实际的时间序列预测由于诸多原因而具有挑战性,这些原因不仅限于问题的特征,例如具有多个输入变量、需要预测多个时间步长以及需要对多个物理站点执行相同类型的预测。
EMC全球数据科学黑客松数据集,或简称“空气质量预测”数据集,描述了多个站点的天气状况,并要求预测未来三天的空气质量测量值。
在深入研究时间序列预测的复杂机器学习和深度学习方法之前,找到经典方法的局限性很重要,例如使用AR或ARIMA方法开发自回归模型。
在本教程中,您将学习如何为多元空气污染时间序列开发自回归模型以进行多步时间序列预测。
完成本教程后,您将了解:
- 如何分析和插补时间序列数据中的缺失值。
- 如何开发和评估用于多步时间序列预测的自回归模型。
- 如何使用替代数据插补方法改进自回归模型。
开始您的项目,阅读我的新书《时间序列预测深度学习》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2020 年 12 月更新:将 ARIMA API 更新为最新版本的 statsmodels。

数据集大小对深度学习模型技能和性能估计的影响
照片作者: Eneas De Troya,部分权利保留。
教程概述
本教程分为六个部分;它们是:
- 问题描述
- 模型评估
- 数据分析
- 开发自回归模型
- 全局插补策略的自回归模型
问题描述
空气质量预测数据集描述了多个站点的天气状况,需要预测未来三天内的空气质量测量值。
具体来说,提供每小时的天气观测数据,如温度、气压、风速和风向,为期八天,针对多个站点。目标是预测多个站点的未来3天的空气质量测量值。预测提前时间不是连续的;相反,必须预测72小时预测期内的特定提前时间。它们是
|
1 |
+1, +2, +3, +4, +5, +10, +17, +24, +48, +72 |
此外,数据集被划分为不相交但连续的数据块,其中包含八天的数据,然后是需要预测的三天。
并非所有站点或数据块都提供所有观测数据,也并非所有站点或数据块都提供所有输出变量。存在大量缺失数据,必须加以解决。
该数据集在 2012 年 Kaggle 网站上作为短期机器学习竞赛(或黑客马拉松)的基础。
比赛的提交内容是根据对参与者隐瞒的真实观测值进行评估,并使用平均绝对误差 (MAE) 进行评分。对于由于数据丢失而无法进行预测的情况,提交要求指定值-1,000,000。实际上,提供了一个模板,用于插入缺失值,并且要求所有提交都采用此模板(真麻烦)。
一位获胜者在保留的测试集(私有排行榜)上使用滞后观测值的随机森林实现了 0.21058 的 MAE。该解决方案的详细说明可在以下帖子中找到
在本教程中,我们将探讨如何为该问题开发朴素预测,这些预测可用作基线,以确定模型是否在该问题上具有技能。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
模型评估
在评估朴素预测方法之前,我们必须开发一个测试工具。
这至少包括如何准备数据以及如何评估预测。
加载数据集
第一步是下载数据集并将其加载到内存中。
可以从 Kaggle 网站免费下载数据集。您可能需要创建帐户并登录才能下载数据集。
将整个数据集(例如“下载所有”)下载到您的工作站,并在当前工作目录中解压缩存档到名为“AirQualityPrediction”的文件夹中。
我们的重点将放在“TrainingData.csv”文件,该文件包含训练数据集,特别是以数据块形式存在的数据,其中每个数据块是八个连续的观测日和目标变量。
我们可以使用 Pandas 的 read_csv() 函数将数据文件加载到内存中,并指定第 0 行作为标题行。
|
1 2 |
# 加载数据集 dataset = read_csv('AirQualityPrediction/TrainingData.csv', header=0) |
我们可以按“chunkID”变量(列索引 1)对数据进行分组。
首先,让我们获取唯一块标识符的列表。
|
1 |
chunk_ids = unique(values[:, 1]) |
然后,我们可以收集每个块标识符的所有行,并将它们存储在字典中以便于访问。
|
1 2 3 4 5 |
chunks = dict() # 按块 ID 排序行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks[chunk_id] = values[selection, :] |
下面定义了一个名为 to_chunks() 的函数,该函数接受加载数据的 NumPy 数组,并返回一个从 chunk_id 到块行的字典。
|
1 2 3 4 5 6 7 8 9 10 |
# 按“chunkID”拆分数据集,返回一个 ID 到行的字典 def to_chunks(values, chunk_ix=1): chunks = dict() # 获取唯一的块 ID chunk_ids = unique(values[:, chunk_ix]) # 按块 ID 分组行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks[chunk_id] = values[selection, :] return chunks |
加载数据集并将其拆分为块的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 加载数据并拆分为块 from numpy import unique from pandas import read_csv # 按“chunkID”拆分数据集,返回一个 ID 到行的字典 def to_chunks(values, chunk_ix=1): chunks = dict() # 获取唯一的块 ID chunk_ids = unique(values[:, chunk_ix]) # 按块 ID 分组行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks[chunk_id] = values[selection, :] return chunks # 加载数据集 dataset = read_csv('AirQualityPrediction/TrainingData.csv', header=0) # 按块分组数据 values = dataset.values chunks = to_chunks(values) print('Total Chunks: %d' % len(chunks)) |
运行示例会打印数据集中块的数量。
|
1 |
总块数:208 |
数据准备
现在我们知道如何加载数据并将其拆分为块,我们可以将其分成训练和测试数据集。
每个块包含八天每小时的观测数据,尽管每个块中实际观测的数量可能差异很大。
我们可以将每个块的前五天的观测数据用于训练,后三天用于测试。
每个观测值都有一行称为“position_within_chunk”(在块内位置),其值从1到192(8天 * 24小时)不等。因此,我们可以将此列中小于或等于120(5 * 24)的所有行作为训练数据,将任何大于120的值作为测试数据。
此外,任何在训练或测试拆分中没有观测值的块都可以被视为不可用而丢弃。
在处理朴素模型时,我们只对目标变量感兴趣,而对气象输入变量不感兴趣。因此,我们可以删除输入数据,使训练和测试数据仅包含每个块的39个目标变量,以及块内位置和观测小时。
下面的 split_train_test() 函数实现了此行为;给定一个块字典,它将每个块拆分为训练和测试块数据的列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 将每个块拆分为训练/测试集 def split_train_test(chunks, row_in_chunk_ix=2): train, test = list(), list() # 前 5 天的每小时观测数据用于训练 cut_point = 5 * 24 # 枚举块 for k,rows in chunks.items(): # 按“position_within_chunk”拆分块行 train_rows = rows[rows[:,row_in_chunk_ix] <= cut_point, :] test_rows = rows[rows[:,row_in_chunk_ix] > cut_point, :] if len(train_rows) == 0 or len(test_rows) == 0: print('>dropping chunk=%d: train=%s, test=%s' % (k, train_rows.shape, test_rows.shape)) continue # 存储块 ID、块内位置、小时和所有目标 indices = [1,2,5] + [x for x in range(56,train_rows.shape[1])] train.append(train_rows[:, indices]) test.append(test_rows[:, indices]) return train, test |
我们不需要整个测试数据集;相反,我们只需要三天内特定提前期处的观测数据,特别是以下提前期
|
1 |
+1, +2, +3, +4, +5, +10, +17, +24, +48, +72 |
其中,每个提前期都相对于训练期结束。
首先,我们可以将这些提前期放入一个函数中,以便于引用
|
1 2 3 |
# 返回相对预测提前期的列表 def get_lead_times(): return [1, 2 ,3, 4, 5, 10, 17, 24, 48, 72] |
接下来,我们可以将测试数据集缩减为仅包含首选提前期的数据。
我们可以通过查看“position_within_chunk”列,并使用提前期作为训练数据集结束的偏移量来实现,例如 120 + 1、120 + 2 等。
如果在测试集中找到匹配的行,则保存该行,否则生成一行 NaN 观测值。
下面的 to_forecasts() 函数实现了此功能,并返回一个 NumPy 数组,其中每个块的每个预测提前期都有一行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 将测试块中的行转换为预测 def to_forecasts(test_chunks, row_in_chunk_ix=1): # 获取提前期 lead_times = get_lead_times() # 前 5 天的每小时观测数据用于训练 cut_point = 5 * 24 forecasts = list() # 枚举每个块 for rows in test_chunks: chunk_id = rows[0, 0] # 枚举每个提前期 for tau in lead_times: # 确定我们想要的提前期在块中的行 offset = cut_point + tau # 使用块中的行号检索提前期的数据 row_for_tau = rows[rows[:,row_in_chunk_ix]==offset, :] # 检查我们是否有数据 if len(row_for_tau) == 0: # 创建一个模拟行 [chunk, position, hour] + [nan...] row = [chunk_id, offset, nan] + [nan for _ in range(39)] forecasts.append(row) else: # 存储预测行 forecasts.append(row_for_tau[0]) return array(forecasts) |
我们可以将所有这些结合起来,将数据集拆分为训练集和测试集,并将结果保存到新文件中。
完整的代码示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
