生成对抗网络(GANs)是一种用于训练强大生成器模型的深度学习架构。
生成器模型能够生成新的、看起来可能来自现有样本分布的人工样本。
GANs由生成器和判别器模型组成。生成器负责从数据域生成新样本,而判别器负责分类样本是真实的还是伪造的(生成的)。重要的是,判别器模型的性能用于更新判别器自身的模型权重和生成器模型。这意味着生成器实际上从未见过来自数据域的样本,而是根据判别器性能的好坏进行调整。
这是一个理解和训练都比较复杂的模型。
为了更好地理解GAN模型及其训练方式,一种方法是为一项非常简单的任务从头开始开发一个模型。
为一项简单的任务从头开始开发一个简单的GAN,一维函数是一个很好的场景。这是因为真实样本和生成的样本都可以被绘制和可视化检查,以了解模型学习到了什么。简单的函数也不需要复杂的神经网络模型,这意味着在架构上使用的特定生成器和判别器模型很容易被理解。
在本教程中,我们将选择一个简单的一维函数,并使用Keras深度学习库从头开始开发和评估一个生成对抗网络。
完成本教程后,您将了解:
- 为简单的一维函数从头开始开发生成对抗网络的好处。
- 如何开发独立的判别器和生成器模型,以及一个复合模型,通过判别器的预测行为来训练生成器。
- 如何在真实样本的背景下主观评估生成的样本。
为你的项目启动,看看我的新书《使用Python进行生成对抗网络》,包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何从头开始使用Keras开发一维生成对抗网络
照片由土地管理局提供,部分权利保留。
教程概述
本教程分为六个部分;它们是:
- 选择一个一维函数
- 定义判别器模型
- 定义生成器模型
- 训练生成器模型
- 评估GAN的性能
- 训练GAN的完整示例
选择一个一维函数
第一步是选择一个要建模的一维函数。
形式为
|
1 |
y = f(x) |
其中 *x* 是输入值,*y* 是函数的输出值。
具体来说,我们想要一个易于理解和绘制的函数。这将有助于设定模型应该生成什么的预期,以及通过对生成的样本进行视觉检查来了解它们的质量。
我们将使用一个简单的 *x*² 函数;也就是说,函数将返回输入的平方。你可能还记得高中代数中的这个函数,它是 *u* 形函数。
我们可以在Python中这样定义这个函数
|
1 2 3 |
# simple function def calculate(x): return x * x |
我们可以将输入域定义为-0.5到0.5之间的实数值,并计算该线性范围内每个输入值的输出值,然后绘制结果以了解输入与输出的关系。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# demonstrate simple x^2 function from matplotlib import pyplot # simple function def calculate(x): return x * x # define inputs inputs = [-0.5, -0.4, -0.3, -0.2, -0.1, 0, 0.1, 0.2, 0.3, 0.4, 0.5] # calculate outputs outputs = [calculate(x) for x in inputs] # 绘制结果 pyplot.plot(inputs, outputs) pyplot.show() |
运行示例将计算每个输入值的输出值,并创建输入与输出值的图。
我们可以看到,远离0.0的值会导致更大的输出值,而接近零的值会导致更小的输出值,并且这种行为在零点附近是对称的。
这是X²一维函数著名的u形图。

X²函数输入与输出的图。
我们可以从该函数生成随机样本或点。
这可以通过生成-0.5到0.5之间的随机值并计算关联的输出来实现。多次重复此操作将得到该函数的样本点,例如“真实样本”。
使用散点图绘制这些样本将显示相同的u形图,尽管由各个随机样本组成。
完整的示例如下所示。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
首先,我们生成0到1之间的均匀随机值,然后将其移到-0.5到0.5的范围内。然后,我们计算每个随机生成输入值的输出值,并将数组组合成一个NumPy数组,其中有 *n* 行(100行)和两列。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# generate random samples from X^2 from numpy.random import rand from numpy import hstack from matplotlib import pyplot # generate random sample from x^2 def generate_samples(n=100): # generate random inputs in [-0.5, 0.5] X1 = rand(n) - 0.5 # generate outputs X^2 (quadratic) X2 = X1 * X1 # stack arrays X1 = X1.reshape(n, 1) X2 = X2.reshape(n, 1) return hstack((X1, X2)) # 生成样本 data = generate_samples() # plot samples pyplot.scatter(data[:, 0], data[:, 1]) pyplot.show() |
运行示例将生成100个随机输入及其计算出的输出,并以散点图绘制样本,显示熟悉的u形。

X²函数随机生成的输入与计算出的输出样本图。
我们可以使用此函数作为为判别器函数生成真实样本的起点。具体来说,一个样本由一个包含两个元素的向量组成,一个用于我们一维函数的输入,一个用于输出。
我们还可以想象生成器模型如何生成新样本,我们可以将其绘制并与X²函数的预期u形进行比较。具体来说,生成器将输出一个包含两个元素的向量:一个用于我们一维函数的输入,一个用于输出。
定义判别器模型
下一步是定义判别器模型。
该模型必须接受我们问题中的样本,例如一个包含两个元素的向量,并输出一个分类预测,以判断样本是真实的还是伪造的。
这是一个二元分类问题。
- 输入:包含两个实数值的样本。
- **输出**:二元分类,样本为真实的(或伪造的)可能性。
问题非常简单,这意味着我们不需要复杂的神经网络来对其进行建模。
判别器模型将有一个包含25个节点的隐藏层,我们将使用ReLU激活函数和一种称为He权重初始化的合适权重初始化方法。
输出层将有一个用于二元分类的节点,使用Sigmoid激活函数。
模型将最小化二元交叉熵损失函数,并且将使用随机梯度下降的Adam版本,因为它非常有效。
下面的`define_discriminator()`函数定义并返回判别器模型。该函数参数化了期望的输入数量,默认为两个。
|
1 2 3 4 5 6 7 8 |
# 定义独立的判别器模型 def define_discriminator(n_inputs=2): model = Sequential() model.add(Dense(25, activation='relu', kernel_initializer='he_uniform', input_dim=n_inputs)) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) return model |
我们可以使用此函数定义判别器模型并对其进行总结。完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 定义判别器模型 from keras.models import Sequential from keras.layers import Dense from keras.utils.vis_utils import plot_model # 定义独立的判别器模型 def define_discriminator(n_inputs=2): model = Sequential() model.add(Dense(25, activation='relu', kernel_initializer='he_uniform', input_dim=n_inputs)) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) return model # 定义判别器模型 model = define_discriminator() # 总结模型 model.summary() # 绘制模型 plot_model(model, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True) |
运行示例将定义判别器模型并对其进行总结。
|
1 2 3 4 5 6 7 8 9 10 11 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= dense_1 (Dense) (None, 25) 75 _________________________________________________________________ dense_2 (Dense) (None, 1) 26 ================================================================= Total params: 101 Trainable params: 101 不可训练参数: 0 _________________________________________________________________ |
还将创建一个模型图,我们可以看到模型接受两个输入并预测一个输出。
注意:创建此图假定已安装pydot和graphviz库。如果存在问题,可以注释掉`plot_model`函数的导入语句和`plot_model()`函数的调用。
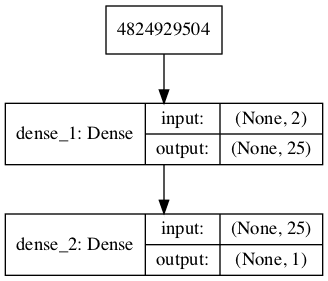
GAN中判别器模型的图。
我们可以现在开始用类标签为1的真实样本和类标签为0的随机生成样本来训练这个模型。
没有必要这样做,但我们将开发的元素将在以后有用,它有助于我们看到判别器只是一个普通的神经网络模型。
首先,我们可以更新预测部分中的`generate_samples()`函数,并将其命名为`generate_real_samples()`,使其还能返回真实样本的输出类标签,特别是,一个包含1值的数组,其中class=1表示真实。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# generate n real samples with class labels def generate_real_samples(n): # generate inputs in [-0.5, 0.5] X1 = rand(n) - 0.5 # generate outputs X^2 X2 = X1 * X1 # stack arrays X1 = X1.reshape(n, 1) X2 = X2.reshape(n, 1) X = hstack((X1, X2)) # 生成类别标签 y = ones((n, 1)) return X, y |
接下来,我们可以创建此函数的副本以创建虚假示例。
在这种情况下,我们将为样本的两个元素生成-1到1范围内的随机值。所有这些示例的输出类标签为0。
此函数将作为我们的虚假生成器模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 生成带有类别标签的 n 个假样本 def generate_fake_samples(n): # generate inputs in [-1, 1] X1 = -1 + rand(n) * 2 # generate outputs in [-1, 1] X2 = -1 + rand(n) * 2 # stack arrays X1 = X1.reshape(n, 1) X2 = X2.reshape(n, 1) X = hstack((X1, X2)) # 生成类别标签 y = zeros((n, 1)) return X, y |
接下来,我们需要一个函数来训练和评估判别器模型。
这可以通过手动枚举训练周期来实现,并在每个周期生成半批次的真实示例和半批次的虚假示例,并分别更新模型。`train()`函数也可以使用,但在这个例子中,我们将直接使用`train_on_batch()`函数。
然后,可以在生成的样本上评估模型,我们可以报告在真实和虚假样本上的分类准确率。
下面的`train_discriminator()`函数实现了这一点,训练模型1000个批次,每个批次使用128个样本(64个虚假和64个真实)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 训练判别器模型 def train_discriminator(model, n_epochs=1000, n_batch=128): half_batch = int(n_batch / 2) # run epochs manually for i in range(n_epochs): # generate real examples X_real, y_real = generate_real_samples(half_batch) # update model model.train_on_batch(X_real, y_real) # generate fake examples X_fake, y_fake = generate_fake_samples(half_batch) # update model model.train_on_batch(X_fake, y_fake) # 评估模型 _, acc_real = model.evaluate(X_real, y_real, verbose=0) _, acc_fake = model.evaluate(X_fake, y_fake, verbose=0) print(i, acc_real, acc_fake) |
我们可以将所有这些内容联系起来,并使用真实和虚假样本训练判别器模型。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
# define and fit a discriminator model from numpy import zeros from numpy import ones from numpy import hstack from numpy.random import rand from numpy.random import randn from keras.models import Sequential from keras.layers import Dense # 定义独立的判别器模型 def define_discriminator(n_inputs=2): model = Sequential() model.add(Dense(25, activation='relu', kernel_initializer='he_uniform', input_dim=n_inputs)) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) return model # generate n real samples with class labels def generate_real_samples(n): # generate inputs in [-0.5, 0.5] X1 = rand(n) - 0.5 # generate outputs X^2 X2 = X1 * X1 # stack arrays X1 = X1.reshape(n, 1) X2 = X2.reshape(n, 1) X = hstack((X1, X2)) # 生成类别标签 y = ones((n, 1)) 返回 X, y # 生成带有类别标签的 n 个假样本 def generate_fake_samples(n): # generate inputs in [-1, 1] X1 = -1 + rand(n) * 2 # generate outputs in [-1, 1] X2 = -1 + rand(n) * 2 # stack arrays X1 = X1.reshape(n, 1) X2 = X2.reshape(n, 1) X = hstack((X1, X2)) # 生成类别标签 y = zeros((n, 1)) 返回 X, y # 训练判别器模型 def train_discriminator(model, n_epochs=1000, n_batch=128): half_batch = int(n_batch / 2) # run epochs manually for i in range(n_epochs): # generate real examples X_real, y_real = generate_real_samples(half_batch) # update model model.train_on_batch(X_real, y_real) # generate fake examples X_fake, y_fake = generate_fake_samples(half_batch) # update model model.train_on_batch(X_fake, y_fake) # 评估模型 _, acc_real = model.evaluate(X_real, y_real, verbose=0) _, acc_fake = model.evaluate(X_fake, y_fake, verbose=0) print(i, acc_real, acc_fake) # 定义判别器模型 model = define_discriminator() # 拟合模型 train_discriminator(model) |
运行示例将生成真实和虚假样本并更新模型,然后在同一样本上评估模型并打印分类准确率。
