对象检测是计算机视觉中的一项任务,涉及识别给定照片中一个或多个对象的存在、位置和类型。
这是一个具有挑战性的问题,它需要建立在物体识别(例如,它们在哪里)、物体定位(例如,它们的范围是什么)和物体分类(例如,它们是什么)方法的基础上。
近年来,深度学习技术在对象检测方面取得了最先进的结果,例如在标准基准数据集和计算机视觉竞赛中。值得注意的是“You Only Look Once”或 YOLO 系列卷积神经网络,它们通过单一的端到端模型实现了接近最先进的结果,能够实时执行对象检测。
在本教程中,您将学习如何开发 YOLOv3 模型来检测新照片中的对象。
完成本教程后,您将了解:
- 用于对象检测的 YOLO 系列卷积神经网络模型,以及称为 YOLOv3 的最新变体。
- Keras 深度学习库 YOLOv3 的最佳开源库实现。
- 如何使用预训练的 YOLOv3 对新照片执行对象定位和检测。
通过我新书《计算机视觉深度学习》开启您的项目,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 更新于 2019 年 10 月:已更新并针对 Keras 2.3.0 API 和 TensorFlow 2.0.0 进行了测试。

如何在 Keras 中使用 YOLOv3 进行对象检测
照片由 David Berkowitz 提供,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- YOLO 用于对象检测
- Experiencor YOLO3 项目
- 使用 YOLOv3 进行对象检测
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
YOLO 用于对象检测
对象检测是一项计算机视觉任务,它涉及在图像中定位一个或多个对象,并对图像中的每个对象进行分类。
这是一项具有挑战性的计算机视觉任务,它需要成功的对象定位(以定位并围绕图像中的每个对象绘制边界框)和对象分类(以预测被定位对象的正确类别)。
“You Only Look Once”(简称 YOLO)系列模型是由 Joseph Redmon 等人设计的、用于快速对象检测的端到端深度学习模型系列,首次在 2015 年的论文“You Only Look Once: Unified, Real-Time Object Detection”中进行了描述。
该方法涉及一个单一的深度卷积神经网络(最初是 GoogLeNet 的一个版本,后来更新并称为基于 VGG 的 DarkNet),它将输入分割成一个网格单元,每个单元直接预测一个边界框和对象分类。结果是大量的候选边界框,它们通过后处理步骤合并成最终预测。
截至撰写本文时,该方法有三个主要变体:YOLOv1、YOLOv2 和 YOLOv3。第一个版本提出了通用架构,而第二个版本优化了设计并使用了预定义的锚框来改进边界框提议,第三个版本进一步优化了模型架构和训练过程。
虽然这些模型的准确性接近但不如基于区域的卷积神经网络(R-CNNs),但它们因其检测速度而成为对象检测的热门选择,通常在视频或摄像头输入上实现实时检测。
单个神经网络通过一次评估即可直接从完整图像预测边界框和类别概率。由于整个检测管道是一个单一的网络,因此可以直接针对检测性能进行端到端优化。
— You Only Look Once: Unified, Real-Time Object Detection,2015。
在本教程中,我们将重点关注 YOLOv3 的使用。
Experiencor Keras-YOLO3 项目
YOLO 每个版本的源代码以及预训练模型均可用。
官方 DarkNet GitHub 存储库包含论文中提到的 YOLO 版本用 C 语言编写的源代码。该存储库提供了如何使用该代码进行对象检测的分步教程。
从头开始实现这个模型是一项挑战,尤其是对于初学者,因为它需要开发许多定制的模型元素来进行训练和预测。例如,即使直接使用预训练模型,也需要复杂的代码来提炼和解释模型预测的边界框。
与其从头开始开发此代码,不如使用第三方实现。有许多第三方实现旨在将 YOLO 与 Keras 结合使用,但没有一个是标准化并设计为用作库的。
The YAD2K project was a de facto standard for YOLOv2 and provided scripts to convert the pre-trained weights into Keras format, use the pre-trained model to make predictions, and provided the code required to distill interpret the predicted bounding boxes. Many other third-party developers have used this code as a starting point and updated it to support YOLOv3.
也许使用预训练 YOLO 模型最广泛使用的项目是名为“keras-yolo3: Training and Detecting Objects with YOLO3”(作者:Huynh Ngoc Anh 或 experiencor)。该项目的代码已根据宽松的 MIT 开源许可证提供。与 YAD2K 一样,它提供了用于加载和使用预训练 YOLO 模型以及用于在新数据集上开发 YOLOv3 模型的迁移学习的脚本。
他还有一个 keras-yolo2 项目,为 YOLOv2 提供了类似的 कोड 以及有关如何使用存储库中代码的详细教程。keras-yolo3 项目似乎是该项目的更新版本。
有趣的是,experiencor 使用该模型作为一些实验的基础,并在标准对象检测问题(如袋鼠数据集、浣熊数据集、红细胞检测等)上训练了 YOLOv3 的版本。他列出了模型性能,提供了模型权重供下载,并提供了模型行为的 YouTube 视频。例如
在本教程中,我们将以 experiencor 的 keras-yolo3 项目为基础,在 Keras 中使用 YOLOv3 模型执行对象检测。
如果存储库发生更改或被移除(第三方开源项目可能会发生这种情况),我们提供了截至撰写本文时的代码分支。
使用 YOLOv3 进行对象检测
The keras-yolo3 project provides a lot of capability for using YOLOv3 models, including object detection, transfer learning, and training new models from scratch.
在本节中,我们将使用预训练模型对未见过的照片执行对象检测。此功能包含在存储库中的一个 Python 文件“yolo3_one_file_to_detect_them_all.py”中,该文件大约有 435 行。该脚本实际上是一个程序,它将使用预训练权重来准备模型,并使用该模型执行对象检测并输出一个模型。它还依赖于 OpenCV。
我们不直接使用这个程序,而是重用这个程序中的元素,并开发我们自己的脚本来首先准备和保存 Keras YOLOv3 模型,然后加载模型以对新照片进行预测。
创建和保存模型
第一步是下载预训练的模型权重。
这些权重是在 MSCOCO 数据集上使用 DarkNet 代码库训练的。下载模型权重并将它们放在当前工作目录中,文件名设置为“yolov3.weights”。这是一个大文件,下载时间可能需要一段时间,具体取决于您的互联网连接速度。
接下来,我们需要定义一个 Keras 模型,该模型具有与下载的模型权重相匹配的正确数量和类型的层。模型架构称为“DarkNet”,最初松散地基于 VGG-16 模型。
The “yolo3_one_file_to_detect_them_all.py” script provides the make_yolov3_model() function to create the model for us, and the helper function _conv_block() that is used to create blocks of layers. These two functions can be copied directly from the script.
现在我们可以定义 YOLOv3 的 Keras 模型。
|
1 2 |
# 定义模型 model = make_yolov3_model() |
接下来,我们需要加载模型权重。模型权重以 DarkNet 使用的任何格式存储。我们不是手动解码文件,而是可以使用脚本中提供的 WeightReader 类。
要使用 WeightReader,需要使用权重文件的路径(例如,‘yolov3.weights’)对其进行实例化。这将解析文件并将模型权重加载到内存中,然后我们可以将其设置到我们的 Keras 模型中。
|
1 2 |
# 加载模型权重 weight_reader = WeightReader('yolov3.weights') |
然后,我们可以调用 WeightReader 实例的 load_weights() 函数,传入我们定义的 Keras 模型以将权重设置到层中。
|
1 2 |
# 将模型权重设置到模型中 weight_reader.load_weights(model) |
就是这样,我们现在有了一个可用的 YOLOv3 模型。
我们可以将此模型保存到 Keras 兼容的 .h5 模型文件中,以便将来使用。
|
1 2 |
# 将模型保存到文件 model.save('model.h5') |
我们可以将所有这些内容整合在一起;完整的代码示例,包括直接从“yolo3_one_file_to_detect_them_all.py”脚本复制的函数,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 |
# 创建一个 YOLOv3 Keras 模型并将其保存到文件 # 基于 https://github.com/experiencor/keras-yolo3 import struct import numpy as np 从 keras.layers 导入 Conv2D from keras.layers import Input 从 keras.层 导入 BatchNormalization from keras.layers import LeakyReLU from keras.layers import ZeroPadding2D from keras.layers import UpSampling2D from keras.layers.merge import add, concatenate from keras.models import Model def _conv_block(inp, convs, skip=True): x = inp count = 0 for conv in convs: if count == (len(convs) - 2) and skip: skip_connection = x count += 1 if conv['stride'] > 1: x = ZeroPadding2D(((1,0),(1,0)))(x) # peculiar padding as darknet prefer left and top x = Conv2D(conv['filter'], conv['kernel'], strides=conv['stride'], padding='valid' if conv['stride'] > 1 else 'same', # peculiar padding as darknet prefer left and top name='conv_' + str(conv['layer_idx']), use_bias=False if conv['bnorm'] else True)(x) if conv['bnorm']: x = BatchNormalization(epsilon=0.001, name='bnorm_' + str(conv['layer_idx']))(x) if conv['leaky']: x = LeakyReLU(alpha=0.1, name='leaky_' + str(conv['layer_idx']))(x) return add([skip_connection, x]) if skip else x def make_yolov3_model(): input_image = Input(shape=(None, None, 3)) # Layer 0 => 4 x = _conv_block(input_image, [{'filter': 32, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 0}, {'filter': 64, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 1}, {'filter': 32, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 2}, {'filter': 64, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 3}]) # Layer 5 => 8 x = _conv_block(x, [{'filter': 128, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 5}, {'filter': 64, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 6}, {'filter': 128, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 7}]) # Layer 9 => 11 x = _conv_block(x, [{'filter': 64, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 9}, {'filter': 128, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 10}]) # Layer 12 => 15 x = _conv_block(x, [{'filter': 256, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 12}, {'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 13}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 14}]) # 第 16 层 => 36 for i in range(7): x = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 16+i*3}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 17+i*3}]) skip_36 = x # 第 37 层 => 40 x = _conv_block(x, [{'filter': 512, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 37}, {'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 38}, {'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 39}]) # 第 41 层 => 61 for i in range(7): x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 41+i*3}, {'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 42+i*3}]) skip_61 = x # 第 62 层 => 65 x = _conv_block(x, [{'filter': 1024, 'kernel': 3, 'stride': 2, 'bnorm': True, 'leaky': True, 'layer_idx': 62}, {'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 63}, {'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 64}]) # 第 66 层 => 74 for i in range(3): x = _conv_block(x, [{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 66+i*3}, {'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 67+i*3}]) # 第 75 层 => 79 x = _conv_block(x, [{'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 75}, {'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 76}, {'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 77}, {'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 78}, {'filter': 512, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 79}], skip=False) # 第 80 层 => 82 yolo_82 = _conv_block(x, [{'filter': 1024, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 80}, {'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 81}], skip=False) # 第 83 层 => 86 x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 84}], skip=False) x = UpSampling2D(2)(x) x = concatenate([x, skip_61]) # 第 87 层 => 91 x = _conv_block(x, [{'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 87}, {'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 88}, {'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 89}, {'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 90}, {'filter': 256, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 91}], skip=False) # 第 92 层 => 94 yolo_94 = _conv_block(x, [{'filter': 512, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 92}, {'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 93}], skip=False) # 第 95 层 => 98 x = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 96}], skip=False) x = UpSampling2D(2)(x) x = concatenate([x, skip_36]) # 第 99 层 => 106 yolo_106 = _conv_block(x, [{'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 99}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 100}, {'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 101}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 102}, {'filter': 128, 'kernel': 1, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 103}, {'filter': 256, 'kernel': 3, 'stride': 1, 'bnorm': True, 'leaky': True, 'layer_idx': 104}, {'filter': 255, 'kernel': 1, 'stride': 1, 'bnorm': False, 'leaky': False, 'layer_idx': 105}], skip=False) model = Model(input_image, [yolo_82, yolo_94, yolo_106]) return model class WeightReader: def __init__(self, weight_file): with open(weight_file, 'rb') as w_f: major, = struct.unpack('i', w_f.read(4)) minor, = struct.unpack('i', w_f.read(4)) revision, = struct.unpack('i', w_f.read(4)) if (major*10 + minor) >= 2 and major < 1000 and minor < 1000: w_f.read(8) else: w_f.read(4) transpose = (major > 1000) or (minor > 1000) binary = w_f.read() self.offset = 0 self.all_weights = np.frombuffer(binary, dtype='float32') def read_bytes(self, size): self.offset = self.offset + size return self.all_weights[self.offset-size:self.offset] def load_weights(self, model): for i in range(106): try: conv_layer = model.get_layer('conv_' + str(i)) print("loading weights of convolution #" + str(i)) if i not in [81, 93, 105]: norm_layer = model.get_layer('bnorm_' + str(i)) size = np.prod(norm_layer.get_weights()[0].shape) beta = self.read_bytes(size) # bias gamma = self.read_bytes(size) # scale mean = self.read_bytes(size) # mean var = self.read_bytes(size) # variance weights = norm_layer.set_weights([gamma, beta, mean, var]) if len(conv_layer.get_weights()) > 1: bias = self.read_bytes(np.prod(conv_layer.get_weights()[1].shape)) kernel = self.read_bytes(np.prod(conv_layer.get_weights()[0].shape)) kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape))) kernel = kernel.transpose([2,3,1,0]) conv_layer.set_weights([kernel, bias]) else: kernel = self.read_bytes(np.prod(conv_layer.get_weights()[0].shape)) kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape))) kernel = kernel.transpose([2,3,1,0]) conv_layer.set_weights([kernel]) except ValueError: print("no convolution #" + str(i)) def reset(self): self.offset = 0 # 定义模型 model = make_yolov3_model() # 加载模型权重 weight_reader = WeightReader('yolov3.weights') # 将模型权重设置到模型中 weight_reader.load_weights(model) # 将模型保存到文件 model.save('model.h5') |
运行此示例在现代硬件上执行可能需要不到一分钟的时间。
在加载权重时,您将看到有关加载内容的调试信息,由WeightReader类输出。
|
1 2 3 4 5 6 7 8 |
... loading weights of convolution #99 loading weights of convolution #100 loading weights of convolution #101 loading weights of convolution #102 loading weights of convolution #103 loading weights of convolution #104 loading weights of convolution #105 |
在运行结束时,model.h5文件将保存在您的当前工作目录中,其大小与原始权重文件(237MB)大致相同,但已准备好直接加载和使用为Keras模型。
进行预测
我们需要一张新的照片来进行对象检测,最好是模型已知的来自MSCOCO数据集的对象。
我们将使用一张由Boegh在一次狩猎中拍摄的三个斑马的照片,并以宽松的许可发布。

三个斑马的照片
由Boegh拍摄,部分权利保留。
下载照片并将其命名为‘zebra.jpg‘,然后将其放在您的当前工作目录中。
进行预测很简单,但解释预测需要一些工作。
第一步是加载Keras模型。这可能是进行预测中最慢的部分。
|
1 2 |
# load yolov3 model model = load_model('model.h5') |
接下来,我们需要加载我们的新照片并将其准备成适合模型的输入。模型期望输入是彩色图像,分辨率为416×416像素。
我们可以使用Keras函数load_img()来加载图像,并使用target_size参数在加载后调整图像大小。我们还可以使用img_to_array()函数将加载的PIL图像对象转换为NumPy数组,然后将像素值从0-255缩放到0-1的32位浮点值。
|
1 2 3 4 5 6 7 |
# load the image with the required size image = load_img('zebra.jpg', target_size=(416, 416)) # 转换为numpy数组 image = img_to_array(image) # scale pixel values to [0, 1] image = image.astype('float32') image /= 255.0 |
稍后我们还需要再次显示原始照片,这意味着我们需要将所有检测到的对象的边界框从正方形形状缩放到原始形状。因此,我们可以加载图像并获取原始形状。
|
1 2 3 |
# load the image to get its shape image = load_img('zebra.jpg') width, height = image.size |
我们可以将所有这些内容整合到一个名为load_image_pixels()的便利函数中,该函数接受文件名和目标大小,并返回已缩放的像素数据,以便作为Keras模型的输入,以及图像的原始宽度和高度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# load and prepare an image def load_image_pixels(filename, shape): # load the image to get its shape image = load_img(filename) width, height = image.size # load the image with the required size image = load_img(filename, target_size=shape) # convert to numpy array image = img_to_array(image) # scale pixel values to [0, 1] image = image.astype('float32') image /= 255.0 # add a dimension so that we have one sample image = expand_dims(image, 0) return image, width, height |
然后,我们可以调用此函数来加载我们的斑马照片。
|
1 2 3 4 5 6 |
# define the expected input shape for the model input_w, input_h = 416, 416 # define our new photo photo_filename = 'zebra.jpg' # load and prepare image image, image_w, image_h = load_image_pixels(photo_filename, (input_w, input_h)) |
现在,我们可以将照片输入Keras模型并进行预测。
|
1 2 3 4 |
# 进行预测 yhat = model.predict(image) # summarize the shape of the list of arrays print([a.shape for a in yhat]) |
好了,至少在进行预测方面是这样。完整的示例将在下面列出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# load yolov3 model and perform object detection # 基于 https://github.com/experiencor/keras-yolo3 from numpy import expand_dims from keras.models import load_model from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array # load and prepare an image def load_image_pixels(filename, shape): # load the image to get its shape image = load_img(filename) width, height = image.size # load the image with the required size image = load_img(filename, target_size=shape) # convert to numpy array image = img_to_array(image) # scale pixel values to [0, 1] image = image.astype('float32') image /= 255.0 # add a dimension so that we have one sample image = expand_dims(image, 0) return image, width, height # load yolov3 model model = load_model('model.h5') # define the expected input shape for the model input_w, input_h = 416, 416 # define our new photo photo_filename = 'zebra.jpg' # load and prepare image image, image_w, image_h = load_image_pixels(photo_filename, (input_w, input_h)) # 进行预测 yhat = model.predict(image) # summarize the shape of the list of arrays print([a.shape for a in yhat]) |
运行此示例将返回一个包含三个NumPy数组的列表,其形状将显示为输出。
这些数组预测边界框和类别标签,但它们是经过编码的。必须对其进行解释。
|
1 |
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)] |
进行预测并解释结果
模型的输出实际上是来自三种不同网格尺寸的编码候选边界框,边界框是根据对MSCOCO数据集对象大小的分析仔细选择的锚框的上下文定义的。
experiencor提供的脚本提供了一个名为decode_netout()的函数,该函数将逐个接收NumPy数组,并解码候选边界框和类别预测。此外,任何不能确信地描述对象的边界框(例如,所有类别概率都低于阈值)都会被忽略。我们将使用60%或0.6的概率。该函数返回一个BoundBox实例列表,这些实例定义了每个边界框在输入图像形状和类别概率的上下文中的角点。
|
1 2 3 4 5 6 7 8 |
# 定义锚框 anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]] # 定义检测对象的概率阈值 class_threshold = 0.6 boxes = list() for i in range(len(yhat)): # 解码网络的输出 boxes += decode_netout(yhat[i][0], anchors[i], class_threshold, input_h, input_w) |
接下来,可以将边界框拉伸回原始图像的形状。这很有帮助,因为它意味着我们之后可以绘制原始图像并绘制边界框,希望能检测到真实的对象。
experiencor脚本提供了correct_yolo_boxes()函数来执行边界框坐标的这种转换,该函数将边界框列表、加载照片的原始形状以及网络的输入形状作为参数。边界框的坐标会直接更新。
|
1 2 |
# 修正边界框的大小以适应图像的形状 correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w) |
模型预测了很多候选边界框,其中大部分框将指向相同的对象。边界框列表可以进行过滤,那些重叠并指向同一对象的框可以合并。我们可以将重叠量定义为一个配置参数,在这种情况下是50%或0.5。这种边界框区域的过滤通常称为非极大值抑制,是一个必需的后处理步骤。
experiencor脚本通过do_nms()函数提供此功能,该函数接受边界框列表和阈值参数。它不是清除重叠框,而是清除它们对重叠类别的预测概率。这允许框保留并用于它们也检测到其他对象类型的情况。
|
1 2 |
# 抑制非极大值框 do_nms(boxes, 0.5) |
这将使我们拥有的框数量不变,但只有很少的框是我们感兴趣的。我们可以检索那些强烈预测对象存在的框:即置信度超过60%的框。这可以通过枚举所有框并检查类别预测值来实现。然后,我们可以查找框对应的类别标签,并将其添加到列表中。每个框都必须针对每个类别标签进行考虑,以防同一个框强烈预测多个对象。
我们可以开发一个get_boxes()函数来实现这一点,该函数将框列表、已知标签和我们的分类阈值作为参数,并返回框、标签和分数的并行列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 获取高于阈值的所有结果 def get_boxes(boxes, labels, thresh): v_boxes, v_labels, v_scores = list(), list(), list() # 枚举所有框 for box in boxes: # 枚举所有可能的标签 for i in range(len(labels)): # 检查此标签的阈值是否足够高 if box.classes[i] > thresh: v_boxes.append(box) v_labels.append(labels[i]) v_scores.append(box.classes[i]*100) # 不打断,一个框可能触发多个标签 return v_boxes, v_labels, v_scores |
我们可以调用此函数来处理我们的框列表。
我们还需要一个字符串列表,其中包含模型已知的类别标签,以及训练期间使用的正确顺序,特别是来自MSCOCO数据集的那些类别标签。幸运的是,这在experiencor脚本中提供了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 定义标签 labels = ["person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"] # 获取检测到的对象的详细信息 v_boxes, v_labels, v_scores = get_boxes(boxes, labels, class_threshold) |
现在我们有了使用YOLOv3模型进行预测、解释结果并绘制它们以供审查所需的所有元素。
|
1 2 3 |
# 总结我们发现的内容 for i in range(len(v_boxes)): print(v_labels[i], v_scores[i]) |
我们还可以绘制原始照片并围绕每个检测到的对象绘制边界框。这可以通过从每个边界框中检索坐标并创建Rectangle对象来实现。
|
1 2 3 4 5 6 7 8 9 |
box = v_boxes[i] # 获取坐标 y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax # 计算框的宽度和高度 width, height = x2 - x1, y2 - y1 # 创建形状 rect = Rectangle((x1, y1), width, height, fill=False, color='white') # 绘制边界框 ax.add_patch(rect) |
我们还可以绘制带有类别标签和置信度的字符串。
|
1 2 3 |
