Pix2Pix GAN 是一种生成模型,用于在配对样本上训练图像到图像的转换。
例如,该模型可用于将白天图像转换为夜晚图像,或将产品(如鞋子)的草图转换为产品照片。
Pix2Pix 模型的好处是,与用于条件图像生成的其他 GAN 相比,它相对简单,并且能够跨各种图像转换任务生成大量高质量图像。
该模型非常出色,但其架构对初学者来说似乎有些复杂。
在本教程中,您将学习如何使用 Keras 深度学习框架从头开始实现 Pix2Pix GAN 架构。
完成本教程后,您将了解:
- 如何为 Pix2Pix GAN 开发 PatchGAN 判别器模型。
- 如何为 Pix2Pix GAN 开发 U-Net 编码器-解码器生成器模型。
- 如何实现用于更新生成器的复合模型,以及如何训练这两个模型。
开启您的项目,阅读我的新书《Python 生成对抗网络》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2021 年 1 月更新:已更新,以便层冻结与批处理归一化一起使用。

如何使用 Keras 从头开始实现 Pix2Pix GAN 模型
照片由 Ray in Manila 拍摄,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 什么是 Pix2Pix GAN?
- 如何实现 PatchGAN 判别器模型
- 如何实现 U-Net 生成器模型
- 如何实现对抗损失和 L1 损失
- 如何更新模型权重
什么是 Pix2Pix GAN?
Pix2Pix 是一种生成对抗网络 (GAN) 模型,专为通用图像到图像翻译而设计。
该方法由 Phillip Isola 等人在其 2016 年题为“Image-to-Image Translation with Conditional Adversarial Networks”(条件对抗网络中的图像到图像翻译)的论文中提出,并于 2017 年在 CVPR 上发表。
GAN 架构包含一个用于输出新的逼真合成图像的生成器模型和一个用于将图像分类为真实(来自数据集)或伪造(生成)的判别器模型。判别器模型直接更新,而生成器模型通过判别器模型更新。因此,这两个模型以对抗过程同时训练,其中生成器试图更好地欺骗判别器,判别器试图更好地识别伪造图像。
Pix2Pix 模型是一种条件 GAN,或 cGAN,其中输出图像的生成取决于输入,在此情况下为源图像。判别器同时接收源图像和目标图像,并必须确定目标图像是否是源图像的合理转换。
同样,判别器模型直接更新,生成器模型通过判别器模型更新,尽管损失函数会更新。生成器通过对抗损失进行训练,该损失鼓励生成器生成目标域中逼真的图像。生成器还通过在生成的图像和期望的输出图像之间测量的 L1 损失进行更新。此额外损失鼓励生成器模型创建源图像的逼真翻译。
Pix2Pix GAN 已在多种图像到图像转换任务中得到证明,例如将地图转换为卫星照片、将黑白照片转换为彩色以及将产品草图转换为产品照片。
现在我们熟悉了 Pix2Pix GAN,让我们探讨如何使用 Keras 深度学习库来实现它。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何实现 PatchGAN 判别器模型
Pix2Pix GAN 中的判别器模型实现为 PatchGAN。
PatchGAN 的设计基于感受野的大小,有时也称为有效感受野。感受野是模型的一个输出激活与输入图像(实际上是输入通道的体积)区域之间的关系。
使用的是 70×70 的 PatchGAN,这意味着模型的输出(或每个输出)映射到输入图像的 70×70 的方形区域。实际上,70×70 的 PatchGAN 将对输入图像的 70×70 的块进行真实或伪造的分类。
……我们设计了一个判别器架构——我们称之为 PatchGAN——它仅在块的尺度上进行惩罚。此判别器尝试对图像中的每个 NxN 块进行真实或伪造的分类。我们跨图像卷积地运行此判别器,并平均所有响应以提供 D 的最终输出。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
在我们深入研究 PatchGAN 的配置细节之前,了解感受野的计算非常重要。
感受野不是判别器模型的输出大小,例如,它不指模型输出的激活图的形状。它是模型的一种定义,指输出激活图中的一个像素与输入图像的关系。模型输出可以是一个单一值,也可以是一个方形激活图,其中值表示输入图像的每个块是真实还是伪造。
传统上,感受野是指单个卷积层相对于该层的输入、滤波器大小和步长计算的激活图大小。有效感受野推广了这一想法,并计算了堆叠卷积层相对于原始图像输入的输出的感受野。这两个术语经常互换使用。
Pix2Pix GAN 的作者提供了一个 Matlab 脚本来计算脚本 receptive_field_sizes.m 中不同模型配置的有效感受野大小。通过举例说明 70×70 PatchGAN 的感受野计算会很有帮助。
70×70 PatchGAN 拥有固定的三层(不包括输出层和倒数第二层),无论输入图像的大小如何。感受野的计算(以一维为例)为:
- 感受野 = (输出尺寸 – 1) * 步长 + 核尺寸
其中输出尺寸是前一层激活图的大小,步长是应用滤波器到激活时滤波器移动的像素数,核尺寸是应用的滤波器的大小。
PatchGAN 使用固定的步长 2×2(输出层和倒数第二层除外)和固定的核尺寸 4×4。因此,我们可以从模型输出的一个像素开始,向后追溯到输入图像,来计算感受野大小。
我们可以开发一个名为 `receptive_field()` 的 Python 函数来计算感受野,然后计算并打印 Pix2Pix PatchGAN 模型中每一层的感受野。完整示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 计算 PatchGAN 感受野的示例 # 计算有效感受野大小 def receptive_field(output_size, kernel_size, stride_size): return (output_size - 1) * stride_size + kernel_size # 输出层 1x1 像素,4x4 核,1x1 步长 rf = receptive_field(1, 4, 1) print(rf) # 倒数第二层,4x4 核,1x1 步长 rf = receptive_field(rf, 4, 1) print(rf) # 3 个 PatchGAN 层,4x4 核,2x2 步长 rf = receptive_field(rf, 4, 2) print(rf) rf = receptive_field(rf, 4, 2) print(rf) rf = receptive_field(rf, 4, 2) print(rf) |
运行示例将打印模型中从输出层到输入层的每一层的感受野大小。
我们可以看到,输出层中的每个 1×1 像素映射到输入层中 70×70 的感受野。
|
1 2 3 4 5 |
4 7 16 34 70 |
Pix2Pix 论文的作者探讨了不同的 PatchGAN 配置,包括一个 1×1 感受野(称为 PixelGAN)和一个与模型输入的 256×256 像素图像匹配(重采样为 286×286)的感受野(称为 ImageGAN)。他们发现 70×70 的 PatchGAN 在性能和图像质量之间取得了最佳的折衷。
70×70 的 PatchGAN [...] 获得了略好的分数。扩展到完整的 286×286 ImageGAN 并未显示出结果视觉质量的提升。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
PatchGAN 的配置在论文附录中提供,并且可以通过查看官方 Torch 实现中的 defineD_n_layers() 函数来确认。
该模型接受两个图像作为输入,具体来说是源图像和目标图像。这些图像在通道级别串联起来,例如,每个图像的 3 个彩色通道变为输入的 6 个通道。
令 Ck 表示一个带有 k 个滤波器的卷积-批归一化-ReLU 层。 […] 所有卷积都是 4×4 的空间滤波器,使用步长为 2。 […] 70×70 的判别器架构是:C64-C128-C256-C512。最后一层之后,应用一个卷积层将特征图映射到一维输出,然后是 Sigmoid 函数。作为上述约定的例外,批归一化未应用于第一个 C64 层。所有 ReLU 都是 leaky ReLU,斜率为 0.2。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
PatchGAN 配置使用简写符号定义为:C64-C128-C256-C512,其中 C 指的是一个卷积-批归一化-LeakyReLU 层块,数字表示滤波器的数量。批归一化不用于第一层。如前所述,核尺寸固定为 4×4,除了模型的最后 2 层外,所有层都使用 2×2 的步长。LeakyReLU 的斜率设置为 0.2,输出层使用 sigmoid 激活函数。
通过将 256×256 的输入图像缩放到 286×286,然后随机裁剪回 256×256 来应用随机抖动。权重从均值为 0、标准差为 0.02 的高斯分布初始化。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
模型权重是通过均值为 0.0、标准差为 0.02 的随机高斯分布初始化的。输入到模型图像为 256×256。
……我们在优化 D 时将目标除以 2,这减慢了 D 相对于 G 的学习速度。我们使用小批量 SGD 并应用 Adam 求解器,学习率为 0.0002,动量参数 β1 = 0.5,β2 = 0.999。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
模型以一个图像的批次大小进行训练,并使用随机梯度下降的 Adam 版本,具有较小的学习范围和适中的动量。在每次模型更新时,判别器的损失加权 50%。
将所有这些结合起来,我们可以定义一个名为 `define_discriminator()` 的函数,该函数创建 70×70 的 PatchGAN 判别器模型。
下面列出了定义模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# 定义 70x70 patchgan 判别器模型的示例 from keras.optimizers import Adam from keras.initializers import RandomNormal from keras.models import Model from keras.models import Input 从 keras.layers 导入 Conv2D from keras.layers import LeakyReLU from keras.layers import Activation from keras.layers import Concatenate 从 keras.层 导入 BatchNormalization from keras.utils.vis_utils import plot_model # 定义判别器模型 def define_discriminator(image_shape): # 权重初始化 init = RandomNormal(stddev=0.02) # 源图像输入 in_src_image = Input(shape=image_shape) # 目标图像输入 in_target_image = Input(shape=image_shape) # 通道级联图像 merged = Concatenate()([in_src_image, in_target_image]) # C64 d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(merged) d = LeakyReLU(alpha=0.2)(d) # C128 d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # C256 d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # C512 d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 倒数第二层输出 d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 补丁输出 d = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d) patch_out = Activation('sigmoid')(d) # 定义模型 model = Model([in_src_image, in_target_image], patch_out) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt, loss_weights=[0.5]) return model # 定义图像形状 image_shape = (256,256,3) # 创建模型 model = define_discriminator(image_shape) # 总结模型 model.summary() # 绘制模型 plot_model(model, to_file='discriminator_model_plot.png', show_shapes=True, show_layer_names=True) |
运行示例首先会总结模型,从而让我们了解输入形状如何在各层之间转换以及模型的参数数量。
我们可以看到,两个输入图像被串联起来,形成一个 256x256x6 的输入,进入第一个隐藏的卷积层。这种输入图像的级联可以在模型输入层之前完成,但让模型执行级联操作可以使模型的行为更加清晰。
我们可以看到,模型的输出将是一个 16×16 像素(或激活)的激活图,具有一个通道,图中的每个值对应于输入 256×256 图像的 70×70 像素块。如果输入图像尺寸减半为 128×128,则输出特征图也将减半为 8×8。