# 将数据拆分为训练集和测试集 from numpy import unique from numpy import nan from numpy import array from numpy import savetxt from pandas import read_csv # 按“chunkID”拆分数据集,返回一个 ID 到行的字典 def to_chunks(values, chunk_ix=1): chunks = dict() # 获取唯一的块 ID chunk_ids = unique(values[:, chunk_ix]) # 按块 ID 分组行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks[chunk_id] = values[selection, :] return chunks # 将每个块拆分为训练/测试集 def split_train_test(chunks, row_in_chunk_ix=2): train, test = list(), list() # 前 5 天的每小时观测数据用于训练 cut_point = 5 * 24 # 枚举块 for k,rows in chunks.items(): # 按“position_within_chunk”拆分块行 train_rows = rows[rows[:,row_in_chunk_ix] <= cut_point, :] test_rows = rows[rows[:,row_in_chunk_ix] > cut_point, :] if len(train_rows) == 0 or len(test_rows) == 0: print('>dropping chunk=%d: train=%s, test=%s' % (k, train_rows.shape, test_rows.shape)) continue # 存储块 ID、块内位置、小时和所有目标 indices = [1,2,5] + [x for x in range(56,train_rows.shape[1])] train.append(train_rows[:, indices]) test.append(test_rows[:, indices]) return train, test # 返回相对预测提前期的列表 def get_lead_times(): return [1, 2 ,3, 4, 5, 10, 17, 24, 48, 72] # 将测试块中的行转换为预测 def to_forecasts(test_chunks, row_in_chunk_ix=1): # 获取提前期 lead_times = get_lead_times() # 前 5 天的每小时观测数据用于训练 cut_point = 5 * 24 forecasts = list() # 枚举每个块 for rows in test_chunks: chunk_id = rows[0, 0] # 枚举每个提前期 for tau in lead_times: # 确定我们想要的提前期在块中的行 offset = cut_point + tau # 使用块中的行号检索提前期的数据 row_for_tau = rows[rows[:,row_in_chunk_ix]==offset, :] # 检查我们是否有数据 if len(row_for_tau) == 0: # 创建一个模拟行 [chunk, position, hour] + [nan...] row = [chunk_id, offset, nan] + [nan for _ in range(39)] forecasts.append(row) else: # 存储预测行 forecasts.append(row_for_tau[0]) return array(forecasts) # 加载数据集 dataset = read_csv('AirQualityPrediction/TrainingData.csv', header=0) # 按块分组数据 values = dataset.values chunks = to_chunks(values) # 分割成训练/测试集 train, test = split_train_test(chunks) # 将训练块平铺成行 train_rows = array([row for rows in train for row in rows]) # print(train_rows.shape) print('Train Rows: %s' % str(train_rows.shape)) # 仅将训练数据缩减到预测提前期 test_rows = to_forecasts(test) print('Test Rows: %s' % str(test_rows.shape)) # 保存数据集 savetxt('AirQualityPrediction/naive_train.csv', train_rows, delimiter=',') savetxt('AirQualityPrediction/naive_test.csv', test_rows, delimiter=',') |
运行示例首先会提示块 69 因数据不足而被从数据集中删除。
然后我们可以看到,训练集和测试集中各有 42 列,其中一列用于块 ID,一列用于块内位置,一列用于一天中的小时,以及 39 个训练变量。
我们还可以看到,测试数据集的版本明显较小,只包含预测提前期处的行。
新的训练和测试数据集分别保存在“naive_train.csv”和“naive_test.csv”文件中。
|
1 2 3 |
>正在删除块=69:训练=(0, 95),测试=(28, 95) 训练行数: (23514, 42) 测试行数: (2070, 42) |
预测评估
一旦做出预测,就需要对其进行评估。
为了评估预测,拥有一个更简单的格式很有帮助。例如,我们将使用[块][变量][时间]的三维结构,其中变量是目标变量编号,从0到38,时间是提前时间索引,从0到9。
模型预计将以这种格式进行预测。
我们还可以重新构造测试数据集,使其具有此数据集以进行比较。下面的 prepare_test_forecasts() 函数实现了此功能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 将块中的测试数据集转换为 [块][变量][时间] 格式 def prepare_test_forecasts(test_chunks): predictions = list() # 枚举要预测的块 for rows in test_chunks: # 枚举块的目标 chunk_predictions = list() for j in range(3, rows.shape[1]): yhat = rows[:, j] chunk_predictions.append(yhat) chunk_predictions = array(chunk_predictions) predictions.append(chunk_predictions) return array(predictions) |
我们将使用平均绝对误差 (MAE) 来评估模型。这是竞赛中使用的指标,考虑到目标变量的非高斯分布,这是一个明智的选择。
如果提前时间在测试集中不包含数据(例如,NaN),则不对该预测计算任何误差。如果提前时间在测试集中有数据,但在预测中没有数据,则观测值的全部幅度将被视为误差。最后,如果测试集有观测值且已进行预测,则将绝对差值记录为误差。
calculate_error() 函数实现了这些规则并返回给定预测的误差。
|
1 2 3 4 5 6 7 |
# 计算实际值和预测值之间的误差 def calculate_error(actual, predicted): # 如果预测值为 nan,则给出完整的实际值 if isnan(predicted): return abs(actual) # 计算绝对差值 return abs(actual - predicted) |
误差在所有块和所有提前期上求和,然后求平均值。
将计算总体 MAE,但我们还将计算每个预测提前期的 MAE。这通常有助于模型选择,因为某些模型在不同的提前期可能表现不同。
下面的 evaluate_forecasts() 函数实现了此功能,它计算给定预测和预期值(以 [块][变量][时间] 格式)的 MAE 和每个提前期 MAE。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 评估 [块][变量][时间] 格式的预测 def evaluate_forecasts(predictions, testset): lead_times = get_lead_times() total_mae, times_mae = 0.0, [0.0 for _ in range(len(lead_times))] total_c, times_c = 0, [0 for _ in range(len(lead_times))] # 枚举测试块 for i in range(len(test_chunks)): # 转换为预测 actual = testset[i] predicted = predictions[i] # 枚举目标变量 for j in range(predicted.shape[0]): # 枚举提前期 for k in range(len(lead_times)): # 如果实际值为 nan 则跳过 if isnan(actual[j, k]): continue # 计算误差 error = calculate_error(actual[j, k], predicted[j, k]) # 更新统计数据 total_mae += error times_mae[k] += error total_c += 1 times_c[k] += 1 # 归一化求和的绝对误差 total_mae /= total_c times_mae = [times_mae[i]/times_c[i] for i in range(len(times_mae))] return total_mae, times_mae |
一旦我们评估了模型,我们就可以展示它。
下面的 summarize_error() 函数首先打印模型性能的一行摘要,然后创建每个预测提前期的 MAE 图。
|
1 2 3 4 5 6 7 8 9 10 |
# 总结得分 def summarize_error(name, total_mae, times_mae): # 打印摘要 lead_times = get_lead_times() formatted = ['+%d %.3f' % (lead_times[i], times_mae[i]) for i in range(len(lead_times))] s_scores = ', '.join(formatted) print('%s: [%.3f MAE] %s' % (name, total_mae, s_scores)) # 绘制摘要 pyplot.plot([str(x) for x in lead_times], times_mae, marker='.') pyplot.show() |
现在我们准备开始探索朴素预测方法的性能。
数据分析
将经典时间序列模型拟合到此数据的第一个步骤是仔细查看数据。
有208个(实际上是207个)可用数据块,每个块有39个时间序列需要拟合;总共需要拟合8,073个单独的模型。这有很多模型,但模型是在相对少量的数据上训练的,最多(5 * 24)或120个观测值,并且模型是线性的,因此它会很快找到拟合。
我们有关于如何配置模型以适应数据的选择;例如
- 所有时间序列的模型配置(最简单)。
- 所有块中所有变量的模型配置(合理)。
- 每个变量每个块的模型配置(最复杂)。
我们将研究最简单的方法,即为所有序列提供一种模型配置,但您可能需要探索一种或多种其他方法。
本节分为三个部分;它们是
