图像由像素值矩阵组成。
黑白图像是单个像素矩阵,而彩色图像为每个颜色通道(如红色、绿色和蓝色)都有一个独立的像素值数组。
像素值通常是0到255范围内的无符号整数。尽管这些像素值可以直接以原始格式呈现给神经网络模型,但这可能在建模过程中带来挑战,例如模型训练速度低于预期。
相反,在建模之前准备图像像素值可能会带来巨大的好处,例如简单地将像素值缩放到0-1范围,进行居中,甚至标准化这些值。
在本教程中,您将学习如何使用深度学习神经网络对图像数据进行建模。
完成本教程后,您将了解:
- 如何将像素值归一化到0到1的范围。
- 如何全局(跨通道)和局部(每个通道)居中像素值。
- 如何标准化像素值以及如何将标准化后的像素值转移到正数域。
通过我的新书《计算机视觉深度学习》启动您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。
教程概述
本教程分为四个部分;它们是
- 示例图像
- 归一化像素值
- 居中像素值
- 标准化像素值
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
示例图像
我们需要一个示例图像用于本教程的测试。
我们将使用“Bernard Spragg. NZ”拍摄的悉尼海港大桥照片,该照片在宽松许可下发布。

“Bernard Spragg. NZ”拍摄的悉尼海港大桥
保留部分权利。
下载照片并将其保存到当前工作目录,文件名为“sydney_bridge.jpg”。
下面的示例将加载图像,显示一些关于加载图像的属性,然后显示图像。
此示例和本教程的其余部分假定您已安装 Pillow Python 库。
|
1 2 3 4 5 6 7 8 9 10 |
# 使用 Pillow 加载并显示图像 from PIL import Image # 加载图像 图像 = Image.打开('sydney_bridge.jpg') # 总结图像的一些详细信息 打印(图像.格式) 打印(图像.模式) 打印(图像.大小) # 显示图像 图像.显示() |
运行示例报告图像的格式是 JPEG,模式是 RGB,表示三个颜色通道。
接下来,报告图像的大小,显示宽度为 640 像素,高度为 374 像素。
|
1 2 3 |
JPEG RGB (640, 374) |
然后使用您工作站上默认的图像显示应用程序预览图像。
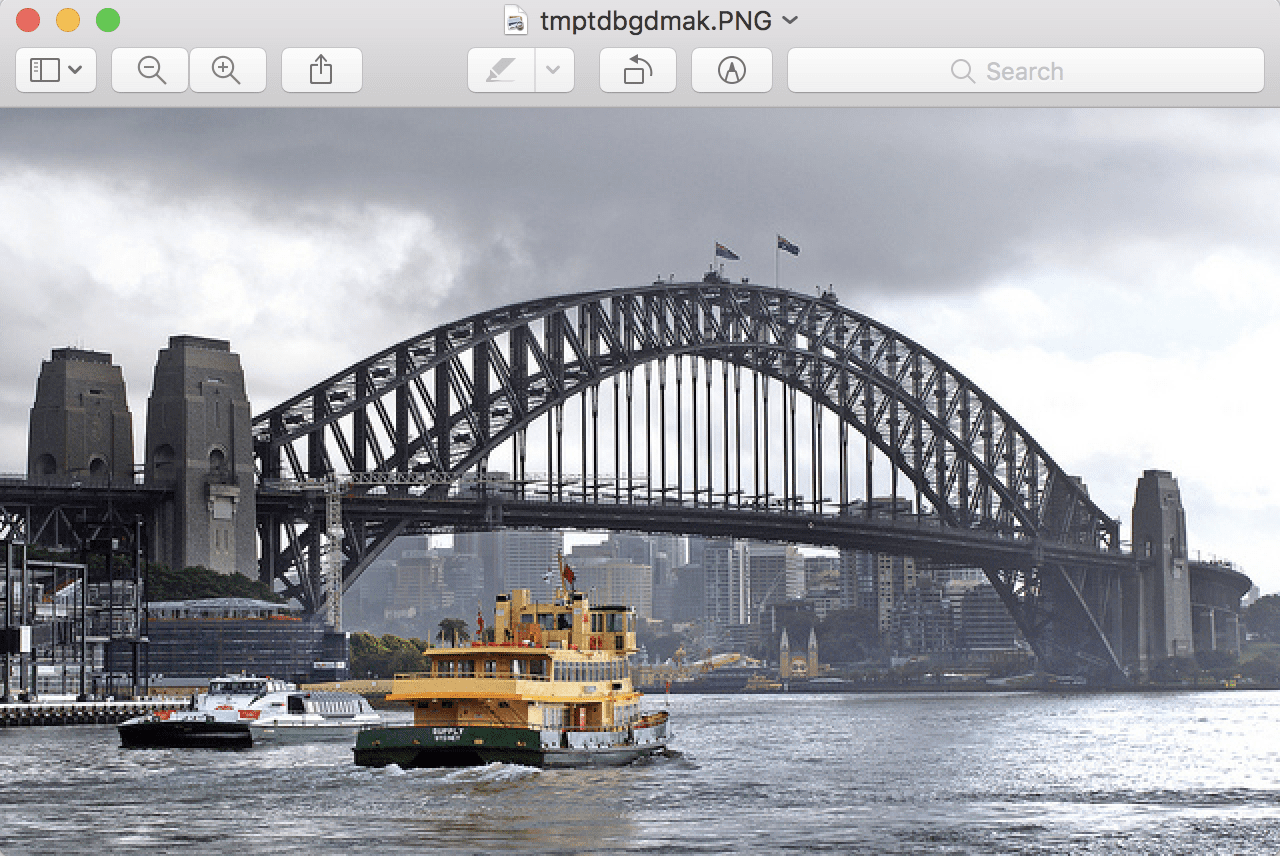
从文件加载的悉尼海港大桥照片
归一化像素值
对于大多数图像数据,像素值是介于0到255之间的整数。
神经网络使用小的权重值处理输入,而具有大整数值的输入可能会干扰或减慢学习过程。因此,最好对像素值进行归一化,使每个像素值介于0和1之间。
图像的像素值在0-1范围内是有效的,并且图像可以正常显示。
这可以通过将所有像素值除以最大像素值(即255)来实现。这适用于所有通道,无论图像中实际存在的像素值范围如何。
下面的示例加载图像并将其转换为 NumPy 数组。报告数组的数据类型,然后打印所有三个通道的最小和最大像素值。接下来,数组转换为浮点数据类型,然后像素值被归一化,并报告新的像素值范围。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 像素归一化示例 from numpy import asarray from PIL import Image # 加载图片 图像 = Image.打开('sydney_bridge.jpg') 像素 = asarray(图像) # 确认像素范围为 0-255 打印('数据类型: %s' % 像素.dtype) 打印('最小: %.3f, 最大: %.3f' % (像素.min(), 像素.max())) # 将整数转换为浮点数 像素 = 像素.astype('float32') # 归一化到 0-1 范围 像素 /= 255.0 # 确认归一化结果 打印('最小: %.3f, 最大: %.3f' % (像素.min(), 像素.max())) |
