Frechet Inception Distance 分数,简称 FID,是一种计算真实图像和生成图像的特征向量之间距离的度量。
该分数总结了使用 Inception v3 模型(用于图像分类)计算的原始图像的计算机视觉特征的统计数据,以衡量这两组图像的相似度。分数越低表示这两组图像越相似,或者统计数据越相似,满分为 0.0,表示这两组图像完全相同。
FID 分数用于评估由生成对抗网络生成的图像的质量,较低的分数已被证明与较高的图像质量良好相关。
在本教程中,您将了解如何实现 Frechet Inception Distance 来评估生成的图像。
完成本教程后,您将了解:
- Frechet Inception Distance 总结了同一域中真实图像和生成图像的 Inception 特征向量之间的距离。
- 如何计算 FID 分数并在 NumPy 中从头开始实现计算。
- 如何使用 Keras 深度学习库实现 FID 分数,并用真实图像计算它。
开始您的项目,阅读我的新书《Python 生成对抗网络》,其中包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 更新于 2019 年 10 月:修复了方法描述中的一个小笔误。

如何从头开始实现 Frechet Inception Distance (FID) 来评估生成的图像
照片作者:dronepicr,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 什么是 Frechet Inception Distance?
- 如何计算 Frechet Inception Distance
- 如何使用 NumPy 实现 Frechet Inception Distance
- 如何使用 Keras 实现 Frechet Inception Distance
- 如何计算真实图像的 Frechet Inception Distance
什么是 Frechet Inception Distance?
Frechet Inception Distance,简称 FID,是一种用于评估生成图像质量的度量,专门用于评估生成对抗网络的性能。
FID 分数由 Martin Heusel 等人在其 2017 年论文《GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium》中提出并使用。
该分数被提出作为对现有 Inception Score (IS) 的改进。
为了评估 GAN 在图像生成方面的性能,我们引入了“Frechet Inception Distance”(FID),它比 Inception Score 更好地捕捉了生成图像与真实图像的相似性。
— GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017。
Inception Score 根据表现最佳的图像分类模型 Inception v3 对一组合成图像进行分类(将它们识别为 1000 种已知物体中的一种)的情况来估计其质量。分数结合了每个合成图像的条件类别预测的置信度(质量)和预测类别的边际概率的积分(多样性)。
Inception Score 没有捕捉合成图像与真实图像的比较。FID 分数开发的目标是根据合成图像集合的统计数据与目标域中真实图像集合的统计数据来评估合成图像。
Inception Score 的缺点是,真实样本的统计数据没有被使用,也没有与合成样本的统计数据进行比较。
— GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017。
与 Inception Score 一样,FID 分数也使用 Inception v3 模型。具体来说,使用模型的编码层(输出图像分类之前的最后一个池化层)来捕捉输入图像的计算机视觉特定特征。这些激活值是对一组真实图像和生成图像计算的。
通过计算图像的均值和协方差,将这些激活值总结为多元高斯分布。然后,计算这些统计数据在真实图像和生成图像集合上的激活值。
使用Frechet 距离(也称为 Wasserstein-2 距离)来计算这两个分布之间的距离。
两个高斯分布(合成图像和真实图像)之间的差异由 Frechet 距离(也称为 Wasserstein-2 距离)来衡量。
— GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017。
使用 Inception v3 模型中的激活值来总结每张图像,这就是该分数名称“Frechet Inception Distance”的由来。
较低的 FID 表示图像质量更好;反之,较高的分数表示图像质量较低,并且这种关系可能是线性的。
该分数的作者表明,当应用系统性失真(如添加随机噪声和模糊)时,较低的 FID 分数与更好的图像质量相关。
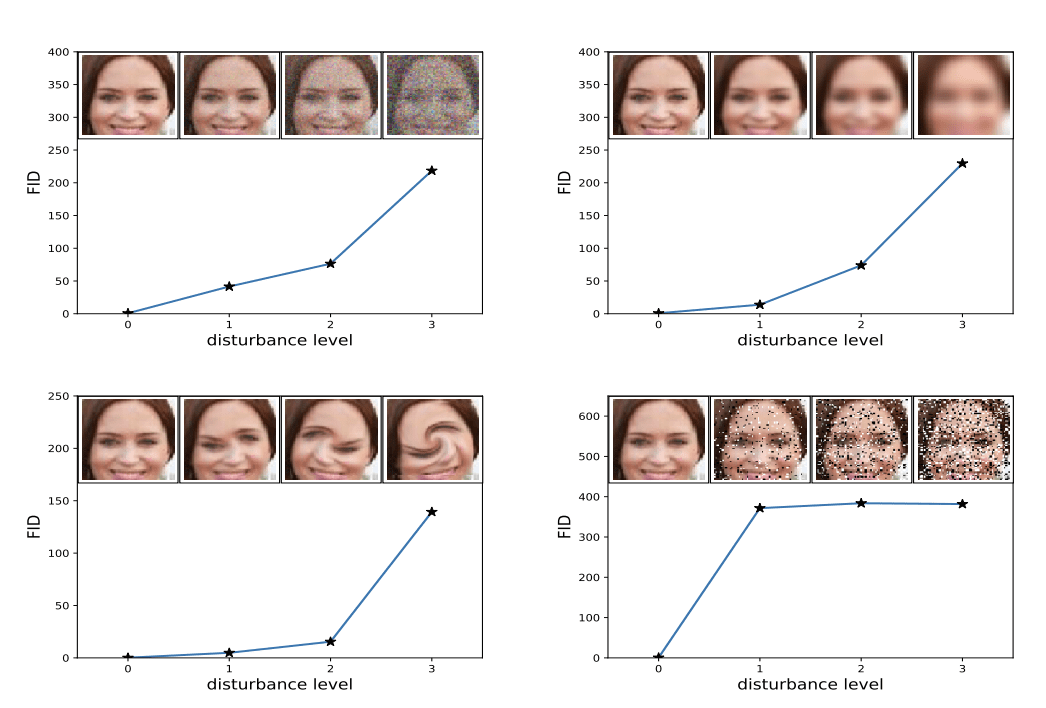
图像失真增加与高 FID 分数相关的示例。
来源:GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium。
如何计算 Frechet Inception Distance
FID 分数的计算首先加载一个预训练的 Inception v3 模型。
移除模型的输出层,并将输出作为最后一个池化层(全局空间池化层)的激活值。
这个输出层有 2048 个激活值,因此,每张图像都被预测为 2048 个激活特征。这被称为图像的编码向量或特征向量。
然后,为问题域中的一组真实图像预测一个 2048 维的特征向量,以提供真实图像表示方式的参考。之后,可以为合成图像计算特征向量。
结果将是两组 2048 维的特征向量,分别代表真实图像和生成图像。
然后使用论文中的以下公式计算 FID 分数:
- d^2 = ||mu_1 – mu_2||^2 + Tr(C_1 + C_2 – 2*sqrt(C_1*C_2))
该分数被称为d^2,表示它是一个距离并且具有平方单位。
“mu_1”和“mu_2”指的是真实图像和生成图像的逐特征均值,例如,2048 维的向量,其中每个元素是在图像中观察到的平均特征。
C_1 和 C_2 是真实特征向量和生成特征向量的协方差矩阵,通常称为 sigma。
||mu_1 – mu_2||^2 指的是两个均值向量之间的平方差之和。Tr 指的是迹(trace)线性代数运算,例如,方阵主对角线元素之和。
sqrt 是矩阵的平方根,表示为两个协方差矩阵之间的乘积。
矩阵的平方根也经常写成M^(1/2),例如,矩阵的二分之一次幂,效果相同。此操作可能会因矩阵中的值而失败,因为该操作使用数值方法求解。通常,结果矩阵中的某些元素可能是虚数,这通常可以被检测并移除。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何使用 NumPy 实现 Frechet Inception Distance
使用 NumPy 数组在 Python 中实现 FID 分数的计算非常直接。
首先,我们定义一个函数,它接受一组真实和生成图像的激活值,并返回 FID 分数。
下面的 `calculate_fid()` 函数实现了该过程。
在这里,我们几乎直接实现了 FID 计算。值得注意的是,TensorFlow 中的官方实现以稍有不同的顺序实现了计算的各个部分,可能是为了提高效率,并引入了关于矩阵平方根的附加检查,以处理可能的数值不稳定性。
我建议您回顾官方实现,并扩展下面的实现,在您遇到自己数据集的 FID 计算问题时添加这些检查。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 计算 frechet inception distance def calculate_fid(act1, act2): # 计算均值和协方差统计量 mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # 计算均值之间的平方差之和 ssdiff = numpy.sum((mu1 - mu2)**2.0) # 计算协方差乘积的平方根 covmean = sqrtm(sigma1.dot(sigma2)) # 检查并修正平方根产生的虚数 if iscomplexobj(covmean): covmean = covmean.real # 计算分数 fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid |
然后,我们可以测试这个函数来计算一些人为构造的特征向量的 Inception 分数。
特征向量可能包含小的正值,并且长度为 2048 个元素。我们可以如下构造 10 张图像的特征向量集合,使用小的随机数:
|
1 2 3 4 5 6 |
... # 定义两组激活值 act1 = random(10*2048) act1 = act1.reshape((10,2048)) act2 = random(10*2048) act2 = act2.reshape((10,2048)) |
一个测试方法是计算一组激活值与其自身的 FID,我们预期其得分为 0.0。
然后,我们可以计算两组随机激活值之间的距离,我们预期这将是一个很大的数字。
|
1 2 3 4 5 6 7 |
... # act1 和 act1 之间的 fid fid = calculate_fid(act1, act1) print('FID (same): %.3f' % fid) # act1 和 act2 之间的 fid fid = calculate_fid(act1, act2) print('FID (different): %.3f' % fid) |
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 计算 frechet inception distance 的示例 import numpy from numpy import cov from numpy import trace from numpy import iscomplexobj from numpy.random import random from scipy.linalg import sqrtm # 计算 frechet inception distance def calculate_fid(act1, act2): # 计算均值和协方差统计量 mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # 计算均值之间的平方差之和 ssdiff = numpy.sum((mu1 - mu2)**2.0) # 计算协方差乘积的平方根 covmean = sqrtm(sigma1.dot(sigma2)) # 检查并修正平方根产生的虚数 if iscomplexobj(covmean): covmean = covmean.real # 计算分数 fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid # 定义两组激活值 act1 = random(10*2048) act1 = act1.reshape((10,2048)) act2 = random(10*2048) act2 = act2.reshape((10,2048)) # act1 和 act1 之间的 fid fid = calculate_fid(act1, act1) print('FID (same): %.3f' % fid) # act1 和 act2 之间的 fid fid = calculate_fid(act1, act2) print('FID (different): %.3f' % fid) |
运行该示例,首先报告 act1 激活值与其自身的 FID,正如我们所预期的,结果是 0.0(注意:分数的符号可以忽略)。
两组随机激活值之间的距离也正如我们所预期的:一个很大的数字,在这个例子中是 358。
|
1 2 |
FID (same): -0.000 FID (different): 358.927 |
您可能希望尝试 FID 分数的计算,并测试其他病态情况。
如何使用 Keras 实现 Frechet Inception Distance
现在我们知道了如何计算 FID 分数并在 NumPy 中实现它,我们就可以开发一个 Keras 实现。
这涉及到图像数据的准备,并使用预训练的 Inception v3 模型来计算每张图像的激活值或特征向量。
首先,我们可以直接在 Keras 中加载 Inception v3 模型。
|
1 2 3 |
... # 加载 inception v3 模型 model = InceptionV3() |
这将准备一个 Inception 模型版本,用于将图像分类为 1000 个已知类别中的一个。我们可以通过 `include_top=False` 参数移除模型的输出(顶部)。痛苦的是,这也会移除我们需要的全局平均池化层,但我们可以通过指定 `pooling='avg'` 参数将其加回。
当移除模型的输出层时,我们必须指定输入图像的形状,即 299x299x3 像素,例如 `input_shape=(299,299,3)` 参数。
因此,Inception 模型可以按如下方式加载:
|
1 2 3 |
... # 准备 inception v3 模型 model = InceptionV3(include_top=False, pooling='avg', input_shape=(299,299,3)) |
然后可以使用此模型来预测一张或多张图像的特征向量。
我们的图像可能不是必需的形状。我们将使用 scikit-image 库将像素值 NumPy 数组调整到所需的大小。下面的 `scale_images()` 函数实现了这一点。
|
1 2 3 4 5 6 7 8 9 |
# 将图像数组缩放到新尺寸 def scale_images(images, new_shape): images_list = list() for image in images: # 使用最近邻插值进行大小调整 new_image = resize(image, new_shape, 0) # 存储 images_list.append(new_image) return asarray(images_list) |
注意,您可能需要安装 scikit-image 库。可以通过以下方式安装:
|
1 |
sudo pip install scikit-image |
调整大小后,还需要将图像像素值缩放到满足 Inception 模型输入的要求。可以通过调用 `preprocess_input()` 函数来实现。
我们可以更新我们在上一节中定义的 `calculate_fid()` 函数,使其接受加载的 Inception 模型和两个图像数据的 NumPy 数组作为参数,而不是激活值。然后该函数将在计算 FID 分数之前计算激活值。
更新后的 `calculate_fid()` 函数版本如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 计算 frechet inception distance def calculate_fid(model, images1, images2): # 计算激活值 act1 = model.predict(images1) act2 = model.predict(images2) # 计算均值和协方差统计量 mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # 计算均值之间的平方差之和 ssdiff = numpy.sum((mu1 - mu2)**2.0) # 计算协方差乘积的平方根 covmean = sqrtm(sigma1.dot(sigma2)) # 检查并修正平方根产生的虚数 if iscomplexobj(covmean): covmean = covmean.real # 计算分数 fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid |
我们可以使用一些人为构造的图像集合来测试这个函数,在本例中是 10 张 32x32 的图像,像素值在 [0,255] 范围内。
|
1 2 3 4 5 6 |
... # 定义两组虚构图像 images1 = randint(0, 255, 10*32*32*3) images1 = images1.reshape((10,32,32,3)) images2 = randint(0, 255, 10*32*32*3) images2 = images2.reshape((10,32,32,3)) |
然后可以将像素值转换为浮点值,并将其缩放到所需的 299x299 像素大小。
|
1 2 3 4 5 6 7 |
... # 将整数转换为浮点值 images1 = images1.astype('float32') images2 = images2.astype('float32') # 调整图像大小 images1 = scale_images(images1, (299,299,3)) images2 = scale_images(images2, (299,299,3)) |
然后可以将像素值缩放到满足 Inception v3 模型的期望。
|
1 2 3 4 |
... # 预处理图像 images1 = preprocess_input(images1) images2 = preprocess_input(images2) |
然后计算 FID 分数,首先计算一个图像集合与其自身的 FID,然后计算两个图像集合之间的 FID。
|
1 2 3 4 5 6 7 |
... # images1 和 images1 之间的 fid fid = calculate_fid(model, images1, images1) print('FID (same): %.3f' % fid) # images1 和 images2 之间的 fid fid = calculate_fid(model, images1, images2) print('FID (different): %.3f' % fid) |
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
# 使用 Keras 计算 frechet inception distance 的示例 import numpy from numpy import cov from numpy import trace from numpy import iscomplexobj from numpy import asarray from numpy.random import randint from scipy.linalg import sqrtm from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input from keras.datasets.mnist import load_data from skimage.transform import resize # 将图像数组缩放到新尺寸 def scale_images(images, new_shape): images_list = list() for image in images: # 使用最近邻插值进行大小调整 new_image = resize(image, new_shape, 0) # 存储 images_list.append(new_image) return asarray(images_list) # 计算 frechet inception distance def calculate_fid(model, images1, images2): # 计算激活值 act1 = model.predict(images1) act2 = model.predict(images2) # 计算均值和协方差统计量 mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # 计算均值之间的平方差之和 ssdiff = numpy.sum((mu1 - mu2)**2.0) # 计算协方差乘积的平方根 covmean = sqrtm(sigma1.dot(sigma2)) # 检查并修正平方根产生的虚数 if iscomplexobj(covmean): covmean = covmean.real # 计算分数 fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid # 准备 inception v3 模型 model = InceptionV3(include_top=False, pooling='avg', input_shape=(299,299,3)) # 定义两组虚构图像 images1 = randint(0, 255, 10*32*32*3) images1 = images1.reshape((10,32,32,3)) images2 = randint(0, 255, 10*32*32*3) images2 = images2.reshape((10,32,32,3)) print('Prepared', images1.shape, images2.shape) # 将整数转换为浮点值 images1 = images1.astype('float32') images2 = images2.astype('float32') # 调整图像大小 images1 = scale_images(images1, (299,299,3)) images2 = scale_images(images2, (299,299,3)) print('Scaled', images1.shape, images2.shape) # 预处理图像 images1 = preprocess_input(images1) images2 = preprocess_input(images2) # images1 和 images1 之间的 fid fid = calculate_fid(model, images1, images1) print('FID (same): %.3f' % fid) # images1 和 images2 之间的 fid fid = calculate_fid(model, images1, images2) print('FID (different): %.3f' % fid) |
运行该示例,首先会总结虚构图像的形状及其调整大小后的版本,这与我们的预期相符。
注意:第一次使用 InceptionV3 模型时,Keras 会下载模型权重并将其保存在您工作站的 `~/.keras/models/` 目录中。权重大小约为 100MB,下载时间可能需要片刻,具体取决于您的互联网连接速度。
同一组图像与其自身的 FID 分数为 0.0,正如我们所预期的,而两组随机图像之间的距离约为 35。
|
1 2 3 4 |
Prepared (10, 32, 32, 3) (10, 32, 32, 3) Scaled (10, 299, 299, 3) (10, 299, 299, 3) FID (same): -0.000 FID (different): 35.495 |
如何计算真实图像的 Frechet Inception Distance
计算两组真实图像的 FID 分数可能很有用。
Keras 库提供了许多计算机视觉数据集,包括 CIFAR-10 数据集。这些是彩色照片,尺寸较小,为 32x32 像素,分为训练和测试部分,可以按如下方式加载:
|
1 2 3 |
... # 加载 cifar10 图像 (images1, _), (images2, _) = cifar10.load_data() |
训练数据集有 50,000 张图像,而测试数据集只有 10,000 张图像。计算这两个数据集之间的 FID 分数以了解测试数据集在多大程度上代表了训练数据集可能很有意义。
