目标检测是计算机视觉中的一项任务,它涉及识别给定照片中一个或多个物体的存在、位置和类型。
这是一个具有挑战性的问题,它需要建立在物体识别(例如,它们在哪里)、物体定位(例如,它们的范围是什么)和物体分类(例如,它们是什么)方法的基础上。
近年来,深度学习技术在目标检测方面取得了最先进的成果,例如在标准基准数据集和计算机视觉竞赛中。其中最著名的是 R-CNN(基于区域的卷积神经网络),以及最新的技术 Mask R-CNN,它能够在各种目标检测任务中取得最先进的成果。
在本教程中,您将学习如何使用 Mask R-CNN 模型检测新照片中的物体。
完成本教程后,您将了解:
- 基于区域的卷积神经网络家族模型用于目标检测以及最新变体 Mask R-CNN。
- Keras 深度学习库中 Mask R-CNN 的最佳开源库实现。
- 如何使用预训练的 Mask R-CNN 对新照片执行目标定位和检测。
通过我的新书《计算机视觉深度学习》来启动您的项目,其中包括分步教程以及所有示例的 Python 源代码文件。
让我们开始吧。

如何在 Keras 中使用 Mask R-CNN 对照片进行目标检测
图片由 Ole Husby 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- R-CNN 和 Mask R-CNN
- Matterport Mask R-CNN 项目
- 使用 Mask R-CNN 进行目标检测
注意:本教程需要 TensorFlow 1.15.3 和 Keras 2.2.4 版本。它不适用于 TensorFlow 2.0+ 或 Keras 2.2.5+,因为在撰写本文时,第三方库尚未更新。
您可以按如下方式安装这些特定版本的库:
|
1 2 |
sudo pip install --no-deps tensorflow==1.15.3 sudo pip install --no-deps keras==2.2.4 |
用于目标检测的 Mask R-CNN
目标检测是一项计算机视觉任务,它涉及在一个图像中定位一个或多个物体,并对图像中的每个物体进行分类。
这是一项具有挑战性的计算机视觉任务,它需要成功地进行目标定位,以便在图像中的每个物体周围定位并绘制一个边界框,以及进行目标分类,以预测所定位物体的正确类别。
目标检测的一个扩展涉及标记图像中属于每个检测到的物体的特定像素,而不是在目标定位期间使用粗略的边界框。这个更难的问题通常被称为物体分割或语义分割。
基于区域的卷积神经网络(R-CNN)是由 Ross Girshick 等人开发的一系列用于目标检测的卷积神经网络模型。
该方法大概有四种主要变体,最终发展为当前的巅峰 Mask R-CNN。每种变体的显著特征可以总结如下:
- R-CNN:“选择性搜索”算法提出边界框,每个边界框都会被拉伸,并通过深度卷积神经网络(例如 AlexNet)提取特征,最后使用线性 SVM 进行最终的对象分类。
- Fast R-CNN:设计简化,采用单一模型,边界框仍作为输入指定,但在深度 CNN 之后使用区域兴趣池化层来整合区域,模型直接预测类别标签和感兴趣区域。
- Faster R-CNN:增加了区域提议网络,该网络解释从深度 CNN 中提取的特征并学习直接提议感兴趣区域。
- Mask R-CNN:Faster R-CNN 的扩展,增加了一个输出模型,用于预测每个检测到的物体的掩码。
Mask R-CNN 模型在 2018 年发表的题为《Mask R-CNN》的论文中提出,是该系列模型中最新的变体,支持目标检测和物体分割。该论文对当时的模型谱系进行了很好的总结:
基于区域的 CNN (R-CNN) 边界框目标检测方法是关注数量可控的候选目标区域,并独立地在每个感兴趣区域上评估卷积网络。R-CNN 得到扩展,允许使用 RoIPool 在特征图上关注感兴趣区域,从而实现更快的速度和更高的准确性。Faster R-CNN 通过使用区域提议网络 (RPN) 学习注意力机制来推进这一流派。Faster R-CNN 具有灵活性和鲁棒性,适用于许多后续改进,是目前在多项基准测试中领先的框架。
— Mask R-CNN, 2018。
该系列方法可能是目标检测中最有效的方法之一,在计算机视觉基准数据集上取得了当时最先进的成果。尽管准确,但与 YOLO 等替代模型相比,这些模型在进行预测时速度较慢,YOLO 可能不太准确,但专为实时预测而设计。
Matterport Mask R-CNN 项目
Mask R-CNN 是一个复杂的模型,尤其与简单甚至最先进的深度卷积神经网络模型相比。
R-CNN 模型的每个版本都提供了源代码,这些源代码在单独的 GitHub 存储库中提供,原型模型基于 Caffe 深度学习框架。例如:
- R-CNN:带有卷积神经网络特征的区域,GitHub.
- Fast R-CNN,GitHub.
- Faster R-CNN Python 代码,GitHub.
- Detectron,Facebook AI,GitHub.
