
如何诊断回归模型失败的原因
图片由 Editor | ChatGPT 提供
引言
在回归模型中,当模型产生不准确的预测时——也就是说,当MAE或RMSE等误差指标很高时——或者当模型部署后,无法很好地泛化到与训练或测试示例不同的新数据时,就会发生模型失败。虽然模型失败通常表现为这两种情况中的一种或两种,但根本原因可能更加多样和微妙。
本文探讨了回归模型表现不佳的一些常见原因,并概述了如何检测这些问题。本文还附带了使用XGBoost的实际代码片段——XGBoost是一种强大且高度可调的基于集成(ensemble-based)的回归模型。尽管XGBoost很受欢迎且功能强大,但如果训练或评估不当,它也可能失败!
回归模型的诊断点
首先,让我们来揭示回归模型失败的一些常见原因,分别描述它们并建议如何诊断它们。
1. 欠拟合
当用于构建模型的训练数据在数量、质量或相关信息方面不足以预测目标标签时,由此产生的模型会过于简单,甚至无法对与训练示例相似的示例提供准确的预测。这种常见的问题,称为欠拟合,很容易诊断:当训练集和测试集上的误差都很高时,就会出现这种情况。
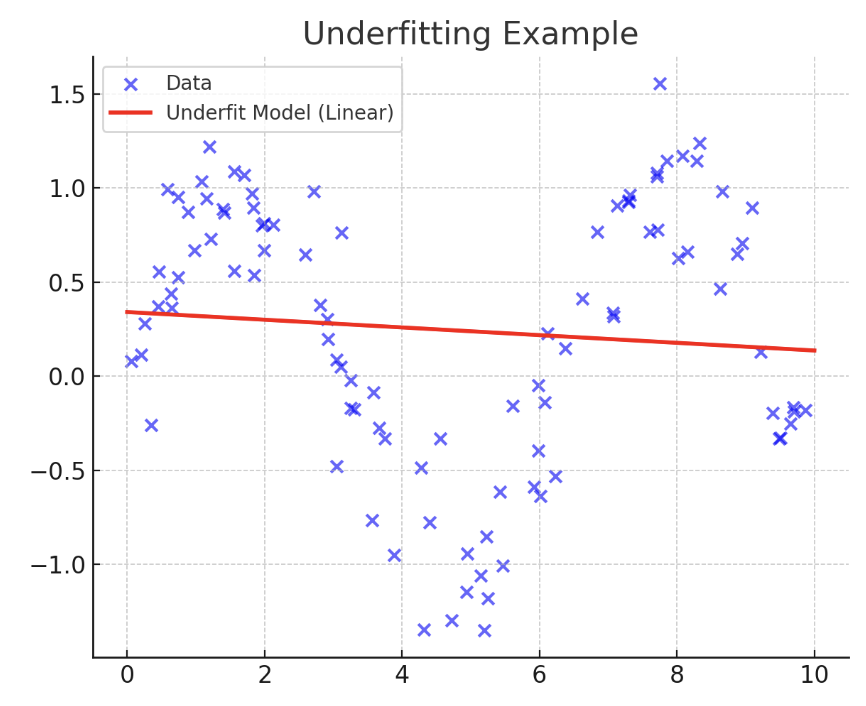
欠拟合的可视化
2. 过拟合
正如其名称所示,过拟合是欠拟合的相反问题。当模型学到或“记忆”训练数据过多时,就会发生过拟合,就像下面所示的那样。当发生过拟合时,一个在训练示例上表现异常出色的模型,在未来未见过的数据上表现会差得多。因此,训练误差低而测试误差高,通常是模型过拟合训练数据的强烈指标。总之,记忆训练示例而不是学习对做出可靠预测至关重要的通用模式和输入-输出关系,会导致模型一旦接收到与之前见过的数据略有不同的输入数据示例时,就会“迷失方向”。
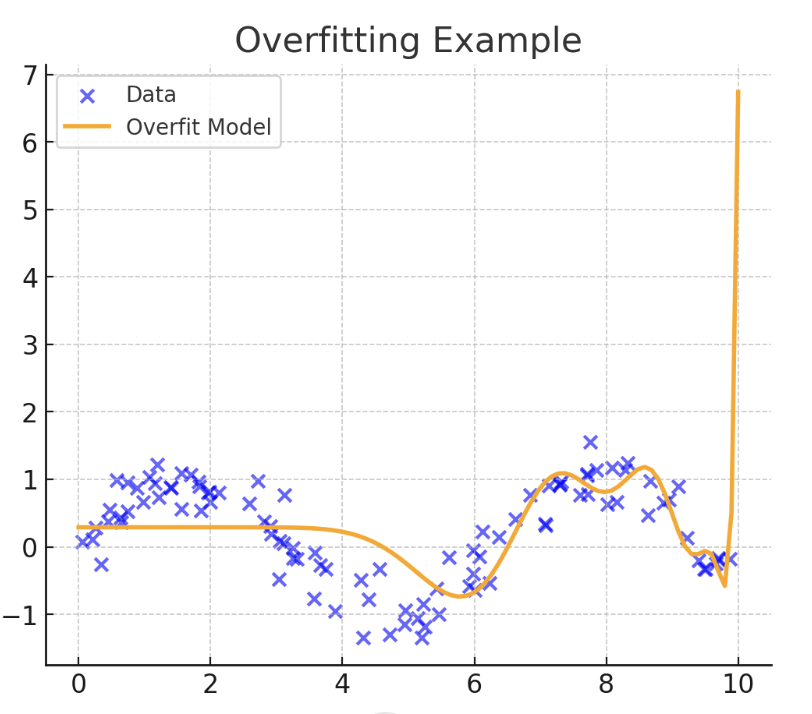
过拟合的可视化
记忆训练示例而不是学习对做出可靠预测至关重要的通用模式和输入-输出关系,会导致模型一旦接收到与之前见过的数据略有不同的输入数据示例时,就会“迷失方向”。
3. 数据泄露
数据泄露发生在机器学习模型在训练期间使用了在推理时不可用的信息来预测目标变量时。与过拟合类似,数据泄露可以使模型在验证期间显得非常准确,但一旦部署,其真实世界的性能通常会显著下降。
然而,与过拟合不同的是,这个问题更多地与训练和部署之间的数据可用性或完整性不匹配有关——例如,当未来或派生自目标的信息(如在房产挂牌中检测到欺诈或可疑的房价后采取的行动)无意中包含在训练中时。
通过注意到不切实际低的验证误差,通常可以诊断出数据泄露,这可能表明模型访问了本不应访问的信息:这些信息在生产环境中进行预测时将不可用。
4. 噪声或不相关特征
在包含大量特征的数据集中,其中一些特征可能对于预测目标值是无信息的甚至是误导性的,这是很常见的。例如,在用于根据房屋属性估算房价的回归模型中,房屋年龄或面积等属性是相关的,而诸如外墙颜色之类的属性可能被认为与房价预测无关。计算特征重要性并使用SHAP等可解释性方法可以帮助确定数据集中某些特征的影响很小或没有影响,应该删除它们以简化模型而不损失准确性。
5. 数据预处理不当
缺失值、尺度差异较大的数值属性和原始分类特征应根据其对当前预测问题的“估计”相关性进行适当的预处理。未能这样做并忽略重要的预处理操作,如缩放、缺失值插补等,也可能对模型性能产生负面影响。通过数据检查和数据剖析方法(如相关性分析、摘要统计或热图来显示缺失值)可以诊断出与数据预处理不当或不足相关的问题。
6. 错误的超参数
像XGBoost这样需要在训练前设置多个超参数的模型,要求您具有很强的专业知识来定义正确的超参数设置,或者(更常见地)使用像交叉验证这样的验证方案进行超参数调优来找到最佳配置。为学习率、决策树深度等超参数设置错误的值会导致模型表现不佳。将您特定的超参数设置与默认模型设置进行比较,以验证您是否使用了合适的配置。