- 缺失数据
- 插补缺失数据
- 自相关图
缺失数据
经典时间序列方法要求时间序列是完整的,例如没有缺失值。
因此,第一步是调查目标变量的完整性或不完整性。
对于给定的变量,可能存在由缺失行定义的缺失观测值。具体来说,每个观测值都有一个“position_within_chunk”(在块内位置)。我们期望训练数据集中每个块有120个观测值,“positions_within_chunk”(在块内位置)从1到120(含)不等。
因此,我们可以为每个变量创建一个包含120个NaN值的数组,使用“positions_within_chunk”(在块内位置)值标记块中的所有观测值,并将剩余部分标记为NaN。然后,我们可以绘制每个变量并查找间隙。
下面的variable_to_series()函数将获取一个块的行和一个给定目标变量的列索引,并返回一个包含120个时间步长的变量序列,其中所有可用数据都用块中的值标记。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 布局具有数据中断的变量以处理缺失位置 def variable_to_series(chunk_train, col_ix, n_steps=5*24): # 布局整个序列 data = [nan for _ in range(n_steps)] # 标记所有可用数据 for i in range(len(chunk_train)): # 获取块内位置 position = int(chunk_train[i, 1] - 1) # 存储数据 data[position] = chunk_train[i, col_ix] return data |
然后,我们可以为其中一个块中的每个目标变量调用此函数,并创建折线图。
下面的名为plot_variables()的函数将实现这一点,并创建一个包含39个水平堆叠的折线图的图形。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 绘制水平变量,并留出缺失数据的间隙 def plot_variables(chunk_train, n_vars=39): pyplot.figure() for i in range(n_vars): # 将目标数字转换为列号 col_ix = 3 + i # 标记变量的缺失观测 series = variable_to_series(chunk_train, col_ix) # 绘图 ax = pyplot.subplot(n_vars, 1, i+1) ax.set_xticklabels([]) ax.set_yticklabels([]) pyplot.plot(series) # 显示绘图 pyplot.show() |
将这些内容整合在一起,完整的示例列在下面。将创建第一个数据块中所有变量的图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# 绘制缺失值 从 numpy 导入 loadtxt from numpy import nan from numpy import unique from matplotlib import pyplot # 按“chunkID”分割数据集,返回块列表 def to_chunks(values, chunk_ix=0): chunks = list() # 获取唯一的块 ID chunk_ids = unique(values[:, chunk_ix]) # 按块 ID 分组行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks.append(values[selection, :]) return chunks # 布局具有数据中断的变量以处理缺失位置 def variable_to_series(chunk_train, col_ix, n_steps=5*24): # 布局整个序列 data = [nan for _ in range(n_steps)] # 标记所有可用数据 for i in range(len(chunk_train)): # 获取块内位置 position = int(chunk_train[i, 1] - 1) # 存储数据 data[position] = chunk_train[i, col_ix] return data # 绘制水平变量,并留出缺失数据的间隙 def plot_variables(chunk_train, n_vars=39): pyplot.figure() for i in range(n_vars): # 将目标数字转换为列号 col_ix = 3 + i # 标记变量的缺失观测 series = variable_to_series(chunk_train, col_ix) # 绘图 ax = pyplot.subplot(n_vars, 1, i+1) ax.set_xticklabels([]) ax.set_yticklabels([]) pyplot.plot(series) # 显示绘图 pyplot.show() # 加载数据集 train = loadtxt('AirQualityPrediction/naive_train.csv', delimiter=',') # 按块分组数据 train_chunks = to_chunks(train) # 选择一个数据块 rows = train_chunks[0] # 绘制变量 plot_variables(rows) |
运行示例将生成一个包含39条线图的图形,每条线图代表第一个数据块中的一个目标变量。
我们可以看到许多变量都存在季节性结构。这表明在建模之前,对每个序列执行24小时的季节性差分可能会有所帮助。
图形较小,您可能需要增大图形的尺寸才能清楚地看到数据。
我们可以看到有些变量我们没有数据。这些变量可以被检测并忽略,因为我们无法对它们进行建模或预测。
我们可以看到许多序列中存在缺失值,但缺失值持续时间较短,最多只有几个小时。这些缺失值可以通过前一个时间步的值或同一序列中相同小时的值进行插补。
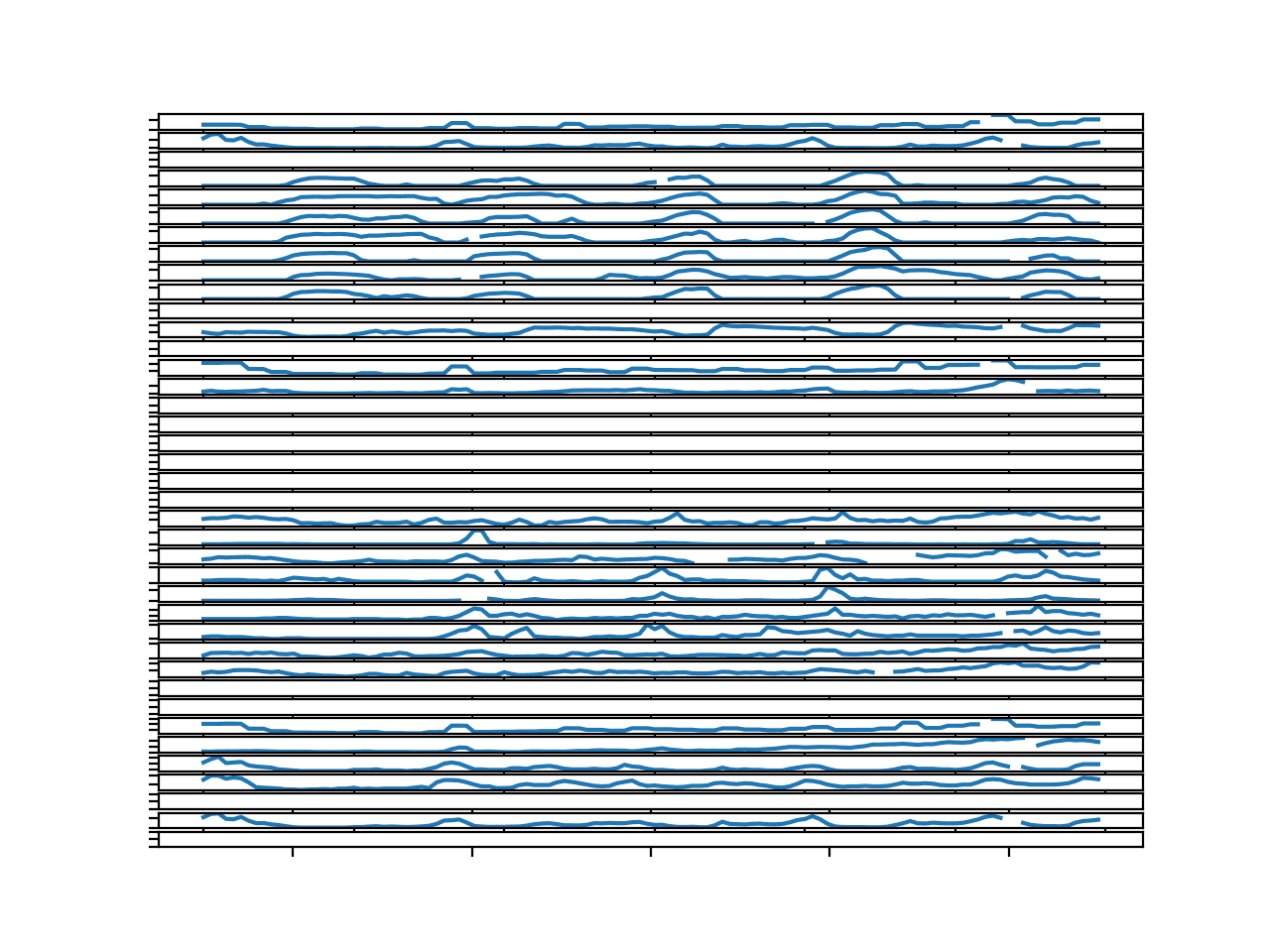
包含缺失值标记的第一个数据块中所有目标的折线图
随机查看其他几个数据块,许多都会产生与此类似的观察结果。
但这并非总是如此。
更新示例以绘制数据集中第4个数据块(索引为3)。
|
1 2 |
# 选择一个数据块 rows = train_chunks[3] |
结果是一个讲述完全不同故事的图形。
我们看到数据中存在持续许多小时甚至可能长达一天或更长时间的缺失值。
在使用经典模型拟合这些序列之前,需要对其进行大幅度的修复。
使用持续性或同一系列中相同小时的值进行插补可能不足够。可能需要使用整个训练数据集的平均值进行填充。
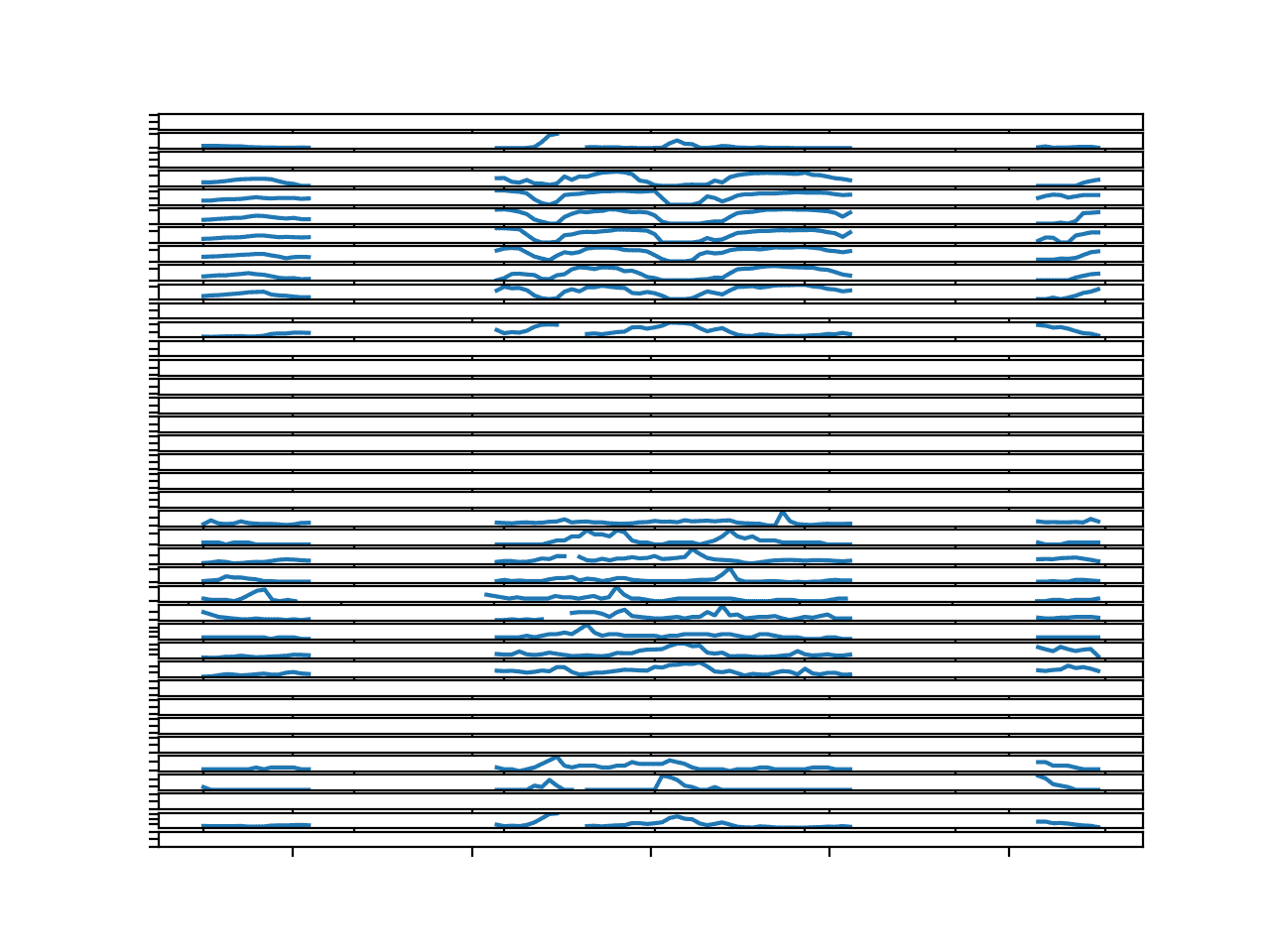
包含缺失值标记的第4个数据块中所有目标的折线图
插补缺失数据
有许多方法可以插补缺失数据,而且我们无法预先知道哪种方法最好。
一种方法是使用多种不同的插补方法来准备数据,并利用拟合在数据上的模型的技能来指导最佳方法。
已提出的一些插补方法包括:
- 保持系列中的最后一个观测值,也称为线性插值。
- 使用系列中同一日期的值或平均值进行填充。
- 使用整个训练数据集中同一日期的值或平均值进行填充。
使用组合也可能有用,例如,对于小范围的缺失,使用该系列的值进行填充;对于大范围的缺失,则从整个数据集中提取值。
我们还可以通过填充缺失数据并查看绘图来研究插补方法的效果,以查看序列是否看起来合理。这是一种粗略但有效且快速的方法。
首先,我们需要计算每个数据块的小时数序列,以便用于插补每个数据块中每个变量的特定小时数据。
给定一个部分填充的小时数序列,下面的 `interpolate_hours()` 函数将填充缺失的小时数。它通过查找第一个标记的小时,然后向前计数,填充小时数,然后向后执行相同的操作来完成此操作。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 在24小时制中原地插值小时数序列 def interpolate_hours(hours): # 查找第一个小时 ix = -1 for i in range(len(hours)): if not isnan(hours[i]): ix = i break # 向前填充 hour = hours[ix] for i in range(ix+1, len(hours)): # 小时数递增 hour += 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 向后填充 hour = hours[ix] for i in range(ix-1, -1, -1): # 小时数递减 hour -= 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 |
我确定有更符合Python风格的编写此函数的方法,但我想把它全部列出来,以便清楚地说明在做什么。
我们可以用一个带有缺失数据的模拟小时列表来测试它。完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 插值小时 from numpy import nan from numpy import isnan # 在24小时制中原地插值小时数序列 def interpolate_hours(hours): # 查找第一个小时 ix = -1 for i in range(len(hours)): if not isnan(hours[i]): ix = i break # 向前填充 hour = hours[ix] for i in range(ix+1, len(hours)): # 小时数递增 hour += 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 向后填充 hour = hours[ix] for i in range(ix-1, -1, -1): # 小时数递减 hour -= 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 定义带有缺失数据的小时 data = [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0, nan, 2, nan, nan, nan, nan, nan, nan, 9, 10, 11, 12, 13, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan] print(data) # 填充缺失的小时 interpolate_hours(data) print(data) |
运行示例,首先打印带有缺失值的小时数据,然后打印填充了所有小时的相同序列。
|
1 2 |
[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, 0, nan, 2, nan, nan, nan, nan, nan, nan, 9, 10, 11, 12, 13, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan] [11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 0, 1] |
我们可以使用此函数为数据块准备小时序列,该序列可用于使用特定于小时的信息填充数据块中的缺失值。
我们可以调用上一节中的 `variable_to_series()` 函数来创建包含缺失值(列索引为2)的小时序列,然后调用 `interpolate_hours()` 来填充缺失值。
|
1 2 3 4 |
