多层感知器,简称 MLP,可以应用于时间序列预测。
使用 MLP 进行时间序列预测的挑战在于数据准备。具体来说,滞后观测值必须扁平化为特征向量。
在本教程中,您将学习如何针对一系列标准时间序列预测问题开发一套 MLP 模型。
本教程的目标是为每种类型的时间序列问题提供每个模型的独立示例,作为您可以复制和改编以解决您的特定时间序列预测问题的模板。
在本教程中,您将学习如何针对一系列标准时间序列预测问题开发一套多层感知器模型。
完成本教程后,您将了解:
- 如何开发用于单变量时间序列预测的 MLP 模型。
- 如何开发用于多变量时间序列预测的 MLP 模型。
- 如何开发用于多步时间序列预测的 MLP 模型。
使用我的新书深度学习时间序列预测启动您的项目,包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。

如何开发用于时间序列预测的多层感知器模型
图片由土地管理局提供,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 单变量 MLP 模型
- 多变量 MLP 模型
- 多步 MLP 模型
- 多变量多步 MLP 模型
单变量 MLP 模型
多层感知器,简称 MLP,可用于建模单变量时间序列预测问题。
单变量时间序列是包含具有时间顺序的单个观测序列的数据集,需要一个模型从过去的观测序列中学习以预测序列中的下一个值。
本节分为两部分;它们是
- 数据准备
- MLP 模型
数据准备
在对单变量序列建模之前,必须对其进行准备。
MLP 模型将学习一个函数,该函数将过去的观测序列作为输入映射到输出观测。因此,观测序列必须转换为模型可以学习的多个示例。
考虑一个给定的单变量序列
|
1 |
[10, 20, 30, 40, 50, 60, 70, 80, 90] |
我们可以将序列分成多个输入/输出模式,称为样本,其中三个时间步用作输入,一个时间步用作输出,用于学习一步预测。
|
1 2 3 4 5 |
X, y 10, 20, 30 40 20, 30, 40 50 30, 40, 50 60 ... |
下面的 `split_sequence()` 函数实现了这种行为,它将给定的单变量序列分成多个样本,其中每个样本具有指定的时间步数,并且输出是一个时间步。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 将单变量序列分成样本 def split_sequence(sequence, n_steps): X, y = list(), list() for i in range(len(sequence)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出序列 if end_ix > len(sequence)-1: break # 收集模式的输入和输出部分 seq_x, seq_y = sequence[i:end_ix], sequence[end_ix] X.append(seq_x) y.append(seq_y) return array(X), array(y) |
我们可以在上面小巧的人造数据集上演示这个函数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 单变量数据准备 from numpy import array # 将单变量序列分成样本 def split_sequence(sequence, n_steps): X, y = list(), list() for i in range(len(sequence)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出序列 if end_ix > len(sequence)-1: break # 收集模式的输入和输出部分 seq_x, seq_y = sequence[i:end_ix], sequence[end_ix] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 raw_seq = [10, 20, 30, 40, 50, 60, 70, 80, 90] # 选择时间步数 n_steps = 3 # 分割成样本 X, y = split_sequence(raw_seq, n_steps) # 汇总数据 for i in range(len(X)): print(X[i], y[i]) |
运行该示例将单变量序列分成六个样本,其中每个样本有三个输入时间步和一个输出时间步。
|
1 2 3 4 5 6 |
[10 20 30] 40 [20 30 40] 50 [30 40 50] 60 [40 50 60] 70 [50 60 70] 80 [60 70 80] 90 |
现在我们知道了如何准备用于建模的单变量序列,接下来我们看看如何开发一个 MLP 模型来学习输入到输出的映射。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
MLP 模型
一个简单的 MLP 模型有一个单层隐藏节点,以及一个用于进行预测的输出层。
我们可以如下定义一个用于单变量时间序列预测的 MLP。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_steps)) model.add(Dense(1)) model.compile(optimizer='adam', loss='mse') |
定义中重要的是输入的形状;即模型期望的每个样本的输入(以时间步长数表示)。
输入的时间步数是我们选择的在准备数据集时作为 `split_sequence()` 函数的参数。
每个样本的输入维度在第一个隐藏层的定义中的input_dim参数中指定。从技术上讲,模型将每个时间步长视为一个单独的特征,而不是单独的时间步长。
我们几乎总是有多个样本,因此,模型将期望训练数据的输入组件具有维度或形状
|
1 |
[样本,特征] |
我们上一节中的split_sequence()函数以[样本,特征]的形状输出X,可用于建模。
模型使用Adam 版本的随机梯度下降进行拟合,并使用均方误差或“mse”损失函数进行优化。
定义模型后,我们可以在训练数据集上对其进行拟合。
|
1 2 |
# 拟合模型 model.fit(X, y, epochs=2000, verbose=0) |
模型拟合后,我们可以使用它进行预测。
我们可以通过提供输入来预测序列中的下一个值
|
1 |
[70, 80, 90] |
并期望模型能预测出类似这样的结果
|
1 |
[100] |
模型期望输入形状是二维的,具有[样本,特征],因此,我们必须在进行预测之前重塑单个输入样本,例如形状为[1, 3],表示 1 个样本和 3 个时间步长作为输入特征。
|
1 2 3 4 |
# 演示预测 x_input = array([70, 80, 90]) x_input = x_input.reshape((1, n_steps)) yhat = model.predict(x_input, verbose=0) |
我们可以将所有这些结合起来,演示如何为单变量时间序列预测开发 MLP 并进行单次预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 单变量 MLP 示例 from numpy import array from keras.models import Sequential from keras.layers import Dense # 将单变量序列分成样本 def split_sequence(sequence, n_steps): X, y = list(), list() for i in range(len(sequence)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出序列 if end_ix > len(sequence)-1: break # 收集模式的输入和输出部分 seq_x, seq_y = sequence[i:end_ix], sequence[end_ix] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 raw_seq = [10, 20, 30, 40, 50, 60, 70, 80, 90] # 选择时间步数 n_steps = 3 # 分割成样本 X, y = split_sequence(raw_seq, n_steps) # 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_steps)) model.add(Dense(1)) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(X, y, epochs=2000, verbose=0) # 演示预测 x_input = array([70, 80, 90]) x_input = x_input.reshape((1, n_steps)) yhat = model.predict(x_input, verbose=0) print(yhat) |
运行该示例会准备数据、拟合模型并进行预测。
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到模型预测了序列中的下一个值。
|
1 |
[[100.0109]] |
多变量 MLP 模型
多变量时间序列数据是指每个时间步有多个观测值的数据。
对于多变量时间序列数据,我们可能需要两种主要模型;它们是
- 多输入序列。
- 多并行序列。
让我们依次看看每一个。
多输入序列
一个问题可能有两个或多个并行输入时间序列和一个依赖于输入时间序列的输出时间序列。
输入时间序列是并行的,因为每个序列在相同的时间步长都有一个观测值。
我们可以用一个简单的例子来演示,其中有两个并行的输入时间序列,输出序列是输入序列的简单相加。
|
1 2 3 4 |
# 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) |
我们可以将这三个数据数组重塑为单个数据集,其中每行是一个时间步长,每列是一个单独的时间序列。这是在 CSV 文件中存储并行时间序列的标准方式。
|
1 2 3 4 5 6 |
# 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 多变量数据准备 from numpy import array from numpy import hstack # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) print(dataset) |
运行该示例会打印数据集,其中每行是一个时间步,每个两输入一输出并行时间序列的列。
|
1 2 3 4 5 6 7 8 9 |
[[ 10 15 25] [ 20 25 45] [ 30 35 65] [ 40 45 85] [ 50 55 105] [ 60 65 125] [ 70 75 145] [ 80 85 165] [ 90 95 185]] |
与单变量时间序列一样,我们必须将这些数据结构化为包含输入和输出样本的样本。
我们需要将数据分成样本,同时保持两个输入序列中观测值的顺序。
如果我们选择三个输入时间步,那么第一个样本将如下所示
输入
|
1 2 3 |
10, 15 20, 25 30, 35 |
输出
|
1 |
65 |
也就是说,每个并行序列的前三个时间步长作为输入提供给模型,模型将此与第三个时间步长处的输出序列中的值相关联,在这种情况下为 65。
我们可以看到,在将时间序列转换为用于训练模型的输入/输出样本时,我们将不得不丢弃输出时间序列中的一些值,因为在之前的时间步长中输入时间序列中没有这些值。反过来,输入时间步长数量的选择将对使用的训练数据量产生重要影响。
我们可以定义一个名为 `split_sequences()` 的函数,它将接收我们定义的以时间步为行、并行序列为列的数据集,并返回输入/输出样本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 将多变量序列分割成样本 def split_sequences(sequences, n_steps): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出数据集 if end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :-1], sequences[end_ix-1, -1] X.append(seq_x) y.append(seq_y) return array(X), array(y) |