7. 数据不足
最后但同样重要的是,数据样本太少而无法学习可靠的预测模式或泛化到未来数据本身就是一个问题——尽管它常常可能是其他问题(如欠拟合或过拟合)的原因之一。数据量在使更复杂的模型时尤其关键,这些模型通常无法从少量标记样本中有效学习。
实际示例:使用XGBoost预测房价
我们将通过以下示例,利用公开可用的加州住房数据集(即scikit-learn库中的版本),来回顾上述讨论中的一些见解,该示例训练回归模型来预测房价。
此代码导入必要的模块,加载数据集,分离预测变量和目标变量,并将数据示例分割成训练集和测试集。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import xgboost as xgb import numpy as np import pandas as pd data = fetch_california_housing() X = pd.DataFrame(data.data, columns=data.feature_names) y = data.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
我们将首先训练一个XGBoost模型,其超参数已随机配置(或有意配置不当),稍后将其用作我们比较的基准模型。
|
1 2 3 4 5 6 7 8 9 10 |
base_model = xgb.XGBRegressor( n_estimators=10, max_depth=1, learning_rate=0.5, random_state=42 ) base_model.fit(X_train, y_train) y_pred_base = base_model.predict(X_test) print("基准模型RMSE:", np.sqrt(mean_squared_error(y_test, y_pred_base))) |
如果您对决策树非常熟悉,您可能已经对 `max_depth=1` 的设置表示怀疑,但为了说明目的,我们展示了一个诊断问题的示例;因此,我们需要一些看起来有问题的东西。
由此产生的误差(RMSE)为0.7630064001489125:考虑到目标变量(房屋价值)是以十万美元为单位的,这个值相当高。
现在,转向一个超参数设置更精心规划的模型,更好地适应数据集的性质和复杂性(请记住,如果您不确定如何进行此设置,有一些搜索技术可以帮助您:请参阅这篇文章和这篇文章)。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
good_model = xgb.XGBRegressor( n_estimators=300, max_depth=6, learning_rate=0.05, subsample=0.8, colsample_bytree=0.8, random_state=42 ) good_model.fit(X_train, y_train) y_pred_good = good_model.predict(X_test) print("好的模型RMSE:", np.sqrt(mean_squared_error(y_test, y_pred_good))) |
此模型的RMSE大幅下降至0.4533940039302877。虽然仍有可能进一步改进,但这相对于基准模型来说是一个巨大的进步。
在这个简短的示例中,我们比较了RMSE以诊断性能问题,但其他诊断模型失败的方法可能包括:
总结
本文探讨了机器学习中回归模型表现不佳的几个常见原因,从数据质量问题到模型配置不当。讨论重点关注了诊断这些表现不佳的回归模型的多样化根本原因的方法,随后举例说明了训练和比较两个XGBoost回归模型,以识别其中一个模型的潜在问题。






暂无评论。