关于如何在磁盘上存储和组织图像数据集有一些惯例,以便在训练和评估深度学习模型时能够快速有效地加载数据。
一旦结构化,您可以使用 Keras 深度学习库中的 `ImageDataGenerator` 类自动加载训练、测试和验证数据集。此外,生成器将逐步加载数据集中的图像,使您能够处理小型和非常大的数据集,这些数据集可能包含数千甚至数百万张图像,而这些图像可能无法完全载入系统内存。
在本教程中,您将学习如何组织图像数据集以及如何在拟合和评估深度学习模型时逐步加载它。
完成本教程后,您将了解:
- 如何将训练、测试和验证图像数据集组织成一致的目录结构。
- 如何使用 `ImageDataGenerator` 类逐步加载给定数据集的图像。
- 如何使用准备好的数据生成器来训练、评估深度学习模型并进行预测。
通过我的新书《计算机视觉深度学习》**启动您的项目**,其中包括**分步教程**和所有示例的 **Python 源代码**文件。
让我们开始吧。
教程概述
本教程分为三个部分;它们是:
- 数据集目录结构
- 示例数据集结构
- 如何逐步加载图像
数据集目录结构
图像数据的建模布局有标准方法。
收集图像后,您必须先按数据集(例如训练集、测试集和验证集)进行排序,然后按其类别进行排序。
例如,设想一个图像分类问题,我们希望根据汽车的颜色(例如红色汽车、蓝色汽车等)对汽车照片进行分类。
首先,我们有一个 `data/` 目录,我们将在其中存储所有图像数据。
接下来,我们将有一个用于训练数据集的 `data/train/` 目录和一个用于保留测试数据集的 `data/test/` 目录。我们还可能有一个 `data/validation/` 目录用于训练期间的验证数据集。
到目前为止,我们有
|
1 2 3 4 |
data/ data/train/ data/test/ data/validation/ |
在每个数据集目录下,我们将有子目录,每个子目录对应一个类别,实际的图像文件将放置在那里。
例如,如果我们有一个二元分类任务,用于将汽车照片分类为红色汽车或蓝色汽车,那么我们将有两个类别,“`red`”和“`blue`”,因此在每个数据集目录下有两个类别目录。
例如:
|
1 2 3 4 5 6 7 8 9 10 |
data/ data/train/ data/train/red/ data/train/blue/ data/test/ data/test/red/ data/test/blue/ data/validation/ data/validation/red/ data/validation/blue/ |
红色汽车的图像将被放置在相应的类别目录中。
例如:
|
1 2 3 4 5 6 7 8 |
data/train/red/car01.jpg data/train/red/car02.jpg data/train/red/car03.jpg ... data/train/blue/car01.jpg data/train/blue/car02.jpg data/train/blue/car03.jpg ... |
请记住,我们不会将相同的文件放在 `red/` 和 `blue/` 目录下;相反,这些是不同的红色汽车和蓝色汽车的照片。
还要记住,我们需要在 `train`、`test` 和 `validation` 数据集中使用不同的照片。
实际图像使用的文件名通常无关紧要,因为我们将加载所有具有给定文件扩展名的图像。
如果您能够始终如一地重命名文件,一个好的命名约定是使用某个名称后跟一个带零填充的数字,例如,如果一个类别有数千张图像,则使用 `image0001.jpg`。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
示例数据集结构
我们可以通过一个示例来具体化图像数据集结构。
假设我们正在对汽车照片进行分类,如上一节所述。具体来说,这是一个关于红色汽车和蓝色汽车的二元分类问题。
我们必须创建上一节中概述的目录结构,具体如下:
|
1 2 3 4 5 6 7 8 9 10 |
data/ data/train/ data/train/red/ data/train/blue/ data/test/ data/test/red/ data/test/blue/ data/validation/ data/validation/red/ data/validation/blue/ |
我们来创建这些目录。
我们也可以在目录中放置一些照片。
您可以使用 知识共享图片搜索 来查找一些具有开放许可证的图片,您可以下载并用于此示例。
我将使用两张图片

红色汽车,作者:丹尼斯·贾维斯(Dennis Jarvis)

蓝色汽车,作者:比尔·史密斯(Bill Smith)
将照片下载到您当前的工作目录,并将红色汽车的照片保存为“`red_car_01.jpg`”,蓝色汽车的照片保存为“`blue_car_01.jpg`”。
我们必须为每个训练集、测试集和验证集准备不同的照片。
为了让本教程保持专注,我们将在三个数据集中重复使用相同的图像文件,但假装它们是不同的照片。
将“`red_car_01.jpg`”文件的副本放入 `data/train/red/`、`data/test/red/` 和 `data/validation/red/` 目录中。
现在将“`blue_car_01.jpg`”文件的副本放入 `data/train/blue/`、`data/test/blue/` 和 `data/validation/blue/` 目录中。
我们现在有一个非常基本的数据集布局,如下所示(来自 `tree` 命令的输出)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
data ├── test │ ├── blue │ │ └── blue_car_01.jpg │ └── red │ └── red_car_01.jpg ├── train │ ├── blue │ │ └── blue_car_01.jpg │ └── red │ └── red_car_01.jpg └── validation ├── blue │ └── blue_car_01.jpg └── red └── red_car_01.jpg |
下面是目录结构的屏幕截图,来自 macOS 上的 Finder 窗口。
