渐进增长生成对抗网络是一种用于训练深度卷积神经网络模型以生成合成图像的方法。
它是对更传统的GAN架构的扩展,涉及在训练期间逐步增加生成图像的大小,从非常小的图像开始,例如4×4像素。这使得能够稳定地训练和增长能够生成非常大、高质量图像的GAN模型,例如尺寸为1024×1024像素的合成名人面部图像。
在本教程中,您将学习如何从头开始使用Keras开发渐进增长的生成对抗网络模型。
完成本教程后,您将了解:
- 如何开发预定义的判别器和生成器模型,以适应不断增长的输出图像尺寸。
- 如何定义复合模型,通过判别器模型来训练生成器模型。
- 如何循环训练每个输出图像尺寸增长阶段的渐进融合版本和正常版本模型。
通过我的新书《Python中的生成对抗网络》开启您的项目,书中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何在Keras中实现渐进式增长GAN模型
照片由 Diogo Santos Silva 拍摄,部分权利保留。
教程概述
本教程分为五个部分;它们是:
- 什么是渐进增长GAN架构?
- 如何实现渐进增长GAN判别器模型
- 如何实现渐进增长GAN生成器模型
- 如何实现用于更新生成器的复合模型
- 如何训练判别器和生成器模型
什么是渐进增长GAN架构?
GAN在生成清晰的合成图像方面很有效,但通常在可以生成的图像尺寸方面受到限制。
渐进增长GAN是对GAN的扩展,它允许训练生成器模型能够输出大尺寸、高质量的图像,例如1024×1024像素的写实人脸。该技术由Nvidia的 Tero Karras 等人在2017年发表的题为“渐进式GAN增长以提高质量、稳定性和变异性”的论文中进行了描述。
渐进增长GAN的关键创新是生成器输出图像尺寸的增量增加,从4×4像素的图像开始,然后翻倍到8×8、16×16等,直到达到所需的输出分辨率。
我们的主要贡献是GAN的训练方法,我们从低分辨率图像开始,然后通过向网络添加层来逐步提高分辨率。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
这是通过一种训练过程实现的,该过程包括在给定输出分辨率下对模型进行微调的时期,以及逐步引入具有更大分辨率的新模型的时期。
当生成器(G)和判别器(D)的分辨率翻倍时,我们会平滑地渐进融合新层。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
在添加新层时,所有层都保持可训练状态,包括现有层。
在整个训练过程中,两个网络中所有现有层都保持可训练状态。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
渐进增长GAN涉及使用具有相同通用结构的生成器和判别器模型,并从非常小的图像开始。在训练过程中,卷积层的新块被系统地添加到生成器模型和判别器模型中。
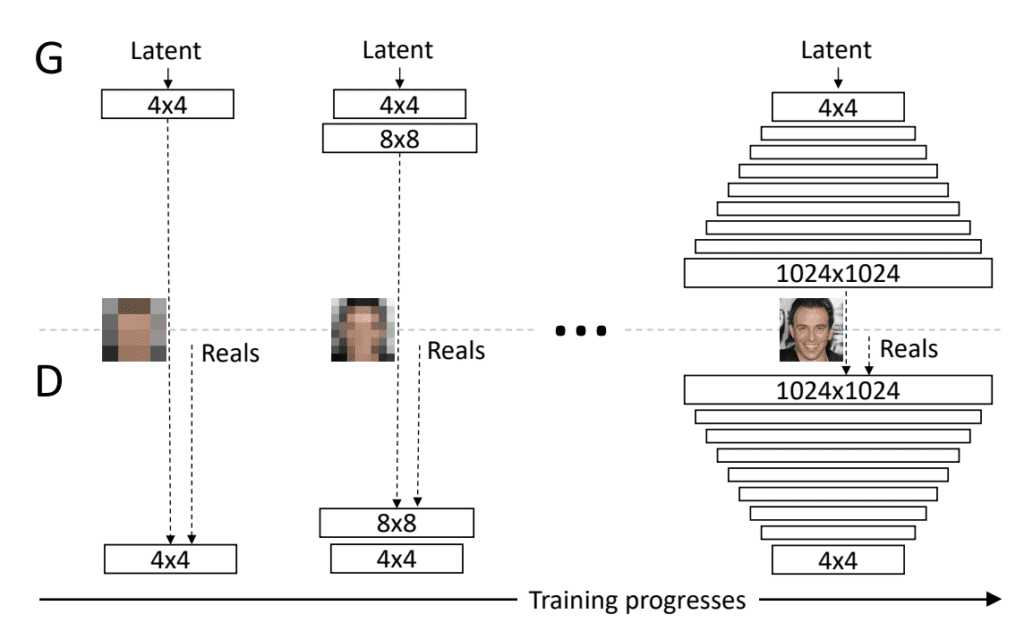
渐进式向生成器和判别器模型添加层的示例。
摘自:《GAN 的渐进式增长以提高质量、稳定性和变异性》。
层的增量添加使得模型能够有效地学习粗粒度细节,然后学习越来越精细的细节,无论是在生成器端还是判别器端。
这种渐进的性质使得模型能够首先发现图像分布的大尺度结构,然后将注意力转移到越来越精细的尺度细节上,而不是必须同时学习所有尺度。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
模型架构很复杂,无法直接实现。
在本教程中,我们将重点介绍如何使用Keras深度学习库实现渐进增长GAN。
我们将逐步介绍如何定义判别器和生成器模型,如何通过判别器模型训练生成器,以及如何在训练过程中更新每个模型。
这些实现细节将为您开发渐进增长GAN以用于您自己的应用程序提供基础。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何实现渐进增长GAN判别器模型
判别器模型接收图像作为输入,并必须将其分类为真实(来自数据集)或虚假(生成)。
在训练过程中,判别器必须增长以支持尺寸不断增加的图像,从4×4像素的彩色图像开始,翻倍到8×8、16×16、32×32等。
这是通过插入一个新的输入层来支持更大的输入图像,然后是一个新的层块来实现的。这个新块的输出被下采样。此外,新图像也直接被下采样并通过旧的输入处理层,然后与新块的输出相结合。
在从较低分辨率过渡到较高分辨率(例如16×16到32×32)的过程中,判别器模型将有两个输入路径,如下所示:
- [32×32 图像] -> [fromRGB Conv] -> [新块] -> [下采样] ->
- [32×32 图像] -> [下采样] -> [fromRGB Conv] ->
新块下采样后的输出与旧输入处理层的输出通过加权平均相结合,加权由称为alpha的新超参数控制。加权和计算如下:
- 输出 = ((1 – alpha) * fromRGB) + (alpha * NewBlock)
这两个路径的加权平均值然后被馈送到现有模型的其余部分。
最初,权重完全偏向旧的输入处理层(alpha=0),并在训练迭代中线性增加,直到新块获得更多权重,最终输出完全是新块的产物(alpha=1)。此时,可以移除旧路径。
可以用论文中的以下图示总结,该图显示了模型增长前(a)、高分辨率渐进融合期间(b)以及渐进融合后(c)。
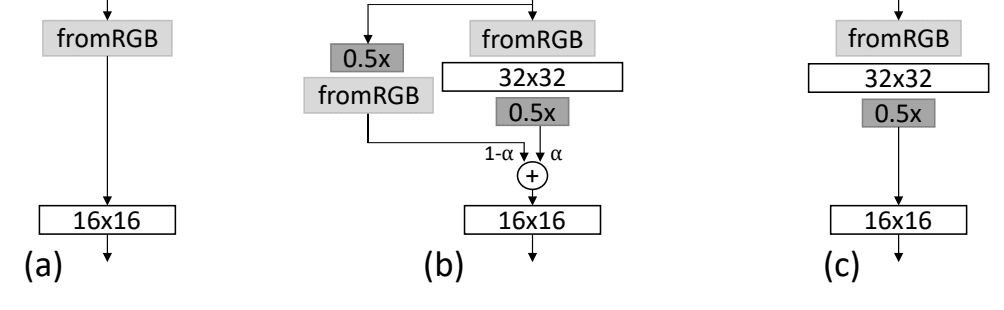
显示判别器模型增长的图示,渐进融合高分辨率前(a)、期间(b)和后(c)。
摘自:《GAN 的渐进式增长以提高质量、稳定性和变异性》。
fromRGB层实现为1×1卷积层。一个块由两个3×3尺寸的卷积层和斜率(slope)为0.2的Leaky ReLU激活函数组成,然后是一个下采样层。平均池化(Average pooling)用于下采样,这与其他大多数使用转置卷积层(transpose convolutional layers)的GAN模型不同。
模型的输出包括两个3×3和4×4尺寸的卷积层以及Leaky ReLU激活,然后是一个输出单一值预测的全连接层。该模型使用线性激活函数而不是像其他判别器模型那样的sigmoid激活函数,并直接通过Wasserstein损失(特别是WGAN-GP)或最小二乘损失进行训练;在本教程中,我们将使用后者。模型权重使用He Gaussian(he_normal)初始化,这与论文中的方法非常相似。
该模型在输出块的开头使用了一个名为Minibatch标准差(Minibatch standard deviation)的自定义层,并且每个层使用局部响应归一化(local response normalization),在论文中称为像素级归一化(pixel-wise normalization),而不是批归一化(batch normalization)。为了简洁起见,我们将在本教程中省略批归一化,使用批归一化。
实现渐进增长GAN的一种方法是在训练期间按需手动扩展模型。另一种方法是在训练之前预先定义所有模型,并仔细使用Keras函数式API来确保层在模型之间共享并继续训练。
我认为后一种方法可能更容易,这也是我们将在本教程中使用的方法。
首先,我们必须定义一个自定义层,当渐进融合新的更高分辨率输入图像和块时可以使用。这个新层必须接受两组具有相同尺寸(宽度、高度、通道)的激活图,并使用加权和将它们相加。
我们可以将其实现为一个名为WeightedSum的新层,它扩展了Add合并层,并使用超参数‘alpha‘来控制每个输入的贡献。这个新类定义如下。该层假定只有两个输入:第一个输入是旧的或现有的层的输出,第二个输入是新添加的层的输出。新的超参数被定义为后端变量,这意味着我们可以通过更改变量的值随时更改它。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 加权和输出 class WeightedSum(Add): # 使用默认值初始化 def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # 输出输入的加权和 def _merge_function(self, inputs): # 只支持两个输入的加权和 assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output |
判别器模型比生成器模型更复杂,因为我们需要更改模型输入,所以我们慢慢来。
首先,我们可以定义一个判别器模型,它接受4×4彩色图像作为输入,并输出该图像是真实还是虚假的预测。该模型由一个1×1的输入处理层(fromRGB)和一个输出块组成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
... # 基础模型输入 in_image = Input(shape=(4,4,3)) # 1x1 卷积 g = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) g = LeakyReLU(alpha=0.2)(g) # 3x3 卷积 (输出块) g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 4x4 卷积 g = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 密集输出层 g = Flatten()(g) out_class = Dense(1)(g) # 定义模型 model = Model(in_image, out_class) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) |
接下来,我们需要定义一个新模型,该模型处理此模型与接受8×8彩色图像的新判别器模型之间的中间阶段。
现有的输入处理层必须接收新8×8图像的下采样版本。必须定义一个新的输入处理层,该层接收8×8输入图像,并通过新的两个卷积层和一个下采样层。新块下采样后的输出与旧输入处理层必须使用我们的新WeightedSum层通过加权和相加,然后必须重用相同的输出块(两个卷积层和输出层)。
鉴于第一个定义的模型以及我们对该模型的了解(例如,输入处理层中卷积层和LeakyReLU的数量为2),我们可以使用旧模型中的层索引来构建这个新的中间或渐进融合模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
... old_model = model # 获取现有模型的形状 in_shape = list(old_model.input.shape) # 将新输入形状定义为当前大小的两倍 input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # 定义新的输入处理层 g = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) g = LeakyReLU(alpha=0.2)(g) # 定义新块 g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = AveragePooling2D()(g) # 对新的较大图像进行下采样 downsample = AveragePooling2D()(in_image) # 将旧模型的输入处理层连接到下采样后的新输入 block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # 使用新输入渐进融合旧模型输入层的输出 g = WeightedSum()([block_old, g]) # 跳过旧模型的输入、1x1卷积和激活 for i in range(3, len(old_model.layers)): g = old_model.layers[i](g) # 定义直通模型 model = Model(in_image, g) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) |
到目前为止,一切顺利。
我们还需要一个与此相同的模型版本,包含相同的层,但不包含来自旧模型输入处理层的渐进融合。
这个直通版本是在我们渐进融合下一个翻倍的输入图像尺寸之前进行训练所必需的。
我们可以更新上面的示例来创建两个模型版本。首先是直通版本,因为它更简单,然后是用于渐进融合的版本,它重用了新块的层和旧模型的输出层。
