里程碑模型中存在离散的架构元素,您可以将其用于设计自己的卷积神经网络。
具体而言,在图像分类等任务中取得最先进结果的模型使用多次重复的离散架构元素,例如 VGG 模型中的 VGG 块、GoogLeNet 中的 Inception 模块以及 ResNet 中的残差模块。
一旦您能够实现这些架构元素的参数化版本,就可以将它们用于设计自己的计算机视觉和其他应用模型。
在本教程中,您将学习如何从零开始实现里程碑卷积神经网络模型中的关键架构元素。
完成本教程后,您将了解:
- 如何实现 VGG-16 和 VGG-19 卷积神经网络模型中使用的 VGG 模块。
- 如何实现 GoogLeNet 模型中使用的朴素和优化 Inception 模块。
- 如何实现 ResNet 模型中使用的恒等残差模块。
通过我的新书《计算机视觉深度学习》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。

如何实现卷积神经网络的主要架构创新
图片由 daveynin 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 如何实现 VGG 块
- 如何实现 Inception 模块
- 如何实现残差模块
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何实现 VGG 块
VGG 卷积神经网络架构以牛津大学的视觉几何组命名,是计算机视觉深度学习方法使用中的一个重要里程碑。
该架构在 Karen Simonyan 和 Andrew Zisserman 于 2014 年发表的题为“用于大规模图像识别的超深度卷积网络”的论文中进行了描述,并在 LSVRC-2014 计算机视觉竞赛中取得了顶级成绩。
该架构的关键创新是定义和重复我们将称之为 VGG 块的结构。这些是使用小滤波器(例如 3×3 像素)的卷积层组,后跟一个最大池化层。
图像经过一系列卷积(conv.)层,我们使用感受野非常小的滤波器:3 x 3(这是捕捉左/右、上/下、中心概念的最小尺寸)。[…] 最大池化在 2 x 2 像素窗口上执行,步幅为 2。
— 用于大规模图像识别的超深度卷积网络,2014 年。
使用 VGG 块的卷积神经网络是开发新模型的合理起点,因为它易于理解、易于实现,并且在从图像中提取特征方面非常有效。
我们可以将 VGG 块的规范概括为:一个或多个卷积层,它们具有相同数量的滤波器和 3×3 的滤波器大小,1×1 的步幅,相同填充,因此每个滤波器的输出大小与输入大小相同,并使用修正线性激活函数。这些层之后是最大池化层,其大小为 2×2,步幅相同。
我们可以使用 Keras 函数式 API 定义一个函数来创建 VGG 块,该函数具有给定数量的卷积层和给定数量的每层滤波器。
|
1 2 3 4 5 6 7 8 |
# 创建 VGG 块的函数 def vgg_block(layer_in, n_filters, n_conv): # 添加卷积层 for _ in range(n_conv): layer_in = Conv2D(n_filters, (3,3), padding='same', activation='relu')(layer_in) # 添加最大池化层 layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in) return layer_in |
要使用该函数,需要传入块之前的层,并接收可用于集成到模型中的块末尾的层。
例如,第一层可能是一个输入层,可以作为参数传递给函数。然后,该函数返回对块中最终层(池化层)的引用,该层可以连接到扁平层和随后的密集层,以进行分类预测。
我们可以通过定义一个小型模型来演示如何使用此函数,该模型期望方形彩色图像作为输入,并向模型添加一个 VGG 块,其中包含两个卷积层,每个卷积层都有 64 个滤波器。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 使用 VGG 块创建 CNN 模型的示例 from keras.models import Model from keras.layers import Input 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.utils import plot_model # 创建 VGG 块的函数 def vgg_block(layer_in, n_filters, n_conv): # 添加卷积层 for _ in range(n_conv): layer_in = Conv2D(n_filters, (3,3), padding='same', activation='relu')(layer_in) # 添加最大池化层 layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in) return layer_in # 定义模型输入 visible = Input(shape=(256, 256, 3)) # 添加 vgg 模块 layer = vgg_block(visible, 64, 2) # 创建模型 model = Model(inputs=visible, outputs=layer) # 总结模型 model.summary() # 绘制模型架构 plot_model(model, show_shapes=True, to_file='vgg_block.png') |
运行该示例会创建模型并总结其结构。
我们可以看到,正如预期的那样,模型添加了一个 VGG 块,其中包含两个卷积层,每个卷积层都有 64 个滤波器,后跟一个最大池化层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= input_1 (InputLayer) (None, 256, 256, 3) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 256, 256, 64) 1792 _________________________________________________________________ conv2d_2 (Conv2D) (None, 256, 256, 64) 36928 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 128, 128, 64) 0 ================================================================= 总参数:38,720 可训练参数:38,720 不可训练参数: 0 _________________________________________________________________ |
还创建了模型架构的图表,这可能有助于使模型布局更加具体。
请注意,创建图表假定您已安装 pydot 和 pygraphviz。如果未安装,您可以注释掉示例中的 import 语句和对 plot_model() 函数的调用。
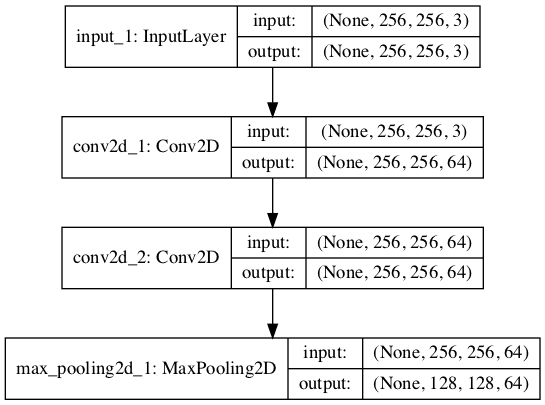
带 VGG 块的卷积神经网络架构图
在您自己的模型中使用 VGG 块应该很常见,因为它们非常简单有效。
