空气污染的特征是地表臭氧浓度。
根据风速和温度等气象测量数据,可以预测明天地表臭氧是否会达到足够高的水平,从而发布公共空气污染警告。
这是一个用于时间序列分类数据集的标准机器学习数据集的基础,简称为“臭氧预测问题”。该数据集描述了休斯顿地区七年来的气象观测数据,以及臭氧水平是否超过了临界空气污染水平。
在本教程中,您将学习如何探索这些数据并开发一个概率预测模型,以预测德克萨斯州休斯顿的空气污染。
完成本教程后,您将了解:
- 如何加载和准备臭氧日标准机器学习预测建模问题。
- 如何开发一个朴素预测模型,并使用Brier技能分数评估预测。
- 如何使用决策树集成开发熟练模型,并通过对成功模型的超参数调优进一步提高技能。
我的新书《时间序列深度学习》将助您启动项目,其中包含所有示例的分步教程和Python源代码文件。
让我们开始吧。

如何开发预测空气污染日的概率预测模型
图片由paramita拍摄,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 臭氧预测问题
- 加载和检查数据
- 朴素预测模型
- 集成树预测模型
- 调整梯度提升
臭氧预测问题
空气污染可定义为地表臭氧含量高,常被称为“坏臭氧”,以区别于高层大气的臭氧。
臭氧预测问题是一个时间序列分类预测问题,它涉及预测第二天是否为高空气污染日(臭氧日)。气象组织可以利用臭氧日的预测来警告公众,以便他们采取预防措施。
该数据集最初由Kun Zhang等人在2006年的论文《预测偏斜偏置随机臭氧日:分析与解决方案》中研究,随后又在其后续论文《预测偏斜偏置随机臭氧日:分析、解决方案及展望》中再次研究。
这是一个具有挑战性的问题,因为高臭氧水平的物理机制(或当时不)完全理解,这意味着预测不能像其他气象预测(如温度和降雨)那样基于物理模拟。
该数据集被用作开发预测模型的基础,这些模型除了少数已知与实际化学过程相关的变量外,还使用了大量可能或可能不与预测臭氧水平相关的变量。
然而,环境科学家普遍认为,目前尚未探索的大量其他特征很可能有助于构建高度准确的臭氧预测模型。然而,对这些特征究竟是什么以及它们在臭氧形成中如何相互作用知之甚少。[...]今天的环境科学尚不知道如何使用它们。这为数据挖掘提供了绝佳的机会。
— 预测偏斜偏置随机臭氧日:分析与解决方案,2006。
预测次日高地表臭氧水平是一个具有挑战性的问题,已知其本质是随机的。这意味着预计将存在预测误差。因此,最好以概率方式对预测问题进行建模,并根据前一天或几天观测到的数据,预测臭氧日或非臭氧日的概率。
该数据集包含德克萨斯州休斯顿、加尔维斯顿和布拉佐里亚地区七年(1998-2004年,共2536天)的每日气象变量观测数据,以及是否出现臭氧日。
每天共观测到72个变量,其中许多变量被认为与预测问题相关,其中10个变量已根据物理学证实相关。
[...]在这72个特征中,只有约10个特征已被环境科学家证实有用且相关,而其他60个特征的关联性目前尚无经验或理论信息。然而,空气质量控制科学家长期以来一直在猜测其中一些特征可能有用,但尚未能发展理论或使用模拟来证明其关联性。
— 预测偏斜偏置随机臭氧日:分析与解决方案,2006。
有24个变量跟踪每小时的风速,另有24个变量跟踪一天中每小时的温度。数据集提供了两个版本,测量值的平均周期不同,分别为1小时和8小时。
似乎缺少但可能有用的是每天观测到的臭氧值,而不是二分法的臭氧日/非臭氧日。参数模型中使用的其他测量值也未提供。
有趣的是,一个基于1999年EPA指南《臭氧预报程序开发指南》中描述的参数臭氧预报模型被用作基线。该文档还描述了验证臭氧预报系统的标准方法论。
总之,这是一个具有挑战性的预测问题,因为
- 变量数量庞大,其重要性通常未知。
- 输入变量及其相互关系可能随时间变化。
- 许多变量存在缺失观测值,需要进行处理。
- 非臭氧日(非事件)远多于臭氧日(事件),导致类别高度不平衡。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
加载和检查数据
该数据集可从UCI机器学习存储库获取。
本教程中,我们将只查看8小时数据。下载“eighthr.data”并将其放置在当前工作目录中。
检查数据文件,我们可以看到不同尺度的观测值。
|
1 2 3 4 |
