生成对抗网络(GANs)是一种用于训练生成模型的架构,例如用于生成图像的深度卷积神经网络。
开发用于生成图像的GAN需要一个判别器卷积神经网络模型(用于分类给定图像是真实还是生成的)和一个生成器模型(使用逆卷积层将输入转换为像素值的完整二维图像)。
理解GAN的运作方式以及GAN架构中如何训练深度卷积神经网络模型进行图像生成可能具有挑战性。对于初学者来说,一个好的起点是练习在计算机视觉领域的标准图像数据集上开发和使用GAN,例如MNIST手写数字数据集。使用小型且易于理解的数据集意味着可以快速开发和训练较小的模型,从而将重点放在模型架构和图像生成过程本身。
在本教程中,您将了解如何使用深度卷积网络开发一个生成对抗网络来生成手写数字。
完成本教程后,您将了解:
- 如何定义和训练独立的判别器模型,以学习区分真实和伪造图像。
- 如何定义独立的生成器模型,并训练组合的生成器和判别器模型。
- 如何评估GAN的性能,并使用最终的独立生成器模型来生成新图像。
用我的新书《Python生成对抗网络》快速启动您的项目,其中包括分步教程以及所有示例的Python源代码文件。
让我们开始吧。

如何从头开始在Keras中为MNIST手写数字开发生成对抗网络
照片来源:jcookfisher,保留部分权利。
教程概述
本教程分为七个部分,它们是:
- MNIST手写数字数据集
- 如何定义和训练判别器模型
- 如何定义和使用生成器模型
- 如何训练生成器模型
- 如何评估GAN模型性能
- MNIST GAN的完整示例
- 如何使用最终的生成器模型生成图像
MNIST手写数字数据集
MNIST 数据集是修改后的美国国家标准与技术研究所数据集的缩写。
这是一个包含70,000张28×28像素的灰度手写数字(0到9)的彩色方形图像的数据集。
任务是将给定的手写数字图像分类到 10 个类别中的一个,这些类别代表从 0 到 9(包括 0 和 9)的整数值。
Keras通过mnist.load_dataset() 函数提供对MNIST数据集的访问。它返回两个元组,一个包含标准训练数据集的输入和输出元素,另一个包含标准测试数据集的输入和输出元素。
下面的示例加载数据集并总结了加载数据集的形状。
注意:第一次加载数据集时,Keras将自动下载该图像的压缩版本,并将其保存在您的主目录下的~/.keras/datasets/中。下载速度很快,因为数据集压缩后的文件大小仅为11兆字节左右。
|
1 2 3 4 5 6 7 |
# 加载 mnist 数据集示例 from keras.datasets.mnist import load_data # 将图像加载到内存中 (trainX, trainy), (testX, testy) = load_data() # 总结数据集的形状 print('Train', trainX.shape, trainy.shape) print('Test', testX.shape, testy.shape) |
运行示例会加载数据集并打印图像训练和测试分割的输入和输出组件的形状。
我们可以看到训练集中有 6 万个样本,测试集中有 1 万个样本,并且每个图像都是 28 x 28 像素的正方形。
|
1 2 |
训练 (60000, 28, 28) (60000,) 测试 (10000, 28, 28) (10000,) |
图像是灰度的,背景为黑色(像素值为0),手写数字为白色(像素值接近255)。这意味着如果绘制这些图像,它们将主要是黑色的,中间有一个白色的数字。
我们可以使用matplotlib库的imshow()函数绘制训练数据集中的一些图像,并通过“cmap”参数指定颜色映射为“gray”,以便正确显示像素值。
|
1 2 |
# 绘制原始像素数据 pyplot.imshow(trainX[i], cmap='gray') |
或者,当我们反转颜色并将背景显示为白色、手写数字显示为黑色时,图像更容易查看。
现在图像大部分是白色,感兴趣区域是黑色,因此它们更容易查看。这可以通过使用反向灰度颜色映射来实现,如下所示:
|
1 2 |
# 绘制原始像素数据 pyplot.imshow(trainX[i], cmap='gray_r') |
下面的示例将在5x5的方格中绘制训练数据集中前25张图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 加载 mnist 数据集示例 from keras.datasets.mnist import load_data from matplotlib import pyplot # 将图像加载到内存中 (trainX, trainy), (testX, testy) = load_data() # 绘制训练数据集中的图像 for i in range(25): # 定义子图 pyplot.subplot(5, 5, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(trainX[i], cmap='gray_r') pyplot.show() |
运行该示例会生成一个由MNIST训练数据集中的25张图像组成的5x5方格图。
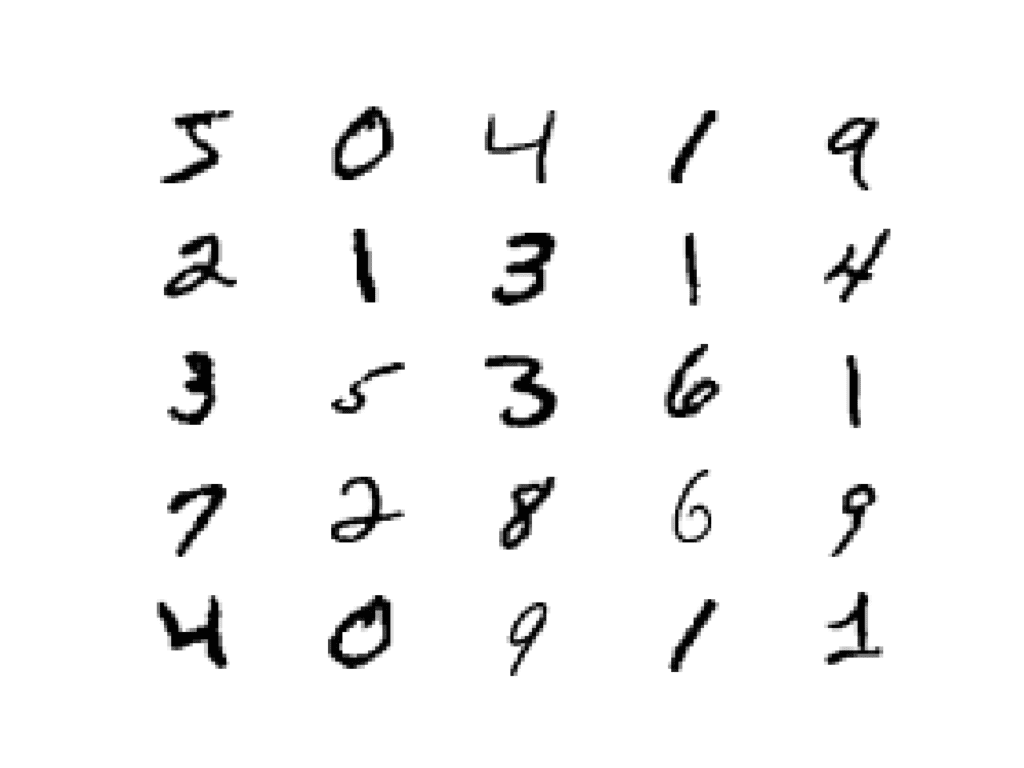
MNIST数据集前25张手写数字的图。
我们将使用训练数据集中的图像作为训练生成对抗网络的基础。
具体来说,生成器模型将学习如何生成新的、看起来像真实的手写数字(0到9),而判别器则会尝试区分来自MNIST训练集中的真实图像和生成器模型输出的新图像。
这是一个相对简单的问题,不需要复杂的生成器或判别器模型,尽管它确实需要生成灰度输出图像。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何定义和训练判别器模型
第一步是定义判别器模型。
该模型必须接收我们数据集中的样本图像作为输入,并输出一个分类预测,以判断样本是真实的还是伪造的。
这是一个二元分类问题
- 输入:具有一个通道、28×28像素大小的图像。
- **输出**:二元分类,样本为真实的(或伪造的)可能性。
判别器模型包含两个卷积层,每个层有64个滤波器,一个小的3x3核大小,以及一个大于常规的2步长。该模型没有池化层,输出层有一个节点,使用sigmoid激活函数来预测输入样本是真实的还是伪造的。模型通过最小化二元交叉熵损失函数进行训练,该函数适用于二元分类。
在定义判别器模型时,我们将使用一些最佳实践,例如使用LeakyReLU代替ReLU,使用Dropout,并使用学习率为0.0002,动量为0.5的Adam优化算法。
下面的define_discriminator()函数定义了判别器模型,并参数化了输入图像的大小。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 定义独立的判别器模型 def define_discriminator(in_shape=(28,28,1)): model = Sequential() model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same', input_shape=in_shape)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) return model |
我们可以使用此函数来定义判别器模型并对其进行总结。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 定义判别器模型的示例 from keras.models import Sequential from keras.optimizers import Adam from keras.layers import Dense 从 keras.layers 导入 Conv2D from keras.layers import Flatten 从 keras.layers 导入 Dropout from keras.layers import LeakyReLU from keras.utils.vis_utils import plot_model # 定义独立的判别器模型 def define_discriminator(in_shape=(28,28,1)): model = Sequential() model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same', input_shape=in_shape)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) return model # 定义模型 model = define_discriminator() # 总结模型 model.summary() # 绘制模型 plot_model(model, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True) |
运行该示例将首先总结模型架构,显示每个层的输入和输出。
我们可以看到,激进的2x2步长对输入图像进行下采样,先是从28x28降到14x14,再降到7x7,然后模型做出输出预测。
这个模式是故意的,因为我们不使用池化层,而是使用大的步长来实现相似的下采样效果。在下一节的生成器模型中,我们将看到一个相似的模式,但方向相反。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= conv2d_1 (Conv2D) (None, 14, 14, 64) 640 _________________________________________________________________ leaky_re_lu_1 (LeakyReLU) (None, 14, 14, 64) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 14, 14, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 7, 7, 64) 36928 _________________________________________________________________ leaky_re_lu_2 (LeakyReLU) (None, 7, 7, 64) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 7, 7, 64) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 3136) 0 _________________________________________________________________ dense_1 (Dense) (None, 1) 3137 ================================================================= 总参数:40,705 可训练参数:40,705 不可训练参数: 0 _________________________________________________________________ |
模型图也会被创建,我们可以看到模型期望两个输入并预测一个输出。
注意:创建此图假定已安装pydot和graphviz库。如果这有问题,可以注释掉plot_model函数的导入语句和plot_model()函数的调用。
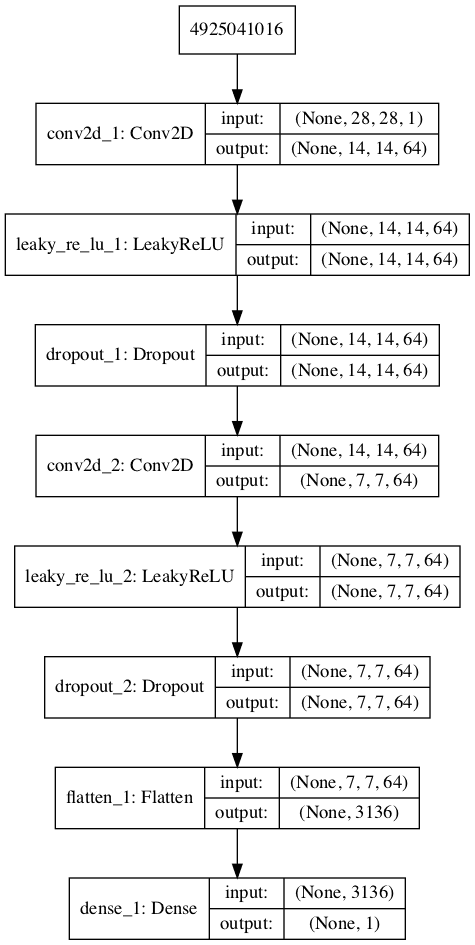
MNIST GAN中判别器模型的图
我们现在就可以用标签为1的真实样本和标签为0的随机生成样本来训练这个模型了。
这些元素的开发以后会很有用,它有助于我们看到判别器只是一个普通的用于二元分类的神经网络模型。
首先,我们需要一个函数来加载和准备真实图像的数据集。
我们将使用mnist.load_data()函数加载MNIST数据集,并仅使用训练数据集的输入部分作为真实图像。
|
1 2 |
# 加载mnist数据集 (trainX, _), (_, _) = load_data() |
图像是像素的二维数组,卷积神经网络期望输入是三维图像数组,其中每个图像有一个或多个通道。
我们必须更新图像以增加灰度通道的维度。我们可以使用expand_dims() NumPy函数来实现这一点,并为通道最后(channels-last)的图像格式指定最后一个维度。
|
1 2 |
# 扩展到3D,例如添加通道维度 X = expand_dims(trainX, axis=-1) |
最后,我们必须将像素值从无符号整数的[0,255]范围缩放到归一化范围[0,1]。
|
1 2 3 4 |
