不平衡分类问题是指训练数据集中类别标签分布不均匀的预测类别标签问题。
对于初学者来说,处理不平衡分类问题的一个挑战是特定倾斜类别分布的含义。例如,1:10与1:100的类别比例之间有什么区别和影响?
不平衡分类问题中类别分布的差异将影响数据准备和建模算法的选择。因此,从业者对不同类别分布的影响建立直观认识至关重要。
在本教程中,您将学习如何对不平衡和高度倾斜的类别分布建立实用的直观认识。
完成本教程后,您将了解:
- 如何为二元分类创建合成数据集并按类别绘制示例。
- 如何创建具有任何给定类别分布的合成分类数据集。
- 不同倾斜类别分布在实践中实际的样子。
通过我的新书《Python不平衡分类》**启动您的项目**,其中包括**逐步教程**和所有示例的**Python源代码文件**。
让我们开始吧。
- **2020年1月更新**:已针对 scikit-learn v0.22 API 的变更进行更新。

建立对严重倾斜类别分布的直觉
图片由Boris Kasimov拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 创建并绘制二元分类问题
- 创建具有类别分布的合成数据集
- 倾斜类别分布的影响
创建并绘制二元分类问题
scikit-learn Python机器学习库提供了用于生成合成数据集的函数。
《make_blobs()函数》可用于从具有指定类别数的测试分类问题中生成指定数量的示例。该函数返回每个示例的输入和输出部分,可用于建模。
例如,以下代码片段将为具有两个输入变量的两类(二元)分类问题生成1,000个示例。类别值分别为0和1。
|
1 2 |
... X, y = make_blobs(n_samples=1000, centers=2, n_features=2, random_state=1, cluster_std=3) |
生成后,我们可以绘制数据集,以直观了解示例之间的空间关系。
由于只有两个输入变量,我们可以创建一个散点图,将每个示例绘制为一个点。这可以通过scatter() matplotlib函数实现。
点的颜色可以根据类别值进行变化。这可以通过首先选择给定类别的示例的数组索引,然后只绘制这些点,然后对其他类别重复选择和绘制过程来实现。where() NumPy函数可用于检索符合条件的数组索引,例如具有给定值的类别标签。
例如:
|
1 2 3 4 5 6 7 |
... # 为每个类别的样本创建散点图 for class_value in range(2): # 获取具有此类别的样本的行索引 row_ix = where(y == class_value) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) |
综合起来,以下是创建二元分类测试数据集并将其示例绘制为散点图的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 生成二元分类数据集并绘制 from numpy import where from matplotlib import pyplot from sklearn.datasets import make_blobs # 生成数据集 X, y = make_blobs(n_samples=1000, centers=2, n_features=2, random_state=1, cluster_std=3) # 为每个类别的样本创建散点图 for class_value in range(2): # 获取具有此类别的样本的行索引 row_ix = where(y == class_value) # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1]) # 显示绘图 pyplot.show() |
运行示例会创建数据集和散点图,显示两个类别的示例,颜色不同。
我们可以看到每个类别中的示例数量相等,在本例中为500个,我们可以想象画一条线来合理地分离这些类别,就像分类预测模型在学习如何区分这些示例时可能做的那样。
