简单的预测方法包括朴素地使用最后一个观测值作为预测,或者使用先前观测值的平均值。
在更复杂的模型之前,评估简单预测方法在单变量时间序列预测问题上的性能很重要,因为它们的性能提供了下界和比较点,可用于确定模型在给定问题上是否具有技能。
尽管简单,像朴素预测和平均预测策略这样的方法可以针对特定问题进行调整,例如选择要持续的先前观测值或要平均的先前观测值的数量。通常,调整这些简单策略的超参数可以提供更稳健和可辩护的模型性能下界,并可能产生令人惊讶的结果,这些结果可以为更复杂模型的选择和配置提供信息。
在本教程中,您将发现如何从头开始开发一个框架,用于对单变量数据进行时间序列预测的简单朴素和平均策略进行网格搜索。
完成本教程后,您将了解:
- 如何开发一个框架,使用前向验证从头开始对简单模型进行网格搜索。
- 如何对每日时间序列出生数据进行简单模型超参数的网格搜索。
- 如何对洗发水销量、汽车销量和温度等月度时间序列数据进行简单模型超参数的网格搜索。
通过我的新书 《深度学习时间序列预测》 快速启动您的项目,包括分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于 2019 年 4 月:更新了数据集链接。
- 更新于 2020 年 2 月:修正了最后两个案例中季节性选择的拼写错误。

如何对单变量时间序列预测的朴素方法进行网格搜索
照片由 Rob and Stephanie Levy 拍摄,部分权利保留。
教程概述
本教程分为六个部分;它们是:
- 简单预测策略
- 开发网格搜索框架
- 案例研究 1:无趋势或季节性
- 案例研究 2:趋势
- 案例研究 3:季节性
- 案例研究 4:趋势和季节性
简单预测策略
在测试更复杂的模型之前,测试简单的预测策略非常重要且有用。
简单预测策略是指那些对预测问题的性质几乎不做假设(或完全不做假设),并且实现和计算速度快的策略。
结果可以用作性能基准,并用作比较的起点。如果一个模型比简单预测策略的性能更好,那么可以说它是熟练的。
简单预测策略主要有两个主题;它们是
- 朴素,即直接使用观测值。
- 平均,即使用先前观测值的统计数据。
让我们仔细看看这两种策略。
朴素预测策略
朴素预测涉及直接使用上一个观测值作为预测,而不进行任何更改。
它通常被称为持久性预测,因为上一个观测值被持久化了。
这种简单的方法可以针对季节性数据进行微调。在这种情况下,可以持久化前一个周期中相同时间点的观测值。
这可以进一步推广到测试历史数据中可用于持久化值以进行预测的每个可能偏移量。
例如,给定序列
|
1 |
[1, 2, 3, 4, 5, 6, 7, 8, 9] |
我们可以将最后一个观测值(相对索引 -1)持久化为值 9,或将倒数第二个先前观测值(相对索引 -2)持久化为 8,依此类推。
平均预测策略
比朴素预测高一步的策略是平均先前值。
收集所有先前观测值,并使用平均值或中位数进行平均,而无需对数据进行其他处理。
在某些情况下,我们可能希望将用于平均计算的历史记录缩短到最近的几个观测值。
我们可以将其推广到测试要包含在平均计算中的每个可能的 n 个先前观测值的集合。
例如,给定序列
|
1 |
[1, 2, 3, 4, 5, 6, 7, 8, 9] |
我们可以平均最后 1 个观测值 (9),最后 2 个观测值 (8, 9),依此类推。
在季节性数据的情况下,我们可能希望在被预测的时间点上,平均最近 n 个先前观测值。
例如,给定一个具有 3 步周期的序列
|
1 |
[1, 2, 3, 1, 2, 3, 1, 2, 3] |
我们可以使用窗口大小为 3,并平均最后 1 个观测值 (-3 或 1),最后 2 个观测值 (-3 或 1,以及 -(3 * 2) 或 1),依此类推。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
开发网格搜索框架
在本节中,我们将开发一个框架,用于对上一节所述的两种简单预测策略,即朴素策略和平均策略进行网格搜索。
我们可以从实现朴素预测策略开始。
对于给定的历史观测数据集,我们可以持久化该历史中的任何值,即从索引 -1 的上一个观测值到历史中的第一个观测值(索引 -(len(data)))。
下面的 `naive_forecast()` 函数实现了朴素预测策略,用于从 1 到数据集长度的给定偏移量。
|
1 2 3 |
# 一步朴素预测 def naive_forecast(history, n): return history[-n] |
我们可以对一个小型的构造数据集测试此函数。
|
1 2 3 4 5 6 7 8 9 10 |
# 一步朴素预测 def naive_forecast(history, n): return history[-n] # 定义数据集 data = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] print(data) # 测试朴素预测 for i in range(1, len(data)+1): print(naive_forecast(data, i)) |
运行示例首先打印构造的数据集,然后打印历史数据集中每个偏移量的朴素预测。
|
1 2 3 4 5 6 7 8 9 10 11 |
[10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] 100.0 90.0 80.0 70.0 60.0 50.0 40.0 30.0 20.0 10.0 |
现在我们可以开始开发一个用于平均预测策略的函数。
平均最后 n 个观测值很简单;例如
|
1 2 |
from numpy import mean result = mean(history[-n:]) |
在观测值分布非高斯的情况下,我们可能还想测试中位数。
|
1 2 |
from numpy import median result = median(history[-n:]) |
下面的 `average_forecast()` 函数实现了这一点,它接受历史数据和一个配置数组或元组,该元组指定要平均的先前值的数量(作为整数),以及描述计算平均值的方式的字符串('mean' 或 'median')。
|
1 2 3 4 5 6 7 8 |
# 一步平均预测 def average_forecast(history, config): n, avg_type = config # 最后 n 个值的平均值 if avg_type is 'mean': return mean(history[-n:]) # 最后 n 个值的中位数 return median(history[-n:]) |
下面列出了对小型构造数据集的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from numpy import mean 从 numpy 导入 median # 一步平均预测 def average_forecast(history, config): n, avg_type = config # 最后 n 个值的平均值 if avg_type is 'mean': return mean(history[-n:]) # 最后 n 个值的中位数 return median(history[-n:]) # 定义数据集 data = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] print(data) # 测试朴素预测 for i in range(1, len(data)+1): print(average_forecast(data, (i, 'mean'))) |
运行示例会将序列中的下一个值预测为从 -1 到 -10(包含)的连续子集中的平均值。
|
1 2 3 4 5 6 7 8 9 10 11 |
[10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] 100.0 95.0 90.0 85.0 80.0 75.0 70.0 65.0 60.0 55.0 |