# 从无符号整数转换为浮点数 X = X.astype('float32') # 从[0,255]缩放到[0,1] X = X / 255.0 |
load_real_samples()函数实现了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 加载和准备mnist训练图像 def load_real_samples(): # 加载mnist数据集 (trainX, _), (_, _) = load_data() # 扩展到3D,例如添加通道维度 X = expand_dims(trainX, axis=-1) # 将无符号整数转换为浮点数 X = X.astype('float32') # 从[0,255]缩放到[0,1] X = X / 255.0 return X |
模型将在批次中更新,具体来说是真实样本集合和生成样本集合。训练时,一个 epoch 被定义为通过整个训练数据集的一次完整遍历。
我们可以系统地枚举训练数据集中的所有样本,这是一种好方法,但通过随机梯度下降进行良好训练要求在每个 epoch 之前对训练数据集进行洗牌。一个更简单的方法是从训练数据集中选择随机样本。
下面的generate_real_samples()函数将以训练数据集为参数,并选择一个随机子集图像;它还将为该样本返回类别标签,具体来说是类别标签1,以表示真实图像。
|
1 2 3 4 5 6 7 8 9 |
# 选择真实样本 def generate_real_samples(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 检索选定的图像 X = dataset[ix] # 生成“真实”类别标签 (1) y = ones((n_samples, 1)) return X, y |
现在,我们需要一个伪造图像的来源。
我们还没有生成器模型,所以我们可以生成由随机像素值组成的图像,具体来说是范围在[0,1]内的随机像素值,就像我们缩放过的真实图像一样。
下面的generate_fake_samples()函数实现了这一行为,生成随机像素值的图像及其相关的类别标签0(表示伪造)。
|
1 2 3 4 5 6 7 8 9 |
# 生成带有类别标签的 n 个假样本 def generate_fake_samples(n_samples): # 生成[0,1]范围内的均匀随机数 X = rand(28 * 28 * n_samples) # 重塑为一批灰度图像 X = X.reshape((n_samples, 28, 28, 1)) # 生成“伪造”类别标签(0) y = zeros((n_samples, 1)) return X, y |
最后,我们需要训练判别器模型。
这包括反复检索真实图像样本和生成图像样本,并在固定数量的迭代中更新模型。
我们暂时忽略 epoch 的概念(即完整遍历训练数据集),而是拟合判别器模型固定数量的批次。该模型将能够快速学会区分真实图像和随机生成的(伪造)图像,因此,在它学会完美区分之前,不需要很多批次。
下面的train_discriminator()函数实现了这一点,使用256张图像的批次大小,其中每次迭代中有128张真实图像和128张伪造图像。
我们单独更新真实样本和伪造样本的判别器,以便在更新之前可以计算模型在每个样本上的准确率。这有助于我们了解判别器模型随时间的表现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 训练判别器模型 def train_discriminator(model, dataset, n_iter=100, n_batch=256): half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_iter): # 获取随机选择的“真实”样本 X_real, y_real = generate_real_samples(dataset, half_batch) # 在真实样本上更新判别器 _, real_acc = model.train_on_batch(X_real, y_real) # 生成“假”示例 X_fake, y_fake = generate_fake_samples(half_batch) # 在伪造样本上更新判别器 _, fake_acc = model.train_on_batch(X_fake, y_fake) # 总结性能 print('>%d real=%.0f%% fake=%.0f%%' % (i+1, real_acc*100, fake_acc*100)) |
将所有这些结合起来,下面列出了在真实和随机生成的(伪造)图像上训练判别器模型实例的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
# 在真实和随机mnist图像上训练判别器模型的示例 from numpy import expand_dims from numpy import ones from numpy import zeros from numpy.random import rand from numpy.random import randint from keras.datasets.mnist import load_data from keras.optimizers import Adam from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 Conv2D from keras.layers import Flatten 从 keras.layers 导入 Dropout from keras.layers import LeakyReLU # 定义独立的判别器模型 def define_discriminator(in_shape=(28,28,1)): model = Sequential() model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same', input_shape=in_shape)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) return model # 加载和准备mnist训练图像 def load_real_samples(): # 加载mnist数据集 (trainX, _), (_, _) = load_data() # 扩展到3D,例如添加通道维度 X = expand_dims(trainX, axis=-1) # 将无符号整数转换为浮点数 X = X.astype('float32') # 从[0,255]缩放到[0,1] X = X / 255.0 return X # 选择真实样本 def generate_real_samples(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 检索选定的图像 X = dataset[ix] # 生成“真实”类别标签 (1) y = ones((n_samples, 1)) 返回 X, y # 生成带有类别标签的 n 个假样本 def generate_fake_samples(n_samples): # 生成[0,1]范围内的均匀随机数 X = rand(28 * 28 * n_samples) # 重塑为一批灰度图像 X = X.reshape((n_samples, 28, 28, 1)) # 生成“伪造”类别标签(0) y = zeros((n_samples, 1)) 返回 X, y # 训练判别器模型 def train_discriminator(model, dataset, n_iter=100, n_batch=256): half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_iter): # 获取随机选择的“真实”样本 X_real, y_real = generate_real_samples(dataset, half_batch) # 在真实样本上更新判别器 _, real_acc = model.train_on_batch(X_real, y_real) # 生成“假”示例 X_fake, y_fake = generate_fake_samples(half_batch) # 在伪造样本上更新判别器 _, fake_acc = model.train_on_batch(X_fake, y_fake) # 总结性能 print('>%d real=%.0f%% fake=%.0f%%' % (i+1, real_acc*100, fake_acc*100)) # 定义判别器模型 model = define_discriminator() # 加载图像数据 dataset = load_real_samples() # 拟合模型 train_discriminator(model, dataset) |
运行该示例首先定义模型,加载MNIST数据集,然后训练判别器模型。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能不同。考虑多次运行示例并比较平均结果。
在这种情况下,判别器模型在大约50个批次内就学会了区分真实MNIST图像和随机生成的MNIST图像。
|
1 2 3 4 5 6 |
... >96 real=100% fake=100% >97 real=100% fake=100% >98 real=100% fake=100% >99 real=100% fake=100% >100 real=100% fake=100% |
现在我们知道如何定义和训练判别器模型,我们需要着手开发生成器模型。
如何定义和使用生成器模型
生成器模型负责创建新的、伪造但看起来真实的手写数字图像。
它通过将潜在空间中的一个点作为输入并输出一个方形灰度图像来实现这一点。
隐空间是一个任意定义的向量空间,由高斯分布值组成,例如100维。它本身没有意义,但通过从这个空间中随机抽取点并将它们在训练过程中提供给生成器模型,生成器模型会为这些隐点以及隐空间赋予意义。直到训练结束,隐向量空间才会代表输出空间(MNIST图像)的压缩表示,而只有生成器知道如何将其转换为逼真的MNIST图像。
- 输入:隐空间中的点,例如一个包含100个高斯随机数的向量。
- 输出:28×28像素的二维方形灰度图像,像素值为[0,1]。
注意:我们不必使用100维向量作为输入;这是一个常用的整数,但我想10、50或500维应该也同样有效。
开发一个生成器模型需要我们将隐空间中的一个100维向量转换为一个28×28(即784个值)的二维数组。
有多种方法可以实现这一点,但在深度卷积生成对抗网络中,有一种方法被证明是有效的。它包含两个主要元素。
第一个是作为第一个隐藏层的密集层(Dense layer),它应该有足够多的节点来表示输出图像的低分辨率版本。具体来说,输出图像尺寸的一半(面积的四分之一)将是14×14,即196个节点;输出图像尺寸的四分之一(面积的八分之一)将是7×7,即49个节点。
我们不只想要图像的一个低分辨率版本;我们想要许多并行版本或输入的解释。这是卷积神经网络的架构创新模式,其中我们有许多并行滤波器,产生多个并行激活图,称为特征图,对输入有不同的解释。我们想要反过来做:我们输出的多个并行版本,具有不同的学习特征,可以在输出层折叠成最终图像。模型需要空间来发明、创造或生成。
因此,第一个隐藏层(密集层)需要有足够多的节点来容纳我们输出图像的多个低分辨率版本,例如128个。
|
1 2 |
# 7x7 图像的基础 model.add(Dense(128 * 7 * 7, input_dim=100)) |
这些节点的激活可以被重塑成类似图像的形式,然后输入到卷积层,例如128个不同的7×7特征图。
|
1 |
model.add(Reshape((7, 7, 128))) |
下一个主要的架构创新涉及将低分辨率图像上采样到更高分辨率的版本。
有两种常见的方法可以实现这种上采样过程,有时称为反卷积。
一种方法是使用一个UpSampling2D层(类似于反向池化层),然后是一个正常的Conv2D层。另一种,也许更现代的方法是将这两个操作合并到一个层中,称为Conv2DTranspose。我们将采用后者的方法来构建我们的生成器。
Conv2DTranspose层可以配置一个步长(2×2),这将使输入特征图的面积翻四倍(宽度和高度翻倍)。使用步长因数(例如两倍)的核大小也是一个好习惯,以避免棋盘格图案,这种图案在上采样时可能会出现。
|
1 2 |
# 上采样到 14x14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) |
这可以重复进行,直到达到我们想要的28×28输出图像。
同样,我们将使用LeakyReLU,默认斜率为0.2,这是在训练GAN模型时推荐的最佳实践。
模型的输出层是一个Conv2D层,带有一个滤波器和7×7的核大小,以及‘same’填充,旨在创建一个单一的特征图并保持其维度为28×28像素。使用sigmoid激活函数是为了确保输出值在所需的[0,1]范围内。
下面的define_generator()函数实现了这一点,并定义了生成器模型。
