小型计算机,例如 Arduino 设备,可用于建筑物内部记录环境变量,并可从中预测简单且有用的属性。
一个例子是根据温度、湿度和相关测量等环境测量值来预测一个或多个房间是否有人占用。
这是一种常见的时序分类问题,称为房间占用分类。
在本教程中,您将学习一个标准的多变量时序分类问题,该问题使用环境变量测量值来预测房间占用率。
完成本教程后,您将了解:
- 机器学习中的占用检测标准时序分类问题。
- 如何加载和可视化多变量时序分类数据。
- 如何开发简单的朴素和逻辑回归模型,这些模型在该问题上实现了近乎完美的技能。
通过我的新书《时间序列预测深度学习》来启动您的项目,其中包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 更新于 2018 年 10 月:更新了数据集来源的描述(我确实弄错了),感谢 Luis Candanedo。
教程概述
本教程分为四个部分;它们是
- 占用检测问题描述
- 数据可视化
- 串联数据集
- 简单预测模型
占用检测问题描述
一个标准的时间序列分类数据集是 UCI 机器学习存储库中提供的“占用检测”问题。
这是一个二元分类问题,需要使用温度和湿度等环境因素的观测值来分类房间是有人占用还是无人占用。
该数据集在 Luis M. Candanedo 和 Véronique Feldheim 于 2016 年发表的论文“使用统计学习模型根据光照、温度、湿度和二氧化碳测量值准确检测办公室占用情况”中有所描述。
该数据集是通过监测一个配备了一套环境传感器的办公室,并使用摄像头确定房间是否有人占用而收集的。
一个办公室房间 […] 的以下变量被监测:温度、湿度、光照和二氧化碳水平。使用微控制器获取数据。一个 ZigBee 无线电连接到它,用于将信息传输到记录站。使用数码相机确定房间是否有人占用。相机每分钟拍摄带有时间戳的照片,然后手动研究这些照片以标记数据。
— 使用统计学习模型根据光照、温度、湿度和二氧化碳测量值准确检测办公室占用情况,2016 年。
提供的数据包括日期时间信息和在多天内每分钟采集的六项环境测量值,具体包括:
- 摄氏温度。
- 相对湿度百分比。
- 光照强度(勒克斯)。
- 二氧化碳浓度(百万分之)。
- 湿度比,由温度和相对湿度推导,以每千克空气中水蒸气千克数测量。
- 占用状态,1 表示有人占用,0 表示无人占用。
这个数据集已被许多简单建模机器学习论文使用。例如,请参阅 2018 年的论文“基于可见光集成学习的占用推理”,以获取更多参考文献。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数据可视化
数据以 CSV 格式提供,分为三个文件,声称用于训练、验证和测试。
这三个文件如下:
- datatest.txt (测试):从 2015-02-02 14:19:00 到 2015-02-04 10:43:00
- datatraining.txt (训练):从 2015-02-04 17:51:00 到 2015-02-10 09:33:00
- datatest2.txt (验证):从 2015-02-11 14:48:00 到 2015-02-18 09:19:00
首先显而易见的是,数据中的分割在时间上不是连续的,并且存在间隔。
测试数据集在时间上早于训练和验证数据集。这可能是文件命名约定中的错误。我们还可以看到,数据范围从 2 月 2 日到 2 月 18 日,总共跨越了 17 个日历日,而不是 20 个。
从此处下载文件并将其放置在当前工作目录中
每个文件都包含一个标题行,但包含一个行号列,而标题行中没有该条目。
为了正确加载数据文件,请将每个文件的标题行更新为如下所示:
从
|
1 |
"date","Temperature","Humidity","Light","CO2","HumidityRatio","Occupancy" |
到
|
1 |
"no","date","Temperature","Humidity","Light","CO2","HumidityRatio","Occupancy" |
下面是修改后的 datatraining.txt 文件的前五行示例。
|
1 2 3 4 5 6 7 |
