随着智能电表和太阳能电池板等发电技术的广泛应用,大量的用电数据可供使用。
这些数据代表了一个与电力相关的多元时间序列,进而可以用于建模甚至预测未来的用电量。
与其他机器学习算法不同,卷积神经网络能够自动从序列数据中学习特征,支持多变量数据,并可以直接输出一个向量用于多步预测。因此,一维 CNN 在具有挑战性的序列预测问题上表现出色,甚至达到了最先进的成果。
在本教程中,您将学习如何开发用于多步时间序列预测的一维卷积神经网络。
完成本教程后,您将了解:
- 如何开发用于单变量数据多步时间序列预测的 CNN 模型。
- 如何开发用于多变量数据多通道多步时间序列预测模型。
- 如何开发用于多变量数据多头多步时间序列预测模型。
使用我的新书《时间序列预测深度学习》启动您的项目,包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 6 月更新:修复了 to_supervised() 中导致最后一星期数据丢失的错误(感谢 Markus)。

如何开发用于多步时间序列预测的卷积神经网络
照片由 Banalities 拍摄,保留部分权利。
教程概述
本教程分为七个部分,它们是:
- 问题描述
- 加载并准备数据集
- 模型评估
- 用于多步预测的 CNN
- 使用单变量 CNN 进行多步时间序列预测
- 使用多通道 CNN 进行多步时间序列预测
- 使用多头 CNN 进行多步时间序列预测
问题描述
“家庭用电量”数据集是一个多变量时间序列数据集,描述了单个家庭四年内的用电量。
数据收集于 2006 年 12 月至 2010 年 11 月期间,每分钟收集一次家庭用电量的观测值。
它是一个多元序列,包含七个变量(除了日期和时间);它们是
- global_active_power:家庭消耗的总有功功率(千瓦)。
- global_reactive_power:家庭消耗的总无功功率(千瓦)。
- voltage:平均电压(伏特)。
- global_intensity:平均电流强度(安培)。
- sub_metering_1:厨房的有功电能(瓦时有功电能)。
- sub_metering_2:洗衣房的有功电能(瓦时有功电能)。
- sub_metering_3:气候控制系统的有功电能(瓦时有功电能)。
有功电能和无功电能指的是交流电的技术细节。
第四个子计量变量可以通过将三个定义的子计量变量的总和从总有功电能中减去来创建,如下所示
|
1 |
sub_metering_remainder = (global_active_power * 1000 / 60) - (sub_metering_1 + sub_metering_2 + sub_metering_3) |
加载并准备数据集
该数据集可以从 UCI 机器学习仓库下载,为一个 20 兆字节的 .zip 文件
下载数据集并将其解压缩到当前工作目录。现在您将拥有文件“household_power_consumption.txt”,其大小约为 127 兆字节,并包含所有观测值。
我们可以使用 read_csv() 函数加载数据,并将前两列合并为一个日期时间列,我们可以将其用作索引。
|
1 2 |
# 加载所有数据 dataset = read_csv('household_power_consumption.txt', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0,1]}, index_col=['datetime']) |
接下来,我们可以将用“?”字符表示的所有缺失值标记为 NaN 值,这是一个浮点数。
这将允许我们以一个浮点值数组而不是混合类型(效率较低)来处理数据。
|
1 2 3 4 |
# 标记所有缺失值 dataset.replace('?', nan, inplace=True) # 使数据集数值化 dataset = dataset.astype('float32') |
现在我们需要填补已标记的缺失值。
一个非常简单的方法是复制前一天同一时间的观测值。我们可以在一个名为 fill_missing() 的函数中实现这一点,该函数将接收数据的 NumPy 数组并复制 24 小时前的值。
|
1 2 3 4 5 6 7 |
# 用一天前同一时间的值填充缺失值 def fill_missing(values): one_day = 60 * 24 for row in range(values.shape[0]): for col in range(values.shape[1]): if isnan(values[row, col]): values[row, col] = values[row - one_day, col] |
我们可以直接将此函数应用于 DataFrame 中的数据。
|
1 2 |
# 填充缺失值 fill_missing(dataset.values) |
现在我们可以创建一个新列,其中包含子计量的剩余部分,使用上一节中的计算。
|
1 2 3 |
# 添加一个用于子计量剩余部分的新列 values = dataset.values dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6]) |
现在我们可以将清理后的数据集保存到一个新文件中;在这种情况下,我们只需将文件扩展名更改为 .csv 并将数据集保存为“household_power_consumption.csv”。
|
1 2 |
# 保存更新后的数据集 dataset.to_csv('household_power_consumption.csv') |
将所有这些串联起来,加载、清理和保存数据集的完整示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 加载和清理数据 from numpy import nan from numpy import isnan from pandas import read_csv from pandas import to_numeric # 用一天前同一时间的值填充缺失值 def fill_missing(values): one_day = 60 * 24 for row in range(values.shape[0]): for col in range(values.shape[1]): if isnan(values[row, col]): values[row, col] = values[row - one_day, col] # 加载所有数据 dataset = read_csv('household_power_consumption.txt', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0,1]}, index_col=['datetime']) # 标记所有缺失值 dataset.replace('?', nan, inplace=True) # 使数据集数值化 dataset = dataset.astype('float32') # 填充缺失值 fill_missing(dataset.values) # 添加一个用于子计量剩余部分的新列 values = dataset.values dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6]) # 保存更新后的数据集 dataset.to_csv('household_power_consumption.csv') |
运行示例会创建一个新的文件“household_power_consumption.csv”,我们可以将其作为建模项目的起点。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
模型评估
在本节中,我们将考虑如何为家庭用电数据集开发和评估预测模型。
本节分为四个部分;它们是
- 问题构建
- 评估指标
- 训练集和测试集
- 逐时验证
问题构建
有许多方法可以利用和探索家庭用电量数据集。
在本教程中,我们将使用数据来探索一个非常具体的问题;那就是
鉴于最近的用电量,未来一周的预期用电量是多少?
这要求预测模型预测未来七天每天的总有功功率。
从技术上讲,由于存在多个预测步骤,这种问题框架被称为多步时间序列预测问题。利用多个输入变量的模型可以被称为多变量多步时间序列预测模型。
这种类型的模型可能有助于家庭规划开支。它也可能有助于供应方规划特定家庭的电力需求。
这种数据集的框架还表明,将每分钟的用电量观测值下采样到每日总计可能很有用。这不是必需的,但考虑到我们关注的是每天的总功率,这样做是合理的。
我们可以使用 pandas DataFrame 上的 resample() 函数轻松实现这一点。使用参数“D”调用此函数,可以将按日期时间索引的加载数据按天分组(查看所有偏移别名)。然后,我们可以计算每天所有观测值的总和,并为八个变量中的每一个创建每日用电量数据的新数据集。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 将分钟数据重新采样为每天的总量 from pandas import read_csv # 加载新文件 dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 将数据重新采样为每日数据 daily_groups = dataset.resample('D') daily_data = daily_groups.sum() # 总结 print(daily_data.shape) print(daily_data.head()) # 保存 daily_data.to_csv('household_power_consumption_days.csv') |
运行示例将创建一个新的每日总用电量数据集,并将结果保存到一个名为“household_power_consumption_days.csv”的单独文件中。
我们可以将其用作拟合和评估所选问题框架的预测模型的数据集。
评估指标
预测将由七个值组成,未来一周的每一天一个值。
在多步预测问题中,通常会单独评估每个预测时间步长。这有几个原因
- 评论特定提前期(例如,+1 天与 +3 天)的技能。
- 根据模型在不同提前期(例如,+1 天擅长的模型与 +5 天擅长的模型)的技能来对比模型。
总功率的单位是千瓦,如果误差指标也采用相同的单位会很有用。均方根误差 (RMSE) 和平均绝对误差 (MAE) 都符合这一要求,尽管 RMSE 更常用,并且将在本教程中采用。与 MAE 不同,RMSE 对预测误差的惩罚更严厉。
此问题的性能指标将是第 1 天到第 7 天每个提前期的 RMSE。
作为一种捷径,为了帮助模型选择,使用单个分数来总结模型的性能可能很有用。
可以使用的一个可能分数是所有预测天的 RMSE。
下面的 evaluate_forecasts() 函数将实现此行为,并根据多个七天预测返回模型的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 针对期望值评估一个或多个每周预测 def evaluate_forecasts(actual, predicted): scores = list() # 计算每一天的 RMSE 分数 for i in range(actual.shape[1]): # 计算 mse mse = mean_squared_error(actual[:, i], predicted[:, i]) # 计算 rmse rmse = sqrt(mse) # 存储 scores.append(rmse) # 计算整体 RMSE s = 0 for row in range(actual.shape[0]): for col in range(actual.shape[1]): s += (actual[row, col] - predicted[row, col])**2 score = sqrt(s / (actual.shape[0] * actual.shape[1])) return score, scores |
运行函数将首先返回与日期无关的整体 RMSE,然后返回每天的 RMSE 分数数组。
训练集和测试集
我们将使用前三年的数据进行预测模型训练,并使用最后一年进行模型评估。
给定数据集中的数据将划分为标准周。这些周以周日开始,以周六结束。
这是使用所选模型框架的一种现实且有用的方式,可以预测未来一周的用电量。它还有助于建模,模型可以用于预测特定的一天(例如星期三)或整个序列。
我们将把数据划分为标准周,从测试数据集倒序进行。
数据的最后一年是 2010 年,2010 年的第一个星期日是 1 月 3 日。数据于 2010 年 11 月中旬结束,数据中最近的最后一个星期六是 11 月 20 日。这提供了 46 周的测试数据。
下面提供了测试数据集的每日数据的起始行和结束行以供确认。
|
1 2 3 |
2010-01-03,2083.4539999999984,191.61000000000055,350992.12000000034,8703.600000000033,3842.0,4920.0,10074.0,15888.233355799992 ... 2010-11-20,2197.006000000004,153.76800000000028,346475.9999999998,9320.20000000002,4367.0,2947.0,11433.0,17869.76663959999 |
每日数据始于 2006 年末。
数据集中的第一个星期日是 12 月 17 日,这是数据的第二行。
