Cycle Generative adversarial Network,简称CycleGAN,是一种用于将图像从一个域转换到另一个域的生成器模型。
例如,该模型可用于将马的图像转换为斑马的图像,或者将夜晚城市景观的照片转换为白天城市景观的照片。
CycleGAN模型的优势在于它可以无需配对样本进行训练。也就是说,它不需要配对的训练样本,例如翻译前后的照片,才能训练模型,例如同一城市景观白天和夜晚的照片。相反,它可以使用来自每个域的照片集,并提取和利用该集中图像的潜在风格来执行翻译。
该模型非常出色,但其架构对于初学者来说似乎相当复杂。
在本教程中,您将学习如何使用Keras深度学习框架从头开始实现CycleGAN架构。
完成本教程后,您将了解:
- 如何实现判别器和生成器模型。
- 如何定义复合模型,通过对抗损失和周期损失来训练生成器模型。
- 如何在每次训练迭代中实现训练过程来更新模型权重。
通过我的新书《Python生成对抗网络》启动您的项目,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。

如何使用Keras从头开始开发CycleGAN模型
照片由 anokarina 提供,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- CycleGAN架构是什么?
- 如何实现CycleGAN判别器模型
- 如何实现CycleGAN生成器模型
- 如何实现用于最小二乘损失和周期损失的复合模型
- 如何更新判别器和生成器模型
CycleGAN架构是什么?
CycleGAN模型由 Jun-Yan Zhu 等人在其2017年的论文“使用周期一致性对抗网络进行非配对图像到图像翻译”中进行了描述。
该模型架构由两个生成器模型组成:一个生成器(生成器-A)用于生成第一个域(域-A)的图像,第二个生成器(生成器-B)用于生成第二个域(域-B)的图像。
- 生成器-A -> 域-A
- 生成器-B -> 域-B
生成器模型执行图像翻译,这意味着图像生成过程依赖于输入图像,特别是来自另一个域的图像。生成器-A以域-B的图像作为输入,生成器-B以域-A的图像作为输入。
- 域-B -> 生成器-A -> 域-A
- 域-A -> 生成器-B -> 域-B
每个生成器都有一个相应的判别器模型。
第一个判别器模型(判别器-A)接收来自域-A的真实图像和来自生成器-A的生成图像,并预测它们是真实的还是伪造的。第二个判别器模型(判别器-B)接收来自域-B的真实图像和来自生成器-B的生成图像,并预测它们是真实的还是伪造的。
- 域-A -> 判别器-A -> [真实/伪造]
- 域-B -> 生成器-A -> 判别器-A -> [真实/伪造]
- 域-B -> 判别器-B -> [真实/伪造]
- 域-A -> 生成器-B -> 判别器-B -> [真实/伪造]
判别器和生成器模型以类似于普通GAN模型的对抗性零和过程进行训练。
生成器学会更好地欺骗判别器,判别器学会更好地检测伪造图像。在训练过程中,模型共同寻找一个平衡点。
此外,生成器模型不仅通过正则化来生成目标域中的新图像,还生成源域输入图像的翻译版本。这是通过将生成图像作为相应生成器模型的输入,并将输出图像与原始图像进行比较来实现的。
将图像通过两个生成器称为一个周期。每对生成器模型都会被训练以更好地重现原始源图像,这被称为周期一致性。
- 域-B -> 生成器-A -> 域-A -> 生成器-B -> 域-B
- 域-A -> 生成器-B -> 域-B -> 生成器-A -> 域-A
架构还有一个额外的元素,称为身份映射。
这是将生成器提供目标域的图像作为输入,并期望生成相同的图像而不做任何更改。此架构的添加是可选的,但可以更好地匹配输入图像的颜色配置文件。
- 域-A -> 生成器-A -> 域-A
- 域-B -> 生成器-B -> 域-B
既然我们已经熟悉了模型架构,我们可以分别详细了解每个模型以及如何实现它们。
该论文对模型和训练过程提供了很好的描述,尽管官方的Torch实现被用作每个模型和训练过程的最终描述,并为下面描述的模型实现提供了基础。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何实现CycleGAN判别器模型
判别器模型负责接收真实或生成的图像作为输入,并预测它是真实的还是伪造的。
判别器模型被实现为PatchGAN模型。
对于判别器网络,我们使用70x70的PatchGAN,它旨在分类70x70的重叠图像块是真实的还是伪造的。
——《使用循环一致性对抗网络进行非配对图像到图像转换》,2017年。
PatchGAN在2016年的论文“使用马尔可夫生成对抗网络进行预计算的实时纹理合成”中进行了描述,并在2016年的论文“条件对抗网络的图像到图像翻译”中描述的pix2pix模型中用于图像翻译。
该架构通过平均源图像中NxN方块或图像块的预测,将输入图像判别为真实或伪造。
…我们设计了一个判别器架构——我们称之为PatchGAN——它只对图像块的尺度进行惩罚。这个判别器试图分类图像中的每个NxN图像块是真实的还是伪造的。我们将这个判别器卷积地应用到图像上,平均所有响应来提供D的最终输出。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
这可以通过直接使用一个相当标准的深度卷积判别器模型来实现。
与传统的判别器模型输出单个值不同,PatchGAN判别器模型可以输出一个方形的或单通道的预测特征图。70x70指的是模型在输入上的有效感受野,而不是输出特征图的实际形状。
卷积层的感受野是指该层的一个输出在输入层映射到的像素数量。有效感受野是指深度卷积模型(多层)的一个输出在输入图像上的映射。在这里,PatchGAN是一种基于有效感受野的深度卷积网络设计方法,其中模型的一个输出激活映射到输入图像的70x70图像块,而与输入图像的大小无关。
PatchGAN的效果是预测输入图像中的每个70x70图像块是真实的还是伪造的。然后,可以将这些预测进行平均以获得模型的输出(如果需要),或者直接与一个矩阵(或展平后的向量)进行比较,该矩阵包含期望值(例如,0或1值)。
论文中描述的判别器模型以256x256的彩色图像作为输入,并定义了一个在所有测试问题上使用的显式架构。该架构使用Conv2D-InstanceNorm-LeakyReLU层块,具有4x4滤波器和2x2步长。
令Ck表示一个具有k个滤波器的4x4卷积-实例归一化-LeakyReLU层,步长为2。在最后一层之后,我们应用一个卷积来产生一个一维输出。我们不对第一个C64层使用实例归一化。我们使用斜率为0.2的Leaky ReLU。
——《使用循环一致性对抗网络进行非配对图像到图像转换》,2017年。
判别器的架构如下:
- C64-C128-C256-C512
在CycleGAN和Pix2Pix的术语中,这被称为一个3层PatchGAN,因为排除第一隐藏层,模型有三个隐藏层,可以根据需要缩放大小以获得不同大小的PatchGAN模型。
论文中未列出的是,模型还有一个最终隐藏层C512,步长为1x1,以及一个输出层C1,也具有1x1步长和线性激活函数。考虑到模型主要用于256x256大小的图像输入,激活输出特征图的大小为16x16。如果使用128x128大小的图像作为输入,则激活输出特征图的大小为8x8。
模型不使用批量归一化;而是使用实例归一化。
实例归一化是在2016年的论文“实例归一化:快速风格化缺失的成分”中描述的。它是一种非常简单的归一化类型,涉及对每个特征图上的值进行标准化(例如,缩放到标准高斯分布)。
目的是在图像生成过程中去除图像特定的对比度信息,从而生成更好的图像。
关键思想是用实例归一化层替换生成器架构中的批量归一化层,并在测试时保留它们(而不是像批量归一化那样冻结并简化它们)。直观地说,归一化过程可以去除内容图像中实例特定的对比度信息,从而简化生成。实际上,这可以大大改善图像。
— 实例归一化:快速风格化缺失的成分,2016。
虽然它为生成器模型设计,但它在判别器模型中也可能有效。
实例归一化的实现包含在keras-contrib项目中,该项目提供社区提供的Keras功能的早期访问。
可以使用pip按以下方式安装keras-contrib库:
|
1 |
sudo pip install git+https://www.github.com/keras-team/keras-contrib.git |
或者,如果您使用的是Anaconda虚拟环境,例如在EC2上
|
1 2 3 |
git clone https://www.github.com/keras-team/keras-contrib.git cd keras-contrib sudo ~/anaconda3/envs/tensorflow_p36/bin/python setup.py install |
然后可以如下使用新的InstanceNormalization层:
|
1 2 3 4 5 |
... from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization # 定义层 layer = InstanceNormalization(axis=-1) ... |
“axis”参数设置为-1,以确保每个特征图的特征都经过归一化。
网络权重初始化为标准差为0.02的高斯随机数,这与DCGANs的一般描述一致。
权重从高斯分布 N (0, 0.02) 初始化。
——《使用循环一致性对抗网络进行非配对图像到图像转换》,2017年。
判别器模型使用最小二乘损失(L2)进行更新,即所谓的最小二乘生成对抗网络,或LSGAN。
…我们用最小二乘损失替换了负对数似然目标。该损失在训练过程中更稳定,并且产生更高质量的结果。
——《使用循环一致性对抗网络进行非配对图像到图像转换》,2017年。
这可以通过计算真实图像类=1和伪造图像类=0的目标值之间的“均方误差”来实现。
此外,论文建议在训练期间将判别器的损失除以二,以减缓判别器相对于生成器的更新速度。
实际上,我们在优化D时将目标除以2,这减慢了D的学习速度,相对于G的学习速度。
——《使用循环一致性对抗网络进行非配对图像到图像转换》,2017年。
这可以通过在编译模型时将“loss_weights”参数设置为0.5来实现。请注意,此权重似乎并未在官方Torch实现中更新判别器模型时在fDx_basic()函数中实现。
我们可以通过下面的示例将所有这些内容整合起来,定义一个define_discriminator()函数来定义PatchGAN判别器。模型配置与论文附录中的描述相匹配,并包含来自官方Torch实现的附加细节,这些细节在defineD_n_layers()函数中定义。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
# 定义一个70x70 patchgan判别器模型的示例 from keras.optimizers import Adam from keras.initializers import RandomNormal from keras.models import Model from keras.models import Input 从 keras.layers 导入 Conv2D from keras.layers import LeakyReLU from keras.layers import Activation from keras.layers import Concatenate 从 keras.层 导入 BatchNormalization from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization from keras.utils.vis_utils import plot_model # 定义判别器模型 def define_discriminator(image_shape): # 权重初始化 init = RandomNormal(stddev=0.02) # 源图像输入 in_image = Input(shape=image_shape) # C64 d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(in_image) d = LeakyReLU(alpha=0.2)(d) # C128 d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # C256 d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # C512 d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # 倒数第二层输出 d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # 补丁输出 patch_out = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d) # 定义模型 model = Model(in_image, patch_out) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.0002, beta_1=0.5), loss_weights=[0.5]) return model # 定义图像形状 image_shape = (256,256,3) # 创建模型 model = define_discriminator(image_shape) # 总结模型 model.summary() # 绘制模型 plot_model(model, to_file='discriminator_model_plot.png', show_shapes=True, show_layer_names=True) |
注意:plot_model()函数需要安装pydot和pygraphviz库。如果这有问题,您可以注释掉导入和对此函数的调用。
运行该示例将显示模型的摘要,显示每个层的输入和输出的大小。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= input_1 (InputLayer) (None, 256, 256, 3) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 128, 128, 64) 3136 _________________________________________________________________ leaky_re_lu_1 (LeakyReLU) (None, 128, 128, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 64, 64, 128) 131200 _________________________________________________________________ instance_normalization_1 (In (None, 64, 64, 128) 256 _________________________________________________________________ leaky_re_lu_2 (LeakyReLU) (None, 64, 64, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 32, 32, 256) 524544 _________________________________________________________________ instance_normalization_2 (In (None, 32, 32, 256) 512 _________________________________________________________________ leaky_re_lu_3 (LeakyReLU) (None, 32, 32, 256) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 16, 16, 512) 2097664 _________________________________________________________________ instance_normalization_3 (In (None, 16, 16, 512) 1024 _________________________________________________________________ leaky_re_lu_4 (LeakyReLU) (None, 16, 16, 512) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 16, 16, 512) 4194816 _________________________________________________________________ instance_normalization_4 (In (None, 16, 16, 512) 1024 _________________________________________________________________ leaky_re_lu_5 (LeakyReLU) (None, 16, 16, 512) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 16, 16, 1) 8193 ================================================================= Total params: 6,962,369 Trainable params: 6,962,369 不可训练参数: 0 _________________________________________________________________ |