"no","date","Temperature","Humidity","Light","CO2","HumidityRatio","Occupancy" "1","2015-02-04 17:51:00",23.18,27.272,426,721.25,0.00479298817650529,1 "2","2015-02-04 17:51:59",23.15,27.2675,429.5,714,0.00478344094931065,1 "3","2015-02-04 17:53:00",23.15,27.245,426,713.5,0.00477946352442199,1 "4","2015-02-04 17:54:00",23.15,27.2,426,708.25,0.00477150882608175,1 "5","2015-02-04 17:55:00",23.1,27.2,426,704.5,0.00475699293331518,1 ... |
然后我们可以使用 Pandas 的 read_csv() 函数加载数据文件,如下所示:
|
1 2 3 4 |
# 加载所有数据 data1 = read_csv('datatest.txt', header=0, index_col=1, parse_dates=True, squeeze=True) data2 = read_csv('datatraining.txt', header=0, index_col=1, parse_dates=True, squeeze=True) data3 = read_csv('datatest2.txt', header=0, index_col=1, parse_dates=True, squeeze=True) |
加载完成后,我们可以为六个系列中的每个系列创建一个图,清晰地显示三个数据集在时间上的分离。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from pandas import read_csv from matplotlib import pyplot # 加载所有数据 data1 = read_csv('datatest.txt', header=0, index_col=1, parse_dates=True, squeeze=True) data2 = read_csv('datatraining.txt', header=0, index_col=1, parse_dates=True, squeeze=True) data3 = read_csv('datatest2.txt', header=0, index_col=1, parse_dates=True, squeeze=True) # 确定特征数量 n_features = data1.values.shape[1] pyplot.figure() for i in range(1, n_features): # 指定子图 pyplot.subplot(n_features, 1, i) # 绘制每个数据集的数据 pyplot.plot(data1.index, data1.values[:, i]) pyplot.plot(data2.index, data2.values[:, i]) pyplot.plot(data3.index, data3.values[:, i]) # 为绘图添加可读名称 pyplot.title(data1.columns[i], y=0.5, loc='right') pyplot.show() |
运行示例会生成一个图,其中每个数据集都使用不同的颜色
- datatest.txt (测试): 蓝色
- datatraining.txt (训练): 橙色
- datatest2.txt (验证): 绿色
我们可以看到测试集和训练集之间的小间隔,以及训练集和验证集之间更大的间隔。
我们还可以看到每个变量系列中与房间占用率相对应的结构(峰值)。
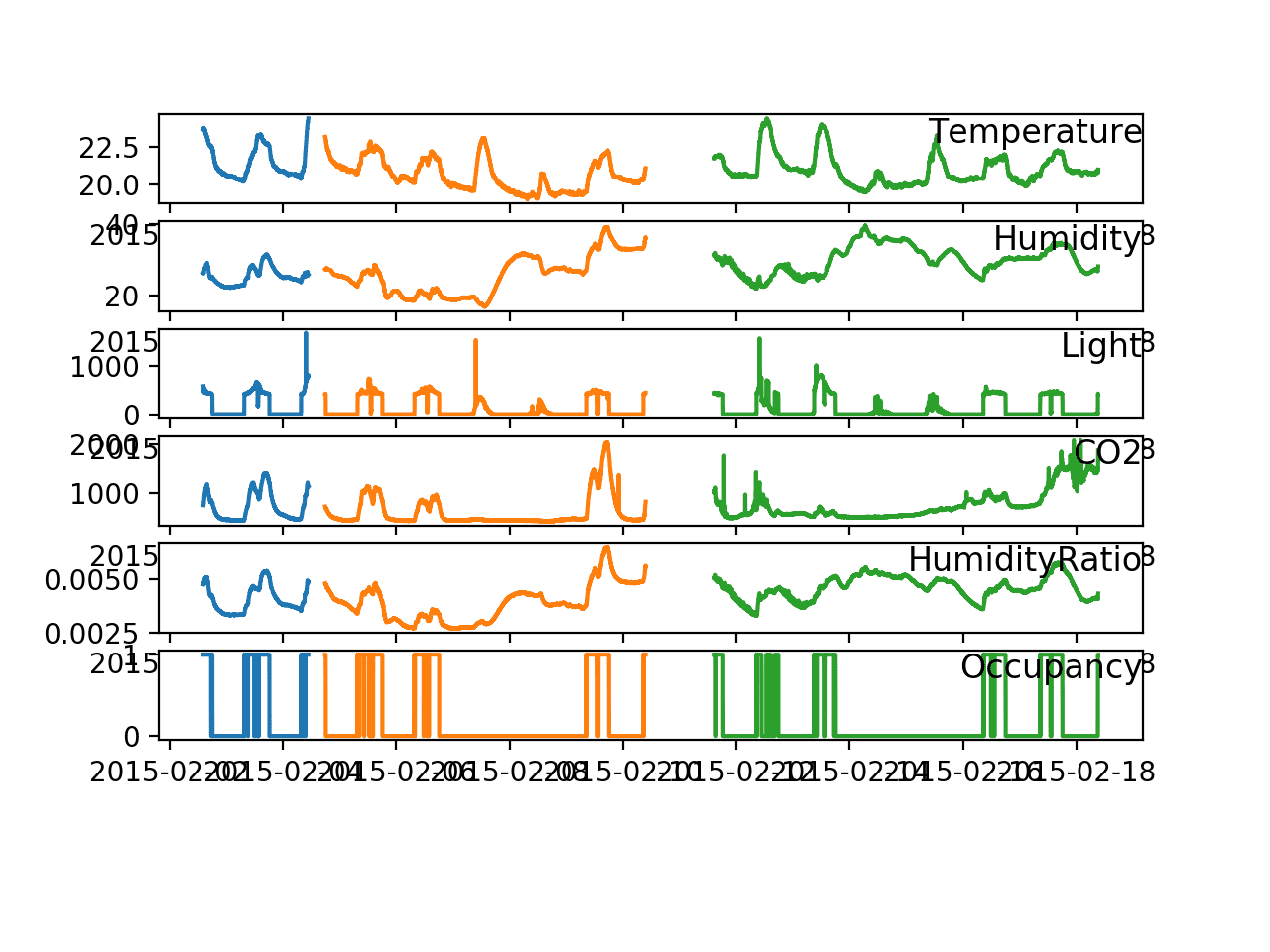
线图显示所有变量和每个数据集的时间序列图
串联数据集
我们可以通过保留数据的时间一致性并将所有三个集合连接成一个数据集来简化数据集,同时删除“no”列。