我们可以使用每个输入时间序列的三个时间步作为输入,在我们的数据集上测试这个函数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 多变量数据准备 from numpy import array from numpy import hstack # 将多变量序列分割成样本 def split_sequences(sequences, n_steps): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出数据集 if end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :-1], sequences[end_ix-1, -1] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps = 3 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps) print(X.shape, y.shape) # 汇总数据 for i in range(len(X)): print(X[i], y[i]) |
运行示例首先打印 X 和 y 组件的形状。
我们可以看到 X 组件具有三维结构。
第一个维度是样本数,本例中为 7。第二个维度是每个样本的时间步长数,本例中为 3,即传递给函数的值。最后,最后一个维度指定了并行时间序列的数量或变量的数量,本例中为 2,表示两个并行序列。
然后,我们可以看到打印了每个样本的输入和输出,显示了每个两个输入序列的三个时间步以及每个样本的相关输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
(7, 3, 2) (7,) [[10 15] [20 25] [30 35]] 65 [[20 25] [30 35] [40 45]] 85 [[30 35] [40 45] [50 55]] 105 [[40 45] [50 55] [60 65]] 125 [[50 55] [60 65] [70 75]] 145 [[60 65] [70 75] [80 85]] 165 [[70 75] [80 85] [90 95]] 185 |
在 MLP 拟合此数据之前,我们必须扁平化输入样本的形状。
MLP 要求每个样本的输入部分的形状是一个向量。对于多变量输入,我们将有多个向量,每个时间步长一个。
我们可以扁平化每个输入样本的时间结构,以便
|
1 2 3 |
[[10 15] [20 25] [30 35]] |
变为
|
1 |
[10, 15, 20, 25, 30, 35] |
首先,我们可以计算每个输入向量的长度,即时间步长数乘以特征数或时间序列数。然后我们可以使用这个向量大小来重塑输入。
|
1 2 3 |
# 扁平化输入 n_input = X.shape[1] * X.shape[2] X = X.reshape((X.shape[0], n_input)) |
我们现在可以为多变量输入定义一个 MLP 模型,其中向量长度用于输入维度参数。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_input)) model.add(Dense(1)) model.compile(optimizer='adam', loss='mse') |
进行预测时,模型需要两个输入时间序列的三个时间步。
我们可以预测输出序列中的下一个值,提供以下输入值
|
1 2 3 |
80, 85 90, 95 100, 105 |
1 个样本、3 个时间步长和 2 个变量的形状将是 [1, 3, 2]。我们必须再次将其重塑为 1 个样本,包含 6 个元素的向量或 [1, 6]
我们期望序列中的下一个值是 100 + 105 或 205。
|
1 2 3 4 |
# 演示预测 x_input = array([[80, 85], [90, 95], [100, 105]]) x_input = x_input.reshape((1, n_input)) yhat = model.predict(x_input, verbose=0) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# 多变量 MLP 示例 from numpy import array from numpy import hstack from keras.models import Sequential from keras.layers import Dense # 将多变量序列分割成样本 def split_sequences(sequences, n_steps): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出数据集 if end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :-1], sequences[end_ix-1, -1] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps = 3 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps) # 扁平化输入 n_input = X.shape[1] * X.shape[2] X = X.reshape((X.shape[0], n_input)) # 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_input)) model.add(Dense(1)) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(X, y, epochs=2000, verbose=0) # 演示预测 x_input = array([[80, 85], [90, 95], [100, 105]]) x_input = x_input.reshape((1, n_input)) yhat = model.predict(x_input, verbose=0) print(yhat) |
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行该示例会准备数据、拟合模型并进行预测。
|
1 |
[[205.04436]] |
还有另一种更精细的建模问题的方法。
每个输入序列可以由一个单独的 MLP 处理,并且每个子模型的输出可以在进行输出序列预测之前进行组合。
我们可以将此称为多头输入 MLP 模型。根据建模问题的具体情况,它可能提供更大的灵活性或更好的性能。
这种类型的模型可以使用 Keras 函数式 API 在 Keras 中定义。
首先,我们可以将第一个输入模型定义为一个 MLP,其输入层期望具有 n_steps 特征的向量。
|
1 2 3 |
# 第一个输入模型 visible1 = Input(shape=(n_steps,)) dense1 = Dense(100, activation='relu')(visible1) |
我们可以用同样的方式定义第二个输入子模型。
|
1 2 3 |
# 第二个输入模型 visible2 = Input(shape=(n_steps,)) dense2 = Dense(100, activation='relu')(visible2) |
现在两个输入子模型都已定义,我们可以将每个模型的输出合并成一个长向量,该向量可以在进行输出序列预测之前进行解释。
|
1 2 3 |
# 合并输入模型 merge = concatenate([dense1, dense2]) output = Dense(1)(merge) |
然后我们可以将输入和输出连接起来。
|
1 |
model = Model(inputs=[visible1, visible2], outputs=output) |
下图提供了该模型的示意图,包括每个层的输入和输出形状。
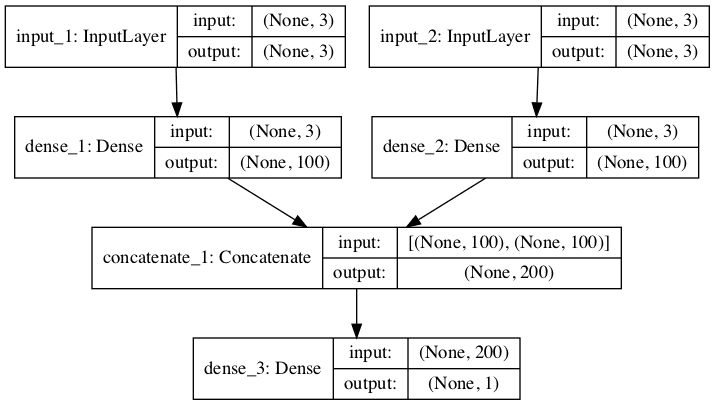
多头 MLP 用于多变量时间序列预测的图示
此模型要求输入提供为包含两个元素的列表,其中列表中的每个元素包含一个子模型的数据。
为了实现这一点,我们可以将 3D 输入数据分成两个单独的输入数据数组:即从形状为 [7, 3, 2] 的一个数组到形状为 [7, 3] 的两个 2D 数组。
|
1 2 3 |
# 分离输入数据 X1 = X[:, :, 0] X2 = X[:, :, 1] |
然后可以提供这些数据来拟合模型。
|
1 2 |
# 拟合模型 model.fit([X1, X2], y, epochs=2000, verbose=0) |
同样,在进行单个一步预测时,我们必须将单个样本的数据准备为两个单独的二维数组。
|
1 2 3 |
x_input = array([[80, 85], [90, 95], [100, 105]]) x1 = x_input[:, 0].reshape((1, n_steps)) x2 = x_input[:, 1].reshape((1, n_steps)) |
我们可以将所有这些结合起来;完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# 多变量 MLP 示例 from numpy import array from numpy import hstack from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers.merge import concatenate # 将多变量序列分割成样本 def split_sequences(sequences, n_steps): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出数据集 if end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :-1], sequences[end_ix-1, -1] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps = 3 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps) # 分离输入数据 X1 = X[:, :, 0] X2 = X[:, :, 1] # 第一个输入模型 visible1 = Input(shape=(n_steps,)) dense1 = Dense(100, activation='relu')(visible1) # 第二个输入模型 visible2 = Input(shape=(n_steps,)) dense2 = Dense(100, activation='relu')(visible2) # 合并输入模型 merge = concatenate([dense1, dense2]) output = Dense(1)(merge) model = Model(inputs=[visible1, visible2], outputs=output) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit([X1, X2], y, epochs=2000, verbose=0) # 演示预测 x_input = array([[80, 85], [90, 95], [100, 105]]) x1 = x_input[:, 0].reshape((1, n_steps)) x2 = x_input[:, 1].reshape((1, n_steps)) yhat = model.predict([x1, x2], verbose=0) print(yhat) |
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行该示例会准备数据、拟合模型并进行预测。
|
1 |
[[206.05022]] |
多并行序列
另一种时间序列问题是存在多个并行时间序列,并且必须为每个序列预测一个值。
例如,给定上一节中的数据
|
1 2 3 4 5 6 7 8 9 |
[[ 10 15 25] [ 20 25 45] [ 30 35 65] [ 40 45 85] [ 50 55 105] [ 60 65 125] [ 70 75 145] [ 80 85 165] [ 90 95 185]] |
我们可能希望预测下一个时间步的三个时间序列中的每一个的值。
这可以被称为多变量预测。
同样,必须将数据拆分为输入/输出样本才能训练模型。
该数据集的第一个样本将如下所示
输入
|
1 2 3 |
10, 15, 25 20, 25, 45 30, 35, 65 |
输出
|
1 |
40, 45, 85 |
下面的 `split_sequences()` 函数将把以时间步为行、每列一个序列的多个并行时间序列分割成所需的输入/输出形状。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 将多变量序列分割成样本 def split_sequences(sequences, n_steps): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出数据集 if end_ix > len(sequences)-1: break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :], sequences[end_ix, :] X.append(seq_x) y.append(seq_y) return array(X), array(y) |