模型架构的图也已创建,以帮助了解输入、输出以及图像数据在模型中的转换。
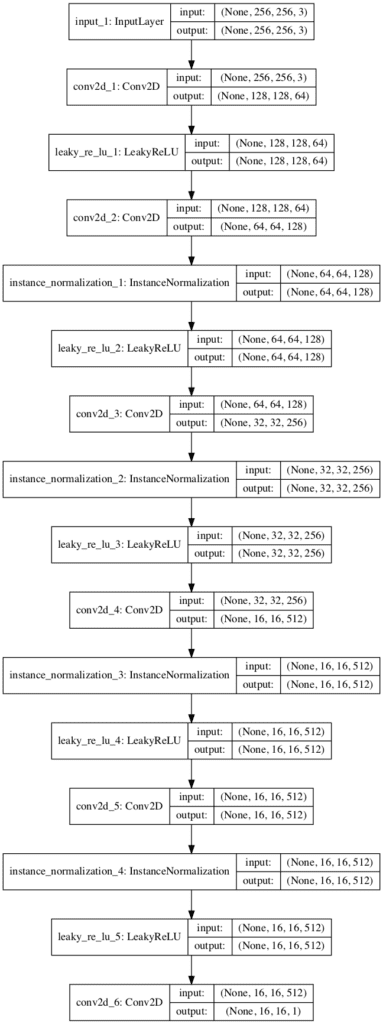
CycleGAN的PatchGAN判别器模型图
如何实现CycleGAN生成器模型
CycleGAN生成器模型接收图像作为输入并生成翻译后的图像作为输出。
该模型使用一系列下采样卷积块来编码输入图像,使用一些残差网络(ResNet)卷积块来转换图像,并使用一些上采样卷积块来生成输出图像。
令c7s1-k表示一个具有k个滤波器的7x7卷积-实例归一化-ReLU层,步长为1。dk表示一个具有k个滤波器的3x3卷积-实例归一化-ReLU层,步长为2。使用反射填充以减少伪影。Rk表示一个残差块,包含两个具有相同数量滤波器的3x3卷积层。uk表示一个具有k个滤波器的3x3分数步长卷积-实例归一化-ReLU层,步长为1/2。
——《使用循环一致性对抗网络进行非配对图像到图像转换》,2017年。
128x128图像的6-resnet块生成器的架构如下:
- c7s1-64,d128,d256,R256,R256,R256,R256,R256,R256,u128,u64,c7s1-3
首先,我们需要一个函数来定义残差块。这些块由两个3x3 CNN层组成,其中块的输入在通道上与块的输出连接。
这在resnet_block()函数中实现,该函数创建两个Conv-InstanceNorm块,具有3x3滤波器和1x1步长,并且在第二个块之后没有ReLU激活,这与官方Torch实现中的build_conv_block()函数相匹配。为简单起见,使用了相同填充而不是论文中推荐的反射填充。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 生成器A残差块 def resnet_block(n_filters, input_layer): # 权重初始化 init = RandomNormal(stddev=0.02) # 第一层卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(input_layer) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # 第二个卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) # 沿通道与输入层进行拼接合并 g = Concatenate()([g, input_layer]) return g |
接下来,我们可以定义一个函数来创建256x256输入图像的9-resnet块版本。通过将image_shape设置为(128x128x3)并将n_resnet函数参数设置为6,可以轻松将其更改为6-resnet块版本。
重要的是,模型输出的像素形状与输入相同,像素值在[-1, 1]范围内,这对于GAN生成器模型来说是典型的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 定义独立的生成器模型 def define_generator(image_shape=(256,256,3), n_resnet=9): # 权重初始化 init = RandomNormal(stddev=0.02) # 图像输入 in_image = Input(shape=image_shape) # c7s1-64 g = Conv2D(64, (7,7), padding='same', kernel_initializer=init)(in_image) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d128 g = Conv2D(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d256 g = Conv2D(256, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # R256 for _ in range(n_resnet): g = resnet_block(256, g) # u128 g = Conv2DTranspose(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # u64 g = Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # c7s1-3 g = Conv2D(3, (7,7), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) out_image = Activation('tanh')(g) # 定义模型 model = Model(in_image, out_image) return model |
生成器模型未被编译,因为它通过复合模型进行训练,该模型将在下一节中介绍。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
# CycleGAN的编码器-解码器生成器示例 from keras.optimizers import Adam from keras.models import Model from keras.models import Input 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import Activation from keras.initializers import RandomNormal from keras.layers import Concatenate from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization from keras.utils.vis_utils import plot_model # 生成器A残差块 def resnet_block(n_filters, input_layer): # 权重初始化 init = RandomNormal(stddev=0.02) # 第一层卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(input_layer) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # 第二个卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) # 沿通道与输入层进行拼接合并 g = Concatenate()([g, input_layer]) return g # 定义独立的生成器模型 def define_generator(image_shape=(256,256,3), n_resnet=9): # 权重初始化 init = RandomNormal(stddev=0.02) # 图像输入 in_image = Input(shape=image_shape) # c7s1-64 g = Conv2D(64, (7,7), padding='same', kernel_initializer=init)(in_image) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d128 g = Conv2D(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d256 g = Conv2D(256, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # R256 for _ in range(n_resnet): g = resnet_block(256, g) # u128 g = Conv2DTranspose(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # u64 g = Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # c7s1-3 g = Conv2D(3, (7,7), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) out_image = Activation('tanh')(g) # 定义模型 model = Model(in_image, out_image) return model # 创建模型 model = define_generator() # 总结模型 model.summary() # 绘制模型 plot_model(model, to_file='generator_model_plot.png', show_shapes=True, show_layer_names=True) |
运行示例首先总结了模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_1 (InputLayer) (None, 256, 256, 3) 0 __________________________________________________________________________________________________ conv2d_1 (Conv2D) (None, 256, 256, 64) 9472 input_1[0][0] __________________________________________________________________________________________________ instance_normalization_1 (Insta (None, 256, 256, 64) 128 conv2d_1[0][0] __________________________________________________________________________________________________ activation_1 (Activation) (None, 256, 256, 64) 0 instance_normalization_1[0][0] __________________________________________________________________________________________________ conv2d_2 (Conv2D) (None, 128, 128, 128 73856 activation_1[0][0] __________________________________________________________________________________________________ instance_normalization_2 (Insta (None, 128, 128, 128 256 conv2d_2[0][0] __________________________________________________________________________________________________ activation_2 (Activation) (None, 128, 128, 128 0 instance_normalization_2[0][0] __________________________________________________________________________________________________ conv2d_3 (Conv2D) (None, 64, 64, 256) 295168 activation_2[0][0] __________________________________________________________________________________________________ instance_normalization_3 (Insta (None, 64, 64, 256) 512 conv2d_3[0][0] __________________________________________________________________________________________________ activation_3 (Activation) (None, 64, 64, 256) 0 instance_normalization_3[0][0] __________________________________________________________________________________________________ conv2d_4 (Conv2D) (None, 64, 64, 256) 590080 activation_3[0][0] __________________________________________________________________________________________________ instance_normalization_4 (Insta (None, 64, 64, 256) 512 conv2d_4[0][0] __________________________________________________________________________________________________ activation_4 (Activation) (None, 64, 64, 256) 0 instance_normalization_4[0][0] __________________________________________________________________________________________________ conv2d_5 (Conv2D) (None, 64, 64, 256) 590080 activation_4[0][0] __________________________________________________________________________________________________ instance_normalization_5 (Insta (None, 64, 64, 256) 512 conv2d_5[0][0] __________________________________________________________________________________________________ concatenate_1 (Concatenate) (None, 64, 64, 512) 0 instance_normalization_5[0][0] activation_3[0][0] __________________________________________________________________________________________________ conv2d_6 (Conv2D) (None, 64, 64, 256) 1179904 concatenate_1[0][0] __________________________________________________________________________________________________ instance_normalization_6 (Insta (None, 64, 64, 256) 512 conv2d_6[0][0] __________________________________________________________________________________________________ activation_5 (Activation) (None, 64, 64, 256) 0 instance_normalization_6[0][0] __________________________________________________________________________________________________ conv2d_7 (Conv2D) (None, 64, 64, 256) 590080 activation_5[0][0] __________________________________________________________________________________________________ instance_normalization_7 (Insta (None, 64, 64, 256) 512 conv2d_7[0][0] __________________________________________________________________________________________________ concatenate_2 (Concatenate) (None, 64, 64, 768) 0 instance_normalization_7[0][0] concatenate_1[0][0] __________________________________________________________________________________________________ conv2d_8 (Conv2D) (None, 64, 64, 256) 1769728 concatenate_2[0][0] __________________________________________________________________________________________________ instance_normalization_8 (Insta (None, 64, 64, 256) 512 conv2d_8[0][0] __________________________________________________________________________________________________ activation_6 (Activation) (None, 64, 64, 256) 0 instance_normalization_8[0][0] __________________________________________________________________________________________________ conv2d_9 (Conv2D) (None, 64, 64, 256) 590080 activation_6[0][0] __________________________________________________________________________________________________ instance_normalization_9 (Insta (None, 64, 64, 256) 512 conv2d_9[0][0] __________________________________________________________________________________________________ concatenate_3 (Concatenate) (None, 64, 64, 1024) 0 instance_normalization_9[0][0] concatenate_2[0][0] __________________________________________________________________________________________________ conv2d_10 (Conv2D) (None, 64, 64, 256) 2359552 concatenate_3[0][0] __________________________________________________________________________________________________ instance_normalization_10 (Inst (None, 64, 64, 256) 512 conv2d_10[0][0] __________________________________________________________________________________________________ activation_7 (Activation) (None, 64, 64, 256) 0 instance_normalization_10[0][0] __________________________________________________________________________________________________ conv2d_11 (Conv2D) (None, 64, 64, 256) 590080 activation_7[0][0] __________________________________________________________________________________________________ instance_normalization_11 (Inst (None, 64, 64, 256) 512 conv2d_11[0][0] __________________________________________________________________________________________________ concatenate_4 (Concatenate) (None, 64, 64, 1280) 0 instance_normalization_11[0][0] concatenate_3[0][0] __________________________________________________________________________________________________ conv2d_12 (Conv2D) (None, 64, 64, 256) 2949376 concatenate_4[0][0] __________________________________________________________________________________________________ instance_normalization_12 (Inst (None, 64, 64, 256) 512 conv2d_12[0][0] __________________________________________________________________________________________________ activation_8 (Activation) (None, 64, 64, 256) 0 instance_normalization_12[0][0] __________________________________________________________________________________________________ conv2d_13 (Conv2D) (None, 64, 64, 256) 590080 activation_8[0][0] __________________________________________________________________________________________________ instance_normalization_13 (Inst (None, 64, 64, 256) 512 conv2d_13[0][0] __________________________________________________________________________________________________ concatenate_5 (Concatenate) (None, 64, 64, 1536) 0 instance_normalization_13[0][0] concatenate_4[0][0] __________________________________________________________________________________________________ conv2d_14 (Conv2D) (None, 64, 64, 256) 3539200 concatenate_5[0][0] __________________________________________________________________________________________________ instance_normalization_14 (Inst (None, 64, 64, 256) 512 conv2d_14[0][0] __________________________________________________________________________________________________ activation_9 (Activation) (None, 64, 64, 256) 0 instance_normalization_14[0][0] __________________________________________________________________________________________________ conv2d_15 (Conv2D) (None, 64, 64, 256) 590080 activation_9[0][0] __________________________________________________________________________________________________ instance_normalization_15 (Inst (None, 64, 64, 256) 512 conv2d_15[0][0] __________________________________________________________________________________________________ concatenate_6 (Concatenate) (None, 64, 64, 1792) 0 instance_normalization_15[0][0] concatenate_5[0][0] __________________________________________________________________________________________________ conv2d_16 (Conv2D) (None, 64, 64, 256) 4129024 concatenate_6[0][0] __________________________________________________________________________________________________ instance_normalization_16 (Inst (None, 64, 64, 256) 512 conv2d_16[0][0] __________________________________________________________________________________________________ activation_10 (Activation) (None, 64, 64, 256) 0 instance_normalization_16[0][0] __________________________________________________________________________________________________ conv2d_17 (Conv2D) (None, 64, 64, 256) 590080 activation_10[0][0] __________________________________________________________________________________________________ instance_normalization_17 (Inst (None, 64, 64, 256) 512 conv2d_17[0][0] __________________________________________________________________________________________________ concatenate_7 (Concatenate) (None, 64, 64, 2048) 0 instance_normalization_17[0][0] concatenate_6[0][0] __________________________________________________________________________________________________ conv2d_18 (Conv2D) (None, 64, 64, 256) 4718848 concatenate_7[0][0] __________________________________________________________________________________________________ instance_normalization_18 (Inst (None, 64, 64, 256) 512 conv2d_18[0][0] __________________________________________________________________________________________________ activation_11 (Activation) (None, 64, 64, 256) 0 instance_normalization_18[0][0] __________________________________________________________________________________________________ conv2d_19 (Conv2D) (None, 64, 64, 256) 590080 activation_11[0][0] __________________________________________________________________________________________________ instance_normalization_19 (Inst (None, 64, 64, 256) 512 conv2d_19[0][0] __________________________________________________________________________________________________ concatenate_8 (Concatenate) (None, 64, 64, 2304) 0 instance_normalization_19[0][0] concatenate_7[0][0] __________________________________________________________________________________________________ conv2d_20 (Conv2D) (None, 64, 64, 256) 5308672 concatenate_8[0][0] __________________________________________________________________________________________________ instance_normalization_20 (Inst (None, 64, 64, 256) 512 conv2d_20[0][0] __________________________________________________________________________________________________ activation_12 (Activation) (None, 64, 64, 