我们可以更新该函数以支持对季节性数据进行平均,并尊重季节性偏移。
可以在函数中添加一个偏移参数,当该参数不设置为 1 时,它将确定在收集要包含在平均值中的值之前,需要向后计数多少个先前观测值。
例如,如果 n=1 且 offset=3,则平均值从 n*offset 或 1*3 = -3 的单个值计算。如果 n=2 且 offset=3,则平均值从 1*3 或 -3 和 2*3 或 -6 的值计算。
我们还可以添加一些保护措施,当季节性配置 (n * offset) 超出历史观测范围时引发异常。
更新后的函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 一步平均预测 def average_forecast(history, config): n, offset, avg_type = config values = list() if offset == 1: values = history[-n:] else: # 跳过错误的配置 if n*offset > len(history): raise Exception('配置超出数据末尾: %d %d' % (n,offset)) # 尝试使用偏移量收集 n 个值 for i in range(1, n+1): ix = i * offset values.append(history[-ix]) # 最后 n 个值的平均值 if avg_type is 'mean': return mean(values) # 最后 n 个值的中位数 return median(values) |
我们可以对具有季节性周期的少量构造数据集进行此函数测试。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from numpy import mean 从 numpy 导入 median # 一步平均预测 def average_forecast(history, config): n, offset, avg_type = config values = list() if offset == 1: values = history[-n:] else: # 跳过错误的配置 if n*offset > len(history): raise Exception('配置超出数据末尾: %d %d' % (n,offset)) # 尝试使用偏移量收集 n 个值 for i in range(1, n+1): ix = i * offset values.append(history[-ix]) # 最后 n 个值的平均值 if avg_type is 'mean': return mean(values) # 最后 n 个值的中位数 return median(values) # 定义数据集 data = [10.0, 20.0, 30.0, 10.0, 20.0, 30.0, 10.0, 20.0, 30.0] print(data) # 测试朴素预测 for i in [1, 2, 3]: print(average_forecast(data, (i, 3, 'mean'))) |
运行示例计算了 [10]、[10, 10] 和 [10, 10, 10] 的平均值。
|
1 2 3 4 |
[10.0, 20.0, 30.0, 10.0, 20.0, 30.0, 10.0, 20.0, 30.0] 10.0 10.0 10.0 |
可以将朴素预测和平均预测策略合并到一个函数中。
这些方法之间存在一些重叠,特别是用于持久化值或确定要平均的值数量的历史偏移量(n-offset)。
让一个函数支持这两种策略很有用,这样我们就可以一次性测试一套配置,作为对简单模型更广泛的网格搜索的一部分。
下面的 `simple_forecast()` 函数将两种策略合并到一个函数中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 一步简单预测 def simple_forecast(history, config): n, offset, avg_type = config # 持久化值,忽略其他配置 if avg_type == 'persist': return history[-n] # 收集要平均的值 values = list() if offset == 1: values = history[-n:] else: # 跳过错误的配置 if n*offset > len(history): raise Exception('配置超出数据末尾: %d %d' % (n,offset)) # 尝试使用偏移量收集 n 个值 for i in range(1, n+1): ix = i * offset values.append(history[-ix]) # 检查是否可以平均 if len(values) < 2: raise Exception('无法计算平均值') # 最后 n 个值的平均值 if avg_type == 'mean': return mean(values) # 最后 n 个值的中位数 return median(values) |
接下来,我们需要构建一些函数,通过前向验证来反复拟合和评估模型,包括将数据集分割为 训练集和测试集,并评估一步预测。
我们可以使用切片根据指定的分割大小(例如,测试集中要使用的时步数)来分割列表或 NumPy 数组。
下面的 `train_test_split()` 函数实现了这一点,它接受一个提供的数据集和要用于测试集的时步数。
|
1 2 3 |
# 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] |
在对测试数据集中的每个步骤进行预测后,需要将它们与测试集进行比较以计算误差分数。
时间序列预测有许多流行的误差得分。在这种情况下,我们将使用均方根误差 (RMSE),但您可以将其更改为您喜欢的度量,例如 MAPE、MAE 等。
下面的 *measure_rmse()* 函数将根据实际值(测试集)和预测值列表计算 RMSE。
|
1 2 3 |
# 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) |
我们现在可以实现 前向验证方案。这是评估时间序列预测模型的标准方法,它尊重观测值的时间顺序。
首先,使用 `train_test_split()` 函数将提供的单变量时间序列数据集分割为 训练集和测试集。然后枚举测试集中的观测值数量。对于每个观测值,我们在所有历史数据上拟合模型并进行一步预测。然后将该时间步的真实观测值添加到历史记录中,并重复该过程。调用 `simple_forecast()` 函数来拟合模型并进行预测。最后,通过调用 `measure_rmse()` 函数将所有一步预测与实际测试集进行比较来计算误差得分。
下面的 `walk_forward_validation()` 函数实现了这一点,它接受一个单变量时间序列、用于测试集的时间步数以及模型配置的数组。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = simple_forecast(history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) return error |
如果您有兴趣进行多步预测,您可以更改 `simple_forecast()` 函数中的 `predict()` 调用,同时更改 `measure_rmse()` 函数中的误差计算方式。
我们可以使用不同的模型配置列表重复调用 *walk_forward_validation()*。
一个可能的问题是,某些模型配置组合可能无法调用模型并会引发异常。