我们可以扩展该示例,演示一个具有三个 VGG 块的单一模型,前两个块分别具有两个卷积层,分别有 64 和 128 个滤波器,第三个块具有四个卷积层,有 256 个滤波器。这是 VGG 块的常见用法,其中滤波器的数量随着模型的深度而增加。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 创建具有多个 VGG 块的 CNN 模型的示例 from keras.models import Model from keras.layers import Input 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.utils import plot_model # 创建 VGG 块的函数 def vgg_block(layer_in, n_filters, n_conv): # 添加卷积层 for _ in range(n_conv): layer_in = Conv2D(n_filters, (3,3), padding='same', activation='relu')(layer_in) # 添加最大池化层 layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in) return layer_in # 定义模型输入 visible = Input(shape=(256, 256, 3)) # 添加 vgg 模块 layer = vgg_block(visible, 64, 2) # 添加 vgg 模块 layer = vgg_block(layer, 128, 2) # 添加 vgg 模块 layer = vgg_block(layer, 256, 4) # 创建模型 model = Model(inputs=visible, outputs=layer) # 总结模型 model.summary() # 绘制模型架构 plot_model(model, show_shapes=True, to_file='multiple_vgg_blocks.png') |
再次运行该示例会总结模型架构,我们可以清楚地看到 VGG 块的模式。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= input_1 (InputLayer) (None, 256, 256, 3) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 256, 256, 64) 1792 _________________________________________________________________ conv2d_2 (Conv2D) (None, 256, 256, 64) 36928 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 128, 128, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 128, 128, 128) 73856 _________________________________________________________________ conv2d_4 (Conv2D) (None, 128, 128, 128) 147584 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 64, 64, 128) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 64, 64, 256) 295168 _________________________________________________________________ conv2d_6 (Conv2D) (None, 64, 64, 256) 590080 _________________________________________________________________ conv2d_7 (Conv2D) (None, 64, 64, 256) 590080 _________________________________________________________________ conv2d_8 (Conv2D) (None, 64, 64, 256) 590080 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 32, 32, 256) 0 ================================================================= 总参数:2,325,568 可训练参数:2,325,568 不可训练参数: 0 _________________________________________________________________ |
创建了一个模型架构图,从不同角度展示了相同的层线性进展。
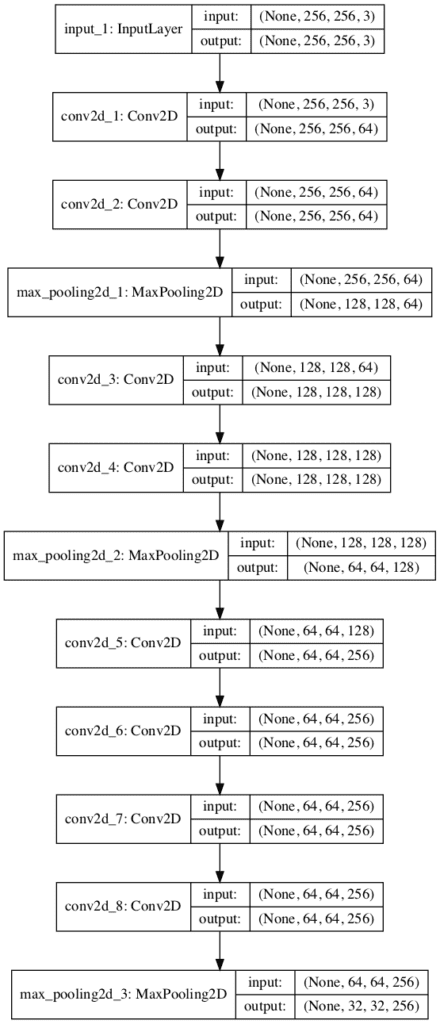
具有多个 VGG 块的卷积神经网络架构图
如何实现 Inception 模块
Inception 模块在 Christian Szegedy 等人于 2015 年发表的题为“通过卷积深入”的论文中,在 GoogLeNet 模型中进行了描述和使用。
与 VGG 模型一样,GoogLeNet 模型在 2014 年 ILSVRC 挑战赛中取得了顶级成绩。
Inception 模型的主要创新被称为 Inception 模块。它是一个并行卷积层块,具有不同大小的滤波器(例如 1×1、3×3、5×5)和一个 3×3 最大池化层,其结果随后被连接起来。
为了避免补丁对齐问题,当前 Inception 架构的版本仅限于 1×1、3×3 和 5×5 的滤波器大小;这个决定更多是基于方便而不是必要性。 […] 此外,由于池化操作对当前卷积网络的成功至关重要,因此建议在每个这样的阶段添加一个替代的并行池化路径也应该具有额外的有益效果。
— 通过卷积深入,2015 年。
这是一个非常简单而强大的架构单元,它允许模型不仅学习相同大小的并行滤波器,还学习不同大小的并行滤波器,从而在多个尺度上进行学习。
我们可以直接使用 Keras 函数式 API 实现一个 Inception 模块。下面的函数将创建一个具有固定数量滤波器的单个 Inception 模块,用于每个并行卷积层。根据论文中描述的 GoogLeNet 架构,它似乎没有对并行卷积层使用系统的滤波器大小调整,因为该模型经过高度优化。因此,我们可以对模块定义进行参数化,以便我们可以指定在每个 1×1、3×3 和 5×5 滤波器中使用的滤波器数量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 用于创建朴素 Inception 块的函数 def inception_module(layer_in, f1, f2, f3): # 1x1 卷积 conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in) # 3x3 卷积 conv3 = Conv2D(f2, (3,3), padding='same', activation='relu')(layer_in) # 5x5 卷积 conv5 = Conv2D(f3, (5,5), padding='same', activation='relu')(layer_in) # 3x3 最大池化 pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in) # 连接滤波器,假设滤波器/通道在最后 layer_out = concatenate([conv1, conv3, conv5, pool], axis=-1) return layer_out |