256) 0 instance_normalization_20[0][0] __________________________________________________________________________________________________ conv2d_21 (Conv2D) (None, 64, 64, 256) 590080 activation_12[0][0] __________________________________________________________________________________________________ instance_normalization_21 (Inst (None, 64, 64, 256) 512 conv2d_21[0][0] __________________________________________________________________________________________________ concatenate_9 (Concatenate) (None, 64, 64, 2560) 0 instance_normalization_21[0][0] concatenate_8[0][0] __________________________________________________________________________________________________ conv2d_transpose_1 (Conv2DTrans (None, 128, 128, 128 2949248 concatenate_9[0][0] __________________________________________________________________________________________________ instance_normalization_22 (Inst (None, 128, 128, 128 256 conv2d_transpose_1[0][0] __________________________________________________________________________________________________ activation_13 (Activation) (None, 128, 128, 128 0 instance_normalization_22[0][0] __________________________________________________________________________________________________ conv2d_transpose_2 (Conv2DTrans (None, 256, 256, 64) 73792 activation_13[0][0] __________________________________________________________________________________________________ instance_normalization_23 (Inst (None, 256, 256, 64) 128 conv2d_transpose_2[0][0] __________________________________________________________________________________________________ activation_14 (Activation) (None, 256, 256, 64) 0 instance_normalization_23[0][0] __________________________________________________________________________________________________ conv2d_22 (Conv2D) (None, 256, 256, 3) 9411 activation_14[0][0] __________________________________________________________________________________________________ instance_normalization_24 (Inst (None, 256, 256, 3) 6 conv2d_22[0][0] __________________________________________________________________________________________________ activation_15 (Activation) (None, 256, 256, 3) 0 instance_normalization_24[0][0] ================================================================================================== Total params: 35,276,553 Trainable params: 35,276,553 不可训练参数: 0 __________________________________________________________________________________________________ |
还创建了生成器模型的图,显示了残差块中的跳跃连接。

CycleGAN生成器模型图
如何实现用于最小二乘损失和周期损失的复合模型
生成器模型不直接更新。相反,生成器模型通过复合模型进行更新。
对每个生成器模型的更新涉及模型权重的更改,这些更改基于四个考虑因素:
- 对抗损失(L2 或均方误差)。
- 身份损失(L1 或平均绝对误差)。
- 前向周期损失(L1 或平均绝对误差)。
- 后向周期损失(L1 或平均绝对误差)。
对抗损失是通过判别器更新生成器的标准方法,但在这种情况下,使用的是最小二乘损失函数而不是负对数似然(例如,二元交叉熵)。
首先,我们可以使用我们的函数来定义CycleGAN使用的两个生成器和两个判别器。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 输入形状 image_shape = (256,256,3) # 生成器:A -> B g_model_AtoB = define_generator(image_shape) # 生成器:B -> A g_model_BtoA = define_generator(image_shape) # 判别器:A -> [真实/伪造] d_model_A = define_discriminator(image_shape) # 判别器:B -> [真实/伪造] d_model_B = define_discriminator(image_shape) |
需要为每个生成器模型创建一个复合模型,该模型负责仅更新该生成器模型的权重,尽管它需要与相关的判别器模型和其他生成器模型共享权重。
这可以通过在复合模型的上下文中将其他模型的权重标记为不可训练来实现,以确保我们只更新目标生成器。
|
1 2 3 4 5 6 7 |
... # 确保正在更新的模型是可训练的 g_model_1.trainable = True # 将判别器标记为不可训练 d_model.trainable = False # 将其他生成器模型标记为不可训练 g_model_2.trainable = False |
可以使用Keras函数式API分步构建模型。
第一步是定义来自源域的真实图像的输入,将其通过我们的生成器模型,然后将生成器的输出连接到判别器并将其分类为真实或伪造。
|
1 2 3 4 5 |
... # 判别器元素 input_gen = Input(shape=image_shape) gen1_out = g_model_1(input_gen) output_d = d_model(gen1_out) |
接下来,我们可以连接身份映射元素,并为目标域的真实图像添加新输入,将其通过我们的生成器模型,并直接输出(希望是)未翻译的图像。
|
1 2 3 4 |
... # 身份元素 input_id = Input(shape=image_shape) output_id = g_model_1(input_id) |
到目前为止,我们有一个复合模型,有两个真实图像输入,以及判别器分类和身份图像输出。接下来,我们需要添加前向和后向周期。
前向周期可以通过将我们生成器的输出连接到另一个生成器来实现,然后可以将第二个生成器的输出与我们生成器的输入进行比较,它们应该相同。
|
1 2 3 |
... # 前向周期 output_f = g_model_2(gen1_out) |
后向周期更复杂,它涉及目标域的真实图像输入通过另一个生成器,然后通过我们的生成器,后者应该与目标域的真实图像匹配。
|
1 2 3 4 |
... # 后向周期 gen2_out = g_model_2(input_id) output_b = g_model_1(gen2_out) |
就是这样。
然后,我们可以定义这个复合模型,它有两个输入:一个用于源域的真实图像,一个用于目标域的真实图像,以及四个输出:一个用于判别器,一个用于身份映射的生成器,一个用于前向周期的另一个生成器,以及一个用于后向周期的我们自己的生成器。
|
1 2 3 |
... # 定义模型图 model = Model([input_gen, input_id], [output_d, output_id, output_f, output_b]) |
判别器输出的对抗损失使用最小二乘损失,该损失实现为L2或均方误差。生成器的输出与图像进行比较,并使用L1损失(实现为平均绝对误差)进行优化。
生成器通过这四种损失值的加权平均值进行更新。对抗损失按正常权重加权,而前向和后向周期损失使用参数lambda加权,该参数设置为10,例如比对抗损失重要10倍。身份损失也按lambda参数的比例加权,在官方Torch实现中设置为0.5 * 10,即5。
|
1 2 3 |
... # 使用最小二乘损失和L1损失的加权来编译模型 model.compile(loss=['mse', 'mae', 'mae', 'mae'], loss_weights=[1, 5, 10, 10], optimizer=opt) |
我们可以将所有这些整合起来,定义define_composite_model()函数来为训练给定的生成器模型创建复合模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 定义一个用于通过对抗损失和周期损失更新生成器的复合模型 def define_composite_model(g_model_1, d_model, g_model_2, image_shape): # 确保正在更新的模型是可训练的 g_model_1.trainable = True # 将判别器标记为不可训练 d_model.trainable = False # 将其他生成器模型标记为不可训练 g_model_2.trainable = False # 判别器元素 input_gen = Input(shape=image_shape) gen1_out = g_model_1(input_gen) output_d = d_model(gen1_out) # 恒等映射元素 input_id = Input(shape=image_shape) output_id = g_model_1(input_id) # 前向循环 output_f = g_model_2(gen1_out) # 后向循环 gen2_out = g_model_2(input_id) output_b = g_model_1(gen2_out) # 定义模型图 model = Model([input_gen, input_id], [output_d, output_id, output_f, output_b]) # 定义优化算法配置 opt = Adam(lr=0.0002, beta_1=0.5) # 使用最小二乘损失和L1损失的加权来编译模型 model.compile(loss=['mse', 'mae', 'mae', 'mae'], loss_weights=[1, 5, 10, 10], optimizer=opt) return model |
这个函数可以被调用来准备一个组合模型,用于训练 both the g_model_AtoB 生成器模型 and the g_model_BtoA 模型;例如
|
1 2 3 4 5 |
... # 组合: A -> B -> [真实/伪造, A] c_model_AtoBtoA = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape) # 组合: B -> A -> [真实/伪造, B] c_model_BtoAtoB = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape) |
总结和绘制组合模型有点混乱,因为它无助于清楚地看到模型的输入和输出。
我们可以总结下面每个组合模型的输入和输出。请记住,如果我们共享或重用同一组权重,如果一个给定模型在组合模型中使用了不止一次。
生成器-A 组合模型
只有生成器 A 的权重是可训练的,其他模型的权重是不可训练的。
- 对抗性损失: 域 B -> 生成器 A -> 域 A -> 判别器 A -> [真实/伪造]
- 恒等损失: 域 A -> 生成器 A -> 域 A
- 前向循环损失: 域 B -> 生成器 A -> 域 A -> 生成器 B -> 域 B
- 后向循环损失: 域 A -> 生成器 B -> 域 B -> 生成器 A -> 域 A
生成器-B 组合模型
只有生成器 B 的权重是可训练的,其他模型的权重是不可训练的。
- 对抗性损失: 域 A -> 生成器 B -> 域 B -> 判别器 B -> [真实/伪造]
- 恒等损失: 域 B -> 生成器 B -> 域 B
- 前向循环损失: 域 A -> 生成器 B -> 域 B -> 生成器 A -> 域 A
- 后向循环损失: 域 B -> 生成器 A -> 域 A -> 生成器 B -> 域 B
为完整起见,下面列出了创建所有模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