运行示例会打印像素值NumPy数组的数据类型,我们可以看到它是一个8位无符号整数。
打印最小和最大像素值,分别显示预期的0和255。像素值被归一化,然后报告新的最小和最大值分别为0.0和1.0。
|
1 2 3 |
数据类型: uint8 最小值: 0.000, 最大值: 255.000 最小值: 0.000, 最大值: 1.000 |
如果您对要执行的数据准备类型有疑问,归一化是一种很好的默认数据准备方法。
它可以对每张图像进行,并且不需要计算整个训练数据集的统计数据,因为像素值范围是一个领域标准。
居中像素值
一种流行的图像数据准备技术是从像素值中减去平均值。
这种方法称为居中,因为像素值分布以零为中心。
居中可以在归一化之前或之后进行。先将像素居中再归一化,意味着像素值将居中在0.5附近,并在0-1范围内。在归一化之后居中,意味着像素将具有正负值,在这种情况下图像将无法正确显示(例如,像素值预期在0-255或0-1范围内)。归一化之后居中可能更受青睐,尽管两种方法都值得测试。
居中要求在从像素值中减去平均像素值之前计算该值。计算平均值有多种方法;例如:
- 每张图像。
- 每批次图像(在随机梯度下降下)。
- 每个训练数据集。
平均值可以针对图像中的所有像素进行计算,这称为全局居中,也可以针对彩色图像中的每个通道进行计算,这称为局部居中。
- 全局居中:计算并减去所有颜色通道的平均像素值。
- 局部居中:计算并减去每个颜色通道的平均像素值。
每图像全局居中很常见,因为实现起来非常简单。同样常见的还有每小批量全局或局部居中,原因相同:它快速且易于实现。
在某些情况下,通道均值是在整个训练数据集上预先计算的。在这种情况下,图像均值必须存储并在训练和将来使用训练模型进行任何推断时使用。例如,ImageNet 训练数据集计算的每通道像素均值如下:
- ImageNet 训练数据集均值: [0.485, 0.456, 0.406]
对于使用这些均值进行居中训练的模型,如果用于新任务的迁移学习,使用相同的均值对新任务的图像进行归一化可能是有益的,甚至是必需的。
我们来看几个例子。
全局居中
下面的示例计算加载图像中所有三个颜色通道的全局平均值,然后使用该全局平均值对像素值进行居中处理。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 全局居中示例(减去平均值) from numpy import asarray from PIL import Image # 加载图片 图像 = Image.打开('sydney_bridge.jpg') 像素 = asarray(图像) # 将整数转换为浮点数 像素 = 像素.astype('float32') # 计算全局平均值 平均值 = 像素.平均值() 打印('平均值: %.3f' % 平均值) 打印('最小: %.3f, 最大: %.3f' % (像素.min(), 像素.max())) # 像素的全局居中 像素 = 像素 - 平均值 # 确认已达到预期效果 平均值 = 像素.平均值() 打印('平均值: %.3f' % 平均值) 打印('最小: %.3f, 最大: %.3f' % (像素.min(), 像素.max())) |
运行示例后,我们可以看到平均像素值约为152。
居中后,我们可以确认像素值的新平均值为0.0,并且新数据范围以该平均值为中心,包含负值和正值。
|
1 2 3 4 |
平均值:152.149 最小值: 0.000, 最大值: 255.000 平均值:-0.000 最小: -152.149, 最大: 102.851 |
局部居中
下面的示例计算加载图像中每个颜色通道的平均值,然后分别对每个通道的像素值进行居中处理。