要使用该函数,请提供对先前层的引用作为输入,以及滤波器数量,它将返回对连接滤波器层的引用,然后您可以将其连接到更多 Inception 模块或子模型以进行预测。
我们可以通过创建一个带有单个 Inception 模块的模型来演示如何使用此函数。在这种情况下,滤波器数量基于论文表 1 中的“Inception (3a)”。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 创建带有 Inception 模块的 CNN 示例 from keras.models import Model from keras.layers import Input 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers.merge import concatenate from keras.utils import plot_model # 用于创建朴素 Inception 块的函数 def naive_inception_module(layer_in, f1, f2, f3): # 1x1 卷积 conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in) # 3x3 卷积 conv3 = Conv2D(f2, (3,3), padding='same', activation='relu')(layer_in) # 5x5 卷积 conv5 = Conv2D(f3, (5,5), padding='same', activation='relu')(layer_in) # 3x3 最大池化 pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in) # 连接滤波器,假设滤波器/通道在最后 layer_out = concatenate([conv1, conv3, conv5, pool], axis=-1) return layer_out # 定义模型输入 visible = Input(shape=(256, 256, 3)) # 添加 Inception 模块 layer = naive_inception_module(visible, 64, 128, 32) # 创建模型 model = Model(inputs=visible, outputs=layer) # 总结模型 model.summary() # 绘制模型架构 plot_model(model, show_shapes=True, to_file='naive_inception_module.png') |
运行该示例会创建模型并总结各层。
我们知道卷积层和池化层是并行的,但此摘要无法轻松捕获其结构。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_1 (InputLayer) (None, 256, 256, 3) 0 __________________________________________________________________________________________________ conv2d_1 (Conv2D) (None, 256, 256, 64) 256 input_1[0][0] __________________________________________________________________________________________________ conv2d_2 (Conv2D) (None, 256, 256, 128) 3584 input_1[0][0] __________________________________________________________________________________________________ conv2d_3 (Conv2D) (None, 256, 256, 32) 2432 input_1[0][0] __________________________________________________________________________________________________ max_pooling2d_1 (MaxPooling2D) (None, 256, 256, 3) 0 input_1[0][0] __________________________________________________________________________________________________ concatenate_1 (Concatenate) (None, 256, 256, 227) 0 conv2d_1[0][0] conv2d_2[0][0] conv2d_3[0][0] max_pooling2d_1[0][0] ================================================================================================== 总参数:6,272 可训练参数:6,272 不可训练参数: 0 __________________________________________________________________________________________________ |
还创建了模型架构图,有助于清晰地看到模块的并行结构以及模块每个元素的输出形状匹配,这允许它们通过第三维(滤波器或通道)直接连接。

带有朴素 Inception 模块的卷积神经网络架构图
我们实现的 Inception 模块版本称为朴素 Inception 模块。
对该模块进行了修改,以减少所需的计算量。具体而言,添加了1×1 卷积层,以减少 3×3 和 5×5 卷积层之前的滤波器数量,并在池化层之后增加滤波器数量。
这导致了 Inception 架构的第二个思想:在计算需求 otherwise 增加过多时,审慎地降低维度。 […] 也就是说,在昂贵的 3×3 和 5×5 卷积之前,使用 1×1 卷积进行降维。除了用作降维之外,它们还包括使用修正线性激活,使其具有双重用途
— 通过卷积深入,2015 年。
如果您打算在模型中使用许多 Inception 模块,则可能需要这种基于计算性能的修改。
下面的函数实现了这种优化改进,并进行了参数化,以便您可以控制 3×3 和 5×5 卷积层之前的滤波器数量减少量以及最大池化后滤波器数量增加量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 用于创建投影 Inception 模块的函数 def inception_module(layer_in, f1, f2_in, f2_out, f3_in, f3_out, f4_out): # 1x1 卷积 conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in) # 3x3 卷积 conv3 = Conv2D(f2_in, (1,1), padding='same', activation='relu')(layer_in) conv3 = Conv2D(f2_out, (3,3), padding='same', activation='relu')(conv3) # 5x5 卷积 conv5 = Conv2D(f3_in, (1,1), padding='same', activation='relu')(layer_in) conv5 = Conv2D(f3_out, (5,5), padding='same', activation='relu')(conv5) # 3x3 最大池化 pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in) pool = Conv2D(f4_out, (1,1), padding='same', activation='relu')(pool) # 连接滤波器,假设滤波器/通道在最后 layer_out = concatenate([conv1, conv3, conv5, pool], axis=-1) return layer_out |