下面的add_discriminator_block()函数实现了这一点,它返回两个已定义模型(直通模型和渐进融合模型)的列表,并将旧模型作为参数,并将输入层数量定义为默认参数(3)。
为了确保WeightedSum层正常工作,我们将所有卷积层固定为始终具有64个滤波器,并输出64个特征图。如果旧模型的输入处理层的特征图数量(通道数)与新块的输出不匹配,则加权和将失败。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 添加一个判别器块 def add_discriminator_block(old_model, n_input_layers=3): # 获取现有模型的形状 in_shape = list(old_model.input.shape) # 将新输入形状定义为当前大小的两倍 input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # 定义新的输入处理层 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # 定义新块 d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = AveragePooling2D()(d) block_new = d # 跳过旧模型的输入、1x1卷积和激活 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model1 = Model(in_image, d) # 编译模型 model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 对新的较大图像进行下采样 downsample = AveragePooling2D()(in_image) # 将旧输入的处理连接到下采样的新输入 block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # 将旧模型输入层的输出与新输入进行渐变叠加 d = WeightedSum()([block_old, block_new]) # 跳过旧模型的输入、1x1卷积和激活 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model2 = Model(in_image, d) # 编译模型 model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) return [model1, model2] |
这个函数不算优雅,因为我们有一些重复的代码,但它是可读的,并且能够完成任务。
随着我们输入图像尺寸的翻倍,我们可以一遍又一遍地调用此函数。重要的是,该函数期望将前一个模型的直通版本作为输入。
下面的示例定义了一个名为 `define_discriminator()` 的新函数,该函数定义了我们的基础模型,它期望一个 4x4 彩色图像作为输入,然后重复添加块以创建新版本的判别器模型,每次都期望图像的面积翻四倍。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 为每个图像分辨率定义判别器模型 def define_discriminator(n_blocks, input_shape=(4,4,3)): model_list = list() # 基础模型输入 in_image = Input(shape=input_shape) # 1x1 卷积 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # 3x3 卷积(输出块) d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 4x4 卷积 d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 密集输出层 d = Flatten()(d) out_class = Dense(1)(d) # 定义模型 model = Model(in_image, out_class) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取没有渐变叠加的前一个模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_discriminator_block(old_model) # 存储模型 model_list.append(models) return model_list |
此函数将返回一个模型列表,其中列表中的每个项都是一个包含两个元素的列表,第一个元素是该分辨率下模型的直通版本,第二个元素是该分辨率下模型渐变叠加的版本。
我们可以将所有这些内容结合起来,定义一个新的“判别器模型”,该模型将从 4x4 增长到 8x8,最后到 16x16。这通过在调用 `define_discriminator()` 函数时将 `n_blocks` 参数设置为 3 来实现,以创建三组模型。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
# 定义渐进增长 GAN 的判别器模型的示例 from keras.optimizers import Adam from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Flatten 从 keras.layers 导入 Conv2D from keras.layers import AveragePooling2D from keras.layers import LeakyReLU 从 keras.层 导入 BatchNormalization from keras.layers import Add from keras.utils.vis_utils import plot_model from keras import backend # 加权和输出 class WeightedSum(Add): # 使用默认值初始化 def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # 输出输入的加权和 def _merge_function(self, inputs): # 只支持两个输入的加权和 assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output # 添加一个判别器块 def add_discriminator_block(old_model, n_input_layers=3): # 获取现有模型的形状 in_shape = list(old_model.input.shape) # 将新输入形状定义为当前大小的两倍 input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # 定义新的输入处理层 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # 定义新块 d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = AveragePooling2D()(d) block_new = d # 跳过旧模型的输入、1x1卷积和激活 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model1 = Model(in_image, d) # 编译模型 model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 对新的较大图像进行下采样 downsample = AveragePooling2D()(in_image) # 将旧输入的处理连接到下采样的新输入 block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # 将旧模型输入层的输出与新输入进行渐变叠加 d = WeightedSum()([block_old, block_new]) # 跳过旧模型的输入、1x1卷积和激活 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model2 = Model(in_image, d) # 编译模型 model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) return [model1, model2] # 为每个图像分辨率定义判别器模型 def define_discriminator(n_blocks, input_shape=(4,4,3)): model_list = list() # 基础模型输入 in_image = Input(shape=input_shape) # 1x1 卷积 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # 3x3 卷积(输出块) d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 4x4 卷积 d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 密集输出层 d = Flatten()(d) out_class = Dense(1)(d) # 定义模型 model = Model(in_image, out_class) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取没有渐变叠加的前一个模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_discriminator_block(old_model) # 存储模型 model_list.append(models) return model_list # 定义模型 discriminators = define_discriminator(3) # 抽查 m = discriminators[2][1] m.summary() plot_model(m, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True) |
运行示例首先总结了第三个模型的渐变叠加版本,显示了 16x16 彩色图像输入和单个值输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_3 (InputLayer) (None, 16, 16, 3) 0 __________________________________________________________________________________________________ conv2d_7 (Conv2D) (None, 16, 16, 64) 256 input_3[0][0] __________________________________________________________________________________________________ leaky_re_lu_7 (LeakyReLU) (None, 16, 16, 64) 0 conv2d_7[0][0] __________________________________________________________________________________________________ conv2d_8 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_7[0][0] __________________________________________________________________________________________________ batch_normalization_5 (BatchNor (None, 16, 16, 64) 256 conv2d_8[0][0] __________________________________________________________________________________________________ leaky_re_lu_8 