将数据组织成标准周后,用于训练预测模型的完整标准周有 159 个。
|
1 2 3 |
2006-12-17,3390.46,226.0059999999994,345725.32000000024,14398.59999999998,2033.0,4187.0,13341.0,36946.66673200004 ... 2010-01-02,1309.2679999999998,199.54600000000016,352332.8399999997,5489.7999999999865,801.0,298.0,6425.0,14297.133406600002 |
下面的 split_dataset() 函数将每日数据拆分为训练集和测试集,并将每个数据集组织成标准周。
使用数据集的已知信息,使用特定的行偏移量来分割数据。然后使用 NumPy split() 函数将分割后的数据集组织成周数据。
|
1 2 3 4 5 6 7 8 |
# 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test |
我们可以通过加载每日数据集并打印训练集和测试集的第一行和最后一行数据来测试此函数,以确认它们符合上述预期。
完整的代码示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 拆分为标准周 from numpy import split from numpy import array from pandas import read_csv # 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test # 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) train, test = split_dataset(dataset.values) # 验证训练数据 print(train.shape) print(train[0, 0, 0], train[-1, -1, 0]) # 验证测试数据 print(test.shape) print(test[0, 0, 0], test[-1, -1, 0]) |
运行示例表明,训练集确实有 159 周的数据,而测试集有 46 周的数据。
我们可以看到,训练集和测试集的第一行和最后一行的总有功功率与我们定义为每个集合标准周边界的特定日期的数据相匹配。
|
1 2 3 4 |
(159, 7, 8) 3390.46 1309.2679999999998 (46, 7, 8) 2083.4539999999984 2197.006000000004 |
逐时验证
模型将使用一种名为滚动预测的方案进行评估。
在这种方法中,模型需要进行一周的预测,然后将该周的实际数据提供给模型,以便将其作为后续预测的基础。这既符合模型在实际中可能的使用方式,也有利于模型,使其能够利用可用的最佳数据。
我们可以在下面通过分离输入数据和输出/预测数据来演示这一点。
|
1 2 3 4 5 |
输入,预测 [第1周] 第2周 [第1周 + 第2周] 第3周 [第1周 + 第2周 + 第3周] 第4周 ... |
下面提供了用于评估该数据集上预测模型的滚动预测方法,命名为 evaluate_model()。
以标准周格式的训练和测试数据集作为参数提供给函数。另外还提供了一个附加参数 n_input,用于定义模型将用作输入以进行预测的先前观测值的数量。
调用了两个新函数:一个用于从训练数据构建模型的函数,名为 build_model(),另一个用于使用模型为每个新标准周进行预测的函数,名为 forecast()。这些将在后续章节中介绍。
我们正在使用神经网络,因此它们通常训练缓慢但评估速度快。这意味着模型的首选用法是在历史数据上构建一次,并使用它们来预测滚动验证的每一步。在评估期间,模型是静态的(即不更新)。
这与其他训练速度更快的模型不同,在这些模型中,随着新数据的可用,模型可能会在滚动验证的每一步重新拟合或更新。在资源充足的情况下,可以使用神经网络以这种方式进行,但本教程中不会这样做。
完整的 evaluate_model() 函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 评估单个模型 def evaluate_model(train, test, n_input): # 拟合模型 model = build_model(train, n_input) # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = forecast(model, history, n_input) # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) # 评估每周的预测天数 predictions = array(predictions) score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores |
一旦我们对模型进行了评估,我们就可以总结其性能。
下面的函数,名为 summarize_scores(),将以单行显示模型的性能,以便于与其他模型进行比较。
|
1 2 3 4 |
# 总结得分 def summarize_scores(name, score, scores): s_scores = ', '.join(['%.1f' % s for s in scores]) print('%s: [%.3f] %s' % (name, score, s_scores)) |
我们现在拥有所有要素,可以开始评估数据集上的预测模型。
用于多步预测的 CNN
卷积神经网络模型,简称 CNN,是一种深度神经网络,专为图像数据(如手写识别)而开发。
在大规模训练以解决图像中物体识别和定位、自动描述图像内容等具有挑战性的计算机视觉问题时,它们被证明非常有效。
卷积层使用一个内核读取输入(例如 2D 图像或 1D 信号),该内核每次读取小片段并跨越整个输入字段。每次读取都会对输入进行解释,并投影到特征图上,代表对输入的一种解释。
池化层提取特征图投影并将其提炼成最基本的元素,例如使用信号平均或信号最大化过程。
卷积层和池化层可以深度重复,提供多层输入信号的抽象。
这些网络的输出通常是一个或多个全连接层,这些层解释已读取的内容并将这种内部表示映射到类别值。
有关卷积神经网络的更多信息,请参阅文章
卷积神经网络可用于多步时间序列预测。
- 卷积层可以读取输入数据序列并自动提取特征。
- 池化层可以提取特征并关注最显著的元素。
- 全连接层可以解释内部表示并输出一个代表多个时间步的向量。
该方法的关键优势在于自动特征学习和模型直接输出多步向量的能力。
CNN 既可以用于递归预测策略,即模型进行一步预测并将输出作为后续预测的输入,也可以用于直接预测策略,即为每个要预测的时间步开发一个模型。或者,CNN 可以用于将整个输出序列作为整个向量的一步预测。这是前馈神经网络的一个普遍优势。
使用 CNN 的一个重要的次要优势是它们可以支持多个 1D 输入以进行预测。如果多步输出序列是多个输入序列的函数,这将非常有用。这可以通过两种不同的模型配置来实现。
- 多输入通道。在这种情况下,每个输入序列都被视为一个单独的通道,就像图像的不同通道(例如红色、绿色和蓝色)一样。
- 多输入头。在这种情况下,每个输入序列都由不同的 CNN 子模型读取,并且内部表示在解释和用于进行预测之前进行组合。
在本教程中,我们将探讨如何开发三种不同类型的 CNN 模型用于多步时间序列预测;它们是
- 用于单变量输入数据的多步时间序列预测的 CNN。
- 通过通道处理多变量输入数据的多步时间序列预测的 CNN。
- 通过子模型处理多变量输入数据的多步时间序列预测的 CNN。
这些模型将在家庭用电量预测问题上进行开发和演示。如果模型性能优于朴素模型(七天预测的整体 RMSE 约为 465 千瓦),则认为模型具有技能。
我们不会专注于调整这些模型以实现最佳性能;相反,我们将止步于与朴素预测相比具有技巧的模型。所选的结构和超参数是通过少量试错选择的。
使用单变量 CNN 进行多步时间序列预测
在本节中,我们将开发一个卷积神经网络,用于仅使用每日用电量的单变量序列进行多步时间序列预测。
具体来说,问题的框架是:
给定一些先前的每日总用电量,预测下一个标准周的每日用电量。
用作输入的先前天数定义了 CNN 将读取并学习提取特征的数据的一维 (1D) 子序列。关于此输入的大小和性质的一些想法包括:
- 所有前几天的数据,最多可达数年。
- 之前的七天。
- 之前的两周。
- 之前的一个月。
- 之前的一年。
- 前一周和一年前要预测的那一周。
没有正确答案;相反,可以测试每种方法以及更多方法,并可以使用模型的性能来选择导致最佳模型性能的输入性质。
这些选择定义了关于实现的一些事情,例如:
- 必须如何准备训练数据才能拟合模型。
- 必须如何准备测试数据才能评估模型。
- 如何在未来使用最终模型进行预测。
一个好的起点是使用前七天。
一维 CNN 模型期望数据的形状为
|
1 |
[样本数, 时间步数, 特征数] |
一个样本将由七个时间步和一个特征组成,用于七天的每日总用电量。
训练数据集有 159 周的数据,因此训练数据集的形状将是
|
1 |
[159, 7, 1] |
这是一个好的开始。这种格式的数据将使用前一个标准周来预测下一个标准周。问题在于 159 个实例对于神经网络来说并不多。
创建更多训练数据的一种方法是在训练期间更改问题,以预测未来七天,给定前七天,无论标准周如何。
这只会影响训练数据,测试问题保持不变:预测下一个标准周的每日用电量,给定前一个标准周。
这需要对训练数据进行一些准备。
训练数据以标准周形式提供,包含八个变量,具体形状为 [159, 7, 8]。第一步是展平数据,以便我们有八个时间序列。
|
1 2 |
# 展平数据 data = data.reshape((data.shape[0]*data.shape[1], data.shape[2])) |
然后,我们需要迭代时间步并将数据划分为重叠窗口;每次迭代沿一个时间步移动并预测随后的七天。
例如
|
1 2 3 4 |
输入,输出 [d01, d02, d03, d04, d05, d06, d07], [d08, d09, d10, d11, d12, d13, d14] [d02, d03, d04, d05, d06, d07, d08], [d09, d10, d11, d12, d13, d14, d15] ... |
我们可以通过在时间步长上迭代展平数据时,跟踪输入和输出的开始和结束索引来做到这一点。
我们还可以以参数化输入和输出数量(例如 n_input、n_out)的方式进行,以便您可以尝试不同的值或根据您自己的问题进行调整。
下面是一个名为 to_supervised() 的函数,它接受一个星期列表(历史数据)以及用作输入和输出的时间步数,并以重叠移动窗口格式返回数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 将历史数据转换为输入和输出 def to_supervised(train, n_input, n_out=7): # 展平数据 data = train.reshape((train.shape[0]*train.shape[1], train.shape[2])) X, y = list(), list() in_start = 0 # 遍历整个历史记录,每次一个时间步长 for _ in range(len(data)): # 定义输入序列的结束位置 in_end = in_start + n_input out_end = in_end + n_out # 确保此实例有足够的数据 if out_end <= len(data): x_input = data[in_start:in_end, 0] x_input = x_input.reshape((len(x_input), 1)) X.append(x_input) y.append(data[in_end:out_end, 0]) # 前进一步 in_start += 1 return array(X), array(y) |
当我们对整个训练数据集运行此函数时,我们将 159 个样本转换为 1,100 个;具体来说,转换后的数据集形状为 X=[1100, 7, 1] 和 y=[1100, 7]。
接下来,我们可以在训练数据上定义和拟合 CNN 模型。
这个多步时间序列预测问题是一个自回归问题。这意味着它最有可能通过以下方式建模:未来七天是先前时间步长观测值的一些函数。这一点和相对少量的数据意味着需要一个小型模型。
我们将使用一个包含 16 个过滤器和内核大小为 3 的卷积层模型。这意味着将以三个时间步长为单位读取七天的输入序列,并且此操作将执行 16 次。池化层将这些特征图缩小到其大小的 1/4,然后将内部表示展平为一个长向量。然后,该向量由一个全连接层进行解释,最后输出层预测序列中的未来七天。
我们将使用均方误差损失函数,因为它与我们选择的 RMSE 误差指标非常匹配。我们将使用高效的Adam随机梯度下降实现,并以 4 的批量大小对模型进行 20 个 epoch 的拟合。
小的批量大小和算法的随机性意味着每次训练时,同一模型都会学习到略有不同的输入到输出映射。这意味着评估模型时结果可能会有所不同。您可以尝试多次运行模型并计算模型性能的平均值。