这将允许对问题的简单直接框架(在下一节中)进行即时测试,这些测试可以在时间一致的方式下,使用即时训练/测试集大小进行。
注意:这种简化没有考虑数据中的时间间隔,依赖于先前时间步序列观测值的算法可能需要不同的数据组织方式。
下面的示例加载数据,将其连接成一个时间上一致的数据集,并将结果保存到一个名为“combined.csv”的新文件中。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from pandas import read_csv from pandas import concat # 加载所有数据 data1 = read_csv('datatest.txt', header=0, index_col=1, parse_dates=True, squeeze=True) data2 = read_csv('datatraining.txt', header=0, index_col=1, parse_dates=True, squeeze=True) data3 = read_csv('datatest2.txt', header=0, index_col=1, parse_dates=True, squeeze=True) # 垂直堆叠并保持时间顺序 data = concat([data1, data2, data3]) # 删除行号 data.drop('no', axis=1, inplace=True) # 保存聚合数据集 data.to_csv('combined.csv') |
运行示例将连接后的数据集保存到新文件“combined.csv”中。
简单预测模型
解决这个问题的最简单方法是根据当前时间的环境条件来预测占用情况。
我将此称为直接模型,因为它不使用先前时间步的环境测量观测值。从技术上讲,这并非序列分类,而是一个直接的分类问题,其中观测值按时间顺序排列。
根据我粗略浏览文献,这似乎是问题的标准表述,令人失望的是,论文似乎使用了 UCI 网站上标记的训练/验证/测试数据。
我们将使用上一节中描述的组合数据集,并通过保留最后 30% 的数据作为测试集来评估模型技能。例如:
|
1 2 3 4 5 6 7 |
# 加载数据集 data = read_csv('combined.csv', header=0, index_col=0, parse_dates=True, squeeze=True) values = data.values # 将数据拆分为输入和输出 X, y = values[:, :-1], values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=1) |
接下来,我们可以评估数据集的一些模型,从朴素预测模型开始。
朴素模型
对于这种问题表述,一个简单的模型是预测最突出的类别结果。
这称为零规则或朴素预测算法。我们将评估预测测试集中所有 0(未占用)和所有 1(已占用)的每个示例,并使用准确率指标评估该方法。
下面是一个函数,它将根据给定的测试集和选择的输出变量执行此朴素预测:
|
1 2 |
def naive_prediction(testX, value): return [value for x in range(len(testX))] |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 朴素预测模型 from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 加载数据集 data = read_csv('../datasets/occupancy_data/combined.csv', header=0, index_col=0, parse_dates=True, squeeze=True) values = data.values # 将数据拆分为输入和输出 X, y = values[:, :-1], values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=1) # 进行朴素预测 def naive_prediction(testX, value): return [value for x in range(len(testX))] # 评估预测每个类别值的技能 for value in [0, 1]: # 预测 yhat = naive_prediction(testX, value) # 评估 score = accuracy_score(testy, yhat) # 总结 print('Naive=%d score=%.3f' % (value, score)) |