请注意,NumPy 允许我们通过“axis”参数指定统计量(如平均值、最小值和最大值)计算的维度。在此示例中,我们将其设置为 (0,1) 用于宽度和高度维度,保留了第三个维度或通道。结果是三个通道数组中每个通道一个平均值、最小值或最大值。
另请注意,当我们计算平均值时,我们将 dtype 指定为“float64”;这是必需的,因为它将使平均值的所有子操作(例如求和)以 64 位精度执行。如果没有此设置,求和将以较低分辨率执行,并且由于精度损失中的累积误差,最终的平均值将是错误的,这反过来意味着每个通道居中像素值的平均值将不为零(或非常接近零的小数)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 每通道居中示例(减去平均值) from numpy import asarray from PIL import Image # 加载图片 图像 = Image.打开('sydney_bridge.jpg') 像素 = asarray(图像) # 将整数转换为浮点数 像素 = 像素.astype('float32') # 计算每通道均值和标准差 均值 = 像素.均值(轴=(0,1), dtype='float64') 打印('均值: %s' % 均值) 打印('最小值: %s, 最大值: %s' % (像素.min(轴=(0,1)), 像素.max(轴=(0,1)))) # 像素的每通道居中 像素 -= 均值 # 确认已达到预期效果 均值 = 像素.均值(轴=(0,1), dtype='float64') 打印('均值: %s' % 均值) 打印('最小值: %s, 最大值: %s' % (像素.min(轴=(0,1)), 像素.max(轴=(0,1)))) |
运行示例首先报告每个通道的平均像素值,以及每个通道的最小和最大值。像素值被居中,然后报告每个通道的新平均值和最小/最大像素值。
我们可以看到新的平均像素值是非常接近零的小数,并且这些值是围绕零居中的负值和正值。
|
1 2 3 4 |
均值: [148.61581718 150.64154412 157.18977691] 最小值: [0. 0. 0.], 最大值: [255. 255. 255.] 平均值: [1.14413078e-06 1.61369515e-06 1.37722619e-06] 最小值: [-148.61581 -150.64154 -157.18977], 最大值: [106.384186 104.35846 97.81023 ] |
标准化像素值
像素值分布通常遵循正态或高斯分布,即钟形曲线。
这种分布可能存在于每张图像、每批次图像或整个训练数据集,并且可以是全局的或每个通道的。
因此,将像素值分布转换为标准高斯分布可能是有益的:即将像素值居中为零,并通过标准差对值进行归一化。结果是像素值的标准高斯分布,均值为0.0,标准差为1.0。
与居中一样,该操作可以对每张图像、每小批次图像和整个训练数据集执行,并且可以在通道之间全局执行或每个通道局部执行。
标准化可能比单独的归一化和居中更受欢迎,它会产生零居中的小输入值,大致在-3到3的范围内,具体取决于数据集的特性。
为了输入数据的一致性,如果可能的话,使用每小批量或整个训练数据集计算的统计数据对图像进行每通道标准化可能更有意义。
让我们看一些例子。
全局标准化
