人脸识别是计算机视觉中的一项任务,旨在根据人脸照片识别和验证个人身份。
最近,深度学习卷积神经网络已经超越了传统方法,并在标准人脸识别数据集上取得了最先进的成果。牛津大学视觉几何组(Visual Geometry Group)开发的 VGGFace 和 VGGFace2 模型就是最先进模型的一个例子。
尽管该模型的实现可能具有挑战性且训练资源密集,但通过使用免费提供的预训练模型和第三方开源库,它可以在 Keras 等标准深度学习库中轻松使用。
在本教程中,您将了解如何使用 VGGFace2 深度学习模型开发用于人脸识别和验证的人脸识别系统。
完成本教程后,您将了解:
- 关于用于人脸识别的 VGGFace 和 VGGFace2 模型,以及如何安装 keras_vggface 库以在 Python 和 Keras 中使用这些模型。
- 如何开发一个人脸识别系统,以预测给定照片中名人的姓名。
- 如何开发一个人脸验证系统,以确认给定人脸照片的个人身份。
通过我的新书《计算机视觉深度学习》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 11 月更新:已针对 TensorFlow v2.0、VGGFace v0.6 和 MTCNN v0.1.0 进行更新。

如何在 Keras 中使用 VGGFace2 卷积神经网络进行人脸识别
照片由 Joanna Pędzich-Opioła 拍摄,保留部分权利。
教程概述
本教程分为六个部分;它们是:
- 人脸识别
- VGGFace 和 VGGFace2 模型
- 如何安装 keras-vggface 库
- 如何检测用于人脸识别的人脸
- 如何使用 VGGFace2 进行人脸识别
- 如何使用 VGGFace2 进行人脸验证
人脸识别
人脸识别是从人脸照片中识别和验证人物的通用任务。
2011年关于人脸识别的书籍《人脸识别手册》描述了人脸识别的两种主要模式:
- 人脸验证。将给定人脸与已知身份进行一对一匹配(例如,*这是这个人吗?*)。
- 人脸识别。将给定人脸与已知人脸数据库进行一对多匹配(例如,*这个人是谁?*)。
人脸识别系统有望自动识别图像和视频中出现的人脸。它可以在两种模式中的一种或两种模式下运行:(1)人脸验证(或身份验证),以及(2)人脸识别(或识别)。
——《人脸识别手册》第1页。2011年。
在本教程中,我们将探讨这两个人脸识别任务。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
VGGFace 和 VGGFace2 模型
VGGFace 指的是由牛津大学视觉几何组 (VGG) 成员开发的一系列用于人脸识别并在基准计算机视觉数据集上演示的模型。
在撰写本文时,有两个主要的人脸识别 VGG 模型;它们是 VGGFace 和 VGGFace2。让我们逐一仔细看看。
VGGFace 模型
后来命名的 VGGFace 模型由 Omkar Parkhi 在 2015 年题为“深度人脸识别”的论文中进行了描述。
该论文的一个贡献是描述了如何开发一个非常大的训练数据集,这是训练基于现代卷积神经网络的人脸识别系统所必需的,以便与 Facebook 和 Google 用于训练模型的大数据集竞争。
…[我们]提出了一种创建合理大型人脸数据集的程序,同时只需要有限的人力进行标注。为此,我们提出了一种利用网络上可用的知识源(第 3 节)收集人脸数据的方法。我们采用此程序构建了一个包含两百多万人脸的数据集,并将免费提供给研究社区。
— 深度人脸识别,2015。
然后,该数据集被用作开发用于人脸识别任务(例如人脸识别和验证)的深度 CNN 的基础。具体来说,模型在非常大的数据集上进行训练,然后在基准人脸识别数据集上进行评估,证明该模型在从人脸生成泛化特征方面是有效的。
他们描述了首先训练一个人脸分类器的过程,该分类器在输出层使用 softmax 激活函数将人脸分类为人物。然后移除该层,使得网络的输出是人脸的向量特征表示,称为人脸嵌入。然后通过微调进一步训练该模型,以便为相同身份生成的向量之间的欧几里德距离变小,而为不同身份生成的向量之间的距离变大。这是通过使用三元组损失函数实现的。
三元组损失训练旨在学习在最终应用中表现良好的分数向量,即通过比较欧几里德空间中的人脸描述符进行身份验证。……三元组 (a, p, n) 包含一个锚点人脸图像以及锚点身份的肯定样本 p != a 和否定样本 n。投影 W’ 在目标数据集上学习。
— 深度人脸识别,2015。
在分类器网络的末端,采用 VGG 风格的深度卷积神经网络架构,其中包含带有小内核和 ReLU 激活的卷积层块,后跟最大池化层,并使用全连接层。
VGGFace2 模型
VGG 的 Qiong Cao 等人在 2017 年发表的题为“VGGFace2:一个用于跨姿态和年龄识别人脸的数据集”的论文中描述了一项后续工作。
他们将 VGGFace2 描述为一个他们为训练和评估更有效的人脸识别模型而收集的更大规模的数据集。
本文介绍了一个名为 VGGFace2 的新大规模人脸数据集。该数据集包含 9131 个主题的 331 万张图像,每个主题平均有 362.6 张图像。图像从 Google 图片搜索下载,在姿态、年龄、光照、种族和职业(例如演员、运动员、政治家)方面具有很大的变化。
— VGGFace2:一个用于跨姿态和年龄识别人脸的数据集,2017。
该论文侧重于该数据集是如何收集、管理以及图像在建模前是如何准备的。然而,VGGFace2 已成为指代已提供的用于人脸识别的预训练模型的名称,这些模型在该数据集上进行了训练。
模型在数据集上进行训练,特别是 ResNet-50 和 SqueezeNet-ResNet-50 模型(称为 SE-ResNet-50 或 SENet),并且这些模型的变体已由作者提供,以及相关的代码。模型在标准人脸识别数据集上进行评估,展示了当时最先进的性能。
…我们证明了在 VGGFace2 上训练的深度模型(ResNet-50 和 SENet)在 […] 基准测试中取得了最先进的性能。
— VGGFace2:一个用于跨姿态和年龄识别人脸的数据集,2017。
具体来说,基于 SqueezeNet 的模型通常提供更好的性能。
ResNet-50 和 SENet(均从头开始学习)之间的比较表明,SENet 在验证和识别方面均表现出持续卓越的性能。 […] 此外,SENet 的性能可以通过在 VGGFace2 和 MS1M 这两个数据集上进行训练来进一步提高,从而利用它们各自的优势。
— VGGFace2:一个用于跨姿态和年龄识别人脸的数据集,2017。
给定模型预测的人脸嵌入是一个长度为 2,048 的向量。然后对向量的长度进行归一化,例如,使用 L2 向量范数(到原点的欧几里德距离)将其归一化为长度 1 或单位范数。这被称为“人脸描述符”。人脸描述符(或称为“主题模板”的人脸描述符组)之间的距离使用余弦相似度计算。
人脸描述符是从分类器层相邻的层中提取的。这会产生一个 2048 维的描述符,然后对其进行 L2 归一化。
— VGGFace2:一个用于跨姿态和年龄识别人脸的数据集,2017。
如何安装 keras-vggface 库
VGGFace2 的作者提供了其模型的源代码,以及可以使用 Caffe 和 PyTorch 等标准深度学习框架下载的预训练模型,尽管没有 TensorFlow 或 Keras 的示例。
我们可以将提供的模型转换为 TensorFlow 或 Keras 格式,并开发模型定义以加载和使用这些预训练模型。幸运的是,这项工作已经完成,可以直接由第三方项目和库使用。
或许,在 Keras 中使用 VGGFace2(和 VGGFace)模型的最佳第三方库是 Refik Can Malli 的 keras-vggface 项目和库。
鉴于这是一个第三方开源项目,并且可能会发生变化,我已在此处创建了该项目的一个分支。
该库可以通过 pip 安装;例如
|
1 |
sudo pip install git+https://github.com/rcmalli/keras-vggface.git |
成功安装后,您应该会看到类似以下消息
|
1 |
成功安装 keras-vggface-0.6 |
您可以通过查询已安装的软件包来确认库是否正确安装
|
1 |
pip show keras-vggface |
这将总结软件包的详细信息;例如
|
1 2 3 4 5 6 7 8 9 10 |
名称:keras-vggface 版本:0.6 摘要:VGGFace 在 Keras 框架中的实现 主页:https://github.com/rcmalli/keras-vggface 作者:Refik Can MALLI 作者电子邮件:mallir@itu.edu.tr 许可证:MIT 位置:... 需要:numpy, scipy, h5py, pillow, keras, six, pyyaml 所需通过 |