注意:生成器模型未编译,也没有指定损失函数或优化算法。这是因为生成器不直接进行训练。我们将在下一节中了解更多关于这方面的内容。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 定义独立的生成器模型 def define_generator(latent_dim): model = Sequential() # 7x7 图像的基础 n_nodes = 128 * 7 * 7 model.add(Dense(n_nodes, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # 上采样到 14x14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) # 上采样到 28x28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Conv2D(1, (7,7), activation='sigmoid', padding='same')) return model |
我们可以总结模型以更好地理解输入和输出形状。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 定义生成器模型的示例 from keras.models import Sequential from keras.layers import Dense from keras.layers import Reshape 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU from keras.utils.vis_utils import plot_model # 定义独立的生成器模型 def define_generator(latent_dim): model = Sequential() # 7x7 图像的基础 n_nodes = 128 * 7 * 7 model.add(Dense(n_nodes, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # 上采样到 14x14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) # 上采样到 28x28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Conv2D(1, (7,7), activation='sigmoid', padding='same')) return model # 定义潜在空间的大小 latent_dim = 100 # 定义生成器模型 model = define_generator(latent_dim) # 总结模型 model.summary() # 绘制模型 plot_model(model, to_file='generator_plot.png', show_shapes=True, show_layer_names=True) |
运行该示例会总结模型的层及其输出形状。
我们可以看到,正如设计的那样,第一个隐藏层有6272个参数,即128 * 7 * 7,其激活被重塑为128个7×7的特征图。然后,特征图通过两个Conv2DTranspose层上采样到所需的28×28输出形状,直到输出层,在那里输出一个单一的激活图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= dense_1 (Dense) (None, 6272) 633472 _________________________________________________________________ leaky_re_lu_1 (LeakyReLU) (None, 6272) 0 _________________________________________________________________ reshape_1 (Reshape) (None, 7, 7, 128) 0 _________________________________________________________________ conv2d_transpose_1 (Conv2DTr (None, 14, 14, 128) 262272 _________________________________________________________________ leaky_re_lu_2 (LeakyReLU) (None, 14, 14, 128) 0 _________________________________________________________________ conv2d_transpose_2 (Conv2DTr (None, 28, 28, 128) 262272 _________________________________________________________________ leaky_re_lu_3 (LeakyReLU) (None, 28, 28, 128) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 28, 28, 1) 6273 ================================================================= Total params: 1,164,289 Trainable params: 1,164,289 不可训练参数: 0 _________________________________________________________________ |
模型图也被创建,我们可以看到模型期望隐空间中的一个100维点作为输入,并输出一个图像。
注意:创建此图假设已安装pydot和graphviz库。如果这是个问题,您可以注释掉plot_model函数的导入语句和plot_model函数的调用。
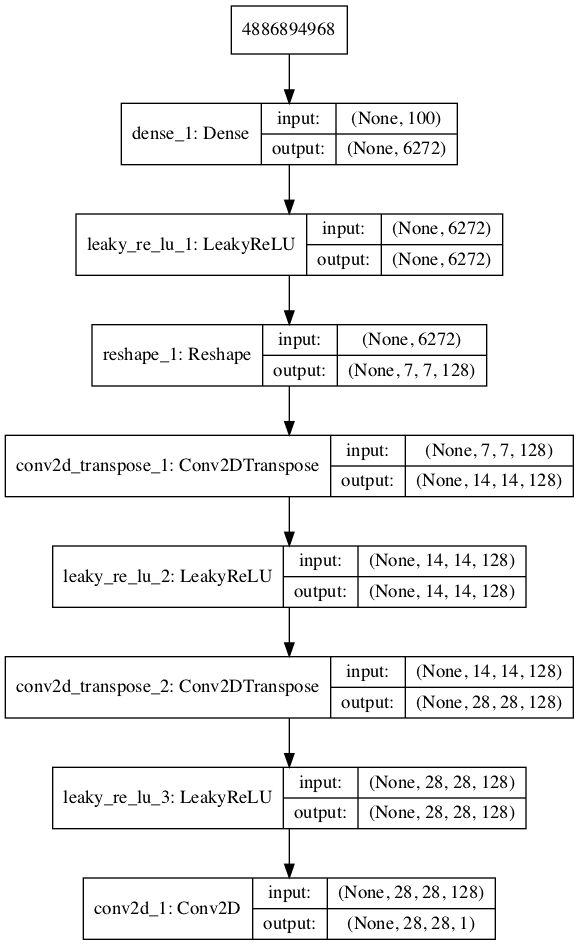
MNIST GAN中生成器模型的图
该模型目前还做不了太多事情。
尽管如此,我们可以演示如何使用它来生成样本。这是一个有用的演示,可以理解生成器只是另一个模型,其中一些元素将在以后使用。
第一步是生成隐空间中的新点。我们可以通过调用randn() NumPy函数来生成从标准高斯分布中抽取的随机数数组。
然后可以将随机数数组重塑为样本,即n行,每行100个元素。下面的generate_latent_points()函数实现了这一点,并在隐空间生成所需数量的点,这些点可以用作生成器模型的输入。
|
1 2 3 4 5 6 7 |
# 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 x_input = x_input.reshape(n_samples, latent_dim) return x_input |
接下来,我们可以使用生成的点作为生成器模型的输入来生成新样本,然后绘制这些样本。
我们可以更新上一节中的generate_fake_samples()函数,使其接受生成器模型作为参数,并通过首先调用generate_latent_points()函数来生成所需数量的样本,以在隐空间生成模型所需的点作为输入。
更新后的generate_fake_samples()函数如下所示,它返回生成的样本和相关的类别标签。
|
1 2 3 4 5 6 7 8 9 |
# 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(g_model, latent_dim, n_samples): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n_samples) # 预测输出 X = g_model.predict(x_input) # 创建“假”类别标签 (0) y = zeros((n_samples, 1)) return X, y |
然后,我们可以像在第一节中处理真实MNIST示例一样,通过调用具有反向灰度颜色映射的imshow()函数来绘制生成的样本。
生成新的MNIST图像(使用未经训练的生成器模型)的完整示例列于下文。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
# 定义和使用生成器模型的示例 from numpy import zeros from numpy.random import randn from keras.models import Sequential from keras.layers import Dense from keras.layers import Reshape 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU from matplotlib import pyplot # 定义独立的生成器模型 def define_generator(latent_dim): model = Sequential() # 7x7 图像的基础 n_nodes = 128 * 7 * 7 model.add(Dense(n_nodes, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # 上采样到 14x14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) # 上采样到 28x28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Conv2D(1, (7,7), activation='sigmoid', padding='same')) return model # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 x_input = x_input.reshape(n_samples, latent_dim) return x_input # 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(g_model, latent_dim, n_samples): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n_samples) # 预测输出 X = g_model.predict(x_input) # 创建“假”类别标签 (0) y = zeros((n_samples, 1)) 返回 X, y # 潜在空间的大小 latent_dim = 100 # 定义判别器模型 model = define_generator(latent_dim) # 生成样本 n_samples = 25 X, _ = generate_fake_samples(model, latent_dim, n_samples) # 绘制生成的样本 for i in range(n_samples): # 定义子图 pyplot.subplot(5, 5, 1 + i) # 关闭轴标签 pyplot.axis('off') # 绘制单个图像 pyplot.imshow(X[i, :, :, 0], cmap='gray_r') # 显示图 pyplot.show() |
运行该示例会生成25个伪造的MNIST图像,并将它们可视化在一个5x5的图像网格上。
由于模型未经训练,生成的图像是[0, 1]范围内的完全随机的像素值。

未经训练的生成器模型输出的25个MNIST图像示例
既然我们知道如何定义和使用生成器模型,下一步就是训练模型。
如何训练生成器模型
生成器模型中的权重根据判别器模型的性能进行更新。
当判别器善于检测假样本时,生成器更新更多;当判别器模型在检测假样本时相对较差或感到困惑时,生成器模型更新较少。
这定义了这两个模型之间的零和或对抗关系。
使用Keras API可以有很多种方法来实现这一点,但也许最简单的方法是创建一个新的模型,该模型结合了生成器和判别器模型。
具体来说,可以定义一个名为GAN的新模型,该模型堆叠生成器和判别器,使得生成器以隐空间中的随机点为输入,并生成馈入判别器模型的样本,然后进行分类。这个更大模型的输出可用于更新生成器的模型权重。
为了说清楚,我们不是在谈论一个全新的第三方模型,只是一个利用已定义的独立生成器和判别器模型的层和权重的新逻辑模型。
只有判别器关心区分真实和伪造的样本,因此判别器模型可以独立地在每种样本上进行训练,就像我们在上面的判别器模型部分中所做的那样。
生成器模型只关心判别器在伪造样本上的表现。因此,当判别器模型作为GAN模型的一部分时,我们将把判别器中的所有层标记为不可训练,这样它们就不会被更新并过度拟合到伪造样本上。
通过这个逻辑GAN模型训练生成器时,还有一个重要的变化。我们希望判别器认为生成器输出的样本是真实的,而不是伪造的。因此,当生成器作为GAN模型的一部分进行训练时,我们将生成的样本标记为真实(类别1)。
为什么要这样做?