注意:鉴于算法或评估程序的随机性,或数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,模型能够快速学会以完美的准确率正确识别真实样本,并且在识别虚假样本方面表现良好,准确率在80%到90%之间。
|
1 2 3 4 5 6 |
... 995 1.0 0.875 996 1.0 0.921875 997 1.0 0.859375 998 1.0 0.9375 999 1.0 0.8125 |
训练判别器模型很简单。目标是训练一个生成器模型,而不是判别器模型,而这才是GAN真正复杂的地方。
定义生成器模型
下一步是定义生成器模型。
生成器模型以潜在空间中的一个点作为输入,并生成一个新样本,例如一个包含我们函数输入和输出元素的向量,例如x和x²。
潜在变量是一个隐藏的或未观察到的变量,而潜在空间是这些变量的多维向量空间。我们可以为我们的问题定义潜在空间的尺寸以及潜在空间中变量的形状或分布。
这是因为潜在空间在生成器模型开始在学习过程中为其点分配意义之前是没有意义的。训练完成后,潜在空间中的点将对应于输出空间中的点,例如在生成的样本空间中。
我们将定义一个五维的小型潜在空间,并使用GAN文献中的标准方法,即为潜在空间中的每个变量使用高斯分布。我们将通过从标准高斯分布(即均值为零,标准差为一)中抽取随机数来生成新输入。
- 输入:潜在空间中的点,例如,高斯随机数的五元素向量。
- 输出:代表我们函数(x和x²)生成样本的二维向量。
生成器模型将与判别器模型一样小。
它将有一个包含五个节点的单个隐藏层,并将使用ReLU激活函数和He权重初始化。输出层将有两个节点,对应于生成向量中的两个元素,并将使用线性激活函数。
使用线性激活函数是因为我们知道我们希望生成器输出一个实值向量,其范围对于第一个元素是[-0.5, 0.5],对于第二个元素大约是[0.0, 0.25]。
模型没有被编译。原因是生成器模型不是直接拟合的。
下面的`define_generator()`函数定义并返回生成器模型。
潜在维度的尺寸被参数化,以防我们以后想对其进行修改,并且模型的输出形状也被参数化,与定义判别器模型的函数相匹配。
|
1 2 3 4 5 6 |
# 定义独立的生成器模型 def define_generator(latent_dim, n_outputs=2): model = Sequential() model.add(Dense(15, activation='relu', kernel_initializer='he_uniform', input_dim=latent_dim)) model.add(Dense(n_outputs, activation='linear')) return model |
我们可以总结模型以更好地理解输入和输出形状。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 定义生成器模型 from keras.models import Sequential from keras.layers import Dense from keras.utils.vis_utils import plot_model # 定义独立的生成器模型 def define_generator(latent_dim, n_outputs=2): model = Sequential() model.add(Dense(15, activation='relu', kernel_initializer='he_uniform', input_dim=latent_dim)) model.add(Dense(n_outputs, activation='linear')) return model # 定义判别器模型 model = define_generator(5) # 总结模型 model.summary() # 绘制模型 plot_model(model, to_file='generator_plot.png', show_shapes=True, show_layer_names=True) |
运行示例会定义生成器模型并进行总结。
|
1 2 3 4 5 6 7 8 9 10 11 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= dense_1 (Dense) (None, 15) 90 _________________________________________________________________ dense_2 (Dense) (None, 2) 32 ================================================================= Total params: 122 Trainable params: 122 不可训练参数: 0 _________________________________________________________________ |
还会创建一个模型的图,我们可以看到该模型需要一个五维的潜在空间点作为输入,并会预测一个二维向量作为输出。
注意:创建此图假定已安装pydot和graphviz库。如果存在问题,可以注释掉`plot_model`函数的导入语句和`plot_model()`函数的调用。
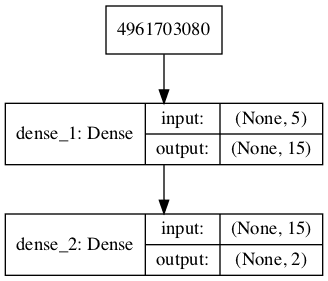
GAN 中生成器模型的图
我们可以看到,模型以潜在空间中一个随机的五维向量作为输入,并输出一个二维向量作为我们的一维函数的输出。
目前该模型还做不了太多事情。尽管如此,我们可以演示如何使用它来生成样本。这不是必需的,但同样,其中一些元素将来可能会有用。
第一步是在潜在空间中生成新的点。我们可以通过调用 randn() NumPy 函数 来实现,该函数用于生成从标准高斯分布中抽取的 随机数 数组。
然后可以将随机数数组重塑为样本:即 n 行,每行包含五个元素。下面的 `generate_latent_points()` 函数实现了这一点,并在潜在空间中生成所需数量的点,这些点可用作生成器模型的输入。
|
1 2 3 4 5 6 7 |
# 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n): # 在潜在空间中生成点 x_input = randn(latent_dim * n) # 重塑为网络的输入批次 x_input = x_input.reshape(n, latent_dim) return x_input |
接下来,我们可以使用生成的点作为生成器模型的输入来生成新样本,然后绘制这些样本。
下面的 `generate_fake_samples()` 函数实现了这一点,它将定义的生成器和潜在空间的大小作为参数传递,以及模型需要生成的点数。
|
1 2 3 4 5 6 7 8 9 |
# use the generator to generate n fake examples and plot the results def generate_fake_samples(generator, latent_dim, n): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n) # 预测输出 X = generator.predict(x_input) # plot the results pyplot.scatter(X[:, 0], X[:, 1]) pyplot.show() |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# define and use the generator model from numpy.random import randn from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot # 定义独立的生成器模型 def define_generator(latent_dim, n_outputs=2): model = Sequential() model.add(Dense(15, activation='relu', kernel_initializer='he_uniform', input_dim=latent_dim)) model.add(Dense(n_outputs, activation='linear')) return model # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n): # 在潜在空间中生成点 x_input = randn(latent_dim * n) # 重塑为网络的输入批次 x_input = x_input.reshape(n, latent_dim) return x_input # use the generator to generate n fake examples and plot the results def generate_fake_samples(generator, latent_dim, n): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n) # 预测输出 X = generator.predict(x_input) # plot the results pyplot.scatter(X[:, 0], X[:, 1]) pyplot.show() # 潜在空间的大小 latent_dim = 5 # 定义判别器模型 model = define_generator(latent_dim) # generate and plot generated samples generate_fake_samples(model, latent_dim, 100) |
运行示例会从潜在空间生成 100 个随机点,将其作为生成器的输入,并从我们的一维函数域生成 100 个假样本。
由于生成器尚未训练,因此生成的点都是无意义的,正如我们所料,但我们可以想象,随着模型的训练,这些点将逐渐开始类似于目标函数及其 U 形。
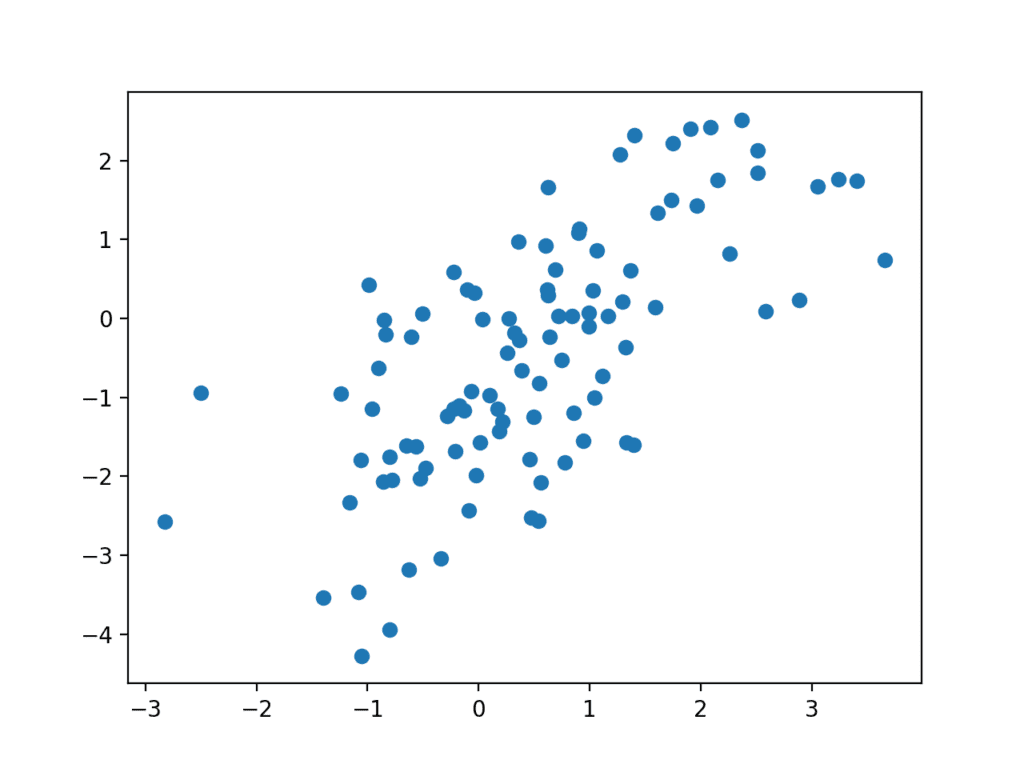
生成器模型预测的假样本散点图。
我们现在已经了解了如何定义和使用生成器模型。我们将需要以这种方式使用生成器模型来创建供判别器分类的样本。
我们还没有看到生成器模型是如何训练的;这将在下一步进行。
训练生成器模型
生成器模型中的权重根据判别器模型的性能进行更新。
当判别器善于检测假样本时,生成器更新更多;当判别器模型在检测假样本时相对较差或感到困惑时,生成器模型更新较少。
这定义了这两个模型之间的零和或对抗关系。
使用 Keras API 实现此目的的方法可能有很多,但也许最简单的方法是创建一个新的模型,该模型包含或封装了生成器和判别器模型。
具体来说,可以定义一个新的 GAN 模型,将生成器和判别器堆叠起来,使生成器接收潜在空间中的随机点作为输入,生成样本后直接输入判别器模型进行分类,然后可以使用这个更大的模型的输出来更新生成器的模型权重。
需要明确的是,我们不是指一个新的第三个模型,而是一个逻辑上的第三个模型,它使用了来自独立生成器和判别器模型的已定义层和权重。
只有判别器负责区分真实和伪造的样本;因此,判别器模型可以在每个样本的示例上以独立的方式进行训练。
生成器模型仅关注判别器在伪造样本上的性能。因此,我们将把判别器中所有层在作为 GAN 模型的一部分时标记为不可训练,这样它们就不会被更新和过度拟合到伪造样本上。
当通过这个封装的 GAN 模型训练生成器时,还有一个重要的改变。我们希望判别器认为生成器输出的样本是真实的,而不是伪造的。因此,当生成器作为 GAN 模型的一部分进行训练时,我们将生成的样本标记为真实(类别 1)。
我们可以想象,判别器随后会将生成的样本分类为非真实(类别 0)或真实的可能性较低(0.3 或 0.5)。用于更新模型权重的反向传播过程将认为这是一个很大的误差,并将更新模型权重(即仅更新生成器中的权重)来纠正这个误差,从而使生成器能够更好地生成逼真的伪造样本。
让我们具体化。
- 输入:潜在空间中的点,例如,高斯随机数的五元素向量。
- **输出**:二元分类,样本为真实的(或伪造的)可能性。
下面的 `define_gan()` 函数以已定义的生成器和判别器模型作为参数,并创建了封装这两个模型的新逻辑第三个模型。判别器中的权重被标记为不可训练,这仅影响 GAN 模型看到的权重,而不影响独立的判别器模型。
GAN 模型随后使用与判别器相同的二元交叉熵损失函数以及高效的 Adam 随机梯度下降版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(generator, discriminator): # 使判别器中的权重不可训练 discriminator.trainable = False # 连接它们 model = Sequential() # 添加生成器 model.add(generator) # 添加判别器 model.add(discriminator) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam') return model |
使判别器不可训练是 Keras API 中的一个巧妙技巧。
`trainable` 属性会影响模型在编译时的行为。判别器模型是用可训练层编译的,因此当通过调用 `train_on_batch()` 更新独立模型时,这些层中的模型权重将被更新。
判别器模型被标记为不可训练,添加到 GAN 模型中,并进行了编译。在此模型中,判别器模型的模型权重是不可训练的,在通过调用 `train_on_batch()` 更新 GAN 模型时不会改变。
Keras API文档中对此行为进行了描述