下面的示例计算加载图像中所有颜色通道的均值和标准差,然后使用这些值对像素值进行标准化。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 全局像素标准化示例 from numpy import asarray from PIL import Image # 加载图片 图像 = Image.打开('sydney_bridge.jpg') 像素 = asarray(图像) # 将整数转换为浮点数 像素 = 像素.astype('float32') # 计算全局均值和标准差 均值, 标准差 = 像素.均值(), 像素.标准差() 打印('均值: %.3f, 标准差: %.3f' % (均值, 标准差)) # 像素的全局标准化 像素 = (像素 - 均值) / 标准差 # 确认已达到预期效果 均值, 标准差 = 像素.均值(), 像素.标准差() 打印('均值: %.3f, 标准差: %.3f' % (均值, 标准差)) |
运行示例首先计算全局平均像素值和标准差,然后对像素值进行标准化,并通过报告新的全局平均值0.0和标准差1.0来确认转换。
|
1 2 |
平均值: 152.149, 标准差: 70.642 均值: -0.000, 标准差: 1.000 |
正全局标准化
可能需要将像素值保持在正数域,也许是为了可视化图像,或者为了模型中选择的激活函数。
实现这一点的一种流行方法是将标准化后的像素值裁剪到[-1, 1]范围,然后将值从[-1,1]重新缩放到[0,1]。
下面的示例更新了全局标准化示例,以演示这种额外的重新缩放。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 全局像素标准化并转移到正数域的示例 from numpy import asarray 从 numpy 导入 clip from PIL import Image # 加载图片 图像 = Image.打开('sydney_bridge.jpg') 像素 = asarray(图像) # 将整数转换为浮点数 像素 = 像素.astype('float32') # 计算全局均值和标准差 均值, 标准差 = 像素.均值(), 像素.标准差() 打印('均值: %.3f, 标准差: %.3f' % (均值, 标准差)) # 像素的全局标准化 像素 = (像素 - 均值) / 标准差 # 将像素值裁剪到 [-1,1] 像素 = clip(像素, -1.0, 1.0) # 从 [-1,1] 转换到 [0,1],平均值为 0.5 像素 = (像素 + 1.0) / 2.0 # 确认已达到预期效果 均值, 标准差 = 像素.均值(), 像素.标准差() 打印('均值: %.3f, 标准差: %.3f' % (均值, 标准差)) 打印('最小: %.3f, 最大: %.3f' % (像素.min(), 像素.max())) |
运行示例首先报告全局均值和标准差像素值;像素被标准化然后重新缩放。
接下来,报告新的平均值和标准差分别约为 0.5 和 0.3,并确认新的最小值和最大值分别为 0.0 和 1.0。
|
1 2 3 |
平均值: 152.149, 标准差: 70.642 均值: 0.510, 标准差: 0.388 最小值: 0.000, 最大值: 1.000 |
局部标准化
下面的示例计算加载图像中每个通道的均值和标准差,然后使用这些统计量分别对每个通道中的像素进行标准化。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 每通道像素标准化示例 from numpy import asarray from PIL import Image # 加载图片 图像 = Image.打开('sydney_bridge.jpg') 像素 = asarray(图像) # 将整数转换为浮点数 像素 = 像素.astype('float32') # 计算每通道均值和标准差 均值 = 像素.均值(轴=(0,1), dtype='float64') 标准差 = 像素.标准差(轴=(0,1), dtype='float64') 打印('均值: %s, 标准差: %s' % (均值, 标准差)) # 像素的每通道标准化 像素 = (像素 - 均值) / 标准差 # 确认已达到预期效果 均值 = 像素.均值(轴=(0,1), dtype='float64') 标准差 = 像素.标准差(轴=(0,1), dtype='float64') 打印('均值: %s, 标准差: %s' % (均值, 标准差)) |