我们可以在人造问题上演示这一点;完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 多变量输出数据准备 from numpy import array from numpy import hstack # 将多变量序列分割成样本 def split_sequences(sequences, n_steps): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出数据集 if end_ix > len(sequences)-1: break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :], sequences[end_ix, :] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps = 3 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps) print(X.shape, y.shape) # 汇总数据 for i in range(len(X)): print(X[i], y[i]) |
运行示例首先打印已准备好的 X 和 y 组件的形状。
X 的形状是三维的,包括样本数(6)、每个样本选择的时间步长数(3)以及并行时间序列或特征数(3)。
y 的形状是二维的,正如我们对样本数(6)和每个样本要预测的时间变量数(3)所预期的那样。
然后,打印每个样本,显示每个样本的输入和输出组件。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
(6, 3, 3) (6, 3) [[10 15 25] [20 25 45] [30 35 65]] [40 45 85] [[20 25 45] [30 35 65] [40 45 85]] [ 50 55 105] [[ 30 35 65] [ 40 45 85] [ 50 55 105]] [ 60 65 125] [[ 40 45 85] [ 50 55 105] [ 60 65 125]] [ 70 75 145] [[ 50 55 105] [ 60 65 125] [ 70 75 145]] [ 80 85 165] [[ 60 65 125] [ 70 75 145] [ 80 85 165]] [ 90 95 185] |
我们现在准备好用这些数据拟合一个 MLP 模型。
与前面多变量输入的情况一样,我们必须将输入数据样本的三维结构扁平化为二维结构 [样本, 特征],其中滞后观测值被模型视为特征。
|
1 2 3 |
# 扁平化输入 n_input = X.shape[1] * X.shape[2] X = X.reshape((X.shape[0], n_input)) |
模型输出将是一个向量,其中每个元素对应三个不同时间序列中的一个。
|
1 |
n_output = y.shape[1] |
我们现在可以定义我们的模型,使用扁平化向量长度作为输入层,并使用时间序列数量作为进行预测时的向量长度。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_input)) model.add(Dense(n_output)) model.compile(optimizer='adam', loss='mse') |
我们可以通过提供每个序列的三个时间步作为输入,预测三个并行序列中的每个序列的下一个值。
|
1 2 3 |
70, 75, 145 80, 85, 165 90, 95, 185 |
进行单次预测的输入形状必须是 1 个样本,3 个时间步长和 3 个特征,即 [1, 3, 3]。同样,我们可以将其扁平化为 [1, 6] 以满足模型的预期。
我们预期向量输出为
|
1 |
[100, 105, 205] |
|
1 2 3 4 |
# 演示预测 x_input = array([[70,75,145], [80,85,165], [90,95,185]]) x_input = x_input.reshape((1, n_input)) yhat = model.predict(x_input, verbose=0) |
我们可以将所有这些结合起来,演示下面用于多变量输出时间序列预测的 MLP。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
# 多变量输出 MLP 示例 from numpy import array from numpy import hstack from keras.models import Sequential from keras.layers import Dense # 将多变量序列分割成样本 def split_sequences(sequences, n_steps): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出数据集 if end_ix > len(sequences)-1: break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :], sequences[end_ix, :] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps = 3 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps) # 扁平化输入 n_input = X.shape[1] * X.shape[2] X = X.reshape((X.shape[0], n_input)) n_output = y.shape[1] # 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_input)) model.add(Dense(n_output)) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(X, y, epochs=2000, verbose=0) # 演示预测 x_input = array([[70,75,145], [80,85,165], [90,95,185]]) x_input = x_input.reshape((1, n_input)) yhat = model.predict(x_input, verbose=0) print(yhat) |
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行该示例会准备数据、拟合模型并进行预测。
|
1 |
[[100.95039 107.541306 206.81033 ]] |
与多输入序列一样,还有另一种更精细的建模问题的方法。
每个输出序列可以由一个单独的输出 MLP 模型处理。
我们可以将其称为多输出 MLP 模型。根据建模问题的具体情况,它可能提供更大的灵活性或更好的性能。
这种类型的模型可以使用 Keras 函数式 API 在 Keras 中定义。
首先,我们可以将输入模型定义为一个 MLP,其输入层期望扁平化的特征向量。
|
1 2 3 |
# 定义模型 visible = Input(shape=(n_input,)) dense = Dense(100, activation='relu')(visible) |
然后我们可以为我们希望预测的三个序列中的每一个定义一个输出层,其中每个输出子模型将预测一个时间步长。
|
1 2 3 4 5 6 |
# 定义输出 1 output1 = Dense(1)(dense) # 定义输出 2 output2 = Dense(1)(dense) # 定义输出 2 output3 = Dense(1)(dense) |
然后我们可以将输入层和输出层连接成一个单一的模型。
|
1 2 3 |
# 捆绑 model = Model(inputs=visible, outputs=[output1,output2,output3]) model.compile(optimizer='adam', loss='mse') |
为了使模型架构清晰,下面的示意图清楚地显示了模型的三个独立输出层以及每个层的输入和输出形状。
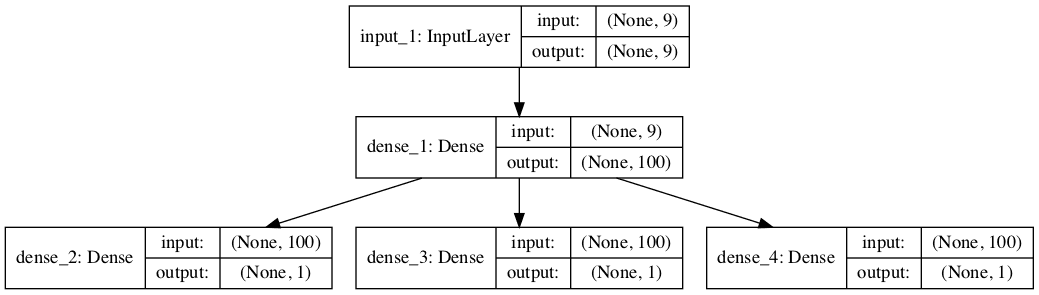
多输出 MLP 用于多变量时间序列预测的图示
训练模型时,每个样本将需要三个独立的输出数组。
我们可以通过将形状为 [7, 3] 的输出训练数据转换为形状为 [7, 1] 的三个数组来实现此目的。
|
1 2 3 4 |
# 分离输出 y1 = y[:, 0].reshape((y.shape[0], 1)) y2 = y[:, 1].reshape((y.shape[0], 1)) y3 = y[:, 2].reshape((y.shape[0], 1)) |
这些数组可以在训练期间提供给模型。
|
1 2 |
# 拟合模型 model.fit(X, [y1,y2,y3], epochs=2000, verbose=0) |
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
# 多变量输出 MLP 示例 from numpy import array from numpy import hstack from keras.models import Model from keras.layers import Input from keras.layers import Dense # 将多变量序列分割成样本 def split_sequences(sequences, n_steps): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps # 检查是否超出数据集 if end_ix > len(sequences)-1: break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :], sequences[end_ix, :] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps = 3 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps) # 扁平化输入 n_input = X.shape[1] * X.shape[2] X = X.reshape((X.shape[0], n_input)) # 分离输出 y1 = y[:, 0].reshape((y.shape[0], 1)) y2 = y[:, 1].reshape((y.shape[0], 1)) y3 = y[:, 2].reshape((y.shape[0], 1)) # 定义模型 visible = Input(shape=(n_input,)) dense = Dense(100, activation='relu')(visible) # 定义输出 1 output1 = Dense(1)(dense) # 定义输出 2 output2 = Dense(1)(dense) # 定义输出 2 output3 = Dense(1)(dense) # 捆绑 model = Model(inputs=visible, outputs=[output1,output2,output3]) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(X, [y1,y2,y3], epochs=2000, verbose=0) # 演示预测 x_input = array([[70,75,145], [80,85,165], [90,95,185]]) x_input = x_input.reshape((1, n_input)) yhat = model.predict(x_input, verbose=0) print(yhat) |
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行该示例会准备数据、拟合模型并进行预测。
|
1 2 3 |
[array([[100.86121]], dtype=float32), array([[105.14738]], dtype=float32), array([[205.97507]], dtype=float32)] |
多步 MLP 模型
实际上,MLP 模型在预测表示不同输出变量(如前面的示例)的向量输出,或者表示一个变量的多个时间步长的向量输出方面,几乎没有区别。
然而,训练数据的准备方式存在细微而重要的差异。在本节中,我们将演示使用向量模型开发多步预测模型的情况。
在我们查看模型的具体细节之前,我们首先看看多步预测的数据准备。
数据准备
与一步预测一样,用于多步时间序列预测的时间序列必须分解为包含输入和输出组件的样本。
输入和输出组件都将由多个时间步组成,并且可能具有或不具有相同数量的步。