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_5[0][0] __________________________________________________________________________________________________ conv2d_9 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_8[0][0] __________________________________________________________________________________________________ average_pooling2d_4 (AveragePoo (None, 8, 8, 3) 0 input_3[0][0] __________________________________________________________________________________________________ batch_normalization_6 (BatchNor (None, 16, 16, 64) 256 conv2d_9[0][0] __________________________________________________________________________________________________ conv2d_4 (Conv2D) (None, 8, 8, 64) 256 average_pooling2d_4[0][0] __________________________________________________________________________________________________ leaky_re_lu_9 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_6[0][0] __________________________________________________________________________________________________ leaky_re_lu_4 (LeakyReLU) (None, 8, 8, 64) 0 conv2d_4[1][0] __________________________________________________________________________________________________ average_pooling2d_3 (AveragePoo (None, 8, 8, 64) 0 leaky_re_lu_9[0][0] __________________________________________________________________________________________________ weighted_sum_2 (WeightedSum) (None, 8, 8, 64) 0 leaky_re_lu_4[1][0] average_pooling2d_3[0][0] __________________________________________________________________________________________________ conv2d_5 (Conv2D) (None, 8, 8, 64) 36928 weighted_sum_2[0][0] __________________________________________________________________________________________________ batch_normalization_3 (BatchNor (None, 8, 8, 64) 256 conv2d_5[2][0] __________________________________________________________________________________________________ leaky_re_lu_5 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_3[2][0] __________________________________________________________________________________________________ conv2d_6 (Conv2D) (None, 8, 8, 64) 36928 leaky_re_lu_5[2][0] __________________________________________________________________________________________________ batch_normalization_4 (BatchNor (None, 8, 8, 64) 256 conv2d_6[2][0] __________________________________________________________________________________________________ leaky_re_lu_6 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_4[2][0] __________________________________________________________________________________________________ average_pooling2d_1 (AveragePoo (None, 4, 4, 64) 0 leaky_re_lu_6[2][0] __________________________________________________________________________________________________ conv2d_2 (Conv2D) (None, 4, 4, 128) 73856 average_pooling2d_1[2][0] __________________________________________________________________________________________________ batch_normalization_1 (BatchNor (None, 4, 4, 128) 512 conv2d_2[4][0] __________________________________________________________________________________________________ leaky_re_lu_2 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_1[4][0] __________________________________________________________________________________________________ conv2d_3 (Conv2D) (None, 4, 4, 128) 262272 leaky_re_lu_2[4][0] __________________________________________________________________________________________________ batch_normalization_2 (BatchNor (None, 4, 4, 128) 512 conv2d_3[4][0] __________________________________________________________________________________________________ leaky_re_lu_3 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_2[4][0] __________________________________________________________________________________________________ flatten_1 (Flatten) (None, 2048) 0 leaky_re_lu_3[4][0] __________________________________________________________________________________________________ dense_1 (Dense) (None, 1) 2049 flatten_1[4][0] ================================================================================================== 总参数量: 488,449 可训练参数量: 487,425 不可训练参数量: 1,024 __________________________________________________________________________________________________ |
同一渐变叠加模型的图也被创建并保存到文件中。
注意: 创建此图假定已安装 pygraphviz 和 pydot 库。如果存在问题,请注释掉 import 语句和 plot_model() 的调用。
该图显示了 16x16 输入图像,它被下采样并通过前一个模型的 8x8 输入处理层(左侧)。它还显示了新块(右侧)的添加以及结合了两个输入流的加权平均,然后使用现有模型层继续处理并输出预测。
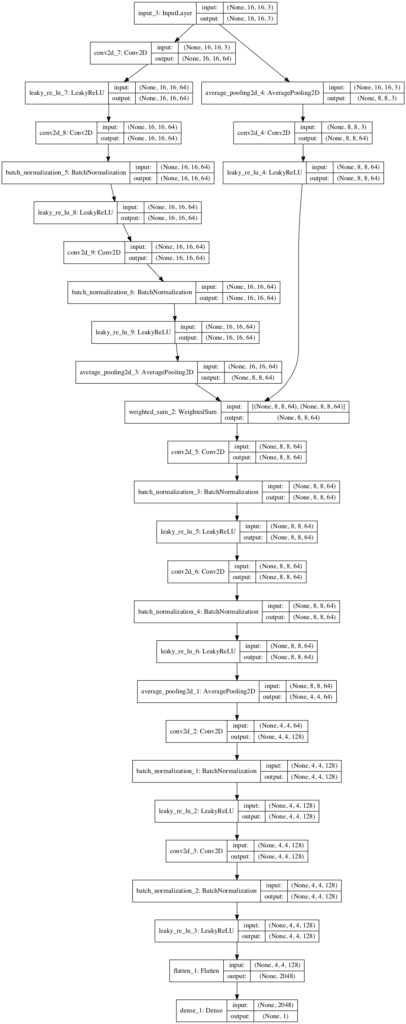
从 8x8 到 16x16 输入图像的渐进增长 GAN 的渐变叠加判别器模型图
既然我们已经了解了如何定义判别器模型,下面我们来看如何定义生成器模型。
如何实现渐进增长GAN生成器模型
渐进增长 GAN 的生成器模型比判别器模型更容易在 Keras 中实现。
这是因为每次渐变叠加都需要对模型的输出进行微小的更改。
增加生成器的分辨率需要首先对最后一个块的末尾进行上采样。然后将其连接到新块和新输出层,以生成高度和宽度尺寸加倍或面积翻四倍的图像。在渐变叠加期间,上采样也连接到旧模型的输出层,并且两个输出层的输出通过加权平均合并。
渐变叠加完成后,将删除旧的输出层。
这可以用下图总结,该图来自论文,显示了一个模型在增长之前 (a)、增长期间(更高分辨率的渐变叠加)(b) 以及增长之后 (c) 的状态。
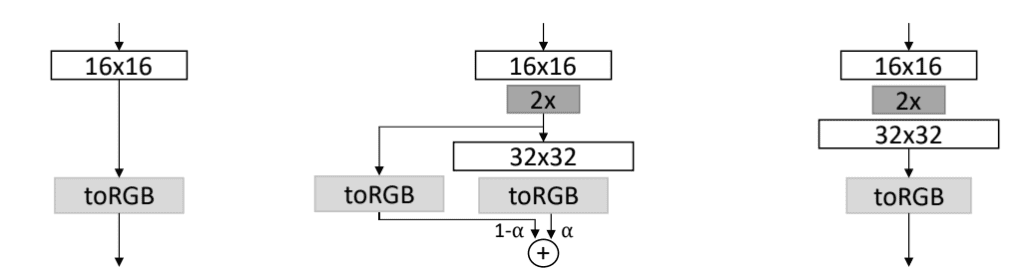
显示生成器模型增长的图,在增长之前 (a)、增长期间 (b) 和增长之后 (c) 高分辨率的渐变叠加。
摘自:《GAN 的渐进式增长以提高质量、稳定性和变异性》。
toRGB 层是一个具有 3 个 1x1 滤波器的卷积层,足以输出彩色图像。
该模型以潜在空间中的一个点为输入,例如论文中描述的 100 维或 512 维向量。这被缩放到为 4x4 激活图提供基础,然后是一个具有 4x4 滤波器的卷积层和另一个具有 3x3 滤波器的卷积层。与判别器一样,使用 LeakyReLU 激活,以及像素归一化,为了简洁起见,我们将用批量归一化代替。
一个块包括一个上采样层,然后是两个具有 3x3 滤波器的卷积层。上采样是通过最近邻方法(例如复制输入行和列)使用 `UpSampling2D` 层实现的,而不是更常见的转置卷积层。
我们可以定义一个基线模型,该模型以潜在空间中的一个点为输入并输出一个 4x4 彩色图像,如下所示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