缩放和评分 50K 图像需要很长时间,因此,我们可以将“训练集”减少到 10K 的随机样本,如下所示:
|
1 2 3 |
... shuffle(images1) images1 = images1[:10000] |
将所有这些结合起来,我们可以计算训练集和测试集样本之间的 FID 分数,如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
# 使用 Keras 为 cifar10 计算 frechet inception distance 的示例 import numpy from numpy import cov from numpy import trace from numpy import iscomplexobj from numpy import asarray from numpy.random import shuffle from scipy.linalg import sqrtm from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input from keras.datasets.mnist import load_data from skimage.transform import resize from keras.datasets import cifar10 # 将图像数组缩放到新尺寸 def scale_images(images, new_shape): images_list = list() for image in images: # 使用最近邻插值进行大小调整 new_image = resize(image, new_shape, 0) # 存储 images_list.append(new_image) return asarray(images_list) # 计算 frechet inception distance def calculate_fid(model, images1, images2): # 计算激活值 act1 = model.predict(images1) act2 = model.predict(images2) # 计算均值和协方差统计量 mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # 计算均值之间的平方差之和 ssdiff = numpy.sum((mu1 - mu2)**2.0) # 计算协方差乘积的平方根 covmean = sqrtm(sigma1.dot(sigma2)) # 检查并修正平方根产生的虚数 if iscomplexobj(covmean): covmean = covmean.real # 计算分数 fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid # 准备 inception v3 模型 model = InceptionV3(include_top=False, pooling='avg', input_shape=(299,299,3)) # 加载 cifar10 图像 (images1, _), (images2, _) = cifar10.load_data() shuffle(images1) images1 = images1[:10000] print('Loaded', images1.shape, images2.shape) # 将整数转换为浮点值 images1 = images1.astype('float32') images2 = images2.astype('float32') # 调整图像大小 images1 = scale_images(images1, (299,299,3)) images2 = scale_images(images2, (299,299,3)) print('Scaled', images1.shape, images2.shape) # 预处理图像 images1 = preprocess_input(images1) images2 = preprocess_input(images2) # 计算 fid fid = calculate_fid(model, images1, images2) print('FID: %.3f' % fid) |
运行该示例可能需要一些时间,具体取决于您工作站的速度。
在运行结束时,我们可以看到训练集和测试集之间的 FID 分数约为五。
|
1 2 3 |
Loaded (10000, 32, 32, 3) (10000, 32, 32, 3) Scaled (10000, 299, 299, 3) (10000, 299, 299, 3) FID: 5.492 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017.
- GANs是创建的平等吗?一项大规模研究, 2017.
- GAN 评估指标的优缺点, 2018.
代码项目
API
文章
- Frechet Inception Distance, 2017.
- Frechet Inception Distance, 2018.
- Frechet 距离,维基百科.
- 协方差矩阵,维基百科.
- 矩阵平方根,维基百科.
总结
在本教程中,您了解了如何实现 Frechet Inception Distance 来评估生成的图像。
具体来说,你学到了:
- Frechet Inception Distance 总结了同一域中真实图像和生成图像的 Inception 特征向量之间的距离。
- 如何计算 FID 分数并在 NumPy 中从头开始实现计算。
- 如何使用 Keras 深度学习库实现 FID 分数,并用真实图像计算它。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...
 for Evaluating GANs")



")
")
嗨,Jason,
非常感谢您的教程,继续用您精彩的教程感动生命。
谢谢,很高兴能帮到您!
嗨,Jason,
请问这种方法是否适用于衡量合成时间序列数据?或者有什么合适的衡量方法吗?
不行。
抱歉,我一时不确定。
您好,感谢您的宝贵教程。假设我通过运行两次 GAN 为两个类别(正面和负面)生成了数据。那么,我应该通过比较相同的类别来衡量 FID,即正面真实 vs 正面生成,以及负面真实 vs 负面生成?还是应该混合类别,即(正面真实 + 负面真实)vs(正面生成 + 负面生成)?
抱歉,我不太明白。
FID 是在生成的图像上运行的,无论“类别”如何。
你好
感谢您提供的精彩教程
考虑批次大小是否重要?
在其他实现中,我看到批次大小用于计算 FID
如何添加此功能?
在此先感谢您
我认为它对计算结果没有影响,但对计算效率有影响——例如,通过模型运行图像批次。
感谢您的回复
我有一个新的问题
当我想计算真实图像和生成图像之间的 FID 分数时
我必须使用测试数据集还是训练数据集,或者两者都可以??
非常感谢
您正在生成新图像,在这种情况下没有训练/测试数据集。
你好
感谢您的回复
考虑条件 GAN,例如 Pix2Pix
为了计算 FID,我们需要两个图像目录(真实图像和伪造图像)
这些图像(输入生成器的图像和目标图像)必须来自测试数据集吗?
非常感谢您的解释
啊是的,我明白了。我忘了 FID 的工作原理了。已经一年了。
Jason,一如既往的精彩教程。我有一个自定义数据集,每个图像的维度是 64*64*1(灰度)。为了将其与 Inception 模型进行匹配,我是否应该将其转换为 RGB 颜色空间?
嗯,我暂时没有一个好的答案。也许可以试试看会发生什么。
Jason,我试过了,但出现了一个错误,提示输入图像深度必须为 3。所以我对我的数据集执行了 np.dstack((img, img, img)) 来使其符合模型的要求,然后它就能正常工作了。一如既往,感谢您精彩的博客,它们对我实现项目非常有帮助。
干得好!