与其从头开始开发 R-CNN 或 Mask R-CNN 模型的实现,不如使用基于 Keras 深度学习框架构建的可靠第三方实现。
Mask R-CNN 的最佳第三方实现是 Mask R-CNN 项目,由 Matterport 开发。该项目以宽松许可证(即 MIT 许可证)开源发布,代码已广泛用于各种项目和 Kaggle 竞赛。
然而,它是一个开源项目,受项目开发人员的意愿影响。因此,我提供了一个该项目的分支,以防将来 API 发生重大更改。
该项目 API 文档较少,但它以 Python Notebook 的形式提供了许多示例,您可以通过示例了解如何使用该库。以下两个 Notebook 可能有助于查阅:
使用 Matterport 库使用 Mask R-CNN 模型主要有三种用例;它们是:
- 目标检测应用:使用预训练模型对新图像进行目标检测。
- 通过迁移学习创建新模型:使用预训练模型作为起点,为新的目标检测数据集开发模型。
- 从头开始创建新模型:为目标检测数据集从头开始开发新模型。
为了熟悉模型和库,我们将在下一节中查看第一个示例。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
使用 Mask R-CNN 进行目标检测
在本节中,我们将使用 Matterport Mask R-CNN 库对任意照片执行目标检测。
就像使用预训练的深度 CNN 进行图像分类一样,例如 VGG-16 在 ImageNet 数据集上训练,我们可以使用预训练的 Mask R-CNN 模型检测新照片中的物体。在这种情况下,我们将使用在 MS COCO 目标检测问题上训练的 Mask R-CNN。
Mask R-CNN 安装
第一步是安装库。
在撰写本文时,该库没有分布式版本,因此我们必须手动安装。好消息是这非常容易。
安装涉及克隆 GitHub 存储库并在您的工作站上运行安装脚本。如果您遇到问题,请参阅库自述文件中的安装说明。
步骤 1. 克隆 Mask R-CNN GitHub 存储库
这就像在命令行中运行以下命令一样简单:
|
1 |
git clone https://github.com/matterport/Mask_RCNN.git |
这将创建一个名为 Mask_RCNN 的新本地目录,其结构如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Mask_RCNN ├── assets ├── build │ ├── bdist.macosx-10.13-x86_64 │ └── lib │ └── mrcnn ├── dist ├── images ├── mask_rcnn.egg-info ├── mrcnn └── samples ├── balloon ├── coco ├── nucleus └── shapes |
步骤 2. 安装 Mask R-CNN 库
该库可以直接通过 pip 安装。
进入 Mask_RCNN 目录并运行安装脚本。
在命令行中,输入以下内容:
|
1 2 |
cd Mask_RCNN python setup.py install |
在 Linux 或 MacOS 上,您可能需要使用 sudo 权限安装软件;例如,您可能会看到如下错误:
|
1 |
error: can't create or remove files in install directory |
在这种情况下,请使用 sudo 安装软件:
|
1 |
sudo python setup.py install |
该库将直接安装,您将看到许多成功的安装消息,最后显示如下内容:
|
1 2 |
... Finished processing dependencies for mask-rcnn==2.1 |
这确认您已成功安装该库,并且拥有最新版本,在撰写本文时是 2.1 版本。
步骤 3:确认库已安装
始终最好确认库已正确安装。
您可以通过 pip 命令查询来确认库是否正确安装;例如:
|
1 |
pip show mask-rcnn |
您应该会看到输出,告知您版本和安装位置;例如:
|
1 2 3 4 5 6 7 8 9 10 |
名称:mask-rcnn 版本:2.1 摘要:用于目标检测和实例分割的 Mask R-CNN 主页:https://github.com/matterport/Mask_RCNN 作者:Matterport 作者电子邮件:waleed.abdulla@gmail.com 许可证:MIT 位置:... 要求 所需通过 |
我们现在可以开始使用该库了。
目标定位示例
我们将使用预训练的 Mask R-CNN 模型在新照片中检测物体。
步骤 1. 下载模型权重
首先,下载预训练模型的权重,特别是针对 MS Coco 数据集训练的 Mask R-CNN 模型。
权重可从项目 GitHub 项目中获取,文件大小约为 250 兆字节。将模型权重下载到当前工作目录中名为“mask_rcnn_coco.h5”的文件。
- 下载权重(mask_rcnn_coco.h5)(246 兆字节)
步骤 2. 下载示例照片
我们还需要一张用于检测物体的照片。
我们将使用一张在宽松许可证下发布的 Flickr 照片,具体是 Mandy Goldberg 拍摄的大象照片。
将照片下载到当前工作目录,文件名为“elephant.jpg”。

大象 (elephant.jpg)
由 Mandy Goldberg 拍摄,保留部分权利。
步骤 3. 加载模型并进行预测
首先,必须通过 MaskRCNN 类的实例来定义模型。
此类别需要一个配置对象作为参数。配置对象定义了模型在训练或推理期间如何使用。
在这种情况下,配置将只指定每批图像的数量(为 1)和要预测的类别数量。
您可以在 config.py 文件中查看配置对象的完整范围以及您可以覆盖的属性。
|
1 2 3 4 5 6 |
# 定义测试配置 class TestConfig(Config): NAME = "test" GPU_COUNT = 1 IMAGES_PER_GPU = 1 NUM_CLASSES = 1 + 80 |
我们现在可以定义 MaskRCNN 实例。
我们将模型定义为“推理”类型,表示我们关注的是进行预测而不是训练。我们还必须指定一个目录来写入任何日志消息,在这种情况下,该目录将是当前工作目录。
|
1 2 |
# 定义模型 rcnn = MaskRCNN(mode='inference', model_dir='./', config=TestConfig()) |
下一步是加载我们下载的权重。
|
1 2 |
# 加载 coco 模型权重 rcnn.load_weights('mask_rcnn_coco.h5', by_name=True) |
现在我们可以对图像进行预测。首先,我们可以加载图像并将其转换为 NumPy 数组。
|
1 2 3 |
# 加载照片 img = load_img('elephant.jpg') img = img_to_array(img) |
然后我们可以用模型进行预测。我们不会像在普通 Keras 模型上那样调用 predict(),而是会调用 detect() 函数并将单个图像传递给它。
|
1 2 |
# 进行预测 results = rcnn.detect([img], verbose=0) |
结果包含我们传递给 detect() 函数的每个图像的字典,在这种情况下,是单个图像的单个字典列表。
该字典包含用于边界框、掩码等的键,每个键指向图像中检测到的多个可能对象的列表。
值得注意的字典键如下:
- “rois”:检测到的对象的边界框或感兴趣区域 (ROI)。
- “masks”:检测到的对象的掩码。
- “class_ids”:检测到的对象的类别整数。
- “scores”:每个预测类别的概率或置信度。
我们可以通过首先获取第一个图像的字典(例如 results[0]),然后检索边界框列表(例如 [‘rois’])来绘制图像中检测到的每个框。
|
1 |