运行示例会打印朴素预测和相关分数。
注意:考虑到算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。建议运行示例几次并比较平均结果。
我们可以看到,通过预测所有 0,即所有未占用,基线准确率约为 82%。
任何被认为在该问题上熟练的模型,其技能都必须达到 82% 或更高。
|
1 2 |
朴素=0 分数=0.822 朴素=1 分数=0.178 |
逻辑回归
粗略浏览文献显示,该问题应用了一系列复杂的神经网络模型。
首先,让我们尝试一个简单的逻辑回归分类算法。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 逻辑回归 from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score 从 sklearn.线性模型 导入 LogisticRegression # 加载数据集 data = read_csv('combined.csv', header=0, index_col=0, parse_dates=True, squeeze=True) values = data.values # 将数据拆分为输入和输出 X, y = values[:, :-1], values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=1) # 定义模型 model = LogisticRegression() # 在训练集上拟合模型 model.fit(trainX, trainy) # 预测测试集 yhat = model.predict(testX) # 评估模型技能 score = accuracy_score(testy, yhat) print(score) |
运行示例会拟合训练数据集上的逻辑回归模型并预测测试数据集。
注意:考虑到算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。建议运行示例几次并比较平均结果。
该模型的技能准确率约为 99%,显示出比朴素方法更高的技能。
通常,我建议在建模之前对数据进行中心化和标准化,但一些尝试和错误表明,对未缩放数据建立的模型技能更高。
|
1 |
0.992704280155642 |
乍一看,这是一个令人印象深刻的结果。
尽管测试设置与研究文献中呈现的不同,但一个非常简单的模型所报告的技能优于更复杂的神经网络模型。
特征选择和逻辑回归
仔细观察时间序列图,可以看到房间被占用时间与环境测量值峰值之间存在清晰的关系。
这很有道理,并解释了为什么这个问题实际上如此容易建模。
我们可以通过单独测试每个环境测量值的简单逻辑回归模型来进一步简化模型。这样做的想法是,我们不需要所有数据来预测占用情况;也许只需其中一个测量值就足够了。
这是最简单的特征选择类型,其中模型是使用每个特征单独创建和评估的。更高级的方法可能会考虑每个特征子组。
下面列出了测试逻辑模型与五个输入特征中的每个特征单独进行的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 逻辑回归特征选择 from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score 从 sklearn.