1/1/1998,0.8,1.8,2.4,2.1,2,2.1,1.5,1.7,1.9,2.3,3.7,5.5,5.1,5.4,5.4,4.7,4.3,3.5,3.5,2.9,3.2,3.2,2.8,2.6,5.5,3.1,5.2,6.1,6.1,6.1,6.1,5.6,5.2,5.4,7.2,10.6,14.5,17.2,18.3,18.9,19.1,18.9,18.3,17.3,16.8,16.1,15.4,14.9,14.8,15,19.1,12.5,6.7,0.11,3.83,0.14,1612,-2.3,0.3,7.18,0.12,3178.5,-15.5,0.15,10.67,-1.56,5795,-12.1,17.9,10330,-55,0,0. 1/2/1998,2.8,3.2,3.3,2.7,3.3,3.2,2.9,2.8,3.1,3.4,4.2,4.5,4.5,4.3,5.5,5.1,3.8,3,2.6,3,2.2,2.3,2.5,2.8,5.5,3.4,15.1,15.3,15.6,15.6,15.9,16.2,16.2,16.2,16.6,17.8,19.4,20.6,21.2,21.8,22.4,22.1,20.8,19.1,18.1,17.2,16.5,16.1,16,16.2,22.4,17.8,9,0.25,-0.41,9.53,1594.5,-2.2,0.96,8.24,7.3,3172,-14.5,0.48,8.39,3.84,5805,14.05,29,10275,-55,0,0. 1/3/1998,2.9,2.8,2.6,2.1,2.2,2.5,2.5,2.7,2.2,2.5,3.1,4,4.4,4.6,5.6,5.4,5.2,4.4,3.5,2.7,2.9,3.9,4.1,4.6,5.6,3.5,16.6,16.7,16.7,16.8,16.8,16.8,16.9,16.9,17.1,17.6,19.1,21.3,21.8,22,22.1,22.2,21.3,19.8,18.6,18,18,18.2,18.3,18.4,22.2,18.7,9,0.56,0.89,10.17,1568.5,0.9,0.54,3.8,4.42,3160,-15.9,0.6,6.94,9.8,5790,17.9,41.3,10235,-40,0,0. ... |
浏览文件,例如到2003年初,我们可以看到缺失的观测值用“?”标记。
|
1 2 3 4 5 6 |
... 12/29/2002,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,11.7,0.09,5.59,3.79,1578,5.7,0.04,1.8,4.8,3181.5,-13,0.02,0.38,2.78,5835,-31.1,18.9,10250,-25,0.03,0. 12/30/2002,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,10.3,0.43,3.88,9.21,1525.5,1.8,0.87,9.17,9.96,3123,-11.3,0.03,11.23,10.79,5780,17,30.2,10175,-75,1.68,0. 12/31/2002,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,8.5,0.96,6.05,11.18,1433,-0.85,0.91,7.02,6.63,3014,-16.2,0.05,15.77,24.38,5625,31.15,48.75,10075,-100,0.05,0. 1/1/2003,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,7.2,5.7,4.5,4,3.6,3.3,3.1,3.2,6.7,11.1,13.8,15.8,17.2,18.6,20,21.1,21.5,20.4,19.1,17.8,17.4,16.9,16.6,14.9,21.5,12.6,6.4,0.6,12.91,-10.17,1421.5,1.95,0.55,11.97,-7.78,3006.5,-14.1,0.44,20.42,-13.31,5640,2.9,30.5,10095,35,0,0. ... |
首先,我们可以使用read_csv() 函数将数据加载为 Pandas DataFrame。数据没有标题,我们可以解析第一列中的日期并将其用作索引;完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 加载并汇总 from pandas import read_csv from matplotlib import pyplot # 加载数据集 data = read_csv('eighthr.data', header=None, index_col=0, parse_dates=True, squeeze=True) print(data.shape) # 汇总类别计数 counts = data.groupby(73).size() for i in range(len(counts)): percent = counts[i] / data.shape[0] * 100 print('Class=%d, total=%d, percentage=%.3f' % (i, counts[i], percent)) |