boxes = results[0]['rois'] |
每个边界框都通过图像中边界框的左下角和右上角坐标来定义
|
1 |
y1, x1, y2, x2 = boxes[0] |
我们可以使用这些坐标从 matplotlib API 创建一个 Rectangle(),并在图像顶部绘制每个矩形。
|
1 2 3 4 5 6 7 8 |
# 获取坐标 y1, x1, y2, x2 = box # 计算框的宽度和高度 width, height = x2 - x1, y2 - y1 # 创建形状 rect = Rectangle((x1, y1), width, height, fill=False, color='red') # 绘制边界框 ax.add_patch(rect) |
为了保持整洁,我们可以创建一个函数来执行此操作,该函数将接收照片的文件名和要绘制的边界框列表,并显示带有框的照片。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 绘制带有检测到物体的图像 def draw_image_with_boxes(filename, boxes_list): # 加载图像 data = pyplot.imread(filename) # 绘制图像 pyplot.imshow(data) # 获取绘制框的上下文 ax = pyplot.gca() # 绘制每个框 for box in boxes_list: # 获取坐标 y1, x1, y2, x2 = box # 计算框的宽度和高度 width, height = x2 - x1, y2 - y1 # 创建形状 rect = Rectangle((x1, y1), width, height, fill=False, color='red') # 绘制框 ax.add_patch(rect) # 显示图 pyplot.show() |
现在我们可以将所有这些结合起来,加载预训练模型,并用它来检测大象照片中的物体,然后绘制带有所有检测到的物体的照片。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# 预训练 coco 模型的推理示例 from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from mrcnn.config import Config from mrcnn.model import MaskRCNN from matplotlib import pyplot from matplotlib.patches import Rectangle # 绘制带有检测到物体的图像 def draw_image_with_boxes(filename, boxes_list): # 加载图像 data = pyplot.imread(filename) # 绘制图像 pyplot.imshow(data) # 获取绘制框的上下文 ax = pyplot.gca() # 绘制每个框 for box in boxes_list: # 获取坐标 y1, x1, y2, x2 = box # 计算框的宽度和高度 width, height = x2 - x1, y2 - y1 # 创建形状 rect = Rectangle((x1, y1), width, height, fill=False, color='red') # 绘制框 ax.add_patch(rect) # 显示图 pyplot.show() # 定义测试配置 class TestConfig(Config): NAME = "test" GPU_COUNT = 1 IMAGES_PER_GPU = 1 NUM_CLASSES = 1 + 80 # 定义模型 rcnn = MaskRCNN(mode='inference', model_dir='./', config=TestConfig()) # 加载 coco 模型权重 rcnn.load_weights('mask_rcnn_coco.h5', by_name=True) # 加载照片 img = load_img('elephant.jpg') img = img_to_array(img) # 进行预测 results = rcnn.detect([img], verbose=0) # 可视化结果 draw_image_with_boxes('elephant.jpg', results[0]['rois']) |
运行此示例将加载模型并执行目标检测。更准确地说,我们执行了目标定位,只在检测到的物体周围绘制了边界框。
在这种情况下,我们可以看到模型已正确地定位了照片中的单个物体,即大象,并在其周围绘制了一个红色框。
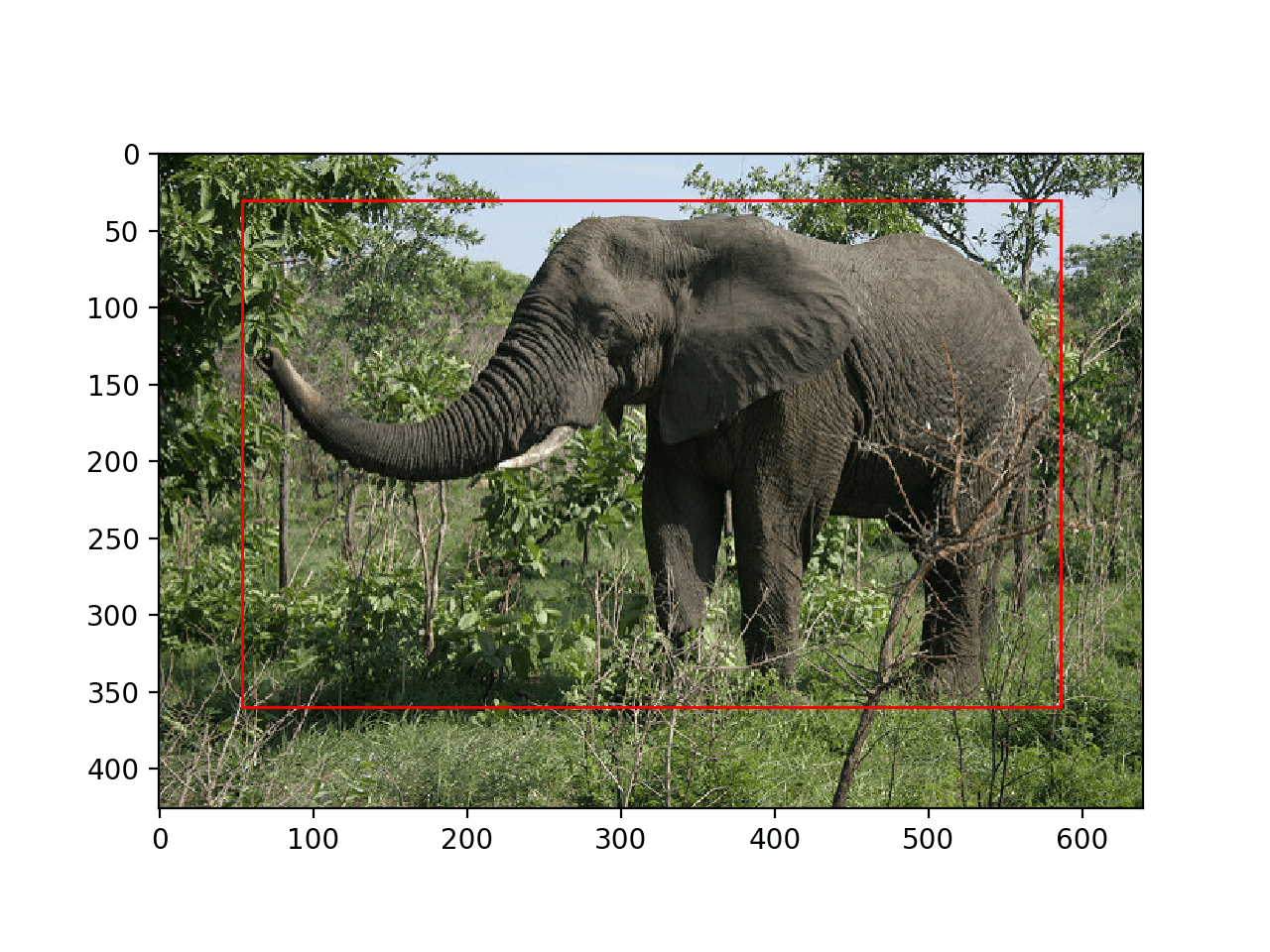
带有所有物体定位边界框的大象照片
目标检测示例
现在我们知道如何加载模型并使用它进行预测,让我们更新示例以执行真正的目标检测。
也就是说,除了定位物体之外,我们还想知道它们是什么。
Mask_RCNN API 提供了一个名为 display_instances() 的函数,该函数将接收加载图像的像素值数组和预测字典的各个方面(例如边界框、分数和类别标签),并将绘制带有所有这些注释的照片。
其中一个参数是预测类别标识符列表,该列表位于字典的“class_ids”键中。该函数还需要一个从 ID 到类别标签的映射。预训练模型使用包含 80 个(包括背景共 81 个)类别标签的数据集进行拟合,这些标签以列表形式在Mask R-CNN 演示,Notebook 教程中提供,如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 定义 coco 模型已知的 81 个类别 class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', '巴士', '火车', '卡车', '船', '交通灯', '消防栓', '停车标志', '停车计时器', '长凳', '鸟', '猫', '狗', '马', '羊', '牛', '大象', '熊', '斑马', '长颈鹿', '背包', '雨伞', '手提包', '领带', '手提箱', '飞盘', '滑雪板', '滑雪板', '运动球', '风筝', '棒球棒', '棒球手套', '滑板', '冲浪板', '网球拍', '瓶子', '酒杯', '杯子', '叉子', '刀', '勺子', '碗', '香蕉', '苹果', '三明治', '橙子', '西兰花', '胡萝卜', '热狗', '披萨', '甜甜圈', '蛋糕', '椅子', '沙发', '盆栽植物', '床', '餐桌', '马桶', '电视', '笔记本电脑', '鼠标', '遥控器', '键盘', '手机', '微波炉', '烤箱', '烤面包机', '水槽', '冰箱', '书', '时钟', '花瓶', '剪刀', '泰迪熊', '吹风机', '牙刷'] |
然后我们可以将大象照片的预测详情提供给 display_instances() 函数;例如:
|
1 2 3 4 |
# 获取第一次预测的字典 r = results[0] # 显示带有边界框、掩码、类标签和分数的照片 display_instances(img, r['rois'], r['masks'], r['class_ids'], class_names, r['scores']) |
display_instances() 函数非常灵活,允许您只绘制掩码或只绘制边界框。您可以在 visualize.py 源文件中了解有关此函数的更多信息。