您还可以通过在脚本中加载库并打印当前版本来确认库是否正确加载;例如
|
1 2 3 4 |
# 检查 keras_vggface 的版本 import keras_vggface # 打印版本 print(keras_vggface.__version__) |
运行示例将加载库并打印当前版本。
|
1 |
0.6 |
如何检测用于人脸识别的人脸
在进行人脸识别之前,我们需要检测人脸。
人脸检测是自动在照片中定位人脸并通过在其周围绘制边界框来确定其范围的过程。
在本教程中,我们还将使用多任务级联卷积神经网络 (MTCNN) 进行人脸检测,例如从照片中查找和提取人脸。这是一个用于人脸检测的最新深度学习模型,在 2016 年题为“使用多任务级联卷积网络进行联合人脸检测和对齐”的论文中有所描述。
我们将使用 Iván de Paz Centeno 在 ipazc/mtcnn 项目中提供的实现。这也可以通过 pip 安装,如下所示
|
1 |
sudo pip install mtcnn |
我们可以通过导入库并打印版本来确认库是否正确安装;例如。
|
1 2 3 4 |
# 确认 mtcnn 是否正确安装 import mtcnn # 打印版本 print(mtcnn.__version__) |
运行示例会打印库的当前版本。
|
1 |
0.1.0 |
我们可以使用 *mtcnn* 库创建一个人脸检测器,并提取人脸以供我们在后续章节中与 VGGFace 人脸检测器模型一起使用。
第一步是将图像加载为 NumPy 数组,我们可以使用 Matplotlib imread() 函数实现这一点。
|
1 2 |
# 从文件加载图像 pixels = pyplot.imread(filename) |
接下来,我们可以创建一个 MTCNN 人脸检测器类,并使用它来检测加载照片中的所有人脸。
|
1 2 3 4 |
# 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 results = detector.detect_faces(pixels) |
结果是一个边界框列表,其中每个边界框定义了边界框的左下角以及宽度和高度。
如果我们的实验假设照片中只有一张脸,我们可以按如下方式确定边界框的像素坐标。
|
1 2 3 |
# 从第一张脸中提取边界框 x1, y1, width, height = results[0]['box'] x2, y2 = x1 + width, y1 + height |
我们可以使用这些坐标来提取人脸。
|
1 2 |
# 提取人脸 face = pixels[y1:y2, x1:x2] |
然后,我们可以使用 PIL 库将这张小人脸图像调整为所需大小;具体来说,模型期望形状为 224x224 的方形输入人脸。
|
1 2 3 4 |
# 将像素大小调整为模型大小 image = Image.fromarray(face) image = image.resize((224, 224)) face_array = asarray(image) |
综合所有这些,函数 *extract_face()* 将从加载的文件名中加载照片并返回提取的人脸。
它假定照片包含一张脸,并将返回检测到的第一张脸。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 从给定照片中提取单张人脸 def extract_face(filename, required_size=(224, 224)): # 从文件加载图像 pixels = pyplot.imread(filename) # 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 results = detector.detect_faces(pixels) # 从第一张脸中提取边界框 x1, y1, width, height = results[0]['box'] x2, y2 = x1 + width, y1 + height # 提取人脸 face = pixels[y1:y2, x1:x2] # 将像素调整到模型大小 image = Image.fromarray(face) image = image.resize(required_size) face_array = asarray(image) return face_array |
我们可以用一张照片测试这个函数。
从维基百科下载一张 2013 年 Sharon Stone 的照片,以宽松许可发布。
下载照片并将其保存到当前工作目录,文件名为“*sharon_stone1.jpg*”。

莎朗·斯通照片 (sharon_stone1.jpg)
斯通,来自维基百科。
下面列出了加载 Sharon Stone 照片、提取人脸并绘制结果的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 使用 mtcnn 进行人脸检测的示例 from matplotlib import pyplot from PIL import Image from numpy import asarray from mtcnn.mtcnn import MTCNN # 从给定照片中提取单张人脸 def extract_face(filename, required_size=(224, 224)): # 从文件加载图像 pixels = pyplot.imread(filename) # 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 results = detector.detect_faces(pixels) # 从第一张脸中提取边界框 x1, y1, width, height = results[0]['box'] x2, y2 = x1 + width, y1 + height # 提取人脸 face = pixels[y1:y2, x1:x2] # 将像素调整到模型大小 image = Image.fromarray(face) image = image.resize(required_size) face_array = asarray(image) return face_array # 加载照片并提取人脸 pixels = extract_face('sharon_stone1.jpg') # 绘制提取的人脸 pyplot.imshow(pixels) # 显示绘图 pyplot.show() |
运行示例会加载照片,提取人脸,并绘制结果。
我们可以看到人脸被正确检测和提取。
结果表明,我们可以使用开发的 *extract_face()* 函数作为后续章节中 VGGFace 人脸识别模型的示例基础。
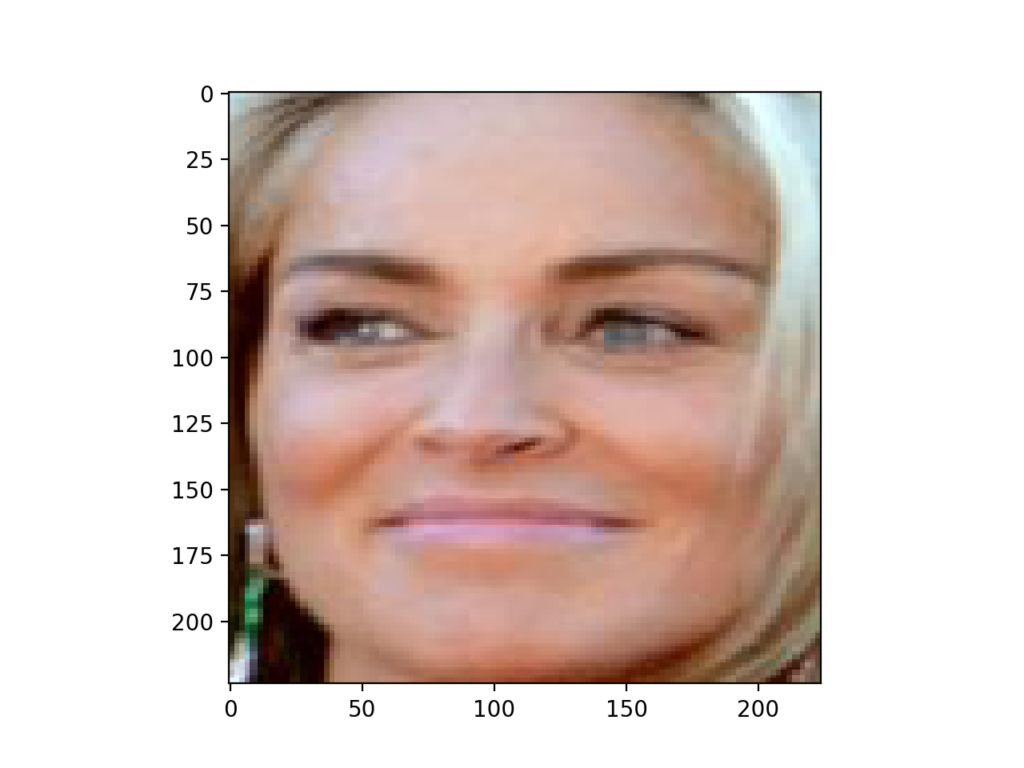
使用 MTCNN 模型从 Sharon Stone 的照片中检测到的人脸
如何使用 VGGFace2 进行人脸识别
在本节中,我们将使用 VGGFace2 模型对维基百科上的名人照片进行人脸识别。
可以通过调用 *VGGFace()* 构造函数并指定通过“*model*”参数创建的模型类型来创建 VGGFace 模型。
|
1 |
model = VGGFace(model='...') |
keras-vggface 库提供了三个预训练的 VGG 模型,一个通过 *model='vgg16'*(默认)的 VGGFace1 模型,以及两个 VGGFace2 模型“*resnet50*”和“*senet50*”。
下面的示例创建了一个“*resnet50*”VGGFace2 模型,并总结了输入和输出的形状。
|
1 2 3 4 5 6 7 |
# 创建人脸嵌入的示例 from keras_vggface.vggface import VGGFace # 创建一个 vggface2 模型 model = VGGFace(model='resnet50') # 总结输入和输出形状 print('Inputs: %s' % model.inputs) print('Outputs: %s' % model.outputs) |
首次创建模型时,库将下载模型权重并将其保存在您主目录中的 *./keras/models/vggface/* 目录中。*resnet50* 模型的权重大小约为 158 兆字节,因此下载可能需要几分钟,具体取决于您的互联网连接速度。