运行示例确认有2534天的数据和73个变量。
我们还可以看到类别不平衡的性质,其中略多于93%的日子是非臭氧日,而大约6%的日子是臭氧日。
|
1 2 3 |
(2534, 73) 类别=0,总计=2374,百分比=93.686 类别=1,总计=160,百分比=6.314 |
我们还可以绘制七年间输出变量的折线图,以了解臭氧日是否发生在一年中的特定时间。
|
1 2 3 4 5 6 7 8 |
# 加载并绘制输出变量 from pandas import read_csv from matplotlib import pyplot # 加载数据集 data = read_csv('eighthr.data', header=None, index_col=0, parse_dates=True, squeeze=True) # 绘制输出变量 pyplot.plot(data.index, data.values[:,-1]) pyplot.show() |
运行示例会创建七年间输出变量的折线图。
我们可以看到,每年的年中都有臭氧日群集:北半球的夏季或温暖月份。
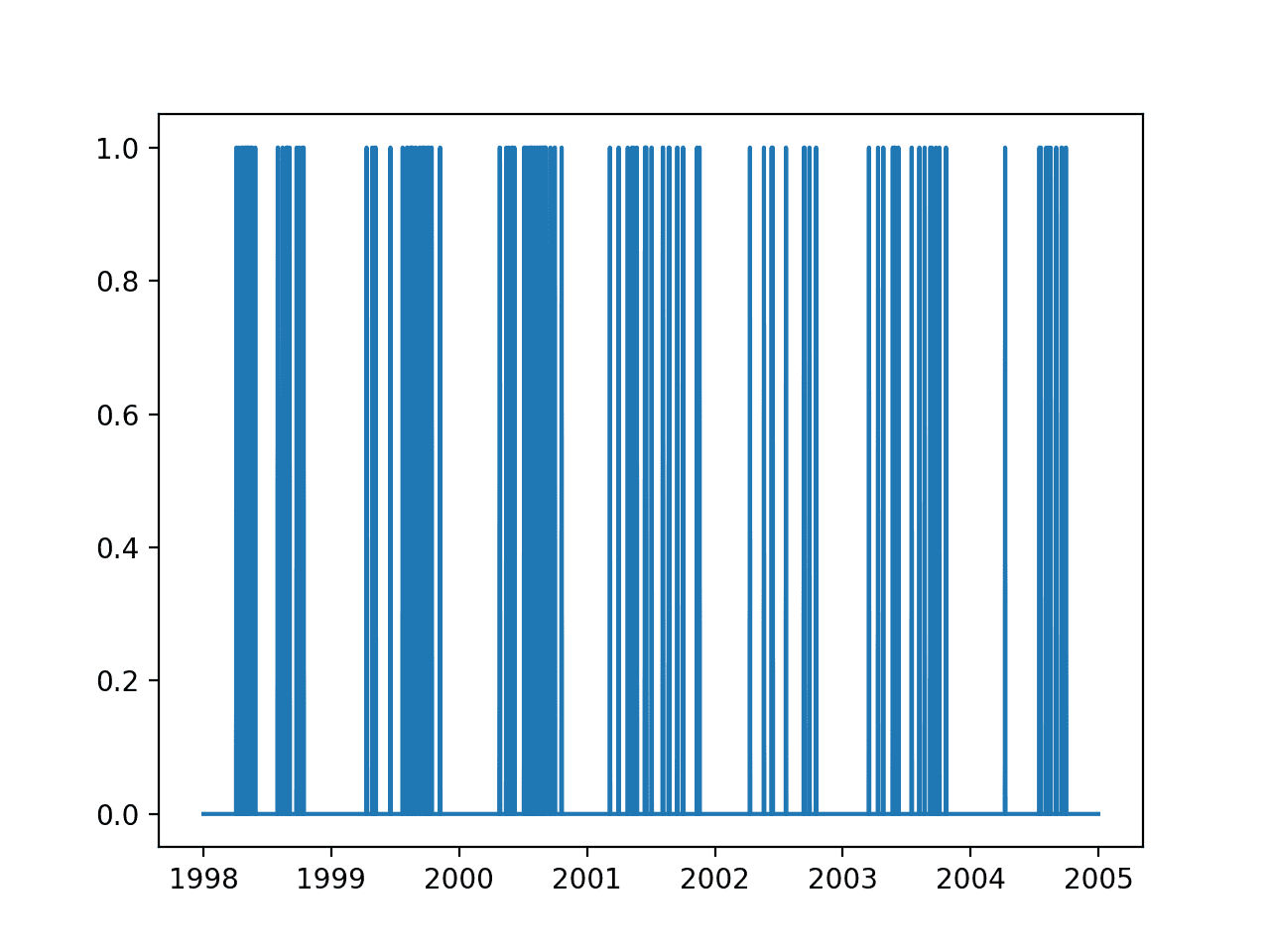
输出变量七年来的折线图
通过简要回顾观测结果,我们可以对如何准备数据有了一些想法。
- 缺失数据需要处理。
- 最简单的框架是根据今天的观测值预测明天的臭氧日。
- 温度可能与季节或一年中的时间相关,并且可能是一个有用的预测因子。
- 数据变量可能需要缩放(归一化),甚至可能需要标准化,具体取决于所选的算法。
- 预测概率将提供比预测类别值更细致的见解。
- 也许我们可以用五年(约72%)来训练模型,用剩下的两年(约28%)来测试模型。
我们可以进行一些最少的数据准备工作。
以下示例加载数据集,将缺失观测值替换为0.0,将数据构造成一个监督学习问题(根据今天的观测值预测明天的臭氧),并根据两年大致天数将数据拆分为训练集和测试集。
您可以探索其他替换缺失值的方法,例如填充平均值。此外,2004年是闰年,因此数据拆分为训练集和测试集并非严格的5-2年拆分,但对于本教程来说已经足够接近。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 加载并准备 from pandas import read_csv from matplotlib import pyplot from numpy import array from numpy import hstack from numpy import savetxt # 加载数据集 data = read_csv('eighthr.data', header=None, index_col=0, parse_dates=True, squeeze=True) values = data.values # 将缺失的观测值替换为0 values[values=='?'] = 0.0 # 构架为监督学习 supervised = list() for i in range(len(values) - 1): X, y = values[i, :-1], values[i + 1, -1] row = hstack((X,y)) supervised.append(row) supervised = array(supervised) # 分割成训练集和测试集 split = 365 * 2 train, test = supervised[:-split,:], supervised[-split:,:] train, test = train.astype('float32'), test.astype('float32') print(train.shape, test.shape) # 保存准备好的数据集 savetxt('train.csv', train, delimiter=',') savetxt('test.csv', test, delimiter=',') |
运行示例将训练集和测试集保存到 CSV 文件,并总结了这两个数据集的形状。
|
1 |
(1803, 73) (730, 73) |
朴素预测模型
一个朴素的模型会预测每天臭氧日的概率。
这是一种朴素的方法,因为它除了事件的基本发生率之外不使用任何信息。在气象预报的验证中,这被称为气候学预报。