例如,给定单变量时间序列
|
1 |
[10, 20, 30, 40, 50, 60, 70, 80, 90] |
我们可以使用最后三个时间步作为输入,并预测接下来的两个时间步。
第一个样本将如下所示
输入
|
1 |
[10, 20, 30] |
输出
|
1 |
[40, 50] |
下面的 `split_sequence()` 函数实现了这种行为,它将给定的单变量时间序列分割成具有指定数量的输入和输出时间步的样本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 将单变量序列分成样本 def split_sequence(sequence, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequence)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out # 检查是否超出序列 if out_end_ix > len(sequence): break # 收集模式的输入和输出部分 seq_x, seq_y = sequence[i:end_ix], sequence[end_ix:out_end_ix] X.append(seq_x) y.append(seq_y) return array(X), array(y) |
我们可以在这个小巧的人造数据集上演示这个函数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 多步数据准备 from numpy import array # 将单变量序列分成样本 def split_sequence(sequence, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequence)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out # 检查是否超出序列 if out_end_ix > len(sequence): break # 收集模式的输入和输出部分 seq_x, seq_y = sequence[i:end_ix], sequence[end_ix:out_end_ix] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 raw_seq = [10, 20, 30, 40, 50, 60, 70, 80, 90] # 选择时间步数 n_steps_in, n_steps_out = 3, 2 # 分割成样本 X, y = split_sequence(raw_seq, n_steps_in, n_steps_out) # 汇总数据 for i in range(len(X)): print(X[i], y[i]) |
运行示例将单变量序列分割成输入和输出时间步,并打印每个时间步的输入和输出组件。
|
1 2 3 4 5 |
[10 20 30] [40 50] [20 30 40] [50 60] [30 40 50] [60 70] [40 50 60] [70 80] [50 60 70] [80 90] |
现在我们知道如何准备多步预测数据,接下来我们来看一个可以学习这种映射的 MLP 模型。
向量输出模型
MLP 可以直接输出一个向量,该向量可以解释为多步预测。
这种方法在上一节中已经出现,其中每个输出时间序列的一个时间步被预测为一个向量。
在 `n_steps_in` 和 `n_steps_out` 变量中指定了输入和输出步数后,我们可以定义一个多步时间序列预测模型。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_steps_in)) model.add(Dense(n_steps_out)) model.compile(optimizer='adam', loss='mse') |
该模型可以对单个样本进行预测。我们可以通过提供输入来预测数据集末尾之后的两个步骤
|
1 |
[70, 80, 90] |
我们预期预测输出为
|
1 |
[100, 110] |
正如模型所期望的,当进行预测时,单个输入数据样本的形状必须是 [1, 3],表示 1 个样本和输入中的 3 个时间步长(特征)以及单个特征。
|
1 2 3 4 |
# 演示预测 x_input = array([70, 80, 90]) x_input = x_input.reshape((1, n_steps_in)) yhat = model.predict(x_input, verbose=0) |
将所有这些联系起来,下面列出了用于单变量时间序列的多步预测的 MLP。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# 单变量多步向量输出 MLP 示例 from numpy import array from keras.models import Sequential from keras.layers import Dense # 将单变量序列分成样本 def split_sequence(sequence, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequence)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out # 检查是否超出序列 if out_end_ix > len(sequence): break # 收集模式的输入和输出部分 seq_x, seq_y = sequence[i:end_ix], sequence[end_ix:out_end_ix] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 raw_seq = [10, 20, 30, 40, 50, 60, 70, 80, 90] # 选择时间步数 n_steps_in, n_steps_out = 3, 2 # 分割成样本 X, y = split_sequence(raw_seq, n_steps_in, n_steps_out) # 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_steps_in)) model.add(Dense(n_steps_out)) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(X, y, epochs=2000, verbose=0) # 演示预测 x_input = array([70, 80, 90]) x_input = x_input.reshape((1, n_steps_in)) yhat = model.predict(x_input, verbose=0) print(yhat) |
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例预测并打印序列中的接下来的两个时间步。
|
1 |
[[102.572365 113.88405 ]] |
多变量多步 MLP 模型
在前面的章节中,我们研究了单变量、多变量和多步时间序列预测。
可以将迄今为止提出的不同类型的 MLP 模型混合搭配用于不同的问题。这也适用于涉及多变量和多步预测的时间序列预测问题,但这可能更具挑战性,尤其是在准备数据和定义模型的输入和输出形状方面。
在本节中,我们将以多变量多步时间序列预测的数据准备和建模的简短示例为模板,以缓解这一挑战,具体而言:
- 多输入多步输出。
- 多并行输入和多步输出。
也许最大的绊脚石在于数据准备,所以这是我们将重点关注的地方。
多输入多步输出
有些多变量时间序列预测问题中,输出序列是独立的,但依赖于输入时间序列,并且输出序列需要多个时间步。
例如,考虑我们之前章节中的多变量时间序列
|
1 2 3 4 5 6 7 8 9 |
[[ 10 15 25] [ 20 25 45] [ 30 35 65] [ 40 45 85] [ 50 55 105] [ 60 65 125] [ 70 75 145] [ 80 85 165] [ 90 95 185]] |
我们可以使用两个输入时间序列中的每个序列的三个先前时间步来预测输出时间序列的两个时间步。
输入
|
1 2 3 |
10, 15 20, 25 30, 35 |
输出
|
1 2 |
65 85 |
下面的 split_sequences() 函数实现了此行为。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 将多变量序列分割成样本 def split_sequences(sequences, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out-1 # 检查是否超出数据集 if out_end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :-1], sequences[end_ix-1:out_end_ix, -1] X.append(seq_x) y.append(seq_y) return array(X), array(y) |
我们可以在我们构造的数据集上演示这一点。完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 多变量多步数据准备 from numpy import array from numpy import hstack # 将多变量序列分割成样本 def split_sequences(sequences, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out-1 # 检查是否超出数据集 if out_end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :-1], sequences[end_ix-1:out_end_ix, -1] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps_in, n_steps_out = 3, 2 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps_in, n_steps_out) print(X.shape, y.shape) # 汇总数据 for i in range(len(X)): print(X[i], y[i]) |
运行示例首先打印已准备好的训练数据的形状。
我们可以看到样本的输入部分是三维的,由六个样本、三个时间步长和两个输入时间序列的两个变量组成。
样本的输出部分是二维的,用于六个样本和每个样本要预测的两个时间步长。
然后打印已准备好的样本,以确认数据已按我们指定的方式准备。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
(6, 3, 2) (6, 2) [[10 15] [20 25] [30 35]] [65 85] [[20 25] [30 35] [40 45]] [ 85 105] [[30 35] [40 45] [50 55]] [105 125] [[40 45] [50 55] [60 65]] [125 145] [[50 55] [60 65] [70 75]] [145 165] [[60 65] [70 75] [80 85]] [165 185] |
我们现在可以开发一个 MLP 模型,用于使用向量输出进行多步预测。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
# 多变量多步 MLP 示例 from numpy import array from numpy import hstack from keras.models import Sequential from keras.layers import Dense # 将多变量序列分割成样本 def split_sequences(sequences, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out-1 # 检查是否超出数据集 if out_end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :-1], sequences[end_ix-1:out_end_ix, -1] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps_in, n_steps_out = 3, 2 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps_in, n_steps_out) # 扁平化输入 n_input = X.shape[1] * X.shape[2] X = X.reshape((X.shape[0], n_input)) # 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_input)) model.add(Dense(n_steps_out)) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(X, y, epochs=2000, verbose=0) # 演示预测 x_input = array([[70, 75], [80, 85], [90, 95]]) x_input = x_input.reshape((1, n_input)) yhat = model.predict(x_input, verbose=0) print(yhat) |
运行示例会拟合模型并预测数据集之外的输出序列的接下来两个时间步。