运行示例首先计算并报告每个通道像素值的均值和标准差。
然后对像素值进行标准化并重新计算统计量,确认新的零均值和单位标准差。
|
1 2 |
均值: [148.61581718 150.64154412 157.18977691], 标准差: [70.21666738 70.6718887 70.75185228] 平均值: [ 6.26286458e-14 -4.40909176e-14 -8.38046276e-13], 标准差: [1. 1. 1.] |
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 开发函数。开发一个函数来缩放提供的图像,使用参数选择要执行的准备类型。
- 投影方法。研究并实现消除像素数据中线性相关性的数据准备方法,例如PCA和ZCA。
- 数据集统计。选择并更新其中一个居中或标准化示例,以计算整个训练数据集的统计数据,然后在为训练或推理准备图像数据时应用这些统计数据。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
文章
- 数据预处理, CS231n 卷积神经网络用于视觉识别
- 为什么在深度学习中,图像归一化要减去数据集的图像均值,而不是当前图像的均值?
- 在图像分类任务中,应用于卷积神经网络之前,有哪些图像预处理方法?
- 对图像分类中的图像预处理感到困惑,Pytorch 问题.
总结
在本教程中,您学习了如何为深度学习神经网络建模准备图像数据。
具体来说,你学到了:
- 如何将像素值归一化到0到1的范围。
- 如何全局(跨通道)和局部(每个通道)居中像素值。
- 如何标准化像素值以及如何将标准化后的像素值转移到正数域。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。





谢谢杰森!对于像我这样在图像预处理方面经验不多的人来说,这非常有趣!
无论如何,我认为这些知识会影响使用VGG16、VGG19、NASNetL等Keras应用程序的迁移学习,因为这些图像应用程序('imagenet')需要特定的图像预处理才能使用完整的预训练权重、模型等。
我特别指的是这些 Keras Apps 附带特定的库模块,例如
从 keras.applications.vgg16 导入 preprocess_input
所以我的问题是,您知道这些应用程序(用于迁移学习)执行了哪些特定的预处理输入图像操作,与您在这篇文章中解释的那些相关联吗?如果您不应用这个 preprocess_input 模块,而是应用您在这里展示的那些,结果会是灾难性的尝试还是仅仅是性能下降?
很好的问题!
是的,如果使用了预训练模型的输入层,例如VGG-16,那么输入数据必须以与训练数据相同的方式准备,这是每个模型提供的预处理函数的工作。
通常这非常简单,例如每通道像素居中并重塑为正确的大小。
我有很多关于使用迁移学习时涵盖此内容的帖子计划——我迫不及待!
你好。我不明白在居中后进行归一化时如何获得0-1范围,且均值约为0.5。我像先归一化后居中一样得到了负值。我决定也许是指在居中后进行最小-最大缩放,但那样值又会像默认归一化一样返回。你能给我解释一下吗?
你可以先居中,让值在0附近有正负值,然后归一化,并对上下限使用相同的缩放值,例如-5,5或-3,3——确保缩放是对称的。这将给出新的0-1范围和0.5的均值。
谢谢杰森,但我看到在您的示例中,无论是标准化还是归一化,您都使用了图像自身的数据,例如图像均值或标准差。在这种情况下,训练集示例和测试集的标准化都会有所不同。我错了吗?
正确。
嗨,杰森,谢谢你的帖子!