# 在左上角绘制文本和分数 label = "%s (%.3f)" % (v_labels[i], v_scores[i]) pyplot.text(x1, y1, label, color='white') |
下面的draw_boxes()函数实现了这一点,它接受原始照片的文件名以及边界框、标签和分数的并行列表,并创建一个显示所有检测到的对象的图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 绘制所有结果 def draw_boxes(filename, v_boxes, v_labels, v_scores): # 加载图像 data = pyplot.imread(filename) # 绘制图像 pyplot.imshow(data) # 获取绘制框的上下文 ax = pyplot.gca() # 绘制每个框 for i in range(len(v_boxes)): box = v_boxes[i] # 获取坐标 y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax # 计算框的宽度和高度 width, height = x2 - x1, y2 - y1 # 创建形状 rect = Rectangle((x1, y1), width, height, fill=False, color='white') # 绘制框 ax.add_patch(rect) # 在左上角绘制文本和分数 label = "%s (%.3f)" % (v_labels[i], v_scores[i]) pyplot.text(x1, y1, label, color='white') # 显示图表 pyplot.show() |
然后,我们可以调用此函数来绘制我们的最终结果。
|
1 2 |
# 绘制我们发现的内容 draw_boxes(photo_filename, v_boxes, v_labels, v_scores) |
现在我们拥有了使用YOLOv3模型进行预测、解释结果并绘制它们以供审查所需的所有元素。
完整的代码列表,包括从experiencor脚本中获取的原始和修改后的函数,为求完整性列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 |
# load yolov3 model and perform object detection # 基于 https://github.com/experiencor/keras-yolo3 import numpy as np from numpy import expand_dims from keras.models import load_model from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from matplotlib import pyplot from matplotlib.patches import Rectangle class BoundBox: def __init__(self, xmin, ymin, xmax, ymax, objness = None, classes = None): self.xmin = xmin self.ymin = ymin self.xmax = xmax self.ymax = ymax self.objness = objness self.classes = classes self.label = -1 self.score = -1 def get_label(self): if self.label == -1: self.label = np.argmax(self.classes) return self.label def get_score(self): if self.score == -1: self.score = self.classes[self.get_label()] return self.score def _sigmoid(x): return 1. / (1. + np.exp(-x)) def decode_netout(netout, anchors, obj_thresh, net_h, net_w): grid_h, grid_w = netout.shape[:2] nb_box = 3 netout = netout.reshape((grid_h, grid_w, nb_box, -1)) nb_class = netout.shape[-1] - 5 boxes = [] netout[..., :2] = _sigmoid(netout[..., :2]) netout[..., 4:] = _sigmoid(netout[..., 4:]) netout[..., 5:] = netout[..., 4] * netout[..., 5:] netout[..., 5:] *= netout[..., 5:] > obj_thresh for i in range(grid_h*grid_w): row = i / grid_w col = i % grid_w for b in range(nb_box): # 4th element is objectness score objectness = netout[int(row)][int(col)][b][4] if(objectness.all() <= obj_thresh): continue # first 4 elements are x, y, w, and h x, y, w, h = netout[int(row)][int(col)][b][:4] x = (col + x) / grid_w # center position, unit: image width y = (row + y) / grid_h # center position, unit: image height w = anchors[2 * b + 0] * np.exp(w) / net_w # unit: image width h = anchors[2 * b + 1] * np.exp(h) / net_h # unit: image height # last elements are class probabilities classes = netout[int(row)][col][b][5:] box = BoundBox(x-w/2, y-h/2, x+w/2, y+h/2, objectness, classes) boxes.append(box) return boxes def correct_yolo_boxes(boxes, image_h, image_w, net_h, net_w): new_w, new_h = net_w, net_h for i in range(len(boxes)): x_offset, x_scale = (net_w - new_w)/2./net_w, float(new_w)/net_w y_offset, y_scale = (net_h - new_h)/2./net_h, float(new_h)/net_h boxes[i].xmin = int((boxes[i].xmin - x_offset) / x_scale * image_w) boxes[i].xmax = int((boxes[i].xmax - x_offset) / x_scale * image_w) boxes[i].ymin = int((boxes[i].ymin - y_offset) / y_scale * image_h) boxes[i].ymax = int((boxes[i].ymax - y_offset) / y_scale * image_h) def _interval_overlap(interval_a, interval_b): x1, x2 = interval_a x3, x4 = interval_b if x3 < x1: if x4 < x1: return 0 else: return min(x2,x4) - x1 else: if x2 < x3: return 0 else: return min(x2,x4) - x3 def bbox_iou(box1, box2): intersect_w = _interval_overlap([box1.xmin, box1.xmax], [box2.xmin, box2.xmax]) intersect_h = _interval_overlap([box1.ymin, box1.ymax], [box2.ymin, box2.ymax]) intersect = intersect_w * intersect_h w1, h1 = box1.xmax-box1.xmin, box1.ymax-box1.ymin w2, h2 = box2.xmax-box2.xmin, box2.ymax-box2.ymin union = w1*h1 + w2*h2 - intersect return float(intersect) / union def do_nms(boxes, nms_thresh): if len(boxes) > 0: nb_class = len(boxes[0].classes) else: return for c in range(nb_class): sorted_indices = np.argsort([-box.classes[c] for box in boxes]) for i in range(len(sorted_indices)): index_i = sorted_indices[i] if boxes[index_i].classes[c] == 0: continue for j in range(i+1, len(sorted_indices)): index_j = sorted_indices[j] if bbox_iou(boxes[index_i], boxes[index_j]) >= nms_thresh: boxes[index_j].classes[c] = 0 # load and prepare an image def load_image_pixels(filename, shape): # load the image to get its shape image = load_img(filename) width, height = image.size # load the image with the required size image = load_img(filename, target_size=shape) # 转换为numpy数组 image = img_to_array(image) # scale pixel values to [0, 1] image = image.astype('float32') image /= 255.0 # add a dimension so that we have one sample image = expand_dims(image, 0) return image, width, height # 获取高于阈值的所有结果 def get_boxes(boxes, labels, thresh): v_boxes, v_labels, v_scores = list(), list(), list() # 枚举所有框 for box in boxes: # 枚举所有可能的标签 for i in range(len(labels)): # 检查此标签的阈值是否足够高 if box.classes[i] > thresh: v_boxes.append(box) v_labels.append(labels[i]) v_scores.append(box.classes[i]*100) # 不打断,一个框可能触发多个标签 return v_boxes, v_labels, v_scores # 绘制所有结果 def draw_boxes(filename, v_boxes, v_labels, v_scores): # 加载图像 data = pyplot.imread(filename) # 绘制图像 pyplot.imshow(data) # 获取绘制框的上下文 ax = pyplot.gca() # 绘制每个框 for i in range(len(v_boxes)): box = v_boxes[i] # 获取坐标 y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax # 计算框的宽度和高度 width, height = x2 - x1, y2 - y1 # 创建形状 rect = Rectangle((x1, y1), width, height, fill=False, color='white') # 绘制框 ax.add_patch(rect) # 在左上角绘制文本和分数 label = "%s (%.3f)" % (v_labels[i], v_scores[i]) pyplot.text(x1, y1, label, color='white') # 显示图表 pyplot.show() # load yolov3 model model = load_model('model.h5') # define the expected input shape for the model input_w, input_h = 416, 416 # define our new photo photo_filename = 'zebra.jpg' # load and prepare image image, image_w, image_h = load_image_pixels(photo_filename, (input_w, input_h)) # 进行预测 yhat = model.predict(image) # summarize the shape of the list of arrays print([a.shape for a in yhat]) # 定义锚框 anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]] # 定义检测对象的概率阈值 class_threshold = 0.6 boxes = list() for i in range(len(yhat)): # 解码网络的输出 boxes += decode_netout(yhat[i][0], anchors[i], class_threshold, input_h, input_w) # 修正边界框的大小以适应图像的形状 correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w) # 抑制非极大值框 do_nms(boxes, 0.5) # 定义标签 labels = ["person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"] # 获取检测到的对象的详细信息 v_boxes, v_labels, v_scores = get_boxes(boxes, labels, class_threshold) # 总结我们发现的内容 for i in range(len(v_boxes)): print(v_labels[i], v_scores[i]) # 绘制我们发现的内容 draw_boxes(photo_filename, v_boxes, v_labels, v_scores) |
运行示例,再次打印模型输出的原始形状。
接下来是模型检测到的对象及其置信度的摘要。我们可以看到模型检测到了三只斑马,置信度都高于 90%。
|
1 2 3 4 |
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)] zebra 94.91060376167297 zebra 99.86329674720764 zebra 96.8708872795105 |
创建了照片的图,并绘制了三个边界框。我们可以看到模型确实成功地检测到了照片中的三只斑马。
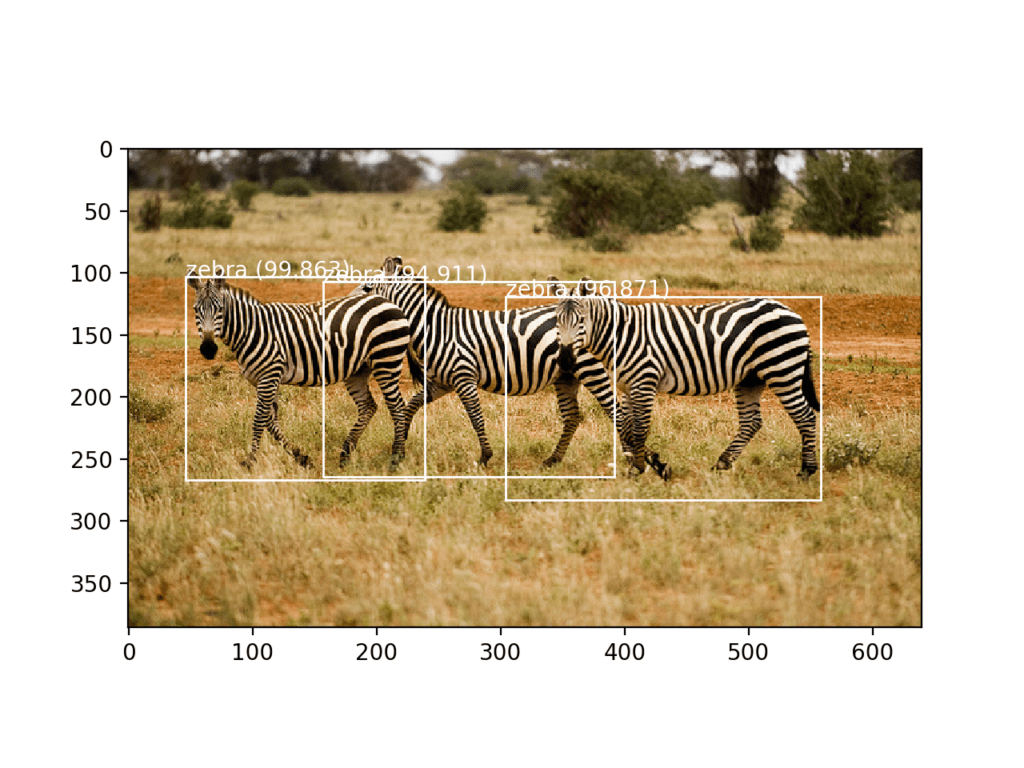
使用 YOLOv3 模型检测斑马并用边界框定位的照片
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- You Only Look Once:统一、实时目标检测, 2015.
- YOLO9000:更好、更快、更强, 2016.
- YOLOv3:渐进式改进, 2018.
API
资源
- YOLO:实时对象检测,主页.
- 官方 DarkNet 和 YOLO 源代码,GitHub.
- 官方 YOLO:实时对象检测.
- Huynh Ngoc Anh, experiencor, 主页.
- experiencor/keras-yolo3, GitHub.
其他 Keras YOLO 项目
总结
在本教程中,您将学习如何为新照片上的对象检测开发 YOLOv3 模型。
具体来说,你学到了:
- 用于对象检测的 YOLO 系列卷积神经网络模型,以及称为 YOLOv3 的最新变体。
- Keras 深度学习库 YOLOv3 的最佳开源库实现。
- 如何使用预训练的 YOLOv3 对新照片执行对象定位和检测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






非常感谢,机器学习用于对象检测!你开阔了我的视野,但我是一名游戏开发者,所以通常边界框是已知的。我对围棋游戏感兴趣,希望能理解围棋中的机器学习,你能给我指个方向吗?
谢谢。
抱歉,我没有关于游戏的教程,我无法给你好的建议。
皮肤伤口护理使用哪种模型?
也许可以在你的问题上测试一系列模型,然后选择表现最好的模型。
太棒了 @Jason Brownlee,我遇到了像 ValueError: If your data is in the form of symbolic tensors, you should specify the
stepsargument (instead of thebatch_sizeargument, because symbolic tensors are expected to produce batches of input data) 这样的问题,当我调用 Model.predict(image) 时。@Jasin Brownlee, It was very interesting and very well narrated. Could you please include , how would we add additional training set and labels ?
Let say, I want this model to train on additional data, to classify Faces, or Hand Scribbled Digits and alphabets ? Suppose I have an additional training & test data set.
Yes, I give an example here
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
@Jason, Could we use this same Yolo Model to train, instead of Mask R-CNN ?
Yes, but I don’t have a tutorial on this, sorry. I hope to cover it in the future.
Hi Jason, thanks for this very nice tutorial.
It would be really interesting to have at the end an example of training this yolo model on a new custom dataset.
What format the label should have? What loss function to use? Thanks!
