数据很少是干净的,通常会有损坏或缺失的值。
在开发机器学习模型时,识别、标记和处理缺失数据非常重要,以便获得最佳性能。
在这篇文章中,您将了解如何使用 Weka 处理机器学习数据中的缺失值。
阅读本文后,您将了解
- 如何标记数据集中的缺失值。
- 如何从数据集中删除包含缺失值的数据。
- 如何估算缺失值。
通过我的新书《Weka 机器学习精通》启动您的项目,包括所有示例的分步教程和清晰的屏幕截图。
让我们开始吧。

如何在 Weka 中处理机器学习的缺失数据
图片由 Peter Sitte 拍摄,保留部分权利。
预测糖尿病发病
本示例中使用的问题是 Pima 印第安人糖尿病发病数据集。
这是一个分类问题,每个实例代表一个患者的医疗详细信息,任务是预测该患者是否会在未来五年内患上糖尿病。
你可以在此处了解更多关于此数据集的信息:
你还可以在Weka安装的`data/`目录下找到名为`diabetes.arff`的此数据集。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
标记缺失值
Pima 印第安人数据集是探索缺失数据的好基础。
某些属性,如血压(pres)和身体质量指数(mass)的值为零,这是不可能的。这些是必须手动标记的损坏或缺失数据的示例。
您可以使用 NumericalCleaner 过滤器在 Weka 中标记缺失值。下面的示例向您展示了如何使用此过滤器标记身体质量指数(mass)属性上的 11 个缺失值。
1. 打开 Weka Explorer。
2. 加载 Pima 印第安人糖尿病发病数据集。
3. 点击过滤器旁边的“选择”按钮,选择 NumericalCleaner,它位于 unsupervized.attribute.NumericalCleaner 下。
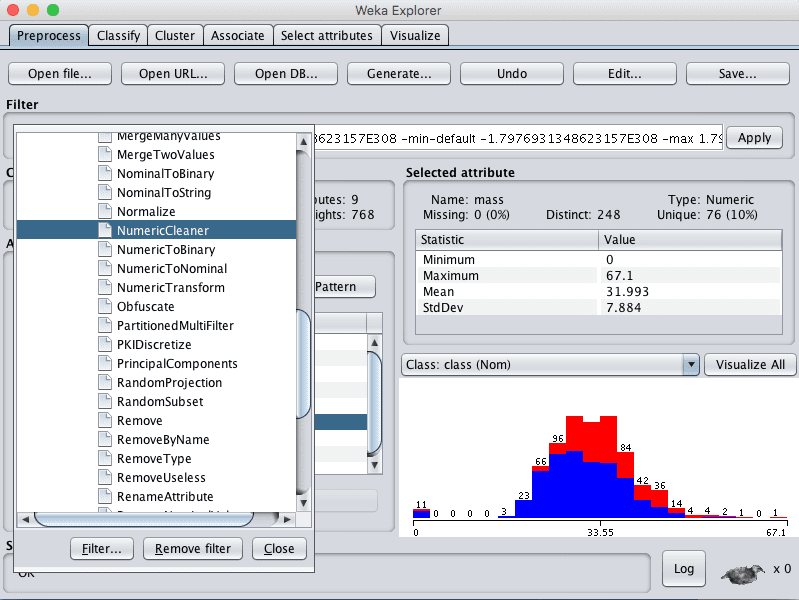
Weka 选择 NumericCleaner 数据过滤器
4. 点击过滤器进行配置。
5. 将 attributeIndicies 设置为 6,即 mass 属性的索引。
6. 将 minThreshold 设置为 0.1E-8(接近零),这是属性允许的最小值。
7. 将 minDefault 设置为 NaN,表示未知,它将替换低于阈值的值。
8. 点击过滤器配置上的“确定”按钮。
9. 点击“应用”按钮以应用过滤器。
在“属性”窗格中点击“mass”,并查看“选定属性”的详细信息。请注意,最初设置为 0 的 11 个属性值现在被标记为缺失。