下面列出了使用 display_instances() 函数进行此更改的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# 预训练 coco 模型的推理示例 from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from mrcnn.visualize import display_instances from mrcnn.config import Config from mrcnn.model import MaskRCNN # 定义 coco 模型已知的 81 个类别 class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', '巴士', '火车', '卡车', '船', '交通灯', '消防栓', '停车标志', '停车计时器', '长凳', '鸟', '猫', '狗', '马', '羊', '牛', '大象', '熊', '斑马', '长颈鹿', '背包', '雨伞', '手提包', '领带', '手提箱', '飞盘', '滑雪板', '滑雪板', '运动球', '风筝', '棒球棒', '棒球手套', '滑板', '冲浪板', '网球拍', '瓶子', '酒杯', '杯子', '叉子', '刀', '勺子', '碗', '香蕉', '苹果', '三明治', '橙子', '西兰花', '胡萝卜', '热狗', '披萨', '甜甜圈', '蛋糕', '椅子', '沙发', '盆栽植物', '床', '餐桌', '马桶', '电视', '笔记本电脑', '鼠标', '遥控器', '键盘', '手机', '微波炉', '烤箱', '烤面包机', '水槽', '冰箱', '书', '时钟', '花瓶', '剪刀', '泰迪熊', '吹风机', '牙刷'] # 定义测试配置 class TestConfig(Config): NAME = "test" GPU_COUNT = 1 IMAGES_PER_GPU = 1 NUM_CLASSES = 1 + 80 # 定义模型 rcnn = MaskRCNN(mode='inference', model_dir='./', config=TestConfig()) # 加载 coco 模型权重 rcnn.load_weights('mask_rcnn_coco.h5', by_name=True) # 加载照片 img = load_img('elephant.jpg') img = img_to_array(img) # 进行预测 results = rcnn.detect([img], verbose=0) # 获取第一次预测的字典 r = results[0] # 显示带有边界框、掩码、类标签和分数的照片 display_instances(img, r['rois'], r['masks'], r['class_ids'], class_names, r['scores']) |
运行示例显示了大象的照片以及 Mask R-CNN 模型预测的注释,具体如下:
- 边界框。每个检测到的对象周围的虚线边界框。
- 类标签。分配给每个检测到的对象的类标签,写在边界框的左上角。
- 预测置信度。每个检测到的对象的类标签预测置信度,写在边界框的左上角。
- 对象掩码轮廓。每个检测到的对象掩码的多边形轮廓。
- 对象掩码。每个检测到的对象掩码的多边形填充。
结果非常令人印象深刻,并激发了许多关于这种强大的预训练模型如何在实践中使用的想法。

带有边界框和掩码检测到所有对象的大象照片
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 用于精确目标检测和语义分割的丰富特征层次结构, 2013.
- 用于视觉识别的深度卷积网络中的空间金字塔池化, 2014.
- 快速R-CNN, 2015.
- Faster R-CNN:迈向实时目标检测,采用区域提议网络, 2016.
- Mask R-CNN, 2017.
API
资源
R-CNN 代码仓库
- R-CNN:带有卷积神经网络特征的区域,GitHub.
- Fast R-CNN,GitHub.
- Faster R-CNN Python 代码,GitHub.
- Detectron,Facebook AI,GitHub.
总结
在本教程中,您学习了如何使用 Mask R-CNN 模型检测新照片中的对象。
具体来说,你学到了:
- 基于区域的卷积神经网络家族模型用于目标检测以及最新变体 Mask R-CNN。
- Keras 深度学习库中 Mask R-CNN 的最佳开源库实现。
- 如何使用预训练的 Mask R-CNN 对新照片执行目标定位和检测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






干得好!关于这个主题的精彩文章。首先要感谢您的努力。但我想知道文本识别如何实现(例如,路边广告)?自定义训练数据集应该如何准备?(图像及其标注)欢迎提供任何来源和帮助。
谢谢。
好问题,你可以先进行对象识别来查找文本,然后使用像 CNN-LSTM 这样的模型来读取文本。也许甚至可以分割文本中的每个字母并逐个读取它们。
我也有同样的疑问,我偶然发现了 coco-text。 https://bgshih.github.io/cocotext/
所以这个帖子可以重新实现,但使用不同的预训练模型。
感谢分享。
有什么先决条件吗?
没有,如果您需要设置 Python 环境,这可能会有所帮助
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
这里有三个我遇到的关于缺失先决条件的错误,以及它们各自的修复方法(我没有使用 anaconda)
1. ModuleNotFoundError: 没有名为 'skimage' 的模块
2. ModuleNotFoundError: 没有名为 'IPython' 的模块
3. AttributeError: 模块 'tensorflow' 没有属性 'placeholder'
1. pip3 install scikit-image
2. pip3 install ipython
3. pip3 install tensorflow==1.7
(从版本 2 降级。https://stackoverflow.com/questions/56226284/why-do-i-get-attributeerror-module-tensorflow-has-no-attribute-placeholder
)
现在它在我的 mac 10.13.4 上完美运行
很棒的资源,谢谢 Jason Brownlee!!
感谢分享。
注意,该代码适用于 TensorFlow 1.13。
非常感谢:)它很容易工作。
但我也想将其用于视频。我该怎么做?只是修改一些代码还是编写其他代码?
也许你可以逐帧应用它,每秒取部分帧。
我遇到了问题 3,但我无法将 TensorFlow 降级到 1.7 或 1.13。我收到以下错误消息
ERROR: 找不到满足 tensorflow==1.13.1 要求的版本(来自版本:2.2.0rc1, 2.2.0rc2, 2.2.0rc3, 2.2.0rc4, 2.2.0, 2.2.1, 2.3.0rc0, 2.3.0rc1, 2.3.0rc2, 2.3.0, 2.3.1)
ERROR: 未找到匹配 tensorflow==1.13.1 的发行版
这有什么帮助吗?(我没有使用 conda)
试试这个
非常感谢您在计算机视觉领域的巨大努力,愿上帝保佑您。如果能再为我们解释一下 concatenate 和 deconvolution,那就更好了。
谢谢!
是的,我已安排了这些主题的教程。
亲爱的杰森。
我正在尝试在我的项目中应用遮罩。
我有这种类型的文件夹结构
── 训练
├── class_1
├── class_2
├── class_3
对象坐标在哪里?
格式是什么?[1, 1, 1, 1] (1,1,1,1)
听起来是一个很棒的项目!
亲爱的 Jason,解释得非常清楚。谢谢你。
我想从头开始使用 tensorflow-keras 编写 Mask RCNN 的代码,您能告诉我如何进行吗?有什么资源或文章可以帮助我吗?