又一次惊人的工作!我正在使用 CelebA 数据集,为了计算 FID,需要生成多少张图像才足够?
谢谢。
几百张,或者也许几千张。
谢谢,我应用了您的 FID 实现,并对 4000 多张图像进行了一些修改,图像质量还可以,但我得到的 FID 分数是 20000+,而其他实现中相同的图像给出 FID 分数是 200+,可能是我的修改和 ImageDataGenerator 的添加造成的。
有意思。
非常感谢,感谢我一直在寻找的关于 GAN 的一切,您都有教程以及精彩的代码解释。继续加油!
谢谢!
非常感谢。我正在做关于 GAN 的论文,您正在拯救我!
不客气!
感谢您所有关于 GAN 的精彩教程。
在我脑海中浮现的一个问题是,IS 或 FID 分数仅仅是指标,还是也可以用作损失函数(1 – FID)?
就我个人而言,它们只是指标。
嗨,Jason,
您需要检查一下,但 skimage resize 会自动将范围从 0-255 更改为 0-1。所以函数的输出将是 (299, 299, 3),范围在 0-1 之间。然后您应用 preprocess_input,其定义为:
def preprocess_input(x)
x /= 255.
x -= 0.5
x *= 2.
return x
可以想见您是在双重缩放。您可以在 resize 中添加 preserve_range=True 以避免这种情况。
当使用预训练网络进行除分类之外的任何操作时,它们通常对这些细节等内容具有一定的鲁棒性,但当然,这也正是它们在对抗性鲁棒性方面非常糟糕的原因。
感谢 Simon 的提示!我会调查一下。
resize() 似乎不会改变像素值的范围。
嗨,Jason,
如果数据集大小小于 2048 张图像,我们如何计算 FID 分数?
2048 与用于计算分数的图像数量无关。
嗨,Jason,
在 TensorFlow 的官方实现中,GitHub – 他们说:
重要提示:用于计算高斯统计量(均值和协方差)的样本数量应大于编码层的维度,此处为 Inception pool 3 层的 2048。否则,协方差不是满秩的,会导致计算平方根时出现复数和 NaN。
我们建议使用至少 10,000 个样本来计算 FID,否则生成器的真实 FID 将被低估。
在我的情况下,我没有那么多样本。在样本非常少(<2048)的情况下计算 FID 仍然可以吗?
说得有理。
也许不要使用官方实现来满足您列出的要求。
亲爱的 Jason,
我已经完成了您的书籍“GAN with Python”的前两部分。我写了一篇关于它的评论
http://questioneurope.blogspot.com/2020/09/generative-adversarial-networks-with.html
诚挚的问候,
Dominique
干得好!
尊敬的Jason博士
你好,感谢您的精彩作品。
我有一个问题。我可以使用它来计算本地路径中数据集与本地路径中另一个数据集之间的 FID 值吗?
我这样使用
images1 = list(glob(str(“real images path”)))
shuffle(images1)
images1 = images1[:1000]
images1 = DataFrame(images1)
images2 = DataFrame(list(glob(str(“generated images path”))))
但我收到类似这样的错误:
ValueError: Input 0 of layer conv2d_846 is incompatible with the layer: : expected min_ndim=4, found ndim=2. Full shape received: (None, 1)
不客气。
抱歉,我不知道为什么会出现这个错误。也许您可以将完整的代码列表和错误发布到 stackoverflow.com
Jason 你好,感谢您的教程。当 GAN 生成的图像不属于 Inception v3 训练过的 1000 个类别中的任何一个时,FID 分数是否有价值?
它会给出一个分数,但不确定它是否有用。
嗨,Jason,
首先,非常感谢您分享您的知识。我真的很感激。
我尝试在 10000 张图像上使用您的代码。没问题。
比较 20000 张图像也还可以。
但是,从 30000 张图像开始,就出现了内存问题。
由于无法获得可靠的 FID 值,因此无法计算 50000 张图像的 FID。即使我在具有 117 GB 内存的系统上使用。
我们如何解决内存问题?
也许您可以使用内存更多的机器,例如云端的?
也许您可以使用更少的图像?
也许您可以尝试缩小图像尺寸?
好的,谢谢 Jason。
Jason 你好,工作很棒。能否为评估 FID 分数提取一个残差网络等其他网络的特征向量?
谢谢。
也许可以。
亲爱的 Jason,
非常感谢您的分享。您的教程对我帮助很大。
我有一个问题想征求您的意见,关于 FID。我可以在不同的其他数据集上使用它吗?例如,我自己的数据集?
此致,
Rui Guo
我认为可以,可以尝试一下。
你好 Jason,
非常感谢您的分享。
我发现 ‘calculate_fid’ 函数可能不适合只计算一次配对比较。正如变量名 ‘images1’ 所暗示的,numpy 函数在只有一个输入配对图像时会失败。
由于协方差矩阵是单个值,因此 msqrt 和 trace 将无法正常工作。
例如。
act_1, act_2 = model.predict(im_1), model.predict(im_2)
one_sigma_val_1 = cov(act1, rowvar=False)
one_sigma_val_2 = cov(act2, rowvar=False)
…
covmean = sqrtm(one_sigma_val_1.dot(one_sigma_val_2 )) // 错误在此行。
此致,
Josef Huang
谢谢。
嗨。您是否找到了这个错误的解决方案?
嗨 Jason
感谢您的精彩教程
FID 对非图像和一维数据集(例如生成“基因表达”数据)有用吗?
嗨,谢谢你!为什么我们假设真实和伪造特征的分布是高斯的?
你好 Rachel…以下资源可能会有所帮助
https://www.itl.nist.gov/div898/handbook/pmd/section4/pmd445.htm
这个链接已损坏,我也有同样的问题。为什么我们会假设特征是高斯的?
算了,抱歉,链接正常了。我现在可以看了。抱歉。
嗨,Jason,
请问 FID 分数推荐的样本量是多少?