运行示例会打印模型的输入和输出张量的形状。
我们可以看到该模型期望输入形状为 244x244 的人脸彩色图像,输出将是 8,631 人的类别预测。这是有道理的,因为预训练模型是在 MS-Celeb-1M 数据集中 8,631 个身份(此 CSV 文件中列出)上进行训练的。
|
1 2 |
输入:[<tf.Tensor 'input_1:0' shape=(?, 224, 224, 3) dtype=float32>] 输出:[<tf.Tensor 'classifier/Softmax:0' shape=(?, 8631) dtype=float32>] |
这个 Keras 模型可以直接用于预测给定人脸属于八千多名已知名人中的一个或多个的概率;例如
|
1 2 |
# 执行预测 yhat = model.predict(samples) |
进行预测后,可以将类别整数映射到名人的姓名,并检索概率最高的五个姓名。
此行为由 keras-vggface 库中的 *decode_predictions()* 函数提供。
|
1 2 3 4 5 |
# 将预测转换为名称 results = decode_predictions(yhat) # 显示最可能的结果 for result in results[0]: print('%s: %.3f%%' % (result[0], result[1]*100)) |
在我们进行人脸预测之前,必须以与 VGGFace 模型拟合时数据准备相同的方式对像素值进行缩放。具体来说,必须使用训练数据集的平均值对每个通道的像素值进行居中处理。
这可以通过使用 keras-vggface 库中提供的 *preprocess_input()* 函数并指定“*version=2*”来实现,这样图像将使用用于训练 VGGFace2 模型而不是 VGGFace1 模型(默认)的平均值进行缩放。
|
1 2 3 4 5 |
# 将一张脸转换为样本 pixels = pixels.astype('float32') samples = expand_dims(pixels, axis=0) # 准备用于模型的脸部,例如中心像素 samples = preprocess_input(samples, version=2) |
我们可以将所有这些整合在一起,并预测我们在上一节中下载的 Shannon Stone 照片的身份,特别是“*sharon_stone1.jpg*”。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 使用 vggface2 模型进行人脸检测的示例 from numpy import expand_dims from matplotlib import pyplot from PIL import Image from numpy import asarray from mtcnn.mtcnn import MTCNN from keras_vggface.vggface import VGGFace from keras_vggface.utils import preprocess_input from keras_vggface.utils import decode_predictions # 从给定照片中提取单张人脸 def extract_face(filename, required_size=(224, 224)): # 从文件加载图像 pixels = pyplot.imread(filename) # 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 results = detector.detect_faces(pixels) # 从第一张脸中提取边界框 x1, y1, width, height = results[0]['box'] x2, y2 = x1 + width, y1 + height # 提取人脸 face = pixels[y1:y2, x1:x2] # 将像素调整到模型大小 image = Image.fromarray(face) image = image.resize(required_size) face_array = asarray(image) return face_array # 加载照片并提取人脸 pixels = extract_face('sharon_stone1.jpg') # 将一张脸转换为样本 pixels = pixels.astype('float32') samples = expand_dims(pixels, axis=0) # 准备用于模型的脸部,例如中心像素 samples = preprocess_input(samples, version=2) # 创建一个 vggface 模型 model = VGGFace(model='resnet50') # 执行预测 yhat = model.predict(samples) # 将预测转换为名称 results = decode_predictions(yhat) # 显示最可能的结果 for result in results[0]: print('%s: %.3f%%' % (result[0], result[1]*100)) |
运行示例会加载照片,提取我们知道存在的单张人脸,然后预测人脸的身份。
然后显示概率最高的五个名称。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
我们可以看到,该模型正确地将人脸识别为属于莎朗·斯通,可能性为 99.642%。
|
1 2 3 4 5 |
b' Sharon_Stone': 99.642% b' Noelle_Reno': 0.085% b' Elisabeth_R\xc3\xb6hm': 0.033% b' Anita_Lipnicka': 0.026% b' Tina_Maze': 0.019% |
我们可以用另一位名人,本例中是男性,查宁·塔图姆来测试该模型。
2017 年拍摄的查宁·塔图姆照片在维基百科上以宽松许可提供。
下载照片并将其保存在当前工作目录,文件名为“*channing_tatum.jpg*”。

查宁·塔图姆的照片,来自维基百科 (channing_tatum.jpg)。
更改代码以加载查宁·塔图姆的照片;例如
|
1 |
pixels = extract_face('channing_tatum.jpg') |
运行带有新照片的示例,我们可以看到模型正确地将人脸识别为查宁·塔图姆,可能性为 94.432%。
|
1 2 3 4 5 |
b' Channing_Tatum': 94.432% b' Eoghan_Quigg': 0.146% b' Les_Miles': 0.113% b' Ibrahim_Afellay': 0.072% b' Tovah_Feldshuh': 0.070% |
您可能希望使用从维基百科获取的其他名人照片尝试此示例。尝试使用不同性别、种族和年龄的多样化集合。您会发现该模型并非完美无缺,但对于它非常了解的名人,它可以是有效的。
您可能希望尝试其他版本的模型,例如“*vgg16*”和“*senet50*”,然后比较结果。例如,我发现对于 奥斯卡·伊萨克 的照片,“*vgg16*”是有效的,但 VGGFace2 模型则无效。
该模型可用于识别新面孔。一种方法是重新训练模型,或许只是模型的分类器部分,使用新的人脸数据集。
如何使用 VGGFace2 进行人脸验证
VGGFace2 模型可用于人脸验证。
这涉及到计算新给定人脸的人脸嵌入,并将该嵌入与系统中已知单个人脸示例的嵌入进行比较。
人脸嵌入是表示从人脸中提取特征的向量。然后可以将其与为其他人脸生成的向量进行比较。例如,另一个接近(通过某种度量)的向量可能是同一个人,而另一个遥远(通过某种度量)的向量可能是不同的人。
通常使用欧几里得距离和余弦距离等度量在两个嵌入之间进行计算,如果距离低于预定义的阈值,则认为人脸匹配或验证,该阈值通常针对特定数据集或应用进行调整。
首先,我们可以加载不带分类器的 VGGFace 模型,方法是将“*include_top*”参数设置为“*False*”,通过“*input_shape*”指定输出形状,并将“*pooling*”设置为“*avg*”,以便模型输出端的过滤器映射通过全局平均池化简化为向量。
|
1 2 |
# 创建一个 vggface 模型 model = VGGFace(model='resnet50', include_top=False, input_shape=(224, 224, 3), pooling='avg') |
然后,该模型可以用于进行预测,这将返回一个或多个人脸的嵌入向量。