我们可以想象,判别器会将生成的样本分类为不真实(类别0)或真实的可能性很低(0.3或0.5)。用于更新模型权重的反向传播过程将看到这是一个很大的错误,并将更新模型权重(即只更新生成器中的权重)来纠正这个错误,从而使生成器能够更好地生成高质量的伪造样本。
让我们具体化。
- 输入:隐空间中的点,例如一个包含100个高斯随机数的向量。
- **输出**:二元分类,样本为真实的(或伪造的)可能性。
下面的define_gan()函数接受已定义的生成器和判别器模型作为参数,并创建了包含这两个模型的新逻辑模型。判别器的权重被标记为不可训练,这仅影响GAN模型看到的权重,而不影响独立的判别器模型。
GAN模型然后使用与判别器相同的二元交叉熵损失函数,以及高效的Adam随机梯度下降版本,学习率为0.0002,动量为0.5,这是训练深度卷积GAN时推荐的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(g_model, d_model): # 使判别器中的权重不可训练 d_model.trainable = False # 连接它们 model = Sequential() # 添加生成器 model.add(g_model) # 添加判别器 model.add(d_model) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt) return model |
使判别器不可训练是 Keras API 中的一个巧妙技巧。
可训练属性在模型编译后才会生效。判别器模型已编译了可训练层,因此在通过调用train_on_batch()函数更新独立模型时,这些层的模型权重将被更新。
然后,判别器模型被标记为不可训练,添加到GAN模型中并进行编译。在此模型中,判别器模型权重是不可训练的,并且在通过调用train_on_batch()函数更新GAN模型时不能被更改。这个可训练属性的改变不会影响独立判别器模型的训练。
Keras API文档中对此行为进行了描述
创建判别器、生成器和组合模型的完整示例列于下文。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
# 演示在GAN中创建三个模型 from keras.optimizers import Adam from keras.models import Sequential from keras.layers import Dense from keras.layers import Reshape from keras.layers import Flatten 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU 从 keras.layers 导入 Dropout from keras.utils.vis_utils import plot_model # 定义独立的判别器模型 def define_discriminator(in_shape=(28,28,1)): model = Sequential() model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same', input_shape=in_shape)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) return model # 定义独立的生成器模型 def define_generator(latent_dim): model = Sequential() # 7x7 图像的基础 n_nodes = 128 * 7 * 7 model.add(Dense(n_nodes, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # 上采样到 14x14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) # 上采样到 28x28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Conv2D(1, (7,7), activation='sigmoid', padding='same')) return model # 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(g_model, d_model): # 使判别器中的权重不可训练 d_model.trainable = False # 连接它们 model = Sequential() # 添加生成器 model.add(g_model) # 添加判别器 model.add(d_model) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt) return model # 潜在空间的大小 latent_dim = 100 # 创建判别器 d_model = define_discriminator() # 创建生成器 g_model = define_generator(latent_dim) # 创建GAN gan_model = define_gan(g_model, d_model) # 总结GAN模型 gan_model.summary() # 绘制GAN模型 plot_model(gan_model, to_file='gan_plot.png', show_shapes=True, show_layer_names=True) |
运行该示例首先会创建一个组合模型的摘要。
我们可以看到,模型期望MNIST图像作为输入,并预测一个单一的输出值。
|
1 2 3 4 5 6 7 8 9 10 11 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= sequential_2 (Sequential) (None, 28, 28, 1) 1164289 _________________________________________________________________ sequential_1 (Sequential) (None, 1) 40705 ================================================================= Total params: 1,204,994 Trainable params: 1,164,289 Non-trainable params: 40,705 _________________________________________________________________ |
模型图也被创建,我们可以看到模型期望隐空间中的一个100维点作为输入,并预测一个单一的输出分类标签。
注意:创建此图假定已安装pydot和graphviz库。如果这有问题,可以注释掉plot_model函数的导入语句和plot_model()函数的调用。
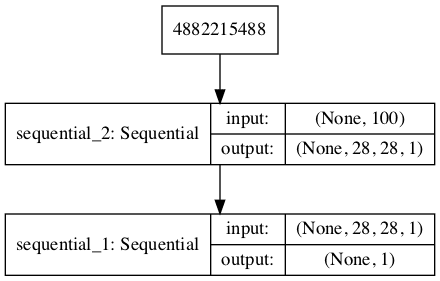
MNIST GAN中组合生成器和判别器模型的图
训练组合模型涉及通过上一节的generate_latent_points()函数生成一个批次的隐空间点,以及class=1标签,并调用train_on_batch()函数。
下面的train_gan()函数演示了这一点,尽管它很简单,因为每个epoch只更新生成器,判别器保持默认的模型权重。
|
1 2 3 4 5 6 7 8 9 10 |
# 训练复合模型 def train_gan(gan_model, latent_dim, n_epochs=100, n_batch=256): # 手动枚举 epoch for i in range(n_epochs): # 准备潜在空间中的点作为生成器的输入 x_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过判别器的误差更新生成器 gan_model.train_on_batch(x_gan, y_gan) |
相反,我们需要首先使用真实和伪样本更新判别器模型,然后通过复合模型更新生成器。
这需要结合前面判别器部分定义的train_discriminator()函数和上面定义的train_gan()函数中的元素。它还需要我们对每个epoch中的epoch和batch进行枚举。
用于更新判别器模型和生成器(通过复合模型)的完整训练函数如下所示。
这个模型训练函数中有几点需要注意。
首先,每个epoch中的batch数量由batch大小除以训练数据集的次数决定。我们有一个60K样本的数据集,向下取整后,每个epoch有234个batch。
判别器模型通过vstack() NumPy函数将一半的伪样本和一半的真实样本组合成一个批次进行更新。您可以单独更新每个半批次的判别器(推荐用于更复杂的数据集),但在长期运行中,特别是在GPU硬件上训练时,将样本组合成一个批次会更快。
最后,我们报告每个batch的损失。密切关注batch上的损失至关重要。原因在于,判别器损失的崩溃表明生成器模型已经开始生成垃圾样本,判别器很容易辨别。
监控判别器损失,并期望它在这个数据集上每个batch的损失在0.5到0.8之间波动。生成器损失不太关键,在这个数据集上可能在0.5到2或更高之间波动。一个聪明的程序员甚至可能尝试检测判别器损失的崩溃,然后停止并重新启动训练过程。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 训练生成器和判别器 def train(g_model, d_model, gan_model, dataset, latent_dim, n_epochs=100, n_batch=256): bat_per_epo = int(dataset.shape[0] / n_batch) half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_epochs): # 枚举训练集中的批次 for j in range(bat_per_epo): # 获取随机选择的“真实”样本 X_real, y_real = generate_real_samples(dataset, half_batch) # 生成“假”示例 X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 创建判别器的训练集 X, y = vstack((X_real, X_fake)), vstack((y_real, y_fake)) # 更新判别器模型权重 d_loss, _ = d_model.train_on_batch(X, y) # 准备潜在空间中的点作为生成器的输入 X_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过判别器的误差更新生成器 g_loss = gan_model.train_on_batch(X_gan, y_gan) # 总结此批次的损失 print('>%d, %d/%d, d=%.3f, g=%.3f' % (i+1, j+1, bat_per_epo, d_loss, g_loss)) |
我们几乎拥有开发MNIST手写数字数据集GAN所需的一切。
剩余的一个方面是模型的评估。
如何评估GAN模型性能
通常,没有客观的方法来评估GAN模型的性能。
我们无法计算生成图像的目标误差分数。对于MNIST图像来说,这可能是可能的,因为图像的约束性很强,但总的来说,这是不可能的(至少目前还不行)。
相反,图像必须由人工操作员主观评估其质量。这意味着我们无法在不查看生成图像示例的情况下知道何时停止训练。反过来,训练过程的对抗性本质意味着生成器在每个batch后都会改变,这意味着一旦生成了“足够好”的图像,图像的主观质量可能会随着后续更新而变化、提高甚至降低。
有三种方法可以处理这种复杂的训练情况。
- 定期评估判别器在真实和伪造图像上的分类准确率。
- 定期生成大量图像并将其保存到文件中以供主观审查。
- 定期保存生成器模型。
所有这三项操作都可以同时在给定的训练epoch中执行,例如每五个或十个训练epoch执行一次。结果将是一个已保存的生成器模型,我们可以通过它来主观评估其输出质量,并客观地了解在模型保存时判别器被愚弄的程度。
将GAN训练数百或数千个epoch,将产生许多模型快照,可以对其进行检查,并从中挑选特定的输出和模型供以后使用。
首先,我们可以定义一个名为summarize_performance()的函数,它将总结判别器模型的性能。它通过检索MNIST真实图像样本,并使用生成器模型生成相同数量的MNIST伪造图像,然后评估判别器模型在每个样本上的分类准确率并报告这些分数来做到这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 评估判别器,绘制生成的图像,保存生成器模型 def summarize_performance(epoch, g_model, d_model, dataset, latent_dim, n_samples=100): # 准备真实样本 X_real, y_real = generate_real_samples(dataset, n_samples) # 评估判别器在真实示例上的表现 _, acc_real = d_model.evaluate(X_real, y_real, verbose=0) # 准备伪示例 x_fake, y_fake = generate_fake_samples(g_model, latent_dim, n_samples) # 评估判别器在伪示例上的表现 _, acc_fake = d_model.evaluate(x_fake, y_fake, verbose=0) # 总结判别器性能 print('>Accuracy real: %.0f%%, fake: %.0f%%' % (acc_real*100, acc_fake*100)) |
此函数可以根据当前 epoch 数,例如每 10 个 epoch 调用一次 train() 函数。
|
1 2 3 4 5 6 7 8 9 10 |
# 训练生成器和判别器 def train(g_model, d_model, gan_model, dataset, latent_dim, n_epochs=100, n_batch=256): bat_per_epo = int(dataset.shape[0] / n_batch) half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_epochs): ... # 有时评估模型性能 if (i+1) % 10 == 0: summarize_performance(i, g_model, d_model, dataset, latent_dim) |
接下来,我们可以更新 summarize_performance() 函数,以保存模型并创建和保存生成的示例图。
可以通过调用生成器模型的 save() 函数并提供基于训练 epoch 数的唯一文件名来保存生成器模型。
|
1 2 3 4 |
... # 保存生成器模型到文件 filename = 'generator_model_%03d.h5' % (epoch + 1) g_model.save(filename) |
我们可以开发一个函数来创建生成的样本图。
由于我们在对 100 个生成的 MNIST 图像评估判别器,因此我们可以将所有 100 张图像绘制成 10x10 的网格。下面的 save_plot() 函数实现了这一点,同样使用基于 epoch 数量的唯一文件名保存结果图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 创建并保存生成的图像图(反转的灰度) def save_plot(examples, epoch, n=10): # 绘制图像 for i in range(n * n): # 定义子图 pyplot.subplot(n, n, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(examples[i, :, :, 0], cmap='gray_r') # 保存图到文件 filename = 'generated_plot_e%03d.png' % (epoch+1) pyplot.savefig(filename) pyplot.close() |
下面列出了更新了这些附加项的 summarize_performance() 函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估判别器,绘制生成的图像,保存生成器模型 def summarize_performance(epoch, g_model, d_model, dataset, latent_dim, n_samples=100): # 准备真实样本 X_real, y_real = generate_real_samples(dataset, n_samples) # 评估判别器在真实示例上的表现 _, acc_real = d_model.evaluate(X_real, y_real, verbose=0) # 准备伪示例 x_fake, y_fake = generate_fake_samples(g_model, latent_dim, n_samples) # 评估判别器在伪示例上的表现 _, acc_fake = d_model.evaluate(x_fake, y_fake, verbose=0) # 总结判别器性能 print('>Accuracy real: %.0f%%, fake: %.0f%%' % (acc_real*100, acc_fake*100)) # 保存图 save_plot(x_fake, epoch) # 保存生成器模型到文件 filename = 'generator_model_%03d.h5' % (epoch + 1) g_model.save(filename) |
MNIST GAN的完整示例