我们可以从训练数据集中估计臭氧日的概率,如下所示。
|
1 2 3 4 5 |
# 加载数据集 train = loadtxt('train.csv', delimiter=',') test = loadtxt('test.csv', delimiter=',') # 估计朴素概率预测 naive = sum(train[:,-1]) / train.shape[0] |
然后,我们可以预测测试数据集中每天臭氧日的朴素概率。
|
1 2 |
# 预测测试数据集 yhat = [naive for _ in range(len(test))] |
一旦我们有了预测,我们就可以对其进行评估。
评估概率预测的有用指标是布里尔分数。该分数可以被认为是预测概率(例如5%)与预期概率(0%或1%)之间的均方误差。它是测试数据集中每天所犯错误的平均值。
我们感兴趣的是最小化布里尔分数,值越小越好,例如误差越小。
我们可以使用scikit-learn库中的brier_score_loss()函数来评估预测的布里尔分数。
|
1 2 3 4 |
# 评估预测 testy = test[:, -1] bs = brier_score_loss(testy, yhat) print('Brier Score: %.6f' % bs) |
一个模型要想具有技巧性,其得分必须优于朴素预测模型的得分。
我们可以通过计算布里尔技巧分数 (BSS) 来使其显而易见,该分数根据朴素预测对布里尔分数 (BS) 进行归一化。
我们期望朴素预测计算出的BSS为0.0。展望未来,我们感兴趣的是最大化这个分数,即更大的BSS分数更好。
|
1 2 3 4 |
# 计算Brier技能分数 bs_ref = bs bss = (bs - bs_ref) / (0 - bs_ref) print('Brier Skill Score: %.6f' % bss) |
朴素预测的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 朴素预测方法 from sklearn.metrics import brier_score_loss from numpy import loadtxt # 加载数据集 train = loadtxt('train.csv', delimiter=',') test = loadtxt('test.csv', delimiter=',') # 估计朴素概率预测 naive = sum(train[:,-1]) / train.shape[0] print(naive) # 预测测试数据集 yhat = [naive for _ in range(len(test))] # 评估预测 testy = test[:, -1] bs = brier_score_loss(testy, yhat) print('Brier Score: %.6f' % bs) # 计算Brier技能分数 bs_ref = bs bss = (bs - bs_ref) / (0 - bs_ref) print('Brier Skill Score: %.6f' % bss) |
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
运行示例,我们可以看到臭氧日事件的朴素概率约为7.2%。
使用基本发生率作为预测,布里尔技巧为0.039,预期布里尔技巧分数为0.0(忽略符号)。
|
1 2 3 |
0.07265668330560178 布里尔分数:0.039232 布里尔技能分数:-0.000000 |
我们现在准备探索一些机器学习方法,看看我们是否能为这个预测增加技巧。
请注意,原始论文直接使用精确度和召回率评估方法的技能,这是一种令人惊讶的方法,用于在方法之间进行直接比较。
也许你可以探索的另一个衡量标准是ROC曲线下面积(ROC AUC)。绘制最终模型的ROC曲线将允许模型操作员选择一个阈值,以在真阳性(命中)和假阳性(误报)率之间提供所需的平衡水平。
集成树预测模型
原始论文报道了袋装决策树取得了一些成功。
尽管我们选择的归纳学习器并非详尽无遗,但本文表明归纳学习可以是臭氧水平预测的首选方法,并且基于集成的概率树比现有方法提供更好的预测(更高的召回率和精确率)。
— 预测偏斜偏置随机臭氧日:分析与解决方案,2006。
这并不奇怪,原因有以下几点
- 袋装决策树不需要任何数据缩放。
- 袋装决策树会自动执行一种特征选择,忽略不相关的特征。
- 袋装决策树预测的概率校准合理(例如与SVM不同)。
这表明在测试机器学习算法解决问题时,这是一个很好的起点。
我们可以通过快速抽查scikit-learn库中一组标准集成树方法的性能来快速开始,这些方法采用默认配置,并将树的数量设置为100。