我们期望接下来的两个步骤是 [185, 205]。
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
这是一个具有很少数据的具有挑战性的问题框架,并且模型是任意配置的,但结果很接近。
|
1 |
[[186.53822 208.41725]] |
多个并行输入和多步输出
并行时间序列问题可能需要预测每个时间序列的多个时间步。
例如,考虑我们之前章节中的多变量时间序列
|
1 2 3 4 5 6 7 8 9 |
[[ 10 15 25] [ 20 25 45] [ 30 35 65] [ 40 45 85] [ 50 55 105] [ 60 65 125] [ 70 75 145] [ 80 85 165] [ 90 95 185]] |
我们可以使用三个时间序列中每个时间序列的最后三个时间步作为模型输入,并预测每个时间序列的接下来时间步作为输出。
训练数据集中的第一个样本如下。
输入
|
1 2 3 |
10, 15, 25 20, 25, 45 30, 35, 65 |
输出
|
1 2 |
40, 45, 85 50, 55, 105 |
下面的 split_sequences() 函数实现了此行为。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 将多变量序列分割成样本 def split_sequences(sequences, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out # 检查是否超出数据集 if out_end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :], sequences[end_ix:out_end_ix, :] X.append(seq_x) y.append(seq_y) return array(X), array(y) |
我们可以在这个小巧的人造数据集上演示这个函数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 多变量多步数据准备 from numpy import array from numpy import hstack # 将多变量序列分割成样本 def split_sequences(sequences, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out # 检查是否超出数据集 if out_end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :], sequences[end_ix:out_end_ix, :] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps_in, n_steps_out = 3, 2 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps_in, n_steps_out) print(X.shape, y.shape) # 汇总数据 for i in range(len(X)): print(X[i], y[i]) |
运行示例首先打印已准备好的训练数据集的形状。
我们可以看到数据集的输入 (X) 和输出 (Y) 元素都是三维的,分别表示样本数、时间步长和变量或并行时间序列。
然后并排打印每个序列的输入和输出元素,以便我们可以确认数据已按预期准备。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
(5, 3, 3) (5, 2, 3) [[10 15 25] [20 25 45] [30 35 65]] [[ 40 45 85] [ 50 55 105]] [[20 25 45] [30 35 65] [40 45 85]] [[ 50 55 105] [ 60 65 125]] [[ 30 35 65] [ 40 45 85] [ 50 55 105]] [[ 60 65 125] [ 70 75 145]] [[ 40 45 85] [ 50 55 105] [ 60 65 125]] [[ 70 75 145] [ 80 85 165]] [[ 50 55 105] [ 60 65 125] [ 70 75 145]] [[ 80 85 165] [ 90 95 185]] |
我们现在可以开发一个 MLP 模型来执行多变量多步预测。
除了像之前的示例一样扁平化输入数据的形状之外,我们还必须扁平化输出数据的三维结构。这是因为 MLP 模型只能接受向量输入和输出。
|
1 2 3 4 5 6 |
# 扁平化输入 n_input = X.shape[1] * X.shape[2] X = X.reshape((X.shape[0], n_input)) # 扁平化输出 n_output = y.shape[1] * y.shape[2] y = y.reshape((y.shape[0], n_output)) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
# 多变量多步 MLP 示例 from numpy import array from numpy import hstack from keras.models import Sequential from keras.layers import Dense # 将多变量序列分割成样本 def split_sequences(sequences, n_steps_in, n_steps_out): X, y = list(), list() for i in range(len(sequences)): # 找到此模式的末尾 end_ix = i + n_steps_in out_end_ix = end_ix + n_steps_out # 检查是否超出数据集 if out_end_ix > len(sequences): break # 收集模式的输入和输出部分 seq_x, seq_y = sequences[i:end_ix, :], sequences[end_ix:out_end_ix, :] X.append(seq_x) y.append(seq_y) return array(X), array(y) # 定义输入序列 in_seq1 = array([10, 20, 30, 40, 50, 60, 70, 80, 90]) in_seq2 = array([15, 25, 35, 45, 55, 65, 75, 85, 95]) out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))]) # 转换为 [行, 列] 结构 in_seq1 = in_seq1.reshape((len(in_seq1), 1)) in_seq2 = in_seq2.reshape((len(in_seq2), 1)) out_seq = out_seq.reshape((len(out_seq), 1)) # 水平堆叠列 dataset = hstack((in_seq1, in_seq2, out_seq)) # 选择时间步数 n_steps_in, n_steps_out = 3, 2 # 转换为输入/输出 X, y = split_sequences(dataset, n_steps_in, n_steps_out) # 扁平化输入 n_input = X.shape[1] * X.shape[2] X = X.reshape((X.shape[0], n_input)) # 扁平化输出 n_output = y.shape[1] * y.shape[2] y = y.reshape((y.shape[0], n_output)) # 定义模型 model = Sequential() model.add(Dense(100, activation='relu', input_dim=n_input)) model.add(Dense(n_output)) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(X, y, epochs=2000, verbose=0) # 演示预测 x_input = array([[60, 65, 125], [70, 75, 145], [80, 85, 165]]) x_input = x_input.reshape((1, n_input)) yhat = model.predict(x_input, verbose=0) print(yhat) |
运行示例会拟合模型并预测数据集末尾之外的接下来两个时间步的三个时间步中的每个时间步的值。
我们期望这些序列和时间步的值如下
|
1 2 |
90, 95, 185 100, 105, 205 |
注意:考虑到算法或评估过程的随机性,或数值精度上的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到模型预测非常接近预期值。
|
1 |
[[ 91.28376 96.567 188.37575 100.54482 107.9219 208.108 ] |
总结
在本教程中,您学习了如何开发一套多层感知器(MLP)模型,以解决各种标准时间序列预测问题。
具体来说,你学到了:
- 如何开发用于单变量时间序列预测的 MLP 模型。
- 如何开发用于多变量时间序列预测的 MLP 模型。
- 如何开发用于多步时间序列预测的 MLP 模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






你好 Jason,
非常好的 MLP 神经网络入门,只是想知道您是否有关于 R 而不是 Python 的相同内容的培训或教程?
抱歉,我只有 Python 示例。
嗨 Jason
很棒的教程。你这样做有什么特别的原因吗?
out_seq = array([in_seq1[i]+in_seq2[i] for i in range(len(in_seq1))])
超过
out_seq = in_seq1 + in_seq2?
谢谢大卫!
如果它们是等价的,那就没什么了。
太棒了!写得很好,学到了很多。我现在正在尝试开发自己的项目,但在尝试将分类变量集成到其中时遇到了一些困难。我想创建一个单变量多步 MLP,但是每个样本都有几个分类变量。我能把它变成一个多变量多步问题吗?例如,假设我有两个独立的商店(商店 A 和商店 B),以及每个商店过去几年的销售历史,我想预测下个月的销售额。
我可以这样生成多变量样本吗?
[10,A]
[20,A]
[30,A]
[40,A]
…
[100,A]
我这里有一些关于多站点预测的建议
https://machinelearning.org.cn/faq/single-faq/how-to-develop-forecast-models-for-multiple-sites
布朗利先生,您好!
我们如何计算均方误差,例如,来评估这个模型的性能?
通常,我们将基础数据分解为训练集和测试集,为什么在这个例子中不是这样?
您可以将“mse”添加到模型计算的指标列表中。
或者您可以使用模型进行预测,然后直接计算 MSE。
嘿,你的博客对我的帮助很大,我正在研究使用神经网络预测特定模型。我只是对这篇论文有一个问题。一开始你有一个数据序列,你可以使用拆分序列命令,但是如果我有一个数据列/列表,我该如何拆分我的数据?
谢谢你
好问题,也许这篇文章会有帮助
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
如何转换 Household Power Consumption 数据集中的输入和输出
多输入多步输出
输入,输出
[d01, d02, d03, d04, d05, d06, d07], [d08, d09, d10, d11, d12, d13, d14]
[d02, d03, d04, d05, d06, d07, d08], [d09, d10, d11, d12, d13, d14, d15]
…
多个并行输入和多步输出
问题是最复杂的,但他的模型是最简单的。
model.add(Dense(100, activation='relu', input_dim=n_input))
我们如何理解多并行输入。
将其视为多变量输入——多个特征,例如并行时间序列。
布朗利先生,您好!