现在,我们拥有了在 MNIST 手写数字数据集上训练和评估 GAN 所需的一切。
完整的示例如下所示。
注意:此示例可以在 CPU 上运行,但可能需要数小时。该示例可以在 GPU 上运行,例如 Amazon EC2 p3 实例,并且将在几分钟内完成。
有关设置 AWS EC2 实例来运行此代码的帮助,请参阅教程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 |
# MNIST 训练 GAN 的示例 from numpy import expand_dims from numpy import zeros from numpy import ones from numpy import vstack from numpy.random import randn from numpy.random import randint from keras.datasets.mnist import load_data from keras.optimizers import Adam from keras.models import Sequential from keras.layers import Dense from keras.layers import Reshape from keras.layers import Flatten 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU 从 keras.layers 导入 Dropout from matplotlib import pyplot # 定义独立的判别器模型 def define_discriminator(in_shape=(28,28,1)): model = Sequential() model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same', input_shape=in_shape)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) return model # 定义独立的生成器模型 def define_generator(latent_dim): model = Sequential() # 7x7 图像的基础 n_nodes = 128 * 7 * 7 model.add(Dense(n_nodes, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # 上采样到 14x14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) # 上采样到 28x28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')) model.add(LeakyReLU(alpha=0.2)) model.add(Conv2D(1, (7,7), activation='sigmoid', padding='same')) return model # 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(g_model, d_model): # 使判别器中的权重不可训练 d_model.trainable = False # 连接它们 model = Sequential() # 添加生成器 model.add(g_model) # 添加判别器 model.add(d_model) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt) return model # 加载和准备mnist训练图像 def load_real_samples(): # 加载mnist数据集 (trainX, _), (_, _) = load_data() # 扩展到3D,例如添加通道维度 X = expand_dims(trainX, axis=-1) # 将无符号整数转换为浮点数 X = X.astype('float32') # 从[0,255]缩放到[0,1] X = X / 255.0 return X # 选择真实样本 def generate_real_samples(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 检索选定的图像 X = dataset[ix] # 生成“真实”类别标签 (1) y = ones((n_samples, 1)) 返回 X, y # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 x_input = x_input.reshape(n_samples, latent_dim) return x_input # 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(g_model, latent_dim, n_samples): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n_samples) # 预测输出 X = g_model.predict(x_input) # 创建“假”类别标签 (0) y = zeros((n_samples, 1)) 返回 X, y # 创建并保存生成的图像图(反转的灰度) def save_plot(examples, epoch, n=10): # 绘制图像 for i in range(n * n): # 定义子图 pyplot.subplot(n, n, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(examples[i, :, :, 0], cmap='gray_r') # 保存图到文件 filename = 'generated_plot_e%03d.png' % (epoch+1) pyplot.savefig(filename) pyplot.close() # 评估判别器,绘制生成的图像,保存生成器模型 def summarize_performance(epoch, g_model, d_model, dataset, latent_dim, n_samples=100): # 准备真实样本 X_real, y_real = generate_real_samples(dataset, n_samples) # 评估判别器在真实示例上的表现 _, acc_real = d_model.evaluate(X_real, y_real, verbose=0) # 准备伪示例 x_fake, y_fake = generate_fake_samples(g_model, latent_dim, n_samples) # 评估判别器在伪示例上的表现 _, acc_fake = d_model.evaluate(x_fake, y_fake, verbose=0) # 总结判别器性能 print('>Accuracy real: %.0f%%, fake: %.0f%%' % (acc_real*100, acc_fake*100)) # 保存图 save_plot(x_fake, epoch) # 保存生成器模型到文件 filename = 'generator_model_%03d.h5' % (epoch + 1) g_model.save(filename) # 训练生成器和判别器 def train(g_model, d_model, gan_model, dataset, latent_dim, n_epochs=100, n_batch=256): bat_per_epo = int(dataset.shape[0] / n_batch) half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_epochs): # 枚举训练集中的批次 for j in range(bat_per_epo): # 获取随机选择的“真实”样本 X_real, y_real = generate_real_samples(dataset, half_batch) # 生成“假”示例 X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 创建判别器的训练集 X, y = vstack((X_real, X_fake)), vstack((y_real, y_fake)) # 更新判别器模型权重 d_loss, _ = d_model.train_on_batch(X, y) # 准备潜在空间中的点作为生成器的输入 X_gan = generate_latent_points(latent_dim, n_batch) # 为伪样本创建反转标签 y_gan = ones((n_batch, 1)) # 通过判别器的误差更新生成器 g_loss = gan_model.train_on_batch(X_gan, y_gan) # 总结此批次的损失 print('>%d, %d/%d, d=%.3f, g=%.3f' % (i+1, j+1, bat_per_epo, d_loss, g_loss)) # 有时评估模型性能 if (i+1) % 10 == 0: summarize_performance(i, g_model, d_model, dataset, latent_dim) # 潜在空间的大小 latent_dim = 100 # 创建判别器 d_model = define_discriminator() # 创建生成器 g_model = define_generator(latent_dim) # 创建GAN gan_model = define_gan(g_model, d_model) # 加载图像数据 dataset = load_real_samples() # 训练模型 train(g_model, d_model, gan_model, dataset, latent_dim) |
选择的配置可实现生成模型和判别模型的稳定训练。
模型性能每批次报告一次,包括判别器(d)和生成器(g)模型的损失。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能不同。考虑多次运行示例并比较平均结果。
在这种情况下,损失在训练过程中保持稳定。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
>1, 1/234, d=0.711, g=0.678 >1, 2/234, d=0.703, g=0.698 >1, 3/234, d=0.694, g=0.717 >1, 4/234, d=0.684, g=0.740 >1, 5/234, d=0.679, g=0.757 >1, 6/234, d=0.668, g=0.777 ... >100, 230/234, d=0.690, g=0.710 >100, 231/234, d=0.692, g=0.705 >100, 232/234, d=0.698, g=0.701 >100, 233/234, d=0.697, g=0.688 >100, 234/234, d=0.693, g=0.698 |
生成器每训练 20 个 epoch 进行一次评估,产生 10 次评估、10 张生成的图像图和 10 个保存的模型。
在这种情况下,我们可以看到准确率在训练过程中有所波动。当同时查看判别器模型的准确率分数和生成的图像时,我们可以看到,对假样本的准确率与图像的感官质量并不密切相关,但对真实样本的准确率可能相关。
这是 GAN 性能的一个粗略且可能不可靠的指标,损失也是如此。
|
1 2 3 4 5 6 7 8 9 10 |
>Accuracy real: 51%, fake: 78% >Accuracy real: 30%, fake: 95% >Accuracy real: 75%, fake: 59% >Accuracy real: 98%, fake: 11% >Accuracy real: 27%, fake: 92% >Accuracy real: 21%, fake: 92% >Accuracy real: 29%, fake: 96% >Accuracy real: 4%, fake: 99% >Accuracy real: 18%, fake: 97% >Accuracy real: 28%, fake: 89% |
在某个点之后进行更多的训练并不意味着生成的图像质量更好。
在这种情况下,10 个 epoch 后的结果质量很低,但我们可以看到生成器已经学会了生成白底黑图(记住我们反转了图中的灰度)。

10 个 epoch 后 100 张 GAN 生成的 MNIST 数字图
再训练 20 或 30 个 epoch 后,模型开始生成非常逼真的 MNIST 数字,这表明对于所选的模型配置,可能不需要 100 个 epoch。

40 个 epoch 后 100 张 GAN 生成的 MNIST 数字图
100 个 epoch 后的生成图像没有太大区别,但我认为我可以检测到曲线中块状感减少。

100 个 epoch 后 100 张 GAN 生成的 MNIST 数字图
如何使用最终的生成器模型生成图像
一旦选定了最终的生成器模型,就可以将其独立用于您的应用程序。
这包括首先从文件加载模型,然后使用它来生成图像。每张图像的生成都需要潜在空间中的一个点作为输入。
下面列出了加载已保存模型并生成图像的完整示例。在这种情况下,我们将使用训练 100 个 epoch 后保存的模型,但使用 40 或 50 个 epoch 后保存的模型效果也一样好。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# 加载生成器模型并生成图像的示例 from keras.models import load_model from numpy.random import randn from matplotlib import pyplot # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 x_input = x_input.reshape(n_samples, latent_dim) return x_input # 创建并保存生成的图像图(反转的灰度) def save_plot(examples, n): # 绘制图像 for i in range(n * n): # 定义子图 pyplot.subplot(n, n, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(examples[i, :, :, 0], cmap='gray_r') pyplot.show() # 加载模型 model = load_model('generator_model_100.h5') # 生成图像 latent_points = generate_latent_points(100, 25) # 生成图像 X = model.predict(latent_points) # 绘制结果 save_plot(X, 5) |
运行示例首先加载模型,从潜在空间采样 25 个随机点,生成 25 张图像,然后将结果绘制成一张图像。
我们可以看到大多数图像都是逼真的,或者说是手写数字逼真的部分。
25 张 GAN 生成的 MNIST 手写数字示例
现在,潜在空间定义了 MNIST 手写数字的压缩表示。
您可以尝试生成此空间中的不同点,看看它们生成了哪些类型的数字。
下面的示例使用全为 0.0 的向量生成一个手写数字。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 为潜在空间中的特定点生成图像的示例 from keras.models import load_model from numpy import asarray from matplotlib import pyplot # 加载模型 model = load_model('generator_model_100.h5') # 全为0 vector = asarray([[0.0 for _ in range(100)]]) # 生成图像 X = model.predict(vector) # 绘制结果 pyplot.imshow(X[0, :, :, 0], cmap='gray_r') pyplot.show() |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能不同。考虑多次运行示例并比较平均结果。
在这种情况下,全零向量会生成一个手写数字 9,或者可能是 8。然后,您可以尝试导航此空间,看看是否能生成一系列相似但不同的手写数字。
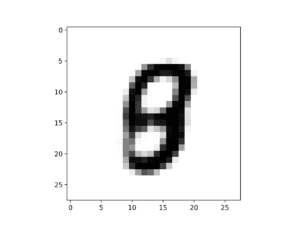
全零向量的 GAN 生成 MNIST 手写数字示例
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- TanH 激活和缩放。更新示例,在生成器中使用 tanh 激活函数,并将所有像素值缩放到 [-1, 1] 范围。
- 更改潜在空间。更新示例,使用更大或更小的潜在空间,并比较结果的质量和训练速度。
- 批量归一化。更新判别器和/或生成器以使用批量归一化,这对于 DCGAN 模型是推荐的。
- 标签平滑。更新示例,在训练判别器时使用单向标签平滑,具体来说,将真实样本的目标标签从 1.0 更改为 0.9,并查看对图像质量和训练速度的影响。
- 模型配置。更新模型配置,使用更深或更浅的判别器和/或生成器模型,可以尝试生成器中的 UpSampling2D 层。
如果您探索了这些扩展中的任何一个,我很想知道。
请在下面的评论中发布您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 第20章。深度生成模型,深度学习,2016年。
- 第8章。生成深度学习,Python深度学习,2017年。
论文
- 生成对抗网络, 2014.
