人脸检测是计算机视觉中的一个问题,涉及在照片中查找人脸。
对人类来说,这是一个很容易解决的问题,并且通过诸如级联分类器之类的经典基于特征的技术已经得到了相当好的解决。最近,深度学习方法在标准基准人脸检测数据集上取得了最先进的结果。一个例子是多任务级联卷积神经网络,简称 MTCNN。
在本教程中,您将学习如何使用经典和深度学习模型在 Python 中执行人脸检测。
完成本教程后,您将了解:
- 人脸检测是识别和定位图像中人脸的一个非平凡的计算机视觉问题。
- 可以使用 OpenCV 库中的经典基于特征的级联分类器来执行人脸检测。
- 通过 MTCNN 库的多任务级联 CNN 可以实现最先进的人脸检测。
通过我的新书《计算机视觉深度学习》来启动您的项目,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于 2019 年 11 月:已更新至 TensorFlow v2.0 和 MTCNN v0.1.0。

如何使用经典和深度学习方法进行人脸检测
照片由 Miguel Discart 拍摄,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 人脸检测
- 测试照片
- OpenCV 人脸检测
- 深度学习人脸检测
人脸检测
人脸检测是计算机视觉中在照片中定位和识别一个或多个面部的问题。
在照片中定位人脸是指找到图像中人脸的坐标,而识别是指标示出人脸的范围,通常是通过围绕人脸的边界框。
该问题的一般陈述可以定义如下:给定一张静态或视频图像,检测并识别任意数量(如果存在)的人脸。
— Face Detection: A Survey, 2001.
对人类来说,在照片中检测人脸很容易解决,但对于计算机来说,鉴于人脸的动态性质,这在历史上一直是一个挑战。例如,必须能够检测到各种朝向或角度的面部、光照条件、衣物、配饰、发色、面部毛发、化妆、年龄等等。
人脸是一个动态对象,其外观具有高度的可变性,这使得人脸检测成为计算机视觉中的一个难题。
— Face Detection: A Survey, 2001.
给定一张照片,人脸检测系统将输出零个或多个包含人脸的边界框。然后,检测到的人脸可以作为输入提供给后续系统,例如人脸识别系统。
人脸检测是人脸识别系统的必要第一步,目的是定位和提取人脸区域与背景。
— Face Detection: A Survey, 2001.
人脸识别可能主要有两种方法:一种是基于特征的方法,它使用手工制作的滤波器来搜索和检测人脸;另一种是基于图像的方法,它整体学习如何从整个图像中提取人脸。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
测试照片
本教程需要用于人脸检测的测试图像。
为了保持简单,我们将使用两张测试图像:一张有两张脸,一张有多张脸。我们不试图挑战人脸检测的极限,只是演示如何使用普通正面照片进行人脸检测。
第一张图片是 CollegeDegrees360 拍摄的两个大学生的照片,并根据允许的许可提供。照片文件名为“test1.jpg”。
下载图片并将其与文件名“test1.jpg”一起放在当前工作目录中。

大学生 (test1.jpg)
照片由 CollegeDegrees360 拍摄,保留部分权利。
第二张图片是 Bob n Renee 拍摄的一群游泳队队员的照片,并根据允许的许可发布。照片文件名为“test2.jpg”。
下载图片并将其与文件名“test2.jpg”一起放在当前工作目录中。

游泳队 (test2.jpg)
照片由 Bob n Renee 拍摄,保留部分权利。
OpenCV 人脸检测
基于特征的人脸检测算法快速有效,并且已经成功使用了几十年。
也许最成功的例子是级联分类器技术,由 Paul Viola 和 Michael Jones 在其 2001 年的论文《Rapid Object Detection using a Boosted Cascade of Simple Features》(使用增强型简单特征的快速对象检测)中首次提出。
在论文中,使用AdaBoost 算法学习有效特征,但重要的是,多个模型被组织成一个层次结构或“级联”。
在论文中,AdaBoost 模型用于学习人脸上的各种非常简单或弱的特征,这些特征共同提供了一个鲁棒的分类器。
……特征选择是通过对 AdaBoost 过程的简单修改来实现的:弱学习器受到约束,使得返回的每个弱分类器都可以仅依赖于一个特征。因此,提升过程的每个阶段,都选择一个新的弱分类器,可以被视为一个特征选择过程。
— Rapid Object Detection using a Boosted Cascade of Simple Features, 2001.
然后将模型组织成一个由简到繁的层次结构,称为“级联”。
较简单的分类器直接作用于候选人脸区域,充当粗略过滤器,而复杂的分类器仅作用于那些最有希望成为人脸的候选区域。
……一种将越来越复杂的分类器组合到级联结构中的方法,通过将注意力集中在图像的有希望的区域来极大地提高了检测器的速度。
— Rapid Object Detection using a Boosted Cascade of Simple Features, 2001.
结果是一种非常快速有效的人脸检测算法,该算法已成为消费类产品(如相机)中人脸检测的基础。
他们称之为级联检测器的检测器,由一系列简单到复杂的面部分类器组成,并吸引了大量的研究工作。此外,级联检测器已部署在许多商业产品中,例如智能手机和数码相机。
— Multi-view Face Detection Using Deep Convolutional Neural Networks, 2015.