感谢您的建议。
也许这个例子会有帮助
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
Thanks, but it would be super cool to have the example with yolov3 instead !
感谢您的建议。
choose steps=2
Nice article,
I found also an interesting beginner’s guide of YOLOv3 here
https://machinelearningspace.com/the-beginners-guide-to-implementing-yolov3-in-tensorflow-2-0-part-1/
感谢分享。
Amazing post, thanks for sharing
谢谢,很高兴它有帮助。
Hi sur, I just want to use the Darknet 53 as a features extractor to my dataset
How can I get these features using Darknet 53 only?
Sorry, I don’t have a tutorial on darknet, I cannot give you good off the cuff advice.
嗨,Jason,
Thanks for this great lesson. Have you tried to run any custom object using experiencor’s codes namely gen_anchor.py and train.py? If so, have you faced any error? gen_anchor.py threw me some errors even with his own config file for raccoon dataset and unfortunately he’s not being responsive. Thank you!
Kindly also make a blog on How we train a custom object detection with YOLO3
很好的建议,谢谢。
Here’s a custom model for kangaroo detection using Mask RCNN
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
Any updates on this??? No where online seems to attempt to even do this…
Hopefully in the future.
Jason, thank you very much for introducing computer vision so clearly! Could you specify in what part we saved our trained model to the disk?
The model was pre-trained, we simply loaded it.
Thank you so much for clean working code!) Could you advise some working and understandable GitHub repository for YOLOv3 for detecting objects on video, experiencer case is not clear in steps(
I hope to cover this in the future, thanks for the suggestion.
Thank you so much Sir! Very amazing and informative tutorial . I am beginner and following your tutorials for learning deep learning.
kindly Sir!
1) use YOLOv3 for camera video or simple video
2) use LSTM for video sequence
It will be great helpful for me
很好的建议,谢谢。
Thanks so much for posting such a good tutorial, thanks!!!
不客气,我很高兴它有帮助。
Thank you so much sir for your helpful tutorial.
Could you tell me how can i change the number and titles of labels in this model ? or labels are unchangeable ?
The number of classes. Yes, you can fit a new object detection model with the image and classes in your dataset.
I given an example here
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
Amazing guide Jason.
At the start I experienced some difficulty with the library, since the latest version of Tensorflow did not work. I downgraded it to v1.12 and it worked.
Thanks for the introduction to CV and YOLOv3. It was fun trying it out with my own images.
Thanks, and well done.
I tested it with TensorFlow 1.13 on Ubuntu Linux and MacOS without incident.
What OS/platform are you on?
i was using pycharm on windows using anaconda as the python interpreter.
Irregardless, I will be moving on to the kangaroo tutorial since I managed to run the process successfully.
Thanks again for creating these tutorials
干得不错。
I am getting “AbortedError: Operation received an exception:Status: 3, message: could not create a dilated convolution forward descriptor, in file tensorflow/core/kernels/mkl_conv_ops.cc:1111
[[{{node conv_1/convolution}}]]” error in predictin step.
Using tensorflow 1.13.1
I have not seen that error before, sorry.
Perhaps try TF 1.14, and check that your keras is up to date?
I have the same error message
Sorry to hear that, I can confirm the example works with the latest versions of all libraries.
也许这里的某些建议会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Great tutorial Jason. Very well laid out and easy to follow. I’m hoping to extend the tutorial to consider training on a custom data set. Would love to see a follow up blog on this 🙂
Keep up the great work!
很好的建议,谢谢。
Perhaps this post will be helpful
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
嗨
How to detect objects using YOLO in videos?
Also, is it possible to detect only 1 particular object (say, person) using this?
Perhaps you can process each frame as an image, or every 25th frame.
你好,
Great tutorial, thank you so much. How can I access the location of an object in an image? I would like to know, for instance, where the zebras are in the image (coordinates of the center of the bounding boxes) and save this data to a file.
The model will output bounding boxes (pixel coordinates) that you can use any way that you wish.
In this tutorial, we simply draw the box.
你好,
I keep getting the following coordinates
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)]
No matter how many different images I’m experimenting with, could you please tell me why?
It doesn’t look like a bounding box to me. Can you check?
I didn’t change anything in the code, only the image files, what should I check?
Thanks for an ELI5 guide Jason!
In interpreting the prediction array with decode_netout(), one of the argument was the anchors that you defined
anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]]
Is this suppose to be an initial guess for a bounding box of where the object may be?
好问题。
It is the shape of the anchor boxes used during training. From the post
But what those anchors are? What are they used for? I’m guessing I my question is the same as Ivan’s.
They are chosen to best capture objects in the image net dataset, chosen based on that dataset.
They are used when making a prediction to help quickly find objects in your new photos – e.g. bounding boxes in the image data.
嗨,Jason,
Question regarding anchors as they are hard coded, is it possible to derive them programmatically from yhat or the three NumPy array values or some other mechanism ?
Also each array of ‘anchors’ having 6 elements is also puzzling, would be nice to know the process/documentation for defining these values.
Good tutorial and helpful in getting started.
A suggestion if you could cover on the the steps to generalize this code e.g. if I pass file path of a photo of a cat or a car etc. code should able to detect that just like it did for zebra ?
非常感谢。
They are derived based on the average size of objects in a training dataset.
You could derive them based on the expected object size in your dataset if you like.
This article helped me understand this.
https://medium.com/analytics-vidhya/yolo-v3-theory-explained-33100f6d193
From what i can gather the algorithm has set bounding box sizes it uses. Each “cell” (IE small division of the larger image) the probability that this cell contains a specific object is computed for each anchor box size.
So if you have an image made up of 10 x 10 cells, and 5 anchor sizes, AND 100 objects to detect you will get an output of size
10 x 10 x 5 x 100
10 x 10 for each cell
x 5 for each anchor size
x 100 for each object
each of these will be a probability and we take probabilities which meet a certain threshold.
I’m just learning this so PLEASE correct me if i’m mistaken.
Yes, it is along those lines.
嗨,Jason,
I have followed through the Experiencor YOLO3 for Keras Project to train with my own data set. If i would like to crop the bounding box from the newly predicted images, how do i go about it?
谢谢你
The model will output bounding boxes, you can use them directly on the image pixels.
Thanks a lot for the response Jason. I managed to get good outputs with new images. However, the mAP performance of the model indicates 0.000 which is very strange. Could there be any reasons for it?
干得好。
Perhaps test a suite of images to see if that uncovers more information?
awesome tutorial sir !! Please answer this question https://datascience.stackexchange.com/questions/54306/transfer-learning-on-yolo-using-keras
many thanks
Perhaps you can summarize it briefly for me?
Great work Jason.
Can you also tell me how to train in with a new dataset?
Mainly the format of annotation of the dataset to train with.(The YOLOv2 of this repository used .xml format like that of pascalVOC).
Is it the same or something different?
Also I need train the model with transfer learning.
So which all layers should I train?
If possible can you please give an idea about the code to use?
谢谢你
I hope to cover that in the future.
Hi Jason, thx for this example !
note that I found that there is some vertical down shift of the output boxes (it can be seen on your “zebra” image output above, the 3 boxes are sligthly too low. The shift can be really bigger on some other images I tested. Even on 416×416 input images)
Any chance you fix this soon ?
Many thanks anyway!
Thanks, I may investigate.
你好,
This is an awesome tutorial. I went through it but at the end did not get a picture with bounding boxes as shown. I only got the array values and predictions for zebra and percentages.
A figure with the bounding boxes wasn’t created.
有什么想法吗?
谢谢你
Did you try running the example from the command line
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
Yes,
I am using Debian stretch subsystem under Windows
Is there in the book any additional content in addition to what is in this article?
Concretely, I would be interested in the training process 😉
Sorry, I don’t have an example of training a YOLO model, only using one.
I do have an example of training a Mask RCNN, which is reported to perform better
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
是的,我这里有一本关于深度学习计算机视觉的书。
https://machinelearning.org.cn/deep-learning-for-computer-vision/
这有帮助吗?
谢谢您的回答。我知道这本书,并且正在考虑购买它,但我不能确定我能否在那里找到我需要的东西。
我需要使用我自己的数据来训练 YOLO 网络。书中有合适的例子吗?关于 YOLO 的内容比这篇文章更多吗?
不,抱歉,书中的例子侧重于训练 Mask R-CNN。
模型的编译是不是缺失了?
这种情况下不需要。
我想运行这段代码。但它太慢了。我认为它没有在 GPU 上运行。如何通过 GPU 测试它?我想在 Jupyter Notebook 中运行它。
也许可以尝试在 AWS EC2 实例上运行?
方法如下
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
非常感谢您发布如此好的教程。我的问题是如何使用 YoloV3 检测自定义类别(标签)?换句话说,如何重用(重新训练)它来检测自定义对象?
我推荐使用 Mask R-CNN,我在这里展示了如何操作。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
谢谢。哪一个(Yolo3 和 Mask R-CNN)更准确,结果更精确?
我认为 YOLO 模型更快,而 R-CNN 模型更好。
如何用我的数据训练模型
您可以按照此教程进行操作。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
一如既往的出色帖子。一个问题。我有一些 .pt(pytorch)格式的 yolo 权重。是否有可能以某种方式加载此 .pt 文件或对其进行转换,以便将其加载到 Keras 实现的 yolo 中?非常感谢!!!
可能可以转换它们。
抱歉,我没有这方面的例子。
感谢您的回复,Jason。我会去查一下。
不客气。
我有一个关于模型的技术问题。最后一层是如何知道哪些单元对应于哪个单元格的,因为它与前一层密集连接?
抱歉,您确切地指什么?
YOLO 网络输出是 S x S x N 个值,其中 S 是两个图像方向上的单元数。因此,网络为图像的每个单元预测 N 个值。
如果我理解得没错,每一组 N 个值都为相应的图像单元提供了预测。
我的问题是,当所有东西都密集地连接在一起时,给定的图像单元如何对应于特定的 N 值集?换句话说,网络是如何“知道”预测值的哪一组是图像的哪个部分的?
我知道这个问题可能有点令人费解,但我希望我现在已经说清楚了。
好问题。
模型的原始输出会经过一些后处理函数,以将一组可能的预测减少到一组有用的清晰预测。
模型的原始输出和处理后的输出在此帖子中有更详细的讨论。
https://machinelearning.org.cn/object-recognition-with-deep-learning/
谢谢您的回答!
不客气。
再问一个问题 😉 输出是一个大小为 n x S x S x (B*5 + C) 的张量,其中 n 是锚点大小的数量,S x S 是单元格的数量,B 是每个大小的锚点数量,C 是类别的数量。在我们的模型中,我们有 3 个不同大小的锚点,MSCOCO 数据集有 80 个类别,所以输出张量的大小应该是:(3,S,S,3*5+80),即 (3,S,S,95)。但是,我们的输出是 (3,S,S,255)。这是为什么?
不完全是,输出是编码的。
您可以查看帖子中的解码函数,了解如何解释 3D 输出。
哦,我明白了。再次感谢!😉
我是机器学习新手。如果我们使用预训练权重来训练自定义(新)对象,它会检测旧对象吗?例如,预训练权重检测 80 个对象(类别),我使用此权重来训练我的新对象(类别)。它会检测 81 个对象还是只有一个(新对象)?
如果它只检测一个(新对象),如何使其检测 81 个对象?
提前感谢
您必须在包含原始训练数据集和新类别的数据集上进行训练。
从预训练权重开始会大大加快速度!
非常感谢您这篇出色的帖子。我有一个问题。在 correct_yolo_boxes() 函数中,计算偏移量和缩放比例的目的是什么?我认为偏移量和缩放比例总是 0 和 1,它们没有影响。
我认为我们正在将框缩放到图像的大小。
你好,correct_yolo_boxes() 实现中是否有错别字?函数中的第一行:new_w, new_h = net_w, net_h 会使偏移量和缩放比例始终为 0 和 1。
感谢您的帖子,它给了我很大的帮助。
谢谢。
那么,这段代码怎么样?
偏移量和缩放比例始终为 0 和 1。
这是错误吗?