该模型是一个二分类模型,意味着它预测的输出是一个在 [0,1] 范围内的概率,即输入图像是真实图像还是来自目标数据集的图像的可能性。可以通过对这些值块求平均来给出模型的真实/伪造预测。在训练时,目标值与目标值矩阵进行比较,伪造为 0,真实为 1。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_1 (InputLayer) (None, 256, 256, 3) 0 __________________________________________________________________________________________________ input_2 (InputLayer) (None, 256, 256, 3) 0 __________________________________________________________________________________________________ concatenate_1 (Concatenate) (None, 256, 256, 6) 0 input_1[0][0] input_2[0][0] __________________________________________________________________________________________________ conv2d_1 (Conv2D) (None, 128, 128, 64) 6208 concatenate_1[0][0] __________________________________________________________________________________________________ leaky_re_lu_1 (LeakyReLU) (None, 128, 128, 64) 0 conv2d_1[0][0] __________________________________________________________________________________________________ conv2d_2 (Conv2D) (None, 64, 64, 128) 131200 leaky_re_lu_1[0][0] __________________________________________________________________________________________________ batch_normalization_1 (BatchNor (None, 64, 64, 128) 512 conv2d_2[0][0] __________________________________________________________________________________________________ leaky_re_lu_2 (LeakyReLU) (None, 64, 64, 128) 0 batch_normalization_1[0][0] __________________________________________________________________________________________________ conv2d_3 (Conv2D) (None, 32, 32, 256) 524544 leaky_re_lu_2[0][0] __________________________________________________________________________________________________ batch_normalization_2 (BatchNor (None, 32, 32, 256) 1024 conv2d_3[0][0] __________________________________________________________________________________________________ leaky_re_lu_3 (LeakyReLU) (None, 32, 32, 256) 0 batch_normalization_2[0][0] __________________________________________________________________________________________________ conv2d_4 (Conv2D) (None, 16, 16, 512) 2097664 leaky_re_lu_3[0][0] __________________________________________________________________________________________________ batch_normalization_3 (BatchNor (None, 16, 16, 512) 2048 conv2d_4[0][0] __________________________________________________________________________________________________ leaky_re_lu_4 (LeakyReLU) (None, 16, 16, 512) 0 batch_normalization_3[0][0] __________________________________________________________________________________________________ conv2d_5 (Conv2D) (None, 16, 16, 512) 4194816 leaky_re_lu_4[0][0] __________________________________________________________________________________________________ batch_normalization_4 (BatchNor (None, 16, 16, 512) 2048 conv2d_5[0][0] __________________________________________________________________________________________________ leaky_re_lu_5 (LeakyReLU) (None, 16, 16, 512) 0 batch_normalization_4[0][0] __________________________________________________________________________________________________ conv2d_6 (Conv2D) (None, 16, 16, 1) 8193 leaky_re_lu_5[0][0] __________________________________________________________________________________________________ activation_1 (Activation) (None, 16, 16, 1) 0 conv2d_6[0][0] ================================================================================================== 总参数:6,968,257 可训练参数:6,965,441 不可训练参数:2,816 __________________________________________________________________________________________________ |
模型图被创建,显示了许多相同的图形信息。模型并不复杂,它有一个线性的路径,有两个输入图像和一个输出预测。
注意:创建图表假设已安装 pydot 和 pygraphviz 库。如果存在问题,可以注释掉 `plot_model()` 函数的导入和调用。
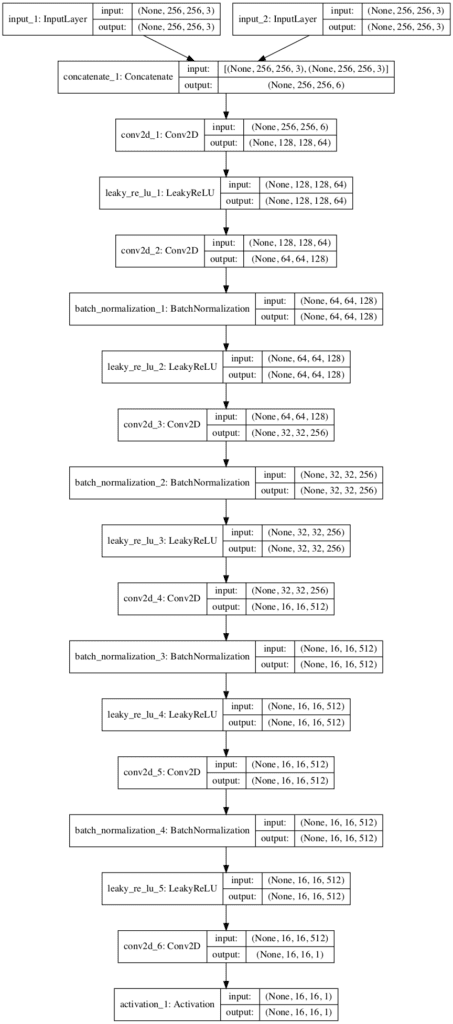
Pix2Pix GAN 架构中使用的 PatchGAN 模型图
现在我们知道如何实现 PatchGAN 判别器模型,接下来我们可以研究实现 U-Net 生成器模型。
如何实现 U-Net 生成器模型
Pix2Pix GAN 的生成器模型实现为 U-Net。
U-Net 模型是一种用于图像翻译的编码器-解码器模型,其中使用跳跃连接将编码器中的层与解码器中具有相同大小特征图的相应层连接起来。
模型编码器部分由卷积层组成,使用 2×2 的步长将输入源图像下采样到瓶颈层。模型解码器部分读取瓶颈输出,并使用转置卷积层上采样到所需的输出图像大小。
……输入通过一系列逐渐下采样的层,直到到达瓶颈层,此时过程反转。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
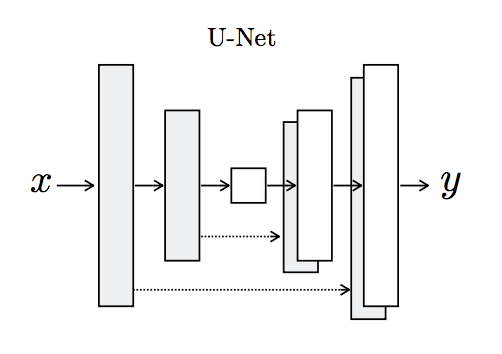
U-Net 生成器模型架构
摘自《条件对抗网络中的图像到图像翻译》。
在具有相同大小特征图的层之间添加了跳跃连接,因此第一个下采样层与最后一个上采样层连接,第二个下采样层与倒数第二个上采样层连接,依此类推。连接将下采样层中的特征图通道与上采样层中的特征图进行级联。
具体来说,我们在每层 i 和层 n-i 之间添加跳跃连接,其中 n 是总层数。每个跳跃连接仅将层 i 的所有通道与层 n-i 的通道进行级联。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
与 GAN 架构中的传统生成器模型不同,U-Net 生成器不从潜在空间获取输入。相反,dropout 层被用作训练期间和模型用于进行预测(例如,在推理时生成图像)时的随机性来源。
同样,在训练和推理过程中,批量归一化(batch normalization)的使用方式也相同,这意味着为每个批次计算统计数据,而不是在训练过程结束时固定。这被称为实例归一化(instance normalization),尤其是在批次大小设置为1时,就像Pix2Pix模型那样。
在推理时,我们以与训练阶段完全相同的方式运行生成器网络。这与通常的协议不同之处在于,我们在测试时应用 dropout,并使用测试批次的统计数据来应用批量归一化,而不是聚合训练批次的统计数据。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
在Keras中,像 Dropout 和 BatchNormalization 这样的层在训练和推理模型中操作方式不同。我们可以在调用这些层时将“training”参数设置为“True”,以确保它们即使在推理时也始终以训练模式运行。
例如,可以按如下方式将一个在推理和训练时都会进行 dropout 的 Dropout 层添加到模型中:
|
1 2 |
... g = Dropout(0.5)(g, training=True) |
与判别器模型一样,生成器模型的配置细节定义在 论文附录 中,并且在与 官方Torch实现中的defineG_unet()函数 进行比较时可以确认。
编码器使用类似判别器模型的卷积-批量归一化-LeakyReLU块,而解码器模型使用卷积-批量归一化-Dropout-ReLU块,dropout率为50%。所有卷积层都使用4x4的滤波器大小和2x2的步幅。
令Ck表示一个具有k个滤波器的卷积-批量归一化-ReLU层。CDk表示一个具有50% dropout率的卷积-批量归一化-Dropout-ReLU层。所有卷积都是4x4的空间滤波器,以步幅2应用。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
U-Net模型的架构使用简写表示法定义为:
- 编码器: C64-C128-C256-C512-C512-C512-C512-C512
- 解码器: CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128
编码器的最后一层是瓶颈层,根据论文的修正和代码中的确认,该层不使用批量归一化,而是使用 ReLU 激活 而不是 LeakyRelu。
……瓶颈层的激活被批量归一化操作归零,有效地跳过了最内层。这个问题可以通过从该层移除批量归一化来修复,正如在公开代码中所做的那样。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
U-Net解码器中的滤波器数量有点误导,因为它是与编码器中相应层连接后的滤波器的数量。当我们创建一个模型图时,这可能会更清楚。
模型的输出使用一个单一的卷积层,具有三个通道,并且在输出层使用tanh激活函数,这对于GAN生成器模型来说是常见的。编码器的第一层不使用批量归一化。
在解码器的最后一层之后,应用一个卷积来映射到输出通道的数量(通常是3 [...]),然后是一个Tanh函数 [...] 编码器的第一个C64层不应用BatchNorm。编码器中的所有ReLU都是 leaky 的,斜率为0.2,而解码器中的ReLU不是 leaky 的。
——《使用条件对抗网络进行图像到图像翻译》,2016年。
总而言之,我们可以定义一个名为define_generator()的函数,该函数定义了U-Net编码器-解码器生成器模型。还提供了两个辅助函数来定义编码器层块和解码器层块。
下面列出了定义模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