# 准备数据块的小时序列 hours = variable_to_series(rows, 2) # 插值小时 interpolate_hours(hours) |
然后,我们可以将小时数传递给任何可能使用它的插补函数。
让我们尝试使用同一系列中相同小时的值来填充数据块中的缺失值。具体来说,我们将查找具有相同小时数的所有行,并计算中位数。
下面的 `impute_missing()` 函数接收数据块中的所有行、数据块的小时数序列,以及变量的缺失值序列和变量的列索引。
它首先检查系列是否全部是缺失数据,如果是,则立即返回,因为无法进行插补。然后,它枚举序列的时间步长,当检测到没有数据的时步时,它会收集该系列中具有相同小时数的行,并计算中位数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 插补缺失数据 def impute_missing(rows, hours, series, col_ix): # 计算缺失观测的数量 n_missing = count_nonzero(isnan(series)) # 计算缺失比例 ratio = n_missing / float(len(series)) * 100 # 检查是否没有数据 if ratio == 100.0: return series # 使用系列中特定小时的中位数插补缺失值 imputed = list() for i in range(len(series)): if isnan(series[i]): # 获取具有相同小时的所有行 matches = rows[rows[:,2]==hours[i]] # 使用中位数填充 value = nanmedian(matches[:, col_ix]) imputed.append(value) else: imputed.append(series[i]) return imputed |
为了观察此插补策略的影响,我们可以更新上一节中的 `plot_variables()` 函数,使其首先绘制插补后的序列,然后绘制带有缺失值的原始序列。
这将使插补值在原始序列的缺失部分中显现出来,我们可以看到结果是否合理。
下面列出了 `plot_variables()` 函数的更新版本,其中包含此更改,并调用 `impute_missing()` 函数来创建插补后的系列,并将小时序列作为参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 绘制水平变量,并留出缺失数据的间隙 def plot_variables(chunk_train, hours, n_vars=39): pyplot.figure() for i in range(n_vars): # 将目标数字转换为列号 col_ix = 3 + i # 标记变量的缺失观测 series = variable_to_series(chunk_train, col_ix) ax = pyplot.subplot(n_vars, 1, i+1) ax.set_xticklabels([]) ax.set_yticklabels([]) # 插补 imputed = impute_missing(chunk_train, hours, series, col_ix) # 绘制插补后的数据 pyplot.plot(imputed) # 绘制带有缺失值的数据 pyplot.plot(series) # 显示绘图 pyplot.show() |
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
# 插补缺失值 从 numpy 导入 loadtxt from numpy import nan from numpy import isnan from numpy import count_nonzero from numpy import unique from numpy import nanmedian from matplotlib import pyplot # 按“chunkID”分割数据集,返回块列表 def to_chunks(values, chunk_ix=0): chunks = list() # 获取唯一的块 ID chunk_ids = unique(values[:, chunk_ix]) # 按块 ID 分组行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks.append(values[selection, :]) return chunks # 插补缺失数据 def impute_missing(rows, hours, series, col_ix): # 计算缺失观测的数量 n_missing = count_nonzero(isnan(series)) # 计算缺失比例 ratio = n_missing / float(len(series)) * 100 # 检查是否没有数据 if ratio == 100.0: return series # 使用系列中特定小时的中位数插补缺失值 imputed = list() for i in range(len(series)): if isnan(series[i]): # 获取具有相同小时的所有行 matches = rows[rows[:,2]==hours[i]] # 使用中位数填充 value = nanmedian(matches[:, col_ix]) imputed.append(value) else: imputed.append(series[i]) return imputed # 在24小时制中原地插值小时数序列 def interpolate_hours(hours): # 查找第一个小时 ix = -1 for i in range(len(hours)): if not isnan(hours[i]): ix = i break # 向前填充 hour = hours[ix] for i in range(ix+1, len(hours)): # 小时数递增 hour += 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 向后填充 hour = hours[ix] for i in range(ix-1, -1, -1): # 小时数递减 hour -= 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 布局具有数据中断的变量以处理缺失位置 def variable_to_series(chunk_train, col_ix, n_steps=5*24): # 布局整个序列 data = [nan for _ in range(n_steps)] # 标记所有可用数据 for i in range(len(chunk_train)): # 获取块内位置 position = int(chunk_train[i, 1] - 1) # 存储数据 data[position] = chunk_train[i, col_ix] return data # 绘制水平变量,并留出缺失数据的间隙 def plot_variables(chunk_train, hours, n_vars=39): pyplot.figure() for i in range(n_vars): # 将目标数字转换为列号 col_ix = 3 + i # 标记变量的缺失观测 series = variable_to_series(chunk_train, col_ix) ax = pyplot.subplot(n_vars, 1, i+1) ax.set_xticklabels([]) ax.set_yticklabels([]) # 插补 imputed = impute_missing(chunk_train, hours, series, col_ix) # 绘制插补后的数据 pyplot.plot(imputed) # 绘制带有缺失值的数据 pyplot.plot(series) # 显示绘图 pyplot.show() # 加载数据集 train = loadtxt('AirQualityPrediction/naive_train.csv', delimiter=',') # 按块分组数据 train_chunks = to_chunks(train) # 选择一个数据块 rows = train_chunks[0] # 准备数据块的小时序列 hours = variable_to_series(rows, 2) # 插值小时 interpolate_hours(hours) # 绘制变量 plot_variables(rows, hours) |
运行示例将生成一个图形,其中包含训练数据集第一个数据块中每个目标变量的39条折线图。
我们可以看到序列是橙色的,显示了原始数据,并且缺失部分已被插补并用蓝色标记。
蓝色段看起来是合理的。
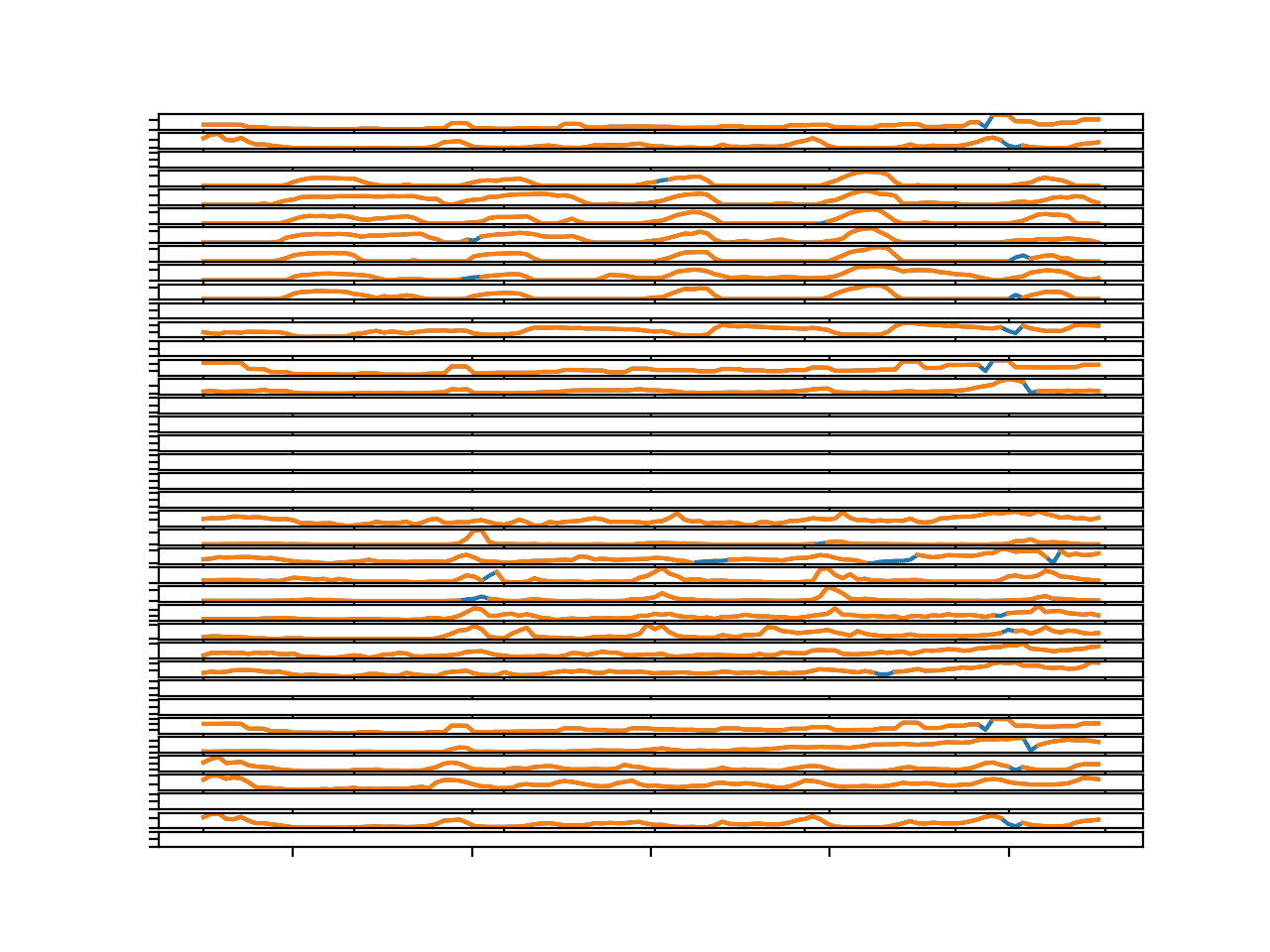
包含插补缺失值的第一个数据块中所有目标的折线图
我们可以尝试将相同的方法应用于数据集中缺失数据量更大的第4个数据块。
|
1 2 |
# 选择一个数据块 rows = train_chunks[0] |
运行示例将生成相同类型的图形,但在这里我们可以看到大段的缺失部分已用插补值填充。
同样,这些序列看起来是合理的,甚至在适当时也显示了日季节性周期结构。
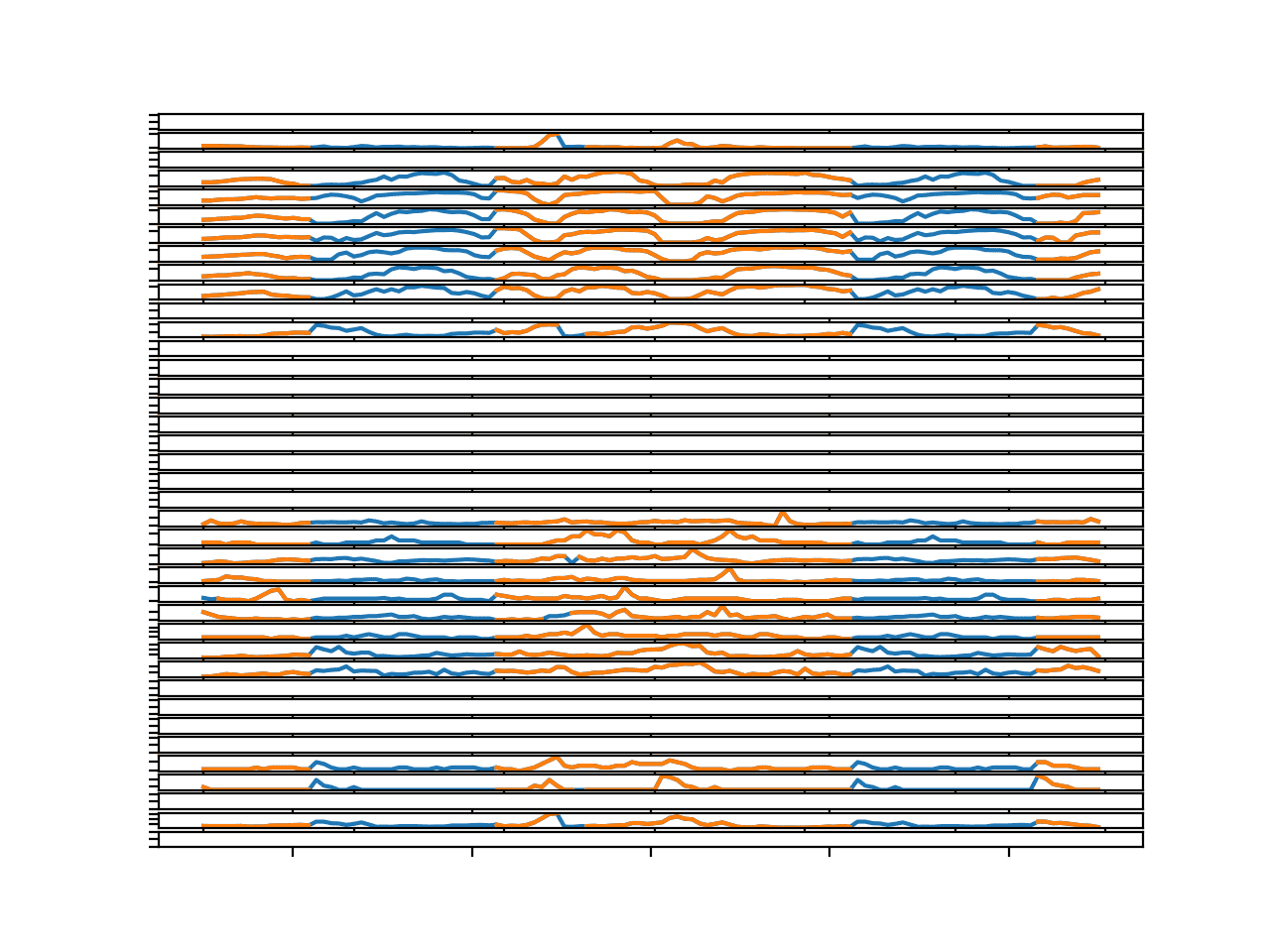
包含插补缺失值的第4个数据块中所有目标的折线图
这看起来是一个不错的开始;您可以探索其他插补策略,并查看它们在折线图或由此产生的模型技能方面如何进行比较。
自相关图
现在我们知道了如何填充缺失值,我们可以看一下序列数据的自相关图。
自相关图总结了每个观测值与先前时间步长的观测值之间的关系。结合偏自相关图,它们可用于确定 ARMA 模型的配置。
statsmodels 库提供了 `plot_acf()` 和 `plot_pacf()` 函数,分别用于绘制 ACF 和 PACF 图。
我们可以更新 `plot_variables()` 来创建这些图,每种类型为39个序列中的每一个绘制一个。这有很多图。
我们将所有 ACF 图堆叠在左侧,所有 PACF 图堆叠在右侧。那是两列,每列39个图。我们将考虑的滞后时间限制为24个时间步长(小时),并忽略每个变量与其自身的相关性,因为这是多余的。
下面列出了用于绘制 ACF 和 PACF 图的 `plot_variables()` 函数的更新版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 为每个插补的变量序列绘制 ACF 和 PACF 图 def plot_variables(chunk_train, hours, n_vars=39): pyplot.figure() n_plots = n_vars * 2 j = 0 lags = 24 for i in range(1, n_plots, 2): # 将目标数字转换为列号 col_ix = 3 + j j += 1 # 获取序列 series = variable_to_series(chunk_train, col_ix) imputed = impute_missing(chunk_train, hours, series, col_ix) # ACF axis = pyplot.subplot(n_vars, 2, i) plot_acf(imputed, ax=axis, lags=lags, zero=False) axis.set_title('') axis.set_xticklabels([]) axis.set_yticklabels([]) # PACF axis = pyplot.subplot(n_vars, 2, i+1) plot_pacf(imputed, ax=axis, lags=lags, zero=False) axis.set_title('') axis.set_xticklabels([]) axis.set_yticklabels([]) # 显示绘图 pyplot.show() |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 |