它是一种适度复杂的分类器,在近 20 年来也经过了调整和改进。
级联分类器人脸检测算法的一个现代实现可以在 OpenCV 库中找到。这是一个 C++ 计算机视觉库,提供了 Python 接口。此实现的好处在于它提供了预训练的人脸检测模型,并提供了在您自己的数据集上训练模型的接口。
可以使用您平台上的包管理器系统或通过 pip 安装 OpenCV;例如
|
1 |
sudo pip install opencv-python |
安装过程完成后,确认库已正确安装非常重要。
可以通过导入库并检查版本号来实现;例如
|
1 2 3 4 |
# 检查 opencv 版本 import cv2 # 打印版本号 print(cv2.__version__) |
运行示例将导入库并打印版本。在这种情况下,我们使用的是该库的 4.0 版本。
|
1 |
4.1.1 |
OpenCV 提供了 CascadeClassifier 类,可用于创建用于人脸检测的级联分类器。构造函数可以接受一个文件名作为参数,该文件名指定了预训练模型的 XML 文件。
OpenCV 在安装中提供了许多预训练模型。这些模型在您的系统上可用,并且在 OpenCV GitHub 项目上也可以找到。
从 OpenCV GitHub 项目下载正面人脸检测的预训练模型,并将其与文件名“haarcascade_frontalface_default.xml”一起放在当前工作目录中。
下载完成后,我们可以像这样加载模型
|
1 2 |
# 加载预训练模型 classifier = CascadeClassifier('haarcascade_frontalface_default.xml') |
加载后,可以通过调用 detectMultiScale() 函数来使用该模型对照片执行人脸检测。
此函数将返回照片中所有检测到的人脸的边界框列表。
|
1 2 3 4 5 |
# 执行人脸检测 bboxes = classifier.detectMultiScale(pixels) # 打印每个检测到的人脸的边界框 for box in bboxes: print(box) |
我们可以用大学生照片(test.jpg)的示例来演示这一点。
可以使用 OpenCV 的 imread() 函数加载照片。
|
1 2 |
# 加载照片 pixels = imread('test1.jpg') |
下面列出了使用 OpenCV 中预训练的级联分类器对大学生照片执行人脸检测的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 使用 opencv 级联分类器进行人脸检测的示例 from cv2 import imread from cv2 import CascadeClassifier # 加载照片 pixels = imread('test1.jpg') # 加载预训练模型 classifier = CascadeClassifier('haarcascade_frontalface_default.xml') # 执行人脸检测 bboxes = classifier.detectMultiScale(pixels) # 打印每个检测到的人脸的边界框 for box in bboxes: print(box) |
运行示例将首先加载照片,然后加载并配置级联分类器;检测到人脸,并打印每个边界框。
每个框列出了边界框左下角的 x 和 y 坐标,以及宽度和高度。结果表明检测到了两个边界框。
|
1 2 |
[174 75 107 107] [360 102 101 101] |
我们可以更新示例以绘制照片并绘制每个边界框。
这可以通过在加载的图像像素上直接为每个框绘制矩形来实现,使用接受两个点的 rectangle() 函数。
|
1 2 3 4 5 |
# 提取 x, y, width, height = box x2, y2 = x + width, y + height # 在像素上绘制矩形 rectangle(pixels, (x, y), (x2, y2), (0,0,255), 1) |
然后我们可以绘制照片,并将窗口保持打开状态,直到我们按下某个键关闭它。
|
1 2 3 4 5 6 |
# 显示图像 imshow('face detection', pixels) # 保持窗口打开直到按下某个键 waitKey(0) # 关闭窗口 destroyAllWindows() |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 使用 opencv 级联分类器绘制带有检测到人脸的照片 from cv2 import imread from cv2 import imshow from cv2 import waitKey from cv2 import destroyAllWindows from cv2 import CascadeClassifier from cv2 import rectangle # 加载照片 pixels = imread('test1.jpg') # 加载预训练模型 classifier = CascadeClassifier('haarcascade_frontalface_default.xml') # 执行人脸检测 bboxes = classifier.detectMultiScale(pixels) # 打印每个检测到的人脸的边界框 for box in bboxes: # 提取 x, y, width, height = box x2, y2 = x + width, y + height # 在像素上绘制矩形 rectangle(pixels, (x, y), (x2, y2), (0,0,255), 1) # 显示图像 imshow('face detection', pixels) # 保持窗口打开直到按下某个键 waitKey(0) # 关闭窗口 destroyAllWindows() |
运行示例,我们可以看到照片被正确绘制,并且每个人脸都被正确检测到。

使用 OpenCV 级联分类器检测到人脸的大学生照片
我们可以将相同的代码用于第二张游泳队照片,特别是“test2.jpg”。
|
1 2 |
# 加载照片 pixels = imread('test2.jpg') |
运行示例,我们可以看到许多人脸被正确检测到,但结果并不完美。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
我们可以看到,第一排或底排的一张脸被检测到了两次,中间排的一张脸没有被检测到,第三排或顶排的背景被检测为人脸。

在对 OpenCV 级联分类器进行一些调整后检测到人脸的游泳队照片
detectMultiScale() 函数提供了一些参数来帮助调整分类器的使用。两个值得注意的参数是 scaleFactor 和 minNeighbors;例如
|
1 2 |
# 执行人脸检测 bboxes = classifier.detectMultiScale(pixels, 1.1, 3) |
scaleFactor 控制在检测之前输入图像如何缩放,例如是放大还是缩小,这有助于更好地在图像中找到人脸。默认值为 1.1(增加 10%),尽管可以将其降低到 1.05(增加 5%)或提高到 1.4(增加 40%)。
minNeighbors 确定每个检测在报告之前必须有多鲁棒,例如找到人脸的候选矩形数量。默认值为 3,但可以将其降低到 1 以检测更多人脸,这可能会增加误报,或者增加到 6 或更高以要求在检测到人脸之前有更高的置信度。
scaleFactor 和 minNeighbors 通常需要针对特定图像或数据集进行调整,以便最好地检测人脸。对一系列值执行敏感性分析,看看在单张或多张照片上普遍有效或最佳的值可能会有所帮助。
一种快速的策略可能是降低(或对于小照片则增加)scaleFactor 直到检测到所有人脸,然后增加 minNeighbors 直到所有误报消失,或接近消失。
通过一些调整,我发现 scaleFactor 为 1.05 成功检测到了所有人脸,但检测到人脸的背景直到 minNeighbors 为 8 才消失,之后中间排的三张人脸不再被检测到。
|
1 2 |
# 执行人脸检测 bboxes = classifier.detectMultiScale(pixels, 1.05, 8) |
结果并不完美,并且通过进一步的调整以及可能对边界框进行后处理,也许可以获得更好的结果。
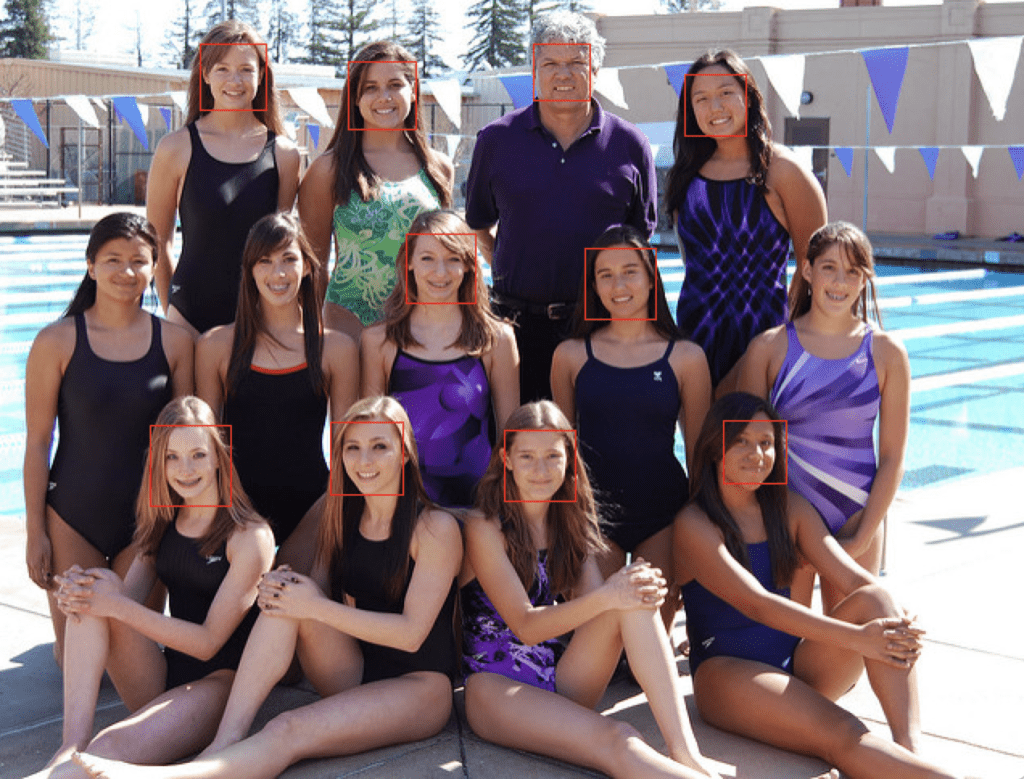
经过一些调整后,使用 OpenCV 级联分类器检测到人脸的游泳队照片
深度学习人脸检测
已经开发并演示了许多深度学习方法用于人脸检测。
也许最流行的方法之一被称为“多任务级联卷积神经网络”,简称 MTCNN,由 Kaipeng Zhang 等人在 2016 年的论文《Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks》(使用多任务级联卷积网络联合人脸检测与对齐)中进行了描述。
MTCNN 之所以流行,是因为它在各种基准数据集上取得了当时最先进的结果,并且还能够识别其他面部特征,如眼睛和嘴巴,称为标志检测。
该网络使用级联结构,包含三个网络;首先,图像被缩放到一系列不同的尺寸(称为图像金字塔),然后第一个模型(Proposal Network 或 P-Net)提出候选人脸区域,第二个模型(Refine Network 或 R-Net)过滤边界框,第三个模型(Output Network 或 O-Net)提出面部标志。
提出的 CNN 由三个阶段组成。在第一阶段,它通过一个浅层 CNN 快速生成候选窗口。然后,它通过一个更复杂的 CNN 来细化窗口,以拒绝大量非人脸窗口。最后,它使用一个更强大的 CNN 来细化结果并输出面部标志位置。
— Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks, 2016.