|
1 2 |
# 执行预测 yhat = model.predict(samples) |
我们可以定义一个新函数,给定包含人脸的照片文件名列表,它将通过上一节中开发的 *extract_face()* 函数从每张照片中提取一张人脸,对 VGGFace2 模型输入所需的预处理可以通过调用 *preprocess_input()* 来实现,然后预测每张人脸的嵌入向量。
下面的 *get_embeddings()* 函数实现了这一点,它返回一个数组,其中包含每张提供的照片文件名的一个人脸嵌入。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 提取人脸并计算照片文件列表的人脸嵌入 def get_embeddings(filenames): # 提取人脸 faces = [extract_face(f) for f in filenames] # 转换为样本数组 samples = asarray(faces, 'float32') # 为模型准备人脸,例如中心像素 samples = preprocess_input(samples, version=2) # 创建一个 vggface 模型 model = VGGFace(model='resnet50', include_top=False, input_shape=(224, 224, 3), pooling='avg') # 执行预测 yhat = model.predict(samples) return yhat |
我们可以将之前使用的 Sharon Stone 照片(例如 *sharon_stone1.jpg*)作为 Sharon Stone 身份的定义,通过计算并存储该照片中人脸的人脸嵌入。
然后,我们可以计算 Sharon Stone 其他照片中人脸的嵌入,并测试我们是否能有效地验证她的身份。我们还可以使用其他人照片中的人脸来确认它们未被验证为 Sharon Stone。
验证可以通过计算已知身份的嵌入与候选人脸嵌入之间的余弦距离来完成。这可以使用 cosine() SciPy 函数实现。两个嵌入之间的最大距离分数为 1.0,而最小距离为 0.0。人脸身份的常用截止值在 0.4 到 0.6 之间,例如 0.5,尽管这应该针对特定应用程序进行调整。
下面的 *is_match()* 函数实现了这一点,它计算了两个嵌入之间的距离并解释了结果。
|
1 2 3 4 5 6 7 8 |
# 确定候选人脸是否与已知人脸匹配 def is_match(known_embedding, candidate_embedding, thresh=0.5): # 计算嵌入之间的距离 score = cosine(known_embedding, candidate_embedding) if score <= thresh: print('>人脸匹配 (%.3f <= %.3f)' % (score, thresh)) else: print('>人脸不匹配 (%.3f > %.3f)' % (score, thresh)) |
我们可以通过从维基百科下载更多莎朗·斯通的照片来测试一些正面示例。
具体来说,一张摄于 2002 年的照片(下载并保存为“*sharon_stone2.jpg*”),以及一张摄于 2017 年的照片(下载并保存为“*sharon_stone3.jpg*”)。
我们将测试这两个正面案例和上一节中的查宁·塔图姆照片作为反面示例。
以下是人脸验证的完整代码示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# 使用 VGGFace2 模型进行人脸验证 from matplotlib import pyplot from PIL import Image from numpy import asarray from scipy.spatial.distance import cosine from mtcnn.mtcnn import MTCNN from keras_vggface.vggface import VGGFace from keras_vggface.utils import preprocess_input # 从给定照片中提取单张人脸 def extract_face(filename, required_size=(224, 224)): # 从文件加载图像 pixels = pyplot.imread(filename) # 创建检测器,使用默认权重 detector = MTCNN() # 检测图像中的人脸 results = detector.detect_faces(pixels) # 从第一张脸中提取边界框 x1, y1, width, height = results[0]['box'] x2, y2 = x1 + width, y1 + height # 提取人脸 face = pixels[y1:y2, x1:x2] # 将像素调整到模型大小 image = Image.fromarray(face) image = image.resize(required_size) face_array = asarray(image) return face_array # 提取人脸并计算照片文件列表的人脸嵌入 def get_embeddings(filenames): # 提取人脸 faces = [extract_face(f) for f in filenames] # 转换为样本数组 samples = asarray(faces, 'float32') # 为模型准备人脸,例如中心像素 samples = preprocess_input(samples, version=2) # 创建一个 vggface 模型 model = VGGFace(model='resnet50', include_top=False, input_shape=(224, 224, 3), pooling='avg') # 执行预测 yhat = model.predict(samples) return yhat # 确定候选人脸是否与已知人脸匹配 def is_match(known_embedding, candidate_embedding, thresh=0.5): # 计算嵌入之间的距离 score = cosine(known_embedding, candidate_embedding) if score <= thresh: print('>人脸匹配 (%.3f <= %.3f)' % (score, thresh)) else: print('>人脸不匹配 (%.3f > %.3f)' % (score, thresh)) # 定义文件名 filenames = ['sharon_stone1.jpg', 'sharon_stone2.jpg', 'sharon_stone3.jpg', 'channing_tatum.jpg'] # 获取嵌入文件文件名 embeddings = get_embeddings(filenames) # 定义莎朗·斯通 sharon_id = embeddings[0] # 验证已知的莎朗照片 print('正面测试') is_match(embeddings[0], embeddings[1]) is_match(embeddings[0], embeddings[2]) # 验证其他人的已知照片 print('负面测试') is_match(embeddings[0], embeddings[3]) |
第一张照片被用作莎朗·斯通的模板,列表中的其余照片是用于验证的正面和负面照片。
运行示例,我们可以看到系统正确验证了两个正面案例,即早期和晚期拍摄的莎朗·斯通照片。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
我们还可以看到查宁·塔图姆的照片被正确地未验证为莎朗·斯通。探索其他负面照片的验证将是一个有趣的扩展,例如其他女性名人的照片。
|
1 2 3 4 5 |
正面测试 >人脸匹配 (0.418 <= 0.500) >人脸匹配 (0.295 <= 0.500) 负面测试 >人脸不匹配 (0.709 > 0.500) |
注意:从模型生成的嵌入不专门针对用于训练模型的名人照片。据信该模型可以为任何面孔生成有用的嵌入;也许可以尝试将其与您自己的照片以及亲友的照片进行比较。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 深度人脸识别, 2015.
- VGGFace2:一个用于跨姿态和年龄识别人脸的数据集, 2017.
- 使用多任务级联卷积网络进行联合人脸检测和对齐, 2016.
书籍
- 人脸识别手册,第二版,2011。
API
- 视觉几何组(VGG)主页.
- VGGFace 主页.
- VGGFace2 主页.
- VGGFace2 官方项目,GitHub.
- keras-vggface 项目,GitHub.
- MS-Celeb-1M 数据集主页.
- scipy.spatial.distance.cosine API
总结
在本教程中,您学习了如何使用 VGGFace2 深度学习模型开发人脸识别和验证系统。
具体来说,你学到了:
- 关于用于人脸识别的 VGGFace 和 VGGFace2 模型,以及如何安装 keras_vggface 库以在 Python 和 Keras 中使用这些模型。
- 如何开发一个人脸识别系统,以预测给定照片中名人的姓名。
- 如何开发一个人脸验证系统,以确认给定人脸照片的个人身份。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
尊敬的Jason博士,
虽然本教程是关于识别人 A(查宁·塔图姆)和人 B(莎朗·斯通)之间的区别,但我的问题是人脸识别系统是否能识别人内部的变化,并且算法能够识别出正确的人。
我说的变化是指,如果一个人有面部毛发,脸变胖了或变瘦了,戴着或没戴眼镜,或者有疤痕。
再说明一下。一个人注册了他/她的脸。后来,这个人的脸可能会有变化;变胖或变瘦,有/没有面部毛发或戴眼镜,需要额外做些什么来处理这些变化。
谢谢你,
悉尼的Anthony
理想情况下,是的,同一人脸在不同时间段的嵌入通常会比不同人脸的嵌入更接近。
你好,
在另一个话题上,您是否计划撰写关于从透视工作和透视网格方面分析视频的博客?
我对分析赛马视频和其他运动很感兴趣。
谢谢你,
Joe
好建议,我希望将来能涵盖这个话题。
你好,先生,
我收到以下错误
from keras.applications.imagenet_utils import _obtain_input_shape
ImportError: cannot import name '_obtain_input_shape' from 'keras.applications.imagenet_utils'
也许检查一下你是否安装了最新版本的 Keras,例如 2.2.4+
嗨,Jason,
感谢您的精彩帖子!非常有用!
我有一个问题,为了识别人,我可以使用像 SVM 或 KNN 这样的分类器来处理人脸编码吗?如果是,哪个更好?
我正在处理很多人(接近一千人),我不确定使用分类器是否是正确的方法。
谢谢你
保罗
是的。
测试一套算法,以发现最适合您的特定数据集的算法。
SVM 效果很好。
我在 decode_prediction 中收到错误
说是
ValueError:
decode_predictions期望一批预测(即形状为 (samples, 1000) 的二维数组)。找到形状为 (1, 8631) 的数组。听到这个消息我很难过,我这里有一些建议可能有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好,先生,
我收到以下错误
cannot import name '_obtain_input_shape' from 'keras.applications.imagenet_utils' (C:\Users\user\Anaconda3\lib\site-packages\keras\applications\imagenet_utils.py)
很抱歉听到这个消息,请确保您安装了 Keras 2.2.4 或更高版本以及 TensorFlow 1.14 或更高版本。
> 他们描述了首先训练一个人脸分类器的过程,该分类器在输出层使用 softmax 激活函数将人脸分类为人物。然后移除该层,使得网络的输出是人脸的向量特征表示,称为人脸嵌入。然后通过微调进一步训练该模型,以便为相同身份生成的向量之间的欧几里德距离变小,而为不同身份生成的向量之间的距离变大。这是通过使用三元组损失函数实现的。
你讲得如此简单易懂,杰森,精彩的教程。
谢谢,很高兴它有所帮助。
“… 然后,通过微调进一步训练模型,使相同身份生成的向量之间的欧几里得距离变小,不同身份生成的向量之间的距离变大。……”
这一步做了什么?
在本教程中,我们不训练人脸模型,我们使用预训练模型。
我想用您在以下网站描述 Facenet 模型的方式使用 vgg face2 模型
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
我该怎么用呢?
我相信这只是一个直接替换。
抱歉,我无法为您编写自定义示例。
好的,谢谢。在这个网站上,vggface2 用于单张图像。如何将其用于包含 9 个人的数据集?
通过多次使用相同的模型为每张图像生成嵌入。
谢谢。如果我使用
model = VGGFace(model=’resnet50′, include_top=False, input_shape=(224, 224, 3), pooling=’avg’)
in
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
那么训练和测试的准确率就会变得非常差。这是为什么呢?
听到这个消息我很难过。
我相信需要进行一些实验来调整模型以适应示例。
尊敬的Jason博士,
我正在寻找预训练 VGGFaceV2 MobileNet 的权重,但 Keras 只支持 VGGFaceV2 的 VGGNet16、ResNet50、SeNet50 的预训练权重。
你知道在哪里可以找到和下载它吗?或者你是否曾经在 VGGFaceV2 数据集上训练过 MobileNet,能分享一下权重吗?
谢谢你。
手头没有,抱歉。
如何将人脸数据存储在数据库中?
也许查阅您的数据库文档,了解如何存储二进制数据?
感谢您,杰森·布朗利先生的这份礼物
不客气,很高兴本教程对您有帮助!