也许从论文开始,并尝试很好地理解每个步骤。
亲爱的杰森:
运行下面的代码时我遇到了一个错误:
rcnn = MaskRCNN(mode='inference', model_dir='./', config=TestConfig())
错误是:ValueError: 尝试将“shape”转换为张量失败。错误:不支持 None 值。
我正在使用 Tensorflow 1.13 和 Keras 2.2.4 运行。而且 mask-rcnn 2.1 似乎已正确安装。
我感到困惑,因为你说它适用于 tf 1.13
很抱歉听到这个消息,我可以确认它适用于 TF 1.13。
您使用的是 Python 3.6 吗?
您是从命令行运行吗?
您复制了示例中的所有代码吗?
我这里有一些可能有所帮助的建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我使用的是 Python 3.7,但我认为这无关紧要。我已复制所有代码并在 PyCharm 中运行它们。
我将重置我的环境并再次尝试本教程,因为我之前使用 TF2.0-gpu,然后更改为 TF1.13-gpu,然后又更改为 TF 1.13。
谢谢您的帮助。您的教程真的帮了我很多。它们在 TF 2.0-gpu beta 版中运行良好,大多数时候我只需要将“import keras.XX”更改为“import tensorflow.keras.XX”。这太棒了!
我建议从命令行运行,而不是从笔记本或 IDE 运行,详情请见此处
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
非常感谢这篇文章。我有一个对象检测代码在 TF 1.xx 上运行,我正试图将其移植到 TF 2.beta。我按照 tf.upgrade_v2 命令操作…;但最终卡在了 maskrcnn.model.py 文件中的“keras.engine as KE”。如果能帮助我了解所有需要更改的代码以使其运行,我将不胜感激。
抱歉,我没有关于 TF 的教程,更不用说从一个 API 转换到另一个 API 了。
也许可以尝试 TF 用户组或 stackoverflow?
要解决 maskrcnn.model.py 文件中的“keras.engine as KE”问题,只需将 KE 替换为 KL。
感谢分享。
嗨,非常感谢您的教程,我有一个用于分类血细胞的 .h5 文件,是否可以将该权重加载到 rcnn.load_weights('blood.h5') 并检测掩码?
如果保存的模型是 Mask RCNN 模型,那么也许可以。
嗨 Jason,如何将它应用于自己的数据集。谢谢
这里有一个例子
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
嗨,杰森先生,我发现 2019 年发布了许多不同的实例分割算法,如 HTC,去年我们有 PANET 等。那么,我们仍然使用 MaskRCNN 开发不同的输出效率如何?您对 MRCNN 有何看法?请给我一些建议。谢谢。
我认为 Mask R-CNN 很棒。
如果你想尝试其他方法,尽管去尝试——但这可能会非常耗费时间和资源。
非常感谢您分享您的知识,我的问题是我想要更改训练数据和类名,因为我有不同的问题,我需要实现这种方法来检测对象
我的问题是需要检测与背景非常相似的物体,它们是非常小的圆形,模型未能检测到它们,所以我认为我需要对这种方法进行调整。
请参阅本教程,了解如何根据您自己的数据拟合模型。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
谢谢你的回复。
请您说明一下这个模型的损失函数是什么??
这个模型是如何训练和进行反向传播的??
我认为这里的损失函数是 MAP???
请您澄清这些点
好问题。
该模型使用多任务损失,结合了分类、边界框和掩码的损失。
您可以在这篇论文中了解更多关于模型的细节
https://arxiv.org/pdf/1703.06870.pdf
出色的教程。
我收到这个错误
rcnn.load_weights('mask_rcnn_coco.h5', by_name=True
>>> rcnn.load_weights('mask_rcnn_coco.h5', by_name=True)
回溯(最近一次调用)
File “”, line 1, in
文件 “C:\Users\srtangel\Documents\OpenCV\Code\Mask_RCNN\mrcnn\model.py”, 第 2115 行,在 load_weights 中
f = h5py.File(filepath, mode='r')
文件 “C:\Users\srtangel\Anaconda\envs\facecourse-py3\lib\site-packages\h5py\_hl\files.py”, 第 394 行,在 __init__ 中
swmr=swmr)
文件 “C:\Users\srtangel\Anaconda\envs\facecourse-py3\lib\site-packages\h5py\_hl\files.py”, 第 170 行,在 make_fid 中
fid = h5f.open(name, flags, fapl=fapl)
File “h5py\_objects.pyx”, line 54, in h5py._objects.with_phil.wrapper
File “h5py\_objects.pyx”, line 55, in h5py._objects.with_phil.wrapper
文件 “h5py\h5f.pyx”, 第 85 行,在 h5py.h5f.open 中
OSError: 无法打开文件(未找到文件签名)
>>>
这表明权重文件不在您的 Python 文件所在的同一目录中。
也许可以尝试从命令行运行示例?请参阅此内容
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
谢谢。我非常喜欢。
不客气。
感谢这篇精彩的教程。
我总是受限于 FPN 中“resnet”或其他预构建架构吗?有没有办法将任意 Conv. 网络整合到 mrcnn-FPN 结构中?看来人们在不同的项目中使用 mrcnn。然而,到目前为止,我只注意到不同类型的 resnet 和 vgg(不太确定)。
我想是可以的。您可能需要深入研究 mask rcnn 代码以替换特征提取器模型。
亲爱的 Jason,谢谢!我真的学到了很多。
我如何在二元分类上应用 Mask R-CNN,即图像上只有人物或什么都没有。
我尝试通过设置 NUM_CLASSES = 1 + 1(背景和人物)来实现它,但是得到了如下错误,
ValueError:层 #389(命名为“mrcnn_bbox_fc”),权重的形状为 (1024, 8),但保存的权重形状为 (1024, 324)。
这是一个你可以作为起点的例子
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
你好,
我是一名开发者,我想探索深度学习的世界。
我学会了如何使用Matterport Mask RCNN项目的迁移学习来构建自己的新模型。多亏了它:https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
我想从头开始创建一个新模型,但我找不到任何关于如何操作的教程。你有什么可以帮忙的吗?
从头开始训练真的更难吗?
谢谢你
抱歉,我没有从头开发模型的例子。
你好,
感谢这篇精彩的文章。我已实现它,并且它正在运行。我尝试从命令提示符运行,也成功了。现在我把权重保存在这个目录中:
目录路径是 /kangaroo/logs/kangaroo20191128T1406/mask_rcnn_kangaroo_0015.h5
如何从Anaconda命令提示符恢复模型在此检查点数据上的训练,如 –0016.h5, –0017.h5 等
python kangaroo.py train –dataset=kangaroo –weights=logs/kangaroo20191128T1406/mask_rcnn_kangaroo_0015.h5 报错:无法识别的参数
谢谢你
干得不错。
或许可以尝试以编程方式加载权重?