下图摘自该论文,提供了一个有用的摘要,从上到下显示了三个阶段,从左到右显示了每个阶段的输出。
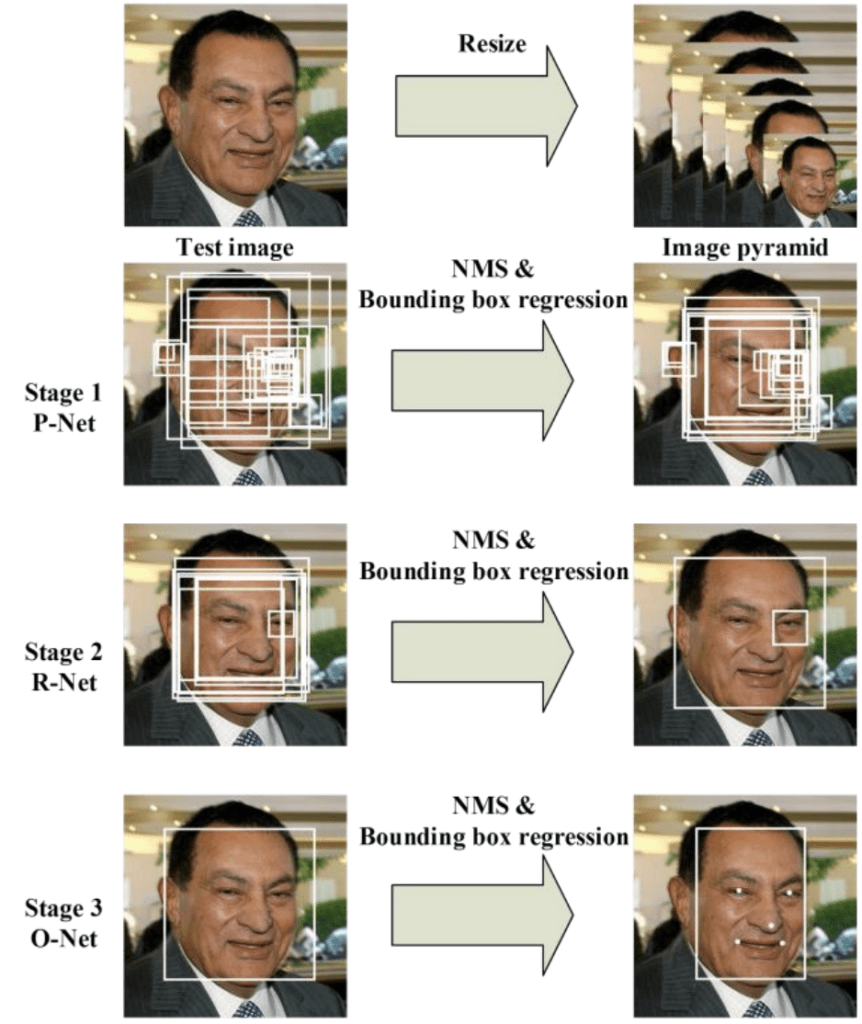
多任务级联卷积神经网络的管道摘自:Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks。
该模型被称为多任务网络,因为级联中的三个模型(P-Net、R-Net 和 O-Net)都在三个任务上进行训练,例如做出三种类型的预测:人脸分类、边界框回归和面部标志定位。
这三个模型不是直接连接的;相反,前一阶段的输出作为输入提供给下一阶段。这允许在阶段之间执行额外的处理;例如,在将第一个 P-Net 提出的候选边界框提供给第二个 R-Net 模型之前,会使用非极大值抑制(NMS)对其进行过滤。
MTCNN 架构的实现相当复杂。值得庆幸的是,有一些开源实现可以用于训练新数据集,也有预训练模型可以直接用于人脸检测。值得注意的是,官方发布提供了论文中使用的代码和模型,并且实现是在 Caffe 深度学习框架中提供的。
也许最好的第三方 Python MTCNN 项目是 Iván de Paz Centeno 的“MTCNN”,也称为 ipazc,并根据宽松的 MIT 开源许可证提供。作为一个第三方开源项目,它可能会发生变化,因此在撰写本文时,我有一个该项目的分支可在此处获取。
MTCNN 项目,我们将其称为 ipazc/MTCNN 以区别于网络名称,它提供了使用 TensorFlow 和 OpenCV 的 MTCNN 架构实现。该项目有两个主要优点:首先,它提供了一个高性能的预训练模型;其次,它可以安装为一个库,供您在自己的代码中使用。
可以通过 pip 安装该库;例如
|
1 |
sudo pip install mtcnn |
安装成功后,您应该会看到类似以下的消息:
|
1 |
Successfully installed mtcnn-0.1.0 |
然后您可以通过 pip 确认库已正确安装;例如
|
1 |
sudo pip show mtcnn |
您应该会看到如下输出。在这种情况下,您可以看到我们正在使用该库的 0.0.8 版本。
|
1 2 3 4 5 6 7 8 9 10 |
Name: mtcnn Version: 0.1.0 Summary: Multi-task Cascaded Convolutional Neural Networks for Face Detection, based on TensorFlow Home-page: http://github.com/ipazc/mtcnn Author: Iván de Paz Centeno Author-email: ipazc@unileon.es 许可证:MIT 位置:... Requires: opencv-python, keras 所需通过 |
您也可以通过 Python 确认库已正确安装,如下所示
|
1 2 3 4 |
# 确认 mtcnn 是否正确安装 import mtcnn # 打印版本 print(mtcnn.__version__) |
运行示例将加载库,确认其已正确安装;并打印版本。
|
1 |
0.1.0 |
现在我们确信库已正确安装,我们可以使用它进行人脸检测。
可以通过调用 MTCNN() 构造函数来创建网络实例。
默认情况下,该库将使用预训练模型,但您可以通过 ‘weights_file‘ 参数指定您自己的模型,并指定路径或 URL,例如
|
1 |
model = MTCNN(weights_file='filename.npy') |
可以通过 ‘min_face_size‘ 参数指定检测人脸的最小边界框大小,该参数默认为 20 像素。构造函数还提供了一个 ‘scale_factor‘ 参数来指定输入图像的比例因子,该参数默认为 0.709。
配置并加载模型后,可以通过调用 detect_faces() 函数直接用于照片中的人脸检测。
这将返回一个 dict 对象列表,每个对象都提供一组键,用于详细说明检测到的每个人脸,包括:
- ‘box‘:提供边界框左下角的 x、y 以及框的 width 和 height。
- ‘confidence‘:预测的概率置信度。
- ‘keypoints‘:提供一个包含‘left_eye’、‘right_eye’、‘nose’、‘mouth_left’ 和 ‘mouth_right’ 的点的字典。
例如,我们可以像这样对大学生照片执行人脸检测
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 使用 mtcnn 在照片上进行人脸检测 from matplotlib import pyplot from mtcnn.mtcnn import MTCNN # 从文件加载图像 filename = 'test1.jpg' pixels = pyplot.imread(filename) # 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 faces = detector.detect_faces(pixels) for face in faces: print(face) |
运行示例将加载照片,加载模型,执行人脸检测,并打印检测到的人脸列表。
|
1 2 |
{'box': [186, 71, 87, 115], 'confidence': 0.9994562268257141, 'keypoints': {'left_eye': (207, 110), 'right_eye': (252, 119), 'nose': (220, 143), 'mouth_left': (200, 148), 'mouth_right': (244, 159)}} {'box': [368, 75, 108, 138], 'confidence': 0.998593270778656, 'keypoints': {'left_eye': (392, 133), 'right_eye': (441, 140), 'nose': (407, 170), 'mouth_left': (388, 180), 'mouth_right': (438, 185)}} |
通过首先使用 matplotlib 绘制图像,然后使用给定的边界框的 x、y 以及 width 和 height 创建一个 Rectangle 对象,我们可以通过绘制框来绘制图像;例如
|
1 2 3 4 |