正确的代码是什么?
anyone trying to understand how the Yolov3 outputs are in the shapes they are, this(https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b) is an amazing resource.
感谢您的代码演练 Jason!
感谢分享。
出色的文章,谢谢。
我使用 Darknet 训练了我自己的 YOLOv3 模型,带有自定义类别(少于默认的 80 个)。因此,我也有一个新的 .cfg 文件和权重文件。
我想使用 Keras 在 TensorFlow 中进行推理,而不是 Darknet。
有没有办法使用您的程序做到这一点?我没有看到可以指定我自己的 .cfg 文件的位置。它似乎只接受权重文件。
谢谢。
可能有一种方法,我暂时不确定,抱歉。可能需要做一些实验。
我尝试将每个 YOLO 层中的过滤器数量从 255 更改为 (num_classes + 5)*3。我能够获得推理结果,但它们与我在原始 Darknet 中获得的结果不匹配。
进展不错!
非常感谢您如此简单而详尽的解释。
代码运行正常,但我有一个问题,无法保存模型。
当我保存任何模型时,都会收到以下错误:
错误!F:\NITD\Project\Code\model.h5 not UTF-8 encoded.
已禁用保存。
这太奇怪了。
也许是您的 h5py 库出了问题?
也许可以尝试在 stackoverflow 上发布/搜索相关问题?
你好,我正在尝试在视频上执行此对象检测,但收到错误。请查看此。
ERROR: rectangle() missing required argument ‘rec’ (pos 2)
这是示例代码。您知道如何修复它吗?我尝试了很多方法。
def cv(frame, x, y, w, h, v_lables, v_scores)
cv2.rectangle(img = frame,
pt1 = (x, y),
pt2 = (x + w, y + h),
color = (0, 0, 255),
thickness = 2,
lineType = cv2.LINE_AA)
cv2.putText(frame, “{}-{}”.format(v_labels,v_scores), (x + w, y),
cv2.FONT_HERSHEY_SIMPLEX,
fontScale = 1, color = (255, 255, 255), thickness = 1, lineType = cv2.LINE_AA)
return frame
reader = imageio.get_reader(‘video.mp4’)
fps = reader.get_meta_data()[‘fps’]
writer = imageio.get_writer(‘output1.mp4’, fps = fps)
for i,frame in enumerate(reader)
image, image_w, image_h = load_image_pixels(frame, (input_w, input_h))
yhat = model.predict(image)
for j in range(len(yhat))
boxes += decode_netout(yhat[j][0], anchors[j], class_threshold, input_h, input_w)
correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w)
do_nms(boxes, 0.5)
v_boxes, v_labels, v_scores = get_boxes(boxes, labels, class_threshold)
for z in range(len(v_boxes))
box = v_boxes[z]
y1, x1, y2, x2 = box.ymin, box.xmin, box.ymax, box.xmax
width = x2 – x1
height = y2 – y1
frame = cv(frame, x1, y1, width, height, v_labels[z], v_scores[z])
writer.append_data(frame)
print(i)
听到这个消息我很难过,我这里有一些建议可能有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好 Sachin,
可以分享一下你检测视频的视频代码吗?
谢谢你
嗨 Sachin,你能发给我视频/网络摄像头对象检测的代码吗?
嘿,你能不能给我视频对象检测的代码?
没关系,我已经解决了。谢谢!
很高兴听到这个消息。
可以分享代码吗?
你好 Jason,
感谢您提供全面的教程。
2 个问题
1)我尝试删除标签中的一些对象,图像打开时没有应用算法,上面没有任何标记。我们如何添加像(罐子、扬声器等)这样的对象,或者修改当前的列表?
2)当算法工作时,它的表现确实很好。我们能否从代码中更改边界框锚点,还是必须从训练源代码中完成?如果我们想增加框的高度怎么办?
我知道这些是深入的问题,如果您能提供任何简短的步骤或来自您的书籍/帖子的研究提示,我将不胜感激。
谢谢!
您可能需要深入研究论文和开源实现,或者转向 Mask R-CNN。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
谢谢!
我会去看看的。
谢谢。
所以,我尝试用上面的代码预测一张图片,但得到了这个错误:
ValueError: If your data is in the form of symbolic tensors, you should specify the
stepsargument (instead of thebatch_sizeargument, because symbolic tensors are expected to produce batches of input data).有没有人知道是什么错了?提前感谢!
也许确认您的库是最新的,并且您将图像加载为 NumPy 数组?
代码适用于 zebra.jpg,但对于从互联网下载的大象和胡萝卜图片则失败了。
也许仔细检查图像是否已正确加载?
阈值过滤掉了正确的结果。不过现在可以了。
很高兴听到这个消息。
你到底是什么意思,它是过滤正确结果的阈值?当我尝试使用大象图片时,也发生了同样的问题,它没有给出 BB?我是否必须在每次输入不同类别的图片时更改阈值?
图片的类别值为 0.7,而我的阈值为 0.8,因此绘图图片没有输出。当我将阈值更改为 0.6 时,绘图图片显示了正确的结果。
感谢您出色的博客,我有一个请求。
就像“MaskR-CNN 的自定义训练”博客一样,也为 YOLO 写一篇博客。
感谢您的建议!
先生,如何将检测到的对象存储在边界框中作为单独的图像?
您可以使用边界框从图像中提取像素,例如对存储像素数据的数组进行索引。
我在这个帖子中提供了一个例子。
https://machinelearning.org.cn/how-to-perform-face-detection-with-classical-and-deep-learning-methods-in-python-with-keras/
感谢您不懈地教导我们这些通过互联网学习的人。互联网是我的大学。我目前正在做一个项目,使用 yolov3 算法从厚血涂片图像中检测疟疾寄生虫。我担心的是,yolov3 可能无法在寄生虫级别检测到对象,因为它们很小。您有什么建议?我有这些显微图像。
这听起来是一个很棒的项目。
我鼓励您测试一套不同的模型,并找出最适合您特定数据集的模型。
我们可以为判别式相关滤波器进行对象跟踪教程吗?https://arxiv.org/pdf/1611.08461.pdf
感谢您的建议。
谢谢。您的解释非常好。
只有一个问题。我怎样才能将带有检测对象的图像保存在磁盘上?
愿主保佑你。
谢谢。
您到底是什么意思?如何保存图像 - 如果是这样,请参阅此教程。
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
很棒的示例,但 decode_netout() 非常慢。有什么建议可以加快速度吗?例如,积极地修剪不需要的物品?
例如,如果我只对一种标签感兴趣怎么办?
好问题。您可能需要进行一些实验。
在这里找到了一个很好的提示。
https://github.com/experiencor/keras-yolo3/issues/177
或者替换
if(objectness.all() <= obj_thresh): continue
用
if (objectness <= obj_thresh).all(): continue
它使该函数的速度提高了几个数量级。
感谢分享。
我认为该行应如下更改:
if netout[int(row)][int(col)][b][5:].max() <= obj_thresh: continue
更正后的行运行良好。
我认为原始代码有错误。它使所有框都有效。
你好 Jason,感谢你提供的所有代码。我的朋友,我将 tensorflow 更新到 2.0 版本,这段代码不起作用。我将导入更改为 tensorflow.keras,但“Add”类在此行“return add([skip_connection, x]) if skip else x”中存在问题。您有什么建议吗?
如果您使用独立的 Keras v2.3.0 并在 TensorFlow 2.0 之上运行,代码可以正常工作。
非常感谢您的分享,我认为我对 YOLOv3 的理解更深了。
但我仍然不明白数字的含义
[(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)]
我认为 13*13 或 26*26 和 52*52 是三种不同大小的锚框。
但数字“1”和“255”是什么意思?
再次感谢您的帮助。
好问题。
是的,第一个维度(1)可以忽略,中间的是大小(13 或 26),最后的是框的数量,需要进行缩减或解释。
(1, 13, 13, 255) 转换成 (13, 13, 3, 85),其中 3 是 anch_boxes 的数量,3*85=255,这只是一个重塑操作
model.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples)
我该如何用这段代码进行检测?
请看标题为“进行预测”的部分。
Jason,
您有才华将这些教程汇编起来。我的学生使用其中一些进行初步培训。
问题:您是否有关于流式视频内容/对象识别的教程,可以在新一批实习生到来时使用?
谢谢,Peter
谢谢。
抱歉,我没有关于处理视频数据的教程,希望将来能涵盖。
你好,
我认为下面这行代码有误
44 netout[…, 4:] = _sigmoid(netout[…, 4:])
应该是
44 netout[…, 4] = _sigmoid(netout[…, 4])
您可以通过比较 experiencor/keras-yolo3 中的 utils.py 源代码和 yolo3_one_file_to_detect_them_all.py 来查看。
谢谢,我会安排时间进行调查。
我创建了一个用于锚框的文本文件,看起来像这样:
C:\path\00000002.jpg 0.33999999999999997,0.6900000000000001,0.7225,0.26,1 0.7775,0.40249999999999997,0.91,0.265,1 0.68,0.97,0.84,0.8025,1
..
(path x1,y1,x2,y2,class)
我是通过将 txt 文件的格式从如下格式转换而来的:
(class x y width height)
*使用不同的标注器
现在,当我尝试运行 train.py 并将我的锚框、类别、图片文件夹和输出文件夹的路径输入时,会收到错误消息。
使用 TensorFlow 后端。
2019-11-13 08:17:06.054804: I C:\tf_jenkins\workspace\rel-win\M\windows\PY\36\tensorflow\core\platform\cpu_feature_guard.cc:140] 您的 CPU 支持此 TensorFlow 二进制文件未编译使用的指令:AVX2
……………………………
回溯(最近一次调用)
File “train.py”, line 190, in
_main()
File “train.py”, line 42, in _main
with open(annotation_path) as f
FileNotFoundError: [Errno 2] No such file or directory: ‘train.txt’
我该怎么办?
很抱歉听到您遇到了这个问题,我这里有一些建议可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
你好,Jason!
您有没有可能写一篇关于如何用新类别重新训练这个 yolo 模型?使用标注数据?使用 labelImg (https://github.com/tzutalin/labelImg) 标注的数据?
是否仍然可以使用 Keras 完成此任务?
提前感谢,
Denis
感谢 Denis 的建议。
感谢与我们分享此教程。
我无法理解锚框大小如何与 decode_netout 中的 yhat 相关联。较小的输出尺寸 (13,13,255) 正与最大的维度锚框 [116,90, 156,198, 373,326] 进行比较。
当我们说锚框的尺寸是 116,90 时,它如何映射到原始图像?这些尺寸的单位是什么?
像素。
非常感谢,您能给我一些关于我如何使用此代码处理多视角数据集(任何一张图像有三个视角)的详细信息吗?
抱歉,我没有处理过多视角数据集的经验。我无法给您提供好的建议。
嗨,Jason,
Thanks for this great lesson. Have you tried to run any custom object using experiencor’s codes namely gen_anchor.py and train.py? If so, have you faced any error? gen_anchor.py threw me some errors even with his own config file for raccoon dataset and unfortunately he’s not being responsive. Thank you!
不。我使用 mask rcnn。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
Jason,感谢您的教程。您能解释一下 decode_netout 函数中第 42 行到第 46 行的代码吗?那部分操作对我来说很模糊。
boxes = []
netout[…, :2] = _sigmoid(netout[…, :2])
netout[…, 4:] = _sigmoid(netout[…, 4:])
netout[…, 5:] = netout[…, 4][…, np.newaxis] * netout[…, 5:]
netout[…, 5:] *= netout[…, 5:] > obj_thresh
特别是第 24 行。
netout[…, 5:] = netout[…, 4][…, np.newaxis] * netout[…, 5:]
您解决这个问题了吗?
嗨,Jason,
感谢您对 YOLO 的清晰演示。但是,我该如何使用此方法/模型来训练我自己的新数据集,而不是预加载的数据集?
非常感谢
Nadav
请看这个教程
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
你好,感谢您的教程,这对我帮助很大。我正在将 yolov3-tiny 实现到 Android 中,我得到了一个 [1,2535,85] 的输出数组。我仍然不清楚该如何处理它?