你好先生,当我运行这段代码时
# 使用 mtcnn 进行人脸检测的示例
from matplotlib import pyplot
from PIL import Image
from numpy import asarray
from mtcnn.mtcnn import MTCNN
# 从给定照片中提取单张人脸
def extract_face(filename, required_size=(224, 224))
# 从文件加载图像
pixels = pyplot.imread(filename)
# 创建检测器,使用默认权重
detector = MTCNN()
# 检测图像中的人脸
results = detector.detect_faces(pixels)
# 从第一张脸中提取边界框
x1, y1, width, height = results[0][‘box’]
x2, y2 = x1 + width, y1 + height
# 提取人脸
face = pixels[y1:y2, x1:x2]
# 将像素大小调整为模型大小
image = Image.fromarray(face)
image = image.resize(required_size)
face_array = asarray(image)
return face_array
# 加载照片并提取人脸
pixels = extract_face(‘sharon_stone1.jpg’)
# 绘制提取的人脸
pyplot.imshow(pixels)
# 显示绘图
pyplot.show()
它给出错误:-
使用 TensorFlow 后端。
非法指令(核心转储)
很抱歉听到这个消息,也许您的开发环境有问题。如果是这样,这可能有所帮助
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
我如何用自己的图片训练模型
请看这个教程
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
嗨,Jason,
我一直在使用 https://github.com/vudung45/FaceRec (Facenet) 一段时间了,但它的准确性很低。
您能建议我哪个更好(Facenet 还是 VGGFace2)
也许可以在你的问题上尝试两者,看看哪种效果最好。
嗨,Jason,
我每个人只有一张脸。在这种情况下,我应该选择基于模型的分类器,比如 SVM,还是应该直接计算与已计算的编码之间的差异?
每个人只有一张脸,对于这种情况,您会建议选择 Facenet 还是 VGGface2?
尝试几种方法,看看哪种最适合您的特定数据集。
感谢这篇教程。
然而,我有一个问题,我如何将余弦相似度计算为准确性百分比?
好问题。我希望将来能涵盖这个话题。
你好……我只是想问一下我是否可以使用相同的模型进行直播人脸识别……?
也许可以试试。
嗨,杰森。我的代码出错了。🙂
对于 yhat = model.predict(samples);
ValueError: 检查输入时出错:预期 input_427 具有 4 个维度,但获得形状为 (224, 224, 3) 的数组。
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
请确认 TensorFlow 2 和 Keras 2.3 版本。
嘿,伙计!感谢您的帖子,我想知道它是否真的适用于 tensorflow2.0?我只需要安装 tensorflow-gpu 2.0,keras 2.2.4 cuda toolkit 10.0 和 cudnn 7.6?(我正在使用 conda)或者在 tensorflow2.0 上安装 keras_vggface 还有其他特殊考虑事项吗?
它与 Python 3.6 上的 TensorFlow 2 和 Keras 2.3 兼容。
这将帮助您设置环境
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
亲爱的杰森,我正在努力弄清楚如何让它运行,我想我的环境设置有问题,但是我收到这个错误
TypeError: 添加的层必须是 Layer 类的实例。找到
我在 stackoverflow 上问过这个问题
https://stackoverflow.com/questions/59763562/canot-use-vggface-keras-on-tensorflow-2-0
我想知道你能不能帮我解决这个问题,提前谢谢你
我相信那个 stackoverflow 帖子上的评论是一个很好的开始。
另外,更新到 TF 2.1 和 Keras 2.3.1。
正在努力,非常感谢。另外我想问一下我应该使用 rcmalli 库还是你的库?
rcmalli 是什么?
是您在帖子中提到的 github 用户,他是项目的所有者,我提醒您链接,
sudo pip install git+https://github.com/rcmalli/keras-vggface.git
现在我应该用那个还是这个?
https://github.com/jbrownlee/keras-vggface
谢谢你的帮助,伙计!
您可以从原始 github 项目或我的项目克隆安装。
两者都可以。
嗨,您有适用于 tensorflow 2.0 的模型吗?
所有代码示例都使用 Keras 2.4,运行在 TensorFlow 2 之上。
感谢您的本教程。
我试过您的代码,它运行完美。但是当我使用自己的图像时,在以下代码中
# 使用 vggface2 模型进行人脸检测的示例
.....
# 从第一张脸中提取边界框
x1, y1, width, height = results[0][‘box’]
在上述行中,出现以下错误
IndexError: 列表索引超出范围
请帮忙。
您可能需要调试错误。或许可以确认您的图片是否正确加载?
谢谢您,先生,代码运行良好。我添加了自己的图像并运行了代码。我得到了以下输出
b’ Downtown_Julie_Brown’: 0.295%
b’ Layne_Staley’: 0.282%
b’ Eugene_H\xc3\xbctz’: 0.260%
b’ Fito_Cabrales’: 0.226%
b’ Stevie_Ray’: 0.204%
运行最后一段代码,我得到了这个输出。
正面测试
>人脸匹配 (0.009 人脸匹配 (0.026 人脸不匹配 (0.876 > 0.500)
它确实证实了我图片中的人脸既不是上面显示的两个名字,但如何才能得到这种输出呢?
b’ Channing_Tatum’: 94.432%
b’ Eoghan_Quigg’: 0.146%
b’ Les_Miles’: 0.113%
b’ Ibrahim_Afellay’: 0.072%
b’ Tovah_Feldshuh’: 0.070%
其中,正确识别的人脸获得了94.432%的可能性。我如何才能在这里看到我的图像名称,例如:
图像 xyz ‘: 94.432%
你可以对模型非常了解的人脸获得良好的预测。
感谢您的回复。我用自己的图片尝试了代码,它运行良好。代码正在计算嵌入,然后在运行时进行比较。我想知道如何保存一个类的嵌入。这样我就可以用它来与新图片的计算嵌入进行比较?
其次,您能否澄清我关于CNN的概念。我们通常有一个大型数据集用于CNN,但在这里,我们只是使用单个图像计算嵌入,然后比较嵌入。在存在遮挡或不同光强度等情况下,我们是否会得到准确的结果?尽管我在测试不同光强度的图像时得到了准确的结果。我不明白为什么这里没有使用大型数据集。
你可以获取嵌入向量并将其numpy数组保存到文件中。
https://machinelearning.org.cn/how-to-save-a-numpy-array-to-file-for-machine-learning/
CNN已经训练好了,我们只是在使用它。
非常感谢。链接中的代码完美运行。
很高兴听到这个!
关于我的第二个问题,我想我找到了答案。我们在这里使用单次学习,使用孪生网络。如果我错了请纠正我。
不,我们正在使用预训练模型来分类已知人脸。
我还有另一个问题。
在测试时如何减少计算时间?
使用更少的数据。
使用更小的模型。
使用更快的机器。
谢谢你的回复。
我查看了MTCNN人脸检测器。它的最后阶段在人脸上创建了5个点。为什么上面的算法没有输出带有5个点的检测到的人脸?是不是代码中缺少了什么?您能指出缺少了什么以及忽略创建这些点的代码的原因是什么吗?这不是MTCNN的基本组成部分吗?
可以,在此代码中我们只使用边界框。您可以将其更改为执行您想要的任何操作。
好的,非常感谢。
你好,
我正在使用VGGFACE2模型进行此教程 ( https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/ )
——当我使用小型数据集时,vggface2比facenet预测速度快
——当我使用大型数据集时,vggface2比facenet预测速度慢
这正常吗,还是有什么错误?
干得不错。
我不知道这是否是一个准确的发现,抱歉。
对于这个项目,你是如何训练模型的?我似乎找不到你训练模型的部分。我想使用这个项目用我自己的图像数据集来训练模型。
我们在这个教程中不训练模型,我们使用一个预训练模型,该模型了解名人。
你可以在这里训练你自己的模型。
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
如果我想使用我训练好的模型,我可以直接替换此教程中获取模型的路径吗?