具体来说,这些方法是
- 袋装决策树(BaggingClassifier)
- 极端随机树(ExtraTreesClassifier)
- 随机梯度提升(GradientBoostingClassifier)
- 随机森林(RandomForestClassifier)
首先,我们必须将训练和测试数据集拆分为输入(X)和输出(y)组件,以便我们可以拟合sklearn模型。
|
1 2 3 4 5 |
# 加载数据集 train = loadtxt('train.csv', delimiter=',') test = loadtxt('test.csv', delimiter=',') # 分割输入/输出 trainX, trainy, testX, testy = train[:,:-1],train[:,-1],test[:,:-1],test[:,-1] |
我们还需要朴素预测的布里尔分数,以便正确计算新模型的布里尔技能分数。
|
1 2 3 4 5 6 |
# 估计朴素概率预测 naive = sum(train[:,-1]) / train.shape[0] # 预测测试数据集 yhat = [naive for _ in range(len(test))] # 计算朴素BS bs_ref = brier_score_loss(testy, yhat) |
我们可以泛化地评估单个 scikit-learn 模型的技能。
下面定义了名为 evaluate_once() 的函数,该函数拟合并评估给定的已定义和配置的 scikit-learn 模型,并返回布里尔技能分数 (BSS)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 评估一个sklearn模型 def evaluate_once(bs_ref, template, trainX, trainy, testX, testy): # 拟合模型 model = clone(template) model.fit(trainX, trainy) # 预测0和1的概率 probs = model.predict_proba(testX) # 只保留类别为1的概率 yhat = probs[:, 1] # 计算Brier分数 bs = brier_score_loss(testy, yhat) # 计算Brier技能分数 bss = (bs - bs_ref) / (0 - bs_ref) return bss |
集成树是一种随机机器学习方法。
这意味着当在相同数据上训练相同模型的相同配置时,它们会做出不同的预测。为了纠正这一点,我们可以多次评估给定模型,例如10次,并计算每次运行的平均技能。
以下函数将评估给定模型10次,打印平均BSS分数,并返回用于分析的分数总体。
|
1 2 3 4 5 |
# 多次评估sklearn模型 def evaluate(bs_ref, model, trainX, trainy, testX, testy, n=10): scores = [evaluate_once(bs_ref, model, trainX, trainy, testX, testy) for _ in range(n)] print('>%s, bss=%.6f' % (type(model), mean(scores))) return scores |
我们现在准备评估一套集成决策树算法。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
# 评估集成树方法 从 numpy 导入 loadtxt from numpy import mean from matplotlib import pyplot from sklearn.base import clone from sklearn.metrics import brier_score_loss from sklearn.ensemble import BaggingClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import RandomForestClassifier # 评估一个sklearn模型 def evaluate_once(bs_ref, template, trainX, trainy, testX, testy): # 拟合模型 model = clone(template) model.fit(trainX, trainy) # 预测0和1的概率 probs = model.predict_proba(testX) # 只保留类别为1的概率 