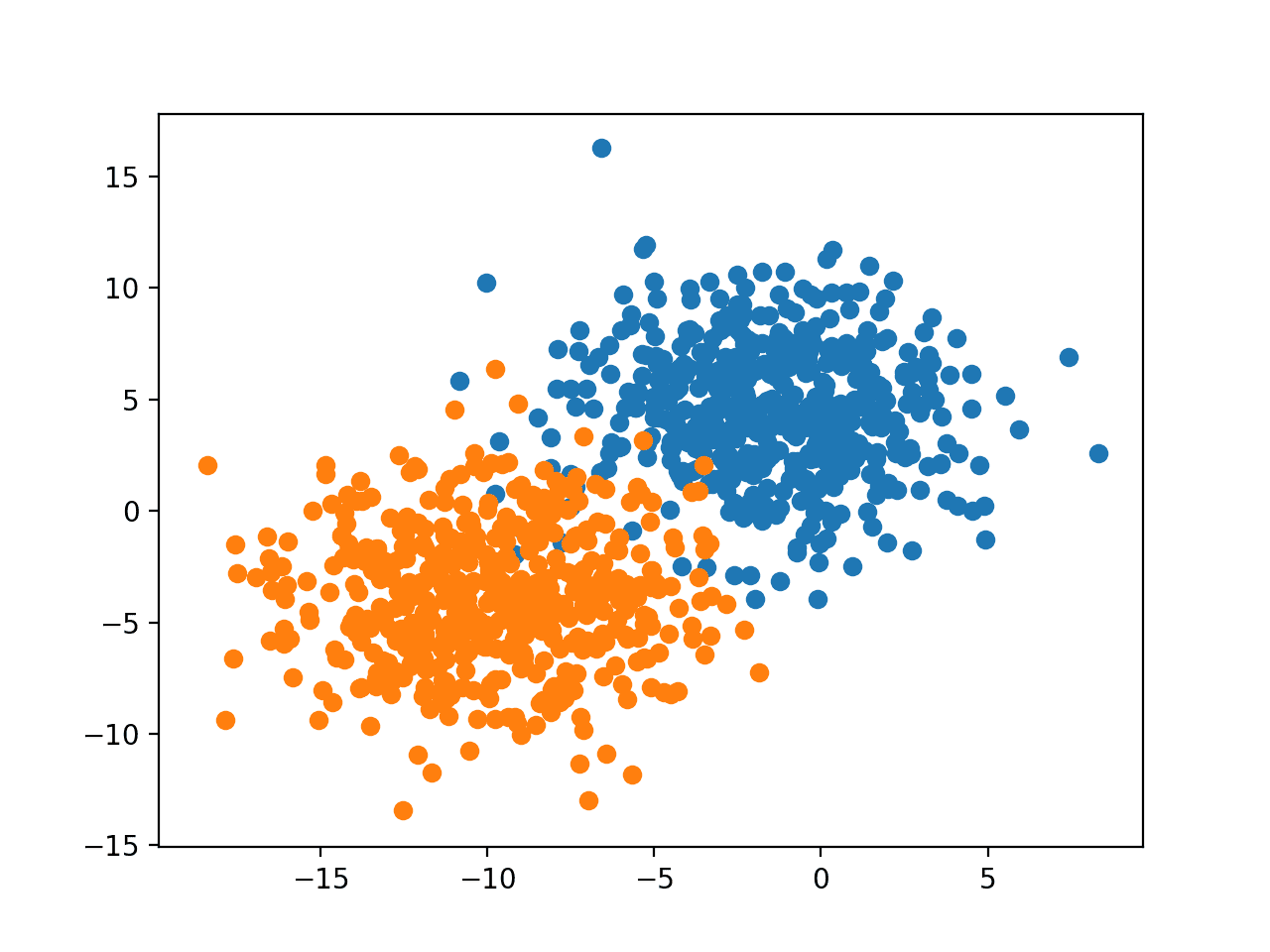
二元分类数据集的散点图
现在我们知道如何创建合成二元分类数据集并绘制示例,接下来我们来看一下类别不平衡对示例的影响。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
创建具有类别分布的合成数据集
make_blobs()函数将始终创建具有相等类别分布的合成数据集。
然而,我们可以使用此函数,通过几行额外的代码,创建具有任意类别分布的合成分类数据集。
类别分布可以定义为一个字典,其中键是类别值(例如0或1),值是要包含在数据集中的随机生成示例的数量。
例如,每个类别有5,000个示例的相等类别分布将定义为
|
1 2 3 |
... # 定义类别分布 proportions = {0:5000, 1:5000} |
然后,我们可以遍历不同的分布并找到最大的分布,然后使用make_blobs()函数为每个类别创建具有那么多示例的数据集。
|
1 2 3 4 5 6 |
... # 确定类别数量 n_classes = len(proportions) # 确定为每个类别生成的示例数量 largest = max([v for k,v in proportions.items()]) n_samples = largest * n_classes |
这是一个很好的起点,但会给我们比每个类别标签所需的更多样本。
然后,我们可以遍历类别标签并为每个类别选择所需数量的示例,以构成将返回的数据集。
|
1 2 3 4 5 6 7 8 |
... # 收集示例 X_list, y_list = list(), list() for k,v in proportions.items(): row_ix = where(y == k)[0] selected = row_ix[:v] X_list.append(X[selected, :]) y_list.append(y[selected]) |
我们可以将这些内容整合到一个名为get_dataset()的新函数中,该函数将接受类别分布并返回具有该类别分布的合成数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 创建一个具有给定类别分布的数据集 def get_dataset(proportions): # 确定类别数量 n_classes = len(proportions) # 确定为每个类别生成的示例数量 largest = max([v for k,v in proportions.items()]) n_samples = largest * n_classes # 创建数据集 X, y = make_blobs(n_samples=n_samples, centers=n_classes, n_features=2, random_state=1, cluster_std=3) # 收集示例 X_list, y_list = list(), list() for k,v in proportions.items(): row_ix = where(y == k)[0] selected = row_ix[:v] X_list.append(X[selected, :]) y_list.append(y[selected]) return vstack(X_list), hstack(y_list) |
该函数可以接受任意数量的类别,尽管我们将其用于简单的二元分类问题。