例如,哪些是类别的概率,哪些是 x、y 位置,哪些是宽度、高度?您能帮我吗?
谢谢。
抱歉,我对该模型不熟悉。
您解决这个问题了吗?
你好,
非常感谢您提供如此详细的教程。我可以在训练和测试时使用二值图像吗?
不客气。
你具体指的是什么?
感谢与我们分享此教程。
我是深度学习的初学者,正在尝试为测试数据集找到 YOLOv3 的准确率。我可以通过代码对单个图像进行预测,但无法对整个数据集进行预测。此外,我需要打印精确度和其他有用的参数来将 YOLOv3 与 MASK R-CNN 等其他方法进行比较。您能指导我如何做吗?
谢谢
不客气。
这会有帮助
https://machinelearning.org.cn/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
你好,
非常感谢您提供如此详细的教程,我是深度学习的初学者。我是否可以将此 YOLOv3 用于 CT 扫描图像中的癌症检测?
也许可以。您需要训练一个针对该领域的新模型。
也许可以考虑使用 mask rcnn。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
嗨,Jason,
感谢分享有趣的博客!
我使用 ssd (mobilenet-v1) 在自定义数据集上训练了目标检测。数据集包含 uno 扑克牌图像(跳过、反转、画四张)。在这所有卡牌上,模型表现都很好,因为我只在这 3 种卡牌上训练了模型(大约 278 张图像,829 个边界框,使用手机收集)。然而,我没有训练模型识别任何其他卡牌,但它仍然在推理(使用网络摄像头)时检测到其他卡牌。
我该如何解决这个问题?
请分享您的看法!
感谢您!
不客气!
可以创建一个“其他”类别,并在训练期间提供属于该类别的各种随机示例,然后编写代码在运行时忽略该类别。
Jason,感谢您的快速回复。
这是否也适用于真实场景?因为,比如说,目前我只寻找三张卡牌(跳过、反转和画四张),而忽略其余的卡牌(近 10 张)。
根据我的兴趣领域(跳过、反转和画四张卡牌),我收集了大约 278 张图像,带有 829 个边界框。正如您建议包含“其他”类别一样,我需要收集更多其他卡牌的图像。但在现实世界中,很难获得其他类别的图像。
您能否分享您的看法?
请随时纠正我。
感谢您!
“其他”只是指非主要关注的对象。您是在教模型忽略项目的主要焦点之外的内容。
或者,您可以在管道的上游设置一个限制模型“看到”的内容——例如,部署模型的环境。
太棒了!
感谢您的解释。我理解了您的第一点。关于您的第二点
[Jason]:您可以设置一个限制模型“看到”的内容
[Saurabh]:这意味着我不应该将其他类别的图像呈现给模型?这是真的吗?
您能否更详细地阐述第二点?
感谢您!
我的意思是,您可以控制模型的使用方式以及提供给它的数据。您控制环境,进而可以利用这一点来限制模型训练的范围/复杂性。
太棒了!
感谢您的解释。我感谢您的辛勤付出!
感谢您!
不客气,很高兴它对您有帮助。
解释得很棒。
如果我们有不同类别的集合,该怎么办?我可以在同一个 yolo 模型上训练我的新数据集吗?
另外,如果我有 10 个不同的目标类别,训练需要多长时间?
您需要训练一个新模型,这里有一个示例。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
是否可以在网络摄像头上进行实时检测并显示分数(百分比)?请提供实时检测的教程。
感谢您的建议。
嗨 Jason,请提供网络摄像头检测的教程。
感谢您的建议,也许将来会有。
你好
我该如何将数据集适配到这个代码的模型中?
我想将 json 文件或 cifar 10 数据集适配到此代码。
也许可以试试这个教程
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
make_yolov3_model()
{‘filter’: 64, ‘kernel’: 3, ‘stride’: 2, ‘bnorm’: True, ‘leaky’: True, ‘layer_idx’: 1},
{‘filter’: 32, ‘kernel’: 1, ‘stride’: 1, ‘bnorm’: True, ‘leaky’: True, ‘layer_idx’: 2},
—-> {‘filter’: 64, ‘kernel’: 3, ‘stride’: 1, ‘bnorm’: True, ‘leaky’: True, ‘layer_idx’: 3}])
ValueError: Variable bnorm_0/moving_mean/biased 不存在,或者不是使用 tf.get_variable() 创建的。您是否打算在 VarScope 中设置 reuse=tf.AUTO_REUSE?
我无法解决这个错误,每次我尝试创建 model = make_yolov3_model() 时
它都会从 make_yolov3_model() 的定义中给出相同的 value error。
很抱歉听到这个消息,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
感谢您考虑我的疑问。最终我能够解决它。这个问题是由于版本不兼容(Tensroflow1.13)造成的,后来我升级了所有东西,错误就消失了。
干得好!
你好 Jason,
我尝试实现了上面的代码。但是,我没有看到我的图像被框检测出来。
我得到了斑马的数组和绘图版本作为输出,但没有检测到。
附注:我没有使用命令提示符。
谢谢,
Rahul
很抱歉听到您遇到了这个问题,我的最好建议是这里。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
您能否解释一下为什么在
def make_yolov3_model()
input_image = Input(shape=(None, None, 3))
输入形状被设置为 None,None 而不是 416×416,我认为这是 yolo v3 的默认输入。
其次,如果我生成并训练一个具有此类 None,None,3 输入的模型,模型摘要将显示输入为 None,None,3。当我尝试将此模型转换为 tflite 时,它会引发错误,提示无法获取输入层的权重——这已在此处讨论过:
https://github.com/qqwweee/keras-yolo3/issues/48#issuecomment-486978323
我通过删除损失层创建了一个新模型,如下所示:
inferenceModel = Model(trainingmodel.input,outputs=[trainingmodel.layers[-7].output]
但是,我不知道如何使用正确的 Keras 语法来删除 None,None,3 输入层并将其替换为推理模型的 416,416,3 输入。
您能帮我吗?
为了保持列/行无边界。
我不知道 tflite,抱歉。
第一个问题,为什么模型创建为 None x None 而不是 416×416,您知道原因吗?
是的,我相信 None,None 的输入是为了让模型通用——让输入尺寸由提供的图像定义。
我明白了,谢谢。如果我的训练图像将具有固定的纵横比(即 416×416),我可以直接将其替换为固定大小——这也将解决 tflite 转换问题。
干得不错。
很棒的课程!!!您能写一篇更详细介绍 YOLO 的博客吗?我想一步一步学习如何构建一个像 YOLO 这样的模型并进行训练和预测。
谢谢。
好建议!
你好,我下载了预训练的权重 yolov3.weights,并将这段代码复制到同一个文件夹中,但却出现了文件未找到的错误。
ipython-input-2-3060e4e6db8a> in __init__(self, weight_file)
1 class WeightReader
2 def __init__(self, weight_file)
—-> 3 with open(weight_file, ‘rb’) as w_f
4 major, = struct.unpack(‘i’, w_f.read(4))
5 minor, = struct.unpack(‘i’, w_f.read(4))
FileNotFoundError: [Errno 2] No such file or directory: ‘C:\\Users\\Joych\\Downloads\\y1\\YOLOV3-master\\yolov3.weights’
尽管如此,错误表明您的代码和权重不在同一个文件夹中。
我在这段代码上遇到了问题。
yhat = model.predict(image)
Jupiter 错误。
AbortedError: Operation received an exception:Status: 3, message: could not create a dilated convolution forward descriptor, in file tensorflow/core/kernels/mkl_conv_ops.cc:1111
[[{{node conv_1_2/convolution}}]]
我的 Keras 版本:2.3.1
请帮助我 🙂
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
想获取 darknet 53 提取的特征。
这是否可能!
很可能。我没有使用该库的示例,抱歉。
嗨...
这真的很棒,对我帮助很大……
我只是问如何配置这个 Yolo 网络来处理新数据,比如车辆检测(微调)。
例如,针对 ua_detrac 数据?
谢谢
这是一个训练 mask rcnn 模型的示例。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
嗨
我需要执行时间大约为每秒 0.05 秒,但这段代码从读取图像到绘制边界框需要 12 秒。有没有什么方法可以缩短这个时间?
也许
更快的机器?
不同的实现?
更小的数据集?
我也遇到了这个问题,如果您知道如何解决,请告诉我。
嗨
非常感谢您提供的分步代码……
我想问一下,如果我想对我的数据进行“迁移学习”,该怎么办?例如,针对车辆……
不客气。
好问题,请看本教程
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
嗨,Jason,
我想在 coco 数据集中不存在的新对象上训练 yolov3。方法是什么?
我没有训练 yolo 的示例,但您可以在这里学习如何训练 rcnn。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
很棒的文章,谢谢。
我想知道 yolo 的输出数组是什么?有没有人能发送整个数组并解释数组的解码?
非常感谢您如此简单而详尽的解释。
我想在 GPU 上运行训练好的 YOLOv3 模型进行目标检测。我现在可以在 CPU 上运行您的代码(上面您解释过的代码),但我不知道如何为单个图像进行 GPU 目标检测。您能帮我解决这个问题吗?我强调,我只想进行单张图像的目标检测,而不是训练模型。
谢谢你
如果您配置了支持 GPU 的 TensorFlow 安装,那么 YOLO 就会在 GPU 上运行。
感谢如此出色的文章。
我想使用 predict_signature_def() 函数将此 yoloV3 模型导出到 tensorflow-serving。但我遇到了输出项
‘list’ 对象没有属性 ‘dtype’。
您有解决此问题的建议吗?非常感谢您的时间!
抱歉,我不知道。也许可以尝试将您的问题发布到 Stack Overflow 上。
Jason,精彩的文章。很喜欢阅读。
关于 netout 函数的代码有个问题。Experiencor 在输出数组的处理中添加了一个 _softmax 函数。这似乎会影响输出中的置信度。只是想听听您的看法。
netout[…, 5:] = netout[…, 4][…, np.newaxis] * _softmax(netout[…, 5:])
谢谢。
谢谢。
抱歉,我对此了解不多。或许可以直接联系他?
嗨,Jason,
我正在使用带有 Tesla-K80 GPU 的 AWS 实例。我首先配置了 TensorFlow 以使用 GPU。然后,我执行了 YOLOv3_model.py 来预测图像中的对象。但它花了大约 20 秒才预测出图像中的对象。我想知道是不是我哪里出错了,因为我期望执行时间是毫秒而不是 20 秒。您认为这个执行时间对于 GPU 上的 YOLO 预测来说正常吗??
谢谢
也许第一次启动会比较慢,后续的调用会更快。
boxes[i].xmin = int((boxes[i].xmin – x_offset) / x_scale * image_w)
ValueError: 无法将浮点数 NaN 转换为整数
我遇到了这个错误,因为很多值都是 nan。
顺便说一句,很棒的文章,谢谢。
看起来您的数据中不知何故出现了 nan?
我使用 AlexeyAB 训练的 yolov3 仓库处理了相同的图像,输出是正确的。
https://github.com/AlexeyAB/darknet#how-to-train-tiny-yolo-to-detect-your-custom-objects
我在您的代码中使用相同的训练权重,但在预测时,有非 nan 数组值,也有很多 nan 数组!
有趣,谢谢分享。
我也在 kaggle notebook 中收到此错误。我已正确复制您的代码。
这是错误
—————————————————————————
ValueError 回溯 (最近一次调用)
in
190 boxes += decode_netout(yhat[i][0], anchors[i], class_threshold, input_h, input_w)
191 # 校正边界框的大小以适应图像的形状
--> 192 correct_yolo_boxes(boxes, image_h, image_w, input_h, input_w)
193 # 抑制非极大值框
194 do_nms(boxes, 0.5)
在 correct_yolo_boxes(boxes, image_h, image_w, net_h, net_w) 中
70 x_offset, x_scale = (net_w – new_w)/2./net_w, float(new_w)/net_w
71 y_offset, y_scale = (net_h – new_h)/2./net_h, float(new_h)/net_h
--> 72 boxes[i].xmin = int((boxes[i].xmin – x_offset) / x_scale * image_w)
73 boxes[i].xmax = int((boxes[i].xmax – x_offset) / x_scale * image_w)
74 boxes[i].ymin = int((boxes[i].ymin – y_offset) / y_scale * image_h)
ValueError: 无法将浮点数 NaN 转换为整数
很抱歉听到这个消息,请尝试在命令行上从您的工作站运行。
嗨,Jason,
很棒的教程。解释和执行代码的过程都很好。如果我更改
输入图像 zebra 为其他图像,结果保持不变。我是否做错了什么?