# 获取坐标 x, y, width, height = result['box'] # 创建形状 rect = Rectangle((x, y), width, height, fill=False, color='red') |
下面是一个名为draw_image_with_boxes()的函数,它显示照片,然后为每个检测到的边界框绘制一个框。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 绘制带边界框的图像 def draw_image_with_boxes(filename, result_list): # 加载图像 data = pyplot.imread(filename) # 绘制图像 pyplot.imshow(data) # 获取绘制框的上下文 ax = pyplot.gca() # 绘制每个框 for result in result_list: # 获取坐标 x, y, width, height = result['box'] # 创建形状 rect = Rectangle((x, y), width, height, fill=False, color='red') # 绘制框 ax.add_patch(rect) # 显示图表 pyplot.show() |
下面列出了使用此功能的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# 使用 mtcnn 在照片上进行人脸检测 from matplotlib import pyplot from matplotlib.patches import Rectangle from mtcnn.mtcnn import MTCNN # 绘制带边界框的图像 def draw_image_with_boxes(filename, result_list): # 加载图像 data = pyplot.imread(filename) # 绘制图像 pyplot.imshow(data) # 获取绘制框的上下文 ax = pyplot.gca() # 绘制每个框 for result in result_list: # 获取坐标 x, y, width, height = result['box'] # 创建形状 rect = Rectangle((x, y), width, height, fill=False, color='red') # 绘制框 ax.add_patch(rect) # 显示图表 pyplot.show() filename = 'test1.jpg' # 从文件加载图像 pixels = pyplot.imread(filename) # 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 faces = detector.detect_faces(pixels) # 在检测到的图像上显示人脸 draw_image_with_boxes(filename, faces) |
运行示例将绘制照片,然后为每个检测到的人脸绘制一个边界框。
我们可以看到两个人脸都已正确检测到。

使用MTCNN为每个人脸绘制边界框的大学生的照片
我们可以通过Circle类绘制眼睛、鼻子和嘴巴的圆圈;例如
|
1 2 3 4 5 |
# 绘制点 for key, value in result['keypoints'].items(): # 创建并绘制点 dot = Circle(value, radius=2, color='red') ax.add_patch(dot) |
下面列出了对draw_image_with_boxes()函数进行此添加的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# 使用 mtcnn 在照片上进行人脸检测 from matplotlib import pyplot from matplotlib.patches import Rectangle from matplotlib.patches import Circle from mtcnn.mtcnn import MTCNN # 绘制带边界框的图像 def draw_image_with_boxes(filename, result_list): # 加载图像 data = pyplot.imread(filename) # 绘制图像 pyplot.imshow(data) # 获取绘制框的上下文 ax = pyplot.gca() # 绘制每个框 for result in result_list: # 获取坐标 x, y, width, height = result['box'] # 创建形状 rect = Rectangle((x, y), width, height, fill=False, color='red') # 绘制框 ax.add_patch(rect) # 绘制点 for key, value in result['keypoints'].items(): # 创建并绘制点 dot = Circle(value, radius=2, color='red') ax.add_patch(dot) # 显示图表 pyplot.show() filename = 'test1.jpg' # 从文件加载图像 pixels = pyplot.imread(filename) # 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 faces = detector.detect_faces(pixels) # 在检测到的图像上显示人脸 draw_image_with_boxes(filename, faces) |
该示例再次绘制了照片,并带有边界框和面部关键点。
我们可以看到,每张脸上的眼睛、鼻子和嘴巴都检测得很好,尽管右边脸的嘴巴检测得可能更好一些,因为点看起来比嘴角低一点。

使用MTCNN为每个人脸绘制边界框和面部关键点的大学生的照片
现在,我们可以尝试对游泳队的照片进行人脸检测,例如图像test2.jpg。
运行示例,我们可以看到所有13张脸都已正确检测到,并且所有面部关键点看起来也都大致正确。
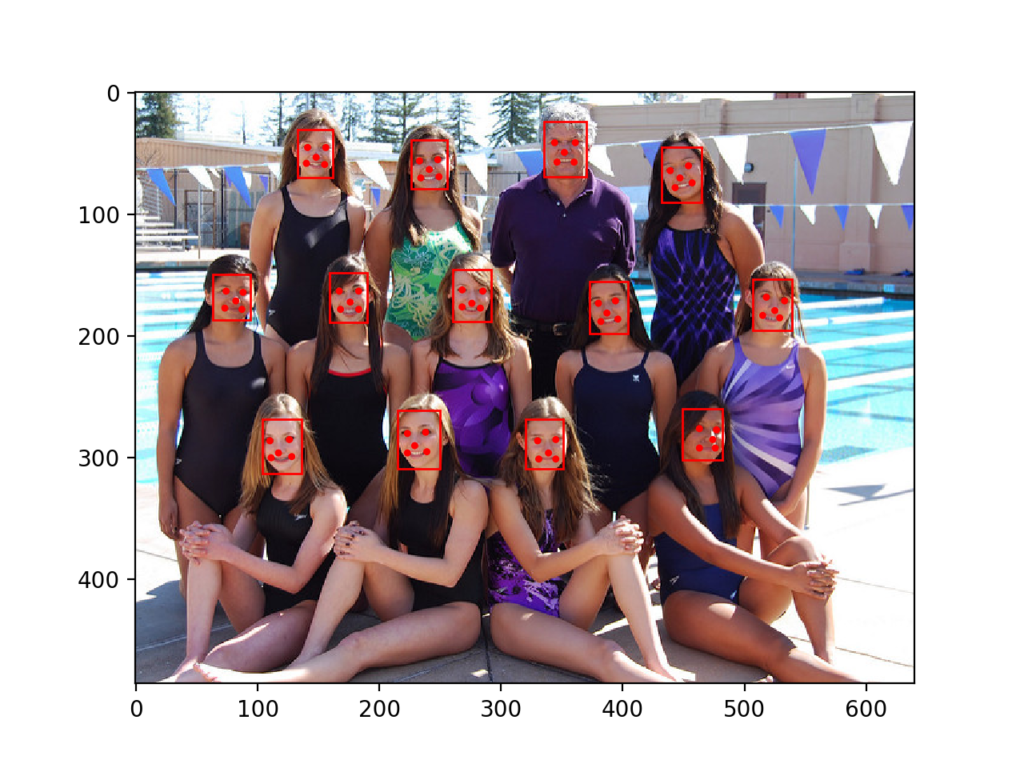
使用MTCNN为每个人脸绘制边界框和面部关键点的游泳队照片
我们可能需要提取检测到的人脸并将它们作为输入传递给另一个系统。
这可以通过直接从照片中提取像素数据来实现;例如
|
1 2 3 4 5 |