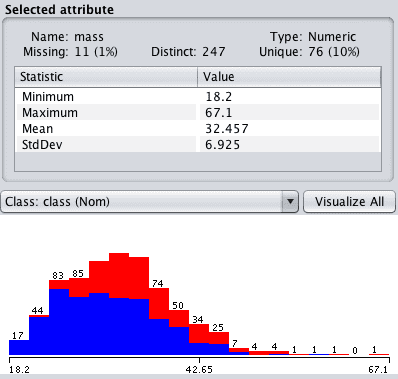
Weka 缺失数据已标记
在此示例中,我们将低于阈值的值标记为缺失。
您也可以轻松地用特定数值标记它们。您还可以标记介于上限和下限之间的缺失值。
接下来,让我们看看如何从数据集中删除包含缺失值的实例。
删除缺失数据
现在您知道如何标记数据中的缺失值,您需要学习如何处理它们。
处理缺失数据的一种简单方法是删除那些具有一个或多个缺失值的实例。
您可以使用 RemoveWithValues 过滤器在 Weka 中执行此操作。
继续上面的示例来标记缺失值,您可以按如下方式删除缺失值:
1. 点击过滤器旁边的“选择”按钮,选择 RemoveWithValues,它位于 unsupervized.instance.RemoveWithValues 下。
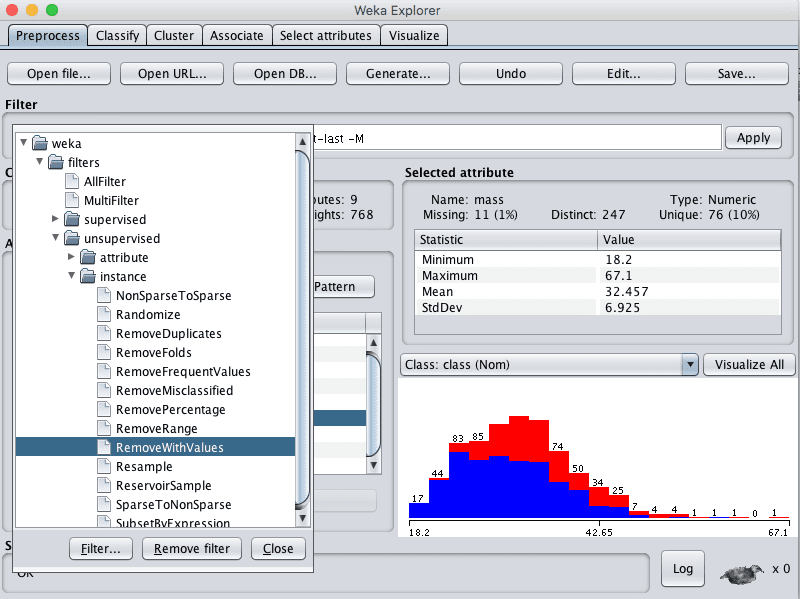
Weka 选择 RemoveWithValues 数据过滤器
2. 点击过滤器进行配置。
3. 将 attributeIndicies 设置为 6,即 mass 属性的索引。
4. 将 matchMissingValues 设置为“True”。
5. 点击“确定”按钮以使用过滤器配置。
6. 点击“应用”按钮以应用过滤器。
在“属性”部分点击“mass”,并查看“选定属性”的详细信息。
请注意,标记为缺失的 11 个属性值已从数据集中删除。
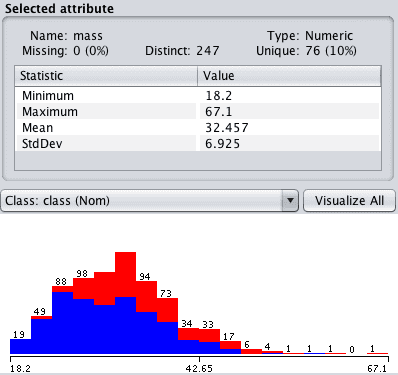
Weka 缺失值已删除
注意,您可以通过点击“撤消”按钮来撤消此操作。
估算缺失值
具有缺失值的实例不必删除,您可以用其他值替换缺失值。
这称为估算缺失值。
通常用数值分布的均值估算缺失值。您可以使用 ReplaceMissingValues 过滤器在 Weka 中轻松完成此操作。
继续上面的第一个示例来标记缺失值,您可以按如下方式估算缺失值:
1. 点击过滤器旁边的“选择”按钮,选择 ReplaceMissingValues,它位于 unsupervized.attribute.ReplaceMissingValues 下。
Weka ReplaceMissingValues 数据过滤器
2. 点击“应用”按钮以将过滤器应用于您的数据集。
在“属性”部分点击“mass”,并查看“选定属性”的详细信息。
请注意,标记为缺失的 11 个属性值已设置为分布的均值。