- 教程:生成对抗网络,NIPS, 2016.
- 使用深度卷积生成对抗网络的无监督表征学习, 2015
API
- Keras 数据集 API
- Keras 序列模型 API
- Keras卷积层API
- 我如何“冻结”Keras层?
- MatplotLib API
- NumPy 随机抽样 (numpy.random) API
- NumPy 数组操作例程
文章
文章
- MNIST 数据集, Wikipedia.
- GAN-in-keras-on-mnist 项目, GitHub.
- Keras-GAN 项目, GitHub.
- Keras-MNIST-GAN 项目, GitHub.
总结
在本教程中,您将学习如何开发一个具有深度卷积网络的生成对抗网络,用于生成手写数字。
具体来说,你学到了:
- 如何定义和训练独立的判别器模型,以学习区分真实和伪造图像。
- 如何定义独立的生成器模型,并训练组合的生成器和判别器模型。
- 如何评估GAN的性能,并使用最终的独立生成器模型来生成新图像。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...

 From Scratch with Keras")


 From Scratch")
 in Keras")
你好,Jason。
很棒的教程。您的 GAN 书何时出版?您会做关于 GAN 的迁移学习教程吗?
谢谢!
我希望在几周内能准备好这本书。
好建议!
您好 Jason 先生,
pyplot.imshow(trainX[i], cmap=’gray’) and pyplot.imshow(testX[i], cmap=’gray’) 出现了错误,因为您传递了变量‘i’。
感谢您提供的精彩教程。
我没有收到错误。您具体遇到了什么错误?
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
太感谢了。
我有 2 个问题,如果可以的话。
# 7x7 图像的基础
model.add(Dense(128 * 7 * 7, input_dim=100)).
我有时会看到 input_dim = 100,那么我们什么时候需要逗号?
我的第二个问题。生成器的输出必须匹配我们 GAN 中判别器的输入,对吗?那么这些 (7,7) 的滤波器尺寸是怎么回事?
非常感谢您的详细解释
此致
很好的问题!
当指定“shape”而不是“dim”时,您需要逗号。
正确,D 的输入匹配 G 的输出。7x7 是我们用于随机图像的起点,我们通过适当的层将其缩放到所需的尺寸。
这有帮助吗?
谢谢 Jason。
判别器的输入是带有 1 个颜色通道的 28x28 图像。如果我们提供不同的形状,可能会出现错误。
我们的输出是 conv2dtransposed 以匹配该尺寸 28x28,但这些 7x7 滤波器是怎么回事?在 GAN 中,我们将生成器的输出堆叠为判别器的输入,所以我认为我们需要 (batch_size, 28,28,1),这与具有这些 7x7 滤波器的生成器的返回值不同。也许我遗漏了什么。
再次感谢您的博客。您的速度和解释非常有价值!
生成器的输出是一个 28x28x1 的矩阵。
感谢您提供详尽的笔记 Jason。我做过一些深度 CNN 作为常规分类器的研究,但这些示例是我进入 GAN 世界的第一步。您的解释非常清晰。
这个工作得很好。有时会出现判别器崩溃到零的问题。这似乎是 GAN 的一个已知特性。有没有已建立的 GAN 技巧可以帮助解决这个问题?
在 100 个 epoch 后查看判别器,它处于一种混淆状态,所有输入它的东西都大约有 50% 的概率是真实/虚假的。我根据判别器的概率对一些生成的示例进行了颜色编码(红色=虚假,绿色=真实,蓝色=基于任意分级的不确定),正如您所提到的,主观性与判别器的输出并不总是匹配。(示例发布在 LinkedIn 上)。判别器概率输出的分布不足以使其有意义。
找到一种衡量生成器好坏的机制以保存“最佳”模型会很好,否则,关于哪个是最佳生成器,似乎仍然非常主观。
是的,这些技巧将有助于减少崩溃的可能性。
我将在未来介绍好的指标/损失。WGAN 可能是最好的。我将发布 2 篇关于此主题的文章。
谢谢,我会留意。在此期间,我将使用此示例作为沙盒来尝试一些建议的技巧。谢谢
好主意!
我花了 28 小时用 CPU 模式(i7,第 8 代 PC)训练并完成了我的模型。它生成的数字图像看起来很好,可识别度达到 90%。这是一个非常好的教程。谢谢。
干得好 Phillip!
敬佩
嗨,Jason,
感谢这个精彩的教程,我正在尝试为 Ising 模型做一个 GAN,我想除了噪声之外,还将温度这个额外的参数传递给生成器。在使用作为生成器的转置 CNN 网络中是否可能?
当然,或许可以看看一些条件 GAN,例如
https://machinelearning.org.cn/how-to-develop-a-conditional-generative-adversarial-network-from-scratch/
您有上面完整代码的 GitHub 链接吗?
完整的代码列在上面的教程中,您可以直接复制粘贴。
如果您需要帮助,请看这个
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
你好,Jason
我尝试了您的一些建议
- 我尝试了 tanh 而不是 sigmoid,但很快判别器的损失就小于 0.5(约 0.2)
- 我在生成器中添加了 batchNormalization,但没有看到结果有很大差异
model = Sequential()
# 7x7 图像的基础
n_nodes = 128 * 7 * 7
model.add(Dense(n_nodes, input_dim=latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Reshape((7, 7, 128)))
# 放大到 14x14
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
# 放大到 28x28
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(1, (7,7), activation=’sigmoid’, padding=’same’))
return model
- 我将 latent_dim 参数从 100 更改为 5000。计算出的模型每次都更大,计算时间每次都更长,在 Nvidia k100 GPU 上从 100 的 45 分钟到 5000 的 120 分钟,而且结果每次都更好。
我将继续努力
保持潜在空间较小,设置为 100。
可以尝试 MSE 损失函数。它效果很好!
嘿,Jason
我从来不理解 dropout 在 conv 层中的工作原理。理论上它对我来说有点奇怪。
https://towardsdatascience.com/dropout-on-convolutional-layers-is-weird-5c6ab14f19b2
这篇文章支持我的直觉。
我尝试了您的模型,但没有 dropout,在第 80 个 epoch 后,准确率达到了 real:100% fake :3%。
如果我的理解是正确的,这意味着我们的生成器已经非常擅长欺骗判别器了。
您如何看待这些结果?您对应用于 conv 层的 dropout 有何看法?
对于 GAN,您希望 D 和 G 具有相同的技能。如果一个比另一个好得多,就会出现故障模式。
https://machinelearning.org.cn/practical-guide-to-gan-failure-modes/
你好 Jason,再次感谢你的精彩发帖,根据你的建议,我使用了生成器的 tanh 函数,并将数据集范围更改为 [-1, 1],但我从生成器得到了黑色的图像,所以我将生成器的最后一个层的滤波器大小改成了更小的值,(3, 3),我不知道为什么,但它奏效了。
干得好!
嗨 Jason
感谢您的教程
为什么您没有像对真实图像那样,将假图像的通道也增强到 3?
假图像直接以 3 个维度生成。
先生,您好,
您有这个项目的相关论文吗?
请回复。
是的,我有一本关于这个主题的书。
https://machinelearning.org.cn/generative_adversarial_networks/
另外,本帖的“进一步阅读”部分列出了论文。
为什么判别器被 train_on_batch 更新两次?我认为这一步会更新两次参数。是这样吗?但在 pytorch 中,我们只是累积了所有梯度(用于真实数据和生成数据),然后通过单步更新参数。
实现 GAN 的方法有很多种。
你好 Jason,我如何在上面的代码中将 MNIST 数据集更改为离线数据集?请分享一些参考。
您可以将数据集加载为 numpy 数组。
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
谢谢 Jason。但我有一个大型数据集,并且我遵循您在以下链接中提供的步骤。
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
我想在半监督 GAN 中应用我的数据集,如下所示:
https://machinelearning.org.cn/semi-supervised-generative-adversarial-network/.
您在您的电子书中涵盖了这些类型的信息吗?如果是,请分享链接。
您可能需要使用自定义数据加载器,因为 GAN 可能与图像数据生成器不兼容。
我通常在拟合 GAN 时将所有数据加载到 RAM 中。例如,使用具有 64GB+ RAM 的 EC2 实例。
感谢您的精彩帖子!我从中学习了很多。但当我训练模型时,我收到了以下警告:
/opt/conda/lib/python3.6/site-packages/keras/engine/training.py:297: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set
model.trainablewithout callingmodel.compileafter ?“可训练权重与收集到的可训练权重之间存在差异”
这重要吗?
