit_generator(train_it, steps_per_epoch=len(train_it),
validation_data=test_it, validation_steps=len(test_it), epochs=11, verbose=1
_, acc = model.evaluate_generator(test_it, steps=len(test_it), verbose=0)
print(‘> %.3f’ % (acc * 100.0))
换句话说,在我看来,您的示例中测试集和验证集是相同的?
请回答这个问题。
Prakhar,您说得对。测试集和验证集通常是不同的数据集。其核心概念是它们都应该是训练过的网络从未见过的数据集。
嗨,Jason,
在本教程的开头,有一个可选的“预处理照片大小”部分,您将照片和标签保存到 .npy 文件中。除了如何将它们加载为 numpy 数组之外,我没有看到您再次引用这些文件。也就是说,您如何将这些文件分割成训练和验证数组;以及如何将它们拟合到您的模型中?
嗨 Delcan……如果您执行代码,您将看到为测试和训练创建的目录。
嗨 James,感谢您这个非常棒的教程。
我很难将这个模型改编为使用K折交叉验证而不是训练/测试分割,特别是因为直接在model.fit()中使用迭代器。它与我在网上找到的交叉验证教程/文档不太兼容,主要是因为那些期望带有标签的.csv文件,并且通常不是图像分类示例。
您能给我指明正确的方向吗?提前感谢您。
嗨 Mateus……请详细说明您的应用程序中具体哪个部分或哪些部分不起作用,以便我更好地指导您。
在本次教程的背景下,一切都运行得很完美,但我希望改用交叉验证而不是训练/测试分割,并且很难在网上找到足够的资料。
嗨 Jason – 喜欢你的工作,我正在努力更熟练地进行图像处理。我已经把程序运行到最后,一切都很好。不过,这花了很多工夫,特别是当我换到带有 GPU 的 MacBook Pro 时——为了让 TensorFlow 在 GPU 上工作,花了很多精力)。
我有一个关于 Kaggle 数据集和 VGG16 模型的问题。我将如何预测 test1 数据集中的图像?
使用这个..
datagen = ImageDataGenerator(featurewise_center=True)
datagen.mean = [123.68, 116.779, 103.939]
train_it = datagen.flow_from_directory(‘dataset_dogs_vs_cats/train/’,
class_mode='binary', batch_size=64, target_size=(224, 224))
test_it = datagen.flow_from_directory(‘dataset_dogs_vs_cats/test/’,
class_mode='binary', batch_size=64, target_size=(224, 224))
full_test = datagen.flow_from_directory('dataset_dogs_vs_cats/test1/',
class_mode='binary', batch_size=64, target_size=(224, 224))
我得到..
找到属于 2 个类别的 18697 张图片。
找到属于 2 个类别的 6303 张图片。
找到0张图片,属于0个类别。
所以这看起来不对。有什么建议吗,或者您的某本书解释了这个问题。我看过红车蓝车博客,但那似乎没有帮助。
谢谢!
再次问好 Jason – 我手动分类了前108张图片。看到不同的猫狗图片,这相当有趣。然后使用您的代码
最终结果 = model.predict(img)
结果 = result[0]
然后创建了一个包含前108个文件名(包括文件路径)的列表。
然后从第一个列表中创建了108个 img 列表
然后使用上面的代码在循环中预测它们,并将结果放入另一个列表中。将它们转换为整数并与我手动预测的列表进行比较。准确率达到了90%。所以我非常满意。感谢您提供出色的代码和讨论。
我想要检测图像中的干湿部分。那么,您能为迁移学习推荐任何预训练模型吗?
嗨 Mayur……以下是与您查询相关的优秀资源
https://www.sciencedirect.com/science/article/pii/S2666827021000359
我希望将这个h5文件用于视频输入的目标检测。我该如何实现呢?
嗨 James,感谢您的教程,它真的很棒,我学到了更多关于如何生成自己模型的过程。
我有几个疑问,生成模型花费了很长时间,所以我将每个动物的图像数量减少到600张而不是15k张。因此我只有600张猫图片和600张狗图片。我猜这样做准确率可能会大大下降,对吗?