下面的 build_model() 准备训练数据,定义模型,并在训练数据上拟合模型,返回准备好进行预测的拟合模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 训练模型 def build_model(train, n_input): # 准备数据 train_x, train_y = to_supervised(train, n_input) # 定义参数 verbose, epochs, batch_size = 0, 20, 4 n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1] # 定义模型 model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', input_shape=(n_timesteps,n_features))) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(10, activation='relu')) model.add(Dense(n_outputs)) model.compile(loss='mse', optimizer='adam') # 拟合网络 model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose) return model |
现在我们知道如何拟合模型了,我们可以看看如何使用模型进行预测。
通常,模型在进行预测时期望数据具有相同的三维形状。
在这种情况下,输入模式的预期形状是一个样本,包含七天的每日用电量的一个特征。
|
1 |
[1, 7, 1] |
在对测试集进行预测以及未来使用最终模型进行预测时,数据必须具有这种形状。如果将输入天数更改为 14,则训练数据的形状和进行预测时新样本的形状必须相应地更改为 14 个时间步。这是一个建模选择,在使用模型时必须遵循。
我们正在使用前一节中描述的滚动验证来评估模型。
这意味着我们有前一周的观测数据,以便预测下一周。这些数据被收集到名为历史记录的标准周数组中。
为了预测下一个标准周,我们需要检索最后几天的观测值。与训练数据一样,我们必须首先展平历史数据以消除每周结构,以便我们最终得到八个并行时间序列。
|
1 2 |
# 展平数据 data = data.reshape((data.shape[0]*data.shape[1], data.shape[2])) |
接下来,我们需要检索过去七天每日总用电量(特征号 0)。我们将像训练数据一样进行参数化,以便将来可以修改模型用作输入的先前天数。
|
1 2 |
# 检索输入数据的最新观测值 input_x = data[-n_input:, 0] |
接下来,我们将输入重塑为预期的三维结构。
|
1 2 |
# 重塑为 [1, n_input, 1] input_x = input_x.reshape((1, len(input_x), 1)) |
然后,我们使用拟合模型和输入数据进行预测,并检索七天输出的向量。
|
1 2 3 4 |
# 预测下一周 yhat = model.predict(input_x, verbose=0) # 我们只想要向量预测 yhat = yhat[0] |
下面的 forecast() 函数实现了这一点,它将拟合在训练数据集上的模型、迄今为止观察到的数据历史以及模型所需的输入时间步数作为参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 进行预测 def forecast(model, history, n_input): # 展平数据 data = array(history) data = data.reshape((data.shape[0]*data.shape[1], data.shape[2])) # 检索输入数据的最新观测值 input_x = data[-n_input:, 0] # 重塑为 [1, n_input, 1] input_x = input_x.reshape((1, len(input_x), 1)) # 预测下一周 yhat = model.predict(input_x, verbose=0) # 我们只想要向量预测 yhat = yhat[0] return yhat |
就是这样;我们现在拥有使用 CNN 模型对每日总用电量单变量数据集进行多步时间序列预测所需的一切。
我们可以将所有这些结合起来。完整的示例列于下方。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 |
# 单变量多步 CNN from math import sqrt from numpy import split from numpy import array from pandas import read_csv from sklearn.metrics import mean_squared_error from matplotlib import pyplot from keras.models import Sequential from keras.layers import Dense from keras.layers import Flatten from keras.layers.convolutional import Conv1D from keras.layers.convolutional import MaxPooling1D # 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test # 针对期望值评估一个或多个每周预测 def evaluate_forecasts(actual, predicted): scores = list() # 计算每一天的 RMSE 分数 for i in range(actual.shape[1]): # 计算 mse mse = mean_squared_error(actual[:, i], predicted[:, i]) # 计算 rmse rmse = sqrt(mse) # 存储 scores.append(rmse) # 计算整体 RMSE s = 0 for row in range(actual.shape[0]): for col in range(actual.shape[1]): s += (actual[row, col] - predicted[row, col])**2 score = sqrt(s / (actual.shape[0] * actual.shape[1])) return score, scores # 总结得分 def summarize_scores(name, score, scores): s_scores = ', '.join(['%.1f' % s for s in scores]) print('%s: [%.3f] %s' % (name, score, s_scores)) # 将历史数据转换为输入和输出 def to_supervised(train, n_input, n_out=7): # 展平数据 data = train.reshape((train.shape[0]*train.shape[1], train.shape[2])) X, y = list(), list() in_start = 0 # 遍历整个历史记录,每次一个时间步长 for _ in range(len(data)): # 定义输入序列的结束位置 in_end = in_start + n_input out_end = in_end + n_out # 确保此实例有足够的数据 if out_end <= len(data): x_input = data[in_start:in_end, 0] x_input = x_input.reshape((len(x_input), 1)) X.append(x_input) y.append(data[in_end:out_end, 0]) # 前进一步 in_start += 1 return array(X), array(y) # 训练模型 def build_model(train, n_input): # 准备数据 train_x, train_y = to_supervised(train, n_input) # 定义参数 verbose, epochs, batch_size = 0, 20, 4 n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1] # 定义模型 model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', input_shape=(n_timesteps,n_features))) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(10, activation='relu')) model.add(Dense(n_outputs)) model.compile(loss='mse', optimizer='adam') # 拟合网络 model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose) return model # 进行预测 def forecast(model, history, n_input): # 展平数据 data = array(history) data = data.reshape((data.shape[0]*data.shape[1], data.shape[2])) # 检索输入数据的最新观测值 input_x = data[-n_input:, 0] # 重塑为 [1, n_input, 1] input_x = input_x.reshape((1, len(input_x), 1)) # 预测下一周 yhat = model.predict(input_x, verbose=0) # 我们只想要向量预测 yhat = yhat[0] return yhat # 评估单个模型 def evaluate_model(train, test, n_input): # 拟合模型 model = build_model(train, n_input) # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = forecast(model, history, n_input) # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) # 评估每周的预测天数 predictions = array(predictions) score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores # 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 分割成训练集和测试集 train, test = split_dataset(dataset.values) # 评估模型并获取分数 n_input = 7 score, scores = evaluate_model(train, test, n_input) # 总结得分 summarize_scores('cnn', score, scores) # 绘制分数 days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat'] pyplot.plot(days, scores, marker='o', label='cnn') pyplot.show() |
运行示例拟合并评估模型,打印出所有七天的总体 RMSE,以及每个预测提前期的每日 RMSE。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,在这种情况下,与朴素预测相比,该模型是有效的,总体 RMSE 约为 404 千瓦,低于朴素模型实现的 465 千瓦。
|
1 |
cnn: [404.411] 436.1, 400.6, 346.2, 388.2, 405.5, 326.0, 502.9 |
还创建了每日 RMSE 的图。该图显示,周二和周五可能比其他日子更容易预测,而标准周末的周六可能最难预测。
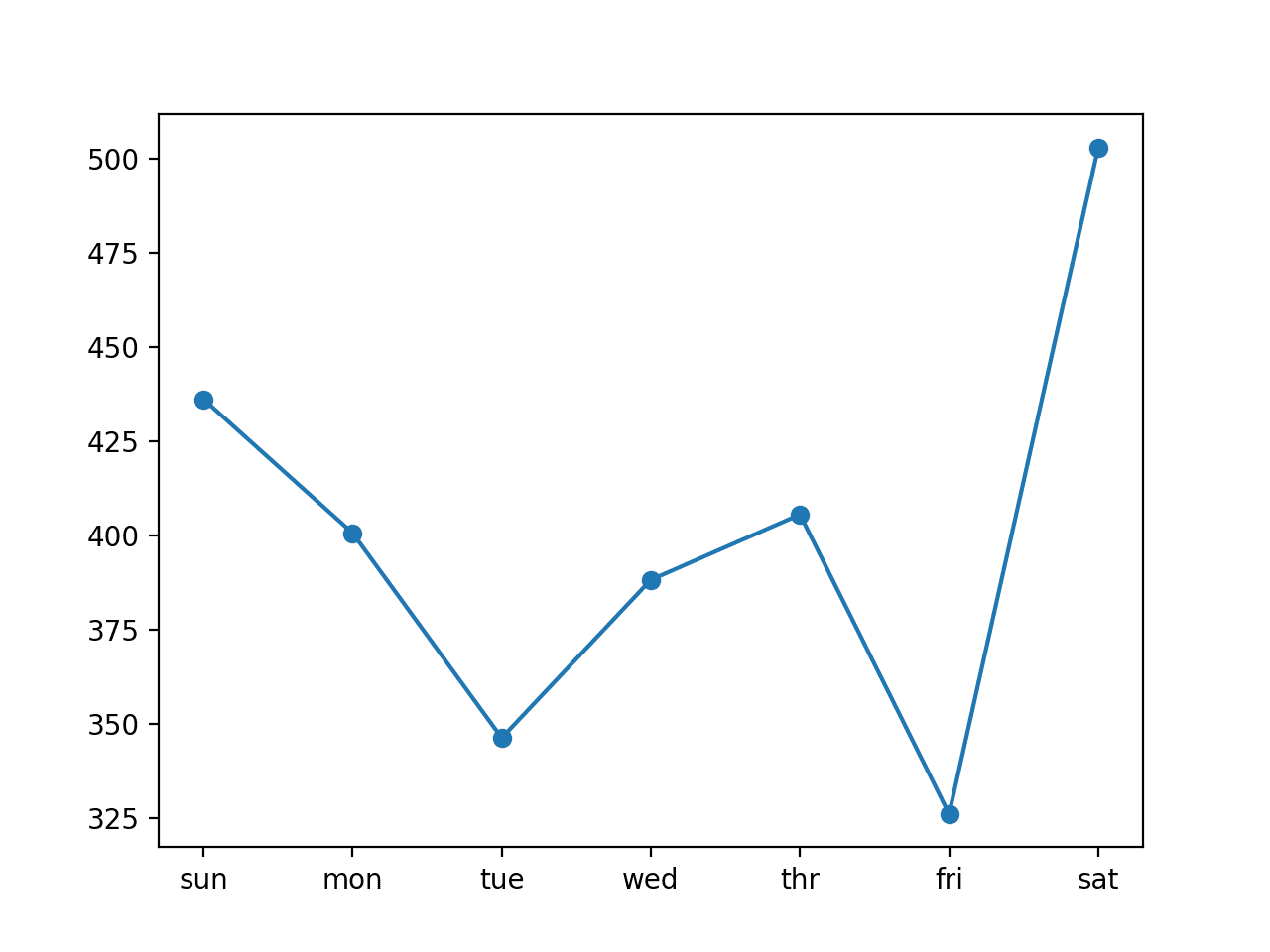
单变量 CNN 7 天输入模型的每日 RMSE 折线图
我们可以通过更改 n_input 变量,将用作输入的先前天数从 7 天增加到 14 天。
|
1 2 |
# 评估模型并获取分数 n_input = 14 |
重新运行带有此更改的示例,首先打印模型性能摘要。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到整体 RMSE 进一步下降,这表明进一步调整输入大小和模型内核大小可能会带来更好的性能。
|
1 |
cnn: [396.497] 392.2, 412.8, 384.0, 389.0, 387.3, 381.0, 427.1 |
比较每日 RMSE 分数,我们发现有些比使用第七个输入更好,有些则更差。
这可能表明以某种方式使用两种不同大小的输入会带来好处,例如这两种方法的集成,或者可能是以不同方式读取训练数据的单个模型(例如多头模型)。
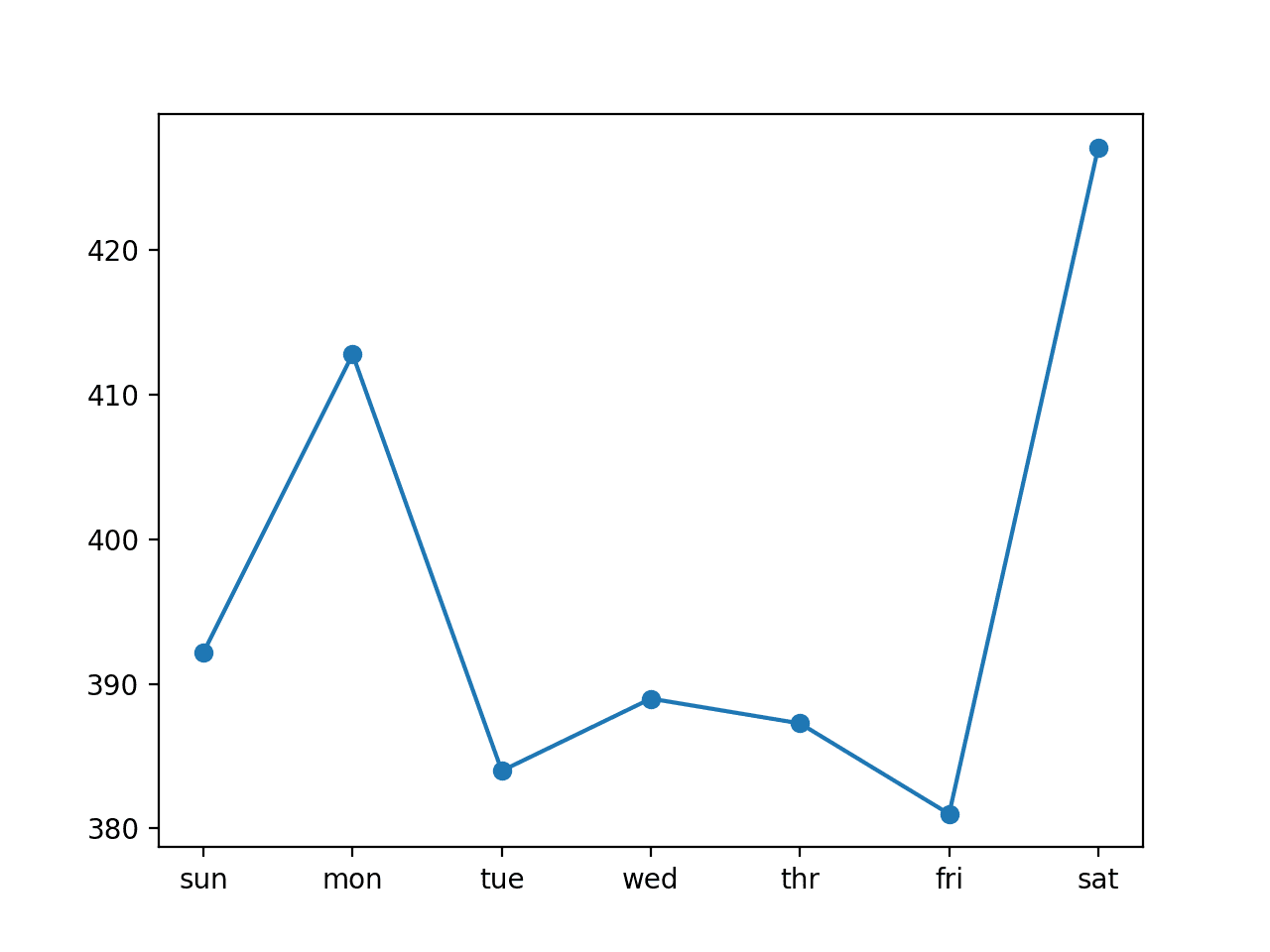
单变量 CNN 14 天输入模型的每日 RMSE 折线图
使用多通道 CNN 进行多步时间序列预测
在本节中,我们将更新上一节中开发的 CNN,以使用八个时间序列变量中的每一个来预测下一个标准周的每日总用电量。