... # 基线模型潜在输入 in_latent = Input(shape=(100,)) # 线性缩放到激活图 g = Dense(128 * 4 * 4, kernel_initializer='he_normal')(in_latent) g = Reshape((4, 4, 128))(g) # 4x4 卷积,输入块 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 3x3 卷积 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 1x1 卷积,输出块 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # 定义模型 model = Model(in_latent, out_image) |
接下来,我们需要定义一个模型版本,该版本使用所有相同的输入层,但添加了一个新块(上采样和 2 个卷积层)和一个新输出层(一个 1x1 卷积层)。
这将是达到新输出分辨率后的模型。这可以通过利用我们对基线模型的了解来实现,即最后一个块的末尾是倒数第二个层,例如模型层列表中的索引为 -2 的层。
添加了新块和输出层的新模型定义如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... old_model = model # 获取最后一个块的末尾 block_end = old_model.layers[-2].output # 上采样,并定义新块 upsampling = UpSampling2D()(block_end) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 添加新输出层 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # 定义模型 model = Model(old_model.input, out_image) |
这相当直接;我们切掉了最后一个块末尾的旧输出层,然后嫁接了一个新块和输出层。
现在我们需要这个新模型的一个版本用于渐变叠加。
这涉及到将旧输出层连接到新块开始处的新上采样层,并使用我们上一节定义的 `WeightedSum` 层的实例来合并旧输出层和新输出层的输出。
|
1 2 3 4 5 6 7 8 9 |
... # 获取旧模型的输出层 out_old = old_model.layers[-1] # 将上采样连接到旧输出层 out_image2 = out_old(upsampling) # 将新图像定义为旧模型和新模型的加权和 merged = WeightedSum()([out_image2, out_image]) # 定义模型 model2 = Model(old_model.input, merged) |
我们可以将这两个操作的定义合并到一个名为 `add_generator_block()` 的函数中,该函数如下定义,它将扩展给定模型并返回添加了块的新生成器模型(`model1`)以及一个具有新块与旧输出层渐变叠加的模型版本(`model2`)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 添加一个生成器块 def add_generator_block(old_model): # 获取最后一个块的末尾 block_end = old_model.layers[-2].output # 上采样,并定义新块 upsampling = UpSampling2D()(block_end) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 添加新的输出层 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # 定义模型 model1 = Model(old_model.input, out_image) # 获取旧模型的输出层 out_old = old_model.layers[-1] # 将上采样连接到旧的输出层 out_image2 = out_old(upsampling) # 定义新的输出图像为旧模型和新模型的加权和 merged = WeightedSum()([out_image2, out_image]) # 定义模型 model2 = Model(old_model.input, merged) return [model1, model2] |
然后,我们可以使用基线模型调用此函数来创建具有一个附加块的模型,并继续调用后续模型以不断添加块。
下面的 define_generator() 函数实现了这一点,它接受潜在空间的大小和要添加的块的数量(要创建的模型)。
基线模型被定义为输出具有 4×4 形状的彩色图像,由默认参数 in_dim 控制。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 定义生成器模型 def define_generator(latent_dim, n_blocks, in_dim=4): model_list = list() # 基础模型潜在输入 in_latent = Input(shape=(latent_dim,)) # 线性缩放到激活图 g = Dense(128 * in_dim * in_dim, kernel_initializer='he_normal')(in_latent) g = Reshape((in_dim, in_dim, 128))(g) # 卷积 4x4,输入块 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 1x1,输出块 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # 定义模型 model = Model(in_latent, out_image) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取没有渐变叠加的前一个模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_generator_block(old_model) # 存储模型 model_list.append(models) return model_list |
我们可以将所有这些结合起来,定义一个基线生成器和两个块的添加,总共三个模型,其中每个模型都有直通版本和渐进版本。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
# 渐进式增长 GAN 的生成器模型定义的示例 from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Reshape 从 keras.layers 导入 Conv2D from keras.layers import UpSampling2D from keras.layers import LeakyReLU 从 keras.层 导入 BatchNormalization from keras.layers import Add from keras.utils.vis_utils import plot_model from keras import backend # 加权和输出 class WeightedSum(Add): # 使用默认值初始化 def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # 输出输入的加权和 def _merge_function(self, inputs): # 只支持两个输入的加权和 assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output # 添加一个生成器块 def add_generator_block(old_model): # 获取最后一个块的末尾 block_end = old_model.layers[-2].output # 上采样,并定义新块 upsampling = UpSampling2D()(block_end) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 添加新的输出层 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # 定义模型 model1 = Model(old_model.input, out_image) # 获取旧模型的输出层 out_old = old_model.layers[-1] # 将上采样连接到旧的输出层 out_image2 = out_old(upsampling) # 定义新的输出图像为旧模型和新模型的加权和 merged = WeightedSum()([out_image2, out_image]) # 定义模型 model2 = Model(old_model.input, merged) return [model1, model2] # 定义生成器模型 def define_generator(latent_dim, n_blocks, in_dim=4): model_list = list() # 基础模型潜在输入 in_latent = Input(shape=(latent_dim,)) # 线性缩放到激活图 g = Dense(128 * in_dim * in_dim, kernel_initializer='he_normal')(in_latent) g = Reshape((in_dim, in_dim, 128))(g) # 卷积 4x4,输入块 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 1x1,输出块 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # 定义模型 model = Model(in_latent, out_image) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取没有渐变叠加的前一个模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_generator_block(old_model) # 存储模型 model_list.append(models) return model_list # 定义模型 generators = define_generator(100, 3) # 抽查 m = generators[2][1] m.summary() plot_model(m, to_file='generator_plot.png', show_shapes=True, show_layer_names=True) |
示例选择渐进模型作为最后一个模型进行总结。
运行该示例首先总结模型中的图层列表。我们可以看到最后一个模型从潜在空间取一个点并输出一个 16×16 的图像。
这与我们的预期相符,因为基线模型输出一个 4×4 的图像,添加一个块会将其增加到 8×8,再添加一个块会将其增加到 16×16。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