我们可以通过将所有对 `walk_forward_validation()` 的调用包装在 try-except 块中并添加一个忽略警告的块来捕获异常和忽略警告。我们还可以添加调试支持,在需要查看实际情况时禁用这些保护。最后,如果发生错误,我们可以返回 `None` 结果;否则,我们可以打印有关每个评估模型的技能的一些信息。当评估大量模型时,这很有帮助。
下面的 `score_model()` 函数实现了这一点,并返回一个 (key, result) 的元组,其中 key 是已测试模型配置的字符串表示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 评估模型,失败时返回 None def score_model(data, n_test, cfg, debug=False): result = None # 将配置转换为键 key = str(cfg) # 如果在调试,则显示所有警告并在异常时失败 if debug: result = walk_forward_validation(data, n_test, cfg) else: # 模型验证过程中的一次失败表明配置不稳定 try: # 网格搜索时从不显示警告,太嘈杂 with catch_warnings(): filterwarnings("ignore") result = walk_forward_validation(data, n_test, cfg) except: error = None # 检查是否有有趣的结果 if result is not None: print(' > Model[%s] %.3f' % (key, result)) return (key, result) |
接下来,我们需要一个循环来测试不同的模型配置列表。
这是驱动网格搜索过程的主要函数,它将为每个模型配置调用 *score_model()* 函数。
我们可以通过并行评估模型配置来显著加快网格搜索过程。一种方法是使用 Joblib 库。
我们可以定义一个 `Parallel` 对象,指定要使用的核心数,并将其设置为您的硬件检测到的分数数。
|
1 |
executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing') |
然后,我们可以创建一个要并行执行的任务列表,这将是 `score_model()` 函数的一次调用,针对我们拥有的每个模型配置。
|
1 |
任务 = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list) |
最后,我们可以使用Parallel对象来并行执行任务列表。
|
1 |
scores = executor(tasks) |
就是这样。
我们还可以提供一个非并行版本的模型配置评估,以防我们想要调试某些东西。
|
1 |
scores = [score_model(data, n_test, cfg) for cfg in cfg_list] |
评估配置列表的结果将是一个元组列表,每个元组都包含一个总结特定模型配置的名称,以及使用该配置评估的模型错误(RMSE)或在发生错误时为None。
我们可以过滤掉所有设置为None的分数。
|
1 |
scores = [r for r in scores if r[1] != None] |
然后我们可以按升序(最佳在前)对列表中所有元组进行排序,然后返回此分数列表以供审查。
下面的grid_search()函数实现了这一行为,给定一个单变量时间序列数据集、一个模型配置列表(列表的列表)以及用于测试集的时步数。可选的并行参数允许在所有核心上评估模型,该参数可以开启或关闭,默认开启。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 网格搜索配置 def grid_search(data, cfg_list, n_test, parallel=True): scores = None if parallel: # 并行执行配置 executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing') tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list) scores = executor(tasks) else: scores = [score_model(data, n_test, cfg) for cfg in cfg_list] # 移除空结果 scores = [r for r in scores if r[1] != None] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) return scores |
我们快完成了。
剩下的唯一一件事是定义要用于数据集的模型配置列表。
我们可以泛化定义这一点。我们可能想要指定的唯一参数是序列中季节性成分的周期性(偏移量),如果存在的话。默认情况下,我们将假设没有季节性成分。
下面的simple_configs()函数将创建要评估的模型配置列表。
该函数仅需要历史数据的最大长度作为参数,以及可选的季节性成分的周期性,默认为1(无季节性成分)。
|
1 2 3 4 5 6 7 8 9 |
# 创建一组简单的配置进行尝试 def simple_configs(max_length, offsets=[1]): configs = list() for i in range(1, max_length+1): for o in offsets: for t in ['persist', 'mean', 'median']: cfg = [i, o, t] configs.append(cfg) return configs |
现在我们有了一个通过单步前向验证来网格搜索简单模型超参数的框架。
它是通用的,适用于作为列表或 NumPy 数组提供的任何内存中单变量时间序列。
我们可以通过在一个构造的 10 步数据集上测试它来确保所有部分协同工作。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 |
# 网格搜索简单预测 from math import sqrt from numpy import mean from numpy import median from multiprocessing import cpu_count from joblib import Parallel from joblib import delayed from warnings import catch_warnings from warnings import filterwarnings from sklearn.metrics import mean_squared_error # 一步简单预测 def simple_forecast(history, config): n, offset, avg_type = config # 持久化值,忽略其他配置 if avg_type == 'persist': return history[-n] # 收集要平均的值 values = list() if offset == 1: values = history[-n:] else: # 跳过错误的配置 if n*offset > len(history): raise Exception('配置超出数据末尾: %d %d' % (n,offset)) # 尝试使用偏移量收集 n 个值 for i in range(1, n+1): ix = i * offset values.append(history[-ix]) # 检查是否可以平均 if len(values) < 2: raise Exception('无法计算平均值') # 最后 n 个值的平均值 if avg_type == 'mean': return mean(values) # 最后 n 个值的中位数 return