我有一个(开放性)问题:当我们向CNN提供3D体数据时,你认为我们应该怎么做?我问这个问题是因为我们正在处理医学成像数据,我们的输入是一个形状为例如(50,50,50)的灰度3D体数据。
在这种情况下,您知道有什么推荐的预处理技术吗?
我们应该逐层标准化,还是应该使用整个体积的均值和标准差?
非常感谢!
抱歉,我没有这方面的教程。
你好,Jason!
我在“归一化像素值”这个话题上遇到了困难。
我按照你的代码操作,得到了和下面一样的结果。
数据类型: uint8
最小值: 0.000, 最大值: 255.000
最小值: 0.000, 最大值: 1.000
现在,我想把这些改动保存到文件里。
有什么办法可以做到吗?
我尝试了下面的方法,但保存的文件仍然在0-255范围内。
image = Image.open(filename.png) // 打开文件
…
…
image.save(filename.png) // 保存文件
是的,请看这个
https://machinelearning.org.cn/how-to-save-a-numpy-array-to-file-for-machine-learning/
我尝试保存0-1范围的图像,结果保存了一张黑色图像?是否有可能保存图像并显示其强度范围在0-1之间?
导入 SimpleITK 作为 sitk
从 pylab 导入 *
img= sitk.ReadImage(“1.2.826.0.1.3680043.9.3218.1.1.2695005.4962.1510228559379.3567.0.dcm”)
#img = sitk.ReadImage(“N:/OPTIMAM_ORIGINAL_new/OPTIMAM_DB/image_db/sharing/omi-db/images/demd1343/1.2.826.0.1.3680043.9.3218.1.1.3822746.1025.1511356299887.6499.0/1.2.826.0.1.3680043.9.3218.1.1.3822746.1025.1511356299887.6540.0.dcm”)
#img= sitk.ReadImage(“1.2.826.0.1.3680043.9.3218.1.1.3822746.1025.1511356299887.6540.0.dcm”)
# 将强度范围从 [-1000,1000] 重新缩放到 [0,255]
img = sitk.IntensityWindowing(img, 0, 4096,0,255)
# 将16位像素转换为8位
img = sitk.Cast(img, sitk.sitkUInt8)
nda = sitk.GetArrayFromImage(img)[0,:,:]
# 确认像素范围为 0-255
ALLOW_THREADS()print('数据类型: %s' % nda.dtype)
print('最小: %.3f, 最大: %.3f' % (nda.min(), nda.max()))
# 将整数转换为浮点数
像素 = nda.astype('float32')
# 归一化到 0-1 范围
像素 /= 255.0
# 确认归一化结果
print('最小: %.3f, 最大: %.3f' % (像素.min(), 像素.max()))
#imshow(img)
sitk.WriteImage(img, “000005.png”)
是的,像素值可以是 0-1 或 0-255,两者都有效。
抱歉,我没有能力调试你的代码
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
我正在尝试保存灰度范围为0-1的图像。如何在python中实现?当我将图像转换为Uint8并保存到DHH时,灰度图像范围为0-255。我已经设法使用命令:plt.imshow(nda, cmap=plt.get_cmap('gray'))显示灰度范围为0-1的图像;其中nda是一个float64的numpy数组。但是当我尝试使用Uint8保存nda时,我自然得到了黑色图像,因为Uint8的范围是0-255。我想知道有没有可能将图像保存为灰度,其值范围在0到1之间。
我不确定您错误的原因,抱歉。
也许可以尝试在 StackOverflow 上发布您的代码和错误。
嗨!我有一个问题,我怀疑它的答案与这个话题密切相关。
假设我有一些在 [0, 6] 区间内的数据。大多数样本是 2D 数组(你可以将它们视为 100x5 的图像),其中一半的值为 0。当我提取均值时,所有 0 值可能会变为 -3,并开始在学习过程中变得相关,而我希望神经网络关注正值并以某种方式丢弃这些空区域。
在这种情况下,正全局标准化会有帮助吗?
所有这些与 ReLU 函数有什么关系?在这种情况下,ReLU 应该真的丢弃负值吗?
这个问题还有其他解决方案吗?