# 获取坐标 x1, y1, width, height = result['box'] x2, y2 = x1 + width, y1 + height # 提取人脸 face = data[y1:y2, x1:x2] |
我们可以通过提取每个人脸并将其作为单独的子图绘制来演示这一点。您也可以将它们保存到文件中。下面的draw_faces()函数提取并绘制照片中的每个人脸。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 分别绘制每个人脸 def draw_faces(filename, result_list): # 加载图像 data = pyplot.imread(filename) # 将每个人脸绘制为子图 for i in range(len(result_list)): # 获取坐标 x1, y1, width, height = result_list[i]['box'] x2, y2 = x1 + width, y1 + height # 定义子图 pyplot.subplot(1, len(result_list), i+1) pyplot.axis('off') # 绘制人脸 pyplot.imshow(data[y1:y2, x1:x2]) # 显示图表 pyplot.show() |
下面列出了为游泳队照片演示此功能的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 提取并单独绘制照片中的每个人脸 from matplotlib import pyplot from matplotlib.patches import Rectangle from matplotlib.patches import Circle from mtcnn.mtcnn import MTCNN # 分别绘制每个人脸 def draw_faces(filename, result_list): # 加载图像 data = pyplot.imread(filename) # 将每个人脸绘制为子图 for i in range(len(result_list)): # 获取坐标 x1, y1, width, height = result_list[i]['box'] x2, y2 = x1 + width, y1 + height # 定义子图 pyplot.subplot(1, len(result_list), i+1) pyplot.axis('off') # 绘制人脸 pyplot.imshow(data[y1:y2, x1:x2]) # 显示图表 pyplot.show() filename = 'test2.jpg' # 从文件加载图像 pixels = pyplot.imread(filename) # 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 faces = detector.detect_faces(pixels) # 在检测到的图像上显示人脸 draw_faces(filename, faces) |
运行示例将创建一个图,显示游泳队照片中检测到的每个人脸。

游泳队照片中检测到的每个人脸的绘图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 人脸检测:调查, 2001.
- 使用简单特征的增强级联进行快速目标检测, 2001.
- 使用深度卷积神经网络进行多视图人脸检测, 2015.
- 使用多任务级联卷积网络进行联合人脸检测和对齐, 2016.
书籍
- 第11章 人脸检测,《人脸识别手册》,第二版,2011年。
API
- OpenCV主页
- OpenCV GitHub项目
- 使用Haar级联进行人脸检测,OpenCV.
- OpenCV的级联分类器训练.
- OpenCV的级联分类器.
- 官方MTCNN项目
- Python MTCNN项目
- matplotlib.patches.Rectangle API
- matplotlib.patches.Circle API
文章
总结
在此教程中,您将学习如何使用经典和深度学习模型在Python中执行人脸检测。
具体来说,你学到了:
- 人脸检测是计算机视觉中的一个问题,用于识别和定位图像中的人脸。
- 可以使用 OpenCV 库中的经典基于特征的级联分类器来执行人脸检测。
- 通过 MTCNN 库的多任务级联 CNN 可以实现最先进的人脸检测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






嗨!
非常感谢这篇精彩的文章!
但是Keras在哪里?
mtcnn模型是一个Keras模型。
你好Jason,我刚刚在mtcnn github repo上查找了keras模型,但实际上我没有在代码中找到任何提及keras的地方。是我遗漏了什么吗?
我想你说得对。
我会更新这篇文章的,谢谢!
更新:是的,它是TensorFlow,我已经从文章标题中删除了“Keras”。
再次感谢!
你好
—————————————————————————
NameError Traceback (最近一次调用)
in
1 # 加载预训练模型
—-> 2 classifier = CascadeClassifier(‘haarcascade_frontalface_default.xml’)
NameError: name ‘CascadeClassifier’ is not defined
我该如何定义CascadeClassifier?
另外,我找不到放置xml文件的位置,
我在我的anaconda文件中哪里能找到它?
抱歉,我对此是新手,希望你能指导我!
这表明你可能遗漏了用于opencv 类的导入。
如何导入opencv 类?
在您给出的步骤中,我没有看到任何关于导入opencv 类的说明。
您可以通过以下方式安装opencv 库
这在文章中有提及。
安装后,您可以使用完整示例,如列表所示。
输入:classifier = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
而不是 classifier = CascadeClassifier(‘haarcascade_frontalface_default.xml’)
您好,感谢您的教程
当我尝试使用以下命令安装opencv时
sudo pip install opencv-python
这是我在控制台中遇到的错误
感谢您的帮助
目录“/home/dongorias/.cache/pip/http”或其父目录不属于当前用户,缓存已被禁用。请检查该目录的权限和所有者。如果使用 sudo 执行 pip,您可能需要 sudo 的 -H 标志。
目录“/home/dongorias/.cache/pip”或其父目录不属于当前用户,缓存 wheels 已被禁用。请检查该目录的权限和所有者。如果使用 sudo 执行 pip,您可能需要 sudo 的 -H 标志。
Requirement already satisfied: opencv-python in /usr/local/lib/python2.7/dist-packages
Requirement already satisfied: numpy>=1.11.1 in /usr/lib/python2.7/dist-packages (from opencv-python)
也许可以尝试先升级到Python 3?