是的。试试看。
我尝试使用这个,它根据验证数据集给出了一个随机结果。是否可以将我自己的训练模型从https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/应用到本教程中?
另一个教程已经向您展示了,请参阅教程的结尾。
好的,明白了,谢谢。
先生您好,我按照您上面的代码操作后出现了以下错误,我的笔记本电脑没有GPU。
ImportError: DLL加载失败,导入_pywrap_tensorflow_internal时:找不到指定模块。
未能加载原生 TensorFlow 运行时。
请帮忙!
谢谢你。
也许这个教程能帮助你设置开发环境。
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
我正在使用PyCharm,我认为您的代码使用了Tensorflow。我安装Theano后如何在这里使用它?
您可以通过更改后端来配置Keras以使用TensorFlow或Theano。
https://keras.org.cn/backend/
库版本
Keras v2.2.4
Tensorflow v1.14.0
警告:Theano后端目前不受支持/测试
干得好!
我刚使用 face_recognition (https://github.com/ageitgey/face_recognition/tree/master/examples) 库来识别人脸名称。那么 vggface2 与 face_recognition 库有什么区别呢?
哪个最好?
谢谢!!
我对那个库不熟悉,抱歉。
通常,库会在内部使用模型。
你好,
在运行 precompute_features.py 时,此模型“batch_fvecs = resnet50_features.predict(images)”在 CPU 上执行推理,有什么办法可以在 GPU 上运行吗?
我有 tensorflow-gpu 1.14,Nvidia 1050i,CUDA 和 CUDNN 库都已就位。实际上,MTCNN 人脸检测只在 GPU 上执行推理。
我是否遗漏了什么?为什么它不在 GPU 上执行推理?
我不知道,抱歉。也许你需要调试你的开发环境?
布朗内尔博士您好。感谢您的精彩教程。
有没有其他SENet架构的keras实现,例如:
– SE-ResNet-50-256D
– SE-ResNet-50-256D
– SE-ResNet-50-128D
也许有,我不知道,抱歉。也许可以尝试谷歌搜索?
嗨,Jason,
谢谢您的帖子。我有两个问题:
也许VGG在树莓派上由于内存限制无法工作,那么我可以使用哪种控制器来构建一个独立系统呢?我如何知道可以识别的不同人脸数量的限制?
如果我用Haar级联代替VGG在树莓派上使用呢?
使用树莓派4可以识别的不同人脸数量的限制是多少?使用更大的micro SD卡会增加这个限制,还是树莓派的RAM影响它?
此致,
马诺尔
我对那个平台不了解,也许可以测试一系列方法,找出最适合你的项目需求的方案。
嗨,Jason,
很棒的帖子。
我正在使用你的代码,通过在我的数据集上训练VGGFace2模型时创建包含已知嵌入和已知名称的pickle文件,然后将该pickle文件应用于测试数据(图像文件),效果非常好。
但是,如果我尝试将pickle文件输出应用于实时网络摄像头数据,则无效。我尝试读取实时数据的方式存在一些预处理问题。
你有没有遇到过在实时数据上实现VGGFace2和MTCNN的情况,如果有,能否分享一下?
敬请,
Twarit
您需要以与训练数据完全相同的方式准备新数据/图像。
您好。
为什么没有像VGGface1那样的VGGface2模型,为什么要使用像resnet这样在VGGface2数据集上训练的其他模型?
请在这里纠正我:VGGface既是一个数据集,也是一个在此数据集上训练的VGG模型。VGGface2只是一个数据集,没有在此数据集上训练的VGG模型。
它们都是模型,后者更好。
真的很棒..我从去年开始就用它进行人脸认证……结合权重印记技术……与dlib相比,甚至获得了更好的FAR……
结果在这里:https://github.com/Bhanuchander210/reality_of_one_shot_learning/blob/master/evaluate_results.md
谢谢。
干得好。
嘿,贾森,我有一个表情符号图片分类的用例。它们不完全是人脸,但确实具有一些特征,比如表情。我不知道是应该重新训练在Imagenet数据上预训练的CNN,还是应该在新表情符号图片上重新训练这个Facenet模型?请指导您认为哪种方法更好?
我猜需要一个新的模型。也许可以借鉴表现良好的图像分类模型,如vgg。
你是说从头开始训练新模型吗?我不能微调在Imagenet上已经训练过的inception/resnet/vgg吗?
我想不行,但你可以试试看。
好的,谢谢,我会尝试的!
你好,
非常有用的帖子!
只是一个简短的问题,为什么在使用网络之前不将图像像素归一化?我以为总是建议归一化输入。如果不是,我们何时应该归一化,何时不应该?
非常感谢!
我们会的,在调用 preprocess_input() 函数时。
它减去了训练均值,但没有进行像素归一化到0到1之间的转换,对吗?是不是不需要?
另外一个问题,为了使用keras-vggface库,输入图像应该是RGB还是BGR格式?我认为是RGB,但我想确认一下。
谢谢!!
您必须通过调用 preprocess_input() 函数来准备模型数据,该函数会将像素值标准化。
我们在此教程中进行了此操作。
图像采用RGB格式。
我认为它们应该是 BGR,因为这个 tensorflow 版本是基于 CAFFE 的,而 CAFFE 是 BGR
感谢这篇精彩的文章!
我很惊讶vggface2也能识别我的一些本地名人!
然而,它仍然无法识别我测试过的一些YouTuber。
我将探索使用迁移学习来识别这些以前未被vggface2识别的人物,以提高我的理解。
任何指导都将不胜感激!
干得好!
这可能有帮助
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
谢谢!这很有帮助!
我将尝试看看是否可以使用不同的图像来预测使用训练好的5位名人模型的身份
不客气。
嗨,Jason博士,
使用此代码查找两个人之间的差异——是否可以安全地假设它也可以用于区分同卵双胞胎。我正在研究区分同卵双胞胎——您能给我一些建议吗?
谢谢,
丽塔
我不期望它对同卵双胞胎有效。
哪个会表现更好?VGGface还是FaceNet
这取决于您要解决的问题。也许可以测试每种方法,然后选择最适合您的方法。
看起来检测器是从左上角开始的。Y轴从顶部0开始,向下延伸到最大高度处。图片的X轴从原点0开始,向右延伸到最大宽度。如果它是左下角,那么人脸将从[y2:y1](从上到下),但我们看到人脸被[y1:y2]高度裁剪。如果我错了,请纠正我。
我不记得了,抱歉。
这些模型可以用于商业用途吗?对于VGGFACE2,它说数据集在创作共用许可下,但没有提及模型本身。对于VGGFACE,它明确禁止商业使用。
问得好,我想这取决于每个模型和业务的具体情况。也许您可以联系给定模型的作者并请求商业许可,或者使用他们的程序生成一个您自己的新模型。
嗨,令人难以置信的工作,非常感谢您的这个教程,它帮了大忙!
不客气!