# 定义用于训练 cyclegan 生成器的组合模型的示例 from keras.optimizers import Adam from keras.models import Model from keras.models import Sequential from keras.models import Input 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import Activation from keras.layers import LeakyReLU from keras.initializers import RandomNormal from keras.layers import Concatenate from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization from keras.utils.vis_utils import plot_model # 定义判别器模型 def define_discriminator(image_shape): # 权重初始化 init = RandomNormal(stddev=0.02) # 源图像输入 in_image = Input(shape=image_shape) # C64 d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(in_image) d = LeakyReLU(alpha=0.2)(d) # C128 d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # C256 d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # C512 d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # 倒数第二层输出 d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # 补丁输出 patch_out = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d) # 定义模型 model = Model(in_image, patch_out) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.0002, beta_1=0.5), loss_weights=[0.5]) return model # 生成器A残差块 def resnet_block(n_filters, input_layer): # 权重初始化 init = RandomNormal(stddev=0.02) # 第一层卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(input_layer) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # 第二个卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) # 沿通道与输入层进行拼接合并 g = Concatenate()([g, input_layer]) return g # 定义独立的生成器模型 def define_generator(image_shape, n_resnet=9): # 权重初始化 init = RandomNormal(stddev=0.02) # 图像输入 in_image = Input(shape=image_shape) # c7s1-64 g = Conv2D(64, (7,7), padding='same', kernel_initializer=init)(in_image) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d128 g = Conv2D(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d256 g = Conv2D(256, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # R256 for _ in range(n_resnet): g = resnet_block(256, g) # u128 g = Conv2DTranspose(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # u64 g = Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # c7s1-3 g = Conv2D(3, (7,7), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) out_image = Activation('tanh')(g) # 定义模型 model = Model(in_image, out_image) return model # 定义一个用于通过对抗损失和周期损失更新生成器的复合模型 def define_composite_model(g_model_1, d_model, g_model_2, image_shape): # 确保正在更新的模型是可训练的 g_model_1.trainable = True # 将判别器标记为不可训练 d_model.trainable = False # 将其他生成器模型标记为不可训练 g_model_2.trainable = False # 判别器元素 input_gen = Input(shape=image_shape) gen1_out = g_model_1(input_gen) output_d = d_model(gen1_out) # 恒等映射元素 input_id = Input(shape=image_shape) output_id = g_model_1(input_id) # 前向循环 output_f = g_model_2(gen1_out) # 后向循环 gen2_out = g_model_2(input_id) output_b = g_model_1(gen2_out) # 定义模型图 model = Model([input_gen, input_id], [output_d, output_id, output_f, output_b]) # 定义优化算法配置 opt = Adam(lr=0.0002, beta_1=0.5) # 使用最小二乘损失和L1损失的加权来编译模型 model.compile(loss=['mse', 'mae', 'mae', 'mae'], loss_weights=[1, 5, 10, 10], optimizer=opt) return model # 输入形状 image_shape = (256,256,3) # 生成器:A -> B g_model_AtoB = define_generator(image_shape) # 生成器:B -> A g_model_BtoA = define_generator(image_shape) # 判别器:A -> [真实/伪造] d_model_A = define_discriminator(image_shape) # 判别器:B -> [真实/伪造] d_model_B = define_discriminator(image_shape) # 组合: A -> B -> [真实/伪造, A] c_model_AtoB = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape) # 组合: B -> A -> [真实/伪造, B] c_model_BtoA = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape) |
如何更新判别器和生成器模型
训练定义的模型相对直接。
首先,我们必须定义一个辅助函数,该函数将选择一批真实图像和相关的目标(1.0)。
|
1 2 3 4 5 6 7 8 9 |
# 选择一批随机样本,返回图像和目标 def generate_real_samples(dataset, n_samples, patch_shape): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 检索选定的图像 X = dataset[ix] # 生成“真实”类别标签 (1) y = ones((n_samples, patch_shape, patch_shape, 1)) return X, y |
同样,我们需要一个函数来生成一批伪图像和相关的目标(0.0)。
|
1 2 3 4 5 6 7 |
# 生成一批图像,返回图像和目标 def generate_fake_samples(g_model, dataset, patch_shape): # 生成伪造实例 X = g_model.predict(dataset) # 创建“假”类别标签 (0) y = zeros((len(X), patch_shape, patch_shape, 1)) return X, y |
现在,我们可以定义单次训练迭代的步骤。我们将根据官方 Torch 实现中的优化参数函数(**注意**:官方代码使用了一个更令人困惑的反向命名约定)的实现来模拟更新顺序。
- 更新生成器 B (A->B)
- 更新判别器 B
- 更新生成器 A (B->A)
- 更新判别器 A
首先,我们必须通过调用两个域的 generate_real_samples() 来选择一批真实图像。
通常,批量大小(n_batch)设置为 1。在这种情况下,我们将假定输入图像为 256x256,这意味着 PatchGAN 判别器的 n_patch 将为 16。
|
1 2 3 4 |
... # 选择一批真实样本 X_realA, y_realA = generate_real_samples(trainA, n_batch, n_patch) X_realB, y_realB = generate_real_samples(trainB, n_batch, n_patch) |
接下来,我们可以使用选定的真实图像批次来生成相应的生成图像或伪图像批次。
|
1 2 3 4 |
... # 生成一批伪样本 X_fakeA, y_fakeA = generate_fake_samples(g_model_BtoA, X_realB, n_patch) X_fakeB, y_fakeB = generate_fake_samples(g_model_AtoB, X_realA, n_patch) |
该论文描述了使用以前生成的图像池,从中随机选择样本并用于更新判别器模型,其中池大小设置为 50 张图像。
… [我们] 使用历史生成的图像来更新判别器,而不是使用最新生成器产生的图像。我们维护一个图像缓冲区,用于存储先前创建的 50 张图像。
——《使用循环一致性对抗网络进行非配对图像到图像转换》,2017年。
这可以通过每个域使用一个列表,并使用一个函数来填充池,然后一旦池已满就随机替换其中的元素来实现。
下面的 update_image_pool() 函数实现了这一点,基于官方 Torch 实现中的 image_pool.lua。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 更新伪图像的图像池 def update_image_pool(pool, images, max_size=50): selected = list() for image in images: if len(pool) < max_size: # 填充池 pool.append(image) selected.append(image) elif random() < 0.5: # 使用图像,但不将其添加到池中 selected.append(image) else: # 替换现有图像并使用替换的图像 ix = randint(0, len(pool)) selected.append(pool[ix]) pool[ix] = image return asarray(selected) |
然后,我们可以使用生成的伪图像更新我们的图像池,其结果可用于训练判别器模型。
|
1 2 3 4 |
... # 从池中更新伪图像 X_fakeA = update_image_pool(poolA, X_fakeA) X_fakeB = update_image_pool(poolB, X_fakeB) |
接下来,我们可以更新生成器 A。
train_on_batch() 函数将返回四个损失函数中的一个值,每个输出一个,以及用于更新模型权重的加权总和(第一个值),我们对此感兴趣。
|
1 2 3 |
... # 通过对抗性和循环损失更新生成器 B->A g_loss2, _, _, _, _ = c_model_BtoA.train_on_batch([X_realB, X_realA], [y_realA, X_realA, X_realB, X_realA]) |
然后,我们可以使用可能来自图像池的伪图像来更新判别器模型。
|
1 2 3 4 |
... # 更新判别器 A -> [真实/伪造] dA_loss1 = d_model_A.train_on_batch(X_realA, y_realA) dA_loss2 = d_model_A.train_on_batch(X_fakeA, y_fakeA) |
然后,我们可以对其他生成器和判别器模型执行相同的操作。
|
1 2 3 4 5 6 |
... # 通过对抗性和循环损失更新生成器 A->B g_loss1, _, _, _, _ = c_model_AtoB.train_on_batch([X_realA, X_realB], [y_realB, X_realB, X_realA, X_realB]) # 更新判别器 B -> [真实/伪造] dB_loss1 = d_model_B.train_on_batch(X_realB, y_realB) dB_loss2 = d_model_B.train_on_batch(X_fakeB, y_fakeB) |
在训练运行结束时,我们可以报告判别器模型在真实和伪造图像上的当前损失以及每个生成器模型的损失。
|
1 2 3 |
... # 总结性能 print('>%d, dA[%.3f,%.3f] dB[%.3f,%.3f] g[%.3f,%.3f]' % (i+1, dA_loss1,dA_loss2, dB_loss1,dB_loss2, g_loss1,g_loss2)) |
将所有这些内容结合起来,我们可以定义一个名为 train() 的函数,该函数接收定义的模型实例和加载的数据集(一个包含两个 NumPy 数组的列表,每个域一个),并训练模型。
批量大小为 1,如论文所述,模型训练 100 个训练周期。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 训练 cyclegan 模型 def train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset): # 定义训练运行的属性 n_epochs, n_batch, = 100, 1 # 确定判别器的输出正方形形状 n_patch = d_model_A.output_shape[1] # 解包数据集 trainA, trainB = dataset # 准备伪图像池 poolA, poolB = list(), list() # 计算每个训练 epoch 的批次数量 bat_per_epo = int(len(trainA) / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 手动枚举 epoch for i in range(n_steps): # 选择一批真实样本 X_realA, y_realA = generate_real_samples(trainA, n_batch, n_patch) X_realB, y_realB = generate_real_samples(trainB, n_batch, n_patch) # 生成一批伪造样本 X_fakeA, y_fakeA = generate_fake_samples(g_model_BtoA, X_realB, n_patch) X_fakeB, y_fakeB = generate_fake_samples(g_model_AtoB, X_realA, n_patch) # 从池中更新伪图像 X_fakeA = update_image_pool(poolA, X_fakeA) X_fakeB = update_image_pool(poolB, X_fakeB) # 通过对抗性和循环损失更新生成器 B->A g_loss2, _, _, _, _ = c_model_BtoA.train_on_batch([X_realB, X_realA], [y_realA, X_realA, X_realB, X_realA]) # 更新判别器 A -> [真实/伪造] dA_loss1 = d_model_A.train_on_batch(X_realA, y_realA) dA_loss2 = d_model_A.train_on_batch(X_fakeA, y_fakeA) # 通过对抗性和循环损失更新生成器 A->B g_loss1, _, _, _, _ = c_model_AtoB.train_on_batch([X_realA, X_realB], [y_realB, X_realB, X_realA, X_realB]) # 更新判别器 B -> [真实/伪造] dB_loss1 = d_model_B.train_on_batch(X_realB, y_realB) dB_loss2 = d_model_B.train_on_batch(X_fakeB, y_fakeB) # 总结性能 print('>%d, dA[%.3f,%.3f] dB[%.3f,%.3f] g[%.3f,%.3f]' % (i+1, dA_loss1,dA_loss2, dB_loss1,dB_loss2, g_loss1,g_loss2)) |
然后可以直接调用 train 函数,传入我们的已定义模型和加载的数据集。
|
1 2 3 4 5 |
... # 加载数据集作为两个 numpy 数组的列表 dataset = ... # 训练模型 train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset) |
作为改进,可以将每个判别器模型的更新合并为单个操作,就像在官方实现中的 fDx_basic() 函数中所做的那样。
此外,论文描述将模型再训练 100 个周期(总共 200 个),此时学习率衰减至 0.0。这也可以作为对训练过程的次要扩展。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 使用循环一致对抗网络的未配对图像到图像转换, 2017.