median(values) # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = simple_forecast(history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) return error # 评估模型,失败时返回 None def score_model(data, n_test, cfg, debug=False): result = None # 将配置转换为键 key = str(cfg) # 如果在调试,则显示所有警告并在异常时失败 if debug: result = walk_forward_validation(data, n_test, cfg) else: # 模型验证过程中的一次失败表明配置不稳定 try: # 网格搜索时从不显示警告,太嘈杂 with catch_warnings(): filterwarnings("ignore") result = walk_forward_validation(data, n_test, cfg) except: error = None # 检查是否有有趣的结果 if result is not None: print(' > Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test, parallel=True): scores = None if parallel: # 并行执行配置 executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing') tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list) scores = executor(tasks) else: scores = [score_model(data, n_test, cfg) for cfg in cfg_list] # 移除空结果 scores = [r for r in scores if r[1] != None] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # 创建一组简单的配置进行尝试 def simple_configs(max_length, offsets=[1]): configs = list() for i in range(1, max_length+1): for o in offsets: for t in ['persist', 'mean', 'median']: cfg = [i, o, t] configs.append(cfg) return configs if __name__ == '__main__': # 定义数据集 data = [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] print(data) # 数据分割 n_test = 4 # 模型配置 max_length = len(data) - n_test cfg_list = simple_configs(max_length) # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('完成') # 列出前 3 个配置 for cfg, error in scores[:3]: print(cfg, error) |
运行示例首先打印人工生成的时间序列数据集。
接下来,模型配置及其错误会在模型评估时被报告。
最后,将报告前三个配置的配置和错误。
可以看到,具有1(例如,持久化最后一个观测值)配置的持久化模型在测试的简单模型中取得了最佳性能,这符合预期。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0] > 模型[[1, 1, 'persist']] 10.000 > 模型[[2, 1, 'persist']] 20.000 > 模型[[2, 1, 'mean']] 15.000 > 模型[[2, 1, 'median']] 15.000 > 模型[[3, 1, 'persist']] 30.000 > 模型[[4, 1, 'persist']] 40.000 > 模型[[5, 1, 'persist']] 50.000 > 模型[[5, 1, 'mean']] 30.000 > 模型[[3, 1, 'mean']] 20.000 > 模型[[4, 1, 'median']] 25.000 > 模型[[6, 1, 'persist']] 60.000 > 模型[[4, 1, 'mean']] 25.000 > 模型[[3, 1, 'median']] 20.000 > 模型[[6, 1, 'mean']] 35.000 > 模型[[5, 1, 'median']] 30.000 > 模型[[6, 1, 'median']] 35.000 完成 [1, 1, 'persist'] 10.0 [2, 1, 'mean'] 15.0 [2, 1, 'median'] 15.0 |
现在我们有了一个网格搜索简单模型超参数的稳健框架,让我们在标准单变量时间序列数据集套件上进行测试。
在每个数据集上展示的结果提供了性能基线,可用于与更复杂的方法进行比较,例如SARIMA、ETS,甚至机器学习方法。
案例研究 1:无趋势或季节性
“每日女性出生人数”数据集汇总了 1959 年美国加利福尼亚州每日女性出生总数。
该数据集没有明显的趋势或季节性成分。
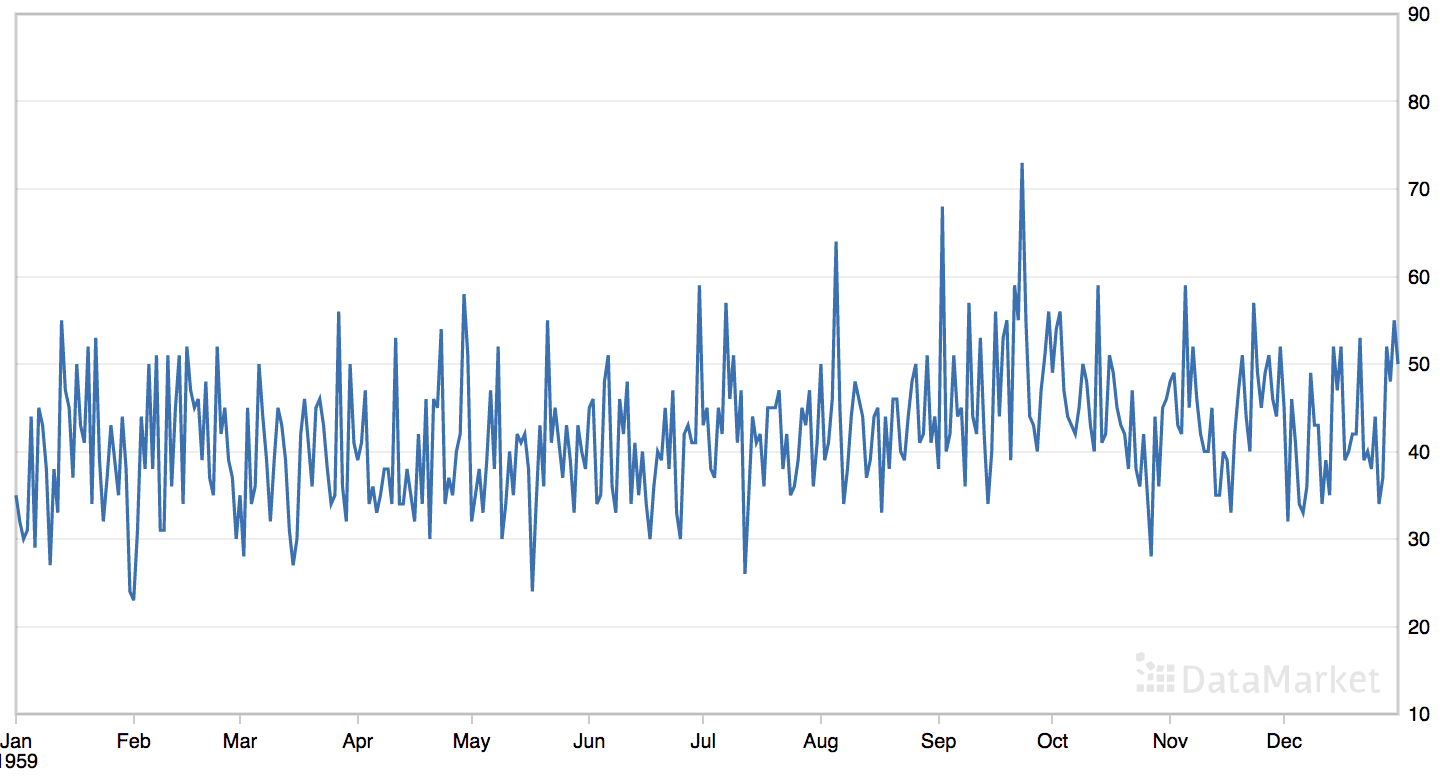
每日女性出生人数数据集的线图
直接从这里下载数据集
将文件保存为“_daily-total-female-births.csv_”在当前工作目录中。
我们可以使用 *read_csv()* 函数将此数据集加载为 Pandas 序列。
|
1 |
series = read_csv('daily-total-female-births.csv', header=0, index_col=0) |
数据集有一年,即 365 个观测值。我们将使用前 200 个进行训练,其余 165 个作为测试集。
下面列出了对每日女性单变量时间序列预测问题进行网格搜索的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
# 为每日女性出生人口网格搜索简单预测 from math import sqrt from numpy import mean from numpy import median from multiprocessing import cpu_count from joblib import Parallel from joblib import delayed from warnings import catch_warnings from warnings import filterwarnings from sklearn.metrics import mean_squared_error from pandas import read_csv # 一步简单预测 def simple_forecast(history, config): n, offset, avg_type = config # 持久化值,忽略其他配置 if avg_type == 'persist': return history[-n] # 收集要平均的值 values = list() if offset == 1: values = history[-n:] else: # 跳过错误的配置 if n*offset > len(history): raise Exception('配置超出数据末尾: %d %d' % (n,offset)) # 尝试使用偏移量收集 n 个值 for i in range(1, n+1): ix = i * offset values.append(history[-ix]) # 检查是否可以平均 if len(values) < 2: raise Exception('无法计算平均值') # 最后 n 个值的平均值 if avg_type == 'mean': return mean(values) # 最后 n 个值的中位数 return median(values) # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = simple_forecast(history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) return error # 评估模型,失败时返回 None def score_model(data, n_test, cfg, debug=False): result = None # 将配置转换为键 key = str(cfg) # 如果在调试,则显示所有警告并在异常时失败 if debug: result = walk_forward_validation(data, n_test, cfg) else: # 模型验证过程中的一次失败表明配置不稳定 try: # 网格搜索时从不显示警告,太嘈杂 with catch_warnings(): filterwarnings("ignore") result = walk_forward_validation(data, n_test, cfg) except: error = None # 检查是否有有趣的结果 if result is not None: print(' > Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test, parallel=True): scores = None if parallel: # 并行执行配置 executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing') tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list) scores = executor(tasks) else: scores = [score_model(data, n_test, cfg) for cfg in cfg_list] # 移除空结果 scores = [r for r in scores if r[1] != None] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # 创建一组简单的配置进行尝试 def simple_configs(max_length, offsets=[1]): configs = list() for i in range(1, max_length+1): for o in offsets: for t in ['persist', 'mean', 'median']: cfg = [i, o, t] configs.append(cfg) return configs if __name__ == '__main__': # 定义数据集 series = read_csv('daily-total-female-births.csv', header=0, index_col=0) data = series.values print(data) # 数据分割 n_test = 165 # 模型配置 max_length = len(data) - n_test cfg_list = simple_configs(max_length) # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('完成') # 列出前 3 个配置 for cfg, error in scores[:3]: print(cfg, error) |
运行示例将打印模型配置和RMSE,这些配置和RMSE在模型评估时被打印出来。
最后将报告前三个模型配置及其错误。
可以看到,最佳结果是约6.93个出生人口的RMSE,配置如下:
- 策略:平均
- n: 22
- 函数:mean()
这有些令人惊讶,因为缺乏趋势或季节性,我本以为持久化-1或平均整个历史数据集会产生最佳性能。
|
1 2 3 4 5 6 7 8 9 10 11 |
... > 模型[[186, 1, 'mean']] 7.523 > 模型[[200, 1, 'median']] 7.681 > 模型[[186, 1, 'median']] 7.691 > 模型[[187, 1, 'persist']] 11.137 > 模型[[187, 1, 'mean']] 7.527 完成 [22, 1, 'mean'] 6.930411499775709 [23, 1, 'mean'] 6.932293117115201 [21, 1, 'mean'] 6.951918385845375 |
案例研究 2:趋势
“洗发水”数据集汇总了三年期间洗发水的月销售额。
该数据集包含一个明显的趋势,但没有明显的季节性成分。
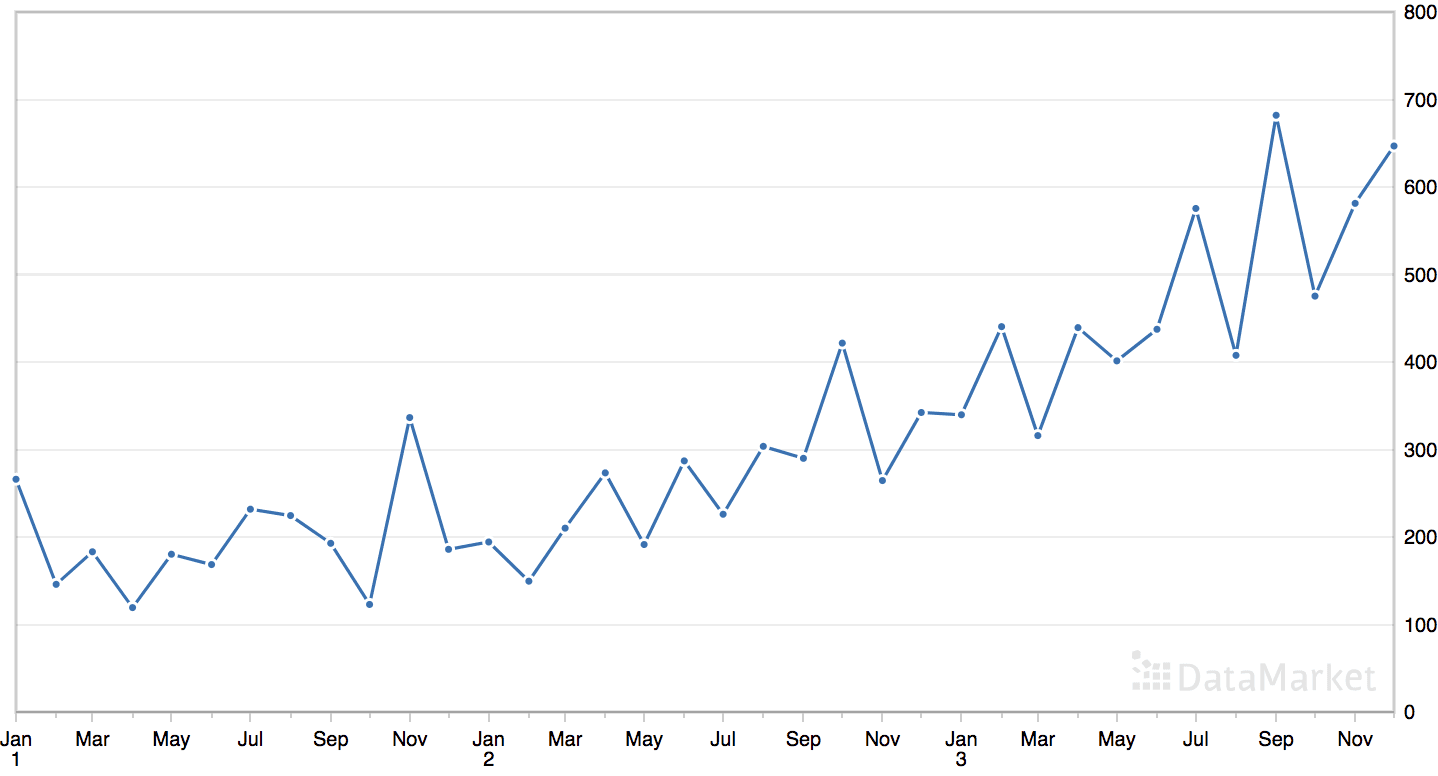
月度洗发水销售数据集的线图
直接从这里下载数据集
将文件保存为‘shampoo.csv’在当前工作目录中。
我们可以使用 *read_csv()* 函数将此数据集加载为 Pandas 序列。
|
1 2 3 4 5 6 |
# 解析日期 def custom_parser(x): return datetime.strptime('195'+x, '%Y-%m') # 加载数据集 series = read_csv('shampoo.csv', header=0, index_col=0, date_parser=custom_parser) |
数据集有三年,即 36 个观测值。我们将使用前 24 个进行训练,其余 12 个作为测试集。
下面列出了对洗发水销售单变量时间序列预测问题进行网格搜索的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
# 为每月洗发水销量网格搜索简单预测 from math import sqrt from numpy import mean from numpy import median from multiprocessing import cpu_count from joblib import Parallel from joblib import delayed from warnings import catch_warnings from warnings import filterwarnings from sklearn.metrics import mean_squared_error from pandas import read_csv from pandas import datetime # 一步简单预测 def simple_forecast(history, config): n, offset, avg_type = config # 持久化值,忽略其他配置 if avg_type == 'persist': return history[-n] # 收集要平均的值 values = list() if offset == 1: values = history[-n:] else: # 跳过错误的配置 if n*offset > len(history): raise Exception('配置超出数据末尾: %d %d' % (n,offset)) # 尝试使用偏移量收集 n 个值 for i in range(1, n+1): ix = i * offset values.append(history[-ix]) # 检查是否可以平均 if len(values) < 2: raise Exception('无法计算平均值') # 最后 n 个值的平均值 if avg_type == 'mean': return