另外,也许可以尝试在stackoverflow上搜索/发帖?我不是调试工作站的专家,抱歉。
您好,感谢您的教程
我在Anaconda提示符中使用pip install mtcnn安装了mtcnn
在运行我的程序时,我收到以下错误:
No module named ‘mtcnn.mtcnn’; ‘mtcnn’ is not a package
感谢您的帮助!
您也必须从命令行运行代码。
当使用mtcnn时,我的摄像头响应非常慢。但使用级联分类器时工作得很流畅。
也许可以尝试处理更少的帧?
你好,
如果我想从这些人脸中分类性别,我该怎么做?你能指导我或者分享任何有用的链接来从这些人脸中分类性别吗?
首先准备一个男性和女性人脸的数据集。
然后将问题建模为二元分类
https://machinelearning.org.cn/how-to-develop-a-convolutional-neural-network-to-classify-photos-of-dogs-and-cats/
你好,
请帮帮我。我想裁剪每个人脸并将其写入存储库。我该如何裁剪每个人脸?
实际上,我正在从事面部表情分类器的工作。在那里,我将每个人脸传递给我的图像分类器以获得所需的结果。我该如何裁剪每个人脸并将其保存到本地存储库。
我在教程的最后展示了如何裁剪人脸。
然后您可以直接保存图像。
非常棒的文章!
我很好奇MTCNN与其他面部检测模型(如dlib(不确定dlib是否是深度学习模型))相比如何。我注意到mtcnn只指向“关键点”的中心,它支持预测整个面部地标索引集吗?
好问题,也许有人已经进行了直接的比较研究。
我鼓励你搜索谷歌学术。
你好,
我遇到一个问题。实际上,我有一张教室的照片(你可以想象学生在教室里坐着的样子)。深度学习模型能够很好地检测图像中的人脸。但问题是,有时人脸会互相重叠。我的意思是,有时只显示眼睛、耳朵或头部,模型就会将它们标记为人脸(通过绘制矩形)。但当我提取感兴趣的区域时,它却不是人脸(只是眼睛或只是头部)。如何只标记那些人脸完整可见的人脸,因为深度学习人脸检测器也会将只有眼睛(或部分人脸)标记为人脸。
你能帮帮我吗?
也许你可以开发第二个模型来分类人脸是否完整?
你真的认为开发第二个模型来交叉检查它是完整的人脸还是不是完整的人脸是有效的方法吗?如果是,你能否建议交叉检查人脸的方法?
实际上,我正在做一个表情分类器,我将所有检测到的人脸传递给面部表情分类模型。所以我在那个点上卡住了。你能给我提供一个解决方案吗?
谢谢
这是我想到的第一个想法。也许可以尝试一系列方法。
我收到一个错误
from mtcnn.mtcnn import MTCNN
ModuleNotFoundError: No module named 'mtcnn.mtcnn'; 'mtcnn' is not a package
我正在从命令提示符运行
您必须安装mtcnn库,例如通过pip。
已解决我遇到的错误。请参考此stackoverflow链接:https://stackoverflow.com/questions/32680081/importerror-after-successful-pip-installation
很高兴听到这个消息。
嗨 Jason
首先,我要赞赏您所做的杰出工作,请继续保持良好势头。您是否有关于图神经网络的材料,无论是用于回归的图循环神经网络还是用于图像分类的图卷积神经网络。提前致谢。
谢谢!
我没有关于这个主题的教程,谢谢您的建议。
你好Jason,为什么提供的
example.py使用了cv2方法而你的驱动程序没有?什么是example.py?
https://github.com/ipazc/mtcnn/blob/master/example.py
cv2的BGR需要转换为RGB才能让mtcnn发挥最佳作用。
我的另一个问题是,您能否列出一些其他的开源实现,我可以在我的数据集上进行迁移学习?
我在其他评论中看到您建议在当前模型的基础上构建一个分类器,使用其输出来作为分类器的输入?
“使用输出作为分类器的输入”——这不是迁移学习,但我认为您是指对发现的边界框运行例如人脸识别算法。
我注意到这个版本的mtcnn在识别朝向侧面(人趴在地上)的正面人脸方面非常弱,所以我将使用y轴的cv2.flip并旋转90、180和270度(总共8张图像),然后输出检测到人脸数量最多(或最接近实际)的图像。
如果没有可用的迁移学习,是否有任何参数可以调整MTCNN的置信度级别、特定人脸的框数量等,以便我们能够控制输出?
不需要迁移学习,您可以直接使用现有模型为人脸识别任务创建人脸嵌入。
我在这里给出了一个例子
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
你见过这个吗? https://github.com/TencentYoutuResearch/FaceDetection-DSFD
他们的结果令人印象深刻,我可以证实,在没有任何翻转或旋转图像的情况下,我得到了好得多的结果。
没有,谢谢链接。
我遇到了很多已弃用的错误。您能提供版本号或requirements.txt吗?
是的,Keras 2.2.4 确实该更新了。
目前可以安全地忽略这些警告。
一切顺利,感谢您提供出色的教程。
我打算进行人脸识别。如何识别一个人在团体照片中的面孔?只有几张照片可用,我曾认为需要为训练目的制作许多同一个人脸的图像。有没有有效的方法?
请指教。再次感谢。
我在这里给出了一个例子
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
很棒的帖子,谢谢分享。
谢谢。
好的,这是一篇非常棒的文章!很高兴人们正在为推进技术而努力!开源真是神奇!不过,我们能否标记每个人脸并用它来训练另一个模型?就像在Tensorflow对象检测API中一样?
抱歉,我不熟悉那个API。
请提供R的代码。
感谢您的建议。
一如既往地棒!谢谢!
不客气,我很高兴它有所帮助。
先生,如何使用深度学习技术将从代码中提取的图像存储到文件中?
您可以使用Pillow保存图像。
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
x1, y1, width, height = result_list[i][‘box’]
x2, y2 = x1 + width, y1 + height
plt.subplot(1, len(result_list), i+1)
plt.axis(‘off’)
# plot face
img=plt.imshow(data[y1:y2, x1:x2])
plt.savefig(“C:/Users/Sukirtha/Desktop/”+str(i)+”.jpg”)
先生,imshow获得的图像需要存储在文件中(例如,如果图片包含两张有人脸的图像,则需要将这两张图像裁剪并作为单独的图像存储在一个文件中)。如何在提供的代码中执行此操作?
抱歉,我没有能力为您编写自定义代码。
我相信这里的教程会指导您如何保存图像。
https://machinelearning.org.cn/how-to-load-convert-and-save-images-with-the-keras-api/
当我运行代码时,它只检测到一个面孔。我该如何解决这个问题?
听到这个消息我很难过,我这里有一些建议可能有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason Brownlee!我们需要在Anaconda终端中运行所有内容吗?我的意思是,我们在哪里编写和运行这段代码?