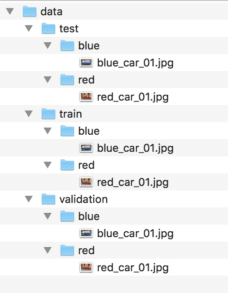
图像数据集目录和文件结构屏幕截图
现在我们已经有了基本的目录结构,让我们练习从文件中加载图像数据以用于建模。
如何逐步加载图像
可以编写代码手动加载图像数据并返回可用于建模的数据。
这包括遍历数据集的目录结构,加载图像数据,并返回输入(像素数组)和输出(类别整数)。
值得庆幸的是,我们不需要编写此代码。相反,我们可以使用 Keras 提供的 `ImageDataGenerator` 类。
使用此类加载数据的主要好处是图像以批次形式加载到单个数据集中,这意味着它可用于加载小型数据集以及包含数千或数百万图像的非常大的图像数据集。
在训练和评估深度学习模型时,它不会将所有图像加载到内存中,而只会加载足以用于当前和可能接下来几个小批次的图像到内存中。我将此称为渐进式加载,因为数据集是从文件逐步加载的,只检索立即所需的数据。
使用 `ImageDataGenerator` 类的另外两个优点是,它还可以自动缩放图像的像素值,并且可以自动生成图像的增强版本。我们将在另一个教程中讨论这些主题,而在这里我们只关注如何使用 `ImageDataGenerator` 类从文件加载图像数据。
使用 ImageDataGenerator 类的模式如下:
- 构建并配置 `ImageDataGenerator` 类的实例。
- 通过调用 `flow_from_directory()` 函数检索迭代器。
- 在模型的训练或评估中使用迭代器。
我们来仔细看看每个步骤。
`ImageDataGenerator` 的构造函数包含许多参数,用于指定加载图像数据后如何对其进行操作,包括像素缩放和数据增强。我们在此阶段不需要这些功能,因此配置 `ImageDataGenerator` 很容易。
|
1 2 3 |
... # 创建数据生成器 datagen = ImageDataGenerator() |
接下来,需要一个迭代器来逐步加载单个数据集的图像。
这需要调用 `flow_from_directory()` 函数并指定数据集目录,例如 `train`、`test` 或 `validation` 目录。
该函数还允许您配置与图像加载相关的更多详细信息。值得注意的是“`target_size`”参数,它允许您将所有图像加载到特定大小,这在建模时通常是必需的。该函数默认为大小为 `(256, 256)` 的正方形图像。
该函数还允许您通过“`class_mode`”参数指定分类任务的类型,特别是它是“`binary`”还是多类别分类“`categorical`”。
默认的“`batch_size`”是 32,这意味着在训练时,每次批处理将返回从数据集中所有类别中随机选择的 32 张图像。可能需要更大或更小的批次。您可能还希望在评估模型时以确定性顺序返回批次,这可以通过将“`shuffle`”设置为“`False`”来实现。
还有许多其他选项,我鼓励您查阅 API 文档。
我们可以使用相同的 `ImageDataGenerator` 为不同的数据集目录准备独立的迭代器。如果我们要对多个数据集(例如训练集、测试集等)应用相同的像素缩放,这会很有用。
|
1 2 3 4 5 6 7 |
... # 加载并迭代训练数据集 train_it = datagen.flow_from_directory('data/train/', class_mode='binary', batch_size=64) # 加载并迭代验证数据集 val_it = datagen.flow_from_directory('data/validation/', class_mode='binary', batch_size=64) # 加载并迭代测试数据集 test_it = datagen.flow_from_directory('data/test/', class_mode='binary', batch_size=64) |
一旦迭代器准备好,我们就可以在拟合和评估深度学习模型时使用它们。
例如,使用数据生成器拟合模型可以通过调用模型上的 `fit_generator()` 函数并传入训练迭代器 (`train_it`) 来实现。验证迭代器 (`val_it`) 可以通过“`validation_data`”参数在调用此函数时指定。
必须为训练迭代器指定“`steps_per_epoch`”参数,以定义多少批图像构成一个时期。
例如,如果训练数据集中有 1,000 张图像(所有类别),批次大小为 64,那么 `steps_per_epoch` 将约为 16,即 1000/64。
同样,如果应用了验证迭代器,则还必须指定“`validation_steps`”参数,以指示验证数据集中定义一个纪元的批次数量。
|
1 2 3 4 5 |
... # 定义模型 model = ... # 拟合模型 model.fit_generator(train_it, steps_per_epoch=16, validation_data=val_it, validation_steps=8) |
模型拟合后,可以使用 `evaluate_generator()` 函数并通过传入测试迭代器 (`test_it`) 在测试数据集上进行评估。“`steps`”参数定义了在停止之前评估模型时要遍历的样本批次数量。
|
1 2 3 |
... # 评估模型 loss = model.evaluate_generator(test_it, steps=24) |
最后,如果您想使用已拟合模型对非常大的数据集进行预测,您也可以为该数据集创建一个迭代器(例如 `predict_it`)并调用模型上的 `predict_generator()` 函数。
|
1 2 3 |
... # 进行预测 yhat = model.predict_generator(predict_it, steps=24) |
让我们使用上一节中定义的小型数据集来演示如何定义 `ImageDataGenerator` 实例并准备数据集迭代器。