接下来,我们可以将上一节中用于为创建的数据集创建散点图的代码放入一个辅助函数中。下面是plot_dataset()函数,它将绘制数据集并显示一个图例,以指示颜色到类别标签的映射。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 数据集的散点图,每个类别使用不同颜色 def plot_dataset(X, y): # 为每个类别的样本创建散点图 n_classes = len(unique(y)) for class_value in range(n_classes): # 获取具有此类别的样本的行索引 row_ix = where(y == class_value)[0] # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(class_value)) # 显示图例 pyplot.legend() # 显示图表 pyplot.show() |
最后,我们可以测试这些新功能。
我们将定义一个数据集,每个类别有5,000个示例(总共10,000个示例),并绘制结果。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# 创建并绘制具有给定类别分布的合成数据集 from numpy import unique from numpy import hstack from numpy import vstack from numpy import where from matplotlib import pyplot from sklearn.datasets import make_blobs # 创建一个具有给定类别分布的数据集 def get_dataset(proportions): # 确定类别数量 n_classes = len(proportions) # 确定为每个类别生成的示例数量 largest = max([v for k,v in proportions.items()]) n_samples = largest * n_classes # 创建数据集 X, y = make_blobs(n_samples=n_samples, centers=n_classes, n_features=2, random_state=1, cluster_std=3) # 收集示例 X_list, y_list = list(), list() for k,v in proportions.items(): row_ix = where(y == k)[0] selected = row_ix[:v] X_list.append(X[selected, :]) y_list.append(y[selected]) return vstack(X_list), hstack(y_list) # 数据集的散点图,每个类别使用不同颜色 def plot_dataset(X, y): # 为每个类别的样本创建散点图 n_classes = len(unique(y)) for class_value in range(n_classes): # 获取具有此类别的样本的行索引 row_ix = where(y == class_value)[0] # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(class_value)) # 显示图例 pyplot.legend() # 显示图表 pyplot.show() # 定义类别分布 proportions = {0:5000, 1:5000} # 生成数据集 X, y = get_dataset(proportions) # 绘制数据集 plot_dataset(X, y) |
运行该示例会创建数据集并像以前一样绘制结果,尽管这次使用了我们提供的类别分布。
在这种情况下,我们每个类别有更多的示例,并且有一个有用的图例来指示绘图颜色到类别标签的映射。
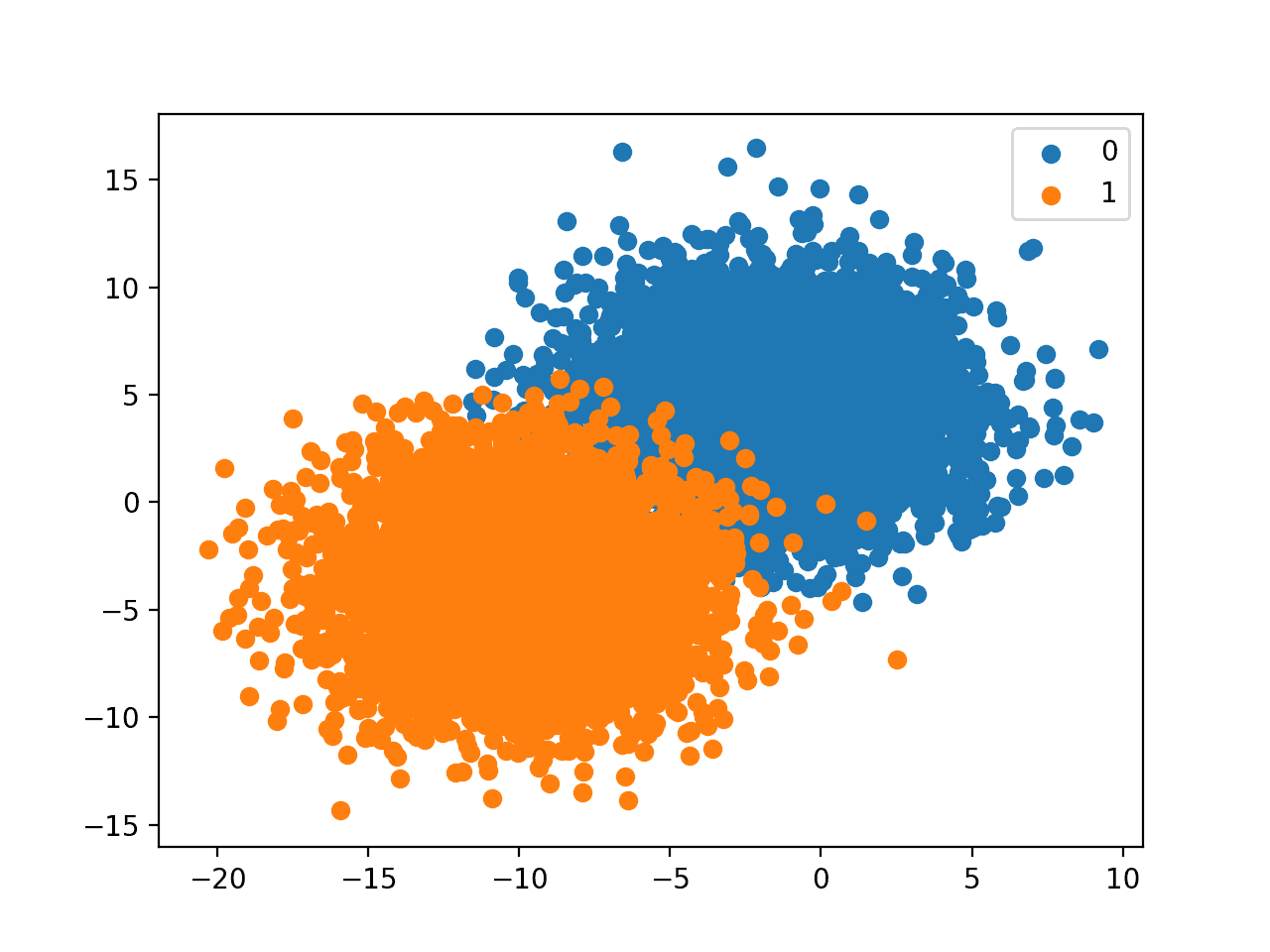
带有指定类别分布的二元分类数据集的散点图
现在我们有了创建和绘制具有任意倾斜类别分布的合成数据集的工具,接下来我们来看看不同分布的影响。
倾斜类别分布的影响
建立对不同类别不平衡的空间关系的直观认识非常重要。
例如,1:1000 的类别分布关系是怎样的?