我建议使用Sublime等文本编辑器将代码写入/保存在文本文件中。
https://machinelearning.org.cn/machine-learning-development-environment/
然后从命令行作为脚本运行。
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
感谢您的反馈,伙计!
不客气!
你好,
感谢这篇文章。
我是圣何塞州立大学的一名机器学习学生。我计划做一个关于涂鸦检测和分类的项目。我计划将涂鸦分类为人类、动物、文本或其他物体。
您能否使用您关于深度学习和计算机视觉的书籍来做到这一点?或者您推荐其他文章或模型吗?
这听起来是个有趣的项目!
也许您可以将其建模为对象检测,或者简单的图像分类。
这里的教程将帮助您入门
https://machinelearning.org.cn/start-here/#dlfcv
你好,如果只需要检测一个人脸,该怎么办?
您可以使用相同的系统。
你到底遇到了什么问题?
我能使用Haar Cascade来识别图片或视频中的人名吗?
它可以找到人脸,之后您可以使用分类器将人脸映射到姓名。
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
您好,我正在寻找实现Voila-Jones方法,而不使用OpenCV,也就是说,我想编写一个Python程序来完成所有步骤,并在训练集上进行训练,然后将其用作分类器来检测图像中的人脸。我想知道如何在不使用OpenCV的情况下实现这一点。
抱歉,我不太清楚,Andy。
尊敬的Jason,非常感谢您提供如此信息丰富的文章!
如果您能分享您对解决以下任务的最佳方法有什么看法,我将非常感激:神经网络必须能够确定上传的照片(身份证照片)是否符合以下要求:
– 眼睛睁开
– 嘴巴闭合
– 头部没有旋转/倾斜
– 如果戴太阳镜,眼睛必须看得清楚
– 没有异物(包括帽子)
– 照片中只有一个人
如果您能就如何训练神经网络给出专业建议,那就太好了。数据集应包含哪些照片,数据集的大小是多少?
谢谢。
我认为您需要一个包含每个方面大量示例的良好数据集才能进行检测。
也许是对象检测?
也许是简单的图像分类?
也许尝试几种方法,看看哪种最适合您的数据集?
有没有好的架构来检测面部表情?
好问题。我不知道。也许可以在Google Scholar上搜索一下?
先生,我遇到了以下错误
File “C:\Users\91798\Anaconda3\lib\site-packages\mtcnn\mtcnn.py”, line 187, in __init__
config = tf.ConfigProto(log_device_placement=False)
AttributeError: module ‘tensorflow’ has no attribute ‘ConfigProto’
为什么会这样?
也许确认一下您使用的是TensorFlow 1.14版本。
先生,我想做多语言字符识别。先生,我的问题是如何将两个数据集合并成一个大规模数据集并进行训练?请回复我。我将非常感谢您。
抱歉,我没有这方面的例子。我无法立即为您提供有用的建议。
嗨,Jason,
我想知道是否可以在Keras中使用MTCNN作为预训练模型,以便我可以在我的训练数据集上训练最后的几层,然后将其应用于测试数据集。
也许可以。
抱歉,我没有MTCNN迁移学习的例子。
你好,
希望您一切安好。
我正在使用MTCNN处理包含多个人脸的图片,它能成功检测到所有人脸。但我需要在实时视频流中处理多个人脸检测。但在实时视频流中,模型表现不佳。只能检测到一张人脸(仅正面人脸)。您能否建议我应该使用什么来在实时视频流中检测多个人脸……?
也许图像的准备或大小存在差异?
也许可以与经典方法进行比较?
你好,
我已经尝试了各种图像尺寸,但都无济于事。MTCNN在实时视频流中只能检测到少数(2、3)正面人脸。我也测试了降低FPS(帧每秒)速率,但都没有成功。
您能否推荐最佳的视频流帧尺寸或FPS?或者您是否推荐使用其他模型来获得最佳的视频人脸检测准确率?期待您的合作。……
抱歉,我没有好的建议,只能建议进行仔细和系统的实验。
能否也告知如何准备上述代码的算法,因为它们非常有帮助?
你具体指的是什么?
我想知道如何将相同的方法用于实时人脸检测?
我希望将来能涵盖这一点。
也许将模型与从相机捕获的图像一起使用?
精彩的教程,先生……您能否将本教程扩展到识别数据集中的人脸?
是的,请参阅本教程
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
先生您好,我们如何对提取的人脸进行对齐?基本上,如何使用人脸对齐?
什么是人脸对齐?
感谢您出色的解释。
不客气。
我能否计算使用MTCNN检测到的人脸数量?如果可以,如何计算?
它提供一个包含人脸的数组,枚举该数组即可知道检测到的人脸数量。
精彩的教程Jason!这似乎能帮助我们大多数在人脸检测问题上挣扎的人!
我想了解一下,一旦将上述模型重写为TensorFlow 2.2,它会更有效率(更快)吗,因为TF 2.2附带了许多附加功能?
谢谢。
不,它在功能上不会有任何不同。
您好,感谢您提供如此清晰的教程。
您提到MTCNN可以使用预训练权重,以及使用我自己的数据集进行训练。(“该架构有一些开源实现,可以在新数据集上进行训练,也有可以直接用于人脸检测的预训练模型。”)
我不太明白,ipazc/mtcnn是否也可以用于训练,还是只能使用预训练模型?
谢谢
我相信您可以使用它进行训练。我只使用了预训练模型。
Jason先生,非常感谢您提供机器学习教程,特别是人脸检测。Haar Cascade代码是否可以使用Matplotlib,就像MTCNN一样?因为我看不到Haar_cascade的边界框结果,但在MTCNN代码中可以看到。您能否提供使用Matplotlib的Haar_cascade教程?谢谢:)
上述教程显示了如何绘制Haar Cascade的结果。也许您应该重新阅读一下?
上述教程中,当我检测到大于600px的图像时,它显示得太大,我无法看到人脸和边界框。而当我使用Matplotlib绘制的MTCNN教程进行检测时,情况就不同了。MTCNN教程会以理想的尺寸显示图片,这样我就可以捕获人脸检测边界框的结果和处理时间(我自己添加的),这就是为什么我想尝试使用Matplotlib进行绘制,而不是只用cv2。
也许可以尝试使用较小的图像。
好的,给出了正确尺寸的良好结果。非常感谢您 🙂
不客气。
当我调用 detect_face 函数时,我遇到了这个错误。
有什么办法可以修复它吗?
AbortedError: Operation received an exception:Status: 2, message: could not create a descriptor for a softmax forward propagation primitive, in file tensorflow/core/kernels/mkl_softmax_op.cc:312
[[node model_3/softmax_3/Softmax (defined at /home/pillai/anaconda3/lib/python3.7/site-packages/mtcnn/mtcnn.py:342) ]] [Op:__inference_predict_function_1745]
Function call stack
predict_function
听到您遇到这个问题,我很遗憾,这或许能帮到您。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Rahul,
您对解决“softmax 前向传播”问题有什么线索吗?