一个完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 逐步从文件加载图像的示例 from keras.preprocessing.image import ImageDataGenerator # 创建生成器 datagen = ImageDataGenerator() # 为每个数据集准备迭代器 train_it = datagen.flow_from_directory('data/train/', class_mode='binary') val_it = datagen.flow_from_directory('data/validation/', class_mode='binary') test_it = datagen.flow_from_directory('data/test/', class_mode='binary') # 确认迭代器正常工作 batchX, batchy = train_it.next() print('Batch shape=%s, min=%.3f, max=%.3f' % (batchX.shape, batchX.min(), batchX.max())) |
运行示例首先创建一个 `ImageDataGenerator` 实例,所有配置均为默认值。
接下来,创建三个迭代器,分别用于训练、验证和测试的二元分类数据集。在创建每个迭代器时,我们可以看到调试消息,报告已发现和准备的图像和类别数量。
最后,我们测试用于拟合模型的训练迭代器。检索到第一批图像,我们可以确认该批次包含两张图像,因为只有两张图像可用。我们还可以确认图像已加载并强制转换为 256 行和 256 列像素的正方形尺寸,并且像素数据未缩放并保持在 [0, 255] 范围内。
|
1 2 3 4 |
Found 2 images belonging to 2 classes. Found 2 images belonging to 2 classes. Found 2 images belonging to 2 classes. Batch shape=(2, 256, 256, 3), min=0.000, max=255.000 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
文章
总结
在本教程中,您学习了如何组织图像数据集以及如何在拟合和评估深度学习模型时逐步加载它。
具体来说,你学到了:
- 如何将训练、测试和验证图像数据集组织成一致的目录结构。
- 如何使用 ImageDataGenerator 类逐步加载给定数据集的图像。
- 如何使用准备好的数据生成器来训练、评估深度学习模型并进行预测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






Jason,一如既往,教程非常清晰且实用。
我想知道您对在 TensorFlow 中使用 Keras,即使用 tf.keras.whatever 有何看法?谢谢
谢谢托尼!
在此阶段没有意见。一旦 TensorFlow 2.0 定稿,我可能会在今年晚些时候介绍它。
最终结果相同,尽管对开发人员来说更令人困惑,因为 TensorFlow 提供了太多方法来做同一件事。
谢谢你杰森。你的教程总是清晰且非常实用。
如果我的数据集不是图像但很大,我如何逐步加载我的数据?非常感谢
您可以编写自定义数据生成器来批量加载和生成数据。
我在这篇文章中给出了一个文本+图像的例子
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/
谢谢你,Jason。
我阅读了您建议的链接,但仍然有一些问题。
1. 通常,当我们训练数据时,我们需要在训练前对它们进行洗牌。如果我们可以将数据加载到内存中,那就没问题了。我不知道您在使用 data_generator 时何时进行了洗牌。我是否需要在收集数据后对数据进行洗牌?
2. 是否可以将数据更改为 .h5 文件,然后逐个加载到内存中?
非常感谢。
是的,尝试随机抽取样本是个好主意。
当然可以。
谢谢你,Jason。
我找不到你在哪里以及何时进行了洗牌。
此外,每次我发表评论后,我都必须再次访问我发表评论的博客,查看是否有您的回复。是否可以通过电子邮件收到您的回复或通知?非常感谢。
您可以将洗牌作为数据生成器的一部分来实现。我没有示例。
感谢您关于电子邮件回复的建议,我会研究一下。
杰森,感谢您的精彩教程。
我正在尝试解决模型中的一个问题,它看起来几乎与您的示例完全相同,只是我将图像像素按 1./255 重新缩放。
在我的模型中,我使用测试集来评估我的模型。但是每次我运行
model.evaluate_generator(test_it, steps=test.sample // batch size=32) 函数会返回不同的分数。我尝试过在 test_it 中设置 shuffle=False,但没有解决问题。
我正在使用检查点(回调)根据 validation_loss 保存最佳参数(权重)。之后,我将权重加载到模型中并应用了 evaluate_generator。我做错什么了吗?
PS:抱歉,英语不是我的母语。
非常感谢!!
模型将返回不同的分数,因为模型每次运行时都是不同的——这是设计使然。
神经网络是随机学习算法。
这会有帮助
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
我想我的问题表述得不够清楚。事实上,当我提到多次运行 model.evaluate_generator 时,我指的是仅运行这一行代码,同时保持网络已训练(相同权重)。但是,按照您的建议,我将测试生成器设置为
test_generator = datagen_test.flow_from_directory (
‘content / cell_images / test’, #测试文件夹路径
target_size = (150,150), #所有图像将被调整大小为 150×150
batch_size = 1,
class_mode = ‘categorical’
shuffle = False)
并将 model.evaluate_generator 中的 steps 参数设置为 test_generator.samples
score = model.evaluate_generator (test_generator, test_generator.samples)
显然它奏效了,如果我多次为相同的神经网络权重运行此代码行,准确性测试值不再改变
再次感谢 Jason 的回复,它对我帮助很大。
做得好,很高兴听到这个消息。
你好!干得好!但是如果我进行标注,那么对于汽车品牌模型分类,哪种分类更好呢?