__________________________________________________________________________________________________ 层(类型) 输出形状 参数 # 连接到 ================================================================================================== input_1 (InputLayer) (None, 100) 0 __________________________________________________________________________________________________ dense_1 (Dense) (None, 2048) 206848 input_1[0][0] __________________________________________________________________________________________________ reshape_1 (Reshape) (None, 4, 4, 128) 0 dense_1[0][0] __________________________________________________________________________________________________ conv2d_1 (Conv2D) (None, 4, 4, 128) 147584 reshape_1[0][0] __________________________________________________________________________________________________ batch_normalization_1 (BatchNor (None, 4, 4, 128) 512 conv2d_1[0][0] __________________________________________________________________________________________________ leaky_re_lu_1 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_1[0][0] __________________________________________________________________________________________________ conv2d_2 (Conv2D) (None, 4, 4, 128) 147584 leaky_re_lu_1[0][0] __________________________________________________________________________________________________ batch_normalization_2 (BatchNor (None, 4, 4, 128) 512 conv2d_2[0][0] __________________________________________________________________________________________________ leaky_re_lu_2 (LeakyReLU) (None, 4, 4, 128) 0 batch_normalization_2[0][0] __________________________________________________________________________________________________ up_sampling2d_1 (UpSampling2D) (None, 8, 8, 128) 0 leaky_re_lu_2[0][0] __________________________________________________________________________________________________ conv2d_4 (Conv2D) (None, 8, 8, 64) 73792 up_sampling2d_1[0][0] __________________________________________________________________________________________________ batch_normalization_3 (BatchNor (None, 8, 8, 64) 256 conv2d_4[0][0] __________________________________________________________________________________________________ leaky_re_lu_3 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_3[0][0] __________________________________________________________________________________________________ conv2d_5 (Conv2D) (None, 8, 8, 64) 36928 leaky_re_lu_3[0][0] __________________________________________________________________________________________________ batch_normalization_4 (BatchNor (None, 8, 8, 64) 256 conv2d_5[0][0] __________________________________________________________________________________________________ leaky_re_lu_4 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_4[0][0] __________________________________________________________________________________________________ up_sampling2d_2 (UpSampling2D) (None, 16, 16, 64) 0 leaky_re_lu_4[0][0] __________________________________________________________________________________________________ conv2d_7 (Conv2D) (None, 16, 16, 64) 36928 up_sampling2d_2[0][0] __________________________________________________________________________________________________ batch_normalization_5 (BatchNor (None, 16, 16, 64) 256 conv2d_7[0][0] __________________________________________________________________________________________________ leaky_re_lu_5 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_5[0][0] __________________________________________________________________________________________________ conv2d_8 (Conv2D) (None, 16, 16, 64) 36928 leaky_re_lu_5[0][0] __________________________________________________________________________________________________ batch_normalization_6 (BatchNor (None, 16, 16, 64) 256 conv2d_8[0][0] __________________________________________________________________________________________________ leaky_re_lu_6 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_6[0][0] __________________________________________________________________________________________________ conv2d_6 (Conv2D) multiple 195 up_sampling2d_2[0][0] __________________________________________________________________________________________________ conv2d_9 (Conv2D) (None, 16, 16, 3) 195 leaky_re_lu_6[0][0] __________________________________________________________________________________________________ weighted_sum_2 (WeightedSum) (None, 16, 16, 3) 0 conv2d_6[1][0] conv2d_9[0][0] ================================================================================================== 总参数:689,030 可训练参数:688,006 不可训练参数量: 1,024 __________________________________________________________________________________________________ |
同一渐变叠加模型的图也被创建并保存到文件中。
注意:创建此图假定已安装 pygraphviz 和 pydot 库。如果存在问题,请注释掉 import 语句和对 plot_model() 的调用。
我们可以看到,最后一个块的输出通过一个 UpSampling2D 层,然后输入到附加块和新的输出层以及旧的输出层,最后通过加权和合并到最终的输出层。
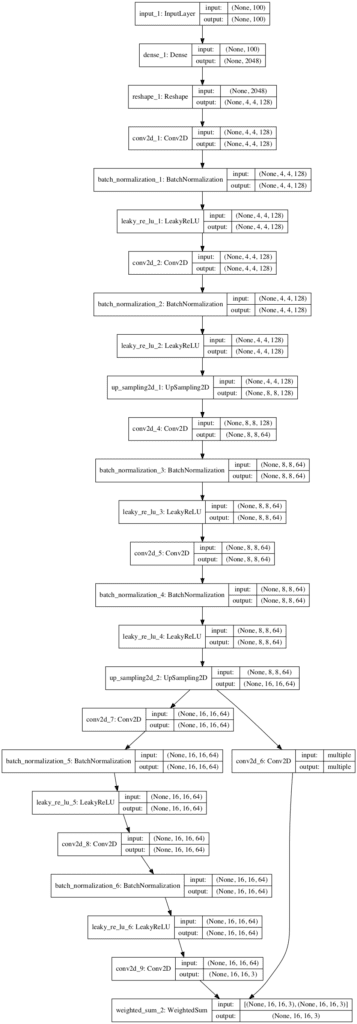
渐进式增长 GAN 的渐进模型图,从 8x8 到 16x16 输出图像的过渡
既然我们已经了解了如何定义生成器模型,我们就可以回顾一下生成器模型是如何通过判别器模型进行更新的。
如何实现用于更新生成器的复合模型
判别器模型直接以真实图像和假图像作为输入进行训练,目标值为假为 0,真为 1。
生成器模型不直接训练;相反,它们通过判别器模型间接训练,就像正常的 GAN 模型一样。
我们可以为模型的每个增长级别创建复合模型,例如,配对 4x4 生成器和 4x4 判别器。我们也可以将直通模型配对,将渐进模型配对。
例如,我们可以检索给定增长级别的生成器和判别器模型。
|
1 2 |
... g_models, d_models = generators[0], discriminators[0] |
然后,我们可以使用它们为直通生成器训练创建一个复合模型,其中生成器的输出直接馈送到判别器以进行分类。
|
1 2 3 4 5 6 |
# 直通模型 d_models[0].trainable = False model1 = Sequential() model1.add(g_models[0]) model1.add(d_models[0]) model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) |
并为渐进生成器创建复合模型执行相同的操作。
|
1 2 3 4 5 6 |
# 渐进模型 d_models[1].trainable = False model2 = Sequential() model2.add(g_models[1]) model2.add(d_models[1]) model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) |
下面的 define_composite() 函数可以自动化此过程;给定一个定义的判别器和生成器模型列表,它将为每个生成器模型训练创建一个适当的复合模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 为通过判别器训练生成器定义复合模型 def define_composite(discriminators, generators): model_list = list() # 创建复合模型 for i in range(len(discriminators)): g_models, d_models = generators[i], discriminators[i] # 直通模型 d_models[0].trainable = False model1 = Sequential() model1.add(g_models[0]) model1.add(d_models[0]) model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 渐进模型 d_models[1].trainable = False model2 = Sequential() model2.add(g_models[1]) model2.add(d_models[1]) model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储 model_list.append([model1, model2]) return model_list |