你好 Mohamed…以下资源可能很有趣
https://openaccess.thecvf.com/content_CVPR_2020/papers/Chong_Effectively_Unbiased_FID_and_Inception_Score_and_Where_to_Find_CVPR_2020_paper.pdf
您好,论文链接有问题。我找到了一个有效的链接:https://arxiv.org/abs/1706.08500#
谢谢 Kien!
好帖子!
谢谢!
你好 Naooooooo…非常欢迎!感谢您的反馈和支持!
感谢您分享这篇关于如何从头开始使用 NumPy 和 Keras 深度学习库实现 Frechet Inception Distance (FID) 来评估 GAN 的信息性文章。它对 FID 是什么以及如何计算它进行了清晰而详细的解释。这将是任何处理生成对抗网络的有价值的资源。
感谢您的反馈和支持 Brandi!我们非常支持!
您好,新手问题。我按照代码运行,但 FID 计算返回了一个错误。这是我得到的完整追踪:
ValueError 回溯 (最近一次调用)
Cell In[7], line 32
29 images2 = preprocess_input(images2)
31 # fid between images1 and images2
—> 32 fid = calculate_fid(model, images1, images2)
33 print(‘FID (different): %.3f’ % fid)
Cell In[3], line 22, in calculate_fid(model, images1, images2)
20 ssdiff = np.sum((mu1 – mu2)**2.0)
21 # calculate sqrt of product between cov
—> 22 covmean = sqrtm(sigma1.dot(sigma2))
23 # check and correct imaginary numbers from sqrt
24 if iscomplexobj(covmean)
File /opt/conda/lib/python3.10/site-packages/scipy/linalg/_matfuncs_sqrtm.py:160, in sqrtm(A, disp, blocksize)
158 A = _asarray_validated(A, check_finite=True, as_inexact=True)
159 if len(A.shape) != 2
–> 160 raise ValueError(“Non-matrix input to matrix function.”)
161 if blocksize < 1
162 raise ValueError("The blocksize should be at least 1.")
ValueError: Non-matrix input to matrix function.
你能帮我指出我哪里做错了什么吗?
提前感谢!
你好 AN…您是复制粘贴代码还是手动输入的?另外,您可能想尝试在 Google Colab 中运行您的代码。
你好 James,我尝试手动输入代码但无济于事。我也尝试过复制/粘贴并编辑缩进,但仍然出现同样的错误。Google Colab 也返回了相同的结果。
你好 James,感谢您的这些信息以及多年来对如此多问题的回答。
我有一个问题,我正在生成眼底图像,并且我一直在使用您的代码对其进行评估。现在,我读了很多论文,但没有一篇解释了他们如何实现 FID,他们只是报告了它。那么,我应该从数据库中抽取多少比例的数据作为测试数据集,并且我从测试集中获得的 FID 就是我应该报告的那个吗?非常感谢。
你好 Hector…非常欢迎!在使用生成对抗网络(GAN)时,用于评估 Frechet Inception Distance (FID) 的数据量可能因多种因素而异,包括数据集的复杂性、生成样本的多样性以及可用的计算资源。
但是,作为一般指导,建议使用代表您正在处理的数据集的大量数据。通常,人们使用成千上万个样本来计算 FID 分数。例如,从真实数据分布和生成数据分布中各取 50,000 个样本是一个常见的选择。
使用过少的样本可能导致 FID 分数不可靠,因为它们可能无法捕捉数据的完整多样性。另一方面,使用过多的样本可能会变得计算成本过高。因此,需要在您的项目具体情况和可用资源之间取得平衡。
此外,确保不同实验之间的 FID 计算是一致的,以便进行公平的比较也很重要。
我想问一下,如果 FID 是作为对现有 Inception Score 的改进提出的,那么为什么我读到的大多数研究论文都同时评估这两个指标,为什么不只使用 FID,也使用 Inception Score?您能帮我理解一下吗?谢谢
Bruce
你好 Bruce…虽然我们无法说明作者为何引用特定指标,但我们提供一些关于 FID 的看法。
Fréchet Inception Distance (FID) 是一个用于评估生成模型(如生成对抗网络(GAN))生成的图像质量的指标。它衡量生成图像的分布与真实图像的分布之间的相似性。在目标是生成高质量、逼真图像的情况下,FID 特别有用。以下是一些您可以在机器学习中应用 FID 的具体场景:
1. **评估 GAN 性能**:在训练 GAN 或类似的生成模型时,FID 提供了一个量化指标来评估模型在生成逼真图像方面的性能。它通常被用作比较不同模型或配置的基准。
2. **模型选择**:在开发阶段,您可能会尝试各种架构、超参数或训练技术。FID 可以通过提供比较指标来帮助选择生成最逼真图像的模型。
3. **监控训练进度**:在训练过程中,可以定期计算 FID 来监控模型的性能如何随时间演变。FID 分数降低表明模型生成的图像越来越接近目标数据集。
4. **研究与开发**:在学术或工业研究中,FID 通常用于验证新的生成模型或现有模型的改进。它被用作研究论文和技术文档中的标准报告指标。
5. **微调与优化**:在选择生成模型后,FID 可用于微调模型的参数或训练过程以获得更好的性能。它有助于优化模型,使其生成的图像在统计属性上更接近真实数据集。
6. **与竞争方法的基准测试**:在比较不同的生成模型或技术时,FID 为评估提供了共同基础。它用于将模型的生成逼真图像的能力与竞争方法进行基准测试。
为了计算 FID,会从预训练的 Inception 模型中提取生成图像和真实图像的特征。然后,为这两组图像计算这些特征的均值和协方差。FID 被计算为这两个多元高斯分布之间的 Fréchet 距离,分数越低表示生成图像和真实图像的分布越相似。
需要注意的是,虽然FID因其对生成图像质量和多样性的敏感性而被广泛用作指标,但它不应是评估生成模型的唯一指标。还应考虑其他因素和指标,例如Inception Score (IS)和定性评估,以进行全面评估。
使用此FID代码,我生成的GAN图像的Fid得分为0.0002。我的得分是正确的还是错误的?