我建议测试一套模型,以发现最适合您特定数据集的模型。
嗨
当我打印时
(os.getcwd())
它正在打印 /content。
但我无法在我的系统中找到此路径,您能帮我解决这个问题吗?
我收到“没有这样的目录”错误。
嗨,Jason,
这是一个非常清晰实用的教程,但我似乎正在努力寻找解决我略有不同问题的方法!
我将所有数据存储在基于类别的子目录中,例如“.\data\flower”、“.\data\cat”等,其中 flower 和 cat 是两个不同的类别。
然而,虽然我希望在运行时将图像加载到模型中,而不是在内存中保留大量图像,但我确实不想在不先尝试一系列可能的拆分的情况下对训练/验证/测试拆分进行硬编码。如果我完全按照您在此处描述的方式进行操作,我将不得不为我测试的每个不同拆分创建整个数据集的副本。
您知道是否有优化此操作的方法不需要定义自定义生成器吗?理想情况下,它能够接受带有目录的文件名列表,并分别将它们分发到训练/验证/测试列表,然后在运行时将每个列表输入到 TensorFlow 或 Keras 生成器中以实际加载图像。
如果我应该澄清任何内容,请告诉我。谢谢!
好问题,雅各布。
一个想法是编写一个脚本,通过移动文件来在磁盘上创建验证数据集,然后为训练和验证创建两个不同的 ImageDataGenerator 实例,分别用于两个不同的目录。
另一个想法是创建自定义数据生成器函数,这些函数使用您喜欢的任何参数将图像拆分为训练/验证。
希望这些能给你一些思路。
我已经训练了我的 CNN 模型,现在我想测试我的模型,您能为我提供相应的测试代码吗?
是的,我相信你可以在这里找到一个例子
https://machinelearning.org.cn/start-here/#dlfcv
嗨,Jason,
感谢您的教程,您总是用简单的方式描述事物。
您是否有关于如何将 TFRecords 用于 Keras 的教程?
谢谢。
感谢您的建议。
谢谢 Jason,
我有单独的测试集和训练集,并且已成功使用迭代器加载它们。请帮助我定义模型。这是一个数字的多类别分类。
也许这个教程可以作为起点
https://machinelearning.org.cn/how-to-develop-a-cnn-from-scratch-for-cifar-10-photo-classification/
我正在使用 flow_from_directory 中的 save_to_dir() 来查看生成器生成的内容,结果让我很困惑。我发现进入文件夹的图像数量差异很大。尝试所有不同的批处理和步长值只会让我更加困惑。在您的示例中,1000 张图像,批处理大小为 64,每 epoch 16 步,如果您 save_to_dir,您会看到 1000 张还是 1024 张图像?
我不确定我是否不理解 batch_size 等是如何实际生成图像集的,或者 save_to_dir 实际上没有达到我预期的效果(向我显示所有使用的图像),或者我是否由于某种原因没有得到预期的结果。
示例(使用小文件夹图像来尝试了解其作用……)
我有 120 张图像,跨越 6 个类别,所以每个类别 20 张。
batch_size 6,steps_per_epoch 20 产生 186 张图像,而不是 120 张。
batch_size 32,steps_per_epoch 4 产生 360 张图像,而不是 128 张
batch_size 32,steps_per_epoch 8 产生 576 张图像,而不是 256 张,也不是我用 4 得到的结果的两倍。
batch_size 12,steps_per_epoch 10 产生 252 张图像
等等。
当它生成的图像数量超过我开始时的数量时,它们会按照 ImageDataGenerator() 中定义的那样被翻转或拉伸,这大概是增强的目的——您可以使用同一图像的几种不同修改副本以获得更多变化。我只是觉得批处理大小和步长与生成的图像没有意义……
另外,就像您的示例一样,我有一个没有拉伸、翻转或缩放的验证生成器,对于这个生成器,我真的只希望使用一次图像,但我不知道如何获得这个结果。选择 batch_size 为 1 且 validation_steps 等于图像数量通常会导致 save_to_dir 保存更多图像(初始图像的副本)
总共 60 张验证图像
batch_size 1, 60 validation_steps, save_to_dir 保存了 71 张图像
batch_size 12, 5 validation_steps, 保存了 156 张图像
我读到的所有关于此的内容都说 batch_size*steps = 图像数量,但我似乎无法理解发生了什么。
是的,我相信它准备的数量比实际需要的要多,例如,在队列中以确保计算效率。
谢谢!我想这是最好的结果,一切都很好,我应该只是查看目录以大致了解拉伸等操作做了什么,而不是纠结于数量。这让我一直很抓狂。
仔细检查所执行的增强操作以确认其是否合理是一个非常好的主意。不假思索地运行代码太容易了。
你好 Jason,
感谢您精彩的教程。我有一个问题,我有一个 .7z 大型数据文件,其中包含图像,我通过 .7z 文件加载图像数据时遇到问题。有什么帮助吗?谢谢!!