结合上面关于判别器和生成器模型的定义,下面列出了在每个预定义增长级别定义所有模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 |
# 渐进式增长 GAN 的复合模型定义的示例 from keras.optimizers import Adam from keras.models import Sequential from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Flatten from keras.layers import Reshape 从 keras.layers 导入 Conv2D from keras.layers import UpSampling2D from keras.layers import AveragePooling2D from keras.layers import LeakyReLU 从 keras.层 导入 BatchNormalization from keras.layers import Add from keras.utils.vis_utils import plot_model from keras import backend # 加权和输出 class WeightedSum(Add): # 使用默认值初始化 def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # 输出输入的加权和 def _merge_function(self, inputs): # 只支持两个输入的加权和 assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output # 添加一个判别器块 def add_discriminator_block(old_model, n_input_layers=3): # 获取现有模型的形状 in_shape = list(old_model.input.shape) # 将新输入形状定义为当前大小的两倍 input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # 定义新的输入处理层 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # 定义新块 d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) d = AveragePooling2D()(d) block_new = d # 跳过旧模型的输入、1x1卷积和激活 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model1 = Model(in_image, d) # 编译模型 model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 对新的较大图像进行下采样 downsample = AveragePooling2D()(in_image) # 将旧输入的处理连接到下采样的新输入 block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # 将旧模型输入层的输出与新输入进行渐变叠加 d = WeightedSum()([block_old, block_new]) # 跳过旧模型的输入、1x1卷积和激活 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model2 = Model(in_image, d) # 编译模型 model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) return [model1, model2] # 为每个图像分辨率定义判别器模型 def define_discriminator(n_blocks, input_shape=(4,4,3)): model_list = list() # 基础模型输入 in_image = Input(shape=input_shape) # 1x1 卷积 d = Conv2D(64, (1,1), padding='same', kernel_initializer='he_normal')(in_image) d = LeakyReLU(alpha=0.2)(d) # 3x3 卷积(输出块) d = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 4x4 卷积 d = Conv2D(128, (4,4), padding='same', kernel_initializer='he_normal')(d) d = BatchNormalization()(d) d = LeakyReLU(alpha=0.2)(d) # 密集输出层 d = Flatten()(d) out_class = Dense(1)(d) # 定义模型 model = Model(in_image, out_class) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取没有渐变叠加的前一个模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_discriminator_block(old_model) # 存储模型 model_list.append(models) return model_list # 添加一个生成器块 def add_generator_block(old_model): # 获取最后一个块的末尾 block_end = old_model.layers[-2].output # 上采样,并定义新块 upsampling = UpSampling2D()(block_end) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(upsampling) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(64, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 添加新的输出层 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # 定义模型 model1 = Model(old_model.input, out_image) # 获取旧模型的输出层 out_old = old_model.layers[-1] # 将上采样连接到旧的输出层 out_image2 = out_old(upsampling) # 定义新的输出图像为旧模型和新模型的加权和 merged = WeightedSum()([out_image2, out_image]) # 定义模型 model2 = Model(old_model.input, merged) return [model1, model2] # 定义生成器模型 def define_generator(latent_dim, n_blocks, in_dim=4): model_list = list() # 基础模型潜在输入 in_latent = Input(shape=(latent_dim,)) # 线性缩放到激活图 g = Dense(128 * in_dim * in_dim, kernel_initializer='he_normal')(in_latent) g = Reshape((in_dim, in_dim, 128))(g) # 卷积 4x4,输入块 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer='he_normal')(g) g = BatchNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 1x1,输出块 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer='he_normal')(g) # 定义模型 model = Model(in_latent, out_image) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取没有渐变叠加的前一个模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_generator_block(old_model) # 存储模型 model_list.append(models) return model_list # 为通过判别器训练生成器定义复合模型 def define_composite(discriminators, generators): model_list = list() # 创建复合模型 for i in range(len(discriminators)): g_models, d_models = generators[i], discriminators[i] # 直通模型 d_models[0].trainable = False model1 = Sequential() model1.add(g_models[0]) model1.add(d_models[0]) model1.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 渐进模型 d_models[1].trainable = False model2 = Sequential() model2.add(g_models[1]) model2.add(d_models[1]) model2.compile(loss='mse', optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储 model_list.append([model1, model2]) return model_list # 定义模型 discriminators = define_discriminator(3) # 定义模型 generators = define_generator(100, 3) # 定义复合模型 composite = define_composite(discriminators, generators) |
现在我们知道如何定义所有模型了,我们可以回顾一下模型在训练过程中是如何更新的。
如何训练判别器和生成器模型
预定义生成器、判别器和复合模型是最困难的部分;训练模型很简单,与训练任何其他 GAN 类似。
重要的是,在每次训练迭代中,每个 WeightedSum 层中的 alpha 变量都必须设置为新值。这必须为生成器和判别器模型中的图层设置,并允许从旧模型层到新模型层的平滑线性过渡,例如,alpha 值在固定的训练迭代次数中从 0 变为 1。
下面的 update_fadein() 函数实现了这一点,它将循环遍历模型列表,并根据给定训练步数中的当前步来设置每个模型的 alpha 值。您也许可以使用回调函数以更优雅的方式实现这一点。
|
1 2 3 4 5 6 7 8 9 |
# 更新 WeightedSum 每个实例的 alpha 值 def update_fadein(models, step, n_steps): # 计算当前 alpha(线性从 0 到 1) alpha = step / float(n_steps - 1) # 更新每个模型的 alpha for model in models: for layer in model.layers: if isinstance(layer, WeightedSum): backend.set_value(layer.alpha, alpha) |
我们可以定义一个通用函数来训练给定的生成器、判别器和复合模型,训练指定的训练周期数。