- 用于实时风格转换和超分辨率的感知损失, 2016.
- 使用条件对抗网络进行图像到图像翻译, 2016.
- 最小二乘生成对抗网络, 2016.
- 预计算的实时纹理合成与马尔可夫生成对抗网络, 2016.
- 实例归一化:快速风格化的缺失要素
- 层归一化
API
项目
- CycleGAN 项目(官方),GitHub
- pytorch-CycleGAN-and-pix2pix(官方),GitHub.
- CycleGAN 项目主页 (官方)
- Keras-GAN:生成对抗网络的 Keras 实现.
- CycleGAN-Keras:使用 tensorflow 后端的 CycleGAN Keras 实现.
- cyclegan-keras:cycle-gan 的 keras 实现
文章
总结
在本教程中,您学习了如何使用 Keras 深度学习框架从头开始实现 CycleGAN 架构。
具体来说,你学到了:
- 如何实现判别器和生成器模型。
- 如何定义复合模型,通过对抗损失和周期损失来训练生成器模型。
- 如何在每次训练迭代中实现训练过程来更新模型权重。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...


 From Scratch in Keras")



你好 Jason,感谢您提供关于 CycleGAN 的精彩教程。我有一个基于物理学的回归问题(约 8 个输入特征和 1 个响应变量),只有 35 个真实世界实验室测试结果数据点。我们有一个一维模拟工具,可以使用它生成任意数量的低保真度人工数据点。
不幸的是,低保真度人工合成数据点与真实世界实验室测试结果的分布不尽相同,并且由于域偏移,真实世界实验室测试和模拟数据之间存在差异。
您能否提供一些关于将 CycleGAN 应用于数值数据集(回归问题)的技巧,以使低保真度(合成数据)看起来更像真实世界实验室测试数据,同时仍保持物理一致性?
好问题。
也许您可以尝试为您的数据调整上述示例?
也许可以尝试使用高斯过程或 kde 方法来模拟点分布并随机采样?
嗨,Jason,
在我的情况下,35 个实验室测试点可以被认为是来自域 A 的数据,而来自一维物理模拟器的数千(或无限)个点可以被认为是来自域 B。我相信这种情况类似于 CycleGAN 通过结合大量的狗照片(理论上是无限的)和数量有限的梵高画作来生成梵高风格的狗画(https://dmitryulyanov.github.io/feed-forward-neural-doodle/),所以我认为 CycleGAN 是我问题的不错选择。我确实有一些简单的问题
对我来说,合成数值数据是否需要
update_image_pool函数来跟踪生成器创建的伪样本?我是否必须在生成器和判别器的架构中采用
Instance normalization或batch normalization?由于我只合成数值数据,我计划使用如下所示的简单生成器和判别器架构,这是否合适?
`def define_discriminator(n_inputs=nr_features)
model = Sequential()
model.add(Dense(n_inputs, activation=’relu’, kernel_initializer=’he_uniform’, input_dim=n_inputs))
model.add(Dense(32,activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
return model
def define_generator(nr_features)
model = Sequential()
model.add(Dense(nr_features, activation=’LeakyReLU’,input_shape=(nr_features,)))
model.add(Dense(32, activation=’LeakyReLU’))
model.add(Dense(1, activation=’linear’))
model.compile(loss=’mse’, optimizer=Adam(lr=0.0002, beta_1=0.5), loss_weights=[0.5])
return model
如果只是数值数据,也许可以使用高斯过程或其他更简单的生成模型?
嗨,Jason,
你能详细说明一下批量归一化和实例归一化吗?为什么在实例归一化中,轴被设置为 -1。
谢谢,
Prisilla
好问题。
基本上,批量归一化在批次之间进行归一化(标准化),实例归一化仅在实例之间进行归一化(标准化)。
这篇论文对此进行了说明
https://arxiv.org/abs/1607.08022
轴 -1 表示我们对单个图像的通道进行归一化,假设是通道优先的图像格式。您可以在此处的 API 文档中看到这一点
https://github.com/keras-team/keras-contrib/blob/master/keras_contrib/layers/normalization/instancenormalization.py
希望这能有所帮助。
嗨,Jason,
感谢您的精彩帖子。只是关于 update_image_pool 函数的一个问题,是否有可能超出池的索引范围?
++ max_size 设置为 50(如果 len(pool) < max_size),因此池索引是从 0 到 49。
++ ix = randint(0, len(pool)),将返回一个介于 0 到 50 之间的整数
所以有可能访问 pool[50],这会超出范围吗?
抓得好!
我应该 len(pool)-1。
尽管如此,python 不会超出边界,索引 50 将变为索引 0。
嗨,Jason,
首先,我要感谢您。我真的很感激您的帖子,它确实帮助我理解了“CycleGan”的整个概念,您做得非常好,解释了一切。
其次,我想问你一些问题。您的训练循环与其他实现(PyTorch 官方,Keras)截然不同。主要是,我指的是您更新模型 G1、D1、G2、D2 的方式,而不是 G1、G2、D1、D2。您决定以这种方式进行是否有任何特定原因,还是只是为了简化而修改的?
谢谢你,
Radu
谢谢 Radu。
是的,模型的更新顺序基于论文随附的官方实现。
嘿 Jason!感谢您对这个复杂主题的精彩且深入的解释。
我感觉问这个问题有点傻,但您能否告诉我如何将图像传递到代码中?我们应该将它们作为列表输入,但这些列表应该是 3 维图像数据吗?
谢谢你。
没有愚蠢的问题!
图像作为 numpy 数组加载,要了解更多信息,请参阅本教程
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
还有这里
https://machinelearning.org.cn/how-to-load-convert-and-save-images-with-the-keras-api/
感谢您写得很好的文章。
我尝试使用 Keras 的 save & load_model 保存和加载模型,但在加载时它无法识别 InstanceNormalization 层。您能提供一个解决方法吗?
另外,有什么方法可以可视化训练几代后的训练图像吗?
好问题,使用
你好,非常感谢你提供的很棒的教程!你能否制作一个关于如何在 keras 中实现 recycleGAN 模型用于视频重定向的教程?谢谢
感谢您的建议!
嗨 Jason,感谢您的精彩讲解。
由于一个错误,我无法正确导入 tensorflow addons(未定义符号错误)
我希望在某个时候能解决这个问题,但我无法使用 Instance normalization 层。
我是否可以将其替换为 BatchNormalization(轴为 -1,与此处相同)或者我需要做其他特殊的事情?
谢谢
并不是真的。
您可以将 InstanceNormalziation 安装为 Keras 扩展,而不是 TensorFlow 扩展。
或者也许可以尝试跳过这一层?
你好,
我对生成器模型中的 Res-Net 架构有一些疑问。在您的 res netblock 中,您是否每次都进行下采样和上采样?在第一个 res 块中,您将 256x64x64 输入到块中并进行拼接。结果是 512x64x64。然后将其输入到 rest netblock。它变成 256x64x64,然后拼接变成 768x54x64。通常,我认为 res-net 块应该进行逐元素相加而不是拼接。
是的,它是根据 cyclegan 论文中的实现进行修改的。
你好,
非常感谢您提供的非常有帮助的教程。这在很大程度上帮助我理解了如何在 Keras 中进行单个模型不同部分的顺序训练。
我有几个问题,鉴于我对 Keras 的不熟悉,这些问题可能有点愚蠢
1) 如果您在创建组合模型时将判别器设置为 trainable=FALSE,那么在运行判别器的 train_on_batch 之前,您是否需要将其设置回 trainable=TRUE?
2) 您能否更详细地解释一下共享层(即也属于组合模型的生成器模型的层)的权重是如何更新的?Keras 中的层是全局实体,因此可以作为不同模型的一部分进行更新,还是层特定于每个模型?