您可以使用 7zip 应用程序解压 7z 文件
https://www.7-zip.org/download.html
如何使用这种结构绘制混淆矩阵?
这会有帮助
https://machinelearning.org.cn/confusion-matrix-machine-learning/
我使用这种方法加载图像,但它似乎在利用 GPU 方面效率很低。我的理解是,您可以将 TF DataSet 生成器馈送到 Keras 并以这种方式获得更高的效率。不幸的是,我一直无法弄清楚如何精确地做到这一点。Keras 和 TF 文档都没有这样的示例,我看到的每个博客文章或 SO 答案都使用预制的 MNIST 或 CIFAR 数据集,这些数据集不存储在文件系统上。如果能看到一篇展示如何将 ImageNet 文件加载到 Keras 中的文章,那将是很棒的。如果我能弄清楚,我会写这样一篇文章!哈哈
好建议,谢谢埃文。
与此同时,尝试更大的批次或自定义数据生成器,它将更多数据加载到内存中。
嗨,Jason,
感谢您的帖子和代码。
您是否碰巧有关于如何将“flow_from_directory”与具有 >4 个波段的图像一起使用的提示?
非常感谢,Mark
谢谢。
你说的“波段”是什么意思?
Jason,谢谢你的提问。
“波段”指的是颜色。所以不仅仅是红色、绿色和蓝色(这将是 3 个波段),还有红色、绿色、蓝色、近红外、中红外……(所以在这个例子中是 5 个或更多波段)。
例如,诸如 Himawari 之类的气象卫星有 16 个波段。
Rajat Garg 在他关于“在 Keras 中训练不适合内存的大型数据集”的帖子中提供了一个提示(https://medium.com/@mrgarg.rajat/training-on-large-datasets-that-dont-fit-in-memory-in-keras-60a974785d71),他建议创建一个自定义生成器类,然后“在 __getitem__(self, idx) 函数中决定数据集在批量加载时发生什么。”例如,计算工程特征。
所以不是 `flow_from_directory` 到 `ImageDataGenerator`,而是 `ImageDataGenerator` 在一个自定义生成器类中?
如果您能提供关于如何容纳具有 >4 个波段的大型图像文件从磁盘加载以及进行增强的提示,那将非常棒。
感谢您的考虑。
祝好,Mark
如果能得到一些
啊,这些被称为颜色通道,代表图像表示作为像素数组的第三个维度。
很好的建议,谢谢。
Jason博士您好,
我们如何对大型时间序列数据进行同样的操作?
此致
您可以开发一个数据生成器来加载数据并一次返回一个批次的样本。
你好,我不知道在数据生成后如何加载数据,或者你说的 flow_from_directory() 是什么意思。我的数据位于:C:\Users\sazid\OneDrive – Texas State University\Desktop\Hipe\images\data\train。
那么如何编写我的路径来加载数据呢?
“flow from directory”函数将接收您的数据集路径。
嗨
我正在尝试使用 CNN 解决多标签图像分类问题。起初我尝试加载所有图像并执行标签与图像的映射,但遇到了内存错误。
然后我查看了您上面的解决方案,但我在这里感到困惑
# 加载并迭代训练数据集
train_it = datagen.flow_from_directory(‘train/’, class_mode=’categorical’, batch_size=12)
# 加载并迭代测试数据集
test_it = datagen.flow_from_directory(‘test/’, class_mode=’categorical’, batch_size=12)
我的问题是,我们将在哪里执行映射,因为从上面的代码看来,我们直接从目录加载图像,然后将其传递给模型,但映射将在哪里以及如何执行,以便模型可以对其进行训练
是的,它假设 /train 和 /test 包含图像子目录,其中每个子目录都是一个类。
我有一个稍微不同的场景
我总共有 3 个标签 (Label1, Label2, Label3),每个标签进一步有 3 个选项 (L, M, H)
我们如何管理数据生成,因为在此博客中,有两个类别红色和蓝色,每个类别都有相关图像,但在我的情况下会怎样
我在这里感到困惑
也许可以把目录结构改成扁平化的?
也许使用自定义数据生成器?
嗨,Jason,
感谢分享。问题是,我有 1TB 的图像用于训练无监督聚类模型。每个 epoch 需要 5 个小时。我应该怎么做才能将时间缩短到 1 小时?
谢谢
一些想法
——使用更少的图片。
——使用更小的模型。
——使用更快的机器。
你好,
我有一个关于根据条件从文件夹中提取图像的问题。我有一个训练集,其中为每个类别设置了单独的文件夹。每个文件夹中都有来自 2 个不同摄像机的对象图像,它们具有相同的 ID,但名称结尾不同(ID_cam1 或 ID_cam2)。我需要仅当两者都存在于文件夹中时才使用图像。我如何添加此条件?
您可能需要编写一些自定义代码来加载或准备您的数据集。
嗨,Jason,我可以问一下您,这种方法是否可以用于从目录中逐步加载跨不同天的数值数据?我的意思是,网络应该接收来自一天的数据集作为输入数据,用它进行训练,然后转到另一天,依此类推。所需的生成器应该一次只加载一天的数据。(对于每一天都有一个相关的数据 CSV 文件,结构类似于您解释的那个)。
您能给我一些建议吗?