我的工作是关于印度道路场景的道路检测。YOLO3 是否用于检测车道?如果是,请告诉我需要进行哪些修改才能实现车道检测。
谢谢。
不,我认为您需要针对您的数据集训练模型,或者使用预训练模型来解决此问题。
你好,我按照你的教程实现了 yolov3 模型,现在我想将我的 monodepth 深度估计模型与 yolov3 合并,我该怎么做?
干得好。
抱歉,我没有例子。
我了解到,为了确定锚框的形状,YoloV3 在其中使用 K-means 聚类。
那么为什么我们应该指定这些大小,
anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]]
在从上述模型获取预测时。
谢谢你。
它们是表现良好的框,可以作为起点。
你好 jason,
关于 YOLO 的绝佳文章。非常感谢
我就是不理解锚框的概念。正如您所提到的,您仔细检查了数据集并创建了这些锚框。如果您能进一步解释,我们可以获得更多知识来为我们的数据集创建自己的锚框。
我没有创建锚框,是 yolo 模型的开发者创建的。
一般来说,您需要一些框来匹配您照片中对象的平均大小。这些就是锚框。
是的,我读了一些关于锚框的更有趣的文章。正如您所提到的,我们最初会给出一些平均大小,这些大小可能覆盖我们的对象,但随着模型的训练,锚框会根据损失进行调整以适应对象。
感谢分享。
非常感谢您,Jason,这篇文章非常清晰地解释了一个高度复杂的模型。您是否了解任何尝试对 3D 数据进行目标检测的案例?在没有超级计算机的情况下训练这样的模型是否可行?
不客气。
抱歉,我对 3D 目标检测不太了解。
感谢这篇很棒的教程。
有没有办法使用相同的实现,但使用 yolo9000 权重和类?我想让 yolov3 检测超过 80 个类,但我没有自定义标记的数据集。我想让它使用 yolo9000 权重和类。这可能吗?
抱歉,我目前不清楚。
嗨,Jason,
您能告诉我们如何展平层,然后在之后添加一个 FC 层吗?
我试过了
flat1 = Flatten()(model.outputs)
class1 = Dense(1024, activation=’relu’)(flat1)
output = Dense(2, activation=’softmax’)(class1)
# 定义新模型
model = Model(inputs=model.inputs, outputs=output)
# 总结
model.summary()
并且遇到了错误“Layer flatten_1 expects 1 inputs, but it received 3 input tensors. Input received: [, , ]”。
我很乐意帮忙,但我没有能力调试您的更改,也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/can-you-change-the-code-in-the-tutorial-to-___
我理解,Jason。
model = Model(input_image, [yolo_82, yolo_94, yolo_106])。这是我们模型的最后一层。
我尝试展平这一层。这就是我遇到错误的原因。
我想我应该获取这三个层的输出,将它们堆叠起来,然后展平。我的想法对吗?
抱歉,我不明白您在做什么,无法给您好的建议。
请告诉我如何在我的数据上自定义 yolo 进行训练?
也许可以试试 Mask RCNN,看看这个教程。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
先生,我有一个关于激活函数的问题。先生,请告诉我为什么我们在 yolov3 中使用激活函数?
为什么我们在任何神经网络模型中使用激活函数?
激活函数为模型增加了非线性,使其能够学习复杂的表示和关系。
首先,感谢您提供的精彩且清晰的教程。
我想问您关于 yolo 检测器的主要思想(非极大值抑制)?您在代码的哪个地方应用了它?
它是在预测之后应用的,通过 do_nms() 函数。
Jason,感谢您提供此教程。
我正在尝试使用我的数据集训练模型,但在 Y_train 上遇到了问题,我不太明白在训练时应该在三个 NumPy 数组中放入什么。
抱歉,我没有训练 YOLO 模型的示例。
这可能有帮助
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
嗨,Jason,
感谢这篇很棒的教程。
我想知道 YOLO 系列是否是手机相机应用程序中用于检测人脸的模型,以及像这样的大模型(237MB)是如何集成到小型相机应用程序中的?
抱歉,我不知道模型的大小或移动应用程序。
我想问:如何定义锚框?
anchors = [[116,90, 156,198, 373,326], [30,61, 62,45, 59,119], [10,13, 16,30, 33,23]]
我认为这些来自论文或原始实现,基于数据集中对象的尺寸。
非常感谢,如何为自定义数据集实现 yolo v3?
我没有训练 yolo 的示例,但这个关于训练 mask rcnn 的示例可能有所帮助。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
如何在我自己的数据集上做到这一点?
看这里
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
Jason,当我运行此代码时,我只得到打印的图像,没有框或概率值。只是普通的原始图像。您能帮忙吗?
听到这个消息很抱歉,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好 Jason,我下载了权重文件并保存在我的电脑上,但当我使用 WeightReader 读取它们时,它给了我一个文件未找到的错误??
也许确保文件路径正确,并从命令行运行脚本。
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
你好 Jason,我有一个问题。您知道有一个经过训练的网络可以识别图像中的背景或场景吗?例如;这张图片中的背景是森林,这张图片中的背景是高速公路。
手头没有,抱歉。
Jason,很棒的教程,非常感谢!我有兴趣重新训练 YOLO 框架以检测其他事物,您在您的书中或别处是否有涵盖这一点?
谢谢
我没有重新训练 YOLO 的示例,但我有一个关于重新训练 Mask RCNN 的示例。
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
下午好 Jason。抱歉打扰。再次祝贺您的解释。Yolo v3 的解释非常好/有趣。但是,我有一个疑问。计算出的 v_boxes 除了边界框外,还提供了每个感兴趣类别的分数。例如,如果我只有一辆汽车,我只能得到一个分数,即仅针对汽车类别的相应分数。如何获得其他类别的相应分数?也就是说,针对同一对象,获得汽车类别的分数,获得人分类别的分数,以及获得自行车类别的分数。
预测将返回一个检测到的对象列表供您枚举。
好的,我会检查。非常感谢。
致以最诚挚的问候。
不客气。
下午好 Jason。抱歉打扰。BoundBox (v_box) 中的“objness”变量是否与置信度分数相同?如果是,objness 是否与 IOU 相同?
此致。
我没有写那个函数,也许可以直接问作者。
好的,我会问的。非常感谢。
Jason 先生您好
您的文章太棒了,内容详尽、令人兴奋且信息丰富。
您在这里使用了 yolov3 训练的权重,这些权重被设置为检测斑马。
我需要能够通过 Yolov3 算法识别汽车的类型及其颜色。
感谢您的帮助。
WhatsApp: 09174286232
谢谢!
也许您可以将示例应用于您的应用程序。
您解释得很清楚,Jason。您的博客是我看到的第一个让我对机器学习有清晰的认识的博客。我将这个博客推荐给了所有问我从哪里学习机器学习的人。在很长一段时间后,我阅读了这篇关于 yolov3 的特殊博客。感谢您的辛勤工作。愿上帝保佑您。
谢谢,很高兴听到这个!
我是机器学习新手。这篇文章是地球上最好的。通过一次复制粘贴,我就得到了我自己的结果图像!非常感谢您,Jason!
有一点,您能否帮助我创建一个 joblib dump 文件,以便我可以在 flask 服务器上运行它?再次感谢。
谢谢!
抱歉,我没有部署教程,也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/how-do-i-deploy-my-python-file-as-an-application
非常有帮助!
谢谢你,Jason!
不客气。
有人计算过以上教程的处理时间吗?
处理单张图像几乎需要 6-7 秒。
当我用它来处理视频时,视频变得非常慢。
有人能提供解决该问题的方法吗?
也许可以处理更少的帧?
或许在更快的机器上运行?
或许尝试一个替代实现?
先生,我有一个包含 21 个类别的图像数据集。类别高度不平衡,例如 5000 辆汽车,另一方面,20 辆警车,3 辆货车,90 辆 SUV……那么如何处理这个问题呢?我在 ultralytics 的 yolov3 中尝试了 focal loss 和 label smoothing,但结果更糟……他们在代码库中更改了很多东西,例如将 crossentropy loss 改为 bcewithlogistic loss 函数……我不知道该怎么办……我应该改用 two-stage detector,如 retina net 吗?或者手动扩充数据来增加类别实例?
我没有处理不平衡对象检测任务的经验,但也许这里的一些技术能给你一些启发
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
这个教程是为 Windows 还是 Linux 准备的。
在 macOS、Windows 和 Linux 上都进行了测试。
Hi Jason, thanks for this very nice tutorial.
模型的输出图像尺寸比输入图像的实际尺寸小得多
如何才能看到与输入图像尺寸相同的输出图像?
模型不输出图像,你可以以任何你喜欢的方式解释模型的预测。
谢谢你,Jason。
不客气。
嗨,我正在对手写段落文档图像进行单词定位(检测)。我正在考虑使用 YOLO,这个模型可以用于此吗?每页平均包含约 40 个单词。
我认为有更专业的文本定位技术,我建议您查阅相关文献。
嗨,Jason,
我有一个问题
如何使用 Yolo 网络输出?
例如,如何访问 b-box 的坐标,以便当它们在图像中的某个位置时,可以执行一些特殊操作?
我该如何以任何我喜欢的方式解释模型的预测?
你可以以任何你喜欢的方式解释预测。
模型输出一个矩形,你可以以任何你喜欢的方式解释它,例如,绘制它或用它来裁剪你的图像。
如何访问这个矩形?
代码的哪个部分允许我访问网络输出?
感谢您的指导
调用 model.predict() 的结果
非常感谢 Jason
不客气。
有史以来最好的对象检测帖子!!
谢谢!
那些锚是什么?
正如教程中所述,它们是训练数据图像中标准的物体尺寸。
感谢您的帖子。我们可以将输入更改为 1 来处理灰度图像吗?
不客气。
或许可以尝试将单个灰度通道复制到 RGB 通道,然后像平常一样提供给模型。
非常感谢这个很棒的教程,对我帮助很大!
不客气!
您的工作易于理解。感谢您的辛勤工作。您能否分享一下用于自定义对象检测的 faster RCNN?
谢谢!
这将有助于您入门
https://machinelearning.org.cn/how-to-train-an-object-detection-model-with-keras/
Jason 先生,您好!
感谢您发布的精彩博文。
我正在为网络摄像头实时馈送实现 yolov4。有一些观察结果需要您的支持
1. 当我在离线 CPU 上对视频运行 yolov4 时,它仅提供 0.2 的速度。
2. 对于图像预测,它每张图像需要 600 毫秒。
3. 请澄清:我们是否可以在 CPU 处理器上对网络摄像头实时馈送运行 yolov4 离线?
4. 如何在 CPU 上实现 yolov4 的硬件部署以进行实时网络摄像头馈送。
5. 我无法将网络摄像头与 yolov4 集成。请提供任何合适的材料或链接。
请指引。非常感谢。
不客气!
抱歉,我没有用网络摄像头使用过 yolo,我认为我不能为您提供好的建议。
它的帧率(每秒帧数)只有 0.2。这太慢了,因此无法在实时视频上运行
或许使用不同的模型?
或许使用更快的机器?
或许使用更少的帧?
或许使用更小的图像?
Jason 先生,感谢您的宝贵建议。
我尝试了一些建议,其观察结果如下:
(1) 我尝试了更小的尺寸,这提高了处理时间但降低了准确性。YOLO 的最小图像尺寸是多少才能获得最佳结果?或者这是一个超参数?