我们将通过将每个一维时间序列作为单独的输入通道提供给模型来实现此目的。
然后,CNN 将使用单独的内核,并将每个输入序列读取到一组单独的滤波器图中,从而从每个输入时间序列变量中学习特征。
这对于输出序列是多个不同特征(而不仅仅是或包括正在预测的特征)先前时间步长观测值的某些函数的问题很有帮助。在用电量问题中是否如此尚不清楚,但我们可以对此进行探索。
首先,我们必须更新训练数据的准备工作,以包含所有八个特征,而不仅仅是每日总用电量这一个。这只需要一行代码:
|
1 |
X.append(data[in_start:in_end, :]) |
此更改后的完整 to_supervised() 函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 将历史数据转换为输入和输出 def to_supervised(train, n_input, n_out=7): # 展平数据 data = train.reshape((train.shape[0]*train.shape[1], train.shape[2])) X, y = list(), list() in_start = 0 # 遍历整个历史记录,每次一个时间步长 for _ in range(len(data)): # 定义输入序列的结束位置 in_end = in_start + n_input out_end = in_end + n_out # 确保此实例有足够的数据 if out_end <= len(data): X.append(data[in_start:in_end, :]) y.append(data[in_end:out_end, 0]) # 前进一步 in_start += 1 return array(X), array(y) |
我们还必须更新用于使用拟合模型进行预测的函数,以使用先前时间步长的所有八个特征。同样,只进行了一个小改动:
|
1 2 3 4 |
# 检索输入数据的最新观测值 input_x = data[-n_input:, :] # 重塑为 [1, n_input, n] input_x = input_x.reshape((1, input_x.shape[0], input_x.shape[1])) |
此更改后的完整 forecast() 如下所示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 进行预测 def forecast(model, history, n_input): # 展平数据 data = array(history) data = data.reshape((data.shape[0]*data.shape[1], data.shape[2])) # 检索输入数据的最新观测值 input_x = data[-n_input:, :] # 重塑为 [1, n_input, n] input_x = input_x.reshape((1, input_x.shape[0], input_x.shape[1])) # 预测下一周 yhat = model.predict(input_x, verbose=0) # 我们只想要向量预测 yhat = yhat[0] return yhat |
我们将使用前14天的观测数据,涉及八个输入变量,这与前一节的最后部分一样,略微提高了性能。
|
1 |
n_input = 14 |
最后,上一节中使用的模型在这个新的问题框架下表现不佳。
数据量的增加需要一个更大、更复杂的模型,并且需要更长的训练时间。
经过一些反复试验,一个表现良好的模型使用了两个带有32个滤波器图的卷积层,然后是池化,接着是另一个带有16个特征图的卷积层和池化。解释特征的全连接层增加到100个节点,模型以16个样本的批量大小拟合70个epoch。
下面列出了在训练数据集上定义和拟合模型的更新后的build_model()函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 训练模型 def build_model(train, n_input): # 准备数据 train_x, train_y = to_supervised(train, n_input) # 定义参数 verbose, epochs, batch_size = 0, 70, 16 n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1] # 定义模型 model = Sequential() model.add(Conv1D(filters=32, kernel_size=3, activation='relu', input_shape=(n_timesteps,n_features))) model.add(Conv1D(filters=32, kernel_size=3, activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Conv1D(filters=16, kernel_size=3, activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(100, activation='relu')) model.add(Dense(n_outputs)) model.compile(loss='mse', optimizer='adam') # 拟合网络 model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose) return model |
我们现在拥有开发多通道CNN所需的所有元素,用于多变量输入数据以进行多步时间序列预测。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
# 多通道多步CNN from math import sqrt from numpy import split from numpy import array from pandas import read_csv from sklearn.metrics import mean_squared_error from matplotlib import pyplot from keras.models import Sequential from keras.layers import Dense from keras.layers import Flatten from keras.layers.convolutional import Conv1D from keras.layers.convolutional import MaxPooling1D # 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test # 针对期望值评估一个或多个每周预测 def evaluate_forecasts(actual, predicted): scores = list() # 计算每一天的 RMSE 分数 for i in range(actual.shape[1]): # 计算 mse mse = mean_squared_error(actual[:, i], predicted[:, i]) # 计算 rmse rmse = sqrt(mse) # 存储 scores.append(rmse) # 计算整体 RMSE s = 0 for row in range(actual.shape[0]): for col in range(actual.shape[1]): s += (actual[row, col] - predicted[row, col])**2 score = sqrt(s / (actual.shape[0] * actual.shape[1])) return score, scores # 总结得分 def summarize_scores(name, score, scores): s_scores = ', '.join(['%.1f' % s for s in scores]) print('%s: [%.3f] %s' % (name, score, s_scores)) # 将历史数据转换为输入和输出 def to_supervised(train, n_input, n_out=7): # 展平数据 data = train.reshape((train.shape[0]*train.shape[1], train.shape[2])) X, y = list(), list() in_start = 0 # 遍历整个历史记录,每次一个时间步长 for _ in range(len(data)): # 定义输入序列的结束位置 in_end = in_start + n_input out_end = in_end + n_out # 确保此实例有足够的数据 if out_end <= len(data): X.append(data[in_start:in_end, :]) y.append(data[in_end:out_end, 0]) # 前进一步 in_start += 1 return array(X), array(y) # 训练模型 def build_model(train, n_input): # 准备数据 train_x, train_y = to_supervised(train, n_input) # 定义参数 verbose, epochs, batch_size = 0, 70, 16 n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1] # 定义模型 model = Sequential() model.add(Conv1D(filters=32, kernel_size=3, activation='relu', input_shape=(n_timesteps,n_features))) model.add(Conv1D(filters=32, kernel_size=3, activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Conv1D(filters=16, kernel_size=3, activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(100, activation='relu')) model.add(Dense(n_outputs)) model.compile(loss='mse', optimizer='adam') # 拟合网络 model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose) return model # 进行预测 def forecast(model, history, n_input): # 展平数据 data = array(history) data = data.reshape((data.shape[0]*data.shape[1], data.shape[2])) # 检索输入数据的最新观测值 input_x = data[-n_input:, :] # 重塑为 [1, n_input, n] input_x = input_x.reshape((1, input_x.shape[0], input_x.shape[1])) # 预测下一周 yhat = model.predict(input_x, verbose=0) # 我们只想要向量预测 yhat = yhat[0] return yhat # 评估单个模型 def evaluate_model(train, test, n_input): # 拟合模型 model = build_model(train, n_input) # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = forecast(model, history, n_input) # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) # 评估每周的预测天数 predictions = array(predictions) score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores # 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 分割成训练集和测试集 train, test = split_dataset(dataset.values) # 评估模型并获取分数 n_input = 14 score, scores = evaluate_model(train, test, n_input) # 总结得分 summarize_scores('cnn', score, scores) # 绘制分数 days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat'] pyplot.plot(days, scores, marker='o', label='cnn') pyplot.show() |
运行示例拟合并评估模型,打印出所有七天的总体 RMSE,以及每个预测提前期的每日 RMSE。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,在这种情况下,使用所有八个输入变量确实导致整体RMSE分数又下降了一小部分。