3) 在编译组合模型时,有 4 个不同的损失函数,即 mae、mse 等。我想问一下这 4 个损失函数的顺序是如何确定的?
我正在尝试使用上述教程来编写我自己的另一个架构,该架构需要对模型的各个部分进行顺序训练,因此才有了我的问题。
不客气。
不,可训练性仅影响模型的范围——对于每次调用 compile()。它本身是可训练的,而不是作为判别器的一部分可训练。
是的,我在另一篇帖子中涵盖了这一点,我想是这篇
https://machinelearning.org.cn/how-to-develop-a-generative-adversarial-network-for-a-1-dimensional-function-from-scratch-in-keras/
顺序很重要,但它是我们指定的线性顺序。
这是一个有趣的模型!坚持住!
你好,
感谢您深入的解释!
我正在尝试将相关的 Pix2pix 模型与 Tensorflow 结合使用,并且我对您使用实例归一化有一个问题。
Tensorflow Pix2Pix 教程在每个下采样(或上采样)步骤中使用批量归一化,而不是实例归一化。
另一方面,他们在 github 上的教程代码(https://github.com/tensorflow/examples/blob/master/tensorflow_examples/models/pix2pix/pix2pix.py)提供了一个实例归一化选项(默认禁用),这与您的实现类似。
据我所理解,实例归一化比批量归一化更适合图像生成,那么我应该在我的模型中使用实例归一化吗?
我的意思是,有没有理由不使用实例归一化而不是批量归一化(如果这很重要,我将始终使用批量大小为 1)?
感谢您的帮助!
抱歉,我对 TensorFlow 的实现不熟悉。也许可以联系作者。
我是根据论文实现的模型。
为了看看是否有区别,也许可以分别测试并比较结果?
我认为我就是这么做的,只是训练起来需要相当长的时间,所以我试图在训练之前把事情弄对。我将首先与一些更简单的数据集进行比较。
再次感谢您就这个主题发表的所有文章!
听起来是个好计划!
0%| | 0/533 [00:00<?, ?it/s]C:\Users\acer\Anaconda3\lib\site-packages\keras\engine\training.py:297: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set
model.trainablewithout callingmodel.compileafter ?'Discrepancy between trainable weights and collected trainable'
C:\Users\acer\Anaconda3\lib\site-packages\keras\engine\training.py:297: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set
model.trainablewithout callingmodel.compileafter ?'Discrepancy between trainable weights and collected trainable'
C:\Users\acer\Anaconda3\lib\site-packages\keras\engine\training.py:297: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set
model.trainablewithout callingmodel.compileafter ?'Discrepancy between trainable weights and collected trainable'
C:\Users\acer\Anaconda3\lib\site-packages\keras\engine\training.py:297: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set
model.trainablewithout callingmodel.compileafter ?'Discrepancy between trainable weights and collected trainable'
在训练模型时,我收到了这个警告。我需要注意这个还是可以忽略?
可以忽略这些警告。
我搜索了一下,找到了一个解决方案。
首先,为什么 keras 会显示此警告:https://github.com/tensorflow/tensorflow/issues/22012#issuecomment-421694071
其次,如何解决:https://github.com/tensorflow/tensorflow/issues/22012#issuecomment-422177897
所以不需要放
g_model_1.trainable = True
d_model.trainable = True
g_model_2.trainable = True
在编译之后。它不会影响任何东西。
好建议!
在上面的教程中,您使用了批量大小为 1,但我使用的是 2,那么我是否还需要在模型架构中更改其他内容才能使其产生良好的结果,或者更改 batch_size 不会影响结果?
我认为该代码是为批量大小为 1 开发的。您可能需要进行重大更改才能支持其他批量大小。
实际上我更改了代码的一些部分,并将批量大小改为 4,图像大小也改为 128。模型正在训练,并且已经达到了第 20 个周期。我只是想知道模型是否也能在我的批量大小下给出良好的结果?
我还对代码进行了另一个更改。我没有一次性加载所有数据,而是创建了一个自定义数据生成器,一次提供 4 张图像,而不是使用整个内存来存储整个数据集。
那么这两个更改会给我带来好结果吗?
我不知道,我认为批量大小为 1 很重要。
测试并比较。
我遇到了资源耗尽错误。那么我需要升级我的 RAM 或 GPU 吗?
也许可以,或者尝试在 AWS EC2 上运行。
那么资源耗尽错误是因为 RAM 还是 GPU?
我不知道,抱歉。我从未遇到过这种情况。也许可以问问 stackoverflow。
通常是 GPU 内存不足。
嗨,Jason,
我对您关于 CycleGAN 实现的帖子感到非常高兴和受益。您非常清晰地解释了这个相当复杂的主题,我非常感激。
我有一个小疑问。在 Resnet Block 创建函数中,当您进行输入层和 g 的拼接时,您写道:
g = Concatenate()[g, input_layer]
参数列表不应该是 [input_layer, g] 吗?因为否则输入层将在合并层中出现在 g 之后。但是,根据论文中的架构,它应该在 g 之前,不是吗?你能帮我弄清楚吗?
非常感谢,
Shuvam Ghosal
谢谢。
我认为这无关紧要。也许可以测试并确认。
好的,Jason。谢谢。
嗨,Jason,
非常感谢这个很棒的教程,它确实有助于理解 CycleGAN 的基本思想。我有一个问题是关于 CycleGAN 的输出
当我将您的实现应用于官方论文中的 apples2oranges 数据集并检查 predict() 方法的输出时,输出质量从未改变。它以一张嘈杂的图像开始,仍然可以看到用于预测的原始输入图像。但是,即使经过 200 个周期,它看起来还是一样的。尽管如此,损失值早期会下降,但在 30-50 个周期后开始停滞。
您知道是什么原因导致了这个问题吗?
再次感谢,并提前致谢!
不客气。
太酷了!
您可能需要调整模型和学习算法以适应数据集的变化。
嘿,
非常感谢您的文章!
g_loss1, g_loss2 非常大(大约 3000),并且没有收敛,您遇到过这种情况吗?我没有更改代码,只是修复了一些导入问题(随机等)。
谢谢!
我忘记提了,我使用的是 horse2zebra 数据集,到目前为止我已经运行了 1000 次迭代,它仍然很大,也许它应该训练几天?
如果生成器损失非常高,您应该检查图像的颜色值。如果它们在 [0..255] 的范围内,损失通常非常大,而对于归一化到 [-1..1] 或 [0..1] 的颜色值(取决于您的激活函数),生成器的损失值已经减小了。
我遇到的另一个与组合模型相关的问题是,我不小心训练了错误的模型,即我使用了错误的模型来生成伪图像。
好建议!
GAN 不会收敛
https://machinelearning.org.cn/faq/single-faq/why-is-my-gan-not-converging
我的问题可能很简单:我在 Google Colab 中训练上述模型(一个受您启发但由我自己编写的代码版本)。由于 train A 文件夹中有大约 1200 张图像,如果我使用 100 个训练周期,我将有 120000 个训练步骤。现在即使有 GPU,我的模型训练也至少需要 24 小时。但考虑到 Colab 上 12 小时的 GPU 限制,这似乎是不可能的。所以我想使用模型检查点,并记下训练停止的步骤。在保存点加载模型权重并从停止的步骤开始剩余的训练是否正确?
这听起来是个好主意!
训练后使用 predict 时,图像像素值在 0-1 之间。这是正确的吗?
输入到模型的任何内容都必须以与训练数据完全相同的方式进行准备。
你好 Jason,精彩的文章!感谢分享在线内容。一个疑问,为什么训练模式首先训练生成器,而不是像简单的 GAN 模型那样先训练判别器?
不客气。
嗨 Jason,我读过您的许多文章,但您能否包含您自己运行此代码的结果,以便人们可以看到最终结果是什么样的,并评估这篇是否值得一读?
我总是这样做(使用博客搜索)!例如
https://machinelearning.org.cn/cyclegan-tutorial-with-keras/
我无法摆脱您的文章有多么有用。我会购买这本书来支持您的工作。
你好,
感谢您的信息性文章。
我正在对我的 3D 数据运行它,问题是判别器精度在达到一定步数后达到 100%,我认为这不好。这是常见情况吗?您知道在这种情况下可以做什么吗?
精度是衡量生成图像质量的糟糕指标。忽略它。
在此过程中生成图像并查看它们,看看是否到了停止训练的好时机。
除非是配对不齐的图像,否则 CycleGAN 与普通 GAN 相比有什么优势?如果我们有配对的图像,是否最好使用 GAN?