下面列出了创建判别器、生成器和复合模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# 演示在GAN中创建三个模型 from keras.models import Sequential from keras.layers import Dense from keras.utils.vis_utils import plot_model # 定义独立的判别器模型 def define_discriminator(n_inputs=2): model = Sequential() model.add(Dense(25, activation='relu', kernel_initializer='he_uniform', input_dim=n_inputs)) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) return model # 定义独立的生成器模型 def define_generator(latent_dim, n_outputs=2): model = Sequential() model.add(Dense(15, activation='relu', kernel_initializer='he_uniform', input_dim=latent_dim)) model.add(Dense(n_outputs, activation='linear')) return model # 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(generator, discriminator): # 使判别器中的权重不可训练 discriminator.trainable = False # 连接它们 model = Sequential() # 添加生成器 model.add(generator) # 添加判别器 model.add(discriminator) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam') return model # 潜在空间的大小 latent_dim = 5 # 创建判别器 discriminator = define_discriminator() # 创建生成器 generator = define_generator(latent_dim) # 创建GAN gan_model = define_gan(generator, discriminator) # 总结GAN模型 gan_model.summary() # 绘制GAN模型 plot_model(gan_model, to_file='gan_plot.png', show_shapes=True, show_layer_names=True) |
运行示例后,首先会生成复合模型的摘要。
|
1 2 3 4 5 6 7 8 9 10 11 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= sequential_2 (Sequential) (None, 2) 122 _________________________________________________________________ sequential_1 (Sequential) (None, 1) 101 ================================================================= Total params: 223 Trainable params: 122 Non-trainable params: 101 _________________________________________________________________ |
还会创建一个模型的图,我们可以看到该模型需要潜在空间中的一个五维点作为输入,并会预测一个单一的输出分类标签。
注意,创建此图假定已安装 pydot 和 graphviz 库。如果存在问题,可以注释掉 `plot_model` 函数的导入语句和 `plot_model()` 函数的调用。
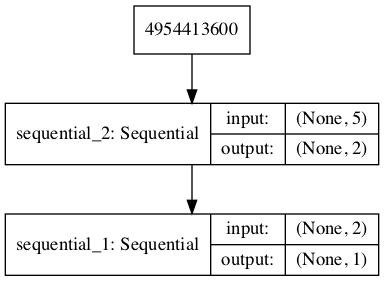
GAN 中复合生成器和判别器模型的图
训练复合模型涉及通过上一节的 `generate_latent_points()` 函数生成一批潜在空间点,以及类别标签 1,并调用 `train_on_batch()` 函数。
下面的 `train_gan()` 函数演示了这一点,尽管它相当无趣,因为每个 epoch 只有生成器会被更新,而判别器则保留默认的模型权重。
|
1 2 3 4 5 6 7 8 9 10 |
# 训练复合模型 def train_gan(gan_model, latent_dim, n_epochs=10000, n_batch=128): # 手动枚举 epoch for i in range(n_epochs): # 准备潜在空间中的点作为生成器的输入 x_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过判别器的误差更新生成器 gan_model.train_on_batch(x_gan, y_gan) |
相反,我们需要首先使用真实和伪样本更新判别器模型,然后通过复合模型更新生成器。
这需要结合判别器部分定义的 `train_discriminator()` 函数和上面定义的 `train_gan()` 函数的元素。它还要求 `generate_fake_samples()` 函数使用生成器模型来生成假样本,而不是生成随机数。
用于更新判别器模型和生成器(通过复合模型)的完整训练函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 训练生成器和判别器 def train(g_model, d_model, gan_model, latent_dim, n_epochs=10000, n_batch=128): # determine half the size of one batch, for updating the discriminator half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_epochs): # 准备真实样本 x_real, y_real = generate_real_samples(half_batch) # 准备伪示例 x_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # update discriminator d_model.train_on_batch(x_real, y_real) d_model.train_on_batch(x_fake, y_fake) # 准备潜在空间中的点作为生成器的输入 x_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过判别器的误差更新生成器 gan_model.train_on_batch(x_gan, y_gan) |
我们几乎准备好了为一维函数开发 GAN 的所有要素。
剩余的一个方面是模型的评估。
评估GAN的性能
通常,没有客观的方法来评估GAN模型的性能。
在这种特定情况下,由于我们知道真实的底层输入域和目标函数,并且可以计算客观误差度量,因此我们可以为生成的样本设计一个客观度量。
尽管如此,我们不会在此教程中计算此客观误差得分。相反,我们将使用大多数 GAN 应用中使用的感性方法。具体来说,我们将使用生成器生成新样本,并相对于域中的真实样本来检查它们。
首先,我们可以使用上面判别器部分开发的 `generate_real_samples()` 函数来生成真实示例。绘制这些示例的散点图将创建我们目标函数熟悉的 U 形。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# generate n real samples with class labels def generate_real_samples(n): # generate inputs in [-0.5, 0.5] X1 = rand(n) - 0.5 # generate outputs X^2 X2 = X1 * X1 # stack arrays X1 = X1.reshape(n, 1) X2 = X2.reshape(n, 1) X = hstack((X1, X2)) # 生成类别标签 y = ones((n, 1)) return X, y |
接下来,我们可以使用生成器模型生成相同数量的假样本。
这需要首先通过上面生成器部分开发的 `generate_latent_points()` 函数生成相同数量的点在潜在空间中。然后可以将它们传递给生成器模型,并用于生成也可以绘制在同一散点图上的样本。
|
1 2 3 4 5 6 7 |
# 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n): # 在潜在空间中生成点 x_input = randn(latent_dim * n) # 重塑为网络的输入批次 x_input = x_input.reshape(n, latent_dim) return x_input |
下面的 `generate_fake_samples()` 函数生成这些假样本以及与之关联的类别标签 0,这在以后会很有用。
|
1 2 3 4 5 6 7 8 9 |
# 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(generator, latent_dim, n): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n) # 预测输出 X = generator.predict(x_input) # 创建类别标签 y = zeros((n, 1)) return X, y |
将两个样本绘制在同一张图上,可以进行直接比较,以确定是否覆盖了相同的输入和输出域,以及是否已适当地捕获了目标函数的预期形状,至少在感性上是如此。
下面的 `summarize_performance()` 函数可以在训练期间随时调用,以创建真实点和生成点的散点图,从而了解生成器模型的当前能力。
|
1 2 3 4 5 6 7 8 9 10 |
# plot real and fake points def summarize_performance(generator, latent_dim, n=100): # 准备真实样本 x_real, y_real = generate_real_samples(n) # 准备伪示例 x_fake, y_fake = generate_fake_samples(generator, latent_dim, n) # scatter plot real and fake data points pyplot.scatter(x_real[:, 0], x_real[:, 1], color='red') pyplot.scatter(x_fake[:, 0], x_fake[:, 1], color='blue') pyplot.show() |
同时,我们也可能对判别器模型的性能感兴趣。
具体来说,我们想知道判别器模型在正确识别真实和伪造样本方面做得有多好。一个好的生成器模型应该会让判别器模型感到困惑,从而在真实和伪造样本上的分类准确率接近 50%。
我们可以更新 `summarize_performance()` 函数,使其还可以接受判别器和当前 epoch 号作为参数,并报告对真实和伪造样本的准确率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# evaluate the discriminator and plot real and fake points def summarize_performance(epoch, generator, discriminator, latent_dim, n=100): # 准备真实样本 x_real, y_real = generate_real_samples(n) # 评估判别器在真实示例上的表现 _, acc_real = discriminator.evaluate(x_real, y_real, verbose=0) # 准备伪示例 x_fake, y_fake = generate_fake_samples(generator, latent_dim, n) # 评估判别器在伪示例上的表现 _, acc_fake = discriminator.evaluate(x_fake, y_fake, verbose=0) # 总结判别器性能 print(epoch, acc_real, acc_fake) # scatter plot real and fake data points pyplot.scatter(x_real[:, 0], x_real[:, 1], color='red') pyplot.scatter(x_fake[:, 0], x_fake[:, 1], color='blue') pyplot.show() |
这个函数可以定期在训练期间被调用。
例如,如果我们选择训练模型 10,000 次迭代,那么每 2,000 次迭代检查一次模型性能会很有趣。
我们可以通过 `n_eval` 参数来设置检查的频率,并在 `train()` 函数中在适当的迭代次数后调用 `summarize_performance()` 函数来实现这一点。
更新后的 `train()` 函数如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 训练生成器和判别器 def train(g_model, d_model, gan_model, latent_dim, n_epochs=10000, n_batch=128, n_eval=2000): # determine half the size of one batch, for updating the discriminator half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_epochs): # 准备真实样本 x_real, y_real = generate_real_samples(half_batch) # 准备伪示例 x_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # update discriminator d_model.train_on_batch(x_real, y_real) d_model.train_on_batch(x_fake, y_fake) # 准备潜在空间中的点作为生成器的输入 x_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过判别器的误差更新生成器 gan_model.train_on_batch(x_gan, y_gan) # evaluate the model every n_eval epochs if (i+1) % n_eval == 0: summarize_performance(i, g_model, d_model, latent_dim) |
训练GAN的完整示例
我们现在已经拥有了在所选一维函数上训练和评估 GAN 所需的所有内容。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 |