一个很好的类比是图像中猫狗在草地上,网络通过学习草地背景而不是特定特征,将它们视为相同的东西。
我想你可能想使用遮罩层
https://keras.org.cn/layers/core/
干得好!我能问一下是否有针对不同图像尺寸的预处理策略吗?我有一个3D图像数据集,其宽度和高度差异很大(22-129,183-329),但长度保持不变。对于图像尺寸归一化有什么建议吗?提前感谢!
越小越快。
谢谢!
不客气。
先生,当我运行这段代码时
# 每通道像素标准化示例
from numpy import asarray
from PIL import Image
# 加载图片
image = Image.open('sydney_bridge.jpg')
pixels = asarray(image)
# 将整数转换为浮点数
pixels = pixels.astype('float32')
# 计算每通道均值和标准差
means = pixels.mean(axis=(0,1), dtype='float64')
stds = pixels.std(axis=(0,1), dtype='float64')
print('均值: %s, 标准差: %s' % (means, stds))
# 像素的每通道标准化
pixels = (pixels - means) / stds
# 确认已达到预期效果
means = pixels.mean(axis=(0,1), dtype='float64')
stds = pixels.std(axis=(0,1), dtype='float64')
print('均值: %s, 标准差: %s' % (means, stds))
我只得到两个值,比如
均值: 128.90747832983968, 标准差: 62.30103035552067
均值: 1.2235509834827096e-07, 标准差: 1.0000000181304383
第三个值呢……我导入了3通道图像……却只得到了这些……
听到这个消息很抱歉,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好先生,请问我很难理解这个意义上的归一化,我有一些问题:归一化后如何下载图像,以及是否可以一次归一化100张图像的数据集?
是的,您可以在像素缩放后保存图像。
是的,您应该缩放数据集中的所有图像。
我们如何做到呢?
和单张图像一样。
.
对所有像素值进行 (像素 - 均值) / 标准差 的操作,使得全局标准化后的均值为 0。
像素 = 红 + 绿 + 蓝 像素
所以
r_pixel = 所有红色通道像素。
.
因此,如果两者都是像素分布,那么通过均值减去它们并除以标准差,它们的均值必须归零。
.
那么
为什么局部标准化后的平均值不等于 [0, 0, 0] 呢?
是的,这些值基本上是零。
你好!在应用归一化和居中时,是应该采用整个数据集的最大像素值来归一化图像,还是只采用局部最大值(每张图像不同于255)?
谢谢!
两种方法都可以使用。
或许可以尝试两种方法,并找出哪种最适合您的模型/数据集。
嗨,Jason,
根据这篇文章,只使用纯标准化,而不进行归一化和居中,会更好吗?优点和缺点是什么?
谢谢
这确实取决于数据和模型。
我的建议是先从标准化开始,但考虑评估每种数据预处理方法,并使用最适合您的数据和模型的方法。
嗨,Jason,
我目前正在做一个关于皮肤病变的项目,涉及2个类别。其中一个类别不能被完美地归类为0。然而,另一个类别可以被完美地预测为1。这与平均像素值有关吗?
如果是这样,我如何获取整个数据集的平均像素值?
谢谢
不确定,因为我无法看到您的皮肤病变图片。但机器学习通常没有100%的准确性,并且存在精确率-召回率的权衡:https://machinelearning.org.cn/roc-curves-and-precision-recall-curves-for-classification-in-python/
如果您只想找到平均像素值,您可以参考代码“pixels.mean()”,只需您需要首先将所有图像加载到一个3D numpy数组“pixels”中。
感谢杰森的文章。我对文章第一节中“归一化”一词的用法有点好奇。我的理解是,将值从0-255转换为0-1实际上是缩放,而不是归一化。归一化意味着改变分布类型,例如通过x - m/std来改变为标准分布。您有什么想法吗?
嗨,VJ…以下内容可能有助于澄清:
https://machinelearning.org.cn/normalize-standardize-time-series-data-python/
归一化后如何保存像素?我想之后将其用于训练..有什么解决方案吗?
嗨 Ze…您可能会发现以下讨论有用
https://stackoverflow.com/questions/62783984/how-to-normalize-pixel-values-in-an-image-and-save-it