我能做到。但它从另一个事件日志开始。在预测时,模型使用的是旧的.h5权重,而不是最新的。
另外,如何获取每个检测到对象的掩模的填充多边形区域。
谢谢。
你调用detect()函数,它会返回结果对象。多边形就在那个对象里。
嘿,Jason和各位读者们。TF 2.0的使用有什么新进展吗?这有可能实现吗?如果不行,还有哪些部分需要转换为2.0代码?
据我所知,Mask RCNN 的作者尚未更新代码库。
测试时置信度得分是如何计算的?
好问题。或许你可以使用预测的类别成员概率作为不确定性分数?
是否可以使用数据生成器与 model.train()?
我不确定,或许你可以试试看?
您能分享一些在自定义数据集上进行此操作的资源吗,包括创建掩码。我搜索了很多,找到了一些,但在图像掩码和模型创建方面遇到了很多障碍。
是的,这里有一个例子
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
如何在 MASK_RCNN 中禁用分类器分支?
抱歉,我没明白。
我正在做一个项目,目标是在不降低掩码精度的情况下提高检测速度。在RCNN掩码中,有三个分支(分类器、边界框和掩码)。我需要边界框和掩码。如何在model.py中删除分类器分支?
这是一个图,你可以根据你选择的元素来格式化一个新的图。
抱歉,我没有TensorFlow的示例。
谢谢你。
您可以发送链接给我,即使它不是针对tensorflow的。
我对我之前进行过推理的同一张图片得到了随机预测。
Mask RCNN成功地检测到我图片中的一个人并应用了掩码。后来,当我尝试为同一张图片创建一个边界框时,它却检测到了一堆随机的东西。
没关系。我找到了问题所在。无论如何,一如既往的精彩文章。
我很高兴听到您解决了您的问题。
在jupyter notebook中运行代码没有错误,但我没有得到任何输出。任何尽早的帮助都将不胜感激。
或许可以尝试从命令行运行代码。
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
嗨!我想将Matterport Mask RCNN模型/Github仓库用于商业用途。这是一个开源项目,还是这个解决方案有一些限制?
是的,我相信你可以直接使用它。这是许可证:
https://github.com/matterport/Mask_RCNN/blob/master/LICENSE
尝试使用Maskrcnn进行自定义训练。训练正在进行,但目前遇到了一个错误:
“无法停止分析。没有分析器正在运行。”)
ProfilerNotRunningError:无法停止分析。没有分析器正在运行。
我猜这与路径定义有关,比如正斜杠/反斜杠,但不确定如何解决。
我使用的是Anaconda,TensorFlow 2.0 CPU和操作系统:Windows 10。
我尝试修改文件,即
log_dir='logs' 改为 log_dir='.\\logs',在callbacks.py中……但这肯定不是正确的方法。正在寻找解决方案。请帮帮我。
Mask RCNN目前不支持TensorFlow 2。或许可以降级到TensorFlow 1.15。
你好 Jason,
感谢您最有用且一流的帮助。您的努力对我意义重大。
我只有一个问题,如何获取预测或分类率并显示它?
另外,如何绘制mrcnn损失和验证损失?
不客气。
您可以在测试数据集上评估您的模型,例如对测试集中的每个示例进行预测,然后计算分类准确率。请记住,maskrcnn不仅仅是图像分类,它还进行目标检测,因此您应该使用一种衡量标准,该标准能够捕捉它是否在每张照片中定位了目标。
是的,已经在测试数据集上评估了我的模型。
得到 r[‘scores’]>0.9
这是预测率吗?
你如何计算分类准确率?
谢谢你。
分数会打印在检测到的物体掩膜旁边,以及物体名称,在我的情况下是“枪”。
这意味着类似于您的教程中边界框左上角打印的值(1.000)以及“大象”的文本。
准确率不适用于目标检测,请使用平均精度均值mAP。
杰森,真棒的教程。
即使按照您在步骤1中的指示设置并安装了所有要求,我仍然收到以下错误:
ModuleNotFoundError: 没有名为“mrcnn”的模块
任何帮助将不胜感激。
错误提示库未安装,或者已安装但无法从您运行代码的位置访问。
我建议从命令行运行示例
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
嗨,Jason,
我已经运行了一个目标检测模型,图像如下:
https://drive.google.com/open?id=1QGAmIv8maV_tY0ynoII8VI-fWlQA6Cz8
https://drive.google.com/open?id=1806mj4c5jftsY98qiUIeqQ04HCb_askY
https://drive.google.com/open?id=1uvNb5eGzQSIKfQExLVgkmuNyA92nRz4Z
https://drive.google.com/open?id=1wbs-HGGAS22G_ys9vinLes3Sc_FW5sU2
– 从航空图像(从谷歌地球保存)中检测砖窑。我使用了Faster R-CNN ResNet 101。我的模型无法从类似图像中检测到任何东西。另外,我只使用了50张图像,所以我认为可能是因为图像太少。
您认为使用这些图像可以吗?另外——对于这项任务,最好的模型和参数设置可能是什么?
我非常感谢您的资源——它总是帮助像我们这样的研究人员。
另外——如果可以的话,您建议至少需要多少张图片?训练和测试?
尽可能多,数千张。如果你无法获得数千张,可以使用数据增强来充分利用你所拥有的。
再说一遍——最后一个问题——不过,这些图像可以吗?您认为我们可以用这些图像检测砖窑吗?
谢谢
或许吧。您需要进行实验来回答这个问题。
这看起来是个很棒的问题。
我建议训练和测试一些不同的模型,并通过结果发现哪种最适合你的图像。
嗨,您的图片是什么格式的?
如果是 tif 格式,将无法使用。
如果是 jpeg、jpg、png 格式,则可以,但大小不应超过一定限制,我猜是 2048。
嗨,Jason博士,
我无法运行第398页关于检测大象的rcnn示例,因为出现了“on module named mrcnn”的错误。当我输入命令“pip show mask-rcnn”时,结果如下:
名称: mask-rcnn 版本: 2.1 摘要: 用于对象检测和实例分割的 Mask R-CNN 主页: https://github.com/matterport/Mask_RCNN 作者: Matterport 作者邮箱: waleed.abdulla@gmail.com 许可证: MIT 位置: … 需要: 被需要
请告诉我为什么?
听到这个消息我很难过。
或许可以确保您正在使用TensorFlow 1.15和Keras 2.2(而不是TensorFlow 2)。
我很乐意进一步讨论,您可以通过这里给我发邮件
https://machinelearning.org.cn/contact/
我直接在提示符下运行了mrcnn,它解决了问题:pip install mrcnn。
干得好!
嗨,杰森博士,
我尝试运行第419页清单26.36的示例,但出现了此错误:
IndexError: index 0 超出轴 2 的范围,大小为 0
请问您知道原因吗?
我很抱歉听到这个消息。
我有一些想法供您检查:
——您能确认Python是最新的吗(例如Python 3.6+等)?
——您能确认您的库是最新的吗(例如每个库的最新版本)?