# train a generative adversarial network on a one-dimensional function from numpy import hstack from numpy import zeros from numpy import ones from numpy.random import rand from numpy.random import randn from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot # 定义独立的判别器模型 def define_discriminator(n_inputs=2): model = Sequential() model.add(Dense(25, activation='relu', kernel_initializer='he_uniform', input_dim=n_inputs)) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) return model # 定义独立的生成器模型 def define_generator(latent_dim, n_outputs=2): model = Sequential() model.add(Dense(15, activation='relu', kernel_initializer='he_uniform', input_dim=latent_dim)) model.add(Dense(n_outputs, activation='linear')) return model # 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(generator, discriminator): # 使判别器中的权重不可训练 discriminator.trainable = False # 连接它们 model = Sequential() # 添加生成器 model.add(generator) # 添加判别器 model.add(discriminator) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam') return model # generate n real samples with class labels def generate_real_samples(n): # generate inputs in [-0.5, 0.5] X1 = rand(n) - 0.5 # generate outputs X^2 X2 = X1 * X1 # stack arrays X1 = X1.reshape(n, 1) X2 = X2.reshape(n, 1) X = hstack((X1, X2)) # 生成类别标签 y = ones((n, 1)) 返回 X, y # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n): # 在潜在空间中生成点 x_input = randn(latent_dim * n) # 重塑为网络的输入批次 x_input = x_input.reshape(n, latent_dim) return x_input # 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(generator, latent_dim, n): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n) # 预测输出 X = generator.predict(x_input) # 创建类别标签 y = zeros((n, 1)) 返回 X, y # evaluate the discriminator and plot real and fake points def summarize_performance(epoch, generator, discriminator, latent_dim, n=100): # 准备真实样本 x_real, y_real = generate_real_samples(n) # 评估判别器在真实示例上的表现 _, acc_real = discriminator.evaluate(x_real, y_real, verbose=0) # 准备伪示例 x_fake, y_fake = generate_fake_samples(generator, latent_dim, n) # 评估判别器在伪示例上的表现 _, acc_fake = discriminator.evaluate(x_fake, y_fake, verbose=0) # 总结判别器性能 print(epoch, acc_real, acc_fake) # scatter plot real and fake data points pyplot.scatter(x_real[:, 0], x_real[:, 1], color='red') pyplot.scatter(x_fake[:, 0], x_fake[:, 1], color='blue') pyplot.show() # 训练生成器和判别器 def train(g_model, d_model, gan_model, latent_dim, n_epochs=10000, n_batch=128, n_eval=2000): # determine half the size of one batch, for updating the discriminator half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_epochs): # 准备真实样本 x_real, y_real = generate_real_samples(half_batch) # 准备伪示例 x_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # update discriminator d_model.train_on_batch(x_real, y_real) d_model.train_on_batch(x_fake, y_fake) # 准备潜在空间中的点作为生成器的输入 x_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过判别器的误差更新生成器 gan_model.train_on_batch(x_gan, y_gan) # evaluate the model every n_eval epochs if (i+1) % n_eval == 0: summarize_performance(i, g_model, d_model, latent_dim) # 潜在空间的大小 latent_dim = 5 # 创建判别器 discriminator = define_discriminator() # 创建生成器 generator = define_generator(latent_dim) # 创建GAN gan_model = define_gan(generator, discriminator) # 训练模型 train(generator, discriminator, gan_model, latent_dim) |
运行示例每 2,000 次训练迭代(批次)报告模型性能,并创建一个图。
注意:鉴于算法或评估程序的随机性,或数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
我们可以看到训练过程相对不稳定。第一列报告迭代次数,第二列报告判别器对真实样本的分类准确率,第三列报告判别器对生成(伪造)样本的分类准确率。
在这种情况下,我们可以看到判别器在真实样本上的困惑度相对较高,而识别伪造样本的性能则有所波动。
|
1 2 3 4 5 |
1999 0.45 1.0 3999 0.45 0.91 5999 0.86 0.16 7999 0.6 0.41 9999 0.15 0.93 |
为了简洁起见,我将省略此处提供的五个创建的图;相反,我们只看两个。
第一个图是在 2,000 次迭代后创建的,显示真实(红色)与伪造(蓝色)样本。模型在初始阶段表现不佳,生成的点集中在正输入域,尽管具有正确的函数关系。
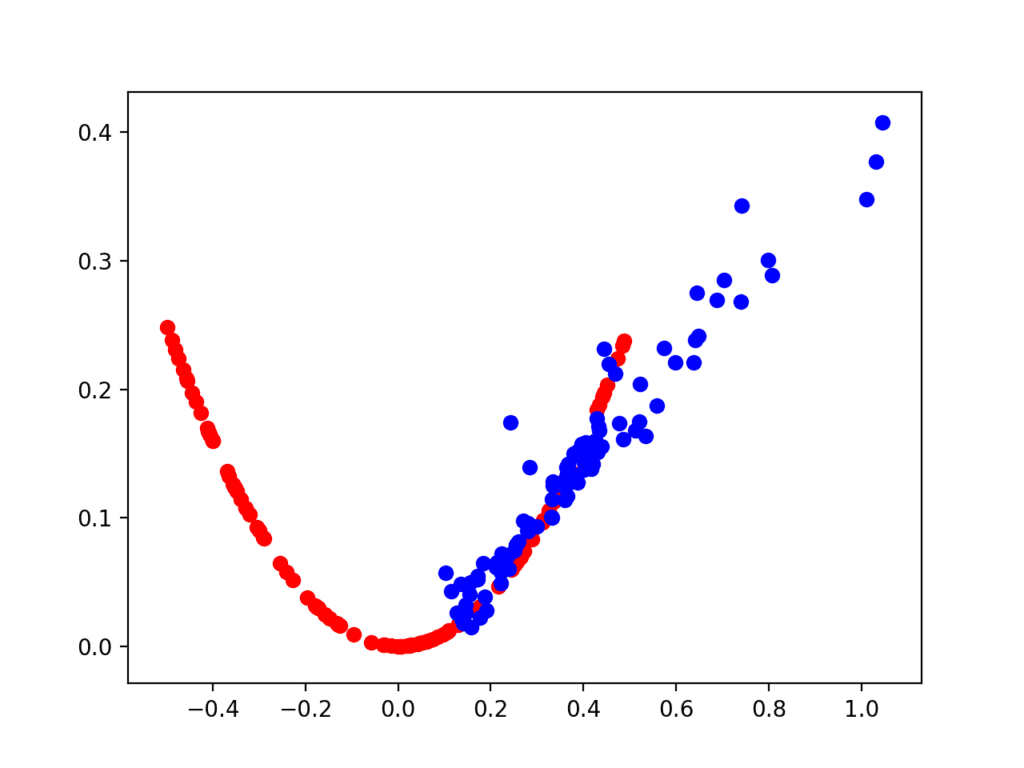
目标函数在 2,000 次迭代后的真实和生成示例散点图。
第二个图显示了 10,000 次迭代后的真实(红色)与伪造(蓝色)样本。
在这里,我们可以看到生成器模型在生成逼真样本方面做得相当不错,输入值在 [-0.5 和 0.5] 之间,输出值显示 X^2 关系,或接近它。
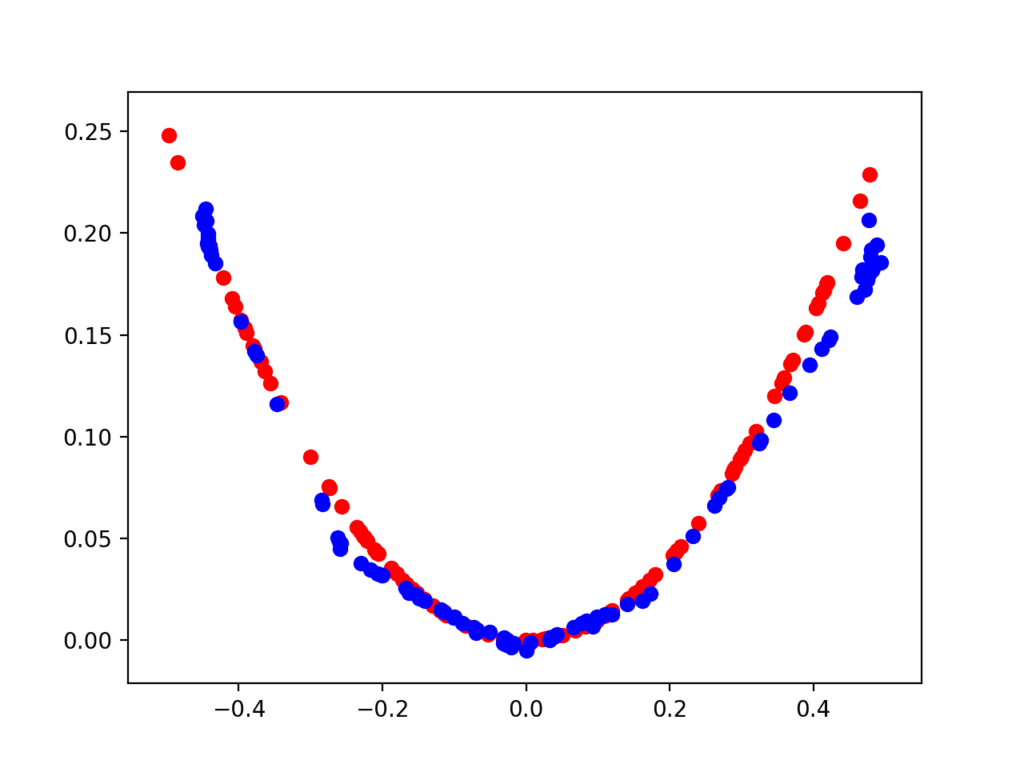
目标函数在 10,000 次迭代后的真实和生成示例散点图。
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 模型架构。尝试判别器和生成器的替代模型架构,例如更多的节点、层,以及 Leaky ReLU 等替代激活函数。
- 数据缩放。尝试双曲正切(tanh)等替代激活函数以及任何所需的训练数据缩放。
- 替代目标函数。尝试一个替代的目标函数,例如简单的正弦波、高斯分布、不同的二次函数,甚至是多模态多项式函数。
如果您探索了这些扩展中的任何一个,我很想知道。
请在下面的评论中发布您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
- Keras API
- 我如何“冻结”Keras层?
- MatplotLib API
- numpy.random.rand API
- numpy.random.randn API
- numpy.zeros API
- numpy.ones API
- numpy.hstack API
总结
在本教程中,您学习了如何从头开始为一维函数开发生成对抗网络。
具体来说,你学到了:
- 为简单的一维函数从头开始开发生成对抗网络的好处。
- 如何开发独立的判别器和生成器模型,以及一个复合模型,通过判别器的预测行为来训练生成器。
- 如何在真实样本的背景下主观评估生成的样本。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...
 From Scratch")
 in Keras")




Fantastic
谢谢!
Can you give some example using 2D convolution layers.
Yes, I have many examples scheduled.
I would be very interested in these examples too. Great post Jason, many thanks
There are many, a good place to start is here
https://machinelearning.org.cn/how-to-develop-a-generative-adversarial-network-for-an-mnist-handwritten-digits-from-scratch-in-keras/
亲爱的 Jason,
great tutorial as always! may i know if there would be any tuorial of using gan to generate time series data? I am really looking forward to that 🙂
此致,
fan
I believe there are papers on the topic, I have not written a tutorial on the topic yet.
Thank you so much, I finally understood the magic behind GANs today. I’ve tried to understand that completely a few times in the past and have failed.
谢谢,很高兴它帮到了你!
Great post. Thanks Jason.
Naive question, how do you the trained model to generate more fake data? Or I am missing something 🙂
很好的问题。
Once the generator model is fit, you can call it all day long with new points from the latent space to generate new output points in the target domain.
嗨 Jason
Thanks for this excellent post.
Are you planning to release GAN about pictures?
Yes, I have many great examples coming.
The first round with the descriminator you have actual real/fake criteria, namely f(x)==x^2. So sometimes the fake data will actually fall on this line. Is this an issue? What about the domain/range of the Generator, is there anything to keep it from narrowing it’s domain/range?
我很快地读完了这篇文章,不久的将来我会更仔细地阅读。谢谢,这是一篇很棒的文章。
我不确定我是否跟上了Matt的思路,抱歉。您能详细说明一下吗?
第一个问题是关于一个罕见的发生情况,但是当您随机生成的数据与真实数据完全相同时,会怎么样?例如,x=0.2 且 y=0.04。
第二个问题是,生成器是否可以学习只为有限范围的 x E [0,0.5] 创建输出,而从不生成负数 x?
随机生成真实观测值非常罕见。例如,随机生成像素并得到一张人脸?不可能。
我不明白这有什么关系,您有什么特别的想法吗?
当然,我们对涉及的模型有完全的控制权。在训练期间采样窄带,然后在推理期间采样宽带以获得更多变化(在图像中)是很常见的。
理论上,这种可能性存在,实际上是零。
你好,杰森,
您写道:“生成器模型将像判别器模型一样小。它将有一个具有五个节点的单个隐藏层”
但您似乎定义了一个拥有15个节点的模型
model.add(Dense(15, activation=’relu’, kernel_initializer=’he_uniform’, input_dim=latent_dim))
latent_dim 参数没有被使用
我是否弄错了?
祝好
是的,一个层,15个节点,以及“latent_dim”定义了输入形状。
你好 Jason
我弄错了,抱歉
祝好
不客气。
先生,请,我很困惑,生成器中的反向传播是如何完成的?看生成器,它输出一个向量,然后将该向量输入到判别器进行预测,但判别器输出一个标量值,那么我们如何更新生成器的权重呢?
好问题,这可能会有帮助
https://machinelearning.org.cn/how-to-code-the-generative-adversarial-network-training-algorithm-and-loss-functions/
谢谢Jason。非常精彩。
你好,Jason
我尝试为判别器添加更多隐藏层并使用LeakyReLu激活(见下文)
结果似乎更稳定一些
祝好
干得好!
你好,Jason
我用这种更密集架构的一些结果示例
1999 0.9 0.9
3999 0.93 0.73
5999 0.8 0.98
7999 0.83 0.98
9999 0.82 0.97
感谢分享,Minel!
非常感谢您这篇精彩的文章
请您能否进一步说明一下为什么您选择使用维度为5的潜在空间。
如果使用10、20、50甚至100而不是5,会有什么影响?
这是任意选择的,并非最优。
您可以尝试不同的尺寸。
你好,Jason
非常感谢您这篇文章,我想将GAN用于图像着色。
您能否告诉我,有哪些重要的文章可能有助于我入门?
我没有关于这个主题的教程,但我希望将来能涵盖它。
你好,Jason
为什么我在训练判别器时出现了错误?错误发生在 model.train_on_batch(X_real, y_real)。它显示 InternalError: Failed to create session。
该错误表明您的开发环境可能存在问题。
也许可以尝试重新安装tensorflow?
*trainable* 属性会影响模型在编译时的状态。**判别器模型**是使用可训练层编译的,因此在通过调用*train_on_batch()*更新独立模型时,这些层的模型权重将被更新。
判别器应该被替换为生成器,对吗?
不,我认为它是正确陈述的。
判别器中的权重是可训练的,而在判别器是复合模型的一部分时,它们是不可训练的。
非常感谢。我明白了。
不客气。
做得真好。
您介意我将您的部分代码用于我的 YouTube 视频吗?
我目前正在学习 GAN,制作视频有助于我
巩固我学到的知识,并迫使我查找我不理解的内容。您的教程非常有帮助。
我将提供您的链接,并让大家知道您的网站。
非常感谢您的博客。
我宁愿您不要。
谢谢 Jason,
为什么您没有像对判别器那样编译生成器?
生成器模型可以在不编译的情况下进行预测吗?
没有必要。生成器不是直接拟合的。
我想知道当我们像您在 define_gan 中那样将两个模型聚合到一个模型中时,模型是什么样的?
您说的“是什么样的”是什么意思?
您可以使用 summary() 或 plot_model()。
嗨,Jason,
我是您教程的忠实粉丝!
不确定您是否已在问答中说明,但如何从最终的生成模型生成更多数据?
我想我明白了。
如果正确,请告诉我。
训练后,我有一个
generator模型已准备就绪。n=100
x,_=generate_fake_samples(generator, latent_dim, n)
看起来不错。
谢谢!