很好的解释。
我想训练一个像VGGface2一样的新模型,它既可以用于人脸验证,也可以用于人脸识别。
我的训练数据集没有标签,我想以无监督的方式进行训练。我该如何实现?
谢谢。
如果您的图像没有标签,我不知道您将如何准备用于验证或识别的模型。
你好,Jason
你的博客太棒了。
在“如何使用VGGFace2进行人脸识别”部分,您使用SoftMax层进行人脸识别。(一对多)
但在“如何使用VGGFace2进行人脸验证”中,您使用SoftMax层之前的最后一层进行人脸验证(一对一)。您获取嵌入并计算相似度(一对一)。所以我的问题是,我们为什么没有对人脸识别采用相同的原则,获取嵌入并计算与多个(一对多)的相似度。为什么我们没有这样做。
谢谢你的回复
谢谢。
模型的使用会根据不同的应用进行调整。
在第一种情况下,我们使用预训练模型对图像进行分类,例如多类分类。
在第二种情况下,我们使用预训练模型,仅在二元分类类型问题中使用嵌入。
您可以根据需要调整模型的使用方式。
你好,Jason
我正在使用这个模型来查找图像中两张脸之间的相似性。
model = VGGFace(model=’resnet50′, include_top=False, input_shape=(224, 224, 3), pooling=’avg’)
# 执行预测
yhat = model.predict(samples)
为什么预测的维度是2048?
那是模型的输出,例如输出层之前的层中的节点数。
你好,
感谢您的精彩教程。我有一个简短的问题:在“如何使用VGGFace2进行人脸验证”部分中的人脸验证,当图像中的人物不在用于训练的8631位名人中时,效果是否同样好?也就是说,当我想检查两张非名人图像是否描绘同一个人时,效果是否同样好?
祝好,
斯特凡
不,必须为该问题创建一个新模型,例如:
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
你好,
感谢您的良好解释。
在“人脸验证”和“人脸识别”之间,哪个更好,哪个使用最多?
这一切都取决于数据集和条件吗?
这取决于您要解决的问题,然后选择解决您问题的解决方案。
你好,
感谢您为我们提供此解释。
我希望您能帮我解决这个疑问:因为我必须将输出值的范围映射到另一个范围,所以我必须知道输出值的范围是多少。您能告诉我它的范围是多少吗?
最后一个输出层函数应该是softmax,对吗?但我得到的范围是[-0.99, 0.99]左右。这怎么可能呢?
谢谢你的帮助。
每个输出的范围是0-1。
如果您需要不同的范围,您可以修改输出函数或在事后将输出缩放到新范围。
runfile(‘C:/Users/Thananyaa/.spyder-py3/vggface1.py’, wdir=’C:/Users/Thananyaa/.spyder-py3′)
回溯(最近一次调用)
文件“C:\Users\Thananyaa\anaconda3\lib\site-packages\keras_vggface\__init__.py”,第7行,在
来自 keras_vggface.vggface 导入 VGG16
文件“C:\Users\Thananyaa\anaconda3\lib\site-packages\keras_vggface\__init__.py”,第1行,在
来自 keras_vggface.vggface 导入 VGGFace
文件“C:\Users\Thananyaa\anaconda3\lib\site-packages\keras_vggface\vggface.py”,第9行,在
来自 keras_vggface.models 导入 RESNET50, VGG16, SENET50
文件“C:\Users\Thananyaa\anaconda3\lib\site-packages\keras_vggface\models.py”,第20行,在
来自 keras.engine.topology 导入 get_source_inputs
ModuleNotFoundError: 没有名为“keras.engine.topology”的模块
很抱歉听到这个消息,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
请编辑 /usr/local/lib/python3.7/dist-packages/keras_vggface/models.py 文件,在此文件中请替换以下行:
来自 keras.engine.topology 导入 get_source_inputs
用
从 keras.utils.layer_utils 导入 get_source_inputs
如果您使用colab pro,可以使用colab终端打开此文件。
或者
一旦出现错误(您提到的那个),查找显示错误的文件。通常它在第一步中显示“from keras_vggface.vggface import VGGFace”的错误,
就在这下面会有一个指向 /usr/local/lib/python3.7/dist-packages/keras_vggface/models.py 文件的另一个错误,点击这个链接并按照上面指定的方式注释该行并替换为新行。
感谢更新。Keras因Tensorflow 2.x成为官方模块而发生变化。因此一些函数被重新定位了。
嗨,Rohith A K。
您是否已找到将Colab上的keras.engine.topology替换为keras.utils.layer_utils以在Jupyter Notebook上解决此问题的确切解决方案?
如果我将Colab笔记本下载到我的Jupyter笔记本,我仍然会收到该错误。我们该如何解决?
你好
我有一个关于人脸嵌入算法的问题。
我目前正在做一个关于通过人脸预测BMI的项目。
在MTCNN之后,对齐的人脸大小不同,调整为224×224(VGG所需),甚至会扭曲比例。您认为直接调整大小重要吗?或者VGG仍然可以给出正确的嵌入?
或者我应该固定比例,然后调整到224×224,但这样会在人脸周围留下黑边……
我认为留黑边应该无关紧要。但我相信严重扭曲的长宽比会产生更负面的影响。我的理由是,对于固定的卷积大小,您现在将更多(或更少)的数据放入每个卷积操作中,并且您提取的特征可能不再相同。
你好,
我尝试过遵循本教程和Facenet教程,但我遇到了与使用Python 3而不是Python 2相关的问题。具体来说,在这种情况下,当导入预训练模型时,我收到一个str对象没有decode属性的错误。(在Facenet的情况下,问题也在尝试加载模型时出现)。您能否就此给我一些建议?
您能指出哪行代码导致错误吗?
我把它弄丢了,也无法重新创建它,看来是由于使用了旧版本的所需软件包而发生的。我重建了我的环境,这解决了大部分问题,只需对vgg_kerasface中的models.py文件进行轻微修改即可使其适用于tensorflow 2。
你好,Jason。
据我所知,VGGFace2是为名人分类而训练的,然后通过三元组损失函数进一步训练。我说得对吗?
嗨
我尝试在anaconda命令行中执行pip install git+https://github.com/rcmalli/keras-vggface.git,但我收到此错误消息:
错误:执行命令git clone -q https://github.com/rcmalli/keras-vggface.git ‘C:\Users\Nuha\AppData\Local\Temp\pip-req-build-ffiv6mrk’时出现错误[WinError 2] 系统找不到指定的文件
错误:找不到命令“git”——您是否安装了“git”并将其添加到PATH中?
你知道我该如何解决吗?
您需要安装git。https://git-scm.cn/download/win
您好,感谢您出色的教程。它对我帮助很大。我好奇您为什么使用余弦距离而不是像欧几里得距离这样的简单距离?这样做有什么目的吗?
嗨,win……非常欢迎!选择它只是为了说明这个过程。你当然可以尝试其他选项。如果你尝试了,请告诉我们你的发现。
嗨 James,
非常感谢您提供这个非常有用的博客。
我收到错误,ValueError:层“model”的输入0与该层不兼容:期望形状=(None, None, None, 3),找到形状=(None, 183, 230, 4)
在使用detector.detect_faces()之前,我们需要重新调整图像形状吗?