yhat = probs[:, 1] # 计算Brier分数 bs = brier_score_loss(testy, yhat) # 计算Brier技能分数 bss = (bs - bs_ref) / (0 - bs_ref) return bss # 多次评估sklearn模型 def evaluate(bs_ref, model, trainX, trainy, testX, testy, n=10): scores = [evaluate_once(bs_ref, model, trainX, trainy, testX, testy) for _ in range(n)] print('>%s, bss=%.6f' % (type(model), mean(scores))) 返回 分数 # 加载数据集 train = loadtxt('train.csv', delimiter=',') test = loadtxt('test.csv', delimiter=',') # 分割输入/输出 trainX, trainy, testX, testy = train[:,:-1],train[:,-1],test[:,:-1],test[:,-1] # 估计朴素概率预测 naive = sum(train[:,-1]) / train.shape[0] # 预测测试数据集 yhat = [naive for _ in range(len(test))] # 计算朴素BS bs_ref = brier_score_loss(testy, yhat) # 评估一系列集成树方法 scores, names = list(), list() n_trees=100 # 装袋法 model = BaggingClassifier(n_estimators=n_trees) avg_bss = evaluate(bs_ref, model, trainX, trainy, testX, testy) scores.append(avg_bss) names.append('bagging') # 额外 model = ExtraTreesClassifier(n_estimators=n_trees) avg_bss = evaluate(bs_ref, model, trainX, trainy, testX, testy) scores.append(avg_bss) names.append('extra') # gbm model = GradientBoostingClassifier(n_estimators=n_trees) avg_bss = evaluate(bs_ref, model, trainX, trainy, testX, testy) scores.append(avg_bss) names.append('gbm') # rf model = RandomForestClassifier(n_estimators=n_trees) avg_bss = evaluate(bs_ref, model, trainX, trainy, testX, testy) scores.append(avg_bss) names.append('rf') # 绘制结果 pyplot.boxplot(scores, labels=names) pyplot.show() |
运行示例总结了每个模型在10次运行中平均的BSS。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
从平均BSS分数来看,表明极端随机树、随机梯度提升和随机森林模型最具技巧。
|
1 2 3 4 |
> > > > |
绘制了每个模型分数的箱线图。
所有模型的所有运行都显示出优于朴素预测的技能(正分数),这非常令人鼓舞。
极端随机树、随机梯度提升和随机森林的BSS分数分布都看起来令人鼓舞。
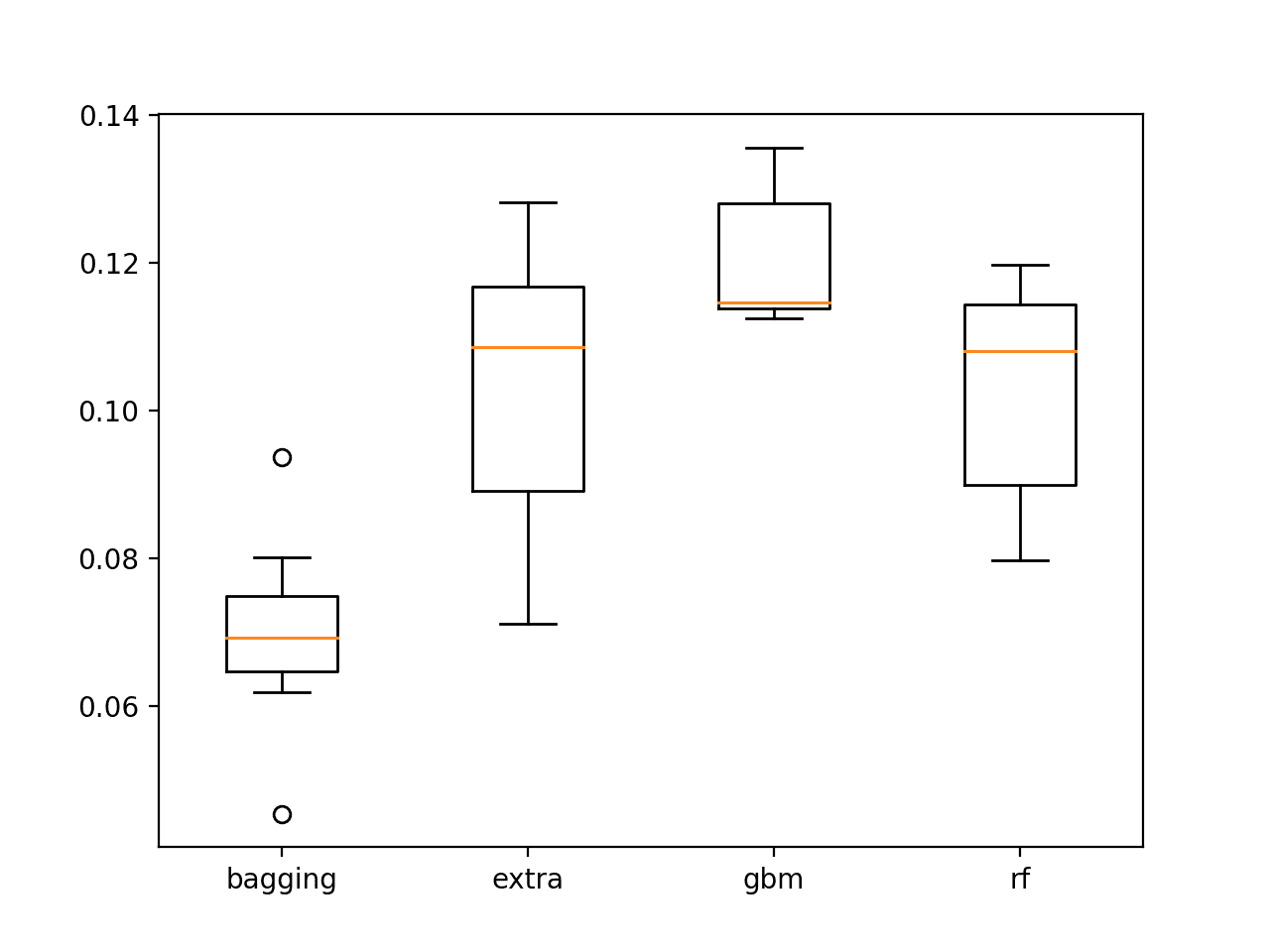
集成决策树在测试集上的BSS分数箱线图
调整梯度提升
鉴于随机梯度提升看起来很有前景,值得探讨模型性能是否可以通过一些参数调优进一步提升。
模型有许多参数可以调整,但调整模型的一些良好启发式方法包括:
- 降低学习率(learning_rate)同时增加决策树的数量(n_estimators)。
- 增加决策树的最大深度(max_depth),同时减少可用于拟合树的样本数量(samples)。
与其网格搜索值,我们可以根据这些原则抽查一些参数。如果您有时间和计算资源,可以自己探索这些参数的网格搜索。
我们将比较四种 GBM 模型配置