这是一种抽象关系,我们需要将其与具体事物联系起来。
我们可以生成具有不同不平衡类别分布的合成测试数据集,并以此为基础,对未来在真实数据集中可能遇到的不同倾斜分布建立直观认识。
回顾不同类别分布的散点图可以让我们对类别之间的关系有一个粗略的感觉,这在未来处理相似类别分布时,考虑技术选择和模型评估时会很有用。它们提供了一个参考点。
我们已经在上一节中看到了1:1的关系(例如5000:5000)。
请注意,在处理二元分类问题,特别是不平衡问题时,将多数类分配给类0,将少数类分配给类1非常重要。这是因为许多评估指标会假定这种关系。
因此,我们可以通过在调用get_dataset()函数时定义多数类和少数类来确保我们的类分布符合此实践;例如
|
1 2 3 4 5 6 |
... # 定义类别分布 proportions = {0:10000, 1:10} # 生成数据集 X, y = get_dataset(proportions) ... |
在本节中,我们将考察少数类数量按对数尺度增加的不同倾斜类别分布,例如:
- 1:10 或 {0:10000, 1:1000}
- 1:100 或 {0:10000, 1:100}
- 1:1000 或 {0:10000, 1:10}
让我们依次仔细研究每个类别分布。
1:10不平衡类别分布
1:10的类别分布,即10,000个示例对应1,000个示例,这意味着数据集中将有11,000个示例,其中类别0约占91%,类别1约占9%。
完整的代码示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# 创建并绘制具有给定类别分布的合成数据集 from numpy import unique from numpy import hstack from numpy import vstack from numpy import where from matplotlib import pyplot from sklearn.datasets import make_blobs # 创建一个具有给定类别分布的数据集 def get_dataset(proportions): # 确定类别数量 n_classes = len(proportions) # 确定为每个类别生成的示例数量 largest = max([v for k,v in proportions.items()]) n_samples = largest * n_classes # 创建数据集 X, y = make_blobs(n_samples=n_samples, centers=n_classes, n_features=2, random_state=1, cluster_std=3) # 收集示例 X_list, y_list = list(), list() for k,v in proportions.items(): row_ix = where(y == k)[0] selected = row_ix[:v] X_list.append(X[selected, :]) y_list.append(y[selected]) return vstack(X_list), hstack(y_list) # 数据集的散点图,每个类别使用不同颜色 def plot_dataset(X, y): # 为每个类别的样本创建散点图 n_classes = len(unique(y)) for class_value in range(n_classes): # 获取具有此类别的样本的行索引 row_ix = where(y == class_value)[0] # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(class_value)) # 显示图例 pyplot.legend() # 显示图表 pyplot.show() # 定义类别分布 proportions = {0:10000, 1:1000} # 生成数据集 X, y = get_dataset(proportions) # 绘制数据集 plot_dataset(X, y) |
运行示例会创建具有定义的类别分布的数据集并绘制结果。
尽管这种平衡看起来很悬殊,但图表显示,与多数类相比,少数类中约10%的点并没有我们想象的那么糟糕。
这种关系似乎是可控的,尽管如果类别之间存在显著重叠,我们可能会想象出截然不同的情况。
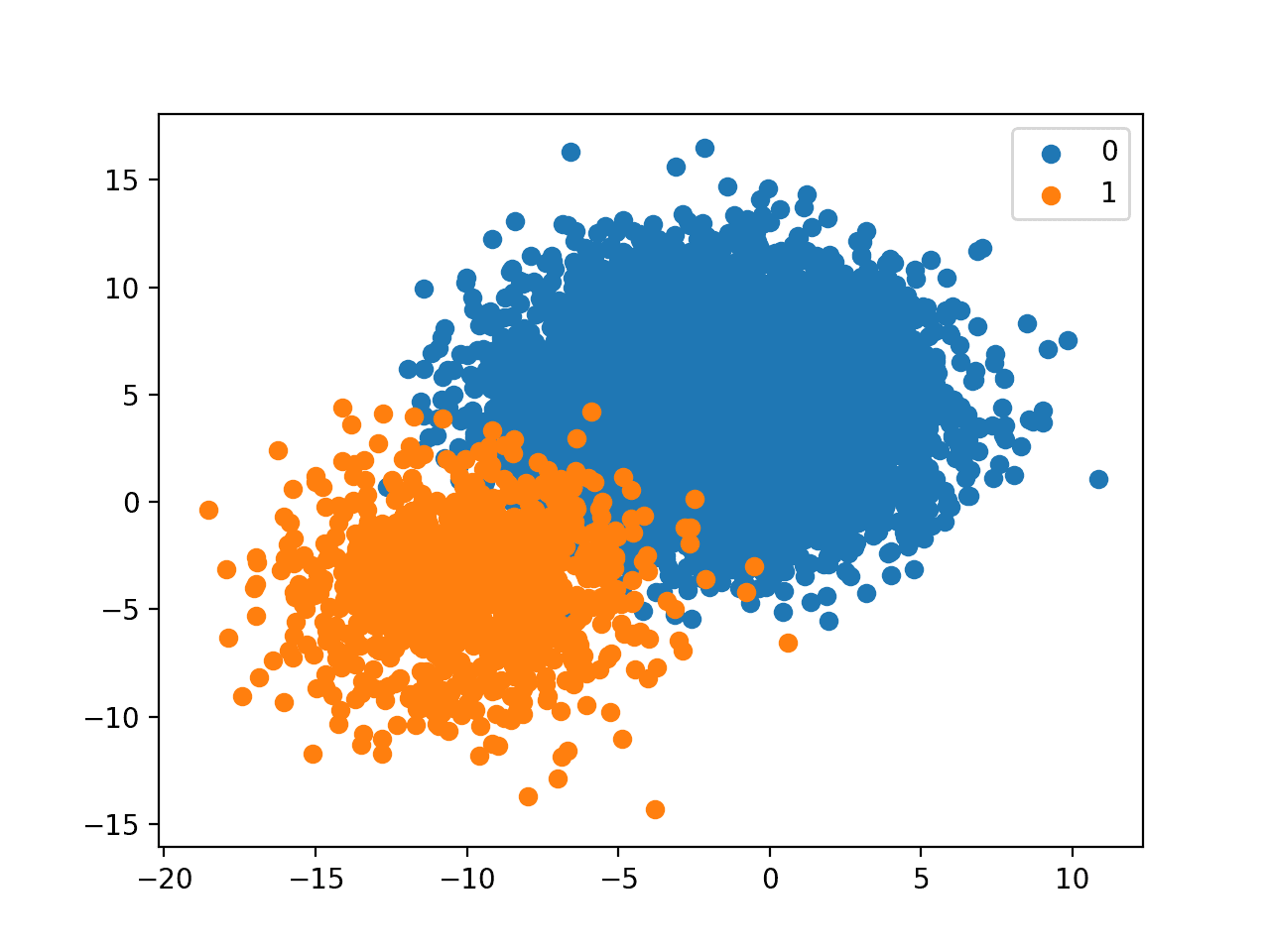
具有1比10类别分布的二元分类数据集散点图
1:100不平衡类别分布
1:100的类别分布,即10,000个示例对应100个示例,这意味着数据集中将有10,100个示例,其中类别0约占99%,类别1约占1%。
完整的代码示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# 创建并绘制具有给定类别分布的合成数据集 from numpy import unique from numpy import hstack from numpy import vstack from numpy import where from matplotlib import pyplot from sklearn.datasets import make_blobs # 创建一个具有给定类别分布的数据集 def get_dataset(proportions): # 确定类别数量 n_classes = len(proportions) # 确定为每个类别生成的示例数量 largest = max([v for k,v in proportions.items()]) n_samples = largest * n_classes # 创建数据集 X, y = make_blobs(n_samples=n_samples, centers=n_classes, n_features=2, random_state=1, cluster_std=3) # 收集示例 X_list, y_list = list(), list() for k,v in proportions.items(): row_ix = where(y == k)[0] selected = row_ix[:v] X_list.append(X[selected, :]) y_list.append(y[selected]) return vstack(X_list), hstack(y_list) # 数据集的散点图,每个类别使用不同颜色 def plot_dataset(X, y): # 为每个类别的样本创建散点图 n_classes = len(unique(y)) for class_value in range(n_classes): # 获取具有此类别的样本的行索引 row_ix = where(y == class_value)[0] # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(class_value)) # 显示图例 pyplot.legend() # 显示图表 pyplot.show() # 定义类别分布 proportions = {0:10000, 1:100} # 生成数据集 X, y = get_dataset(proportions) # 绘制数据集 plot_dataset(X, y) |
运行示例会创建具有定义的类别分布的数据集并绘制结果。
1比100的关系是一个很大的偏差。
图表清楚地表明了这一点,与多数类的巨大体量相比,少数类只感觉像零星散布的点。
真实世界的数据集很可能介于1:10和1:100的类别分布之间,而1:100的图表确实强调了仔细考虑少数类中每个点的必要性,无论是从测量误差(例如异常值)还是从模型可能产生的预测误差方面。
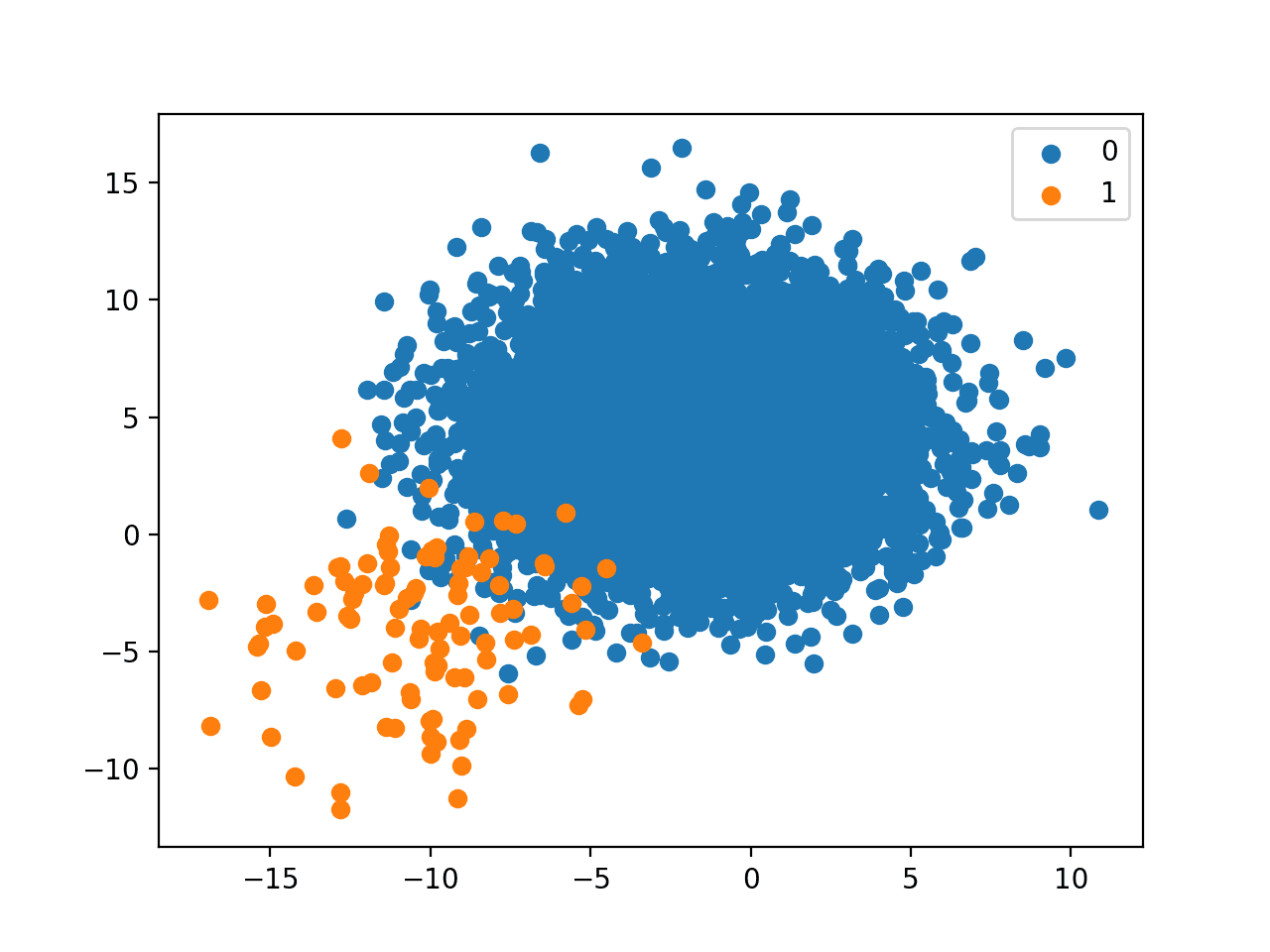
具有1比100类别分布的二元分类数据集散点图
1:1000 不平衡类别分布
1:100的类别分布,即10,000个示例对应10个示例,这意味着数据集中将有10,010个示例,其中类别0约占99.9%,类别1约占0.1%。
完整的代码示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# 创建并绘制具有给定类别分布的合成数据集 from numpy import unique from numpy import hstack from numpy import vstack from numpy import where from matplotlib import pyplot from sklearn.datasets import make_blobs # 创建一个具有给定类别分布的数据集 def get_dataset(proportions): # 确定类别数量 n_classes = len(proportions) # 确定为每个类别生成的示例数量 largest = max([v for k,v in proportions.items()]) n_samples = largest * n_classes # 创建数据集 X, y = make_blobs(n_samples=n_samples, centers=n_classes, n_features=2, random_state=1, cluster_std=3) # 收集示例 X_list, y_list = list(), list() for k,v in proportions.items(): row_ix = where(y == k)[0] selected = row_ix[:v] X_list.append(X[selected, :]) y_list.append(y[selected]) return vstack(X_list), hstack(y_list) # 数据集的散点图,每个类别使用不同颜色 def plot_dataset(X, y): # 为每个类别的样本创建散点图 n_classes = len(unique(y)) for class_value in range(n_classes): # 获取具有此类别的样本的行索引 row_ix = where(y == class_value)[0] # 创建这些样本的散点图 pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(class_value)) # 显示图例 pyplot.legend() # 显示图表 pyplot.show() # 定义类别分布 proportions = {0:10000, 1:10} # 生成数据集 X, y = get_dataset(proportions) # 绘制数据集 plot_dataset(X, y) |
运行示例会创建具有定义的类别分布的数据集并绘制结果。
正如我们可能已经怀疑的,1比1,000的关系是极端的。在我们选择的设置中,少数类只有10个示例,而多数类有10,000个示例。
由于数据如此匮乏,我们可以看到,在具有如此剧烈倾斜的建模问题上,我们应该花大量时间在可用的实际少数类示例上,看看是否可以以某种方式利用领域知识。自动建模方法将面临严峻挑战。
这个例子也突出了另一个与类别分布无关的重要方面,那就是示例的数量。例如,尽管数据集具有1:1000的类别分布,但只有10个少数类示例是非常具有挑战性的。然而,如果我们拥有相同类别分布,但多数类有1,000,000个示例,少数类有1,000个示例,那么额外的990个少数类示例可能在开发有效模型方面具有不可估量的价值。
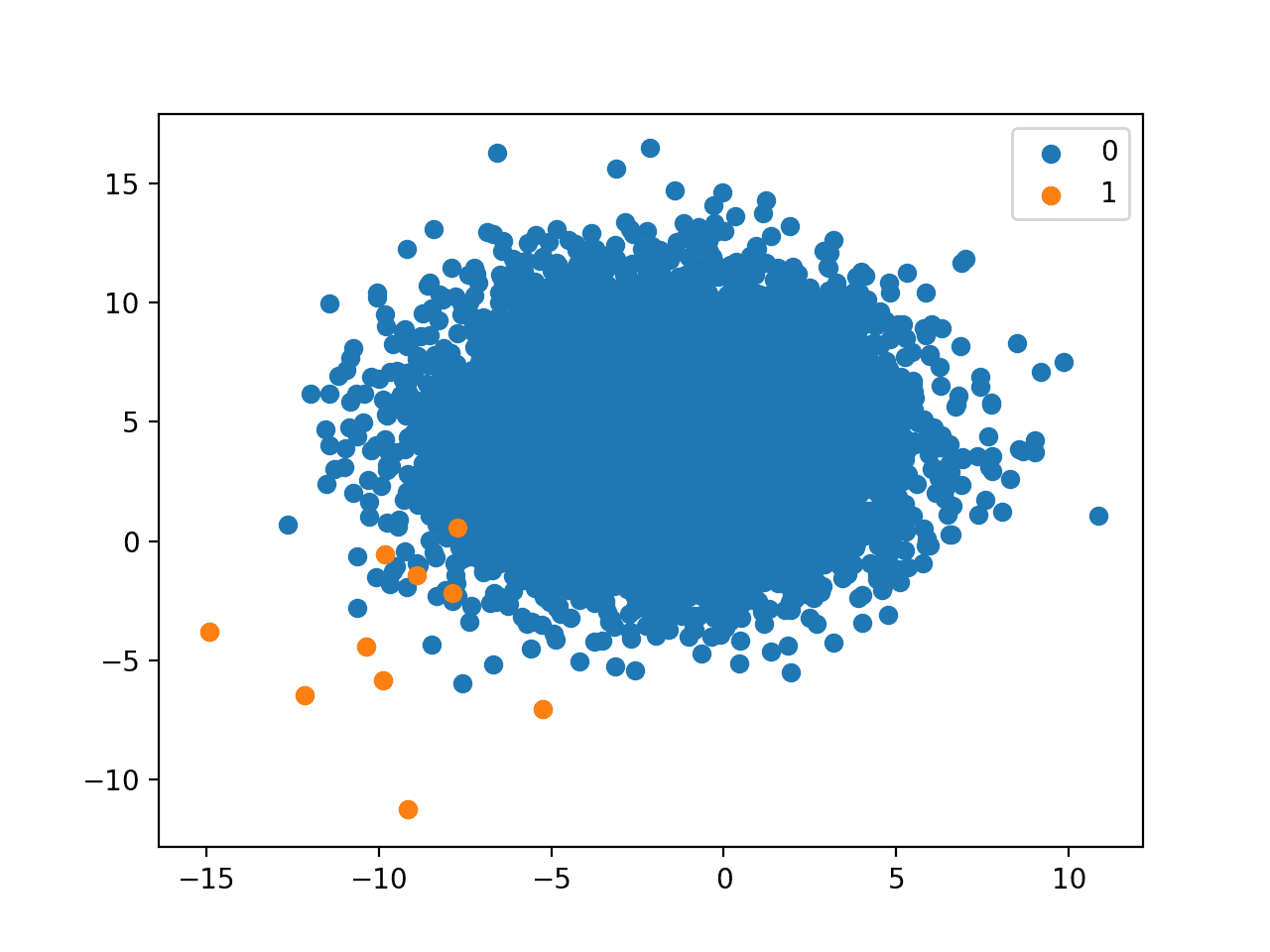
具有1比1000类别分布的二元分类数据集散点图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
总结
在本教程中,您学习了如何对不平衡和高度倾斜的类别分布建立实用的直观认识。
具体来说,你学到了:
- 如何为二元分类创建合成数据集并按类别绘制示例。
- 如何创建具有任何给定类别分布的合成分类数据集。