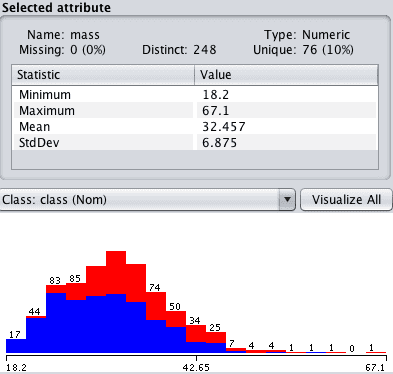
Weka 估算值
总结
在这篇文章中,您发现了如何使用 Weka 处理机器学习数据集中的缺失数据。
具体来说,你学到了:
- 如何将数据集中损坏的值标记为缺失。
- 如何从数据集中删除包含缺失值的实例。
- 如何为数据集中缺失值估算均值。
您对缺失数据或本教程有任何疑问吗?请在下面的评论中提出您的问题,我将尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






我想问一个问题,当数据具有缺失数值(空白)并进行分类(例如多层感知器)时,Weka 会取什么值进行计算。
Ramesh 您好,您可以预处理数据以用均值或其他常量值估算缺失值。
您好,感谢您的指导。现在我已删除具有特定缺失属性值的实例,我想用剩余数据进行训练以预测我刚刚删除的缺失值,我该怎么做?
Enrique 您好,我最好的建议是保存您转换后的数据集的副本。
然后您可以在将来加载它,并将其用于您的探索和实验。
先生您好,感谢您如此富有成果的演示。我想问一下我们是否可以使用 Weka 的 KNN 估算。或者任何其他基于最近邻的估算方法
Shah 您好,我手头不确定。
但我们甚至不确定 WEKA 使用哪种机器学习技术进行估算或替换值。
ReplaceMissingValues 过滤器分别用实数值的均值和名义值的众数替换值。
你可以在这里了解更多
http://weka.sourceforge.net/doc.stable/weka/filters/unsupervised/attribute/ReplaceMissingValues.html
我想预测一个属性,该属性存在于训练数据集中,但不存在于测试数据集中。即使它存在,我也尝试将这些品牌实例用作 Null 或缺失值。我正在使用随机森林,它被封装在输入映射分类器中,尽管它执行了,但它只预测“?”标记(即 Null)。
我使用的数据集包含进口商名称、单位、货币、关税值、品牌规格(文本、部分为数字或实数)。我尝试预测的值是文本(名义)。大多数文本数据可以很容易地标记为二进制数据类型。
嗨
有新帖子或新闻稿时请通知我。
此致,
穆罕默德
您可以在此处访问 RSS feed
https://machinelearning.org.cn/feed/
嗨,Jason,
很棒的文章,但是,我感觉您错过了一个很好的点来解释应该采取哪些步骤来处理缺失数据,所以我有点困惑。
在什么时候我宁愿删除包含缺失信息的样本,而不是选择估算它们?