# ACF 和 PACF 图 从 numpy 导入 loadtxt from numpy import nan from numpy import isnan from numpy import count_nonzero from numpy import unique from numpy import nanmedian from matplotlib import pyplot from statsmodels.graphics.tsaplots import plot_acf from statsmodels.graphics.tsaplots import plot_pacf # 按“chunkID”分割数据集,返回块列表 def to_chunks(values, chunk_ix=0): chunks = list() # 获取唯一的块 ID chunk_ids = unique(values[:, chunk_ix]) # 按块 ID 分组行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks.append(values[selection, :]) return chunks # 插补缺失数据 def impute_missing(rows, hours, series, col_ix): # 计算缺失观测的数量 n_missing = count_nonzero(isnan(series)) # 计算缺失比例 ratio = n_missing / float(len(series)) * 100 # 检查是否没有数据 if ratio == 100.0: return series # 使用系列中特定小时的中位数插补缺失值 imputed = list() for i in range(len(series)): if isnan(series[i]): # 获取具有相同小时的所有行 matches = rows[rows[:,2]==hours[i]] # 使用中位数填充 value = nanmedian(matches[:, col_ix]) imputed.append(value) else: imputed.append(series[i]) return imputed # 在24小时制中原地插值小时数序列 def interpolate_hours(hours): # 查找第一个小时 ix = -1 for i in range(len(hours)): if not isnan(hours[i]): ix = i break # 向前填充 hour = hours[ix] for i in range(ix+1, len(hours)): # 小时数递增 hour += 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 向后填充 hour = hours[ix] for i in range(ix-1, -1, -1): # 小时数递减 hour -= 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 布局具有数据中断的变量以处理缺失位置 def variable_to_series(chunk_train, col_ix, n_steps=5*24): # 布局整个序列 data = [nan for _ in range(n_steps)] # 标记所有可用数据 for i in range(len(chunk_train)): # 获取块内位置 position = int(chunk_train[i, 1] - 1) # 存储数据 data[position] = chunk_train[i, col_ix] return data # 为每个插补的变量序列绘制 ACF 和 PACF 图 def plot_variables(chunk_train, hours, n_vars=39): pyplot.figure() n_plots = n_vars * 2 j = 0 lags = 24 for i in range(1, n_plots, 2): # 将目标数字转换为列号 col_ix = 3 + j j += 1 # 获取序列 series = variable_to_series(chunk_train, col_ix) imputed = impute_missing(chunk_train, hours, series, col_ix) # ACF axis = pyplot.subplot(n_vars, 2, i) plot_acf(imputed, ax=axis, lags=lags, zero=False) axis.set_title('') axis.set_xticklabels([]) axis.set_yticklabels([]) # PACF axis = pyplot.subplot(n_vars, 2, i+1) plot_pacf(imputed, ax=axis, lags=lags, zero=False) axis.set_title('') axis.set_xticklabels([]) axis.set_yticklabels([]) # 显示绘图 pyplot.show() # 加载数据集 train = loadtxt('AirQualityPrediction/naive_train.csv', delimiter=',') # 按块分组数据 train_chunks = to_chunks(train) # 选择一个数据块 rows = train_chunks[0] # 准备数据块的小时序列 hours = variable_to_series(rows, 2) # 插值小时 interpolate_hours(hours) # 绘制变量 plot_variables(rows, hours) |
运行示例将生成一个包含许多绘图的图形,这些绘图是训练数据集第一个数据块中的目标变量。
您可能需要增加绘图窗口的大小才能更好地看到每个绘图的细节。
我们可以看到左侧的大多数 ACF 图在滞后1-2个时间步长处显示出显着的自相关(超出显著性区域的点),在某些情况下可能为滞后1-3个时间步长,然后随滞后时间的增加而缓慢稳定地减小。
类似地,右侧的 PACF 图在滞后1-2个时间步长处显示出显着的滞后,并且急剧下降。
这强烈表明自相关过程的阶数可能为1、2或3,例如 AR(3)。
在左侧的 ACF 图中,我们还可以看到相关性中的日周期。这可能表明在建模前对数据进行季节性差分或使用能够进行季节性差分的 AR 模型可能有所好处。

ACF 和 PACF 绘制的第一个数据块的目标变量图
我们可以重复对其他数据块的目标变量进行此分析,结果基本相同。
这表明我们可以为所有数据块中的所有序列配置通用的 AR 模型。
开发自回归模型
在本节中,我们将为插补的目标序列数据开发一个自回归模型。
第一步是实现一个通用函数,用于为每个数据块进行预测。
该函数接收训练数据集以及测试集的输入列(数据块 ID、数据块中的位置和小时),并返回所有数据块的预测,格式为预期的 3D 格式:[数据块][变量][时间]。
该函数枚举预测中的数据块,然后枚举 39 个目标列,调用一个名为 forecast_variable() 的新函数,以便为给定目标变量的每个预测前沿时间进行预测。
完整的函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 每个数据块的预测,返回 [数据块][变量][时间] def forecast_chunks(train_chunks, test_input): lead_times = get_lead_times() predictions = list() # 枚举要预测的块 for i in range(len(train_chunks)): # 准备数据块的小时序列 hours = variable_to_series(train_chunks[i], 2) # 插补小时 interpolate_hours(hours) # 枚举块的目标 chunk_predictions = list() for j in range(39): yhat = forecast_variable(hours, train_chunks[i], test_input[i], lead_times, j) chunk_predictions.append(yhat) chunk_predictions = array(chunk_predictions) predictions.append(chunk_predictions) return array(predictions) |
我们现在可以实现 forecast_variable() 的一个版本。
对于每个变量,我们首先检查是否有数据(例如,全是 NaN),如果有,则为每个预测前沿时间返回一个 NaN 预测。
然后,我们使用 variable_to_series() 从该变量创建一个序列,然后通过调用 impute_missing() 来插补该序列内的缺失值,这两个函数都在上一节中开发。
最后,我们调用一个名为 fit_and_forecast() 的新函数,该函数拟合模型并预测 10 个预测前沿时间。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 预测所有前沿时间,用于一个变量 def forecast_variable(hours, chunk_train, chunk_test, lead_times, target_ix): # 将目标数字转换为列号 col_ix = 3 + target_ix # 检查是否没有数据 if not has_data(chunk_train[:, col_ix]): forecast = [nan for _ in range(len(lead_times))] return forecast # 获取序列 series = variable_to_series(chunk_train, col_ix) # 插补 imputed = impute_missing(chunk_train, hours, series, col_ix) # 拟合 AR 模型并预测 forecast = fit_and_forecast(imputed) return forecast |
我们将拟合一个 AR 模型到给定的插补序列。为此,我们将使用 statsmodels ARIMA 类。我们将使用 ARIMA 而不是 AR,以便在您想探索 ARIMA 模型系列中的任何模型时提供一定的灵活性。
首先,我们必须定义模型,包括自回归过程的阶数,例如 AR(1)。
|
1 2 |
# 定义模型 model = ARIMA(series, order=(1,0,0)) |
接下来,将模型拟合到插补序列。我们通过将 disp 设置为 False 来关闭拟合过程中的详细信息。
|
1 2 |
# 拟合模型 model_fit = model.fit() |
然后使用拟合的模型来预测序列末尾之后的未来 72 小时。
|
1 2 |
# 预测 72 小时 yhat = model_fit.predict(len(series), len(series)+72) |
我们只对特定的前沿时间感兴趣,因此我们准备一个包含这些前沿时间的数组,减去 1 将它们转换为数组索引,然后使用它们来选择我们感兴趣的 10 个预测前沿时间的对应值。
|
1 2 3 4 |