线性模型 导入 LogisticRegression # 加载数据集 data = read_csv('combined.csv', header=0, index_col=0, parse_dates=True, squeeze=True) values = data.values # 基本特征选择 features = [0, 1, 2, 3, 4] for f in features: # 将数据分成输入和输出 X, y = values[:, f].reshape((len(values), 1)), values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=1) # 定义模型 model = LogisticRegression() # 在训练集上拟合模型 model.fit(trainX, trainy) # 预测测试集 yhat = model.predict(testX) # 评估模型技能 score = accuracy_score(testy, yhat) print('feature=%d, name=%s, score=%.3f' % (f, data.columns[f], score)) |
运行示例会打印特征索引、名称以及在该特征上训练并在测试集上评估的逻辑模型的技能。
注意:考虑到算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。建议运行示例几次并比较平均结果。
我们可以看到,只需要“光照”变量即可在此数据集上实现 99% 的准确率。
很可能记录环境变量的实验室房间有一个光传感器,当房间有人占用时会打开内部灯光。
另外,或许光照是在白天记录的(例如通过窗户的阳光),并且房间在每天或每周的特定日子有人占用。
至少,本教程的结果对任何使用此数据集的研究论文提出了一些严峻问题,因为显然这不是一个具有挑战性的预测问题。
|
1 2 3 4 5 |
特征=0,名称=温度,分数=0.799 特征=1,名称=湿度,分数=0.822 特征=2,名称=光照,分数=0.991 特征=3,名称=CO2,分数=0.763 特征=4,名称=湿度比,分数=0.822 |
扩展
这些数据可能仍然值得进一步调查。
一些想法包括
- 如果移除光照列,问题可能会更具挑战性。
- 也许这个问题可以被框定为一个真正的多变量时间序列分类问题,其中模型使用了滞后观测值。
- 也许环境变量中明显的峰值可以被用于预测。
我简要尝试了所有这些模型,但没有令人兴奋的结果。
如果您探索了这些扩展或在网上找到了相关示例,请在下方评论中告诉我。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 占用检测数据集,UCI 机器学习存储库
- GitHub 上的占用检测数据
- 一种基于多传感器的占用估计模型,用于支持按需 HVAC 操作, 2012.
- 使用统计学习模型从光照、温度、湿度和二氧化碳测量值准确检测办公室占用情况, 2016.
- 基于可见光的集成学习占用推理, 2018.
总结
在本教程中,您学习了一个标准的多变量时间序列分类问题,该问题使用环境变量测量值来预测房间占用率。
具体来说,你学到了:
- 机器学习中的占用检测标准时序分类问题。
- 如何加载和可视化多变量时序分类数据。
- 如何开发简单的朴素和逻辑回归模型,这些模型在该问题上实现了近乎完美的技能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。
")





嗨!很棒的博客!谢谢!有一件事,你为什么不在脚本末尾使用 plt.tight_layout() 以避免图形重叠呢?
好建议,谢谢!
我有这段代码
来计算逻辑回归并显示其结果,但是当我在 PyCharm 中运行它时,我看到了这个错误
我该怎么办?
抱歉,我没有能力调试你的代码,我这里有一些建议
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
我相信你已经定义了 value = requests.get(url) 并且调用了 values[:,:-1],其中多了一个“s”@Star
你能帮我找出数据集的 5 个假设吗?
抱歉,我不明白你的问题。或许你可以详细说明一下。
嗨,Jason,根据 AQI 预测占用率技术上是否不正确?因为 AQI 是因变量,而占用率是自变量。我们不应该根据占用率预测 AQI 吗?
嗨 Navneet…你可以确定是否存在任何相关性
https://machinelearning.org.cn/how-to-use-correlation-to-understand-the-relationship-between-variables/