删除样本也引出了一个问题:您的数据集中应保留的样本的最小阈值是多少,才能使其仍然代表您要实现的目标?
我们无法知道哪种方法对给定的问题是“最好”的。
系统地尝试多种方法,并选择在您的问题上提供最佳预测模型的方法。
所需的数据量也取决于问题的复杂性。
抱歉,没有简单的答案。应用机器学习需要大量的实验和试错。开发一个健壮的测试工具!
在 Weka 工具中,当我点击分类下的树时,它没有显示 J48,我该如何添加它?
您好,对于名义属性,我如何删除缺失的实例(例如用“?”标记的)?我没有找到过滤器。应用“Remove with values”应该可以,但它没有起作用。谢谢。
您可以使用教程中演示的 pandas 函数吗?
我相信列的类型不应该影响所使用的 dataframe 函数。
嗨,Jason,
我想问一下缺失数据。我知道有时缺失数据对我们来说太重要了,不能完全从分析中删除。例如,我有一个数据集,其中有 30% 的总数据缺失。我正在尝试进行时间序列预测,并且数据在五年内持续缺失周六和周日的数据。我正在使用卡尔曼平滑法来填充这两天的空白……
您认为这种方法可能相对可以吗?或者您认为我应该删除具有缺失值的行吗?
尝试不同的方法,看看哪种方法最适合您的问题。先验地说哪种方法最好是很难(甚至不可能!)的。
您能否提一些评估(如果有)技术来检查我替换缺失数据的方法效果如何?我怎么知道哪种方法最好,因为我永远无法知道这些缺失数据是什么。
先谢谢您了。
是的,专注于用您进行估算的数据训练的模型预测能力。
嗨,Jason,
好文章 🙂
我有一些疑问。我生成了我的模型,在缺失属性处我插入了符号“?”
您知道当属性值缺失为“?”时 Weka 是如何工作的吗?
您能给我一篇关于这个的论文吗?
此致
这个教程对您有用吗?
非常抱歉,Jason,我的技术不同……
我不想填充这些值,我想让它们保持空白……
您知道当我这样做时算法是如何工作的吗?
再次感谢 🙂
你好,杰森 🙂
我学习了 🙂 …
如果您使用 MLP,缺失值将被忽略,通过将输入值设置为零。
如果您使用 SMOreg 或线性回归,缺失值将用于均值/众数估算。
不错。
嗨,杰森,我正在使用朴素贝叶斯进行预测,我的数据集中有很多缺失值,目前我使用替换缺失值,然后进行预处理和预测,如果我删除 95% 缺失值的属性会不会更好?
我建议尝试一套不同的方法,看看哪种方法最适合您的特定数据。
我不太明白文章中处理缺失值的方式与仅使用“替换缺失值”过滤器之间有什么区别?
我正是这么做的。
我遇到了问题
我没有缺失值,但当在 weka 中应用时出现了符号 (?)
抱歉,我没听懂,您具体是什么意思?
当您的数据集中没有缺失值时,您如何处理详细精度表中的问号 (?) 问题?
嗨,Greg……更多想法可以在这里找到
https://machinelearning.org.cn/handle-missing-data-python/
当我们在 weka 中尝试应用无监督属性替换缺失值过滤器时,我能够获得填充的缺失值作为输出
干得好!
嗨,我在处理缺失值时遇到了麻烦。
问题是回归,而不是分类。有什么方法可以使用机器学习来处理缺失值吗?
我束手无策。
谢谢你
是的,您可以使用均值作为一个好的起点。
嗨,杰森。信息量很大。谢谢。我想问一下 Weka 的默认设置(没有过滤器)如何处理缺失值?训练/测试示例是 1) 按案例排除(任何带有缺失预测器的示例都被排除)2) 从可用特征属性的均值/中位数中估算?