# 定义一个U-Net编码器-解码器生成器模型的示例 from keras.initializers import RandomNormal from keras.models import Model from keras.models import Input 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU from keras.layers import Activation from keras.layers import Concatenate 从 keras.layers 导入 Dropout 从 keras.层 导入 BatchNormalization from keras.layers import LeakyReLU from keras.utils.vis_utils import plot_model # 定义一个编码器块 def define_encoder_block(layer_in, n_filters, batchnorm=True): # 权重初始化 init = RandomNormal(stddev=0.02) # 添加下采样层 g = Conv2D(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in) # 有条件地添加批量归一化 if batchnorm: g = BatchNormalization()(g, training=True) # leaky relu 激活 g = LeakyReLU(alpha=0.2)(g) return g # 定义一个解码器块 def decoder_block(layer_in, skip_in, n_filters, dropout=True): # 权重初始化 init = RandomNormal(stddev=0.02) # 添加上采样层 g = Conv2DTranspose(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in) # 添加批量归一化 g = BatchNormalization()(g, training=True) # 有条件地添加 dropout if dropout: g = Dropout(0.5)(g, training=True) # 与跳跃连接合并 g = Concatenate()([g, skip_in]) # relu 激活 g = Activation('relu')(g) return g # 定义独立的生成器模型 def define_generator(image_shape=(256,256,3)): # 权重初始化 init = RandomNormal(stddev=0.02) # 图像输入 in_image = Input(shape=image_shape) # 编码器模型:C64-C128-C256-C512-C512-C512-C512-C512 e1 = define_encoder_block(in_image, 64, batchnorm=False) e2 = define_encoder_block(e1, 128) e3 = define_encoder_block(e2, 256) e4 = define_encoder_block(e3, 512) e5 = define_encoder_block(e4, 512) e6 = define_encoder_block(e5, 512) e7 = define_encoder_block(e6, 512) # 瓶颈层,无批量归一化和 relu b = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(e7) b = Activation('relu')(b) # 解码器模型:CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128 d1 = decoder_block(b, e7, 512) d2 = decoder_block(d1, e6, 512) d3 = decoder_block(d2, e5, 512) d4 = decoder_block(d3, e4, 512, dropout=False) d5 = decoder_block(d4, e3, 256, dropout=False) d6 = decoder_block(d5, e2, 128, dropout=False) d7 = decoder_block(d6, e1, 64, dropout=False) # 输出 g = Conv2DTranspose(3, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d7) out_image = Activation('tanh')(g) # 定义模型 model = Model(in_image, out_image) return model # 定义图像形状 image_shape = (256,256,3) # 创建模型 model = define_generator(image_shape) # 总结模型 model.summary() # 绘制模型 plot_model(model, to_file='generator_model_plot.png', show_shapes=True, show_layer_names=True) |
运行示例首先总结了模型。
该模型有一个输入和一个输出,但跳跃连接使得摘要难以阅读。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_1 (InputLayer) (None, 256, 256, 3) 0 __________________________________________________________________________________________________ conv2d_1 (Conv2D) (None, 128, 128, 64) 3136 input_1[0][0] __________________________________________________________________________________________________ leaky_re_lu_1 (LeakyReLU) (None, 128, 128, 64) 0 conv2d_1[0][0] __________________________________________________________________________________________________ conv2d_2 (Conv2D) (None, 64, 64, 128) 131200 leaky_re_lu_1[0][0] __________________________________________________________________________________________________ batch_normalization_1 (BatchNor (None, 64, 64, 128) 512 conv2d_2[0][0] __________________________________________________________________________________________________ leaky_re_lu_2 (LeakyReLU) (None, 64, 64, 128) 0 batch_normalization_1[0][0] __________________________________________________________________________________________________ conv2d_3 (Conv2D) (None, 32, 32, 256) 524544 leaky_re_lu_2[0][0] __________________________________________________________________________________________________ batch_normalization_2 (BatchNor (None, 32, 32, 256) 1024 conv2d_3[0][0] __________________________________________________________________________________________________ leaky_re_lu_3 (LeakyReLU) (None, 32, 32, 256) 0 batch_normalization_2[0][0] __________________________________________________________________________________________________ conv2d_4 (Conv2D) (None, 16, 16, 512) 2097664 leaky_re_lu_3[0][0] __________________________________________________________________________________________________ batch_normalization_3 (BatchNor (None, 16, 16, 512) 2048 conv2d_4[0][0] __________________________________________________________________________________________________ leaky_re_lu_4 (LeakyReLU) (None, 16, 16, 512) 0 batch_normalization_3[0][0] __________________________________________________________________________________________________ conv2d_5 (Conv2D) (None, 8, 8, 512) 4194816 leaky_re_lu_4[0][0] __________________________________________________________________________________________________ batch_normalization_4 (BatchNor (None, 8, 8, 512) 2048 conv2d_5[0][0] __________________________________________________________________________________________________ leaky_re_lu_5 (LeakyReLU) (None, 8, 8, 512) 0 batch_normalization_4[0][0] __________________________________________________________________________________________________ conv2d_6 (Conv2D) (None, 4, 4, 512) 4194816 leaky_re_lu_5[0][0] __________________________________________________________________________________________________ batch_normalization_5 (BatchNor (None, 4, 4, 512) 2048 conv2d_6[0][0] __________________________________________________________________________________________________ leaky_re_lu_6 (LeakyReLU) (None, 4, 4, 512) 0 batch_normalization_5[0][0] __________________________________________________________________________________________________ conv2d_7 (Conv2D) (None, 2, 2, 512) 4194816 leaky_re_lu_6[0][0] __________________________________________________________________________________________________ batch_normalization_6 (BatchNor (None, 2, 2, 512) 2048 conv2d_7[0][0] __________________________________________________________________________________________________ leaky_re_lu_7 (LeakyReLU) (None, 2, 2, 512) 0 batch_normalization_6[0][0] __________________________________________________________________________________________________ conv2d_8 (Conv2D) (None, 1, 1, 512) 4194816 leaky_re_lu_7[0][0] __________________________________________________________________________________________________ activation_1 (Activation) (None, 1, 1, 512) 0 conv2d_8[0][0] __________________________________________________________________________________________________ conv2d_transpose_1 (Conv2DTrans (None, 2, 2, 512) 4194816 