|
1 |
CNN:[385.711] 422.2, 363.5, 349.8, 393.1, 357.1, 318.8, 474.3 |
对于每日RMSE分数,我们确实看到有些比上一节的单变量CNN好,有些则差。
最后一天,星期六,仍然是一个具有挑战性的预测日,而星期五则是一个容易预测的日子。设计模型以专门减少较难预测日期的误差可能会有一些好处。
看看经过调优的模型或多个不同模型的集成是否能进一步减少每日分数之间的方差可能会很有趣。比较使用七天甚至21天输入数据的模型的性能,看看是否能取得进一步的收益也可能会很有趣。
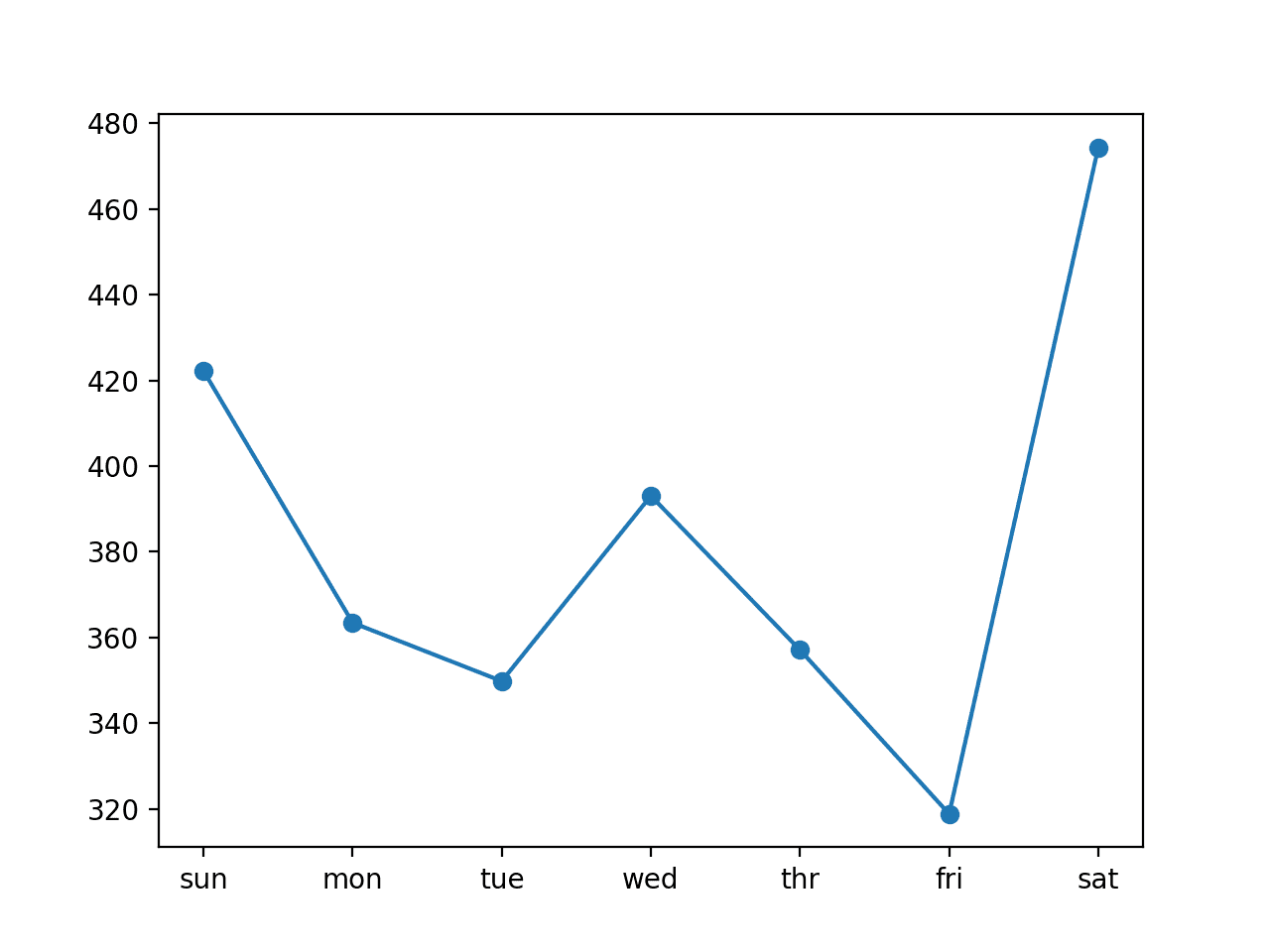
14天输入的通道CNN的每日RMSE折线图
使用多头 CNN 进行多步时间序列预测
我们可以进一步扩展CNN模型,为每个输入变量设置一个单独的子CNN模型或头部,我们可以将其称为多头CNN模型。
这需要修改模型的准备,进而修改训练和测试数据集的准备。
从模型开始,我们必须为八个输入变量中的每一个定义一个单独的CNN模型。
模型的配置,包括层数及其超参数,也进行了修改,以更好地适应新方法。新配置不是最优的,是通过一些反复试验找到的。
多头模型是使用更灵活的用于定义Keras模型的函数式API指定的。
我们可以遍历每个变量并创建一个子模型,该子模型接受一个14天数据的一维序列,并输出一个包含从序列中学习到的特征摘要的扁平向量。这些向量中的每一个都可以通过连接合并,形成一个非常长的向量,然后由一些全连接层解释,最后进行预测。
当我们构建子模型时,我们会在列表中跟踪输入层和扁平层。这样我们就可以在模型对象的定义中指定输入,并在合并层中使用扁平层列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 为每个变量创建一个通道 in_layers, out_layers = list(), list() for i in range(n_features): inputs = Input(shape=(n_timesteps,1)) conv1 = Conv1D(filters=32, kernel_size=3, activation='relu')(inputs) conv2 = Conv1D(filters=32, kernel_size=3, activation='relu')(conv1) pool1 = MaxPooling1D(pool_size=2)(conv2) flat = Flatten()(pool1) # 存储层 in_layers.append(inputs) out_layers.append(flat) # 合并头部 merged = concatenate(out_layers) # 解释 dense1 = Dense(200, activation='relu')(merged) dense2 = Dense(100, activation='relu')(dense1) outputs = Dense(n_outputs)(dense2) model = Model(inputs=in_layers, outputs=outputs) # 编译模型 model.compile(loss='mse', optimizer='adam') |
当模型被使用时,它将需要八个数组作为输入:每个子模型一个。
在训练模型、评估模型和使用最终模型进行预测时,这是必需的。
我们可以通过创建3D数组列表来实现这一点,其中每个3D数组包含[样本数,时间步长,1],具有一个特征。
我们可以按以下格式准备训练数据集
|
1 |
input_data = [train_x[:,:,i].reshape((train_x.shape[0],n_timesteps,1)) for i in range(n_features)] |
下面列出了经过这些更改的更新后的build_model()函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# 训练模型 def build_model(train, n_input): # 准备数据 train_x, train_y = to_supervised(train, n_input) # 定义参数 verbose, epochs, batch_size = 0, 25, 16 n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1] # 为每个变量创建一个通道 in_layers, out_layers = list(), list() for i in range(n_features): inputs = Input(shape=(n_timesteps,1)) conv1 = Conv1D(filters=32, kernel_size=3, activation='relu')(inputs) conv2 = Conv1D(filters=32, kernel_size=3, activation='relu')(conv1) pool1 = MaxPooling1D(pool_size=2)(conv2) flat = Flatten()(pool1) # 存储层 in_layers.append(inputs) out_layers.append(flat) # 合并头部 merged = concatenate(out_layers) # 解释 dense1 = Dense(200, activation='relu')(merged) dense2 = Dense(100, activation='relu')(dense1) outputs = Dense(n_outputs)(dense2) model = Model(inputs=in_layers, outputs=outputs) # 编译模型 model.compile(loss='mse', optimizer='adam') # 绘制模型 plot_model(model, show_shapes=True, to_file='multiheaded_cnn.png') # 拟合网络 input_data = [train_x[:,:,i].reshape((train_x.shape[0],n_timesteps,1)) for i in range(n_features)] model.fit(input_data, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose) return model |
模型构建完成后,将创建模型结构图并保存到文件中。
注意:调用plot_model()需要安装pygraphviz和pydot。如果这有问题,您可以注释掉此行。
网络结构如下所示。
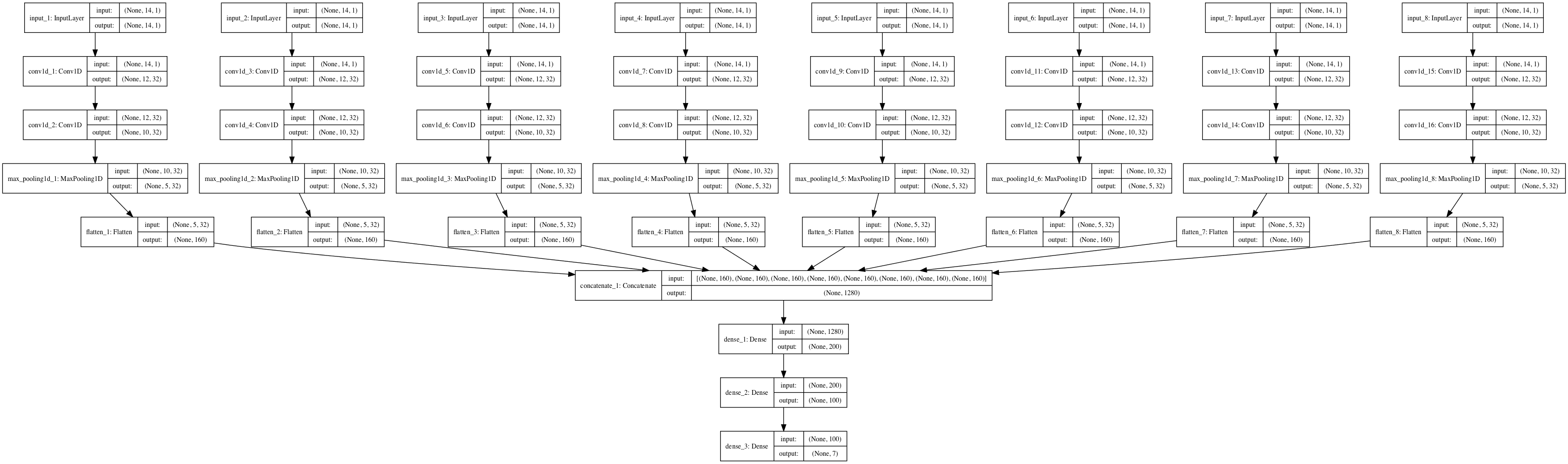
多头卷积神经网络的结构
接下来,我们可以更新在对测试数据集进行预测时输入样本的准备。
我们必须执行相同的更改,其中[1, 14, 8]的输入数组必须转换为包含八个3D数组的列表,每个数组为[1, 14, 1]。
|
1 |
input_x = [input_x[:,i].reshape((1,input_x.shape[0],1)) for i in range(input_x.shape[1])] |
下面列出了经过此更改的forecast()函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 进行预测 def forecast(model, history, n_input): # 展平数据 data = array(history) data = data.reshape((data.shape[0]*data.shape[1], data.shape[2])) # 检索输入数据的最新观测值 input_x = data[-n_input:, :] # 重塑为n个输入数组 input_x = [input_x[:,i].reshape((1,input_x.shape[0],1)) for i in range(input_x.shape[1])] # 预测下一周 yhat = model.predict(input_x, verbose=0) # 我们只想要向量预测 yhat = yhat[0] return yhat |
就是这样。
我们可以将所有这些结合起来;完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 |
# 多头多步CNN from math import sqrt from numpy import split from numpy import array from pandas import read_csv from sklearn.metrics import mean_squared_error from matplotlib import pyplot from keras.models import Sequential from keras.layers import Dense from keras.layers import Flatten from keras.layers.convolutional import Conv1D from keras.layers.convolutional import MaxPooling1D from keras.models import Model from keras.layers import Input from keras.layers.merge import concatenate # 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test # 针对期望值评估一个或多个每周预测 def evaluate_forecasts(actual, predicted): scores = list() # 计算每一天的 RMSE 分数 for i in range(actual.shape[1]): # 计算 mse mse = mean_squared_error(actual[:, i], predicted[:, i]) # 计算 rmse rmse = sqrt(mse) # 存储 scores.append(rmse) # 计算整体 RMSE s = 0 for row in range(actual.shape[0]): for col in range(actual.shape[1]): s += (actual[row, col] - predicted[row, col])**2 score = sqrt(s / (actual.shape[0] * actual.shape[1])) return score, scores # 总结得分 def summarize_scores(name, score, scores): s_scores = ', '.join(['%.1f' % s for s in scores]) print('%s: [%.3f] %s' % (name, score, s_scores)) # 将历史数据转换为输入和输出 def to_supervised(train, n_input, n_out=7): # 展平数据 data = train.reshape((train.shape[0]*train.shape[1], train.shape[2])) X, y = list(), list() in_start = 0 # 遍历整个历史记录,每次一个时间步长 for _ in range(len(data)): # 定义输入序列的结束位置 in_end = in_start + n_input out_end = in_end + n_out # 确保此实例有足够的数据 if out_end <= len(data): X.append(data[in_start:in_end, :]) y.append(data[in_end:out_end, 0]) # 前进一步 in_start += 1 return array(X), array(y) # 绘制训练历史 def plot_history(history): # 绘制损失 pyplot.subplot(2, 1, 1) pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.title('loss', y=0, loc='center') pyplot.legend() # 绘制rmse pyplot.subplot(2, 1, 2) pyplot.plot(history.history['rmse'], label='train') pyplot.plot(history.history['val_rmse'], label='test') pyplot.title('rmse', y=0, loc='center') pyplot.legend() pyplot.show() # 训练模型 def build_model(train, n_input): # 准备数据 train_x, train_y = to_supervised(train, n_input) # 定义参数 verbose, epochs, batch_size = 0, 25, 16 