我们可以创建带有两个优化 Inception 模块的模型,以具体了解该架构在实践中的外观。
在这种情况下,滤波器配置数量基于论文表 1 中的“inception (3a)”和“inception (3b)”。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 使用高效 Inception 模块创建 CNN 的示例 from keras.models import Model from keras.layers import Input 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers.merge import concatenate from keras.utils import plot_model # 用于创建投影 Inception 模块的函数 def inception_module(layer_in, f1, f2_in, f2_out, f3_in, f3_out, f4_out): # 1x1 卷积 conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in) # 3x3 卷积 conv3 = Conv2D(f2_in, (1,1), padding='same', activation='relu')(layer_in) conv3 = Conv2D(f2_out, (3,3), padding='same', activation='relu')(conv3) # 5x5 卷积 conv5 = Conv2D(f3_in, (1,1), padding='same', activation='relu')(layer_in) conv5 = Conv2D(f3_out, (5,5), padding='same', activation='relu')(conv5) # 3x3 最大池化 pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in) pool = Conv2D(f4_out, (1,1), padding='same', activation='relu')(pool) # 连接滤波器,假设滤波器/通道在最后 layer_out = concatenate([conv1, conv3, conv5, pool], axis=-1) return layer_out # 定义模型输入 visible = Input(shape=(256, 256, 3)) # 添加 Inception 块 1 layer = inception_module(visible, 64, 96, 128, 16, 32, 32) # 添加 Inception 块 1 layer = inception_module(layer, 128, 128, 192, 32, 96, 64) # 创建模型 model = Model(inputs=visible, outputs=layer) # 总结模型 model.summary() # 绘制模型架构 plot_model(model, show_shapes=True, to_file='inception_module.png') |
运行该示例会创建层级的线性摘要,这并不能真正帮助理解正在发生的事情。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_1 (InputLayer) (None, 256, 256, 3) 0 __________________________________________________________________________________________________ conv2d_2 (Conv2D) (None, 256, 256, 96) 384 input_1[0][0] __________________________________________________________________________________________________ conv2d_4 (Conv2D) (None, 256, 256, 16) 64 input_1[0][0] __________________________________________________________________________________________________ max_pooling2d_1 (MaxPooling2D) (None, 256, 256, 3) 0 input_1[0][0] __________________________________________________________________________________________________ conv2d_1 (Conv2D) (None, 256, 256, 64) 256 input_1[0][0] __________________________________________________________________________________________________ conv2d_3 (Conv2D) (None, 256, 256, 128) 110720 conv2d_2[0][0] __________________________________________________________________________________________________ conv2d_5 (Conv2D) (None, 256, 256, 32) 12832 conv2d_4[0][0] __________________________________________________________________________________________________ conv2d_6 (Conv2D) (None, 256, 256, 32) 128 max_pooling2d_1[0][0] __________________________________________________________________________________________________ concatenate_1 (Concatenate) (None, 256, 256, 256) 0 conv2d_1[0][0] conv2d_3[0][0] conv2d_5[0][0] conv2d_6[0][0] __________________________________________________________________________________________________ conv2d_8 (Conv2D) (None, 256, 256, 128) 32896 concatenate_1[0][0] __________________________________________________________________________________________________ conv2d_10 (Conv2D) (None, 256, 256, 32) 8224 concatenate_1[0][0] __________________________________________________________________________________________________ max_pooling2d_2 (MaxPooling2D) (None, 256, 256, 256) 0 concatenate_1[0][0] __________________________________________________________________________________________________ conv2d_7 (Conv2D) (None, 256, 256, 128) 32896 concatenate_1[0][0] __________________________________________________________________________________________________ conv2d_9 (Conv2D) (None, 256, 256, 192) 221376 conv2d_8[0][0] __________________________________________________________________________________________________ conv2d_11 (Conv2D) (None, 256, 256, 96) 76896 conv2d_10[0][0] __________________________________________________________________________________________________ conv2d_12 (Conv2D) (None, 256, 256, 64) 16448 max_pooling2d_2[0][0] __________________________________________________________________________________________________ concatenate_2 (Concatenate) (None, 256, 256, 480) 0 conv2d_7[0][0] conv2d_9[0][0] conv2d_11[0][0] conv2d_12[0][0] ================================================================================================== 总参数: 513,120 可训练参数: 513,120 不可训练参数: 0 __________________________________________________________________________________________________ |
创建的模型架构图清楚地展示了每个模块的布局以及第一个模型如何馈送到第二个模块。
请注意,出于空间原因,每个 Inception 模块中的第一个 1×1 卷积位于最右侧,但除此之外,其他层在每个模块中都是从左到右排列的。
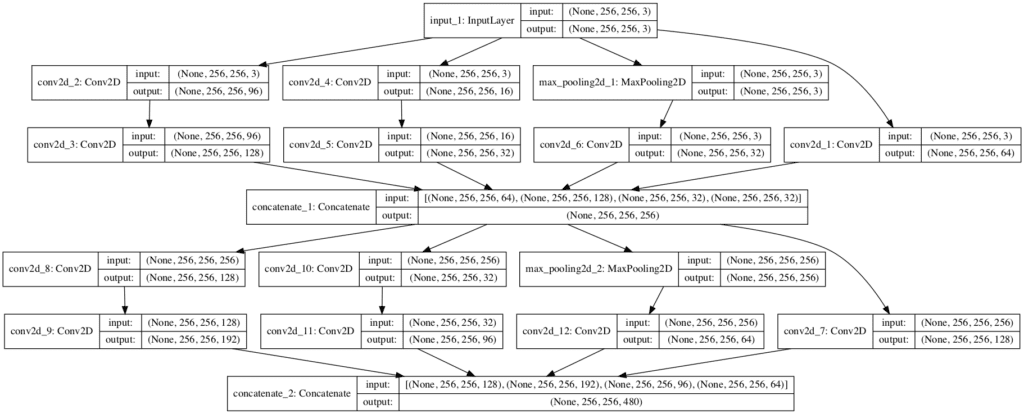
带有高效 Inception 模块的卷积神经网络架构图
如何实现残差模块
卷积神经网络的残差网络(ResNet)架构由 Kaiming He 等人在其 2016 年发表的题为《深度残差学习用于图像识别》的论文中提出,该架构在 2015 年的 ILSVRC 挑战中取得了成功。
ResNet 的一个关键创新是残差模块。残差模块,特别是恒等残差模型,是由两个具有相同滤波器数量和较小滤波器尺寸的卷积层组成的块,其中第二层的输出与第一个卷积层的输入相加。以图表形式表示,模块的输入与模块的输出相加,这被称为快捷连接。
我们可以使用 Keras 的函数式 API 和 add() 合并函数直接实现这一点。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 用于创建恒等残差模块的函数 def residual_module(layer_in, n_filters): # conv1 conv1 = Conv2D(n_filters, (3,3), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in) # conv2 conv2 = Conv2D(n_filters, (3,3), padding='same', activation='linear', kernel_initializer='he_normal')(conv1) # 添加滤波器,假设滤波器/通道在最后 layer_out = add([conv2, layer_in]) # 激活函数 layer_out = Activation('relu')(layer_out) return layer_out |
这种直接实现的一个限制是,如果输入层的滤波器数量与模块中最后一个卷积层的滤波器数量(由 n_filters 定义)不匹配,则会报错。
一个解决方案是使用 1×1 卷积层,通常被称为投影层,以增加输入层的滤波器数量或减少模块中最后一个卷积层的滤波器数量。前者解决方案更有意义,也是论文中提出的方法,被称为投影快捷连接。
当维度增加时[……],我们考虑两种选择:(A) 快捷连接仍然执行恒等映射,并为增加的维度填充额外的零条目。此选项不引入额外的参数;(B) 投影快捷连接[……]用于匹配维度(通过 1×1 卷积完成)。
—— 深度残差学习用于图像识别,2015 年。
下面是该函数的更新版本,如果可能,它将使用恒等映射;否则,如果输入的滤波器数量与 n_filters 参数不匹配,则使用投影。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 用于创建恒等或投影残差模块的函数 def residual_module(layer_in, n_filters): merge_input = layer_in # 检查是否需要增加滤波器数量,假设通道在最后 if layer_in.shape[-1] != n_filters: merge_input = Conv2D(n_filters, (1,1), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in) # conv1 conv1 = Conv2D(n_filters, (3,3), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in) # conv2 conv2 = Conv2D(n_filters, (3,3), padding='same', activation='linear', kernel_initializer='he_normal')(conv1) # 添加滤波器,假设滤波器/通道在最后 layer_out = add([conv2, merge_input]) # 激活函数 layer_out = Activation('relu')(layer_out) return layer_out |
