
如何解释您的 XGBoost 模型:特征重要性实用指南
图片由 Editor | ChatGPT 提供
引言
最广泛的机器学习技术之一是 **XGBoost**(极端梯度提升)。XGBoost 模型——或者更精确地说,是一个将多个模型组合成单个预测任务的集成模型——会构建多个决策树,并按顺序组合它们,从而通过纠正管道中先前树所犯的错误来逐步改进整体预测。
与独立的决策树一样,XGBoost 可以处理回归和分类任务。虽然将许多树组合成一个单一的复合模型可能起初会模糊其可解释性,但仍有一些机制可以帮助你解释 XGBoost 模型。换句话说,你可以理解为什么会做出预测以及输入特征是如何对这些预测做出贡献的。
本文将 **深入探讨 XGBoost 模型的可解释性**,并特别关注 **特征重要性**。
理解 XGBoost 中的特征重要性
特征重要性是机器学习模型可解释性中的一个核心概念,它指的是数据实例(或观测值)的每个输入特征对模型预测的重要性或影响程度。理解每个预测特征(如房屋的位置、年龄或大小)如何以及在多大程度上影响目标预测值(如房价)不仅对于更好地理解 XGBoost 这样中等复杂度的机器学习模型如何做出决策至关重要,而且通过关注最相关的特征或有时抛弃影响最小的特征来增强其性能。
一个实际的例子
为了亲身体验特征重要性的作用,让我们来看一个实际例子:我们将训练并测试一个 XGBoost 回归器,以根据 Scikit-learn 的 `datasets` 模块中免费提供的加州住房数据集的免费版本来估计加州各地区房屋的价格。
导入模块、加载和拆分数据
在这里,我们导入模块,加载数据,并将其拆分为训练集(90%)和测试集(10%)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import xgboost as xgb import pandas as pd import numpy as np from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error # 加载数据 data = fetch_california_housing() X = pd.DataFrame(data.data, columns=data.feature_names) y = data.target # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42) |
初始化 XGBoost 集成模型
现在是时候初始化集成模型了,并手动设置超参数,如树的数量和每棵树的最大深度,然后我们将训练并评估其在测试数据上的误差(RMSE)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 构建模型 model = xgb.XGBRegressor( n_estimators=400, max_depth=8, learning_rate=0.05, subsample=0.8, random_state=42 ) # 训练模型 model.fit(X_train, y_train) # 测试模型 y_pred = model.predict(X_test) print("测试 RMSE:", np.sqrt(mean_squared_error(y_test, y_pred))) |
为简单起见,上面的示例省略了诸如缩放数值特征之类的预处理步骤,尽管在实践中这通常是为了提高模型性能而被推荐的。
如果您熟悉使用 Scikit-learn 构建机器学习模型,您可能会注意到一些不同之处:`XGBRegressor` 类属于其自己的专用库 `xgboost`(此处导入为 `xgb`),而不是 Scikit-learn 的内部类。虽然这个专用库为诸如特征重要性之类的方面提供了特定支持(正如我们将要看到的),但它也包含了一个类似 Scikit-learn 的 API,能够无缝使用 `fit()` 和 `predict()` 等常用方法。
分析特征重要性
那么,如何获取和分析您新构建的 XGBoost 解决方案的特征重要性呢?最简单的方法是创建一个条形图,显示数据集中输入特征的重要性,如下所示:
|
1 2 3 4 5 |