n_timesteps, n_features, n_outputs = train_x.shape[1], train_x.shape[2], train_y.shape[1] # 为每个变量创建一个通道 in_layers, out_layers = list(), list() for i in range(n_features): inputs = Input(shape=(n_timesteps,1)) conv1 = Conv1D(filters=32, kernel_size=3, activation='relu')(inputs) conv2 = Conv1D(filters=32, kernel_size=3, activation='relu')(conv1) pool1 = MaxPooling1D(pool_size=2)(conv2) flat = Flatten()(pool1) # 存储层 in_layers.append(inputs) out_layers.append(flat) # 合并头部 merged = concatenate(out_layers) # 解释 dense1 = Dense(200, activation='relu')(merged) dense2 = Dense(100, activation='relu')(dense1) outputs = Dense(n_outputs)(dense2) model = Model(inputs=in_layers, outputs=outputs) # 编译模型 model.compile(loss='mse', optimizer='adam') # 拟合网络 input_data = [train_x[:,:,i].reshape((train_x.shape[0],n_timesteps,1)) for i in range(n_features)] model.fit(input_data, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose) return model # 进行预测 def forecast(model, history, n_input): # 展平数据 data = array(history) data = data.reshape((data.shape[0]*data.shape[1], data.shape[2])) # 检索输入数据的最新观测值 input_x = data[-n_input:, :] # 重塑为n个输入数组 input_x = [input_x[:,i].reshape((1,input_x.shape[0],1)) for i in range(input_x.shape[1])] # 预测下一周 yhat = model.predict(input_x, verbose=0) # 我们只想要向量预测 yhat = yhat[0] return yhat # 评估单个模型 def evaluate_model(train, test, n_input): # 拟合模型 model = build_model(train, n_input) # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = forecast(model, history, n_input) # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) # 评估每周的预测天数 predictions = array(predictions) score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores # 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 分割成训练集和测试集 train, test = split_dataset(dataset.values) # 评估模型并获取分数 n_input = 14 score, scores = evaluate_model(train, test, n_input) # 总结得分 summarize_scores('cnn', score, scores) # 绘制分数 days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat'] pyplot.plot(days, scores, marker='o', label='cnn') pyplot.show() |
运行示例拟合并评估模型,打印出所有七天的总体 RMSE,以及每个预测提前期的每日 RMSE。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,在这种情况下,与朴素预测相比,总体RMSE表现出色,但根据所选配置,其性能可能不如上一节中的多通道模型。
|
1 |
CNN:[396.116] 414.5, 385.5, 377.2, 412.1, 371.1, 380.6, 428.1 |
我们还可以看到每日RMSE分数有不同的、更明显的分布,其中周一至周二和周四至周五对于模型来说可能比其他预测日更容易预测。
这些结果与另一个预测模型结合使用时可能会很有用。
探索在架构中合并每个子模型输出的替代方法可能会很有趣。
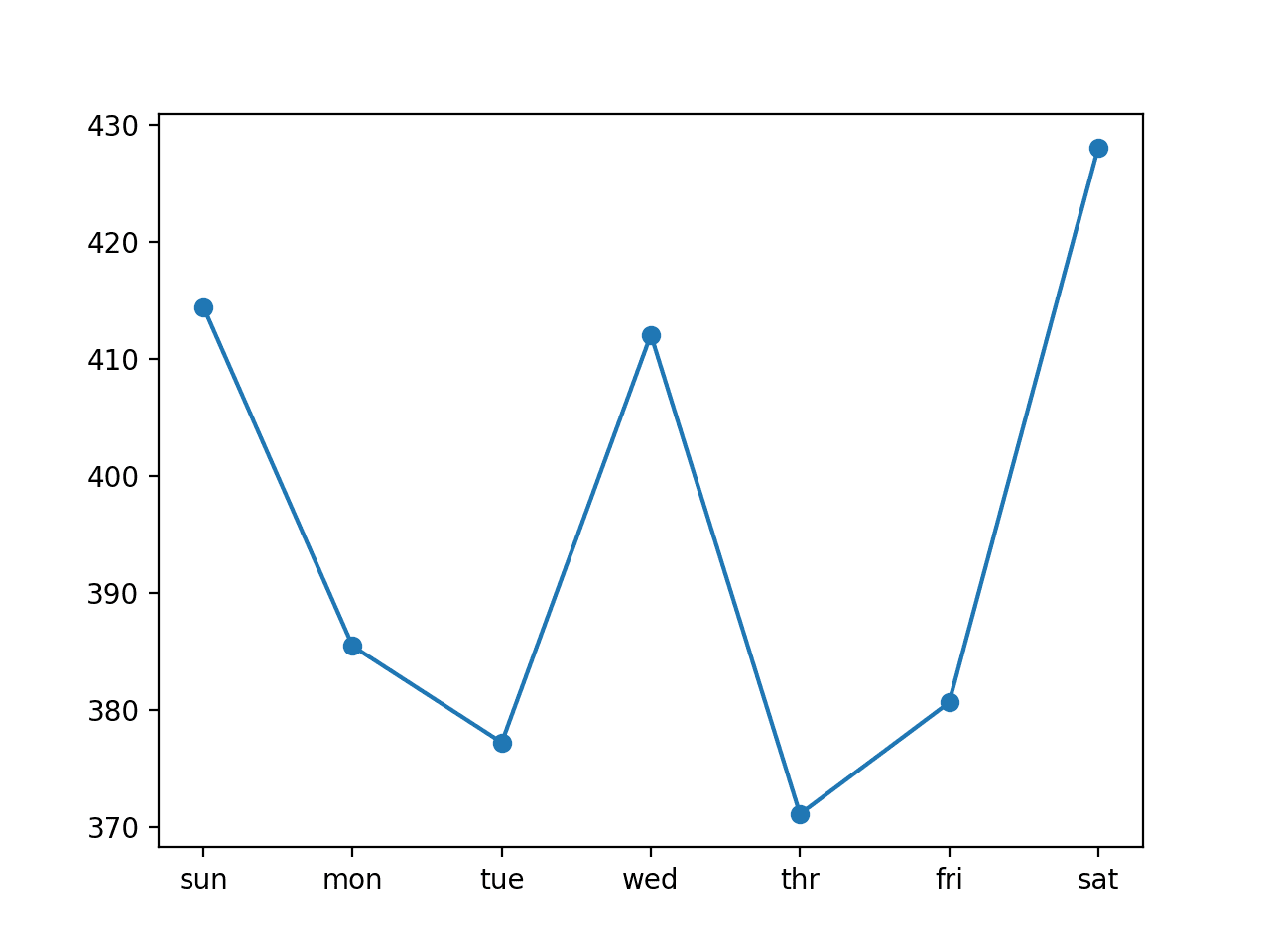
具有14天输入的多头CNN的每日RMSE折线图
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- **输入大小**。探索模型输入的更多或更少天数,例如3天、21天、30天或更多。
- **模型调优**。调整模型的结构和超参数,并平均提升模型性能。
- **数据缩放**。探索是否可以使用数据缩放(例如标准化和归一化)来提高任何CNN模型的性能。
- **学习诊断**。使用诸如训练和验证损失以及均方误差的学习曲线等诊断方法,以帮助调整CNN模型的结构和超参数。
- **变化内核大小**。将多通道CNN与多头CNN结合,并为每个头部使用不同的内核大小,以查看此配置是否可以进一步提高性能。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
- pandas.read_csv API
- pandas.DataFrame.resample API
- 重采样偏移别名
- sklearn.metrics.mean_squared_error API
- numpy.split API
文章
总结
在本教程中,您学习了如何开发用于多步时间序列预测的一维卷积神经网络。
具体来说,你学到了:
- 如何开发用于单变量数据多步时间序列预测的 CNN 模型。
- 如何开发用于多变量数据多通道多步时间序列预测模型。
- 如何开发用于多变量数据多头多步时间序列预测模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






你好Jason,感谢你的教程。一个简单的问题:对于最后一个完整的代码,如何使预测固定/可重现?我尝试了“from numpy.random import seed”“seed(1)”,但是运行两次时分数仍然不同。
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/what-value-should-i-set-for-the-random-number-seed
很棒的文章——感谢您的代码示例。我真的很喜欢看您的作品,因为我正在努力学习ML/DL。问题是——如果我想单独预测所有变量而不是一个总的每日功耗,该怎么办?
先谢谢您了。
这将是一个多步多变量问题。我在书中展示了如何解决。
我建议将其视为一个seq2seq问题,并预测输出序列中每一步的n个变量。一个带有CNN或LSTM输入模型的编码器-解码器模型将是合适的。
感谢您的回复,Jason。您指的是哪本书?
这本书
https://machinelearning.org.cn/deep-learning-for-time-series-forecasting/
你好。当你通过重叠数据来增加训练示例的数量时,你不会冒模型过拟合的风险吗?你实际上是在多次给模型提供相同的数据。
有可能,这就是我们如此依赖模型验证方法的原因。
请教我们capsnet。
感谢您的建议。
你为什么想使用胶囊网络?对我来说它们似乎很边缘化。
谢谢——我已经购买了你的电子书。
谢谢你的支持,吉姆。
对于多通道模型(使用8个输入,2个卷积层池化,1个卷积和池化),当使用n_input = 7时,实际上会收到错误。您有什么想法吗?
错误实际上是
负维度大小,原因是“conv1d_55/convolution/Conv2D”(操作:“Conv2D”)从1中减去3,输入形状为:[?,1,1,32],[1,3,32,16]。
也许模型的配置需要与输入的变化协调一致地进行更改?
你好,kim和Josom。当使用模型和n_input = 7时,我遇到了同样的问题,你们是如何解决的?
“负维度大小,原因是‘conv1d_55/convolution/Conv2D’(操作:‘Conv2D’)从1中减去3,输入形状为:[?,1,1,32],[1,3,32,16]。”
谢谢Jason,我相信特征图对层来说太小了,导致了错误。
另外,需要注意的是,我的多通道模型表现不如您的示例。(随机的)。然而,它实际上比n_input = 21的单变量模型表现更差!
有意思。
嗨,Jason,
首先祝贺并非常感谢您的教程!我有一些问题
在第一个使用单变量CNN的evaluate_model函数中,您写了“history = [x for x in train]”。为什么?不应该是“history = [x for x in test]”吗,因为我们想要评估模型?
如果我也将to_supervised函数用于测试集,然后按如下方式进行预测
test_x, test_y = array(X), array(y)
# 预测下一周
yhat = model.predict(test_x, verbose=0)
…………
………..
score, scores = evaluate_forecasts(test_y, yhat)
这样对吗?
谢谢
Andrea
是的,但是我们需要测试集的第一次预测的输入,这会/可能来自训练集的末尾。
谢谢回复!
嗨,杰森!如何下载“household_power_consumption.zip”?
因为我点击后,网站无法打开。
链接对我有效。
这是第二个下载位置
https://raw.githubusercontent.com/jbrownlee/Datasets/master/household_power_consumption.zip
嗨,Jason,
据我理解,歌曲分类是时间序列数据的一种情况,对吗?你能写一个关于这个话题的文章吗?
谢谢你
感谢您的建议。
嗨,杰森,一如既往的精彩教程!我有一个关于多头CNN的问题,使用不同的CNN架构而不是使用相同的架构会是个好主意吗?
谢谢你
Madriss
这真的取决于问题。也许可以尝试一下并比较结果。
嗨,Jason,
我注意到训练期间损失非常高。在某些任务中,损失必须接近0。
理想情况下是这样,但如果模型过拟合,这并不总是可能,甚至不总是可取的。
特征归一化后,损失接近0。
如果归一化特征,如何在步进验证中反转实际值和预测值的缩放?
我对此非常怀疑,尤其是本文中的CNN模型。
您能给我一些建议吗?
谢谢!
如果您使用sklearn进行标准化,它提供了`inverse_transform()`函数,可以将数据返回到原始尺度。
如果您手动进行缩放,您可以编写一个手动函数来反转转换。
也许这会有帮助。
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
嗨,Jason,感谢您的这些示例。您认为多通道CNN和多头CNN在多变量数据的使用结果上有什么区别吗?您对使用这两种不同方法有什么建议?
嗯,好问题。
两者都尝试一下,看看哪种适合你。我喜欢多头多通道,这样我就可以在相同的数据上使用不同的核大小——很像ResNet类型的设计。
嗨,Jason,您对多通道和多头方法何时会更好有什么建议吗?
我建议使用多通道,并将其与多头上的多通道进行比较,以允许使用不同的内核大小。
嗨 Jason
您能提供代码链接,说明如何将时间序列数据转换为图像形式以输入CNN吗?
以及如何转换为二维?
抱歉,我没有这方面的例子。
没有必要,一维CNN可以直接对数据进行操作,并且表现非常好!
我运行了你的两段代码,它报错了
“数组分割未导致相等划分”)
ValueError: 数组分割未导致相等划分
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
遇到了和Danial一样的错误..代码不起作用!
我可以确认所有示例都有效。
请确认您使用的是Python 3.6或更高版本,Keras 2.3和TensorFlow 2。
还请确认您精确复制了所有代码并从命令行运行了示例。
感谢您的本教程以及电子书版本。我试图将观测值与给定时间步长的预测值以日期为x轴绘制出来,但未能成功。您能在这方面提供帮助吗?谢谢!
抱歉,我没有能力审查和调试您的代码。
我有许多关于如何绘制时间序列的文章,也许可以从这里开始
https://machinelearning.org.cn/start-here/#timeseries
也许尝试将您的代码和错误发布到stackoverflow?