您可以保存生成器,然后使用来自潜在空间的点调用 model.predict() 来生成新示例。
我提供了许多示例,或许可以从这里开始
https://machinelearning.org.cn/start-here/#gans
Jason您好,感谢您这篇简单、清晰且精彩的文章。我一直在寻找如何使用GAN来建模数值数据,而这篇文章真的帮助了我。我将这里的实现应用于我的问题数据集并使其正常工作,尽管我没有得到预期的结果。您可以在这个Google Colab Notebook中看到实现
https://colab.research.google.com/drive/1erOPC6w9szqVDX9oU6gJfE88N1y1Tfwf
我的数据集非常稀疏,只有约34个数据点来自实验室测试。我的目标是使用GAN来合成更多符合该实验室测试数据分布的数据点。我在训练过程中注意到,有时在某个epoch中,准确率会达到0.5左右的平衡点,但仍然,所有假数据点都与真实数据不接近。我尝试更改
train和summarize_performance函数中的batch size和nr_samples,但没有得到好的结果。我不确定还能尝试什么。我应该使用更高的latent_dim还是增加生成器或判别器模型的层数和神经元数量?1.) 您能否看一下Google Colab Notebook并给我一些关于如何改进合成数据质量的建议?
2.) 在散点图中,我只绘制了两个最重要的变量(Xf 和 Xr_y),因为我知道这两个变量之间存在很强的相关性。但是,对于我的多变量数据,我如何实际确定GAN生成的合成数据是否有效?
谢谢!
我很乐意帮忙,但我没有能力审查/调试您的代码。
您可以在此处了解如何诊断GAN问题
https://machinelearning.org.cn/practical-guide-to-gan-failure-modes/
并在此处修复GAN问题
https://machinelearning.org.cn/how-to-code-generative-adversarial-network-hacks/
嗨,Jason,
感谢您推荐您其他精彩且有用的帖子。从您的GAN故障模式帖子中,我了解了如何绘制判别器和生成器的损失来推断更多关于GAN模型的性能。
dmodel.train_on_batch(x,y)打印的准确率分数与discriminator.evaluate(x,y)打印的准确率分数不同d_loss1, d_acc1 = d_model.train_on_batch(x_real, y_real)
d_loss2, d_acc2 = d_model.train_on_batch(x_fake, y_fake)
上面的代码会打印这一行
Epoch:1999, disc_loss_real=0.693, disc_loss_fake=0.695 gen_loss=0.693, disc_acc_real=64, disc_acc_fake=37
_, acc_real = discriminator.evaluate(x_real, y_real, verbose=0)
_, acc_fake = discriminator.evaluate(x_fake, y_fake, verbose=0)
上面的代码会打印这一行
Epoch:1999 Accuracy(RealData): 0.64 Accuracy(FakeData): 0.47
在生成此U形函数时,训练迭代10,000个epoch,有时两个行的准确率分数部分匹配,而其他时候则完全不同。
Epoch:1999, disc_loss_real=0.693, disc_loss_fake=0.695 gen_loss=0.693, disc_acc_real=64, disc_acc_fake=37
Epoch:1999 Accuracy(RealData): 0.64 Accuracy(FakeData): 0.47
Epoch:3999, disc_loss_real=0.689, disc_loss_fake=0.691 gen_loss=0.693, disc_acc_real=67, disc_acc_fake=56
Epoch:3999 Accuracy(RealData): 0.67 Accuracy(FakeData): 0.39
....
Epoch:7999, disc_loss_real=0.691, disc_loss_fake=0.695 gen_loss=0.695, disc_acc_real=57, disc_acc_fake=50
Epoch:7999 Accuracy(RealData): 0.39 Accuracy(FakeData): 0.61
Epoch:9999, disc_loss_real=0.689, disc_loss_fake=0.690 gen_loss=0.695, disc_acc_real=68, disc_acc_fake=57
Epoch:9999 Accuracy(RealData): 0.69 Accuracy(FakeData): 0.49
1.) 您能否简要解释一下为什么
train_on_batch(x,y)和disc.evaluate(x,y)产生的准确率分数会不同?2.) 最后,您能否快速推断一下这个准确率图(https://colab.research.google.com/drive/1erOPC6w9szqVDX9oU6gJfE88N1y1Tfwf#scrollTo=MC9IhQC6X00v)中发生了什么,因为我在您的GAN故障模式帖子中找不到任何解释这种奇怪图景的说明?
不客气。
您可以忽略准确率分数。
损失可能在该图中表现良好。
很好的资料,很想得到一份副本
谢谢,您可以在此处查看我关于该主题的最佳免费教程
https://machinelearning.org.cn/start-here/#gans
这是一篇很棒的文章。感谢您提供详细的示例。它有助于阐明GAN及其实现。
谢谢,我很高兴它有帮助!
嗨,Jason,
谢谢您的文章。如果我想有两个生成器怎么办?一个生成随机实数,另一个生成随机假数,判别器会尝试检测一维中的实数。我是否应该像您的代码结构一样,只添加另一个生成器 model_2,然后用三个参数编译模型?
我不确定我是否理解。为什么?您到底想实现什么目标?
嗨,Jason,
我已经编译了2个生成器和1个判别器。似乎numpy输入值存在问题。我得到了这个
ValueError: Dimensions must be equal, but are 1 and 5 for ‘sequential_3/dense_5/MatMul’ (op: ‘MatMul’) with input shapes: [?,1], [5,15]。
我试图从生成器1生成一些假的变量,并从生成器2生成真的变量。判别器的唯一目的是绘制/识别边界。
我正在尝试按照这里的说明进行实现,我注意到所有数据都用于判别器或生成器模型。我之前学习的ML算法有训练、验证和测试数据。您能解释一下GAN在这方面的区别吗?
好问题。
我们不是在使用输入进行预测。GAN不是预测模型。
相反,我们正在从无到有地生成新的合成示例。GAN是生成模型。
这有帮助吗?
是的,这很有帮助。非常感谢您的解释和澄清。
不客气。
Great post. Thanks Jason.
谢谢!
非常有帮助,谢谢!我正在尝试向此模型添加卷积层,但我遇到了第一层输入错误。有什么建议吗?
谢谢。
是的,请改用此示例
https://machinelearning.org.cn/how-to-develop-a-generative-adversarial-network-for-an-mnist-handwritten-digits-from-scratch-in-keras/
嗨 Jason,我买了您关于 GAN 的书,并正在学习 GAN。这是一本关于 GAN 的精彩书籍,使我的实验更容易。
我输入了 5000*100 的数值特征数组。我试图生成 5000*100 的假数据。迭代次数是
1999 1.0 1.0
3999 1.0 1.0
5999 1.0 1.0
7999 0.9838 0.9778
9999 0.9508 0.9698
现在我可以得出以下结论了吗?
1.判别器完美地学习了真实数据和假数据。
2.判别器成为了分类真实数据和假数据方面的专家。
3.生成器生成的 x_fake 数据可以作为假数据,用于与我用于生成真实样本的数据进行对抗。
谢谢你的支持!
也许吧。您到底想实现什么目标?
嗨 Jason
我有一个 5000*100 的签名特征数据集。其中 1*100 的每一行代表一个签名的特征。现在我想生成相同的数据集,即签名特征。
如果数据是表格数据,也许可以尝试 SMOTE 等技术?
也许可以直接生成图像,GAN 更适合。
你好 jason,
是否可以将判别器和生成器更改为循环网络以处理时间序列数据?
也许吧。我没试过。
嗨
我总是对你帖子里的图片感到困惑。它们似乎无关,例如这篇帖子里的森林。
它们只是漂亮的图片,提醒我们电脑之外还有一个世界。
我在这里解释了更多
https://machinelearning.org.cn/faq/single-faq/what-do-you-use-photos-in-your-blog-posts
嗨 Jason,我买了您关于 GAN 的书并正在练习。
以下是我的模型的真实准确率和假准确率(每 1000 个 epoch)。您能否澄清我的生成器是否学习得好。
[0, 26.153846153846157, 61.53846153846154]
[1, 53.84615384615385, 61.53846153846154]
[2, 49.23076923076923, 50.76923076923077]
[3, 56.92307692307692, 44.61538461538462]
[4, 1.5384615384615385, 96.92307692307692]
[5, 63.07692307692307, 36.92307692307693]
[6, 36.92307692307693, 61.53846153846154]
[7, 4.615384615384616, 92.3076923076923]
[8, 7.6923076923076925, 100.0]
[9, 29.230769230769234, 70.76923076923077]
[10, 64.61538461538461, 56.92307692307692]
[11, 95.38461538461539, 36.92307692307693]
[12, 93.84615384615384, 10.76923076923077]
[13, 26.153846153846157, 60.0]
[14, 56.92307692307692, 53.84615384615385]
[15, 72.3076923076923, 33.84615384615385]
[16, 69.23076923076923, 32.30769230769231]
[17, 24.615384615384617, 69.23076923076923]
[18, 58.46153846153847, 30.76923076923077]
[19, 61.53846153846154, 1.5384615384615385]
[20, 58.46153846153847, 21.53846153846154]
[21, 70.76923076923077, 27.692307692307693]
[22, 100.0, 0.0]
[23, 0.0, 100.0]
[24, 58.46153846153847, 38.46153846153847]
[25, 41.53846153846154, 44.61538461538462]
谢谢!
最好关注损失,并在生成器和判别器模型之间寻求平衡。
嗨,Jason,
感谢精彩的教程
当我尝试运行完全相同的代码时——它会抛出错误并且无法运行
:
‘”UserWarning: trainable weights and collected trainable weights 之间存在差异,您是否在调用
model.compile之前设置了model.trainable?‘trainable weights and collected trainable 之间存在差异’”
许多用户在其他论坛上报告了类似的错误,当时他们设置了 model.trainable=False
https://github.com/tensorflow/tensorflow/issues/22012
这是因为 TensorFlow 版本的问题吗?我正在 macOS 10.15 上使用 TensorFlow 2.0?
这只是一个警告,不是错误,也不是 bug。
您可以安全地忽略它。
你好,Jason,你的工作很棒,恭喜你。
我想问一个问题。我想从当前信号生成脑电图信号。但当我尝试使其与你的工作相似时,我无法生成与当前信号相似的信号。
是否有使用 Keras 库的示例?如果您能提供帮助,我将非常高兴。
例如;第一列:750, -1230, -870, -665, -51
第二列:675, -1270, -590, -830, -160
第三列:650, -1100, -300,-860, -370
…对比
当我想用 GAN 生成一个与这些信号相似的新信号时,生成的信号一点也不相似。
我没有示例——我希望将来能提供时间序列 GAN 的示例。
谢谢。我可以使用哪种 GAN 结构来实现它?
需要立即解决。如何修复以下代码。非常感谢
def define_discriminator(n_inputs=nr_features)
model = Sequential()
model.add(Dense(256, activation=’tanh’, kernel_initializer=’he_uniform’, input_dim=n_inputs))
model.add(Dropout(0.4))
model.add(Dense(1, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
return model
def define_generator(latent_dim, n_outputs=nr_features)
model = Sequential()
model.add(Dense(latent_dim, activation=’relu’, kernel_initializer=’he_uniform’, input_dim=latent_dim))
model.add(Dense(128,activation = ‘relu’))
model.add(Dense(n_outputs, activation=’relu’))
return model
我推荐这个
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
我不确定,我还没有阅读/编写过关于这个主题的内容。
感谢精彩的帖子!
我一直在玩代码,看看它是否能匹配比 X^2 更复杂的图,并注意到它在 x^3 和其他类似函数上表现良好。但是,它难以映射锯齿状等形状或具有尖锐过渡的图。
您能否推荐一些可能在这些区域提高性能的更改?代码似乎想要找到最佳拟合线,从而使生成器的图“平滑化”。
再次感谢您,您的帖子极大地提高了我的理解,并且因此我对 GAN 的理解更深了。
很酷,干得好!
想法:更大的模型、更小的学习率、不同的激活函数,以及这里的想法
https://machinelearning.org.cn/how-to-code-generative-adversarial-network-hacks/
嗨 Jason,很棒的帖子!
我想知道是否可以从 GAN 生成的新人工样本中提取相关特征,这是否可能(如何)?
不确定我是否理解你的意思,抱歉。你能详细说明一下吗?
是的,当然。
在你给的例子中,数据是由你生成的,根据规则:x*x。
假设你得到了一些根据更复杂的规则生成的数据,比如
A*x**2 + B*x**-5 ,
其中 A 和 B 是某些值。
现在,你不知道生成这些数据的规则,但你可以训练一个 GAN 来很好地模仿这些数据。
我想知道是否可以从中提取 A 和 B?
是的,但 GAN 不适合。你应该使用线性回归。
嗨,Jason,
我的数据集包含类似 [ 800 980 760 457 ……. 678] 的值。现在要生成类似范围的值
1) 在 0 到 1 之间生成潜在点是否不正确?请确认。
2) 为了生成类似范围的值,我通过取数据集的最小值和最大值修改了函数,如下所示。
Please suggest.
抱歉,我不明白你的问题。也许你可以重新措辞?