# 提取前沿时间 lead_times = array(get_lead_times()) indices = lead_times - 1 return yhat[indices] |
statsmodels ARIMA 模型在后台使用线性代数库来拟合模型,有时拟合过程在某些数据上可能不稳定。因此,它可能会引发异常或报告大量警告。
我们将捕获异常并返回一个 NaN 预测,并忽略拟合和评估过程中的所有警告。
下面的 fit_and_forecast() 函数将所有这些整合在一起。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 拟合 AR 模型并生成预测 def fit_and_forecast(series): # 定义模型 model = ARIMA(series, order=(1,0,0)) # 发生异常时返回 NaN 预测 try: # 忽略 statsmodels 警告 with catch_warnings(): filterwarnings("ignore") # 拟合模型 model_fit = model.fit() # 预测 72 小时 yhat = model_fit.predict(len(series), len(series)+72) # 提取前沿时间 lead_times = array(get_lead_times()) indices = lead_times - 1 return yhat[indices] except: return [nan for _ in range(len(get_lead_times()))] |
我们现在可以评估每个数据块中的 39 个序列的自回归过程。
我们将从测试 AR(1) 过程开始。
完整的代码示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 |
# 自回归预测 从 numpy 导入 loadtxt from numpy import nan from numpy import isnan from numpy import count_nonzero from numpy import unique from numpy import array from numpy import nanmedian from statsmodels.tsa.arima.model import ARIMA from matplotlib import pyplot from warnings import catch_warnings from warnings import filterwarnings # 按“chunkID”分割数据集,返回块列表 def to_chunks(values, chunk_ix=0): chunks = list() # 获取唯一的块 ID chunk_ids = unique(values[:, chunk_ix]) # 按块 ID 分组行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks.append(values[selection, :]) return chunks # 返回相对预测提前期的列表 def get_lead_times(): return [1, 2, 3, 4, 5, 10, 17, 24, 48, 72] # 在24小时制中原地插值小时数序列 def interpolate_hours(hours): # 查找第一个小时 ix = -1 for i in range(len(hours)): if not isnan(hours[i]): ix = i break # 向前填充 hour = hours[ix] for i in range(ix+1, len(hours)): # 小时数递增 hour += 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 向后填充 hour = hours[ix] for i in range(ix-1, -1, -1): # 小时数递减 hour -= 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 如果数组包含任何非 NaN 值,则返回 true def has_data(data): return count_nonzero(isnan(data)) < len(data) # 插补缺失数据 def impute_missing(rows, hours, series, col_ix): # 使用系列中特定小时的中位数插补缺失值 imputed = list() for i in range(len(series)): if isnan(series[i]): # 获取具有相同小时的所有行 matches = rows[rows[:,2]==hours[i]] # 使用中位数填充 value = nanmedian(matches[:, col_ix]) if isnan(value): value = 0.0 imputed.append(value) else: imputed.append(series[i]) return imputed # 布局具有数据中断的变量以处理缺失位置 def variable_to_series(chunk_train, col_ix, n_steps=5*24): # 布局整个序列 data = [nan for _ in range(n_steps)] # 标记所有可用数据 for i in range(len(chunk_train)): # 获取块内位置 position = int(chunk_train[i, 1] - 1) # 存储数据 data[position] = chunk_train[i, col_ix] return data # 拟合 AR 模型并生成预测 def fit_and_forecast(series): # 定义模型 model = ARIMA(series, order=(1,0,0)) # 发生异常时返回 NaN 预测 try: # 忽略 statsmodels 警告 with catch_warnings(): filterwarnings("ignore") # 拟合模型 model_fit = model.fit() # 预测 72 小时 yhat = model_fit.predict(len(series), len(series)+72) # 提取前沿时间 lead_times = array(get_lead_times()) indices = lead_times - 1 return yhat[indices] except: return [nan for _ in range(len(get_lead_times()))] # 预测所有前沿时间,用于一个变量 def forecast_variable(hours, chunk_train, chunk_test, lead_times, target_ix): # 将目标数字转换为列号 col_ix = 3 + target_ix # 检查是否没有数据 if not has_data(chunk_train[:, col_ix]): forecast = [nan for _ in range(len(lead_times))] return forecast # 获取序列 series = variable_to_series(chunk_train, col_ix) # 插补 imputed = impute_missing(chunk_train, hours, series, col_ix) # 拟合 AR 模型并预测 forecast = fit_and_forecast(imputed) return forecast # 每个数据块的预测,返回 [数据块][变量][时间] def forecast_chunks(train_chunks, test_input): lead_times = get_lead_times() predictions = list() # 枚举要预测的块 for i in range(len(train_chunks)): # 准备数据块的小时序列 hours = variable_to_series(train_chunks[i], 2) # 插补小时 interpolate_hours(hours) # 枚举块的目标 chunk_predictions = list() for j in range(39): yhat = forecast_variable(hours, train_chunks[i], test_input[i], lead_times, j) chunk_predictions.append(yhat) chunk_predictions = array(chunk_predictions) predictions.append(chunk_predictions) return array(predictions) # 将块中的测试数据集转换为 [块][变量][时间] 格式 def prepare_test_forecasts(test_chunks): predictions = list() # 枚举要预测的块 for rows in test_chunks: # 枚举块的目标 chunk_predictions = list() for j in range(3, rows.shape[1]): yhat = rows[:, j] chunk_predictions.append(yhat) chunk_predictions = array(chunk_predictions) predictions.append(chunk_predictions) return array(predictions) # 计算实际值和预测值之间的误差 def calculate_error(actual, predicted): # 如果预测值为 nan,则给出完整的实际值 if isnan(predicted): return abs(actual) # 计算绝对差值 return abs(actual - predicted) # 评估 [块][变量][时间] 格式的预测 def evaluate_forecasts(predictions, testset): lead_times = get_lead_times() total_mae, times_mae = 0.0, [0.0 for _ in range(len(lead_times))] total_c, times_c = 0, [0 for _ in range(len(lead_times))] # 枚举测试块 for i in range(len(test_chunks)): # 转换为预测 actual = testset[i] predicted = predictions[i] # 枚举目标变量 for j in range(predicted.shape[0]): # 枚举提前期 for k in range(len(lead_times)): # 如果实际值为 nan 则跳过 if isnan(actual[j, k]): continue # 计算误差 error = calculate_error(actual[j, k], predicted[j, k]) # 更新统计数据 total_mae += error times_mae[k] += error total_c += 1 times_c[k] += 1 # 归一化求和的绝对误差 total_mae /= total_c times_mae = [times_mae[i]/times_c[i] for i in range(len(times_mae))] return total_mae, times_mae # 总结得分 def summarize_error(name, total_mae, times_mae): # 打印摘要 lead_times = get_lead_times() formatted = ['+%d %.3f' % (lead_times[i], times_mae[i]) for i in range(len(lead_times))] s_scores = ', '.join(formatted) print('%s: [%.3f MAE] %s' % (name, total_mae, s_scores)) # 绘制摘要 pyplot.plot([str(x) for x in lead_times], times_mae, marker='.') pyplot.show() # 加载数据集 train = loadtxt('AirQualityPrediction/naive_train.csv', delimiter=',') test = loadtxt('AirQualityPrediction/naive_test.csv', delimiter=',') # 按块分组数据 train_chunks = to_chunks(train) test_chunks = to_chunks(test) # 预测 test_input = [rows[:, :3] for rows in test_chunks] forecast = forecast_chunks(train_chunks, test_input) # 评估预测 actual = prepare_test_forecasts(test_chunks) total_mae, times_mae = evaluate_forecasts(forecast, actual) # 总结预测 summarize_error('AR', total_mae, times_mae) |
运行示例后,首先报告测试集的总体 MAE,然后是每个预测前沿时间的 MAE。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。可以尝试运行几次示例并比较平均结果。
我们可以看到,该模型实现了大约 0.492 的 MAE,低于朴素持久性模型实现的 MAE 0.520。这表明该方法确实具有一定的技能。
|
1 |
AR: [0.492 MAE] +1 0.225, +2 0.342, +3 0.410, +4 0.475, +5 0.512, +10 0.593, +17 0.586, +24 0.588, +48 0.588, +72 0.604 |
创建了 MAE 按预测前沿时间绘制的折线图,显示了随着预测前沿时间的增加,预测误差呈线性增加。
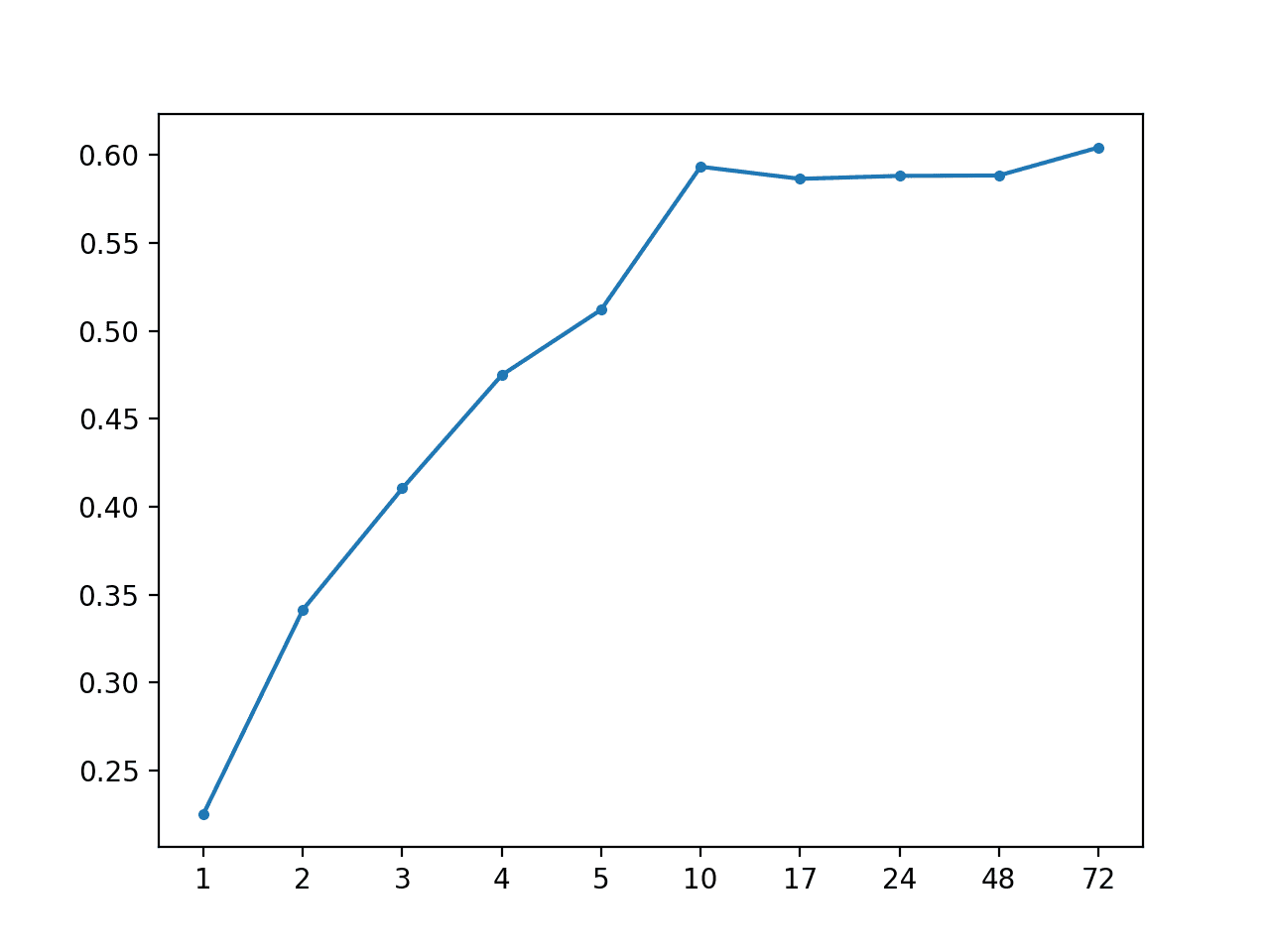
AR(1) 的 MAE 与预测前沿时间的对比图
我们可以更改代码来测试其他 AR 模型。特别是在 fit_and_forecast() 函数中 ARIMA 模型的阶数。
AR(2) 模型可以定义为
|
1 |
model = ARIMA(series, order=(2,0,0)) |
运行更新后的代码后,误差进一步下降,总体 MAE 约为 0.490。
|
1 |
AR: [0.490 MAE] +1 0.229, +2 0.342, +3 0.412, +4 0.470, +5 0.503, +10 0.563, +17 0.576, +24 0.605, +48 0.597, +72 0.608 |
我们也可以尝试 AR(3)
|
1 |
model = ARIMA(series, order=(3,0,0)) |
重新运行示例并更新后,总体 MAE 相较于 AR(2) 有所增加。
AR(2) 可能是一个不错的全局配置,尽管为每个变量或每个序列量身定制的模型整体表现可能会更好。
|
1 |
AR: [0.491 MAE] +1 0.232, +2 0.345, +3 0.412, +4 0.472, +5 0.504, +10 0.556, +17 0.575, +24 0.607, +48 0.599, +72 0.611 |
全局插补策略的自回归模型
我们可以使用另一种插补策略来评估 AR(2) 模型。
我们不是计算数据块中序列在同一小时的中位数,而是可以计算所有数据块中该变量的中位数。
我们可以更新 impute_missing() 函数以接受所有训练数据块作为参数,然后收集给定小时所有数据块的行,以计算用于插补的中位数。该函数的更新版本如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 插补缺失数据 def impute_missing(train_chunks, rows, hours, series, col_ix): # 使用所有序列中同一小时的中位数来插补缺失值 imputed = list() for i in range(len(series)): if isnan(series[i]): # 收集所有数据块中该小时的所有行 all_rows = list() for rows in train_chunks: [all_rows.append(row) for row in rows[rows[:,2]==hours[i]]] # 计算目标的集中趋势 all_rows = array(all_rows) # 使用中位数填充 value = nanmedian(all_rows[:, col_ix]) if isnan(value): value = 0.0 imputed.append(value) else: imputed.append(series[i]) return imputed |
为了将 train_chunks 传递给 impute_missing() 函数,我们必须更新 forecast_variable() 函数,使其也接受 train_chunks 作为参数并将其传递下去,并相应地更新 forecast_chunks() 函数以传递 train_chunks。
使用全局插补策略的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 |
# 使用全局插补策略的自回归预测 从 numpy 导入 loadtxt from numpy import nan from numpy import isnan from numpy import count_nonzero from numpy import unique from numpy import array from numpy import nanmedian from statsmodels.tsa.arima.model import ARIMA from matplotlib import pyplot from warnings import catch_warnings from warnings import filterwarnings # 按“chunkID”分割数据集,返回块列表 def to_chunks(values, chunk_ix=0): chunks = list() # 获取唯一的块 ID chunk_ids = unique(values[:, chunk_ix]) # 按块 ID 分组行 for chunk_id in chunk_ids: selection = values[:, chunk_ix] == chunk_id chunks.append(values[selection, :]) return chunks # 返回相对预测提前期的列表 def get_lead_times(): return [1, 2, 3, 4, 5, 10, 17, 24, 48, 72] # 在24小时制中原地插值小时数序列 def interpolate_hours(hours): # 查找第一个小时 ix = -1 for i in range(len(hours)): if not isnan(hours[i]): ix = i break # 向前填充 hour = hours[ix] for i in range(ix+1, len(hours)): # 小时数递增 hour += 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 向后填充 hour = hours[ix] for i in range(ix-1, -1, -1): # 小时数递减 hour -= 1 # 检查是否需要填充 if isnan(hours[i]): hours[i] = hour % 24 # 如果数组包含任何非 NaN 值,则返回 true def has_data(data): return count_nonzero(isnan(data)) < len(data) # 插补缺失数据 def impute_missing(train_chunks, rows, hours, series, col_ix): # 使用所有序列中同一小时的中位数来插补缺失值 imputed = list() for i in range(len(series)): if isnan(series[i]): # 收集所有数据块中该小时的所有行 all_rows = list() for rows in train_chunks: [all_rows.append(row) for row in rows[rows[:,2]==hours[i]]] # 计算目标的集中趋势 all_rows = array(all_rows) # 使用中位数填充 value = nanmedian(all_rows[:, col_ix]) if isnan(value): value = 0.0 imputed.append(value) else: imputed.append(series[i]) return imputed # 布局具有数据中断的变量以处理缺失位置 def variable_to_series(chunk_train, col_ix, n_steps=5*24): # 布局整个序列 data = [nan for _ in range(n_steps)] # 标记所有可用数据 for i in range(len(chunk_train)): # 获取块内位置 position = int(chunk_train[i, 1] - 1) # 存储数据 data[position] = chunk_train[i, col_ix] return data # 拟合 AR 模型并生成预测 def fit_and_forecast(series): # 定义模型 model = ARIMA(series, order=(2,0,0)) # 发生异常时返回 NaN 预测 try: # 忽略 statsmodels 警告 with catch_warnings(): filterwarnings("ignore") # 拟合模型 model_fit = model.fit() # 预测 72 小时 yhat = model_fit.predict(len(series), len(series)+72) # 提取前沿时间 lead_times = array(get_lead_times()) indices = lead_times - 1 return yhat[indices] except: return [nan for _ in range(len(get_lead_times()))] # 预测所有前沿时间,用于一个变量 def forecast_variable(hours, train_chunks, chunk_train, chunk_test, lead_times, target_ix): # 将目标数字转换为列号 col_ix = 3 + target_ix # 