mean(values) # 最后 n 个值的中位数 return median(values) # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = simple_forecast(history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) return error # 评估模型,失败时返回 None def score_model(data, n_test, cfg, debug=False): result = None # 将配置转换为键 key = str(cfg) # 如果在调试,则显示所有警告并在异常时失败 if debug: result = walk_forward_validation(data, n_test, cfg) else: # 模型验证过程中的一次失败表明配置不稳定 try: # 网格搜索时从不显示警告,太嘈杂 with catch_warnings(): filterwarnings("ignore") result = walk_forward_validation(data, n_test, cfg) except: error = None # 检查是否有有趣的结果 if result is not None: print(' > Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test, parallel=True): scores = None if parallel: # 并行执行配置 executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing') tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list) scores = executor(tasks) else: scores = [score_model(data, n_test, cfg) for cfg in cfg_list] # 移除空结果 scores = [r for r in scores if r[1] != None] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # 创建一组简单的配置进行尝试 def simple_configs(max_length, offsets=[1]): configs = list() for i in range(1, max_length+1): for o in offsets: for t in ['persist', 'mean', 'median']: cfg = [i, o, t] configs.append(cfg) return configs # 解析日期 def custom_parser(x): return datetime.strptime('195'+x, '%Y-%m') if __name__ == '__main__': # 加载数据集 series = read_csv('shampoo.csv', header=0, index_col=0, date_parser=custom_parser) data = series.values print(data.shape) # 数据分割 n_test = 12 # 模型配置 max_length = len(data) - n_test cfg_list = simple_configs(max_length) # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('完成') # 列出前 3 个配置 for cfg, error in scores[:3]: print(cfg, error) |
运行示例将打印配置和RMSE,这些配置和RMSE在模型评估时被打印出来。
最后将报告前三个模型配置及其错误。
可以看到,最佳结果是约95.69次的销量RMSE,配置如下:
- 策略:持久化
- n: 2
这有些令人惊讶,因为数据的趋势结构表明持久化前一个值(-1)是最佳方法,而不是持久化第二个最后的值。
|
1 2 3 4 5 6 7 8 9 10 11 |
... > 模型[[23, 1, 'mean']] 209.782 > 模型[[23, 1, 'median']] 221.863 > 模型[[24, 1, 'persist']] 305.635 > 模型[[24, 1, 'mean']] 213.466 > 模型[[24, 1, 'median']] 226.061 完成 [2, 1, 'persist'] 95.69454007413378 [2, 1, 'mean'] 96.01140340258198 [2, 1, 'median'] 96.01140340258198 |
案例研究 3:季节性
“月平均气温”数据集总结了 1920 年至 1939 年间英国诺丁汉城堡的月平均气温(华氏度)。
该数据集具有明显的季节性成分,但没有明显的趋势。
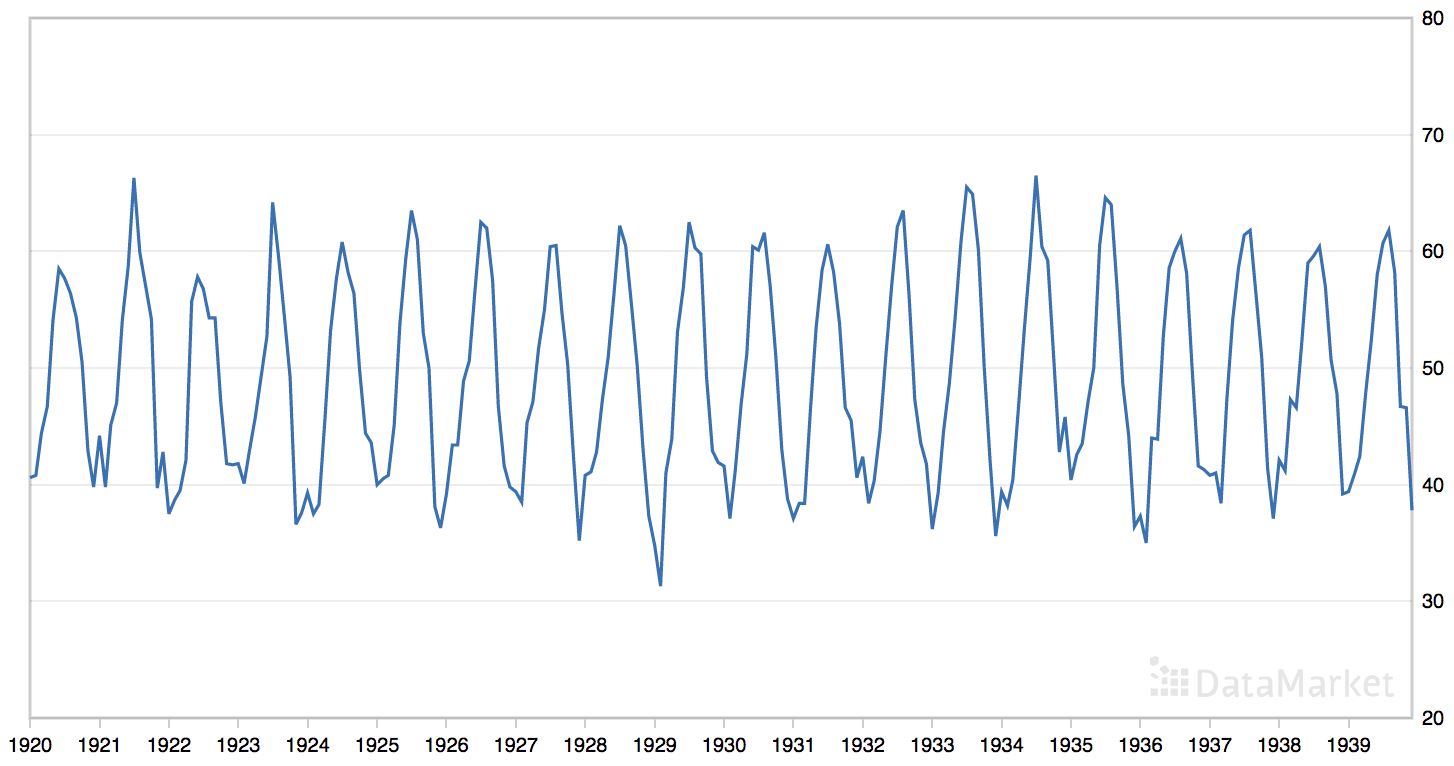
月平均气温数据集的线图
直接从这里下载数据集
将文件保存为‘monthly-mean-temp.csv’在当前工作目录中。
我们可以使用 *read_csv()* 函数将此数据集加载为 Pandas 序列。
|
1 |
series = read_csv('monthly-mean-temp.csv', header=0, index_col=0) |
该数据集包含20年,即240个观测值。我们将数据集截断到过去五年的数据(60个观测值),以加快模型评估过程,并使用最后一年或12个观测值作为测试集。
|
1 2 |
# 将数据集裁剪为 5 年 data = data[-(5*12):] |
季节性成分的周期约为一年,即12个观测值。我们将此作为调用simple_configs()函数时准备模型配置的季节性周期。
|
1 2 |
# 模型配置 cfg_list = simple_configs(max_length, offsets=[1,12]) |
下面列出了对月平均气温时间序列预测问题进行网格搜索的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
# 为每月平均气温网格搜索简单预测 from math import sqrt from numpy import mean from numpy import median from multiprocessing import cpu_count from joblib import Parallel from joblib import delayed from warnings import catch_warnings from warnings import filterwarnings from sklearn.metrics import mean_squared_error from pandas import read_csv # 一步简单预测 def simple_forecast(history, config): n, offset, avg_type = config # 持久化值,忽略其他配置 if avg_type == 'persist': return history[-n] # 收集要平均的值 values = list() if offset == 1: values = history[-n:] else: # 跳过错误的配置 if n*offset > len(history): raise Exception('配置超出数据末尾: %d %d' % (n,offset)) # 尝试使用偏移量收集 n 个值 for i in range(1, n+1): ix = i * offset values.append(history[-ix]) # 