嗨,Jason,
如果生成器有 mse 损失。那么如何在 define gan 方法中编译模型?我们就以判别器的二元交叉熵和生成器的 mse 为例。
我不知道那会是什么情况。
嗨,Jason,
我尝试了没有 define gan 方法的示例,因为你知道一些架构有多个判别器和生成器。我将 gan_model.train_on_batch(x_gan, y_gan) 替换为 g_model.train_on_batch(x_gan, y_gan) 并编译了 generator model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])。但是,我遇到了这个错误
“ValueError: Error when checking target: expected dense_4 to have shape (2,) but got array with shape (1,)”
你能帮帮我吗?
抱歉,我没有能力调试你的更改。
你好,Jason。
感谢你的精彩帖子。不过我有一个问题
关于最终的图(10,000 次迭代后),你提到
“这里我们可以看到生成器模型在生成合理样本方面做得很好,输入值在 [-0.5 和 0.5] 的正确域内,输出值显示 X^2 关系,或接近它”
但在 10,000 次迭代后的性能评估中,判别器的表现为
9999 0.15 0.93
真实样本的准确率为 0.15,虚假样本的准确率为 0.93。这如何解释?在图中,我们看到生成的样本接近真实样本,但判别器并没有被欺骗。准确率不应该是接近 0.50 吗?但它是 0.15 和 0.93?我不明白,因为在图上,我们明显可以看到生成样本和真实样本之间存在合理的拟合。
希望你能/会对此进行解释。
此致
Søren Egedorf
准确率可能不是训练 GAN 时需要关注的好指标。
https://machinelearning.org.cn/how-to-evaluate-generative-adversarial-networks/
嗨,Jason,
感谢您提供有用的教程,它们简单易懂。我有两个问题:
1- 是否有方法可以控制潜在空间?我注意到模型生成了一些超出范围的点(大于或小于 0.5)。我想找到一种方法来强制模型将所有点保持在范围内。
2- 我尝试将模型重构为二维,以便同时处理 100 个点,而不是只有一个点
x(x0 -…-x99), y(y0-…-y99) 所以判别器评估给定的 200 个点(x 和 y)并将其标记为假或真,生成器生成 100 个点(x)和 100 个点(y)。您是否有任何技巧可以帮助我快速实现这一点?
最后,我期待学习更多关于 GAN 的知识,但不想像大多数人那样专注于图像,您能否推荐一些能帮助我的书籍?
也许可以使用输出的传递函数或在计算误差之前缩放输出。
不,抱歉,我的 GAN 教程绝大多数都是针对图像的。这个回归示例只是一个演示——它不适合用 GAN 来解决问题。可以研究一下更好的生成模型。
我最终成功地为 2D 数据制作了示例,创建了一个包含 1000 个子集的数据集,每个子集包含 70 个点的 x 和 y= x^2。尽管判别器的准确率对真实和虚假数据都达到了 1,但生成器无法生成任何逼真的数据。在 100,000 个 epoch 之后,似乎生成器已经了解到 x 的范围在 +/- 0.6 左右。
我的判别器包含 6 层,输入形状为 (70,2),我的生成器包含 5 层,除了输出层使用 tanh 外,其余层都使用 relu 激活,并且我尝试了 BatchNormalization,但没有帮助。
您有什么想法为什么生成器不起作用或我可以改进什么吗?
它并不是一个真正适合表格数据的模型——它更多地是 GAN 技术的演示。
我强烈建议研究更合适的生成模型,例如贝叶斯网络。
https://machinelearning.org.cn/introduction-to-bayesian-belief-networks/
很棒的教程,真的帮了我很多!
我尝试将 GAN 应用于二次函数以外的其他函数。我实际上想尝试将其应用于正弦数据,但效果不佳。您教授的架构相当简单,所以我猜 GAN 无法检测和生成正弦数据。您有什么建议可以改进 GAN 以识别此类数据吗?我尝试添加卷积层,但我一直在处理一维数据使用的维度。
祝好!
这纯粹是为了好玩。
对于有用的 1D 数据生成模型,我推荐其他方法。
https://en.wikipedia.org/wiki/Generative_model
嗨,Jason,
感谢这篇精彩的文章。
我正在尝试为医疗 ECG 数据(1D,时间序列)开发 GAN。我尝试复制本篇论文中的架构:https://www.nature.com/articles/s41598-019-42516-z
我遇到了一个问题。当训练判别器时,我在第一个 epoch 得到 acc_real=1 和 acc_fake=0。接下来的 epoch 也一样。会不会是梯度消失问题?
我使用了 2 个 conv1D 层,每个层后跟一个 maxPooling1D 层(这些层的参数按如下方式设置:https://www.nature.com/articles/s41598-019-42516-z/tables/1)
之后,我使用展平层、一个全连接层,我的最后一层是——> model.add(Dense(1, activation=’softmax’))。
然后我按照你的建议编译模型。
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
我按照你在 def train_discriminator 函数中提到的方式训练判别器,我的批大小是 100 个信号(50 个假,50 个真)。我的 x_real 和 x_fake 的输入形状是 (50, 3120, 1) = 50 个长度为 3120 的信号。y_real 是 1,y_fake 是 0。
我期望的准确率是 acc_real=0,8 和 acc_fake=0,9 之类的。
您有什么技巧可以帮助我达到这些准确率吗?
再次感谢您知识渊博的网站和文章。
抱歉,我没有用 GAN 来生成时间序列。
我相信有一些专门为生成时间序列设计的方法,我建议在尝试 GAN 之前先研究它们——GAN 是为图像数据设计的。
尽管如此,也许关于故障模式和 GAN 技巧的教程会对您有所帮助。
https://machinelearning.org.cn/start-here/#gans
时间序列与生成 x^2 函数或甚至正弦波有什么不同?除了它们的复杂性之外,我期望 GAN 的行为在某种程度上相似。信号只是一组时间上的值。与正弦波相同,但具有不同的内部表示(如果我理解正确,GAN 正试图模拟/学习)。我已经成功地用 GAN 生成了 x^2 和简单的正弦波。我以为将输入切换到信号会带来更大的复杂性,但不会改变训练的原理。
感谢您的快速回复。
我还找到了另一种方法,他们将一维信号转换为简单的 64×64 图像(4096 个向量值到 RGB 灰度)。然后学习 GAN 来生成类似的图像,这些图像被“转换回”以创建新的一维信号。我也会尝试这个概念,如果您不介意的话,会在这里留下评论。
时间序列的观测值之间存在顺序依赖性——这是一个根本性的区别。
正弦波也具有相同的显著区别。
是的,你说得对。我的错误。我通过将判别器中的 model.add(Dense(1, activation=’softmax’)) 替换为 model.add(Dense(1)) 来最终修复了问题。我使用二元交叉熵作为损失函数,它似乎“内部”已经包含了一个 sigmoid 激活。我不完全确定这是否是问题所在,但现在它工作得更好了。
判别器可以快速学会正确识别真实样本(准确率从 0% 到 98%),并且从第一个 epoch 开始就能以 100% 的准确率识别假样本,这有点奇怪。我将尝试遵循您的文章使模型更稳定——> https://machinelearning.org.cn/how-to-code-generative-adversarial-network-hacks/
谢谢!
干得好!
您好,您介意分享您如何使用 GANs 处理时间序列数据的代码吗?我一直在这方面遇到问题,因为互联网上大多数 GANs 教程主要涉及图像或语音识别。我将非常感谢任何帮助。
嗨,Jason,
我有一个关于时间序列预测与 GAN 的问题。我们能否以自回归的方式进行一步预测?
在此先感谢。
GAN 用于时间序列生成似乎很自然。但对于时间序列预测来说,它并不那么简单。如果您有兴趣,这里有一篇最近的论文:https://arxiv.org/abs/2105.13859
我还没有尝试过。所以不确定它是否好。
很棒的教程,感谢您的分享。
如果您能提供一个像这个一样简单的关于 GANs 处理时间序列的教程,那就太好了。例如,我尝试使用 GANs 生成具有给定数据集相似特征的时间序列数据结构。这样一个关于如何使用 GANs 处理时间序列的简单教程将非常受欢迎。
不客气!
感谢您的建议。GANs 确实是用于图像数据的,我相信有更好的生成模型用于时间序列。
感谢您的教程。一如既往地精彩。
我一直在使用您提供的代码来尝试从我收集的数据中生成一些合成数据。
根据文献所说,模型需要达到纳什均衡才能认为合成数据足够好。
因此,在训练过程中,我正在尝试了解何时可以停止训练或在特定步骤加载神经网络的权重来生成合成数据。
例如,在第 99999 轮的性能摘要中
Epoch:99999, disc_loss_real=0.108, disc_loss_fake=0.059 gen_loss=3.742, disc_acc_real=95, disc_acc_fake=100
Epoch: 99999 Accuracy(RealData): 0.99 Accuracy(FakeData): 1.0
准确率很高,意味着判别器可以很好地对假数据和真实数据进行分类。
据我理解,那并不好。
然而在第 70999 轮,
Epoch:70999, disc_loss_real=0.876, disc_loss_fake=0.683 gen_loss=1.208, disc_acc_real=57, disc_acc_fake=60
Epoch: 70999 Accuracy(RealData): 0.55 Accuracy(FakeData): 0.77
所以我认为第 70999 轮的输出比 99999 轮的更好?!真实数据的准确率为 0.55,假数据的准确率为 0.77。在最佳情况下,准确率应该都接近 0.5 吗??
另外,为了量化 GAN 的表现有多好,我想知道如何将 Frechet Inception Score、重构误差等纳入代码?!是否有任何存储库可以参考?
不客气。
评估 GAN 是一个开放性问题
https://machinelearning.org.cn/how-to-evaluate-generative-adversarial-networks/
通常,我建议生成样本并在检查点保存模型,然后停止运行,审查所有结果,并选择主观上样本最好的模型/检查点。至少对于图像数据来说,这是有效的。
很棒的教程,
感谢您制作了这个很棒的教程和很好的解释。
我一直在使用您在这篇博文中提供的代码来尝试生成合成数据。在这篇博文中,您通过使用真实的“合成”数据(由 generate_real_samples 函数生成)作为示例。
目前,在相同的概念和流程下,我正在尝试从 IMU(即加速度计数据)生成人类活动识别(HAR)领域的合成数据。我相信 GAN 可以应用于此类数据。
例如,
假设我有 (xyz) 加速度计数据,有 3 个类别标签(即坐着、走路、站着)。要生成合成数据,我们可以直接从潜在向量生成,然后生成器生成合成数据。
但是,我很难确定合成数据的类别标签。您对此有什么建议吗?
非常感谢……。
GANs 适用于图像数据,我建议寻找一种专门的技术来生成合成序列数据。
亲爱的 Jason,
感谢您的精彩教程。
目前我正在尝试使用 GANs 生成时间序列数据,正如之前有人请求的那样,您能否为我们提供一个关于使用 GANs 处理时间序列数据的教程。
非常感谢您,并致以最美好的祝愿。
抱歉,我认为 GAN 不适合生成时间序列数据——它们是用于图像的。
我预计专门的方法会更合适。
您好,生成器从假样本开始,最终生成能够欺骗判别器的对吧?我如何看到生成器生成的数据?
更具体地说,生成器开始时生成的是垃圾数据,然后开始生成可能使判别器大约一半时间被欺骗的样本。
是的,你说得对。您能告诉我如何查看生成器生成的值吗?
使用 model.predict() 来查看生成器的输出。
谢谢。我一直在查看每个 epoch 的 x_fake 值。x_fake 显示的是生成器生成的值,对吗?我的意思是生成器生成的垃圾值。
不客气!
抱歉,我不明白。您能详细说明您看到的内容以及您遇到的问题吗?
您好。我没有问题。在您的代码中,我为每个 epoch 打印了 x_fake 的值。x_fake 提供的是生成器的值,对吗?我的意思是生成器生成的垃圾值。
是的。
生成器学会生成逼真的值——这是练习的目的。
嗨,Jason,
您提供的教程确实非常棒。
我有一个快速的问题——
假设我有一个函数:y = f(x1, x2, x3…) 多达 5 个维度。您建议如何使用 GAN 方法来生成新样本?
所以,在我的例子中,生成器模型输出的样本是 (x1,x2,x3,x4,x5,y)。
请帮忙!
谢谢你
谢谢。
不,使用 SMOTE
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
谢谢你,Jason。
那么,SMOTE 是否有助于为 N 维函数生成人工数据?
我现在有上面提到的 5 维函数的 100 个样本。我目标是生成更多人工样本。您能解释一下为什么 GAN 不能使用吗?
我没有“y”和“x”之间的解析关系。我正在进行实验,通过不同的“x1, x2, x3, x4, x5”组合来测量“y”。因此,归根结底,我拥有的测量数据是一个包含 100 个测量值的表格。
鉴于这是问题陈述,SMOTE 能帮助我生成更多数据吗?