下面的 train_epochs() 函数实现了这一点,首先判别器模型在真实和假图像上进行更新,然后生成器模型进行更新,该过程根据数据集大小和训练周期数重复所需的训练迭代次数。
此函数调用辅助函数,通过 generate_real_samples() 获取真实图像批次,使用生成器 generate_fake_samples() 生成假样本批次,并生成潜在空间点样本 generate_latent_points()。您可以自己轻松定义这些函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 训练生成器和判别器 def train_epochs(g_model, d_model, gan_model, dataset, n_epochs, n_batch, fadein=False): # 计算每个训练 epoch 的批次数量 bat_per_epo = int(dataset.shape[0] / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 计算半批样本的大小 half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_steps): # 在淡入新块时更新所有 WeightedSum 图层的 alpha if fadein: update_fadein([g_model, d_model, gan_model], i, n_steps) # 准备真实和虚假样本 X_real, y_real = generate_real_samples(dataset, half_batch) X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 更新判别器模型 d_loss1 = d_model.train_on_batch(X_real, y_real) d_loss2 = d_model.train_on_batch(X_fake, y_fake) # 通过判别器的误差更新生成器 z_input = generate_latent_points(latent_dim, n_batch) y_real2 = ones((n_batch, 1)) g_loss = gan_model.train_on_batch(z_input, y_real2) # 总结此批次的损失 print('>%d, d1=%.3f, d2=%.3f g=%.3f' % (i+1, d_loss1, d_loss2, g_loss)) |
图像必须缩放到每个模型的大小。如果图像在内存中,我们可以定义一个简单的 scale_dataset() 函数来缩放加载的图像。
在这种情况下,我们使用 scikit-image 库中的 skimage.transform.resize 函数,使用最近邻插值将像素的 NumPy 数组调整到所需的大小。
|
1 2 3 4 5 6 7 8 9 |
# 将图像缩放到首选大小 def scale_dataset(images, new_shape): images_list = list() for image in images: # 使用最近邻插值进行大小调整 new_image = resize(image, new_shape, 0) # 存储 images_list.append(new_image) return asarray(images_list) |
首先,必须为指定的训练周期数拟合基线模型,例如输出 4x4 大小图像的模型。
这将要求将加载的图像缩放到由生成器模型输出层的大小定义的所需大小。
|
1 2 3 4 5 6 7 8 |
# 拟合基线模型 g_normal, d_normal, gan_normal = g_models[0][0], d_models[0][0], gan_models[0][0] # 将数据集缩放到适当的大小 gen_shape = g_normal.output_shape scaled_data = scale_dataset(dataset, gen_shape[1:]) print('Scaled Data', scaled_data.shape) # 训练常规或直通模型 train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch) |
然后,我们可以处理每个增长级别,例如第一个是 8x8。
这包括首先检索模型,将数据缩放到适当的大小,然后拟合渐进模型,然后训练模型的直通版本进行微调。
我们可以在循环中为每个增长级别重复此操作。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 处理每个增长级别 for i in range(1, len(g_models)): # 检索此增长级别的模型 [g_normal, g_fadein] = g_models[i] [d_normal, d_fadein] = d_models[i] [gan_normal, gan_fadein] = gan_models[i] # 将数据集缩放到适当的大小 gen_shape = g_normal.output_shape scaled_data = scale_dataset(dataset, gen_shape[1:]) print('Scaled Data', scaled_data.shape) # 训练渐进式增长模型以实现下一级别增长 train_epochs(g_fadein, d_fadein, gan_fadein, scaled_data, e_fadein, n_batch) # 训练正常或直通模型 train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch) |
我们可以将这些结合起来,定义一个名为 train() 的函数来训练渐进式增长 GAN 函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 训练生成器和判别器 def train(g_models, d_models, gan_models, dataset, latent_dim, e_norm, e_fadein, n_batch): # 拟合基线模型 g_normal, d_normal, gan_normal = g_models[0][0], d_models[0][0], gan_models[0][0] # 将数据集缩放到适当的大小 gen_shape = g_normal.output_shape scaled_data = scale_dataset(dataset, gen_shape[1:]) print('Scaled Data', scaled_data.shape) # 训练正常或直通模型 train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch) # 处理每个增长级别 for i in range(1, len(g_models)): # 检索此增长级别的模型 [g_normal, g_fadein] = g_models[i] [d_normal, d_fadein] = d_models[i] [gan_normal, gan_fadein] = gan_models[i] # 将数据集缩放到适当的大小 gen_shape = g_normal.output_shape scaled_data = scale_dataset(dataset, gen_shape[1:]) print('Scaled Data', scaled_data.shape) # 训练渐进式增长模型以实现下一级别增长 train_epochs(g_fadein, d_fadein, gan_fadein, scaled_data, e_fadein, n_batch, True) # 训练正常或直通模型 train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm, n_batch) |
正常阶段的 epoch 数量由 e_norm 参数定义,渐变阶段的 epoch 数量由 e_fadein 参数定义。
必须根据图像数据集的大小指定 epoch 数量,并且可以使用与论文中相同的 epoch 数量用于每个阶段。
我们从 4x4 分辨率开始,训练网络,直到鉴别器总共看到 800k 张真实图像。然后我们在两个阶段之间交替:在接下来的 800k 张图像中渐变第一个 3 层块,稳定网络 800k 张图像,然后在 800k 张图像中渐变下一个 3 层块,依此类推。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
然后,我们可以像上一节一样定义我们的模型,然后调用训练函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 增长阶段数量,例如 3 = 16x16 图像 n_blocks = 3 # 潜在空间的大小 latent_dim = 100 # 定义模型 d_models = define_discriminator(n_blocks) # 定义模型 g_models = define_generator(100, n_blocks) # 定义复合模型 gan_models = define_composite(d_models, g_models) # 加载图像数据 dataset = load_real_samples() # 训练模型 train(g_models, d_models, gan_models, dataset, latent_dim, 100, 100, 16) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
官方
- GAN 的渐进式增长以提高质量、稳定性和变异性, 2017.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性,官方.
- progressive_growing_of_gans 项目(官方),GitHub.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性。开放评论.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性,YouTube.
- 用于提高质量、稳定性和变异性的 GAN 渐进式增长,KeyNote,YouTube.
API
- Keras 数据集 API.
- Keras 序列模型 API
- Keras卷积层API
- 我如何“冻结”Keras层?
- Keras Contrib 项目
- skimage.transform.resize API
文章
- Keras-progressive_growing_of_gans 项目,GitHub.
- Hands-On-Generative-Adversarial-Networks-with-Keras 项目,GitHub.
总结
在本教程中,您学习了如何从头开始使用 Keras 开发渐进式增长生成对抗网络模型。
具体来说,你学到了:
- 如何开发预定义的判别器和生成器模型,以适应不断增长的输出图像尺寸。
- 如何定义复合模型,通过判别器模型来训练生成器模型。
- 如何循环训练每个输出图像尺寸增长阶段的渐进融合版本和正常版本模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...




 From Scratch in Keras")
 From Scratch with Keras")
你好,
我是机器学习新手。
我有一个关于 Keras 中 predict 的问题。
我有以下代码片段。
predictions = model.predict(test_images)
predictions[0]
np.argmax(predictions[0])
为什么我必须使用 predictions[0](以及为什么是“0”)而不是只使用 predictions?