你可以放心忽略此警告。
感谢您的回复!
我想知道如何获得最先进的性能?即使我尝试了您列出的所有技巧,我发现有些生成的图像很棒,而其他图像仍然无法识别数字是什么?有什么建议吗?
最好的建议是测试不同的模型、不同的配置等。
嗨,Jason,
感谢您与我们分享本教程。它非常有用且写得很好。
我想问一个问题。如果我有一个包含一百万张彩色图像的数据集,每张图像的尺寸为28 x 28像素,您会推荐哪种GAN架构?
提前感谢。
不客气。
也许可以从一个简单的DCGAN和一个较小的数据样本开始,然后调整模型以发现什么效果最好。
从这里的一些教程开始,以获取模型架构和调整技巧的灵感。
https://machinelearning.org.cn/start-here/#gans
嗨,Jason,
出色的教程。
我有一个问题。如果生成器和判别器现在已合并,那么保留“原始”判别器(除了用于评估其损失值)有什么意义?
谢谢。
判别器必须作为独立模型进行更新。
生成器必须通过判别器进行更新。
最后,判别器和组合模型将被丢弃,我们保留独立的生成器。
有关GAN基础知识的更多信息,请从这里开始。
https://machinelearning.org.cn/start-here/#gans
嗨Jason,感谢您的回复。
我明白判别器(未组合的那个)是作为独立模型更新的。但是,当您说“生成器必须通过判别器进行更新”时,
您指的是“原始”判别器吗?还是组合模型中的那个?如果是后者,生成器如何使用它来更新自身,因为“组合”判别器的权重是不可训练的?我感觉我错过了一个关键步骤。
谢谢。
请参阅本教程以了解GAN训练算法,例如通过判别器进行生成器训练。
https://machinelearning.org.cn/how-to-code-the-generative-adversarial-network-training-algorithm-and-loss-functions/
出色的教程!
我有一个关于train函数的问题,该函数以d_model、g_model和gan_model(以及其他)作为输入。
在该函数中,有一个d_model和g_model。gan_model中也有一个d_model和gan_model中的g_model。
您运行d_model.train_on_batch来更新d_model权重。之后,需要将更新后的权重传递给gan_model中的d_model,然后才能运行gan_model.train_on_batch,但我没有看到任何执行此操作的代码行。
同样,在训练gan_model以更新gan_model中的g_model权重后,这些权重应传递给g_model以进行下一次假图像生成。同样,我没有看到任何执行此目的的代码。
这一切都与模型以某种全局方式保存有关吗?您能解释一下吗?
g和d中的权重在组合模型中是共享的。相同的权重,不同的逻辑模型。
你可以在这里了解更多
https://machinelearning.org.cn/how-to-code-the-generative-adversarial-network-training-algorithm-and-loss-functions/
解释得很棒。
我有一个问题。
我想计算准确率,以确定生成的最终图像与输入的原始图像之间的差异不大。
为此,我需要图像中的数字作为矩阵。
有没有办法通过任何模型从图像中获取数字,以便我可以比较原始图像和最终图像?
请回复!
提前感谢!
谢谢。
您可以使用在MNIST上训练的模型来分类生成的图像。
我想开发一个生成模型,它可以接受两张图像作为输入(它们是两张不同的图像,但彼此相关),学习图像之间的关系,并生成两张输出图像,同时保持两张图像之间的一致性。您能否推荐一种方法来解决这个问题?
我不知道有任何能够做到这一点的架构,也许可以从cyclegan或pix2pix开始,然后探索原型。
Jason,
尊重您出色的工作!
谢谢!
先生,这是一个非常出色的教程。
但是,在训练判别器模型时,我们是否需要对真实样本和假样本进行洗牌,因为我们只是将真实样本和假样本堆叠在一起了?
所以,您不认为我们应该洗牌,因为我听人们说您的数据应该始终洗牌,这样您的模型才能更好地训练?
那么,您为什么没有洗牌?
我们每批次都会选择随机样本,这具有相同的效果。
先生,再次感谢您的出色教程!
我遇到了一个问题,我得到了奇怪的生成图像,所以我复制了您的全部代码并粘贴到Google Colab中,然后运行它,仍然得到了奇怪的生成图像。
您能告诉我这是怎么回事吗?
我没有使用Google Colab。
https://machinelearning.org.cn/faq/single-faq/do-code-examples-run-on-google-colab
你好 Jason,
我知道我问了太多问题,对此很抱歉。
我尝试了与您的代码完全相同的代码,唯一的变化是我更改了判别器和生成器模型。
这是我的判别器模型
Model = Sequential([
Conv2D(32, (3, 3), padding=’same’, input_shape=in_shape),
BatchNormalization(),
LeakyReLU(alpha=0.2),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.2),
Conv2D(64, (3,3), padding=’same’),
BatchNormalization(),
LeakyReLU(alpha=0.2),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.3),
Conv2D(128, (3,3), padding=’same’),
BatchNormalization(),
LeakyReLU(alpha=0.2),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.3),
Flatten(),
Dense(1, activation=’sigmoid’)
])
这是生成器模型
Model = Sequential([
Dense(128*7*7, input_dim=in_shape),
BatchNormalization(),
LeakyReLU(alpha=0.2),
Reshape((7, 7, 128)),
Conv2DTranspose(16, (3,3), strides=(2,2), padding=’same’),
BatchNormalization(),
LeakyReLU(alpha=0.2),
Conv2DTranspose(1, (4,4), strides=(2,2), activation=’sigmoid’, padding=’same’),
])
但是用这些模型,在200个epoch内都无法生成好的图像。(我们可以看到它在尝试生成一些图像,但它们不好,不像您在100个epoch内达到的效果)。
然后我稍微修改了判别器模型,将其更改为此
Model = Sequential([
Conv2D(32, (3, 3), padding=’same’, activation=’softmax’, input_shape=in_shape),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.2),
Conv2D(64, (3,3), padding=’same’),
BatchNormalization(),
LeakyReLU(alpha=0.2),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.3),
Conv2D(128, (3,3), padding=’same’),
BatchNormalization(),
LeakyReLU(alpha=0.2),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.3),
Flatten(),
Dense(1, activation=’sigmoid’)
])
并将生成器模型与我之前在此评论中提到的模型保持不变。
我只是去掉了判别器起始阶段的Batch Normalization和Leaky relu层,并将Leaky relu激活替换为softmax激活(对我来说,这毫无意义。因为我只在模型的最后层使用softmax进行预测,并且我从没想到在GAN的判别器起始层使用softmax)。
但令我惊讶的是,生成的图像在大约90个epoch内变得很好,效果优于之前的模型。我以为这只是一种运气。所以,我运行了这2个判别器模型2到4次,每次,带有softmax的判别器模型都比另一个好得多。
您能解释一下为什么会这样吗?
是的,有很多方法可以解决给定的问题。
Jason您好,我找到了原因。两个模型(一个在判别器第一层使用softmax激活,另一个是我在评论开头提到的,在其中包含Batch Normalization和Max Pooling)性能相同。我在Pycharm(Python IDE)上测试了这两个模型,它们都以相同的精度生成图像。我认为这是Google Colab的某种故障。很抱歉打扰您。
但是,既然它们都以相同的精度生成图像,我想问一下,带有softmax激活的模型的图像是否应该非常糟糕?因为,在我看来,在判别器第一层使用softmax是没有意义的。那么,为什么它们效果很好呢?
干得好。
也许,可能需要调查原因。
先生,您好,
您能否告诉我GAN是否可以用于文本生成,例如摘要任务?如果可以,该如何做?
我相信存在文本生成GAN,抱歉我没有关于该主题的教程。
我建议使用语言模型。
https://machinelearning.org.cn/?s=word+embedding&post_type=post&submit=Search
嗨,Jason,
非常喜欢您的教程布局。我尝试使用您实现的一个变体来生成256x256的面部图像(参见24个epoch后的示例):https://drive.google.com/file/d/103Gcml_lmlJw7cDstCdKiLUsOxw8fTGn/view?usp=sharing
当我连续训练模型时,一切都进展顺利。但是,当我将Gen和Disc模型保存为h5文件并尝试在加载保存的文件后进一步训练时,判别器总是跟不上,并且损失会随着时间的推移而增加。我甚至尝试更改两个优化器的学习率,以便Disc学习得更快,但这只会使事情变慢。有什么建议吗?
很有趣,不知道为什么会这样,抱歉。
为什么要继续训练?
我正在Google Colab中训练我的模型,它会在一段时间后超时。所以我尝试从上次中断的地方继续。我现在意识到模型正在经历模式崩溃。我可以看到输出图像看起来都一样了。有什么办法解决这个问题吗?
也许可以尝试在您拥有控制权的环境中运行代码,例如EC2。
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
我发现问题所在了。在加载模型时,判别器默认设置为trainable=False。将该参数设置为true已解决了问题。感谢您花时间回复我。
很高兴听到您解决了问题。
亲爱的 Jason,
感谢您整理了DCGAN的优秀入门教程。如果您能增加阅读区域到屏幕宽度,并将字体稍微调大一点,我将不胜感激。
感谢您的建议。
嗨,Jason,
非常感谢您的教程。
这是一个很好的例子,概括了所有内容。
我在Google Colab上使用GPU运行了它,它运行得相当快。
不过有一个问题,如果判别器对假数据的准确率约为90%,这是否意味着生成器做得不好?我也不明白为什么对真实数据的准确率会如此之低。看起来判别器可以轻松识别假数据但无法识别真实数据,这是否意味着它只是一个非常糟糕的判别器+非常糟糕的生成器?
谢谢!
也许,也许不是。通常不是。唯一可靠的评估生成器的方法是生成图像的主观质量。
Jason您好,感谢您的教程。
有没有办法自动输出与随机生成数据相关联的标签?
否则,如果使用此GAN生成形式为集合的额外数据,您是否需要自己对其进行标记?
您可以训练一个模型来对以前标记的图像进行分类,然后使用该模型对GAN生成的图像进行分类。
您还可以将分类器作为GAN的一部分进行训练,例如auxiliary GAN等。
您能否为每个数据类别训练一个GAN,从而生成可以简单标记为该类别的图像输出?
是的,这是一个很好的建议!