import matplotlib.pyplot as plt xgb.plot_importance(model, importance_type='gain', height=0.4) plt.title('特征重要性(增益)') plt.show() |
结果如下:
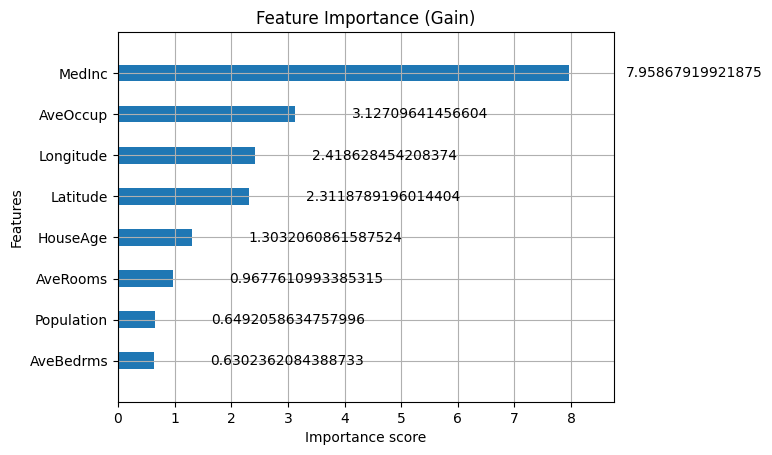
特征重要性条形图
作者提供图片
乍一看,似乎 `MedInc`(中位数收入)属性是预测地区房价的最具影响力的特征,其次是 `AveOccup`(平均入住率)以及地区的地理位置(经度和纬度)。同时,像平均卧室数量这样的其他属性在预测地区房价方面被认为不那么重要。但在接受这些假设之前,让我们更仔细地看看我们刚刚做了什么。
`plot_importance` 方法自动使用经过训练的 XGBoost 回归器的特征。此方法的一个关键设置是 `importance_type` 参数。此参数允许您显示不同的重要性类型,其中 `'gain'` 是其中之一。Gain 代表在集成模型中当某个特征用作树的一部分时,模型性能的平均改进(或损失减少)。更具体地说,我们指的是当该特征用于 分割树中的数据 时所带来的改进。因此,正确解读上述特征重要性图的方法是,较长的条形(较高的增益)与对减少预测错误贡献最大的特征相关联。
Gain 只是特征重要性可以衡量的几个维度之一;另外两个是 `'weight'` 和 `'cover'`。
- Weight(`'weight'`):这表示一个特征在 XGBoost 集成中被用于树分裂的次数,因此是该特征影响和对最终预测贡献的更“直接”和基于频率的指标。
- Coverage(`'cover'`):这是使用特定特征进行分裂所影响的样本(训练实例)的平均数量。例如,如果与中位数收入属性相关的分裂节点通常包含大量实例,则该特征的覆盖率往往更高。
通过可视化这两个额外的特征重要性“视图”,我们可以更好地理解我们集成模型的不同细微差别。
|
1 2 3 4 5 6 7 8 9 10 |
fig, axes = plt.subplots(1, 2, figsize=(14, 6)) xgb.plot_importance(model, importance_type='weight', height=0.4, ax=axes[0], color='green') axes[0].set_title('特征重要性(权重)') xgb.plot_importance(model, importance_type='cover', height=0.4, ax=axes[1], color='orange') axes[1].set_title('特征重要性(覆盖范围)') plt.tight_layout() plt.show() |
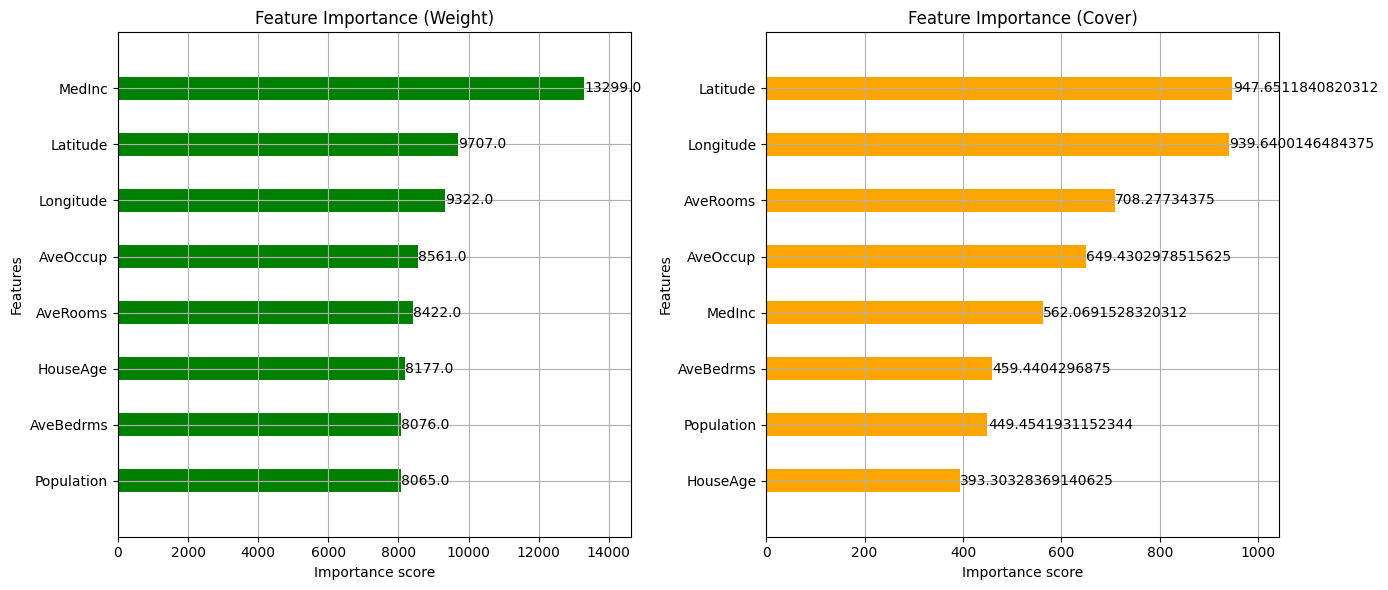
基于权重和覆盖范围的特征重要性
作者提供图片
一些关键的见解包括:
- 如果我们比较这三个图,我们可以看到,根据我们观察特征重要性的角度(增益 vs. 权重 vs. 覆盖范围),按重要性对属性进行排名可能会有所不同。以两个地理特征(纬度和经度)为例:虽然在对性能增益的贡献方面,它们落后于平均入住率特征,但从权重角度来看,这些属性在实际预测中更具影响力,因为它们在整个集成过程中更常用于分裂。
- 某些属性的重要性可能因我们分析的具体方面而异。一个明显的例子是中位数收入特征,它在增益和权重方面是最重要的,但在覆盖范围方面变得重要性大大降低。换句话说,虽然该特征在提高模型性能方面贡献最大,并且比其他任何属性的使用次数都多,但使用它的分裂倾向于包含更少的实例。这表明 `MedInc` 特征经常用于对性能产生积极影响的分裂,但这些分裂覆盖了较少的数据部分,这可能是因为它们位于树的更深层或更窄的部分,而不是影响许多实例的较浅分裂。
总结
XGBoost 是一种通用的机器学习技术。除了其能够处理中等复杂数据集的预测问题之外,其独特之处在于它拥有一套用于分析其可解释性的机制——即:决策(预测)是如何做出的,以及更重要的是,不同的输入数据特征如何不仅对预测做出贡献,而且对模型的性能也做出贡献。
本文通过深入了解特征重要性,对 XGBoost 模型的可解释性进行了实际的探索。






暂无评论。