我们可以通过一个简单的模型来演示这个模块的用法。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 带有恒等或投影残差模块的 CNN 模型示例 from keras.models import Model from keras.layers import Input from keras.layers import Activation 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import add from keras.utils import plot_model # 用于创建恒等或投影残差模块的函数 def residual_module(layer_in, n_filters): merge_input = layer_in # 检查是否需要增加滤波器数量,假设通道在最后 if layer_in.shape[-1] != n_filters: merge_input = Conv2D(n_filters, (1,1), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in) # conv1 conv1 = Conv2D(n_filters, (3,3), padding='same', activation='relu', kernel_initializer='he_normal')(layer_in) # conv2 conv2 = Conv2D(n_filters, (3,3), padding='same', activation='linear', kernel_initializer='he_normal')(conv1) # 添加滤波器,假设滤波器/通道在最后 layer_out = add([conv2, merge_input]) # 激活函数 layer_out = Activation('relu')(layer_out) return layer_out # 定义模型输入 visible = Input(shape=(256, 256, 3)) # 添加 vgg 模块 layer = residual_module(visible, 64) # 创建模型 model = Model(inputs=visible, outputs=layer) # 总结模型 model.summary() # 绘制模型架构 plot_model(model, show_shapes=True, to_file='residual_module.png') |
运行该示例首先创建模型,然后打印各层的摘要。
由于该模块是线性的,因此此摘要有助于了解正在发生的情况。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_1 (InputLayer) (None, 256, 256, 3) 0 __________________________________________________________________________________________________ conv2d_2 (Conv2D) (None, 256, 256, 64) 1792 input_1[0][0] __________________________________________________________________________________________________ conv2d_3 (Conv2D) (None, 256, 256, 64) 36928 conv2d_2[0][0] __________________________________________________________________________________________________ conv2d_1 (Conv2D) (None, 256, 256, 64) 256 input_1[0][0] __________________________________________________________________________________________________ add_1 (Add) (None, 256, 256, 64) 0 conv2d_3[0][0] conv2d_1[0][0] __________________________________________________________________________________________________ activation_1 (Activation) (None, 256, 256, 64) 0 add_1[0][0] ================================================================================================== 总参数: 38,976 可训练参数: 38,976 不可训练参数: 0 __________________________________________________________________________________________________ |
还创建了模型架构图。
我们可以看到模块中输入滤波器数量的膨胀以及模块末尾两个元素的相加。
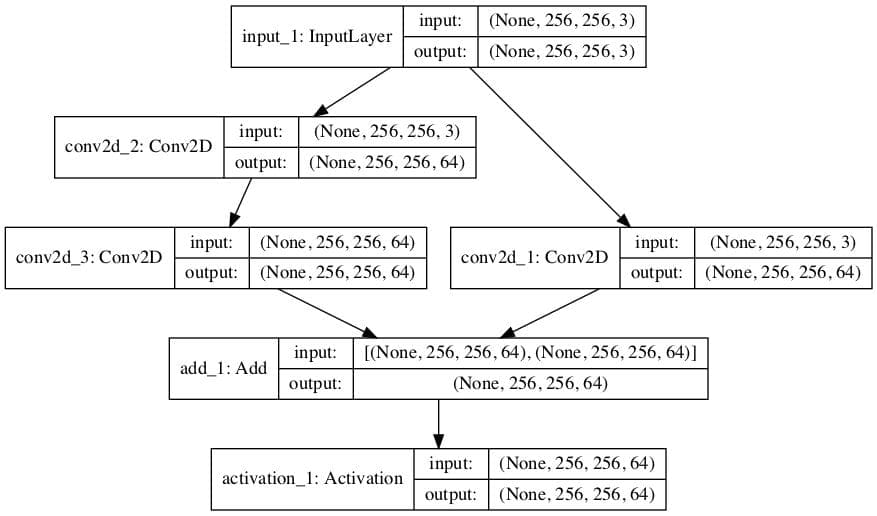
带有残差模块的卷积神经网络架构图
该论文描述了其他类型的残差连接,例如瓶颈。这些留给读者作为练习,可以通过更新 residual_module() 函数轻松实现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
论文
- 基于梯度的学习应用于文档识别,(PDF) 1998 年。
- 使用深度卷积神经网络进行 ImageNet 分类, 2012.
- 用于大规模图像识别的超深度卷积网络, 2014.
- 使用卷积网络更深入, 2015.
- 用于图像识别的深度残差学习, 2016
API
总结
在本教程中,您学习了如何从头开始实现里程碑式卷积神经网络模型的关键架构元素。
具体来说,你学到了:
- 如何实现 VGG-16 和 VGG-19 卷积神经网络模型中使用的 VGG 模块。
- 如何实现 GoogLeNet 模型中使用的朴素和优化 Inception 模块。
- 如何实现 ResNet 模型中使用的恒等残差模块。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。
 for Evaluating GANs")
 for Evaluating GANs")


 From Scratch with Keras")

我喜欢您的代码片段和实际实现示例。这些正是初学者在实验时需要的省时工具和错误避免器。非常感谢。不过,我仍然对 1×1 卷积滤波器的概念有些困惑。如果能专门针对这个主题,更详细地解释该层实际做了什么以及它是如何工作的,将会非常有帮助。(我想我需要重新阅读并多次尝试这篇文章。评论是在初读之后写的。)
谢谢。
我希望很快能有一篇专门讨论这个主题的文章。
感谢您的努力。我从您这里学到了很多。
不客气。
谢谢 Jason,
您的博客和解释总是非常有用和精炼。您的书籍也同样出色。
我对 CNN 和 LSTM 的组合非常感兴趣,阅读了您的所有博客,购买了时间序列和最新书籍,尤其是在处理有关从植物获取图像以诊断疾病随时间发展的时间序列问题方面。
如果您能写一篇关于这两种模型组合的博客,并用一个独特的例子来阐明,我将不胜感激。您的建议非常受欢迎。
感谢您的建议。
我相信 LSTM 一书中有一个处理图像随时间变化的示例。我希望将来能涵盖更多示例。
我猜在最后一部分有一个错误,当使用 merge_input 时,conv1 不应该连接到 layer_in,而是连接到 merge_input,不是吗?