我相信它会按原样使用数据,例如“缺失”值被视为值。
抱歉,没太明白。希望能更清楚地解释一下。如何将“缺失”值视为值?它正如所暗示的那样是“缺失的”。
在某些情况下,缺失值可能会用一个值标记,例如“none”或“nan”。像决策树这样的方法可以根据这个值做出分裂决策。
如果数据实际上是缺失的,那么行或值可能只是被算法忽略,尽管这取决于算法。
嗨!
我正在尝试对缺失数据执行估算(最初是为了测试这个过程,这些缺失数据是通过随机删除数据集中属性中的数据生成的)。我想通过使用 ANN 来实现这一点。所以我的问题是,如果我在 weka 中训练 ANN 并将类设置为实际类,那么我是否可以使用这个 ANN 通过将实例的类设置为这个缺失属性来预测缺失值?我正在尝试这样做,但我收到“未定义输入实例格式”错误。
如果答案是否定的,那么我是否必须为每个缺失属性训练 ANN,将此特定属性中的数据类设置为将要预测的类,然后一旦 ANN(或任何其他分类器)经过训练,就使用该实例作为输入。对我来说,这意味着需要为每个缺失属性执行一次训练(实际上是一台机器)。
我认为我正在问的是执行回归,但我没有找到如何在 weka 中执行此操作。
该模型将被训练以预测缺失值,而不是类别值。例如,一种估算方法。
是的,我相信每个特征都会训练一个模型。
非常感谢。我最终决定为每个属性在一个批处理过程中训练一个“方法”,以便稍后进行快速估算。
非常感谢您的回答!
已成功完成
干得好!
我们怎么知道它是使用均值还是众数来替换值?
嗨,ydil…在 Weka 中,处理缺失值通常使用
ReplaceMissingValues过滤器完成,该过滤器可以将缺失值替换为均值(对于数值属性)或众数(对于标称属性)。以下是如何在 Weka 中检查或更改默认行为:
1. **打开 Weka Explorer:**
– 启动 Weka 并进入 Explorer。
2. **加载您的数据集:**
– 加载您要预处理的数据集。
3. **选择过滤器:**
– 转到“预处理”选项卡。
– 点击“Filter”部分下的“Choose”按钮。
– 选择
weka.filters.unsupervised.attribute.ReplaceMissingValues。4. **检查过滤器选项:**
– 选择过滤器后,您可以点击过滤器名称(例如,
ReplaceMissingValues)来查看和配置其选项。但是,此特定过滤器不提供更改默认行为(数值的均值和标称的众数)的选项,因为它是内置的。5. **应用过滤器:**
– 点击“Apply”按钮将过滤器应用于您的数据集。
6. **验证更改:**
– 应用后,您可以检查转换后的数据集,看看缺失值是如何处理的。
**注意:** 如果您想更精确地控制如何替换缺失值(例如,使用中位数而不是均值),您可能需要使用其他过滤器或自定义脚本手动预处理数据。
### 使用 Weka 的命令行界面
如果您正在从命令行使用 Weka,您可以使用以下命令应用
ReplaceMissingValues过滤器:sh
java -cp weka.jar weka.filters.unsupervised.attribute.ReplaceMissingValues -i input.arff -o output.arff
在此命令中:
–
-i input.arff指定输入文件。–
-o output.arff指定替换了缺失值的输出文件。### Weka GUI 中的示例
1. **加载数据:**
– 点击“Open file…”并选择您的数据集(例如,
data.arff)。2. **应用过滤器:**
– 选择
ReplaceMissingValues过滤器。– 点击“Apply”。
3. **查看结果:**
– 检查生成的数据集以确认更改。
默认情况下,Weka 的
ReplaceMissingValues过滤器对数值属性使用均值,对标称属性使用众数,并且此行为通常无法直接在过滤器设置中配置。如果您需要不同的方法,请考虑在将数据导入 Weka 之前使用其他预处理步骤或外部数据准备工具。