谢谢,
Twarit
您解决您的问题了吗?我遇到同样的问题
使用 conda env 和 conda 安装的 tensorflow 也出现了同样的问题。
我创建了一个 venv(不是 conda env),并使用 ‘pip’ 安装了包,然后就可以正常工作了!
好建议。
AttributeError: 模块‘tensorflow’没有属性‘get_default_graph’
我的 tensorflow 版本是 2.0
听到这个消息很抱歉,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
问题已解决!!!
我创建了一个带有 python 3.7.7 和 tensorflow 2.0 的新环境
它开始正常工作了。
干得好!
error: OpenCV(4.1.2) /io/opencv/modules/objdetect/src/cascadedetect.cpp:1389: error: (-215:Assertion failed) scaleFactor > 1 && _image.depth() == CV_8U in function ‘detectMultiScale’
当我将我的图像输入 detectMultiScale() 时,我遇到了这个错误。
听到这个消息很难过,也许可以确认一下 open cv 是否安装正确并且是最新版本。
这项工作对我的论文很有用。非常感谢您,先生。
非常欢迎。
我可以在我自己的图像集上训练 mtcnn 模型吗?
也许可以,但为什么要这样做。它在提取人脸方面已经做得非常好了——为什么要搞砸呢?
直接使用模型,无需重新训练。
先生您好,如何定义结果的宽度和高度为特定的尺寸,例如 (224px, 224px)?
抱歉,我不明白您的问题。也许您可以详细说明或重新表述一下?
谢谢您,先生,对如此清晰的解释。
非常敬佩
不客气。
您好,是否有关于仅使用 Haarcascades 模型进行头发分割和皮肤分割的文档或示例?
可能有一些,抱歉我没有关于这些特定主题的教程。
您好,我正在使用 MTCNN 为我的项目检测人脸,在人脸检测器之后,我想将 MTCNN 从 GPU 中移除,您能告诉我如何将 MTCNN 从 GPU 中移除吗?
我的 MTCNN 版本是 0.1.0
模型将直接在 CPU 上运行。
我在任务管理器中查阅了,模型正在占用 GPU。
它占用了我 GPU 的全部 8 GB。
我将附上图片供您参考。
最好的 Steps_thershold = [ , , ] 是什么?
根据源代码,Steps_thershold = [ 0.6 , 0.7 , 0.7 ]
因为不同的 Steps_thershold = [ , , , ] 会给出不同的边界框值。
您能澄清一下吗?
抱歉,我不知道“Steps_thershold”指的是什么?
抱歉,我无法帮助您配置 GPU。这不是我的专业领域。
嗨,
有人有使用网络摄像头/视频进行人脸识别的工作示例吗?
如果共享 git 仓库,我会很感激。
谢谢
我没有直接处理视频的示例。
很棒的教程!
谢谢你。
不客气!
嘿,当我尝试运行检测人脸的代码时,会出现以下错误。这是最开始的部分,看起来我的图像处理或 detectMultiScale 函数有问题。提前谢谢!
cv 版本 4.5.1
回溯(最近一次调用)
File “C:/Users/Arngr/PycharmProjects/faceRec/FaceRecognition.py”, line 14, in
bboxes = classifier.detectMultiScale(pixels)
cv2.error: OpenCV(4.5.1) C:\Users\appveyor\AppData\Local\Temp\1\pip-req-build-kh7iq4w7\opencv\modules\objdetect\src\cascadedetect.cpp:1689: error: (-215:Assertion failed) !empty() in function ‘cv::CascadeClassifier::detectMultiScale’
很抱歉听到这个消息,也许这个会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
您好。感谢这篇文章。非常有启发性。我正在尝试实现这一点,以便为我的 CNN 模型训练输入数据来检测面部表情。在整个数据集上检测人脸时,我似乎遇到了一些问题。我是否需要创建面部嵌入?我一直收到这个“list index out of range”错误。我需要一些帮助。谢谢。
list index out of range 错误肯定是由代码中的某个问题引起的。堆栈跟踪应该会告诉您在哪里触发了它。请确保输入维度与函数期望的完全匹配。
您好,我们可以在 tensorflow 中做同样的事情吗?
当然。这篇文章可能有助于您入门: https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
你好 Adrian!我从您的教程中学到了很多,并且刚刚完成了这一个。我想做一个项目,如果可以的话,我想向您请教或与您讨论。我正在考虑从图片中进行人脸检测,并使用检测到的人脸作为训练数据,类似于您的“5 个人脸识别项目”,但我提供了我自己的数据。我收集了很多我喜欢的音乐组合的个人照片,我想制作他们的人脸检测/识别模型。有些照片只包含一个人,但有些是合影。是否可以使用合影中检测到的人脸作为训练数据,或者建议使用单人照片?测试/验证数据呢?我希望我的问题足够清晰。我仍然是一名机器学习新手,所以提前为任何误解表示歉意。谢谢!
如果您谈论的是人脸识别,那么一次应该只有一个面孔。在合影中,您需要先进行人脸检测,然后进行识别。将其视为先处理一张大图的目标检测问题,然后对检测到的对象进行对象分类问题。但一些先进的算法可以同时做到这两点。
感谢本教程,对我项目非常有帮助。
但是,当我使用从热像仪拍摄的图像时,我遇到了一个问题,当我运行代码时,它无法检测到这个人。但如果我使用普通图像运行代码,它就可以检测到。
您认为算法无法检测到人的热图像的可能原因是什么?有什么方法可以修复它吗?
或者 MTCNN 算法不适合检测人的热图像?如果是这样,您能否建议一些其他算法来检测人?如果您也有相关的教程,能否分享链接将非常棒。
谢谢。
你好 Vincent…虽然我不能直接谈论您的项目,但以下论文可能是一个很好的起点
http://uu.diva-portal.org/smash/get/diva2:1275338/FULLTEXT01.pdf
感谢您的及时回复,我会仔细研究的。
我还想知道,除了您在此用于人脸检测的 MTCNN 和 OpenCV 之外,还有其他人脸检测算法吗?如果有,我将非常感谢您分享链接到相关资源,或者只是提及它们,我就可以自己查找。
谢谢。
谢谢,非常有帮助。
我有一个问题,当我构建一个通用的面部表情识别模型时
我可以在任何面部表情识别领域的应用中使用它吗?(例如,检测司机的愤怒)
精彩的解释,易于上手。
您能告诉我人脸检测的最新算法是什么,以及 MTCNN 需要进行哪些改进吗?
能否修改此模型以用于产品识别和产品采购,而不是面部识别?或者程序必须完全为该目的重新设计?
你好 Tom…您可以修改训练和测试数据集以用于其他目的。这个概念被称为“迁移学习”。
https://machinelearning.org.cn/how-to-improve-performance-with-transfer-learning-for-deep-learning-neural-networks/
嘿,杰森!
很棒的教程。我能问一下为什么您使用 data[y1:y2, x1:x2] 而不是 data[x1:x2, y1:y2] 吗?为什么 y 轴是第一个,而不是通常的 x 轴在第一个?
你好 Ian…在这种情况下,结果应该不会有影响。您看到结果有任何问题吗?