我不认为有错误。
您具体指的是哪个例子?
最后一行代码的第 17 行。
你说得对,谢谢!已修复。
更新一下,不,那不是一个错误。
只有当输入的通道数与输出的通道数不匹配时,才需要 1×1 投影。
嗨 Jason!这是一篇关于 VGG 和 Inception 的精彩教程。谢谢你。但我有一个问题。您在本教程中开发代码的方式对我来说有点新。在您之前的帖子中,您使用顺序模型,然后使用“model.add”。这是开发 VGG 的特定方式,还是我们仍然可以使用该格式(例如“model.add”)来开发这些架构?提前谢谢您!
是的,这里我们使用的是函数式 API,您可以在这里了解更多信息
https://machinelearning.org.cn/keras-functional-api-deep-learning/
哦,谢谢!您是最棒的,Jason!
不客气。
一如既往,感谢 Jason 带来又一篇精彩教程!
许多 Keras 应用模型需要 224×224 图像。
有没有办法在不调整大小的情况下使用更大的图像与预训练模型?
如果没有,有没有办法至少使用它们的架构而不使用它们的权重,然后从头开始训练?
谢谢!
是的,您可以指定一个具有您偏好尺寸的新输入层。
这个可能会有帮助
https://machinelearning.org.cn/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
哇,太简单了!“input_tensor=new_input” 谢谢!顺便问一下,如果我的评论收到回复,我是否会收到电子邮件通知?
是的,非常简单。
不,我没有在博客评论上设置电子邮件通知——至少目前还没有。
精彩的教程!!!
谢谢。
嗨,Jason,
我们为了减少计算量,在投影 Inception 模块中的 3×3 和 5×5 层之前添加了 1×1 卷积层。然而,我们可以很容易地看到,例如,对于朴素 Inception 模块中 128 个大小为 3×3 的滤波器,参数数量从 3584 增加到 110720。我想知道为什么它增加了,而我们本意是减少它!您是否介意给我一些关于如何计算参数数量的提示?万分感谢!
很好的观察。我们正在权衡空间复杂度与时间复杂度。例如,更少的计算量但更多的权重。
谢谢!但我猜这样我们把负担放在了内存而不是 GPU 上。比如当我尝试将此模块用于顺序数据时,即用 CONVLSTM2D 替换 CONV2D,因为我得到了 >500M 参数,所以我遇到了 OOM!而使用 VGA 我得到了 40M,我的 RAM (16Gb) 可以计算。
我不知道为什么,但由于某些原因,当我只使用一个块时,参数数量变成了负数!
那太令人惊讶了!
您的内容对新手非常有帮助。谢谢!!
谢谢,很高兴听到这个。
Jason,我真的很喜欢您的教程。如果我想将上述模型用于单类目标检测,该怎么做?
谢谢!
或许可以从这里开始
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
Jason,在上述链接中,您使用了预定义的 mrcnn 模型。我想知道深度学习模块(如 SSD、VGG、Inception 和 ResNet)是如何用于目标检测的。我理解了上述模型如何用作分类器,但是当我尝试将相同的模型用于目标检测时,我感到困惑。
基于 SSD 的图像分类器和基于 SSD 的目标检测之间有什么主要区别?
非常感谢您的帮助。
目标检测和图像分类是非常不同的问题,使用不同的模型。
例如,Mask RCNN 和 YOLO 用于目标检测。VGG 用于图像分类。
这篇文章将帮助您了解这些差异
https://machinelearning.org.cn/object-recognition-with-deep-learning/
詹森,
感谢您的快速回复。我已阅读了建议的材料。在该博客中,您提到了 VGG-16 作为目标检测的特征提取器模型。我希望了解更多关于目标检测架构的信息。
如果您想了解更多关于 RCNN 和 YOLO 的信息,我有相关的教程。除此之外,您可以深入研究这些主题的论文。
嗨,Jason,
感谢这篇令人印象深刻的文章。
我正在尝试实现朴素 Inception 模块,但我遇到了错误“ValueError: Error when checking target: expected concatenate_2 to have 4 dimensions, but got array with shape (2, 5)”。如果您不介意,能否帮我理解这是怎么回事?特别是关于“shape (2,5)”。供您参考,我按照您的解释即插即用地使用了朴素 Inception 模块。
非常感谢。
听到这个消息我很难过。
或许可以从博客文章中的简单示例开始,先让它运行起来,然后慢慢地根据您的需求进行调整?