activation_1[0][0] __________________________________________________________________________________________________ batch_normalization_7 (BatchNor (None, 2, 2, 512) 2048 conv2d_transpose_1[0][0] __________________________________________________________________________________________________ dropout_1 (Dropout) (None, 2, 2, 512) 0 batch_normalization_7[0][0] __________________________________________________________________________________________________ concatenate_1 (Concatenate) (None, 2, 2, 1024) 0 dropout_1[0][0] leaky_re_lu_7[0][0] __________________________________________________________________________________________________ activation_2 (Activation) (None, 2, 2, 1024) 0 concatenate_1[0][0] __________________________________________________________________________________________________ conv2d_transpose_2 (Conv2DTrans (None, 4, 4, 512) 8389120 activation_2[0][0] __________________________________________________________________________________________________ batch_normalization_8 (BatchNor (None, 4, 4, 512) 2048 conv2d_transpose_2[0][0] __________________________________________________________________________________________________ dropout_2 (Dropout) (None, 4, 4, 512) 0 batch_normalization_8[0][0] __________________________________________________________________________________________________ concatenate_2 (Concatenate) (None, 4, 4, 1024) 0 dropout_2[0][0] leaky_re_lu_6[0][0] __________________________________________________________________________________________________ activation_3 (Activation) (None, 4, 4, 1024) 0 concatenate_2[0][0] __________________________________________________________________________________________________ conv2d_transpose_3 (Conv2DTrans (None, 8, 8, 512) 8389120 activation_3[0][0] __________________________________________________________________________________________________ batch_normalization_9 (BatchNor (None, 8, 8, 512) 2048 conv2d_transpose_3[0][0] __________________________________________________________________________________________________ dropout_3 (Dropout) (None, 8, 8, 512) 0 batch_normalization_9[0][0] __________________________________________________________________________________________________ concatenate_3 (Concatenate) (None, 8, 8, 1024) 0 dropout_3[0][0] leaky_re_lu_5[0][0] __________________________________________________________________________________________________ activation_4 (Activation) (None, 8, 8, 1024) 0 concatenate_3[0][0] __________________________________________________________________________________________________ conv2d_transpose_4 (Conv2DTrans (None, 16, 16, 512) 8389120 activation_4[0][0] __________________________________________________________________________________________________ batch_normalization_10 (BatchNo (None, 16, 16, 512) 2048 conv2d_transpose_4[0][0] __________________________________________________________________________________________________ concatenate_4 (Concatenate) (None, 16, 16, 1024) 0 batch_normalization_10[0][0] leaky_re_lu_4[0][0] __________________________________________________________________________________________________ activation_5 (Activation) (None, 16, 16, 1024) 0 concatenate_4[0][0] __________________________________________________________________________________________________ conv2d_transpose_5 (Conv2DTrans (None, 32, 32, 256) 4194560 activation_5[0][0] __________________________________________________________________________________________________ batch_normalization_11 (BatchNo (None, 32, 32, 256) 1024 conv2d_transpose_5[0][0] __________________________________________________________________________________________________ concatenate_5 (Concatenate) (None, 32, 32, 512) 0 batch_normalization_11[0][0] leaky_re_lu_3[0][0] __________________________________________________________________________________________________ activation_6 (Activation) (None, 32, 32, 512) 0 concatenate_5[0][0] __________________________________________________________________________________________________ conv2d_transpose_6 (Conv2DTrans (None, 64, 64, 128) 1048704 activation_6[0][0] __________________________________________________________________________________________________ batch_normalization_12 (BatchNo (None, 64, 64, 128) 512 conv2d_transpose_6[0][0] __________________________________________________________________________________________________ concatenate_6 (Concatenate) (None, 64, 64, 256) 0 batch_normalization_12[0][0] leaky_re_lu_2[0][0] __________________________________________________________________________________________________ activation_7 (Activation) (None, 64, 64, 256) 0 concatenate_6[0][0] __________________________________________________________________________________________________ conv2d_transpose_7 (Conv2DTrans (None, 128, 128, 64) 262208 activation_7[0][0] __________________________________________________________________________________________________ batch_normalization_13 (BatchNo (None, 128, 128, 64) 256 conv2d_transpose_7[0][0] __________________________________________________________________________________________________ concatenate_7 (Concatenate) (None, 128, 128, 128 0 batch_normalization_13[0][0] leaky_re_lu_1[0][0] __________________________________________________________________________________________________ activation_8 (Activation) (None, 128, 128, 128 0 concatenate_7[0][0] __________________________________________________________________________________________________ conv2d_transpose_8 (Conv2DTrans (None, 256, 256, 3) 6147 activation_8[0][0] __________________________________________________________________________________________________ activation_9 (Activation) (None, 256, 256, 3) 0 conv2d_transpose_8[0][0] ================================================================================================== 总参数量: 54,429,315 可训练参数量: 54,419,459 不可训练参数量: 9,856 __________________________________________________________________________________________________ |
创建了模型的图,显示了很大程度上相同的信息。模型很复杂,而图有助于理解跳跃连接及其对解码器滤波器数量的影响。
注意:创建图表假设已安装 pydot 和 pygraphviz 库。如果存在问题,可以注释掉 `plot_model()` 函数的导入和调用。
从输出层倒推,如果我们查看 Concatenate 层和解码器的第一个 Conv2DTranspose 层,我们可以看到通道数量为:
- [128, 256, 512, 1024, 1024, 1024, 1024, 512].