您可以实现自己的数据生成器来向网络馈送数据。
当我运行带有 `flow_from_directory('dataset/training_set/'...` 的代码时
我收到以下消息:`No such file or directory:'dataset/training_set/'`
我正在 MacOs pycharm 中工作
尝试从命令行运行
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
由于我没有 xtrain 和 ytrain,如何使用 GridSearch?
不,您必须编写一个自定义 for 循环来遍历要测试的配置。
感谢您这篇非常实用且急需的帖子。如果您能帮助我找出如何为图像序列(例如视频)进行数据生成,以用于视频分类,我将不胜感激。我认为由于 Keras 没有这种类型的类,我们需要开发自己的自定义数据生成器,对吗?
是的,您将需要一个用于视频数据的自定义生成器。
如何开发改进的模型[完成分类,模型评估方法后]..
和
如何最终确定模型并进行所有必要的评估和预测……。
混淆矩阵……
希望得到立即回复 先生
先生 先生
如何改进深度学习模型
https://machinelearning.org.cn/start-here/#better
如何最终确定模型
https://machinelearning.org.cn/train-final-machine-learning-model/
accuracy: 0.9472 – val_loss: 0.6782 – val_accuracy: 0.9677
为什么
val_accuracy 大于 acc ………..
如何计算 TR_accuracy………….>??????
这可能不是真实的,它们是批次的平均值。进行独立评估。
此外,由于随机偶然性,这也是可能的。
谢谢您这篇精彩的教程。我有一个问题。我有大量的图像,但基本上每个类别都在其各自的文件夹中,但它们尚未被划分为训练集、验证集和测试集。事实上,我比您开始本教程的步骤提前了一步。您可能会猜到,由于内存限制,我无法加载整个图像来将它们划分为训练集、验证集和测试集。如何解决这个问题?
不客气。
也许你可以编写一个脚本来随机将图像分成子集?
感谢您提供的有用教程。我正在使用 h5 数据集,我想知道是否有任何解决方案可以直接从目录而不是 jpg 图像加载 h5 文件?
不客气。
是的,您可以使用 `load_model()` 函数加载 h5 模型文件,如果 h5 是数据,您可以使用 h5py 库。
谢谢您的回复。
不客气。
先生,您能告诉我如何使用 imagedatagenrator 与 TPU 吗?
请帮忙。
代码与运行它的位置无关。使用 TPU/GPU/CPU 由 TensorFlow 库控制。
您好,先生,这对我非常有用,首先感谢您。
我只是想知道在此之后我想预测,如何实现这一部分?
调用 model.predict()
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
运行上述代码时出现此错误
ImportError: Could not import PIL.Image. The use of `load_img` requires PIL.
请问有什么建议吗
看来您需要安装 PIL/Pillow
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
非常感谢您最快的回复和大力支持。
不客气。
嗨,JASON,一如既往,您的教程非常棒,我从中学会了数据生成器。我唯一关心的是,我使用这种技术训练了一个模型,我的数据只有两个类别(狗,猫)。我生成了训练模型预测的混淆矩阵,混淆矩阵不太好,显示的结果准确率约为 50%(TP 和 TN 几乎等于 FP 和 FN)。另一方面,我用传统方式生成了另一个模型,没有数据生成器,例如使用 train_test_split 等 API,通过这种方式,我能够生成一个非常好的混淆矩阵,即准确率达到 95% 或更高。所以请教我如何在 Keras flow_from_dir 和数据生成器的情况下调整混淆矩阵。
谢谢
Jitender
我认为数据加载方式不会影响模型性能。
也许可以确认您的两个不同程序之间的数据准备、架构和训练是相同的。
你好。我正在遵循本教程,但我的情况有点不同,所有数据集图像都在一个文件夹中,此外,该文件夹的子目录的文件名不是我模型的目标类,因此 flow_from_directory 不适用于我的情况,有什么解决方案吗?
也许可以尝试根据您的特定结构进行调整?
我有一个疑问,我有一个包含多个类别的数据集,并且它们是不平衡的,那么使用图像生成器是否有一种方法可以只从每个类别加载等量的数据,或者是否有其他方法?
也许可以尝试生成许多示例,将它们保存到目录中,手动平衡它们,然后使用新数据集进行训练?
你好。我正在使用本教程,但我的情况有点不同。所有图像都在一个文件夹中,该文件夹的子目录的文件名不是预期目标类,因此 flow_from_directory 将不起作用。有什么建议吗?