- 不同倾斜类别分布在实践中实际的样子。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






嗨,Jason,
在 Python 中,通常以如下方式导入 numpy:
> import numpy as np
为什么不遵循这个惯例?
祝好,
我觉得读起来不简洁。
感谢 Jason 对不平衡概念的精彩解释。但是,我想了解一下在现实世界中如何解决这种情况。您能就此提出建议吗?
另外,您对使用神经网络处理此类不平衡情况有何看法?神经网络是否能够处理不平衡数据?
先生,请指教。
是的,我很快就会发布这方面的教程。
神经网络可以通过在Keras中调用fit()时设置class_weight参数来处理不平衡分类。
它们在某些情况下表现良好,在其他情况下表现不佳。务必尝试多种方法。
谢谢Jason。您能否在此帖子或未来的教程中:
— 举例说明如何在 Keras 中应用 class_weight 参数;
— 解释为什么它们只间歇性地起作用;以及
— 解释我们应该尝试哪些方法?
非常感谢!
很棒的建议,谢谢。
嗨,Jason,
首先,感谢您创建了这些主题的宝贵资源。我有一个关于您最后一句话的问题:
“然而,如果我们在多数类有1,000,000个示例,少数类有1,000个示例的情况下,拥有相同的类分布,那么额外的990个少数类示例可能会对开发一个有效的模型非常有价值。”
但是,如果我们考虑经典抽样理论,为什么少数类中额外的990个案例不会对我们的模型更好地训练少数类行为有很大帮助呢?我理解抽样比例不会改变,但如果少数类的一个案例与同一类别的1000个案例对模型来说是相等的,我会觉得很奇怪。
在此先感谢,
Tamas
不客气。
抱歉造成困惑。这些问题是不可比的。我的观点是,我们更倾向于对少数类提供更多观测值的领域进行建模——假设决策边界并非微不足道。
一如既往的精彩。非常感谢
谢谢戴夫!
你好,
您能否在教程中包含关于多类别不平衡数据集分类的教程?
很好的建议,谢谢。
您在不平衡多类问题上具体遇到了什么问题?
你好,
您可以为合成数据集包含不平衡多类分类。此外,如何处理/识别和可视化类别分离,如重叠类别、异常值或重叠类别多类不平衡数据集?
谢谢。
我倾向于处理1:10范围的数据,我发现梯度提升算法始终优于其他算法,这并不奇怪。然而,平衡数据似乎从未带来显著优势。当输入值超过2个(例如10个或更多)时,如何可视化分布?
很好,谢谢分享您的发现。
您可以为两个以上的变量使用成对散点图,即所谓的散点图矩阵。
非常感谢您分享这些精彩的资料。我很好奇您是否可以分享任何与在大数据领域处理严重不平衡类别相关的教程。例如,Blackbaze硬盘故障数据,特别是希捷型号,数据量极其庞大!使用sklearn包或Pandas数据框很困难!
不客气!
也许可以使用相同的技术,但使用大数据框架实现。
抱歉,我没有任何处理大数据的示例。
非常感谢您的回复!我非常感谢!在某些情况下,处理大数据具有挑战性。PySpark 在处理严重不平衡数据方面的资源有限!