(2) 我尝试了 YOLO-tiny 版本。它的速度提高了近四倍,但准确性却急剧下降。例如,白色的狗被预测为绵羊,而且它也错过了许多物体。
(3) 减少类别/数量可以提高处理时间吗?
(3) 我们可以在 CPU 上部署 YOLO(在 GPU 上训练后)吗?……是/否??
请进一步指导。谢谢!
此致
NKM
干得好!
不确定最小尺寸,但使用非常小的图像可能还需要新的锚框尺寸。
是的,减少类别将降低问题的复杂性,从而需要一个更小的模型,该模型将更快。
YOLO 可以在 CPU 上正常运行,但可能较慢。
您有 YouTube 频道吗,或者您打算创建一个频道吗?
目前没有,也没有计划。
我认为视频不是学习应用机器学习的有效方式
https://machinelearning.org.cn/faq/single-faq/do-you-have-videos
一切都很好,但当我运行时
yhat = model.predict(image)。
我收到此错误
UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node conv_0_4/convolution (defined at C:\Users\CIEDEV\miniconda3\envs\nabin\lib\site-packages\keras\backend\tensorflow_backend.py:3009) ]] [Op:__inference_keras_scratch_graph_62618]
Function call stack
keras_scratch_graph
看起来您的 keras 安装/配置可能存在问题。
Jason 先生,您好。
感谢您的指导。
现在,我已经使用 YOLO 在 CPU 上实现了自定义对象检测器(离线)。
当我在 CPU 上运行此命令时
!./darknet detector demo data/obj.data cfg/yolov4-obj.cfg yolov4-obj_final.weights -dont_show MVI_1615_VIS.avi -i 0 -out_filename results.avi
我收到以下错误:
GPU 未使用
OpenCV 版本:3.2.0
names: 使用默认的 'data/names.list'
无法打开文件:data/names.list
请帮助。
我很抱歉听到这个消息。
或许检查一下您的库是否已更新?
你好。我复制了所有代码,并且运行成功了,但没有找到任何框。
它仍然输出 [(1, 13, 13, 255), (1, 26, 26, 255), (1, 52, 52, 255)]
但没有找到任何框,所以这是一张未改变的斑马图片。
您知道可能是什么出了问题吗?
decode_netout 现在也需要 nms_thresh,所以我尝试了一下。
这真是太奇怪了。
也许这些提示会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,我遇到了和 Kevin Lin 同样的问题,
我注意到
loading weights of convolution #99
no convolution #99
loading weights of convolution #100
no convolution #100
loading weights of convolution #101
no convolution #101
loading weights of convolution #102
no convolution #102
loading weights of convolution #103
no convolution #103
loading weights of convolution #104
no convolution #104
loading weights of convolution #105
no convolution #105
所以它没有加载所有的权重,尤其是最后的那些。我认为是权重/架构之间存在不匹配?
我可以确认,使用最新版本的 Keras 和 TensorFlow,模型可以正确加载和运行。
也许这些提示会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我成功地在本地的 jupyter 中运行了它。似乎由于某种原因,它在 google colab 上无法正常工作。
干得好!
Notebook 通常会给许多人带来很多问题
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
Brownlee 博士,
下午好,先生!这个教程,以及您总体上的《深度学习计算机视觉》书籍,都非常出色。我度过了过去的几个周末,仔细地阅读了您的书(接下来是 LSTMs,然后是 GANs),学到了很多东西。非常感谢您的所有工作!
敬礼,
Jeremy
谢谢 Jeremy!
Jason 先生,您好。
我正在尝试在网络摄像头上运行 YOLO,其中实时馈送来自摄像头以检测对象。
如何衡量模型的性能?如何计算准确率、精确率、召回率?现在,我只能根据执行每一帧所花费的时间来衡量速度。
恳请指导。
您可以定义一个测试数据集并选择一个指标,然后计算模型在该数据集上的预测指标。
运行时我发现了这个错误
ValueError: Dimension 1 in both shapes must be equal, but are 24 and 25. Shapes are [?,24,24] and [?,25,25]. for ‘{{node functional_1/concatenate/concat}} = ConcatV2[N=2, T=DT_FLOAT, Tidx=DT_INT32](functional_1/up_sampling2d/resize/ResizeNearestNeighbor, functional_1/add_18/add, functional_1/concatenate/concat/axis)’ with input shapes: [?,24,24,256], [?,25,25,512], [] and with computed input tensors: input[2] = .
有人能帮帮我吗?
或许这些提示会有帮助
https://machinelearning.org.cn/ufaqs/why-does-the-code-in-the-tutorial-not-work-for-me/
谢谢您,您的帖子真的帮了我很多!
不客气。
我没有在任何地方找到如何使用和链接已识别对象的边界框数据(yolo/keras 输出)作为机器学习算法的输入。您能给些建议吗?
此致
这称为数据标注,抱歉我没有关于此主题的教程。
好的,我会搜索这个主题,感谢您的澄清!
不客气。
嗨,Jason!
一如既往的精彩教程。它极大地帮助了我完成我自己的项目。
尽管如此,我有一个关于 YOLO 和将其与其他深度学习模型使用的问题。
你看,我想使用 GAN 进行分类(具有共享权重的独立判别器模型),我正在考虑使用 YOLO 的对象检测属性来提高准确率。
问题是我不知道如何组合这两个输出。
我曾考虑过
1. 获取 GAN 模型的输出
2. 获取 YOLO 模型的边界框和提取的类别
并以某种方式连接两个输出(也许使用 Keras API 和 concatenate 函数),但我不知道这是否有意义。
希望您能理解这一点并提供帮助。
附注:下个月我计划购买您的 CV 和 GAN 书籍。您是否还有其他与计算机视觉及相关主题相关的书籍?
我现在不知道,您需要编写自定义代码并进行一些实验,才能发现适合您的情况的方法。
我没有关于此主题的确切书籍或教程。
查看 yolov3 的默认推理,对我帮助很大
https://github.com/trainOwn/yolov3-Inference
感谢分享。
嗨,Jason,
我很高兴我购买了您的《深度学习计算机视觉》书籍,它对我的学习非常有帮助。
我有一个关于使用附加数据(如照片元数据)进行训练的问题。
例如,假设我想检测汽车,我有一堆汽车照片,有些是真实的,有些是模型汽车。我认为 DL 模型将能够检测到汽车,但在区分模型和真实汽车方面存在困难。
如果照片有额外的元数据,例如 35mm 焦距,是否可以添加一个层到模型中,以便考虑这些元数据以区分模型汽车和真实汽车?
谢谢!
模型可以训练成标记/分类不同的项目。
你好,
谢谢您的回复。
我不确定那是否会起作用。
例如,如果我使用这张照片 http://www.paudimodel.com/wp-content/uploads/2018/03/Infiniti-QX60-2017-BL-3.jpg,这是一辆 Infiniti QX60 2017 的 1/18 比例模型,模型将如何知道这是比例模型,而不是这张照片 https://www.thecarmagazine.com/wp-content/uploads/2017/04/20170410220126267.jpg 中的真实汽车。
此致
嗨,Jason,
您能给我一个关于构建自定义训练 YOLOv3 对象检测器的例子吗?
因为图像背景不同
感谢您的建议,也许将来会考虑。
嗨,Jason,
很棒的教程,谢谢。
我遇到一个问题。模型可以预测我的对象,当我运行这个
for i in range(len(v_boxes))
print(v_labels[i], v_scores[i])
我得到分数和标签,但在图中没有边界框。
不客气。
也许您可以检查模型提供的边界框,并确认它们具有正确的图像坐标。
嗨,Jason,
很棒的教程,谢谢。
我想问一个问题,我记得yolov3有53层,但是代码有106层。为什么是双倍?也许这不是一个好问题……但我想知道……
谢谢!!
你在哪里看到它有53层?这是YOLOv3原始作者的网页,其中一张图上写着106层:https://pjreddie.com/darknet/yolo/
有时人们的计数方式不同。可能是只计算卷积层?
我明白了。是我的问题……抱歉……
我以为从19层改为53层就是整个架构了……
所以有53层用于ImageNet训练,另外53层用于检测任务。
如果还是错了,请告诉我!
感谢您回复我的问题!!
很高兴你找到了。
你好,您能否发布一个使用Kears的yolo进行自定义数据集训练的文章?有一些文章,但不如您发表的清晰。
嘿,很棒的教程。我是一个新手,我有一个请求,您能否提供一个函数,它执行“decode_netout()”的逆操作,也就是说,它将普通图像注释(bbox x-y坐标,图像中的人脸数量)转换为netout。我想为人脸检测训练您的实现,并且“experiencor/keras-yolo3”repo中的train.py脚本对我来说有点难理解。任何帮助都将不胜感激。
看起来你需要写那个函数。
嘿
我如何使用fit或train_on_batch训练这个模型?
这个模型的输入和目标是什么样的?
如果你是指从头开始训练,你需要获取COCO数据集并像其他模型一样从头开始训练。这并不推荐,因为在家庭电脑上收敛需要很长时间(几天甚至几个月!)。
我将使用预训练的权重,只训练输出层。
我只是不确定如何调用train_on_batch来使用这个创建的模型。
train_on_batch的x和y参数应该是什么样的?
请参阅train_on_batch()的文档以了解可能的参数:https://tensorflowcn.cn/api_docs/python/tf/keras/Model#train_on_batch
但是,要只训练输出层,你需要将层标记为“不可训练”:https://tensorflowcn.cn/guide/keras/transfer_learning
你好,
我正在使用这行代码
draw_boxes(image, v_boxes, v_labels, .6) 在jupyter notebooks中,但没有显示图像或框。我对opencv不太熟悉,任何建议都将不胜感激。
Jupyter可能需要一些额外的函数或“魔术命令”来显示它。不同之处在于,在命令行控制台中,您可以创建一个新窗口并显示图片。在Jupyter中,一切都必须先变成HTML才能在浏览器中显示。
Jason你好,感谢这个很棒的教程。我只是好奇将这个YOLOv3模型开发成YOLOv4模型需要多少努力,以及这样做是否有意义?
名称相似但完全是不同的东西。你最好采用YOLOv4代码并从头开始。
嗨,
我如何获得模型的准确性?
此致。
我们通常使用平均精度均值 (mAP)。
你好,
如果我想只检测一个类(人),有可能吗?如果可以,我需要对代码进行哪些更改才能实现?
是的,这是可能的。最简单的更改是选择结果中的一个类别,然后丢弃其余的。
管用,伙计!我的方法就像你说的,让引擎盖下的马达完成所有的繁重工作,而我们只做调整和微调。别忘了在开始之前加载所有必需的支持文件。准确地预测了斑马图像,然后加载了一张包含10种已灭绝鸟类的图像,再次,程序准确地预测了所有10种。
继续努力。
ScanBopAI你好!非常感谢您的反馈和好评。
Jason你好,很棒的教程!
YOLO v3团队还发布了一个在Google Open Images数据集(约500个类别)上训练的目标检测模型的权重文件。为了运行这些模型的权重进行推理,上述模型需要进行哪些更改?
感谢您的反馈,Ved!
您可能会发现以下内容很有趣
https://machinelearning.org.cn/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
Jason博士您好
我能问一下如何输出对象的X、Y坐标吗?
非常感谢
用于作物和病虫害检测的模型是什么?
Navnath你好……请澄清或重述您的问题,以便我们能更好地帮助您。
Jason你好,很棒的教程!
我想问如何连接3个层的输出。
谢谢你
Jack你好……您可能会发现以下内容很有趣
https://keras.org.cn/api/layers/merging_layers/concatenate/
Jason博士,您好,
感谢您提供宝贵的解释。
目前,我正在处理一个目标检测问题,该问题要求在两个级别上检测目标。在第一级,它有类别,在第二级,它有子类别。例如,类别是军舰、商船或私船。军事舰艇的子类别是例如驱逐舰、护卫舰或巡防舰。对于子类别级别的检测,需要为子类别级别的检测添加额外的CNN和Dense层。
在当前的YOLOv4代码中,我无法更新神经网络的层架构。
请就实施提出建议/指导。
先谢谢您。