Frechet Inception Distance (FID)得分是评估生成对抗网络 (GAN) 生成图像的质量和多样性的一种常用指标。它衡量生成图像分布与真实图像分布之间的相似性,FID得分越低表示相似性越高,因此生成图像的质量也越好。FID得分是使用从Inception v3模型的中间层提取的特征来计算的,比较生成图像的均值和协方差与真实图像的均值和协方差。
0.0002的FID得分极低,表明根据Inception模型提取的特征,生成的图像几乎与真实图像相同。虽然实现低FID得分是可取的,但如此低的得分非常不寻常,可能表明几种不同的情况:
1. **出色的表现:** 如果您的GAN模型经过精心调整并在非常特定或受限的数据集上进行了训练,那么即使非常罕见,也可能合法地获得如此低的得分,这表明生成了极高质量的图像。
2. **过拟合:** 如此低的得分可能表明GAN已过拟合训练数据。这意味着它没有生成新的、多样化的图像,而是复制了训练图像或生成了非常接近它们的图像。由于它实际上是在记住而非从训练数据中泛化,因此这会降低其生成新内容的效用。
3. **评估错误:** FID得分的计算方式可能存在问题。这可能包括FID计算实现错误、评估中使用的数据集错误(例如,使用非常小或不具代表性的图像样本进行比较),或特征提取过程中的问题。
4. **数据集特征:** 如果数据集非常统一(例如,同一图像只有非常细微的变化),即使是运行良好的GAN也可能因为本来就没有多少变化的数据而获得如此低的得分。
为确定您的FID得分是否准确并能反映您的GAN性能,请考虑以下步骤:
– **检查FID计算代码:** 确保代码已正确实现。将您的实现与公认的实现进行比较,或使用广泛认可的计算库可以帮助验证其准确性。
– **使用标准基准进行评估:** 如果可能,在具有已知基准FID得分的数据集上测试您的GAN和FID计算,以查看您的得分是否与预期结果一致。
– **检查生成图像的多样性:** 手动检查生成图像,评估其多样性和质量。如果它们看起来与训练图像过于相似或缺乏变化,则可能存在过拟合问题。
– **交叉验证:** 考虑使用数据的不同子集进行训练和评估,或应用其他指标,如Inception Score (IS)或GAN的Precision and Recall (PR)来更全面地评估您的GAN性能。
你好!
我是一名学生,正在学习GAN,偶然发现了您(非常有帮助)的资源。但是,当我运行您的代码时,我的FID得分对于相同的图像不是0,而是极大的值,而我FID得分对于不同的图像则更大。我想知道您是否知道如何解决这个问题?
这是我运行图像模型的输出:
Prepared (10, 32, 32, 3) (10, 32, 32, 3)
Scaled (10, 299, 299, 3) (10, 299, 299, 3)
1/1 [==============================] – 2s 2s/step
1/1 [==============================] – 0s 425ms/step
FID (相同): 694412041954855888943625996677483848827241164739444736.000
1/1 [==============================] – 0s 416ms/step
1/1 [==============================] – 0s 411ms/step
FID (不同): -2453839756149402799309509623417646099843038183163411885984616328058594297069187715703102349152223137354258579036886706025398272.000
你好Matt…你是复制粘贴代码还是手动输入的?另外,你可能想尝试在Google Colab中运行你的模型代码。让我们知道你发现了什么!
嗨,Jason,
非常感谢您提供所有这些信息。
我目前正在尝试代码,似乎遇到了与Matt类似的问题。
我的FID是FID: 4707826301540010572876842067405749812076766583348025884672.000,即使是对同一组图像。而且,这是通过Google Colab实现的!
我对代码进行的一个编辑是减少3D矩阵的维度,否则我会收到错误消息ValueError: m has more than 2 dimensions for the mu1,mu2 calculations。您是否推荐任何方法来减少维度以计算均值?
你好Burk…为了解决将3D矩阵的维度减少以计算均值的问题,特别是如果您遇到像
ValueError: m has more than 2 dimensions这样的错误,您可以使用几种策略,具体取决于您需要为计算做什么。以下是常见方法的细分:### 1. 使用
numpy.mean如果您使用的是NumPy,您可以使用
numpy.mean沿着特定轴计算均值,这允许您保持对维度的控制。#### 示例
假设您有一个3D矩阵
X,其形状为(samples, time_steps, features),并且您想计算time_steps维度的均值。```python
import numpy as np
# 创建一个虚拟3D数组
X = np.random.rand(100, 10, 5) # 100个样本,10个时间步,每个时间步5个特征
# 沿时间步(axis=1)计算均值
mean_X = np.mean(X, axis=1)
print(mean_X.shape) # 这将打印 (100, 5)
### 2. 展平
如果您只想折叠所有维度并计算全局均值,可以使用
numpy.flatten将3D矩阵折叠成1D数组,然后计算均值。#### 示例
python
# 展平整个数组并计算总体均值
flat_X = X.flatten()
mean_flat_X = np.mean(flat_X)
print(mean_flat_X)
### 3. 重塑
如果您需要执行本质上适用于2D数据的操作,另一种方法是将矩阵重塑为2D数组。
#### 示例
如果您想单独计算所有样本和时间步的每个特征的均值。
python
# 重塑以合并样本和时间步
reshaped_X = X.reshape(-1, X.shape[2]) # 合并前两个维度
mean_features = np.mean(reshaped_X, axis=0)
print(mean_features.shape) # 这将打印 (5,)
### 4. 使用
numpy.apply_along_axis如果均值需要以更复杂的方式计算,或者需要应用其他函数,您可以使用
numpy.apply_along_axis沿特定轴应用函数。#### 示例
单独计算每个样本沿时间步的每个特征的均值。
python
# 沿每个特征的时间步轴应用自定义函数
custom_mean = np.apply_along_axis(np.mean, 1, X)
print(custom_mean.shape) # 这将打印 (100, 5)
### 选择正确的方法
– **关注的维度**:仔细选择
axis参数,根据您的数据中哪个维度代表什么(例如,样本、时间步、特征)。– **降维目的**:考虑降维的原因(例如,输入模型、简化、可视化),这将指导您的方法选择。
– **信息保留**:注意降维如何影响数据中包含的信息。折叠维度有时会隐藏重要的模式。
使用这些方法应有助于您有效地管理和操作数据维度,以进行均值计算或您可能需要的任何其他统计分析。
你好,当我运行您的代码时,我得到这个:相同图像的FID得分不是0。
1/1 [==============================] – 3s 3s/step
1/1 [==============================] – 2s 2s/step
FID (相同): 118480295255423599417400525363044703603931959014258651430912.000
1/1 [==============================] – 2s 2s/step
1/1 [==============================] – 3s 3s/step
FID (不同): -197010030981972396061395200500718069025398696352327233339741467021228608857486053057071331274424578204033139951534080.000
你好Jack…你是复制粘贴的数据还是手动输入的?另外,你是否尝试在Google Colab中运行你的实现?