当我像这样更新我的 txt 文件中的数据时
with open('testfile.txt') as inputfile
for line in inputfile
raw_seq.append(line.strip().split(','))
#print (raw_seq)
…
look_for = raw_seq[len(raw_seq)-n_steps_in:len(raw_seq)]
x_input = array(look_for)
,它给我这个错误
”
文件 "C:\Users\AppData\Local\Programs\Python\Python36\lib\site-packages\keras\engine\training_utils.py", 第 127 行, 在 standardize_input_data 中
‘形状为 ’ + str(data_shape))
ValueError: 检查输入时出错:期望 dense_1_input 具有 2 个维度,但得到形状为 (6, 1, 1) 的数组
”
你能告诉我一下吗,拜托!
此致
也许将您的代码和错误发布到 Stack Overflow。
请问,在这种情况下我们该如何处理?
时间序列:[2 4 6 0 1 3 5 0 6 7 8 0],我们发现每 3 个值后它会返回 0。
从逻辑上讲,我们必须在预测中包含此特征,例如 [2 4 6 0 1 3 5 0 6 7 8 0 V1 V2 V3 0 V'1 ...]
我该怎么办?
我是否一直预测直到得到这个?还是有参数可以定义?
谢谢你的回答
抱歉,我不明白你的问题,也许你可以详细说明你遇到的问题?
杰森,干得好!
我有一个关于我们输入模型的最终 X 的简单问题。如果我改变 X 的列索引顺序,会有影响吗?
例如,假设数组
X=([[10, 15, 20, 25, 30, 35],
[20, 25, 30, 35, 40, 45],…]),
如果我把 X 改成
X=([[10, 20, 15, 25, 35, 30],
[20, 30, 25, 35, 45, 40],…]),
???
列的顺序在训练和测试之间必须保持一致。
你好杰森。这很有趣,也很有帮助。我可以将相同的技术应用于多元时间序列数据的极限学习机吗?
谢谢你
也许可以。
你好杰森,你知道如何拆分预测结果吗?
[[102.572365 113.88405 ]] -> [[102.572365]] , [[113.88405 ]]
谢谢
你可以索引数组中的元素。
在此处了解有关如何索引 NumPy 数组的更多信息
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
嗨,Jason,
对于单变量模型,我使用了
raw_seq = [10, 0, 0, 20, 0, 0, 0, 30, 0, 40, 0, 0]
预测结果为 [40, 0, 0]
预测结果是 [[-33.33]].. 如何避免负面预测?
谢谢!
也许在建模之前对输入和输出进行缩放,例如尝试对数据进行归一化?
在训练并选择正确的模型后,我们如何保存它以便将来用于其他预测数字?
您可以调用
你好,杰森。
MLP 能否进行多元时间序列预测?如何实现?
抱歉,我读了您的后续文章,我的问题得到了解答。文章很棒,谢谢。
不客气。
是的,我在上面的教程中有示例。
杰森·布朗利你好!我想向您表达我深切的感谢!仅仅通过您的速成课程,我就学到了很多东西。谢谢您,请继续努力!
我有一个问题:有没有办法让训练好的模型预测的值比它训练时使用的值更多?
使用多元多步示例,模型使用3个输出进行训练。有没有办法告诉模型,除了3个输出之外,尝试预测最佳的5个输出?
不完全是。你可以递归地使用模型。
https://machinelearning.org.cn/multi-step-time-series-forecasting/
你好,Jase,
你有没有使用LSTM模型.h5的例子?
(已保存为.h5)
谢谢您。
你可以使用load_model()函数加载模型。
更多信息在这里
https://keras.org.cn/getting-started/faq/#how-can-i-save-a-keras-model
Jason,
我注意到你在.fit部分打乱了数据。这是一种正确的方法吗?
是的,fit()函数会打乱样本。
请记住,MLP是一个静态模型。还要记住,通过滚动验证进行数据分离不会引入数据泄露。
嗨,Jason,
您能详细说明一下您的评论吗?我不明白您的意思。
ML作为静态模型与我们打乱时间序列数据有什么关系?我以为对于时间序列,我们不想打乱数据以保留时间顺序,对吗?在这个例子中,我们不能使用滚动验证吗?
MLP不关心训练期间是否所有历史数据都被打乱。MLP是静态的,而LSTM不是,打乱数据会导致批次中样本的信息丢失以及模型维护的状态丢失。
此外,打乱样本也不会影响模型评估策略,只要使用滚动验证来估计模型在未来样本外的技能。
不确定这是否有帮助,也许我错过了你潜在的担忧?
嗨,Jason,
感谢您的快速回复!我被“静态”这个词搞糊涂了,您不能使用滚动验证(在测试/输出数据中,每次预测/时间步后重新训练/重新拟合MLP),从而使NN成为动态模型吗?您有没有这样的例子,即关于您(动态地)使用滚动验证评估MLP的博客文章?谢谢。
是的,你可以那样做。我说的静态不是这个意思,请看关于某些模型有状态而MLP没有状态的说明。
你好 Jason。首先,我要感谢你的精彩博客。
如果我想获取预测输出 (t) 然后用它作为训练来预测我的下一个输出 (t+1),并一直持续到 t+100,怎么办?
如果可以,如果我已知值并想进行验证,我该如何优化错误?
提前感谢。
是的,这是一个递归多步预测,这里有更多细节
https://machinelearning.org.cn/multi-step-time-series-forecasting/
感谢您的快速回复。我现在知道我的问题是一个递归多步预测。您是否有任何博客链接解释了带有示例的这个内容?
提前感谢。
我可能会,我经常使用直接或序列预测方法代替。
一个好的起点是这里
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好 Jason Brownlee!在这种情况下,参数(权重、偏置)的数量大于样本数量。是否存在过拟合问题?LSTM中也存在同样的问题。
有可能,在这种情况下通常需要正则化。
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
我有点困惑。您有使用 MLP 和 LSTM 进行时间序列预测的教程。我以为 LSTM 由于其循环结构更适合时间序列问题。LSTM 中的输入维度也不同,我们将特征数量作为 3D 张量考虑在内。
您能建议我对于 n_step=1 的多元时间序列应该选择哪种方法(MLP 或 LSTM)吗?
没有一个单一的算法对所有问题都好/最好。
事实上,对于单变量时间序列问题,大多数神经网络的表现不如线性方法。
你好,布朗利大师,在多头MLP中,预测的输出打印出来是这样的:[array([[49.88555]], dtype=float32, array[[88.384747]], dtype=float32]]) ]
请问我如何才能让预测只表示值,或者我如何才能在脚本中只获取这些值?非常感谢
您可以通过使用数组索引来访问数组的值。
这里有更多关于如何索引numpy数组的信息
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
假设我们有每小时数据,并且想使用过去200个时间步作为特征来预测接下来的4小时。一个只输出1个值并将其重新输入数据以预测下一个值并重复直到我们有4个预测的单变量模型,与一个设计/训练为一次预测未来4小时(即多步)的单变量模型之间有区别吗?
感谢您为初学者提供免费教程所做的努力,它们提供了至关重要的帮助。
一个友好的建议是更多地阐述理论。社区需要的是对理论的良好解释,不遗漏任何部分或跳过数学,以及该理论在工作代码中的实现,这些代码可以推广到读者的目的。
是的,存在差异,这种差异可能对您的数据集有影响,也可能没有影响。
我建议您测试这两种(以及更多)方法,看看哪种方法适用于您的特定数据集。
理论不会帮助您做出更好的预测,没有将算法映射到数据集的理论。您必须进行实验。
您建议我们如何在多步单变量模型中可视化/绘制预测值与实际值?例如,测试集中每个预测的输出会与接下来的几个以及之前的几个重叠,具体取决于 n_steps_out。
我建议为单变量序列绘制预期输出和预测输出的折线图。
上面的多元多步MLP代码是否可以从文件中接收数据?
怎么做?
谢谢。
这篇文章将向您展示如何加载数据
https://machinelearning.org.cn/load-machine-learning-data-python/
嘿,Jason!我尝试在 Anaconda 上使用你的代码,但是没有成功。
它给我发来了这个。
使用 TensorFlow 后端。
—————————————————————————
ModuleNotFoundError Traceback (最近一次调用)
in
32 from numpy import array
33 from numpy import hstack
—> 34 from keras.models import Sequential
35 from keras.layers import Dense
36
~\Anaconda3\lib\site-packages\keras\__init__.py in
1 from __future__ import absolute_import
2
—-> 3 from . import utils
4 from . import activations
5 from . import applications
~\Anaconda3\lib\site-packages\keras\utils\__init__.py in
4 from . import data_utils
5 from . import io_utils
—-> 6 from . import conv_utils
7
8 # Globally-importable utils.
~\Anaconda3\lib\site-packages\keras\utils\conv_utils.py in
7 from six.moves import range
8 import numpy as np
—-> 9 from .. import backend as K
10
11
~\Anaconda3\lib\site-packages\keras\backend\__init__.py in
87 elif _BACKEND == ‘tensorflow’
88 sys.stderr.write(‘Using TensorFlow backend.\n’)
—> 89 from .tensorflow_backend import *
90 else
91 # Try and load external backend.