我不太明白。
非常感谢
也许这会有帮助。
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
谢谢你的帮助。
我还有一个问题。是否有关于使用 LSTM 和 Keras 的教程?
非常感谢
是的,我有数百篇。从这里开始
https://machinelearning.org.cn/start-here/#lstm
关于时间序列和 LSTM,请看这里
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨
您能解释一下下采样到底是什么意思吗?
谢谢!
使用统计方法从更高的分辨率移到更低的分辨率。
很棒的文章,您有笔记本的链接吗?
我不使用笔记本,并建议不要使用它们,原因如下
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
嗨,Jason,
感谢您实现了渐进式 GAN 论文。我一直在查看代码,并且有这个疑问。对于每个新的分辨率,您使用 g_models[i] 和 d_models[i] 中的生成器和鉴别器。在训练更高分辨率的模型之前,会加载前一个分辨率的权重吗?我检查了 train_epoch 函数和它之前的代码块,但之前训练过的权重似乎没有在训练新分辨率之前显式加载。
祝好!
权重会在新模型中重复使用。
也就是说,我们使用旧模型的各个部分来构建新模型,包括它们的权重。
这有帮助吗?
为了澄清,例如,您训练了 g_normal (g_model[0][0])。下一轮训练 g_model[1][0]。这不就是另一个具有未训练权重的实例吗?以前训练过的权重是如何重复使用的?谢谢你的帮助!
不,我们是将新层嫁接到现有层上,并用这些层定义一个新模型。权重不变——所有层在模型之间都指向内存中的同一个矩阵。
非常感谢您的解释!更高分辨率的权重确实使用了在较低分辨率训练期间学到的权重。很棒的作品!
谢谢。
我认为在生成器中的旧输出层之前插入上采样是错误的,因为您用旧形状(直通模型)训练该层,然后用另一个形状在渐变模型中训练该层(这就是您在绘图的“输出形状”列中获得“多个”值的原因)。您需要将上采样插入到右侧分支的旧卷积之后以及左侧分支的新卷积之前。
我相信我的实现符合论文。
to_rgb 是 1x1 卷积,所以它只是通道特征图的加权和,因此它是在上采样之前还是之后并不重要(在这种情况下)。将上采样放在旧输出层之前更佳,因为我们可以只做一次而不是做两次,并获得相同的结果。
我的生成器输出有问题。
如果不定义激活层,我会得到带有负值的图像。
如果我添加激活层(sigmoid),在渐变阶段会遇到问题。
避免此问题的最佳实践是什么?
提前感谢。
也许可以看看这个工作示例
https://machinelearning.org.cn/how-to-train-a-progressive-growing-gan-in-keras-for-synthesizing-faces/
谢谢!
在哪里可以找到 load_real_samples 函数的定义?
你可以用自己的数据自己编写。
或者,我有一个完整的教程在这里
https://machinelearning.org.cn/how-to-train-a-progressive-growing-gan-in-keras-for-synthesizing-faces/
我可以从以下内容获得帮助吗?
你在这个代码中遇到了什么问题?
您好,您总是制作很棒的教程,我总是阅读您的主题。我有一个问题,我是 GAN 领域的新手,我才刚刚开始学习,并且有些困惑。我训练了 DCGAN 模型并保存了模型,训练后我想使用该模型创建新图像。如何使用现有模型创建新图像?我不知道如何调用现有模型并生成新图像。谢谢
谢谢!
您可以在这里找到数十个关于此的示例
https://machinelearning.org.cn/start-here/#gans
谢谢。祝您好运。
您好,d_loss1、d_loss2 和 g_loss 是什么?此外,GAN 训练完成后,这些变量的最佳值是多少?
它们是鉴别器和生成器模型的损失值。
损失没有最佳值,GAN 不会收敛。
https://machinelearning.org.cn/faq/single-faq/why-is-my-gan-not-converging
嗨,Jason,
我正在实施渐进式增长 GAN 来生成伪照片级真实感的计算机图形图像。当我运行以下代码时,我收到一个名为“alpha”未定义的错误。请在这方面帮助我。
# 加权和输出
class WeightedSum(Add)
# 使用默认值初始化
def __init__(self, alpha=0.0, **kwargs)
super(WeightedSum, self).__init__(**kwargs)
self.alpha = backend.variable(alpha, name=’ws_alpha’)
# 输出输入的加权和
def _merge_function(self, inputs)
# 只支持两个输入的加权和
assert (len(inputs) == 2)
# ((1-a) * input1) + (a * input2)
output = ((1.0 – self.alpha) * inputs[0]) + (self.alpha * inputs[1])
return output
很抱歉听到这个消息,这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我纠正了错误。缩进问题。
干得好!
嘿
经过几个小时的调查,我发现是学习率导致了糟糕的输出和达到 3000 的损失问题,学习率应该是 0.0002 左右,而本教程中是 0.001。
喜欢你的教程!请不要停!
干得好!
AttributeError: 'int' object has no attribute 'value'
input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value)
错误已解决,是由于 tensorflow 版本。
很高兴听到这个!
您知道什么条件下训练会收敛吗?您的代码中是否有停止训练的条件?如果有,您能指给我看吗?另外,我们是否需要处理 alpha 在加权和中达到 1 的情况?否则它会超过 1。
GAN 不会收敛。
https://machinelearning.org.cn/faq/single-faq/why-is-my-gan-not-converging
您好,我尝试运行鉴别器的完整示例。看起来第一个层(4x4)模型附加了 2 个直通鉴别器模型,而不是一个直通和一个渐变版本。这是否正确,还是我有什么误解?
我刚意识到我的错误,每层都包含下面一层的渐变,而不是上面一层的。请随意删除这些评论。
很高兴听到现在明白了。
我可以在这个 Keras 版本网络中使用另一个数据集吗?
是的。
您是否将代码上传到 GitHub?
不,我更喜欢不将我的代码放在 GitHub 上。
这会帮助您复制代码
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
还有一个问题……训练结束后,我如何生成更多的人工图像?
调用生成器。
这是一个例子
https://machinelearning.org.cn/how-to-train-a-progressive-growing-gan-in-keras-for-synthesizing-faces/
非常感谢您的帖子,我认为它非常有帮助。
不客气!
我注意到在这个(以及许多其他)Prog GAN 实现中有一个常见的错误,就是它没有包含等效的学习率(或者至少我没有看到)。它之所以如此重要是因为它使 Prog GAN 非常稳定,并且结果更好。作者没有使用 He 初始化来初始化权重,而是使用随机正态分布来初始化它们,并且每当调用权重时,它们都会乘以 He 初始化中的一个常数,但这个常数不会通过梯度下降进行更新,只有权重会被更新。没有这个,由于渐进式增长,学习率可能会变得太小或太大。
谢谢您的留言。
请告诉我如何使代码适用于灰度图像。
好问题,我没有例子。也许可以尝试一下。
我遇到了与“snaily”之前发布的相同的错误。
AttributeError: 'int' object has no attribute 'value'
input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value)
Snaily 说这与 TensorFlow 版本有关。我在 Google Colab 中运行此代码,TF 版本为 2.7.0。这可能是问题所在吗?这个版本是用什么写的?
你好,
我对渐变参数有点困惑,我们不应该关闭它的梯度计算吗?我认为它只是一个超参数。
您好 Maria… 以下是一个很好的资源来理解这个概念
https://towardsdatascience.com/progressively-growing-gans-9cb795caebee