是的,尝试一下,并与其他方法进行比较。
是的。
GANs 是为图像数据设计的。
你好,
如何在模型训练期间获取生成器的损失?
我之所以这样问,是因为我们没有编译生成器模型。
谢谢你
生成器的损失是通过复合模型提供的。
谢谢!
不客气。
关于生成器还有另一个问题:我们如何访问训练好的生成器(它是 GAN 模型的一部分),以便生成合成数据?
抱歉问了这样一个相对简单的问题,我正在学习如何使用 Keras。
谢谢
好问题,您可以保存“g_model”模型,并在之后随时调用 predict() 来生成新样本。
请参阅 generate_fake_samples() 函数了解示例。
谢谢!
不客气。
嗨 Jason
我非常渴望学习 GAN 的概念,而您的教程提供了一个绝佳的沉浸式体验。谢谢。
在我看来,GAN 的核心思想是允许生成器模型(生成假数据的模型)“欺骗”判别器模型(决定什么是真实的或假的),告诉它其数据是真实的(标签=1),从而判别器模型进行修正(教学)生成器,以便构建更真实的数据。将生成器模型与判别器模型(GAN 最终模型)组合在一起,可以被视为(至少对我而言)某种“寄生”关系,因为生成器通过“寄生”判别器模型来获取资源(学习)。此外,将两个模型(判别器和生成器(通过 GAN 帮助生成器获得更好的假数据))置于竞争之中。
在这里,我分享一些我基于您的代码进行的实验,希望能帮助到任何人!
实验
1)我的结果表明,判别器模型的假数据和真实数据的准确率非常相似,都在 40-60% 左右。这似乎比这里显示的(90-10 或 10-90)更合理。
2)如果我在 GAN 模型中不将假标签更改为真(以欺骗它),模型就无法学习。因此,在 GAN 模型中欺骗标签至关重要。
3)如果我只训练 GAN 模型而不训练判别器模型(甚至加载预训练的判别器模型),假数据也无法学习!因此,两个模型的竞争对 GAN 至关重要!
4)如果我“过度训练”判别器,将判别器的权重设置为 trainable=true,在 GAN 模型中,假数据确实能学到“一些东西”(还不错),但肯定比我在 GAN 中不训练判别器(如建议的)要差。
6)如果我改变训练的尺度,假数据总能学到东西(在训练尺度内,但不在极端超出范围的限制处),例如,我将初始值 [-0.5, 0.5] 更改为 [-5., 5.] 甚至 [-50., 50.],但在极端尺度和最后超出范围的值处结果却差很多,并且随着尺度的增加而变差!。
7)我未能成功实现“归一化”将所有尺度值压缩到 [0,1] 中。事实上,我根本没有学到假数据。这没有道理!所以一定是我做错了什么!
8)我测试了其他数据函数,如三角函数(例如正弦)和指数函数。对于这两种函数,我通过将两个模型中的神经元单元数加倍(从 25 到 50,从 15 到 30)并将两个模型的密集层数从 1 增加到 2,取得了更好的结果。
但是,如果正弦函数变化很快(例如高频),假数据仍然无法学到东西。
9)对于指数函数,假数据在 -0.5 到 0.5 之外表现很差。然后我尝试实现更多的每层单元数(判别器从 25 加倍到 50,生成器从 15 加倍到 30),并将两个模型的密集层数从 1 加倍到 2,取得了更好的假数据结果。
10)如果我只增加更多的单元数(从 50 增加到 75,从 30 增加到 45),我会得到更差的假数据结果。可能是因为对于很小的批次大小引入了过多的复杂性。
11)我将二次函数的 epoch 调整为 15,000,对于指数函数方法调整为 8,000,对于正弦函数保留为 10,000。但是如果我运行更多 epoch,假数据的结果会变差。可能是因为过拟合问题。
12)如果我将这个 GAN 模型与一个简单而独特的 NN 模型进行比较来逼近(一个函数),就像您在其他教程中提供的那样……我的结论是,GAN 模型在函数逼近方面,不如那些简单的学习模型准确且更复杂!
抱歉写得太长了!
非常酷的实验和发现,感谢您的分享!
毫无疑问,由于您的探索,您对该技术有了更深入的理解。
你好 Jason,
感谢您详细的解释!我想知道 GAN 模型是否适用于非二元判别器?例如:而不是真实或虚假,您可以为标签设置例如:[A,B,C,fake]。因此,在用真实数据训练判别器时,您会得到标签 [1,0,0,0];[0,1,0,0] 或 [0,0,1,0]。用假数据训练时,您只会有一个标签 [0,0,0,1]。我们如何评估这样一个可以输出这三个类别中任何一个的生成器的性能,如示例所示?
我认为您指的是 ACGAN 或条件 GAN,或许可以从这里开始
https://machinelearning.org.cn/start-here/#gans
太好了!这看起来正是我想要的,谢谢 Jason!
不客气!
.
现在在
train 函数
我们首先训练判别器(d_model)
我们创建潜在点并生成假样本
我们给所有假(生成样本)类标签 1
接下来,我们从判别器的输出来训练生成器(gan_model)
.
现在在 gan_model 中
1. 生成器有 2 个输出 [x , x^2]
2. 判别器将这 2 个作为输入
3. 判别器的任务是预测 [x, x^2] 是真实的(P 接近 1)还是假的(P 接近 0)的概率
.
现在在训练过程中
我们将假(生成)输入提供给 gan_model,并将其标记为 1
那么在训练结束时,
判别器不应该被我们的假输入愚弄吗?
并且它不应该给出 1 的概率或接近 100% 的准确率吗?
.
那么为什么说 50% 就是愚弄了判别器,并且是最好的呢?
.
在章节:评估 GAN 的性能 —
“一个好的生成器模型应该让判别器模型感到困惑,从而导致对真实和虚假样本的分类准确率接近 50%。”
.
请帮助。
.
通常,准确率是衡量 GAN 的一个糟糕指标。相反,应该关注在训练过程中不同阶段模型生成的内容。
嗨,Jason,
签名是 X 和 y 坐标之间的相关性。如何开发一个 FAN 来接受 X 和 y 坐标作为输入并生成相似的序列。
好问题,也许您可以使用 LSTM 作为序列的生成模型?
嗨,Jason,
感谢您提供这个 1D GAN 的示例。为什么生成器模型没有编译?您能解释一下吗。
如果您能提供一些用于异常检测的 1D GAN 和 Keras 中的对抗性自编码器的示例,将不胜感激。
因为它没有被直接训练。
我不确定 GAN 是否适用于异常检测。感谢您的建议。
从上面的讨论中,我了解到 GAN 是为图像数据生成而设计的。我们不能使用 GAN 来生成表格合成数据,就像 SMOTE 可以提高不平衡数据分类的性能一样。我想知道您是否可以推荐其他类似 GAN 的模型来生成合成表格数据,以提高预测性能。我赞赏您的出色工作!
好问题,是的,在现有数据上添加高斯噪声是一种简单有效的方法。
另外,朴素贝叶斯也可以用作生成模型。
非常感谢您的回复!我仍然对合成表格数据的生成感到困惑。由于SMOTE在高维严重偏斜的大数据上效果不佳,您能否推荐其他类似GAN的模型来生成合成表格数据以提高分类器性能?
如果还有其他模式,我恐怕不知道,我不是生成模型方面的专家。
我建议您查阅文献。
嗨,Jason,
如果我想看到GAN生成的合成数据,我应该如何以及在哪里打印它?
调用predict,然后调用print(),并将模型的输出作为参数传递。
谢谢!那么应该是 gan_model.predict(latent_dim) 吗?
不,是 generator.predict(x_input)。
请参阅 generate_fake_samples() 函数。
你好,
如果我想将此从一维GAN扩展到包含多个变量,我需要在代码中进行哪些更改?
您需要更改模型的训练方式,以及判别器输入和生成器输出的预期。
我需要如何更改模型的训练?
提供额外的数据。
也许可以尝试并发现所需的具体更改。这很简单。
嗨,Jason,
我应用了您相同的模型(判别器、生成器和GAN),但不是针对二次函数示例,而是针对您在时间序列应用帖子中经常使用的航空旅客真实数据集。
我试图回答GAN技术是否可以成功应用于时间序列应用,以便预测某物的未来时间序列演变。
这个实验的结果是,我通过生成器模型(假数据生成器)得到了一条近乎完美的趋势线(穿过每年中间水平线),但我失去了所有与季节性效应相关的波动细节……仅供在您的帖子中分享。
有意思。
我认为关于用于序列数据的GAN有一些严肃的研究。但我还没有深入研究过这个领域。
你好,
请,我想修改相同的代码,只生成X^2数据(而不是[X, X^2])。这样,我就可以得到 Y=generator(X) 且 Y = X^2。
也就是说,生成器的输出是单个数据(n_outputs=1)。
此致,
那么就不需要GAN了,你可以直接使用预测模型。
https://machinelearning.org.cn/neural-networks-are-function-approximators/
感谢您的回答,
但我需要使用GAN将其与预测模型在性能上进行比较,以用于此应用。
事实上,GAN在图像到图像的转换中效果很好(与Y=f(X)的应用类似)……
最终的应用将是生成一个N x 2的数组(实部和虚部),然后进行转换……
此致,
Nizar
你好,
也许还有一个问题。生成器的“n_outputs=1”是否可能?
模型需要做哪些更改?
此致,
您可以按您喜欢的方式调整示例。
如果您不确定您更改的影响,请尝试一下看看。
你好 Jason,
首先,感谢您提供了如此丰富内容的精彩网站!
我注意到了一些在本次教程代码中调整参数的情况。
当使用余弦函数(范围[-4, 4])时,这一点更为清晰:当我让GAN尝试学习余弦函数,使用与您相同的层和参数时,模型的“策略”似乎找到了函数的通用形状,但比例不对,快到结尾时,它最终“找到”了正确的比例并匹配了余弦函数。
当我再次尝试在判别器中添加一个具有更多参数的Dense层(第一个Dense层150,第二个Dense层50,两者都使用ReLU激活,第一个Dense层有一个输出单元)时,模型的策略似乎找到了一个线性关系,其中大多数点都符合余弦函数(通常在[0.5, 2.5]之间),然后试图让这些点沿着余弦函数“滑动”以接近余弦函数的曲线。
网络根据其结构“选择”的这类策略是否是已知的且已确定的?
谢谢!
不客气。
太棒了,一次精彩的实验!
是的,模型正在通过对抗性优化过程进行“学习”。它会在这些约束下尽一切可能。
谢谢 🙂
另一个问题:我尝试在GAN模型训练之前,而不是在训练过程中,来训练判别器。出现的行为是生成器只专注于图上的一个点。可以这么理解吗,在这种情况下,判别器对生成器来说太“严厉”了,以至于生成器只“专注于”第一个被判别器验证的点?