我之所以问这个问题,是因为当 CycleGAN 用于翻译任务时,它通常会导致结果
缺乏清晰度和精细的细节结构。
配对图像您应该使用 pix2pix
未配对图像您应该使用 cyclegan。
普通 GAN 无法进行条件图像生成。
ResNet 的结构有一个重大错误。ResNet 不会将输入和输出连接起来,而是将它们相加。拼接会导致特征图具有数千个通道深度,这会大大减慢学习速度。要更改这一点,您只需将 concatenate 替换为 add。它还缺少末尾的 Relu(下一个 res 块的输入需要激活)。此更改使网络拥有大约 1/3 的参数量,这是非常重要的。
当然,但我们没有实现 resnet。这里的实现与 cyclegan 论文中的修改后的 resnet 块匹配。
我绝对会再看一眼以确保。该论文只说它使用了残差块。我在 github 上找到的所有 cycleGan 的实现都使用加法,就像 ResNet 论文中一样。
谢谢提示。
看起来是加法
https://github.com/junyanz/CycleGAN/blob/master/models/architectures.lua#L221
我会看看如何更新它。
这有点令人困惑,因为Torch的实现使用“concatTable”来实现跳跃连接,而PyTorch的实现则使用直接的“+”运算符。我见过的其他Keras实现使用了Add层。我对torch和lua不太熟悉,但也许concatTable这个名字有点误导?总而言之,感谢您的深入研究和精彩的教程。
同意。
不客气。
您好,在使用PatchGAN作为判别器时,为什么有时损失函数是mse,有时是binary_crossentropy?
在这里,您使用mse作为损失函数,但在pix2pix模型中,您使用binary_crossentropy。
是的,定义对抗损失的不同方法。
你好,我只是人工智能的菜鸟。
我做过的几个AI项目都使用了Tensor Dataset,训练速度很快。然而,当我运行这个使用Numpy数组的代码时,它运行得非常慢。这是使用NumPy数组的固有问题,还是我做错了什么?如果这是使用NumPy数组的问题,有没有办法修改代码使其使用张量?
非常感谢!
抱歉,我不太明白,张量就是一个NumPy数组(或者可以用NumPy数组表示)
https://machinelearning.org.cn/introduction-to-tensors-for-machine-learning/
也许你的意思是GPU和CPU上运行代码有很大区别,这个教程可以帮助你通过AWS EC2在GPU上运行代码。
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
嗨,Jason,
感谢您的教程,非常有帮助。但是,我目前正面临GANs的常见问题(模式崩溃),即判别器损失很快降至零,而生成器在不同的输入下仍然生成相同的图像。您能建议一些解决这个问题的方法吗?
再次感谢您的帖子。
是的,试试这些想法。
https://machinelearning.org.cn/how-to-code-generative-adversarial-network-hacks/
老师,这个教程非常棒!
我有一个问题:为什么我们在生成器模型中使用resnet块。在pix2pix的生成器模型中,我们没有resnet块,那么为什么您在这里添加它呢?如果它们都做同样的事情(我指的是cycle gan的生成器和pix2pix的生成器),那么为什么我们在这里添加resnet块。
请指导。
谢谢你
谢谢!
我们正在遵循论文中的模型描述。也许可以查阅论文了解他们的理由。
老师,我还有个问题。
我们如何自己开发模型!
自己创造模型并编写代码更有趣!那么我们如何构建自己的模型呢?
[模型是指像CycleGan,Normal Gan,或者只是一个完成某项任务的简单模型]
再说一次,教程很棒!
通常,学者会从头开始开发新东西,而从业者和工程师则使用有效的方法来解决问题。
我专注于教授从业者和工程师。
请解释一下使用身份图像(图像ID)的概念。
是的,我建议阅读CycleGAN论文,它对此有很好的解释。
这可能是一个愚蠢的问题,但你们说将数据集加载为两个NumPy数组的列表是什么意思?我经验不足,而且我对Keras的经验不多。
如果你刚开始学习数组,这可能会有帮助。
https://machinelearning.org.cn/gentle-introduction-n-dimensional-arrays-python-numpy/
这会帮助你学习Python列表。
https://docs.pythonlang.cn/3/tutorial/datastructures.html
我在评估时遇到一个错误。我引用了“如何开发一个用于生成MNIST手写数字的GAN”。我尝试在“如何用Keras从头开始实现CycleGAN模型”中实现“summarize_performance”函数,但遇到了一个错误。
_, acc_realB = d_model_B.evaluate(X_realB, y_realB, verbose=1)
TypeError: cannot unpack non-iterable float object
def summarize_performance(epoch, g_model_AtoB, d_model_B, dataset, n_batch, n_patch)
# unpack dataset
trainA, trainB = dataset
# 选择一批真实样本
X_realA, _ = generate_real_samples(trainA, n_batch, n_patch)
X_realB, y_realB = generate_real_samples(trainB, n_batch, n_patch)
# 生成一批伪样本
X_fakeB, y_fakeB = generate_fake_samples(g_model_AtoB, X_realA, n_patch)
# evaluate discriminator on real examples
_, acc_realB = d_model_B.evaluate(X_realB, y_realB, verbose=2)
# evaluate discriminator on fake examples
_, acc_fakeB = d_model_B.evaluate(X_fakeB, y_fakeB, verbose=2)
# summarize discriminator performance
print(‘>Accuracy real: %.0f%%, fake: %.0f%%’ % (acc_realB * 100, acc_fakeB * 100))
# save plot
save_plot(X_fakeB, epoch)
# 保存生成器模型到文件
filename_g_model_AtoB = ‘generator_model_g_model_AtoB_%03d.h5’ % (epoch + 1)
filename_d_model_B = ‘generator_model_d_model_B_%03d.h5’ % (epoch + 1)
g_model_AtoB.save(filename_g_model_AtoB)
d_model_B.save(filename_d_model_B)
听到这个消息很遗憾,也许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Jason,非常感谢这篇文章。
在“generate_real_samples”函数中,您是随机选择图像的。我想知道为什么不为每个 epoch 迭代整个数据集呢?哪种方法更好?
为了让示例简单化。
您可以将其更改为枚举所有图像,这是一个很好的改动。
嘿,非常感谢这篇文章。您知道为什么生成器模型会输出与输入相同的图像(只是质量不同,但图像相同)吗?我正在尝试在自定义数据集上运行它。
这可能是一种失效模式。
https://machinelearning.org.cn/practical-guide-to-gan-failure-modes/
亲爱的 Jason,
我刚刚完成了整个训练过程,但是在尝试转换照片时遇到了以下错误。
以下是转换照片的代码。
img_x = data_photo[5]
monet_style_img = g_model_AtoB.predict(
img_x)
这是错误信息。
ValueError: Input 0 is incompatible with layer model_2: expected shape=(None, 256, 256, 3), found shape=(32, 256, 3)
我错过了哪个部分?
亲爱的 Jason,
我找到了答案。代码应该是
‘monet_style_img = g_model_AtoB.predict_on_batch(img_x)’。
太棒了!
一张显卡有4GB的GPU内存,但无法运行此代码,显示OOM。
- 如何调整此代码以在GPU上运行?
在另一台拥有6GB GPU内存的计算机上,它可以运行。
在两台计算机上,它都显示(尽管运行)
”
WARNING:tensorflow:5 out of the last 7 calls to <function Model.make_predict_function..predict_function at 0x000001C0BA937310> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
WARNING:tensorflow:6 out of the last 8 calls to <function Model.make_predict_function..predict_function at 0x000001C0B22F85E0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/guide/function#controlling_retracing and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
”
如何纠正这些问题?
谢谢。
Apple
这些只是警告,所以你可以忽略它们。但这可能意味着你的代码中有一些不是TensorFlow原生的东西,所以它无法快速运行。消息已经说明了一切:“可能是由于(1)在循环中反复创建@tf.function,(2)传入不同形状的张量,(3)传入Python对象而不是张量。”
嗨,Jason,
请问环境问题?对于您的代码,CUDA、Python、Tensorflow-gpu和Keras的兼容版本是多少?我总是遇到GPU错误。
我的版本是
CUDA = 10.2
Python = 3.7
TF-gpu = 2.0.0
Keras = 2.3.0
如何更改我环境中的版本?
你好Shenglin…请提供您收到的错误消息,以便我们更好地帮助您。
我的版本是
CUDA = 10.2
Python = 3.7
TF-gpu = 2.3.0
Keras = 2.4.3
我解决了TF和Keras版本之间的冲突。
我的电脑
处理器:Core i9
内存:64GB
GPU:2080Ti
但是,我只加载了每种域的1000张图像,例如(1000,400,400,3),(1000,400,400,3)。
我遇到了类似“ResourceExhaustedError”的错误。
‘ResourceExhaustedError: OOM when allocating tensor with shape[16,1792,100,100] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node functional_11/functional_1/concatenate_5/concat (defined at :27) ]]
提示:如果您想在OOM发生时看到已分配张量的列表,请为当前分配信息添加report_tensor_allocations_upon_oom到RunOptions。
[Op:__inference_train_function_39883]
Errors may have originated from an input operation.
Input Source operations connected to node functional_11/functional_1/concatenate_5/concat
functional_11/functional_1/instance_normalization_14/add_1 (defined at E:\Anaconda3\envs\YOLO-gpu\lib\site-packages\keras_contrib\layers\normalization\instancenormalization.py:130)
Function call stack
train_function’
我该如何解决这个问题?非常感谢。
嗨,Jason,
我有一个关于批次大小的问题,为什么设置批次大小为1很容易陷入局部最小值。