感谢您关于 CNN 架构的帖子,
我正在使用我的数据集尝试您的“投影 Inception 模块”,然后添加
x = Flatten()(layer)
x =(Dense(128, activation=’sigmoid’))(x)
x = (Dense(15, activation=’softmax’))(x)
model = Model(inputs=visible, outputs=x, name=’Simple_inception_v3′)
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
不幸的是,我所有 epoch 的准确率和损失都相同。
第 1/10 纪元
1811675/1811675 [=========] – 516s 285us/步 – 损失: 0.7715 – 准确率: 0.8030 – val_损失: 0.7724 – val_准确率: 0.8027
第 2/10 纪元
1811675/1811675 [=========] – 512s 282us/步 – 损失: 0.7713 – 准确率: 0.8031 – val_损失: 0.7691 – val_准确率: 0.8027
第 3/10 纪元
1811675/1811675 [=========] – 480s 265us/步 – 损失: 0.7712 – 准确率: 0.8031 – val_损失: 0.7706 – val_准确率: 0.8027
第 4/10 纪元
1811675/1811675 [=========] – 477s 263us/步 – 损失: 0.7712 – 准确率: 0.8031 – val_损失: 0.7711 – val_准确率: 0.8027
第 10/10 纪元
1811675/1811675 [=========] – 508s 280us/步 – 损失: 0.7713 – 准确率: 0.8031 – val_损失: 0.7720 – val_准确率: 0.8027
您能否给我一些改进模型的建议
非常感谢
干得好。
是的,这里的一般建议将帮助您提高模型性能
https://machinelearning.org.cn/start-here/#better
你好,谢谢你的努力,我是机器学习的初学者,我有一个关于使用 kitti 数据集从单张图像获取单目深度图的项目,你能指导我如何开始编写代码吗?提前谢谢你。
或许可以从这里的教程开始,熟悉这类项目
https://machinelearning.org.cn/start-here/#dlfcv
示例中是哪种 ResNet?谢谢
论文已直接引用并链接。
嗨,Jason!
在ResNet模块中,您选择了使用线性激活。我可以知道您选择这种特定激活的原因吗?如果我们需要进行批归一化,您会选择在它之前使用吗?
这个例子实现了论文中定义的ResNet块。
嗨,Jason,
非常感谢您的精彩解释。
我有一个关于ResNet架构中反向传播的问题。BP是否通过短路连接更新参数,但是那里没有可学习的参数?同样的问题也适用于加法过程,因为如果查看模型的摘要,加法层也没有可学习的参数。所以,我的问题是反向传播是如何对下层执行的?我对此有点困惑。这将非常有帮助。
谢谢!
不客气。
是的,当错误通过网络反向传播时,反向传播会流经所有连接。
你好,Jason。
对于Resnet,我们知道跳过连接有助于网络学习恒等映射(在主分支中)。
但是如何证明ResNet的某个块已经学习了恒等映射?有什么想法吗?
谢谢
Mike
目前没有,也许您可以尝试进行一些小的修改并比较结果。
非常感谢您的教程,我经常阅读您的教程。我想问一下您是否有更多关于Inception和Resnet的实现(示例)?我读到有Inception3和Inception4,但在您的网站上没有找到实现。
我认为没有。
关于如何实现不同模型的精彩介绍。我是深度学习概念的初学者。我一直在研究伪造图像(复制-移动/图像拼接)。我想找到图像中复制粘贴区域的确切位置。先生,您能建议一些学习概念来识别图像中存在的伪造区域吗?
也许您可以将这个问题视为一个目标检测类型的问题,例如,训练一个模型来定位您准备好的数据集上的这些编辑区域。
您好。感谢您的工作。
我有一个问题——我在ResNet论文中没有找到答案。在捷径卷积层中,您使用了 activation='relu'
if layer_in.shape[-1] != n_filters
merge_input = Conv2D(n_filters, (1,1), padding=’same’, activation=’relu’ …
这个激活函数应该选择线性激活吗?
在Inception-V4论文中,ADD层之前总是线性的
https://arxiv.org/pdf/1602.07261.pdf
太棒了!
我认为没有。
嗨,Jason,
有什么方法可以将Keras应用程序(如VGG、Resnet和Inception)用于非图像类数据吗?以上所有示例都需要形状为(256, 256,3)的图像类数据。例如,我有一个形状为(300,1)的声音时间序列数据。我可以提取声音的频谱图,它具有图像类数据的形状,但我想避免这样做,因为它太耗时了。我想直接将时间特征输入到VGG或ResNet之类的架构中。
考虑到这些层已经学习了图像数据的特征,这样做并没有实际意义。
亲爱的Jason
我想将ResNet定义的模型用于我的(340,340,1) 3类别分类。
张量包含数据点,它们不是图像。
我在定义中做了这些更改
visible = Input(shape=(340, 340, 1))
然后我使用
model.compile(loss=’categorical_crossentropy’, optimizer=’Adam’, metrics = [‘accuracy’])
model.fit(X_train, y_train, batch_size = 4, epochs = 2, validation_data=(X_test, y_test),callbacks=[callback])
results = model.evaluate(X_test, y_test)
我正在使用独热编码进行标签。
我收到了这个错误
ValueError: Shapes (None, 3) and (None, 340, 340, 64) are incompatible
您建议如何解决这个问题?
祝好。
你好Mesut…你正在实现一个CNN模型吗?