检查是否没有数据 if not has_data(chunk_train[:, col_ix]): forecast = [nan for _ in range(len(lead_times))] return forecast # 获取序列 series = variable_to_series(chunk_train, col_ix) # 插补 imputed = impute_missing(train_chunks, chunk_train, hours, series, col_ix) # 拟合 AR 模型并预测 forecast = fit_and_forecast(imputed) return forecast # 每个数据块的预测,返回 [数据块][变量][时间] def forecast_chunks(train_chunks, test_input): lead_times = get_lead_times() predictions = list() # 枚举要预测的块 for i in range(len(train_chunks)): # 准备数据块的小时序列 hours = variable_to_series(train_chunks[i], 2) # 插补小时 interpolate_hours(hours) # 枚举块的目标 chunk_predictions = list() for j in range(39): yhat = forecast_variable(hours, train_chunks, train_chunks[i], test_input[i], lead_times, j) chunk_predictions.append(yhat) chunk_predictions = array(chunk_predictions) predictions.append(chunk_predictions) return array(predictions) # 将块中的测试数据集转换为 [块][变量][时间] 格式 def prepare_test_forecasts(test_chunks): predictions = list() # 枚举要预测的块 for rows in test_chunks: # 枚举块的目标 chunk_predictions = list() for j in range(3, rows.shape[1]): yhat = rows[:, j] chunk_predictions.append(yhat) chunk_predictions = array(chunk_predictions) predictions.append(chunk_predictions) return array(predictions) # 计算实际值和预测值之间的误差 def calculate_error(actual, predicted): # 如果预测值为 nan,则给出完整的实际值 if isnan(predicted): return abs(actual) # 计算绝对差值 return abs(actual - predicted) # 评估 [块][变量][时间] 格式的预测 def evaluate_forecasts(predictions, testset): lead_times = get_lead_times() total_mae, times_mae = 0.0, [0.0 for _ in range(len(lead_times))] total_c, times_c = 0, [0 for _ in range(len(lead_times))] # 枚举测试块 for i in range(len(test_chunks)): # 转换为预测 actual = testset[i] predicted = predictions[i] # 枚举目标变量 for j in range(predicted.shape[0]): # 枚举提前期 for k in range(len(lead_times)): # 如果实际值为 nan 则跳过 if isnan(actual[j, k]): continue # 计算误差 error = calculate_error(actual[j, k], predicted[j, k]) # 更新统计数据 total_mae += error times_mae[k] += error total_c += 1 times_c[k] += 1 # 归一化求和的绝对误差 total_mae /= total_c times_mae = [times_mae[i]/times_c[i] for i in range(len(times_mae))] return total_mae, times_mae # 总结得分 def summarize_error(name, total_mae, times_mae): # 打印摘要 lead_times = get_lead_times() formatted = ['+%d %.3f' % (lead_times[i], times_mae[i]) for i in range(len(lead_times))] s_scores = ', '.join(formatted) print('%s: [%.3f MAE] %s' % (name, total_mae, s_scores)) # 绘制摘要 pyplot.plot([str(x) for x in lead_times], times_mae, marker='.') pyplot.show() # 加载数据集 train = loadtxt('AirQualityPrediction/naive_train.csv', delimiter=',') test = loadtxt('AirQualityPrediction/naive_test.csv', delimiter=',') # 按块分组数据 train_chunks = to_chunks(train) test_chunks = to_chunks(test) # 预测 test_input = [rows[:, :3] for rows in test_chunks] forecast = forecast_chunks(train_chunks, test_input) # 评估预测 actual = prepare_test_forecasts(test_chunks) total_mae, times_mae = evaluate_forecasts(forecast, actual) # 总结预测 summarize_error('AR', total_mae, times_mae) |
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。可以尝试运行几次示例并比较平均结果。
运行示例后,总体 MAE 进一步下降至约 0.487。
探索根据序列中缺失数据的数量或正在填补的间隔来交替使用缺失数据填充方法的插补策略可能会很有趣。
|
1 |
AR: [0.487 MAE] +1 0.228, +2 0.339, +3 0.409, +4 0.469, +5 0.499, +10 0.560, +17 0.573, +24 0.600, +48 0.595, +72 0.606 |
还创建了 MAE 与预测前沿时间对比的折线图。
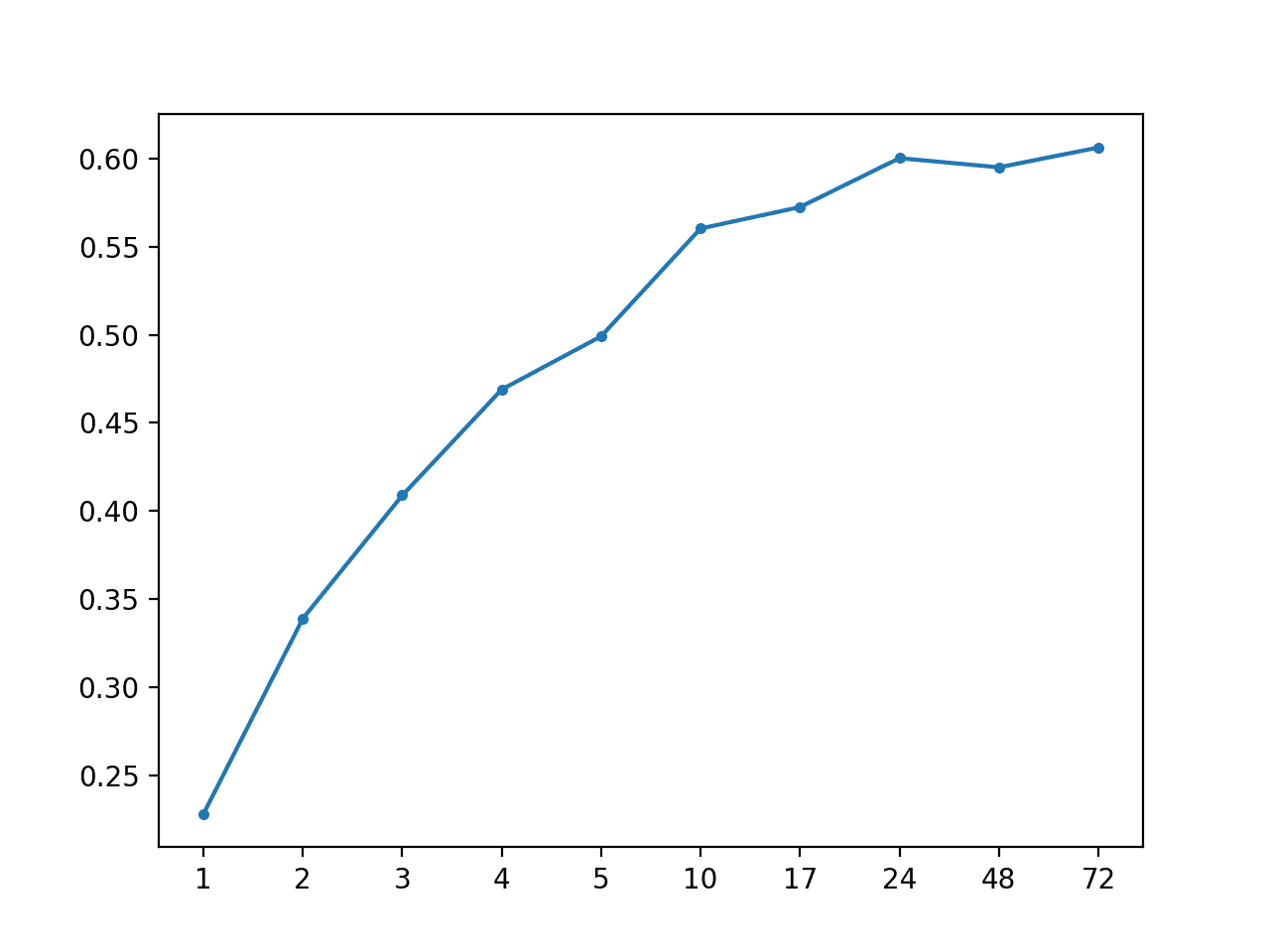
AR(2) 使用全局策略插补的 MAE 与预测前沿时间的对比图
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 插补策略。为每个序列中的缺失数据开发并评估一个额外的备选插补策略。
- 数据准备。探索是否对每个序列应用数据准备技术(如标准化、归一化和幂变换)可以提高模型技能。
- 差分。探索差分(如 1 步或 24 步(季节性差分))是否可以使每个序列平稳,并进而产生更好的预测。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
API
文章
总结
在本教程中,您学习了如何为多站点空气污染时间序列开发多步时间序列自回归模型。
具体来说,你学到了:
- 如何分析和插补时间序列数据中的缺失值。
- 如何开发和评估用于多步时间序列预测的自回归模型。
- 如何使用替代数据插补方法改进自回归模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






Brownlee 博士!一如既往的出色工作!非常感谢您的贡献。
我想知道是否可以实现某种机器学习方法来填充邻近站点的数据缺失。我的意思是,如果存在几个具有相关观测时间序列的站点,并且我想使用它们来填充用于建模的站点中的缺失时间序列数据。通常使用成对相关性方法来处理此类任务,它是一种基于统计学的方法,也许使用神经网络会更好。您怎么看?谢谢。
当然,您可以尝试一下,然后告诉我结果。
感谢您分享上述有趣的分析。
但是,我想知道是否可以为每个站点/位置找到最佳 ARIMA 模型,而不是为每个数据块,因为我们有少数站点的数据(目标/变量)。
对于这种方法,我们可以使用气象数据来寻找站点之间的相关性吗?
有什么建议吗?提前感谢!
也许可以尝试一下。
你好,
我想知道如何在 R 中做同样的事情?
抱歉,我没有 R 的示例。
感谢您分享上述有趣的分析
为什么我的一步预测结果与我的多步结果的第一步预测结果不同?
由于机器学习模型训练存在随机性,因此训练的模型不总是匹配。
嗨,Jason,
如果我理解正确,在本教程中,您预测了每个变量(风速、温度等),然后空气质量是这些输出的函数?换句话说,我们是否没有拟合 ARIMA 模型来整合所有这些外生因素来预测空气质量?
我之所以这样问,是因为这正是我正在尝试使用电力负荷和温度的时间序列进行的操作。我的目标是在考虑其对室外温度的依赖性的同时预测电力负荷。因此,我正在使用具有温度时间序列作为外生变量的 sarimax 模型,并通过网格搜索来获得最佳模型。但随后我遇到了一些问题
- sarimax 模型只为温度提供一个系数,类似于线性回归。鉴于负荷对温度的响应存在惯性,我理想情况下希望有一个自回归模型,不仅针对负荷本身,也针对温度。也就是说,整合时间 t 的温度 T,以及温度的滞后项。您是否知道是否可以通过 sarimax 来实现这一点,例如通过具有多个外生回归变量?或者我最终应该尝试另一个模型,比如 LTSM?如果我想整合其他数据(如风速或太阳辐射)以提高负荷预测的准确性,同样的问题也适用。
- 我有十年的小时数据,并且只使用了冬季。我的最终目标是预测一年的负荷并专门得出峰值负荷。因此,我需要使用不同年份的数据作为训练数据的一部分,并在一个年份/一部分年份进行测试。您有什么建议可以确保 x 年 3 月至 11 月之间的不连续期间不会损害预测?
- 我的最后一个问题与数据中的趋势有关,因为消费量逐年普遍增加(非线性增加)。但是,这是一个缓慢的趋势,在一年内的观测数据中无法观察到,尤其是我认为负荷的变化主要与室外温度有关。(例如,一个“温暖”的冬天负荷较低,而一个“寒冷”的冬天负荷较高,因此这个趋势很难跨年观察到)。因此,我计划仅使用有限的连续年份数据进行训练,以限制这种影响,但同时我需要将此趋势整合到我的模型中,以便对未来进行准确预测。我该如何做到这一点,并确保如果我没有用最近的年份进行训练,我就不会得到一个不能代表真实演变的模型?
我希望我的问题能够得到清晰的解答,我非常感谢您的帮助。我阅读您的文章已有数月,并且大多数时候都能在评论中找到我的答案,但这些我还没有找到 :)
诚挚的问候,
Magali
嗨 Magali,
虽然我无法就您的具体应用发表评论,但我强烈建议您研究多变量 LSTM 模型。
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/