~\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py in
3 from __future__ import print_function
4
—-> 5 import tensorflow as tf
6 from tensorflow.python.framework import ops as tf_ops
7 from tensorflow.python.training import moving_averages
~\Anaconda3\lib\site-packages\tensorflow\__init__.py in
26
27 # pylint: disable=g-bad-import-order
—> 28 from tensorflow.python import pywrap_tensorflow # pylint: disable=unused-import
29 from tensorflow.python.tools import module_util as _module_util
30
~\Anaconda3\lib\site-packages\tensorflow\python\__init__.py in
47 import numpy as np
48
—> 49 from tensorflow.python import pywrap_tensorflow
50
51 # 协议缓冲区
~\Anaconda3\lib\site-packages\tensorflow\python\pywrap_tensorflow.py in
23 import traceback
24
—> 25 from tensorflow.python.platform import self_check
26
27
ModuleNotFoundError: 没有名为“tensorflow.python.platform”的模块
错误提示 Keras 可能未安装。
试试这个教程
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
成功了,你真棒。非常感谢!!
干得好!
你好 Jason,感谢你的文章,它们对我很有帮助。
我尝试了“多并行序列”与多元输出 MLP 示例,我使用了你的示例帖子中的输出子模式。
你能解释一下两个预测结果之间的区别吗?还是我错了?
当
x_input = array([[70,75,145], [80,85,165], [90,95,185]])
yhat = model.predict(x_input, verbose=0)
结果
[array([[101.30953]], dtype=float32), array([[106.59332]], dtype=float32), array([[207.61252]], dtype=float32)]
它几乎符合预期。
但是当
x_input = array([[70,75,145], [80,85,165], [90,95,185], [100,105,205], [110,115,225], [120,125,245]])
x_input = x_input.reshape((2, n_input))
pre = model.predict(x_input, verbose=0)
np.reshape(pre, (2,3))
结果
array([[101.30955, 135.60982, 106.5933 ],
[141.29143, 207.61253, 275.84082]], dtype=float32)
谢谢你的帮助
你可以忽略这些测试问题。
测试问题不是真实的,也无意每次都正确预测——它们旨在作为基础,以便您了解模型和模型架构。
谢谢,
我的意思是,为什么同一个模型
再次预测相同的数据会产生不同的结果?
第一次和第二次结果不同
x_input = array ([[70,75,145], [80,85,165], [90,95,185]])
预期:[100, 105, 205]
结果
[array ([[101.30953]], dtype = float32), array ([[106.59332]], dtype = float32), array ([[207.61252]], dtype = float32)]
当用2个x_input进行预测时
x_input = array ([[70,75,145], [80,85,165], [90,95,185], [100,105,205], [110,115,225], [120,125,245]])
预期:[100, 105, 205], [130, 135, 265]
结果
array ([[101.30955, 135.60982, 106.5933],
[141.29143, 207.61253, 275.84082]], dtype = float32)
我认为第二次预测的结果必须与第一次相同
[array ([[101.30953]], dtype = float32), array ([[106.59332]], dtype = float32), array ([[207.61252]], dtype = float32)]
但它不同
我相信这是一个常见问题,我在这里回答了
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
感谢您的解释,对我很有用。如果可以的话,我想问一下如何调整用于时间序列的MLP的超参数?
谢谢,很高兴对您有帮助。
是的,这篇文章会有帮助
https://machinelearning.org.cn/how-to-grid-search-deep-learning-models-for-time-series-forecasting/
你好 Jason,
正如其他人所做的那样,我感谢您这篇非常有趣的文章。
无论如何我有一个问题。我们通常将初始数据分为训练集和测试集以检查过拟合。所以有两个问题
1) 为什么这个例子中不是这样?
2) 在这种时间序列预测中,我们如何管理训练集和测试集?
我们使用滚动验证。您可以在这里了解更多信息。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
感谢Jason的文章。它对我帮助很大。
我想知道如果输入序列在不同的时间步长下,例如:
input1 = [1, 3, 5] # 每2小时记录一次
input2 = [1, 2, 3, 4, 5, 6] # 每小时记录一次
您会如何设计模型来同时接收input1和input2?
输入将用零填充以使其长度相同。
https://machinelearning.org.cn/data-preparation-variable-length-input-sequences-sequence-prediction/
你好 Jason,感谢你的教程。我有一个问题。我正在研究癫痫脑电图数据集的时间序列预测。我想将 MLP 应用到我的数据集。你可能已经在这里看到了:http://epileptologie-bonn.de/cms/front_content.php?idcat=193&lang=3&changelang=3
我该如何将其应用于 MLP?
谢谢。
也许可以从上面教程中的一些模型开始。
此外,使用滚动验证来估计模型的性能。
这里的一些教程将帮助您入门
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好,
感谢这篇文章,我想知道何时应该使用MLP而不是LSTM或RNN方法。如果我有一个相关的、来自多个设备的能源消耗时间序列数据。您会推荐哪种方法,为什么?哪种方法更擅长捕捉季节性?特别是您可以将季节性传递给MLP多元模型?
提前感谢!
从 MLP 开始,然后是 CNN,然后是 LSTM,然后是混合模型。在这之前,尝试朴素和线性模型。
您可以在这里找到此过程的概述
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
你好。在多输入序列的情况下。网络到底在学习什么?它是在学习应该把最后几个加起来的事实吗?还是试图预测单独时间序列的下一个值然后将它们加起来?
我面临以下问题:我想预测下一步的通货膨胀,它是5个时间序列组的线性组合。所以我希望模型训练到时间t,使用5个时间序列,然后它给出t+1的通货膨胀指数。这个模型适用于这种情况吗?
它正在学习从输入序列到目标值的映射,无论这对于该领域可能意味着什么。
我鼓励你遵循这个框架
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
嗨,Jason,
多层感知机模型(MLP)属于“深度学习”类型吗?我想知道这种方法是否需要像LSTM、CNN、RNN那样的带单元的网络。您同意吗?非常感谢。
任何神经网络,例如MLP、CNN、RNN,都可以被视为深度学习的一种类型。
https://machinelearning.org.cn/what-is-deep-learning/
你好,先生,
这个教程真的很棒。但我有一个疑问。我正在使用Jupyter Notebook,在实现单变量MLP之后,我实现了多元MLP的多个输入。根据这篇文章,预期答案是205.04436,但我得到的值是100.59,这是我的单变量MLP的结果。您能告诉我我是哪里出错了,还是Jupyter Notebook的技术问题?
非常感谢
谢谢!
考虑到学习算法的随机性,您可能需要多次运行示例。
你好 Jason,
感谢您提供如此有用的教程。
您是否有关于使用带有反向传播的多层感知器进行时间序列预测的资料?我查看了您关于带有反向传播的MLP的其他教程,但它是用于分类目的的。这个关于时间序列的教程也很有趣,但它没有使用反向传播。
提前感谢。
上述教程就是这样——通过反向传播拟合的MLP用于时间序列预测。
你好 Jason,非常感谢你的教程!!!帮了我大忙!!!
在你看来,MLP在降水预测方面比LSTM更好吗?还是取决于其他因素?
提前感谢!
我推荐这个过程
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
是否有更多使用真实数据(例如:Kaggle 数据)进行多元多步数据预测的例子?
是的,请看这个
https://machinelearning.org.cn/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/
你好 Jason,
我正在尝试创建一个模型来预测流域的降雨径流过程。这看起来与您在示例中展示的非常相似,但有一个小区别。我可以访问来自天气模型的降雨预测(例如提前15天和45天),这在径流预测中会非常有帮助。
是否有可能创建一个MLP和/或LSTM,不仅使用过去的值,还使用外生变量(降雨)的预测?
我对此类示例做了一些研究,但没有找到任何。您有什么建议或参考资料来解决此类问题吗?
任何帮助都将不胜感激。
提前感谢。
是的,可能有很多方法可以实现这一点。
这里的一些想法将是一个很好的起点
https://machinelearning.org.cn/multi-step-time-series-forecasting/
你好 Jason 先生,您能告诉我为什么我们在时间序列预测中使用 ReLU 吗?
在时间序列预测中,我们还可以使用其他激活函数吗?
我发现 ReLU 效果很好,也许可以在你的数据集上与 sigmoid 和 tanh 进行比较。
您好,请告诉我如何编写使用 MLP、CNN 和 LSTM 通过 read_csv 进行时间序列预测的代码(示例)。抱歉,我编程不太好,经常出错
是的,您可以在这里找到每个示例的链接
https://machinelearning.org.cn/start-here/#deep_learning_time_series
我认为在split_sequence()函数中,对于单个变量,它应该是
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix-1]
就像多变量函数的实现一样
你好先生,您能告诉我,在使用MLP时,时间序列数据是否必须进行差分处理?