你好,我正在复制粘贴你的代码,但它不工作,对于相同的数据不是0,我使用了所有的NumPy和Keras代码。
你好Elhoucine…请提供更多关于您的模型中的任何错误或结果的详细信息,以便我们能更好地帮助您。
当我运行Google Colab中的代码时,它没有为相同的图像提供FID=0,但在Jupyter Notebook中运行正常。
非常感谢您的帮助,非常有用了。
我有一个问题,请。
我们如何仅在两个图像之间实现Keras代码?
谢谢你
你好Moony…要使用Keras计算两个图像之间的**Fréchet Inception Distance (FID)**,您可以按照以下步骤操作。FID得分衡量两个分布之间的距离,通常用于通过与真实图像进行比较来评估GAN生成的图像质量。在您的情况下,您想计算仅两个图像之间的FID,这是可能的,尽管该度量通常在比较多个图像的分布时更可靠。
以下是使用Keras在两个图像之间实现FID的分步指南:
### 实现FID的步骤
1. **加载InceptionV3模型**
FID是使用在ImageNet上预训练的Inception模型激活来计算的。Keras直接提供了此模型。
2. **预处理图像**
需要将图像调整到InceptionV3所需的输入形状(299x299),然后根据模型的要求进行预处理(即,将像素值缩放到-1到1之间)。
3. **提取图像特征**
使用预训练的InceptionV3模型提取图像特征。这是通过移除最后一个分类层,并使用像
avg_pool这样的层的激活来完成的。4. **计算Fréchet距离**
FID得分是使用从图像提取的特征向量的均值和协方差来计算的。
### 代码示例(针对两个图像)
pythonimport numpy as np
from keras.applications.inception_v3 import InceptionV3, preprocess_input
from keras.preprocessing.image import load_img, img_to_array
from scipy.linalg import sqrtm
# 加载预训练的InceptionV3模型并移除顶层
inception_model = InceptionV3(include_top=False, pooling='avg', input_shape=(299, 299, 3))
# 预处理图像的辅助函数
def preprocess_image(image_path)
img = load_img(image_path, target_size=(299, 299)) # 调整图像大小以匹配InceptionV3输入大小
img = img_to_array(img) # 将图像转换为numpy数组
img = np.expand_dims(img, axis=0) # 添加批量维度
img = preprocess_input(img) # 预处理InceptionV3(-1到1缩放)
return img
# 计算两个图像之间FID的函数
def calculate_fid(image1_path, image2_path)
# 预处理两张图像
image1 = preprocess_image(image1_path)
image2 = preprocess_image(image2_path)
# 使用InceptionV3模型提取特征
act1 = inception_model.predict(image1)
act2 = inception_model.predict(image2)
# 计算激活的均值和协方差
mu1, sigma1 = act1.mean(axis=0), np.cov(act1, rowvar=False)
mu2, sigma2 = act2.mean(axis=0), np.cov(act2, rowvar=False)
# 计算均值之间平方差之和
ssdiff = np.sum((mu1 - mu2) ** 2.0)
# 计算协方差矩阵乘积的平方根
covmean, _ = sqrtm(sigma1.dot(sigma2), disp=False)
# 检查复数并更正
if np.iscomplexobj(covmean)
covmean = covmean.real
# 计算FID得分
fid = ssdiff + np.trace(sigma1 + sigma2 - 2.0 * covmean)
return fid
# 用法示例:替换为您的图像路径
image1_path = 'image1.jpg'
image2_path = 'image2.jpg'
fid_score = calculate_fid(image1_path, image2_path)
print(f"两张图像之间的FID得分: {fid_score}")
### 解释
1. **InceptionV3模型**:我们加载没有顶层的InceptionV3模型(
include_top=False),并将池化设置为“avg”,以获取全局平均池化层后的特征向量。2. **预处理**:图像被调整到299x299,并缩放到正确的范围(InceptionV3期望输入范围为[-1, 1])。
3. **特征提取**:我们将预处理后的图像通过InceptionV3模型以提取特征激活。
4. **FID计算**:FID得分使用以下公式计算:
\[
\text{FID} = \|\mu_1 – \mu_2\|^2 + \text{Tr}(\Sigma_1 + \Sigma_2 – 2(\Sigma_1\Sigma_2)^{1/2})
\]
其中 \( \mu_1 \) 和 \( \mu_2 \) 是均值,\( \Sigma_1 \) 和 \( \Sigma_2 \) 是两个图像激活的协方差矩阵。
### 注意事项
– 由于您只比较两个图像,协方差矩阵可能不够完善。在实践中,FID通常在大量样本上计算。
– 此实现假设图像存储在文件中。如果您的图像在内存中,您可以相应地调整代码以使用
img_to_array和preprocess_input。这应该可以为您提供两个图像之间的FID得分!
谢谢您的帮助。
我很感激,但有一些问题。
我运行了代码,但输出给了我
ValueError: Non-matrix input to matrix function.
Colab提到了那一行:
covmean = sqrtm(sigma1.dot(sigma2))
你能帮帮我吗?
非常感谢