——您能尝试运行随书提供的代码文件(而不是从PDF复制粘贴)吗?
——您能尝试直接从命令行执行代码吗(例如不在IDE或notebook中)?
告诉我进展如何。
嗨,杰森博士,
我尝试运行第428页清单26.47的示例,但出现了此错误:
AttributeError: 'Model' 对象没有 'metrics_tensors' 属性
请问我该怎么做?
抱歉,我没有见过这个错误。
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,杰森博士
深度学习AMI(Amazon Linux)版本22.0 – ami-0283132d7b60d70b9。
我使用了这个实例,因为深度学习AMI(Amazon Linux)版本21.1不可用。
可以吗?
是的。
嗨 Jason
第534页的 chmod 600 keras-aws-keypair.pem 在命令提示符(管理员)窗口中无法识别。您能告诉我如何解决这个问题吗?谢谢!
(管理员)窗口。您能告诉我如何解决这个问题吗?请。
抱歉,我没用过Windows。
嗨,Jason,
感谢您的解释。
分类后是否已知物体位置?
或者例如,每个已分类物体到摄像机的距离是多少?
谢谢!
模型会通过边界框定位物体,从而给出物体的位置。
嗨,杰森博士
由于亚马逊已经十多天没有增加我的实例限制,而且他们还需要大约四天时间。此外,由于中断,我只能短时间运行我的实例。我想在Google Colab上运行list26.66。请问哪种设置适合keras和tensorflow?
抱歉,我对colab不了解,从未使用过。
嗨,谢谢,我能得到矩形位置(X_start,Y_start)吗,谢谢
模型输出矩形。
嗨,Jason,
感谢您的示例。我想知道平均推理时间是多少?您是否使用CPU进行过任何测量?
我正在尝试调整我的设置。
谢谢
手头没有。
或许您可以在您的硬件上亲自测量一下?
这已经完成了,我想知道这个算法的性能如何。因此正在寻找参考资料。
目前对我来说是5秒/帧。我只使用CPU,没有GPU。我的下一步计划是也用GPU和目标设备(小型GPU)运行它。
如果您能记住任何数值并与我分享,将非常有帮助。
谢谢!
嗨,Jason,
我在我的笔记本电脑上连续运行了26.47列表十天,而在google colab上运行了数小时。我得到了
相同的结果:Epoch 1/5
请问您有什么办法解决这个问题吗?
或许可以尝试在快速的EC2实例上运行,比如p3。
嗨,Jason,
我能得到 mask_rcnn_kangaroo_cfg_0005.h5 权重文件吗?因为我在亚马逊云、Google Colab 或我的笔记本电脑上都无法运行清单 26.47。请,非常感谢。
因为我在亚马逊云、Google Colab 或我的笔记本电脑上都无法运行清单 26.47。请,非常感谢
抱歉,我不分享已训练的模型。
嗨,Jason博士,
我想测量两个检测到的物体之间的实际距离,例如图像中两辆车之间的距离。有什么办法可以做到吗?您有什么建议?
抱歉,我目前不确定。或许可以查阅相关文献。
嗨,Jason博士,
我无法通过我的笔记本电脑或Google Colab打开mask_rcnn_coco.h5文件,请
请将此文件副本发送到我的邮箱:hamedmmsuliman@gmail.com
非常感谢
该文件的链接已在教程中提供。您可以直接下载。
你好 Jason,
感谢您最有用且一流的帮助。您的努力对我意义重大。
我只有一个问题,如何获取预测或分类率并显示它?
另外,如何绘制mrcnn损失和验证损失?
我建议使用平均精度均值,或mAP。请参阅此内容:
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
你好 Jason,
我可以使用MRCNN来检测视频中的移动物体吗?如何实现?
非常感谢
我看不出为什么不。
您可以将视频的每一帧或部分帧传递给模型。
你好 Jason,
如何将图像中分割出来的部分保存为单独的图像?画布大小应等于分割部分的宽高,且我不希望有任何空白区域。我正在尝试这样做,但卡住了。您能帮忙吗?
此致,
尼维坦
您可以使用预测返回的掩码来裁剪您的原始图像并保存这些元素。
抱歉,我没有能力为您准备自定义示例。如果您是图像处理新手,或许可以从这里开始:
https://machinelearning.org.cn/start-here/#dlfcv
嗨,Jason,
我已经修改了这段代码,使其能够检测多个类别,但我好奇如何在一个来自网络摄像头的实时视频流上进行操作?我知道会涉及使用opencv,但我在弄清楚是否需要修改display_instances或者其他什么才能将掩码叠加到视频流中看到的类别上时卡住了。
抱歉,我没有这方面的例子,或许以后会有。
听起来非常有趣,也是我一直试图解决的挑战。Rachel,你是怎么做到的?请问可以分享你的代码吗?
如何在COCO数据集上使用此模型进行训练。
提前感谢。希望能收到你的回复
该模型已在数据集上训练完成,您可以直接下载使用。
嗨,Jason,
两个问题,如果可以的话……
1) 是否可以提取对象掩码轮廓的 x,y 位置?例如,构成对象掩码周长的每个 x,y 像素?我对此数据在几何形态测量形状分析中的应用感兴趣,因此能够提取此数据而不是手动选择周长将是理想的。
2) 对于使用 Google 的 ShapeMask 而不是 MaskRCNN,您有什么看法?
感谢您的宝贵时间
是的,我相信该模型返回的是图像空间中的多边形。
我对 Google 模型不熟悉。
你好,
感谢您的精彩教程。到目前为止,一切正常。但在 Tensorboard 和我添加的 CSVCallback 中,只记录了“loss”和“val_loss”。为了更好地评估训练过程,我想了解并记录其他损失,如掩码损失和边界框损失。有什么方法可以启用这些日志吗?
再次感谢这个易于理解的教程!
很抱歉回调不起作用。
也许你可以编写一个非常简单的自定义回调,将损失打印到标准输出,然后将其管道输出到一个日志文件。
如何只对4个类别而不是1+81个类别进行预测?我们需要做什么样的改变?
您可以使用自己的数据集对您感兴趣的类别进行模型训练,这里有一个例子
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
我在 Jetson TX2 上运行 MRCNN,但速度很慢。请问如何提高性能?