- 基线:如上一节中测试的(learning_rate=0.1,n_estimators=100,subsample=1.0,max_depth=3)
- lr,学习率较低,树更多(learning_rate=0.01,n_estimators=500,subsample=1.0,max_depth=3)
- depth,增加最大树深度并减少数据集采样(learning_rate=0.1,n_estimators=100,subsample=0.7,max_depth=)
- all,包含所有修改。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
# 调整gbm配置 从 numpy 导入 loadtxt from numpy import mean from matplotlib import pyplot from sklearn.base import clone from sklearn.metrics import brier_score_loss from sklearn.ensemble import BaggingClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import RandomForestClassifier # 评估一个sklearn模型 def evaluate_once(bs_ref, template, trainX, trainy, testX, testy): # 拟合模型 model = clone(template) model.fit(trainX, trainy) # 预测0和1的概率 probs = model.predict_proba(testX) # 只保留类别为1的概率 yhat = probs[:, 1] # 计算Brier分数 bs = brier_score_loss(testy, yhat) # 计算Brier技能分数 bss = (bs - bs_ref) / (0 - bs_ref) return bss # 多次评估sklearn模型 def evaluate(bs_ref, model, trainX, trainy, testX, testy, n=10): scores = [evaluate_once(bs_ref, model, trainX, trainy, testX, testy) for _ in range(n)] print('>%s, bss=%.6f' % (type(model), mean(scores))) 返回 分数 # 加载数据集 train = loadtxt('train.csv', delimiter=',') test = loadtxt('test.csv', delimiter=',') # 分割输入/输出 trainX, trainy, testX, testy = train[:,:-1],train[:,-1],test[:,:-1],test[:,-1] # 估计朴素概率预测 naive = sum(train[:,-1]) / train.shape[0] # 预测测试数据集 yhat = [naive for _ in range(len(test))] # 计算朴素BS bs_ref = brier_score_loss(testy, yhat) # 评估一系列集成树方法 scores, names = list(), list() # 基础 model = GradientBoostingClassifier(learning_rate=0.1, n_estimators=100, subsample=1.0, max_depth=3) avg_bss = evaluate(bs_ref, model, trainX, trainy, testX, testy) scores.append(avg_bss) names.append('base') # 学习率 model = GradientBoostingClassifier(learning_rate=0.01, n_estimators=500, subsample=1.0, max_depth=3) avg_bss = evaluate(bs_ref, model, trainX, trainy, testX, testy) scores.append(avg_bss) names.append('lr') # 深度 model = GradientBoostingClassifier(learning_rate=0.1, n_estimators=100, subsample=0.7, max_depth=7) avg_bss = evaluate(bs_ref, model, trainX, trainy, testX, testy) scores.append(avg_bss) names.append('depth') # 全部 model = GradientBoostingClassifier(learning_rate=0.01, n_estimators=500, subsample=0.7, max_depth=7) avg_bss = evaluate(bs_ref, model, trainX, trainy, testX, testy) scores.append(avg_bss) names.append('all') # 绘制结果 pyplot.boxplot(scores, labels=names) pyplot.show() |
运行示例将打印每个模型在10次运行中平均的BSS,用于每种配置。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
结果表明,单独改变学习率和树的数量就比默认配置有所提升。
结果还表明,包含所有更改的“all”配置产生了最佳的平均BSS。
|
1 2 3 4 |
> > > > |
创建了每种配置的BSS分数箱线图。我们可以看到,包含所有更改的配置明显优于基线模型和其他配置组合。
也许通过对模型参数进行微调,甚至可能获得进一步的改进。
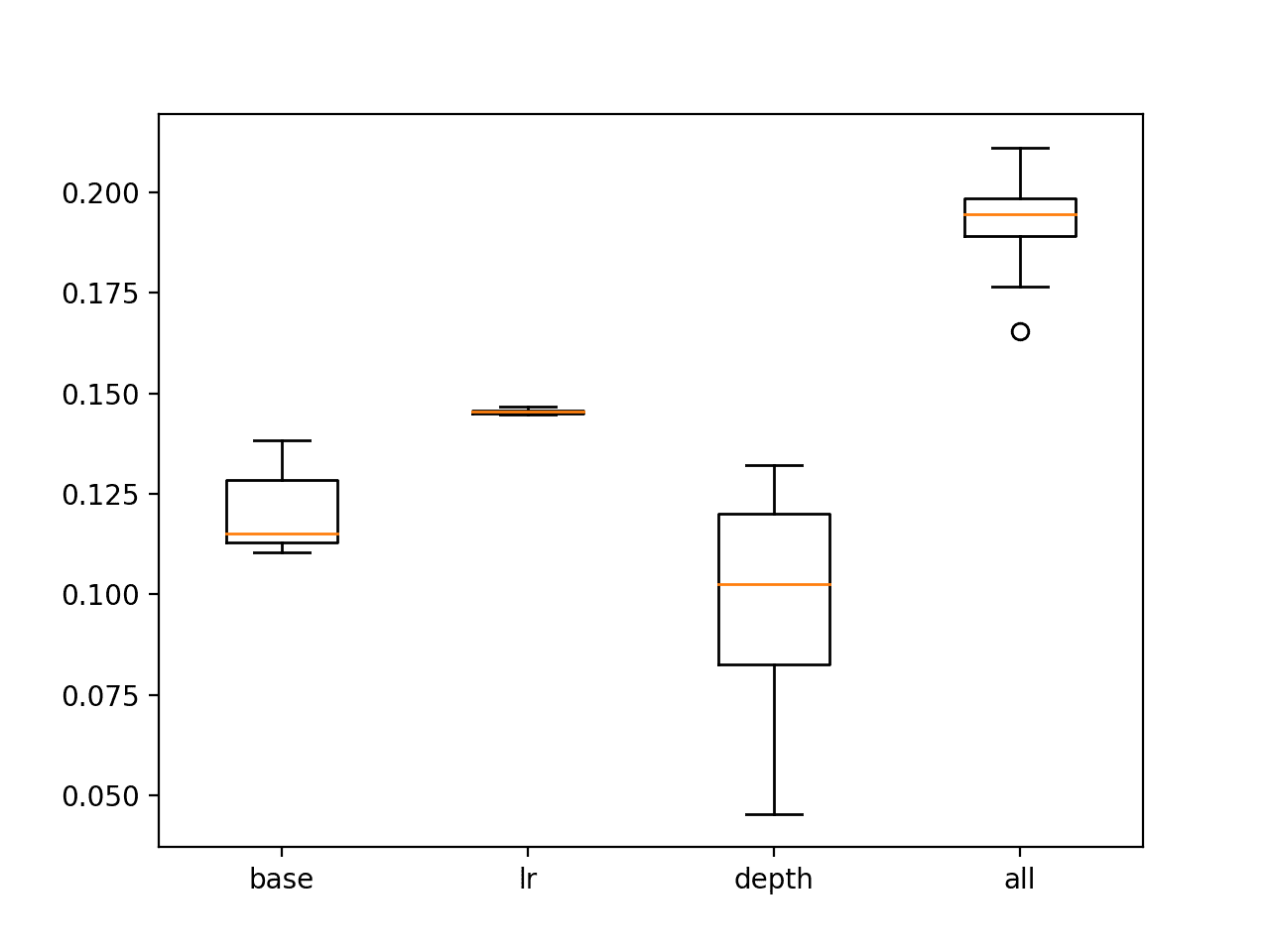
经过调优的GBM模型在测试集上的BSS分数箱线图
有趣的是,获取论文中描述的参数模型以及使用它所需的数据,以便将其技能与此最终模型的技能进行比较。
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 探索使用来自多个先前日期的观测值来构建模型。
- 探索使用ROC曲线图和ROC AUC指标进行模型评估。
- 网格搜索梯度提升模型参数,并可能探索其他实现,例如XGBoost。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 臭氧水平检测数据集,UCI机器学习存储库.
- 预测偏斜偏置随机臭氧日:分析与解决方案, 2006.
- 预测偏斜偏置随机臭氧日:分析、解决方案及展望, 2008.
- CAWCR 验证页面
- 维基百科上的受试者工作特征
总结
在本教程中,您学习了如何开发一个概率预测模型,以预测德克萨斯州休斯顿的空气污染。
具体来说,你学到了:
- 如何加载和准备臭氧日标准机器学习预测建模问题。
- 如何开发一个朴素预测模型,并使用Brier技能分数评估预测。
- 如何使用决策树集成开发熟练模型,并通过对成功模型的超参数调优进一步提高技能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






嗨,我非常喜欢您的博客文章,发现它是这个数据集和类似数据集的一个很好的起点。我是一名专业数据科学家,但您的文章的简洁性、清晰度和实用性为投入的时间提供了巨大的价值,我发现自己渴望更多。
谢谢,我很高兴这些帖子有用!
非常棒的案例研究。它包含在你的时间序列深度学习书中吗?
谢谢。不,它不在书中。
谢谢分享。
我很高兴它能帮到你。
“这个分数可以被认为是预测概率(例如5%)与预期概率(0%或1%)之间的均方误差。”——这不应该是将预测概率与观测概率进行比较吗,观测概率是0%或100%?
我只是将预测值 (5%) 与预期值 (1%) 进行对比。抱歉没有说清楚。
你好,Julian!我可以使用LSTM进行概率分类预测吗?例如,我有3个条件。第一个条件是先热后冷,然后正常。输入数据后,我想知道(输出)每个类别的概率。每个类别都有一个分数范围,例如热(≥33°C),冷(≤1°C)等。
嗨,@Jason Brownlee。
我总是参考您的帖子学习,它们非常有帮助。
这次我面临一个问题:Bagging通过随机选取数据来创建子集,因此如果我们要使用lstm作为集成模型的基础模型来预测未来值,那么我们需要保留历史序列,在这种情况下,我们不能使用BaggingRegressor()。
所以请给我一些建议,如何在考虑k个过去值来预测k+1值的情况下,为lstm模型使用集成方法。
好问题,我暂时不确定。
也许可以尝试不同长度的序列?
或者从序列中随机删除观测值?
也许可以尝试一系列方法,看看哪种方法适用于您的特定数据和模型。
你好,Jason!我可以使用LSTM进行概率分类预测吗?例如,我有3个条件。第一个条件是先热后冷,然后正常。输入数据后,我想知道(输出)每个类别的概率。每个类别都有一个分数范围,例如热(≥33°C),冷(≤1°C)等。