在建模之前对时间序列进行差分处理有助于消除趋势和/或季节性。
先生,我还有一个疑问,先生,如果我给出价格数据,那么MSE会非常大,比如达到千位数,所以我必须将数据缩放到0-1或-1到1的范围吗?请给我建议,先生,我有每日价格数据。
抱歉,我不太明白你的问题,你能重新组织一下吗?
你好 Jason,
感谢您的这篇文章。
我有一个大约100万行和80列的数据集(对应于不同时间步的特征)。
我正在寻求构建一个模型,例如CNN、LSTM或混合模型等。
但我希望在任何所需的时间步获得输出。假设我想预测时间步3、20或80处的特征。这些模型可以做到这一点吗,还是只能预测最后一个时间步?或者您有什么建议?
谢谢
您必须设计预测问题,例如您用例所需的输入和输出数量。这完全取决于您。
也许您希望模型始终预测20步或80步。
也许您希望模型始终预测1步,但随后您希望以递归方式将输出作为输入,最多80步。
您可以按照自己喜欢的方式构建预测问题。
嗨,Jason,
非常好的教程……我非常喜欢您对解决多元问题的两种模型选项的示意图
– 2个输入(特征)层和1个输出层,以应对具有3个时间步和2个特征(总共6个输入)以及一个1个时间步输出(总共1个输出)的多元模型问题。
– 与1个输入(或1个单输入层)和3个输出层,以应对具有3个时间步x 3个特征(总共9个输入)和3个1个时间步输出(总共3个输出)的多元问题。
如果这可行……我想我们可以组合许多选项问题来定义许多灵活的模型来应对
– 许多特征(我认为您称之为多元)和许多时间步(在某些术语中称为滞后)以及许多时间步预测(对于1个输出甚至几个输出)
所以时间序列数据准备是关键,以及它们相关的模型架构……这是我对本教程的理解
并使用concatenate模型keras方法(用于聚合多个输入)和/或使用多个输出(如果您允许我使用这个词,某种“反连接”)将它们混合……
谢谢!
是的,我喜欢你的方法。
此外,这可能会给你一些关于数据准备的思路
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
很棒的“个性化”支持!
非常感谢 Jason!
不客气。
嗨 Jason
你能在训练中添加虚拟变量来表示一周中的时间进行独热编码的变量吗?我的数据是每小时和每半小时类型的。好奇这对于“split_sequences”函数来说是不是一个禁忌。我正在尝试一个多序列类型的时间序列问题。谢谢!
是的,您需要先添加变量/列,然后将数据拆分为训练/测试和滚动验证。
你好 Jason,唯一让我困惑的是 out_seq。我正在尝试一个建筑用电数据集,其中目标变量是电力 kW,自变量是天气数据。也许我完全想错了,out_seq 永远不会是建筑 kW,它似乎更像是一个通过 numpy hstack 计算出来的数据点。我是否完全想错了?您有什么建议来预测带有天气数据的建筑 kW 吗?我原以为我可以采用更经典的多元回归方法。
out_seq 是输出序列的长度。
也许我没有理解你的问题?
你好 Jason,我已经关注你一年左右了。你维护的博客信息量很大。我正在时间序列上使用 MLP 的多输出和多头架构。我得到的 RMSE 差异巨大(分别为 5.2 和 0.32)。我检查了代码的每一行,但没有任何线索。请提示我可能出了什么问题。
谢谢!
在训练神经网络模型时得到不同的结果是很常见的,请看这个
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
谢谢 Jason,感谢你的工作。我非常感谢你以简单直观的方式提供的所有信息。
不客气。
谢谢 Jason。这是一篇很棒的文章。
你认为在MLP模型中,我们可以有[x,y]作为输入,[a,b,c,d]作为输出吗?我看到你的例子中包含了所有变量,除了输出多于输入的情况。我想知道这是否有意义。
是的,这是一个向量输出或直接预测模型。
感谢您提供的示例。我目前正在尝试使用mlp模型和series_to_supervised实现多元输入。在将训练模型重新塑形为(X_train.shape[0], lookback, no.features)后,建模时似乎出现错误,因为输入维度问题。我应该如何修正?
因为这个例子假设的是一维序列,而你的是多维序列。尝试在第一个Dense()层之前添加一个Flatten()层应该可以解决问题。
看起来 input_dim 不再是 Keras Dense 层的参数了。
改用 input_shape,例如:
您好,非常感谢您的信息丰富的文章。我的问题是如何找到最佳的 n_steps 数量?我的意思是我想知道是使用过去 30 天的数据还是 60 天的数据作为输入更好?如何找到最佳数量?
你好玛丽……你可能想探索优化技术
https://machinelearning.org.cn/optimization-for-machine-learning-crash-course/
你好 Jason,我试图在你其他代码的帮助下开发一个带有滚动验证的单变量多步 MLP 预测模型。
下面是我的代码。我想知道你是否能告诉我它是否可以。
# 评估单个模型
def evaluate_model(train, test ,data , n_input)
# 拟合模型
model = build_model(train , test, config )
data2=data[-n_input-n_test:]
test1x , test1y=series_to_supervised(data2 , n_input , n_output)
history = [x for x in train]
# 步进验证
predictions = list()
for i in range(len(test)-n_output+1)
# 预测天数
yhat_sequence = model_predict(model, history, n_input)
# 存储预测结果
predictions.append(yhat_sequence)
# 获取真实观测值并添加到历史记录中以预测未来几天
history.append(test[i])
# 将列表转换为数组
predictions = array(predictions)
prediction=predictions.reshape(len(test1y) , n_output ,1)
score = evaluate_forecasts(test1y, prediction)
return score
你好 Najes……这看起来是一个很好的开始。执行它并分享你的结果!
非常感谢您的快速回复。我不明白通过以下方法获得的RMSE与通过滚动验证方法获得的RMSE之间的区别。您能给我解释一下吗?
forecast= model.predict(test_x)
RMSE= evaluate_forecast(forecast, test_y)
你好 Tason。我不明白通过以下方法获得的RMSE与通过滚动验证方法获得的RMSE之间的区别。您能给我解释一下吗?
forecast= model.predict(test_x)
RMSE= evaluate_forecast(forecast, test_y)n
嗨,Jason,
我正在密切关注您的博客以完成一个项目。
我有一个建筑数据集,包含3000个样本,每15分钟有10个特征。这些特征包括温度、湿度、太阳辐射、能源消耗等。
我的目标是预测未来24小时(即96个时间步)的室内温度和能源消耗。我正在考虑这是一个多输入-多输出的多步预测案例。我无法使用Keras顺序模型实现它。您认为函数式模型可以是解决方案吗?
你好 Kangkana……我建议为此目的研究LSTM
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
嗨 Jason
非常感谢您的教程,它真的很有用。
我对多元多步模型有困难。我的问题出在StandardScaler部分。由于只有一个变量作为输出进行预测,我无法使用scaler.inverse_transform。您能帮我一下吗?
你好玛丽……请详细说明你在执行逆变换时遇到的情况。
你好 James,
感谢您的精彩教程。您能告诉我如何从它生成准确度和损失曲线吗?我已将模型与我的数据一起实现,并且运行良好。但是,我想使用早停和 Dropout 层等方法来防止过拟合,并且需要查看损失曲线来达到此目的。
你好 Tahia……非常欢迎你!以下内容可能对你感兴趣
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
嗨 James,
谢谢你的回复。我理解了文章中的概念——但是,我更倾向于代码方面。
具体来说,在按照你的博客文章实现多步MLP模型后,我如何用代码生成损失和准确度曲线?如果我不能这样做,我如何诊断模型是否过拟合?
你好 Jason,祝贺您拥有最好的机器学习网站!!!!
我有一个关于代码部分的问题,在
# 扁平化输入
n_input = X.shape[1] * X.shape[2]
X = X.reshape((X.shape[0], n_input))
因为,X.shape[2] 返回
IndexError Traceback (最近一次调用)
~\AppData\Local\Temp/ipykernel_18452/544936341.py in
—-> 1 X.shape[2]
IndexError: 元组索引超出范围
我想,如果我改成
# 扁平化输入
n_input = X.shape[1] * n_steps
X = X.reshape((X.shape[0], n_input))
我错了吗,还是有道理???
谢谢
你好 Wilson……你输入的代码是手打的还是复制粘贴的?你也可以尝试在 Google Colab 中运行。