反转此列表即可得到论文中提到的解码器各层滤波器数量的配置:
- CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128
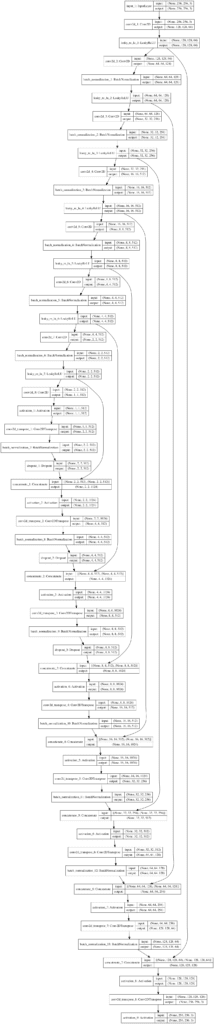
Pix2Pix GAN 架构中使用的 U-Net 编码器-解码器模型图
现在我们已经定义了两个模型,我们可以看看生成器模型是如何通过判别器模型进行更新的。
如何实现对抗损失和 L1 损失
判别器模型可以直接更新,而生成器模型必须通过判别器模型更新。
这可以通过在Keras中定义一个新的复合模型来实现,该模型将生成器模型的输出连接到判别器模型的输入。然后,判别器模型可以预测生成的图像是真实的还是伪造的。我们可以以一种方式更新复合模型的权重,使生成的图像具有“真实”的标签而不是“伪造”的标签,这将促使生成器权重更新以生成更好的伪造图像。在此上下文中,我们还可以将判别器权重标记为不可训练,以避免误导性更新。
此外,还需要更新生成器以更好地匹配目标翻译。这意味着复合模型还必须直接输出生成的图像,以便将其与目标图像进行比较。
因此,我们可以将此复合模型的输入和输出总结如下:
- 输入: 源图像
- 输出: 真实/伪造分类,生成的目标图像。
生成器的权重将通过判别器输出的对抗损失和直接图像输出的L1损失进行更新。损失分数被加在一起,其中L1损失被视为一个正则化项,并通过一个称为lambda的超参数加权,该超参数设置为100。
- loss = 对抗损失 + lambda * L1 损失
下面的define_gan()函数实现了这一点,它将定义的生成器和判别器模型作为输入,并创建可用于更新生成器模型权重的复合GAN模型。
源图像输入同时提供给生成器和判别器作为输入,生成器的输出也连接到判别器作为输入。
在模型编译时,为判别器和生成器输出分别指定了两个损失函数。loss_weights参数用于定义当它们加在一起以更新生成器模型权重时每个损失的权重。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(g_model, d_model, image_shape): # 使判别器中的权重不可训练 for layer in d_model.layers: if not isinstance(layer, BatchNormalization): layer.trainable = False # 定义源图像 in_src = Input(shape=image_shape) # 将源图像连接到生成器输入 gen_out = g_model(in_src) # 将源输入和生成器输出连接到判别器输入 dis_out = d_model([in_src, gen_out]) # 源图像作为输入,生成的图像和分类作为输出 model = Model(in_src, [dis_out, gen_out]) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss=['binary_crossentropy', 'mae'], optimizer=opt, loss_weights=[1,100]) return model |
将前面章节的模型定义与此结合,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 |
# 训练生成器模型的复合模型示例 from keras.optimizers import Adam from keras.initializers import RandomNormal from keras.models import Model from keras.models import Input 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU from keras.layers import Activation from keras.layers import Concatenate 从 keras.layers 导入 Dropout 从 keras.层 导入 BatchNormalization from keras.layers import LeakyReLU from keras.utils.vis_utils import plot_model # 定义判别器模型 def define_discriminator(image_shape): # 权重初始化 init = RandomNormal(stddev=0.02) # 源图像输入 in_src_image = Input(shape=image_shape) # 目标图像输入 in_target_image = Input(shape=image_shape) # 通道级联图像 merged = Concatenate()([in_src_image, in_target_image]) # C64 d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(merged) d = LeakyReLU(alpha=0.2)(d) # C128 d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # C256 d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # C512 d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 倒数第二层输出 d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 补丁输出 d = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d) patch_out = Activation('sigmoid')(d) # 定义模型 model = Model([in_src_image, in_target_image], patch_out) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt, loss_weights=[0.5]) return model # 定义一个编码器块 def define_encoder_block(layer_in, n_filters, batchnorm=True): # 权重初始化 init = RandomNormal(stddev=0.02) # 添加下采样层 g = Conv2D(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in) # 有条件地添加批量归一化 if batchnorm: g = BatchNormalization()(g, training=True) # leaky relu 激活 g = LeakyReLU(alpha=0.2)(g) return g # 定义一个解码器块 def decoder_block(layer_in, skip_in, n_filters, dropout=True): # 权重初始化 init = RandomNormal(stddev=0.02) # 添加上采样层 g = Conv2DTranspose(n_filters, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(layer_in) # 添加批量归一化 g = BatchNormalization()(g, training=True) # 有条件地添加 dropout if dropout: g = Dropout(0.5)(g, training=True) # 与跳跃连接合并 g = Concatenate()([g, skip_in]) # relu 激活 g = Activation('relu')(g) return g # 定义独立的生成器模型 def define_generator(image_shape=(256,256,3)): # 权重初始化 init = RandomNormal(stddev=0.02) # 图像输入 in_image = Input(shape=image_shape) # 编码器模型:C64-C128-C256-C512-C512-C512-C512-C512 e1 = define_encoder_block(in_image, 64, batchnorm=False) e2 = define_encoder_block(e1, 128) e3 = define_encoder_block(e2, 256) e4 = define_encoder_block(e3, 512) e5 = define_encoder_block(e4, 512) e6 = define_encoder_block(e5, 512) e7 = define_encoder_block(e6, 512) # 瓶颈层,无批量归一化和 relu b = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(e7) b = Activation('relu')(b) # 解码器模型:CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128 d1 = decoder_block(b, e7, 512) d2 = decoder_block(d1, e6, 512) d3 = decoder_block(d2, e5, 512) d4 = decoder_block(d3, e4, 512, dropout=False) d5 = decoder_block(d4, e3, 256, dropout=False) d6 = decoder_block(d5, e2, 128, dropout=False) d7 = decoder_block(d6, e1, 64, dropout=False) # 输出 g = Conv2DTranspose(3, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d7) out_image = Activation('tanh')(g) # 定义模型 model = Model(in_image, out_image) return model # 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(g_model, d_model, image_shape): # 使判别器中的权重不可训练 for layer in d_model.layers: if not isinstance(layer, BatchNormalization): layer.trainable = False # 定义源图像 in_src = Input(shape=image_shape) # 将源图像连接到生成器输入 gen_out = g_model(in_src) # 将源输入和生成器输出连接到判别器输入 dis_out = d_model([in_src, gen_out]) # 源图像作为输入,生成的图像和分类作为输出 model = Model(in_src, [dis_out, gen_out]) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss=['binary_crossentropy', 'mae'], optimizer=opt, loss_weights=[1,100]) return model # 定义图像形状 image_shape = (256,256,3) # 定义模型 d_model = define_discriminator(image_shape) g_model = define_generator(image_shape) # 定义复合模型 gan_model = define_gan(g_model, d_model, image_shape) # 总结模型 gan_model.summary() # 绘制模型 plot_model(gan_model, to_file='gan_model_plot.png', show_shapes=True, show_layer_names=True) |
运行示例,首先会总结复合模型,展示 256×256 的图像输入,来自 *model_2*(生成器)的相同形状的输出,以及来自 *model_1*(判别器)的 PatchGAN 分类预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_4 (InputLayer) (None, 256, 256, 3) 0 __________________________________________________________________________________________________ model_2 (Model) (None, 256, 256, 3) 54429315 input_4[0][0] __________________________________________________________________________________________________ model_1 (Model) (None, 16, 16, 1) 6968257 input_4[0][0] model_2[1][0] ================================================================================================== 总参数:61,397,572 可训练参数量: 54,419,459 不可训练参数:6,978,113 __________________________________________________________________________________________________ |