YOLO 可以在自定义数据上训练吗?非常感谢。
也许这些建议中的一些会对您有所帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-speed-up-the-training-of-my-model
请帮我解决问题
model = MaskRCNN(mode=”inference”, model_dir=MODEL_DIR, config=MaskRCNNConfig())
AttributeError Traceback (最近一次调用)
in
1 # 创建一个推理模式下的 Mask-RCNN 模型
—-> 2 model = MaskRCNN(mode=”inference”, model_dir=MODEL_DIR, config=MaskRCNNConfig())
~\anaconda3\lib\site-packages\mrcnn\model.py in __init__(self, mode, config, model_dir)
1830 self.model_dir = model_dir
1831 self.set_log_dir()
-> 1832 self.keras_model = self.build(mode=mode, config=config)
1833
1834 def build(self, mode, config)
~\anaconda3\lib\site-packages\mrcnn\model.py in build(self, mode, config)
2028 # 提议分类器和 BBox 回归器头部
2029 mrcnn_class_logits, mrcnn_class, mrcnn_bbox =\
-> 2030 fpn_classifier_graph(rpn_rois, mrcnn_feature_maps, input_image_meta,
2031 config.POOL_SIZE, config.NUM_CLASSES,
2032 train_bn=config.TRAIN_BN,
~\anaconda3\lib\site-packages\mrcnn\model.py in fpn_classifier_graph(rois, feature_maps, image_meta, pool_size, num_classes, train_bn, fc_layers_size)
925 # ROI 池化
926 # 形状: [批次, 框数, 池化高度, 池化宽度, 通道数]
–> 927 x = PyramidROIAlign([pool_size, pool_size],
928 name=”roi_align_classifier”)([rois, image_meta] + feature_maps)
929 # 两个 1024 全连接层(为保持一致性用 Conv2D 实现)
~\anaconda3\lib\site-packages\tensorflow\python\keras\engine\base_layer.py in __call__(self, *args, **kwargs)
923 # >> model = tf.keras.Model(inputs, outputs)
924 if _in_functional_construction_mode(self, inputs, args, kwargs, input_list)
–> 925 return self._functional_construction_call(inputs, args, kwargs,
926 input_list)
927
~\anaconda3\lib\site-packages\tensorflow\python\keras\engine\base_layer.py in _functional_construction_call(self, inputs, args, kwargs, input_list)
1115 try
1116 with ops.enable_auto_cast_variables(self._compute_dtype_object)
-> 1117 outputs = call_fn(cast_inputs, *args, **kwargs)
1118
1119 except errors.OperatorNotAllowedInGraphError as e
~\anaconda3\lib\site-packages\tensorflow\python\autograph\impl\api.py in wrapper(*args, **kwargs)
256 except Exception as e: # pylint:disable=broad-except
257 if hasattr(e, ‘ag_error_metadata’)
–> 258 raise e.ag_error_metadata.to_exception(e)
259 else
260 raise
AttributeError: in user code
C:\Users\Office1\anaconda3\lib\site-packages\mrcnn\model.py:390 call *
roi_level = log2_graph(tf.sqrt(h * w) / (224.0 / tf.sqrt(image_area)))
C:\Users\Office1\anaconda3\lib\site-packages\mrcnn\model.py:341 log2_graph *
return tf.log(x) / tf.log(2.0)
AttributeError: module ‘tensorflow’ has no attribute ‘log’
看起来您正在使用 TensorFlow 2,请尝试降级到 TensorFlow 1,说明在上面的教程中。
亲爱的 Jason Brownlee,
我非常感谢你。这个出色的教程在我的研究生项目中提供了很大的帮助。
不客气,我很高兴听到这个消息。
如何使用 display_instances() 函数只绘制掩码而不绘制边界框,以及反之?
我相信可以,也许可以查看函数的代码或文档,或者直接尝试使用该函数。
我是机器学习的初学者。我困惑于在哪里编写标题“物体定位示例”下的第3步代码。
我正在使用 Anaconda 虚拟环境及其命令行
我困惑于将此代码放在哪里。
# 定义测试配置
class TestConfig(Config)
NAME = “test”
GPU_COUNT = 1
IMAGES_PER_GPU = 1
NUM_CLASSES = 1 + 80
我已按照上面显示的代码更新了 config.py 文件。
现在当我执行时
rcnn = MaskRCNN(mode='inference', model_dir='./', config=TestConfig())
回溯(最近一次调用)
File “”, line 1, in
NameError: 名称 'MaskRCNN' 未定义
如何解决这个问题?
这些技巧会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Shankhanil Borthakur,请问您找到问题解决方案了吗?不幸的是,我遇到了同样的问题。谢谢
托马斯
我建议复制该部分末尾完整示例中的代码。
大家好,你们的工作很有趣,
你能推荐使用 Mask R-CNN 来检测昏暗图像/环境中的物体吗?或者有没有其他更好的最近算法专门用于检测昏暗/低分辨率图像中的物体。
谢谢。
也许您可以预处理图像?
也许您可以为您的数据集重新训练模型?
嗨 Jason,我有一个设置了所有库的 python 3.6 虚拟环境。代码运行正常。但是,当最后显示大象时,边界框完全不正确。当我运行原始存储库中的演示笔记本时,也会发生这种情况。我尝试多次重新创建我的虚拟环境,每次边界框都严重不正确。您有什么关于如何调试这个问题的想法吗?
很抱歉听到这个消息,也许这些提示会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
非常感谢你
我在 pycharm 中实现了这一步,但显示错误:ModuleNotFoundError: No module named 'mrcnn',请问如何纠正?
这些技巧会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
谢谢
不客气。
嗨 Jason,首先,我非常感谢你的工作,我喜欢你的教程。我还看了你关于使用 MASK-RCNN 对袋鼠数据集进行实例分割的另一个教程,所以,我有一个问题,是否有办法使用相同的 数据集进行图像分割,使用任何其他预训练模型,如 VGG 或 ResNet?
谢谢。
谢谢。
也许可以尝试一下,看看它是否适合您的项目/数据集。
Jason 先生,感谢您提供如此宝贵的知识。我想问一个关于 Mask R-CNN 的问题,是否可以使用这种方法来检测狗的关键点(类似于狗的姿态估计)?
任何评论都会有帮助。
谢谢。
嗨 Mukul…以下内容可能对您有帮助
https://machinelearning.org.cn/deep-learning-for-computer-vision/
为什么会出现这个错误,NameError: name 'MaskRCNN' is not defined
正在运行此命令。
# 定义模型
rcnn = MaskRCNN(mode='inference', model_dir='./', config=TestConfig())
在 Colab 上运行,TF_version, python_version 都看起来正确
感谢您的反馈,Mak!
你好,詹姆斯,你能否帮我解决如何绘制训练准确率和验证准确率,以及最终准确率的问题,因为我的导师对这些图表和指标很感兴趣
嗨 Philmonna…以下资源可能对您非常有帮助
https://machinelearning.org.cn/display-deep-learning-model-training-history-in-keras/
是的,但那对 Mask R-CNN 不起作用,因为它使用 model.train 而不是 model.fit 进行训练。我发现 Mask R-CNN 模型与其他模型不同。请参考 matterport mask rcnn
@James Carmichael 所以我需要支持来可视化 Mask R-CNN 输出参数的准确率和损失图。
提前感谢!!!
这里做得很好。我有一个非常简单的问题,这个模型是否可以用于检测多个类别?
我需要开发一个模型来检测建筑缺陷,如裂缝、风化、锈斑等。
提前感谢您的回复。
嗨 Sushant…以下资源可能有助于澄清
https://discuss.pytorch.org/t/multi-class-implementation-mask-rcnn/70476/11