大家好,感谢您的教程。你们中有谁有任何epoch的生成器模型保存吗?我昨晚启动了它,我的Google Colab会话停止了……我丢失了epoch 10和20的保存。如果你们中的任何人能给我一个生成器模型的保存,这样我就不必重新开始整个过程,那就太好了。
不客气。
是的,您可以随时保存模型。
抱歉,我不知道Google Colab。
https://machinelearning.org.cn/faq/single-faq/do-code-examples-run-on-google-colab
我将您的代码应用于我的手写字符数据集,但它在100个epoch后对真实和虚假样本都给出了100%的准确率,如下所示:
>100, 81/92, d=0.000, g=9.672
>100, 82/92, d=0.000, g=9.683
>100, 83/92, d=0.000, g=9.765
>100, 84/92, d=0.000, g=9.668
>100, 85/92, d=0.000, g=9.816
>100, 86/92, d=0.000, g=9.730
>100, 87/92, d=0.000, g=9.758
>100, 88/92, d=0.000, g=9.740
>100, 89/92, d=0.000, g=9.716
>100, 90/92, d=0.000, g=9.735
>100, 91/92, d=0.000, g=9.804
>100, 92/92, d=0.000, g=9.763
>真实准确率:100%,虚假准确率:100%
我不明白,当我评估模型时,它在生成图像时会产生空白区域。请回复。
也许可以尝试多次运行示例并比较结果?
也许这些提示会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我搜索了您网站上的所有内容,试图找出您示例代码中不同颜色代表什么意思,您是否有关于此的文章?
这是Python的标准语法高亮。没有真正的意义,把它当作文本阅读。
感谢您的教程。它对初学者理解GAN的概念非常有帮助。先生,我们能否在数据集较小的情况下使用GAN进行回归类问题来生成更多样本?您能否提供一些链接?
不客气。
如果您的输入数据不是图像,那么就不能。最好使用另一种类型的生成模型或过采样技术。
谢谢先生。我的研究不包含图像,全是数值数据。您能提一下其他生成模型及其链接吗?
朴素贝叶斯可以作为生成模型使用,并且是一个很好的起点。
嗨,Jason!
感谢您出色的教程。我经常在实现自己的模型时将它们作为重要参考。
我有一个问题……在生成器中,您使用了正态分布,这在GAN中是标准做法。但是,您没有使用生成器来生成样本来训练判别器,而是使用了均匀分布来模拟原始的归一化数据。
我想知道这是否是常规做法,因为据我所知,我认为您会直接从生成器中提取分布,并与真实样本一起训练判别器。我能想到的唯一原因是,绘制均匀分布可以绕过通过生成器进行前向传递的需要,从而节省计算。但是,判别器是否不希望随着生成器性能的提高而暴露于改进的假数据?
我希望这有意义……基本上,您为什么在训练判别器时使用均匀分布而不是从生成器中提取假数据?
再次感谢您的所有精彩工作。
谢谢!
潜空间是高斯分布。
图像是从均匀分布中提取的。
这些事情是完全不相关的。
希望这能有所帮助。
你好 Jason,
非常感谢您的精彩教程。我有2个问题:
1)理想情况下,我们应该期望“真实”和“虚假”的准确率都接近1,同时期望生成和判别损失都接近0?我的理解正确吗?那么,从“现实”的角度来看,这些值之间的权衡通常是怎样的?
2)我使用了您的教程来复习一些深度学习技术,用于二元分类,但是使用了电子表格而不是图像。在对您的代码进行一些调整后,我成功地使我的项目运行起来了。然而,我得到的值是这样的:
Epoch # 41 (Batch: 15/ 15) ==> Discriminative loss=0.690821, Generative loss=0.660293
Epoch # 42 (Batch: 15/ 15) ==> Discriminative loss=0.700096, Generative loss=0.643866
Epoch # 43 (Batch: 15/ 15) ==> Discriminative loss=0.688565, Generative loss=0.671959
Epoch # 44 (Batch: 15/ 15) ==> Discriminative loss=0.694672, Generative loss=0.690171
Epoch # 45 (Batch: 15/ 15) ==> Discriminative loss=0.713714, Generative loss=0.675221
Epoch # 46 (Batch: 15/ 15) ==> Discriminative loss=0.686037, Generative loss=0.661391
Epoch # 47 (Batch: 15/ 15) ==> Discriminative loss=0.653045, Generative loss=0.695576
Epoch # 48 (Batch: 15/ 15) ==> Discriminative loss=0.681511, Generative loss=0.673666
Epoch # 49 (Batch: 15/ 15) ==> Discriminative loss=0.684036, Generative loss=0.677329
Epoch # 50 (Batch: 15/ 15) ==> Discriminative loss=0.696159, Generative loss=0.669947
>真实准确率:80%,虚假准确率:92%
不幸的是,除了您最初的项目和我自己的项目之外,我没有太多GAN的经验。您认为这些值是否“可接受”,可以开始从少数类中预测样本?
提前非常感谢。
你可以忽略准确率,它是GAN的一个糟糕的度量。
你好 Jason,
确实,准确率是一个糟糕的度量,这引发了两个额外的问题
1) 那么为什么这里选择了准确率呢?我认为这只是作为“生成网络与判别网络行为的一种快照”,对吧?
2) 我读了你的文章“如何评估生成对抗网络”中推荐的论文“GAN评估度量的优缺点”。我无法进行定性评估,因为正如我之前所说,我处理的不是图像,而是数值向量,我无法判断它们是否OK;此外,那篇论文基本上得出结论,“到目前为止还没有一个通用的度量”。我现在正在做的是凭直觉选择在玩具数据集上具有最高精确率-召回率-F1的模型(这是上述论文中的方法#24,通过修改你的代码,用这些度量替换准确率来实现),选择显示最佳度量的模型,然后将这些样本输入另一个分类器网络,看看生成样本的表现如何。这样做对吗?
提前非常感谢。
出于兴趣包含准确率,最好的“度量”是生成图像并对其进行审查。
如果你直接处理MNIST,那么对生成图像进行分类听起来是合理的,至少如果你使用一个在所有MNIST上预训练过的模型而不是判别器。
感谢这篇帖子。它对我的论文非常有帮助。关于保存模型有什么建议吗?我之前使用了keras的save_model。
不,像平常一样保存模型,只需要保存生成器。
感谢您提供的精彩教程。我对您在生成器模型中使用的最后一个Conv2D层感到困惑。您说:“该模型的输出层是Conv2D,具有一个滤波器和7x7的卷积核以及‘same’填充,旨在创建一个单一的特征图并保持其维度为28x28像素。”
您为什么选择7x7这么大的卷积核?我们通常使用3x3或5x5的小卷积核。您能解释一下吗?
我相信我测试了不同的配置,并发现这种配置在这种情况下效果很好。
谢谢 Jason。
不客气。
我使用了你的代码来训练模型,但不知道模型保存在哪里。当我重新加载模型时,它显示找不到模型?你能告诉我我哪里做错了
“g_model.save(filename)”这一行将你的模型保存到“filename”。尝试在运行代码的目录下查找同一个文件。
谢谢 Jason。您的教程对我来说效果很好。我非常喜欢读您的文章。再次感谢。
我目前正在研究深度学习隐写模型,我打算将彩色图像隐藏在另一张彩色图像(称为封面图像)中。
请问如何使用cycleGAN和DCGAN执行编码模型?
另外,如何使用CNN执行解码模型来检索原始封面图像和秘密图像?
任何线索或代码都会有帮助。
谢谢你
你好 Uche,
你可能会对以下内容感兴趣
https://machinelearning.org.cn/what-are-generative-adversarial-networks-gans/
此致,
“可训练属性会影响模型在编译之后。”——你的意思是“仅在编译之前”吗?
谢谢 Jason。您的教程非常有帮助。我非常喜欢读您的文章。
当我使用KL损失而不是“binary__crossentropy”时,我遇到了一个问题。几个epoch后,判别器在真实样本上的准确率为100%,但在假样本上的准确率为0%。
你能给我一些解决这个问题的思路吗?
你好 Qian…你可能会对以下内容感兴趣
你可能正在处理回归问题并实现零预测误差。
或者,你可能正在处理分类问题并实现 100% 的准确率。
这很不寻常,原因有很多,包括:
你不小心在训练集上评估了模型性能。
你的保留数据集(训练集或验证集)太小或不具代表性。
你的代码中引入了一个错误,它正在做一些与你预期不同的事情。
你的预测问题很容易或微不足道,可能不需要机器学习。
最常见的原因是你的保留数据集太小或不代表更广泛的问题。
可以通过以下方法解决:
使用 k 折交叉验证来估计模型性能,而不是训练/测试拆分。
收集更多数据。
使用不同的数据拆分进行训练和测试,例如 50/50。
你好,我在使用一本优秀数据科学书中的模型时遇到了问题,所以我复制代码并运行了20多个epoch。我似乎在你的模型上也遇到了同样的问题。
生成的图像都非常相似,完全不像数字。它们看起来不像完全随机的噪声,因为它们集中在中心。我的收敛性与你图像中的(以及我使用的书中的)不符。我认为这可能是“模式崩溃”。相同的代码产生如此大的差异是常见的吗?我不知道该怎么办。
你好 James…你有没有尝试在Google Colab中运行你的代码,与本地安装的Anaconda进行比较?你可能遇到了某些库的差异。
更新一下…问题似乎出在M1 Mac上的Apple Metal插件对TensorFlow的支持上。当在GPU上执行某些计算时,似乎会出现问题。这个问题已经在Apple开发者论坛上发布了,但6个月后仍未解决。所以,如果你有M1 Mac,也许应该使用标准的TensorFlow(而不是Apple的版本)。
我在Colab和自己的机器上(没有Apple的TensorFlow插件)再次运行了代码,没有遇到任何问题。
谢谢 James 的反馈!我很感激你分享这些信息。
我试试。谢谢你的建议。
我对数据有疑问。我从加速度计获取数据,并想为它扩充数据。我有一个加速度计数据的短时傅里叶变换。这个傅里叶变换可以判断一个人是否从床上摔下来。所以我想为一个人从床上摔下来的情况扩充数据。我能为这种应用使用GAN或VAE吗?我尝试实现它,但没有成功。你能指导我一下吗?
你好 Yash…下面的资源可能对你有帮助
https://machinelearning.org.cn/impressive-applications-of-generative-adversarial-networks/
你好 James,谢谢分享,教程很棒。我可以用RGB图像练习你的代码吗?
你好 Edyta…不客气!请继续你的想法,并让我们知道你的发现!