复合模型的图也会被创建,展示输入图像如何流经生成器和判别器,并且模型有两个输出或终结点,分别来自两个模型。
注意:创建图表假定已安装 pydot 和 pygraphviz 库。如果存在问题,可以注释掉 plot_model() 函数的导入和调用。
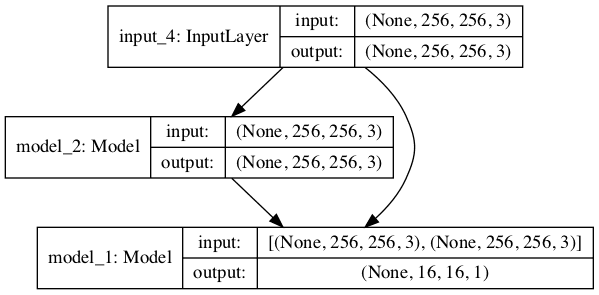
Pix2Pix GAN 架构中用于训练生成器的复合 GAN 模型图
如何更新模型权重
训练定义的模型相对直接。
首先,我们必须定义一个辅助函数,该函数将选择一批真实的源图像和目标图像以及相关的输出(1.0)。在这里,数据集是两个图像数组的列表。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 选择一批随机样本,返回图像和目标 def generate_real_samples(dataset, n_samples, patch_shape): # 解包数据集 trainA, trainB = dataset # 选择随机实例 ix = randint(0, trainA.shape[0], n_samples) # 检索选定的图像 X1, X2 = trainA[ix], trainB[ix] # 生成“真实”类别标签 (1) y = ones((n_samples, patch_shape, patch_shape, 1)) return [X1, X2], y |
同样,我们需要一个函数来生成一批假图像和相关的输出(0.0)。在这里,样本是源图像的数组,将为其生成目标图像。
|
1 2 3 4 5 6 7 |
# 生成一批图像,返回图像和目标 def generate_fake_samples(g_model, samples, patch_shape): # 生成伪造实例 X = g_model.predict(samples) # 创建“假”类别标签 (0) y = zeros((len(X), patch_shape, patch_shape, 1)) return X, y |
现在,我们可以定义单次训练迭代的步骤。
首先,我们必须调用 *generate_real_samples()* 来选择一批源图像和目标图像。
通常,批次大小 (*n_batch*) 设置为 1。在这种情况下,我们将假设输入图像为 256×256,这意味着 PatchGAN 判别器的 *n_patch* 将为 16,表示 16×16 的输出特征图。
|
1 2 3 |
... # 选择一批真实样本 [X_realA, X_realB], y_real = generate_real_samples(dataset, n_batch, n_patch) |
接下来,我们可以使用选定的真实源图像批次来生成相应的生成或假目标图像批次。
|
1 2 3 |
... # 生成一批假样本 X_fakeB, y_fake = generate_fake_samples(g_model, X_realA, n_patch) |
然后,我们可以使用真实和虚假图像以及它们的目标来更新独立的判别器模型。
|
1 2 3 4 5 |
... # 更新真实样本的判别器 d_loss1 = d_model.train_on_batch([X_realA, X_realB], y_real) # 更新生成样本的判别器 d_loss2 = d_model.train_on_batch([X_realA, X_fakeB], y_fake) |
到目前为止,这与在 Keras 中更新 GAN 是一样的。
接下来,我们可以通过对抗损失和 L1 损失来更新生成器模型。回想一下,复合 GAN 模型以源图像批次作为输入,首先预测真实/虚假分类,然后生成的目标。在这里,我们向复合模型的判别器输出提供一个目标,以指示生成的图像是“*真实*”(类别=1)。真实的目标图像用于计算它们与生成的目标图像之间的 L1 损失。
我们有两个损失函数,但为批次更新计算了三个损失值,其中只有第一个损失值是相关的,因为它是在批次上对抗损失和 L1 损失的加权和。
|
1 2 3 |
... # 更新生成器 g_loss, _, _ = gan_model.train_on_batch(X_realA, [y_real, X_realB]) |
就是这样。
我们可以将所有这些定义在一个名为 *train()* 的函数中,该函数接受定义的模型和一个加载的数据集(作为两个 NumPy 数组),并训练模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 训练 pix2pix 模型 def train(d_model, g_model, gan_model, dataset, n_epochs=100, n_batch=1, n_patch=16): # 解包数据集 trainA, trainB = dataset # 计算每个训练 epoch 的批次数量 bat_per_epo = int(len(trainA) / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 手动枚举 epoch for i in range(n_steps): # 选择一批真实样本 [X_realA, X_realB], y_real = generate_real_samples(dataset, n_batch, n_patch) # 生成一批伪造样本 X_fakeB, y_fake = generate_fake_samples(g_model, X_realA, n_patch) # 更新真实样本的判别器 d_loss1 = d_model.train_on_batch([X_realA, X_realB], y_real) # 更新生成样本的判别器 d_loss2 = d_model.train_on_batch([X_realA, X_fakeB], y_fake) # 更新生成器 g_loss, _, _ = gan_model.train_on_batch(X_realA, [y_real, X_realB]) # 总结性能 print('>%d, d1[%.3f] d2[%.3f] g[%.3f]' % (i+1, d_loss1, d_loss2, g_loss)) |
然后可以直接调用 train 函数,传入定义的模型和加载的数据集。
|
1 2 3 4 5 |
... # 加载图像数据 dataset = ... # 训练模型 train(d_model, g_model, gan_model, dataset) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
官方
- 使用条件对抗网络进行图像到图像翻译, 2016.
- 使用条件对抗网络进行图像到图像翻译,主页.
- 使用条件对抗网络进行图像到图像翻译,GitHub.
- pytorch-CycleGAN-and-pix2pix,GitHub.
- 交互式图像到图像演示, 2017.
- Pix2Pix 数据集
API
文章
- 卷积神经网络的感受野计算指南, 2017.
- 问题:PatchGAN 判别器, 2017.
- receptive_field_sizes.m
总结
在本教程中,您学习了如何使用 Keras 深度学习框架从头开始实现 Pix2Pix GAN 架构。
具体来说,你学到了:
- 如何为 Pix2Pix GAN 开发 PatchGAN 判别器模型。
- 如何为 Pix2Pix GAN 开发 U-Net 编码器-解码器生成器模型。
- 如何实现用于更新生成器的复合模型,以及如何训练这两个模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...
 From Scratch in Keras")
 From Scratch with Keras")




这本书是否涵盖了 TensorFlow 2.0?
不,TensorFlow 2.0 尚未发布,仍处于 beta 版。
好????
谢谢!
你是最棒的。
谢谢!
假设我想保存最好的模型。应该考虑哪个损失来保存模型,或者进行提前停止?
哎哟。很好的问题!
都不是。损失不是衡量 GAN 生成图像质量的好指标。WGAN 损失可以是,LS 损失也可以是,但我不会在实践中依赖它们。
相反,一直保存模型——例如每个周期,用它们生成样本,并根据生成样本的质量来选择模型。
使用 Incept Score 或 FID 等指标评估样本(教程即将推出)。
感谢您的宝贵贡献。
您说解压数据集。但我无法弄清楚如何加载数据集。据我所知,我们应该有两个数据集,一个是要翻译成预期图像的源数据,另一个是用于应用于源图像的真实图像。但我们如何加载这些数据集呢?
# 加载图像数据
dataset = … (这里应该输入两个数据集的目录吗?但我无法弄清楚)
如果我的问题很奇怪,请原谅。
正确,数据集包含配对的图像。
我在这里提供了一个完整的示例,其中包含真实数据集
https://machinelearning.org.cn/how-to-develop-a-pix2pix-gan-for-image-to-image-translation/
当您将判别器的 Trainable 设置为 False 时,它在所有后续训练批次中不都是不可训练的吗?在训练判别器之前,您不应该每次都将其设置为 True,并在训练整个 GAN 模型时将其更改为 False 吗?
是的,但这仅在复合模型中。
独立的判别器不受影响。
为什么 GAN 的批次大小通常是 1?
不总是,但在这种情况下是因为我们为每个图像进行更新。
您在哪里使用了 lambda?
我找不到那个参数。
好问题,在 compile() 的 loss_weights 参数中。
你好 Adrian,
感谢您提供如此精彩的文章。
有没有办法通过负的损失权重来编写代码,而不是交换标签?
是的,但我没有可运行的示例,抱歉。
抱歉,我本来想评论“如何编写 GAN 训练算法和损失函数”。是我的错。
不客气。
亲爱的 Jason,
您写的这个判别器的有效感受野不是 142 吗?因为我们有 4 个卷积层,核大小为 4,步幅为 2,最后两个层核大小为 4,步幅为 1,这使得感受野为 142。
不,可运行示例从第一个卷积层开始,而不是从像素开始。
亲爱的Jason
在“Image-to-Image Translation with Conditional Adversarial Networks”论文中
70×70 判别器架构是
C64-C128-C256-C512
在最后一层之后,应用卷积将其映射到
一个一维输出,然后是 Sigmoid 函数。
但您的实现中有两个 C512 层
我不明白……
感谢您的精彩网站
是的,该实现与他们提供的代码匹配,其中最后的 C512 “解释”了 70×70 的输出。
嗨,Jason,
我有一个关于感受野计算的问题。我仍然不明白为什么 70X70 PatchGAN 的实现代码中有 6 个卷积层,但在计算感受野时只使用了 5 个卷积层。有一个(filter size = 4, stride = 2)卷积层是为了什么目的而被遗漏的?您能详细解释一下吗?谢谢。
最后一层解释了感受野,与论文和官方实现匹配。
这也在代码注释中有所说明。
感谢这个出色的资源!
如果我在作者的原始实现中使用 torch_summary 打印模型,它似乎没有这个额外的 C512 层。
—————————————————————-
层(类型) 输出形状 参数 #
================================================================
Conv2d-1 [-1, 64, 128, 128] 6,208
LeakyReLU-2 [-1, 64, 128, 128] 0
Conv2d-3 [-1, 128, 64, 64] 131,072
BatchNorm2d-4 [-1, 128, 64, 64] 256
LeakyReLU-5 [-1, 128, 64, 64] 0
Conv2d-6 [-1, 256, 32, 32] 524,288
BatchNorm2d-7 [-1, 256, 32, 32] 512
LeakyReLU-8 [-1, 256, 32, 32] 0
Conv2d-9 [-1, 512, 31, 31] 2,097,152
BatchNorm2d-10 [-1, 512, 31, 31] 1,024
LeakyReLU-11 [-1, 512, 31, 31] 0
Conv2d-12 [-1, 1, 30, 30] 8,193
================================================================
总参数:2,768,705
请注意,它比添加该额外 conv2d 层的模型少了约 400 万个参数。
感谢您的反馈,Jagannath!