谢谢您的回复。也许我没说清楚,问题不是关于绘图本身,而是如何提取每个时间步的预测值,以便能够与观测值进行比较。(例如,仅仅提前1天的预测值)与测试集test[:, :, 0]进行比较。谢谢。
您可以使用model.predict()进行预测
我甚至在教程中为您提供了一个预测函数。
也许我仍然不明白您遇到的问题?
嗨,Jason,非常感谢您的教程。它对我帮助很大。我将此代码应用于我的数据(一段时间序列的速度数据),效果非常好。但是,我需要在相同的数据上运行Resnet,我用残差块替换了def 'build_model',但它不起作用。请问,我应该更改您的代码中的哪些部分才能拥有残差神经网络?如果您已经有示例,那就太好了。非常感谢您的支持。
也许你可以使用预训练模型
https://keras.org.cn/applications/#resnet50
感谢您的精彩教程!我想知道多变量通道方法是否适用于高维数据,例如,对于100个可能影响结果的变量?
是的,这可能有效。试一试看看?
我正在研究它,但我对您使用的“历史记录”感到困惑。我不明白为什么您不直接使用测试数据来预测y_hat_sequence。在我看来,您将测试集的样本i附加到历史记录中(前两个示例中的第117行),然后您预测历史记录的最后7天,即测试集的样本i。
请告诉我推理中的错误在哪里。
我正在使用步进验证,这是评估时间序列预测模型的首选方法。
你可以在这里了解更多
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
你好..我使用70/30的比例对我的数据进行CNN训练和测试,以预测。我如何预测未来几天或几小时的预测?我应该使用步进验证吗?
步进验证实际上只用于评估模型。
您可以使用所有可用数据拟合模型,并通过model.predict()进行预测。
你好 Jason,
我目前正在尝试使用单变量CNN进行多步时间序列预测,并且在批量大小和输入形状方面遇到了问题。
目前我的数据很少,30天的传感器测量数据,每天1440个时间步。我的目标是预测另一天,也就是另外1440个时间步。我使用的input_shape是(30, 1440, 1),所以在Conv1D层我将input_shape设置为(1440, 1)。
然后我基本上按照您的说明构建了网络的其余部分,以查看其工作原理,但在运行它时(无论批量大小是多少)都会出现错误。
我是否做错了什么显而易见的事情?
我应该使用不同的形状吗?
提前感谢您的时间和您之前非常有用的教程。如果这是一个过时的问题或超出了您的知识范围,请多多包涵。
以下是错误信息,以帮助您理解
—————————————————————————
ValueError 回溯 (最近一次调用)
in
16 # 拟合网络
17 #model.summary()
—> 18 model.fit(train, y_train, epochs=epochs, verbose=verbose, batch_size =2)
c:\users\hark\anaconda3\envs\tf\lib\site-packages\keras\engine\training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, **kwargs)
950 sample_weight=sample_weight,
951 class_weight=class_weight,
–> 952 batch_size=batch_size)
953 # Prepare validation data.
954 do_validation = False
c:\users\hark\anaconda3\envs\tf\lib\site-packages\keras\engine\training.py in _standardize_user_data(self, x, y, sample_weight, class_weight, check_array_lengths, batch_size)
787 feed_output_shapes,
788 check_batch_axis=False, # 不强制批量大小。
–> 789 exception_prefix=’target’)
790
791 # 根据`sample_weight`生成样本权重值
c:\users\hark\anaconda3\envs\tf\lib\site-packages\keras\engine\training_utils.py in standardize_input_data(data, names, shapes, check_batch_axis, exception_prefix)
126 ':预期' + names[i] + '有' +
127 str(len(shape)) + '维度,但得到了数组'
–> 128 '形状为' + str(data_shape))
129 如果没有check_batch_axis
130 data_shape = data_shape[1:]
ValueError:检查目标时出错:dense_45预期有2个维度,但得到了形状为(1440, 30, 1)的数组
错误提示数据形状与模型预期形状不匹配。
您可以重塑数据或更改模型的预期。
嗨,Jason,
我正在阅读您关于多变量、多步(例如20天回溯)时间序列预测使用LSTM神经网络的教程。
我想将LSTM的结果与这里的CNN结果进行比较。您介意解释一下如何使用该示例中重构的数据应用于此处的日常预测示例吗?
您可以使用相同结构的数据直接评估RNN和CNN。
嗨,Jason,
首先感谢您的文章和书籍!
我有一个问题(可能很愚蠢)。如果您只有每年几个月而不是12个月的数据怎么办?您在那个时间段内没有连续数据,或者我们只是假设您不关心所有月份(也许是季节性时间序列分析)。这个特定问题的数据是在2006年12月至2010年11月之间收集的,假设您只想研究每年(2007、2008、2009、2010)的4月至7月。第一种方法是每年作为一个不同的问题,并为每个问题创建一个模型(或使用相同的模型)并比较结果。我想有办法“组合”这种类型的数据并一起使用每年的数据。我假设我们不能简单地“堆叠”数据,即2007年7月之后不能直接连接2008年4月,因为7月的值可能对预测4月的值没有用。
您有什么建议吗?(很抱歉如果您在其他帖子中已经解决了这个问题,如果是,请告诉我具体是哪一个)
谢谢 🙂
用您拥有的数据建模,并将其结果与朴素方法进行比较,看看您是否可以开发一个具有技能的模型。
谢谢回复。我不明白你说的“用我拥有的建模”是什么意思。
如果我有来自y个不同年份(假设3个月)的x个月的数据,我假设我有3个时间序列。每个时间序列都是从这些x个月中收集的数据,对应于每一年。
有没有办法将这些时间序列组合成一个数据集?或者完全没有意义将它们组合起来?
如果只对夏季几个月的电力消耗感兴趣,并且想使用多年数据,那该怎么办?
或者,如果您只获得某些年份期间的数据,而不是12个月的数据,那该怎么办?
是的,如果这3年是连续的并且观察到相同的特征,那么它就是一个跨越3年的时间序列。
您可以按照自己的意愿构建问题,我鼓励您发挥创造力。
例如,您可以开发一个模型只预测感兴趣的时间间隔,或者开发一个通用模型并将其应用于感兴趣的时间间隔,等等。测试几种方法,找出最适合您需求的方法。
嗨,Jason,
感谢关于时间序列的精彩文章。我想知道在步骤不是连续时间的情况下,您将如何处理多步时间序列。例如,一个序列可以是7天前的值1、25天前的值2、33天前的值3,用于预测90天前的值4。然后是2天前的值1、5天前的值2、7天前的值3,用于预测20天前的值4,等等。时间应该作为一个特征并行读取(有点像2D图像),还是应该有2个并行CONV1D网络在后期步骤进行池化?感谢您的意见。
是的,您可以尝试直接建模作为第一步,然后尝试使用零填充使间隔均匀,并使用掩码层跳过填充(对于LSTM模型)。
有趣,谢谢Jason。
嗨,Jason,
我成功地将您的方法应用于我的项目,感谢您的教程。
但我想知道在生产环境中训练新数据需要多长时间,我如何减少处理时间?在我的案例中,使用GPU训练时间约为30分钟。任何指点都会不胜感激。
您可以减少训练数据量,使用较小的模型,或者使用更快的机器。
嗨,Jason,
我有两个问题
1. 我认为这里的Y是家庭消耗的总有功功率(千瓦),对吗?那么在这个代码片段中,Y应该是0 ->> y.append(data[in_end:out_end, 0])。如果Y在最后一列,那会是-1吗?
2. 我有兴趣在一个图表中比较给定时间步长预测的预测值和实际值。您能告诉我怎么做吗?
在这种情况下,我们正在处理单变量时间序列,正如标题“使用单变量CNN进行多步时间序列预测”所述。只会有一个特征。
是的,您可以使用已拟合的模型进行预测,例如model.predict(),并将输出与预期值进行比较。
对于实际值与预测结果的图表,这在您的电子书《时间序列多变量多步预测》中有所介绍吗?
没有,但这些更具介绍性的教程中可能有所涉及
https://machinelearning.org.cn/start-here/#timeseries
例如这个
https://machinelearning.org.cn/time-series-data-visualization-with-python/
我是机器学习新手,如果我问了一些愚蠢的问题,请见谅 🙂
澄清一下,我正在构建一个用于多变量(15个)特征的模型,Y位于最后一列(索引15)。我按照您的建议尝试了以下代码
if out_end <= len(data)
X.append(data[in_start:in_end, :])
y.append(data[in_end:out_end, -1])
我这样做对吗?
使用RNN和CNN处理时间序列比其他模型更复杂。我建议您先阅读此内容
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
嗨,Jason
我有一个快速问题,为什么你在拆分数据时,train使用data[1:-328],test使用[-328:-6]?
将数据分成7天一周。
嗨
抱歉一直问,但我无法理解数字1 -328 和 -328及 -6 从何而来
谢谢你
劳拉
没问题,劳拉。
我们有很多行数据,但本教程中我们希望处理从某一天开始到某一天结束(周日-周六,或周一-周日等)的一致的周。
数据没有这种结构,所以我们剪掉一行开头和一些行结尾,以确保我们有这种结构——这样我们只有完整的周。
我们还将这些一致的周数据分成训练集和测试集。
这些数字指的是数据中的行数。
如果数组索引和切片/范围对您来说是新的,请参阅此文章
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
你好,Jason。
非常感谢您的巨大努力和教程。我从您的教程中学到了很多。
我想预测电价,我只有电价的时间序列和电力负荷的时间序列。例如,我有1000天的电价和负荷数据。但是我想在不提交任何X值的情况下预测未来14天的电价。例如,如果我不知道未来任何相关值(x_values)的值,我如何预测第1001天、第1002天、第1003天、……、第1014天的电价?
在你的“forecast()”函数中,你写了这样的代码
yhat = pipeline.predict(x_input)[0]
但是,如果我没有未来几天的任何x_input,我该怎么办。我特别针对CNN,ANN,RNN(LSTM),直接或递归多步预测等提出了这个问题。
谢谢你的帮助。
您的大部分教程
专注于问题的框架,在预测时模型将有哪些输入,以及您从模型中需要什么来做一次预测。
一旦定义了这些,就准备好数据以匹配,然后拟合模型来完成它。
我拥有的数据是以秒为单位的,您使用了每周数据并相应地进行了拆分:train = array(split(train, len(train)/7))。请告诉我如何拆分我以秒为单位的数据。
您可以根据自己的意愿构建问题。我建议尝试几种不同的方法,看看哪种最适合您的特定数据集。
我的数据是以秒为单位的,这意味着它每秒都在变化,我应该使用多大的窗口大小???正如您将数据重构为每周时间框架一样……我如何重构我以秒为单位的数据……请帮助
你好,
数字465从何而来,以及如何构建“朴素预测”?
我们可以看到,在这种情况下,与朴素预测相比,该模型是有效的,总体 RMSE 约为 404 千瓦,低于朴素模型实现的 465 千瓦。
请看这个教程
https://machinelearning.org.cn/naive-methods-for-forecasting-household-electricity-consumption/
太棒了,明白了!
还有两件事
1. 如何为多步时间序列预测与多通道CNN示例绘制实际值与预测值的图?
2. 在哪里决定应该预测哪个特征。最后一层是model.add(Dense(N_OUTPUTS)),但N_OUTPUTS指的是要提前预测的时间步长吗?还是这个模型为每个特征(列)输出一个预测?
您可以使用matplitlib的plot()函数创建实际观测值的折线图,然后将预测值的图添加到同一图中。
输出层定义了要进行的预测数量。对于多个变量,您可以使用编码器-解码器,其中repeatvector层定义输出时间步长,模型的输出层定义特征。
谢谢,是的,如何绘图不是问题,问题更多的是“什么”。
在这个具体示例中:多步时间序列预测与多通道CNN,如何检索正确的值。在evaluate_forecasts函数中,有mse = mean_squared_error(actual[:, i], predicted[:, i]),但绘制actual或predicted会返回一个有多条线的图,这与我的预期不符!?