检查是否可以平均 if len(values) < 2: raise Exception('无法计算平均值') # 最后 n 个值的平均值 if avg_type == 'mean': return mean(values) # 最后 n 个值的中位数 return median(values) # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = simple_forecast(history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) return error # 评估模型,失败时返回 None def score_model(data, n_test, cfg, debug=False): result = None # 将配置转换为键 key = str(cfg) # 如果在调试,则显示所有警告并在异常时失败 if debug: result = walk_forward_validation(data, n_test, cfg) else: # 模型验证过程中的一次失败表明配置不稳定 try: # 网格搜索时从不显示警告,太嘈杂 with catch_warnings(): filterwarnings("ignore") result = walk_forward_validation(data, n_test, cfg) except: error = None # 检查是否有有趣的结果 if result is not None: print(' > Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test, parallel=True): scores = None if parallel: # 并行执行配置 executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing') tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list) scores = executor(tasks) else: scores = [score_model(data, n_test, cfg) for cfg in cfg_list] # 移除空结果 scores = [r for r in scores if r[1] != None] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # 创建一组简单的配置进行尝试 def simple_configs(max_length, offsets=[1]): configs = list() for i in range(1, max_length+1): for o in offsets: for t in ['persist', 'mean', 'median']: cfg = [i, o, t] configs.append(cfg) return configs if __name__ == '__main__': # 定义数据集 series = read_csv('monthly-mean-temp.csv', header=0, index_col=0) data = series.values print(data) # 数据分割 n_test = 12 # 模型配置 max_length = len(data) - n_test cfg_list = simple_configs(max_length, offsets=[1,12]) # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('完成') # 列出前 3 个配置 for cfg, error in scores[:3]: print(cfg, error) |
运行示例将打印模型配置和RMSE,这些配置和RMSE在模型评估时被打印出来。
最后将报告前三个模型配置及其错误。
可以看到,最佳结果是约1.501度的RMSE,配置如下:
- 策略:平均
- n: 4
- 偏移量: 12
- 函数:mean()
这个发现并不令人意外。鉴于数据的季节性结构,我们预计在先前周期点上的最后几个观测值的函数将是有效的。
|
1 2 3 4 5 6 7 8 9 10 |
... > 模型[[227, 12, 'persist']] 5.365 > 模型[[228, 1, 'persist']] 2.818 > 模型[[228, 1, 'mean']] 8.258 > 模型[[228, 1, 'median']] 8.361 > 模型[[228, 12, 'persist']] 2.818 完成 [4, 12, 'mean'] 1.5015616870445234 [8, 12, 'mean'] 1.5794579766489512 [13, 12, 'mean'] 1.586186052546763 |
案例研究 4:趋势和季节性
“月度汽车销量”数据集总结了 1960 年至 1968 年间加拿大魁北克的月度汽车销量。
该数据集具有明显的趋势和季节性成分。
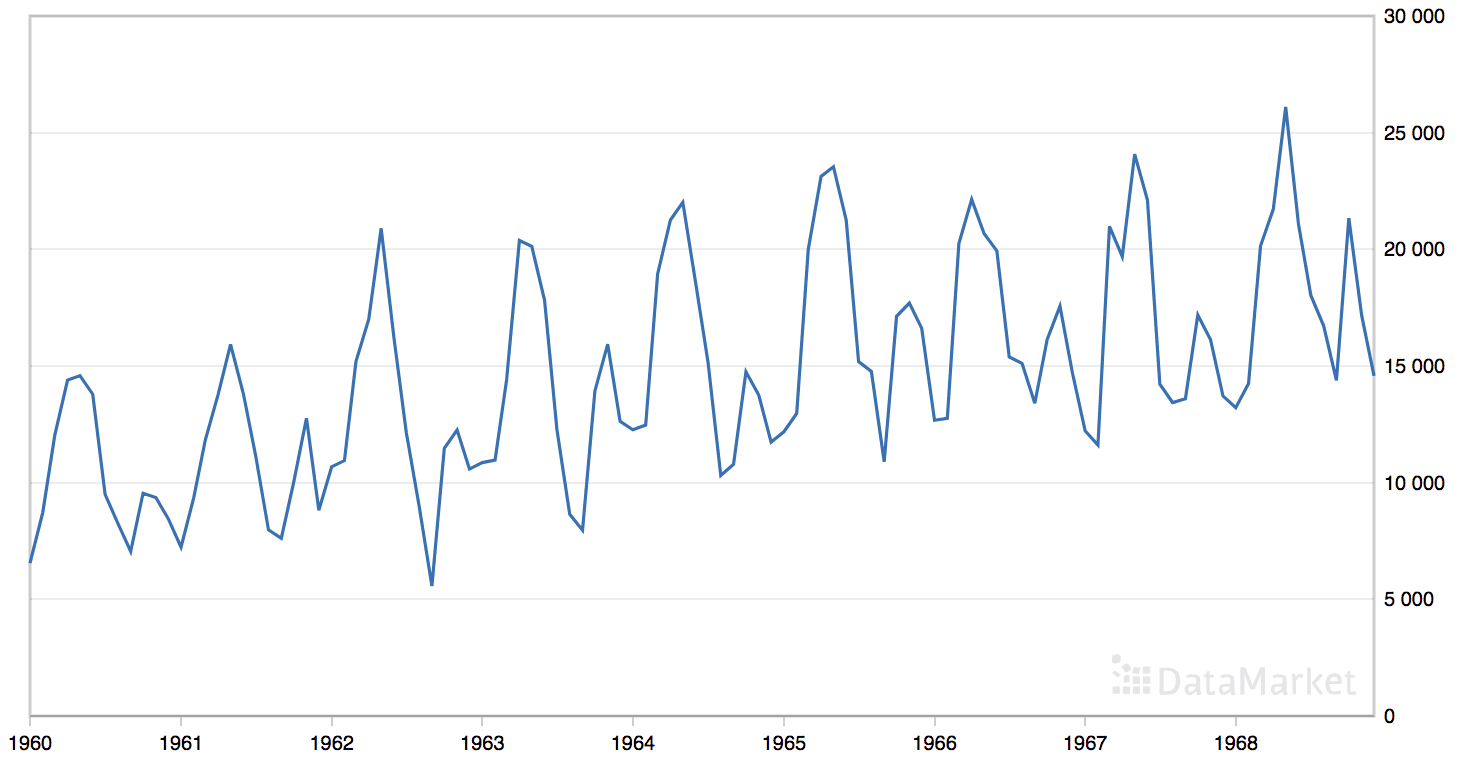
月度汽车销量数据集的线图
直接从这里下载数据集
将文件保存为“_monthly-car-sales.csv_”在当前工作目录中。
我们可以使用 *read_csv()* 函数将此数据集加载为 Pandas 序列。
|
1 |
series = read_csv('monthly-car-sales.csv', header=0, index_col=0) |
该数据集有9年,即108个观测值。我们将最后一年或12个观测值作为测试集。
季节性成分的周期可能是12个月。我们将此作为调用simple_configs()函数时准备模型配置的季节性周期。
|
1 2 |
# 模型配置 cfg_list = simple_configs(max_length, offsets=[1,12]) |
下面列出了对月度汽车销量时间序列预测问题进行网格搜索的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
# 为每月汽车销量网格搜索简单预测 from math import sqrt from numpy import mean from numpy import median from multiprocessing import cpu_count from joblib import Parallel from joblib import delayed from warnings import catch_warnings from warnings import filterwarnings from sklearn.metrics import mean_squared_error from pandas import read_csv # 一步简单预测 def simple_forecast(history, config): n, offset, avg_type = config # 持久化值,忽略其他配置 if avg_type == 'persist': return history[-n] # 收集要平均的值 values = list() if offset == 1: values = history[-n:] else: # 跳过错误的配置 if n*offset > len(history): raise Exception('配置超出数据末尾: %d %d' % (n,offset)) # 尝试使用偏移量收集 n 个值 for i in range(1, n+1): ix = i * offset values.append(history[-ix]) # 检查是否可以平均 if len(values) < 2: raise