亲爱的 Jason,
感谢这篇文章。它非常有帮助,我从中理解了 pix2pix 模型。是否有关于 Star GAN 的 Keras 文章?
https://arxiv.org/abs/1711.09020
谢谢你
感谢您的建议,我将来可能会涵盖它。
你好 Jason,
再次感谢您出色的教程。
我想知道是否可以保存判别器、生成器和 GAN 的状态,稍后加载它们并继续训练?
您能否为我指明方向?
谢谢你
是的,您可以使用每个模型的 save() 方法。
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
嗨,Jason,
感谢您的建议。您是否有保存所有三个模型、加载它们然后再次训练的代码示例?我尝试保存和加载所有三个模型,但尝试再次训练时,判别器和生成器的损失为 0 且保持为 0。我搜索了很多论坛但都没有找到解决方案。
关于这个特定主题是否有任何示例?我认为这将对很多人有所帮助
我在这里有一个关于训练、保存、加载和使用模型的例子
https://machinelearning.org.cn/how-to-develop-a-pix2pix-gan-for-image-to-image-translation/
在所有例子中,生成器模型仅在训练后保存和加载,用于预测/生成新图像。不过,还是要感谢 Jason 的教程。
亲爱的 Jason,
非常感谢。非常有帮助。那 pix2pixHD 呢?
谢谢!
我希望将来能介绍它。
你好,
感谢这篇精彩的文章!
我有一个关于这个段落的疑问
“我们可以看到,模型输出将是一个激活图,大小为 16×16 像素或激活,以及一个通道,图中的每个值对应于输入 256×256 图像的 70×70 像素块。如果输入图像的尺寸减半到 128×128,那么输出特征图也会减半到 8×8。”
-> 16×16 中的每个值对应输入图像的 70×70 像素块是如何确定的?
-> 如果我想将其应用于输入图像的 16×16 块,输出尺寸应该是多少?
-> 输入图像是指 256x256x6(连接后)的图像还是连接前的图像?
非常感谢!
谢谢。
请参阅标题为“如何实现 PatchGAN 判别器模型”的部分,了解 PatchGAN 的计算方法。您可以插入任何您想要的数字。
您好,在您的代码中,您只采用了一个输入层。您是如何处理两个图像 A 和 B 的?我无法理解。我一直在尝试构建自己的模型,我所做的是:
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=”binary_crossentropy”,
optimizer=optimizer,
loss_weights=[0.5])
print(“## DISCRIMINATOR ##”)
self.discriminator.summary()
# plot_model(self.discriminator, to_file=’discriminator.png’, show_shapes=True, show_layer_names=True)
self.generator = self.build_generator()
print(“## GENERATOR ##”)
self.generator.summary()
# plot_model(self.generator, to_file=”generator.png”, show_shapes=True, show_layer_names=True)
lr = Input(shape=self.img_shape)
hr = Input(shape=self.img_shape)
sr = self.generator(lr)
valid = self.discriminator([sr,hr])
self.discriminator.traininable = False
self.combined = Model(inputs=[lr,hr], outputs=[valid,sr])
self.combined.compile(loss=[‘binary_crossentropy’,’mae’],
loss_weights=[1,100],
optimizer=optimizer)
self.combined.summary()
这是我的 GAN 的摘要
Model: “model_2”
__________________________________________________________________________________________________
层(类型)输出形状参数 # 连接到
==================================================================================================
input_4 (InputLayer) [(None, 512, 512, 3) 0
__________________________________________________________________________________________________
model_1 (Model) (None, 512, 512, 3) 54429315 input_4[0][0]
__________________________________________________________________________________________________
input_5 (InputLayer) [(None, 512, 512, 3) 0
__________________________________________________________________________________________________
model (Model) (None, 32, 32, 1) 6968257 model_1[1][0]
input_5[0][0]
==================================================================================================
总参数:61,397,572
可训练参数:61,384,900
不可训练参数:12,672
我不明白为什么使用两个输入层是错误的?为什么我的判别器不接受 trainable=False?
您能帮我解答这些疑问吗?
我很乐意提供帮助,但我没有能力调试您的代码。
也许这里的建议会有所帮助
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
感谢这篇精彩的文章。
是否必须输入 256x256x3 的图像?
我们可以输入 480x480x3 等不同尺寸的图像吗?
是否可以将非方形图像输入网络,而不是方形图像?
是的,但您需要更改模型。
请解释一下对于方形或非方形图像,在模型-网络方面需要进行哪些更改。
抱歉,我没有能力为您定制示例。
非常有用的信息!
根据下面这行代码,我对我的黑白数据集做了一个小的修改:
“在解码器的最后一层之后,应用一个卷积来映射到输出通道数(通常是 3 […])”
我正在训练一些黑白数据,形状为 [256,256,1],注意到在 define_generator 的末尾有一个硬编码的“3”
在 define_generator 的末尾
g = Conv2DTranspose(3, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)(d7)
您默认使用 3 通道图像,但您的 input_shape 可以处理其他变体,只需进行此修改:
g = Conv2DTranspose(input_shape[2], (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)(d7)
谢谢你做这个
谢谢!
Scott,好建议。
您好,我想问一个问题。
我正在尝试使用 PyTorch 复现 pix2pix,但在实现判别器时,如果我将最后两个层的核大小设置为 4,步幅设置为 1,那么输出必须是一个 14×14 的矩阵(考虑到官方 github 项目中的 padding=1)。我不明白 padding='same' 如何使其保持 16×16。
也许可以使用现有 PyTorch 实现的模型?
将真实图像和生成图像连接起来作为输入传递给判别器的目的是什么?
为了在更新权重时,批量中有两种图像类型。
Jason 您好,我有一个关于 70×70 PatchGAN 感受野的问题。在 pix2pix 论文中,他们的架构是 C64-C128-C256-C512-C1,所有卷积层都有 4×4 滤波器和步幅 2(第 16 页),这与您的实现略有不同。根据感受野计算,我得到
receptive_field(1, 4, 2)
Out[3]: 4
receptive_field(4, 4, 2)
Out[4]: 10
receptive_field(10, 4, 2)
Out[5]: 22
receptive_field(22, 4, 2)
Out[6]: 46
receptive_field(46, 4, 2)
Out[7]: 94
他们改变了架构吗?
没有,但如果您查看代码,他们使用了一个 patchgan,并且在论文描述中不包含输出层之前的块。我提出的实现是基于他们发布的代码。
尊敬的作者,我在加载和保存 GAN 进行研究时遇到了困难。您能否回答我关于所有类型的 GAN 都可以保存和加载模型的问题?非常感谢您给我这个留言的机会。
你可以在这里看到例子
https://machinelearning.org.cn/how-to-develop-a-pix2pix-gan-for-image-to-image-translation/
您能分享一个可以下载此模型的链接(Github 或某个在线存储链接)吗?
不。我不分享训练好的模型。我的重点是帮助开发人员构建模型和类似的模型。
为什么您的网站屏蔽伊朗的 IP?
我们只是渴望学习的学生,您的网站非常有帮助。
一些政府阻止了对我的网站的访问,我不知道为什么
https://machinelearning.org.cn/faq/single-faq/why-is-your-website-blocked-in-my-country
如何处理大于 256×256 且不一定是方形的图像?
要么将图像缩放到匹配模型,要么更改模型来匹配图像。
Jason 您好。在“如何实现对抗和 L1 损失”部分,我们不应该使用自定义损失函数而不是 mae 吗?
def L1(y_true, y_pred)
x = K.abs(y_true – y_pred)
return K.sum(x)
类似于这个,而不是 mae。
是的,我们这样做,请参阅“组合模型中使用的 mae”损失。
在这种情况下,我们使用 L1 对抗损失,正如论文中所述。
好的,感谢您澄清了这一点,Jason。另外,我注意到 compile 函数中没有指定 metrics。在 GAN/图像生成问题中,我们应该将它留空吗?
是的。评估 GAN 非常困难,视觉评估是最可靠的方法。
https://machinelearning.org.cn/how-to-evaluate-generative-adversarial-networks/
嗨,Jason,
组合模型如何知道对哪个输出应用哪个损失?是损失的顺序吗?那么第一个损失(“二元交叉熵”)将为输出的第一个参数计算,mae 将为第二个计算?
如果我想为一个输出计算多个损失,我该怎么做?