也许可以更改目录结构以满足 API 的期望。
也许可以手动加载图像。
嗨,Jason,非常感谢您的回复,我非常感谢。我已多次检查,但仍无法找出问题所在。我可以在这里发布我的程序吗?请您检查一下。谢谢:)
# 开始
def count_files(dir_path, image_type)
return len(list(glob.iglob(dir_path+”/*/*.”+image_type, recursive=True)))
# 我们图像的维度。
img_width, img_height = 150, 150
train_data_dir = 'dataset/animals_finetune/train'
validation_data_dir = 'dataset/animals_finetune/validation'
nb_train_samples = count_files(train_data_dir,’jpg’)
nb_validation_samples = count_files(validation_data_dir,’jpg’)
print('nb_train_samples: ', nb_train_samples)
print('nb_validation_samples: ', nb_validation_samples)
epochs = 50
batch_size = 32
if K.image_data_format() == 'channels_first'
input_shape = (3, img_width, img_height)
else
input_shape = (img_width, img_height, 3)
print('input_shape: ',input_shape)
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation(‘sigmoid’))
model.compile(loss=’binary_crossentropy’,
optimizer='rmsprop',
metrics=['accuracy'])
# 这是我们将用于训练的增强配置
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# 这是我们将用于测试的增强配置
# 仅重新缩放
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
model.save_weights('first_try.h5')
# 混淆矩阵和分类报告
Y_pred = model.predict_generator(validation_generator, nb_validation_samples // batch_size+1)
y_pred = np.argmax(Y_pred, axis=1)
print('Confusion Matrix')
print(confusion_matrix(validation_generator.classes, y_pred))
print('Classification Report')
target_names = ['cats', 'dogs']
print(classification_report(validation_generator.classes, y_pred, target_names=target_names))
# 结束
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
您好 Jason,感谢您非常清晰的博文。我正在一个相当大的数据集(几百万张图片)上训练 ResNet 152,并且使用 ImageDataGenerator flow_from_directory 方法进展顺利。然而,训练仍然有点慢。我检查了任务管理器,发现只使用了 20% 的 GPU 和 15% 的 CPU 容量。我认为迭代器从系统拉取图像可能是瓶颈。
您知道这是否确实是问题所在吗?此外,是否有一种方法可以预加载批次或缓存它们,同时仍然使用 ImageDataGenerator?我仍然不知道如何解决这个问题。
也许您可以预先生成图像并使用大型 AWS EC2 实例,并将大部分图像加载到内存中——如果这是瓶颈的话。
干得漂亮,Jason!!!
我用我的模型试了一下,但遇到了一个问题:当使用 fit_generator 函数和 ImageDataGenerator 训练各种模型时,我发现第一个 epoch 花费的时间比后续的要长得多。这是什么原因呢?
例如,第一个 epoch 花了3492秒,然后所有后续的都只花了大约30秒
谢谢!
抱歉,我不知道,我不记得见过这个问题。也许它是在前期将大量图像缓存到内存中。
谢谢……
您的文章对初学者非常有帮助。而且能由作者亲自回答我们的问题简直太棒了!!!!
继续努力!
谢谢!
你好 Jason,
我读了你的文章。我的代码一次只能处理一张图片,但我希望在我的代码中加载多张图片用于检测。我正在使用retinanet模型。我想从包含6个类别的目录中加载图片。你能帮帮我吗?请告诉我应该修改代码的哪些部分,使其能够接受多张图片作为输入。
你可以直接使用上述教程中的代码来开始。
我的数据集大约有48k的大小,(输入-输出)都是图像,但无法像您那样加载,这种情况下该怎么办?
一些想法
也许可以将您的数据集结构更改为与示例匹配?
或许使用其他API来加载您的图像?
或许编写自定义代码来加载您的图像?
希望这能有所帮助。
请帮我编写这部分代码
抱歉,我没有能力为您准备代码。也许您可以聘请一位承包商。
先生,我有一些好的图像和一些坏的图像……我只想训练好的图像并预测坏的图像以检测坏的……
但是,我无法只训练好的图像……你能告诉我训练部分的代码应该是什么样的吗?
为了让模型区分好坏图像,它必须同时在好坏图像上进行训练。
嗨,Jason,
感谢这篇很棒的教程。
我正在尝试使用 flow_from_directory 来校准一个大型数据集的二分类器(x_train=21047张220x220图像;x_validation = 2629张220x220图像;x_test = 2633张220x220图像)。
我能这样使用吗?
calibrated = CalibratedClassifierCV(KerasModel, method=’sigmoid’, cv=5)
STEP_SIZE_TRAIN=train_generator.n//train_generator.batch_size
train_generator.reset()
calibrated.fit_generator(train_generator,train_generator.lables, steps=STEP_SIZE_TRAIN, sample_weight=None)
probs = calibrated.predict_proba_generator(test_generator, steps=STEP_SIZE_TEST,verbose=1)
抱歉,我认为校准分类器和带有目录流的 Keras 封装器不兼容。您可能需要编写一些自定义代码。
嘿 Jason,干得太棒了!!!
我想问的是,我的驱动器中有测试数据,其中的图像仅在用户名上略有不同。如果测试数据未标记,我可以使用循环进行分类检查吗?
抱歉,我不理解您的问题,也许您可以重新措辞或详细说明一下?