您能否用一个具体的例子/几行代码来回应,非常感谢。
附言
在evaluate_model函数中,history = [x for x in train]不应该是history = [x for x in test]吗?
是的,调用model.predict()来获取预测,博客上有很多例子,例如
https://machinelearning.org.cn/start-here/#deep_learning_time_series
我们必须用训练数据初始化历史记录,然后一次一个时间步地遍历测试数据。
谢谢你的回答,我想这里有一个误解,我还不清楚的是
当我这样做的时候
train_x, train_y = to_supervised(train, n_input)
然后
plt.plot(train_y [-10:])
结果看起来像这样
https://i.imgur.com/RyCmMJq.png
预期应该是一条单线,预测数组也一样!?
或许检查一下你要绘制的数据的形状?
我想你期待的是一个单变量序列,而得到的是一个多变量序列?
我明白了,如果其他人也遇到同样的情况,关键是预测数组的形状是(n_samples, n_timesteps, n_columns)。直接绘制它会得到上面显示的图片。
正确的方法是从每个预测中只提取一个时间步,像这样:predictions[:, -1],输入_X也一样。
现在的结果是一个漂亮的“实际值与预测值”图,重用了evaluate_model()中进行的计算,唯一的修改是让forecast()也返回x_input。
做得好,很高兴听到!
我如何确定要预测哪一列数据?我没有看到您给出预测全局_acitve_power的参数。我只看到它。扔掉一些数据,过滤,最大池化,扁平化,循环等等,然后输出结果。
同时,我对此仍有疑问
merged = concatenate(out_layers)
为什么要将其连接成一维数组?仅仅是为了格式化以便于后续输入吗?它们由七个不同的变量组成,所以可以不加区分地组合吗?
感谢您的阅读。我将一直等待您的回复
一般来说,也许可以使用这个框架
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
实际上,它通常是最右边的列。
每个变量都像一个单独的“通道”作用于一维CNN。这有帮助吗?
这篇文章改过吗?我以前没见过“多头卷积神经网络结构”图。这张图显示了从input_1到input_8的八个变量。然后进行conv1D、max_pooling、扁平化。然后将它们连接在一起,我们没有说明它们的关系。然后Dense到(None,7),我们要预测谁,这还没有解释,在最右边?那么我们原始数据的功能是什么?八个变量经历了相同的变化。为什么我们预测global_active_power而不是其他变量,比如电压。
抱歉我这么粗鲁,我只是为此快要疯了。有什么神经网络文章可以推荐吗?我想学更多。
它一直都在。
这是一个复杂的模型,可能对许多数据集没有意义。
这可能有助于理解多输入模型
https://machinelearning.org.cn/keras-functional-api-deep-learning/
我读了你推荐给我的框架,但我对这个网络还不太了解
这可能也有帮助,这是我产生这个想法的地方
https://machinelearning.org.cn/develop-n-gram-multichannel-convolutional-neural-network-sentiment-analysis/
嗨 Jason,
很棒的教程。我实现了一个与此架构类似的1D CNN,但我首先进行一阶差分和0到1之间的缩放,并使用relu。
——我的模型正在进行负面预测。你以前也遇到过类似的情况吗?我预测的是百分比,所以在反转归一化和一阶差分后不应该有负值。
——你有两个密集层。最后一个层具有输出的维度。你如何选择前一个密集层的神经元数量?
提前感谢,
是的,根据您的设计,它正在预测“差分值”。在输出节点中使用线性激活函数。
输出层中的节点数量与对一个样本进行的预测数量相匹配。
嗨,Jason,
您有没有示例展示如何在CNN中使用seq2seq进行多步时间序列?
上面的教程提供了一个使用1D CNN进行多步预测的例子。
嗨,Jason,
您认为我如何能让网络给出范围输出而不是点预测。我曾考虑使用softmax函数,但不确定它在这里会如何表现。
谢谢你
您可以使用回归模型集成来获取点预测的分布,称为预测区间。
嗨 Jason,
很棒的教程。但我有一个地方不明白:为什么“使用单变量CNN进行多步时间序列预测”这一章的结果是“使用7天输入的单变量CNN每天RMSE折线图”?我如何获得“单变量CNN每天有功功率预测折线图”?
您可以使用model.predict()进行单次预测。然后,给定预测数组,调用matplotlib的plot()函数来绘制预测图。
如果您对绘制时间序列不熟悉,请参阅此入门教程
https://machinelearning.org.cn/load-explore-time-series-data-python/
嗨,Jason,
又是我。您能解释一下Conv1D设置中filter和kernel_size的区别吗?filter和kernel_size在代码中是如何工作的?
根据您的设置(filter = 16,kernel_size=3),我得到了这个图:https://imgur.com/a/4MM310r(蓝色 - 预测,橙色 - 实际)。
我想改进我的预测模型,我需要改变哪个参数才能获得更好的结果?
没有提高性能的公式,相反,你必须使用系统性的实验来发现最有效的方法。
这里的建议会有所帮助
https://machinelearning.org.cn/start-here/#better
至于核的含义,请参阅此处
https://machinelearning.org.cn/convolutional-layers-for-deep-learning-neural-networks/
嗨,Json,
在我们得到平均RMSE和个体RMSE之后,例如,
cnn: [1300.269] 1308.5, 1300.8, 1305.1, 1296.6, 1307.7, 1290.3, 1292.7
n_input = 1000
split_rate = 0.70
kernel_size = 50
epochs = 450
batch_size = 100
我们如何计算模型准确率?
有没有具体的公式?
谢谢你
我们无法计算回归的准确性
https://machinelearning.org.cn/faq/single-faq/how-do-i-calculate-accuracy-for-regression
嗨,Json,
感谢您的回复。
我看到R-Squared可以衡量回归精度(但仅限于线性模型)。但这是一种非线性模型。
有没有方法可以说明模型的准确性。RMSE值足以说明模型预测事物的准确性吗?
请帮忙。
谢谢你。
您必须选择一个最能体现模型对您或您的项目利益相关者重要性的指标。
好的,杰森,谢谢你
不客气。
亲爱的 Jason,
感谢这本优秀的著作。
我刚刚读完,花了大约3.5周,我在这里写了书评
http://questioneurope.blogspot.com/2020/07/deep-learning-for-time-series.html
诚挚的问候,
Dominique
谢谢多米尼克,你取得了很好的进步!
嗨,Jason,
这种方法是否与也用于序列建模任务的时间卷积网络 (TCN) 相同?
我对TCN不熟悉,抱歉。它到底是什么?
我也不熟悉。我在一篇文章中看到,作者提到他将测试一个TCN,以改善通过RNN获得的结果。但谢谢你的回复!!
def split_dataset(data)
# 拆分为标准周
train, test = data[1:-328], data[-328:-6]
为什么train从[1:-328开始而不是[0:-328。
你为什么跳过第一个条目?
为了处理完整“周”的数据。
也许可以重新阅读描述我们如何分割数据的那一部分。
Hi Jason,是否可以进行二元多步预测?就像一个分类问题?
我对于最后一层应该有多少个神经元感到困惑,因为在您的示例中,最后一层有n_output个神经元。在分类问题中,如果我没记错,最后一层有类的数量(如果是二元的,则为2)。那么在二元多步预测中会是怎样呢?
提前感谢。希望我表达清楚了。
谢谢。祝您有美好的一天。
是的,它与数值多步预测相同,只是激活函数将是sigmoid而不是线性,损失函数将是二元交叉熵。
这真是金子般的财富。感谢分享。我将在这里尝试一些东西。
喜欢你的博客!
谢谢!
嗨,Jason,
感谢您提供此示例。
我一直在尝试在Jupyter库中复制代码,到目前为止,我遇到了每一步或每一行代码的错误。您能给我任何建议吗?我也是Python新手。
不客气。
我建议不要使用notebook——它们几乎给所有人带来了问题
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
嗨,Jason,
感谢您的建议,如果我们将“步进验证”(Walk-Forward Validation)用于回归目的,那么我们是否应该对预测的每一步(特征和目标)都进行训练集和验证集的缩放,因为当我们想使用inverse_transform()时,每一步的数据大小(指训练集)都会改变。
或者我们不应该在每一步都缩放数据;我认为调用全部数据(对训练集进行fit_transform,对测试集进行transform)并将其传递给每一步在逻辑上是错误的,不是吗?
我非常感谢您能提供的任何帮助。
不客气。
对输入和目标进行缩放通常是回归和时间序列预测的好主意。
你好 Jason。感谢您的这个教程,非常感谢。
我想知道;如果我想扩展您的教程并进行30天的预测,我需要改变/考虑什么?为什么?
也许您可以重构数据集,使其在一个样本中包含30个输出值,然后调整模型以进行此预测。
或者,您可以使用一种以递归方式预测几个时间步长的模型。
或许可以尝试几种方法,并找出哪种方法最适合您的特定数据集。
你好 Jason,
感谢这个精彩的教程。我想知道您是否能就使用深度学习进行能源分解提供一些指导。特别是,我手头有以下每天15分钟窗口的标记数据
总/聚合能源使用量
设备1能源使用量
设备2能源使用量
:
设备n能源使用量
其他/未知能源使用量。
因此,我每天有96行这样的数据,持续1年,涉及多个家庭。我想训练一个深度学习模型进行能源分解(即,给定一天15分钟的聚合能源测量值,预测每日设备使用量)。您会推荐本文中类似的方法来解决这个问题吗?我们可以在这个问题上使用CNN或RNN吗?
非常感谢。
我相信您可以尝试构建一个模型,看看它的准确性如何。每个数据集都不同,因此很难笼统地说一个模型是否有效。但是CNN应用于时间序列的本质是查看一个窗口,而RNN是一次一个时间步地扫描整个时间序列。思考模型的性质是否对您的数据或问题有意义。这将是一个很好的开始方式。
嗨,Jason,
关于我的问题,我的n_input =1, n_out=1, n_timesteps =1, n_features = 20。
我在def split_dataset(data)中“# split into standard weeks”之后立即使用了StandardScaler,像这样:train = scaler.fit_transform(train), test = scaler.transform(test)
然后,我在def evaluate_model(train, test, n_input)中对test和predictions都实现了scaler.inverse_transform,像这样:predictions=scaler.inverse_transform(predictions), test = scaler.inverse_transform(test)
我遇到了这样的挑战:“ValueError: shape (361,1)的不可广播输出操作数与广播形状(361,20)不匹配”
关于如何处理上述错误,有什么建议吗?
非常感谢!
你好,Jason!感谢您,这帮助太大了!我有一件事不明白,evaluate_forecasts(actual, predicted)中的actual是从哪里来的?我在该函数中实际遇到了形状问题,因为我使用的数据集形状是(x,y),而本教程的数据形状是(x,y,z)。为了更好地理解这个问题,我一直试图弄清楚实际的形状到底是什么,但我无法弄清楚它来自哪里。
任何见解都将不胜感激! 🙂
Hi Sarah…以下资源可能有助于解决重塑问题。本教程讨论了LSTM,但也适用于CNN。
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
更多背景信息:我正在使用一个包含月度数据的数据集,而且我没有像本教程那样将其分解成更大的块,即把每日数据转换为每周块。
你好 Jashon,
很高兴看到你的文章。
我是一个初学者,我正在谷歌 Colab 中运行相同的多步时间序列预测代码,数据也和你给的相同。但它持续显示错误“TypeError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/numpy/lib/shape_base.py in split(ary, indices_or_sections, axis)
866 try
–> 867 len(indices_or_sections)
868 except TypeError
TypeError: object of type ‘float’ has no len()”我无法解决,也找不到问题在哪里。请帮帮我。
在处理上述异常时,发生了另一个异常:
嗨 Vineet…非常欢迎!你是否可以在本地机器上安装Anaconda并尝试实现?
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/