这样做的原因是,由于某些原因,Tensorflow 无法识别我的 GPU,所以我只能运行我的 CPU,而且我认为这会花费更长的时间(除了我不想把它烧坏哈哈),我尝试了多次重新安装 Cuda 和 Cudnn,在 Windows 上运行,但没有成功,任何建议都欢迎。
然而,这样做我成功生成了模型,我应该期望0(猫)到1(狗)之间的浮点值,但有一张猫图像返回了 [4.047696e-22],我不确定这意味着什么。您能帮我理解这还能给我带来哪些其他值以及为什么吗?
再次感谢
嗨 Jordi……您可以考虑尝试使用带有GPU选项的Google Colab Pro。
关于你提到的那个低值,在我看来它应该被认为是0。
你好詹姆斯
在上述 final_model.h5 的帮助下,我想通过视频检测猫和狗。并且想在检测到的猫和狗上放置矩形框。您能给我一些逻辑建议吗?我是初学者。
请回复。
model.save() 不起作用。它显示“AttributeError: 'History' object has no attribute 'save'”
嗨 Amir……您是否搜索过您收到的错误?另外,您是从示例中复制粘贴代码的吗?
嗨 James,谢谢您的教程。它真的很有帮助。非常棒。
抱歉,我的意思是谢谢你 Jason。我弄错了。
不客气,Kobe!
请问在这个例子中如何使用准确率、ROC曲线和AUC,谢谢。
你好,Jason。
如果我们只使用验证集,在 run_test_harness() 函数中,像这样:
# 创建数据生成器
datagen = ImageDataGenerator(rescale=1.0/255.0, validation_split=0.2)
和
# 准备迭代器
train_it = datagen.flow_from_directory(‘dataset_dogs_vs_cats/train/’,
class_mode='binary', batch_size=16, target_size=(200, 200), subset='training')
test_it = datagen.flow_from_directory('dataset_dogs_vs_cats/train/',
class_mode='binary', batch_size=16, target_size=(200, 200), subset='validation')
如果我只使用一个CNN层,只有4个单元
model.add(Conv2D(4, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(200, 200, 3)))
结果是验证损失在增加,而验证准确率在前2、3个epoch时略微增加,然后以非常小的速率下降。
如果你想看图片,请查看这个 https://ibb.co/HzXhZx4。
我们能从这个结果中得出什么结论?因为它看起来像是过拟合。但是,只有一个CNN层和4个单元吗?
如果我使用完整的CNN模型,就像您在代码中那样,仍然看起来像是过拟合,与之前的结果类似,但速率更小。
遇到了和另一个发帖人一样的问题,但建议没有帮助。
“要求检索元素0,但序列长度为0”
如果完全按照您的代码操作,怎么会出错呢?
谢谢。
嗨 Matt……请提供您遇到的确切错误信息。这将使我们能够更好地帮助您。
嗨 James,我只用猫数据集做这个。我的意思是我想识别图像是否是猫的。但是每次运行时,即使图像不是猫,它也总是给出0。我该怎么办?
嗨 Samiun……您可能正在处理一个回归问题,并且实现了零预测误差。
或者,你可能正在处理分类问题并实现 100% 的准确率。
这很不寻常,原因有很多,包括:
你不小心在训练集上评估了模型性能。
你的保留数据集(训练集或验证集)太小或不具代表性。
你的代码中引入了一个错误,它正在做一些与你预期不同的事情。
你的预测问题很容易或微不足道,可能不需要机器学习。
最常见的原因是你的保留数据集太小或不代表更广泛的问题。
可以通过以下方法解决:
使用 k 折交叉验证来估计模型性能,而不是训练/测试拆分。
收集更多数据。
使用不同的数据拆分进行训练和测试,例如 50/50。
你好!
很棒的教程!我成功运行了AI,并且效果很好。然而,当图片看起来既像狗又像猫时,我的AI总是返回一个数字:0.6123894。请问谁能告诉我这是为什么?这是应该发生的事情吗?非常感谢您的提前帮助!
嗨 Eugene……不客气!我们建议您使用更多的训练数据和/或使用图像增强来提升性能。
https://machinelearning.org.cn/image-augmentation-deep-learning-keras/