我们精心构建了模型。
也许从这个更简单的 GAN 开始可以帮助您理解模型是如何关联的。
https://machinelearning.org.cn/how-to-develop-a-generative-adversarial-network-for-a-1-dimensional-function-from-scratch-in-keras/
嗨,Jason,
您能否在 TensorFlow 中使用 ResNet 块实现非配对图像到图像的翻译?我想学习这个。如果您能从头开始构建模型,那将很有帮助。
原始论文:https://arxiv.org/abs/1703.10593
您可以使用 CycleGAN 进行非配对图像到图像的翻译。
https://machinelearning.org.cn/cyclegan-tutorial-with-keras/
嗨,Jason,
感谢这篇信息丰富的教程。我正尝试将此用于 81*81 的图像而不是 256*256,但我遇到了一些问题。最主要的问题是 Conv2DTranspose 的维度不一致。
是否需要针对此特定尺寸进行任何调整?
谢谢你
您需要根据新尺寸调整模型。这可能需要一些试验和错误。
你好 Jason,
我正在尝试将 UNet CNN 应用于与图像到图像翻译非常相似的任务。网络的输入是大小为 (64,256) 的二进制矩阵,输出是大小为 (64,32)。训练数据的准确率约为 90%,而测试数据的准确率约为 50%。这里的准确率是指每张图像中正确条目的平均百分比。此外,在训练期间,验证损失增加而损失减少,这是过拟合的明显迹象。我已经尝试了大多数正则化技术,也尝试减小模型的容量,但这只会减小训练误差而不会改善泛化误差。有什么建议或想法吗?
有意思。
也许这里的一些想法可以尝试。
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
非常感谢您的课程。我尝试绘制组合(GAN)模型,但没有更改您的任何代码,但遇到了以下错误:
AttributeError: ‘ListWrapper’ object has no attribute ‘name’
很抱歉听到这个消息,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Jason 您好。我正在尝试根据 https://jleinonen.github.io/2019/11/07/gan-elements-2.html 添加梯度惩罚,以及 Wasserstein 损失(来自您的一篇文章)。我不太清楚如何修改判别器的 train_on_batch。您能给我一些指导吗?
抱歉,我不熟悉那篇文章,也许直接问作者?
.
非常重要的问题。
在章节:“如何更新模型权重”
在最终代码中
def train ()
g_loss, _, _ = gan_model.train_on_batch(X_realA, [y_real, X_realB])
.
.
现在在 gan_model() 中
model = Model(in_src, [dis_out, gen_out])
.
.
它的 gen_out == generator 的输出
但 g_loss, _, _ = gan_model.train_on_batch(X_realA, [y_real, X_realB])
它被分配为
gen_out = X_realB。这让我感到困惑,因为 X_realB 是“目标”真实图像。
.
gen_out 是生成器的输出。
在 train 函数中
X_fakeB 是生成器生成的“目标”图像。
那么为什么使用 X_realB 而不是 X_fakeB?
.
您具体遇到了什么问题?也许您可以详细说明一下?
嗨!
感谢这篇精彩的文章!
我有一个小小的困惑,在此文章和下一篇文章之间:
https://machinelearning.org.cn/how-to-develop-a-pix2pix-gan-for-image-to-image-translation/
在这里,您提到‘patch_shape’参数在‘generate_fake_samples’和‘generate_real_samples’中应为 16,在“如何更新模型权重”部分,但您在另一篇文章中将 patch_shape 传递为 1。您能否解释一下两个示例的区别?这将非常有帮助。
据我所知,Patch GAN 判别器的架构在这两篇文章中是相同的。Patch_shape 为 16 在这里有意义,正如您在此解释的那样,但 patch_shape 为 1 有点令人困惑。
不客气。
也许上面我们一起计算 PatchGAN 感受野的示例会对此有所帮助?尝试完成教程的这部分。
是的,我确实遵循了那个示例计算,但是在这里,我对‘patch_shape’参数在‘generate_fake_samples’和‘generate_real_samples’中取什么值感到困惑?16×16 的输出形状在这里这篇文章中有意义,但在您之前的这篇(https://machinelearning.org.cn/how-to-develop-a-pix2pix-gan-for-image-to-image-translation/)
您将相同的 patch_shape 参数设置为 1。(在 summarize_performance() 函数中,代码的第一行和第二行)。是不是我错过了什么地方?
不,我相信它们是相同的。
你好,Jason。
我审查了几乎所有不同教程中的问题,但没有找到我的答案。
我想使用大小为 52*52*1 的图像,无法将其调整为 256*256,所以我猜我必须自己更改模型。
如果我只更改输入图像大小来运行它,我在连接时会遇到一些问题:一边是 (None, 2, 2, 512),另一边是 (None, 1, 1, 512)。我认为我必须删除一些层,所以这是我天真地尝试的方法,但仍然存在类似的错误,直到我只保留了一个编码层和一个解码层。根据较小的输入图像尺寸修改模型,这是正确的方法吗?
我还必须更改什么?瓶颈处的“512”?
提前感谢您的回复,尽可能准确!
是的,您可能(将!)需要自定义层数和大小来实现您想要的输入和输出。
我非常感谢您提供的这些精彩教程。
我只想纠正一个小的排版错误。
在定义 U-net 生成器的第一个解码器块时,您说:
“解码器的第一层不使用批归一化。”
但是,解码器的第一层使用了批归一化。我认为应该是编码器,而不是解码器,因为编码器的第一层 C64 不使用批归一化。
谢谢!
谢谢,已修复!
嗨,Jason!
这是一个非常有用的教程。我学习并根据我的需求修改了代码,但在训练模型时,速度非常慢。我有 380 个训练样本和 100 个 epoch,批次大小为 1,这使得迭代次数高达 38000。
我看了您的图像翻译代码,您训练了大约 10 万次迭代。您的训练时间是多少?也许我犯了什么错误。
我不记得了,抱歉,我想我在 AWS EC2 实例上训练了一夜。
我的 g_loss 太高了,大约 17000。之前我是在 CPU 上运行模型的,但现在我切换到了 GPU,速度快了很多。
损失可能不是 GAN 模型性能的好指标。请查看生成的图像。
嗨,Jason,
感谢您提供的精彩教程。我从中学到了很多。
我已经实现了您的代码,并添加了一行代码来保存整个 GAN 模型(在 summarize_performance 中添加 gan_name = ‘GAN_%06d.h5’ % (step+1) 和 gan_model.save(gan_name)),但当我加载模型并继续训练时,判别器的损失很快就降到了 0。如果我不加载模型只进行训练,那么一切正常。如果我们只加载 d 和 g 的权重,我认为 Adam 的衰减会重置回 beta_1 参数的初始值。
我保存了 GAN 模型,以便它能记住 Adam 衰减的状态,但不确定为什么这会导致模型在加载后停止学习。我可能犯了错误,但找不到哪里。
您能否稍微扩展一下这个教程,并向我们展示如何特别保存和恢复此模型的训练?我相信这会极大地帮助所有人,因为 Google Colab 和许多人的计算机无法长时间保持开启状态,必须稍后恢复。
我相信这将非常受大家欢迎。
谢谢!
感谢您的建议。我们计划撰写这方面的内容。
你好 Adrian,
我发现使用 TensorFlow Checkpoints 可以保存所有超参数的状态,并在实例化后恢复优化器。
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer, discriminator_optimizer=discriminator_optimizer, generator=generator, discriminator=discriminator)
然后
checkpoint.save(…)
嗨,Jason,
感谢这篇教程。
我想使用 pix2pix 来去除图像水印。
我的数据集有 60K 个样本,包含 160 种不同的彩色水印。
我训练了 pix2pix 大约 40000 步,但没有任何效果,生成器的输出与输入相同,没有任何变化。
我想知道您是否能帮助我。
我不太可能提供详细的帮助。但 pix2pix 是一个 GAN,您应该检查您的编码器和解码器部分是否构建正确。另外,为了验证输入和输出不相同,请验证数值而不是视觉外观。您可能只是训练得不够。
您好,我也在尝试使用 pix2pix gan 来去除水印。我刚开始。您能告诉我是否应该继续使用 pix2pix gan,还是应该更换它?
你好 Adrian,
您详细的解释太棒了。我使用了您的代码结构,但用我自己的方式在 pytorch 中进行了编码。效果非常好。您的教程帮助我取得了出色的成果。
谢谢你
不是 Adrian,抱歉有错别字。功劳归于 Jason Brownlee。
您的解释非常简单易懂。
我想运行上面的代码。
您能告诉我上面的代码是否有效吗?
谢谢你。
您好 YooJC……感谢您的反馈!请随时执行代码并告知您的发现。