我理解这样做会取消生成器和判别器的对抗性,但我希望理解为什么在这种情况下生成器只会专注于一个点。
是的,GAN方法的核心思想就是对抗性训练。如果去掉它,它就不再是GAN了——而且实际上也无法工作。
def train_gan(gan_model, x_train, y_train, x_val, y_val, x_test, y_test , epoch, train_batch_size, val_batch_size)
metric = ‘val_mean_absolute_error’
checkpoint = ModelCheckpoint(filepath=r”/content/gdrive/My Drive/Colab Notebooks/{}”.format(“gan.h5”), monitor=metric, verbose=1, save_best_only=True, save_weights_only=False, mode=’auto’, period=1)
early = EarlyStopping(monitor=metric, min_delta=0, patience=20, verbose=1, mode=’auto’)
history = gan_model.fit(steps_per_epoch=train_batch_size, x= x_train, y = y_train, validation_data= (x_val, y_val), validation_steps=val_batch_size, epochs=epoch, callbacks=[checkpoint])
plt.ylabel(“LOSS”)
plt.xlabel(“EPOCH”)
plt.plot(history.history[‘loss’], c = ‘r’)
plt.plot(history.history[‘val_loss’], c = ‘y’)
plt.legend([‘train_loss’, ‘val_loss’])
plt.yscale(‘linear’)
plt.grid(True)
plt.show()
plt.ylabel(“MEAN ABSOLUTE ERROR”)
plt.xlabel(“EPOCH”)
plt.plot(history.history[‘mean_absolute_error’], c = ‘b’)
plt.plot(history.history[‘val_mean_absolute_error’], c = ‘g’)
plt.legend([‘mean_absolute_error’, ‘val_mean_absolute_error’])
plt.yscale(‘linear’)
plt.grid(True)
plt.show()
plt.plot(history.history[‘loss’], c = ‘r’)
plt.plot(history.history[‘val_loss’], c = ‘y’)
plt.plot(history.history[‘mean_absolute_error’], c = ‘b’)
plt.plot(history.history[‘val_mean_absolute_error’], c = ‘g’)
plt.legend([‘train_loss’, ‘val_loss’, ‘mean_absolute_error’, ‘val_mean_absolute_error’])
plt.yscale(‘linear’)
plt.grid(True)
plt.show()
return history
x_gan, y_gan = generate_latent_points(n,1)
x_train_gan, x_test_gan, y_train_gan, y_test_gan = train_test_split(x_gan, y_gan, test_size=0.3)
x_val_gan, x_test_gan, y_val_gan, y_test_gan = train_test_split(x_test_gan, y_test_gan, test_size=0.5)
train_batch_size_gan = len(x_train_gan)//batch_size
val_batch_size_gan = len(x_test_gan)//batch_size
discriminator = load_model(“/content/gdrive/My Drive/Colab Notebooks/discriminator.h5”)
c = train_gan(gan_model, x_train_gan, y_train_gan, x_val_gan, y_val_gan, x_test_gan, y_test_gan , epoch, train_batch_size, val_batch_size)
ValueError:在用户代码中
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:805 train_function *
返回step_function(self, iterator)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:795 step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
/usr/local/lib/python3.7/dist-packages/tensorflow/python/distribute/distribute_lib.py:1259 run
return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/distribute/distribute_lib.py:2730 call_for_each_replica
return self._call_for_each_replica(fn, args, kwargs)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/distribute/distribute_lib.py:3417 _call_for_each_replica
return fn(*args, **kwargs)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:788 run_step **
outputs = model.train_step(data)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:754 train_step
y_pred = self(x, training=True)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/base_layer.py:998 __call__
input_spec.assert_input_compatibility(self.input_spec, inputs, self.name)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/input_spec.py:259 assert_input_compatibility
‘ but received input with shape ‘ + display_shape(x.shape))
ValueError: Input 0 of layer sequential_46 is incompatible with the layer: expected axis -1 of input shape to have value 5 but received input with shape (5, 1)
先生,我正在使用model.fit而不是手动运行循环,我已经将latient_dim设置为n,即输入数据的形状,并且出现了这个错误。
或许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
def train(g_model, d_model, gan_model, latent_dim, epochs, batch_size, dataset_size, n_eval=100)
batches_per_epoch = dataset_size // batch_size
n_steps = batches_per_epoch * epochs
prg = ProgressBar()
for i in prg(range(n_steps))
x_real, y_real = generate_real_pairs(batch_size)
x_fake, y_fake = generate_non_real_pairs(g_model, latent_dim, batch_size)
# update discriminator
d_model.train_on_batch(x_real, y_real)
d_model.train_on_batch(x_fake, y_fake)
# prepare points in latent space as input for the generator
x_gan = generate_latent_points(latent_dim, batch_size)
# create inverted labels for the fake samples
y_gan = np.ones((batch_size, 1))
# update the generator via the discriminator’s error
metric = ‘val_accuracy’
checkpoint = ModelCheckpoint(filepath=r”/content/gdrive/My Drive/Colab Notebooks/{}”.format(“trained_gan.h5”), monitor=metric, verbose=1, save_best_only=True, save_weights_only=False, mode=’auto’, period=1)
early = EarlyStopping(monitor=metric, min_delta=0, patience=20, verbose=1, mode=’auto’)
gan_model.train_on_batch(x_gan, y_gan, callbacks=[checkpoint])
# evaluate the model every n_eval epochs
if (i+1) % n_eval == 0
summarize_performance(i, g_model, d_model, latent_dim)
return gan_model
先生,我正在尝试保存训练的最佳模型,但由于我们是手动逐批次训练,因此无法使用上一个代码所示的early stopping和checkpoint,您能否解释一下正确的做法?
我们不能使用early stopping来处理GAN,但您可以每隔一个epoch或类似的方式保存模型,并在选择最终模型之前检查每个模型的能力。
先生,在这个案例中,我们没有使用图像,我该如何实现 Frechet Inception Distance?
您不能。
先生,当我们生成伪随机数而不是一个数的平方时,请也指导我如何选择合适的生成器。
GAN并不是生成随机数的合适工具。
先生,您能为相同的事情推荐正确的工具吗?
是的,请看这个
https://machinelearning.org.cn/how-to-generate-random-numbers-in-python/
谢谢您,先生 🙂
不客气。
嗨,Jason。BatchSize对生成器学习有影响吗?因为GAN在Batch Size = 16时生成质量极佳的图像,如果我尝试Batch Size = 2,相同的代码效果就不好了。您能确认一下吗?
是的,在使用GAN时,批次大小通常会保持较小,并且真实/虚假样本的组合通常会经过仔细管理。
为什么训练中只有一个for循环?然而,GAN论文的伪代码中有两个循环。
因为当k=1时,论文中的内循环是多余的。
那么当k>1时,我们需要训练判别器多次而生成器一次吗?然而,如果是这样,这在任何GAN的代码中都没有实现。
不。k是同一两个模型在每个训练步的样本数。
也许重新阅读一下论文
https://arxiv.org/pdf/1406.2661.pdf
我想实现EEG数据的GAN,我需要做哪些更改?
我认为GAN不是时间序列的合适生成模型。至少,我对此话题不太了解。
我们可以使用GAN来进行回归问题的过采样吗?
也许可以,尽管我怀疑更简单的生成模型可能更合适。
你好,
我正在处理一个非图像数据集,或者更确切地说是一个入侵检测数据集,我正在尝试实现GAN并生成真实和虚假样本,如果您能告诉我生成器需要什么输入来生成真实和虚假样本,我将非常感激。
也许SMOTE会更合适。
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
先生,您能指导我如何计算两个3D(266,256,3)数组之间的水平、垂直和对角线相关系数吗?
感谢您的建议,也许将来会考虑。
嗨,在summarize_performance函数中,generate_fake_samples(generator, latent_dim)的标签不应该是ones而不是zeros吗?因为我们想看到判别器对这些假样本是真实的有多自信?
不,GAN生成数据的评估是看它看起来有多真实。
嗨,Jason,
如何在此代码中获取判别器或生成器的权重?类似于model.getWeights()?
您可以使用 get_weights() 来获取每个独立模型的权重。
你好,Jason。
我有几个问题,希望您能帮我。您说
“第一步是在潜在空间中生成新的点。我们可以通过调用 NumPy 的 randn() 函数来生成从标准高斯分布中抽取的随机数数组来实现。”
问题是:为什么是标准高斯分布而不是均匀分布?还有:是否有证据(论文或书籍)详细说明了潜在空间分布使用差异?
提前感谢您的支持。
这是我选择的分布,您也可以根据需要进行更改。
是的,人们尝试过各种各样的分布,有些在某些领域效果更好。
我认为n维(n=5甚至更多)潜在空间能给模型更新权重的灵活性更大。一个随机生成的输入可能需要很多个epoch才能更新其权重以输出一个可接受的判别器层输入。
如果我说错了,请纠正我。
你好,
我稍微修改了您的代码(通过添加隐藏层和节点使模型更复杂,并更改了批次大小和潜在空间)。fake_accuracy为1并且不变化。为什么会发生这种情况,我该如何解决?这是过拟合吗?
不确定,但准确率1对假得太真了。我建议您追溯您输入网络的内容以及它输出的原始内容,以了解发生了什么。
我发现生成器试图模仿信号的一部分,而另一部分(峰值)被忽略了。我认为这被称为模式崩溃。那么,如何克服模式崩溃呢?
如果您确定是模式崩溃,请看这里:https://developers.google.com/machine-learning/gan/problems
(您需要处理判别器来修复生成器)
你好,
我有一个包含许多函数的训练数据集,这些函数接近高斯分布,具有不同的幅度和宽度,每个曲线对应不同的输入(例如,强度……)。我想知道如何根据输入参数来训练生成器和判别器?
您想将GAN用于高斯函数?这应该不难,但提供更多关于您尝试过的内容的细节可以帮助我对此发表评论。
它们并不完全是高斯函数,它们并不总是很好地拟合高斯函数,其形状高度依赖于不同的输入。这就是为什么我想在我的生成器和判别器中使用这些输入,以便它们学会根据这些参数改变形状。
您尝试过什么吗?在我看来这是可行的,但网络的設計应该能反映出您对函数应该是什么样子的直觉。
尊敬的Jason Brownlee,您能帮助我用LSTM层修改模型吗?
你好Chandrasen…以下应该有助于澄清
https://machinelearning.org.cn/lstm-autoencoders/
很棒的帖子!
出于好奇,您将如何使此方法适用于不连续函数,例如 x y=-x; 2>x>0 -> y=2; x>=2 ->y=x*x?
对于连续函数,您的方法对我来说效果很好,但上述示例效果不佳。
你好Boris…您遇到了什么错误消息或结果,我们也许能帮助您?
没有错误消息;代码运行正常。我只是在调整参数,看看会发生什么。使用上面给出的不连续函数,模型倾向于将p(0,0)近似为一条直线到p(2,4),而对于区间x=(0,2],实际点都在y=2处。在区间x=(0,2]之外,它的表现很好。
我只是想知道不连续数据的行为是否是该方法的限制,或者我是否需要调整激活函数。如果这是一个很傻的问题,我很抱歉。
嗨,Jason,
感谢您提供的精彩教程!
我注意到在最后的训练中,我们对判别器使用了 `train_on_batch`。然而,由于我们在 `define_gan` 函数中将其设置为 `False`,此时判别器是不可训练的。
我们是否应该在 `train_on_batch` 之前将 `discriminator.trainable = True`,之后再将其设置回 `False`?
你好Mihai…您实现过代码并尝试执行过模型吗?如果执行了,您发现了什么?
我完全无法复现这些结果。当我运行您提供的代码并训练10,000个 epoch 后,生成器仍然产生垃圾数据。看起来它根本没有从任何 epoch 中学习,只是生成相同的数据。它只是生成一条远离 x^2 线段的直线。
我是否遗漏了什么?或者有什么东西改变了?非常感谢您能提供任何见解。谢谢!
你好Sam…听起来您的1D GAN中的生成器未能学习,这在GAN中可能由于多种原因发生。以下是一些常见问题和潜在解决方案:
1. **学习率**
– 如果您的生成器或判别器的学习率过高或过低,生成器可能难以收敛。过高的学习率可能导致模型过冲最优权重,而过低的学习率可能使学习过于缓慢或无效。
– 尝试调整学习率,从大约 `1e-4` 或 `1e-5` 开始。
2. **网络架构**
– 生成器和判别器的网络架构都应仔细平衡。如果判别器比生成器强大得多,它可能会压倒生成器,使生成器无法学习。
– 检查您的生成器是否具有足够的层和容量来建模期望的输出,并确保您的判别器不太深。
3. **批量归一化和Dropout**
– 在某些GAN架构中,在生成器中使用 `BatchNormalization` 层和在判别器中使用 `Dropout` 层有助于稳定训练。这些层可以防止模式崩溃(即生成器重复生成相同输出)。
– 如果缺少这些层,请添加它们,特别是添加到ReLU等激活函数之后的生成器层。
4. **损失函数**
– GAN训练对损失函数的选择高度敏感。如果您同时为生成器和判别器使用 `binary_crossentropy` 或类似的损失,请确保两个模型都得到了正确的优化。有时使用不同的损失,如Wasserstein损失,可以帮助提高训练稳定性。
– 您可以尝试Wasserstein GAN (WGAN) 架构,它使用批评家而不是判别器,并且通常能带来更稳定的训练。
5. **训练过程**
– 确保您正确地交替训练生成器和判别器。对于每个 epoch,在真实和虚假数据上训练判别器,然后训练生成器以欺骗判别器。如果一个模型训练的次数过多,会使学习不稳定。
– 每次 epoch 后对数据集进行洗牌以避免过拟合也很重要。
6. **梯度裁剪**
– 在某些情况下,梯度可能会爆炸或消失。梯度裁剪可以帮助防止模型发散。在Wasserstein GANs中,也建议裁剪判别器的权重。
– 您可以尝试在优化器设置中添加梯度裁剪
python
optimizer = Adam(lr=learning_rate, beta_1=0.5, clipvalue=1.0)
7. **评估和可视化**
– 在训练过程中定期检查中间输出(生成的样本),以查看生成器是否有所改进。有时GAN需要数十万个 epoch 才能收敛,所以10,000个 epoch 在您的情况下可能不够。
– 可视化生成器和判别器的损失曲线,以检查是否有一个模型压倒了另一个模型(即,判别器的损失过快地趋近于0)。
如果您按照原样实现了原始架构并且仍然遇到问题,尝试一个接一个地进行这些调整可能有助于提高GAN的训练和输出质量。