Exception('无法计算平均值') # 最后 n 个值的平均值 if avg_type == 'mean': return mean(values) # 最后 n 个值的中位数 return median(values) # 均方根误差或 RMSE def measure_rmse(actual, predicted): return sqrt(mean_squared_error(actual, predicted)) # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test], data[-n_test:] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test, cfg): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 拟合模型并对历史数据进行预测 yhat = simple_forecast(history, cfg) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 估计预测误差 error = measure_rmse(test, predictions) return error # 评估模型,失败时返回 None def score_model(data, n_test, cfg, debug=False): result = None # 将配置转换为键 key = str(cfg) # 如果在调试,则显示所有警告并在异常时失败 if debug: result = walk_forward_validation(data, n_test, cfg) else: # 模型验证过程中的一次失败表明配置不稳定 try: # 网格搜索时从不显示警告,太嘈杂 with catch_warnings(): filterwarnings("ignore") result = walk_forward_validation(data, n_test, cfg) except: error = None # 检查是否有有趣的结果 if result is not None: print(' > Model[%s] %.3f' % (key, result)) return (key, result) # 网格搜索配置 def grid_search(data, cfg_list, n_test, parallel=True): scores = None if parallel: # 并行执行配置 executor = Parallel(n_jobs=cpu_count(), backend='multiprocessing') tasks = (delayed(score_model)(data, n_test, cfg) for cfg in cfg_list) scores = executor(tasks) else: scores = [score_model(data, n_test, cfg) for cfg in cfg_list] # 移除空结果 scores = [r for r in scores if r[1] != None] # 按误差升序排序配置 scores.sort(key=lambda tup: tup[1]) 返回 分数 # 创建一组简单的配置进行尝试 def simple_configs(max_length, offsets=[1]): configs = list() for i in range(1, max_length+1): for o in offsets: for t in ['persist', 'mean', 'median']: cfg = [i, o, t] configs.append(cfg) return configs if __name__ == '__main__': # 定义数据集 series = read_csv('monthly-car-sales.csv', header=0, index_col=0) data = series.values print(data) # 数据分割 n_test = 12 # 模型配置 max_length = len(data) - n_test cfg_list = simple_configs(max_length, offsets=[1,12]) # 网格搜索 scores = grid_search(data, cfg_list, n_test) print('完成') # 列出前 3 个配置 for cfg, error in scores[:3]: print(cfg, error) |
运行示例将打印模型配置和RMSE,这些配置和RMSE在模型评估时被打印出来。
最后将报告前三个模型配置及其错误。
可以看到,最佳结果是约1841.155次的销量RMSE,配置如下:
- 策略:平均
- n: 3
- 偏移量: 12
- 函数:median()
模型是先前周期中相同时间点的最后几个观测值的函数,这并不令人意外,尽管使用中位数而不是平均值可能并不显而易见,并且结果比平均值好得多。
|
1 2 3 4 5 6 7 8 9 10 |
... > 模型[[79, 1, 'median']] 5124.113 > 模型[[91, 12, 'persist']] 9580.149 > 模型[[79, 12, 'persist']] 8641.529 > 模型[[92, 1, 'persist']] 9830.921 > 模型[[92, 1, 'mean']] 5148.126 完成 [3, 12, 'median'] 1841.1559321976688 [3, 12, 'mean'] 2115.198495632485 [4, 12, 'median'] 2184.37708988932 |
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- **绘制预测图**。更新框架以使用最佳配置重新拟合模型并预测整个测试数据集,然后将预测与测试集中的实际观测值进行比较绘制图。
- 漂移方法。为简单预测实现漂移方法,并将结果与平均和朴素方法进行比较。
- 另一个数据集。将开发的框架应用于额外的单变量时间序列问题。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
总结
在本教程中,您将发现如何从头开始开发一个框架,用于对单变量数据进行时间序列预测的简单朴素和平均策略进行网格搜索。
具体来说,你学到了:
- 如何开发一个框架,使用前向验证从头开始对简单模型进行网格搜索。
- 如何对每日时间序列出生数据进行简单模型超参数的网格搜索。
- 如何对洗发水销量、汽车销量和温度等月度时间序列数据进行简单模型超参数的网格搜索。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。




先生,这是关于学习的优秀博客。我也在写关于机器学习和区块链的博客,如果您能帮我一下
我不知道区块链,抱歉。
嗨,Jason,
我正试图根据您在下面给出的提示,为您的代码添加多步预测功能。
“如果您有兴趣进行多步预测,您可以更改simple_forecast()函数中predict()的调用,并更改measure_rmse()函数中错误的计算”。
但是,我在simple_forecast()函数中没有看到可以更改的predict(),它会影响measure_rmse()的计算。
我只是在simple_configs()中更改了cfg配置,无法信任我的结果。
您能否为多步预测功能提供更多提示?
提前感谢你
关于朴素方法,您必须自己开发predict函数。
多步预测的朴素预测可能涉及将最后一个观测值向前预测n次,其中n是预测的时步数。
如果您觉得这有挑战性,这里是开始时间序列预测的好地方。
https://machinelearning.org.cn/start-here/#timeseries
好的,谢谢