我需要帮助将图像加载到子目录中。我正在kaggle.com上处理一组完全不同的图像,并且已经为它们创建了目录和子目录,但是实际将图像加载到子目录中却遇到了困难。
图像格式的一个示例是“input_100_10_10.jpg”
这是我创建的目录和子目录
path = ‘../input/chinese-mnist/data/data/’
base_dir = ‘/kaggle/working/mnist’
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, ‘train’)
os.mkdir(train_dir)
train_set = os.path.join(train_dir, ‘train_data’)
os.mkdir(train_set)
我用来将图像加载到子目录的命令是
fnames = [‘input_{}_{}_{}.jpg’.format(i) for i in range(0, int(15000*0.80), 1)]
for name in fnames
src = os.path.join(path, name)
dst = os.path.join(train_set, name)
shutil.copyfile(src, dst)
请告诉我我哪里做错了
或许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
谢谢
嗨,Jason,
我有一个问题,我想使用数据生成器只加载没有标签的图像。我正在ImageNet数据集上训练一个用于图像重建的自编码器。
train_it = datagen.flow_from_directory(directory=”/dataset/Imagenet2012/train/”,
target_size=(224, 224),
color_mode=”rgb”,
batch_size=32,
class_mode=None,
shuffle=True,
seed=42
)
我已将 class_mode 更改为 None,但仍然遇到以下错误。
当数据是生成器或序列实例时,不支持 `y` 参数。请将目标作为生成器的第二个元素传递。
我想将原始图像作为 y 变量传递。
请帮我解决这个问题。
谢谢
抱歉,不确定,您可能需要进行试验。
或者开发一个自定义数据生成器。
Jason 博士您好
一如既往地感谢您在我们需要帮助时提供信息丰富的文章。
我有一个疑问,当问题是多标签分类时,我们会在 class-mode 参数中提供“categorical”吗?
谢谢
丹尼斯
我建议查阅文档
https://keras.org.cn/api/preprocessing/image/
嗨,Jason,
感谢您所有优秀的教程
我的问题与仿真配置有关。
Tensorflow 1.15 或最新版本 2.0 可以用于训练或推理的多个 GPU 吗?
以及 images_per_gpu 参数,如何根据数据集中的图像数量和 GPU 数量进行最佳配置?
非常感谢!
不客气。
我相信是这样,抱歉,我没有例子。
嗨 Jason,自定义加载器会给出 (batchX, batchY)。我正在处理一个 Keras 模型有多个输入的问题。我们是否可以重新利用自定义生成器来输出类似 (batchX1, batchX2, batchY) 的内容,其中 X1(图像)和 X2(一些其他数值)是 Keras 模型的两个不同输入。
您可能需要编写自定义数据生成器并手动加载您的数据。
我在这里给出了一个例子
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/
嗨,Jason,
尽管我已经创建了与您类似的数据目录结构,但仍然收到以下错误。
FileNotFoundError: [Errno 2] No such file or directory: ‘C:\\Users\\test\\dataset\\training_set\\’
我尝试了所有目录路径的组合(单个正斜杠、双正斜杠、反斜杠),所有方法都试过了,但都没有用。您能帮帮我吗?
很抱歉听到这个消息,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我会包含如何导入例如 ImageDataGenerator。
上面的例子展示了如何导入该类。
我有一系列七张卫星图像,用于应用回归任务并预测时间序列中的下一个序列。由于图像数量较少,我如何将它们上传到 CNN 模型?可以使用 ImageDataGenerator 吗?具体怎么做?
或许 CNN-LSTM 模型更适合图像序列。
您可能需要编写自定义代码来加载您的图像序列数据集。
谢谢你的提示。您有关于图像的 CNN-LSTM 教程吗?
是的,LSTM 书中有个例子
https://machinelearning.org.cn/lstms-with-python/
嗨,Jason。
如果我们得到图像在单独的文件夹中(根据它们的类别)位于一个目录文件夹下,
我们可以使用 keras 函数 – flow_from_directory() 并通过指定 validation_split 创建训练和验证数据集。
但是我们如何使用 flow_from_directory() 创建测试数据呢??
您可以先将图像分离为单独的训练/测试折叠,然后分别加载它们。
另一种方法可能是使用 image_dataset_from_directory()
https://keras.org.cn/api/preprocessing/image/
谢谢 Jason。我会尝试 image_dataset_from_directory(),因为执行是在 Kaggle 上,无法在那里创建单独的文件夹。
祝你好运!
嗨 Jason。使用 image_dataset_from_directory(),它返回了两个批处理数据集对象——一个用于训练,另一个用于验证。因此无法进一步拆分为测试数据集。
所以我最终创建了自己的测试图像数据集并上传到 Kaggle。正在尝试中。
谢谢!!
祝你好运!
嗨,音频数据集有类似的东西吗?
可能存在,抱歉,我不知道。
谢谢 Jason!
如何将fit_generator()函数与X和y作为numpy数组一起使用?
我没有例子,抱歉。或许可以查看 API 文档。
例如:
import tensorflow.keras as keras
来自 keras.models import Sequential
from keras.layers import Dense
import numpy as np
from sklearn.datasets import make_blobs
import math
from tensorflow.keras.utils import Sequence
batch_size = 30
nb_epoch = 5
# 定义数据集
X, y = make_blobs(n_samples=3000, centers=2, random_state=1)
嗨 Jason
感谢您所有优秀的教程
我们如何将此方法用于语义分割?
我们有图像和标签,没有任何类别
以及如何同时读取图像及其标签?
这里的代码似乎已被 Keras 弃用。它的替代品是一个更强大的函数。看看这两个链接是否有帮助
– https://keras.org.cn/api/preprocessing/image/
– https://tensorflowcn.cn/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator